
4
Tests and Testing in the United States: A Picture of Diversity
In Chapter 2 we examine the factors that must be considered in determining the validity of linkage. In this chapter we examine the way these factors are reflected in tests in the United States and in the potential impact on attempts to link tests.
Educational testing in the United States is a diverse and complex enterprise. This diversity reflects both the current availability of a vast array of instruments to measure student achievement and the American decentralized system of educational governance, which allows officials in 50 states and approximately 15,000 school districts to choose what tests will be used in their jurisdictions. Thirty years ago, assessment of student achievement was synonymous with norm-referenced testing and an almost exclusive reliance on multiple-choice measures that ranked students, schools, and states in comparison with one another (McDonnell, 1994). Now, educators and policy makers are able to select from a variety of tests based on local educational needs and local decisions about what students should know and be able to do, as well as beliefs about the nature of accountability for students, teachers, and schools.
The diversity in educational testing has increased as states and districts have moved rapidly to revise their curricular goals, to reflect high expectations for student learning, and have adopted or created new instruments to measure student performance that are aligned with those goals.
The diversity of tests and testing programs can be characterized on three dimensions: (1) test type, or the kind of instrument used to assess performance; (2) test content, or the skills and knowledge measured by a particular test; and (3) the purposes for testing and selecting specific instruments.
In this chapter we examine these three dimensions in the context of linking. It is important to note that we focus here on large-scale assessments, which are used by states, districts, and the nation to measure the achievement of large groups of students. Teacher-made classroom assessments and school- and district-developed assessments, while important tools for instruction and program planning, are beyond the scope of our discussion.
Types of Tests
Item Format
Many different item and task formats are used in assessments of student achievement, and the effect of format differences on linkages can be substantial. Selected-response items, such as multiple-choice questions, require test takers to select the one best answer from a set of alternatives and to mark the answer on a separate answer sheet or directly on a test paper. Constructed-response items require the test taker to answer questions without being provided alternatives from which to select the correct response. Constructed-response items include short-answer format items that may require a test taker to fill in a blank or to answer a question by writing a short response on the test paper or an answer sheet (e.g., 13 + 28 = _____). A longer constructed-response item may require test takers to make simple lists; to write one or two sentences, a paragraph, or an extended essay; or to solve multiple-step mathematics problems and explain how they arrived at their solutions. (These latter two examples can also be considered performance tasks.)
Students who have not had experience with different item types may perform poorly on unfamiliar formats not because they do not know the material, but because they do not know how to devise responses. As a consequence, students who have little or no experience with answering long constructed-response items may simply omit them on a test, thereby producing a misleadingly low score. If a test that requires students to answer questions posed in an unfamiliar or difficult format is linked to a
test with a more familiar format, it could be difficult to determine whether the relationship between the two linked tests is a result of test format differences or a valid comparison of student achievement.
There are other issues and cautions regarding attempts to link different assessments that contain different item types. In writing, for example, different item types measure writing ability in different ways. Selected-response items that measure vocabulary, grammar, writing mechanics, and editing skills might positively correlate with performance on an item requiring a constructed-response items that measures the quality of student prose. But who would assert that an extensive vocabulary, proper use of grammar, capitalization, punctuation, and good editing skills are the same as the creative process of writing? It is likely that using a statistical linking procedure to predict expected performance on a performance-based writing assessment from the results obtained from selected-response items (and vice versa) could provide inappropriate and misleading information.
Scoring
Different types of items require different scoring methods. Selected-response items are generally scored by machine. Examinees fill in a "box" or "bubble" indicating their answers, and the answer form is scanned into a computer, which also contains the answer key that specifies the response options that are correct. There is only one right answer, and the response is marked as "right" or “wrong." This type of scoring is relatively inexpensive and is highly reliable.
Constructed-response items must be scored by expert judges or raters, using specified scoring guides or rubrics. The reliability of the scoring process depends on such factors as the specificity of the scoring rubric, the raters level of expertise, the quality of the training provided to the raters, and the extent of monitoring of interrater reliability throughout the scoring process. If any of these factors varies significantly, test reliability will be affected and measurement errors will be introduced (Herman, 1997). For example, several studies have demonstrated the differential effects of students' handwriting on raters scoring of constructed-response answers on tests (see, e.g., Breland et al., 1994) This differential scoring affected the reliability of the grades assigned to some constructed-response items. Linking tests with different measurement error (reliability) could produce different linked results for each administration of the tests. In the diverse
and complex landscape of testing, it is not uncommon to find variation in scoring practices among states. Scoring is a major concern in linking tests containing constructed-response items.
Increasingly, both "off-the-shelf" commercial tests and tests customized to consumer specifications are being constructed as mixed-model assessments that contain items of different types in varying proportions. The mix of item formats on a test makes a difference in student performance (see, e.g., Shavelson et al., 1992; Wester, 1995; Yen and Ferrara, 1997). Two tests of the same subject domain but containing a different mix of item formats may not be comparable in terms of difficulty and may not be equally reliable. Thus, linking tests that are not similar in format may challenge the ability to draw valid inferences from the linked results.
