
Page 165
State of the Art in Continuous Speech Recognition
SUMMARY
In the past decade, tremendous advances in the state of the art of automatic speech recognition by machine have taken place. A reduction in the word error rate by more than a factor of 5 and an increase in recognition speeds by several orders of magnitude (brought about by a combination of faster recognition search algorithms and more powerful computers), have combined to make high-accuracy, speaker-independent, continuous speech recognition for large vocabularies possible in real time, on off-the-shelf workstations, without the aid of special hardware. These advances promise to make speech recognition technology readily available to the general public. This paper focuses on the speech recognition advances made through better speech modeling techniques, chiefly through more accurate mathematical modeling of speech sounds.
INTRODUCTION
More and more, speech recognition technology is making its way from the laboratory to real-world applications. Recently, a qualitative change in the state of the art has emerged that promises to bring speech recognition capabilities within the reach of anyone with access to a workstation. High-accuracy, real-time, speaker-independent,
Page 166
continuous speech recognition for medium-sized vocabularies (a few thousand words) is now possible in software on off-the-shelf workstations. Users will be able to tailor recognition capabilities to their own applications. Such software-based, real-time solutions usher in a whole new era in the development and utility of speech recognition technology.
As is often the case in technology, a paradigm shift occurs when several developments converge to make a new capability possible. In the case of continuous speech recognition, the following advances have converged to make the new technology possible:
• higher-accuracy continuous speech recognition, based on better speech modeling techniques;
• better recognition search strategies that reduce the time needed for high-accuracy recognition; and
• increased power of audio-capable, off-the-shelf workstations.
The paradigm shift is taking place in the way we view and use speech recognition. Rather than being mostly a laboratory endeavor, speech recognition is fast becoming a technology that is pervasive and will have a profound influence on the way humans communicate with machines and with each other.
This paper focuses on speech modeling advances in continuous speech recognition, with an exposition of hidden Markov models (HMMs), the mathematical backbone behind these advances. While knowledge of properties of the speech signal and of speech perception have always played a role, recent improvements have relied largely on solid mathematical and probabilistic modeling methods, especially the use of HMMs for modeling speech sounds. These methods are capable of modeling time and spectral variability simultaneously, and the model parameters can be estimated automatically from given training speech data. The traditional processes of segmentation and labeling of speech sounds are now merged into a single probabilistic process that can optimize recognition accuracy.
This paper describes the speech recognition process and provides typical recognition accuracy figures obtained in laboratory tests as a function of vocabulary, speaker dependence, grammar complexity, and the amount of speech used in training the system. As a result of modeling advances, recognition error rates have dropped several fold. Important to these improvements have been the availability of common speech corpora for training and testing purposes and the adoption of standard testing procedures.
This paper also reviews more recent research directions, including the use of segmental models and artificial neural networks in
Page 167
improving the performance of HMM systems. The capabilities of neural networks to model highly nonlinear functions can be used to develop new features from the speech signal, and their ability to model posterior probabilities can be used to improve recognition accuracy.
We will argue that future advances in speech recognition must continue to rely on finding better ways to incorporate our speech knowledge into advanced mathematical models, with an emphasis on methods that are robust to speaker variability, noise, and other acoustic distortions.
THE SPEECH RECOGNITION PROBLEM
Automatic speech recognition can be viewed as a mapping from a continuous-time signal, the speech signal, to a sequence of discrete entities, for example, phonemes (or speech sounds), words, and sentences. The major obstacle to high-accuracy recognition is the large variability in the speech signal characteristics. This variability has three main components: linguistic variability, speaker variability, and channel variability. Linguistic variability includes the effects of phonetics, phonology, syntax, semantics, and discourse on the speech signal. Speaker variability includes intra- and interspeaker variability, including the effects of coarticulation, that is, the effects of neighboring sounds on the acoustic realization of a particular phoneme, due to continuity and motion constraints on the human articulatory apparatus. Channel variability includes the effects of background noise and the transmission channel (e.g., microphone, telephone, reverberation). All these variabilities tend to shroud the intended message with layers of uncertainty, which must be unraveled by the recognition process.
General Synthesis/Recognition Process
We view the recognition process as one component of a general synthesis/recognition process, as shown in Figure 1. We assume that the synthesis process consists of three components: a structural model, a statistical variability model, and the synthesis of the speech signal. The input is some underlying event, such as a sequence of words, and the output is the actual speech signal. The structural model comprises many aspects of our knowledge of speech and language, and the statistical variability model accounts for the different variabilities that are encountered. The recognition process begins with analysis of the speech signal into a sequence of feature vectors. This analysis serves to reduce one aspect of signal variability due to changes in
Page 168
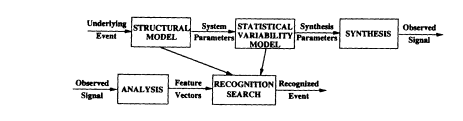
FIGURE 1 General synthesis/recognition process.
pitch, etc. Given the sequence of feature vectors, the recognition process reduces to a search over all possible events (word sequences) for that event which has the highest probability given the sequence of feature vectors, based on the structural and statistical variability models used in the synthesis.
It is important to note that a significant and important amount of speech knowledge is incorporated in the structural model, including our knowledge of language structure, speech production, and speech perception. Examples of language structure include the fact that continuous speech consists of a concatenation of words and that words are a concatenation of basic speech sounds or phonemes. This knowledge of language structure is quite ancient, being at least 3000 years old. A more recent aspect of language structure that was appreciated in this century is the fact that the acoustic realization of phonemes is heavily dependent on the neighboring context. Our knowledge of speech production, in terms of manner of articulation (e.g., voiced, fricated, nasal) and place of articulation (e.g., velar, palatal, dental, labial), for example, can be used to provide parsimonious groupings of phonetic context. As for speech perception, much is known about sound analysis in the cochlea, for example, that the basilar membrane performs a form of quasi-spectral analysis on a nonlinear frequency scale, and about masking phenomena in time and frequency. All this knowledge can be incorporated beneficially in our modeling of the speech signal for recognition purposes.
Units of Speech
To gain an appreciation of what modeling is required to perform recognition, we shall use as an example the phrase "grey whales," whose speech signal is shown at the bottom of Figure 2 with the corresponding spectrogram (or voice print) shown immediately above. The spectrogram shows the result of a frequency analysis of the speech,
Page 169

FIGURE 2 Units of speech.
with the dark bands representing resonances of the vocal tract. At the top of Figure 2 are the two words "grey" and "whales," which are the desired output of the recognition system. The first thing to note is that the speech signal and the spectrogram show no separation between the two words ''grey" and "whales" at all; they are in fact connected. This is typical of continuous speech; the words are connected to each other, with no apparent separation. The human perception that a speech utterance is composed of a sequence of discrete words is a purely perceptual phenomenon. The reality is that the words are not separated at all physically.
Below the word level in Figure 2 is the phonetic level. Here the words are represented in terms of a phonetic alphabet that tells us what the different sounds in the two words are. In this case the phonetic transcription is given by [g r ey w ey 1 z ]. Again, while the sequence of phonemes is discrete, there is no physical separation
Page 170
between the different sounds in the speech signal. In fact, it is not clear where one sound ends and the next begins. The dashed vertical lines shown in Figure 2 give a rough segmentation of the speech signal, which shows approximately the correspondences between the phonemes and the speech.
Now, the phoneme [ey] occurs once in each of the two words. If we look at the portions of the spectrogram corresponding to the two [ey] phonemes, we notice some similarities between the two parts, but we also note some differences. The differences are mostly due to the fact that the two phonemes are in different contexts: the first [ey] phoneme is preceded by [r] and followed by [w], while the second is preceded by [w] and followed by [1]. These contextual effects are the result of what is known as coarticulation, the fact that the articulation of each sound blends into the articulation of the following sound. In many cases, contextual phonetic effects span several phonemes, but the major effects are caused by the two neighboring phonemes.
