
Traffic Management for High-Speed Networks
Abstract
Network congestion will increase as network speed increases. New control methods are needed, especially for handling "bursty" traffic expected in very high speed networks such as asynchronous transfer mode (ATM) networks. Users should have instant access to all available network bandwidth when they need it, while being assured that the chance of losing data in the presence of congestion will be negligible. At the same time, high network utilization must be achieved, and services requiting guaranteed performance must be accommodated. This paper discusses these issues and describes congestion control solutions under study at Harvard University and elsewhere. Motivations, theory, and experimental results are presented.
Why New Control Methods are Needed
Rapid Increase in Network Speeds
Over the past decade, the speed of computer and telecommunications networks has improved substantially. To wit:
- 1980s
|
- |
1.5-Mbps (megabits per second) T1 |
|
- |
4- or 16-Mbps Token Rings |
|
- |
10-Mbps Ethernet |
- 1990s
|
- |
45-Mbps T3 |
|
- |
100-Mbps Ethernet |
|
- |
100-Mbps FDDI |
|
- |
155-Mbps OC-3 ATM |
|
- |
622-Mbps OC-12 ATM |
This rapid growth in speed is expected to continue over the next decade, because many new applications in important areas such as data and video will demand very high network bandwidths. These high-speed networks are introducing major new challenges in network congestion control, as explained in the next two sections. That the high-speed networks would make the solution for network congestion harder is contrary to what one's intuition might suggest.
Network Congestion Problem
Any network has bottlenecks or congestion points, i.e., locations where more data may arrive than the network can carry. A common cause for congestion is a mismatch in speed between networks. For example, a typical high-performance local area network (LAN) environment in the next several years may have the architecture shown in Figure 1. While the servers will use new high-speed asynchronous transfer mode (ATM) connections at the OC-3 rate of 155 Mbps, many clients will still depend on old, inexpensive but slower, 10-Mbps Ethernet connections. Data flowing from the servers at 155 Mbps to the clients at 10 Mbps will experience congestion at the interface between the ATM and Ethernet networks.
Congestion can also occur inside a network node that has multiple ports. Such a node can be a switch such as an ATM switch or a gateway such as a router. As depicted in Figure 2, congestion arises when data, destined for a single output port, arrive at many different input ports. The faster and more numerous these input ports are, the severer the congestion will be.
A consequence of congestion is the loss of data due to buffer overflow. For data communications in which every bit must be transmitted correctly, lost data will have to be retransmitted, and will result in degraded network utilization and increased communications delay for end users.
Inadequacy of Brute-Force Approach to Providing Large Buffers
A universal solution to the problem of losing data because of congestion involves buffer memory in which a congested point can temporarily queue data directed at overloaded output ports. This use of buffer is illustrated in Figure 2. However, simply providing large buffers would likely incur prohibitively high memory cost for high-speed networks, because as network speed increases, so also will the following factors:
- Buffer overloading rate. Suppose that data from multiple input ports feed to a single output port, and that all the ports are of the same speed. If all these ports now increase their speed by a factor of X, then the overloading rate to the node buffer will also increase
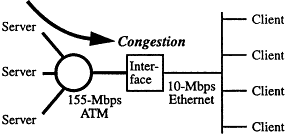
Figure 1
Congestion due to a mismatch in speed between 155-Mbps ATM network and 10-Mbps Ethernet.
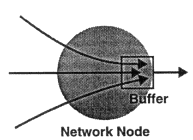
Figure 2
Congestion, in a switch or gateway, due to multiple arrivals at the same output.
- by the same factor of X. If, to prevent buffer overflow, the same congestion control scheme is used as was used before, then the feedback delay in the control system, which is a function of propagation delays and largely independent of link speed, will remain essentially the same. An increase in link speed will therefore demand an X-fold increase in the required buffer size, if possible data loss is to be kept to the same level as before.
- Packet or burst size. For high-speed networks, high-level protocols will use data packets with an increased number of bytes, in order to reduce packet processing overhead at end systems, such as the packet interrupt frequency at receiving hosts. These large packets introduce large bursts of data that may arrive at congestion points at the same time. Assuming the same average load as before, bursts of increased size imply increased overlapping of arriving bursts at congestion points. A larger buffer is thus needed to accommodate these simultaneously arriving large bursts.
- Transient traffic. Typical Transmission Control Protocol (TCP) sessions involve a few dozen kilobytes [19], and the required transmission time on an OC-3 link at 155 Mbps is only a few milliseconds. (A survey of Unix file sizes [7] has also shown a similar result for file sizes. That is, the average file length is only around 22 kbytes, and most files are smaller than 2 kbytes.) Thus, for high-speed networks, these sessions will not be long enough to achieve steady-state traffic flow beyond a local or metropolitan area. When facing this type of transient traffic over a wide area, traditional end-to-end flow control methods such as TCP will incur relatively long feedback control delays, and thus such methods cannot be effective in reducing buffer usage inside a network.
- Bandwidth mismatch. As new networks are deployed, many of the relatively old, inexpensive, low-bandwidth networks will still be in use. As these new networks with higher and higher speeds emerge, gaps in speed between old and new networks will increase. For handling the same load, this greater mismatch in bandwidth again implies the need for larger buffers.
- Load speed from computer sources. A single workstation or personal computer can now consume the whole bandwidth of an OC-3 link. High-end computers such as servers tend to support high-bandwidth network interfaces that run as fast as the fastest computer networks available. One can expect that, at any point in time in the foreseeable future, several high-performance computers, if not just one, will always be able to saturate the fastest links in any network.
To prevent data loss due to congestion, network buffers could be increased to accommodate the increase in each of the above factors. But these factors increase independently, and the multiplicative effects of such increases will demand enormously large buffers. In addition, as network usage increases, so also will the expected number of active sessions on the network and their peak bandwidths. For each session, a network node may have to buffer all the on-the-fly data from a distant sending host to itself when congestion occurs. The buffers occupied by the session can be the entire TCP window if TCP is used. If there are N sessions, N times the size/capacity of this buffer will be needed.
For all these reasons, brute-force methods of using larger and larger buffers cannot solve the congestion problems to be expected with high-speed networks.



