
Chapter 6
Invited Session on Business and Miscellaneous Record Linkage Applications
Chair: Richard Allen, National Agricultural Statistics Service
Authors:
Jenny B.Wahl, St. Olaf College
Philip M.Steel and Carl A.Konschnik, Bureau of the Census
Edward H.Porter and William E.Winkler, Bureau of the Census
Linking Federal Estate Tax Records
Jenny B.Wahl, St. Olaf College
Abstract
This chapter focuses on the construction of a dataset that links together tax records and contemplates possible uses of these data. I first provide an overview of scholarly work regarding inherited wealth and establish the need for intergenerationally linked data. I then discuss techniques that I used to work with Federal estate tax returns filed in Wisconsin up to 1981 (which included 93,539 decedents and their 299,688 beneficiaries). By combining a standardizing/matching software package with a series of SAS programs. I linked these records to form a database containing 27,535 observations. Each observation has information on an individual who was reported on at least two estate tax returns: once as a decedent and at least once as a beneficiary. Of the 27,535 observations, 6,453 are matched pairs and the remaining 21,082 are likely pairs. I conclude by revealing certain problems associated with linking together tax records and by suggesting future research.
Introduction
The only sure things in life are death and taxes—and, unfortunately for some, death taxes. Fortunately for the rest of us, Federal estate tax data offer a rare opportunity to observe the total wealth, portfolios, and bequest behavior of certain individuals. Not only that, these data can be linked across generations, providing testing grounds for hypotheses about motives for intergenerational transfers, tradeoffs of family size and bequest amount, and the like. I have used all the estate tax records filed in Wisconsin from 1916 to 1981 to assemble just such a data set. These data consist of 27,535 observations; each observation has information on a single individual who was reported on two estate tax records: once as a decedent and once as a beneficiary[1]. Of this number, 6,453 are matched pairs and the remaining 21,082 are likely pairs. Figure 1 illustrates the configuration of each observation. In addition to the linked data, a residual set of 272,153 beneficiaries did not match to any decedent.
Figure 1. —Configuration of an Observation in the Matched Data Set
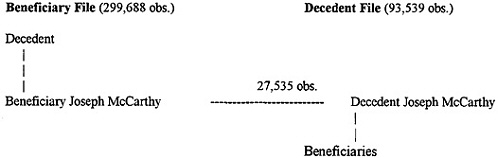
What follows is, first, a brief overview of some of the questions and theories that scholars have put forth regarding wealth and intergenerational transfers. I then turn to a fuller description of the data, a discussion of the linking methodology, and a short mention of the empirical work that lies ahead.
The Importance of Inherited Wealth
For a variety of reasons, scholars have studied the transfer of wealth across generations. Some have focused on macroeconomic issues such as the influence of wealth transfers on the distribution of wealth (Menchik, 1979; Kotlikoff and Summers, 1981; Modigliani, 1988; and Tachibanaki, 1994), the degree to which intergenerational wealth transfers affect savings rates across countries (Darby, 1979; Hayashi, 1986; and Kotlikoff, 1988), and the interaction of cross-generational transfers and fiscal policy (Barro, 1974; and Aaron and Munnell, 1992). Others have concentrated on microeconomic questions such as the propensity of parents to compensate their less able children or, alternatively, to leave more money to their relatively capable offspring (Becker and Tomes, 1979; and Tomes, 1981).
In the process, researchers have speculated as to the appropriate model of behavior. Do individuals leave bequests because they care about their descendants or other heirs? Or do people design bequests strategically to induce potential heirs to offer attention and companionship? Or might the leaving of an estate simply be a mistake born of miscalculating one's own mortality? (Kotlikoff and Spivak, 1981; Bemheim, Schleifer, and Summers, 1985; Abel, 1985; Hurd, 1987; Modigliani, 1988; Lord and Rangazas, 1991; Altonji, Hayashi, and Kotlikoff; 1992; Gale and Scholz, 1994; Abel and Kotlikoff, 1994; Hurd, 1994; Arrondell, Perelman, and Pestieau, 1994; Yagi and Maki, 1994; and Tachibanaki and Takata, 1994.) Professors Martin David and Paul Menchik (1982) took yet a different tack. They used wealth data to estimate propensities to bequeath out of earnings. Although they did not propose any new theories, David and Menchik cast doubt on an old one: their results indicated that the life-cycle hypothesis cannot explain the bequest behavior of a set of Wisconsin decedents[2].
Others have posed additional interesting questions. Do people behave differently—choose alternative occupations or retire early, for example —if they receive or anticipate a bequest? What relationship do estate size and life insurance bear to a decedent's earnings? What connections exist among fertility, estate size, and earnings? Can one find evidence, for instance, of a tradeoff between the number of children and the wealth left to each one (Becker and Tomes, 1976; Behrman, Pollak, and Taubman, 1982; Wahl, 1986; and Wahl, 1991)? Do people tend to allocate estates equally among their children? Are people increasingly “spending the kids' inheritance,” as the bumper stickers proclaim? What patterns in charitable giving have appeared over the years? Is age at death related to lifetime earnings? Many of these questions remain open. Answering them requires a sufficiently large, intergenerationally linked data set that contains comprehensive demographic and socioeconomic information.
The Original Estate Tax Data: Saved in the Nick of Time
Estate tax records contain a wealth of data on a nation's citizens. One can find not only detailed information on accumulated capital and portfolio holdings but also clues about family composition, residence and migration patterns, fertility, and mortality. By dint of much effort (and good computer software) one can even link records together to reconstitute families and their financial and demographic histories. I have drawn upon Federal estate tax records to do just this.
Let me offer a short history of the initial data collection effort. In 1916, the modern Federal estate tax came into being—well before modern computers, but recently enough that paper documents still existed in
archives seven decades later. In efforts to clean house during the Reagan years, zealous politicians nearly caused an untimely end for the boxed estate tax returns that were scattered in warehouses around the country. Fortunately, the Statistics of Income (SOI) Division at the Internal Revenue Service marshaled its forces to preserve these important historical artifacts in computerized form. The result was two enormous files: one consisting of economic and demographic information on decedents, the other of information on beneficiaries (linked via record number to the original estate tax record).
Any attempt to match these two files required reducing their size. Because other researchers have used Wisconsin data to investigate wealth and estate issues (for example, David and Menchik, 1982), SOI extracted all the Wisconsin estate tax returns to use for a pilot project. The result was a decedent file with 93,711 observations and a beneficiary file with 300,269 observations. In the decedent file, 93,539 are unique individuals. For consistency's sake, omitting records from the decedent file meant purging the same records from the beneficiary file. The outcome was a file of 299,688 beneficiaries. Of this number, 188 seem to be duplicates on the same estate tax record—that is, beneficiaries with the same name and same relationship code to the decedent, but appearing twice on a given tax return. Such apparent duplicates may, however, represent different persons with the same name—cousins, for example. Alternatively, these may constitute separate bequests to a single individual—one direct and one in trust. Rather than investigate these observations before the match procedure, I simply marked them so that, if any appeared after the match, I could inspect them more carefully at that time.
Linking the Data: Overlapping Estate Tax Returns
Linking data from one set of records to another requires much information and, frequently, creative computer programming (Fellegi and Sunter, 1969). The AUTOMATCH software written by Matt Jaro provides a solid foundation (Jaro, 1997); variations on his programs coupled with SAS programming produced the linked estate tax records. The critical linkage was this: Joseph McCarthy, say, appears as a beneficiary on his father's estate tax return. In turn, the estate of Joseph McCarthy also files a tax return. The two are linked into a single observation, given consistency in social security numbers, sex, years of birth and death, and the like. Each observation then contains detailed information about the Joseph the decedent: his portfolio, age, marital status, and number of children, for instance. Information about Joseph the beneficiary appears as well: his relationship to his benefactor, receipt of a trust, and sometimes the size of his bequest.
The AUTOMATCH software contains several attractive features that help create good links between records. It standardizes individual names and creates NYSIIS and Soundex codes. (Because I had maiden names for many women, I ran the standardization/coding step twice.) These codes work well as blocking variables in the match process. The software also allows specification of values for missing variables; this helps distinguish between true mismatches and apparent mismatches caused by missing data. The match procedure itself allows multiple rounds so that I could block and match over different sets of variables. Table 1 shows the salient variables for each match round.