To account for the fact that the same phoneme has different acoustic realizations, depending on the context, we refer to each specific context as an allophone. Thus, in Figure 2, we have two different allophones of the phoneme [ey], one for each of the two contexts in the two words. In this way, we are able to deal with the phonetic variability that is inherent in coarticulation and that is evident in the spectrogram of Figure 2.
To perform the necessary mapping from the continuous speech signal to the discrete phonetic level, we insert a model—a finite-state machine in our case—for each of the allophones that are encountered. We note from Figure 2 that the structures of these models are identical; the differences will be in the values given to the various model parameters. Each of these models is a hidden Markov model, which is discussed below.
HIDDEN MARKOV MODELS
Markov Chains
Before we explain what a hidden Markov model is, we remind the reader of what a Markov chain is. A Markov chain consists of a number of states, with transitions among the states. Associated with each transition is a probability and associated with each state is a symbol. Figure 3 shows a three-state Markov chain, with transition probabilities aij. between states i and j. The symbol A is associated with state 1, the symbol B with state 2, and the symbol C with state 3. As one transitions from state 1 to state 2, for example, the symbol B is
Page 171
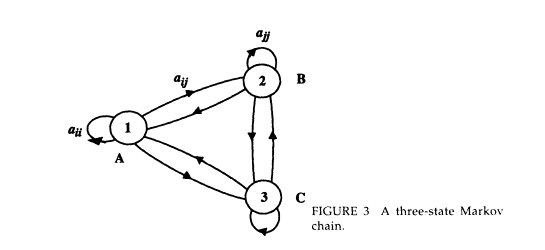
produced as output. If the next transition is from state 2 to itself, the symbol B is output again, while if the transition were to state 3, the output would be the symbol C. These symbols are called output symbols because a Markov chain is thought of as a generative model; it outputs symbols as one transitions from one state to another. Note that in a Markov chain the transitioning from one state to another is probabilistic, but the production of the output symbols is deterministic.
Now, given a sequence of output symbols that were generated by a Markov chain, one can retrace the corresponding sequence of states completely and unambiguously (provided the output symbol for each state was unique). For example, the sample symbol sequence B A A C B B A C C C A is produced by transitioning into the following sequence of states: 2 11 3 2 2 1 3 3 3 1.
Hidden Markov Models
A hidden Markov model (HMM) is the same as a Markov chain, except for one important difference: the output symbols in an HMM are probabilistic. Instead of associating a single output symbol per state, in an HMM all symbols are possible at each state, each with its own probability. Thus, associated with each state is a probability distribution of all the output symbols. Furthermore, the number of output symbols can be arbitrary. The different states may then have different probability distributions defined on the set of output symbols. The probabilities associated with states are known as output probabilities. (If instead of having a discrete number of output sym-
Page 172
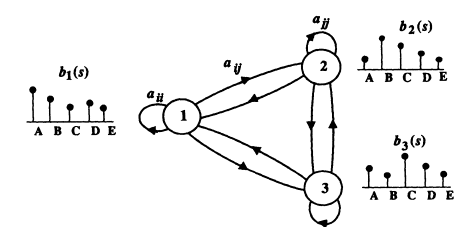
FIGURE 4 A three-state hidden Markov model.
bols we have a continuously valued vector, it is possible to define a probability density function over all possible values of the random output vector. For the purposes of this exposition, we shall limit our discussion to discrete output symbols.)
Figure 4 shows an example of a three-state HMM. It has the same transition probabilities as the Markov chain of Figure 3. What is different is that we associate a probability distribution b,(s) with each state i, defined over the set of output symbols s—in this case we have five output symbols—A, B, C, D, and E. Now, when we transition from one state to another, the output symbol is chosen according to the probability distribution corresponding to that state. Compared to a Markov chain, the output sequences generated by an HMM are what is known as doubly stochastic: not only is the transitioning from one state to another stochastic (probabilistic) but so is the output symbol generated at each state.
Now, given a sequence of symbols generated by a particular HMM, it is not possible to retrace the sequence of states unambiguously. Every sequence of states of the same length as the sequence of symbols is possible, each with a different probability. Given the sample output sequence—C D A A B E D B A C C—there is no way for sure to know which sequence of states produced these output symbols. We say that the sequence of states is hidden in that it is hidden from the observer if all one sees is the output sequence, and that is why these models are known as hidden Markov models.
Even though it is not possible to determine for sure what se-
Page 173
quence of states produced a particular sequence of symbols, one might be interested in the sequence of states that has the highest probability of having generated the given sequence. To find such a sequence of states requires a search procedure that, in principle, must examine all possible state sequences and compute their corresponding probabilities. The number of possible state sequences grows exponentially with the length of the sequence. However, because of the Markov nature of an HMM, namely that being in a state is dependent only on the previous state, there is an efficient search procedure called the Viterbi algorithm (Forney, 1973) that can find the sequence of states most likely to have generated the given sequence of symbols, without having to search all possible sequences. This algorithm requires computation that is proportional to the number of states in the model and to the length of the sequence.
Phonetic HMMs
We now explain how HMMs are used to model phonetic speech events. Figure 5 shows an example of a three-state HMM for a single phoneme. The first stage in the continuous-to-discrete mapping that

FIGURE 5 Basic structure of a phonetic HMM.
Page 174
is required for recognition is performed by the analysis box in Figure 1. Typically, the analysis consists of estimation of the short-term spectrum of the speech signal over a frame (window) of about 20 ms. The spectral computation is then updated about every 10 ms, which corresponds to a frame rate of 100 frames per second. This completes the initial discretization in time. However, the HMM, as depicted in this paper, also requires the definition of a discrete set of "output symbols." So, we need to discretize the spectrum into one of a finite set of spectra. Figure 5 depicts a set of spectral templates (known as a codebook) that represent the space of possible speech spectra. Given a computed spectrum for a frame of speech, one can find the template in the codebook that is "closest" to that spectrum, using a process known as vector quantization (Makhoul et al., 1985). The size of the codebook in Figure 5 is 256 templates. These templates, or their indices (from 0 to 255), serve as the output symbols of the HMM. We see in Figure 5 that associated with each state is a probability distribution on the set of 256 symbols. The definition of a phonetic HMM is now complete. We now describe how it functions.
Let us first see how a phonetic HMM functions as a generative (synthesis) model. As we enter into state 1 in Figure 5, one of the 256 output symbols is generated based on the probability distribution corresponding to state 1. Then, based on the transition probabilities out of state 1, a transition is made either back to state 1 itself, to state 2, or to state 3, and another symbol is generated based on the probability distribution corresponding to the state into which the transition is made. In this way a sequence of symbols is generated until a transition out of state 3 is made. At that point, the sequence corresponds to a single phoneme.
The same model can be used in recognition mode. In this mode each model can be used to compute the probability of having generated a sequence of spectra. Assuming we start with state 1 and given an input speech spectrum that has been quantized to one of the 256 templates, one can perform a table lookup to find the probability of that spectrum. If we now assume that a transition is made from state 1 to state 2, for example, the previous output probability is multiplied by the transition probability from state 1 to state 2 (0.5 in Figure 5). A new spectrum is now computed over the next frame of speech and quantized; the corresponding output probability is then determined from the output probability distribution corresponding to state 2. That probability is multiplied by the previous product, and the process is continued until the model is exited. The result of multiplying the sequence of output and transition probabilities gives the total probability that the input spectral sequence was "generated" by
Page 175
that HMM using a specific sequence of states. For every sequence of states, a different probability value results. For recognition, the probability computation just described is performed for all possible phoneme models and all possible state sequences. The one sequence that results in the highest probability is declared to be the recognized sequence of phonemes.
