
3
Item Development and Review
American Institutes for Research (AIR) and its subcontractors had developed a modest number of potential Voluntary National Tests (VNT) items before the stop-work order in September 1997, but item development began in earnest only after approval of the test specifications by the National Assessment Governing Board (NAGB) in March 1998. Mathematics items were drafted by Harcourt-Brace Educational Measurement; reading items were drafted by Riverside Publishing. There have been several stages of content review by AIR staff and external experts, and through the cognitive laboratories. There are also several stages of review for bias and sensitivity.
Our general finding with respect to item development is that NAGB and its contractors appear on track for a pilot test in spring 1999:
|
The rest of this chapter details our findings on each of these points.
Number of Items
As of July 15, 1998, more than 3,000 items had been written for the VNT and were in various stages of review and revision. Table 3-1 shows the number of items written, in comparison to the number needed for the pilot and field tests. Current plans for the pilot test require creating 24 forms containing 45 reading items each and 18 forms containing 60 mathematics items each—a combined total of 2,160
TABLE 3-1 Number of Items Available and Required for Pilot and Field Tests
|
Item Status |
Reading |
Math |
Total |
|
Developed as of 7/15/98 |
1,744 |
1,466 |
3,210 |
|
Needed for Pilot Test |
1,080 (24 forms) |
1,080 (18 forms) |
2,160 |
|
Needed for Field Test |
270 (6 forms) |
360 (6 forms) |
630 |
|
Items Per Form |
45 |
60 |
|
items. Roughly two-thirds of the existing items would have to survive the review and revision process to meet the item requirements for the pilot test. Field test plans require assembly of 6 reading and 6 mathematics forms—a combined total of 630 items, roughly one-third of the items included in the pilot test. In this chapter we review the adequacy of the sample of items developed thus far for meeting the pilot test requirements. In Chapter 4, we review the pilot test requirements themselves.
As described below, each of the various review steps results in a recommendation to accept, revise, or drop an item. The quantity of items developed to date will allow one-third of the items to be dropped in one or more of the review steps. Our experience with survival rates during test development is limited to screening that incorporates empirical data. In such cases, survival rates range from 30 to 70 or even 75 percent, depending on item format, the care taken in initial review and editing, and other characteristics of the testing program. For the VNT, these figures would be comparable to the combined survival rates from item review and from the pilot test. While we do not have industry information on survival rates through the review process alone, data presented later in this chapter indicate that overall survival rates from the different reviews of the VNT items are running well above the 67 percent needed to meet pilot test requirements.
Meeting the pilot test requirements, however, is somewhat more complicated. The intention is that each pilot test form will resemble an operational form in the distribution of items by content and format categories. AIR provided us with a copy of its item tracking database that includes information on the content categories for each item initially assigned by the item writers. Each item identifier included codes that indicate the content and format categories initially assigned to that item by the item writers. For mathematics, one coding scheme was used for the items developed prior to the suspension of item writing in fall 1997 and a different scheme was used for items developed subsequently. The initial coding scheme did not include codes for calculator use and had a 1-digit year code. The revised scheme included codes for mathematical ability and power as well as calculator use, but most of the time these codes were missing.
Tables 3-2 through 3-5 show comparisons of the required and available numbers of items for each content and format category described in the test specifications for mathematics and reading, respectively. Tables 3-2 and 3-4 show requirements included in the overall test specifications approved by NAGB; Tables 3-3 and 3-5 show requirements in AIR's more detailed test plans. NAGB and AIR are currently reviewing the content classification of each of the existing items, so the results presented here are far from definitive. In addition, a mapping of items onto the National Assessment of Educational Progress (NAEP) achievement-level descriptions is also planned for completion before November 1998. Since there was no initial mapping, that breakout cannot be provided here. Also, in mathemat-
TABLE 3-2 Number of Mathematics Items by NAGB Specification Categories
|
Description |
Percent |
Number per Form |
Number Needed for Pilot Test |
Number Developed as of 7/15/98 |
Minimum Needed to Retain: Percent |
|
By Content Strand |
|||||
|
A. Number, properties, and operations |
25 |
15 |
270 |
442 |
61 |
|
B. Measurement |
15 |
9 |
162 |
319 |
51 |
|
C. Geometry and spatial sense |
20 |
12 |
216 |
233 |
93 |
|
D. Data analysis, statistics, and probability |
15 |
9 |
162 |
207 |
78 |
|
E. Algebra and functions |
25 |
15 |
270 |
265 |
102 |
|
By Mathematical Abilities |
|||||
|
C. Conceptual knowledge |
33 |
20 |
360 |
||
|
P. Procedural knowledge |
33 |
20 |
360 |
||
|
S. Problem solving |
33 |
20 |
360 |
||
|
By Calculator Use |
|||||
|
1. Calculator activeb |
33 |
20 |
360 |
444 |
81 |
|
2. Calculator neutralc |
17 |
10 |
180 |
187 |
96 |
|
3. Calculator inactived |
50 |
30 |
540 |
650 |
83 |
|
By Item Format |
|||||
|
Multiple choice |
70 |
42 |
756 |
953 |
79 |
|
Gridded responsee |
10 |
6 |
108 |
164 |
66 |
|
Drawnf |
g |
g |
g |
20 |
0 |
|
Short constructed responseh |
17 |
10 |
180 |
274 |
66 |
|
Extended constructed responsei |
3 |
2 |
36 |
55 |
65 |
|
a Many items have not yet been classified by mathematical ability. b Calculator active: items require the use of a calculator. c Calculator neutral: items may or may not require the use of a calculator. d Calculator inactive: items for session 1 where calculators will not be permitted. e Gridded response: items require students to bubble in answers in the test booklet. f Drawn: items require a drawn response. g Drawn items are not included in the current test specifications. h Short constructed response: items require students to briefly explain an answer and show their work. i Extended constructed response: items require students to provide a more detailed answer to a question, to support their position or argument with specific information from the text. |
|||||
ics, many of the items have not yet been classified into ability categories, and the classification of items into calculator use categories is tentative, at best.