The matching process itself also has nice characteristics. I could request multiple matches—important, because Joseph McCarthy may have inherited from more than one person. Each matching variable has a designation to control for miskeying in the original data. For example, I could allow for mismatched numbers in the social security number string and mismatched letters in the name character strings. These designations also allow matching around intervals, which proved essential for my year-of-birth variables because I had to construct them from rounded-year ages. Each matching variable also carries a set of probabilities to allow for type I and type II errors[3]. All together, these probabilities translate into a single weight associated with each match in each match round. I could choose two cutoff weights per round:
one the lower bound for declared matches, the other the lower bound for potential matches. After each match round, I could perform an interactive clerical review on the potential matches and change their status to declared matches or residuals. Following the clerical review, the software outputs all residuals to the next match round.
Table 1. —Matching Rounds
|
Match Pass |
Blocking Variables |
Matching Variables |
Original Matches |
Original Clerical |
Final Matches |
Final Clerical |
|
1 |
SSN |
surname first name maiden name suffix initial sex year of birth |
4,805 |
119 |
4,884 |
0 |
|
2 |
SSN |
surname/ maiden name first name suffix initial sex year of birth |
4,906 |
43 |
4,928 |
0 |
|
3 |
surname NYSIIS first name Soundex sex |
SSN surname first name maiden name initial suffix year of birth |
5,514 |
30,651 |
5,514 |
30,651 |
|
4 |
surname/ maiden name NYSIIS first name Soundex sex |
SSN surname/ maiden name first name initial suffix year of birth |
5,515 |
30,652 |
5,515 |
30,652 |
The clerical review process is extremely time-consuming. Although I used it for the first two match rounds, thereafter I used SAS programs to decide whether to change the status of potentially matched pairs [4]. Simply put, I distilled a set of decision rules into SAS programs rather than using the same rules on an interactive, case-by-case basis. For example, suppose the initial matching process paired Joseph McCarthy from the decedent file to Joseph McCarthy from the beneficiary file. The beneficiary file in-
cludes a date of death for the Joe's benefactor. If this date of death was after the date of death of Joe the decedent, I called it a nonmatch.
Particular Features of Estate Tax Data
Any two data sets have quirks that make matching difficult. Let me point out a few issues associated with matching data on people observed at two different points in time, often several years apart.
Some problems pertained primarily to females. During the time period covered by my data, a woman often took her husband's social security number at marriage. Sorting and matching by SSN for women was therefore problematic if a woman got married after receiving a bequest. Women also sometimes changed their middle initials upon marriage to reflect their maiden names. I had to take care, then, with the probabilities placed on type I and type II errors when initials appeared as matching variables.
Yet women provided information—namely, maiden names—that helped me refine the likelihood of matches as well. Suppose a decedent carried the maiden name Scheuren. Say that the decedent potentially matches to a beneficiary, whose benefactor carried the last name Scheuren. Provided that birth and death years were logical, I could declare this a match. By the same token, if a (potentially matched) decedent had the last name Winkler and the benefactor named on the beneficiary file had the maiden name Winkler, again this might be considered a match.
Males created certain problems as well, albeit less directly than females. I had hoped to use cities as matching variables. Yet this hope was dashed: Wisconsin men seemed to like passing their names on to their sons, people did not seem to move around much, and missing ages for beneficiaries frequently meant that I could not screen matches by birth year. As a result, I could not use locational variables to improve the matching process.
A last discovery: one should always assign unique record identification numbers to observations on each file. Initially, the beneficiary file contained identifiers that pointed back to the estate tax record, but it did not have unique identifiers. Because my original files were so large, I excluded some variables while performing the match. When I attempted to reattach data after the match, I could not be sure that the right data went to the right individual. I therefore had to retrace my steps, this time with unique identifiers for each original file.
What Lies Ahead
In the coming months, I will use these linked data to fulfill two objectives. One is to compare matched and unmatched beneficiaries and report any significant differences. The other is to generate a proxy for bequest amount. To proceed, I must convert dollar figures to constant-dollar amounts, control for changes in filing thresholds, and implement a logical cutoff process so as to separate nonmatches from impossibilities. That is, I do not want to call unmatched data a “nonmatch” if the individual could not possibly have entered the matched data set because he or she was born before 1916 or was still living after 1981. Eventually, I hope to extend matches forward and back to reconstitute multiple generations of families.
Acknowledgments
Many thanks to Fritz Scheuren, who made sure this work saw the light of day; Dan Skelly, who encouraged me to dirty my hands with these data; and Barry Johnson, who answered my questions and did most of the hard stuff.
Footnotes
[1] Individuals can appear as beneficiaries on more than one estate tax return. The pairs do not therefore represent unique persons.
[2] The life-cycle hypothesis, associated originally with Franco Modigliani, suggests that people tend to decumulate wealth after a certain age, as they begin to anticipate death. For a review, see Ando and Modigliani (1963) and Modigliani (1988).
[3] Type I errors occur when true matches are declared nonmatches; Type II errors occur when nonmatches are declared matches.
[4] Here is a time comparison: using the clerical review process on 3,827 potential pairs took me seven hours. Writing and running SAS programs with embedded decision rules took about one-half hour for the same data.
References
Aaron, H. and Munnell, A. ( 1992). Reassessing the Role for Wealth Transfer Taxes, National Tax, Journal 45:119–44.
Abel, A. ( 1985). Precautionary Saving and Accidental Bequests, American Economic Review, 75:777–91.
Abel, A. and Kotlikoff, L. ( 1994). Intergenerational Altruism and the Effectiveness of Fiscal Policy —New Tests Based on Cohort Data, Savings and Bequests, ed. T.Tachibanaki, Ann Arbor: University of Michigan Press, 167–96.
Altonji, J; Hayashi, F.; and Kotlikoff, L. ( 1992). Is the Extended Family Altruistically Linked? New Tests Based on Micro Data, American Economic Review, 82:1177–98.
Ando, A. and Modigliani, F. ( 1963). Lifecycle Hypothesis of Savings: Aggregate Implications and Tests American Economic Review, 53.
Arrondell, L.; Perelman, S.; and Pestieau, P. ( 1994). The Effect of Bequest Motives on the Composition and Distribution of Assets in France, Savings and Bequests, ed. T.Tachibanaki, Ann Arbor: University of Michigan Press, 229–44.
Barro, R. ( 1974). Are Government Bonds Net Wealth? Journal of Political Economy, 82:1095–1118.
Becker, G. and Tomes, N. ( 1976). Child Endowments and the Quantity and Quality of Children, Journal of Political Economy, 84:143–62.
Becker, G. and Tomes, N. ( 1979). An Equilibrium Theory of the Distribution of Income and Intergenerational Mobility, Journal of Political Economy, 87:1153–89.
Behrman, J.; Pollak, R.; and Taubman, P. ( 1982). Parental Preferences and Provision for Progeny, Journal of Political Economy, 90:52–73.
Bernheim, B.D.; Schleifer, A.; and Summers, L. ( 1985). The Strategic Bequest Motive, Journal of Political Economy, 93:1045–76.
Darby, M. ( 1979). The Effects of Social Security on Income and the Capital Stock, Washington, DC: American Enterprise Institute.
David, M. and Menchik, P. ( 1982). Modeling Household Bequests, University of Wisconsin, working paper.
Fellegi, I. and Sunter, A. ( 1969). A Theory for Record Linkage, Journal of the American Statistical Association, 64:1183–1210.
Gale, W. and Scholz, J.K. ( 1994). Intergenerational Transfers and the Accumulation of Wealth, Journal of Economic Perspectives, 8:145–60.
Hayashi, F. ( 1986). Why is Japan's Saving Rate So Apparently High, NBER Macro Annual, ed. S. Fisher, Cambridge: MIT Press.
Hurd, M. ( 1987). Savings of the Elderly and Desired Bequests, American Economic Review, 77:298– 312.
Hurd, M. ( 1994). Measuring the Bequest Motive: The Effect of Children on Saving by the Elderly in the U.S., Savings and Bequests, ed. T.Tachibanaki, Ann Arbor: University of Michigan Press, 111–36.
Jaro, M. ( 1997). Matchware Product Overview, Record Linkage Techniques -1997, eds. W.Alvey and B.Jamerson, Washington, D.C.: Office of Management and Budget.
