
Chapter 11
Selected Related Papers, 1986–1997
Authors:
Howard B.Newcombe, Consultant, and Martha E.Fair and Pierre Lalonde, Statistics Canada
Matthew A.Jaro, System Automation Corporation
Nancy P.NeSmith, The Church of Jesus Christ of Latter-Day Saints
David White, Utah State University and Church of Jesus Christ of Latter-Day Saints
William E.Winkler, Bureau of the Census
Fritz Scheuren, Ernst and Young, LLP
Martha E.Fair, Statistics Canada
Latanya Sweeney, Massachusetts Institute of Technology
The Use of Names for Linking Personal Records
Howard B.Newcombe, Consultant Martha E.Fair and Pierre Lalonde, Statistics Canada
The skill of a human who searches large files of personal records depends much on prior knowledge of how the names vary in successive documents pertaining to the same individuals (e.g., as with ANTHONY-TONY, JOSEPH-JOE, WILLIAM-BILL). Now, an essentially exact procedure enables computers to make similar use of an accumulated memory of their own past experiences when searching for, and linking, records that relate to particular persons. This knowledge is further applied to quantify the benefits from various refinements of the rules by which the discriminating powers of names are calculated when they do not precisely agree or are substantially dissimilar. Of the six refinements tested, by far the most important is the recently developed exact approach for calculating the ODDS associated with comparisons of names that are possible synonyms.
KEY WORDS: Data base maintenance; File searching; Probabilistic linkage; Quantitative judgment; Record linkage.
Personal documentation in machine-readable form has become so extensive in any advanced society as to constitute, collectively, a detailed but highly fragmented life history for virtually all its members. The files exist to serve the needs of people and of society as a whole, and frequent access is involved. Much of the searching is necessarily based on names and personal particulars that are apt to be reported differently on successive documents for the same individuals. The problems are familiar to clerks, but now access by computer is becoming the norm.
With automated searching, many choices are possible between refinements and simplifications in the way that names get compared. Rarely, however, have the merits of alternative approaches been quantified in terms of gains or losses of discriminating power, so as to reduce the guesswork when designing a system. The potential for sophistication in automated comparisons of names is substantial. Humans develop special skills in recognizing nicknames, ethnic variants, diminutives, and corrupted forms due to truncations, misspellings, and typographical errors. This is known to be based on a relatively simple rationale, supported by remembered data. If a machine is to acquire similar ability, it too must rely on past experience (Newcombe, Fair, and Lalonde 1989; Newcombe, Kennedy, Axford, and James 1959). Although there is now an essentially exact way of measuring the discriminating powers of comparison pairs like CARL-KARL, GEORGE-GYORGY, JACOB-JAKE, JOHN-JACK, and WILLIAM-BILL, much clerical labor and large amounts of data are needed to set it up (Fair, Lalonde, and Newcombe 1990, 1991; Newcombe et al. 1989). Simpler comparisons are, therefore, likely to remain popular in many procedures that use names to access files.
Whether or not this exact approach becomes widely applied, its existence now provides a convenient standard against which to judge the performance of other treatments of names. So we have used the approach in this article to quantify the gains and losses of discriminating power due to various refinements and shortcuts commonly used in automated searching and linkage.
The test is special to names as identifiers; is suitable for fine-tuning this component of a record linkage system; and is uninfluenced by the adequacy of the rest of the identifiers. It differs from, but is complementary to, more direct tests of overall performance.
1. COMPUTER LINKAGE
Where a computer is used to search large files of personal records and bring together the records for particular individuals, it may emulate with varying degrees of success the strategies of a human clerk who does the same job. To determine whether a pair of records is correctly matched, the names are compared along with other identifiers (e.g., year, month, and day of birth; sex and marital status; and various geographic particulars such as place of birth, residence, work, or death). Sometimes, however, these comparisons point in different directions.
The problem then is to determine, as in a court of law, where the preponderance of the evidence lies. The comparisons must be considered not only separately but also in combination. A particular comparison outcome (e.g., JOHN-JOHN or JOHN-JACK) will argued for linkage when it is more common among correctly matched pairs than among random false matches. Conversely (as with JOHN-JOE), an outcome will argue against linkage when the opposite is the case. These likelihood ratios (or individual ODDS in favor of linkage) may be combined to assess the collective evidence from the full set. But this is not the whole of the relevant information.
In addition, a human clerk may recognize two further factors: the size of the file being searched and the likelihood that the individual is represented in it. Thus, when looking for a particular JOHN BROWN in the telephone directory for a small town where he is thought to reside, finding the name suggests that it may well belong to the right person. This would definitely not be so when searching a large national death register, especially if this JOHN BROWN were unlikely to have died.
Automated searches have from the outset used much the same reasoning as does a human clerk; this provides numerous options when calculating the ODDS for particular
|
* |
Howard B.Newcombe is a consultant, P.O. Box 135, Deep River, Ontario K0J 1P0, Canada. Martha E.Fair is Chief and Pierre Lalonde is Project Manager, Occupational and Environmental Health Research Section, Canadian Centre for Health Information, Statistics Canada, Ottawa, Ontario K1A 0T6, Canada. The authors thank John Armstrong, Michael Eagen, and William E.Winkler for helpful critical comments on an early version of this article, and also the associate editors and referees who substantially influenced its final form. |
identifiers. However, where the two factors described in the previous paragraph are wrongly overlooked, confusion arises and persists concerning the distinction between overall relative ODDS as opposed to absolute ODDS (in the sense of true “betting odds” that the record pair is correctly matched). Formal theory, which was introduced later, has as yet not dealt explicitly with the implications of this distinction. These matters are considered further in this article.
Clerical searchers are not technical people. So, when describing the insights on which their success depends, it is best that plain language be used such as they would understand.
1.1 Brief History
The earliest probabilistic linkages were carried out more than three decades ago as a hands-on kind of experiment at the Chalk River Laboratories of Atomic Energy of Canada Limited in Ontario (Newcombe et al. 1959). This was a conscious attempt to observe and understand the stratagems of a perceptive human when confronted with pairs of records that might, or might not, relate to the same individual or family. This study found that people often compare identifiers in unexpected ways whenever there is a need for added discriminating power.
The circumstances surrounding this laboratory study were particularly favorable in that the records contained an abundance of personal identifiers. Birth registrations for the province of British Columbia were to be linked into sibship groups along with parental marriage records, under conditions of strict confidentiality. Identifiers for husbands and wives were present and included maiden surnames. S.J.Axford of Statistics Canada suggested that both parental surnames be phonetically (Soundex) coded and that the files be sorted by the male code followed by the female code. This created pockets (or “blocks”) within which other identifiers could be compared. (For details of the coding, see Newcombe et al. 1959 and Newcombe 1988.)
For a preliminary test, Axford produced a modest listing of stillbirths spanning a number of years, arrayed in the double surname sequence. The visual impact was substantial and influenced much of the thinking that followed. Stillbirths repeat in families, and the discriminating power of the double surname codes ensured that most of the records in a single pocket would already be correctly grouped. Where more than one sibship was represented, appropriate separation was indicated by the parental initials, provinces or foreign countries of birth, and their ages when adjusted for the intervals between events. A visual scan revealed how often various identifiers agreed or disagreed in correctly matched pairs (LINKS), and it was not difficult to determine the corresponding likelihoods for a control group of falsely matched random pairs (NONLINKS).
The linkage rationale first emerged from this small manual test with the stillbirth records. As a broad generalization, any outcome from the comparison of any identifier will argue for linkage if it is more typical of the LINKS and against linkage if it is more typical of the random NONLINKS. The identifier might be a surname, given name, initial, some part of the date of birth, or perhaps the place of birth; the comparison outcome might be an agreement, disagreement, some specified level or kind of similarity or dissimilarity, or any other comparison outcome no matter how defined. The reasoning holds even where agreements argue against linkage (as with two stillbirth records that both have birth order = 1), and even where two different identifiers are compared (as when the birth of a fifth child seems unlikely out of the first year of a marriage). Without exception, both the direction and the strength of the evidence are indicated by the likelihood ratio. There appear to be no constraints limiting how a comparison outcome may be defined,
This linkage rationale next was applied clerically on a larger scale to searches for parental marriage records, initiated by British Columbia birth records. When the rationale had been shown to work in a manual simulation of an automated procedure, J.M.Kennedy was asked if he could program the same steps for Chalk River's first-generation (Datatron) computer. The automated separation of LINKS from NONLINKS likewise left only a small proportion of doubtful pairings (Newcombe et al. 1959).
A decade later, the linkage rationale was restated and expanded into a formal mathematical theory by Fellegi and Sunter at Statistics Canada (Fellegi 1985; Fellegi and Sunter 1969; Sunter 1968). These authors confirmed what had not been rigorously proved earlier and chose for purposes of illustration such simple outcome definitions as disagreement (nonspecific for value) and agreement (with or without recognition of the value of the identifier; for example, “name agrees and has any value” or “name agrees and the value is JOHN”). Thus the theory is best viewed not so much as a blueprint for linkage, but more as a framework within which many options are possible. Its existence does not make the human strategies less relevant or the intimate contact with the files less important.
Meanwhile, independent of the formal theory and prior to it linkage practice and manual testing resulted in refinements of a different sort. The aim was to make maximum use of any conceivable source of discriminating power in the available identifiers. Because simple agreement and disagreement outcomes are grossly wasteful in many situations, more sophisticated comparison procedures were developed. Pairs of initials that disagreed on straight comparison were now routinely cross-compared to pick up instances of inversion. Near agreements in the birthdate components (e.g., discrepancies of 1, 2, 3, and so forth days, months, or years) were now grouped into multiple levels. Also, unusual comparisons were being made (as between the birth order of a child and the duration of the marriage). All of these refinements served to exploit hidden discriminating power (Newcombe and Kennedy 1962). Other refinements were tested by measuring the benefits from using additional identifiers (e.g., parental ages), multiple alternative file sequences for blocking, and a coefficient of specificity to identify the “best” sequence when relying on just one (Newcombe 1967; Smith and Newcombe 1975, 1979). From the beginning, frequent close scrutiny of difficult matches provided insights that would have been missed had refinement been sought through
theory alone (Newcombe and Kennedy 1962; Newcombe et al. 1987). (The need for practice and theory to complement each other is discussed elsewhere; see Scheuren, Alvey, and Kilss 1986; Winkler 1989b.)
When Statistics Canada first actually used probabilistic linkage in the early 1980s, based on the Fellegi-Sunter theory, it was to search the newly established Canadian mortality data base, which extended back to 1950. Their linkage system, known as CANLINK or GIRLS (for Generalized Iterative Record Linkage System) included innovations described by Howe and Lindsay (1981), Hill (1981), Hill and Pring-Mill (1985). In particular, a preliminary linkage step was introduced that temporarily ignored specific values of names, thereby eliminating in a simple fashion many unpromising record pairs, and an iterative update of the outcome frequencies from LINKED pairs of records was used. The preliminary step was needed because the death files were now blocked by just a single surname (as a NYSIIS phonetic code; see Appendix H of Newcombe 1988), and the blocks were larger than those based on pairs of surnames for family linkage. The iterative updates were required because to get new linkage jobs started, outcome frequencies from earlier linkages were often used initially and replaced later with increasingly appropriate data as the new files of LINKS were progressively improved. (The effect of omitting this update is considered in Sec. 3.4.) A further intended refinement, recognition of partial agreements of names (like THOMAS-TOM), was less successful; as a result, modified procedures had to be devised (Eagen and Hill 1987; Fair et al. 1990, 1991; Newcombe 1988; Newcombe et al. 1987, 1989; Winkler 1985, 1989a.) The matter is referred to again in Section 3.5.
Howe and Lindsay (1981) also recognized explicitly, for the first time, the concept of the prior odds or prior likelihood but failed to apply it to create a scale of absolute ODDS that might be used for setting thresholds. Earlier, two thresholds had been proposed as part of the Fellegi-Sunter theory to distinguish positive links and positive nonlinks, plus an intermediate category of ambiguous matches called possible links. The thresholds were to be calculated in advance as “error bounds” that would limit the numbers of false-positive and false-negative links and would identify pairs in need of special assessment. But when the ODDS from the full sets of identifiers were combined, it was found that the resulting overall ODDS served only to array the record pairs, relative to one another, in descending order of the likelihood of a correct match. Thus, in practice, the two thresholds got assigned subjectively. On the scale of relative ODDS available at the time, they fell high above the crossover or 50/50 odds point (e.g., in the case of the death searches by a factor of well over 1 million, and greater than the size of the file being searched).
An empirical conversion to a scale of presumed absolute ODDS indicated why. When allowance was made for the size of the death file, 1/N(File B), and for the proportion of search records that find a matching death record in it, N(A | LINK)/N(File A), the new scale brought the subjective thresholds close to the crossover or 50/50 odds point. Together, these two factors were taken to represent the prior likelihood of a correct match on a single random pairing (i.e., before examining any identifier or blocking information).
The new scale of absolute ODDS was controversial at first, although the results were consistently believable over many empirical tests, whereas those from the alternative were not Later, it was shown to use just a variant of the prior odds, P(LINK)/P(NONLINK), already recognized by Howe and Lindsay (1981). The implications are substantial but were not explored by those authors (see Secs. 2.3 and 3.1 and Fig. 1). In practice, however, it was soon found that the concept of the prior likelihood could be applied with great flexibility in many ways. For example, as a refinement it was calculated separately for subsets with differing prior likelihoods (see Newcombe 1988, chap. 28 and apps. B and D.3).
What refining the practice achieved, as distinct from formal theory, was enhanced flexibility in the access to discriminating power. Individual identifiers were compared freely, just as a human might do when seeking clues to the true linkage status of a record pair; and the prior likelihood of a correct match, in the case of a death search, was exploited to take into account the age of the individual in a given year, and the actuarial likelihood that he or she might have died in that year. For linkages of cancer records with death files, the approach even used survival curves appropriate to particular diagnoses. The practices are fully described, but in nontechnical language for those working close to the files, who design, implement, and test the detailed procedures (see, for example, Newcombe 1988, sec. 28.2 and apps. D.2 and D.3).
This is the technological setting within which the current study has been carried out.
1.2 General Method
Any formal statement of the comparison procedure for individual identifiers should allow for the flexibility that exists in practice. This is especially true of names when they do not precisely agree (e.g., as allowing recognition of the comparison DANIEL-DANNY). Moreover, because some kind of grouping of possible synonyms is inevitable, this too must be exceedingly flexible if discriminating power is not to be wasted (Scheuren 1985). We will deal first with formal expressions that permit flexibility when estimating likelihood ratios (or ODDS in favor of linkage as indicated by particular comparisons), and second with grouping under conditions of minimum constraints. (Other accounts use logarithms of the likelihood ratios and refer to them as “weights.” The ratios may also be viewed as factors by which comparisons of particular identifiers raise or lower the overall “betting odds ” in favor of linkage.)
Conceptually, each first given name on one file is compared with every first given name on the other file, and second given names are likewise compared. Generally, LINKED pairs (of names or records) are vastly outnumbered by possible NONLINKED pairs, i.e., actual plus potential. (This concept is fundamental and is not altered by “blocking” that reduces the actual numbers of comparison pairs; see Fellegi 1985.) Although LINKS and NONLINKS are thought of as uncon-
taminated with pairs of the opposite kind, modest admixtures have only slight effects on the ODDS.
When comparing value Ax from a Record A (which is used to initiate a search) with value By from a Record B (which is in the file being searched), the ODDS in favor of a correct LINK associated with outcome Ax · By (i.e., the comparison pair of values) may be written in terms of the relative probability of occurrence of the particular outcome in LINKS as compared with NONLINKS; that is,
ODDS = P(Ax· By | LINK)/P(Ax·By | NONLINK). (1.1)
But except where files A and B are both very small, the denominator in this expression will be closely approximated by P(Ax) · P(By), because any fortuitous LINKS in the random pairs will be vastly outnumbered by the NONLINKS. Thus the expression may be converted to
ODDS = P(Ax· By | LINK)/P(Ax) · P(By). (1.2)
This implies that we need to know in advance the number of LINKS with values Ax and By. In practice crude approximations are estimated initially from sample linkages carried out manually or from previous linkage studies and are revised iteratively as the current LINKS are progressively refined.
An expanded form of this procedure is sometimes used to support an existing practice in the case of death searches. This involves ignoring the frequency of value Ax, both in File A and in the LINKS, on the grounds that names are unlikely to be strongly correlated with the probability of death and with whether a Record A is LINKED to a Record B. Justification depends on the magnitude of the error introduced by the assumption. The expanded version has two parts:

(1.3)
Current practice views the second part (the “correction factor”) as approximating unity, so it can be ignored, except where the assumption is thought to be seriously misleading (as it might be if ethnicity and ethnic names were correlated with mortality).
What the relative probabilities fail to do is indicate explicitly how the ODDS should be calculated using data that are in short supply. Examples include outcome values Ax·By that are represented only once or twice in an available real file of LINKS and, especially, numerous other outcome values representing pairs of possible synonyms that have not actually occurred in the available LINKS but probably would occur if that file were larger. Because crucial steps in the reasoning have to do with numbers of outcome values, as distinct from their likelihoods, it is helpful to convert the last two expressions to a form actually used to obtain estimated relative probabilities, as
(1.4)
and

(1.5)
where the general term N(* | LINK) represents the number of records among LINKED pairs that have attribute (*), N(LINKS) = number of linked pairs, N(A) = number of records in File A, N(B) = number of records in File B, N(Ax) = number of records in File A with value x, and N(By) = number of records in File B with value y. (For the origins of this version, see Newcombe et al. 1989.)
It is convenient to retain the distinction between a search file (File A) and a file being searched (File B), even though conceptually the roles could be reversed. For one thing, the search file usually is smaller than the file being searched. Also, the distinction has special significance for the death searches, because informal versions of a given name (e.g., nicknames) are more commonly used by employers and others while one is alive rather than by undertakers after one has died.
Here we need to introduce two concepts related to the ways in which the range of possible outcomes may be handled:
-
Grouping or “pooling” of similar values of Ax·By, which individually are represented poorly or not at all in the available LINKS (the “quantity” problem)
-
Increasing sacrifice of discrimination as the withingroup heterogeneity grows when its definition is broadened to ensure representation in the LINKS (the “quality” problem).
A tradeoff between “quantity” and “quality” is unavoidable. The definition of an outcome group needs to be broad enough so that N(Ax · By | LINK) is represented by at least one comparison pair. Otherwise, no ODDS can be calculated. But because the definition is widened to increase the representation, it will also let more heterogeneity into the group. (Thus as the error due to statistical fluctuation diminishes, so the error due to lessened specificity increases.)
The earliest linkage operations simplified matters by recognizing just two categories of outcome—agreements and disagreements—and by attributing specificity for value only to the former category. But major errors arose from an unsuccessful attempt to adapt the earlier procedures, to recognize “partial agreements” such as JOSEPH-JOE (Newcombe et al. 1987). (The term “partial agreement” is commonly applied, for reasons of convenience, to any possible synonyms regardless of similarity, as with ELIZABETH– BETTY.)
The problem posed by the value-specific partial agreements of names may be handled in various ways, but only one of
these appears to be precise. A compromise solution, now in routine use, is based on the numbers of early characters that agree. ODDS are first calculated for different levels of agreement (i.e., one, two, three, four or more agree); actual values are ignored at this stage. Such “global ODDS” are later adjusted upward or downward, depending on whether the particular values of the agreement portions are rare or common (Eagen and Hill 1987; Newcombe 1988; Newcombe et al. 1987), but this neglects the values of the disagreement portions (e.g., it wrongly treats diverse name pairs like JOHN-JONATHAN and JOHN-JOSEPH as equally likely to be synonyms). An alternative approach that recognizes phonetic components common to the two names has also been developed (Winkler 1985, 1989a).
