
Page 467
Speech Technology in 2001: New Research Directions
SUMMARY
Research in speech recognition and synthesis over the past several decades has brought speech technology to a point where it is being used in "real-world" applications. However, despite the progress, the perception remains that the current technology is not flexible enough to allow easy voice communication with machines. The focus of speech research is now on producing systems that are accurate and robust but that do not impose unnecessary constraints on the user. This chapter takes a critical look at the shortcomings of the current speech recognition and synthesis algorithms, discusses the technical challenges facing research, and examines the new directions that research in speech recognition and synthesis must take in order to form the basis of new solutions suitable for supporting a wide range of applications.
INTRODUCTION
After many years of research, speech recognition and synthesis systems have started moving from the controlled environments of research laboratories to applications in the real world. Voice-processing technology has matured to such a point that many of us wonder why the performance of automatic systems does not approach the quality of human performance and how soon this goal can be reached.
Page 468
Rapid advances in very-large-scale integrated (VLSI) circuit capabilities are creating a revolution in the world of computers and communications. These advances are creating an increasing demand for sophisticated products and services that are easy to use. Automatic speech recognition and synthesis are considered to be the key technologies that will provide the easy-to-use interface to machines.
The past two decades of research have produced a stream of increasingly sophisticated solutions in speech recognition and synthesis (Rabiner and Juang, 1993). Despite this progress, the perception remains that the current technology is not flexible enough to allow easy voice communication with machines. This chapter reviews the present status of this important technology, including its limitations, and discusses the range of applications that can be supported by our present knowledge. But as we look into the future and ask which speech recognition and synthesis capabilities will be available about 10 years from now, it is important also to discuss the technical challenges we face in realizing our vision of the future and the directions in which new research should proceed to meet these challenges. We will examine these issues in this paper and take a critical look at the shortcomings of the current speech recognition and synthesis algorithms.
Much of the technical knowledge that supports the current speech-processing technology was created in a period when our ability to implement technical solutions on real-time hardware was limited. These limitations are quickly disappearing, and we look to a future at the end of this decade when a single VLSI chip will have a billion transistors to support much higher processing speeds and more ample storage than is now available.
The speech recognition and synthesis algorithms available at present work in limited scenarios. With the availability of fast processors and a large memory, tremendous opportunity exists to push speech recognition technology to a level where it can support a much wider range of applications. Speech databases with utterances recorded from many speakers in a variety of environments have been important in achieving the progress that has been realized so far. But on the negative side, these databases have encouraged speech researchers to rely on trial-and-error methods, leading to solutions that are narrow and that apply to specific applications but do not generalize to other situations. These methods, although fruitful in the early development of the technology, are now a hindrance as we become much more ambitious in seeking solutions to bigger problems. The time has come to set the next stage for the development of speech technology, and it is important to realize that a solid base of scientific understanding is
Page 469
absolutely necessary if we want to move significantly beyond where we are today.
The 1990s will be a decade of rising expectations for speech technology, and speech research will expand to cover many areas, from traditional speech recognition and synthesis to speech understanding and language translation. In some areas we will be just scratching the surface and defining the important issues. But in many others the research community will have to come up with solutions to important and difficult problems in a timely fashion. This paper cannot discuss all the possible new research directions but will be limited to examining the most important problems that must be solved during this decade.
CURRENT CAPABILITIES
Voice communication from one person to another appears to be so easy and simple. Although speech technology has reached a point where it can be useful in certain applications, the prospect of a machine understanding speech with the same flexibility as humans do is still far away. The interest in using speech interface to machines stems from our desire to make machines easy to use. Using human performance as a benchmark for the machine tells us how far we are from that goal. For clean speech, automatic speech recognition algorithms work reasonably well (Makhoul and Schwartz, in this volume; Miller et al., 1961) with isolated words or words spoken in grammatical sentences, and the performance is continuing to improve. Figure 1 shows the word error rate for various test materials and the steady decrease in the error rate achieved from 1980 to 1992. This performance level is not very different from that obtained in intelligibility tests with human listeners. The performance of automatic methods, however, degrades significantly in the presence of noise (or distortion) (Juang, 1991) and for conversational speech.