We note in Figure 5 that not all transitions are allowed (i.e., the transitions that do not appear have a probability of zero). This model is what is known as a "left-to-right" model, which represents the fact that, in speech, time flows in a forward direction only; that forward direction is represented in Figure 5 by a general left-to-right movement. Thus, there are no transitions allowed from right to left. Transitions from any state back to itself serve to model variability in time, which is very necessary for speech since different instantiations of phonemes and words are uttered with different time registrations. The transition from state 1 to state 3 means that the shortest phoneme that is modeled by the model in Figure 5 is one that is two frames long, or 20 ms. Such a phoneme would occupy state 1 for one frame and state 3 for one frame only. One explanation for the need for three states, in general, is that state 1 corresponds roughly to the left part of the phoneme, state 2 to the middle part, and state 3 to the right part. (More states can be used, but then more data would be needed to estimate their parameters robustly.)
Usually, there is one HMM for each of the phonetic contexts of interest. Although the different contexts could have different structures, usually all such models have the same structure as the one shown in Figure 5; what makes them different are the transition and output probabilities.
A HISTORICAL OVERVIEW
HMM theory was developed in the late 1960s by Baum and colleagues (Baum and Eagon, 1967) at the Institute for Defense Analyses (IDA). Initial work using HMMs for speech recognition was performed in the 1970s at IDA, IBM (Jelinek et al., 1975), and Carnegie-Mellon University (Baker, 1975). In 1980 a number of researchers in speech recognition in the United States were invited to a workshop in which IDA researchers reviewed the properties of HMMs and their use for speech recognition. That workshop prompted a few organizations, such as AT&T and BBN, to start working with HMMs (Levinson et al., 1983; Schwartz et al., 1984). In 1984 a program in continuous speech recognition was initiated by the Advanced Research Projects Agency (ARPA), and soon thereafter HMMs were shown to be supe-
Page 176
rior to other approaches (Chow et al., 1986). Until then, only a handful of organizations worldwide had been working with HMMs. Because of the success of HMMs and because of the strong influence of the ARPA program, with its emphasis on periodic evaluations using common speech corpora, the use of HMMs for speech recognition started to spread worldwide. Today, their use has dominated other approaches to speech recognition in dozens of laboratories around the globe. In addition to the laboratories mentioned above, significant work is taking place at, for example, the Massachusetts Institute of Technology's Lincoln Laboratory, Dragon, SRI, and TI in the United States; CRIM and BNR in Canada; RSRE and Cambridge University in the United Kingdom; ATR, NTT, and NEC in Japan; LIMSI in France; Philips in Germany and Belgium; and CSELT in Italy, to name a few. Comprehensive treatments of HMMs and their utility in speech recognition can be found in Rabiner (1989), Lee (1989), Huang et al. (1990), Rabiner and Juang (1993), and the references therein. Research results in this area are usually reported in the following journals and conference proceedings: IEEE Transactions on Speech and Audio Processing; IEEE Transactions on Signal Processing; Speech Communication Journal; IEEE International Conference on Acoustics, Speech, and Signal Processing; EuroSpeech; and the International Conference on Speech and Language Processing.
HMMs have proven to be a good model of speech variability in time and feature space. The automatic training of the models from speech data has accelerated the speed of research and improved recognition performance. Also, the probabilistic formulation of HMMs has provided a unified framework for scoring of hypotheses and for combining different knowledge sources. For example, the sequence of spoken words can also be modeled as the output of another statistical process (Bahl et al., 1983). In this way it becomes natural to combine the HMMs for speech with the statistical models for language.
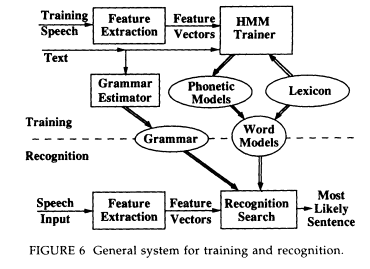
TRAINING AND RECOGNITION
Figure 6 shows a block diagram of a general system for training and recognition. Note that in both training and recognition the first step in the process is to perform feature extraction on the speech signal.
Page 177
Feature Extraction
In theory it should be possible to recognize speech directly from the signal. However, because of the large variability of the speech signal, it is a good idea to perform some form of feature extraction to reduce that variability. In particular, computing the envelope of the short-term spectrum reduces the variability significantly by smoothing the detailed spectrum, thus eliminating various source characteristics, such as whether the sound is voiced or fricated, and, if voiced, it eliminates the effect of the periodicity or pitch. The loss of source information does not appear to affect recognition performance much because it turns out that the spectral envelope is highly correlated with the source information.
One reason for computing the short-term spectrum is that the cochlea of the human ear performs a quasi-frequency analysis. The analysis in the cochlea takes place on a nonlinear frequency scale (known as the Bark scale or the mel scale). This scale is approximately linear up to about 1000 Hz and is approximately logarithmic thereafter. So, in the feature extraction, it is very common to perform a frequency warping of the frequency axis after the spectral computation.
Researchers have experimented with many different types of features for use with HMMs (Rabiner and Juang, 1993). Variations on the basic spectral computation, such as the inclusion of time and frequency masking, have been shown to provide some benefit in certain cases. The use of auditory models as the basis for feature extrac-
Page 178
tion has been useful in some systems (Cohen, 1989), especially in noisy environments (Hunt et al., 1991).
Perhaps the most popular features used for speech recognition with HMMs today are what are known as mel-frequency cepstral coefficients or MFCCs (Davis and Mermelstein, 1980). After the mel-scale warping of the spectrum, the logarithm of the spectrum is taken and an inverse Fourier transform results in the cepstrum. By retaining the first dozen or so coefficients of the cepstrum, one would be retaining the spectral envelope information that is desired. The resulting features are the MFCCs, which are treated as a single vector and are typically computed for every frame of 10 ms. These feature vectors form the input to the training and recognition systems.
Training
Training is the process of estimating the speech model parameters from actual speech data. In preparation for training, what is needed is the text of the training speech and a lexicon of all the words in the training, along with their pronunciations, written down as phonetic spellings. Thus, a transcription of the training speech is made by listening to the speech and writing down the sequence of words. All the distinct words are then placed in a lexicon and someone has to provide a phonetic spelling of each word. In cases where a word has more than one pronunciation, as many phonetic spellings as there are pronunciations are included for each word. These phonetic spellings can be obtained from existing dictionaries or they can be written by anyone with minimal training in phonetics.
Phonetic HMMs and Lexicon
Given the training speech, the text of the speech, and the lexicon of phonetic spellings of all the words, the parameters of all the phonetic HMMs (transition and output probabilities) are estimated automatically using an iterative procedure known as the Baum-Welch or forward-backward algorithm (Baum and Eagon, 1967). This algorithm estimates the parameters of the HMMs so as to maximize the likelihood (probability) that the training speech was indeed produced by these HMMs. The iterative procedure is guaranteed to converge to a local optimum. Typically, about five iterations through the data are needed to obtain a reasonably good estimate of the speech model. (See the paper by Jelinek in this volume for more details on the HMM training algorithm.)
It is important to emphasize the fact that HMM training does not
Page 179
require that the data be labeled in detail in terms of the location of the different words and phonemes, that is, no time alignment between the speech and the text is needed. Given a reasonable initial estimate of the HMM parameters, the Baum-Welch training algorithm performs an implicit alignment of the input spectral sequence to the states of the HMM, which is then used to obtain an improved estimate. All that is required in addition to the training speech is the text transcription and the lexicon. This is one of the most important properties of the HMM approach to recognition. Training does require significant amounts of computing but does not require much in terms of human labor.
In preparation for recognition it is important that the lexicon contain words that would be expected to occur in future data, even if they did not occur in the training. Typically, closed-set word classes are filled out—for example, days of the week, months of the year, numbers.
After completing the lexicon, HMM word models are compiled from the set of phonetic models using the phonetic spellings in the lexicon. These word models are simply a concatenation of the appropriate phonetic HMM models. We then compile the grammar (which specifies sequences of words) and the lexicon (which specifies sequences of phonemes for each word) into a single probabilistic grammar for the sequences of phonemes. The result of the recognition is a particular sequence of words, corresponding to the recognized sequence of phonemes.