A precise treatment of partial agreements of names recognizes both values in a comparison pair and avoids resorting to globally defined (i.e., value-nonspecific) levels of agreement. This permits it to deal with outwardly dissimilar comparison pairs (e.g., EDWARD-TED, MARGARET-PEGGY). Any necessary groupings must be defined in value-specific ways. The frequency with which the two values are related by actual usage then determines the magnitude of the precise ODDS. A modest manual test showed that the approach worked where sufficient data from LINKED pairs of records could be made available (Newcombe et al. 1989). That was followed by an expanded application based on an accumulated composite file of LINKS from many past searches of the Canadian mortality data base (Fair et al. 1990, 1991). This refinement will be considered further in Section 3.5.
(The current emphasis on flexibility also extends to other identifiers that are apt to be reported differently on separate occasions or that may change over time, as with MARITAL STATUS, OCCUPATION, INDUSTRY, and PLACES OF RESIDENCE, WORK, and DEATH. For these, there likewise is no need to prejudge in which direction the comparisons will argue. “Agreement” and “disagreement” are often poor indicators, but the ODDS—when they have been calculated— will decide.)
1.3 Combining the ODDS
When the likelihood ratios or ODDS for particular identifiers are combined over the full set in a record pair, it is usual to assume as a tolerable approximation that the identifiers are independent of one another. The overall absolute ODDS (in the sense of “betting odds” in favor of linkage) may then be represented by
Absolute ODDS = R1 · R2 · · · · · Rn · P(LINK), (1.6)
where R1 to Rn are the likelihood ratios (ODDS) for identifiers 1 to n (including any used for blocking) and are independent of each other, and P(LINK) is the prior likelihood of a correct match on a singly random pairing. The latter term is similar to the prior odds, P(LINK)/P(NONLINK), recognized but not used by Howe and Lindsay (1981). Confusion remains concerning the implications, and is not explicitly addressed by existing formal theory (see Sec. 2.1).
The version of this expression used to calculate estimated absolute ODDS from actual counts is unfamiliar to many, so it is necessary to be explicit: R1 to Rn become frequency ratios, and P(LINK) becomes N(LINKS)/N(LINKS + NONLINKS). Because each linked pair contains one record from File A and one from File B, N(LINKS) = N(A|LINK) = N(B|LINK). Also, where each record on File A is compared in succession with every record on File B, the total number of comparison pairs, regardless of their linkage status, will together equal the product of the two file sizes; that is, N(LINKS + NONLINKS) = N(File A) · N(File B). The concept is valid even where, in practice, only the pairings that occur within blocks are actually seen; but this implies that likelihood ratios for blocking identifiers will be taken into account. Thus by substitution we may obtain
Absolute ODDS
(1.7)
Howe and Lindsay (1981) had felt that their prior odds, P(LINK)/P(NONLINK), could not be readily estimated. The solution came to us by observing human stratagems and through reasoning based on counts rather than on probabilities. At first, it was hard to persuade others that this practice is valid, perhaps because our way of thinking was unconventional (David Binder and Geoffrey Howe, personal communication, November 10 to December 11, 1982). A further possible reason might be the common custom of not calculating frequency ratios for blocking identifiers; but then NA and NB would represent the sizes of Files A and B within the particular block, and the prior likelihoods would differ from block to block.
Calculation (1.7) has been used over the past decade for searches of Canadian death files. The application is exceedingly flexible and allows refinement through redefinition of Files A and B to represent, separately, a multiplicity of subsets (based on age, death year, selected diagnoses, and so on) of populations that are internally heterogeneous. (For details, see Newcombe 1988 chap. 28 and apps. B and D.2.)
2. EMPIRICAL DISTRIBUTIONS OF LINKS AND NONLINKS
A feedback of empirical data from the LINKS and NONLINKS is the most basic requirement of a linkage system. For example, the expressions by which the ODDS for the individual identifiers are calculated require these data as input. Also, such data are needed when assessing errors due to assumptions that are not strictly correct.
Above all, direct observation of individual record pairs often yields clues to more suitable comparison steps. These clues are most likely to become apparent to humans when resolving difficult matches manually. An experienced person can be less bound by artificial constraints than the automated system, and he or she is still, given existing linkage systems, in a better position to be guided by memories of past encounters with similar problems.
Theoretical papers on linkage make strong assumptions to get results, and linkage practice does the same to simplify
procedures. Examples include the use of artificially simplified ways of comparing names, which may not adequately exploit their true discriminating power, and the practice of simply multiplying the ODDS for individual identifiers to combine them for a whole set, which would be strictly proper only if they were independent of each other (Fellegi and Sunter 1969; Howe and Lindsay 1981).
Only with better data from LINKS and NONLINKS can many of the uncertainties be resolved Recognition of this has led, in part, to the idea of accumulating large files of LINKS and creating even larger files of NONLINKS (see, for example, Fair et al. 1990, 1991; Lalonde 1989; Newcombe et al. 1989). It has also emphasized the use of additional evidence on the true linkage status of record pairs assigned borderline absolute ODDS in an automated operation (Fair, Newcombe, and Lalonde 1988a; Fair, Newcombe, Lalonde, and Poliquin 1988b).
We will deal first with the latter point
2.1 The Assumption of Independence
Calculated overall “absolute ODDS” usually assume that the components in the identifier sets are independent of each other. Rarely is this assumption strictly correct. It can be seen to be misleading when scanning visually for record pairs that were wrongly classed as positive LINKS and positive NONLINKS. Our unpublished observations include examples of multiple agreements (e.g., of rare ethnic names and related places of birth) that have spuriously raised the ODDS to create false positives. Conversely, there are examples of multiple disagreements (especially on year, month, and day of birth— perhaps due to multiple wrong guesses by an informant at the time of a death), which have spuriously lowered the ODDS to create false negatives.
The effects of these and other such biases are best visualized in the overlap between the numbers of verified LINKS and NONLINKS, when distributed along a scale of absolute ODDS that assumes independence, as in Figure 1 (data of Fair et al. 1988a, 1988b; and Lalonde 1986). We will refer to points on this scale as “theoretical” ODDS to distinguish them from the “empirical” ODDS, which are the ratios of observed counts of LINKS/NONLINKS at various points on the same scale. (Total LINKS and NONLINKS are not shown in the Figure; but conceptually the latter vastly outnumber the former.)
In practice there is no need to actually create the bulk of the possible NONLINKS, because most would fall so very low on the scale. Major misunderstanding arises, however, when the enormous preponderance of actual plus potential NONLINKS over LINKS is not kept in mind. Thus the distributions and their crossover points serve little purpose if
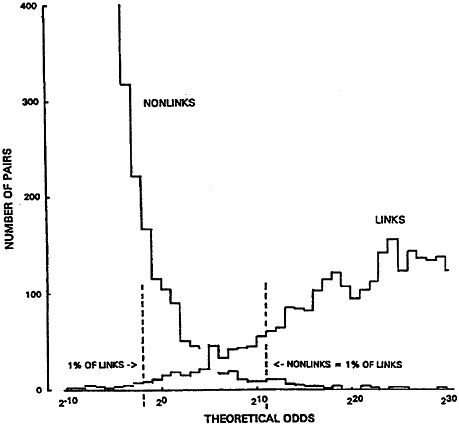
Figure 1. Overlapping Parts of the Distributions of LINKS and NONLINKS, on a Scale of Theoretical ODDS (Lalonde 1986). Note that empirical error bounds (broken lines), set at the 1% levels, are displaced upward on the theoretical scale.
plotted as proportions of LINKS compared with proportions of NONLINKS. Likewise, upper and lower “error bounds,” when expressed in such terms, make nonsense of the concept. (The data in Figure 1 are from searches of 1,300,000 death records, initiated by 30,000 work records, yielding 2254 LINKS; the vital status of doubtful pairs was confirmed using taxation files. Because the number of possible pairings, i.e., actual plus potential, is the product of the two file sizes, NONLINKS outnumber LINKS by 17,000,000 to 1.)
Marked discrepancies are revealed in Figure 1 between the theoretical ODDS scale, based on the assumption of independence, and the corresponding observed ratios of LINKS versus NONLINKS. For example, where the theory indicates that the ODDS in favor of linkage are 1/1, in reality they are only 1/6; and where the observed ODDS are 1/1, the theory says that they should be 16/1. Moreover, if one wants to set lower and upper thresholds to limit the number of LINKS wrongly classed as “positive nonlinks” to 1% of all LINKS, and to likewise limit the NONLINKS wrongly classed as “positive links” to a similar number (i.e., 1% of the LINKS), the correct thresholds would be represented by theoretical ODDS of approximately 1/4 and 2,000/1. Thus the true error bounds are displaced upward on a scale of ODDS that assumes independence.
There has been confusion in the past, which is best avoided by thinking in terms of numbers (i.e., counts) as distinct from proportions. One does not limit false positives to 1% of NONLINKS because, in our example, that would create 17,000,000 times as many false positives as false negatives. Indeed, the Fellegi-Sunter theory emphasizes that NONLINKS typically will greatly outnumber LINKS; for example, see slides #9 and #10 of Fellegi 1985. More explicitly, where this is the case “no one could possibly conclude” that the two error bounds would be properly set at equal proportions (i.e., 1%) of the LINKS and of the NONLINKS (I. P.Fellegi, personal communication July 8, 1987).
2.2 Data on Name Comparisons Involving Synonyms
Value-specific information to do with N(Ax· By | LINK), heretofore lacking in quantity, is contained in a composite file of 64,937 LINKED pairs of male given names derived from 26 linkage projects. All of the projects involved searches of the Canadian Mortality Data Base (File B, containing 3,397,860 male given names), initiated by records of various study cohorts, including employment records, survey responses, cancer registrations, birth records, and entries in a national radiation dose register (composite File A, containing
Table 1. Common Male Given Names From the Canadian Death File, 1950–1977
|
Total observed |
|||
|
Rank |
Name* |
Number |
Percent |
|
Formal Names |
|||
|
1 |
JOHN |
187,486 |
5.30 |
|
2 |
WILLIAM |
170,669 |
4.83 |
|
3 |
JAMES |
111,513 |
3.16 |
|
4 |
JOSEPH |
104,767 |
2.96 |
|
5 |
GEORGE |
95,188 |
2.69 |
|
6 |
CHARLES |
70,040 |
1.98 |
|
7 |
ROBERT |
66,575 |
1.88 |
|
8 |
THOMAS |
64,182 |
1.82 |
|
9 |
HENRY |
55,718 |
1.61 |
|
10 |
EDWARD |
55,837 |
1.68 |
|
11 |
ARTHUR |
52,221 |
1.48 |
|
12 |
ALBERT |
47,660 |
1.35 |
|
13 |
ALEXAND(ER) |
38,343 |
1.09 |
|
14 |
FREDERI(CK) |
36,864 |
1.04 |
|
15 |
DAVID |
33,530 |
.95 |
|
16 |
ERNEST |
32,041 |
.91 |
|
17 |
ALFRED |
30,902 |
.87 |
|
18 |
FRANK |
29,376 |
.83 |
|
19 |
PAUL |
26,919 |
.76 |
|
20 |
PETER |
26,889 |
.76 |
|
21 |
WALTER |
26,718 |
.76 |
|
22 |
HARRY |
24,830 |
.70 |
|
23 |
MICHAEL |
24,645 |
.70 |
|
24 |
RICHARD |
24,070 |
.68 |
|
25 |
LOUIS |
23,860 |
.68 |
|
26 |
JEAN (male) |
22,661 |
.64 |
|
27 |
FRANCIS |
21,596 |
.61 |
|
28 |
HAROLD |
21,588 |
.61 |
|
29 |
GORDON |
19,158 |
.54 |
|
30 |
HERBERT |
19,133 |
.54 |
|
31 |
SAMUEL |
18,927 |
.54 |
|
32 |
ANDREW |
18,440 |
.52 |
|
33 |
DONALD |
17,416 |
.49 |
|
34 |
DANIEL |
16,076 |
.46 |
|
35 |
STANLEY |
14.575 |
.41 |
|
36 |
PATRICK |
13,402 |
.38 |
|
37 |
NORMAN |
13.270 |
.38 |
|
38 |
ROY |
12,943 |
.37 |
|
39 |
RAYMOND |
12,338 |
.35 |
|
40 |
EMILE |
12,261 |
.35 |
|
41 |
HENRI |
12.107 |
.34 |
|
42 |
KENNETH |
12,076 |
.34 |
|
43 |
DOUGLAS |
11,843 |
.34 |
|
44 |
LEONARD |
10,978 |
.31 |
|
45 |
EUGENE |
10,968 |
.31 |
|
46 |
VICTOR |
10,797 |
.31 |
|
47 |
GEORGES |
10,446 |
.30 |
|
48 |
ALLAN |
10,384 |
.29 |
|
49 |
LEO |
10,200 |
.30 |
|
50 |
EDWIN |
10,156 |
.29 |
|
51 |
CLARENC(E) |
9,974 |
.28 |
|
Informal Variants |
|||
|
1 |
FRED |
7,947 |
.23 |
|
2 |
JACK |
5,575 |
.16 |
|
3 |
ALEX |
3,550 |
.10 |
|
4 |
MIKE |
3,267 |
.10 |
|
5 |
SAM |
2,014 |
.06 |
|
6 |
RAY |
1,911 |
.056 |
|
7 |
TOM |
990 |
.029 |
|
8 |
JOE |
866 |
.025 |
|
9 |
DAN |
781 |
.023 |
|
10 |
BILL |
314 |
.009 |
|
11 |
PETE |
265 |
.008 |
|
12 |
DON |
240 |
.007 |
|
13 |
ANDY |
220 |
.006 |
|
14 |
DAVE |
179 |
.005 |
|
15 |
ED |
43 |
.001 |
Table 2. Pooling of Synonyms in Value-Specific Groups: Example Based on CHARLES Compared with KARL and Related Variants
|
Value of name |
Numbers in File B* |
|
KARL |
3,002 |
|
KARLA |
1 |
|
KARLDON |
1 |
|
KARLE |
6 |
|
KARLEY |
1 |
|
KARLHEI |
2 |
|
KARLIE |
1 |
|
KARLIOU |
1 |
|
KARLIS |
82 |
|
KARLMER |
1 |
|
KARLO |
36 |
|
KARLOFF |
1 |
|
KARLOL |
1 |
|
KARLOS |
1 |
|
KARLS |
2 |
|
KARLSEN |
2 |
|
KARLSON |
2 |
|
KARLSSO |
1 |
|
KARLTON |
1 |
|
KARLY |
2 |
|
* Truncated at seven characters in the records of the Canadian mortality data base. * Based on an alphabetic listing from the death file. Of these names, only KARL was actually interchanged with CHARLES in the linked pairs of records. However, with CHARLES cannot be classed as full disagreements. |
|
1,574,661 male given names). (For details, see Fair et al. 1990, 1991.)
The data used in the current study are from the LINKED pairs of names containing any of the 51 most common given names in the death file or any of the 15 most common informal variants. These names are listed in Table 1, together with their counts and percentage frequencies in the death file.
The 51 common names account for more than half (1,842,327/3,397,860) of all given names in the death records of males. Among 64,937 LINKED pairs of male given names, they were present 33,183 times on the Records A (25,673 as first names and 7,510 as second names) and 33,988 times on the Records B (26,536 as first names and 7,452 as second names), for a total of 67,171 times. A name pair that partially agrees may occur in either of two configurations, e.g., as FRANK-FRANCIS or as FRANCIS-FRANK, depending on which value comes from File A and which value comes from File B. Where two or more of the 51 names get interchanged with each other (as happens with HARRY, HENRI, and HENRY), some of the same information may be duplicated in a slightly different form within the tables.
The 15 common informal variants represent less than 1% (28,164/3,397,860) of all given names in the death records of males. Among the 64,937 LINKED pairs of male given names, these were present 1,554 times on the Records A
Table 3. Examples of Partial Agreements That Are Well Represented
|
Values* |
Numbers observed |
||||
|
Rank |
x |
y |
Total |
N(Ax· By| LINK) |
N(Bx· Ay| LINK) |
|
1. |
MICHAEL |
–MIKE |
173 |
12 |
161 |
|
2. |
FREDERI |
–FRED |
169 |
12 |
157 |
|
3. |
ALEXAND |
–ALEX |
152 |
11 |
141 |
|
4. |
JOHN |
–JACK |
90 |
23 |
67 |
|
5. |
FRANCIS |
–FRANK |
73 |
19 |
54 |
|
6. |
JOSEPH |
–JOE |
62 |
2 |
60 |
|
7. |
FREDERI |
–FREDRIC |
52 |
28 |
24 |
|
8. |
ALLAN |
–ALLEN |
47 |
28 |
19 |
|
9. |
HENRY |
–HENRI |
44 |
40 |
4 |
|
10. |
SAMUEL |
–SAM |
37 |
3 |
34 |
|
11. |
PETER |
–PETE |
33 |
3 |
30 |
|
12. |
THOMAS |
–TOM |
33 |
7 |
26 |
|
13. |
WILLIAM |
–WILLI |
20 |
18 |
2 |
|
* Truncated at seven characters in the LINKS of Fair et al. (1991). |
|||||
Table 4. Examples of Partial Agreements That Are Not Well Represented
|
Values* |
Total observed |
|
|
x |
y |
|
|
ALBERT |
–ALBERTO |
1 |
|
ARTHUR |
–ARTIMUS |
1 |
|
DOUGLAS |
–DOUGLES |
1 |
|
ERNEST |
–ERNES |
1 |
|
HAROLD |
–HARLOD |
1 |
|
LEO |
–LEODA |
1 |
|
PETER |
–PEDER |
1 |
|
VICTOR |
–VIATEUR |
1 |
|
ALBERT |
–ALBERTS |
0 |
|
ARTHUR |
–ARTIMON |
0 |
|
DOUGLAS |
–DOUGLIS |
0 |
|
ERNEST |
–ERNE |
0 |
|
HAROLD |
–HARLOE |
0 |
|
LEO |
–LEODAS |
0 |
|
PETER |
–PEDAR |
0 |
|
VICTOR |
–VIATIAR |
0 |
|
* Truncated at seven characters in the LINKS of Fair et al. (1991). |
||
(1,426 as first names and 128 as second names) and 701 times on the Records B (633 as first names and 68 as second names), for a total of 2,255 times.
xApplication of the linkage rationale to outcomes defined in wholly value-specific ways depends on more than just the ODDS formula for its success. The chief obstacle is created by the many value pairs that are rare in the available LINKS, plus the even more numerous possible ones that have not been observed at all. Grouping is necessary, but must be based on wholly value-specific group definitions. The roles played in the process by Files A and B and the LINKS are illustrated in Tables 2–5. Group definitions are based on selected blocks of names in alphabetic listings, chosen to bring rare synonyms into the same groups with common forms (Table 2). Comparison pairs that are common in the LINKS present no special problem (Table 3). However, possible pairs that are rare or absent in the available LINKS need to be grouped with others that are more common (Table 4). ODDS are calculated for specific name pairs and for specific groups as a whole, using expression 1.4 (Table 5). (For details see Fair et al. 1990, 1991.)
There are no rules explicitly stating how the boundaries of the groups should be determined, except that variants known to yield widely different ODDS on their own should not be put into the same group. Apart from this, the process is unavoidably subjective—but it is far from entirely arbitrary. In particular, it is greatly aided by strong impressions gained while perusing alphabetical listings of names from Files A and B.
3. APPLICATION: REFINEMENTS AND SHORTCUTS
Many choices have had to be made in the past between shortcuts in the way the ODDS are calculated versus corresponding refinements in which the shortcuts are not used. Such choices are inescapable, but only rarely have their effects on the calculated ODDS been quantified. Indeed, where data to support the more refined alternative were lacking, the comparison often was not possible. But now the extensive data from large files of LINKS accumulated at Statistics Canada make it attractive to assess the effects on discriminating power when people 's names are compared in alternative ways.
