
Chapter 7
Contributed Session on More Applications of Probabilistic Record Linkage
Chair: Jennifer Madans, National Center for Health Statistics
Authors:
Tony LaBillois, Marek Wysocki, and Frank J.Grabowiecki, Statistics Canada
Kenneth Robertson, Larry Huff, Gordon Mikkelson, Timothy Pivetz, and Alice Winkler, Bureau of Labor Statistics
Sandra Johnson, National Highway Traffic Safety Administration
Eva Miller, New Jersey Department of Education
A Comparison of Direct Match and Probabilistic Linkage in the Death Clearance of the Canadian Cancer Registry
Tony LaBillois, Marek Wysocki, and Frank J.Grabowiecki, Statistics Canada
Abstract
The Canadian Cancer Registry (CCR) is a longitudinal person-oriented database containing all the information on cancer patients and their tumours registered in Canada since 1992. The information at the national level is provided by the Provincial and Territorial Cancer Registries (PTCRs). An important aspect of the CCR is the Death Clearance Module (DCM). It is a system that is designed to use the death records from the Canadian Mortality Data Base to confirm the deaths of the CCR patients that occurred during a pre-specified period. After extensive preprocessing, the DCM uses a direct match approach to death confirm the CCR patients that had a death registration number on their record and it performs a probabilistic record linkage between the remaining CCR patients and death records. For one province, death registration numbers are not provided with the cancer patient records. All these records go directly to the probabilistic linkage. For the rest of the country, a good proportion of the cancer patients reported as dead by the PTCRs have such a number that can be used to match directly the two databases. After an overview of the CCR and its DCM, this presentation will compare the situation where the direct match is used in conjunction with the probabilistic linkage to death confirm cancer patients versus the case where the probabilistic record linkage is used alone.
Introduction
In combining two sources of data, it is sometimes possible to match directly the records that represent the same units if these two sources have one common unique identifier. Nevertheless, it is often not possible to find all the common units using only this approach, either because the two sources do not have a common unique identifier, or because, even when used, it is not complete for all the records on the files.
The case of the Death Clearance (DC) of the Canadian Cancer Registry (CCR) is an example of the latter. The purpose of this task is to associate cancer patient records with death certificate records to identify the individuals that are present on both files. The CCR already contains the death registration identifier for some patients, but not for all that may indeed be deceased. Consequently, the most reasonable process involves matching directly all the CCR patient records that have this information, and then using probabilistic record linkage in an attempt to couple the remaining records that could not directly match. It is our belief that this maximises the rate of association between the two files while reducing the processing cost and time. In this situation, one could also use probabilistic linkage, alone, to perform the same task. The intention of this study is to compare these two approaches.
Firstly, this paper provides an overview of the CCR with emphasis on the Death Clearance module. Secondly, the characteristics of the populations used in the study are described. Next, the paper explains
the comparisons between the two approaches (process, results and interpretations); and finally, it presents the conclusions of this study.
Overview of the Canadian Cancer Registry
The Canadian Cancer Registry at Statistics Canada is a dynamic database of all Canadian residents diagnosed with cancer[1] from 1992 onwards. It replaced the National Cancer Incidence Reporting System (NCIRS) as Statistics Canada's vehicle for collecting information about cancer across the country. Data are fed into the CCR by the 11 Provincial and Territorial Cancer Registries (PTCRs) that are principally responsible for the degree of coverage and the quality of the data. Unlike the NCIRS that targeted and described the number of cancers diagnosed annually, the CCR is a patient-based system that records the kind and number of primary cancers diagnosed for each person over a number of years until death. Consequently, in addition to cancer incidence, information is now available about the characteristics of patients with multiple tumours, as well as about the nature and frequency of these tumours. Very importantly, since patients' records remain active on the CCR until confirmation of their death, survival rates for various forms of cancer can now be calculated.
The CCR comprises three modules: core, internal linkage and death clearance. The core module builds and maintains the registry. It accepts and validates PTCR data submissions, and subsequently posts, updates or deletes information on the CCR data base. The internal linkage module assures that the CCR is truly a person-based file, with only one patient record for each patient diagnosed with cancer from 1992 onwards. As a consequence, it also guarantees that there is only one tumour record for each, unique, primary tumour. The internal linkage identifies and eliminates any duplicate patient records that may have been loaded onto the database as a result of name changes, subsequent diagnoses, or relocations to other communities or provinces/territories. Finally, death clearance essentially completes the information on cancer patients by furnishing the official date and cause of their death. It involves direct matching and probabilistic linking cancer patient records to death registrations at the national level.
The Death Clearance Module
Death clearance is conducted on the CCR in order to meet a certain number of objectives (Grabowiecki, 1997). Among them, it will:
-
permit the calculation of survival rates for patients diagnosed with cancer;
-
facilitate epidemiological studies using cause-of-death; and
-
help file management of the CCR and PTCRs.
The death clearance module confirms the death of patients registered on the CCR by matching/linking[2] their patient records to death registrations on the Canadian Mortality Data Base (CMDB), or to official sources of mortality information other than the CMDB. These other sources include foreign death certificates and other legal documents attesting to, or declaring death (they are added to the CMDB file before processing).
The first major input to this module is the CCR database that is built of patient and tumour records. For every person described on the CCR, there is only one patient record, but as many tumour records as there are distinct, primary cancers diagnosed for that person. Patient records contain nominal, demographic and mortality information about the person, while tumour records principally describe the characteristics of the cancer and its diagnosis. CCR death clearance uses data from the patient record augmented with some
fields from the tumour record (the tumour record describing the patient 's most recently diagnosed tumour when there is more than one). More details on the variables involved are available in Grabowiecki (1997) and Statistics Canada (1994).
The second main input is the Canadian Mortality Data Base. This file is created by Statistics Canada's Health Division from the annual National Vital Statistics File of Death Registrations, also produced by Statistics Canada. Rather than going directly to the Vital Statistics File, death clearance uses the CMDB as the principal information source about all deaths in Canada, because of improvements that make it a better tool for record linkage. A separate record exists on the CMDB for every unique reported surname on each Vital Statistics record—viz.: the deceased's surname, birth/maiden name, and each component of a hyphenated surname (e.g., Gérin-Lajoie, Gérin, and Lajoie). All of the above surnames and the Surname of the Father of the Deceased have been transformed into NYSIIS[3] codes. For details on the CMDB data fields needed for death clearing the CCR, consult Grabowiecki (1997) and Statistics Canada (1997).
Death clearance can be performed at any time on the CCR. However, the most efficient and effective moment for performing death clearance is just after the completion of the Internal Record Linkage module, that identifies and removes any duplicate patient records on the CCR data base.
The death clearance process has been divided into five steps.
-
Pre-Processing
In this phase the input data files for death clearance are verified and prepared for the subsequent processing steps. The specific years of CMDB data available to this death clearance cycle are entered into the system. Based upon these years, the cancer patient population from the CCR, and mortality records from the CMDB are selected.
-
Direct Match (DM)
The unique key to all the death registrations on the CMDB is a combination of three data fields:
-
Year of Death
-
Province (/Territory/Country) of Death
-
Death Registration Number.
These three fields are also found on the CCR patient record. PTCRs can obtain this information by doing their own death clearance, using local provincial/territorial files of death registrations. Patient records having responses for all three key fields first pass through a direct match with the CMDB in an attempt to find mortality records with identical common identifiers. If none is found, they next pass through the probabilistic record linkage phase, along with those patient records missing one or more of the key match fields. For the records that do match, five data items common to both the patient and CMDB records are compared (Sex, Day of Death, Month of Death, Year of Birth, Month of Birth). On both the CCR patient records and matched CMDB records, the responses must be non-missing and identical. If they are not, both the patient and mortality records are free to participate in the record linkage, where they may link together. Matched pairs that pass the comparison successfully are considered to represent the same person; they then will move on to the post-processing phase.
-
Probabilistic Linkage (PL)
In order to maximise the possibility of successfully linking to the CMDB file, the file of unmatched CCR patient records is exploded by creating, for every person, a separate patient record for each unique Surname, each part of a hyphenated Surname, and the Birth/Maiden Name—a process similar to the one used to create the CMDB, described in above. NYSIIS codes are generated for all names.