Grammar
Another aspect of the training that is needed to aid in the recognition is to produce the grammar to be used in the recognition. Without a grammar, all words would be considered equally likely at each point in an utterance, which would make recognition difficult, especially with large vocabularies. We, as humans, make enormous use of our knowledge of the language to help us recognize what a person is saying. A grammar places constraints on the sequences of the words that are allowed, giving the recognition fewer choices at each point in the utterance and, therefore, improving recognition performance.
Most grammars used in speech recognition these days are statistical Markov grammars that give the probabilities of different sequences of words—so-called n-gram grammars. For example, bigram grammars give the probabilities of all pairs of words, while trigram grammars give the probabilities of all triplets of words in the lexicon. In practice, trigrams appear to be sufficient to embody much of the
Page 180
natural constraints imposed on the sequences of words in a language. In an n-gram Markov grammar, the probability of a word is a function of the previous n - 1 words. While this assumption may not be valid in general, it appears to be sufficient to result in good recognition accuracy. Furthermore, the assumption allows for efficient computation of the likelihood of a sequence of words.
A measure of how constrained a grammar is is given by its perplexity (Bahl et al., 1983). Perplexity is defined as 2 raised to the power of the Shannon entropy of the grammar. If all words are equally likely at each point in a sentence, the perplexity is equal to the vocabulary size. In practice, sequences of words have greatly differing probabilities, and the perplexity is often much less than the vocabulary size, especially for larger vocabularies. Because grammars are estimated from a set of training data, it is often more meaningful to measure the perplexity on an independent set of data, or what is known as test-set perplexity (Bahl et al., 1983). Test-set perplexity Q is obtained by computing
![]()
where w1 w2 ... wM is the sequence of words obtained by concatenating all the test sentences and P is the probability of that whole sequence. Because of the Markov property of n-gram grammars, the probability P can be computed as the product of consecutive conditional probabilities of n-grams.
Recognition
As shown in Figure 6, the recognition process starts with the feature extraction stage, which is identical to that performed in the training. Then, given the sequence of feature vectors, the word HMM models, and the grammar, the recognition is simply a large search among all possible word sequences for that word sequence with the highest probability to have generated the computed sequence of feature vectors. In theory the search is exponential with the number of words in the utterance. However, because of the Markovian property of conditional independence in the HMM, it is possible to reduce the search drastically by the use of dynamic programming (e.g., using the Viterbi algorithm). The Viterbi algorithm requires computation that is proportional to the number of states in the model and the length of the input sequence. Further approximate search algorithms have been developed that allow the search computation to be reduced further, without significant loss in performance. The most com-
Page 181
monly used technique is the beam search (Lowerre, 1976), which avoids the computation for states that have low probability.
STATE OF THE ART
In this section we review the state of the art in continuous speech recognition. We present some of the major factors that led to the relatively large improvements in performance and give sample performance figures under different conditions. We then review several of the issues that affect performance, including the effects of training and grammar, speaker-dependent versus speaker-independent recognition, speaker adaptation, nonnative speakers, and the inclusion of new words in the vocabulary. Most of the results and examples below have been taken from the ARPA program, which has sponsored the collection and dissemination of large speech corpora for comparative evaluation, with specific examples taken from work most familiar to the authors.
Improvements in Performance
The improvements in speech recognition performance have been so dramatic that in the ARPA program the word error rate has dropped by a factor of 5 in 5 years! This unprecedented advance in the state of the art is due to four factors: use of common speech corpora, improved acoustic modeling, improved language modeling, and a faster research experimentation cycle.
Common Speech Corpora
The ARPA program must be given credit for starting and maintaining a sizable program in large-vocabulary, speaker-independent, continuous speech recognition. One of the cornerstones of the ARPA program has been the collection and use of common speech corpora for system development and testing. (The various speech corpora collected under this program are available from the Linguistic Data Consortium, with offices at the University of Pennsylvania.) The first large corpus was the Resource Management (RM) corpus (Price et al., 1988), which was a collection of read sentences from a 1000-word vocabulary in a naval resource management domain. Using this corpus as the basis for their work, the various sites in the program underwent a series of tests of competing recognition algorithms every 6 to 9 months. The various algorithms developed were shared with the other participants after every evaluation, and the successful
Page 182
ones were quickly incorporated by the different sites. In addition to the algorithms developed by the sites in the program, other algorithms were also incorporated from around the globe, especially from Europe and Japan. This cycle of algorithm development, evaluation, and sharing of detailed technical information led to the incredible reduction in error rate noted above.
Acoustic Modeling
A number of ideas in acoustic modeling have led to significant improvements in performance. Developing HMM phonetic models that depend on context, that is, on the left and right phonemes, have been shown to reduce the word error rate by about a factor of 2 over context-independent models (Chow et al., 1986). Of course, with context-dependent models, the number of models increases significantly. In theory, if there are 40 phonemes in the system, the number of possible triphone models is 403 = 64,000. However, in practice, only a few thousand of these triphones might actually occur. So, only models of the triphones that occur in the training data are usually estimated. If particular triphones in the test do not occur in the training, the allophone models used may be the diphones or even the context-independent models. One of the properties of HMMs is that different models (e.g., context-independent, diphone, and triphone models) can be interpolated in such a way as to make the best possible use of the training data, thus increasing the robustness of the system.
Because most systems are implemented as word recognition systems (rather than phoneme recognition systems), it is usually not part of the basic recognition system to deal with cross-word contextual effects and, therefore, including those effects in the recognition can increase the computational burden substantially. The modeling of cross-word effects is most important for small words, especially function words (where many of the errors occur), and can reduce the overall word error rate by about 20 percent.
In addition to the use of feature vectors, such as MFCCs, it has been found that including what is known as delta features—the change in the feature vector over time—can reduce the error rate by a factor of about 2 (Furui, 1986). The delta features are treated like an additional feature vector whose probability distribution must also be estimated from training data. Even though the original feature vector contains all the information that can be used for the recognition, it appears that the HMM does not take full advantage of the time evolution of the feature vectors. Computing the delta parameters is a
Page 183
way of extracting that time information and providing it to the HMM directly (Gupta et al., 1987).
Proper estimation of the HMM parameters—the transition and output probabilities—from training data is of crucial importance. Because only a small number of the possible feature vector values will occur in any training set, it is important to use probability estimation and smoothing techniques that not only will model the training data well but also will model other possible occurrences in future unseen data. A number of probability estimation and smoothing techniques have been developed that strike a good compromise between computation, robustness, and recognition accuracy and have resulted in error rate reductions of about 20 percent compared to the discrete HMMs presented in the section titled ''Hidden Markov Models" (Bellegarda and Nahamoo, 1989; Gauvain and Lee, 1992; Huang et al., 1990; Schwartz et al., 1989).
Language Modeling
As mentioned above, statistical n-gram grammars, especially word trigrams, have been very successful in modeling the likely word sequences in actual speech data. To obtain a good language model, it is important to use as large a text corpus as possible so that all the trigrams to be seen in any new test material are seen in the training with about the same probability. Note that only the text is needed for training the language model, not the actual speech. Typically, millions of words of text are used to develop good language models. A number of methods have been developed that provide a robust estimate of the trigram probabilities (Katz, 1987; Placeway et al., 1993).
For a large-vocabulary system, there is little doubt that the completeness, accuracy, and robustness of the language model can play a major role in the recognition performance of the system. Since one cannot always predict what new material is possible in a large-vocabulary domain, it will be important to develop language models that can change dynamically as the input data change (Della Pietra et al., 1992).
Research Experimentation Cycle
We have emphasized above the recognition improvements that have been possible with innovations in algorithm development. However, those improvements would not have been possible without the proper computational tools that have allowed the researcher to shorten the research experimentation cycle. Faster search algorithms, as well
Page 184
as faster workstations, have made it possible to run a large experiment in a short time, typically overnight, so that the researcher can make appropriate changes the next day and run another experiment. The combined increases in speed with better search and faster machines have been several orders of magnitude.