Table 5. Comparison Outcomes for the Given Name GEORGE, With Examples of Possible Groupings
|
Values* |
Total outcomes |
ODDS |
|
|
x |
y |
||
|
Full Agreement |
|||
|
GEORGE–GEORGE |
3,130 |
89.7/1 |
|
|
Partial Agreement |
|||
|
GEORGE–GEO |
6 |
87.9/1 |
|
|
GEORGE–GEOR to GEORGDZ (including GEORDIE) |
11 |
14.9/1 |
|
|
GEORGE–GEORGES |
28 |
12.1/1 |
|
|
GEORGE–GEORGET to GEORGZ (including GEORGIO) |
3 |
21.6/1 |
|
|
Other (Including disagreements) |
|||
|
GEORGE–G* (*=other; few synonyms) |
16 |
1/5.6 |
|
|
GEORGE–non-G (full disagreements) |
175 |
1/13.2 |
|
|
* Data for Ax·By and Bx·Ay are pooled. |
|||
We consider here six shortcuts (and their corresponding refinements):
-
Use of the simplified formula (see expression 1.5)
-
Pooling of first and second given names, to reduce the number of look-up tables of the value-specific frequencies, N(By)/N(B), when using the simplified formula
-
Use of a wholly versus a partially global term in the numerator of the simplified formula when calculating ODDS for the various levels of outcome (i.e., both Ax and By being nonspecific in the LINKS, versus Ax being specified as equal, successively, to each of the 51 common names)
-
Not updating the global ODDS
-
Recognizing the specificities of just the agreement portions of names that only partially agree
-
Pooling complementary partial agreements (e.g., Ax·By = MICHAEL-MIKE, plus Ay·Bx = MIKE-MICHAEL).
Past and current practices with regard to these shortcuts are reviewed elsewhere (Hill 1981; Howe and Lindsay 1981; Newcombe 1988).
The importance of a given refinement as compared with its corresponding shortcut is assessed by comparing the ODDS when calculated in the two ways. The ratios of the two ODDS will be termed “error factors ” or “correction factors.” These factors vary for different names as represented in File A (e.g., the given name JOHN) and for different comparison outcomes (e.g., JOHN-JACK). One such type of “correction factor” is defined in the second part of expression 1.5. Its use as part of the full expression constitutes a refinement, its omission constitutes a shortcut, and its use on its own reveals the factor difference between the ODDS as obtained in the two ways.
Comparisons between different refinement/shortcut choices may be based either on the frequency distributions of the error levels, as defined earlier, or on the median and maximum error factors. Sometimes a combination of the two may be appropriate. Data from the six types of comparisons are presented in Figure 2 (parts a to f) and Table 6 (lines 1 to 6). The histograms in Figure 2 are appropriately weighted throughout; for example, in part a of Figure 2 by the frequencies of the names in File A.
The magnitudes of such error factors may vary with the particular name or linkage project; that is, forming a distribution of error factors as shown in Figure 2. The log error factor approach, with base 2, is used in this Figure. (Log error factor = 1 indicates a difference by a factor of 2, log error factor = 2 indicates a difference by a factor of 4, and so on.) Because we are dealing with a spectrum of error factors and need to divide it into discrete levels, we have recognized central values of 1, 2, 4, 8, 16, and so on (equivalent to logs to the base 2 = 0, 1, 2, 3, 4, and so on). Standard founding of the logs is used to assign the appropriate central values.
3.1 Ranking the Choices
The effect of choosing a shortcut, or its corresponding refinement, is best seen in a listing of the associated error factors in descending order. These create in the mind a compelling picture. What they teach us is that the feedback of actual data does away with the need for guesswork. For our current purposes it is sufficient that the results of the tests be summarized (Fig. 2, Table 6) and that examples be given.
Use of the simplified formula, for example, results in error factors as high as 6.4, with 13% of the 34,737 comparisons associated with the four-fold level of error. Nine of the 51 common names and 5 of the 15 informal names are involved (i.e., DOUGLAS, ERNEST, EMILE, FRANK, HAROLD, CLARENCE, ALFRED, HERBERT, HARRY, FRED, PETE, MIKE, SAM, ALEX). Similarly modest error factors result from pooling of first plus second names, use of a wholly global numerator, and pooling complementary partial agreements. In these examples the magnitudes of the error factors vary with the values of the given names.
The effects of not updating the ODDS differ in that the error factors vary with the quality of the files used to initiate the death searches and, therefore, with the particular linkage study. Error factors are greater for the partial agreements than for the full agreements and disagreements, independent of the actual values of the names; for this reason, only the partial agreements are considered here. Again, the effects of the shortcut are modest. The largest are associated with search files (Files A) in which the quality of the identifiers differed most widely from the average; that is, were either much better
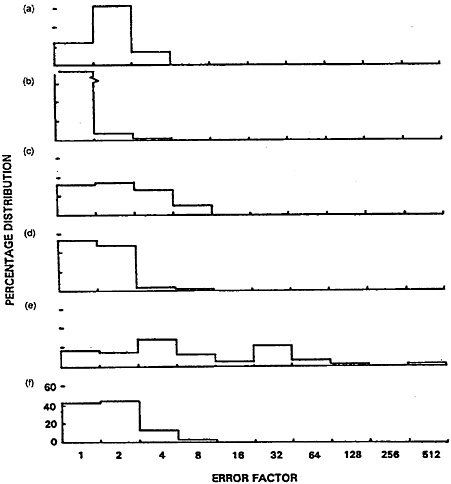
Figure 2. Frequency Distributions of Error Factors Resulting From Shortcuts In the Comparison Procedures for Male Given Names, (a) Simplified formula; (b) Pooled first plus second names; (c) Wholly global numerator; (d) Not updating the ODDS; (e) Recognizing the specificities of just the agreement portions; (f) Pooling complementary partial agreements.
(as with infant death-to-birth linkages) or much worse (as with certain employment records). This is because in such cases the composite ODDS most poorly represent the ODDS appropriate for the particular project.
Only for one kind of choice are the error factors truly large. This has to do with the practice of recognizing the specificities of only the agreement portions of names that do not fully agree (versus recognizing the full specificities of both members). The most extreme examples
Table 6. Ranking the Choices Between Refinements Versus Shortcuts: Partial Agreements Only
|
Shortcut |
Median error |
Maximum error |
Rank* |
|
1. Simple Formula |
1.7 |
6.4 |
(3) |
|
2. Pooling First and Second |
1.1 |
14.2 |
(6) |
|
3. Global Numerator |
2.1 |
12.2 |
(2) |
|
4. Update Omitted |
1.4 |
6.4 |
(5) |
|
5. Partial Specificity |
4.9 |
686.7 |
(1) |
|
6. Complementary Partials |
1.4 |
11.2 |
(4) |
(with their error factors) include WALTER–WLADYSL (686.7), ERNEST –EARNEST (412.7), PETER0–PIO (190.2), WILLIAM–BILLY (160.6), ROY–LEROY (155.8), JOHN– JUHO (82.6), LEONARD–LENARD (82.4), RAYMOND– RAIMOND (77.6), LOUIS–LOIS (72.7), and JOHN-JAN (57.7). Only when the full specificities are taken into account does the discriminating power get efficiently exploited.
*Rank based on median error factor, followed by maximum.
4. CONCLUSIONS AND RECOMMENDATIONS
Current tests assess the degree to which inherent discriminating power is exploited where names are used to bring together records of the same persons, especially when alternative forms of a name are compared. The emphasis differs from that of procedures based on degrees of phonetic similarity plus lists of exceptions, in that both values get recognized and necessary data are drawn from large accumulations of linked pairs of records.
Motivation to achieve maximum refinement in record linkage comes from the social trend towards larger and more
numerous personal data banks. Complex influences govern the trend. Records proliferate because people rely on governments and the commercial sector for increased security and benefits of many sorts, plus conveniences and luxuries where possible. The process is slowed by fears that the right to privacy might suffer, but it is also accelerated by public insistence on a right to know whether perceived threats to health and well-being are real, because the best answers often come only through increased access to personal data banks (in Canada, see Bouchard, Roy, and Casgrain 1985; Fair 1989; Jordan-Simpson, Fair, and Poliquin 1988; Leyes 1990; Medical Research Council of Canada 1968; Newcombe et al. 1983; Roos, Wajda, and Nichol 1986; Smith and Newcombe 1980, 1982; elsewhere, see Arellano, Petersen, Pettiti, and Smith 1984; Baldwin, Acheson, and Graham 1987; Copas and Hilton 1990; Jaro 1989; Kilss and Alvey 1985; Patterson 1980; Rogot, Sorlie, Johnson, Glover, and Treasure 1988; Winkler 1989a,b,c,d; also see early reviews by Acheson 1967 and Farr 1875). A logical step in this evolution is the automation of registers embracing whole populations (Dunn 1946; Leyes 1990; Marshall 1947; Redfern 1990; Scheuren 1990).
The current approach follows a general trend in statistics, which is to develop empirical reference distributions using computers, rather than to rely mainly on theoretical distributions. Here, we use large composite files of LINKS (Fair et al. 1990, 1991) and even larger files of random pairs to serve as NONLINKS (Lalonde 1989). Examples as applied to other statistical problems include uses of the “bootstrap” method (Efron and Tibshirani 1986, 1992). Moreover, those involved with linkage technology stress the need to archive empirical data from past linkage studies, and use it to compare the performances of different systems (see, for example, Howe 1986; Howe and Spasoff 1986a,b; Jabine and Scheuren 1986; Scheuren et al. 1986; Science Council of Canada 1986; Smith 1986).
In a sense, we emphasize here a role for semiautomated “learning,” from past experience. Complexity need not be a serious barrier, because complex procedures, once developed, may be used repeatedly and can evolve through successive refinements.
[Received October 1989. Revised May 1991.]
REFERENCES
Acheson, E.D. ( 1967), Medical Record Linkage. Oxford, U.K.: Oxford University Press.
Arellano, M.G., Petersen, G.R., Petitti, D.B., and Smith, R.E. ( 1984), “The California Automated Mortality Linkage System,” American Journal of Public Health, 74, 1324–1330.
Baldwin, J.A., Acheson, E.D., and Graham, W.J. (eds.) ( 1987), Textbook of Medical Record Linkage. Oxford, U.K.: Oxford University Press.
Bouchard, G., Roy, R., and Casgrain, B. ( 1985), Reconstitution Automatiques des Familles, le Système SOREP (Vols. I and II), Chicoutimi, Quebec: Centre Interuniversitaire de Reserches sur les Populations (SOREP)
Copas, J.B., and Hilton, F.J. ( 1990), “Record Linkage: Statistical Models for Matching Computer Records, ” Journal of the Royal Statistical Society, Ser. A, 153 (Part 3), 287–320.
Dunn, H.L. ( 1946), “Record Linkage,” American Journal of Public Health, 36, 1412–1416.
Eagen, M., and Hill, T. ( 1987), “Record Linkage Methodology and its Application,” in Statistical Uses of Administrative Data, Proceedings of an International Symposium, eds. J.W.Coombs and M.P.Singh, Ottawa: Statistics Canada, pp. 139–150.
Efron, B., and Tibshirani, R. ( 1986), “The Bootstrap Method for Assessing Statistical Accuracy” (with discussion), Statistical Science, 1, 54–77.
—— ( 1992), “Statistical Data Analysis in the Computer Age,” Science, in press.
Fair, M.E. ( 1989), Studies and References Relating to Uses of the Canadian Mortality Data Base, Ottawa: Statistics Canada, August 1989.
Fair, M.E., Lalonde, P., and Newcombe, H.B. ( 1990), Tables of ODDS For Partial Agreements of Male Given Names in Linking Records, Report OEHRS No. 9, Ottawa: Statistics Canada.
—— ( 1991), “Application of Exact ODDS for Partial Agreements ofNames in Record Linkage,” Computers and Biomedical Research, 24, 58–71.
Fair, M.E., Newcombe, H.B., and Lalonde, P. ( 1988a), Improved Mortality Searches for Ontario Miners Using Social Insurance Index Identifiers , Report No. INFO-0264, Ottawa: Atomic Energy Control Board.
Fair, M.E., Newcombe, H.B., Lalonde, P., and Poliquin, C ( 1988b), “Alive” Searches as Complementing Death Searches in the Epidemiological Follow-Up of Ontario Miners, Report No. INFO-0266, Ottawa: Atomic Energy Control Board.
Farr, W. ( 1875), in Supplement to the 35th Annual Report of the Registrar General, London: Her Majesty's Stationery Office, p. 110.
Fellegi, I.P. ( 1985), “Tutorial on the Fellegi-Sunter Model for Record Linkage,” in Record Linkage Techniques—1985 (Proceedings of the Workshop on Exact Matching Methodologies, Arlington, Virginia, May 9–10, 1985), eds. B.Kilss and W.Alvey, Washington, DC: Department of the Treasury, Internal Revenue Service, pp. 127–138.
Fellegi, I.P., and Sunter, A.B. ( 1969), “A Theory of Record Linkage,” Journal of the American Statistical Association, 40, 1183–1210.
Hill, T. ( 1981), Generalized Iterative Record Linkage System: GIRLS. Ottawa: Statistics Canada.
Hill, T., and Pring-Mill, F. ( 1985), “Generalized Iterative Record Linkage System,” in Record Linkage Techniques—1985, (Proceedings of the Workshop in Exact Matching Methodologies Arlington, Virginia, May 9– 10, 1985). eds. B.Kilss and W.Alvey, Washington, DC Department of the Treasury, Internal Revenue Service, pp. 327–333.
Howe, G.R. ( 1986), “Possible Future Directions in Record Linkage,” in Proceedings of the Workshop in Computerized Record Linkage in Health Research (Ottawa, Ontario, May 21–23, 1986), eds. G.R.Howe and R.A.Spasoff, Toronto: University of Toronto Press, pp. 231–233.
Howe, G.R., and Lindsay, J. ( 1981), “A Generalized Iterative Record Linkage Computer System for Use in Medical Follow-Up Studies,” Computers and Biomedical Research, 14, 327–340.
Howe, G.R., and Spasoff, R.A. (eds.) ( 1986a), Proceedings of the Workshop on Computerized Record Linkage in Health Research (Ottawa, Ontario, May 21–23, 1986), Toronto: University of Toronto Press.
—— ( 1986b), “Recommendations of the Workshop on Computerized Linkage in Health Research,” in Proceedings of the Workshop on Computerized Record Linkage in Health Research (Ottawa, Ontario, May 21– 23, 1986), eds. G.R.Howe and R.A.Spasoff, Toronto: University of Toronto Press, pp. 18–23.
Jabine, T.B., and Scheuren, F. ( 1986), “Record Linkages for Statistical Purposes: Methodological Issues,” Journal of Official Statistics, 2, 255– 277.
Jaro, M.A. ( 1989), “Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida,” Journal of the American Statistical Association, 84, 414–420.
Jordan-Simpson, D., Fair, M.E., and Poliquin, C. ( 1988), “Canadian Farm Operator Study. Methodology,” Health Reports (Statistics Canada), 2, 141–155.
Kilss, B., and Alvey, W. (eds.) ( 1985), Record Linkage Techniques—1985, (Proceedings of the Workshop on Exact Matching Methodologies, Arlington, Virginia, May 9–10, 1985), Washington, DC: Department of the Treasury, Internal Revenue Service.
Lalonde, P. ( 1989), “Deriving Accurate Weights Using Non-Links,” in Proceedings of the Record Linkage Sessions and Workshop, Canadian Epidemiology Research Conference—1989, eds. M.Carpenter and M.E.Fair, Ottawa: Statistics Canada, pp. 149–157.
Leyes, J. ( 1990), “Release of a Pilot Longitudinal Administrative Database,” The Daily (Statistics Canada), Monday, October 22, 1990, p. 6.
Marshall, J.T. ( 1947), “Canada's National Vital Statistics Index,” Population Studies, 1, 204–211.
Medical Research Council of Canada ( 1968), Health Research Uses of Record Linkage in Canada, Report No. 3, Ottawa: Author.
Newcombe, H.B. ( 1967), “Record Linking: The Design of Efficient Systems for Linking Records into Individual and Family Histories,” American Journal of Human Genetics, 19, 335–359.
—— ( 1988). Handbook of Record Linkage: Methods for Health and Sta-
tistical Studies. Administration and Business , Oxford, U.K.: Oxford University Press.
Newcombe, H.B., Fair, M.E., and Lalonde, P. ( 1987), “Concepts and Practices that Improve Probabilistic Record Linkage, ” in Statistical Uses of Administrative Data, Proceedings of an International Symposium (Ottawa, Ontario, November 23–25, 1987), eds. J.W.Coombs and M.P. Singh, Ottawa: Statistics Canada, pp. 127–138.
—— ( 1989), “Discriminating Powers of Partial Agreements of Names for Linking Personal Records, Part I: The Logical Basis, and Part II: The Empirical Test,” Methods of Information in Medicine, 28, 86–91, 92–96.
Newcombe, H.B., and Kennedy, J.M. ( 1962), “Record Linkage: Making Maximum Use of the Discriminating Power of Identifying Information,” Communications of the Association for Computing Machinery. 5, 563– 566.
Newcombe, H.B., Kennedy, J.M., Axford, S.J., and James, A.P. ( 1959), “Automatic Linkage of Vital Records,” Science, 130, 954–959.
Newcombe, H.B., Smith, M.E., Howe, G.R., Mingay, J., Strugnell, A., and Abbatt, J.D. ( 1983), “Reliability of Computer versus Manual Death Searches in a Study of Eldorado Uranium Workers,” Computers in Biology and Medicine, 13, 157–169.
Patterson, J.E. ( 1980), “The Establishment of a National Death Index in the United States, ” in Cancer Incidence in Defined Populations (Banbury Report No. 4). eds. J.Cairns, J.L.Lyon, and M.Skolnick, Cold Spring Harbor, Long Island, New York, Cold Spring Harbor Laboratory, pp. 443–451.
Redfern, P. ( 1990), “Sources of Population Statistics: An International Perspective,” in Population Projections: Trends. Methods and Uses. OPCS Occasional Paper 38, London: Office of Population Censuses and Surveys, Her Majesty's Stationery Office.
Rogot, E., Sorlie, P.D., Johnson, N.J., Glover, C.S., and Treasure, D.W. ( 1988), A Mortality Study of One Million Persons: First Data Book, NIH Publication No. 88–2896, Bethesda, MD: Public Health Service, National Institutes of Health.
Roos, L.L., Wajda, A., and Nicol, J.P. ( 1986), “The Art and Science of Record Linkage: Methods that Work with Few Identifiers,” Computers in Biology and Medicine, 16, 45–57.
Scheuren, F. ( 1985), “Methodological Issues in Linkage of Multiple Data Bases,” Record Linkage Techniques—1985, Washington, DC: Department of the Treasury, Internal Revenue Service, pp. 155–178.
—— ( 1990), Discussion of “Rolling Samples and Censuses,” by L.Kish, Survey Methodology, 16, 72–79.
Scheuren, R, Alvey, W., and Kilss, B. ( 1986), “Record Linkage for Statistical Purposes in the United States,” in Proceedings of the Workshop in Computerized Record Linkage in Health Research (Ottawa, Ontario, May 21– 23, 1986), eds. G.R.Howe and R.A.Spasoff, Toronto: University of Toronto Press, pp. 198–210.
Science Council of Canada ( 1986), Proceedings: A National Workshop on the Role of Epidemiology in the Risk Assessment Process in Canada , Catalogue No. SS24–23/1985, Ottawa: Author.
Smith, M.E. ( 1986), “Future Needs and Directions for Computerized Record Linkage in Health Research in Canada: Future Study Plans,” in Proceedings of the Workshop in Computerized Record Linkage in Health Research (Ottawa, Ontario, May 21–23, 1986), eds. G.R.Howe and R.A.Spasoff, Toronto: University of Toronto Press, pp. 211–230.