Our analysis suggests that if the current item classifications hold up, additional mathematics items will be needed for the content strands in algebra and functions and probably also in geometry and spatial sense. Only 264 items are currently classified as algebra and functions items; 270 will be needed for the pilot test. For geometry and spatial sense, there are currently 233 items; 216 will be needed for the pilot test, leaving little room for rejections during review. It is also possible that more “calculator neutral” items will be needed, although it may not be difficult to move some of the calculator inactive items into this category. In reading, it seems likely that additional short literary passages will be needed
TABLE 3-3 Number of Mathematics Items by AIR Strand by Format Plan
|
Strand and Formata |
Number per Formb |
Number Needed for Pilot Test |
Number Developed as of 7/15/98 |
Minimum Needed to Retain: Percent |
|
A. Number, Properties, and Operations |
||||
|
Multiple choice |
11 |
198 |
324 |
61 |
|
Gridded response |
2 |
36 |
45 |
80 |
|
Short constructed response |
3 |
54 |
65 |
83 |
|
Extended constructed response |
0 |
0 |
8 |
0 |
|
Total |
16 |
288 |
442 |
65 |
|
B. Measurement |
||||
|
Multiple choice |
7 |
126 |
202 |
62 |
|
Gridded response |
2 |
36 |
36 |
100 |
|
Short constructed response |
1 |
18 |
66 |
27 |
|
Extended constructed response |
0 |
0 |
14 |
0 |
|
Total |
10 |
180 |
318 |
57 |
|
C. Geometry and Spatial Sense |
||||
|
Multiple choice |
7 |
126 |
123 |
102 |
|
Gridded response |
1 |
18 |
30 |
60 |
|
Short constructed response |
2 |
36 |
47 |
77 |
|
Extended constructed response |
1 |
18 |
19 |
95 |
|
Total |
11 |
198 |
219 |
90 |
|
D. Data Analysis, Statistics, and Probability |
||||
|
Multiple choice |
6 |
108 |
115 |
94 |
|
Gridded response |
1 |
18 |
39 |
46 |
|
Short constructed response |
2 |
36 |
43 |
84 |
|
Extended constructed response |
0 |
0 |
7 |
0 |
|
Total |
9 |
162 |
204 |
79 |
|
E. Algebra and Functions |
||||
|
Multiple choice |
11 |
198 |
189 |
105 |
|
Gridded response |
0 |
0 |
14 |
0 |
|
Short constructed response |
2 |
36 |
53 |
68 |
|
Extended constructed response |
1 |
18 |
7 |
257 |
|
Total |
14 |
252 |
263 |
96 |
|
Total |
||||
|
Multiple choice |
42 |
756 |
953 |
79 |
|
Gridded response |
6 |
108 |
164 |
66 |
|
Short constructed response |
10 |
180 |
274 |
66 |
|
Extended constructed response |
2 |
36 |
55 |
66 |
|
Total |
60 |
1,080 |
1,446 |
75 |
|
a The current specifications do not include drawn response items, so the 20 drawn response items developed have been excluded from this table. b The AIR plan meets specifications for testing time by Strand. However, due to differences in the proportion of short and extended constructed response items within each strand, the total items for each strand shown here differ slightly from those shown in Table 3-2. |
||||
TABLE 3-4 Number of Reading Items by NAGB Specification Categories
|
Description |
Percent |
Number per Form |
Number Needed for Pilot Test |
Number Developed as of 7/15/98 |
Minimum Needed to Retain: Percent |
|
Passages by Type and Lengtha |
|||||
|
Short literaryb |
|
1 |
12 |
11 |
109 |
|
Medium literary |
|
1 |
12 |
16 |
75 |
|
Long literary |
|
1 |
12 |
26 |
46 |
|
Short informationalc |
|
1 |
12 |
18 |
66 |
|
Medium informational |
|
2 |
24 |
30 |
80 |
|
Items by Stance |
|||||
|
Initial understandingd |
12 |
5 |
130 |
216 |
60 |
|
Developing an interpretatione |
53 |
24 |
572 |
971 |
59 |
|
Reader-text connectionsf |
10 |
5 |
108 |
158 |
68 |
|
Critical stanceg |
25 |
11 |
270 |
399 |
68 |
|
Total |
100 |
45 |
1,080 |
1,744 |
62 |
|
