
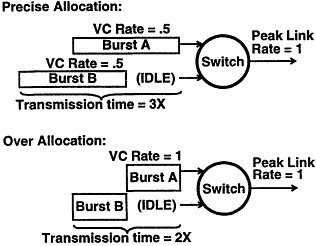
Figure 13
Both bursts A and B complete transmission earlier and make higher utilization of switch output link in the overallocating case than in the precise case.
of bandwidth 1, and that each has a data burst that would take a unit time to transmit over a link of bandwidth 1. Suppose that the B burst arrives 1 unit time later than the A burst. Then as Figure 13 depicts, in the precise rate-setting case where each VC is set with a rate of 0.5, it would take a total of 3 time units to complete the transmission of both the A and B bursts. In contrast, in the overallocating rate-setting case where each VC is set with a rate of 1, it would take only 2 time units to do the same. This need for overallocating resources is similar to that discussed above for credit control.
Since adaptation cannot and should not be precise, rates set by the adaptation may not be totally correct. Bounding the liability of overrunning switch buffers is therefore a first-order issue. This explains why credit-based flow control has been desired to control buffer allocation and monitor the buffer usage, directly.
CreditNet ATM SWITCH
To study ATM-layer flow control, BNR and Harvard University have jointly developed an experimental ATM switch [2], with both 622-Mbps (OC-12) and 155-Mbps (OC-3) ports. This effort is part of the CreditNet research project supposed, in part, by the Defense Advanced Research Projects Agency (DARPA). Under this project, BNR and Hazard have developed the ATM switch described here, whereas Carnegie Mellon University (CMU) and Intel have developed an ATM-PCI host interface at both OC-3 and OC-12 rates.
This experimental CreditNet switch has a number of unique features. These include ATM-layer credit-based flow control, per-VC round-robin cell scheduling, multicast support in hardware, highly programmable microprocessor-based switch port cards, and built in instrumentation for performance measurement. (Independently, Digital Equipment Corporation (DEC) has also developed a credit-based ATM network.)
Five of these experimental switches have been built; the first one has been operational since spring 1995. Several ATM host adapters have been used in conjunction with the switch. These include those from DEC (for TurboChannel), Sun (S-Bus), Intel (PCI) and Zeitmet (PCI). Both the OC-3 and OC-12 links have been used in various experiments. In addition, a Q93B signaling
system has been successfully implemented on the switch. As of spring 1996, one of the switches now operates on site at Harvard, one is temporarily at a Sprint site to support a WAN congestion control trial, and others are at BNR and CMU.
To implement credit-based flow control, the switch monitors the buffer use of each VC and provides feedback to the immediately preceding switch or host along the VC's path. Since each switch has precise knowledge of the resources a circuit is consuming, and the feedback loop is only one link long instead of the length of the entire end-to-end connection, this flow control system allows much more efficient use of buffer memory and link bandwidth.
As shown in Figure 14, the switch is physically organized as 16 modules that plug into a backplane and memory buffer system. One of the modules is the switch control module for call processing using the Q93B signaling standard.
The rest of the modules are port modules. Each port module has two 960 microprocessors, one for scheduling mentioned above and one to handle real-time monitoring and control. These two microprocessors are not necessary for a minimum implementation of a credit-based switch, but they provide the programming flexibility necessary to study many research issues. For example, these processors provide the flexibility to experiment with different ways of observing and reacting to network load conditions. Each port module also has a fiber-optic link interface using Synchronous Optical Network (SONET) framing. The cell-handling hardware is built from field-programmable gate arrays for control, and from static random access memories (RAMs) for tables and queues.
When a cell arrives at the switch, the input port broadcasts the cell's circuit identifier and address in the common memory on the arrival bus on the backplane. Each output port monitors this backplane; when a port notices that a cell has arrived for a circuit that leaves that port, it adds the cell's memory address to a queue.
When a cell leaves an output port, its circuit identifier is broadcast on the departure bus on the backplane. By watching the arrival and departure buses, each input port maintains a count of the number of cells buffered for each circuit that enters that port. This count is used both to provide credit-based flow-control feedback and to decide which circuits are using so much memory that their data should be discarded.
The common memory architecture allows the switch to support multicast in an efficient way. A common memory allocation engine maintains a list of free locations in the shared common
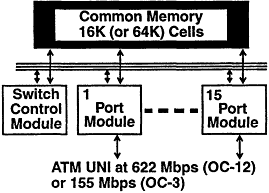
Figure 14
Architecture overview of CreditNet switch.
memory. Entries from this list are allocated to cells as they arrive. When a multicast cell's information is broadcast on the arrival bus, more than one port module will enqueue this cell in its list of cells to send. However, the cell requires only one common memory location.
The allocation engine hands out addresses of free slots in the common memory to the ports on demand, so that they can store incoming data. When it does this, it initializes a list of egress ports that must send this cell out. When a port sends out a cell, the presence of the cell's identifier on the departure bus tells the allocation engine to remove it from the list. When the list becomes empty, the common memory location is recycled for future use. All this is done by efficient hardware: the allocation engine requires only four memory accesses per port per cell cycle.
