
5
THE SILENT SAFETY PROGRAM REVISITED
INTRODUCTION
Although industrial safety engineering has a long history, system-safety engineering is a relatively new discipline that grew out of the aviation and missile systems of the 1950s. The potential destructiveness of such systems and their cost and complexity made it clear that the old approach of fly-fix-fly would no longer be adequate. Instead, system-safety attempts to anticipate and avoid accidents through the application of scientific, managerial, and engineering principles. Conditions that could lead to accidents (i.e., hazards) are identified before accidents occur and then eliminated or controlled to an acceptable level.
NASA was the first group outside of the military to adopt system-safety engineering and, spurred on by the Apollo fire in 1967, established one of the best system-safety programs of the time. The General Electric Company and others were commissioned to develop policies and procedures that became models for civilian aerospace activities. Specialized safety efforts were given a prominent role in the top levels of NASA and throughout the centers and programs.
The NASA approach to safety assigns responsibility for risk management to the program and line management while the safety organizations are responsible for providing the support necessary for program-management decision making. The safety staff provides this support through risk assessment and hazard analyses and by assuring that the activities associated with controlling risk are carried out and documented.
One of the analyses that NASA uses to ensure reliability is Failure Modes and Effects Analysis (FMEA). This is used to identify hardware items that are critical to the performance and safety of the vehicle and the mission, and to identify items that do not meet design requirements. Each possible failure mode of a hardware component is identified and then analyzed to determine the resulting performance of the system and to ascertain the worst-case effect that could result from a failure in that mode. All the identified critical items are then categorized according to the worst-case effect of the failure on the crew, the vehicle, and the mission. If the worst-case effect is loss of life or vehicle, the item is categorized as criticality 1 (1R if the error is redundant). Criticality 2 and 2R are cases where loss of mission could result. A Critical Items List (CIL) is produced that contains information about all criticality 1 components.
While the FMEA/CIL is basically a bottom-up reliability analysis that examines the effect of every type of component failure, hazard analyses are top-down safety analyses that start from a hazard (i.e., state that could lead to an accident) and attempt to determine what conditions could cause that hazard. NASA hazard analyses consider not only the failures identified in the FMEA process but also other potential threats posed by the environment, crew/machine
interfaces, and mission activities. They examine cross-system causes and effects rather than single subsystems. Identified hazards and their causes are analyzed to find ways to eliminate or control the hazard.
Although many of the ideas originally developed by the military and NASA were adopted by other industries, none of the industry programs have approached the quality of the military and aerospace programs. Perhaps because of the success of the NASA program, the Challenger accident was a surprise to safety professionals. What happened? Some safety professionals have cited a combination of complacency (which is inherent in any successful program), politics, and budget cuts.
The Rogers Commission report 1 on the Challenger accident identified many safety engineering and management problems at NASA and speaks of a Silent Safety Program that had, for some reason, lost at least some of its effectiveness after the Apollo flights. As the report says:
The unrelenting pressure to meet the demands of an accelerating flight schedule might have been adequately handled by NASA if it had insisted upon the exactingly thorough procedures that were its hallmark during the Apollo program. An extensive and redundant safety program comprising interdependent safety, reliability, and quality-assurance functions existed during and after the lunar program to discover any potential safety problems. Between that period and 1986, however, the program became ineffective. This loss of effectiveness seriously degraded the checks and balances essential for maintaining flight safety.
The major factors in the NASA safety organization that the Rogers Commission cited as contributing to the accident were
-
reductions in the safety, reliability, and quality-assurance work force;
-
lack of independence, in management structure, of safety organizations from the organizations they are to check;
-
inadequate problem reporting requirements and failure to get information to the proper levels of management;
-
inadequate trend analysis of failures;
-
misrepresentation of criticality; and
-
lack of involvement of safety personnel in critical discussions.
An important factor cited in the Rogers Commission report was complacency and reduction of activity after the Shuttle program became operational.
Following successful completion of the orbital flight test phase of the Shuttle program, the system was declared to be operational. Subsequently, several safety, reliability, and
|
1 |
Report of the Presidential Commission on the Space Shuttle Challenger Accident, William P. Rogers, Chairman. (Washington, D.C.: Government Printing Office, 1986). |
quality-assurance organizations found themselves with reduced and/or reorganized functional capability.
