
5
Memory and Learning
Memory and learning have been the chief concern of experimental psychology since that field's inception and have been at the center of cognitive psychology and cognitive science. Thus there is an enormous literature on the subject, both empirical and theoretical, ranging from animal behavior to high-level human cognition, from behavioral studies to neuroscience, from applied research to basic mechanisms, and from very short-term memories (a few hundred milliseconds) to the development of expertise and skill (perhaps 10 years). A great portion of this research is directly or potentially relevant to the representation of human behavior in military simulations, but even a survey of the field would require several long books. Thus this chapter provides an extremely selective survey of those elements that seem particularly relevant to simulations of interest to defense forces. After briefly reviewing the basic structures associated with memory and learning, the chapter examines modeling of the various types of memory and then of human learning. The final section presents conclusions and goals in the area of memory and learning.
BASIC STRUCTURES
There is general agreement that human memory is best modeled in terms of a basic division between active short-term memory and a passive storehouse called long-term memory.1 Short-term memories include sensory memories, such
as the visual icons originally studied by Sperling (1960), which operate fairly automatically and decay autonomously within several hundred milliseconds, and a variety of more central memories, including so-called "working memories," that are used to carry out all the operations of cognition (e.g., Baddeley, 1986, 1990). Short-term memories allow control processes to be carried out because they hold information for temporary periods of, say, up to a minute or more. The long-term memory system can be divided by function or other properties into separate systems, but this is a matter of current research. The operations associated with memory include those of rehearsal and coding used to store new information in long-term memory; operations that govern the activities of the cognitive system, such as decisions; and operations used to retrieve information from long-term memory. Almost all simulations incorporate such structural features.
Different aspects of memory and learning are important for simulations aimed at different purposes. For example, a simulation of a tank gunner might rely heavily on short-term vision, short-term working memory, and whatever task procedures have been learned previously and stored in long-term memory. Retrieval from visual short-term memory may be important, for example, when the positions of recent targets and terrain features must be retained during a series of maneuvers that move these targets and features out of direct vision. For a gunner in a short firefight, learning during the task may be relatively unimportant since the gunner will rely primarily on previously trained procedures and strategies or decisions made in working memory. In addition, the process of accessing learned procedures in long-term memory may not need to be modeled, only assumed (since this process may be well learned and automatic). On the other hand, strategic decision making by a battle commander will involve working memory and the processes of long-term retrieval. Sensory memories and the retention role of short-term memories may be relatively unimportant. Finally, in the course of a war lasting several years, learning will probably be critical for models of personnel at all levels of command.
It should be obvious that the process of learning itself is critical whenever training and the development of skill and expertise are at issue. The nature of storage, the best means of retrieval, ways to utilize error correction, and best modes of practice are all essential components of a simulation of the learner. It is well known that the largest effects on performance observed in the literature are associated with the development of expertise (see also Chapter 4). The development of skills can proceed quite quickly in short periods of time, but typically continues for long periods. Given motivation and the right kinds of practice, development of the highest levels of skill in a task may require 3 to 4 hours a day of rigorous practice for a period of 10 years (e.g., Ericcson et al., 1993; Ericcson, 1996). Although the nature of the learning process in such situations is not yet understood in detail, there is much empirical evidence (starting with Chase and Simon, 1973) demonstrating that a critical component of the learning of a skill is the storage of massive amounts of information about particular situations and
procedures, information that apparently becomes retrievable in parallel with increasing ease.
Several researchers (Van Lehn, 1996; Logicon, 1989; Brecke and Young, 1990) have constructed frameworks showing the relationship between the development of expertise and changes in the content and structure of knowledge stored by the individual as he or she moves from novice to expert. These researchers argue that experts have simpler but more effective and more richly related knowledge about a domain or situation than do novices, who may know more facts but fewer useful relationships among them. Thus, a key to the evolution of expertise is the evolution of representation: as expertise increases, knowledge is represented in a more abstract way, reducing the need to manipulate massive amounts of information.
Modeling the learning process itself, as in the development of expertise, can be important in another way. Even if one is concerned only with the end state of learning and wishes to model the procedures used by a well-trained individual in a given military situation, there are usually many possible models of such procedures. Modeling of the course of learning itself can be used to generate an effective representation for a given level of skill.
Although modeling the course of learning over 10 years of intensive practice may be useful for military simulations only in rare instances, other sorts of learning over shorter time spans will often be important. To carry this discussion further, it is necessary to discuss the different types of memory and their modeling.
MODELING OF THE DIFFERENT TYPES OF MEMORY
Memory can be broken down into three broad categories: (1) episodic, generic, and implicit memory; (2) short-term and working memory; and (3) long-term memory and retrieval.
Episodic, Generic, and Implicit Memory
Episodic memory refers to memory of events that tend to be identified by the context of storage and by personal interaction with the rememberer; successful retrieval of such memories tends to require contextual and personal cues in the memory probe. Examples might include the positions of enemy forces identified in the last several minutes of a firefight and, in general, all attended recent events. Many terms have been used to refer to aspects of general knowledge, some with particular theoretical connotations. In an attempt to remain neutral, we use the term generic memory to refer to general knowledge—knowledge not necessarily identified by circumstances of storage or requiring contextual cues for retrieval to occur. Examples might include the sequence of moves needed to aim and fire a familiar weapon, the rules for addition, and most general knowledge of facts and procedures. Finally, implicit memory refers to effects on retrieval of general
knowledge that result from recent experience, even if the recent experience is not recalled. For example, a gunner who saw a picture of a particular weapon in a magazine the previous evening would be more likely to notice that same weapon under battlefield conditions in the field the following day, even if the magazine event were totally forgotten and unavailable.