Smith, M.E., and Newcombe, H.B. ( 1975), “Methods for Computer Linkage of Hospital Admission-Separation Records into Cumulative Health Histories,” Methods of Information in Medicine, 14, 118–125.
—— ( 1979), “Accuracies of Computer Versus Manual Linkages of Routine Health Records, ” Methods of Information in Medicine, 18, 89–97.
—— ( 1980), “Automated Follow-up Facilities in Canada for Monitoring Delayed Health Effects,” American Journal of Public Health, 73, 39–46.
—— ( 1982), “Use of the Canadian Mortality Data Base for Epidemiological Follow-up, ” Canadian Journal of Public Health, 73, 39–46.
Sunter, A.B. ( 1968), “A Statistical Approach to Record Linkage,” in Record Linkage in Medicine (Proceedings of the International Symposium, Oxford, July 1967), ed. E.D.Acheson, London: E & S Livingstone, pp. 89–109.
Winkler, W.E. ( 1985), “Preprocessing of Lists and String Comparison,” in Record Linkage Techniques—1985, eds. W.Alvey and B.Kilss, Washington, DC: Department of the Treasury, U.S. Internal Revenue Service, pp. 181–187.
—— ( 1989a). String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage (Technical Report), (paper presented at the Annual ASA Meeting in Anaheim, CA) Washington, DC: Statistical Research Division, U.S. Bureau of the Census.
—— ( 1989b), “The Interaction of Record Linkage Practice and Theory,” in Proceedings of the Record Linkage Sessions and Workshop, Canadian Epidemiology Research Conference—1989, eds. M.Carpenter and M.E. Fair, Ottawa: Statistics Canada, pp. 139–148.
—— ( 1989c), “Near Automatic Weight Computation in the Fellegi-Sunter Model of Record Linkage,” in Proceedings of the Fifth Census Bureau Annual Research Conference, Washington, DC: U.S. Bureau of the Census, pp. 145–155.
—— ( 1989d), “Methods for Adjusting for Lack of Independence in an Application of the Fellegi-Sunter Model of Record Linkage,” Survey Methodology, 15, 101–117.
Comment
MAX G.ARELLANO*
Because the discussion is focused primarily on first name variants, the title perhaps should more appropriately be “The Use of Given Names for Linking Personal Records.” While not stated, the implication is that the “special skill” developed by humans is of considerable value in the decision making process. The fact is that the “special skills” vary considerably from person to person and that the biases that they bring to the evaluation may hinder rather than assist in the record linkage process.
The “past experience” argument is spurious. There is no reason to believe that the lessons learned from a Canadian mortality study will be of any benefit to an evaluation of a Cuban expatriate population or that experience gained in a study of mortality among Chicago nurses will be of any benefit to a study of child abuse in Seattle.
It does not follow at all that “if a machine is to acquire similar ability, it too must rely on past experience.” For instance, an analysis of the decisions made by the operators may well reveal that their judgments are based primarily on their perceptions of probability of occurrence and the reliability of the data. These factors are quantifiable and not dependent on past experience.
|
* |
Max G.Arellano is Chief Scientist Advanced Linkage Technologies of America, Inc., Berkeley, CA 94707. |
1. COMPUTER LINKAGE
The presentation is much too informal. It is difficult enough to figure out how the authors derive their likelihood ratio without trying to deduce how they arrived at the “two additional factors. ” What are the consequences of failure to recognize these two factors? The authors' arguments would be much easier to follow if they were presented in mathematical terms.
I fail to see the relevance of “describing the insights on which their success depends” in “plain language…such as they would understand” to the clerical searchers?
Probabilistic linkage procedures must be based on a probability model with definable probability distribution or density functions. The Fellegi-Sunter model is a probability model; I see no evidence of a probability model in this article. This is not to say that there is no merit in the approach presented in this article; however, it should properly be presented as a subjective probability or expert system.
The concept of falsely matched random pairs is a fascinating topic. But if, as the authors state in the first paragraph of page 7, “ it was not difficult to determine the corresponding likelihoods for a control group of falsely matched random pairs (NONLINKS),” then why didn't they present the procedures that they used to obtain this value? I believe that this would have contributed immensely to their presentation.
I understand the context within which the historical development is being presented, and I am in complete sympathy with the authors ' objectives. However, the point must be made that the validity of the linkage rationale that they describe is a function of the correctness of the linkage decisions that were made. A statement is badly needed regarding whether it was possible to confirm their decisions or how they were able to establish a level of confidence in them. After all, this is the central issue in record linkage.
The authors seem to feel that refinements in linkage decision criteria only proceeded “independent of the formal theory” (p. 1194). There is no reason, however, to believe that these or similar developments could not have or did not proceed within the context of the formal theory, perhaps without the knowledge of the authors.
Routine cross-comparisons can also be extremely wasteful of available resources if they are not called for by the nature of the data. In most linkage evaluations, 85–90% of the correct linkages can readily be detected as exact matches on name and birthdate.
The authors state that “frequent close scrutiny of difficult matches provided insights that would have been missed had refinement been sought through theory alone” (pp. 1194– 1195). In view of the fact that, as the authors readily admit, their procedures are not based on the formal theory, the validity of this statement is doubtful. How can they be sure of the correct direction of these “difficult matches” without reference to the subjects whose records are being linked?
In the development of their decision criteria, Fellegi and Sunter stated very clearly that the effect of their weight computation is “to array the record pairs, relative to one another, in descending order of the likelihood of a correct match.”
If the authors had observed the strict requirements of the Fellegi-Sunter model, they would have realized that the restriction of the comparison-space to linkages with identical surname phonetic codes requires an adjustment to the computation of the surname weights. This adjustment would have compensated for the distortion that they observed in the “crossover ” point.
The discussion of prior likelihood is unnecessarily vague. What are prior likelihoods? How are they estimated? It is not sufficient to simply show these as P(LINK)/P(NONLINK).
The authors would do better to present their derivation in terms of the Fellegi-Sunter model Within the context of the Fellegi-Sunter model, there is no need for concern about “fortuitous LINKS in the random pairs.”
“ODDS” should be expanded on. ODDS of what?
One cannot have conditional probabilities without either a probability distribution or density function. I don't see any evidence of either.
The derivation leads to the conclusion that we need to know the number of links with value Ax and By (p. 1196). But this is exactly what we are trying to accomplish with the linkage; that is, this information is not known. The authors gloss over this point without explaining how they intend to fill in the blanks.
The “tradeoff” argument (p. 1196) is completely spurious. The categories are determined by the characteristics of the data. It is not reasonable to assume that the operators of linkage software can be expected to ensure that every outcome group is broad enough so that “N(Ax·By|LINK) is represented by at least one comparison pair. Otherwise no ODDS can be calculated” (p. 1196). This sounds as though the procedure is controlling the application. Linkage software can readily be designed so that empty categories are either assigned zero values or some predetermined default value.
Partial given name agreements can be easily handled by phonetically encoding the name and constructing an exception list. This procedure has been in use by most organizations with which I am familiar for at least the past 16 years.
The authors state that “confusion still remains concerning the implications, and is not explicitly addressed by existing formal theory” (p. 1197), The authors are obviously privy to some controversy to which I am not.
We keep coming back to the fact that N(A|LINK) is unknown. The authors should have expanded on how they obtain this value.
2. EMPIRICAL DISTRIBUTIONS OF LINKS AND NONLINKS
The authors apparently believe that the results of particular linkage evaluations can be extrapolated to other linkage evaluations. Although this may be true in general, it cannot be relied on as a matter of policy. For instance, the reporting of demographic information by psychiatric patients may be much less reliable than information gathered for epidemiologic research purposes, the point being that “memories of past encounters with similar problems” may well lead you astray.
Although the authors criticize the practice of simply multiplying the ODDS for individual identifiers to combine them
for a whole set “which would only be proper if they were independent of each other, ” (p. 1198) this appears to be exactly what they do—or do they believe that the P(LINK) term corrects for the dependence among the identifiers?
The authors appear obsessed by the presence of false-positive links and false-negative links. The purpose of a record linkage, however, is not to eliminate these links, but rather to minimize them. There is a point beyond which the cost of refining the rules outweighs the advantages of applying them, particularly if the refinement requires an extensive amount of manual review.
The authors state that the number of possible pairings is the product of the two file sizes. This is true, however, only if all possible pairwise comparisons are actually formed between the two files—a practice that would be prohibitively expensive. The actual number of pairings is a function of the blocking strategy that was used. The difference is not at all trivial.
The problem to which the authors allude beginning on page 1199, of establishing upper and lower threshold values is not related to the independence problem. It is a function of the far greater size of NONLINKS relative to the LINKS— a fact, by the way, that is well known to persons involved in probability linkage, despite the concerns expressed by the authors. The threshold problem would exist even if a correction for the dependence of the identifiers could be incorporated into the computation of the total odds.
The “strong impressions gained while perusing alphabetic listings of names from Files A and B” (p. 1200) are of value only if their validity can be established by reference to the truely valid linkages. Under any circumstances, however, unless these “impressions” can be translated into formal rules, these procedures are obviously not suitable for mass production purposes.
3. CONCLUSIONS AND RECOMMENDATIONS
Rarely, if ever, does an experienced human clerk obtain feedback regarding the validity of a difficult linkage decision. Without this information, the clerk cannot possibly know whether his intuition was correct or not. If the clerk is not routinely receiving this feedback, the rules he has been developing may well lead to the systematic introduction of error into the decision criteria he is applying to the linkages.
The authors contend that the thought patterns (of the “experienced human clerk”) clearly differ from those of a skilled mathematician. However, the consensus among most persons involved in probability linkage with whom I am familiar is that subjective judgment is based on perceptions of probabilities of occurrence, a feel for the reliability of the data, and a familiarity with the various ways in which the same item of information can be recorded. There is no mystery; all of these factors are readily quantifiable.
Before one can “learn” from past experiences (p. 1203), two elements are necessary:
-
One must rigorously define how to measure a “success.” The authors have failed to do so.
-
One must demonstrate that the lessons learned from a particular linkage evaluation have relevance to the new linkage evaluations that are under active consideration. Personally, I would hesitate to apply the lessons which the authors have learned from their Canadian experience to our ongoing linkage evaluations in California.
4. REVIEWER'S SUMMARY
The authors' bias toward an informal approach to the development of linkage decision criteria is obvious, as is their sentiment that no real value can come from pursuing formal probability linkage models such as the Fellegi-Sunter model. One must ask, however, if the authors are aware of any objective basis for their assertion that an informal approach is superior to an approach based on a formal mathematical model.
Organizations with which I have been affiliated have used various versions of the Fellegi-Sunter probability linkage model for the past 17 years, with a great deal of success. Our linkage evaluations have included files with over one million records. Although manual review of the borderline linkages is an essential element of our linkage processing, because of the very large number of linkages identified it would be impractical for us to become overly involved in resolution of the difficult matches. Although we routinely observe the instances in which there is a substantial amount of conflict among the identifiers, I would question the wisdom of applying the lessons learned from the outcome of one difficult match to another difficult match.
Newcombe would do well to explore the operation of systems that use a formal probability linkage model; perhaps he would then gain a greater appreciation of them. We welcome his call for greater mutual cooperation. If there is sufficient interest, we would be glad to participate in a comparative linkage methodology evaluation study.
REFERENCE
Fellegi. I., and Sunter, A. ( 1969), “A Theory for Record Linkage,” Journal of the American Statistical Association, 64, 1183–1210.
Rejoinder
HOWARD B.NEWCOMBE, MARTHA E.FAIR, and PIERRE LALONDE
Arellano has provided a detailed critique of our article, much of which does not actually contradict what we have said or conflict with our own understanding, even though the language may differ. Any rejoinder, therefore, should confine itself to major points of difference on matters of emphasis or fact.
We do not, for example, believe that added refinement is always cost-effective in all situations. But by exploring the ways in which the comparison space may be more finely partitioned, we hope to expand both the present and the future potential for improved linkage performance at acceptable cost. It was the crudity of the popular agreement-disagreement distinction that provided the initial major motivating force. What impressed us as a source of innovation was the wealth of alternative comparison procedures and of multiple alternative outcome definitions, that got applied freely by a person's mind. Many of these proved highly effective in the case of difficult links, once the true status of the record pairs was confirmed later by independent means.
The emphasis we have placed on multiple partitioning of the comparison space has applications that are not confined to any particular identifier field. For example, colleagues at one time were concerned that our recognition of multiple outcomes from comparisons of place of work with place of death, when doing death searches, might be contrary to linkage theory. The observation was that workers at an Ontario uranium refinery who migrated before dying tended to die more often, either in the home province or in western Canada, but less often in eastern Canada and only rarely in the most easterly province, as compared with the random expectation. A somewhat different pattern (i.e., empirical distribution) was observed for workers in the uranium mines of Saskatchewan and the Northwest Territories; so there was no question of extrapolating from one subset of the cohort to the other. Here, final verification of the linkage status of the record pairs was not in doubt. Even before that verification, however, approximate likelihood ratios contributed to the linkage process and to the updating and iterative refinement, both of the linked files and of the likelihood ratios together. To establish useful comparison rules, we first needed to “learn” what only the linked files could “teach” concerning the empirical distributions and the outcome definitions most likely to exploit their discriminating power to good advantage. Earlier objections to the approach were later withdrawn. But if this broad emphasis on added partitioning of the comparison space to reveal a greater diversity of usable differences in observed versus random distributions is indeed fundamentally flawed, as Arellano seems to believe, we would welcome from him a concrete example to that effect.
We also appreciate Arellano's stated interest in “comparative linkage methodology evaluation studies,” especially if this interest encompasses the current focus on given names. Thus he could readily compare his own practice of recognizing phonetic similarity plus an exception list with our wholly value-specific approach, using Canadian data that have been published in great detail for just such a purpose (Fair, Lalonde, and Newcombe 1990). Moreover, Figure 2 of our article indicates a convenient way to display the results. Indeed, the two approaches need not be mutually exclusive, since ours provides what might be viewed as just a very long “exception list” based on the most appropriate data for searches of the particular File B.
We are aware that in principle any use of data from old linkages when starting a new linkage operation must involve some degree of extrapolation, at least initially. But this is not necessarily so for the later stages, after there has been opportunity for iterative adjustments based on the new links.
Arellano has alluded to a number of exceedingly simple concepts which appear to him to give rise to logical difficulties. For example:
-
“We keep coming back to the fact that N(A|LINK) is unknown.”
-
“The concept of falsely matched random pairs is a fascinating topic. But, …why didn't they present the procedures that they used to obtain this value?”
-
“The problem…of establishing an upper and lower threshold value is not related to the independence problem.”
At the risk of repeating what is in the article, we will consider these together here:
-
N(A|LINK): The simple answer is that one may do a small preliminary linkage, perhaps manually, to arrive at the approximate proportion of records in File A that will find a correct match in File B. There is no serious obstacle to this because, as Arellano points out, often 85 to 90% of the linkages are easy anyway. What is curious about the question itself is that this first step is the same as is routinely employed to obtain preliminary estimates of the likelihood ratios. The process thereafter, of iteratively refining early crude estimates, has been repeatedly emphasized in the literature (e.g., see Howe and Lindsay 1981).
-
Random Pairs: Again, only modest ingenuity is needed to solve the problem. Where the outcomes of interest are defined in complicated ways, there is no need to resort to theory to determine their frequencies of occurrence in random pairs. Instead, one uses the computer to put together large numbers of random pairs, among which the proportions of the outcomes of special interest may be determined by tabulation (Lalonde
-
1989). Alternatively, for simple value specific outcomes such as ROBERT compared with BOB, the random expectation is just the product of the proportions of these two values in Files A and B (or Files B and A) prior to linking.
-
Thresholds and Independence: The statement that lack of independence has no effect on the placing of the upper and lower thresholds is too sweeping to be correct Where correlated disagreements (e.g., due to multiple wrong guesses on the part of an informant) have spuriously moved true links downward below the lower threshold, or where correlated agreements of rare specific values (e.g., of ethnic surnames and forenames, plus places of birth) have spuriously moved false matches upward above the upper threshold, preset thresholds will no longer accurately perform their intended function. Such effects are often too large to be ignored when setting the thresholds.
Initially it had not been our intention to raise in this article the contentious matter of the “prior likelihood” of a correct match on a single random pairing. Indeed, we did not invent the concept—but we did devise the procedure for estimating the magnitude. For all practical purposes, prior likelihoods are essentially similar to the “prior odds” that appear explicitly in the weight formula of Howe and Lindsay. The idea is also implicit in the Fellegi-Sunter theory, where two conditional probabilities (i.e., of a link and of a nonlink) are described (Fellegi and Sunter 1969, exps. 6 and 7, pp. 1185– 1186). Each contains a term for a prior probability (of a match and of a non-match, respectively) before the comparison of any identifiers. These terms are P[(a, b)|M] and P[(a, b)|U], and their ratio represents the prior odds contained in the Howe-Lindsay weight formula. In an early version of our article, Figure 1 drew criticism from reviewers as being unsupported and incorrect. This is why details of our use and derivation of an estimated “prior likelihood” are included here together with the related idea that blocking be treated as not altering, either the total number of possible record pairings (actual plus potential), or the use of likelihood ratios derived from the blocking identifiers. Indeed, unless valid links are known to be lost due to blocking and their numbers can be estimated, there is no special reason why blocking need make any difference at all to the calculation of total weights or absolute odds in favor of a correct match.
Alternatively, of course, one may legitimately view each block as containing its own Files A and B; then, likelihood ratios for blocking identifiers are ignored, but a separate prior likelihood is required for every block, which may be cumbersome. Falling in between these two legitimate alternatives is a common practice that recognizes blocks and ignores likelihood ratios based on blocking identifiers, but omits the prior likelihood. Test results from this might seem satisfactory where the blocks happen to be small and most search records find a correct match, but it is hardly justified on logical grounds. As well, for searches of an accumulated national death file, with large blocks based only on a single surname code and with most cohort members still alive, the scale of odds that this incomplete treatment yields does not even remotely approximate the absolute scale needed for predefined error bounds.
Finally, although we are mindful of major differences of emphasis in various workers, we are unaware of any fundamental conflict between our approach and existing theory. If Arellano believes that there is such a conflict, we hope that its nature will get spelled out clearly in the future. Because much of record linkage development and application is of necessity in the hands of people trained in disciplines other than mathematics, any such clarifications ought to be in a form understandable by all who are engaged in implementing the linkage rationale.
Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida
Matthew A.Jaro, System Automation Corporation
A test census of Tampa, Florida and on Independent postenumeration survey (PES) were conducted by the U.S. Census Bureau in 1985. The PES was a stratified block sample with heavy emphasis placed on hard-to-count population groups. Matching the individuals in the census to the individuals in the PES is an important aspect of census coverage evaluation and consequently a very important process for any census adjustment operations that might be planned. For such an adjustment to be feasible, record-linkage software had to be developed that could perform matches with a high degree of accuracy and that was based on an underlying mathematical theory. A principal purpose of the PES was to provide an opportunity to evaluate the newly implemented record-linkage system and associated methodology. This article discusses the theoretical and practical issues encountered in conducting the matching operation and presents the results of that operation. A review of the theoretical background of the record-linkage problem provides a framework for discussions of the decision procedure, file blocking, and the independence assumption. The estimation of the parameters required by the decision procedure is an important aspect of the methodology, and the techniques presented provide a practical system that is easily implemented. The matching algorithm (discussed in detail) uses the linear sum assignment model to “pair” the records. The Tampa, Florida, matching methodology is described in the final sections of the article. Included in the discussion are the results of the matching itself, an independent clerical review of the matches and nonmatches, conclusions, problem areas, and future work required.
KEY WORDS: Census adjustment; Census coverage evaluation; EM algorithm; Postenumeration survey.