a The NAGB specifications require 50 percent of the items to be from literary passages and 50 percent to be from informational passages. AIR has further divided passages by length. b Literary passages: readers develop and extend their understanding of text by making connections to their own knowledge and ideas. c Informational passages: readers establish a notion of what the text is about and maintain a focus on points of information related to the topic they have identified. d Initial understanding: the reader's initial impressions or global understanding immediately after finishing the text. e Developing an interpretation: the reader's ability to develop a more complete understanding or comprehension of what is read. f Reader-text connections: the reader's ability to connect specific information in the text with more general information the reader may bring to bear in answering the question. g Critical stance: the reader's ability to look objectively at the test and to answer questions related to the author's use of character descriptions, story elements, the clarity of information provided, and related topics. |
|||||
to meet the pilot test requirements. Currently, 11 of the 101 passages approved by NAGB are short literary passages, and 12 will be required for the pilot test.
In response to our interim letter report of July 16, 1998 (National Research Council, 1998), NAGB has launched plans for supplemental item development, if more items are required. We believe the requirements for additional items will be modest. Given the speed with which a very large bank of items has already been developed, there should not be any insurmountable problem in creating the additional items needed to meet pilot test requirements in each item category. Since the items have not yet been mapped to the NAEP achievement levels, however, we have no basis for determining whether the current distribution of items appropriately reflects the knowledge and skills described for each level or whether a significant number of additional items might be needed to ensure adequate coverage at all levels.
TABLE 3-5 Number of Reading Items by AIR Passage Type by Format Plan
|
Type and Format |
Number per Form |
Number Needed for Pilot Test |
Number Developed as of 7/15/98 |
Minimum Needed to Retain: Percent |
|
Short Literary |
||||
|
Multiple choice |
5–6 |
120–144 |
126 |
105 |
|
Short constructed response |
1 |
24 |
35 |
69 |
|
Extended constructed response |
0 |
0 |
0 |
0 |
|
Total |
6–7 |
144–168 |
161 |
97 |
|
Medium Literary |
||||
|
Multiple choice |
5 |
120 |
176 |
68 |
|
Short constructed response |
1–2 |
24–48 |
56 |
64 |
|
Extended constructed response |
0 |
0 |
0 |
0 |
|
Total |
6–7 |
144–168 |
232 |
67 |
|
Long Literary |
||||
|
Multiple choice |
8–9 |
192–216 |
399 |
51 |
|
Short constructed response |
1–2 |
24–48 |
104 |
35 |
|
Extended constructed response |
1 |
24 |
41 |
59 |
|
Total |
10–12 |
240–288 |
544 |
49 |
|
Short Informational |
||||
|
Multiple choice |
4–5 |
96–120 |
192 |
56 |
|
Short constructed response |
1 |
24 |
57 |
42 |
|
Extended constructed response |
0 |
0 |
2 |
0 |
|
Total |
5–6 |
120–144 |
251 |
53 |
|
Medium Informational |
||||
|
Multiple choice |
9–10 |
216–240 |
332 |
69 |
|
Short constructed response |
1 |
24 |
66 |
36 |
|
Extended constructed response |
1 |
24 |
44 |
55 |
|
Total |
11–12 |
264–288 |
442 |
62 |
|
Intertextuala |
||||
|
Multiple choice |
2 |
48 |
75 |
64 |
|
Short constructed response |
1 |
24 |
39 |
62 |
|
Total |
3 |
96 |
114 |
84 |
|
Total |
||||
|
Multiple choice |
33–37 |
840 |
1,300 |
65 |
|
Short constructed response |
7–9 |
192 |
357 |
54 |
|
Extended constructed response |
2 |
48 |
87 |
55 |
|
Total |
45 |
1,080 |
1,744 |
62 |
|
a Items that require students to answer questions based on their reading of two passages pertaining to the same or similar topics. |
||||
Bias and Sensitivity Reviews
The VNT specifications provide several opportunities for bias and sensitivity reviews, which differ only slightly for reading and mathematics. For 4th-grade reading, NAGB specifies (National Assessment Governing Board, 1998b:13):
|
The specifications for bias and sensitivity review of mathematics items are identical, except there is no need for NAGB preclearance of reading passages. At the present time, final NAGB review of the reading and mathematics items has not yet taken place, and—in advance of the pilot test—it is not possible to carry out the DIF (differential item functioning) analyses (see Chapter 4).
