
5
Statistical Challenges
In comparison with other engineering disciplines, software engineering is still in the definition stage. Characteristics of established disciplines include having defined, time-tested, credible methodologies for disciplinary practice, assessment, and predictability. Software engineering combines application domain knowledge, computer science, statistics, behavioral science, and human factors issues. Statistical research and education challenges in software engineering involve the following:
-
Generalizing particular experimental results to other settings and projects,
-
Scaling up results obtained in academic studies to industrial settings,
-
Combining information across software engineering projects and studies,
-
Adopting exploratory data analysis and visualization techniques,
-
Educating the software engineering community as to statistical approaches and data issues,
-
Developing analysis methods to cope with qualitative variables,
-
Providing models with the appropriate error distributions for software engineering applications, and
-
Improving accelerated life testing.
The following sections elaborate on certain of these challenges.
SOFTWARE ENGINEERING EXPERIMENTAL ISSUES
Software engineering is an evolutionary and experimental discipline. As argued forcefully by Basili (1993), it is a laboratory or experimental science. The term "experimental science" has different meanings for engineers and statisticians. For engineers, software is experimental because systems are built, studied, and evaluated based on theory. Each system investigates new ideas and advances the state of the art. For statisticians, the purpose of experiments is to gather statistically valid evidence about the effects of some factor, perhaps involving the process, methodology, or code in a system.
There are three classes of experiments in software engineering:
-
Case studies,
-
Academic experiments, and
-
Industrial experiments.
Case studies are perhaps the most common and involve an "experiment" on a single large-scale project. Academic experiments usually involve a small-scale experiment, often on a program or
methodology, typically using students as the experimental subjects. Industrial experiments fall somewhere between case studies and academic experiments. Because of the expense and difficulty of performing extensive controlled experiments on software, case studies are often resorted to. The ideal situation is to be able to take advantage of real-world industrial operations while having as much control as is feasible. Much of the present work in this area is at best anecdotal and would benefit greatly from more rigorous statistical advice and control. The panel foresees an opportunity for innovative work on combining information (see below) from relatively disparate experiences.
Conducting statistically valid software experiments is challenging for several reasons:
-
The software production process is often chaotic and uncontrolled (i.e., immature);
-
Human variability is a complicating factor; and
-
Industrial experiments are very costly and therefore must produce something useful.
Many variables in the software production process are not well understood and are difficult to control for. For software engineering experiments, the factors of interest include the following:
-
"People" factors: number, level, organization, process experience;
-
Problem factors: application domain, constraints, susceptibility to change;
-
Process factors: life cycle model, methods, tools, programming language;
-
Product factors: deliverables, system size, system reliability, portability; and
-
Resource factors: target and development machines, calendar time, budget, existing software, and so on.
Each of these characteristics must be modeled or controls done for the experiment to be valid.
Human variability is particularly challenging, given that the difference in quality and productivity between the best and worst programmers may be 20 to 1. For example, in an experiment comparing batch versus interactive computing, Sackman (1970) observed differences in ability of up to 28 to 1 in programmers performing the same task. This variation can overwhelm the effects of a change in methodology that may account for a 10% to 15% difference in quality or productivity.
The human factor is so strongly integrated with every aspect of the subjective discipline of software engineering that it alone is the prime driver of issues to be addressed. The human factor creates issues in the process, the product, and the user environment. Measurements of the objects (the product and the process) are obscured when qualified by the attributes (ambiguous requirements and productivity issues are key examples). Recognizing and characterizing the human attributes within the context of the software process are key to understanding how to include them in system and statistical models.
The capabilities of individuals strongly influence the metrics collected throughout the software production process. Capabilities include experience, intelligence, familiarity with the application domain, ability to communicate with others, ability to envision the problem spatially, and ability to verbally describe that spatial understanding. Although not scientifically founded, anecdotal information supports the incidence of these capabilities (Curtis, 1988).