There are many factors besides noise that influence the performance of speech recognition systems. The most important of these are the size of the vocabulary and the speaking style. Figure 2 shows examples of automatic speech recogition tasks that can be handled by automatic methods for different vocabulary sizes and speaking styles. Generally, the number of confused words increases with the vocabulary size. Current systems can properly recognize a vocabulary of as many as a few thousand words, while the speaking style can vary over a wide range, from isolated words to spontaneous speech. The recognition of continuously spoken (fluent) speech is significantly more difficult than that of isolated words. In isolated words, or speech
Page 470
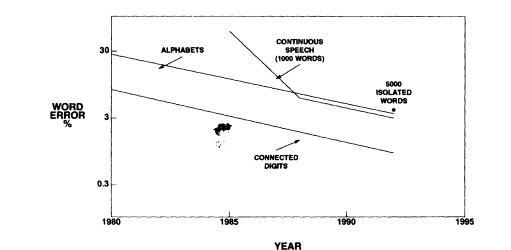
FIGURE 1 Reduction in the word error rate for different automatic speech recognition tasks between 1980 and 1992.
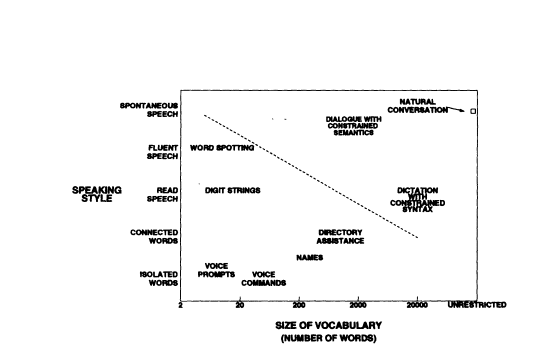
FIGURE 2 Different speech recognition tasks shown in a space of two dimensions: speaking style and size of vocabulary.
Page 471
where words are separated by distinct pauses, the beginning and the end of each word are clearly marked. But such boundaries are blurred in fluent speech. The recognition of spontaneous speech, such as is produced by a person talking to a friend on a well-known subject, is even harder.
Examples of speech recognition applications that can be handled by the current technology are shown on the left side of the diagonal line in Figure 2. These include recognition of voice commands (prompts), names, digit strings, and key-word spotting. New applications in speech recognition are rapidly emerging (Wilpon, in this volume). Commercial products are available for the recognition of isolated words, connected digit strings, and speech with vocabularies of up to several thousand words spoken with pauses between words.
The items on the right of the diagonal line in Figure 2 are examples of speech recognition tasks that work in laboratory environments but that need more research to become useful for real applications (Roe, in this volume). Automatic recognition of fluent speech with a large vocabulary is not feasible unless constraints on the syntax or semantics are introduced. The present knowledge in handling natural languages and in following a dialogue is very much limited because we do not understand how to model the variety of expressions that natural languages use to convey concepts and meanings.
Text-to-speech synthesis systems suffer from much of the same kinds of problems as speech recognition. Present text-to-speech systems can produce speech that is intelligible (although significantly lower intelligibility than natural speech) but not natural sounding. These systems can synthesize only a few voices reading grammatical sentences but cannot capture the nuances of natural speech.
CHALLENGING ISSUES IN SPEECH RESEARCH
For speech technology to be used widely, it is necessary that the major roadblocks faced by the current technology be removed. Some of the key issues that pose major challenges in speech research are listed below:
• Ease of use. Unless it is easy to use, speech technology will have limited applications. What restrictions are there on the vocabulary? Can it handle spontaneous speech and natural spoken language?
• Robust performance. Can the recognizer work well for different speakers and in the presence of the noise, reverberation, and spectral distortion that are often present in real communication channels?