Sample Performance Figures
Figure 7 gives a representative sampling of state-of-the-art continuous speech recognition performance. The performance is shown in terms of the word error rate, which is defined as the sum of word substitutions, deletions, and insertions, as a percentage of the actual number of words in the test. All training and test speakers were native speakers of American English. The error rates are for speaker-independent recognition, that is, test speakers were different from the speakers used for training. All the results in Figure 7 are for laboratory systems; they were obtained from the following references (Bates et al., 1993; Cardin et al., 1993; Haeb-Umbach et al., 1993; Huang et al., 1991; Pallett et al., 1993).
The results for four corpora are shown: the TI connected-digit corpus (Leonard, 1984), the ARPA Resource Management corpus, the ARPA Airline Travel Information Service (ATIS) corpus (MADCOW, 1992), and the ARPA Wall Street Journal (WSJ) corpus (Paul, 1992).
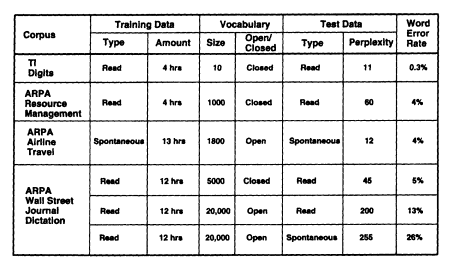
FIGURE 7 State of the art in speaker-independent, continuous speech recognition.
Page 185
The first two corpora were collected in very quiet rooms at TI, while the latter two were collected in office environments at several different sites. The ATIS corpus was collected from subjects trying to access airline information by voice using natural English queries; it is the only corpus of the four presented here for which the training and test speech are spontaneous instead of being read sentences. The WSJ corpus consists largely of read sentences from the Wall Street Journal, with some spontaneous sentences used for testing. Shown in Figure 7 are the vocabulary size for each corpus and whether the vocabulary is closed or open. The vocabulary is closed when all the words in the test are guaranteed to be in the system's lexicon, while in the open condition the test may contain words that are not in the system's lexicon and, therefore, will cause errors in the recognition. The perplexity is the test-set perplexity defined above. Strictly speaking, perplexity is not defined for the open-vocabulary condition, so the value of the perplexity that is shown was obtained by making some simple assumptions about the probability of n-grams that contain the unknown words.
The results shown in Figure 7 are average results over a number of test speakers. The error rates for individual speakers vary over a relatively wide range and may be several times lower or higher than the average values shown. Since much of the data were collected in relatively benign conditions, one would expect the performance to degrade in the presence of noise and channel distortion. It is clear from Figure 7 that higher perplexity, open vocabulary, and spontaneous speech tend to increase the word error rate. We shall quantify some of these effects next and discuss some important issues that affect performance.
Effects of Training and Grammar
It is well recognized that increasing the amount of training data generally decreases the word error rate. However, it is important that the increased training be representative of the types of data in the test. Otherwise, the increased training might not help.
With the RM corpus, it has been found that the error rate is inversely proportional to the square root of the amount of training data, so that quadrupling the training data results in cutting the word error rate by a factor of 2. This large reduction in error rate by increasing the training data may have been the result of an artifact of the RM corpus, namely, that the sentence patterns of the test data were the same as those in the training. In a realistic corpus, where the sentence patterns of the test can often be quite different from the
Page 186
training, such improvements may not be as dramatic. For example, recent experiments with the WSJ corpus have failed to show significant reduction in error rate by doubling the amount of training. However, it is possible that increasing the complexity of the models as the training data are increased could result in larger reduction in the error rate. This is still very much a research issue.
Word error rates generally increase with an increase in grammar perplexity. A general rule of thumb is that the error rate increases as the square root of perplexity, with everything else being equal. This rule of thumb may not always be a good predictor of performance, but it is a reasonable approximation. Note that the size of the vocabulary as such is not the primary determiner of recognition performance but rather the freedom in which the words are put together, which is represented by the grammar. A less constrained grammar, such as in the WSJ corpus, results in higher error rates.
Speaker-Dependent vs. Speaker-Independent Recognition
The terms speaker-dependent (SD) and speaker-independent (SI) recognition are often used to describe different modes of operation of a speech recognition system. SD recognition refers to the case when a single speaker is used to train the system and the same speaker is used to test the system. SI recognition refers to the case where the test speaker is not included in the training. HMM-based systems can operate in either SD or SI mode, depending on the training data used. In SD mode training speech is collected from a single speaker only, while in SI mode training speech is collected from a variety of speakers.
SD and SI modes of recognition can be compared in terms of the word error rates for a given amount of training. A general rule of thumb is that, if the total amount of training speech is fixed at some level, the SI word error rates are about four times the SD error rates. Another way of stating this rule of thumb is that, for SI recognition to have the same performance as SD recognition, requires about 15 times the amount of training data (Schwartz et al., 1993). These results were obtained when one hour of speech was used to compute the SD models. However, in the limit, as the amount of training speech for SD and SI models is made larger and larger, it is not clear that any amount of training data will allow SI performance to approach SD performance.
The idea behind SI recognition is that the training is done once, after which any speaker can use the system with good performance. SD recognition is seen as an inconvenience for potential users. How-
Page 187
ever, one must keep in mind that SI training must be performed for each new use of a system in a different domain. If the system is used in a domain in which it was not trained, the performance degrades. It has been a historical axiom that, for optimal SI recognition performance, it is best to collect training speech from as many speakers as possible in each domain. For example, instead of collecting 100 utterances from each of 100 speakers, it was believed that it is far superior to collect, say, 10 utterances from each of 1000 speakers. Recent experiments have shown that, for some applications, collecting speech from only a dozen speakers may be sufficient for good SI performance. In an experiment with the WSJ corpus, for a fixed amount of training data, it was shown that training with 12 speakers gave basically the same SI performance as training with 84 speakers (Schwartz et al., 1993). This is a welcome result; it makes it easier to develop SI models in a new domain since collecting data from fewer speakers is cheaper and more convenient.
The ultimate goal of speech recognition research is to have a system that is domain independent (DI), that is, a system that is trained once and for all so that it can be used in any new domain and for any speaker without retraining. Currently, the only method used for DI recognition is to train the system on a very large amount of data from different domains. However, preliminary tests have shown that DI recognition on a new domain not included in the training can increase the error rate by a factor of 1.5 to 2 over SI recognition when trained on the new domain, assuming that the grammar comes from the new domain (Hon, 1992). If a good grammar is not available from the new domain, performance can be several times worse.
Adaptation
It is possible to improve the performance of an SI or DI system by incrementally adapting to the voice of a new speaker as the speaker uses the system. This would be especially needed for atypical speakers with high error rates who might otherwise find the system unusable. Such speakers would include speakers with unusual dialects and those for whom the SI models simply are not good models of their speech. However, incremental adaptation could require hours of usage and a lot of patience from the new user before the performance becomes adequate.
A good solution to the atypical speaker problem is to use a method known as rapid speaker adaptation. In this method only a small amount of speech (about two minutes) is collected from the new speaker before using the system. By having the same utterances collected
Page 188
previously from one or more prototype speakers, methods have been developed for deriving a speech model for the new speaker through a simple transformation on the speech model of the prototype speakers (Furui, 1989; Kubala and Schwartz, 1990; Nakamura and Shikano, 1989). It is possible with these methods to achieve average SI performance for speakers who otherwise would have several times the error rate.
One salient example of atypical speakers are nonnative speakers, given that the SI system was trained on only native speakers. In a pilot experiment where four nonnative speakers were tested in the RM domain in SI mode, there was an eight-fold increase in the word error rate over that of native speakers! The four speakers were native speakers of Arabic, Hebrew, Chinese, and British English. By collecting two minutes of speech from each of these speakers and using rapid speaker adaptation, the average word error rate for the four speakers decreased five-fold.
Adding New Words
Out-of-vocabulary words cause recognition errors and degrade performance. There have been very few attempts at automatically detecting the presence of new words, with limited success (Asadi et al., 1990). Most systems simply do not do anything special to deal with the presence of such words.