For software engineering experiments, the key problems involve small sample sizes, high variability, many uncontrolled factors, and extreme difficulty in collecting experimental data. Traditional statistical experimental designs, originally developed for agricultural experiments, are not well suited for software engineering. At the panel's forum, Zweben (1993) discussed an interesting example of an experiment from object-oriented programming, involving a fairly complex design and analysis. Object-oriented programming is an approach that is sweeping the software industry, but for which much of the supporting evidence is anecdotal.
Example. The purpose of the software design and analysis experiment was to gather statistically valid evidence about the effect—on effort and quality—of using the principles of abstraction, encapsulation, and layering to enhance components of software systems. The experiment was divided into two types of tasks:
-
Enhancing an existing component to provide additional functionality, and
-
Modifying a component to provide different functionality.
The experimental subjects were students in graduate classes on software component design and development. The two approaches for this maintenance problem are "white box," which involves modifying the old code to get the new functionality, and "black box," which involves layering on the new functionality. The experiments were designed to detect, for each task, differences between the two approaches in the time required to make the modification and in the number of associated faults uncovered. Three experiments were conducted. Experiment A involved an unbounded queue component. The subjects were given a basic Ada package implementing enque, deque, and is empty, and the task was to implement the operators add, copy, clear, append, and reverse. The subject was instructed to keep track of the time spent in designing, coding, testing, and debugging each operator, and also the associated number of bugs uncovered in each task. The tasks were completed in two ways: by directly implementing new operations using the representation of the queue, and by layering on the new operators as capabilities. Experiment B involved a partial map component, and experiment C involved an almost constant map component. Given that in experiments involving students, the results may be invalidated by problems with data integrity, for this experiment the student participants were told that the results of the experiment would have no effect on course grades. The code was validated by an instructor to ensure that there were no lingering defects. The experimental plan was conducted using a crossover design. Each subject implemented the enhancements twice, using both the white box and the black box methods. This particular experimental design could test for the treatment (layering or not) effect and treatment by sequence interaction. The subject differences were nested within the sequences, and the sequences were counterbalanced based on experience level. The carryover effect of the first treatment influences the choice regarding the correct way of testing for treatment effects.
The statistical model used to represent the behavior in the number of bugs was sophisticated as well, an overdispersed log linear model. The use of this model allowed for an analysis of nonnormal response data while also preventing invalid inferences that would have occurred had
overdispersion not been taken into account. Indeed, only experiment B displayed a significant treatment effect after adjustment for overdispersion.
COMBINING INFORMATION
The results of many diverse software projects and studies tend to lead to more confusion than insight. The software engineering community would benefit if more value were gained from the work that is being done. To the extent that projects and studies focus on the same end point, statistics can help to fuse the independent results into a consistent and analytically justifiable story.
The statistical methodology that addresses the topic of how to fuse such independent results is relatively new and is termed ''combining information"; a related set of tools is provided by meta-analysis. An excellent overview of this methodology was produced by a CATS panel and documented in an NRC report (NRC, 1992) that is now available as an American Statistical Association publication (ASA, 1993). The report documents various approaches to the problem of how to combine information and describes numerous specific applications. One of the recommendations made in it (p. 182) is crucial to achieving advances in software engineering:
The panel urges that authors and journal editors attempt to raise the level of quantitative explicitness in the reporting of research findings, by publishing summaries of appropriate quantitative measures on which the research conclusions are based (e.g., at a minimum: sample sizes, means, and standard deviations for all variables, and relevant correlation matrices).
It is not sensible to merely combine p-values from independent studies. It is clearly better to take weighted averages of effects when the weights account for differences in size and sensitivity across the studies to be combined.
Example. Kitchenham (1991) discusses an issue in cost estimation that involves looking across 10 different sources consisting of 17 different software projects. The issue is whether the exponent ß in the basic cost estimation model, effort ∝ size ß , is significantly different from 1. The usual interpretation of ßis the "overhead introduced by product size," so that a value greater than 1 implies that relatively more effort is required to produce large software systems than to produce smaller ones. Many cite such "diseconomies of scale" in software production as evidence in support of their models and tools.