Although the existence of implicit memory effects is well established, the importance of including them in military models and simulations is not yet clear. Therefore, the focus here is on episodic and generic storage and retrieval, both of which are essential components of any simulation of human behavior. It is important to note that retrieval in all episodic tasks relies on a combination of generic and episodic access. For example, an externally provided retrieval cue, such as a word, will first be used to access generic, lexical, and semantic knowledge, which will join the surface features in a probe of episodic traces. A soldier prompted by a loud sound to recall the position of a recently seen tank, for example, will automatically be prompted to access long-term memory for associations with such a sound, perhaps recovering knowledge of the sorts of weapon systems that produce such a sound. The issue of whether both types of retrieval occur in episodic retrieval is largely independent of whether both must be included in a simulation; that answer depends on the particular application.
Short-Term and Working Memory
Short-term memory is the term used most often when one is interested more in the retention properties of the short-term system than in the control operations involved. Conversely, working memory is the term used most often when one is concerned with the operations carried out in active memory. These are not universal usages, however, and there is no hard and fast line between the two terms. The retention properties of the short-term systems are still an active area of study today, and there is no shortage of mathematical and simulation models of the retention of item and order information (e.g., Schweikert and Boruff, 1986; Cowan, 1993). Models of working memory that address the control of cognition are still in their infancy, and until very recently dealt only with certain specific control processes, such as rehearsal, coding, and memory search. What seems to be clear is that a successful model of short-term memory (and of memory in general) must deal with both the retention and control properties of the system. It seems clear that a model useful for military simulations must incorporate both aspects. Recent models of working memory are increasingly modular, with greater limitations of capacity within rather than between functional modules. Examples are the Soar architecture (e.g., Laird et al., 1987), the adaptive control of thought (ACT)-R model (Anderson, 1993), and the recent executive-process interactive control (EPIC) model of Meyer and Kieras (1997a); these are discussed in detail in Chapter 3.
Having pointed out the need for such a model, we must also note that a
complete model of short-term memory (in this general sense, which includes all the control processes used to store, retrieve, and decide) is tantamount to a complete model of cognition. The field is a long way from having such a model. Thus for the foreseeable future, short-term memory simulations will need to be tailored carefully to the requirements and specifications of the particular task being modeled.
Long-Term Memory and Retrieval
For most modelers, long-term memory denotes a relatively permanent repository for information. Thus models of long-term memory consist of representation assumptions (e.g., separate storage of exemplars, distributed representations, networks of connected symbolic nodes) and retrieval assumptions. The latter assumptions are actually models of a certain set of control and attention operations in short-term memory, but it is traditional to treat them separately from the other operations of short-term memory.
For episodic storage and retrieval, the best current models assume separate storage of events (e.g., the search of associative memory [SAM] model of Raaijmakers and Shiffrin, 1981; the ACT-R model of Anderson, 1993; the retrieving effectively from memory [REM] model of Shiffrin and Steyvers, 1997; Altmann and John, forthcoming); however, there may be equivalent ways to represent such models within sparsely populated distributed neural nets. Retrieval of all types is universally acknowledged to be driven by similarities between probe cues and memory traces, with contextual cues playing an especially significant role in episodic storage and retrieval.
It seems likely at present that different modes of retrieval are used for different tasks. For example, free recall (recall of as many items as possible from some loosely defined set) is always modeled as a memory search, with sequential sampling from memory (e.g., Raaijmakers and Shiffrin, 1981). Recognition (identification of a test item as having occurred in a specific recent context) is almost always modeled as a process of comparing the text item in parallel with all traces in memory (e.g., Gillund and Shiffrin, 1984). Cued recall (recall of one of a pair of studied items when presented with the other) is still a matter of debate, though response time data favor a sequential search model for episodic tasks (e.g., Nobel, 1996).
Most current models, and those with an elaborated structure, have been developed to predict data from explicit memory tests. Models for retrieval from generic memory are still in their infancy. One problem hindering progress in this arena is the likelihood that a model of retrieval from generic memory may require, in principle, an adequate representation of the structure of human knowledge. Except for some applications in very limited domains, the field is quite far from having such representations, and this state of affairs will probably continue for some years to come.
The situation may not be hopeless, however, because several types of simplified representations sufficient for certain needs are currently being used. First, there are exemplar-based systems (described later in the section on learning). These systems generally assume that knowledge consists of the storage of multiple copies (or strengthened copies) of repeated events. The more sophisticated of these systems place these copies in a high-dimensional metric space, in which smaller distances between exemplars represent increased similarity (e.g., Logan and Bundesen, 1997; Hintzman, 1986; Nosofsky and Palmeri, 1997; Landauer and Dumais, 1997). For some purposes, such as modeling improvements with practice and the production of errors based on similarity, this approach has proved fruitful. Second, neural net-based learning systems develop limited structural representations through the process of modifying connections between nodes. Although the structure thus developed is usually not transparent to the external observer, typically it is limited to connections between a few layers of nodes, and may not have any relation to actual cognitive structure. The developed representations capture much of the statistical structure of the inputs that are presented to the nets during learning and have often proved useful (Plaut et al., 1996). Other models that capture the statistical structure of the environment have also proved extremely promising (such as the modeling of word meanings developed by Landauer and Dumais, 1997). Third, in a number of application domains, experts have attempted to build into their representations those aspects they feel are necessary for adequate performance; examples include rule-based systems such as the Soar system (see the next section) and certain applications within the ACTR system (see Anderson, 1993). Although none of these approaches could be considered adequate in general, separately or in combination they provide a useful starting point for the representation of knowledge.