After the user realizes that some of the errors are being caused by new words and determines what these words are, it is possible to add them to the system's vocabulary. In word-based recognition, where whole words are modeled without having an intermediate phonetic stage, adding new words to the vocabulary requires specific training of the system on the new words (Bahl et al., 1988). However, in phonetically based recognition, such as the phonetic HMM approach presented in this paper, adding new words to the vocabulary can be accomplished by including their phonetic pronunciations in the system's lexicon. If the new word is not in the lexicon, a phonetic pronunciation can be derived from a combination of a transcription and an actual pronunciation of the word by the speaker (Bahl et al., 1990a). The HMMs for the new words are then automatically compiled from the preexisting phonetic models, as shown in Figure 6. The new words must also be added to the grammar in an appropriate manner.
Experiments have shown that, without additional training for the new words, the SI error rate for the new words is about twice that with training that includes the new words. Therefore, user-specified vocabulary and grammar can be easily incorporated into a speech
Page 189
recognition system at a modest increase in the error rate for the new words.
REAL-TIME SPEECH RECOGNITION
Until recently, it was thought that to perform high-accuracy, real-time, continuous speech recognition for large vocabularies would require either special-purpose VLSI hardware or a multiprocessor. However, new developments in search algorithms have sped up the recognition computation at least two orders of magnitude, with little or no loss in recognition accuracy (Austin et al., 1991; Bahl et al., 1990b; Ney, 1992; Schwartz and Austin, 1991; Soong and Huang, 1991). In addition, computing advances have achieved two-orders-magnitude increase in workstation speeds in the past decade. These two advances have made software-based, real-time, continuous speech recognition a reality. The only requirement is that the workstation must have an A/D converter to digitize the speech. All the signal processing, feature extraction, and recognition search is then performed in software in real time on a single-processor workstation.
For example, it is now possible to perform a 2000-word ATIS task in real time on workstations such as the Silicon Graphics Indigo R3000 or the Sun SparcStation 2. Most recently, a 20,000-word WSJ continuous dictation task was demonstrated in real time (Nguyen et al., 1993) on a Hewlett-Packard 735 workstation, which has about three times the power of an SGI R3000. Thus, the computation grows much slower than linear with the size of the vocabulary.
The real-time feats just described have been achieved at a relatively small cost in word accuracy. Typically, the word error rates are less than twice those of the best research systems.
The most advanced of these real-time demonstrations have not as yet made their way to the marketplace. However, it is possible today to purchase products that perform speaker-independent, continuous speech recognition for vocabularies of a few thousand words. Dictation of large vocabularies of about 30,000 words is available commercially, but the speaker must pause very briefly between words, and the system adapts to the voice of the user to improve performance. For more on some of the available products and their applications, the reader is referred to other papers in this volume.
ALTERNATIVE MODELS
HMMs have proven to be very good for modeling variability in time and feature space and have resulted in tremendous advances in
Page 190
continuous speech recognition. However, some of the assumptions made by HMMs are known not to be strictly true for speech—for example, the conditional independence assumptions in which the probability of being in a state is dependent only on the previous state and the output probability at a state is dependent only on that state and not on previous states or previous outputs. There have been attempts at ameliorating the effects of these assumptions by developing alternative speech models. Below, we describe briefly some of these attempts, including the use of segmental models and neural networks. In all these attempts, however, significant computational limitations have hindered the full exploitation of these methods and have resulted only in relatively small improvements in performance so far.
Segmental Models
Phonetic segmental models form a model of a whole phonetic segment, rather than model the sequence of frames as with an HMM. Segmental models are not limited by the conditional assumption of HMMs because, in principle, they model dependencies among all the frames of a segment directly. Furthermore, segmental models can incorporate various segmental features in a straightforward manner, while it is awkward to include segmental features in an HMM. Segmental features include any measurements that are made on the whole segment or parts of a segment, such as the duration of a segment.
There have been few segmental models proposed, among them stochastic segment models and segmental neural networks (to be described in the next section). Stochastic segment models view the sequence of feature vectors in a phonetic segment as a single long feature vector (Ostendorf et al., 1992). The major task is then to estimate the joint probability density of the elements in the feature vector. However, because the number of frames in a segment is variable, it is important first to normalize the segment to a fixed number of frames. Using some form of interpolation, typically quasi-linear, a fixed number of frames are generated that together form the single feature vector whose probability distribution is to be estimated. Typically, the distribution is assumed to be multidimensional Gaussian and its parameters are estimated from training data. However, because of the large size of the feature vector and the always limited amount of training data available, it is not possible to obtain good estimates of all parameters of the probability distribution. Therefore, assumptions are made to reduce the number of parameters to be estimated.
Because segmental models model a segment directly, a segmentation of the speech into phonetic segments must be performed prior to
Page 191
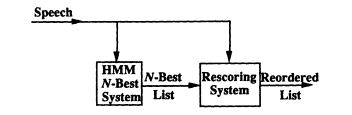
FIGURE 8 N-best paradigm for combining knowledge sources.
modeling and recognition. In theory one would try all possible segmentations, compute the likelihood of each segmentation, and choose the one that results in the largest likelihood given the input speech. However, to try all possible segmentations is computationally prohibitive on regular workstations. One solution has been to use an HMM-based system to generate likely candidates of segmentations, which are then rescored with the segment models.
Figure 8 shows the basic idea of what is known as the N-Best Paradigm (Ostendorf et al., 1991; Schwartz and Chow, 1990). First, an HMM-based recognition system is used to generate not only the top-scoring hypothesis but also the top N-scoring hypotheses. Associated with each hypothesis is a sequence of words and phonemes and the corresponding segmentation. For each of these N different segmentations and labelings, a likelihood is computed from the probability models of each of the segments. The individual segmental scores are then combined to form a score for the whole hypothesis. The hypotheses are then reordered by their scores, and the top-scoring hypothesis is chosen. Typically, the segmental score is combined with the HMM score to improve performance.
Using the N-best paradigm with segmental models, with N = 100, has reduced word error rates by as much as 20 percent. The N-best paradigm has also been useful in reducing computation whenever one or more expensive knowledge sources needs to be combined, for example, cross-word models and n-gram probabilities for n > 2. N-best is a useful paradigm as long as the correct sentence has a high probability of being among the top N hypotheses. Thus far the paradigm has been shown to be useful for vocabularies up to 5,000 words, even for relatively long sentences.
Neural Networks
Whatever the biological motivations for the development of "artificial neural networks" or neural nets (Lippman, 1987), the utility of
Page 192
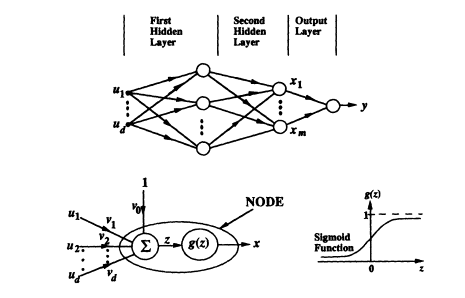
FIGURE 9 Feedforward neural network.
neural nets is best served by understanding their mathematical properties (Makhoul, 1991). We view a neural net as a network of interconnected simple nonlinear computing units and the output of a neural net as just a complex nonlinear function of its inputs. Figure 9 shows a typical feedforward neural network, that is, it has no feedback elements. Although many different types of neural nets have been proposed, the type of network shown in Figure 9 is used by the vast majority of workers in this area. Shown in the figure is a three-layer network, with each layer consisting of inputs, a number of nodes, and interconnecting weights. (The term "hidden" has been used to describe layers that are not connected directly to the output.) All the nodes are usually identical in structure as shown in the figure. The inputs u to a node are multiplied by a set of weights v and summed to form a value z. A nonlinear function of z, g(z), is then computed. Figure 9 shows one of the most typical nonlinear functions used, that of a sigmoid. The output y of the network is then a nonlinear function of the input vector. In general, the network may have a vector of outputs as well.