Norm-Referenced and Criterion-Referenced Test Interpretations
Although it is common practice to do so, labeling assessment instruments as norm-referenced or criterion-referenced is somewhat misleading (see, e.g., Cronbach, 1984; Glaser, 1963; Messick, 1989; Feldt and Brennan, 1989). It is the interpretation of the resulting scores that is norm-referenced or criterion-referenced, not the test instrument itself. In fact, raw scores, the exact count or measure of how many items a test taker answered correctly, can be interpreted within both norm-referenced and criterion-referenced frameworks.
Norm-referenced interpretations provide a means for comparing a student's achievement with that of others, determining how a student ranks in comparison with a sample of students, or norm group. When test developers create a new test or a new version of a test, they first administer it to a sample of students across the nation; this sample becomes the norm group. The composition of this sample varies by publisher, test, and the publisher's beliefs about what constitutes an appropriate sample.
The composition of a norm group has an effect on the validity of the inferences that can be drawn from the results and, hence, on the validity of any inferences drawn from comparisons between results on different tests (Peterson et al., 1993). For example, percentile rank, a term that expresses what part of the norm group earned scores that fell below the test taker's score, must always be interpreted with reference to the group from which they were derived (Cronbach, 1984). One norm group could be composed of relatively high-performing students, and a student taking
a test normed against that group would have to perform very well in order to end up in a high percentile ranking. In contrast, a student taking a test normed against relatively poor performers would not have to perform as well in order to achieve a high percentile ranking. Therefore, if two students taking different tests normed on different groups both are in the 85th percentile on their respective tests, one has no way of knowing how well they performed in comparison with each other. While it is unlikely they performed equally well (because the norm groups differ), it is not possible to know with precision how much better one student performed than the other. Thus, linking scores from achievement tests that were normed on different groups will affect the validity of the inferences drawn from the link.
Examples of nationally normed achievement tests currently used by many states and school districts include the Iowa Tests of Basic Skills (ITBS), published by Riverside Publishing Company; the Stanford Achievement Test-Ninth Edition (SAT-9), published by Harcourt Brace Educational Measurement; and TerraNova, published by CTB/McGraw-Hill. Although these commercially developed achievement tests appear on the surface to be similar (see Chapter 2), they are, in fact, quite different in frameworks, content emphasis, item difficulty, and item sampling techniques, and they are normed on different populations. These differences may reflect the publishers' efforts to capture specialized markets and meet state and local demands for tests with particular features (see, e.g., Yen, 1998), or they may be the result of historical differences in test development. School officials and policy makers often choose a particular test because of the ways in which it differs from other, similar tests. However, the degree to which tests differ will affect the validity of any links between them.
Criterion-referenced interpretations indicate the student's level of performance relative to a criterion, or standard of performance, rather than relative to other students' performance. This interpretation is based on descriptions or standards of what students should know and be able to do, with performance being gauged against the established standard. Frequently, the meaning is given in terms of a cutscore: students who score above a certain point are considered to have mastered the material, and those who score below it are considered to have not fully met the standard. Established levels of mastery on state assessments vary from test to test and application to application, even when tests purport to measure the same content domain. This variation further complicates linkage.
An analogy that is often used to illustrate the difference between norm-referenced and criterion-referenced interpretations is mountain climbing. Norm-referenced interpretations can tell where the members of the climbing party are relative to each other—who is in the lead, who is in the middle, and who is lagging behind; however, they cannot tell you the location of the climbing party on the mountain. For example, the leaders might be less than half-way up the mountain or at the peak, and norm-referenced interpretations cannot distinguish between the two possibilities. A criterion-referenced interpretation, however, can tell you which of the climbers has achieved the target level of performance, say, the summit, and which are the less proficient climbers who need more instruction, training, or equipment. But note that neither kind of measure can tell you how high the mountain is or how the climber is performing relative to other climbers who are climbing other mountains in other places; this kind of analysis requires linking.
Tests that provide norm-referenced interpretations are designed to produce a range of scores, in order to show how students rank against their peers and against the norm group. To maximize the reliability of a percentile ranking within a group, test developers try to create a test that is able to generate scores from near zero to the highest possible score. To accomplish this, test developers include a few items that are so easy that virtually all of the test takers will get them correct and a few items that are so difficult that only the highest achievers can answer them correctly. The majority of the items, however, are of medium difficulty. In contrast, developers of standards-based assessments do not focus as much on generating scores that represent the full range of possible scores: rather, they try to include items that measure the full range of knowledge and skills necessary to demonstrate mastery of a concept. Standards-based assessments and other measures designed to provide criterion-referenced interpretations incorporate specified performance goals that are set by educators or policy makers in accordance with beliefs about what constitutes adequate performance. Their designers select items that will help to identify to what degree students have mastered the skills being assessed. These tests may be more difficult on some dimensions and easier on others than the tests designed for norm-referenced interpretations. Attempts to link tests with markedly different levels or ranges of difficulty may challenge the validity of the inferences that can be drawn from the linkage.