The two files are then passed through the Generalised Record Linkage System (GRLS), and over 20 important fields are compared using a set of 22 rules. Based on the degree of similarity found in the comparisons, weights are assigned, and the CCR-CMDB record pairs with weights above the pre-established threshold are considered to be linked. When patient records link to more than one mortality record, the pair with the highest weight is taken and the other(s) rejected. Similarly, if two or more patients link to the same CMDB record, the pair with the highest weight is selected.
The threshold weight has been set at such a level that the probability of the linked pairs describing the same person is reasonably high; consequently, manual review is not necessary in the linkage phase. At the same time, the threshold has not been positioned too high, in order to avoid discarding too many valid links, and thus reducing the effectiveness of the record linkage process.
The death information of linked CMDB records is posted onto the CCR patient records, overlaying any previously reported data in these fields. The linked pairs and unlinked CCR patient records join the matched pairs in proceeding to the post processing phase of death clearance.
-
Post-Processing
Essentially, this phase updates the CCR data base with the results from the match and linkage phases. Also, the results are communicated to the PTCRs for their review, and for input into their own data bases. Before being updated, copies are made of the patient records from the database. This makes it possible to restore them to their pre-death confirmed state should the matches/linkages be judged to be incorrect later by the PTCRs.
-
Refusal Processing
Refusals are PTCR decisions, taken after their review of the feedback reports and files generated in the post processing phase, that specific matches and linkages are incorrect—i.e., that the persons described on the CCR patient records are not the same persons to whose death registrations they matched or linked. In this step, the affected patient records have their confirmation of death reversed, and are restored to their pre-death clearance state.
A description of the entire DC Module is available in Grabowiecki (1997) and the detailed specifications of the Direct Match and Probabilistic Linkage can be found in Wysocki and LaBillois (1997).
Characteristics of the Target Populations for this Study
To perform our comparisons, a subset of the CCR population was selected that could best illustrate the effect of direct match versus probabilistic linkage. Three provinces were chosen: British Columbia, Ontario and Quebec. They were picked because they contain, within Canada, the largest populations of
cancer patients, and the size of their respective populations is in the same order of magnitude. Quebec was specifically taken because its provincial cancer registry does not do death clearance. Consequently, the patient files sent to the CCR by this registry never contain complete death information. Therefore, no cancer patient record from Quebec can obtain a confirmation of death by means of the Direct Match process; all Quebec records participate in the Probabilistic Linkage. All other provinces do their own DC, and a significant number of their records on the CCR stand a good chance of being confirmed as dead as a result of the Direct Match.
Due to the availability of data from the CCR and the CMDB at this time, we used reference years of diagnosis 1992 and 1993. The distribution by age and sex of the cancer patients in the three provinces is shown in Figure 1, below. It appears that there are only minor differences in the populations of cancer patients between these three provinces. Consequently, such differences are not expected to cause differences in the results of the death clearances.
Figure 1. —Demographic Characteristics of the Populations of Cancer Patients
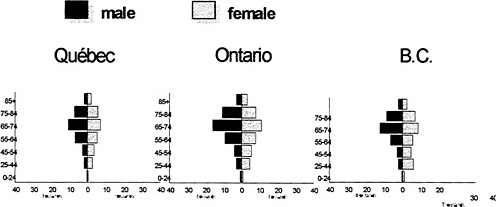
It is also important to note that the data coming from different provinces are gathered by different PTCRs. Even though there is little difference between them, in terms of coding practices, definitions and timeliness, certain variations still exist. In particular, the data sources used by the PTCRs to build their registries vary considerably among them (Gaudette et al., 1997). These considerations are taken into account in the interpretation of the results.
Direct Match and Probabilistic Linkage Vs. Only Probabilistic Linkage (Within the Same Province)
Process
This comparison is done by running the complete DC Module on the CCR data from British Columbia and Ontario. Both the DM and the PL are used to identify pairs for death confirmation. In the second run, any death information contained on the CCR records from these provinces is ignored. The system thus channels all the records directly to the PL. Quebec data are not usable for this comparison because of the
absence of complete death information on their CCR records. By comparing the two sets of pairs obtained in each approach for death confirmation, it is possible to measure different phenomena:
-
overall percentage of accepted pairs (death confirmations) for each approach;
-
percentage of pairs that are common to both approaches;
-
percentage of pairs that were present in the regular DC process (DM & PL) but not in the PL only;
-
percentage of pairs that were not present in the regular DC process (DM & PL) but were found in the PL only; and
-
computer time and cost for each approach.
These measures help to evaluate the usefulness of the Direct Match in the DC process and contrarily, the impact of not having the CCR death information previously supplied by PTCRs.
Results and Observations
The results of this process are summarised in Figure 2, below. When both a DM and PL were performed, the majority of the pairs formed (approximately 95%) came from the DM. This was the case for both of the provinces involved in this part of the study. This result emphasises the importance of high quality death information in effectively matching records on these two files. There can be no direct match unless all of the death fields are identical on the two files, and these account for all but 5% of the total of pairs created in the DM and PL process.
Figure 2. —Comparison of Ontario and British Columbia Using Both Methods
|
DC Population |
DM and PL |
PL |
|||||
|
Matched |
Linked |
Total |
% |
Total |
% |
||
|
Ont. |
84,926 |
22,648 |
1,183 |
23,831 |
28.1 |
23,670 |
27.9 |
|
B.C. |
33,103 |
8,058 |
360 |
8,418 |
25.4 |
8,367 |
25.3 |
|
Total |
118,029 |
30,706 |
1,543 |
32,249 |
27.3 |
32,037 |
27.1 |
It is evident that in terms of the number of pairs obtained in the end, one can expect little difference between the two methods of death clearance. Additionally, the particular pairs obtained (which specific patients are confirmed) will also be very similar. In this regard, there was less than a 1% difference in the two methods. Those differences that did exist tended to reflect favourably on the DM-PL method. Both methods found the same 32,035 pairs. On a net basis, the DM-PL method found 214 more pairs than did the PL only method. In percentage terms, this represented a negligible amount (again, less than 1%). Of those 214 pairs, roughly 94% were found in the direct match portion of the run; the others were found in the linkage. There were two pairs identified by the linkage-only method and not by its counterpart.
In regard to the actual cost of running the programs under the two different methods, the total for the DM-PL approach was 54% of the total cost incurred in running the PL alone. There is a certain small
amount of instability in these numbers since the cost was dependent in part on the level of activity on the mainframe computer at the time that the programs were run. However, the percentage difference in the two costs is substantial even when this is considered. The relatively high cost of the linkage-only approach is due to the fact that the usual preprocessing steps must still be done but, at the same time, the number of records that are compared in the probabilistic linkage is considerably higher than the number used in the DM-PL approach (since many patient records, and their associated death records, will have been accounted for in the DM).
A Province With Only Probabilistic Linkage Vs. Provinces With Direct Match and Probabilistic Linkage
Process
For this part, the complete death clearance system is used to process the data of the three selected provinces. It will automatically produce death confirmation pairs by using the Direct Match and the Probabilistic Linkage for British Columbia and Ontario. Simultaneously, it will only apply the Probabilistic Linkage for Quebec, because the Quebec cancer registry does not report the necessary identifiers for the Direct Match to the CCR. In comparing the death confirmation results obtained for each of the three provinces, it is possible to observe different phenomena. The first is the overall percentage of accepted pairs (death confirmations) for each province, and the possible contrast between Quebec and the two others. Another aspect to consider is the comparison of the percentage of death confirmation in Quebec versus those obtained with PL only for British Columbia and Ontario in the previous Section. It is also interesting to evaluate the impact of not having the CCR death information previously supplied by PTCRs.
Results and Observations
The results obtained from the above process are summarised in Figure 3.
Figure 3. —Ontario and British Columbia vs. Quebec, Where Only PL Was Possible
|
DC Population |
DM and PL |
PL |
|||||
|
Matched |
Linked |
Total |
% |
Total |
% |
||
|
Qué. |
57,252 |
– |
– |
– |
– |
18618 |
32.5 |
|
Ont. |
84,926 |
22,648 |
1,183 |
23,831 |
28.1 |
– |
– |
|
B.C. |
33,103 |
8,058 |
360 |
8,418 |
25.4 |
– |
– |
The percentage of pairs found from among the Quebec data is rather higher than the corresponding percentages for the other provinces. In addition, all the Quebec patient records which contained some death information were successfully linked to a mortality record during probabilistic linkage. This was not the case for all of the Ontario and BC records which contained death information; that is, there were some patients reported as deceased by Ontario and BC which neither matched or linked to a CMDB record. Overall, 32.5% of the Quebec records that were in scope were successfully linked to the death file, while 28.1% of the Ontario records and 25.4% of the BC records were matched or linked. As previously noted, the data from Quebec does not contain complete death information; it does, however, contain some records where
the patient was reported as deceased by this province. It is probable that these were hospital deaths and so it is in turn very unlikely that the corresponding patients are being mistakenly reported as deceased. In essence, these patients can be anticipated to be good candidates to be successfully linked to a death record.