The apparent reason for such actions was a perception that less safety, reliability, and quality-assurance activity would be required during routine Shuttle operations. This reasoning was faulty. The machinery is highly complex, and the requirements are exacting. The Space Shuttle remains a totally new system with little or no history. As the system matures and the experience changes, careful tracking will be required to prevent premature failures. As the flight rate increased, more hardware operations were involved, and more total in-flight anomalies occurred. Tracking requirements became more rather than less critical because of implications for the next flight in an accelerating program.
The inherent risk of the Space Shuttle program is defined by the combination of a highly dynamic environment, enormous energies, mechanical complexities, time-consuming preparations and extremely time-critical decision making. Complacency and failures in supervision and reporting seriously aggravate these risks.
Rather than weaken safety, reliability, and quality-assurance programs through attrition and reorganization, NASA must elevate and strengthen these vital functions. In addition, NASA's traditional safety, reliability, and quality-assurance efforts need to be augmented by an alert and vigorous organization that oversees the flight safety program.
After this report, NASA fixed many of the problems identified by the Rogers Commission. An NRC report, in 1988, evaluated the progress made in these areas and made additional recommendations. Our Committee did not further evaluate the current system-safety program but concentrated only on the software aspects of safety.
SOFTWARE SYSTEM SAFETY
Safety is a system property, not a component property. Handling software safety issues at the system level is somewhat different than for other components since the software usually acts as a controller. That is, the software not only has interfaces with other components, but it is often responsible for controlling the behavior of other hardware components and the interactions between components. Therefore, software can have important ramifications for system safety and must be included in system-safety analyses.
Software can affect system safety in two ways: (1) the software can fail to recognize or handle hardware failures that it is required to control or to respond to in some way or (2) the software can issue incorrect or untimely outputs that contribute to the system reaching a hazardous state. Both of these types of software safety issues must be handled in an effective system-safety program.
Software does not have random failure modes as does hardware: it is an abstraction, and its failures are, therefore, due to logic or design errors. Once software is loaded and executed on a computer, however, the software becomes essentially the design of a special purpose machine (to which the general purpose computer has been temporarily transformed, e.g., a guidance machine or an inertial navigator). Like any other machine, the hardware components
may fail. The primary protection against this in the Shuttle is the use of multiple (four) computers running the PASS (i.e., the standard hardware technique of n-fold modular redundancy) for certain critical operations during liftoff and reentry. A fifth computer, running a different version of the software, the BFS, provides a monitoring and standby sparing role.
A computer can also behave in an incorrect fashion due to logic errors in the software (i.e., the design of the special purpose machine). These logic errors can result from:
-
The software being written from incorrect requirements (i.e., the code matches the requirements but the behavior specified in the requirements is not that desired from a system perspective), or
-
coding errors (i.e., the requirements are correct but the implementation of the requirements in a programming language is faulty and, therefore, the behavior of the code does not satisfy the behavior specified in the requirements).
Both of these types of errors must be considered when attempting to increase software reliability and safety.
There are three ways to deal with software logic errors. The first, and most obvious, approach is just to get the requirements and code correct. This is an enticing approach since it is theoretically possible compared with the impossibility of eliminating wear-out failures in hardware devices. Many people have realized, however, that, although perfect software could be constructed theoretically, it is impossible from a practical standpoint to build complex software that will behave exactly as it should under all conditions, no matter what changes occur in the other components of the system (including failures), in the environment, and in the software itself. Of course, getting correct software is an appropriate and important goal, but engineers (software, system, and safety) need to consider what will happen in case the goal is not achieved.
A second approach to dealing with logic errors in software is to enhance software reliability by making the software fault-tolerant through the use of various types of redundancy. On the Shuttle, the primary use of logical redundancy is the use of the BFS to backup the PASS for some critical operations. Since the requirements and algorithms used for PASS and BFS are the same, protection is not provided for errors resulting from incorrect requirements or algorithms, only for coding errors (errors in the translation of the requirements and algorithms into a programming language). Even this is limited since experiments testing this approach have shown that programmers often make the same mistakes, and independently coded software does not necessarily fail in an independent manner. 2 Mathematical analysis and models have demonstrated limitations in the actual amount of reliability improvement possible using this approach.