Test companies often claim that their tests can yield norm-referenced
and criterion-referenced interpretations, which raises the possibility that two types of linkages could be established. The committee did not address this specific question in detail, but we note that in evaluating the quality of linkages one would not necessarily wish to adopt standards that exceed those that are applied to tests themselves.
Test Content
In addition to the variations in frameworks, content emphasis, item difficulty, and sampling techniques, tests vary significantly in their most fundamental aspect: the knowledge and skills they ask students to demonstrate. No test can possibly tap all the concepts and processes embodied in a subject area as vast as reading or mathematics. Instead, test makers construct a sample from the entire subject matter, called a domain. The samples that different test makers choose differ substantially. Thus, one can conclude that not only are the domains of reading and mathematics complex, but there are many subdomains and subsets of test elements (e.g., items) that can be used to measure them.
As discussed in Chapter 1, defining the domain is the first step in developing any test or assessment. The subject matter to be measured must be specified and distinguished from other, different subject matter. Distinctions among different domains are obvious. For example, reading, mathematics, and science are fundamentally different intellectual disciplines. The absolute nature of these distinctions begins to blur however, when one realizes that while the process of reading and the knowledge of science are certainly not the same thing, they overlap. Science knowledge is gained partly through reading, and effective reading enables students to gain science knowledge from a science text. Mathematics knowledge also is gained partly through reading, and science uses mathematics as a tool for scientific discovery. These overlaps among reading, mathematics, and science illustrate the challenges of defining any domain.
The diversity and variety in content domain sampling have implications for linking. Tests that measure different dimensions of a content domain must be viewed judiciously in any linkage project. When the content of two tests is the same, statistical linkage is possible; when the dimensions of content that have been sampled in two tests is not similar, limits on the inferences of linkage are substantial. Therefore, the content similarity of two tests is a high priority in evaluating and describing the linkage between them. In the next two sections we explore some dimensions
of the domains of mathematics and reading to illustrate some of the issues involved in specifying a part of a domain for test purposes.
Mathematics
The domain of mathematics is very complex, and for all practical purposes mathematics curriculum and test developers must focus their efforts on only a part of the domain. That is, in defining a mathematics curriculum or developing a mathematics test, they must select topics from the whole domain of mathematics, based on a particular set of needs and purposes. For example, school mathematics—the mathematical concepts and processes relevant for kindergarten through high school (K-12)—can be thought of as one subdomain of the larger domain of mathematics. In addition, the various curricula taught in different school systems, and the various ways the schools choose to assess student mastery of content, are further subdomains of the subdomain of school mathematics.
A characterization of the subdomain of the K-12 school mathematics curriculum appears in Curriculum and Evaluation Standards for School Mathematics (hereafter, Standards) of the National Council of Teachers of Mathematics (NCTM) (1989). The Standards characterize the K-12 curriculum using three grade-level clusters that are roughly equivalent to the elementary (K-4), middle school (grades 5-8), and secondary (grades 9-12) levels, and it identifies four cognitive processes—problem solving, communication, reasoning, and connections—that cut across all grade levels; see Box 4-1 for a description. The Standards also define a number of widely recognized mathematical content topics (e.g., number and number relationships, algebra, statistics, geometry, measurement, and trigonometry), which are emphasized differently at different grade levels. For example, informal algebra topics, such as patterns, are introduced in the grade K-4 and grade 5-8 clusters, but a more formal treatment of algebra does not occur until the grade 9-12 cluster. To the extent test developers adhere to the Standards , their tests will share these emphases. However, while the NCTM Standards have been adopted widely by test publishers on a general level, at a specific level adherence to them may vary. Therefore, tests may vary in their mix of topics at particular grades.
|
Box 4-1 Cognitive Processes of Math Problem Solving. The process of mathematical problem solving is often characterized by the words of mathematician George Polya (1980:1) "To solve a problem is to find a way where no way is known offhand, to find a way out of difficulty, to find a way around an obstacle, to attain a desired end, that is not immediately attainable, by appropriate means." Problem solving is a method of inquiry and application that provides a context for learning and applying mathematics. Communication. Communication as a mathematical process involves learning the signs, symbols, and terms of mathematics and thus has an important relationship to the disciplines of reading and writing. Students acquire the ability to communicate mathematically by reading, writing, and discussing mathematical concepts. Reasoning. Mathematical reasoning involves making conjectures, gathering evidence, and building an argument. Reasoning is recognized by the mathematics education community as fundamental to knowing and doing mathematics. Connections. There are two types of connections: connections between content areas such as geometry and algebra and connections between mathematics and other disciplines such as science, reading, and social studies. Within the K-12 mathematics curriculum, the Standards promote connections among the various content topics and between mathematics and these other disciplines. SOURCE: National Council of Teachers of Mathematics (1989). |
Reading
The skills that make up the domain of reading are characterized by Standards for the English/Language Arts, recently published by the National Council of Teachers of English (1996) as a joint project with the International Reading Association. Although the Standards and the processes of language and thinking that underlie them are inherently integrated in use and in teaching, reading tests tend to emphasize one of four dimensions in this domain: word recognition, passage comprehension, vocabulary, and reading inquiry. These dimensions are justifiable on the basis of the moderate to low correlations among them and fundamental differences in their psychological and educational meanings; see Box 4-2 for a description of these four dimensions.