More generally, some cancer patients in Quebec receive treatment entirely outside of hospitals and such patients may not then be reported to the CCR. The data from Quebec might, therefore, contain a greater proportion of more serious cancers than do the data from the other provinces used in the study. This offers a possible explanation for the higher percentages of cancer patients confirmed in Quebec compared to Ontario and B.C.
Finally, we have seen that the differences between the outcomes observed for the Ontario-BC data, using the match and linkage, and the linkage only, in terms of the total number of pairs found, were relatively minor. Again, a greater percentage of pairs were found in Quebec than in the other provinces, and possibly because of the reasons outlined above.
Conclusions
Death Clearance of the CCR using PL only can be conducted with equal effectiveness as the DM-PL approach because of the reporting of high-quality personal and cancer data by the PTCRs. The advantages of the DM-PL method include lower operating costs to perform death clearance (increased efficiency), and greater certainty with the results (minimum manual review of cancer-mortality record pairs by PTCRs).
Footnotes
[1] The cancers that are reported to the CCR include all primary, non-benign tumours (with the exception of squamous and basal cell skin cancers, having morphology codes 805 to 808 or 809 to 811, respectively), as well as primary, benign tumours of the brain and central nervous system. In the International Classification of Diseases System—9th Revision (ICD-9), the following codes are included: for benign tumours, 225.0 to 225.9; for in situ/intraepithelial/noninfiltrating/noninvasive carcinomas, 230.0 to 234.9; for uncertain and borderline malignancies, 235.0 to 239.9; and finally, for primary site malignancies, 140.0 to 195.8, 199.0, 199.1, and 200.0 to 208.9. Similarly, according to the International Classification of Diseases for Oncology—2nd Edition (ICD-O-2), the target population of cancers includes: all in situ, uncertain/borderline, and primary site malignancies (behaviour codes 1, 2, or 3), as well as benign tumours (behaviour code 0) with topography codes in the range C70.0 to C72.9 (brain and central nervous system).
[2] Matching entails finding a unique, assigned, identification number on two or more records, thus identifying them as belonging to the same person; whereas linkage concludes that two or more records probably refer to the same person because of the number of similar, personal characteristics found on them.
[3] NYSIIS (New York State Identification and Intelligence System) assigns the same codes to names that are phonetically similar. It is used to group like-sounding names and thus take into account, during record linkage, variations (and errors) in spelling—e.g., Burke and Bourque, Jensen and Jonson, Smith and Smythe.
References
Gaudette, L.; LaBillois, T.; Gao, R.-N.; and Whittaker, H. ( 1997). Quality Assurance of the Canadian Cancer Registry, Symposium 96, Nonsampling Errors, Proceedings, Ottawa, Statistics Canada.
Grabowiecki, F. ( 1997). Canadian Cancer Registry, Death Clearance Module Overview, Statistics Canada (internal document).
Statistics Canada ( 1994). Canadian Cancer Registry Data Dictionary, Health Statistics Division.
Statistics Canada ( 1997). Canadian Mortality Data Base Data Dictionary, Health Statistics Division, (preliminary version).
Wysocki, M. and LaBillois, T. ( 1997). Death Clearance Record Linkage Specifications, Household Survey Methods Division (internal document).
Note: For further information, contact: Tony LaBillois, Senior Methodologist, Household Survey Methods Division, Statistics Canada, 16-L, R.H. Coats Building, Ottawa, Ontario K1A 0T6, e-mail: labiton@statcan.ca; Marek Wysocki, Methodologist, Household Survey Methods Division, Statistics Canada, 16-L, R.H. Coats Building, Ottawa, Ontario K1A 0T6, e-mail: wysomar@statcan.ca; Frank Grabowiecki, Project Manager, Health Division, Statistics Canada, 18-H, R.H. Coats Building, Ottawa, Ontario K1A 0T6, e-mail: grabfra@statcan.ca.
Improvements in Record Linkage Processes for the Bureau of Labor Statistics' Business Establishment List
Kenneth Robertson, Larry Huff, Gordon Mikkelson, Timothy Pivetz and Alice Winkler, Bureau of Labor Statistics
Abstract
The Bureau of Labor Statistics has historically maintained a Universe Database file that contains quarterly employment and wage information for all covered employees under the Unemployment Insurance Tax system. It is used as a sampling frame for establishment surveys, and also as a research database. Each quarter approximately seven million records are collected by the States and processed for inclusion on the file. There are many data items of interest associated with this database, such as an establishment's industry, county, employment information, and total wages. Historically, this database has contained five quarters of data. These data have been linked across the five quarters both administrative codes and through a weighted match process. Recently, a project has been undertaken to expand this database so that it will include multiple years of data. Once several years of data have been linked, the database will expand as new data are obtained. This will create a new “longitudinal” establishment information database, which will be of prime interest to economic researchers of establishment creation, growth, decline, and destruction.
As one step in the creation of this new resource, research was initiated to refine the existing record linkage process. This paper will provide details of the processes used to link these data. First, we will briefly cover the processes in place on the current system. Then we will provide details of the refinements made to these processes to improve the administrative code match. These processes link nearly 95 percent of the file records. The remaining records are processed via a revised weighted match process. Information on the current state of the revised weighted match will be provided, as well as the details of work still in progress in this area.
Introduction
In preparation for the building of a new longitudinally-linked establishment database, the Bureau of Labor Statistics decided to review its current system for linking business establishments across time. Because the new database will be used to produce statistics on business births and deaths and job creation and destruction, we had to ensure that the linkage procedures used in building the database would yield the most accurate results possible. Since the current linkage system was built for different purposes than the new system, there were areas where we could potentially improve the process. This paper provides an explanation of the current linkage procedures, details of the work completed to date, and areas of research that need to be explored in the future.
Background
Quarterly Unemployment Insurance Address File
The Bureau of Labor Statistics oversees the Covered Employment and Wages, or ES-202 program, that provides a quarterly census of information on employers covered under the State Unemployment Insurance (UI) laws. These data are compiled into a data file, the Quarterly Unemployment Insurance (QUI) Address File.
The QUI file includes the following information for each active employer subject to UI coverage during the reported quarter: State UI Account Number, Establishment Reporting Unit Number (RUN), federal Employer Identification Number (EIN), four-digit Standard Industrial Classification (SIC) code, county/township codes, monthly employment during the quarter, total quarterly wages, and the establishment's name(s), address and telephone number. Known predecessor and successor relationships are also identified by UI Account Number and Establishment Reporting Unit Number (UI/RUN). These numbers are used as administrative codes for matching records from one quarter to the next. The State code, EIN, and UI/RUN allow establishments to be uniquely identified. Imputed employment and wage data are assigned specific codes to distinguish them from reported data. Codes are placed on the records to identify the type of address (i.e., physical location, mailing address, corporate headquarters, address on UI tax file, or “unknown”).
The Universe Database
The State QUI files are loaded to a database, the Universe Database (UDB), for access by users for survey sampling and research purposes. The UDB is composed primarily of data elements drawn from the QUI files. In addition, there are a few system-assigned and derived data elements, as well as information on SIC code changes merged from other sources. An important system-assigned field is the UDB Number, a unique number identifying continuous business establishments.
UDB Record Linkage
When considering the linkage of these records, the reader should understand that we are linking files which have the same structure across time. These files are linked to a new iteration of themselves each quarter. This linkage allows us to identify business establishments which may have gone out of business; establishments which remain in business for both periods; and, new establishments. The quality of the administrative codes are very good, so we expect that we correctly link most records which should be linked. We follow the administrative code match with a probability-based match. This procedure is followed to identify the small percentage of links which are missing the appropriate administrative codes.
Each quarter prior to loading the QUI files to the UDB, a matching procedure is performed to link businesses. By default, all units that do not link are identified as either new establishments or closed establishments. In order to have accurate data on business births and deaths, it is critical that the matching system accurately link establishments. The intent of the original linkage system was to minimize the number of invalid matches. Unfortunately, however, this causes some good matches to be missed. Because statistics on business births and deaths were not being produced from these linked data and only a small percentage of the total number of records was affected, this situation was acceptable.