A second problem just now surfacing in the field is the nature of retrieval from generic memory: To what degree are generic retrieval processes similar to those used in explicit retrieval (i.e., retrieval from episodic memory)? Even more generally, many operations of cognition require a continuing process of retrieval from long-term (episodic and generic) memory and processing of that information in short-term memory that can last for periods longer than those usually thought to represent short-term retention. These processes are sometimes called ''long-term" or "extended" working memory. Some recent neurophysiological evidence may suggest that different neural structures are active during explicit and generic retrieval, but even if true this observation says little about the similarity of the retrieval rules used to access the stored information. The models thus far have largely assumed that retrieval processes involved in explicit and generic retrieval are similar (e.g., Humphreys et al., 1989; Anderson, 1993; Shiffrin and Steyvers, 1997). This assumption is not yet well tested, but probably provides a useful starting point for model development.
With regard to models of human behavior of use to the military, there is little question that appropriate models of explicit and generic retrieval and their inter-
action (as studied in implicit memory, for example) are all critical. Because accurate and rapid access to general and military knowledge, as opposed to access to recent events, is of great importance in producing effective action and in modeling the cognition of participants in military situations, and because this area of modeling is not yet well developed, the military may eventually need to allocate additional resources to this area of work.
MODELING OF HUMAN LEARNING
Two types of learning are of potential importance for military simulations. The first is, of course, the learning process of military or other personnel. The second, superficially unrelated, is the possibility of learning within and by the simulations themselves. That is, any simulation is at best a gross approximation of the real processes underlying behavior. Given appropriate feedback, a simulation program itself could be made to learn and adapt and improve its representation. There is no necessary reason why the learning process by which a simulation program adapts its representation should match the learning process of people, but experience suggests the processes assumed for people would provide a good starting point. First, many recent models of cognition have made considerable headway by adopting the assumption that people operate in optimal fashion (subject to certain environmental and biological constraints); examples are found in the work of Anderson (1990) and Shiffrin and Steyvers (1997). Second, there is a virtually infinite set of possible learning mechanisms. Evolution may well have explored many of these in settling on the mechanisms now employed by humans. Given the complexity of representing general human behavior in simulations, the potential benefit of allowing simulations themselves to learn and evolve should not be underestimated. The discussion here concentrates, however, on models of human learning.
Learning from experience with the outcomes of previous decisions is a necessary component of the design of an intelligent computer-generated agent. No intelligent system would continue repeating the same mistakes without correction, nor would it continue to solve the same problem from first principles. Human commanders can learn how decision strategies perform across a variety of engagements and different types of opponents. Human soldiers can learn how to become more effective in carrying out their orders on the basis on successive encounters with a weapon system. The capability of learning to anticipate the consequences of an action is essential for the survival of any intelligent organism. Thus whenever the goal is to provide a realistic approximation of human behavior, computer-generated agents must have the capability of learning from experience. However, most simulations do not have such lofty goals.
There are two cases in which it is especially important to build models of learning into a simulation. The first occurs whenever the task being modeled
lasts long enough that the operator learns and adapts his or her behavior accordingly. The development of skill during training is an obvious example, but some learning can occur even in relatively short time spans, such as the course of a battle or even a short firefight. If one is interested in modeling learning that occurs with extended practice, one must include a model of the way the storage of episodic memories leads to the storage of lexical/semantic generic memories and generic procedural memories. Models of such a transition are still at an early stage of development (e.g., Shiffrin and Steyvers, 1997)
The second case requiring the incorporation of learning into a simulation is one in which it is assumed that performance, strategies, and decisions are relatively static during the task being modeled, so that the participants are not learning over the course of the task. Nonetheless, the procedures and rules used by a participant in such a situation are frequently quite complicated, and specifying them is often inordinately difficult. Current simulation developers have expended a great deal of effort on extracting knowledge from experts and coding this knowledge into forms suitable for computer programs. These efforts are typically very demanding and not always successful. Thus the need for learning mechanisms in military simulations has been clear from the beginning: learning mechanisms have the potential to provide a way of automatically training a computerized agent to have various levels of knowledge and skill. In fact, machine-learning algorithms and the technology for introducing them into simulations have existed for quite some time (see, e.g., Langley, 1996), but the technology has either been underutilized or omitted in computer-generated agents for military simulations (for example, the Soar-intelligent forces [IFOR] project that does not include learning).