|
Box 4-2 Dimensions Emphasized in Reading Tests Word Recognition. Initial reading acquisition is fundamentally a process of learning to recognize words. The cognitive, language, and neurological processes under girding this process are not simple. Passage Comprehension. Understanding the main idea of a passage is integral to reading. Comprehension of a paragraph may be measured by free recall, multiple-choice items, and short-answer questions. Passage comprehension depends on the ability to summarize, to use background knowledge to understand new information, to self-monitor the comprehension process, to know word meanings, and to build causal connections during reading. A wide array of complex cognitive processes is known to underlie passage comprehension (Kintsch, 1998; Lorch and Van den Broek, 1997; Pressley and Afflerbach, 1996). Many types of genres are used, including stories, poetry, exposition, and documents such as directions, to test possible comprehension. Vocabulary. A traditional aspect of reading is word knowledge. Many assessments use multiple-choice formats to test students' knowledge of word meaning. Students may be asked to identify synonyms, antonyms, or definitions. Knowledge of individual word meanings is highly associated with passage comprehension, but word knowledge is not the same as understanding the main idea of a paragraph, and the moderate correlations between tests of vocabulary and comprehension reflect this relationship. Reading Inquiry. Reading inquiry has been identified as a dimension of reading separable from passage comprehension. It involves cognitive strategies for judging relevance, locating important information, identifying information in different locations, and building a knowledge network from separate passages of text. |
The diversity in defining and teaching the domain of reading and differences in emphases in curriculum and instructional methodology are reflected in the diversity of assessments that purport to measure the domain. Assessments of reading, like assessments of mathematics, vary in terms of the content, level of difficulty, and the cognitive skills tapped by the items selected for the test.
Sampling a Domain for Assessment
The domains of reading and mathematics are broad and heterogeneous. They both contain different components and dimensions. Any
particular assessment of reading or mathematics taps a limited sample of the domain. No test asks all possible questions that could be asked. The content domain and sampling strategy for any given test are based on the purposes for assessment, the age of the students being tested, and beliefs about reading or mathematics processes.
States have different purposes for testing students and try to select tests that sample content domains appropriately for the intended use. Examples of two broad purposes that are directly affected by sampling are: obtaining student-level achievement information that can be used to report individual student progress and obtaining student-level achievement information to provide a picture of school-level achievement for accountability or for school improvement. Tests that yield norm-referenced interpretations are frequently used to obtain measures of individual students achievement. These tests are designed to distinguish among students as fully, quickly, and simply as possible. These criteria lead to using the fewest items and the fewest possible dimensions of the content domain while retaining high test reliability. The principle is to reduce the test to its minimum number of constructs and items while maximizing its ability to distinguish individual differences in achievement. For school accountability purposes, tests that yield criterion-referenced interpretations and include a broad array of constructs within the content domain are often used. Tests used effectively for accountability sample subdomains broadly, include cognitive processes needed across the domain, and require performance on complex tasks. The goal is to expand the number of constructs measured and, thus, taught. The test developer's aim is to maximize the scope of the assessment, rather than to minimize it. Linking the results from tests that sample a domain differently may lead to invalid inferences about student achievement and school performance.
Testing in States and Districts
Trends in State Student Assessment Programs, published by the Council of Chief State School Officers (Bond et al., 1998), and Quality Counts '98 (Education Week, 1998), published in collaboration with the Pew Charitable Trusts, indicate that nearly all states now have statewide assessment programs. These two reports indicate that states have made a major shift from off-the-shelf tests to state-developed criterion-referenced tests and customized tests that allow both norm-referenced and criterion-referenced
interpretations. In different states, these assessments may stand alone, be given in conjunction with each other, or be paired with performance tasks, portfolio assessments, and writing samples.
Given the wide array of choices of test type, format, and content, officials in states and schools districts have much to choose from when designing testing programs; and they have chosen in many different ways (Table 4-1). These decisions are most often guided by the purposes for which the testing program is designed. In this section we discuss some of the decisions that policy makers and educators make in determining the scope and format of large-scale testing programs and the impact of these factors on linking.