Kotlikoff, L. ( 1988). Intergenerational Transfers and Savings, Journal of Economic Perspectives, 2:48– 51.
Kotlikoff, L. and Spivak, A. ( 1981). The Family as an Incomplete Annuities Market, Journal of Political Economy, 89: 372–91.
Kotlikoff, L. and Summers, L. ( 1981). The Role of Intergenerational Transfers in Aggregate Capital Accumulation Journal of Political Economy, 89:706–32.
Lord, W. and Rangazas, P. ( 1991). Savings and Wealth in Models with Altruistic Bequests, American Economic Review, 81:289–96.
Menchik, P. ( 1979). Intergenerational Transmission of Inequality: An Empirical Study of Wealth Mobility, Economica, 46:749–62.
Modigliani, F. ( 1988). The Role of Intergenerational Transfers and Life Cycle Saving in the Accumulation of Wealth, Journal of Economic Perspectives, 2:15–40.
Tachibanaki, T, ed. ( 1994). Savings and Bequests., Ann Arbor: University of Michigan Press.
Tachibanaki, T. and Takata, S. ( 1994). Bequest and Asset Distribution: Human Capital Investment and Intergenerational Wealth Transfers, Savings and Bequests, ed. T.Tachibanaki, Ann Arbor: University of Michigan Press, 197–228.
Tomes, N. ( 1981). The Family, Inheritance, and Intergenerational Transmission of Inequality Journal ofPolitical Economy, 89:928–58.
Wahl, J. ( 1991). American Fertility Decline in the Nineteenth Century: Tradeoff of Quantity and Quality? Essays in Honor of Robert William Fogel, eds. C.Goldin and H.Rockoff, Chicago: University of Chicago Press.
Wahl, J. ( 1986). New Results on the Decline in Household Fertility in the United States from 1750 to 1900, Studies in Income and Wealth, eds. R.Gallman and S.Engerman, Chicago: University of Chicago Press, 391–438.
Yagi, T. and Maki, H. ( 1994). Cost of Care and Bequests, Savings and Bequests, ed. T.Tachibanaki, Ann Arbor: University of Michigan Press, 39–62.
Post-Matching Administrative Record Linkage Between Sole Proprietorship Tax Returns and the Standard Statistical Establishment List
Philip M.Steel and Carl A.Konschnik, Bureau of the Census
Abstract
In 1992 a match was performed between the IRS Form 1040, Schedule C file and the Standard Statistical Establishment List (SSEL). The match supplemented existing linkages already established between the two files. Though no matching operation has been performed on subsequent 1040 files, the links established on the 1992 data continue to be based in the processing of these files. We are now in a position to analyze the long term effectiveness of the procedure and how frequently it should be applied.
As a by product of the matching operation we obtained a measure of the fit between two records. We explore the possibility of utilizing this measure to link records or select records to be subjected to a matching procedure. The measure of fit derived from the 1992 processing can also be applied to test the validity of existing linkages derived from other procedures.
Introduction
This paper describes a matching process which improves the linkage between sole proprietorship income tax return records from the Internal Revenue Service (IRS) and their associated payroll records on the Census Bureau's Standard Statistical Establishment List (SSEL).
The matching process supplements the linkages made previously based on a common primary identifying number on the two types of records. This number is the Employer Identification Number (EIN), issued by IRS to businesses with employees, and used by them as a principal taxpayer identification number. Unfortunately this common identifier is omitted on roughly 30 percent of the annual income tax returns on which it should appear. In matching, our aim was to make the linkages more complete by using other information besides the EIN—chiefly, name, city, state, ZIP code, payroll and kind-of-business activity code.
Context and Motivation for the Matching
Linking receipts and payroll records depends largely on associating the correct EIN with each annual income tax return. A sole proprietorship business, when filing the required annual Form 1040, Schedule C, (or, briefly, 1040-C) tax return with the IRS, uses the owner's social security number (SSN) as its taxpayer identification number. If the business has employees, it is required to have an EIN and use it for filing IRS Form 941, Employer's Quarterly Federal Tax Return. When it files its annual 1040-C tax return, the sole proprietorship business is asked to provide its EIN if it has one. This reported EIN is the principal link between the annual business income and quarterly payroll tax returns for sole proprietorship employers.
The IRS provides Form 941 payroll data to the Census Bureau weekly for updating the SSEL. These payroll records, along with data received monthly from the IRS Business Master File (BMF), serve to keep the SSEL current with name and address, employment, payroll, form of organization, and other key data for business. The primary identifier used for the BMF and the 941 files, is, of course, the EIN. By natural extension, for processing administrative records, the EIN is also the primary identifier on the SSEL. All employers—corporation and partnership employers, as well as sole proprietorship employers, file their Form 941 under their EIN. Because partnership and corporation income tax returns are filed under an EIN, the linkage between receipts from annual tax returns and payroll records for these businesses is readily available. However, for sole proprietorships, if the EIN is missing or incorrect on the 1040-C, we obviously can't rely on the EIN to update the appropriate SSEL payroll record with 1040-C receipts.
Complete updating of receipts on the SSEL is important because the Census Bureau's economic censuses use the SSEL as a frame and use IRS tax return data from the 1040-C to tabulate receipts for single-establishment (singleunit), sole proprietorship businesses with payroll below prescribed cutoff levels. These cutoffs vary by kind of business. Singleunit businesses with payroll above the cutoffs and all multi-establishment (multiunit) businesses from the SSEL are mailed a census form. Tax return data from the 1040-Cs are also used to account for those who fail to respond to the mailing.
Incomplete linkage between 1040-C employers and the SSEL means that the file of 1040-C records from IRS for a census year such as 1992 (after removing 1040-C linked to the SSEL) still contains some employer as well as all nonemployer businesses. This causes two problems:
-
tax-return receipts are not available on the SSEL for tabulating inscope EINs with nonzero 1992 payroll and missing receipts for the economic censuses; and
-
the 1040-C file includes an unknown number of employers with unknown total receipts—therefore, we cannot use it directly to tabulate census year receipts for nonemployer businesses.
Both problems are alleviated by improving the linkage between the file of 1040-C records and the SSEL. For the 1992 censuses, we obtained an EIN to SSN cross-reference (x-ref) file from IRS to aid in linking records. In addition to this, we used matching techniques to associate 1040-C records with their associated SSEL payroll record. In the following sections, we present the technical details of this matching work and discuss the impact it had on the 1992 census estimates.
Description of the Files for Matching
After updating the SSEL using the reported EIN on the 1040-C and the SSN to EIN cross-reference file from the BMF, we were left with EINs on the SSEL which were still missing receipts. A file of these EINs drawn from the SSEL, formed the primary file for the matching. The number of unlinked, potentially matchable EINs, on the file at this point was 419,494. The criteria for selecting these cases were that:
-
the EIN be within U.S. boundaries;
-
the Legal Form of Organization (LFO) be a sole proprietorship or form of organization unknown (as opposed to a partnership or a corporate form of organization);
-
the EIN be taxable or have tax status unknown; and
-
the EIN reported nonzero payroll for the 1992 census year.
The second file for matching consisted of 1040-C sole proprietorship tax return records. A 1040-C may have (in census processing) up to three schedules, each representing a separate business. The schedule, together with the name and address from the main 1040, form our 1040-C record. The SSN, together with one schedule number, formed the identifier for the second file. The original 1040-C file included those with EINs that linked to the SSEL, this file contained 16,540,844 schedules in all. Because this large file size exceeded the capacity of our software platform (a VAX minicomputer cluster), our matching was performed with this file split into 36 pieces.
Variables for Matching and their Comparability
Records on both files contain name, address, kind-of-business and payroll fields. Each of these fields has associated problems.
-
Name Fields. —The primary name field from the SSEL may be the name of a business, e.g., the American Bank Note Company, but in the case of sole proprietors this field is usually the proprietor's name, even where the LFO has not been determined. On the other hand, the 1040-C record has the Form 1040 name, which is a personal name, often including both husband and wife for joint filing. There are several other name fields available on the SSEL, such as the census name, physical location name, and mailing name. These were examined as candidates for matching fields, but appeared to contribute very little to establishing new linkages (during testing, the census name field update was incomplete, and may yet be shown to be useful for future matching). To summarize, on the EIN file we have a name field that may or may not contain a personal name; on the 1040-C file we have a name field that may contain compound names, with either of the components a candidate for matching. To deal with this, our name parser rejects records with identifiable business names from the EIN file and generates two records for compound names on both the 1040-C file and (in a few cases) the EIN file.