• Automatic learning of new words and sounds. In real applica-
Page 472
tions the users will often speak words or sounds that are not in the vocabulary of the recognizer. Can it learn to recognize such new words or sounds automatically?
• Grammar for spoken language. The grammar for spoken language is quite different from that used in carefully constructed written text. How does the system learn this grammar?
• Control of synthesized voice quality. Can text-to-speech synthesis systems use more flexible intonation rules? Can prosody be made dependent on the semantics?
• Integrated learning for speech recognition and synthesis. Current speech synthesis systems are based on rules created manually by an experienced linguist. Such systems are constrained in what they can do. Can new automatic methods be developed for the training of the recognizer and synthesizer in an integrated manner?
Some of the issues mentioned above, such as ease of use and robustness, need to be addressed in the near future and resolved. Others, such as automatic learning of new words and sounds or grammar for spoken language, will need major advances in our knowledge. Understanding of spontaneous speech will require tight integration of language and speech processing.
A number of methods have been proposed to deal with the problem of robustness. The proposed methods include signal enhancement, noise compensation, spectral equalization, robust distortion measures, and novel speech representations. These methods provide partial answers valid for specific situations but do not provide a satisfactory answer to the problem. Clean, carefully articulated, fluent speech is highly redundant, with the signal carrying significantly more information than is necessary to recognize words with high accuracy. However, the challenge is to realize the highest possible accuracy when the signal is corrupted with noise or other distortions and part of the information is lost. The performance of human listeners is considered to be very good, but even they do not approach high intelligibility for words in sentences unless the signal-to-noise (S/N) ratio exceeds 18 dB (Miller et al., 1961).
THE ROBUSTNESS ISSUE
Let us consider the robustness issue in more detail. Current speech recognition algorithms use statistical models of speech that are trained from a prerecorded speech database. In real applications the acoustic characteristics of speech often differ significantly from that of speech in the training database, and this mismatch causes a drop in the
Page 473
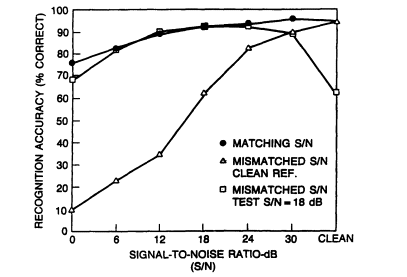
FIGURE 3 Speech recognition performances in noisy conditions: ··, training
and testing have matched S/N ratios; A, only clean training data are used; ž;
training and testing S/N ratios are mismatched with test S/N ratio fixed at
18 dB (after Juang, 1991).
recognition accuracy. This is illustrated for noise-contaminated speech in Figure 3, which shows the recognition accuracy as a function of the S/N ratio for both matched and mismatched training and test conditions (Dautrich et al., 1983; Juang, 1991). These results point to a serious problem in current speech recognition systems: the performance degrades whenever there is a mismatch between levels of noise present in training and test conditions. Similar problems arise with spectral distortion, room reverberation, and telephone transmission channels (Acero and Stern, 1990). Achieving robust performance in the presence of noise and spectral distortion has become a major issue for the current speech recognition systems.
Robust performance does not come by chance but has to be designed into the system. Current speech recognition algorithms are designed to maximize performance for the speech data in the training set, and this does not automatically translate to robust performance on speech coming from different user environments. Figure 4 shows the principal functions of an automatic speech recognition system. The input speech utterance is analyzed in short quasi-stationary segments, typically 10 to 30 ms in duration, to provide a parametric representation at the acoustic level. The parameters from the unknown
Page 474
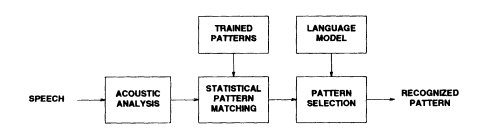
FIGURE 4 Principal functions of an automatic speech recognition system.
input utterance are then compared to patterns derived from a large training set of speech utterances collected from many speakers in many different speaking environments. This comparison provides a set of scores representing the similarity between the unknown pattern and each of the prestored patterns. The last step combines these scores together with other knowledge about the speech utterance, such as the grammar and semantics, to provide the best transcription of the speech signal. To achieve robustness, each function shown in the block diagram must be designed to minimize the loss in performance in situations when there is a mismatch between the training and test conditions.