There are two important mathematical properties of neural nets that form the cornerstones upon which successful applications have been developed. The first is a function approximation property: it
Page 193
has been shown that a two-layer neural net is capable of approximating any function arbitrarily closely in any finite portion of the input space (Cybenko, 1989). One could use more than two layers for the sake of parsimony, but this property says that two layers are sufficient (with a possibly large number of nodes in the hidden layer) to approximate any function of the input. For applications where some nonlinear function of the input is desired, the neural net can be trained to minimize, for example, the mean squared error between the actual output and the desired output. Iterative nonlinear optimization procedures, including gradient descent methods, can be used to estimate the parameters of the neural network (Rumelhart et al., 1986).
The second important property of neural nets relates to their use in classification applications: a neural net can be trained to give an estimate of the posterior probability of a class, given the input. One popular method for training the neural net in this case is to perform a least squares minimization where the desired output is set to 1 when the desired class is present at the input and the desired output is set to 0 otherwise. One can show that by performing this minimization the output will be a least squares estimate of the probability of the class given the input (White, 1989). If the classification problem deals with several classes, a network is constructed with as many outputs as there are classes, and, for a given input, the class corresponding to the highest output is chosen.
As mentioned above, estimating the parameters of a neural net requires a nonlinear optimization procedure, which is very computationally intensive, especially for large problems such as continuous speech recognition.
Neural nets have been utilized for large-vocabulary, continuous speech recognition in two ways:
• They have been used to model the output probability density for each state in an HMM (Renals et al., 1992).
• Segmental neural nets have been used to model phonetic segments directly by computing the posterior probability of the phoneme given the input (Austin et al., 1992).
In both methods the neural net system is combined with the HMM system to improve performance. In the case of segmental neural nets, the N-best paradigm is used to generate likely segmentations for the network to score. Using either method, reductions in word error rate by 10 to 20 percent have been reported. Other neural net methods have also been used in various continuous speech recognition experiments with similar results (Hild and Waibel, 1993; Nagai et al., 1993).
Page 194
CONCLUDING REMARKS
We are on the verge of an explosion in the integration of speech recognition in a large number of applications. The ability to perform software-based, real-time recognition on a workstation will no doubt change the way people think about speech recognition. Anyone with a workstation can now have this capability on their desk. In a few years, speech recognition will be ubiquitous and will enter many aspects of our lives. This paper reviewed the technologies that made these advances possible.
Despite all these advances, much remains to be done. Speech recognition performance for very large vocabularies and larger perplexities is not yet adequate for useful applications, even under benign acoustic conditions. Any degradation in the environment or changes between training and test conditions causes a degradation in performance. Therefore, work must continue to improve robustness to varying conditions: new speakers, new dialects, different channels (microphones, telephone), noisy environments, and new domains and vocabularies. What will be especially needed are improved mathematical models of speech and language and methods for fast adaptation to new conditions.
Many of these research areas will require more powerful computing resources—more workstation speed and more memory. We can now see beneficial utility for a two-orders-magnitude increase in speed and in memory. Fortunately, workstation speed and memory will continue to grow in the years to come. The resulting more powerful computing environment will facilitate the exploration of more ambitious modeling techniques and will, no doubt, result in additional significant advances in the state of the art.
REFERENCES
Asadi, A., R. Schwartz, and J. Makhoul, ''Automatic Detection of New Words in a Large Vocabulary Continuous Speech Recognition System," IEEE International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, pp. 125128, April 1990.
Austin, S., R. Schwartz, and P. Placeway, "The Forward-Backward Search Algorithm," IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, Canada, pp. 697-700, 1991.
Austin, S., G. Zavaliagkos, J. Makhoul, and R. Schwartz, "Speech Recognition Using Segmental Neural Nets," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, pp. 1-625-628, March 1992.
Bahl, L. R., F. Jelinek, and R. L. Mercer, "A Maximum Likelihood Approach to Continuous Speech Recognition," IEEE Trans. Pat. Anal. Mach. Intell., Vol. PAMI-5, No. 2, pp. 179-190, March 1983.
Page 195
Bahl, L., P. Brown, P. de Souza, R. Mercer, and M. Picheny, "Acoustic Markov Models used in the Tangora Speech Recognition System," IEEE International Conference on Acoustics, Speech, and Signal Processing, New York, pp. 497-500, April 1988.
Bahl, L., S. Das, P. deSouza, M. Epstein, R. Mercer, B. Merialdo, D. Nahamoo, M. Picheny, and J. Powell, "Automatic Phonetic Baseform Determination," Proceedings of the DARPA Speech and Natural Language Workshop, Hidden Valley, Pa., Morgan Kaufmann Publishers, pp. 179-184, June 1990a.
Bahl, L. R., P. de Souza, P. S. Gopalakrishnan, D. Kanevsky, and D. Nahamoo, "Constructing Groups of Acoustically Confusable Words," IEEE International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, pp. 85-88, April 1990b.
Baker, J. K., "Stochastic Modeling for Automatic Speech Understanding," in Speech Recognition, R. Reddy, Ed., Academic Press, New York, pp. 521-542, 1975.
Bates, M., R. Bobrow, P. Fung, R. Ingria, F. Kubala, J. Makhoul, L. Nguyen, R. Schwartz, and D. Stallard, "The BBN/HARC Spoken Language Understanding System," IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, pp. 11-111-114, April 1993.
Baum, L. E., and J. A. Eagon, "An Inequality with Applications to Statistical Estimation for Probabilistic Functions of Markov Processes and to a Model of Ecology," Am. Math. Soc. Bull., Vol. 73, pp. 360-362, 1967.
Bellegarda. J. R., and D. H. Nahamoo, "Tied Mixture Continuous Parameter Models for Large Vocabulary Isolated Speech Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, Glasgow, Scotland, pp. 13-16, May 1989.
Cardin, R., Y. Normandin, and E. Millien, "Inter-Word Coarticulation Modeling and MMIE Training for Improved Connected Digit Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, pp. 11-243246, April 1993.
Chow, Y. L., R. M. Schwartz, S. Roucos, O. A. Kimball, P. J. Price, G. F. Kubala, M. O. Dunham, M. A. Krasner, and J. Makhoul, "The Role of Word-Dependent Coarticulatory Effects in a Phoneme-Based Speech Recognition System," IEEE International Conference on Acoustics, Speech, and Signal Processing, Tokyo, pp. 1593-1596, April 1986.
Cohen, J., "Application of an Auditory Model to Speech Recognition," J. Acoust. Soc. Am., Vol. 85, No. 6, pp. 2623-2629, June 1989.
Cybenko, G. "Approximation by Superpositions of a Sigmoidal Function," Math. Contr. Signals Sys., pp. 303-314, Aug. 1989.
Davis, S., and P. Mermelstein, "Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences," IEEE Trans. Acoust., Speech, Signal Process., Vol. ASSP-28, No. 4, pp. 357-366, August 1980.
Della Pietra, S., V. Della Pietra, R. Mercer, and S. Roukos, "Adaptive Language Modeling Using Minimum Discriminant Estimation," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, pp. 1-633-636, March 1992.
Forney, G. D., "The Viterbi Algorithm," Proc. IEEE, Vol. 61, pp. 268-278, 1973.
Furui, S., "Speaker-Independent Isolated Word Recognition Based on Emphasized Spectral Dynamics," IEEE International Conference on Acoustics, Speech, and Signal Processing, Tokyo, pp. 1991-1994, 1986.
Furui, S., "Unsupervised Speaker Adaptation Method Based on Hierarchical Spectral Clustering," IEEE International Conference on Acoustics, Speech, and Signal Processing, Glasgow, Scotland, paper S6.9, May 1989.
Page 196
Gauvain, J. L., and C-H. Lee, "Bayesian Learning for Hidden Markov Model with Gaussian Mixture State Observation Densities," Speech Comm., Vol. 11, Nos. 2-3, 1992.
Gupta, V. N., M. Lennig, and P. Mermelstein, "Integration of Acoustic Information in a Large Vocabulary Word Recognizer," IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, pp. 697-700, April 1987.
Haeb-Umbach, R., D. Geller, and H. Ney, "Improvements in Connected Digit Recognition Using Linear Discriminant Analysis and Mixture Densities," IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, pp. 11-239-242, April 1993.