The 17 software projects are listed in Table 4. Fortunately, the cited sources contain both point estimates (b) of the exponent and its estimated standard error. These summary statistics can be used to estimate a common exponent and ultimately test the hypothesis that it is different from 1.
Table 4. Reported and derived data on 17 projects concerned with cost estimation.
|
Study |
b |
SE (b) |
Var (b) |
w |
|
Bai-Bas |
0.951 |
0.068 |
0.004624 |
21.240 |
|
Bel-Leh |
1.062 |
0.101 |
0.010200 |
18.990 |
|
Your |
0.716 |
0.230 |
0.052900 |
10.490 |
|
Wing |
1.059 |
0.294 |
0.086440 |
7.758 |
|
Kemr |
0.856 |
0.177 |
0.031330 |
13.550 |
|
Boehm.Org |
0.833 |
0.184 |
0.033860 |
13.100 |
|
Boehm.semi |
0.976 |
0.133 |
0.017690 |
16.630 |
|
Boehm.Emb |
1.070 |
0.104 |
0.010820 |
18.770 |
|
Kit-Tay.ICL |
0.472 |
0.323 |
0.104300 |
6.813 |
|
Kit-Tay.BTSX |
1.202 |
0.300 |
0.090000 |
7.550 |
|
Kit-Tay.BTSW |
0.495 |
0.185 |
0.034220 |
13.040 |
|
DS1.1 |
1.049 |
0.125 |
0.015630 |
17.220 |
|
DS1.2 |
1.078 |
0.105 |
0.011020 |
18.700 |
|
DS1.3 |
1.086 |
0.289 |
0.083520 |
7.938 |
|
DS2.New |
0.178 |
0.134 |
0.017960 |
16.550 |
|
DS2.Ext |
1.025 |
0.158 |
0.024960 |
14.830 |
|
DS3 |
1.141 |
0.077 |
0.005929 |
20.670 |
|
SOURCE: Reprinted, with permission, from Kitchenham (1992). (c)1992 by National Computing Centre, Ltd. |
||||
Following the NRC recommendations on combining information across studies (NRC, 1992), the appropriate model (the so-called random effects model in meta-analysis) allows for a systematic difference between projects (e.g., bias in data reporting, management style, and so on) that averages to zero. Under this model, the overall exponent is estimated as a weighted average of the individual exponents where the weights have the form wi = var (bi ) + τ2 and the common between-project component of variance is estimated by
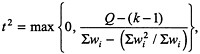
where ![]() . The statistic Q is itself a test of the homogeneity of projects and under a normality assumption is distributed as X2k-1 . For these data one obtains Q = 55.19, which strongly indicates heterogeneity across projects. Although the random effects model anticipates such heterogeneity, other approaches that model the differences between projects (e.g.,
. The statistic Q is itself a test of the homogeneity of projects and under a normality assumption is distributed as X2k-1 . For these data one obtains Q = 55.19, which strongly indicates heterogeneity across projects. Although the random effects model anticipates such heterogeneity, other approaches that model the differences between projects (e.g.,
regression models) may be more informative. Since no explanatory variables are available, this discussion proceeds using the simpler model.
The estimated between-project component of variance is t2 = 0.0425, which is surprisingly large and is perhaps highly influenced by two projects with b's less than 0.5. Combining this estimate with the individual within-project variances leads to the weights given in the final column of Table 4. Thus the overall estimated exponent is ![]() with estimated standard error
with estimated standard error ![]() . Combining these two estimates leads readily to a 95% confidence interval for ß of (0.78, 1.04). Thus the data in these studies do not support the diseconomies-of-scale argument.
. Combining these two estimates leads readily to a 95% confidence interval for ß of (0.78, 1.04). Thus the data in these studies do not support the diseconomies-of-scale argument.
Even better than published summaries would be a central repository of the data arising from a study. This information would allow assessment of various determinations of similarities between studies, as well as potential biases. The panel is aware of several initiatives to build such data repositories. The proposed National Software Council has as one of its primary responsibilities the construction and maintenance of a national software measurements database. At the panel's forum, a specialized database on software projects in the aeronautics industry was also discussed (Keller, 1993).