A speech recognizer can be regarded as a method for compressing speech from a high rate needed to represent individual samples of the waveform to a low phonemic rate to represent speech sounds. Let us look at the information rate (bit rate) at different steps in the block diagram of Figure 4. The bit rate of the speech signal represented by its waveform at the input of the recognizer is in the range of 16 to 64 kb/s. The rate is reduced to approximately 2 kb/s after acoustic analysis and to a phonemic rate in the range 30 to 50 b/s after pattern matching and selection.
The bit rate at the acoustic parameter level is large, and therefore the pattern-matching procedure must process speech in ''frames" whose duration is only a small fraction of the duration of a sound. The scores resulting from such a pattern-matching procedure are unreliable indicators of how close an unknown pattern from the speech signal is to a particular sound. The reliability can be improved by reducing the maximum number of acoustic patterns in the signal (or its bit rate) that are evaluated for pattern matching. The bit rate for representing the speech signal depends on the duration of the time window that is used in the analysis shown in Figure 5 and is about 200 b/s for a window of 200 ms. Suppose we wish to compute the score for a speech segment 100 ms in duration, which is roughly the average length of a speech sound. The number of acoustic patterns
Page 475
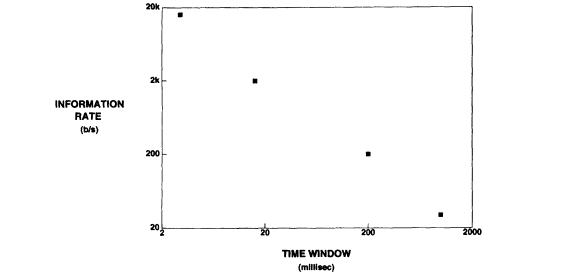
FIGURE 5 Information rate (b/s) of speech signal as a function of the length of the time window used in the analysis.
that the pattern-matching step has to sort out is 2200 at 2000 b/s, but that number is reduced to only 220 at 200 b/s. This is a reduction of 218° in the number of patterns that the pattern-matching procedure has to handle. The present speech analysis methods generate a static (quasi-stationary) representation of the speech signal. To achieve robust performance, it is important to develop methods that can efficiently represent speech segments extending over a time interval of several hundred milliseconds. An example of a method for representing large speech segments is described in the next section.
SPEECH ANALYSIS
The goal of speech analysis is to provide a compact representation of the information content in the speech signal. In general, those representations that eliminate information not pertinent to phonetic differences are effective. The short-time power spectrum of speech, obtained either from a filter bank, Fourier transform, or linear prediction analysis, is still considered the most effective representation for speech recognition (the power spectrum is often converted into the cepstrum to provide a set of 10 to 15 coefficients). However, the power spectrum is affected by additive noise and linear-filtering distortions. We need new representations that go beyond the power spectrum and represent the frequency content of the signal.
Page 476
The cepstral coefficients are instantaneous (static) features. One of the important advances in the acoustic representation of speech has been the introduction of dynamic features (Furui, 1986), such as first- and second-order derivatives of the cepstrum. Recently, new representations based on human hearing have been proposed (Ghitza, 1992), but these representations have not yet been found to have significant advantage over the spectral representation. The following is a list of interesting new research directions in speech analysis:
• Time-frequency and wavelet representations. Time-frequency representations map a one-dimensional signal into a two-dimensional function of time and frequency (Daubechies, 1990; Hlawatsch and Boudreaux-Bartels, 1992; Rioul and Vetterli, 1991). The traditional Fourier analysis methods divide the time-frequency plane in an inflexible manner not adapted to the needs of the signal. New methods of time-frequency analysis are emerging that allow more general partitioning of the time-frequency plane or tiling that adapts to time as well as frequency as needed (Daubechies, 1990; Herley et al., 1993).