Hild, H., and A. Waibel, "Multi-Speaker/Speaker-Independent Architectures for the Multi-State Time Delay Neural Network," IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, pp. 11-255-258, April 1993.
Hon, H. W., "Vocabulary-Independent Speech Recognition: The VOCIND System," Doctoral Thesis, Carnegie-Mellon University, Pittsburgh, Pa., 1992.
Huang, X. D., Y. Ariki, and M. A. Jack, Hidden Markov Models for Speech Recognition, Edinburgh University Press, Edinburgh, 1990.
Huang, X. D., K. F. Lee, H. W. Hon, and M-Y. Hwang, "Improved Acoustic Modeling with the SPHINX Speech Recognition System," IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, Canada, Vol. SI, pp. 345-347, May 1991.
Hunt, M., S. Richardson, D. Bateman, and A. Piau, "An Investigation of PLP and IMELDA Acoustic Representations and of their Potential for Combination," IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, Canada, pp. 881-884, May 1991.
Jelinek, F., L. R. Bahl, and R. L. Mercer, "Design of a Linguistic Statistical Decoder for the Recognition of Continuous Speech," IEEE Trans. Info. Theory, Vol. 21, No. 3, pp. 250-256, May 1975.
Katz, S., "Estimation of Probabilities from Sparse Data for the Language Model Component of a Speech Recognizer," IEEE Trans. Acoust., Speech, Signal Process., Vol. 35, No. 3, pp. 400-401, March 1987.
Kubala. F, and R. Schwartz, "Improved Speaker Adaptation Using Multiple Reference Speakers," International Conference on Speech and Language Processing, Kobe, Japan, pp. 153-156, Nov. 1990.
Lee, K.-F., Automatic Speech Recognition: The Development of the Sphinx System, Kluwer Academic Publishers, 1989.
Leonard, R. G., "A Database for Speaker-Independent Digit Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, paper 42.11, March 1984.
Levinson, S. E., L. R. Rabiner, and M. M. Sondhi, "An Introduction to the Application of the Theory of Probabilistic Functions of a Markov Process to Automatic Speech Recognition," Bell Sys. Tech. J., Vol. 62, No. 4, pp. 1035-1073, April 1983.
Lippman, R. P., "An Introduction to Computing with Neural Nets," IEEE ASSP Magazine, pp. 4-22, April 1987.
Lowerre, B. T., "The Harpy Speech Recognition System," Doctoral Thesis, CarnegieMellon University, Pittsburgh, Pa., 1976.
MADCOW, "Multi-Site Data Collection for a Spoken Language Corpus," Proceedings of the DARPA Speech and Natural Language Workshop, Harriman, N.Y., Morgan Kaufmann Publishers, pp. 7-14, Feb. 1992.
Makhoul, J., "Pattern Recognition Properties of Neural Networks," Neural Networks
Page 197
for Signal Processing—Proceedings of the 1991 IEEE Workshop, IEEE Press, New York, pp. 173-187, 1991.
Makhoul, J., S. Roucos, and H. Gish, "Vector Quantization in Speech Coding," Proc. IEEE, Vol. 73, No. 11, pp. 1551-1588, Nov. 1985.
Nagai, A., K. Yamaguchi, S. Sagayama, and A. Kurematsu, "ATREUS: A Comparative Study of Continuous speech Recognition Systems at ATR," IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, pp. 11-139142, April 1993.
Nakamura, S., and K. Shikano, "Speaker Adaptation Applied to HMM and Neural Networks," IEEE International Conference on Acoustics, Speech, and Signal Processing, Glasgow, Scotland, paper S3.3, May 1989.
Ney, H., "Improvements in Beam Search for 10000-Word Continuous Speech Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, pp. 1-9-12, March 1992.
Nguyen, L., R. Schwartz, F. Kubala, and P. Placeway, "Search Algorithms for Software-Only Real-Time Recognition with Very Large Vocabularies," Proceedings of the ARPA Workshop on Human Language Technology, Morgan Kaufmann Publishers, Princeton, N.J., pp. 91-95, March 1993.
Ostendorf, M., A. Kannan, S. Austin, O. Kimball, R. Schwartz, and J. R. Rohlicek, "Integration of Diverse Recognition Methodologies through Reevaluation of N-Best Sentence Hypotheses," Proceedings of the DARPA Speech and Natural Language Workshop, Monterey, Calif., Morgan Kaufmann Publishers, pp. 83-87, February 1991.
Ostendorf, M., I. Bechwati, and 0. Kimball, "Context Modeling with the Stochastic Segment Model," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Fransisco, pp. 1-389-392, March 1992.
Pallett, D., J. Fiscus, W. Fisher, and J. Garofolo, "Benchmark Tests for the DARPA Spoken Language Program," Proceedings of the ARPA Workshop on Human Language Technology, Morgan Kaufmann Publishers, Princeton, N.J., pp. 7-18, March 1993.
Paul, D., "The Design for the Wall Street Journal-based CSR Corpus," Proceedings of the DARPA Speech and Natural Language Workshop, Morgan Kaufmann Publishers, pp. 357-360, Feb. 1992.
Placeway, P., R. Schwartz, P. Fung, and L. Nguyen, "The Estimation of Powerful Language Models from Small and Large Corpora," IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, pp. 11-33-36, April 1993.
Price, P., W. M. Fisher, J. Bernstein, and D. S. Pallett, "The DARPA 1000-Word Resource Management Database for Continuous Speech Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, New York, pp. 651-654, April 1988.
Rabiner, L. R., "A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition," Proc. IEEE, Vol. 77, No. 2, pp . 257-286, Feb. 1989.
Rabiner, L. R., and B.-H. Juang, Fundamentals of Speech Recognition, Prentice-Hall, Englewood Cliffs, N.J., 1993.
Renals, S., N. Morgan, M. Cohen, and H. Franco, "Connectionist Probability Estimation in the Decipher Speech Recognition System," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, pp. 1-601-603, March 1992.
Rumelhart, D., C. Hinton, and R. Williams, "Learning Representations by Error Propagation," in Parallel Distributed Processing: Explorations in the Microstructure of Cognition, D. Rumelhart and J. McClelland (eds.), MIT Press, Cambridge, Mass., Vol. 1, pp. 318-362, 1986.
Page 198
Schwartz, R., and S. Austin, "A Comparison of Several Approximate Algorithms for Finding Multiple (N-Best) Sentence Hypotheses," IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, Canada, pp. 701-704, 1991.
Schwartz, R., and Y. L. Chow, "The N-Best Algorithm: An Efficient and Exact Procedure for Finding the N Most Likely Sentence Hypotheses," IEEE International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, pp. 81-84, April 1990.
Schwartz, R. M., Y. Chow, S. Roucos, M. Krasner, and J. Makhoul, "Improved Hidden Markov Modeling of Phonemes for Continuous Speech Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, pp. 35.6.1-35.6.4, March 1984.
Schwartz, R., O. Kimball, F. Kubala, M. Feng, Y. Chow, C. Barry, and J. Makhoul, "Robust Smoothing Methods for Discrete Hidden Markov Models," IEEE International Conference on Acoustics, Speech, and Signal Processing, Glasgow, Scotland, paper S10b.9, May 1989.
Schwartz, R., A. Anastasakos, F. Kubala, J. Makhoul, L. Nguyen, and G. Zavaliagkos, "Comparative Experiments on Large Vocabulary Speech Recognition," Proceedings of the ARPA Workshop on Human Language Technology, Morgan Kaufmann Publishers, Princeton, N.J., pp. 75-80, March 1993.
Soong, F., and E. Huang, "A Tree-Trellis Based Fast Search for Finding the N Best Sentence Hypotheses in Continuous Speech Recognition," IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, Canada, pp. 705-708, 1991.
White, H., "Learning in Artificial Neural Networks: A Statistical Perspective," Neural Computation, pp. 425-464, 1989.


