Recently, a technology assessment of command decision modeling (U.S. Army Artificial Intelligence Center, 1996) identified a number of approaches for modeling learning that are promising candidates for improving the performance of military simulations. The technology assessment included rule-based learning models, exemplar- or case-based learning models, and neural network learning models. These three types of learning models, which have also been extensively developed and tested in cognitive psychology, are reviewed in the following subsections. The discussion focuses on models that have undergone extensive experimental testing and achieved considerable success in explaining a broad range of empirical phenomena. Rule-based models are reviewed first because they are the easiest to implement within the current rule-based systems developed for military simulations. The exemplar (case)-based models are discussed next; they have been more successful than rule-based models in explaining a broad range of human learning data. Neural network models are reviewed last; although they hold the most promise for providing powerful learning models, they are also the most difficult to integrate into current military simulations. Research is needed to develop a hybrid system that will integrate the newer neural network technology into the current rule-based technology.
Rule-Based Models
Some of the most advanced systems for computer-generated agents used in military simulations are based on the Soar architecture (Laird et al., 1987; see also Chapter 3). Soar, originally constructed as an attempt to provide a unified theory of human cognition (Newell, 1991), is a production rule system in which all knowledge is represented in the form of condition-action rules. It provides a learning mechanism called chunking, but this option is not activated in the current military simulations. When this mechanism is activated, it works as follows. The production rule system takes input and produces output during each interval defined as a decision cycle. Whenever the decision cycle of the production system reaches an impasse or conflict, a problem solving process is activated. Eventually, this problem solving process results in a solution, and Soar overcomes the impasse. Chunking is applied at this point by forming a new rule that encodes the conditions preceding the impasse and encodes the solution as the action for this new rule. Thus the next time the same situation is encountered, the same solution can be provided immediately by the production rule formed by the chunking mechanism, and the problem solving process can be bypassed. There are also other principles for creating new productions with greater discrimination (additional conditions in the antecedent of the production) or generalization (fewer conditions in the antecedent) and for masking the effects of the older productions.
A few empirical studies have been conducted to evaluate the validity of the chunking process (Miller and Laird, 1996; Newell and Rosenbloom, 1981; Rieman et al., 1996). More extensive experimental testing is needed, however, to determine how closely this process approximates human learning. There are reasons for questioning chunking as the primary model of human learning in military situations. One problem with the current applications of Soar in military simulations thus far is that the system needs to select one operator to execute from the many that are applicable in each decision cycle, and this selection depends on preference values associated with each operator. Currently, these preference values are programmed directly into the Soar-IFOR models, rather than learned from experience. In future military Soar systems, when new operators are learned, preferences for those operators will also need to be learned, and Soar's chunking mechanism is well suited for this purpose. Given the uncertain and dynamic environment of a military simulation, this preference knowledge will need to be continually updated and adaptive to its experience with the environment. Again, chunking can, in principle, continually refine and adjust preference knowledge, but this capability must be shown to work in practice for large military simulations and rapidly changing environments.
A second potential problem is that the conditions forming the antecedent of a production rule must be matched exactly before the production will fire. If the current situation deviates slightly from the conditions of a rule because of noise in the environment or changes in the environment over time, the appropriate rule
will not apply. Although present technology makes it possible to add a huge number of productions to simulations to handle generalization and encounters with new situations, this is not the most elegant or efficient solution. Systems with similarity-based generalization and alternative learning approaches are worth considering for this reason. Some artificial intelligence research with regard to learning in continuous environments has demonstrated proof-of-concept models in which Soar learns appropriately (Modi et al., 1990; Rogers, 1996). However, it is uncertain whether these techniques are veridical models of human learning in continuous domains.
An alternative to the Soar model of learning is ACT-R, a rule-based learning model (see Chapter 3). During the past 25 years, Anderson (1993) and colleagues have been developing an alternative architecture of cognition. During this time they also have been systematically collecting empirical support for this theory across a variety of applications, including human memory, category learning, skill learning, and problem solving. There are many similarities between ACT-R and Soar. For example, some versions of ACT-R include a chunking process for learning solutions to problems. But there are also some important differences.
First, ACT-R assumes two different types knowledge—declarative knowledge, representing facts and their semantic relations (not explicit in Soar), and production rules, used for problem solving (as in Soar). Anderson and Lebiere (1998) have accumulated strong empirical evidence from human memory research, including fan effects and interference effects, to support his assumptions regarding declarative memory.
A second important feature of ACT-R concerns the principles for selecting productions. Associated with each production rule is an estimate of its expected gain and cost, and a production rule is selected probabilistically as a function of the difference between the two. The expected gain and cost are estimated by a Bayesian updating or learning model, which provides adaptive estimates for the values of each rule.
A third important feature of ACT-R concerns the principles for activating a production rule. A pattern-matching process is used to match the current situation to the conditions of a rule, and an associative retrieval process is used to retrieve information probabilistically from long-term memory. The retrieval process also includes learning mechanisms that change the associative strengths based on experience.
One drawback of ACT-R is that it is a relatively complex system involving numerous detailed assumptions that are important for its successful operation. Finally, it is necessary to compare the performance of ACT-R with that of some simpler alternatives presented below.
Some of the most advanced military simulation models employ the Soar architecture, but without the use of the chunking learning option. The simplest way to incorporate learning into these simulations would be to activate this option. In the long run, it may prove useful to explore the use of ACT-R in such
situations because it has been built systematically on principles that have been shown empirically to approximate human behavior.