State Approaches
In recent years, states have taken various approaches to meet ever-increasing demands for higher standards of student performance in academic content and skill areas. Current efforts focus on comprehensive systems of assessment that attempt to:
- incorporate content standards (statements of what students should know and be able to do);
- incorporate performance standards (descriptors of what kinds and levels of performance represent adequate learning);
- reflect curriculum and instruction designed to effectively deliver the knowledge and skills necessary for student learning and performance relative to content standards;
- determine the extent to which students have mastered the content and skills represented by the standards; and
- develop accountability indices that show how well students, schools, school districts, states, and other entities are demonstrating desirable levels of student achievement.
Purposes
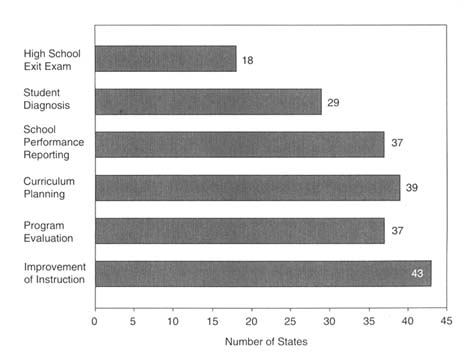
It is safe to say that the ultimate purpose of assessment is to improve instruction and student learning. But many states differ in their relative emphasis on the use of assessments in program evaluation, curriculum planning, school performance reporting, and student diagnosis (Roeber et al., 1998), all of which are activities aimed at the ultimate goal of
Table 4-1 State Testing: A Snapshot of Diversity
|
State |
Use of Commercial Tests |
Use of Other Assessments |
|
Alabama |
Stanford Achievement Test 9, Otis Lennon School Ability Test |
Alabama Kindergarten Assessment, Alabama Direct Assessment of Writing, Differential Aptitude Test, Basic Competency Test, Career Interest Inventory, End-of-Course Algebra and Geometry Test, Alabama High School Basic Skills Exit Exam |
|
Alaska |
California Achievement Test 5 |
|
|
Arizona |
Stanford Achievement Test 9 |
|
|
Arkansas |
Stanford Achievement Test 9 |
High School Proficiency Test |
|
California |
Stanford Achievement Test 9 |
Golden State Examinations |
|
Colorado |
Custom developed |
CTB/McGraw-Hill item banks, NAEP items, and state items |
|
Connecticut |
Custom developed |
Connecticut Mastery Test, Connecticut Academic Performance Test |
|
Delaware |
Custom developed |
State-developed writing assessment |
|
Florida |
Custom developed |
High School Competency Test, Florida Writing Assessment Program |
|
Georgia |
Iowa Tests of Basic Skills, Tests of Achievement Proficiency |
Curriculum-Based Assessments, Georgia High School Graduation Tests, Georgia Kindergarten Assessment Program, Writing Assessment |
|
Hawaii |
Stanford Achievement Test 8 |
Hawaii State Test of Essential Competencies, Credit by Examination |
|
Idaho |
Iowa Tests of Basic Skills Form K, Tests of Achievement Proficiency |
Direct Writing Assessment, Direct Mathematics Assessment |
|
Illinois |
Custom developed |
Illinois Goals Assessment Program |
|
Indiana |
Custom developed |
Indiana Statewide Testing for Educational Progress Plus |
|
Iowa |
No mandated statewide testing program, approximately 99 percent of all districts participate in the Iowa Tests of Basic Skills on a voluntary basis |
|
|
State |
Use of Commercial Tests |
Use of Other Assessments |
|
Kansas |
Custom developed |
Kansas Assessment Program (Kansas University Center for Educational Testing and Evaluation) |
|
Kentucky |
Custom developed |
Kentucky Instructional Results Information System |
|
Louisiana |
California Achievement Test 5 |
Louisiana Educational Assessment Program |
|
Maine |
Custom developed |
Maine Educational Assessment (Advanced Systems in Measurement, Inc.) |
|
Maryland |
Custom developed, Comprehensive Test of Basic Skills 5 |
Maryland Student Performance Assessment Program, Maryland Functional Tests, Maryland Writing Test |
|
Massachusetts |
Iowa Tests of Basic Skills, Iowa Tests of Educational Development |
|
|
Michigan |
Custom developed |
Michigan Educational Assessment Program: Criterion-referenced tests of 4th-, 7th-, and 11th-grade students in mathematics and reading and 5th-, 8th-, and 11th-grade students in science and writing; Michigan High School Proficiency Test |
|
Minnesota |
Custom developed |
1996-1997 students took minimum competency literacy tests in reading and mathematics |
|
Mississippi |
Iowa Tests of Basic Skills, Tests of Achievement Proficiency |
Functional Literacy Examination, Subject Area Testing Program |
|
Missouri |
Custom developed, TerraNova |
Missouri Mastery and Achievement Test |
|
Montana |
Stanford Achievement Test, Iowa Tests of Basic Skills, Comprehensive Test of Basic Skills |
|
|
Nebraska |
No statewide assessment program in 1996-1997 |
|
|
State |
Use of Commercial Tests |
Use of Other Assessments |
|
Nevada |
TerraNova |
Grade 8 Writing Proficiency Exam, Grade 11 proficiency exam |
|
New Hampshire |
Custom developed |
New Hampshire Education Improvement and Assessment Program (Advanced Systems in Measurement and Evaluation, Inc.) |
|
New Jersey |
Custom developed |
Grade 11 High School Proficiency Test, Grade 8 Early Warning Test |