The previous two approaches attempt to increase safety by increasing software reliability. Although this is appropriate, it must be realized that, just as for hardware, increasing reliability may not be adequate. Accidents have happened in systems where there were no failures or where the reliability was very high. In software this often occurs when the software correctly
|
2 |
Although, strictly speaking, software cannot fail by the usual engineering definition of this term, software failure is usually defined as the production of incorrect or untimely outputs. |
implements the requirements but the requirements include behavior that is not safe from a system standpoint. In fact, this is the most common cause of accidents that have involved software. However, it is possible to make systems safe despite failures and despite a relatively low reliability level of individual components.
Instead of attempting merely to increase software reliability, a third approach to dealing with software errors applies techniques commonly used in system-safety engineering. For example, the identified system hazards can be traced to particular software requirements (and from there to particular software modules). Those requirements and modules are then subjected to special analysis and testing to make them extra reliable. Another approach, also using the system-hazard analysis, is to identify the particular software behaviors that can lead to system hazards and either protect the system against those types of behavior through changes to the system design (e.g., the use of hardware interlocks) or to build in special protection against them within the software itself, such as using special software interlocks, fail-safe software, and software monitoring or self-checking mechanisms.
NASA, in the Shuttle software, has emphasized the first two approaches, although early development efforts did attempt to include the software in the system-safety design efforts and especially to evaluate the requirements from a system-safety viewpoint. For example, in 1979 TRW performed a software hazard analysis that identified 38 potentially hazardous software behaviors. For some reason--perhaps budget cuts or perhaps because it was erroneously believed that such an activity was not necessary once the software was completed--this effort ended in 1979. The current approach to software safety appears to focus almost exclusively on getting the software upgrades correct and eliminating any requirements or logic errors that are found. The Committee could find no evidence of the recent use of the TRW hazard analysis (in fact, the software developers appear to be unaware of its existence) or any current attempts to update it or use similar techniques. Currently, the system-safety effort appears to have little connection to the software development and maintenance effort.
In summary, NASA established an excellent system-safety program during the Apollo program. After Apollo, however, NASA seemed to grow complacent with success, until learning from Challenger, it corrected many of its previous mistakes. However, software has been and still is under-emphasized in the NASA system-safety program and many of the same mistakes that contributed to the Challenger accident are now being repeated with respect to software, especially with respect to the belief that safety procedures can be relaxed for operational programs.
SOFTWARE SAFETY STANDARDS
Finding #5: Current NASA safety standards and guidelines do not include software to any significant degree. A software safety guideline has been in draft form for four years. Decisions are being made and safety-critical software is being built without minimal levels of software safety analysis or management control being applied.
After the Challenger accident, a complete reevaluation of safety in NASA programs occurred with an increased awareness, by some, of the need to include software in the safety
efforts. New standards and guidelines were drafted, which include methodologies for software safety analyses and requirements for the conduct of NASA software safety activities.
Although some details may differ, the draft software safety guideline is similar to the major defense software safety standard, MIL-STD-882B, which is widely used both inside and outside the defense community. The goal of both is to identify potential software-related system hazards early in the development process and to establish requirements and design features to eliminate or control the hazards. Both also recognize that the software safety activity, to be effective, must be implemented as a part of the overall system-safety effort with direct channels of information and coordination between them.
The draft NASA software safety guideline identifies the major safety activities to be accomplished in each phase of the software development and maintenance life cycle and the subtasks of the system-safety analyses that are related to software. These are
-
Preliminary Hazard Analysis;
-
System-Hazard Analysis;
-
Subsystem-Hazard Analysis; and
-
Operating-System-Hazard Analysis.
For example, as a subtask of the preliminary hazard analysis, a preliminary software hazard analysis is conducted to identify (1) parts of the software that are safety-critical, (2) any contribution of the software to potential system mishaps, and (3) software safety design criteria that are essential to control safety-critical software commands and responses. Later in the life cycle, analyses are conducted to determine (1) the potential contribution of software, as designed and implemented, to the safety of the system; (2) that the safety criteria in the software specifications have been satisfied; and (3) that the method of implementation of the software design and corrective actions has not impaired or degraded system safety nor introduced new hazards. In addition, several specific software hazard analysis tasks are identified:
-
Software Requirements Hazard Analysis: The purpose of the Software Requirements Hazard Analysis is to (1) identify required and recommended actions to eliminate identified hazards or reduce their associated risk to an acceptable level and (2) establish preliminary testing requirements. This analysis ensures an accurate flow-down of the system-safety requirements into the software requirements.