As noted above, we observed the external reviews for bias and sensitivity. Riverside Publishing convened the review of reading items in Chicago, Illinois, on July 6–8, 1998, and Harcourt-Brace Educational Measurement convened the review of mathematics items in San Antonio, Texas, on July 6–7, 1998. Each group of reviewers included about two dozen individuals from diverse groups. For example, the mathematics review group included a male American Indian, several African Americans (male and female), two Asian Americans (one male and one female), two individuals of Latin American descent, one individual who was Islamic, and one individual who was in a wheelchair. It appeared, however, that most of the reviewers were from education-related professions. For example, in the case of the reading reviewers, several were 4th-grade school teachers, and the rest were superintendents, assistant superintendents for curriculum or research, Title I coordinators, coordinators for English-language instruction programs or special education, and other education workers.
In each bias review session, the reviewers were well trained, and the staff of the publishing companies were friendly, expert, and at ease with the situation. Training materials included test specifications, a glossary of testing terms, and illustrative bias problems. Reviewers were permitted to comment on item content as well as bias problems, but most of their attention focused on bias and sensitivity issues.
Passages and items were explored from several perspectives: inappropriate language, group stereotyping, and controversial or emotionally charged topics. An effort was also made to discuss representational fairness—the inclusion of all groups in some reading passages in roles that are not stereotypical. Problems of language and stereotyping were more prevalent in the literary passages, some of which were written many years ago. Controversial or emotionally charged material—including death and disease, personal appearance, politics, religion, and unemployment—cropped up in informational as well as literary passages. Problems with mathematics items included ethnic stereotyping and the use—and overuse—of specific and sometimes nonessential commercial names in items dealing with retail pur-
chases. Religious and ethnic differences in conventions for addressing adults—e.g., as Mr. or Mrs. or by first names—were sometimes problematic.
At both locations, the staff of the publishing companies encouraged the reviewers to report any possible problems with the items—to err on the side of excessive caution—but the percentage of items in which serious problems occurred was low. For example, in the reading review, about 5 percent of passages (though a somewhat larger percentage of specific items) were identified as problematic, and 10–15 percent of mathematics items were identified as possibly biased. We judge that the reviewers were thorough and that the review process was balanced and without doctrinaire overtones. Some passages and items were flagged for removal, but in most cases, biases could be corrected by editorial revision. However, such revision presents a nontrivial problem in the case of copyrighted reading passages.1 In the mathematics review, staff of Harcourt-Brace Educational Measurement also expressed their desire to avoid “form bias,” that is, the possibility that similar, but otherwise acceptable items might be grouped on the same form to a degree that would be unacceptable.
Content Reviews.
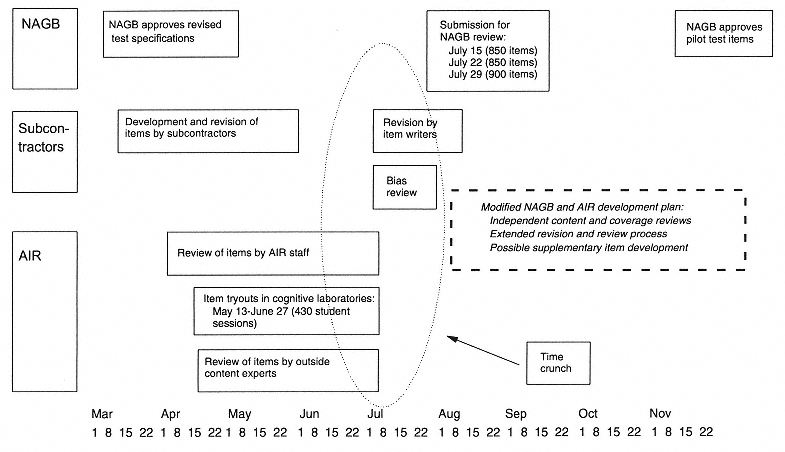
After the items were delivered to AIR from the subcontractors in reading or mathematics, they were reviewed individually for content, both by AIR staff and by external experts who are familiar with NAEP items.2 In addition, a subset of almost 600 items was tried out in talk-aloud sessions with 4th- or 8th-grade students. As shown in Figure 3-1, all of these review processes took place simultaneously with item writing, between early April and late June 1998. According to the original plan, item revision and bias review would take place during the first week of July, and by mid-July AIR would begin to deliver items for final review by NAGB in three weekly batches of 850 to 900 each. NAGB would then have until its November meeting to review the item pool and approve a sufficient number as candidates for pilot testing. As described below, these plans were changed by NAGB in light of our interim report in July (National Research Council, 1998), which recommended changes in item review and revision schedules and processes.