The match system was composed of four main components. The first component identified the most obvious continuous establishments— those with the same State code-UI/RUN combination. These are establishments that from one quarter to the next did not change their UI reporting —no change of ownership, reorganization, etc. The second component matched units that States submitted with codes identifying predecessor/successor relationships. Given that State personnel have access to the information needed to determine these relationships, they are assumed to be correct.
The third component matched units based upon certain shared characteristics. Prespecified weights were assigned based on data element values that the units had in common. This weighted match routine processed the data in three steps (or blocks). All three blocks limited potential matches to those units coded in the same 4 digit SIC code and county. (The New England States also use township codes.) The first block included all units that also matched on a key constructed from the Trade Name field. This “Name Search Key” was composed of the first seven consonants of the Trade Name. The second block included all units that also matched on the first 15 positions of the Street Address field. The third block included all units that also contained identical phone numbers. Two matched units were considered a valid match when they exceeded a cutoff weight. A limitation stemming from this three-block structure is that units that had a valid relationship but had different 4 digit SIC or county codes are missed by the linkage system.
The fourth component of the matching routine attempted to capture changes that occurred within a quarter. It first linked units that had State-identified predecessor relationships already coded. It next performed a within-quarter weighted match to capture relationships not previously identified by the States. A significant restriction placed upon both parts of the within-quarter matching was that the potential predecessors had to contain zero employment in the third month of the quarter while the potential successor units had to contain zero employment in the first month of the quarter. Because of inconsistencies in reporting by some employers, valid relationships could exist that did not meet this criteria, and were not matched.
Reasons for Modifying the UDB Record Linkage Process
The UDB record linkage process effectively linked over 96 percent of all the records received each quarter. Nevertheless, because its methodology was designed to limit the number of false matches, the original linkage system may not have been the most effective at identifying all valid relationships that existed between the remaining four percent of establishments. The result was a potential under-counting of continuous businesses and over-counting of business births and deaths. It is for that reason that the research described in this paper was undertaken.
Furthermore, experience with the previous matching process had highlighted specific areas of the process that needed improvement or enhancement. Although these areas affect only the four percent of the records mentioned above, the net effect on the number of births and deaths identified could be significant.
New Approach
The matching process consists of the two major procedures described below—an administrative code match and a probability-based weighted match.
Administrative Code Match
Imputed Records
The first step in our new linkage process is to identify the imputed records (i.e., non-reporting records that are assumed to remain in business), and flag the corresponding record in the preceding quarter of the match. We then temporarily remove the imputed records from the current quarter file. Rather than assume that these units are delinquent, we attempt to identify the units that actually may have been reported under new ownership. At the end of all of the other match processes, we identify the unmatched flagged records on the past quarter file. These records have their matching imputed record restored to the current quarter file, and the link is made between them.
Within-Quarter Matches
Establishments that experience a reporting change within a quarter are generally assigned either a predecessor code or successor code pointing to another record within the same quarter. We determined that these within-quarter links were legitimate, so we included a process to find them.
Remove Breakouts and Consolidation
After the within-quarter matches were identified, we examined situations where multi-establishment reporters changed the way they reported. States encourage these reporters to supply data for each worksite. When a reporter changes from reporting all worksites on one report to supplying multiple reports, there is a possibility of failing to capture this as a non-economic event. If we were just counting records, it would look like we have a lot more establishments in the current quarter than we did in the past quarter. The reverse situation is also possible.
We were interested in identifying these links in order to exclude them in the counts as business openings or closings. The limited number of situations found were sent to a data editing routine, where the employment values were checked for reasonableness. If the match failed the edits, it was not counted as a breakout or a consolidation, and not included in counts of establishments increasing or decreasing in employment. Those cases failing the edits were still linked. However, since there is some type of economic change occurring along with the reporting change, the units failing the edits are included in counts of establishments increasing or decreasing in employment.
All Other Administrative Code Matches
The files were then linked by UI/RUN. These administrative codes linked most of the records. Additional links were identified using Predecessor and Successor codes. In general these administrative code match processes link over 96 percent of the current quarter file, depending on economic conditions.
Probability-Based Match
The probability-based weighted match process involves only the unmatched records from the administrative code match process. In this process we generally expect to match less than one-half of one percent of the current quarter records. This can also be expressed as linking less than ten percent of the current quarter residuals. While this is not a large portion of the overall records, it is still an important part
of the overall process. The more accurate we can make the overall linkage process, the more useful the database will be in identifying economic occurrences.
Theoretical Basis for Weighted Matching
The weighted match process is accomplished using the software packages AutoStan and Automatch, from Matchware Technologies Incorporated. The first is a software package used to standardize names and addresses for linking. The second package uses a record linkage methodology based on the work of Ivan P. Felligi and Alan B.Sunter. Automatch uses the frequency of occurrence of selected variable values to calculate the probability that a variable's values agree at random within a given block. The probability that the variable's values agree given that the record is a match can also be calculated by the software. These match and nonmatch probabilities form the basis of the weight assigned to the variable in the match process. The sum of these variable weights are assigned as the overall weight for a given record pair. The distribution of these summed weights, along with a manual review of selected cases, allows us to determine an appropriate region where we find mostly matches. The lower bound of this region is set as the match cutoff value. We expect that above this cutoff will be mostly good matches, and that below this cutoff will be mostly bad matches.
These theoretical constructs are the foundation of probability-based record linkage. However, the nature of the data, in combination with software, hardware, and resource limitations, sometimes requires that additional steps be taken to fine-tune this process. Fortunately, Automatch provides some capabilities in this direction. The weights assigned to a matched or nonmatched variable can be overwritten or augmented as needed. This allows the user to augment the weight of important variables, as well as to penalize certain combinations of variable values, so that a record pair will not match.
Weighted Matches
Blockings
While the UDB Record Linkage system only utilized three basic blocks (trade name, address, and phone number), the new system, using Automatch, provides the option to use as many blockings as needed to match records. Based on empirical studies using California data, we constructed 21 blocks for the new system. All blocks match on two to four data elements. Within these 21 blocks, there are three groups which block on certain data elements. The first group contains blocks that include either exact name or exact street address. The second group blocks on phone number, and the third group blocks on various other data elements, such as ZIP code and EIN.
Adjustments to Blockings
After the first few runs of Automatch, we adjusted the blockings and their probability weights to enhance their matching potential. One weight adjustment we made was to records with similar street addresses. If the street addresses contained different suite numbers, we reduced the weight. Similarly, we reduced the weight if primary names contained different unit numbers. If one data element was unknown or blank, we increased the weight because these data elements did not necessarily disagree. However, if both data elements were unknown or blank, we deducted weight because there was a greater possibility that they would disagree. Finally, we deducted weight if both records were part of a multi-establishment employer.
We also made adjustments based on the address types. Some accountants submit data for many companies. Therefore, more than one record could have the same accountant's address and telephone
number. If two records contained the same physical location address, they were considered a good match and we gave them more weight. If one record contained a physical location address and the other record contained an unknown or tax address, it is possible that it would be a good match, so we gave it slightly more weight.
Subjective Results and Cutoffs
Although these records contained some common data elements, frequently it was difficult for us to decide whether the records were good matches. We subjectively identified matches as being “good,” “bad,” or “questionable.” We reviewed these data to determine the quality of each matched pair. Then we set the cutoff weights for each of the 21 blocks, approximately in the middle of the questionable records.
Results
California data files were linked forward from the first quarter of 1994 (1/94) through the first quarter of 1995 (1/95). We evaluated the matches resulting from the final two quarters (4/94 to 1/95). These results are shown in Tables 1 though 4. Additionally, two quarters of data were matched for three other States—West Virginia, Georgia, and Florida—using preliminary match parameters developed for California. The results were evaluated by the four analysts using the same rules used in evaluating the California results. Although the results are not tabulated, they are approximately equivalent to those obtained for California. This finding is significant since there are insufficient resources to manually review cases which fall close to the match cutoff parameter. It is, therefore, important that we find match cutoff parameters for each block which produce satisfactory results in all States.