-
Top-Level Design-Hazard Analysis: Top-level design-hazard analysis relates the identified hazards from the Subsystem Hazard Analysis, the Preliminary Hazard Analysis, and the Software Requirements Hazard Analysis to the software components that may affect or control the hazards. It also includes a definition and analysis of the safety-critical software components.
-
Detailed Design-Hazard Analysis: Detailed design-hazard analysis verifies the correct implementation of the safety requirements and compliance with safety criteria. Hazards are related to the lower-level software components defined in the detailed design, safety-critical computer software units are identified, and the code developers are provided with explicit safety-related coding recommendations and safety requirements.
-
Code-Level Software Hazard Analysis: Code-Level Software Hazard Analysis examines the actual source and object code to verify the implementation of safety requirements and design criteria.
-
Software/User Interface Analysis: Software user interface analysis ensures the system can be operated in a safe manner.
The guideline includes requirements for special software safety testing if the normal development testing is not adequate to ensure safety. Finally, the software developer must take positive measures to be sure that all safety objectives and requirements have been included in the software design (requirements traceability). These measures must be documented and traceable from the system-level specifications through each level of lower-tier software documentation including actual code-level implementation.
Efforts at getting this draft software safety guideline approved have been stalled for many years. At the same time, changes are being made to Shuttle software and new programs are being started, such as the Space Station Freedom, without adequate standards for software safety in place. The sticking point seems to be the NASA requirement for consensus on all standards and guidelines. It seems odd to the Committee that those responsible for safety do not have the authority to impose the standards that are needed to achieve it. Four years is too long to wait for consensus.
The Committee understands that there is a good chance the NASA draft software safety guideline may be approved soon. However, even then, it will be possible for the various centers and programs to tailor their software safety programs without approval from those responsible for safety at headquarters. From what the Committee can determine, the headquarters S&MQ Office is limited to providing comments and conducting audits whose results are advisory. Again, those with responsibility must be given authority to carry out their job. The current situation does not appear to meet the original Rogers Commission recommendation to set up this headquarters group, which specifically stated that the S&MQ Office should have direct authority for safety, reliability, and quality assurance throughout the agency.
Recommendation #5: NASA should establish and adopt standards for software safety and apply them as much as possible to Shuttle software upgrades. The standards should be applied in full to new projects such as the space station. NASA should not be building any software without such standards in place.
Recommendation #6: NASA should provide headquarters S&MQ with the authority to approve or reject any tailoring of the software safety standards for individual programs and minimize the differences between the safety programs being followed at different centers within a single program.
SOFTWARE SAFETY PROCEDURES
Finding #6: The Committee found insufficient coordination between the Shuttle system-safety program and the software activity. There is no tracing of system hazards to
software requirements and no criticality assessment of software requirements or components (except when they are changed). There is no baseline software hazard analysis that can be used to evaluate the criticality of software modifications and no documentation of the software safety design rationale. There appear to be gaps in the reporting of identified software hazards to the system-level hazard auditing function; for example, a criticality 1 hazard can be accepted by the program without being evaluated by the Shuttle Avionics Software Configuration Board or the center safety office.
The Committee found evidence that, during the development of the Shuttle, safety issues with respect to software were considered carefully, and a software hazard analysis was performed. Somehow, this concern waned after the Shuttle became operational and attention was turned to software maintenance and upgrades. Although the individual software developers have implemented some safety programs on their own, there appears to be little direction provided by NASA and little integration with the system-safety efforts.
For proper decision making, a program must have traceability of safety requirements in both directions--down from the system to the subsystems and from the subsystems back up to the system level. Software is somewhat unique in that it can be considered a subsystem, but it controls other subsystems and operates as the interface between subsystems. Therefore, software analysis must be closely integrated into the system-safety activity.