• Better understanding of auditory processing of signals. Although auditory models have not yet made a significant impact on automatic speech recognition technology, they exhibit considerable promise. What we need is a better understanding of the principles of signal processing in the auditory periphery that could lead to more robust performance in automatic systems.
• Articulatory representation. Models that take advantage of the physiological and physical constraints inherent in the vocal-tract shapes used during speech production can be useful for speech analysis. Significant progress (Schroeter and Sondhi, 1992) has been made during the past decade in developing articulatory models whose parameters can be estimated from the speech signal.
• Coarticulation models at the acoustic level. During speech production, the articulators move continuously in time, thereby creating a considerable overlap in the acoustic realizations of phonemes. Proper modeling of coarticulation effects at the acoustic level can provide better accuracy and higher robustness in speech recognition.
Temporal Decomposition
We discussed earlier the importance of extending the quasi-stationary static model of speech to a dynamic model that is valid over much longer nonstationary segments. We describe here one such model, known as temporal decomposition (Atal, 1983). The acoustics of the speech signal at any time are influenced not only by the sound
Page 477
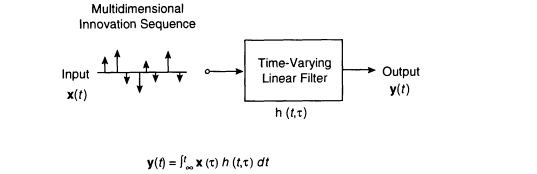
FIGURE 6 Temporal decomposition model to represent coarticulation at the acoustic level.
being produced at that time but also by neighboring sounds. Temporal decomposition seeks to separate the contributions of the neighboring sounds on the acoustic parameters by using a coarticulation model in which the contributions of sounds are added together with proper weights (Atal, 1983, 1989; Cheng and O'Shaughnessy, 1991, 1993).
In the temporal decomposition model the continuous variations of acoustic parameters are represented as the output of a linear time-varying filter excited by a sequence of vector-valued delta functions located at nonuniformly spaced time intervals (Atal, 1989). This is illustrated in Figure 6, where the linear filter with its impulse response specified by h(t, T) (response at time t due to a delta function input at time T) has the role of smoothing the innovation x(t) that is assumed to be nonzero only at discrete times corresponding to the discrete nature of speech events. The number of nonzero components in the innovation in any given time interval is roughly equal to the number of speech events (and silence) contained in that interval of the spoken utterance. Speech analysis techniques have been developed to determine both the innovation and the time-varying impulse response of the filter for any utterance (Atal, 1989; Cheng and O'Shaughnessy, 1991, 1993). Figure 7 shows an example of this decomposition for the word "four." The three parts of the figure show: (a) even components of the linear predictive coding (LPC) line spectral frequencies as a function of time, (b) the filter impulse responses for each speech event, and (c) the waveform of the word "four." In this example the entire variations in the acoustic parameters over 0.5 s of the utterance for the word "four" can be represented as the sum of five overlapping speech events. We find that the information rate
Page 478
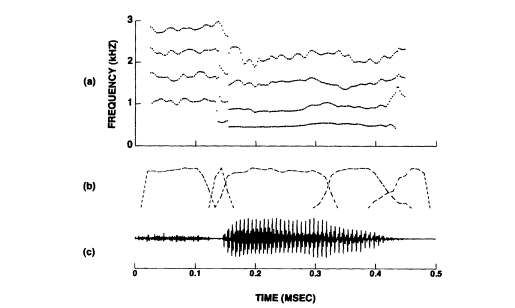
FIGURE 7 Temporal decomposition of the spoken word "four": (a) LPC line
spectral parameters, (b) filter impulse responses for the different speech events,
and (c) speech waveform for the speech utterance.
of the innovation signal x(t) is about 100 b/s, which is much lower than the corresponding rate for the acoustic parameters y(t).