Number of Units Matched
Table 1 provides a summary of the matches in California which were obtained from the current matching procedures and the new procedures as tested. Both procedures produce the same number of matches on administrative number identifiers (79.58% of the file matched on UI/RUN). The first improvement in the matching process appears among those “delinquent ” reporters which are assumed to remain in business. In the new procedures being tested, these imputed records are not generated until after all other matching processes are completed. The rationale for this change is that these non-reporting records may represent administrative business changes such as a change in ownership and may be reporting with a new UI/RUN. These units were matched with new UI/RUNs in 342 cases in California (0.04 percent of the file). These cases represent Type II errors (erroneous matches) for the previous matching process. The remaining 154,143 delinquent reporters were later matched to a new imputed record, as in current procedures.
The second improvement in the matching process appears in the within-quarter administrative match. These within-quarter matches represent units which have undergone some administrative change such as a change in ownership in a quarter and appear twice in the quarter with different UI/RUNs. It has become apparent during study of these files over several years that these units do not always cease reporting in one month during the quarter and begin reporting as a new entity in the next month of the quarter. The previous match procedures restricted these within-quarter matches to those reporters which report in a very precise manner. The new procedures allow for some reporting discrepancies in the monthly employment in matching these cases. The new procedures obtained approximately 1,110 (0.12%) additional matches for these situations.
Table 1. —Results: Match Comparison for CA 95 Qtr. 1
Finally, the third improvement in the matching process is in the weighted matching for all units in both quarters which do not match during any of the administrative matching procedures. The new procedures make use of many additional block structures which make possible incremental increases in the number of matches without significantly increasing the number of Type II errors. This is accomplished by tailoring the match cutoff parameter for each block so that most of the good matches fall above the match cutoff parameter without including a large number of Type II errors. The good matches falling below the parameter in one block are captured as matches in other blocks without picking up significant numbers of additional errors. The number of weighted matches went from 686 to 1,513 for an increase of 827 (0.09%). The total number of additional matches from the new procedures over the current procedures is 1,642. This reduces the number of business births (and business deaths) by 1,642 per quarter.
Although the results of the new linkage procedures do not appear dramatically different from the results of the current linkage procedures, the marginal improvements are significant in terms of the uses of the linkages. As stated earlier, one of the principal uses of the linked data files is to estimate the number and characteristics of business births and deaths and to track business births over time to determine when they increase or decrease their employment and how long they continue in business. It is easy to see that even though a large portion of the units match through the administrative codes, it is the remainder of the units which are considered business births and business deaths. Marginal improvements in matching these other units can have a relatively large impact on the number of business births and deaths and the ability to track them over time.
Quality of Matched Units
Tables 2 and 3 compare the quality of the weighted matches resulting from each procedure. There are two conclusions of interest from these tables. First, there are many more good matches resulting from the new procedures and fewer Type II matching errors. Also, there are approximately 150 to 300 good or questionable weighted matches obtained from the current matching procedures which are not being identified during the new weighted matching procedures. There are two possible explanations. The first is that we are missing these matches with the new procedures and we must find methods which will identify the good matches. The second is that although we are not identifying these matches during the weighted match, they may be identified in the enhanced administrative matching procedures which would preclude them from the weighted matching process. The truth may he somewhere between these possibilities and will be one focus of our fixture research efforts.
Table 2. —A Comparison of Weighted Match Counts and Quality
Table 3 continues the comparison of the quality of matches obtained from the current and new match procedures. It is obvious from this table that, although, the new match procedures apparently miss some good and questionable matches at or near the cutoff parameters for a match, the new procedures identify many additional good matches which are missed by the current weighted match procedures. This is accomplished by the new procedures while picking up fewer questionable and bad matches than the current procedures.
Table 3. —Weighted Matches
|
Match Quality |
Current Method Only |
New Method Only |
Both Methods |
|||
|
Count |
% |
Count |
% |
Count |
% |
|
|
Good |
156 |
38.4 |
1,211 |
87.4 |
76 |
91.6 |
|
Questionable |
178 |
43.8 |
153 |
11.0 |
7 |
8.4 |
|
Bad |
72 |
17.7 |
21 |
1.5 |
0 |
0 |
|
Total |
406 |
1,385 |
83 |
|||
Finally, Table 4 provides an analysis of the overall quality of the weighted matches obtained from the new procedures. Those units above the match cutoff parameter are identified as matches while the units below the match cutoff parameter are not identified as matches. There are at least 23 Type II errors while there are at least 51 Type I errors. This rough balance in these error Types seems a reasonable one for the purposes for which we are matching the files. Since there are only 142 good or questionable matches which fall below the match cutoff parameter, it seems that a substantial portion of the weighted matches identified only by the current weighted match procedures are identified during the enhanced new administrative match procedures.
Table 4. —New Weighted Match Distribution and Quality
Future Areas of Research
The results shown in Tables 1 through 4 are based on the research completed to date. As we are now aware from this preliminary effort, the matching procedures used here can be improved and there are more areas of study which may yield further improvement. In addition, there is additional testing which will be necessary to complete an initial assessment of the quality of the matching process.
-
Since the files which make up the UDB are the product of each of the State Employment Security Agencies, it is important that the new match procedures be tested on data files from each of the States. This is the only way to insure that anomalies in any of the State files will not adversely affect the match results. The short time available for completing each of the quarterly matches and the size of the files does not allow for a manual review of the quarterly results. This initial review of the matching process using the final parameter values will provide some measure of the quality of matches obtained. It may also be advantageous to tailor the match cutoff parameters independently for each State.
-
It is apparent from our initial analysis that additional analysis of the results of the current and new match procedures is necessary to determine how many good matches are being missed by the new procedures and how many of these are being identified by the new enhanced administrative match procedures. Once it is determined how many of these matches are being missed by the new procedures and their characteristics, the new match procedures must be modified to identify these matches.
-
Intra-quarter weighted matching procedures should be tested to determine if such a procedure should be added to the new match procedures and its impact on overall results.
-
Once the new procedures are enacted, an ongoing review of selected States may be recommended to insure that the match results do not deteriorate over time.
Acknowledgments
The authors would like to acknowledge the contributions of Larry Lie and James Spletzer of the Bureau of Labor Statistics and Catherine Armington of Westat, Inc.
|
Disclaimer Any opinions expressed in this paper are those of the authors and are not to be considered the policy of the Bureau of Labor Statistics. |
Technical Issues Related to the Probabilistic Linkage of Population-Based Crash and Injury Data
Sandra Johnson, National Highway Traffic Safety Administration
Abstract
NHTSA's Crash Outcome Data Evaluation System (CODES) project demonstrated the feasibility of using probabilistic linkage technology to link large volumes of frequently inaccurate state data for highway safety analyses. Hawaii, Maine, Missouri, New York, Pennsylvania, Utah, and Wisconsin were funded by NHTSA to generate population-based medical and financial outcome information from the scene to final disposition for persons involved in a motor vehicle crash. This presentation will focus on the technical issues related to the linkage of population-based person-specific state crash and injury data.
Data Sources and Access
Data for the CODES project included records for the same person and crash event located in multiple different files collected by different providers in different health care settings and insurance organizations at different points in time. Each data file had a different owner, was created for a specific use, and was not initially designed to be linked to other files. Crash data were more likely to be in the public domain. Injury data were protected to preserve patient confidentiality. Each data source added incremental information about the crash and the persons involved.
Six of the seven states linked person-specific crash data statewide to EMS and hospital data. The EMS data facilitated linkage of the crash to the hospital data because they included information about the scene (pick-up) location and the hospital destination. The seventh state was able to link directly to the hospital data without the EMS data because date of birth and zip code of residence were collected on the crash record for all injured persons. Other data files, such as vehicle registration, driver licensing, census, roadway/ infrastructure, emergency department, nursing home, death certificate, trauma/spinal/head registries, insurance claims and provider specific data, were incorporated into the linkage when available and appropriate to meet the state 's analytical needs.
Importance of Collaboration
Collaboration among the owners and users of the state data was necessary to facilitate access to the data. A CODES Advisory Committee was convened within each state to resolve issues related to data availability, patient confidentiality, and release of the linked data. The committee included the data owners such as the Departments of Public Safety, Health, Office of EMS, Vital Statistics, private and public insurers of health care and vehicles among others. Users included the owners, researchers, governmental entities, and others interested in injury control, improving medical care, reducing health care costs, and improving highway safety.
File and Field Preparation
File preparation usually began with the creation of a person-specific crash file to match the person-specific injury data. Some of the data files only had one record per person; others, such as the EMS and hospital data files had more than one, reflecting the multiple agencies providing EMS care and the multiple hospital admissions for the same injury problem respectively. In some instances, all of the records were included in the linkage; at other times, the extra records were stored in a separate file for reference and analysis.