|
New Mexico |
Iowa Tests of Basic Skills, Form K |
New Mexico High School Competency Exam, Portfolio Writing Assessment, Reading Assessment for Grades 1 and 2 |
|
New York |
Custom developed |
Occupational Education Proficiency Examinations, Preliminary Competency Tests, Program Evaluation Tests, Pupil Evaluation Program Tests, Regents Competency Tests, Regents Examination Program, Second Language Proficiency Examinations |
|
North Carolina |
Iowa Tests of Basic Skills |
North Carolina End-of-Grade Tests |
|
North Dakota |
Comprehensive Test of Basic Skills/4, TCS |
|
|
Ohio |
Custom developed |
4th-, 6th-, 9th-, and 12th-Grade Proficiency Tests |
|
Oklahoma |
Iowa Tests of Basic Skills |
Oklahoma Core Curriculum Tests |
|
Oregon |
Custom developed |
Reading, Writing, and Mathematics Assessment |
|
Pennsylvania |
Custom developed |
Writing, Reading, and Mathematics Assessment |
|
Rhode Island |
Metropolitan Achievement Test 7, Custom developed |
Health Performance Assessment, Mathematics Performance Assessment, Writing Performance Assessment |
|
South Carolina |
Metropolitan Achievement Test 7, Custom developed |
Basic Skills Assessment Program |
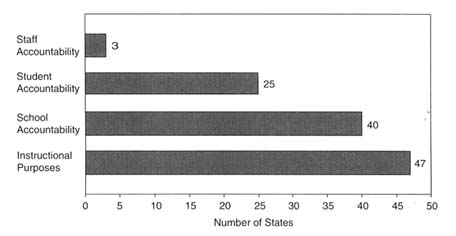
improved education; see Figures 4-1 and 4-2. More and more states are using (or are contemplating using) their assessment programs to make high-stakes decisions about people and programs, such as promoting students to the next grade, determining whether students will graduate from high school, grouping students for instructional purposes, making decisions about teacher tenure or bonuses, allocating resources to schools, or imposing sanctions on schools and districts (see, e.g., McLaughlin et al., 1995; McDonnell, 1997; National Research Council, 1999c).
Table 4-2 shows many of the varied uses of tests in the nation's schools today. Decisions about the purposes for testing will guide decisions about the content and format of selected tests; who should be tested and when; how results will be aggregated and reported; and who will be held accountable. Assessment programs that seek to guide instruction and those that seek to provide accountability may have significant differences in test design. When the same test is used for multiple purposes, the validity of the inference that can be drawn from the results may be jeopardized.
The committee realizes that information such as that in Tables 4-1 and 4-2 changes frequently and can be summarized differently in different reports. These tables are complied from data collected by the Council of Chief State School Officer's Annual State Student Assessment Survey. The data are self-reported by the assessment director in the states' education departments and describe the assessment programs they operated during the 1996-1997 school year (Roeber et al., 1998). It is considered accurate at the time of reporting. These tables are included to show the choices states make in selecting assessment instruments and the diversity of purposes for the tests. They paint a clear picture that states' testing programs are diverse.
Population Tested
States make different determinations about who should be tested and how the testing should be conducted, especially with regard to students with disabilities or limited English-language proficiency. The movement toward educational accountability for all students is gaining momentum and is serving as an impetus for the inclusion of students with special needs who were formerly excluded from statewide assessments. In order to provide special needs students with access to assessments and an equal opportunity to demonstrate knowledge and skills, many states are offering
accommodations or modifications to their assessments. Currently, test accommodations are the most common response to the need to include more students in state assessments.
Test accommodations are changes made to test administration procedures in order to provide a student with access to the assessment and an equal opportunity to demonstrate knowledge and skills without affecting the reliability or validity of the assessment. That is, the accommodation should not change the test content, instructional level, performance criteria, or expectations for student performance. The purpose of accommodation is to remove variance that is not related to the domain of the test—that is, to level the playing field by eliminating irrelevant sources of differences in student performance. The most common test accommodations are changes in the timing or scheduling of the assessment; mode of presentation, such as Braille or large-print versions for the visually impaired or reading a writing assessment item to an auditory learner; or mode of responses, such as use of a scribe to record oral responses and fill in the test booklet. These approaches, when designed and implemented properly, provide scores that permit interpretations of student's knowledge or mastery of the domain without confounding the effects of their disability.