The first step in any software safety program is the generation of a baseline hazard analysis that identifies potential hazardous behavior of the software that could contribute to system hazards. The Committee independently discovered that TRW was under contract in 1979 to do a Software Hazard Analysis for the Shuttle. The reports generated include Initial Identification of Software Hazards (38 were identified for the orbiter), Software Hazard Analysis, and Software Fault-Tree Analysis of Data Management System Purge Ascent and Entry Critical Functions. The TRW approach included:
-
a critical-functions analysis by subsystem for pre-launch, ascent, on-orbit, and landing;
-
a list of the critical commands (what are the undesired events and what are the potential hazards);
-
a Fault-Tree Analysis on the critical functions;
-
a check for coding errors;
-
an examination of software interfaces; and
-
an examination of the hardware/software interface and determination if the software could cause a hardware failure or vice versa.
Except for one person in the headquarters S&MQ Office (who had worked on the analysis while previously employed by TRW), none of the people involved in the software development seemed to be aware of this effort when the Committee inquired about it. The results are apparently not used today. Instead, criticality levels are assigned to software changes presented to the SASCB in a seemingly ad hoc fashion, starting the analysis basically from scratch each time. The program needs a baseline software hazard analysis to use in this process. The hazards should then be traced to the software requirements and the software modules,
identifying the requirements and modules that are criticality 1 and 2. The analysis itself may identify some necessary changes to the software, but its primary use would be to help make decisions on proposed changes to the Shuttle software in the SASCB. The original TRW software hazard analysis might serve as a starting point for this effort if it is still relevant to the current design.
The current process relies too heavily on corporate memory and individual expertise, which allows for the possibility of mistakes and redundant effort. Although the Committee found that careful design rationales exist for the original software and hardware design decisions with respect to safety, these have not been documented and are being lost when personnel changes. Without this crucial information, changes can be inadvertently made that undo important safety design considerations. NASA should document these design-rationale decisions. The resulting documentation should be used when deciding about potential changes to the software.
The previous NRC committee recommended consideration of performing FMEAs on software. The current committee does not believe that this is a practical or useful approach. However, since DRs are currently being assigned criticality levels, they need to be related to the CIL or system hazards in some way. Furthermore, decisions are being made about changes and enhancements to the software, and these also must be evaluated with respect to their safety implications. In response to a written question, JSC and MSFC both stated that system-level hazards (i.e., items on the CIL) are not traced to software requirements, components, or functions.
Although FMEAs on software do not make sense, hazard analyses that determine the critical outputs and behavior of software and trace from system hazards to software requirements and modules could be very useful. They have been performed on software for many years and in many different applications, and they are included in the draft software safety guideline. The Shuttle program goes through this process informally every time a change is assigned a criticality level (usually by the developer). The process needs to be formalized. By doing a SoftwareChange Hazard Analysis based on the information contained in the baseline hazard analysis, redundant effort will be eliminated and, more important, the chance for errors will be reduced, and the oversight ability of the NASA S&MQ staff will be enhanced.
Communication and traceability must also proceed in the other direction, from the software change activities to the system-safety activity. The Committee could not find a clear reporting channel from the SASCB to the Level 2 boards responsible for system safety. Communication is apparently through the center SR&QA software representative, who has joint membership on several boards, and through Safety Assessment and Hazard Analysis Reports, which do not appear to be used consistently throughout the program. Very few hazard reports are ever written for software. This might be justified for software errors that are removed (and, thus, are no longer hazards) but does not apply to accepted software hazards and software-related problems for which the resolution is a User Note 3 rather than a software change.
|
3 |
A User Note is a document that is included in the description of the software for use by the crew during training and during a mission. These notes typically describe situations that have been recognized as anomalies in the software, but that have been deemed to be sufficiently benign that they do not require an immediate fix, or for which adequate software is not possible. |
The Committee found little formal (documented) information flowing upward and little coordination between the SASCB and the Level 2 safety boards (the System-Safety Review Panel and the Payload Safety Review Board). When asked how software changes are noted or reported to those responsible for system-hazard auditing, JSC replied, “All proposed software changes and detected errors are reviewed by the SASCB.” However, the SASCB is the software configuration management control board and not the group responsible for system-hazard auditing. MSFC answered that they sent Safety Assessment and Hazard Analysis Reports to the higher levels, but did not describe how often or how thoroughly they are used. Furthermore, the Committee found evidence that not all detected errors or hazards in the software are reviewed by the SASCB.