Exemplar-Based Models
Exemplar-based learning models are simple yet surprisingly successful in providing extremely good predictions for human behavior in a variety of applications, including skill learning (Logan, 1992), recognition memory (Hintzman, 1988), and category learning (Medin and Shaffer, 1978; Nosofsky and Palmeri, 1997). Furthermore, exemplar-based models have provided a more complete account of learning phenomena in these areas than rule-based learning models. Essentially, learning occurs in an exemplar-based model through storage of a multitude of experiences with past problems; new problems are solved through the retrieval of solutions to similar past problems. However, it is important to select the right assumptions about the retrieval of past examples if exemplar-based learning models are to work well.
Before these assumptions are described, it may be helpful to have a simple example in mind. Suppose a commander is trying to decide whether a dangerous threat is present on the basis of a pattern of cues provided by intelligence information. The cues are fuzzy and conflicting, with some positive evidence signaling danger and other, negative evidence signaling no danger. The cues also differ according to their validity, some being highly diagnostic and others having low diagnosticity. The optimal or rational way to make this inference is to use a Bayesian inference approach (see also Chapter 7). But using this approach would require precise knowledge of the joint probability distributions over the competing hypotheses, which is unrealistic for many military scenarios. Usually the decision maker does not have this information available, and instead must base the decision on experience with previous situations that are similar to the present case.
According to exemplar-based learning models, each experience or episode is coded or represented as an exemplar and stored in long-term memory. After, say, n episodes or training trials, the memory contains n stored exemplars, and new learning is essentially the storage of new exemplars. Thus one of the key assumptions of the exemplar-based models is massive long-term memory storage capacity. A second critical assumption is that each exemplar is represented as a point in a multidimensional feature space, denoted Xj for the jth exemplar. Multidimensional scaling procedures are used to locate the exemplars in this multidimensional space, and the distances among the points are used to represent the dissimilarities among the episodes. Each coordinate Xij of this multidimensional space of exemplars represents a feature that is used to describe an episode. Some features receive more weight or attention than others for a particular inference task, and the amount of attention given to each feature is also learned from experience.
When a new inference is required, such as deciding whether a dangerous threat is present based on a pattern of cues from intelligence information, the cue pattern is used to retrieve exemplars from memory. The cue pattern is represented as a point within the same multidimensional space as the exemplars, denoted C. It activates each memory trace in parallel, similar to an echo or resonance effect. The activation aj of a stored exemplar by the cue pattern is based on the similarity between the cue pattern C and the stored exemplar Xj The similarity is assumed to be inversely related to the distance between Xj and C:
Evidence for one hypothesis, such as the presence of a threat, is computed by summing all of the activated exemplars that share the hypothesis (threatening feature):
Evidence for the alternative hypothesis, for example the absence of a threat, is computed by summing all of the activated exemplars that share the alternative hypothesis (absence feature):
The final decision is based on a comparison of the evidence for each hypothesis, and the probability of choosing the threat hypothesis over the absence hypothesis is obtained from the following ratio:
Exemplar-based and rule-based models are not necessarily mutually exclusive alternatives. First, it is possible to include exemplar learning processes into the current rule-based architectures by modifying the principles for activation and selection of rules. The gain achieved by including this simple but effective learning process would offset the cost of making such a major modification. Second, hybrid models have been proposed that allow the use of either rules or exemplars, depending on experience within a domain (see, e.g., Logan, 1988, 1992).
Although exemplar-based models have proven to be highly successful in explaining human learning across a wide range of applications, there are some problems with this theoretical approach. One problem is determining how to allocate attention to features, depending on the task. Complex environments involve a very large number of features, and some allocation of attention is required to focus on the critical or most diagnostic features. This allocation of attention needs to be learned from experience for each type of inference task, and current exemplar models have failed to provide such a learning mechanism. Another problem with these models is that they fail to account for sequential effects that occur during training; this failure results in systematic deviations
between the predicted and observed learning curves. Some of these problems are overcome by the neural network learning models discussed next.
Neural Networks
The greatest progress in learning theory during the past 10 years has occurred in the field of artificial neural networks, although the early beginnings of these ideas can be traced back to seminal works by the early learning theorists (Hull, 1943; Estes, 1950; Bush and Mostellor, 1955). These models have proven to be highly successful in approximating human learning in many areas, including perception (Grossberg, 1980), probability learning (Anderson et al., 1977), sequence learning (Cleermans and McClelland, 1991), language learning (Plaut et al., 1996), and category learning (Kruschke, 1992). Moreover, several direct comparisons of neural network learning models with exemplar-based learning models have shown that the former models provide a more accurate account of the details of human learning than do exemplar models (Gluck and Bower, 1988; Nosofsky and Kruschke, 1992). Because neural networks provide robust statistical learning in noisy, uncertain, and dynamically changing environments, these models hold great promise for future technological developments in learning theory (see Haykin, 1994, for a comprehensive introduction).
Artificial neural networks are based on abstract principles derived from fundamental facts of neuroscience. The essential element is a neural unit, which cumulates activation provided by inputs from other units; when this activation exceeds a certain threshold, the neural unit fires and passes its outputs to other units. Connection weights are used to represent the synaptic strengths and inhibitory connections that interconnect the neural units. A neural unit does not necessarily correspond to a single neuron, and it may be more appropriate to think of a neural unit as a group of neurons with a common function.