For most purposes, the ingress and egress sides of a port are effectively independent. However, they have an important interaction required for the credit protocol. Essentially, the credit protocol requires a sender to have a credit for a given VC, before sending cells on it. Credit is granted by sending credit cells opposite the flow of data (from receiver to sender). Thus, when the ingress side of a port realizes that a number of cells for that VC have left the switch, it notifies the egress side of the same port to send a credit cell.
Experimental Network Configurations
The CreditNet switch has been used to experiment with TCP performance over ATM networks. The experiments described below use two network configurations in a LAN environment. The first, shown in Figure 15 (a), involves host A sending a continuous stream of data through the switch to host B. Host A's link to the switch runs at 155 Mbps, while host B's link runs at only 53 Mbps, enforced by a properly programmed scheduler on the link input. This is one of the simplest configurations in which congestion occurs. Note that after SONET and ATM overhead, a 155-Mbps link can deliver roughly 134 Mbps or 17 megabytes per second (Mbyte/sec) of useful payload to a host. A 53-Mbps link can deliver about 5.7 Mbyte/sec.
The second configuration, shown in Figure 15 (b), involves four hosts. Host A sends data to host C, and host B to host D. The four host links run at 155 Mbps, and the bottleneck link between the switches runs at 53 Mbps. The purpose of this configuration is to show how two conversations interact.
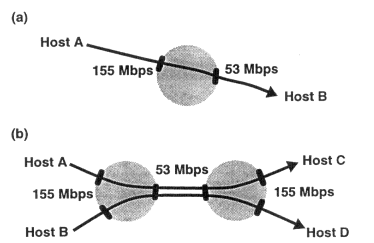
Figure 15
(a) Network configuration for single TCP experiments on CreditNet and (b) configuration for two competing TCPs. The shaded circles represent switches. Each darkened bar denotes a switch port.
The hosts in all these experiments are DEC Alpha 3000/400 workstations running OSF/1 V3.0. The OSF/1 TCP implementation [5], used in all the experiments reported in this paper, is derived from 4.3-Reno [21]. This TCP tends to acknowledge, and thus transmit, pairs of packets. The TCP window size for these experiments is limited to no more than 64 kbytes, and the packet size to 9180, except when noted. The workstations use 155-Mbps OTTO TurboChannel adapters provided by DEC. The Alphas can send or receive TCP using the OTTOs at about 15 Mbyte/sec. The OTTO drivers optionally implement CreditNet's credit-based flow control partially in software; with credit turned on they can send and receive TCP at 13 Mbyte/sec.
The measurements are all directly derived from the instrumentation counters in the CreditNet switch hardware. The hardware keeps track of the total number of cells sent by each VC and the number of cells buffered for each VC.
Measured Performance on CreditNet Experimental Switches
ATM-layer credit-based flow control resolves some TCP performance problems over ATM networks when packets are lost because of congestion [16]. The bottleneck switch no longer discards data when it runs out of buffer memory and possibly causes TCP to endure lengthy time-out periods. Instead, it withholds credit from the switches and/or hosts upstream from it, causing them to buffer data rather than sending it. This backpressure can extend all the way back through a network of switches to the sending host. The effect is that a congested switch can force excess data to be buffered in all the upstream switches and in the source host. Data need never be lost because of switch buffer overran. Thus, if TCP chooses a window that is too large, the data will simply be buffered in the switches and in the host; no data loss and retransmission time-outs will result.
Table 2 compares the useful bandwidths achieved with and without credit-based ATM-layer flow control in the configurations shown in Figure 15. For the flow-controlled cases, the switch has 100 cell buffers (4800 payload bytes) reserved per-VC. For the non-flow-controlled cases, the switch has 682 (32 payload kbytes) cells of buffering per-VC. Recall that for the configuration in Figure 15 the slow link can deliver at most 5.7 payload Mbps, and the fast link 17. Thus in both the one TCP and two TCPs cases, TCP with credit-based flow control achieves its maximum-possible bandwidth.
Using a configuration similar to that shown in Figure 15 (b), experiments involving one TCP and one UDP, instead of two TCPs, have also been carded out. A typical measured result is as follows. When ATM-layer credit-based flow control is used, UDP gets its maximum bandwidth limited only by the source, while TCP gets essentially the remaining bandwidth of the bottleneck link between the two switches. However, when credit-based flow control is turned off, TCP's throughput drops significantly and the total utilization on the bottleneck link by both TCP and UDP is reduced to less than 45 percent. Thus, when competing with UDP, TCP with ATM-layer flow control can keep up its throughput even though UDP does not reduce its bandwidth during network congestion.
TABLE 2
Measured Total Bandwidth Achieved with and without ATM-Layer Credit-based Flow Control, for the (a) and (b) configurations of Figure 15
|
|
Without ATM-Layer Flow Control |
With ATM-Layer Flow Control |
|
(a) One TCP |
0.1 Mbyte/sec |
5.7 Mbyte/sec |
|
(b) Two TCPs |
0.2 Mbyte/sec |
5.7 Mbyte/sec |