Review and Revision Process
The item review and revision process includes a set of sequential and overlapping steps:
|
-
(8)
review of test items by NAGB; and
-
(9)
NAGB signoff on test items.
As shown in Figure 3-1, steps 1–5 above were to be completed by June 30, so that revisions to at least a subset of the approximately 2,600 items would be possible prior to the bias review that was scheduled for July 6–8. This bias review and the previously provided review information was to be the basis for additional item revision prior to NAGB's review and approval. NAGB was scheduled to review items in three waves, one beginning July 15, the next beginning on July 22, and the final beginning on July 29. Approval of the items would be sought at the November 1998 NAGB meeting. Approved items then would be assembled in draft test forms for the proposed pilot administration of the VNT in spring 1999. In this schedule, it was unclear what activities NAGB planned to undertake for its review between July 15 and the November meeting.
Assessment of Review and Revision Process: Interim Report
Our concern with the schedule resulted primarily from data obtained in our third workshop, on June 2–3, with a group of outside experts with experience in the development and evaluation of conventional and performance-based test materials (see Appendix C). The test developers supplied a list of items that represented the VNT specifications for content coverage and item formats. We selected a total of 60 mathematics items from a pool of 120 items provided by the prime contractor. Similarly, we selected 6 reading passages with a total of 45 items from a pool of 12 reading passages with roughly 90 questions. The sample of items we selected matched the VNT specifications for the length of a test form as well as for content coverage and item formats.
The experts examined and rated a subset of secure test items in their area of expertise.3 Because the items we examined in June were products of the initial stages of item development, we did not expect them to reflect the complete development process. Many items had been through content review, and a number were being tried out with small numbers of students to assess item clarity and accuracy, but none of the items had been reviewed for bias or sensitivity, revised by test writers, or submitted for NAGB review and approval.
At the workshop, the experts independently identified the knowledge and skills likely to be measured by each item and attempted to match them to the content and skill outlines for the VNT. The experts also appraised item quality and identified ambiguities that might lead students to invalid responses (correct or incorrect). After the item rating exercise, the principal investigators and staff met jointly with the experts, NAGB, and the developers of the VNT to discuss issues of item quality and coverage and to discuss plans for item review and quality assurance. The principal investigators and staff also met separately with the experts for further discussion of the item materials.
On the basis of our evaluation of the information provided at the workshop, subsequent discussions, and the process and products of item development, we wrote an interim letter report in July (National Research Council, 1998). Although we benefited greatly from the views of the experts with whom we worked, we stress that the findings, conclusions, and recommendations were solely those of the authors and the NRC. We summarize that report here, but we stress that these findings apply only to the materials available to us by early June.
The review plans for VNT items are appropriate and extend beyond procedures typically employed in test development. The plans for content review, student tryouts of items, and bias and sensitivity review appeared rigorous and thorough. The plans for student tryouts, in particular, went well beyond item review procedures found in most test development programs (see below, “Cognitive Laboratories”). These tryouts included extensive probes to determine the validity of the students' scored responses and to identify problems that may lead to correct answers when students do not have the targeted knowledge or skill or lead to incorrect answers when they do.
The draft items we examined were at an early stage of development, and many of them need improvement. We and out experts found items with ambiguities and other problems of construction. In the case of reading items, for example, there were items for which there was no clearly correct response, some with two possibly correct responses, and some with distracter options that might signal the correct answer. In addition, some items could possibly be answered without reading the associated passages, and others appeared to ask students to use supporting information for their response that was not in the text. Expert panelists flagged roughly one-half of the items available for our examination as requiring further review and possible revision.
It is critical to keep this finding in proper perspective. First, it is common to find problems with a significant number of items early in the item development process: Why conduct rigorous item reviews if not to weed out items that do not pass muster? The VNT developers, in fact, expected that 15 percent of the items would be eliminated from consideration even before pilot testing, and they also expected that only one-third or one-fourth of the piloted items would be used in the initial forms to be field tested for possible operational use. Moreover, as specific items were discussed at the workshop, the test developers who were present largely agreed with our assessment of item problems and in several cases reported that they had earlier come to the same conclusions.
Thus we conclude that there has not been sufficient time for the test development contractors to act on weaknesses in the test items. This conclusion about the unrefined state of the items we reviewed was by no means a final assessment of their quality. Rather, it signaled that a significant amount of review and revision would be required to achieve a final set of high-quality items. Furthermore we found:
- The items examined did not appear to represent the full range of knowledge and skills targeted by the VNT content and skill outlines. Although there were items that represented varied content areas and many of the less complex skill areas, few of the items in the sample were likely to assess higher-order thinking skills, as required by the approved test specifications. It will not be easy to revise items to cover these important parts of the skill specifications or the subareas of knowledge that might be underrepresented.