An issue related to combining information from diverse sources concerns the translation to industry of small experimental studies and/or published case studies done in an academic environment. Serious doubts exist in industry as to the upward scalability of most of these studies because populations, project sizes, and environments are all different. Expectations differ regarding quality, and it is unclear whether variables measured in a small study are the variables in which industry has an interest. The statistical community should develop stochastic models to propagate uncertainty (including variability assessment) on different control factors so that adjustments and predictions applicable to industry-level environments can be made.
VISUALIZATION IN SOFTWARE ENGINEERING
Scientific visualization is an emerging technology that is driven by ever-decreasing hardware prices and the associated increasing sophistication of visualization software. Visualization involves the interactive pictorial display of data using graphics, animation, and sound. Much of the recent progress in visualization has come from the application of computer graphics to three-dimensional image analysis and rendering. Data visualization, a subset of scientific visualization, focuses on the display and analysis of abstract data. Some of the earliest and best-known examples of data visualization involve statistical data displays.
The motivation for applying visualization to software engineering is to understand the complexity, multidimensionality, and structure embodied in software systems. Much of the original research in software visualization—the use of typography, graphic design, animation, and cinematography to facilitate the understanding and enhancement of software systems-was performed by computer scientists interested in understanding algorithms, particularly in the
context of education. Applying the quantitative focus of statistical graphics methods to currently popular scientific visualization techniques is a fertile area for research.
Visualizing software engineering data is challenging because of the diversity of data sets associated with software projects. For data sets involving software faults, times to failure, cost and effort predictions, and so on, there is a clear statistical relationship of interest. Software fault density may be related to code complexity and to other software metrics. Traditional techniques for visualizing statistical data are designed to extract quantitative relationships between variables. Other software engineering data sets such as the execution trace of a program (the sequence of statements executed during a test run) or the change history of a file are not easily visualized using conventional data visualization techniques. The need for relevant techniques has led to the development of specialized domain-specific visualization capabilities peculiar to software systems. Applications include the following:
-
Configuration management data (Eick et al., 1992b),
-
Function call graphs (Ganser et al., 1993),
-
Code coverage,
-
Code metrics,
-
Algorithm animation (Brown and Hershberger, 1992; Stasko, 1993),
-
Sophisticated typesetting of computer programs (Baecker and Marcus, 1988),
-
Software development process,
-
Software metrics (Ebert, 1992), and
-
Software reliability models and data.
Some of these applications are discussed below.
Configuration Management Data
A rich software database suitable for visualization involves the code itself. In production systems, the source code is stored in configuration management databases. These databases contain a complete history of the code with every source code change recorded as a modification request. Along with the affected lines, the source code database usually contains other information such as the identity of the programmer making the changes, date the changes were submitted, reason for the change, and whether the change was meant to add functionality or fix a bug. The variables associated with source code may be continuous, categorical, or binary. For a line in a computer program, when it was written is (essentially) continuous, who wrote it is categorical, and whether or not the line was executed during a regression test is binary.
Example. Figure 1 (see "Implementation" in Chapter 3) shows production code written in C language from a module in AT&T's 5ESS switch (Eick, 1994). In the display, row color is tied to the code's age: the most recently added lines are in red and the oldest in blue, with a color spectrum in between. Dynamic graphics techniques are employed for increasing the effectiveness of the display. There are five interactive views of data in Figure 1:
-
The rows corresponding to the text lines,
-
The values on the color scale,
-
The file names above the columns,
-
The browser windows, and
-
The bar chart beneath the color scale.
Each of the views is linked, united through the use of color, and activated by using a mouse pointer. This mode of manipulating the display, called brushing by Becker and Cleveland (1987) and by Becker et al. (1987), is particularly effective for exploring software development data.