A large collection of such units is interconnected to form a network. A typical network is organized into several layers of neural units, beginning with an input layer that interfaces with the stimulus input from the environment and ending with an output layer that provides the interface of the output response with the environment. Between the input and output layers are several hidden layers, each containing a large number of neural units.
The neural units may be interconnected within a layer (e.g., lateral inhibition) or across layers, and activation may pass forward (projections) or backward (feedback connections). Each unit cumulates activation from a number of other units, computes a possibly nonlinear transformation of the cumulative activation, and passes this output on to many other units with either excitatory or inhibitory connections. When a stimulus is presented, activation originates from the inputs, cycles through the hidden layers, and produces activation at the outputs.
The activity pattern across the units at a particular point in time defines the state of the dynamic system at that time. The state of activation evolves over time
until it reaches an equilibrium. This final state of activation represents information that is retrieved from the memory of the network as a result of the input stimulus. The persistence of activation produced by stimulus is interpreted as the short-term memory of the system.
Long-term storage of knowledge is represented by the strengths of the connection weights. The initial weights represent knowledge before training begins; during training, the weights are updated by a learning algorithm. The learning algorithm is designed to search the weight space for a set of weights that maximizes a performance function (e.g., maximum likelihood estimation), and the weights are updated in the direction of steepest ascent for the objective function.
Universal approximation theorems have shown that these networks have sufficient computational power to approximate a very large class of nonlinear functions. Convergence theorems have been used to prove that the learning algorithm will eventually converge on a maximum. The capability of deriving general mathematical properties from neural networks using general dynamic system theory is one of the advantages of neural networks as compared with rule-based systems.
Neural networks can be roughly categorized according to (1) the type of feedback provided on each trial (unsupervised learning with no feedback, reinforcement learning using summary evaluations, error correction with target output feedback), and (2) whether the system contains feedback connections (strictly feedforward versus recurrent networks with feedback connections).
Recurrent unsupervised learning models have been used to discover features and self-organize clusters of stimuli (Grossberg, 1980, 1988). Error correction feedforward learning models (also known as backpropagation models) have been used extensively for performing pattern recognition, for learning nonlinear mappings, and for solving prediction problems (see Rumelhart and McClelland, 1986). Reinforcement learning is useful for decision making and for learning to control dynamic systems (Sutton, 1992). Recurrent backpropagation models are useful for learning of sequential behaviors, such as sequences of motor movements (Jordan, 1990), or for problem solving. Most recently, work has been under way on developing modular neural network models, in which each module learns to become an expert for a particular problem domain, and a learning algorithm provides a mechanism for learning how to select each module depending on the current context (Jacobs et al., 1991).
Neural networks offer great potential and power for developing new learning models for use in computer-generated agents. However, these models are also the most difficult to integrate into existing military simulations. Recently, a considerable effort has been made to integrate rule-based systems with neural networks (see the recent volume by Sun and Alexandre, 1997). But this is currently an underdeveloped area, and a substantial amount of further research is needed to develop hybrid systems that will make it possible to begin systematically integrating the two approaches.
Adaptive Resonance Theory: An Illustration of Neural Networks
ART is a sophisticated and broadly applicable neural network architecture that is currently available. It is based on the need for the brain to continue to learn about a rapidly changing world in a stable fashion throughout life. This learning includes top-down expectations, the matching of these expectations to bottom-up data, the focusing of attention on the expected clusters of information, and the development of resonant states between bottom-up and top-down processes as they reach an attentive consensus between what is expected and what is there in the outside world. In ART these resonant states trigger learning of sensory and cognitive representations. ART networks create stable memories in response to arbitrary input sequences with either fast or slow learning. ART systems provide an alternative to classical expert systems from artificial intelligence. These self-organizing systems can stably remember old classifications, rules, and predictions about a previous environment as they learn to classify new environments and build rules and predictions about them.
ART was introduced as a theory of human cognitive information processing (Grossberg, 1976). It led to an evolving series of real-time neural network models that perform unsupervised and supervised category learning and classification, pattern recognition, and prediction: ART 1 (Carpenter and Grossberg, 1987a) for binary input patterns, ART 2 (Carpenter and Grossberg, 1987b) for analog and binary input patterns, and ART 3 (Carpenter and Grossberg, 1990) for parallel search of distributed recognition codes in a multilevel network hierarchy. The ART architecture is supported by applications of the theory to psychophysical and neurobiological data about vision, visual object recognition, auditory streaming, variable-rate speech perception, cognitive information processing, working memory, temporal planning, and cognitive-emotional interactions, among others (e.g., Bradski et al., 1994; Carpenter and Grossberg, 1991; Grossberg, 1995; Grossberg et al., 1997; Grossberg and Merrill, 1996). The basic ART modules have recently been augmented by ARTMAP and Fuzzy ARTMAP models (Carpenter et al., 1992) to carry out supervised learning. Fuzzy ARTMAP (e.g., Gaussian ARTMAP by Williamson, 1996) is a self-organizing radial basis production system; ART-EMAP (Carpenter and Ross, 1995) and VIEWNET (Bradski and Grossberg, 1995) use working memory to accumulate evidence about targets as they move with respect to a sensor through time.