-
Address Fields. —Both files have address fields containing street address, city, state and ZIP code. However, the address on the SSEL is generally the business address and the 1040-C address is a personal address. Using a test file containing only known linkages between the EIN and 1040C records, we found that the street addresses matched partially or better only 30 percent of the time (+/- 6%) based on a clerical review of a sample of 248 cases. This eventually led us to drop the street address as a matching variable. The same problem—that the 1040-C address and SSEL address of known linkages can be different—applies to city, state and ZIP code, but to a lesser degree. These variables were retained for matching.
-
Business Classification Codes. —The EIN's business activity code from the SSEL is the Standard Industrial Classification (SIC) code, whereas the 1040-C record has a converted Primary Business Activity (PBA) code. The PBA code is an abbreviated but roughly comparable coding system. The SIC on the SSEL is generally coded from various sources. In contrast, the PBA is a self-reported code by the taxpayer. Previous studies indicate that we can expect the self-reported code to match the SIC code no more than about 67 percent of the time at the four-digit level and 75 percent at the two-digit level. See Konschnik et al., (1993) for more on the quality of self-coded PBAs.
-
Annual Payroll. —We obtain a single annual payroll figure for EIN records from the SSEL. The 1040-C has two fields related to payroll—wages and cost of labor. Technically, the wages field is supposed to correspond to payroll, and cost of labor to represent contracted labor where the employment taxes are born by the employer of the contracted laborers. Examination of the data shows this is not always the case. Although for most of the time, the SSEL payroll figure agrees with the wages figure from the 1040-C, the exact number sometimes appears in the cost of labor field or even split across both fields. Whether this is due to taxpayer reporting error, or keying error is an open question. Since legitimate (nonpayroll) data also appears in the cost of labor field, a statistical solution was required.
Software Used for the Matching
For the matching software, we used Winkler's mf3 matcher, with match specific modifications. We used both character-by-character comparisons and one of the native string comparators. For the numeric comparison on the payroll variable, we developed a new module, about which we will go into in some detail.
The EIN records from the SSEL were extracted and “prepped,” forming a “stationary” file of 351,141 records. The 1040-C files were preprocessed and matched in 36 separated cuts of roughly 750,000 records (each).
Blocking Criteria
The blocking criteria, defined as the minimum characteristics necessary to consider a pair of records in the match, were the first six letters of the last name and the first letter of the first name. We originally explored the possibility of blocking by ZIP code but abandoned this when we realized the scope of the problem in business versus home addresses.
Matching Variables and Weights
The fit between any pair of records is determined by the sum of the weights of the match variables. We assign positive weights for agreement and negative weights for nonagreement. Below, in Table 1, is a list of the match variables, along with their positive and negative weights. A record from the 1040-C file is considered a match to a record from the SSEL file when the pair's match score (sum of weights) exceeds 15.15.
The match variables fall into three groups: Name, Location, and Business. This suggests the general strategy we employed for determining the weights. The role of the Name group was to further (beyond blocking) qualify pairs—a failure on more than one of the name variables here should disqualify a record. The other two groups were weighted to balance one another—a weak score on Location required a strong score on Business and vice versa, with Business given slight precedence over Location.
Table 1. —Match Variables by Weights
|
Group |
Description |
Positive Weight |
Negative Weight |
|
Name |
last name |
5.01 |
-8.11 |
|
first name remainder |
5.01 |
-7.82 |
|
|
middle initial |
3.00 |
-8.06 |
|
|
middle name remainder |
2.18 |
-0.01 |
|
|
Location |
city |
3.04 |
-0.00 |
|
state |
0.00 |
-6.31 |
|
|
5 digit zip code |
3.04 |
-0.00 |
|
|
first 3 digits of zip |
3.04 |
-0.00 |
|
|
first 2 digits of zip |
3.00 |
-2.00 |
|
|
Business |
entire SIC |
3.06 |
-0.00 |
|
first 2 digits of SIC |
3.00 |
-3.00 |
The annual payroll variable was handled somewhat differently when determining weights. The payroll variable looks at the ratio of 1040-C payroll (wages+cost of labor, combined in the prep phase) + 5,000 to SSEL payroll + 5,000. Calling this ratio R, weights were assigned based on the interval in which R fell (see Table 2). The factor of 5,000 keeps a small absolute difference of say 1,000 (possibly a rounding error) from making R too large or too small.
Table 2. —Weights for Payroll Variables
|
Range |
Weight |
||
|
0.00 |
< R |
< = 0.64 |
-7.00 |
|
0.64 |
< R |
< = 0.87 |
0.00 |
|
0.87 |
< R |
< = 0.93 |
4.50 |
|
0.93 |
< R |
<= 1.05 |
7.50 |
|
1.05 |
< R |
<= 1.13 |
4.50 |
|
1.13 |
< R |
< = 2.25 |
0.00 |
|
2.25 |
< R |
-7.00 |
|
How the Model for Relating the Payroll Variables was Determined
We constructed two files to test competing models for the payroll comparison. A file of randomly joined payrolls from a known sole proprietors file and a sample file of 1040-Cs was created (random set). Both payrolls were taken from an EIN linked file of sole proprietors to create the second file (truth set). Next, we tested three models as shown below.
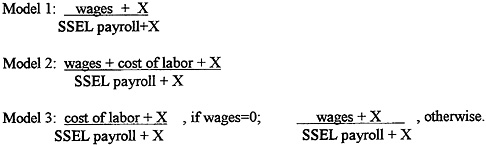
The discriminating power of the variable must contrast the behavior over the truth set against its behavior on the random set. The addition of a term to top and bottom of the ratio pulls the distributions toward 1. In fact, the distribution centralizes faster on the truth set than it does on the random set.
The criteria for selection was to select the model that produced the most ratios near 1 and the fewest ratios at the extremes on the truth set, and simultaneously produced the fewest ratios near 1 and the most at the extremes on the random set. Models 2 and 3 were clearly better than Model 1, Model 3 slightly better than Model 2. Model 3 was a later invention and did not make it into production. For the selected model, value of X = 5,000, and the four most critical conditions, we have:
P(strong agree|match) = 53.05
P(strong agree|nonmatch) = 0.4
P(disagree|match) = 12.3
P(disagree|nonmatch) = 88.8.
Match Results
The Parser
The parser behaved very differently on the two files. The 1040-C name field is highly structured, generally well keyed, and contains no legitimate business names. The SSEL name field may have a sole proprietor 's personal or business name, or it may have the name of a corporation or partnership—this latter group a contribution from the unknown LFO. The personal names include more abbreviations and are less structured.
Looking at the results of the parser on the 1040-C file (excluding schedules linked to the SSEL), we see that 23,670 of 14,894,578 (0.16 percent) schedules failed to parse and were not included in the match. Almost all failures were due to complicated name structures. About 10.6 million records with duplicate identifiers were created from joint returns—i.e., roughly 10 duplicates for every 14 schedules. With duplicates, the prepped 1040-C file had 25,429,164 records.
From a test of confirmed sole proprietors (of about 19,000 records) we know that the parser succeeds about 97.4 percent of the time. The unparsed SSEL file, which included records with LFO unknown, had 419,494 records—332,441 of which parsed. Using the known rate we can deduce that the unparsed file contained about 341,315 sole proprietors (virtually none of the non-sole-proprietors parse). Hence, we have an estimated 8,874 sole proprietor establishments whose name failed to parse, and, consequently, were not included in the match. Roughly 25 percent of failures were due to unrecognized name patterns, the re-
mainder were recognized as business names. We can infer from this that sole proprietors use a business name on the SSEL rather than their personal name about 1.9 percent of the time. This is computed by (8,874)(.75)/341,315. In the matter of duplication, in contrast to the 1040-C file, only about 5.6 percent of the parsable names on the SSEL file generate duplicates.
Unduplication
There were several varieties of duplicates among the files produced by the match. In all cases, the pair with the highest match score was designated to be the match. In the event of a tie, the first pair was taken or both discarded depending on the type of duplication. Unduplication proceeded first by EIN then by SSN/Schedule Number.