1. INTRODUCTION
Record-linkage methodology and software were developed at the U.S. Bureau of the Census during the past several years primarily to support census coverage evaluation efforts. By matching individuals counted in a census to those counted in an independent postenumeration (or pre-enumeration) survey, estimates of the quality of the enumeration can be produced. An important use of matching is to support an adjustment operation if it is decided to adjust the 1990 decennial census.
Clerical procedures typically used for such evaluations are too costly, unreproducible, error-prone, and time-consuming to be a viable alternative for such an adjustment (especially in view of the fact that state-level tabulations are due to the U.S. president by December 31, 1990). Therefore, the technical success of any adjustment procedure rests primarily on the ability to match a large number of records quickly, economically, and accurately. Even a few matching errors may be of critical importance, since population adjustments can be less than 1% in some instances. A complete discussion of the adjustment and census methodology issues can be found in Citro and Cohen (1985), Ericksen and Kadane (1985), and Wolter (1986).
Record linkage has numerous applications in both the private and public sectors. Examples include purging a list of duplicates, determining multiple-frame survey overlap, and geographic coding.
The Record Linkage Staff of the Statistical Research Division was established to implement a statistically justifiable, economical, and accurate record-linkage system to replace previous ad hoc systems and to reduce the number of cases that must be manually matched (see Jaro 1985).
Generalized computer programs have been written to implement the methodology discussed in this article. The first test of this software was the 1985 census of Tampa, Florida. The actual matching was conducted using a personal computer, although a mainframe version of the software also exists. Generalization is achieved through a program that automatically “writes” a customized program that will perform the matching for a particular application. The user specifies the fields to be matched, the record formats, parameters, blocking variables, etcetera, and the generation program creates a matcher that can be run with the desired files. This software generation technique results in a program that executes efficiently—a requirement for matching very large files.
This article presents the theoretical background necessary to understand the statistical basis of record linkage in general, the methodology developed for the estimation of parameters required by any record-linkage activity, the basic algorithmic approach used by the matcher, the specific methodology used for matching the 1985 census of Tampa to the postenumeration survey (PES). and the results of this process.
2. THEORETICAL CONCEPTS
2.1 Background
Consider two computer files, A and B, consisting of records taken from a population. Each file consists of a
|
* |
Matthew A.Jaro is Director of Research and Development, System Automation Corporation. Silver Spring, MD 20910. This work was accomplished while he was a Principal Researcher, Statistical Research Division, U.S. Bureau of the Census. The author acknowledges the contributions of R.P.Kelley on the parameter estimation methodology; Danny R.Childers, who designed and tabulated the PES; and Sue Finnegan, who directed the manual matching activities. |
number of fields, or “components,” and a number of records, or “observations.” Typically, each observation corresponds to a member of the population and the fields are attributes identifying the individual observation, such as name, address, age, and sex. The objective of the record linkage or matching process is to identify and link the observations on each file that correspond to the same individual. The records are taken to contain no unique identifiers that would make the matching operation trivial. That is, the individual fields are all subject to error.
We can define two disjoint sets M and U formed from the cross-product of A with B, the set A × B. A record pair is a member of set M, if that pair represents a true match. Otherwise, it is a member of U. The record-linkage process attempts to classify each record pair as belonging to either M or U.
2.2 Weights
The components (fields) in common between the two files are useful for matching. Not all components, however, contain an equal amount of information, and error rates vary. For example, a field such as sex only has two value states and consequently could not impart enough information to identify a match uniquely. Conversely, a field such as surname imparts much more information, but it may frequently be reported or transcribed (keyed) incorrectly.
Weights are used to measure the contribution of each field to the probability of making an accurate classification. Newcombe and Kennedy (1962) discussed the concept of weights based on probabilities of chance agreement of component value states. Fellegi and Sunter (1969) extended these concepts into a more rigorous mathematical treatment of the record-linkage process. Their definition of weights takes into account the error probabilities for each field by using a log-likelihood ratio. Let mi = Pr{component i agrees | r ∈ M} and ui = Pr{component i agrees | r ∈ U} for all record pairs r. If, for a given record pair, component i agrees (matches), then the weight for component i, wi = log2(mi/ui). If component i disagrees, then the weight wi = log2((1 − mi)/(1 − ui)).
2.3 Decision Procedure
For any record pair, a composite weight can be computed by summing the individual component weights. Since mi > ui in most cases, fields that agree make a positive contribution to this sum, whereas fields that disagree make a negative contribution. A most significant concept advanced by Fellegi and Sunter (1969) is an optimal decision procedure for record linkage. For this procedure, three states are defined. A record pair is classified as a match if the composite weight is above a threshold value, a nonmatch if the composite weight is below another threshold value, and an- undecided situation if the composite weight is between these two thresholds.
The threshold values can be calculated (see Sec. 3.4) given the acceptable probability of false matches (the probability that a record pair is classified as a match when the records do not represent the same individual) and the probability of false nonmatches,
2.4 Estimation of the ui
Values for the mi and the ui probabilities must be estimated for each pair of files to be matched. Estimating the ui (the probability that a component agrees given U) is simplified by the fact that the cardinality of the set U (denoted by |U|) is generally much greater than that of M. For two files, both of equal size, F, |M| = pF, where p is the proportion of matched pairs, and |U| = F2— pF. Consequently, estimates for the u probabilities can be obtained by ignoring the contribution from M and considering only the probability of chance agreement of the component i. Usually this can be estimated from a sample of pairs rather than from all pairs.
Estimating the mi probabilities (the probability that a component agrees given M) is more difficult. Conditioning on M presupposes an a priori knowledge of correctly matched pairs. This could be obtained by a prelinked sample of the population. If such a sample were obtained clerically, much expense would be involved and the error rates for the clerical operation might be too high to permit accurate parameter estimation. One solution is blocking and using a latent trait model.
2.5 Blocking
For files of average size |A × B| is too great to consider all possible record pairs. Since there are many more record pairs in U than in M and 2n possible comparison configurations involving n fields, drawing record pairs at random would require a sample size approaching all record pairs (for typical applications) to obtain sufficient information about the relatively rare M cases.
The two files can be partitioned into mutually exclusive and exhaustive blocks designed to increase the proportion of matched pairs observed while decreasing the number of record pairs to compare. Comparisons are restricted to record pairs within each block. Consequently, blocking is important for the actual matching and for parameter estimation activities. Blocking is generally implemented by means of sorting the two files on one or more variables. For example, if both files were sorted by zip code, the pairs to be compared would only be drawn from those records where zip codes agree. Record pairs disagreeing on zip code would not be considered and hence would be automatically classified as nonmatches (elements of U).
To be effective at enriching the M cases, such blocking variables must contain a large number of value states that are fairly uniformly distributed and such variables must have a low probability of reporting error (i.e., a high weight). Blocking is a trade-off between computation cost (examining too many record pairs) and false nonmatch rates (classifying record pairs as nonmatches because the records are not members of the same block). Multiple-pass matching techniques using independent blocking variables for each run can minimize the effect of errors in a set of blocking variables. R.P.Kelley has developed an algo-
rithm that may assist in choosing the best blocking scheme in light of these trade-offs (see Kelley 1984).
3. PARAMETER ESTIMATION METHODOLOGY
3.1 Comparison Configuration Frequencies
This section discusses the methodology used to estimate the mi probabilities. Information about the comparison configurations observed is provided by the matching software itself, which tabulates frequencies for all 2n possible patterns of agreement and disagreement on n fields. To increase the proportion of matched pairs examined, these tabulations are performed using just those record pairs in which both observations come from the same block. Fortunately, the mi probabilities may reasonably be expected to be independent of the blocking schemes chosen as long as errors in the blocking variables do not exclude an excessive number of matched records from the tabulations. This is consistent, however, with the goal of choosing blocking variables with low reporting error rates. The independence of the mi probabilities to choices in blocking and the effect of errors in the blocking variables to the final estimates are yet to be determined.
Given frequencies for all possible agreements and disagreements, the mi probabilities can be estimated using any of several procedures. The EM algorithm described here is the most effective of those developed and tested.
3.2 The EM Algorithm
Given n fields and a sample of N record pairs drawn from A × B, let ![]() if field i agrees for record pair j, let
if field i agrees for record pair j, let ![]() if field i disagrees for record pair j, for i = 1, . . . , n and j = 1, . . . , N. Further, let γi be the vector of ones and zeros showing field agreements and disagreements for the jth pair in the sample, and let γ be the vector containing all of the γi.
if field i disagrees for record pair j, for i = 1, . . . , n and j = 1, . . . , N. Further, let γi be the vector of ones and zeros showing field agreements and disagreements for the jth pair in the sample, and let γ be the vector containing all of the γi.
The mi and ui probabilities can be defined as ![]()
![]() and
and ![]() for a randomly selected record pair ri and i = 1, 2, . . . , n. Define p as the proportion of matched pairs equal to |M|/ |M ∪ U|. The elements of M ∪ U (i.e., all record pairs rj) are distributed according to a finite mixture with the unknown parameters Φ = (m, u, p). We will use an EM algorithm to estimate these parameters; in particular, the m vector is of the greatest interest. Notation is consistent with that used in Dempster, Laird, and Rubin (1977).
for a randomly selected record pair ri and i = 1, 2, . . . , n. Define p as the proportion of matched pairs equal to |M|/ |M ∪ U|. The elements of M ∪ U (i.e., all record pairs rj) are distributed according to a finite mixture with the unknown parameters Φ = (m, u, p). We will use an EM algorithm to estimate these parameters; in particular, the m vector is of the greatest interest. Notation is consistent with that used in Dempster, Laird, and Rubin (1977).
Let x be the complete data vector equal to (γ, g), where gi = (1, 0) iff ri ∈ M and gi = (0, 1) iff ri ∈ U. Then, the complete data log-likelihood is
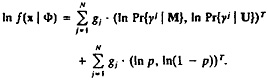
Although it is quite reasonable to expect the empirical frequencies to belie independence, since errors in one component will often induce errors in another, such departures will not likely disturb the ordering by composite weights of the 2n configurations. Consequently, we will assume an independence model:
(1)
and
(2)
Our application of the EM algorithm begins with estimates of the unknown parameters ![]() and consists of iterative applications of the expectation (E) and maximization (M) steps until the desired precision is obtained. The algorithm is not particularly sensitive to starting values, and the initial
and consists of iterative applications of the expectation (E) and maximization (M) steps until the desired precision is obtained. The algorithm is not particularly sensitive to starting values, and the initial ![]() values can be guessed. It is important, however, that the
values can be guessed. It is important, however, that the ![]() values be greater than their corresponding
values be greater than their corresponding ![]() values. For Tampa, .9 was used for all of the initial
values. For Tampa, .9 was used for all of the initial ![]() . Estimation of
. Estimation of ![]() is discussed in Section 2.4.
is discussed in Section 2.4.
For the E step, replace gj with ![]() , where
, where
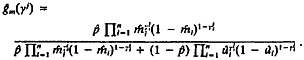
![]() can be derived similarly.
can be derived similarly.
For the M step, the complete data log-likelihood can be separated into three maximization problems. Setting the partial derivatives equal to 0 and solving for ![]() yields
yields
Further, the matrix of second partial derivatives can be shown to be negative-definite.
In practice, we store frequency counts, f(γi) for each of the possible 2n patterns of γi. These counts are obtained as follows: each file is partitioned into blocks by means of the blocking variables. For each block, all record pairs in the block are examined. For each record pair, the comparison vector γi is computed and 1 is added to the frequency count for that particular configuration. There are 2n such counters. The counters are not reset after a block is processed, but represent the number of observations of each configuration over all blocks. Both estimation and actual matching are accomplished using the same blocks. The EM algorithm is run once using these frequencies.
The E step computes ![]() for each of the 2n patterns. This can be done without examining the individual observations, since the frequencies are a sufficient statistic for the M step. By replacing the individual observations with the frequencies, we obtain
for each of the 2n patterns. This can be done without examining the individual observations, since the frequencies are a sufficient statistic for the M step. By replacing the individual observations with the frequencies, we obtain
The arguments for the u probabilities are similar.
Finally, the proportion of matched pairs p can be esti-
mated by
It must be remembered that the frequencies used for the p, m, and u estimates were obtained from record pairs within blocks and represent an accumulation over all blocks. Since blocking greatly reduces the number of nonmatched pairs observed and because blocking selects record pairs that are likely to match, the u probability estimates obtained using blocked data will be biased. Consequently, the u probabilities must be computed directly on unblocked data, as explained in Section 2.4, and the EM algorithm is only used to compute the m probabilities, where blocking enriches the number of matched pairs observed while avoiding comparisons on relatively large numbers of unmatched pairs.
The EM algorithm is highly stable and the least sensitive to the starting values of any of the methods studied. The algorithm is very simple to implement, and the probabilities will always be within bounds. The other methods are based on numerical analysis techniques, and it is possible for probabilities to exceed 1. The greater stability of the EM algorithm comes from the fact that logarithms lower the degree of the equations, whereas the method-of-moments techniques described subsequently use squared products of probabilities that are close to 1 and 0.
Comparison of the convergence criteria, rapidity of convergence, and sensitivity to independence for these methods are currently being studied.
3.3 Other Estimation Methods
The second estimation technique studied involves minimizing a system of 2n equations (one for each comparison vector configuration) using the IMSL routine ZXSSQ [minimum of the sum of squares of m functions in n variables using a finite difference Levenberg-Marquardt algorithm (see IMSL 1984)]. The system was more sensitive to initial values, and it was possible for solution sets to have probabilities out of bounds.
The third method examined was due to Fellegi and Sunter (1969, app. II), The authors presented an algebraic solution for three fields, but it is easy to generalize the equations and solve the system of nonlinear simultaneous equations using numerical methods. The results agree with the other two methods used. However, the system is rather sensitive to the starting values, and in one case a penalty function had to be introduced to keep the probabilities within bounds.
3.4 Calculation of Threshold Values
An algorithm in our matcher determines the threshold weights as follows. There are 2n possible configurations of agreement and disagreement of n components. These configurations can be ordered by the composite weight (the sum of the individual weights, wi, for each component). After ordering the composite weights, the sum of Pr(• | M) and 1 minus the sum of Pr(• | U) can be calculated [see Eqs. (1) and (2), Sec. 3.2]. The maximum weight for a nonmatch decision is the weight of the configuration where the sum of Pr(• | M) does not exceed the desired probability that a matched pair should be classified as unmatched. The minimum weight for a match decision is the weight of the configuration where 1 minus the sum of Pr(• | U) does not exceed the desired probability that an unmatched pair should be classified as matched. Weights between these two thresholds are undecided cases.
For applications such as census matching, with approximately 10 components, this technique is computationally feasible. Unpublished experimentation has been performed by sampling component configurations for problems having many components, but the large number of cells makes it difficult to obtain a sufficient number of observations in each cell, so sampling error is not an overpowering factor.
4. MATCHING ALGORITHM
This section describes the basic operation of the matcher. Before matching, fields such as house address should be separated into components and spellings should be standardized. Both files must be sorted by the blocking variables.
4.1 Composite Weight Calculation
The matcher processes one block at a time, building a matrix (C) containing the composite weights for all pairs within the block being processed. The composite weights are computed by summing the individual weights for agreement or disagreement on each field (see Sec. 2.2). The simple agreement/disagreement dichotomy modeled by the theory is too simplistic for noncategorical fields. For example, character strings are compared using an information-theoretic character comparison algorithm that provides for random insertion, deletion, replacement, and transposition of characters. The weight assigned for such comparisons is prorated according to a measure of similarity between character fields (see Jaro 1978, pp. 106– 108). If two character fields match exactly, the full weight for agreement is assigned to the comparison. If they disagree slightly, however, it would be wrong to assign the disagreement weight. Consequently, the weight assigned for the comparison will be somewhat less than the full agreement weight.
Similarly, weights for integer or continuous variables such as age can be prorated proportionally to the ratio of the difference and the minimum of the two values being compared (delta percent). For example, if age disagrees by one year in an 80-year-old man, it is less serious a mismatch than for a 1-year-old baby.
4.2 Assignment
After the matrix containing the composite weights for all pairs within the block is constructed (Cij in the following), the records can be paired up (assigned). One record on file A can be assigned to one and only one record on file B, and vice versa. We wish to choose an assignment
scheme that maximizes the sum of the composite weights of the assigned record pairs. This is a degenerate transportation problem known as the linear sum assignment problem, which can be solved by a simple method requiring only addition and subtraction. The use of such a linear programming model to provide the assignments represents an advance over previous ad hoc assignment methods. The problem can be formulated as follows: Maximize
subject to
and
where Cij is the cost (weight) of matching record i on file A with record j on file B, Xij is an indicator variable that is 1 if record i is assigned to record j and 0 if i is not assigned to j, ka is the number of records in the block being processed from file A, kb is the number of records in the block being processed from file B, and k = maximum(ka, kb). If ka ≠ kb, the matrix is made square (with dimension k) by inserting entries whose values are large negative numbers (less than any possible composite weight). This prevents these entries from being assigned.
An excellent discussion of the theory of assignment problems can be found in Cooper and Steinberg (1974, chap. 11). The computer algorithm was obtained from Burkard and Derigs (1981) and is highly efficient and economical of storage since the original matrix elements remain unaltered (the computations are performed on vectors, since all operations apply to entire rows or columns).
Once an optimal assignment vector is obtained, an assigned pair can be classified as a match if the composite weight is greater than the Fellegi-Sunter threshold value. After all assigned pairs in the block are processed, the records for the next block can be read.
4.3 Duplicates
Duplicates can be detected by examining each, row or column of the assignment matrix. If more than one entry is above the cutoff threshold, then there is a possibility of a duplicate. Two similar records on both files would probably be two separate individuals (a father and son, for example), but two similar records on only one file would probably be a duplicate.
4.4 File Preparation
To match any file, free-form information must be standardized. This is especially true of fields such as street address and person name. The components of the name should be separated into individual fields (given name, middle initial, and surname). This is much more effective and accurate than trying to match an entire name as a single character string. For street address, the various components of the address should be placed in individual fields and the spellings of common abbreviations (such as BD, BLVD) should be standardized. Punctuation should be removed from the fields.
The technique of SOUNDEX encoding (Knuth 1973, pp. 391–392) is a method of transforming a person's name into some code that tends to bring together all variants of the same name. For example, Smith and Smythe would both be coded as S530. Surname is often an important blocking variable. To maximize the chance that similarly spelled surnames reside in the same block, the SOUNDEX system can be used to code the names, and the SOUNDEX code can be used as a blocking variable. There are better encoding schemes than SOUNDEX, but SOUNDEX with relatively few states and poor discrimination helps ensure that misspelled names receive the same code.
SOUNDEX is not recommended for matching non-blocking variables, since nonphonetic errors Result in different codes and different names may receive the same code.
5. TAMPA MATCHING METHODOLOGY
This section describes the computer match of the 1985 census of Tampa, Florida, to the PES, The object of the matching study was to identify all individuals who responded to both the PES and to the census. The records consisted of individual data and contained name, address, and demographic characteristics. The primary goal of the computer matcher was to eliminate the first-level clerical match (where matches could be determined with relatively unsophisticated personnel). The system exceeded this goal. A multiple blocking strategy was used to increase the numbers of matched records given errors in the blocking variables. The strategies are called Pass I and Pass II, respectively.
5.1 Pass I Match
The following variables were used for matching:
-
Census block numbering area (CBNA) (blocking variable)
-
Census block number (blocking variable)
-
Surname (SOUNDEX) (blocking variable)
-
Given name (m = .98, u = .09)
-
Middle initial (m = .35, u = .03)
-
Relation to head of household (m = .39, u = .20)
-
Sex and marital status (combined) (m = .82, u = .21)
-
Birthdate (m = .94, u = .04)
-
Race and Hispanic origin (combined) (m = .90, u = .67)
-
Street name (m = .96, u = .03)
-
House number (m = .99, u = .01)
-
Apartment number (m = .35, u = .26)
The blocking variables for Pass I were census block numbering area (CBNA), census block number, and SOUN-
DEX code of surname. CBNA and census block number were used as blocking variables, since only census data for PES sample blocks were keyed and, consequently, it would be unlikely that data would be available for units geocoded to incorrect blocks. All records failing to match in Pass I would participate in the Pass II match, which used different variables for blocking.