Except for Wisconsin which benefited from state data which were extensively edited routinely, all of the states spent time, sometimes months, preparing their data for linkage. In most states, the hospital data required the least amount of editing. Preparation included converting the coding conventions for town/county codes, facility/provider, address, gender, and date in one file to match similar codes in the file being linked. Newborns were separated from unknown age. Date of birth and age discrepancies were resolved. Out of sequence times were corrected and minutes were added when only hour was documented. New variables were created to designate blocks of time, service areas for police, EMS and the hospital, probable admit date and others. Ancillary linkages to other data files were performed to beef up the discriminating power of the existing variables. Name and date of birth were the most common data added to the original files to improve the linkage.
Blocking and Linking Data Elements
Persons and events were identified using a combination of indirect identifiers and, in some linkages, unique personal identifiers, such as name, when they existed. Each of the CODES states used different data elements to block and link their files. Which variables were used for blocking and which for linkage depended upon both the reliability and availability of the data within the state, the linkage phase, and the files being linked. Most states used location, date, times, provider service area, and hospital destination to discriminate among the events. Age, date of birth, gender, and description of the injury were used most often to discriminate among persons. Hawaii, Missouri, New York, and Utah had access to name or initials for some of the linkages.
Linkage Results
Conditions of uncertainty govern the linkage of crash and injury state data. It is not certain which records should link. In the ideal world, records should exist for every crash and should designate an injury when one occurs; injury records should exist documenting the treatment for that injury and the crash as the cause; and the crash and injury records should be collected and computerized statewide. Linkage of a crash with an injury record should confirm and generate medical information about the injury. No linkage should confirm the absence of an injury. But that is the ideal world. In the real world, the crash record may not indicate an injury even though an injury occurred; the matching injury record may not indicate a crash or even be accessible; so it is difficult to know which records should link.
Linkage rates varied according to the type of data being linked. In each of the CODES states, about 10% of the person-specific police crash reports linked to an EMS record and slightly less than 1.8% linked to a hospital inpatient record, a reflection of the low rate of EMS transport and hospitalization for crash injuries. The linkage rates also varied by police designated severity level (KABCO). Linkage to the fatal injury records was not always 100%, but varied according to whether deaths at the scene were transported either by EMS or a non-medical provider. For the non-fatal injuries, linkage rates were higher for the more
severe cases which by definition were likely to require treatment and thus to generate a medical record. About 76–87% of the drivers with incapacitating injuries linked to at least one injury or claims record (except for Wisconsin, which had limited access to outpatient data and Pennsylvania which used 6 levels to designate severity). Linkage rates for persons with possible injuries varied widely among the seven states. Because of extensive insurance data resources, about two-thirds of the possible injuries linked in Hawaii and New York compared to a third or less in the other states. Many more records indicating “no injuries” matched in New York and Utah, again because of access to extensive computerized outpatient data for the minor injuries. Included in this group of not injured were people who appeared uninjured at the scene but who hours or days after the crash sought treatment for delayed symptoms, such as whiplash. Overall, the CODES states without access to the insurance data linked between 7–13% of the person-specific crash reports for crashes involving a car/light truck/van to at least one injury record compared to 35–55% for Hawaii and New York, the states with extensive outpatient data. Wisconsin linked 2% of its drivers to the hospital inpatient state data and this rate matched that for the seven states as a group.
Linkage of the records for the motorcycle riders was much higher than the car/light truck/van group, a reflection of the high injury rate for cyclists involved in police reported crashes. As expected the linkage rates were lower for the lower severities. Except for Pennsylvania and Wisconsin, more than 45 per cent of the person-specific motorcycle crash records linked to at least one injury record.
Validation of the Linkages
Causes of false negatives and false positives vary with each linkage because each injury data file is unique. Since it is unknown which records should link, validation of the linkage results is difficult. The absence of a record in the crash file prevents linkage to an injury record; the absence of a cause of injury code in the injury record risks a denominator inflated with non-motor vehicle crashes. The states assigned a high priority to preventing cases which should not match from matching and conservatively set the weight defining a match to a higher positive score. At the same time, they were careful not to set the weight defining a nonmatch too low so that fewer pairs would require manual review. The false positive rate ranged from 3.0–8.8 percent for the seven states and was viewed as not significant since the linked data included thousands of records estimated to represent at least half of all persons involved in motor vehicle crashes in the seven CODES states.
False positives were measured by identifying a random sample of crash and/or injury records and reviewing those that linked to verify that a motor vehicle crash was the cause of injury. Maine, Pennsylvania, and Wisconsin read the actual paper crash, EMS, and hospital records to validate the linkage. Missouri compared agreement on key linkage variables such as injury county, last initial, date of event, trafficway/trauma indicators, date of birth, or sex. Wisconsin determined that the false positive rate for the Medicaid linkage varied from that for hospitalizations generally since Medicaid cases were more likely to be found in urban areas.
False negatives were considered less serious than a false positive so the states adjusted the cut-off weight defining a nonmatch to give priority to minimizing the total matched pairs requiring manual review. A false negative represents an injury record with a motor vehicle crash designated as the cause which did not link to a crash report or a crash record with a designated severe injury (i.e., fatal, incapacitating) for which no match was found. The rates for false negatives varied from 4–30 percent depending on the linkage pass and the files being linked. The higher rates occurred when the power of the linkage variables to discriminate among the crashes and the persons involved was problematical. False negatives were measured by first identifying the records which should match. These included crash reports indicating ambulance transport, EMS records indicating motor vehicle crash as the cause of injury or hospital records listing an E
code indicating a motor vehicle crash. These records were then compared to the linked records to identify those that did not link. False negatives were also identified by randomly selecting a group of crash reports and manually reviewing the paper records to identify those which did not link.
Crash and injury records failed to match when one or the other was never submitted, the linking criteria were too restrictive, key data linkage variables were in error or missing, the case selection criteria, such as the E-code, were in error or missing, the crash-related hospitalization occurred after several hours or days had passed, the crash or the treatment occurred out-of-state, etc. Lack of date of birth on the crash report for passengers was a major obstacle to linkage for all of the states except Wisconsin which included this information for all injured passengers. (As the result of the linkage process, Maine targeted the importance of including this data element on the crash report.) Among the total false negatives identified by Wisconsin, 12 percent occurred because the admission was not the initial admission for the crash and 10 percent occurred because key linkage variables were missing. Another 7.5 percent occurred because the linking criteria were too strict. About 7 percent were missing a crash report because the crash occurred out of state or the patient had been transferred from another institution. Twelve percent of the false negatives were admitted as inpatients initially for other reasons than the crash. It was not possible to determine the false negative rates when the key data linkage variables or E-code were in error, when out of state injuries were treated in Wisconsin Hospitals and when the crash record was not received at DOT.
In spite of the failure of some records to match, the estimates of matching among those that could be identified as “should match” was encouraging. Missouri estimated linkage rates of 65 percent of the hospital discharge, 75 percent of the EMS records, and 88 percent of the head and spinal cord injury registry records when motor vehicle crash as the cause of injury was designated on the record. Comparison of Missouri's linked and unlinked records suggested that actual linkage rates were even higher, as unlinked records contained records not likely to be motor vehicle related injuries (such as gunshot, laceration, punctures, and stabs). The linked records showed higher rates of fractures and soft tissue injuries, which are typical of motor vehicle crashes. Seventy-nine percent of the fractures were linked, as were 78 percent of soft tissue injuries.
The comparison of linked and unlinked records does not suggest that significant numbers of important types of records are not being linked, though perhaps some less severely injured patients may be missed. Because ambulance linkage was used as an important intermediate link for the hospital discharge file, some individuals not injured severely enough to require an ambulance may have been missed, but they would also be less likely to require hospitalization. Any effect of this would be to erroneously raise slightly the estimate of average charges for hospitalized patients.
Significance of the False Positive and False Negative Rates
Although the rates for the false negatives and false positives were not significant for the belt and helmet analyses, they may be significant for other analyses using different outcome measures and smaller population units. For example, analyses of rural/urban patterns may be sensitive to missing data from specific geographic areas. Analyses of EMS effectiveness may be sensitive to missing data from specific EMS ambulance services or age groups. Another concern focuses on the definition of an injury link. Defining an injury to include linkage to any claim record that indicated medical treatment or payment increases the probability of including uninjured persons who go to the doctor for physical exams to rule out an injury. But this group also includes persons who are saved from a more serious injury by using a safety device, so although they inflate the number of total injuries, they are important to highway safety. When minor injuries are defined as injuries only if their existence is verified by linkage, then by definition the unlinked cases become non-injuries relative to the data sources used in the linkage. States using data
sources covering the physician's office through to tertiary care will have more linkages and thus more “injuries.” Estimates of the percentage injured, transported, admitted as inpatients, and the total charges will vary accordingly.