Over half the duplication was caused by duplicates created in the name parse. In effect, the matcher picks two best candidate for these records. Ties frequently occurred where husband and wife appeared in the name field of both records. For duplicates fitting this pattern, both candidates having the same EIN and the same SSN, the pair with the highest match strength. In event of a tie, the first record was taken.
When pairs were presented with the same EIN and different SSNs, the highest match strength was taken. In the event of a tie, no match was made for that EIN. Family businesses seemed to be the main cause for ties. The file of ties has been retained for further study.
After the EIN side was resolved, the file was resorted to look for instances of the same Schedule C attempting to match more than one EIN record. This occurred almost exactly 1 percent of the time. Again, if the matcher rated one pair higher than all others, this pair was designated a match. Otherwise, although rarely, the first instance of the tied match strength was taken. An examination of the file of duplicates and winners revealed the following common pattern. Husband and wife had distinct businesses on the SSEL, each under their individual names. In theory each business should correspond to a distinct schedule, but for some reason one of the businesses did not fit any of the schedules. If the 1040-C had only one schedule the same error would occur.
Table 3 gives the unduplication by type and the final number of designated matches.
Table 3. —Unduplication of Matches
|
Unduplication Type |
No. of Records |
|
Match pairs before unduplication |
156,836 |
|
EIN unduplication (records dropped): |
|
|
Same EIN, same SSN, same schedule no. |
5,211 |
|
Same EIN, same SSN, diff. sched. no. |
100 |
|
Same EIN, diff. SSN, same match strength |
506 |
|
SSN Unduplication (records dropped): |
|
|
Same SSN, diff. EIN, same schedule |
156 |
|
Match pairs after unduplication |
148,679 |
Match Error Rates
Modeling the Error
Our approach to error estimation is to study a population, similar to the match population, where the link between pairs has already been established. From a 1 in 50 master sample of the original 1040-C file, we identified 18,595 records that reported an EIN on the 1040-C, are known matches to a record on the SSEL, and meet the following conditions:
-
the EIN was valid;
-
the EIN was reported on only 1 schedule;
-
the EIN record had a sole proprietorship LFO compatible with a 1040-C filing;
-
the pair passed a mild payroll/receipts edit;
-
the name field on the EIN record was parsable; and
-
the EIN had positive 1992 payroll on the SSEL,
The count of the 1 in 50 sample that parsed, and including the 18,595 links based on a reported EIN, was 559,514 records. This set of record was used to model two situations: first, where there existed a 1040-C that ought to be linked to the SSEL record (“matchable”); and second, where no record should be linked to an SSEL record (“unmatchable”). By including or excluding the 18,595 linked 1040-C records, and always retaining the linked SSEL records, we modeled both conditions.
False Match Rate for “Matchable” Records
A match was performed with the 559,514 parsed 1040-C records against approximately 361,000 parsed SSEL records. The 1040-C file contained 18,595 linked records, the remaining 540,919 were used to represent the 25,429,164 parsed 1040-C records, giving each a weight of 47. The results of the match on the known links are shown in Table 4, below.
Table 4. —Matches of Linked Records
|
Condition |
No. of Records |
|
True matches |
16,364 |
|
Type A false matches |
100 |
|
Type B false matches |
1 |
|
False nonmatches |
2,130 |
|
Total |
18,595 |
The type A false matches involved a correct linkage between EIN and SSN, but with the incorrect schedule number. This can only happen within the sample of 559,514, since the sample was based on SSN and every (prior) linked SSN had all schedules present for the match. Thus, type A false matches represent only themselves. The type B false match involved an incorrect linkage between EIN and SSN, and the one occurrence represents approximately 47 others. Since the event is so rare, we calculated an upper bound and used it in subsequent calculations.
The apparent rate is so low, 1 in 540,919, that we are required to estimate from the binomial probabilities—the normal approximation does not apply and the Poisson approximation is poorest near the mean, where our estimation occurs. We observe that for any p>4.6/540,919 the probability of getting only 1 occurrence is less than
(540,919) (.0000085) (1-.0000085)540,919 » 05;
i.e., if the number of type B false matches were greater than 216 (i.e., 4.6 × 47) across all 25.5 million records, we would have less than a 5 percent chance of getting 1 occurrence in our sample. The question then arises how to distribute the additional 215 estimated false matches between converted true matches and converted false nonmatches. We assume a range on the match score of a false match from 15.15 to 20.51, where 20.51 was the highest false match score observed during all testing. This range contains 1456 of the true matches—those which are in a range where it is fairly believable that they can be supplanted by a false match. Assuming an even distribution between these and the false nonmatch set, the additional false matches should be allocated by the proportion 1456:2130 or 87:128; i.e., we will take 87 from the true match count and 128 from the false nonmatch count. In Table 5, we estimate the results if we were to run against the whole 1040-C file.
Table 5. —Estimated Matches for 1040C File
|
Condition |
Frequency |
Percent of File |
|
True match |
16,277 |
87.5 |
|
Type A false match |
100 |
.5 |
|
Type B false match |
216 |
1.2 |
|
False nonmatch |
2,002 |
10.8 |
False Match Rate for “Unmatchable” Records
We reran the match excluding the 1040-Cs belonging to the truth set. Four matches were produced, linking a SSEL truth record to a 1040-C when the true 1040-C was suppressed. We can only have (type B) false matches and true nonmatches on this set. The highest match strength among the 4 was 20.5. Again resorting to the binomial calculation, we estimate the upper bound for the number of false matches in a hypothetical run of the whole file to be 390. That is a false match rate of 2.1 percent on “unmatchable” records.
Error Estimation
We are now in a position to recover the composition of the original SSEL file. Let x be the number of “matchable” records and y be the number of “unmatchable” records. Then, using upper bounds and adding the type A and B false match rates, 5% + 1.2% = 1.7%, we must solve:
(.875+.017)x + 021y = 148,679
x + y = 332,443;
i.e., x = 162,684, and y = 169,759. From this we computed the upper estimate of the false match rate to be 4.3% as indicated below.
(.017×162,684 + 021×169,759)/148,679 = 043.
This is an upper bound only. A similar calculation on the point estimate gives an error rate of less than 2 percent.
Conclusion
What was the impact of our matching efforts in the context of the overall task of linking SSEL payroll records of sole proprietors with their 1040-C tax return? For the 1992 tax year, about 1.37 million sole proprietors had their 1040-C tax return linked to their payroll records on the SSEL. The breakdown by source of linkage is given in Table 6.
Table 6. —SSEL-IRS Linkages by Source
|
Source |
Linked Cases |
|
An EIN reported on 1040-C |
71% |
|
Use of the EIN-SSN x-ref file |
15% |
|
Use of the x-ref file & matching |
4% |
|
Matching on name, address, etc. |
10% |
After all attempts at linking, we still have about 200,000 inscope sole proprietors on the SSEL for which we could not post receipts. Of these, we estimate that about 170,000 had no 1040-C on the file we used. We believe this may be due to non-filing of the 1040-Cs because of extensions or other late filings. We estimate that about 6,000 were linked but failed to have receipts posted because they failed a payroll to receipts edit. About 9,000 failed to match due to parse failures. We have estimated (above) that there are about 15,000 false nonmatches—i.e., a 1040-C was on the file but the matching program failed to link to it.
The linkage for the 1992 censuses were much more complete than for the 1987 censuses, since in 1987 we used only the reported EIN on the 1040-C for linking purposes. The EIN-SSN x-ref file from IRS provided substantial additional links, and has been improved in subsequent years. These were nearly equaled by our matching. Moreover the additional links continue to contribute to the completeness of the SSEL in subsequent years. A check in 1997 showed 115,000 of the 148,000 still reside on the SSEL, though some portion of these may have reported an EIN or otherwise been linked during the intervening years. This is consistent with a 10–12 percent death process for small sole proprietors. Overall, the matching operations were quite efficient, and added significantly to the quality of the 1992 censuses.
Reference
Konschnik, C.; Black, J.; Moore, R.; and Steel, P. ( 1993). An Evaluation of Taxpayer-Assigned Principal Business Activity (PBA) Codes on the 1987 Internal Revenue Service (IRS) Form 1040, Schedule C, Proceedings of the International Conference on Establishment Surveys , American Statistical Association, 745–750.
Bibliography
Cochran, W.G. ( 1977). Sampling Techniques, Third edition, New York: J.Wiley.