For example, the Committee (accidently) found three instances of acceptance of a software hazard related to the avionics software that were not officially reported either to the SASCB or to higher-level boards. These three DRs were originally assigned a severity of 1 or 1N and were downgraded to 5 (the designation that corresponds to No DR) and signed off only by the Flight Data Systems Division flight software manager, not the SASCB.
The first of these three DRs, 101041 (Premature Solid Rocket Booster Separation), was determined to be a valid problem that had been previously unrecognized. The contractor and the Flight Data Systems Division manager decided that the hazard was covered by an existing FMEA/CIL-accepted hazard and so it was signed off. However, the existence of another path to this hazard (through software) was never reported to those responsible for the FMEA/CIL auditing. Thus, the hazard was accepted at an inappropriate level without documentation in the FMEA/CIL database and without official examination or concurrence by the SASCB or JSC Safety Office.
In another case, DR 103752, the severity 1 problem was judged unsolvable by software means and the disposition recommended that a new User Note be created. However, this DR was never seen by the SASCB and apparently never evaluated by the center SR&QA software staff. The only way for the SR&QA Office to have been assured that the User Note was actually added would have been for them to have found this DR in one of the several databases used to track this type of information. Other DRs that resulted in changing the User Notes (e.g., 105706, Entry Guidance Drag Reference Divergence) also were never seen by the SASCB or higher-level safety boards. In this case, an assigned severity 3 error (no check seems to have been made on the assigned level by anyone other than the contractor), was acknowledged as a problem for the crew. The DR form says that it was decided, rather than to change the algorithm, to handle the problem procedurally by modifying the User Notes and adding a discussion of the problem to the specification. The Committee cannot understand why such DRs are never reviewed by or reported to the SASCB and the Safety Office except through an entry in one of the many data bases.
In a third severity 1 DR, 105711 (Multiple Post-MECO Events Cause A/C power failure), the problem is noted as being recognized as a valid concern by the Shuttle Community, and as prompting a power-load and timing analysis that concluded that the problem does not occur. However, this problem was never dispositioned or signed off by the SASCB and there is no indication that the Safety Office was involved in or reviewed the evaluation.
These three incidents were discovered by the Committee during an unrelated examination by the Committee of several DRs. The Committee does not know how many other examples
exist. Putting such DRs in one of the several data bases used throughout the program is not sufficient to assure proper visibility.
The previous NRC committee examining the Space Shuttle process recommended that “NASA take firm steps to ensure a continuing and iterative linkage between the formal risk assessment process (e.g., FMEA/CIL and HA) and the STS engineering change activities.” This has yet to be done with respect to the STS software change activities.
Recommendation #7: For the Shuttle software safety process, NASA should provide a software safety program plan (as described in the draft software safety guideline) that is reviewed and approved by headquarters S&MQ, the SR&QA managers at the centers, and the Shuttle program manager. This plan should describe the organizational responsibilities, functions, and interfaces associated with the conduct of the Shuttle software safety program.
Recommendation #8: NASA should perform a hazard analysis for the Shuttle software, as described in the draft software safety guideline. NASA also should implement the other appropriate aspects of the draft software safety guideline (testing, change hazard analysis, system-safety requirements traceability) and provide a software safety design-rationale document. NASA should establish (if necessary) and use reporting channels from software to system-safety activities.
PERSONNEL
Finding #7: The SR&QA offices at the centers have limited personnel to support software-related activities. The assignment of one civil servant to software safety is not adequate to do more than just attend meetings.
Finding #8: There is little oversight or evaluation of software development activities by the center SR&QA offices.
The 1988 NRC committee report on the Shuttle reported that:
Members of the Committee were told by JSC representatives that, because of limited staff, the JSC SR&QA organization now provides little independent review and oversight of the software activities in the NSTS program.
There is little involvement of the JSC SR&QA organization in software reviews, due to the limitations on staff. As a result, there is little independent QA [quality assurance] for software.