The results of the Pass I match were as follows: 7,358 PES records rend, 8,798 census records read, 4,375 matched pairs, 165 nonclassified pairs, 628 unmatched PES records, 702 unmatched census records, 2,190 skipped PES records, and 3,556 skipped census records. Records are said to be skipped when one or more of the blocking variables do not match. The nonclassified, unmatched, and skipped records are input to the Pass II process.
5.2 Pass II Match
In an attempt to match records that failed to match in Pass I, an independent blocking scheme was chosen for Pass II. The blocking variables were CBNA, census block number, SOUNDEX of street name, house number, and apartment number. CBNA and block number were reused, since no records exist outside of the sample area and detecting geocoding errors would be unlikely.
Apartment number had to be used, since some highrise developments contained more than 500 units at a single address and the matcher has a maximum block size that cannot be exceeded. Subsequently, the matcher was modified to correct this problem by flagging such “overflow ” blocks, which could be processed in a separate subsequent run.
A blank apartment number may mean either that the apartment number is not appropriate or that the value was not reported. Since apartment numbers are sometimes not appropriate, blank apartment numbers would be accepted as a valid value.
The Pass II match was useful, since it displayed record pairs and groups in household sequence.
The results from Pass II were as follows: 2,983 PES records read, 4,423 census records read, 212 matched pairs, 885 nonclassified pairs, 1,114 unmatched PES records, 1,321 unmatched census records, 772 skipped PES records, and 2,005 skipped census records. The matching decisions were made very conservatively to limit the number of false matches. This is important where estimation of relatively rare events is required (such as for undercount estimation). The tight error tolerances account for the high number of nonclassified cases. Most of these could be resolved quickly, since records are already paired. All nonclassified pairs, unmatched records, and skipped records would be processed clerically. Many records were unmatched because of construction and demolition in the PES area, vacancies, noninterviews, proxy data, geocoding errors, etcetera.
The total number of records matched automatically from both passes was 4,587, with 885 nonclassified pairs that could be rapidly resolved. Approximately 40 minutes (wallclock time) were required to conduct the Pass I match on an IBM PC-AT. with 20 minutes required for Pass II. Sorts required about 15 minutes each.
6. CLERICAL REVIEW AND FINAL MATCHING RESULTS
After the computer matching was completed, the records were grouped by household and printed on a computer-generated matching form for clerical review. Many of the nonmatches were easily converted to matches by reviewing the persons in the household together.
A total of 5,343 persons were matched in the entire process, with 4,587 matched by the computer (85.9%). Of the 885 nonclassified persons, 225 were at vacant addresses or were noninterviews, leaving 660 persons that could be resolved clerically. Of these 660 persons, 83.39% were determined to be actual matches. The number of persons who were either matched automatically or with a quick verification of the computer-assigned possible match is 5,177 (computed by 4,587 persons matched automatically plus 83.39% of 660 persons). A total of 5,177 but of the 5,343 cases yield an effective match rate of 96.89% for the automated system, leaving only about 3% of the cases for extensive clerical intervention. The clerical and professional review staffs were able to match only 19.47% of the residual nonmatched records from the computer operation.
6.1 Review of Computer Matches
All of the matches assigned by the computer were reviewed to evaluate the computer matching. Eight persons assigned by the computer matcher were actual errors, yielding an error rate of 174% (8 of 4,587). Inferences regarding the matcher's accuracy, however, should not be made from this one case study, as results can vary with the accuracy of the geographic reference material, data entry procedures, and numbers of hard-to-count population groups in a specific area.
6.2 Matching In Neighboring Blocks and Duplicates
The census questionnaire information was only entered for the PES sample blocks. Therefore, it was impossible to detect geographic coding errors automatically by the computer (since no machine-readable data were available). The blocks that bordered the sample blocks, however, were searched clerically to attempt to reduce the number of nonmatches.
Of 1,692 persons not matched in the sample blocks, 726 were matched to neighboring blocks, resulting in a 42.9% reduction in the nonmatch rate. The largest reduction was in blocks that were predominantly black and Hispanic and contained multi-unit structures.
The matching processes (both automatic and clerical) include the detection of duplicate records for an individual. Searching on neighboring blocks uncovered 32 census duplicates. The total number of duplicates within the sample and surrounding blocks was 145 (2.6% of the matched records).
7. CONCLUSIONS AND FUTURE WORK
The automated matching system greatly exceeded expectations in terms of both match rate and accuracy: 96.89% of the records that were matched were matched either automatically or could be quickly verified. The error rate was 174% (again, no inferences should be drawn from this). The 1986 test census of Los Angeles, California, includes an automated extended search to detect movers and geocoding errors. Several matching errors were due to problems in high-rise multi-unit structures. A new methodology that should eliminate these problems has been developed.
The use of the EM algorithm for parameter estimation appears to be the most promising of all techniques attempted in terms of insensitivity to choice of starting values and ease of implementation.
Additional work is required in a number of areas. Questions to be answered include: What is the sensitivity of the final classification to parameter estimation error and statistical dependence of reporting errors and/or value states of fields? Can successful models for multiple state comparison vectors be developed? For example, instead of agreement and disagreement states, the vector could be augmented to include cases where values are missing (currently, these receive zero weight). Can cutoff thresholds be computed by means of a closed-form equation without enumerating 2n configurations, or can such a form be developed for changes in only one weight? If so, then weights could be adjusted by means of a Bayesian procedure to account for changes in the distribution of the value states of a field in different geographic areas, and, further, weights could be adjusted where value state distributions are likely to be skewed. For example, an agreement on a name like Humperdinck should carry more weight than an agreement on Smith, but strictly speaking, the cutoff thresholds would change if the weights for a field were changed, and a closed-form equation for the thresholds would permit changing the cutoff values for particular cases during the matching process. Can the errors in both the automated and manual phases of matching be properly modeled, and can variances be computed?
A calibration data set is being developed from the Tampa, Florida, experience. A linked file such as this can be used to measure sensitivity and the relative merits of various matching schemes. I will attempt to answer systematically most of the questions posed in this article and to improve the mathematical underpinning of record-linkage methodology.
[Received January 1997. Revised October 1988.]
REFERENCES
Burkard, R.E., and Derigs, U. ( 1981), “Assignment and Matching Problems: Solution Methods With FORTRAN-Programs, ” in Lecture Notes in Economics and Mathematical Systems (No. 184), New York: Springer-Verlag, pp. 1–11.
Citro, C.F., and Cohen, M.L. ( 1985), The Bicentennial Census, New Directions for Methodology in 1990, Washington, DC: National Academy Press.
Cooper, L., and Steinberg, D. ( 1974), Methods and Applications of Linear Programming, Philadelphia: W.B.Saunders.
Dempster, A.P., Laird, N.M., and Rubin, D.B. ( 1977), “Maximum Likelihood From Incomplete Data Via the EM Algorithm,” Journal of the Royal Statistical Society, 39, 1–38.
Ericksen, E.P., and Kadane, J.P. ( 1985), “Estimating the Population in a Census Year: 1980 and Beyond” (with discussion), Journal of the American Statistical Association, 80, 98–131.
Fellegi, I.P., and Sunter, A.B. ( 1969), “A Theory for Record Linkage,” Journal of the American Statistical Association, 64, 1183–1210.
International Mathematical and Statistical Libraries, Inc. ( 1984), User's Manual, Houston: Author.
Jaro, M.A. ( 1978), “UNIMATCH: A Record Linkage System, User's Manual,” Washington, DC: U.S. Bureau of the Census.
—— ( 1985), “Current Record Linkage Research,” in Proceedings of the Statistical Computing Section, American Statistical Association , pp. 140–143.
Kelley, R.P. ( 1984), “Blocking Considerations for Record Linkage Under Conditions of Uncertainty, ” in Proceedings of the Social Statistics Section, American Statistical Association, pp. 602–605.
Knuth, D.E. ( 1973), The Art of Computer Programming, Volume 3: Sorting and Searching, Reading, MA: Addison-Wesley.
Newcombe, H.B., and Kennedy, J.M. ( 1962), “Record Linkage,” Communications of the Association for Computing Machinery, 5,563– 566.
Wolter, K.M. ( 1986), “Some Coverage Error Models for Census Data,” Journal of the American Statistical Association, 81, 338–346.
Matt Jaro, Founder, President & CEO:
Match Ware Technologies Inc.'s founder, CEO and director of technology, Matt Jaro, enjoys 30+ years of experience in the science of probabilistic record linkage and information technology. Jaro has led MatchWare to a position of global leadership in the practical implementation and use of this methodology.
Matt Jaro conceived, designed, and authored Match Ware's proprietary software. Well known as a speaker and author in (he fields of address matching and geographic information systems, Matt is regarded as an international authority on probabilistic record linkage methodology.
Jaro holds degrees in mathematics from California State, and computer science from George Washington. Prior to founding MatchWare, he held a variety of information technology positions with public and private sector organizations including: Booz-Allen Applied Research, the U.S. Census Bureau, The Corporation for Applied Systems, Public Technology, Inc., and System Automation.
In the mid-80's, Jaro was a principal researcher at the U.S. Census Bureau where he developed the mathematical methodology and software to perform statistically valid matching procedures in support of estimating census coverage. Although application specific, the census estimation methodology Matt developed was precedent-setting in the field of probabilistic record linkage.
Record Linkage and Genealogical Files
Nancy P.NeSmith
The Church of Jesus Christ of Latter-Day Saints
Whenever there are large computerized genealogical files the problem of duplication of records for the same individual or family within the file always exist. Many indexing schemes can be used which allow some matching of entries being added to the files with slight variations, but computer technology in the past has been limited in matching entries in which more than one field such as surname, given names, date or locality have disagreement.
Genealogists know that disagreement comes through different record sources used for identification or through transcription errors. Bringing together records with discrepancies has always been a genealogical nightmare. If the records don't even come together using various sorting schemes, how can the records be analyzed for matching or merging decisions? In other words, how does one know if two different records refer to the same individual or family?
One solution to this dilemma is the use of Record Linkage theory. Record linkage refers to a computer program which uses a detailed algorithm based on probability to determine if two records being compared represent the same individual. This technique, developed in Canada by Howard B.Newcombe (1988), has been used in the statistical, demographic, and medical disciplines to identify and link two or more records representing the same person or entity.
The theory underlying record linkage was developed around the need for an algorithm which would mimic human decision making in comparing a record from one file with a record from a second file. To do this, two records which represent the same person are studied and field comparisons made. Fields are items of information in the record, such as, given name, surname, birthdate, birthplace, etc. The outcome of this comparison (agreement, disagreement or partial agreement) that is common in linked records is noted. If there is enough agreement, the probability is high the records being compared from the two different files represent the same individual. If the comparison outcome is more common to unlinked records, the probability is high the records being compared represent two different individuals.
Using the comparison statistics, a record linkage system computes the odds in favor of a match or against a match for any two records selected for comparison. For example, if a surname in two records matches, the computer calculates the odds of the two names matching by chance and how often the surname field agrees in the truly linked records contained in the comparison file. From these two statistics the program determines a score which represents the odds above chance the two surnames matching are for the same person.
Each algorithm may be tailored to the uniqueness of the genealogical data elements in its geographic area. This eliminates applying an “English” standard to all geographic areas of the world. Another advantage is the algorithm may be refined to specific cultural or variable record types.
To develop the algorithm, samples of files which need to be matched or merged are examined by specialists to locate duplicates for statistical analysis. Based on their analysis and the purpose of the linkage for the file, the specialists choose blocking, weighting, and threshold parameters which will be used by the computer for each geographic area to determine if the records being compared are a match.
Searching the File—Blocking
When searching a file to see if there is a record which matches the request, it would be ideal to compare every record in the file with the request. However, this is not practical in most data bases so an indexing scheme is used to retrieve only the entries in the file which are most likely to match the request. This is called blocking or retrieval. The intent is to reduce the number of comparisons the computer must make. The implicit assumption is that only records with a reasonable chance of being linked are retrieved.
Blocking effectiveness can be described in terms of “recall” and “precision.” Recall is a measure of how many relevant records in the file are included by the blocking scheme. Precision is a measure of how many of the total records retrieved by the blocking scheme are relevant.
For example, if you're looking for a record of Joseph Jones, and the file contained two records for him, one in which he is identified as Joseph Jones and the other as J.Jones, the system would exhibit good recall if it retrieved both records. However, the system tuned to recall near matches such as J.Jones may retrieve irrelevant entries where the letter J. stood for John or James rather than Joseph. These irrelevant entries are known as “noise.”
Precision measures the amount of noise. A problem with a system tuned for precision over recall is relevant entries can be missed because the narrower search parameters used to limit the noise also limit the recall. Whenever you tune for recall you increase the noise; when you tune for precision you decrease recall. The two concepts have been found to be in opposition. The goal is to find an acceptable balance between the two which suits each specific application.
It is possible to enhance the recall of a system without greatly reducing the precision by using some form of authority control to bring together the equivalent names of people which are spelled differently and locality names which are different but refer to the same locality. Blocking schemes are tuned to the specific file or part of the file being searched. Those fields which are accurate, discriminating, and most often present in the records are chosen because they help give a balance between precision and recall.
Weight Calculations
Using the blocking parameters the computer retrieves a set of records which can now be compared in detail with the query to determine their similarity to it. As fields in the query and candidate record are compared, a statistical score or weight is computed which reflects agreement, partial agreement, or disagreement of the two fields being compared. A positive weight is calculated for agreement, a smaller positive weight is calculated for partial agreement, and a negative weight is calculated for non-agreement on that field. If either record has missing information in the field being compared, a weight of zero is assigned. The weights are added to each other to obtain a total weight which reflects the similarity of the pair of records being compared.
The weights are tailored to the locality or record source. For example, surnames for England agree more often than surnames in Denmark and other countries which have patronymic surnames. This affects the
have a higher negative weight for disagreement on surname than Denmark because the surnames seldom disagrees for England. Also taken into consideration for the calculation of the weight is the relative size of the name pool. For example, there are fewer surnames in England than there are in United States records. The fewer the names, the less significant is the agreement. These types of calculations and comparisons are done on the fields for gender, names, localities, and dates.
It is not necessary to weight all of the fields in a record. Generally fields which were used as blocking parameters are not weighted. The fields are not weighted because the records retrieved have already matched on these fields and weighting them only increases the overall score of each record by the same amount. Other fields may not be weighted because they are not statistically discriminating and don 't contribute significantly to the equation.
Threshold Determination
Once the file records have been retrieved using the blocking scheme, compared field by field to the query, each field weighted, and each total record's weight determined; then a decision can be made about whether or not a duplicate was found. The total weight which is used to decide whether a record should be considered a match or non-match with the retrievals from the file is called the threshold.
Generally, scores above a certain threshold indicate a match and those below it indicate a non-match. For example, if the weight of 40 is considered the threshold, then all retrievals scoring less than 40 are considered non-matches. All retrievals with scores of 40 and above are considered matches. The threshold decision is based on the total weights of truly matched records for that specific locality (truly matched means the two records are known to refer to the same person).
There is often a small range of scores which includes intermingled matches and non-matches. This is called the gray area. For example in a study of criminals and law abiding citizens, the range of scores could be from -150 to 150. Criminals have scores ranging from -150 to +50. Citizens had scores ranging from +30 to +150. Everyone with a score below 30 is a criminal, everyone with a score above 50 is a citizen. Those with a score between 30 and 50 could be either a citizen or a criminal. This is the gray area for this study, meaning if 40 is picked as the threshold score there is the possibility of a non-match scoring high enough to appear to be a match (false positive) or there is a possibility of a match scoring so low it appears to be a non-match (false negative). Which number to pick is called the threshold decision.
In making a threshold decision it is important to decide the purpose of the links. For optimal linkage it is important to follow the rule which states that before a threshold is picked, decide the purpose of the links. If the goal is to arrest all the criminals in a town and not let any of them go free, then a threshold of 50 would be picked. But as a result, some law abiding citizens would be arrested because their score would be similar to criminals. If the goal is to arrest as many criminals in a town but to not falsely arrest any citizens, then a threshold of 30 would be picked. As a result, some criminals would go free, but no citizens would be arrested.
The Family History Department and Record Linkage
The theory underlying this technology is the best approach known to the scientific community. For this reason, the Family History Department of The Church of Jesus Christ of Latter-day Saints has chosen to implement its usage in their genealogical systems and databases. It is currently being used to retrieve entries within the department 's genealogical files, and will be used in match and merge decisions. The results have been very satisfying and its efficiency has been improved by taking full advantage of name and locality authority systems. The use of record linkage for the massive files and record linking needs of Family History
makes the most efficient use of the Department's computer resources in eliminating or matching duplicates in their files. This technology has not been employed in the Personal Ancestral File7 as that program was developed before the implementation of Record Linkage in 1988.
References
Newcombe, Howard ( 1988). Handbook of Record Linkage: Methods for Health and Statistical Studies, Administration and Business, Oxford: Oxford University Press.
Wrigley, E.A. (ed). ( 1973). Identifying People in the Past, London: Edward Arnold.
* Nancy P.NeSmith, 5440 South Lighthouse Road, Salt Lake City, Utah 84123. Miss NeSmith received a BS in Genealogy and undertook graduate studies in Family History at Brigham Young University. She is currently a Systems User Specialist in the LDS Family History Department.
Personal Ancestral File is a registered trademark of The Church of Jesus Christ of Latter-day Saints.
A Review of the Statistics of Record Linkage for Genealogical Research
As Used for the Family History Library, Church of Jesus Christ of Latter-Day Saints
David White, Utah State University and Church of Jesus Christ of Latter-Day Saints
Introduction
The Church of Jesus Christ of Latter Day Saints maintains massive genealogical files, which consist of millions of names. The two largest files are the International Genealogical Index (IGI) and the Ancestral File. The IGI contains over 200 million individual vital records and, because of its size, is divided into geographical subfiles. The Ancestral File contains over 21 million names arranged in family groups and pedigrees. These files are growing, and one of the major challenges is to be able to query these files in such a way that correct records are retrieved for various genealogical purposes and adding duplicates to these files is avoided. Record linkage is used for this purpose.
For this paper, a record will be defined as the collection of items that refer to a specific event, such as a birth or christening. Each item for the event, such as the day, month, year of birth, surname, and given names of the father and mother, is stored in what are called fields in computing terminology. Two records are defined as “linked” if the odds are high that they represent the same person. One of the first challenges for record linkage is finding those fields that are useful for calculating these odds. Although all the records in the IGI are birth and marriage events, they come from various sources. The same is true for the Ancestral File. For example, a birth record for the same individual may come from a civil record, an ecclesiastical record, or a family source. This may result in multiple records in the file for the same person when the available information is sparse or varies.
Comparing a Pair of Records (Calculating the Odds)
We begin with statements about the comparison of field entries coming from two records when it is known that these records refer to the same person. Such records are termed “matched” or “duplicates” by researchers. The records may or may not be from the same source. An example of different sources containing records about the same person would be births coming from civil records and ecclesiastical records. An example where only one source is involved would be ecclesiastical records about the same person who has moved from one jurisdiction to another within the same denomination, and the record keeping agency includes both jurisdictions.