- NAGB and its development contractor have also not yet had time to determine the extent to which the pool of items being developed will enable reporting of student performance in relation to NAEP's achievement levels, a central goal of VNT development. As noted above, NAGB has developed specific descriptions of the skills associated with NAEP's basic, proficient, and advanced achievement levels for 4th-grade reading and 8th-grade mathematics (see the achievement-level descriptions in Appendix E). The validity of the achievement levels, which has been a topic of considerable discussion, depends on whether the description of each achievement level matches the skills of students classified at those levels (see Burstein et al., 1996; Linn, 1998; National Academy of Education, 1996; U.S. General Accounting Office, 1993). Comparing candidate VNT test items with the achievement-level descriptions is an important step to ensure coverage of each achievement level. In the items we and our experts reviewed, there appeared to be a shortage of items tapping higher-order skills. We urged NAGB
- and its contractors to determine whether additional time and development were needed to produce enough items that test skills at the advanced achievement level.
- The current schedule does not provide sufficient time for the provision of item review and tryout results to item authors and for the revision of item materials to ensure their accuracy, clarity, and quality. Because of that schedule, a number of review activities that were more logically conducted in succession had been conducted simultaneously. These activities include content reviews by the prime contractor and its consultants, reviews by content experts, and the item tryouts. Furthermore, very little time was available to act on the results from each step in the review process: see the zone labeled “time crunch” in Figure 3-1. For the student tryout results to be of full use in further item development, reports on specific items had to be summarized and generalizations applied to the larger set of items not examined in the tryouts. Yet the schedule allowed less than 1 week between the conclusion of the cognitive sessions and the provision of feedback to the item writers. It also provided less than 1 week for revision of a large number of items prior to the bias and sensitivity review, planned for July 6, and only another week between the bias and sensitivity review and submission of the first wave of items to NAGB for its final review beginning July 15.
Given the large volume of items being developed, it appeared unlikely that any of these steps—summarizing review and tryout results, responding to bias and sensitivity reviews, and item revision—could be adequately completed, let alone checked, within the 1-week time frame scheduled for each of them. In other testing programs with which we are familiar, such as the Armed Services Vocational Aptitude Battery, the Medical College Admission Test, the Kentucky Instructional Results Information System, and the National Assessment of Educational Progress, this review and revision process takes several months.
These findings led to our central conclusion: While the procedures planned for item review and revision are commendable, the current schedule for conducting review and revision appeared to allow insufficient time for the full benefit of those procedures to be realized.
This conclusion led to our central recommendation: We urge NAGB to consider adjusting the development schedule to permit greater quality control, and we suggest that it might be possible to do so without compromising the planned date for the administration of pilot tests (spring 1999). Specifically:
- We recommend that NAGB consider whether the remaining time for refinement of item materials by VNT developers and for item review and approval by NAGB should be reallocated to allow more time for the developers' careful analysis of item review information and for the application of this input to the entire set of items. The period of time allocated for NAGB's review of item materials might be reduced correspondingly, to allow for full and complete attention to item revision and quality assurance by the test development contractors.
- We recommend that NAGB and its contractors consider efforts now to match candidate VNT items to the NAEP achievement-level descriptions to ensure adequate accuracy in reporting VNT results on the NAEP achievement-level scale.
- We recommend that NAGB and its contractors consider conducting a second wave of item development and review to fill in areas of the content and skill outlines and achievement-level descriptions that appeared to be underrepresented in the current set of items.
It is not yet possible to know the effect of our interim letter report and of NAGB's responses to it on the quality of the item pool for the VNT pilot test. However, NAGB's positive and constructive response to our recommendations leaves us cautiously optimistic about the outcome. As shown in Figure 3-1, NAGB modified the item development process, all consistent with its approval of the item pool by late November:
|
Cognitive Laboratories
A total of 584 items—312 in mathematics and 272 in reading—were assessed in cognitive labs (see Table 3-6).4 An attempt was made to include all of the extended constructed response items; however not all of the reading passages were approved in time for their associated constructed response items to be included. Between May 11 and July 2, 234 students participated in the reading lab sessions and 196 students participated in mathematics lab sessions. The use of cognitive labs in a project of this kind is an innovative and potentially significant tool for test item development. Information from the cognitive labs could improve item quality in two ways: by providing specific information about items that were tried out in the labs and by providing information that could be generalized and applied in the evaluation of items that were not tried out in the labs. Because of its potential importance, we observed and monitored the lab process from training through completion, and we subsequently observed a number of videotaped interviews and compared our assessments of items with those by AIR staff. (See Appendix G for the list of dates and sites at which training sessions and cognitive interviews were observed live or on videotape.)