Function Call Graphs
Perhaps the most common visualization of software is a function call graph as shown in Figure 5. Function call graphs are a widely used, visual, tree-like display of the function calls in a piece of code. They show calling relationships between modules in a system and are one representation of software structure. A problem with function call graphs is that they become overloaded with too much information for all but the smallest systems. One approach to improving the usefulness of function call graphs might involve the use of dynamic graphics techniques to focus the display on the visually informative regions.
Test Code Coverage
Another interesting example of source code visualization involves showing test suite code coverage. Figure 6 shows the statement coverage and execution "hot spots" for a program that has been run through its regression test. The row indentation and line length have been turned off so that each line receives the same amount of visual space. The most frequently executed lines are shown in red and the least frequently in blue, with a color spectrum in between. There are two special colors: the black lines correspond to nonexecutable lines of C code such as comments, variable declarations, and functions, and the gray lines correspond to the executable lines of code that were not executed. These are the lines that the regression test missed.
Code Metrics
As discussed in Chapter 4 (in the section "Software Measurement and Metrics"), static code metrics attempt to quantify and measure the complexity of code. These metrics are used to identify portions of programs that are particularly difficult and are likely to be subject to defects. One visualization method for displaying code complexity metrics uses a space-filling representation (Baker and Eick, 1995). Taking advantage of the hierarchical structure of code, each subsystem, module, and file is tiled on the display, which shows them as nested, space-filling rectangles with area, color, and fill encoding software metrics. This technique can display
the relative sizes of a system's components, the relative stability of the components, the location of new functionality, the location of error-prone code with many fixes to identified faults, and, using animation, the historical evolution of the code.
Example. Figure 7 displays the AT&T 5ESS switching code using the SeeSys( system, a dynamic graphics metrics visualization system. Interactive controls enable the user to manipulate the display, reset the colors, and zoom in on particular modules and files, providing an interactive software data analysis environment. The space-filling representation:
-
Shows modules, files, and subsystems in context;
-
Provides an overview of a complete software system; and
-
Applies statistical dynamic graphics techniques to the problem of visualizing metrics.
A major difference in the use of graphics in scientific visualization and statistics is that for the former, graphs are the end, whereas for the latter, they are more often the means to an end. Thus visualizations of software are crucial to statistical software engineering to the extent that they facilitate description and modeling of software engineering data. Discussed below are some possibilities related to the examples described in this chapter.
The rainbow files in Figure 1 suggest that certain code is changed frequently. Frequently changed code is often error-prone, difficult to maintain, and problematic. Software engineers often claim that code, or people's understanding of it, decays with age. Eventually the code becomes unmaintainable and must be rewritten (re-engineered). Statistical models are needed to characterize the normal rate of change and therefore determine whether the current files are unusual. Such models need to take account of the number of changes, locations of faults, type of functionality, past development patterns, and future trends. For example, a common software design involves having a simple main routine that calls on several other procedures to invoke needed functionality. The main routine may be changed frequently as programmers modify small snippets of code to access large chunks of new code that is put into other files. For this code, many simple, small changes are normal and do not indicate maintenance problems. If models existed, then it would be possible to make quantitative comparisons between files rather than the qualitative comparisons that are currently made.
Figure 5 suggests some natural covariates and models for improving the efficiency of software testing. Current compiler technology can easily analyze code to obtain the functions, lines, and even the paths executed by code in test suites. For certain classes of programming errors such as typographical errors, the incremental code coverage is an ideal covariate for estimating the probability of detecting an error. The execution frequency of blocks of code or functions is clearly related to the probability of error detection. Figure 5 shows clearly that small portions of the program are heavily exercised but that most of the code is not touched. In an indirect way operational profile testing attempts to capture this idea by testing the features, and therefore the code, in relation to how often they will be used. This notion suggests that statistical techniques involving covariates can improve the efficiency of software testing.