Next, consider birth records and, within a birth record, the field containing the given name of the mother. We consider a pair of birth records and desire evidence to either confirm or deny that these records represent the same person. Suppose the given name of the mother shows up in both records, and we have n pairs of such records, which are matched (i.e., each pair is known to refer to the same person). Further, suppose that in k instances, the mother's given name for one record of the pair is the same as that for the other record. Then, the probability that the given names are the same when the records are matched is estimated by k/n, and we use the equation
P(S|M) ≌ k/n (1)
where ≌ means that the two sides of the equation are “close,” although they may not be exactly equal. We read P(S|M) as the probability that an entry in a specific field is the same for both members of a pair, given that we have a matched pair.
Next, consider the probability that the given names of the mother are the same when the two records are randomly paired. Such pairs of records are termed “unlinkable” by Newcombe. As an example, suppose we have a file with a total of m different given names appearing for the mothers of the child. Then, a typical event describing a pair with the same given names is:
Both given names are Dorothy, or
Both given names are Phyllis, or
....
....
Both given names are Agnes,
where Agnes completes the total of the m given names appearing in the records.
First, assume that the records come from the same file and that there are N1 records with the name Dorothy, N2 records with the name Phyllis, and so on, to Nm for Agnes. If N1 + N2 + . . . + Nm = N, then the probability that one element of a pair is Dorothy will be estimated by N1/N and that both elements are Dorothy will be estimated by (N1/N) 2 —we multiply the probabilities for the two elements together since the events are independent (any two records were randomly paired). Since we allow that both elements having the same given name can happen with any one of the m alternatives, we add the probabilities for the m possible given names together, to get
P(S) ≌ (N1/N)2 + (N2/N)2 + ..... + (Nm/N)2
≌ Σj=1m (Nj/N)2. (2)
We read P(S) as the probability that two corresponding elements of a pair are the same when the records have been selected at random.
Now, assume that the records come from different files, and that there are m first given names for mothers in common between the two files. Assume that there are L1 records in the first file with the name Dorothy, and N1 corresponding records in the second file, or in general, Lj and Nj records with the jth given name.
Then, the probability that the given name of the mother will be the same is estimated by
P(S) ≌ (L1N1/LN + (L2N2)/LN + ..... + (LmNm)/LN (3)
≌ Σj=1m (LjNj)/LN,
where now,
L = Σj Lj and N = Σj Nj (4)
and the summation of the subscript j is not limited to the m alternatives in common, since each file may have alternatives not in common with the other file.
We now have P(S|M), the probability that two elements in a pair are the same, given that the pair is matched, and P(S), the probability that they are the same when they have been paired randomly. For the rest of the paper, we will deal only with the case where the two elements come from the same file; the other case corresponds in the same way as described above.
Another way to estimate P(S) is to actually create a set of randomly matched pairs and calculate the proportion of matches obtained. This way is computationally less intensive and may be a practical alternative for people with more meager computational resources.
We next consider the probability law:
P(M|S)P(M) = P(S|M)P(S). (5)
What we want is P(M|S), which is the probability that two records of a pair do, in fact, represent the same person when the first given names of the mothers are the same. P(S|M), which we have, is the probability that the elements of a pair are the same when they are matched. Using equation (5), we get
P(M|S) = [P(S|M)P(M)]/P(S). (6)
This is an application of what is sometimes called “Bayes' Rule,” being used more often in recent years and which has caused a good deal of controversy in the statistical community; it has been used successfully in Record Linkage.
Perhaps the pair of records does, in fact, represent the same person, even though the records of birth give a different given name for the mother. We then want P(M|Sc), where Sc means the two elements in a pair do not agree. (Sc is read as the “complement” of S), Then, the analogue of equation (6) gives
P(M|Sc) = [P(Sc|M)P(M)]/P(Sc). Further, (7)
P(Sc) = 1 − P(S) = 1 − [(N1/N)2 + (N2/N)2 + .... + (Nm/N)2], and (8)
P(Sc|M) = 1 − P(S|M) = 1− k/n, (9)
so that we get for the probability of a match when the elements are not the same,
P(M|Sc) = [(1− k/n)P(M)]/{1 − [(N1/N)2 + (N2/N)2 + ..... + (Nm/N)2]}. (10)
Note that k and n are different from N1, N2, . . ., Nm or N. This is because they come from a sample of duplicates of size n, whereas N1, N2, . . . , Nm are the total numbers of records in the file for each of the names. Recall that k is the number of pairs of records in the set of duplicates (or matches) for which the given name of the mother is the same. P(M) in equations (5), (6), (7), and (10) is the probability that two records “match” (represent the same person) when they have been paired at random. It will be very small.
Next, let E be the event describing whether the mothers ‘given names are the same, not the same, or missing. Then,
P(M|E) ≅ P(M) times (k/n)/ [(N1/N)2 + (N2/N)2 + ..... + (Nm/N)2] (11)
if the names are the same
and P(M|E) ≅ P(M) times (1 − k/n)/{1 − [(N1/N)2 + (N2/N)2 + . . . . . +(Nm/N)2]}
if they are different.
We further define P(M|E) = P(M) if one or both elements are missing in the record pair. This makes sense, since E tells us nothing new about the match when the information is missing.
Since virtually all records contain more than one element or “field,” we must allow for this in our formulas. We let Q be the number of elements or fields common to both records and consider the ith field, where i ranges from 1 to Q. Then, let ni be the number of elements with both entries present for the ith field in the sample of duplicates, and ki be the number of element pairs in the ith field which are the same. Letting Ei be the event for the ith field (same, not same, or missing), we get the following:
P(M|Ei) ≅ P(M)P(Ei/M)/P(Ei) = P(M) times (ki/ni)/[Σj(Nij/Ni)2], (12)
when the ith elements are the same and where the summation Σj is over all possible values of j in Nij/Ni for the ith element or field. Note that Nij now has two subscripts, the first subscript (i) to account for the field and the second (j) to account for the alternative values for the ith field. The range of j is from 1 to Ji because there are a different number of alternatives in each field. For example, there are two alternatives for gender and, in our case, m alternatives for the given name of the mother.
If the elements for the ith field are not the same, the formula is:
P(M|Ei) ≅ P(M)P(Ei/M)/P(Ei) = P(M) times (1 − ki/ni)/{1 − [Σj(Nij/Ni)2]} and (13)
P(M|Ei) = P(M) when one or both of the ith elements are missing.
P(Ei|M)/P(Ei) (14)
can be referred to as the “odds” in favor of a match, given the event Ei with respect to the ith field. Note that P(M) does not appear in (14). It does appear in (12) and (13), however, which are the probabilities that two records refer to the same person, given the event Ei for the ith field. There are Q events for each pair of records (an event for each of the fields). Next, we consider
P(M|E1, E2, . . . , EQ), (15)
which is the probability that both members of the pair represent the same person when events E1 and E2 and… EQ have occurred. If most of the paired fields are the same, this probability will be close to 1, and we should conclude the pair is “linked,” as distinguished from the cases where they are known to have been matched by prior identification of duplicates. If most of the paired fields are not the same, (15) will be close to zero, and we conclude the records are not a match. There is a gray area in between where the evidence is not conclusive. We assume that the events E1, . . . , EQ are independent (that is, that one pair of fields being the same tells us nothing about the “sameness” of any other pair).
If we assume this, we get the formula:
P(M|E1, E2, . ., EQ) = P(M|E1)P(M|E2) … P(M|EQ) = Πi=1QP(M|Ei) (16)
= Πi=1QP(Ei|M)P(M)/P(Ei)
= P(M)[Πi=1QP(Ei|M)]/[Πj=1QP(Ei)].
(Note that Πi=1QP(Ei|M) means to take the product of the P(Ei|M) as the subscript j ranges from 1 to Q; similarly for Πj=1QP(Ei) in the above expression.)
The “odds” in favor of the records representing the same person are calculated as the probability of the above events when the records are matched, divided by the same probabilities when the records are randomly paired —which is the last expression of (16), except that P(M) would be dropped. Referring to the second page of NeSmith's paper, the probability of the two names “matching by chance” is
Πj=1QP(Ei) (17)
while the probability of the names being the same in the “truly linked records” is
Πi=1QP(Ei|M). (18)
These are the two statistics used to calculate the odds. As before stated, this is (18) divided by (17).
Blocking
Finding the matches or duplicates (those pairs which are known to represent the same person) involves the time of experienced researchers who must consider a large sample of record pairs and find those which will be identified as duplicates. If all possible pairs are to be considered for the cases of interest, we will have an impossible task before us, with literally billions of pairs to evaluate. To cut down on the enormity of this task, we attempt to gather together records, which are likely to be matches, by sorting on fields, which will put potential matches close to each other in a listing of available records. Such fields usually include a surname code (such as Soundex), a given name code, and possibly a range for birthdates, and a county identification of some kind. If these four fields were used, a listing of records would put people together if they had the same surname code, given name within the surname code, birthdate range within the names, and the same county.
A block is defined as the set of records whose pairs are the same with respect to a set of fields, such as the above four fields. Each distinct set of fields used for this purpose is called a blocking scheme. The records whose blocking fields match will be adjacent to each other in a file, which has been indexed on the basis of these fields. Such a list can be constructed with any good data base management system. A block may, and probably will, contain a number of records, which are not duplicates; but a qualified researcher can browse the list and determine which of the pairs within the block should be considered as representing the same person. The size of the block should be modest—not more than 10 to 20 records, so that the worker can compare them on a monitor screen. In order to find as many duplicates as possible, this process must be repeated for several blocking schemes. Even then, the number of blocks for a data bank may be too numerous to make searching all of them for duplicates feasible. Then, a subset is used, such as some representative date ranges. One of the problems of interest is how large the sample of duplicates obtained by the workers should be. Current practice
is to find about 1,000 to 1,500 duplicates—a substantial amount of work.
One blocking scheme will often have better properties than another. Measures of how good a scheme is include:
-
Blocking Recall. —It often happens that when a second blocking scheme is used, there will be a few of the duplicate pairs found in the first scheme, which will now be separated; that is, the two members of the pair will not show up in the same block. Since our searching procedures only look for record matches within the same block, such duplicates will not be detected using the second scheme. If we now consider several blocking schemes, the percentage of known duplicate pairs, which are picked up with any one of the schemes, may well be less than 100%. Hopefully, we will find one of them, which picks up a higher percentage of duplicate pairs than do the others. Blocking recall is defined as the percentage of known duplicates, which are identified with a particular blocking scheme.
-
Block Noise. —This is the number of non-duplicates in the blocks divided by the total of the block sizes in the blocking scheme. Greater block noise requires more computing time for a search, but recall for the scheme is usually better.
-
Block Precision. —For a blocking scheme, this is the ratio of the number of duplicates to the number of non-duplicates in the blocks, multiplied by 100. A blocking scheme with high precision has mostly duplicate pairs within the block. There are not many non-duplicates.
The greater the precision, the less recall, as a general rule, as indicated on the third page of NeSmith (1994). Her comment about increasing recall without seriously reducing precision relates to the use of a name code, such as Soundex, and a place code, which different versions of place names are tied to. This can be considered as a partial agreement for the fields concerned, and the blocks that use these fields will be somewhat larger, including proper and/or place names, which are “close” to each other. We decrease the block noise and increase the block precision by increasing the number of fields used for blocking. Fewer fields, conversely, increase both noise and recall.
Calculating the Weights
The weights are obtained from the odds by taking logarithms. Using equation (16), we take logarithms, to get
log P(M|E1,E2,..,EQ) = log P(M) + Si=1Qlog{P(Ei|M)/P(Ei)}. (19)
Note that P(M) is a constant term, which factors out of (16), and is simply an additive constant in (19). Such a constant does not influence the results. We can drop this constant and simply consider the term
L = Si=1Qlog{P(Ei|M)/P(Ei)}. (20)
The “weights” referred to in the NeSmith paper are the individual terms
wi = log{P(Ei|M)/P(Ei)}. (21)
For each field, there are three weights—one for when the two field entries are the same, one for when they are not, and zero for when one or both entries are missing. This weight will be a positive value when the two fields are the same; it will tend to be negative if the entries for the two fields are different.
If the probability is high that the records are for the same person, then most of the Ei will be in agreement (the ith elements are the same for most of the i), and the sum of the weights (sum of the “log-odds”) will be high, usually positive. If the probability is low, then most of the Ei will not be in agreement, and the sum of the weights will be low, usually negative. If data are missing in the ith field, so that P(M|Ei) = P(M), then from (12), P(Ei|M)/P(Ei)=1 and log[P(Ei|M)/P(Ei)=0. That is, the weight is zero if one or both field elements are missing. Fields with missing elements, therefore, neither add to nor subtract from the evidence we are interested in.
The researcher must identify each of the pairs in the subset of blocks as either a duplicate or a non-duplicate, and the weights are calculated from the duplicate pairs in the blocks, plus a set of counts (the Nij) for each field. The counts do not come from the blocks but from the complete set of records to be linked— that is, from the entire file. Note that as per the comment in NeSmith on the fifth page, the weights are not calculated for the fields used as blocks because those fields always are the same for the records in the blocks, whether duplicates or not, and thus have little or no discriminating power. For the same kind of reason, some fields have poor discriminating power because they do not change a great deal in some files— such as a geographical area in which a few family names predominate. A small amount of variability in a field reduces its usefulness for linkage algorithms. Algebraically, this shows up in the denominator of (18)/(17), above, because the chance of the fields being the same with random pairing becomes larger. But this is (17), which thus decreases the odds for a link when the field entries are the same.
Thresholds
Many genealogical tasks involve a search for someone in a large data bank. This search is usually termed “query,” and the framework for this is the set of linkage algorithms described above. One uses the fields available for the person to be searched for, chooses a blocking scheme employing some of those fields, and then searches the block into which the person being searched for fits. If a record in the block, when paired with the query, has the sum of the weights higher than a value called the threshold, a link has been found for the query. High recall for a blocking scheme means that there is a good chance of finding this link if it exists—but since high recall goes with more “noise,” more computing time is involved. If a large number of queries are involved, the computing time may become an important issue.
The threshold is simply a constant value, C, which is a cutoff point for L, the sum of the log-odds for a pair. We consider the pair as representing the same person if L is greater than or equal to C; that is, the pair is “linked.” The pair is not linked (i.e., considered as representing different people) if L is less than C. As an illustration for thresholds, we consider five sets of date ranges, which were used with Norway data (1736– 1755), (1781–1794), (1805–1814), (1836–1845), (1866–1875). These subsets of the complete set of data were used because finding duplicates for the complete set would have been too time-consuming. Several blocking schemes were used for identifying duplicates. For each blocking scheme and for each block in the scheme, all possible pairs were obtained, and the worker identified each pair as either a match (i.e., a duplicate) or a non-match. The scheme chosen as best for linking on the basis of precision and recall used the fields: birth year, birth county code (to standardize county names), the given name code for the principal (whose birth is recorded), and the father's given name code. A block consisted of all records, which were the same for all four of the above fields. The fields used for weighting purposes were:
-
the latitude minutes of the birth town
-
the birth day
-
the birth month
-
the death day
-
the death month
-
the death year
-
the mother's given name code, and
-
the mother's surname code.
The Nij were obtained with the computer from all records in the Norway File. The weights were then calculated with computing facilities for each of the eight fields, according to the formulas described in the preceding section and using the duplicates identified by the researchers. Next, for each pair of records within each block (duplicates or not) and for each field in the pair, the weights are then used. The total of the weights is obtained to get the value for the sum of the log-odds (see equation (17)). We now have a set of weight totals for the duplicates (matched pairs) and another set for the non-duplicates (unmatched pairs). A frequency histogram was obtained for both the matched and the unmatched pairs; these appear in Table 1.
Table 1. —Frequency Distributions for Matched and Unmatched Pairs
|
Class Limits for Weight Totals |
Unmatched Pairs |
Matched Pairs |
|
-34.35 to -27.56 |
0 |
0 |
|
-27.55 to -20.76 |
6 |
0 |
|
-20.75 to -13.96 |
257 |
0 |
|
-13.95 to -7.16 |
602 |
1 |
|
-7.15 to -0.36 |
381 |
33 |
|
-0.35 to 6.44 |
58 |
255 |
|
6.45 to 13.24 |
2 |
540 |
|
13.25 to 20.04 |
0 |
344 |
|
20.05 to 26.84 |
0 |
15 |
|
26.85 to 33.64 |
0 |
19 |
|
33.65 to 40.44 |
0 |
13 |
|
40.45 to 47.24 |
0 |
0 |
Minimizing False Duplicates
It will be noted that the scores for the unmatched pairs are consistently lower than for the matched pairs, but that occasionally, the scores for the unmatched pairs will be higher than some of the scores for the matched pairs. Figure 1, below, provides graphs for both histograms. The vertical line for both distributions represents the threshold, or value above which a pair will be linked (i.e., considered as representing the same person). In the top graph, consisting of the unmatched pairs, there are a few weight sums for pairs, which fall above the threshold and thus will be “linked” (i.e., considered as representing the same person, even though the pair was judged by the worker to represent different people). These are the “false duplicates.”
Minimizing Missed Duplicates
Now, consider the distribution of duplicates or “matched pairs” in the lower graph of Figure 1. Notice that with the threshold illustrated, there is a substantial proportion of duplicates that will be unlinked (i.e., considered as representing different people). Rather few of the unmatched pairs will be considered as matched (i.e., will be linked); but substantially more of the duplicates (matched pairs) will fail to be linked. These are the “missed duplicates.” The higher proportion of these is due to minimizing the false duplicate error.
Figure 1. —Threshold which Minimizes False Duplicates
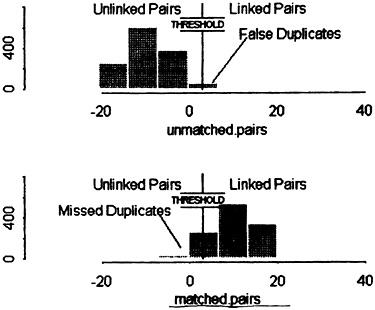
It may be that we consider the “missed duplicate” problem as more serious than the “false duplicate” issue. In this case, we can minimize the missed duplicates by moving the threshold to the left, as in Figure 2. Here, the false duplicate rate (the proportion of non-duplicates which are linked) is now larger than that for the missed duplicates.
Figure 2. —Threshold which Minimizes Missed Duplicates
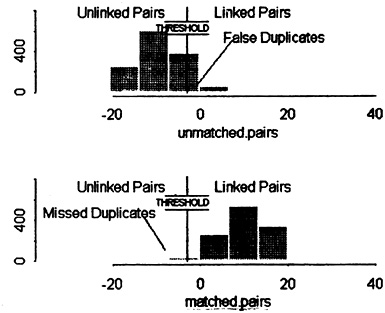
We have now considered two kinds of errors:
-
We can fail to identify a genuine match because our “linking” algorithm did not give the sum of the weights above the threshold (missed duplicates).
-
We can “link” a non-duplicate because our algorithm gave the sum of the weights above the threshold (false duplicates).
Table 2 gives both errors for ten alternative threshold values. Note that increasing the threshold value decreases false duplicates but increases the percentage of missed duplicates.
Table 2. —Duplicates and Missed Duplicates for Alternative Thresholds
|
Threshold Value for Sum of Log=Odds |
% False Duplicates in Nonmatched Sample |
% Missed Duplicates in Matched Sample |
|
-8.81 |
26.85 |
0.00 |
|
-7.03 |
26.52 |
0.08 |
|
-5.25 |
26.38 |
0.08 |
|
-3.48 |
7.66 |
2.21 |
|
-1.70 |
5.11 |
2.62 |
|
0.06 |
4.66 |
2.78 |
|
1.84 |
4.66 |
2.78 |
|
3.61 |
1.54 |
16.47 |
|
5.39 |
0.21 |
23.60 |
|
7.16 |
0.21 |
23.93 |
Now consider Figure 3. If, now, we identify non-links as those to the left of the lower threshold (THRESHOLD 1) and links as those to the right of the upper threshold (THRESHOLD 2), we have a small error rate for both decisions—but now, we have a new problem.