The cognitive labs were spread out nationally across six sites: AIR offices in Palo Alto, California; Washington, D.C.; Concord, Massachusetts; newly developed sites in East Lansing, Michigan; San Antonio, Texas; and Raleigh, North Carolina.5 Student participants in the labs were recruited through schools, churches, and youth organizations. The process was not random, but site coordinators monitored and controlled the demographic profile of participants in terms of race, ethnicity, gender, urban location, family income, and language use. Recruited students were of diverse social origins, but minority and Hispanic students, students from families of high socioeconomic status, and suburban and rural students were overrepresented. In addition, there were 23 students who are bilingual or for whom English is a second language, 11 in reading and 12 in math, who were provided translators as needed. In
TABLE 3-6 Distribution of Items Used in Cognitive Laboratories
|
Description |
Number Developed as of 7/15/98 |
Number in Labs |
Percent in Labs |
|
Mathematics Items by Strand |
|||
|
Number, properties, and operations |
442 |
70 |
16 |
|
Measurement |
319 |
56 |
18 |
|
Geometry and spatial sense |
233 |
66 |
28 |
|
Data analysis, statistics, and probability |
207 |
50 |
24 |
|
Algebra and functions |
265 |
70 |
26 |
|
Total |
1,466 |
312 |
21 |
|
Mathematics Items by Format |
|||
|
Multiple choice |
953 |
65 |
7 |
|
Gridded response |
164 |
49 |
30 |
|
Drawn |
20 |
8 |
40 |
|
Short constructed response |
274 |
143 |
52 |
|
Extended constructed response |
55 |
47 |
86 |
|
Total |
1,466 |
312 |
21 |
|
Reading Items by Stance (Approach) |
|||
|
Initial understanding |
216 |
52 |
24 |
|
Developing an interpretation |
971 |
82 |
8 |
|
Reader-text connect |
158 |
60 |
38 |
|
Critical stance |
399 |
78 |
20 |
|
Total |
1,744 |
272 |
16 |
|
Reading Items by Format |
|||
|
Multiple choice |
1,300 |
80 |
6 |
|
Short constructed response |
357 |
146 |
41 |
|
Extended constructed response |
87 |
46 |
53 |
|
Total |
1,744 |
272 |
16 |
reading, 32 students had special educational needs, and in mathematics 19 had special educational needs: the only accommodation provided for these students, however, was extra breaks during the 2-hour interview period.
Items were grouped in packets of about 14 mathematics items or 10 reading items. Each item was analyzed, and a written protocol, describing potential paths to correct or incorrect responses, was prepared as a guide for the interviewer. An effort was made to assess, before the actual interviews, what might be likely paths toward “hits” or “misses” that were “valid” or “invalid,” that is, how a student might reach either a correct or incorrect answer for the right or wrong reasons. Some of the interviewers and protocol developers were novices and some were experienced cognitive interviewers. Some were knowledgeable about teaching and learning in the relevant grade levels and subjects, but others were not. All were trained and practiced intensively for this project. Each packet of items was assigned to two of the laboratory sites, yielding a total of no more than nine interviews per packet.
Cognitive interviews were videotaped to permit later staff review. After appropriate consent forms were signed, students were trained in the think-aloud protocol—attempting to verbalize their thoughts as they responded. For each item, the tryout was in two parts, a first phase “in which the interviewers
used only general, neutral prompts while the students read through each question, thought aloud, and selected their answers,” and a second phase, in which “the interviewers verified whether the students encountered any problems with the specific item, … the interviewers used more direct prompts and probes” (from AIR procedural report, p. 3). Students were encouraged to work through items at their own pace, and each packet was administered in the same order in each interview. Consequently, items that appeared toward the end of packets were sometimes skipped. Following the interview, a summary report on each item was to be prepared by the interviewer (on a “1-1 form”). AIR staff summarized findings from the nine tryouts of each item (on a “9-1-1 form”), entered the summaries in a database of potential items, and prepared feedback to item writers.
Our observations and monitoring of the training sessions, protocols, cognitive interviews, and item summaries show a mixed picture of operational and analytic achievement and of missed opportunity. Some of the problems are due, no doubt, to the compression of the item development schedule, both before and (as originally planned) after the completion of the laboratory sessions. We offer the following assessment of the cognitive labs:
|
uneven distribution of experience and skill across sites, there were operational problems in the coordination of activities and the workload distribution. However, in most cases, these problems were accommodated flexibly by redistribution of workload and of staff among sites.
|
The prima facie case for the value of cognitive interviews in item development remains strong. Direct evidence of students' understandings of language and items clarifies item content in ways that may not be apparent to adult experts. The cost-effectiveness issue is different: whether enough improvement was gained to warrant the expense is unknown and probably cannot be learned from these data. We think that it would be useful for AIR to attempt to draw general lessons from its experience in the current round of item development. those data cannot, however, be useful in addressing the cost-benefit question because unrefined items were tested in the cognitive labs. Moreover, at this time there is inadequate evidence either of the specific or general contributions of the cognitive labs for VNT item review and revision. We think it is possible to produce and use such evidence in the item review and revision process before the November NAGB meeting, and we encourage NAGB to solicit this information before memories fade or the relevant AIR staff turn to other activities.