Figure 7 suggests novel ways of displaying software metrics. The current practice is to identify overly complex files for special care and management attention. The procedures for
identifying complex code are often based on very clever and sophisticated arguments, but not on data. A statistical approach might attempt to correlate the complexity of code with the locations of past faults and investigate their predictive power. Statistical models that can relate complexity metrics to actual faults will increase the models' practical efficiency for real-life systems. These models should not be developed in the absence of data about the code. Simple ways of presenting such data, such as an ordered list of fault density, file by file, can be very effective in guiding the selection of an appropriate model. In other cases, microanalysis, often driven by graphical browsers, might suggest a richer class of models that the data could support. For example, software fault rates are often quoted in terms of the number of faults per 1,000 lines of NCSL. The lines in Figure 1 can be color-coded to show the historical locations of past faults. In other representations (not shown), clear spatial patterns with faults are concentrated in particular files and in particular regions of the files, suggesting that spatial models of fault density might work very well in helping to identify fault-prone code.
Challenges for Visualization
The research opportunities and challenges in visualizing software data are similar to those for visualizing other large abstract databases:
-
Software data are abstract; there is no natural two-dimensional or three-dimensional representation of the data. A research challenge is to discover meaningful representations of the data that enable an analyst to understand the data in context.
-
Much software data are nontraditional statistical data such as the change history of source code, duplication in manuals, or the structure of a relational database. New metaphors must be discovered for harmonious transfer information.
-
The database associated with large software systems may be huge, potentially containing millions of observations. Effective statistical graphics techniques must be able to cope with the volume of data found in modern software systems.
-
The lack of easy-to-use software tools makes the development of high-quality custom visualizations particularly difficult. Currently, visualizations must be hand-coded in low-level languages such as C or C++. This is a time-consuming task that can be carried out only by the most sophisticated programmers.
Opportunities for Visualization
Visualizations associated with software involve the code itself, data associated with the system, the execution of the program, and the process for creating the system. Opportunities include the following:
-
Objects/Patterns. Object-oriented programming is rapidly becoming standard for development of new systems and is being retrofitted into existing systems. Effective
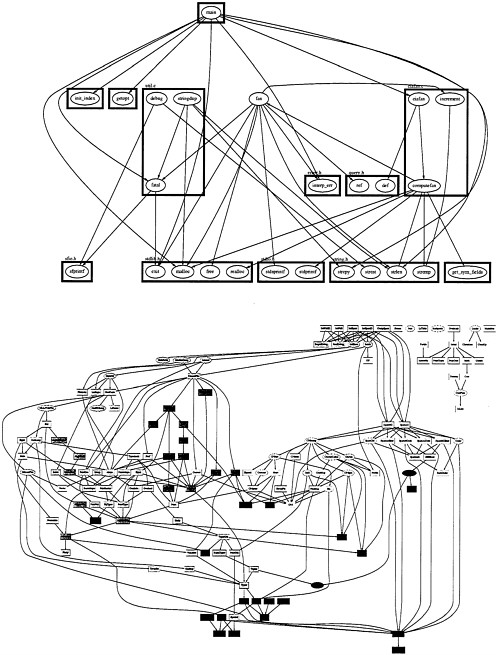

Figure 6. a SeeSoftTM display showing code coverage for a program executing its regression test. The color of each line is determined by the number of times that it executed. The colors range from red (the "hot spots") to deep blue (for code executed only once) using a red-green-blue color spectrum. There are two special colors: the black lines are non-executable lines of code such as variable declarations and comments, and the gray lines are the non-executed (not covered) lines. The figure shows that generating regression tests with high coverage is quite difficult. Source: Eick(1994).
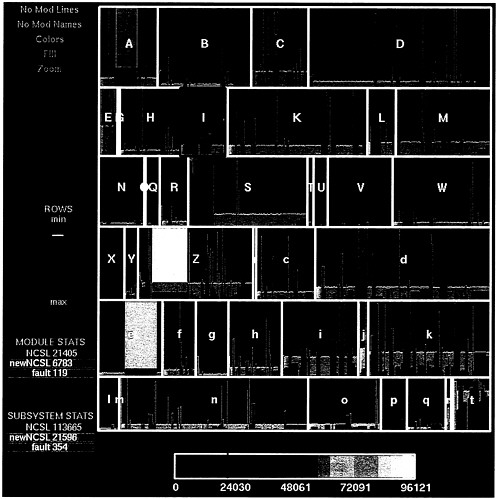
Figure 7. A display of software metrics for a million-line system. The rectangle forming the outermost boundary represents the entire system. The rectangles contained within the boundary represent the size (in NCSLs) of individual subsystems (each labeled with a single character A-Z, a-t), and modules within the subsystems. Color is used here to redundantly encode size according to the color scheme in the slider at the bottom of the screen.