Match-Based and Error-Based Learning Match-based learning achieves ART stability by allowing memories to change only when attended portions of the external world match internal expectations or when something completely new occurs. When the external world fails to match an ART network's expectations or predictions, a search or hypothesis testing process selects a new category to represent a new hypothesis about important features of the present environment. The stability of match-based learning makes ART well suited to problems that
require online learning of large and evolving databases. Error-based learning, as in back propagation and vector associative maps, is better suited to problems, such as the learning of sensory-motor maps, that require adaptation to present statistics rather than construction of a knowledge system.
ART Search Figure 5.1 illustrates a typical ART model, while Figure 5.2 illustrates a typical ART search cycle. Level F1 in Figure 5.2 contains a network of nodes, each representing a particular combination of sensory features. Level F2 contains a second network that represents recognition codes, or categories, selectively activated by patterns at F1. The activity of a node in F1 or F2 is called a short-term memory trace, and can be rapidly reset without leaving an enduring trace. In an ART model, adaptive weights in both bottom-up (F1 to F2) paths and top-down (F2 to F1) paths store long-term memory. Auxiliary gain control and
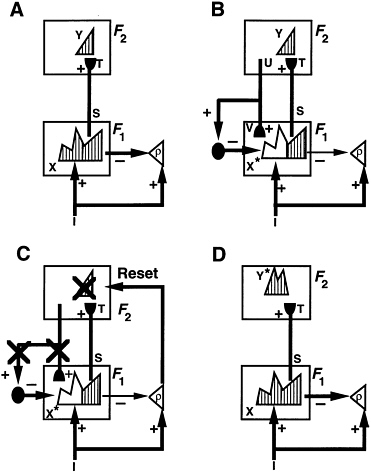
FIGURE 5.1 A typical unsupervised adaptive resonance theory neural network.
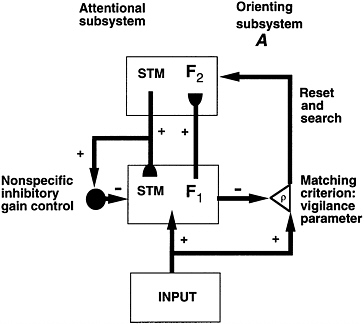
FIGURE 5.2 Adaptive resonance theory (ART) search cycle.
orienting processes regulate category selection, search, and learning, as described below.
An ART input vector I registers itself as a pattern X of activity across level F1 (Figure 5.2A). The F1 output vector S is transmitted through converging and diverging pathways from F1 to F2. Vector S is multiplied by a matrix of adaptive weights, or long-term memory traces, to generate a net input vector T to F2. Competition within F2 contrast-enhances vector T. The resulting F2 activity vector Y includes only one or a few active nodes—the ones that receive maximal filtered input from F1. Competition may be sharply tuned to select only that F2 node which receives the maximal F1 to F2 input (i.e., ''winner-take-all"), or several highly activated nodes may be selected. Activation of these nodes defines the category, or symbol, of the input pattern I. Such a category represents all the F1 inputs I that send maximal input to the corresponding F2 node. These rules constitute a self-organizing feature map (Grossberg, 1972, 1976; Kohonen, 1989; von der Malsburg, 1973), also called competitive learning or learned vector quantization.
Activation of an F2 node "makes a hypothesis" about an input I. When Y becomes active, it sends an output vector U top-down through the second adaptive filter. After multiplication by the adaptive weight matrix of the top-down filter, a learned expectation vector V becomes the input to F1 (Figure 3.3B). Activation of V by Y "tests the hypothesis" Y. The network then matches the "expected prototype" V of the category against the active input pattern, or exem-
plar, I. Nodes in F1 that were activated by I are suppressed if they are not supported by large long-term memory traces in the prototype pattern V. Thus F1 features that are not "expected" by V or not "confirmed" by hypothesis Y are suppressed. The resultant matched pattern X* encodes the features in I that are relevant to hypothesis Y. Pattern X* is the feature set to which the network "pays attention."
Resonance, Attention, and Learning If expectation V is close enough to input I, resonance develops: the attended pattern X* reactivates hypothesis Y, and Y reactivates X*. Resonance persists long enough for learning to occur. ART systems learn prototypes, rather than exemplars, because memories encode the attended feature vector X*, rather than the input I itself.
The ART matching rule enables the system to search selectively for objects or events that are of interest while suppressing information that is not. An active top-down expectation can thereby "prime" an ART system to get ready to experience a sought-after target or event so that when it finally occurs, the system can react to it quickly and vigorously.
To achieve priming, a top-down expectation, by itself, cannot activate cells well enough to generate output signals. When large bottom-up inputs and top-down expectations converge on these cells, they can generate outputs. Bottom-up inputs can also, by themselves, initiate automatic processing of inputs.
Vigilance Control of Generalization A vigilance parameter defines the criterion of an acceptable ART match. Vigilance weighs how close input I must be to prototype V for resonance to occur. Varying vigilance across learning trials lets the system learn recognition categories of widely differing generalization, or morphological variability. Low vigilance leads to broad generalization and abstract prototypes. High vigilance leads to narrow generalization and to prototypes that represent few input exemplars. At very high vigilance, prototype learning reduces to exemplar learning. Thus a single ART system may learn abstract categories of vehicles and airplanes, as well as individual types.