Given this year's experience, if the VNT project continues, we believe that AIR and its subcontractors should be well prepared to carry out and profit from cognitive laboratories of items during later rounds of item development. It should be possible to organize and schedule this activity to provide a cost-benefit analysis of standard item review and revision procedures in comparison with processes that include cognitive laboratories.
Ongoing Review Process
To assess progress in revising and editing VNT items, we visited AIR on July 28 and reviewed file information for a sample of reading and mathematics items. The sample, carefully selected to represent the entire domain of VNT items, consisted of three strata. The first stratum consisted of 30 of the mathematics items and 4 or 5 reading passages with about 20 associated items from the set of 105 items reviewed at the June 2–3 workshop. The second stratum consisted of 30 mathematics items and 4 reading passages with 20 associated items that were used in the four cognitive laboratory protocols that
had previously been selected for intensive observation. The purpose of choosing these two strata was to allow us to examine progress in identifying and fixing specific item problems that we had identified earlier. The final stratum consisted of another 30 mathematics items and 20 reading items selected from items that had been added to the item bank after our June workshop.6
In all, we sought information on the status of 90 mathematics items and 60 reading items. For each sampled item, we recorded whether a folder was located; if so, the number of item reviews documented in the folder; the summary recommendation (accept, revise, drop) of each reviewer; whether reports from the cognitive laboratories were present; if so, whether changes were recommended to the item or to the scoring rubric (or both); and whether a final determination had been made to accept, drop, or revise the item.
Mathematics
File information was found for all but five of the items selected for our study: the missing five files were either in use by AIR staff or had been filed improperly and could not easily be located.
- Roughly 90 percent of the folders contained at least one review; 85 percent contained comments from more than one reviewer; 67 percent had three or more reviewers' comments.
- For 90 percent of the items at least one reviewer had recommended some revision. The percent of items that one or more reviewers recommended dropping was about 17 percent.
- Cognitive laboratory results were found for roughly two-thirds of the items that had been subjected to cognitive laboratories. Some of the information from the cognitive laboratories had not yet been put into the item folders, and some information may have been taken out for copying in response to a separate request we had made for information on laboratory results. When cognitive laboratory information was available, there were changes recommended to either the items or the scoring rubrics (or both) for 52 percent of the items.
Our best assessment of the position of these 90 mathematics items as of July 28 is that 13 percent would be accepted with no further changes, 57 percent would be accepted with minor revisions, 19 percent would be accepted with more significant revisions, and about 12 percent would be dropped. Overall, roughly 67 percent of the items that have been developed are required for the pilot test. For the items that we examined, the apparent retention rate (88 percent) was well above this level.
Reading
The reading files were kept by passage. Two of the passages that we selected had been dropped on the basis of bias reviewer comments or the cognitive laboratories. The file folder was not available for one other passage, and we obtained the folder for an additional passage used in our June workshop as a replacement. Reviewer comments were available for each of the passages we selected, and cognitive laboratory results were also available for each of the passages that had been included in one of the cognitive protocols. Most of the passages were still being worked on. It appears that about 30 percent of the sampled items would be accepted with no change, 49 percent would be accepted with revision,
and about 20 percent would be dropped. This number was also above the overall target of a 67 percent acceptance rate needed for the item requirements for the pilot test.
Summary
Overall, we recorded 24 specific comments made at our June workshop. Almost one-half of these concerns were also identified by the contractors' reviewers. Other comments may be picked up in subsequent reviews by contractor staff or by NAGB. Their reviewers also identified issues not raised at our expert workshop.
Our review of item files indicates a vigorous ongoing review and revision process. We believe that it confirms the concerns expressed in our interim letter report that the process could not have been successfully concluded by the end of July. As of the end of July, reviews had been completed on roughly one-third of the items in the pool, and it appears that the item drop rates will be less than the one-third anticipated in AIR's item development plans. Given that the majority of the items were still under review, this figure is rather tentative, and we cannot reach definitive conclusions about the quality or effect of the overall review process.
Recommendations
3-1. More time should be allowed for review and revision in future cycles of item development. To the extent possible, reviews should be conducted in sequence rather than in parallel so that the maximum benefit may be derived from each step in the review process.
3-2. The developers should improve and automate procedures for tracking items as they progress through the development cycle so as to provide timely warnings when additional items will be needed and historical information on item survival rates for use in planning future item development cycles. NAGB and the development contractor should monitor summary information on available items by content and format categories and by match to NAEP achievement-level descriptions to assure the availability of sufficient quantities of items in each category.
3-3. NAGB should undertake a careful study of the costs and benefits of the cognitive laboratories to determine their appropriate use in future development cycles.


