The Linkage Methodology is Robust and the Linked Data Are Useful
Seven states with different routinely collected data that varied in quality and completeness were able to generate from the linkage process comparable results that could be combined to calculate effectiveness rates. The states also demonstrated the usefulness of the linked data. They developed state-specific applications to identify populations at risk and factors that increased the risk of high severity and health care costs. They used the linked data to identify issues related to roadway safety and EMS, to support safety legislation, to evaluate the quality of their state data and for other state specific purposes.
Record Linkage of Progress Towards Meeting the New Jersey High School Proficiency Testing Requirements
Eva Miller, Department of Education, New Jersey
Abstract
The New Jersey Department of Education has undertaken a records linkage procedure to follow the progress of New Jersey's Public school students in meeting the state standardized graduation test-the High School Proficiency Test (HSPT). The HSPT is a test of higher order thinking skills mandated by state legislation in 1988 as a graduation requirement which measures “those basic skills all students must possess to function politically, economically, and socially in a democratic society. ” The HSPT is first administered in the fall of the student's eleventh grade. If the student is not successful in any of the three test sections—reading, mathematics, writing—he/she has additional opportunities, each semester, to retake those test sections for which the requirement is still unmet. In terms of public accountability of educational achievement, it is very important to define a population clearly and then to assess the quality of public education in two ways—the ability of the educational program to meet the challenge of the graduation test at the first opportunity (predominantly an evaluation of the curriculum); and the ability of the school system, essentially through the effectiveness of its interventions or remediations, to help the population meet the graduation requirement over the time remaining within a routine progression to graduation.
New Jersey uses a unique student identifier (not social security number) and has designed a complete mechanism for following the students through the use of test answer folders, computerized internal consistency checks, and queries to the school districts. The system has been carefully designed to protect confidentiality while tracking student progress in the many situations of moving from school to school or even in and out of the public school system, changes in grade levels and changes in educational programs (such as mainstreaming, special education, and limited English proficient programs).
Preserving confidentiality, linking completely to maintain the accuracy and completeness of the official records, definitions and analysis will be discussed.
Introduction
The New Jersey Department of Education has undertaken a record linkage procedure involving use of computers in the deterministic matching of student records to follow the progress of New Jersey's public school students in meeting the state standardized graduation test —the High School Proficiency Test (HSPT). The HSPT is a test of higher order thinking skills mandated by state legislation in 1988 as a graduation requirement which measures “those basic skills all students must possess to function politically, economically, and socially in a democratic society.” The HSPT is first administered in the fall of the
students' eleventh grade. If the student is not successful in any of the three test sections—reading, mathematics, writing—he/she has additional opportunities, each semester, to retake test section(s) not yet passed.
On first glance it would seem that New Jersey Department of Education 's records linkage task is an easy and straightforward one. Since in October 1995, 62,336 eleventh grade students were enrolled in regular educational programs in New Jersey's public schools and 51,601 (or 82.8%) of these students met the HSPT testing requirement on their first testing opportunity (also includes eleventh grade students who may have met the requirement in one or more test sections while categorized by their local educators as “retained tenth grade” students), only 10,730 students need to be followed forward for three more semesters until graduation! Since some of these students (probably half again) will meet the requirement upon each testing opportunity, the number diminishes and the task should be trivial…right? We have high speed computers and the public wanting this information thinks we just have to push a few buttons!
The problem is complicated, however, especially by flows of migration (students entering or leaving New Jersey's public schools) and mobility (students transferring from one public school to another), and gets increasingly more subject to error as time from the original eleventh grade enrollment passes. From the perspective of the policy maker in the Department of Education whose intent it is to produce a report of test performance rates which are comparable over schools, districts, and socio-demographic aggregations, the problem is further complicated by the fact that grade designation is a decision determined by local educators and rules may vary from school district to school district. Changes in a student's educational status with respect to Limited English Proficiency programs and/or Special Education programs also complicate tracking.
In terms of public accountability of educational achievement, it is very important to define a population clearly and then to assess the quality of public education in two ways:
-
the ability of the educational program to meet the challenge of the graduation test at the first opportunity (predominantly an evaluation of the curriculum); and
-
the ability of the school system, essentially through the effectiveness of its interventions or remediations, to help the population meet the graduation requirement over the time remaining within a routine progression to graduation.
Before the New Jersey Department of Education developed the cohort tracking system, information on HSPT test performance was reported specific to each test administration. This cross-sectional method of analysis was dependent on which students attended school during the test administration, and even more dependent on local determination of students' grade level attainments than in a longitudinal study. Using the cross-sectional reports, it was very difficult, if not impossible, to meaningfully interpret reports which were for predominantly retested student populations (i.e., what did the fall grade 12 test results report really mean?).
Methodology
The cohort tracking project is a joint effort involving the New Jersey Department of Education, National Computer Systems (NCS), and New Jersey educators in public high schools. The department is responsible for articulation of the purpose of the project and establishing procedures to be used—including such activities as statistical design and decision-making rules, maintaining confidentiality of individual performance information, and assuring appropriate use and interpretation of reported information. NCS is
responsible for development and support of a customized computer system, its specifications and documentation. The system is written in COBOL and provides features necessary for generation of the identifier; sorting and matching; data query regarding mismatches, nonmatches the uniqueness of the identifier, and assurances of the one-to-one correspondence of identifier to student. The department and NCS share responsibility in maximizing the efficiency and effectiveness of the system and in trying to reduce the burden of paper work involved in record keeping, minimizing queries back to local educators, utilizing the computer effectively in checking information for internal consistency, developing and maintaining quality control procedures of interim reports to the local educators and public reports, and maximizing yield of accurate information. The local educator maintains primary responsibility related to the validity of the information by: assuring the accuracy of identifier information about individual students, reviewing reports sent to them to assure the accuracy and completeness of information about their enrolled and tested student population; and the responsibility to ascertain that every enrolled student is listed on the school's roster once and only once!
At its inception in October 1995, the cohort tracking project was intended to follow a defined population of eleventh grade students forward to their anticipated graduation (the static cohort). Local educators objected to this methodology because they could only educate students who were currently enrolled. To address this very important concern, the dynamic cohort was defined (see Figure 1). In effect, the dynamic cohort represents statistical adjustment of the original static cohort at each test administration to allow students who have left the reference group (school, district, or statewide) without meeting the graduation testing requirement to be removed from observation and adds those students who entered the reference group after fall of the eleventh grade and have not already met the testing requirement. Statistics produced for either the static cohort (prospective perspective) or the dynamic cohort (retrospective perspective) were not true rates, but rather were indices since after the first test administration (on the last day of testing in the fall of the eleventh grade) these populations are no longer groups of students served within a school, district, or state at a specific moment in time.
The mobility index—simply the sum of the number of students entering and the number of students leaving the reference group since the last day of testing in fall of the eleventh grade, divided by the reference group at the initial time point—was designed to help the user interested in evaluating educational progress as assessed by the HSPT (educator, parent, student, citizen and/or policy maker) decide which set of statistics, static or dynamic, would be more appropriate with respect to a particular reference group (school, district, or state). The higher the mobility level, the greater the difference between the set of statistics, and the more likely reliance should be made of the dynamic statistics.
In developing the system, the department had a need for a cost-effective, accurate, and timely system. The department needed exact matches and, therefore, could not rely on probability matching or phonetic schemes such as NYSIIS. A system with a number of opportunities for the local educator to review and correct the information was developed. A mismatch (or Type II error) was considered to have far more serious consequences in this tracking application than a nonmatch (or Type I error) because an educator might be notified that a student met requirements in one or more testing sections when that has not yet occurred (and the student might have been denied an opportunity to participate in a test administration based on a mismatch). The nonmatch is especially of concern to the local educator, because the most likely scenario here is that the student is listed in the file more than once, and none of these (usually incomplete) student records are likely to show all of the student's successes, therefore, the student was in the denominator population multiple times and had little or no chance of entering the numerator of successful students. In working with various lists and HSPT ID discrepancy reports, local educators have had heightened awarenesses of the “Quality in…Quality out” rule mentioned by Martha Fair (Fair and Whitridge, 1997).