TRAINING AND PATTERN-MATCHING ISSUES
The application of hidden Markov models (HMMs) has been a major factor behind the progress that has been achieved in automatic speech recognition (Rabiner and Juang, 1993). The HMM framework provides a mathematically tractable approach to the training and classification problems in speech recognition. While the speech recognition algorithms based on the HMM are important at the current state of the technology, these algorithms suffer from fundamental shortcomings (Juang and Rabiner, 1971) that must be overcome.
The HMM method is based on the Bayesian approach to pattern classification, which assumes that the statistical distributions of the HMM states are known or can be estimated. In the HMM, therefore, the problems of training and recognition are transformed to the problem of estimating distributions from the training data. In reality this is a difficult task requiring untested assumptions about the form and the
Page 479
underlying parameters of the distributions. Moreover, the misclassification errors depend on the amount of overlap between the tails of the competing distributions and not on the exact shape of the distributions for the classes. Thus, the emphasis in the HMM approach on distribution estimation is unnecessary; a cost function defined in a suitable fashion is all that is required.
Other approaches to speech recognition based on discriminant functions are being investigated and appear to be promising. Significant progress has been made in formulating the discriminant approach for speech recognition and in developing methods that seek to minimize the misclassification errors (Juang and Katagiri, 1992). The major issues in training and recognition are listed below:
• Training and generalization. An important question is whether the trained patterns characterize the speech of only the training set or whether they also generalize to speech that will be present in actual use.
• Discriminative training. Although the discriminative training does not require estimation of distributions, they still need knowledge of the discriminant functions. What are the most appropriate discriminant functions for speech patterns?
• Adaptive learning. Can the learning of discriminant functions be adaptive?
• Artificial neural networks. Despite considerable research, neural networks have not yet shown significantly better performance than HMM algorithms. New research must address the important issue—what is the potential of neural networks in providing improved training and recognition for speech patterns?
ADDITIONAL ISSUES IN SPEECH SYNTHESIS
Much of what has been discussed so far applies to speech synthesis as well. However, there are additional research issues that must be considered. We will discuss some of these issues in this section.
The core knowledge that forms the basis of current speech recognition and synthesis algorithms is essentially the same. However, there are important differences in the way the two technologies have evolved. Speech synthesis algorithms generate continuous speech by concatenating segments of stored speech patterns, which are selected to minimize discontinuities in the synthesized speech. Segmentation of speech into appropriate units, such as diphones or syllables, was therefore incorporated into the speech synthesis technology at an early stage and required the assistance of trained people (or phoneticians)
Page 480
to learn the segmentation task. Lack of accurate models for representing the coarticulation in speech and the dynamics of parameters at the acoustic or the articulatory level has been the major obstacle in developing automatic methods to carry out the segmentation task. Without automatic methods, it is difficult to process large speech databases and to develop models that represent the enormous variability present in speech due to differences in dialects, prosody, pronunciation, and speaking style. Future progress in synthesizing speech that offers more than minimal intelligibility depends on the development of automatic methods for extracting parameters from speech to represent the important sources of variability in speech in a consistent fashion. Automatic methods for segmentation are also needed in order to develop multilingual capability in speech synthesis.
The primary goal of speech synthesis systems so far has been to synthesize speech from text—a scenario coming out of an earlier interest in "reading machines for the blind." New applications of speech synthesis that do not depend on synthesizing speech from text are rapidly emerging. As we proceed to develop new applications that involve some kind of dialogue between humans and machines, it is essential that the issue of synthesizing speech from concepts be addressed.
CONCLUSIONS
Voice communication holds the promise of making machines easy to use, even as they become more complex and powerful. Speech technology is reaching an important phase in its evolution and is getting ready to support a wide range of applications. This paper discussed some of the important technical challenges in developing speech recognition and synthesis technology for the year 2001 and the new research directions needed to meet these challenges.
Robust performance in speech recognition and more flexibility in synthesizing speech will continue to be major problems that must be solved expeditiously. The solutions will not come by making incremental changes in the current algorithms but rather by seeking new solutions that are radically different from the present.