In the instances described above, those of accommodation, the same test is administered to all students, although the conditions in which the test is administered vary, which allows all students to participate. In contrast, a modification to an assessment changes the validity of the assessment since the test content, difficulty level, performance criteria, or expectations of the student may be different from that of the regular assessment. In a word, a different test is administered to some students. A common test modification is to read a reading assessment to an auditory learner. This changes what is measured: it is no longer an assessment of the ability to decode, comprehend, and use written information, but an assessment of the ability to decode, comprehend, and use oral information (see National Research Council, 1998).
In establishing linkages between different statewide assessment programs, it is important to ask how many students with disabilities or with limited English-language proficiency participate in a state's assessment programs, what kinds of accommodations and modifications are allowed that enable participation, and what scores are included in state reports of assessment results. One of the major considerations in linking two assessments is the comparability of the populations tested. For example, an
Table 4-2 Student Testing: Diversity of Purpose
|
State |
Decisions for Students |
Decisions for Schools |
Instructional Purposes |
|
Alabama |
High school graduation |
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Alaska |
|
School performance reporting |
Improve instruction |
|
Arizona |
|
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Arkansas |
|
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
California |
Student diagnosis or placement |
|
Student diagnosis or placement |
|
Coloradoa |
|
|
|
|
Connecticut |
Student diagnosis or placement |
Awards or recognition; school performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Delaware |
|
|
Student diagnosis or placement; improve instruction; program evaluation |
|
Florida |
High school graduation |
|
Improve instruction; program evaluation |
|
Georgia |
High school graduation |
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Hawaii |
High school graduation |
Awards or recognition; school performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Idaho |
|
School performance reporting |
Improve instruction |
|
Iowaa |
|
|
|
|
Illinois |
|
Accreditation |
|
|
Indiana |
|
Awards or recognition; school performance reporting; accreditation |
Student diagnosis or placement; improve instruction; program evaluation |
|
Kansas |
|
School performance reporting; accreditation |
Student diagnosis or placement; improve instruction; program evaluation |
|
Kentucky |
|
Awards or recognition |
Improve instruction; program evaluation |
|
Louisiana |
Student promotion; high school graduation |
Awards or recognition; school performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Maine |
Student diagnosis or placement |
|
Improve instruction; program evaluation |
|
Maryland |
High school graduation |
School performance reporting; skills guarantee; accreditation |
Student diagnosis or placement; improve instruction; program evaluation |
|
Massachusetts |
|
School performance reporting |
Improve instruction |
|
Michigan |
Student diagnosis or placement; endorsed diploma |
Awards or recognition; School performance reporting; accreditation |
Improve instruction; program evaluation |
|
Minnesotaa |
|
|
|
|
Mississippi |
High school graduation |
School performance reporting; skills guarantee; accreditation |
Student diagnosis or placement; improve instruction; program evaluation |
|
Missouri |
|
School performance reporting; accreditation |
Improve instruction; program evaluation |
|
Montana |
|
|
Improve instruction; program evaluation |
|
State |
Decisions for Students |
Decisions for Schools |
Instructional Purposes |
|
Nebraskaa |
|
|
|
|
Nevada |
High school graduation |
School performance reporting; accreditation |
Improve instruction; program evaluation |
|
New Hampshire |
|
|
Improve instruction; program evaluation |
|
New Jersey |
High school graduation |
School performance reporting; accreditation |
Student diagnosis or placement; improve instruction |
|
New Mexico |
High school graduation |
School performance reporting; accreditation |
Student diagnosis or placement; improve instruction; program evaluation |
|
New York |
Student diagnosis or placement; student promotion; honors diploma; endorsed diploma; high school graduation |
School performance reporting |
Improve instruction; program evaluation |
|
North Carolina |
Student diagnosis or placement; student promotion; high school graduation |
|
Improve instruction; program evaluation |
|
North Dakota |
Student diagnosis or placement |
|
Student diagnosis or placement; improve instruction; program evaluation |
|
Ohio |
High school graduation |
Awards or recognition; school performance reporting |
Improve instruction; program evaluation |
|
Oklahoma |
|
School performance reporting; accreditation |
Student diagnosis or placement; improve instruction; program evaluation |
|
Oregon |
|
School performance reporting |
Improve instruction; program evaluation |
|
Pennsylvania |
|
School performance reporting |
Student diagnosis or placement; program evaluation |
|
Rhode Island |
|
School performance reporting |
Improve instruction; program evaluation |
|
South Carolina |
Student promotion; high school graduation |
Awards or recognition; school performance reporting; skills guarantee |
Student diagnosis or placement; improve instruction; program evaluation |
|
South Dakota |
|
|
Improve instruction; program evaluation |
|
Tennessee |
Endorsed diploma; high school graduation |
|
Student diagnosis or placement; improve instruction; program evaluation |
|
Texas |
Student diagnosis or placement; high school graduation |
|
Student diagnosis or placement; improve instruction; program evaluation |
|
Utah |
Student diagnosis or placement |
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Vermont |
|
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Virginia |
Student diagnosis or placement; student; promotion high school graduation |
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
Washington |
|
School performance reporting |
Student diagnosis or placement; improve instruction; program evaluation |
|
West Virginia |
|
Skills guarantee; accreditation |
Improve instruction |
|
Wisconsin |
|
School performance reporting |
Program evaluation |
|
Wyoming |
|
|
Improve instruction; program evaluation |
|
a Colorado, Minnesota, and Nebraska did not administer any statewide assessments in 1995-1996. Iowa does not administer a statewide assessment. SOURCE: Data from 1996 Council of Chief State School Officers Fall State Student Assessment Program Survey. |
|||
attempt to link two assessments, only one of which allows accommodations, is in some respects an attempt to equate test results for two different populations. Results of previous studies investigating the feasibility of linking large-scale assessments have shown that the linking functions can produce different results for different subpopulations (Linn and Kiplinger, 1995).