If expectation V and input I are too novel, or unexpected, to satisfy the vigilance criterion, the orienting subsystem (Figure 5.1) triggers hypothesis testing, or memory search. Search allows the network to select a better recognition code or hypothesis to represent input I. This search process allows ART to learn new representations of novel events without risking unselective forgetting of previous knowledge. Search prevents associations from forming between Y and X* if X* is too different from I to satisfy the vigilance criterion. Search resets Y before such an association can form (Figure 5.2C). Search may select a familiar category if its prototype is similar enough to input I to satisfy the vigilance criterion. Learning may then refine the prototype using the information carried by I. If I is too different from any previously learned prototype, the uncommitted
F2 nodes are selected to establish a new category. A network parameter controls the depth of search.
Direct Access to the Globally Best Match Over learning trials, the system establishes stable recognition categories as the inputs become "familiar." All familiar inputs activate the category that provides the globally best match in a one-pass fashion, and search is automatically disengaged. Learning of unfamiliar inputs can continue online, even as familiar inputs achieve direct access, until the network fully uses its memory capacity, which can be chosen arbitrarily large.
Supervised Learning and Prediction Supervised ARTMAP architectures learn maps that associate categories of one input space with another. ARTMAP can organize dissimilar patterns (e.g., multiple views of different types of tanks) into distinct recognition categories that then make the same prediction (e.g., "enemy tank"). ARTMAP systems have an automatic way of matching vigilance to task demands: following a predictive failure during learning, mismatch of a prototype with a real target raises vigilance just enough to trigger memory search for a better category. ARTMAP thereby creates multiple scales of generalization, from fine to coarse, as needed. This "match tracking" process realizes a minimax learning rule that conjointly minimizes predictive error and maximizes generalization using only information that is locally available under incremental learning conditions in a nonstationary environment.
Automatic Rule Extraction ARTMAP learned weights translate into IF-THEN rules at any stage of learning. Suppose, for example, that the input vectors encode different biochemicals and that the output vectors encode different clinical effects of these biochemicals on humans. Different biochemicals may achieve the same clinical effects for different chemical reasons. At any time during learning, an operator can test how to achieve a desired clinical effect by checking which long-term memory traces are large in the pathways from recognition categories to the nodes coding that effect. The prototype of each recognition category characterizes a "rule," or bundle of biochemical features, that predicts the desired clinical effect. A list of these prototype vectors provides a transparent set of rules that all predict the desired outcome. Many such rules may coexist without mutual interference in ARTMAP, in contrast with many other learning models, such as back propagation.
Other Learning Models
Beyond neural networks, there are several other more complex forms of learning that may prove useful. One promising area is research on simulated annealing programs that are used to search very high-dimensional parameter spaces for global minimums or maximums (Kirkpatrick et al., 1983). Simulated
annealing programs use a probabilistic search mechanism that helps avoid getting stuck in local minimums or maximums. Another area of note is research on genetic programming algorithms that are used to construct new rules (Holland, 1975). New rules are formed from old ones by mutation and evolutionary principles derived from biology and genetics. Finally, another important approach to learning is provided by what are called decision-tree algorithms—a machine-learning approach to complex concept formation (Quillen, 1986; Utgoff, 1989).
CONCLUSIONS AND GOALS
Models of short-term and working memory are an obvious necessity that have been and should continue to be an active focus of work within the field and in the military simulation community. Models of explicit retrieval (retrieval of recent and personal events) have been well developed, and could be applied in military simulations where needed. Models of retrieval from generic memory (i.e., retrieval of knowledge) are of critical importance to military simulations, but are as yet least well developed in the field. The approaches used thus far in military situations are relatively primitive. It is this area that may require the greatest commitment of resources from defense sources.
Learning is an essential ability for intelligent systems, but current military simulations make little or no use of learning models. There are several steps that can be taken to correct this lack. A simple short-term solution is to continue working within the rule-based systems that provide the basis for most of the simulations developed to date, but to activate the learning mechanisms within these systems. An intermediate solution is to modify the current rule-based systems to incorporate exemplar (or case)-based learning processes, which have enjoyed greater empirical support in the psychological literature. Neural networks may offer the greatest potential and power for the development of robust learning models, but their integration into current simulation models will require much more time and effort. One way to facilitate this integration is to develop hybrid models that make use of rule-based problem solving processes, exemplar representations, and neural network learning mechanisms.
Short-Term Goals
-
Incorporate the latest models of memory and retrieval into existing simulation models.
-
Add learning mechanisms to current simulations.
-
Begin the process of extending current models to include both generic (knowledge) and explicit (episodic) storage and retrieval.
-
Better integrate the operations of working memory and its capacity into models of long-term memory and learning.
Intermediate-Term Goals
-
Validate the simulation models against complex data gathered in military domain situations.
-
Compare and contrast alternative models with respect to their ability to predict both laboratory and real-world data.
-
Within the models, integrate the storage and retrieval of generic knowledge, of episodic knowledge, and of learning.
-
Start the process of developing hybrid models of learning and memory, incorporating the best features of rule-based, exemplar-based, evolutionary, and neural net representations.
-
Develop process models of those factors treated as moderator variables.
Long-Term Goals
-
Develop larger-scale models that are capable of handling explicit, generic, and implicit memory and learning and are applicable to complex real-world situations.
-
Validate these models against real-world data.
-
Begin to explore the effects of learning, memory, and retrieval processes on group behavior.





