-
displays need to be developed for understanding the inheritance (or dependency) structure, semantic relationships among objects, and the run-time life cycle of objects.
-
Performance. Software systems inevitably run too slowly, making run-time performance an important consideration. Host systems often collect large volumes of fine-grain (that is, low-level) performance data including function calling patterns, line execution counts, operating system page faults, heap usage, and stack space, as well as disk usage. Novel techniques to understand and digest dynamic program execution data would be immediately useful.
-
Parallelism. Recently, massively parallel computers with tens to thousands of cooperating processors have started to become widely available. Programming these computers involves developing new distributed algorithms that divide important computations among the processors. Most often an essential aspect of the computation involves communicating interim results between processors and synchronizing the computations. Visualization techniques are a crucial tool for enabling programmers to model and debug subtle computations.
-
Three-dimensional. Workstations capable of rendering realistic three-dimensional displays are rapidly becoming widely available at reasonable prices. New visualization techniques leveraging three-dimensional capabilities should be developed to enable software engineers to cope with the ever-increasing complexity of modern software systems.
ORTHOGONAL DEFECT CLASSIFICATION
The primary focus of software engineering is to monitor a software development process with a view toward improving quality and productivity. For improving quality, there have been two distinct approaches. The first considers each defect as unique and tries to identify a cause. The second considers a defect as a sample from an ensemble to which a formal statistical reliability model is fitted. Chillarege et al. (1992) proposed a new methodology that strikes a balance between these two ends of spectrum. This method, called orthogonal defect classification, is based on exploratory data analysis techniques and has been found to be quite useful at IBM. It recognizes that the key to improving a process is to quantify various cause-and-effect relationships involving defects.
The basic approach is as follows. First, classify defects into various types. Then, obtain a distribution of the types across different development phases. Finally, having created these reference distributions and the relationships among them, compare them with the distributions observed in a new product or release. If there are discrepancies, take corrective action.
Operationally, the defects are classified according to eight ''orthogonal" (mutually exclusive) defect types: functional, assignment, interface, checking, timing, build/package/merge, data structures and algorithms, and documentation. Further, development phases are divided into four basic stages (where defects can be observed): design, unit test, function test, and system test. For each stage and each defect type, a range of acceptable baseline defect rates is defined by experience. This information is used to improve the quality of a new product or release. Toward
this end, for a given defect type, defect distributions across development stages are compared with the baseline rates. For each chain of results—say, too high early on, lower later, and high at the end—an implication is derived. For example, the implication may be that function testing should be revamped.
This methodology has been extended to a study of the distribution of triggers, that is, the conditions that allow a defect to surface. First, it is implicit in this approach that there is no substitute for a good data analysis. Second, assumptions clearly are being made about the stationarity of reference distributions, an approach that may be appropriate for a stable environment with similar projects. Thus, it may be necessary to create classes of reference distributions and classes of similar projects. Perhaps some clustering techniques may be valuable in this context. Third, although the defect types are mutually exclusive, it is possible that a fault may result in many defects, and vice versa. This multiple-spawning may cause serious implementation difficulties. Proper measurement protocols may diminish such multipropagation. Finally, given good-quality data, it may be possible to extend orthogonal defect classification to efforts to identify risks in the production of software, perhaps using data to provide early indicators of product quality and potential problems concerning scheduling. The potential of this line of inquiry should be carefully investigated, since it could open up an exciting new area in software engineering.


