The present committee found that this situation has not changed. At JSC, there is one civil service employee and four contractors to support the flight software activities in the Safety Division of SR&QA. The same number support the Reliability Division, and the Quality Division has the equivalent of one and one half Civil Service employees and four and one half support contractors. This makes for a total of sixteen staff supporting Shuttle flight software (out of a total of nearly 400 working in SR&QA at JSC). At MSFC, Software Safety has one civil service employee and the equivalent of one half of a support contractor. The number is the same for Software Reliability, and Software Quality Assurance has two civil service employees and one support contractor, which makes a total of six in the SR&QA Division.
It may not be possible to immediately implement the Committee's recommendations due to lack of adequate, trained personnel. The Committee recommends that, while the in-house expertise is being established, NASA contract separately with software safety evaluation contractors using the concept of designated NASA representatives as defined in the draft software safety guideline. The use of designated representatives is similar to what is currently done by the FAA in the certification of commercial aircraft.
Recommendation #9: NASA should build up expertise on software and software safety within the center SR&QA groups and headquarters and provide adequate personnel to perform flight software S&MQ activities.
SYSTEM-SAFETY ORGANIZATIONAL ROLES AND RESPONSIBILITIES
Finding #9: The reporting relationship between the centers and headquarters S &MQ is ill-defined. There is little interaction between the JSC SR &QA Office and the software development activities within IBM and Rockwell. Headquarters has no enforcement power (i.e., no authority for performance). Multiple centers on the same program may be enforcing different standards and procedures.
The Committee found that the headquarters Safety Office has responsibility for safety without the authority to do what is necessary to ensure it. The headquarters Safety Office appears to be limited, for the most part, to making recommendations. There also appear to be ill-defined reporting relationships. For example, the dotted-line 4 relationship (see Figure 5-1) between the headquarters Safety Office and the center S&MQ offices is undefined and ambiguous in practice. In answer to a written question by the Committee about the relationship between headquarters S&MQ and the centers, NASA replied, “Code Q [headquarters S&MQ] is responsible for providing NASA policies, standards, and guidance. They are not on the
|
4 |
The term dotted-line is often used to describe two organizations between which there is no formal line of authority. The term originates from organization charts that have a solid line to indicate formal reporting relationships and dotted lines to indicate less formal relationships. The relationship between the headquarters S&MQ and the center SR&QA groups is informal in the sense that headquarters cannot compel the center offices to perform specific tasks or provide information. On the other hand, the center offices receive some of their funding from the headquarters office and so there is some incentive, albeit informal, to cooperate. |
distribution for reports on verification and validation, software QA [quality assurance], and software reliability from the centers. ” This appears to contradict the original recommendation of the Rogers Commission for establishing this office:
NASA should establish an Office of Safety, Reliability, and Quality Assurance to be headed by an Associate Administrator, reporting directly to the NASA Administrator. It would have direct authority for safety, reliability, and QA throughout the agency. The office should be assigned the work force to ensure adequate oversight of its functions and should be independent of other NASA functional and program responsibilities. The responsibilities of this office should include:
-
the SR&QA functions as they relate to all NASA activities and programs; and
-
direction of reporting and documentation of problems, problem resolution, and trends associated with flight safety.
The relationship between the safety office at each center and the safety efforts within the development contractors appears also to be nonexistent or indirect (i.e., through the SASCB). This is in contrast to the practice of most military system-safety programs that use System-Safety Working Groups and Software System-Safety Working Groups to coordinate safety efforts in complex systems. The System-Safety or Software-Safety Working Group is a functional organization with the objective of ensuring that the interactions between the agency safety efforts and its contractors and subcontractors are effective. Members are usually the agency safety manager, the integration contractor safety manager, representatives from appropriate offices within the agency, and the safety managers within the contractors and subcontractors. Members of the group are responsible for coordinating the efforts within their respective organizations and reporting the status of issue resolutions. The Committee believes that such a group or groups within the Shuttle program would help to solve communication problems and provide a more coherent software safety program.