Accountability and Stakes
Changes in how tests are used inevitably lead to changes in how teachers and students react to them (Koretz, 1998). Indeed, one of the underlying rationales for test-based accountability is to spur changes in teaching and learning. The merits of using tests for such purposes are beyond the scope of this report. For our purposes, however, it is crucial to note that the difficulty of maintaining linkages between tests is exacerbated when consequences of test results for individuals or schools vary.
When test results have significant consequences, teachers may change what and how they teach to help students respond to the content and problems on the test (Shepard and Dougherty, 1991; National Research Council, 1999c), schools and districts may align curriculum more closely with test content, and test takers may have stronger motivation to do well (e.g., Koretz et al., 1991). Performance gains on tests used for accountability (high-stakes tests) will often not be reflected in scores on tests used for monitoring or other nonaccountability (low-stakes) purposes. The resulting differences in student performance could alter the relationship between linked tests over time (Shepard et al., 1996; Yen, 1996). Hence, any valid linkages created initially would have to be reestablished regularly.
The effects of test use on student and teacher behavior pose a special problem for linkage with NAEP. To protect its historical purpose as a monitor of educational progress, NAEP was designed expressly with safeguards to prevent it from becoming a high-stakes test. As a result, the motivation level of students who participate in NAEP may be low (O'Neil et al., 1992; Kiplinger and Linn, 1996), and they may not always exhibit peak performance. Linkages between a low-stakes instrument like NAEP and high-stakes state or commercial tests may not be sustained over time because teachers and students are likely to place greater emphasis on improving performance on the latter.
Reporting
One of the functions of state educational testing programs is to communicate, or report, results of student performance to parents, educators, policy makers, and the public. How results are aggregated and reported to these audiences, and the way these results are used, vary significantly among commercially published tests and state assessments, and these differences play a role in the ability to establish useful links between tests.
The results of student performance on a large-scale assessment may be reported in many ways. Results from tests intended to yield norm-referenced interpretations are often reported as grade equivalents, percentile ranks, stanines, or normal curve equivalents (see, e.g., Anastasi, 1982). These types of scores provide an indication of how the performance of students or groups of students who took the test compare with students in the same grade or of a similar age who were part of the norming sample. Criterion-referenced interpretations may be used to provide a status report or “snapshot" of what an individual student or all of the state's students know and are able to do in relation to the state's content standards or to other performance criterion. Individual student or group results earned on a criterion-referenced or standards-based assessment are most often reported in terms of "meeting the criterion or standard" or in terms of performance levels, which describe what students are expected to know and be able to do in order to be classified in each of the levels.
The level of data reported varies according to the purposes of the assessment and state requirements and specifications. Individual data may be reported for each test taker or aggregated and reported only at the school, district, or state-level (Frechtling, 1993). Aggregated data may also be reported by various groupings, for example, by race, ethnicity, gender, school or district size, special education or nonspecial education program participation, accommodated or nonaccommodated assessment.
Comparing results earned on different types of measures and reported at different levels of aggregation is a challenge with serious implications for the ability to link tests to each other or to NAEP. Currently administered state and commercial achievement tests and NAEP vary significantly in terms of their content emphasis, types and difficulty of test questions, and the thought processes they require of students. In addition, these tests vary substantially in how and when they are administered, whether all students respond to the same sets of questions, how closely the tests are related to what is taught in school, how they are
scored, and how the scores are reported and used (Roeber et al., 1998). Moreover, different test takers might use different cognitive processes on the same item. These factors contribute to the challenges faced by policy makers and others who seek to reconcile the dual goals of local control of educational decision making and national comparability and accountability.


