New speech analysis methods must move beyond quasi-stationary representations of the power spectrum to dynamic representations of speech segments. Solution of the coarticulation problem at the acoustic level remains one of the most important problems in speech recognition and synthesis. Temporal decomposition is a promising method along this direction.
In speech recognition, new training procedures based on discriminant functions show considerable promise and could avoid the limitations
Page 481
of the HMM approach. The discriminant function approach achieves higher performance by using a criterion that minimizes directly the errors due to misclassification. In speech synthesis, articulatory models and automatic methods for determining their parameters offer the best hope of providing the needed flexibility and naturalness in synthesizing a wide range of speech materials.
REFERENCES
Acero. A, and R. M. Stern, "Environmental robustness in automatic speech recognition," Proc. ICASSP-90, pp. 849-852, Albuquerque, NM, 1990.
Atal, B. S., "Efficient coding of LPC parameters by temporal decomposition," Proceedings of the International Conference IEEE ASSP, Boston, pp. 81-84, 1983.
Atal, B. S., "From speech to sounds: Coping with acoustic variabilities," Towards Robustness in Speech Recognition, Wayne A. Lea (ed.), pp. 209-220, Speech Science Publications, Apple Valley, Minn., 1989.
Cheng, Y. M., and D. O'Shaughnessy, "Short-term temporal decomposition and its properties for speech compression," IEEE Trans. Signal Process., vol. 39, pp. 12821290, 1991.
Cheng, Y. M., and D. O'Shaughnessy, "On 450-600 b/s natural sounding speech coding," IEEE Trans. Speech Audio Process., vol. 1, pp. 207-220, 1993.
Daubechies, I., "The wavelet transform, time-frequency localization and signal analysis," IEEE Trans. Inf. Theory, vol. 36, pp. 961-1005, Sept. 1990.
Dautrich, B. A., L. R. Rabiner, and T. B. Martin, "On the effects of varying filter bank parameters on isolated word recognition," IEEE Trans. Acoust., Speech, Signal Process., vol. ASSP-31, pp. 793-806, Aug. 1983.
Furui, S., "On the role of spectral transitions for speech perception," J. Acoust. Soc. Am., vol. 80, pp. 1016-1025, Oct. 1986.
Ghitza, O., "Auditory nerve representation as a basis for speech processing," Advances in Speech Signal Processing, S. Furui and M. M. Sondhi (eds.), pp. 453485, Marcel Dekker, New York, 1992.
Herley, C., et al., "Time-varying orthonormal tilings of the time-frequency plane," IEEE Trans. Signal Process., Dec. 1993.
Hlawatsch, F., and G. F. Boudreaux-Bartels, "Linear and quadratic time-frequency signal representations," IEEE Signal Process. Mag., pp. 21-67, Apr. 1992.
Juang, B. H., "Speech recognition in adverse environments," Comput. Speech Lang., vol. 5, pp. 275-294, 1991.
Juang, B. H., and S. Katagiri, "Discriminative learning for minimum error classification," IEEE Trans. Signal Process., vol. 40, pp. 3043-3054, Dec. 1992.
Juang, B. H., and L. R. Rabiner, "Hidden Markov models for speech recognition," Technometrics, vol. 33, pp. 251-272, Aug. 1991.
Miller, G. A., G. A. Heise, and W. Lichten, "The intelligibility of speech as a function of the context of the test materials," J. Exp. Psychol., vol. 41, pp. 329-335, 1961.
Rabiner, L. R., and B. H. Juang, Fundamentals of Speech Recognition, Prentice-Hall, Englewood Cliffs, N.J., 1993.
Rioul, O., and M. Vetterli, "Wavelets and signal processing," IEEE Signal Process. Mag., pp. 14-38, Oct. 1991.
Schroeter, J., and M. M. Sondhi, "Speech coding based on physiological models of speech production," Advances in Speech Signal Processing, S. Furui and M. M. Sondhi (eds.), pp. 231-267, Marcel Dekker, New York, 1992.