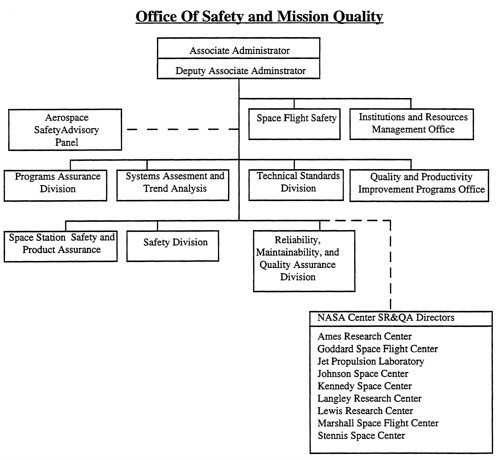
Source: NASA Office of Safety and Mission Quality
Figure 5-1 The dotted-line relationship between the Headquarters Safety and Mission Quality (S&MQ) Office and the center Safety, Reliability, and Quality Assurance (SR&QA) offices is undefined and ambiguous in practice and appears to contradict the original recommendation of the Rogers Commission for establishing these offices.
The Committee is also concerned about the safety certification process in NASA. The Committee notes the existence of program-independent safety certification boards in other agencies. For example, the Navy Weapon System Explosives Safety Review Board must assure the incorporation of explosives safety criteria in all weapon systems. This is accomplished through reviews conducted throughout all life-cycle phases of the weapon system. This board reviews system-safety and software-safety analyses that include:
-
identification of hazards;
-
identification of causal links to software;
-
identification of safety-critical computer software components and units;
-
development of safety design requirements;
-
identification of generic safety design requirements from generic documents and lessons learned;
-
tracing of safety design requirements;
-
identification and analysis of critical source code and methodology chosen;
-
results of detailed safety analyses of critical functions;
-
analysis of design-change recommendations for potential safety impacts; and
-
final assessment of safety issues.
The Weapons Review Board is supported in these tasks by a Software Systems Safety Technical Review Board. An important feature of these boards is that they are separate from the programs and, thus, allow an independent evaluation and certification of safety.
There is no equivalent program-independent review board in NASA. The Aerospace Safety Advisory Board does not consider programs at this level of detail and does not have the responsibility to certify the safety of particular programs. The Level 2 System-Safety Review Panel and Payload Safety Review Board review only hazard reports and do not evaluate or certify the safety-related software activities and products. Such an independent certification board would best be established under the control of the headquarters Safety Office.
Finally, the use of senior managers, scientists, and engineers on high-level peer committees is one measure of the quality of and commitment to a safety program. NASA and the U.S. Congress set up an Aerospace Safety Advisory Panel (ASAP) after the Apollo Command Module fire in 1967 to act as a senior advisory committee to NASA. The panel 's charter states:
The panel shall review safety studies and operations plans referred to it and shall make reports thereon, shall advise the Administrator with respect to the hazards of proposed operations and with respect to the adequacy of proposed or existing safety standards, and shall perform such other duties as the Administrator may request.
The panel provides independent review and an open forum for NASA and contractor personnel to air technical strengths and weaknesses to a group that reports directly to the NASA Administrator and Congress. The ASAP does not supersede the efforts of the various NASA safety, reliability, and quality-assurance organizations nor interfere with them, but it adds weight to management's emphasis on safety that is not obtainable in other ways because of the panel's
position in the organizational matrix, the members' individual and collective expertise, their independence, and their impartiality.
Thus, such a panel provides additional benefits to those provided by the ongoing safety efforts: independence and lack of involvement in internal politics, additional confidence that nothing falls through the cracks from a safety viewpoint, accountability to management and the public, and a means for an open forum and expanded communications for all levels and types of technical and administrative personnel.
Although software should be part of the normal ASAP activities, special expertise is needed to deal with software issues. A special subcommittee of the ASAP to consider software safety issues could demonstrate and give visibility to NASA's understanding of the growing importance of, and dependence upon, software to the safe accomplishment of NASA 's mission and its commitment to resolving the issues related to this relatively new technology.
Recommendation #10: NASA should establish better reporting and management relationships between developers, centers, programs, and the headquarters Safety Office.
Recommendation #11: NASA should consider the establishment of a NASA safety certification panel or board separate from the program offices and also the establishment of a subcommittee of the Aerospace Safety Advisory Panel to deal with software issues.
