Fellegi, I.P. and Sunter, A.B. ( 1969). A Theory for Record Linkage, Journal of the American Statistical Association,
Winkler, W.E. ( 1992). Comparative Analysis of Record Linkage Decision Rules, Proceedings of the Section on Survey Research Methods, American Statistical Association, 829–833.
Winkler, W.E. ( 1995). Matching and Record Linkage, in B.G.Cox (Ed.), Business Survey Methods, New York: J.Wiley, 355–384 (also in this volume).
Note: A version of this paper appears in the 1994 ASA Proceedings as: Administrative Record Matching for the 1992 Economic Census.
Approximate String Comparison and its Effect on an Advanced Record Linkage System
Edward H.Porter and William E.Winkler, Bureau of the Census
Abstract
Record linkage, sometimes referred to as information retrieval (Frakes and Baeza-Yates, 1992) is needed for the creation, unduplication, and-maintenance of name and address lists. This paper describes string comparators and their effect in a production matching system. Because many lists have typographical errors in more than 20 percent of first names and also in last names, effective methods for dealing with typographical error can greatly improve matching efficacy. The enhanced methods of approximate string comparison deals with typographical variations and scanning errors. The values returned by the string comparator are used in a statistical model for adjusting parameters that are automatically estimated by an expectation-maximization algorithm for latent class, log linear models of the type arising in the Fellegi-Sunter model of record linkage (1969). Overall matching efficacy is further improved by linear assignment algorithm that forces 1–1 matching.
Introduction
Modern record linkage represents a collection of methods from three different disciplines: computer science, statistics, and operations research. While the foundations are from statistics, beginning with the seminal work of Newcombe (Newcombe et al., 1959, also Newcombe, 1988) and Fellegi and Sunter (1969) the means of implementing the methods have primarily involved computer science. Record linkage begins with highly evolved software for parsing and standardizing names and addresses that are used in the matching. Name standardization identifies components such as first names, last names (surnames), titles, and middle initials. Address standardization locates components such as house numbers, street names, PO Boxes, apartment numbers, and rural routes. With good standardization, effective comparison of corresponding components of information and the advanced methods described in this paper become possible.
Because pairs of strings often exhibit typographical variation (e.g., Smith versus Smoth), the record linkage needs effective string comparator functions that deal with typographical variations. While approximate string comparison has been a subject of research in computer science for many years (see survey article by Hall and Dowling, 1980), some of the most effective ideas in the record linkage context were introduced by Jaro (1989) (see also Winkler, 1985, 1990). Budzinsky (1991), in an extensive review of twenty string comparison methods, concluded that the original Jaro method, the extended method due to Winkler (1990) and a widely used computer science method called bigrams worked well. This paper describes two new enhancements to the string comparators used at the Census Bureau. The first, due to McLaughlin (1993), adds logic for dealing with scanning errors (e.g., “I” versus “1”) and certain common keypunch errors (e.g., “V” versus “B”). The second due to Lynch and Winkler (1994) makes adjustments
for pairs of long strings having a high proportion of characters in common. We also describe the method of computing bigrams and present results comparing them with the other string comparators of this paper.
Our record linkage system uses the Expectation-Maximization (EM) algorithm (Dempster, Laird, and Rubin, 1977) to estimate optimal matching parameters. We use a linear sum assignment procedure (Isap) to force 1–1 matching. Jaro (1989) introduced the Isap as a highly effective means of eliminating many pairs that ordinarily might be clerically reviewed. With a household data source containing multiple individuals in a household, it effectively keeps the four pairs associated with father-father, mother-mother, son-son, and daughter-daughter pairs while eliminating the remaining twelve pairs associated with the household.
The next section describes the string comparator. In the third section, we provide a summary of the parameters that are obtained via the EM algorithm. The results of section four provide empirical examples of how matching efficacy is improved for three, small pairs of high quality lists. The final section consists of a summary and conclusion.
Approximate String Comparison
Dealing with typographical error can be vitally important in a record linkage context. If comparisons of pairs of strings are only done in an exact character-by-character manner, then many matches may be lost. An extreme example is the Post Enumeration Survey (PES) (Winkler and Thibaudeau, 1991; also Jaro, 1989) in which, among true matches, almost 20 percent of last names and 25 percent of first names disagreed character-by-character. If matching had been performed on a character-by-character basis, then more than 30 percent of matches would have been missed by computer algorithms that were intended to delineate matches automatically. In such a situation, required manual review and (possibly) matching error would have greatly increased.
Jaro (1989) introduced a string comparator that accounts for insertions, deletions, and transpositions. In a small study, Winkler (1985) showed that the Jaro comparator worked better than some others from computer science. In a large study, Budzinsky (1991) concluded that the comparators due to Jaro and Winkler (1990) were the best among twenty in the computer science literature. The basic Jaro algorithm is: compute the string lengths, find the number of common characters in the two strings, and find the number of transpositions. The definition of common is that the agreeing character must be within 1/2 the length of the shorter string. The definition of transposition is that the character from one string is out of order with the corresponding common character from the other string. The string comparator value (rescaled for consistency with the practice in computer science) is:
jaro(s1,s2) = 1/3(#common/str_len1 + #common/str_len2 +
0.5 #transpositions/#common), (1)
where s1 and s2 are the strings with lengths str_len1 and str_len2, respectively.
The new string comparator algorithm begins with the basic Jaro algorithm and then proceeds to three additional loops corresponding to the enhancements. Each enhancement makes use of information that is obtained from the loops prior to it.
The first enhancement due to McLaughlin (1993) assigns value 0.3 to each disagreeing but similar character. Each exact agreement gets value 1.0 and all exact agreements are located prior to searching for similar characters. Similar characters might occur because of scanning errors (“1” versus “1”) or keypunch (“V” versus “B”). The number of common characters (#common) in equation (1) gets increased by 0.3 for
each similar character, is denoted by #similar, and #similar is substituted for #common in the first two components of equation (1).
The second enhancement due to Winkler (1990) gives increased value to agreement on the beginning characters of a string. It was based on ideas from a very large empirical study by Pollock and Zamora (1984) for the Chemical Abstracts Service. The study showed that the fewest errors typically occur at the beginning of a string and the error rates by character position increase monotonically as the position moves to the right. The enhancement basically consisted of adjusting the string comparator value upward by a fixed amount if the first four characters agreed; by lesser amounts if the first three, two, or one characters agreed. The string comparator examined by Budzinsky (1991) consisted of the Jaro comparator with only the Winkler enhancement.
The final enhancement due to Lynch and Winkler (1994) adjusts the string comparator value if the strings are longer than six characters and more than half the characters beyond the first four agree. The final enhancement was based on detailed comparisons between versions of the comparator. The comparisons involved tens of thousands of pairs of last names, first names, and street names that did not agree on a character-by-character basis but were associated with truly matching records.
A common string comparison methodology is comparing the bigrams that two strings have in common. A bigram is two consecutive letters with a string. Hence the word “bigram” contains the bigrams “bi,” “ig,” “gr,” “ra,” and “am.” The bigram function also returns a value between 0 and 1. The return value is the total number of bigrams that are in common divided by the average number of bigrams in the two strings. Bigrams are known to be a very effective, simply programmed means of dealing with minor typographical errors. They are widely used by computer scientists working in information retrieval (Frakes and Baeza-Yates, 1992).
Table 1 illustrates the effect of the new enhanced comparators on last names, first names, and street names, respectively. To make the value returned by bigram weighting function more comparable to the other string comparators, we make a functional adjustment. If x is the value returned by the bigram weighting function, we use f(x) = x0.2435 if x is greater than 0.8 and 0.0 otherwise. If each string in a pair is less than four characters, then the Jaro and Winkler comparators return the value zero. The Jaro and Winkler comparator values are produced by the loop from the main production software (e.g., Winkler and Thibaudeau 1991) which is only entered if the two strings do not agree character-by-character. The return value of zero is justified because if each of the strings has three or less characters, then they necessarily disagree on at least one.
In record linkage situations, the string comparator value is used in adjusting the matching weight associated with the comparison downward from the agreement weight toward the disagreement weight. Using crude statistical modeling techniques, Winkler (1990) developed downweighting functions for last names, first names, street names, and some numerical comparisons that generalized the original down-weighting function introduced by Jaro.