Considerations Regarding the Identifier
This records linkage application is a relational database dependent on a unique identifier—the HSPT identification number (HSPT ID) —and supported by the following secondary fields: name (last and first but not middle initial), date of birth, and gender. In determining a unique identifier, the department first considered the use of social security number because it is a number which has meaning to the individual (is known), and is nearly universal and readily available to the individual. However, the department abandoned the plan to use SSN before the tracking project was implemented because citizens complained—both verbally and in writing. Concerns included not wanting to draw attention to illegal aliens and considerations of the reasonableness of the number in terms of an individual's willingness to disclose it to school officials for this purpose and how use of the SSN may make it possible to access other unrelated files.
In reviewing Fair's criteria for a personal identifier (permanence, universality, reasonableness with respect to lack of objection to its disclosure, economy, simplicity, availability, having knowledge or meaning to the individual, accuracy, and uniqueness), the HSPT ID received low marks related to permanence and having the property of being easily known or meaningful to the student. The HSPT ID rated high marks on universality and reasonableness, with respect to lack of objection to its disclosure, precisely because it lacked meaning and could not be easily related to other records. The HSPT ID is also economical, simple, accurate, and is secured and safeguarded—procedures have been implemented which assure that only appropriate school officials can access specific HSPT IDs for their enrolled populations and next access confidential information associated with these students' records of test results, in accordance with concerns regarding data confidentiality (U.S. Department of Education, 1994). Work involving assurance that there is only one number per student includes an HSPT ID update report, an HSPT ID discrepancy report, and multiple opportunities for record changes to correct information on student identifiers based on local educators ' reviews of rosters (lists) of their students' test results.
The HSPT ID has been generated within the tracking system on the answer folder for each first-time test taker. Repeat test takers were to use stickers with student identifiers contained in a computer bar code label provided by NCS. District test coordinators can also contact staff at NCS, and after reasonable security checks are completed, obtain the HSPT ID and test results (from previous test administrations) for entering students who have already been tested.
A cohort year designation is to be assigned to a student once and only once. Safeguards are currently being developed to assure that despite grade changes over time, each student is followed based upon the initial (and only) cohort year designation.
Validity Assurances
The department and NCS are currently developing additional computerized procedures to assure the one-to-one correspondence of the HSPT ID to the student. A critical element in the assurance of the validity of the correct identification of each enrolled student as well as pass/fail indicators (for each test section and the total test requirement) is the review of the static roster immediately following the fall eleventh grade test administration.
Recently also, safeguards have been added to the computer system to assure:
-
that for a given HSPT ID once a passing score in a particular test section has been obtained by a student, no further information on testing in that test section can be accepted by the cohort tracking system because the first passing score is the official passing score; and
-
that for a student who has met the testing requirement by passing all test sections the HSPT ID number is locked and the system accepts no new information to be associated with that HSPT ID.
Quality Control Procedures for Cohort Reports
Quality control of cohorts reports is a joint effort on the part of the department and NCS. Quality control procedures include visual review of student rosters and statistical report, utilization of a system of SAS programs generated under the same project definitions and decision-making rules by a different programmer in order to check the logic used in the COBOL programs. To date, this quality control has been conducted three times. There is a written quality control protocol which has made it possible to move from the implicit understanding of records linkage methodology and computer systems capabilities to explicit criteria for this particular application. These explicit criteria are identified, clearly articulated, and observable. This protocol has been very useful in that it:
-
helped clarify expectations for NCS,
-
allowed more department staff to participate fully in the quality control process while minimizing need for specific project orientation or training time, and
-
more complete documentation of the quality control effort for each cohort after each test administration. Refinement of these quality control procedures is on-going.
Confidentiality
In addition to the procedures for release of HSPT ID described above, confidentiality is preserved on cohort dynamic out rosters in that students who have left a school are listed without pass/fail indicators for test sections and the total testing requirement.
With respect to public reporting, the department has been very conservative in using a rule of “10” instead of the rule of “three”; in this way individual student test performance information is not discemable from information reported publicly.
Results
Actual test performance results based on this longitudinal study have been reported only once to date (Klagholz, L. et al., 1996). These results were for the first cohort, juniors in October 1995, and followed students through one academic year (two test administrations). The audience of public users seemed to receive the information well and are currently anticipating the December 1997 release of information which is to include the academic progress of the 1995 cohort toward graduation and, in comparison to last year's public release, the academic progress of the second cohort, juniors in October 1996, through their junior year.
While there are a variety of ways to correct and update the cohort tracking master data base, a key (and predominant) method is the first record change process after receiving initial test results. The record change process is an opportunity for correction of erroneous data related to permanent student identifiers (name, date of birth, and gender), personal status identifiers (school enrollment, grade, participation in special programs (such as Special Education, Limited English Proficiency programs, and Title I), and test
related information (attendance at time of testing each content area, void classifications, and first time or retest taking statuses).
There were a total of 2,526 record changes processed at this first opportunity for data review. This is not an unduplicated students count, since one student's records might have needed several variables to be corrected. It is not readily obvious what denominator to suggest in determining rates—93,627 for total students enrolled (including students in special programs) would be most appropriate in determining a proportion of the total population to be tested for a cohort year. Another approach, however, would be that record changes as they relate to the cohort tracking project, should be segmented and the number of record changes for the students who had one or more test sections yet to pass after the October test administration would be useful; however, that statistic is not readily available.
Numbers of record changes by reason were as follows:
|
Student identifiers: |
name: |
447 |
|
date of birth: |
218 |
|
|
gender: |
41 |
|
|
school: |
53 |
|
|
Status: |
grade: |
367 |
|
Special Education: |
631 |
|
|
Limited English Proficiency: |
196 |
|
|
Title I: |
153 |
|
|
Test specific information: |
attendance on test days: |
43 |
|
void classifications: |
57 |
|
|
first time or retest status |
381. |
A systematic error regarding 731 students who were tested for the first time in April 1996 occurred. These students were not appropriately reflected in the dynamic cohort statistics. The computer system has been corrected to handle these cases correctly. This also necessitated tightening the quality control protocol and procedures. Corrected test performance rates for that same time point in the longitudinal study will be released in December 1997. While no one ever wants to release erroneous information, it was interesting to note the order of magnitude: for 51 schools there was no change, for 44 schools the correction increased pass rates by up to 0.8%, and for 136 schools passed rates decreased (by within 1.0% for 104 schools and between 1.1% and 4.2% for 32 schools).
The mobility index was designed to measure the stress on student populations caused by students who change the educational climate by either entering or leaving a particular high school after October of their junior year. This index was considered to be needed to guide the decision as to whether the set of static or dynamic statistics would be more appropriate measures of progress for a given reference group (school, district, state). The mobility index was observed to have a highly negative correlation with test performance. This finding was especially important to educators in communities with high mobility in that it helped these educators quantify the seriousness of the socio-economic problem, and communicate it in understandable terms regarding the consequences of these moves upon the continuity of students' educational experiences and educational progress in meeting performance standards.
Plans for the Future
The department has an ambitious plan to increase the graduation test (and assessments at fourth and eighth grades) to include eight test sections (content areas). The cohort tracking project is to be expanded to include all test sections on the graduation test. Cohort tracking is also to be extended vertically to the other grades for which there is a statewide assessment program.
The possibility of developing a population register for students enrolled in New Jersey's public schools is under discussion. Then the cohort tracking system would be incorporated into a larger department information system for reviewing educational programs, attendance, and school funding as well as outcome measures such as test results. In discussions about a population registry, social security number has been proposed for the linkage variable.
References
Fair, M. and Whitridge, P. ( 1997). Record Linkage Tutorial, Records Linkage Techniques—1997, Washington, D.C.: Office of Management and Budget.
Klagholz, L.; Reece, G.T.; and DeMauro, G.E. ( 1996). 1995 Cohort State Summary: Includes October 1995 and April 1996 Administrations Grade 11 High School Proficiency Test, New Jersey Department of Education.
U.S. Department of Education, ( 1994). Education Data Confidentiality: Two Studies, Issues in Education Data Confidentiality and Access and Compilation of Statutes, Laws, and Regulations Related to the Confidentiality of Educational Data , Washington, D.C.: National Center for Education Statistics, National Forum on Education Statistics.


