Table 1. —Comparison of String Comparators Using Last Names, First Names, and Street Names
|
Two Strings |
Jaro |
String Comparator Values |
||||
|
Wink |
McLa |
Lynch |
Bigram |
|||
|
SHACKLEFORD |
SHACKELFORD |
0.970 |
0.982 |
0.982 |
0.989 |
0.925 |
|
DUNNINGHAM |
CUNNIGHAM |
0.896 |
0.896 |
0.896 |
0.931 |
0.917 |
|
NICHLESON |
NICHULSON |
0.926 |
0.956 |
0.969 |
0.977 |
0.906 |
|
JONES |
JOHNSON |
0.790 |
0.832 |
0.860 |
0.874 |
0.000 |
|
MASSEY |
MASSIE |
0.889 |
0.933 |
0.953 |
0.953 |
0.845 |
|
ABROMS |
ABRAMS |
0.889 |
0.922 |
0.946 |
0.952 |
0.906 |
|
HARDIN |
MARTINEZ |
0.000 |
0.000 |
0.000 |
0.000 |
0.000 |
|
ITMAN |
SMITH |
0.000 |
0.000 |
0.000 |
0.000 |
0.000 |
|
JERALDINE |
GERALDINE |
0.926 |
0.926 |
0.948 |
0.966 |
0.972 |
|
MARHTA |
MARTHA |
0.944 |
0.961 |
0.961 |
0.971 |
0.845 |
|
MICHELLE |
MICHAEL |
0.869 |
0.921 |
0.938 |
0.944 |
0.845 |
|
JULIES |
JULIUS |
0.889 |
0.933 |
0.953 |
0.953 |
0.906 |
|
TANYA |
TONYA |
0.867 |
0.880 |
0.916 |
0.933 |
0.883 |
|
DWAYNE |
DUANE |
0.822 |
0.840 |
0.873 |
0.896 |
0.000 |
|
SEAN |
SUSAN |
0.783 |
0.805 |
0.845 |
0.845 |
0.800 |
|
JON |
JOHN |
0.917 |
0.933 |
0.933 |
0.933 |
0.847 |
|
JON |
JAN |
0.000 |
0.000 |
0.860 |
0.860 |
0.000 |
|
BROOKHAVEN |
BRROKHAVEN |
0.933 |
0.947 |
0.947 |
0.964 |
0.975 |
|
BROOK HALLOW |
BROOK HLLW |
0.944 |
0.967 |
0.967 |
0.977 |
0.906 |
|
DECATUR |
DECATIR |
0.905 |
0.943 |
0.960 |
0.965 |
0.921 |
|
FITZRUREITER |
FITZENREITER |
0.856 |
0.913 |
0.923 |
0.945 |
0.932 |
|
HIGBEE |
HIGHEE |
0.889 |
0.922 |
0.922 |
0.932 |
0.906 |
|
HIGBEE |
HIGVEE |
0.889 |
0.922 |
0.946 |
0.952 |
0.906 |
|
LACURA |
LOCURA |
0.889 |
0.900 |
0.930 |
0.947 |
0.845 |
|
IOWA |
IONA |
0.833 |
0.867 |
0.867 |
0.867 |
0.906 |
|
1ST |
IST |
0.000 |
0.000 |
0.844 |
0.844 |
0.947 |
Data and Matching Weights—Parameters
In this section, we describe the fields and the associated matching weights that are used in the record linkage decision rule. We do not give details of the EM algorithm or the assignment algorithm because they have been given elsewhere (Winkler, 1994).
The fields used in the creation of mailing list during the 1995 test census are first name, last name (surname), sex, month of birth, day of birth, year of birth, race, and Hispanic origin. The census file is linked with an update file. These update files have been either IRS, driver's license, or school records. Only fields whose housing unit identifier agreed are compared in the first pass. The housing unit identifiers were calculated by the Census Bureau's geography division's address standardization software. It consists of a State Code, County Code, TIGER Line ID (e.g., a city block), Side ID (right or left), house number,
and apartment number. In the 1995 test census of Oakland, California 95.0 percent of the records file were geocoded with housing unit identifier. Also, 94.7 percemt of the IRS file records for the corresponding area were geocoded with housing unit identifier. The names were standardized at a 95.2 percent rate in the test census file and 99.0 percent rate in the IRS file.
Each parameter was assigned an agreement and disagreement weight. (See Table 2.) Certain parameters such as first name are assigned a higher agreement weight. Since matching was done within a household, surname carried had less distinguishing power than first name. After initial trial runs and research of the output, the expectation-maximization software (EM) was run to produce the parameters for the test.
Table 2. —Parameters Used in Matching for the 1995 Test Census of Oakland, California
|
Parameter |
Agreement Weight |
Disagreement Weight |
|
first |
4.3385 |
-2.7119 |
|
last(surname) |
2.4189 |
-2.5915 |
|
sex |
0.7365 |
-3.1163 |
|
month |
2.6252 |
-3.8535 |
|
day |
3.5206 |
-2.9652 |
|
year |
1.7715 |
-4.1745 |
|
Hispanic |
0.2291 |
-0.3029 |
|
race |
0.5499 |
-0.5996 |
String comparators were only used with first names and surnames. For example, if the first names were Martha and Marhta. The matching weight would be computed as follows:
|
Jaro |
Wink |
McLa |
Lynch |
|
|
Comparator Value |
0.944 |
0.961 |
0.961 |
0.971 |
|
Matching Weight |
3.943 |
4.063 |
4.063 |
4.134 |
The piecewise linear function that uses the value returned by the different string comparators to adjust the matching agreement weight downward is detailed in Winkler (1990).
Results
Results are presented in two parts. In each part, the different string comparators are substituted in the string comparison subroutine of an overall matching system. The matching weights returned by the EM algorithm are held constant. Two different versions of a linear sum assignment procedure are used. For the description of the Isap, see Winkler (1994). The main empirical data consists of three pairs of files having known matching status. In the first part, we show how much the string comparators can improve the matching results. The second part provides an overall comparison of matching methods that utilize various combinations of the new and old string comparators and the new and old assignment algorithms.
Exact Matching Versus String Comparator Enhanced Matching
In Table 3, we illustrate how much string comparators improve matching in comparison with exact matching. After ordering pairs by decreasing matching weight in the first and third of the empirical data files, we plot the proportion of false matches against the total number of pairs. We see that, if matching is adjusted for bigrams and the string comparators, then error rates error rates are much lower than those obtained when exact matching is used. Since exact matching is not competitive, remaining results are only presented when string comparators are used.
Table 3. —Matching Results at Different Error Rates: First Pair of Files with 4,539 and 4,859 Records 38,795 Pairs Agreeing on Block and First Character of Last Name
|
Link Error Rate |
Link Match/Nonm |
Clerical Match/Nonm |
|
0.002 |
||
|
base |
3172/6 |
242/64 |
|
s_ c |
3176/6 |
236/64 |
|
as |
3176/6 |
234/64 |
|
os_l |
3174/6 |
242/64 |
|
bigram |
3224/ 7 |
174/63 |
|
0.005 |
||
|
base |
3363/17 |
51/53 |
|
s_c |
3357/17 |
55/53 |
|
as |
3357/17 |
53/53 |
|
os_l |
3364/17 |
52/53 |
|
bigram |
3327/17 |
71/53 |
|
0.010 |
||
|
base |
3401/34 |
13/36 |
|
s_c |
3396/34 |
16/36 |
|
as |
3396/34 |
14/36 |
|
os_l |
3402/34 |
14/36 |
|
bigram |
3376/34 |
22/36 |
|
0.020 |
||
|
base |
3414/70 |
0/0 |
|
s_c |
3411/70 |
0/0 |
|
as |
3410/70 |
0/0 |
|
os_l |
3416/70 |
0/0 |
|
bigram |
3398/70 |
0/0 |
Overall Comparison of Matching Methods
The baseline matching is done under 3-class, latent class models under the conditional independence assumption. The 3-class models are essentially the same ones used in Winkler (1994). In Table 4, results are reported for error rates of 0.002, 0.005, 0.01, and 0.02, respectively. Link, Nonlink, and Clerical (or Possible Link) are the computer designations, respectively. Match and Nonmatch are the true statuses, respectively. The baseline results (designated by base) are produced using the existing Isap algorithm and the previous string comparator (see e.g., Winkler, 1990) but use the newer, 3-class EM procedures for parameter estimation (Winkler, 1994). The results with the new string comparator (designated s_c) are produced with the existing string comparator replaced by the new one. The results with the new assignment algorithm (designated as) use both the new string comparator and the new assignment algorithm. For comparison, results produced using the previous string comparator but with the new assignment algorithm (designated by os_l) are also given. Finally, results using the bigram adjustments are denoted by bigram.
Table 4. —Matching Results at Different Error Rates: Second Pair of Files with 5,022 and 5,212 Records 37,327 Pairs Agreeing on Block and First Character of Last Name
|
Link Error Rate |
Link Match/Nonm |
Clerical Match/Nonm |
|
0.002 |
||
|
base |
3475/7 |
63/65 |
|
s _c |
3414/7 |
127/65 |
|
as |
3414/7 |
127/65 |
|
os_l |
3477/7 |
63/65 |
|
bigram |
3090/7 |
461/66 |
|
0.005 |
||
|
base |
3503/18 |
35/54 |
|
s_c |
3493/18 |
48/54 |
|
as |
3493/18 |
48/54 |
|
os_l |
3505/18 |
36/54 |
|
bigram |
3509/18 |
42/55 |
|
0.010 |
||
|
base |
3525/36 |
13/36 |
|
s _c |
3526/36 |
15/36 |
|
as |
3526/36 |
15/36 |
|
os_l |
3527/36 |
14/36 |
|
bigram |
3543/36 |
8/73 |
|
0.020 |
||
|
base |
3538/72 |
0/0 |
|
s_c |
3541/72 |
0/0 |
|
as |
3541/72 |
0/0 |
|
os_l |
3541/72 |
0/0 |
|
bigram |
3551/73 |
0/0 |
As Table 5 shows, matching efficacy improves if more pairs can be designated as links and nonlinks at fixed error rate levels. In Tables 3–5, computer-designated links and clerical pairs are subdivided into (true) matches and nonmatches. Only the subset of pairs produced via 1–1 assignments are considered. In producing the tables, pairs are sorted by decreasing weights. The weights vary according to the different model assumptions and string comparators used. The number of pairs above different thresholds at different link error rates (0.002, 0.005, 0.01, and 0.02) are presented. False match error rates above 2 percent are not considered because the sets of pairs above the cutoff threshold contain virtually all of the true matches from the entire set of pairs when error rates rise to slightly less than 2 percent. In each line, the proportion of nonmatches (among the sum of all pairs in the Link and Clerical columns) is 2 percent.
Table 5. —Matching Results at Different Error Rates: Third Pair of Files with 15,048 and 12,072 Records 116,305 Pairs Agreeing on Block and First Character of Last Name
|
Link Error Rate |
Link Match/Nonm |
Clerical Match/Nonm |
|
0.002 |
||
|
base |
9696/19 |
155/182 |
|
s_c |
9434/19 |
407/182 |
|
as |
9436/19 |
406/182 |
|
os_l |
9692/19 |
157/182 |
|
bigram |
9515/19 |
335/182 |
|
0.005 |
||
|
base |
9792/49 |
59/152 |
|
s_c |
9781/49 |
60/152 |
|
as |
9783/49 |
57/152 |
|
os_l |
9791/49 |
58/152 |
|
bigram |
9784/49 |
66/152 |
|
0.010 |
||
|
base |
9833/99 |
18/102 |
|
s_c |
9822/99 |
19/102 |
|
as |
9823/99 |
17/102 |
|
os_l |
9831/99 |
18/102 |
|
bigram |
9823/99 |
27/102 |
|
0.020 |
||
|
base |
9851/201 |
0/0 |
|
s_c |
9841/201 |
0/0 |
|
as |
9842/201 |
0/0 |
|
os_l |
9849/201 |
0/0 |
|
bigram |
9850/201 |
0/0 |
The results generally show that the different string comparators improve matching efficacy. In all of the best situations, error levels are very low. The new string comparator produces worse results than the previous one (see e.g., Winkler, 1990) and the new assignment algorithm (when combined with the new string comparator) performs slightly worse (between 0.1 and 0.01 percent) than the existing string com-
parator and Isap algorithm. In all situations (new or old string comparator), the new assignment algorithm slightly improves matching efficacy.
To test the effect of the Winkler variant of the Jaro string comparator and bigrams on more recent files, we use 1995 test census files from Oakland, California. (See Table 6.) The match rates were as follows. In the first matching pass, we only used pairs of records that agreed on housing unit ID. Those that were not matched were processed in a second pass. Blocking during the second pass was on house number and first character of the first name. The results generally show that either string comparator produces good results. The variant of the Jaro string comparator yields a slightly smaller clerical review region.
Table 6. —First Pass—Housing Unit Identifier Match: Matching Results of a Pair of Files with 226,713 and 153,644 Records, Respectively
|
Jaro String Comparator |
Bigram |
|||
|
Links |
Clerical |
Links |
Clerical |
|
|
78814 |
5091 |
78652 |
5888 |
|
|
Estimated false match rate |
0.1% |
30% |
0.1% |
35% |
|
Second Pass—House Number and First Character of First Name: Matching Results of a Pair of Files with 132,100 and 64,121 Records, Respectively |
||||
|
Links |
Clerical |
|||
|
16893 |
7207 |
|||
|
Estimated false match rate |
0.3% |
40% |
||
Summary and Conclusion
Application of new string comparator functions can improve matching efficacy in the files having large amounts of typographical error. Since many of the files typically have high typographical error rates, the string comparators can yield increased accuracy and reduced costs in matching of administrative lists and census.
References
Budzinsky, C. D, ( 1991). Automated Spelling Correction, Statistics Canada.
Dempster, A.P.; Laird, N.M.; and Rubin, D.B. ( 1977). Maximum Likelihood from Incomplete Data via the EM Algorithm, Journal of the Royal Statistical Society, series B, 39, 1–38.
Fellegi, I.P. and Sunter, A.B. ( 1969). A Theory for Record Linkage, Journal of the American Statistical Association, 64, 1183–1210.
Frakes, W.B. and Baeza-Yates, R. (eds.) ( 1992). Information Retrieval: Data Structures and Algorithms, Upper Saddle River, NJ: Prentice-Hall PTR.
Hall, P.A.V. and Dowling, G.R. ( 1980). Approximate String Comparison, Computing Surveys, 12, 381– 402.
Jaro, M.A. ( 1989). Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida, Journal of the American Statistical Association, 89, 414–420.
Lynch, M.P. and Winkler, W.E. ( 1994). Improved String Comparator, Technical Report, Statistical Research Division, Washington, DC: U.S. Bureau of the Census.
McLaughlin, G. ( 1993). Private Communication of C-String-Comparison Routine.
Newcombe, H.B. ( 1988). Handbook of Record Linkage: Methods for Health and Statistical Studies, Administration, and Business, Oxford: Oxford University Press.
Newcombe, H.B.; Kennedy, J.M.; Axford, S.J.; and James, A.P. ( 1959). Automatic Linkage of Vital Records, Science, 130, 954–959.
Pollock, J. and Zamora, A. ( 1984). Automatic Spelling Correction in Scientific and Scholarly Text, Communications of the ACM, 27, 358–368.
Winkler, W.E. ( 1985). Preprocessing of Lists and String Comparison, Record Linkage Techniques— 1985, W.Alvey and B.Kilss, (eds.), U.S. Internal Revenue Service, Publication 1299, 181–187.
Winkler, W.E. ( 1990). String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage, Proceedings of the Section on Survey Research Methods, American Statis tical Association, 354–359.
Winkler, W.E. ( 1994). Advanced Methods for Record Linkage, Technical Report, Statistical Research Division, Washington, DC: U.S. Bureau of the Census.
Winkler, W.E. and Thibaudeau, Y. ( 1991). An Application of the Fellegi-Sunter Model of Record Linkage to the 1990 U.S. Decennial Census, Statistical Research Division Report 91/09, Washington, DC: U.S. Bureau of the Census.
*This paper reports general results of research by Census Bureau staff. The views expressed are attributable to the authors and do not necessarily reflect those of the U.S. Bureau the Census.
