There is a “gray” area between THRESHOLD 1 and THRESHOLD 2 where there is no rule on how to make a decision. If the pairs in the gray area need to be inspected manually in order to make a decision, this becomes a task of prohibitive magnitude with large files. If one does not need to make a decision with every pair, the use of two thresholds may be the best alternative. NeSmith notes on the final page of her paper that the purpose of linking needs to be considered when setting the threshold. If missed duplicates are the most serious risk, then a lower threshold as in Figure 2 would be preferred. This would make sense for genealogical queries where the failure to find a genuine link could not be compensated for, while a false duplicate would ordinarily be easy to detect on examination. If a large file is to be “cleaned up,” however, a false duplicate might be more serious, since merging two individuals would then lose information on one of them. A duplicate of an individual would also be a problem, but possibly less serious, and the higher threshold of Figure 1 might be better. If the file were small enough, then cleaning it up might be best with the two thresholds of Figure 3, with manual inspection of the pairs whose linkage scores fell in the gray area.
Figure 3. —Using Two Thresholds to Control Both Kinds of Errors
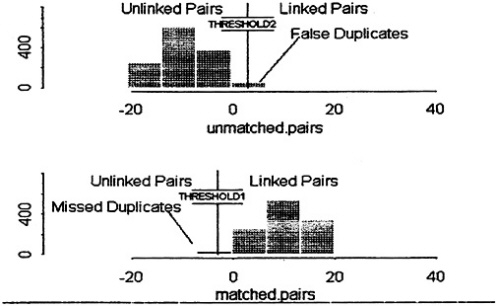
Summary
The procedure has several main phases:
-
Select a file (or set of files) in which to identify duplicates.
-
Pick fields for ordering the records to put likely duplicates close together, using a data base management system with “browsing” capacity (blocking).
-
Manually identify between 1,000 and 1,500 duplicate pairs.
-
Use the duplicate pairs and the preceding formulas to construct weights for all fields, except those used for blocking.
-
Select one or two thresholds to use for “linking” pairs of records as estimated duplicates. The position of the threshold or thresholds depends on the desired type and size of the error rates (see Figures 1–3).
-
Merge records which have been linked, allowing storage space for possible conflicts. If the entries for a specific field do not match, both entries should be stored, so that a genealogical researcher using the data bank can evaluate them both.
-
Use these algorithms to identify duplicates when records are added to the file, and when queries are being made.
This type of project can be repeated with many different geographical areas: the problems and sets of weights appropriate for use with patronymics will be much different than those associated with the U.S. and Canada. There are many refinements, which need to be investigated, including the use of value-specific techniques, partial agreements, lack of independence between field entries, and the use of other statistical procedures to enhance current techniques.
Note
David White is professor emeritus at Utah State University, Department of Mathematics, Logan, Utah 84322 and has been statistical consultant to the Record Linkage Team, Family History Department, Church of Jesus Christ of Latter-Day Saints.
References
Baldwin, J.A.; Acheson, E.D.; and Graham, W.J. (Eds.) ( 1987). Textbook of Medical Record Linkage, New York: Oxford University Press.
NeSmith, Nancy P. ( 1992). Record Linkage and Genealogical Files, Genealogical Journal, 20, 3–4, 113–119.
Newcombe, H.B. ( 1988). Handbook of Record Linkage, New York: Oxford University Press.
|
This paper is designed as a companion to “Record Linkage and Genealogical Files,” by Nancy P.NeSmith (in this volume) and parallels as much as possible the description of record linkage given there with the formulas used to put the theory into practice. The material included here is not in any sense original but derives from the work of H.B.Newcombe (1988) and researchers, such as those included in Baldwin, Acheson, and Graham (1987), who have been working in this area, primarily from the decade of the 1960's and after. If there are any questions relative to the material of these papers, please contact Ms. NeSmith at the address given in her paper, or Dr. White, with respect to the statistics. |
Matching and Record Linkage
William E.Winkler, Bureau of the Census
Matching has a long history of uses for statistical surveys and administrative data files. Business registers of names, addresses, and other information such as total sales are constructed by combining tax, employment, or other administrative databases (see Chapter 2). Surveys of retail establishments or farms often combine results from an area frame and a list frame. To produce a combined estimator, units must be identified from the area frame sample that are also found on the list frame (see Chapter 11). To estimate the size of a population via capture-recapture techniques, units common to two or more independent listings must be accurately determined (Sekar and Deming 1949; Scheuren 1983; Winkler 1989b), Samples must be drawn appropriately to estimate overlap (Deming and Gleser 1959).
Rather than develop a special survey to collect data for policy decisions, it is sometimes more appropriate to match data from administrative data sources. An economist, for instance, might wish to link a list of companies and the energy resources they consume with a comparable list of companies and the types, quantities, and dollar amounts of the goods they produce. There are potential advantages to using administrative data in analyses. Administrative data sources may contain greater amounts of data and that data may be more accurate due to improvements over time. In addition, virtually all cost of data collection is borne by the administrative programs, and respondent burden associated with a special survey is eliminated. Brackstone (1987) discusses these and other advantages of administrative sources as a substitute for surveys. Methods of adjusting analyses for matching error in merged databases are also available (Neter et al. 1965, Scheuren and Winkler 1993).
|
1 |
The author appreciates many useful comments by Brenda G.Cox. the section editor, and an anonymous reviewer. The opinions expressed are those of the author and not necessarily those of the U.S. Bureau of the Census. Business Survey Methods, Edited by Cox, Binder, Chinnappa, Christianson. Colledge, Kott. ISBN 0–471–59852–6 © 1995 John Wiley & Sons, Inc. |
This chapter addresses exact matching in contrast to statistical matching (Federal Committee on Statistical Methodology 1980). An exact match is a linkage of data for the same unit (e.g., business) from different files; linkages for units that are not the same occur only because of error. Exact matching uses identifiers such as name, address, or tax unit number. Statistical matching, on the other hand, attempts to link files that have few units in common. Linkages are based on similar characteristics rather than unique identifying information, and strong assumptions about joint relationships are made. Linked records need not correspond to the same unit.
Increasingly, computers are used for exact matching to reduce or eliminate manual review and to make results more easily reproducible. Computer matching has the advantages of allowing central supervision of processing, better quality control, speed, consistency, and reproducibility of results. When two records have sufficient information for making decisions about whether the records represent the same unit, humans can exhibit considerable ingenuity by accounting for unusual typographical errors, abbreviations, and missing data. For all but the most difficult situations, however, modern computerized record linkage can achieve results at least as good as a highly trained clerk. When two records have missing or contradictory name or address information, then the records can only be correctly matched if additional information is obtained. For those cases when additional information cannot be adjoined to files automatically, humans are often superior to computer matching algorithms because they can deal with a variety of inconsistent situations.
In the past, most record linkage has been done manually or via elementary but ad hoc computerized rules. This chapter focuses on computer matching techniques that are based on formal mathematical models subject to testing via statistical and other accepted methods. A description is provided of how aspects of name, address, and other file information affect development of automated procedures. The algorithms I describe are based on optimal decision rules that Fellegi and Sunter (1969) developed for methods first introduced by Newcombe et al. (1959). Multidisciplinary in scope, these automated record linkage approaches involve (1) string comparator metrics, search strategies, and name and address parsing/standardization from computer science; (2) discriminatory decision rules, error rate estimation, and iterative fitting procedures from statistics; and (3) linear programming methods from operations research. This chapter contains many examples because its purpose is to provide background for practitioners. While proper theory plays an important role in modern record linkage, my intent is to summarize theoretical ideas rather than rigorously develop them. The seminal paper by Fellegi and Sunter (1969) is still the best reference on theory and related computational methods.
20.1 TERMINOLOGY AND DEFINITION OF ERRORS
Much theoretical work and associated software development for matching and record linkage have been done by different groups working in relative isola-
tion, resulting in varied terminology across groups. In this chapter I use terminology consistent with Newcombe (Newcombe et al. 1959; Newcombe 1988) and Fellegi and Sunter (1969).
In the product A × B of files A and B, a match is an aibj pair that represents the same business entity and a nonmatch is a pair that represents two different entities. Within a single list, a duplicate is a record that represents the same business entity as another record in the same list. Rather than consider all pairs in A × B, attention is sometimes restricted to those pairs that agree on certain identifiers or blocking criteria. Blocking criteria are also called pockets or sort keys. For instance, instead of making detailed comparisons of all 90 billion pairs from two lists of 300,000 records representing all businesses in a particular state, it may be reasonable to limit comparisons to the set of 30 million pairs that agree on U.S. Postal ZIP code. Errors of omission can result from use of such blocking criteria; missed matches are those false nonmatches that do not agree on a set of blocking criteria.
A record linkage decision rule is a rule that designates a pair either as a link, a possible link, or a nonlink. Possible links are those pairs for which the identifying data are insufficient to decide if the pair is a match. Typically, clerks review possible links and determine their match status. In a list of farms, name information alone is not sufficient for deciding whether “John K Smith, Jr, Rural Route 1” and “John Smith, Rural Route 1” represent the same operation. The second “John Smith” may be the same person as “John K Smith, Jr” or may be his father or grandfather. Mistakes can and do occur in matching. False matches are those nonmatches that are erroneously designated as links by a decision rule. False nonmatches are either (1) matches designated as nonlinks by the decision rule as it is applied to a set of pairs or (2) missed matches that are not in the set of pairs to which the decision rule is applied. Generally, link/nonlink refers to designations under decision rules and match/ nonmatch refers to true status.
Matching variables are common identifiers (such as name, address, annual receipts, or tax code number) that are used to identify matches. Where possible, a business name such as “John K Smith Company” is parsed or separated into components such as first name “John,” initial “K,” surname “Smith,” and business key word “Company.” The parse allows better comparison of names and hence improves matching accuracy. Similarly, an address such as “1423 East Main Road” might be parsed into location number “1423,” direction “East,” street name “Main,” and street type “Road.” Matching variables do not necessarily uniquely identify matches. For instance, in constructing a frame of a city's retail establishments, name information such as “Hamburger Heaven” may not allow proper linkage if “Hamburger Heaven” has several locations. The addition of address information can sometimes help, but not if many businesses have different addresses on different lists. In such a situation there is insufficient information to separate new units from existing units that have different mailing addresses associated with them. The matching weight or score is a number assigned to a pair that simplifies assignment of link and nonlink status via decision rules. A procedure, or matching variable,
has more distinguishing power if it is better able to delineate matches and nonmatches than another.
20.2 IMPROVED COMPUTER-ASSISTED MATCHING METHODS
Historically, record linkage has been assigned to clerks who reviewed the lists, obtained additional information when matching information was missing or contradictory, and made linkage decisions following established rules. Typically these lists were sorted alphabetically by name or address characteristics to simplify the review process. If a name contained an unusual typographical variation, the clerks might not find its matches. For large files, matches could be separated by several pages of printouts, so that some matches might be missed. Even after extensive training, the clerks' matching decisions were not always consistent. All work required extensive review. Each major update required training the clerical staff again.
On the other hand, development of computer matching software can require person-years of time from proficient computer scientists. Existing software may not work optimally on files having characteristics significantly different from those for which they were developed. The advantages of automated methods far outweigh these disadvantages. In situations for which good identifiers are available, computer algorithms are fast, accurate, and yield reproducible results. Search strategies can be far faster and more effective than those applied by clerks. As an example, the best computer algorithms allow searches using spelling variations of key identifiers. Computer algorithms can also account for the relative distinguishing power of combinations of matching fields as input files vary. In particular, the algorithms can deal with the relative frequency that combinations of identifiers occur.
As an adjunct to computer operations, clerical review is still needed to deal with pairs having significant amounts of missing information, typographical errors, or contradictory information. Even then, using the computer to bring pairs together and having computer-assisted methods of review at terminals is more efficient than manual review of printouts.
By contrasting the creation of mailing lists for the U.S. Census of Agriculture in 1987 and 1992, the following example dramatically illustrates how enhanced computer matching techniques can reduce costs and improve quality. Absolute numbers are comparable because 1987 proportions were multiplied by the 1992 base of six million. To produce the address list, duplicates were identified in six million records taken from 12 different sources. Before 1982, listings were reviewed manually and an unknown proportion of duplicates remained in files.
In 1987, the development of effective name parsing and adequate address parsing software allowed creation of an ad hoc computer algorithm for automatically designating links and creating subsets for efficient clerical review. Within pairs of records agreeing on ZIP code, the ad hoc computer algorithm
used surname-based information, the first character of the first name, and numeric address information to designate 6.6 percent (396,000) of the records as duplicates and 28.9 percent as possible duplicates to be clerically reviewed. About 14,000 person-hours (as many as 75 clerks for 3 months) were used in this clerical review, and an additional 450,000 duplicates (7.5 percent) were identified. Many duplicates were not located, compromising subsequent estimates based on the list.
In 1992, Fellegi-Sunter algorithms were developed that used effective computer algorithms for dealing with typographical errors. The computer software designated 12.8 percent of the file as duplicates and another 19.7 percent as needing clerical review. About 6500 person-hours were used and an additional 486,000 duplicates (8.1%) were identified. Even without further clerical review, the 1992 computer procedures identified almost as many duplicates as the 1987 combination of computer and clerical procedures. The cost of software development was $110,000 in 1992. The rates of duplicates identified by computer plus clerical procedures were 14.1 percent in 1987 and 20.9 percent in 1992. The 1992 computer procedures lasted 22 days; in contrast, the 1987 computer plus clerical procedure needed 3 months.
20.3 STANDARDIZATION AND PARSING
Appropriate parsing of name and address components is crucial for computerized record linkage. Without it, many true matches would erroneously be designated as nonlinks because identifying information could not be adequately compared. For specific types of business lists, the drastic effect of parsing failure has been quantified (Winkler 1985b, 1986). DeGuire (1988) presents concepts needed for parsing and standardizing addresses; name parsing requires similar concepts.
20.3.1 Standardization of Names and Addresses
The basic ideas of standardization are to (1) replace the many spelling variations of commonly occurring words with standard spellings such as fixed abbreviations or spellings and (2) use key words found during standardization as hints for parsing subroutines. In standardizing names, words of little distinguishing power such as “Corporation” or “Limited” are replaced with consistent abbreviations such as “CORP” and “LTD,” respectively. First name spelling variations such as “Rob” and “Bobbie” might be replaced with a consistent, assumed, original spelling such as “Robert” or an identifying root word such as “Robt” because “Bobbie” could refer to a woman with “Roberta” as her legal first name. The purpose of name standardization is to allow name-parsing software to work better, by presenting names consistently and by separating out name components that have little value in matching. When business-associated words such as “Company ” or “Incorporated” are en-
countered, flags are set that force entrance into different name-parsing routines than would be used otherwise.
Standardization of addresses operates like standardization of names. Words such as “Road” or “Rural Route” are typically replaced by appropriate abbreviations. For instance, when a variant of “Rural Route” is encountered, a flag is set that forces parsing into routines different from routines associated with house-number/street-name addresses. When reference lists containing city, state or province, and postal codes are available from the national postal service or another source, then city names in address lists can be placed in a standard form that is consistent with the reference list.
20.3.2 Parsing of Names and Addresses
Parsing divides a free-form name field into a common set of components that can be compared. Parsing algorithms often use hints based on words that have been standardized. For instance, words such as “CORP” or “CO” might cause parsing algorithms to enter different subroutines than words such as “MRS” or “DR.” In the examples of Table 20.1, “Smith” is the name component with the most identifying information. PRE refers to a prefix, POST1 and POST2 refer to postfixes, and BUS1 and BUS2 refer to commonly occurring words associated with businesses. While exact, character-by-character comparison of the standardized but unparsed names would yield no matches, use of the subcomponent last name “Smith” might help designate some pairs as links. Parsing algorithms are available that deal with either last-name-first types of names such as “John Smith” or last-name-last types such as “Smith, John.” None are available that can accurately parse both types of names in a single file.
Humans can easily compare many types of addresses because they can associate corresponding subcomponents in free-form addresses. To be most effective, matching software requires address subcomponents to be in identified locations. As the examples in Table 20.2 show, parsing software divides a free-form address field into a set of corresponding components in specific locations on the data record.
20.3.3 Examples of Names
The main difficulty with business names is that even when they are properly parsed, the identifying information may be indeterminate. In each example of Table 20.3, the pairs refer to the same business entity in a survey frame. Alternatively, in Table 20.4, each pair refers to different business entities that have similar names. Because the name information in Tables 20.3 and 20.4 may be insufficient for accurately determining match status, address information or other identifying characteristics may have to be obtained via clerical review. If the additional address information is indeterminate, then at least one establishment in each pair may have to be contacted.
Table 20.1 Examples of Name Parsing
|
Parsed |
||||||||
|
Standardized |
PRE |
FIRST |
MIDDLE |
LAST |
POST1 |
POST2 |
BUS1 |
BUS2 |
|
DR John J Smith MD |
DR |
John |
J |
Smith |
MD |
|||
|
Smith DRY FRM |
Smith |
DRY |
FRM |
|||||
|
Smith & Son ENTP |
Smith |
Son |
ENTP |
|||||
Table 20.2 Examples of Address Parsing
|
Parsed |
||||||||||
|
Standardized |
Pre2 |
Hsnm |
Stnm |
RR |
Box |
Post1 |
Post2 |
Unit1 |
Unit2 |
Bldg |
|
16 W Main ST APT 16 |
W |
16 |
Main |
ST |
16 |
|||||
|
RR 2 BX 215 |
2 |
215 |
||||||||
|
Fuller BLDG SUITE 405 |
405 |
Fuller |
||||||||
|
14588 HWY 16 W |
14588 |
HWY |
W |
|||||||
Table 20.3 Names Referring to the Same Business Entities
|
Name |
Reason |
|
John J Smith ABC Fuel Oil |
One list has owner name while the other list has business entity name. |
|
John J Smith, Inc. J J Smith Enterprises |
Either name may be used by the business. |
|
Four Star Fuel, Exxon Distrib. Four Star Fuel |
Independent fuel oil dealer is associated with major oil company. |
|
Peter Knox Dairy Farm Peter J Knox |
One list has establishment name while the other has owner name. |
Table 20.4 Names Referring to Different Businesses
|
Name |
Reason |
|
John J Smith Smith Fuel |
Similar initials or names but different companies |
|
ABC Fuel ABC Plumbing |
Same as previous |
|
North Star Fuel, Exxon Distrib. Exxon |
Independent affiliate and company with which affiliated |
20.4 MATCHING DECISION RULES
For many projects, automated matching decision rules are developed using ad hoc, intuitive approaches. For instance, the decision rule might be as follows:
-
If the pair agrees on a specific three characteristics or agrees on four or more within a set of five characteristics, designate the pair as a link.
-
If the pair agrees on a specific two characteristics, designate the pair as a possible link.
-
Otherwise, designate the pair as a nonlink.
Ad hoc rules are easily developed and may yield good results. The disadvantage is that ad hoc rules may not be applicable to pairs that are different from those used in defining the rule. Users seldom evaluate ad hoc rules with respect to false match and false nonmatch rates.
In the 1950s, Newcombe et al. (1959) introduced concepts of record linkage that were formalized in the mathematical model of Fellegi and Sunter (1969). Computer scientists independently rediscovered the model (Cooper and Maron 1978, Van Rijsbergen et al. 1981, Yu et al. 1982) and showed that the model's decision rules work best among a variety of rules based on competing mathe-
matical models. Fellegi and Sunter's ideas are a landmark in record linkage theory because they introduce many ways of computing key parameters needed for the matching process. Their paper provides (1) methods of estimating outcome probabilities that do not rely on intuition or past experience, (2) estimates of error rates that do not require manual intervention, and (3) automatic threshold choice based on estimated error rates. In my view the best way to build record linkage strategies is to start with formal mathematical techniques based on the Fellegi-Sunter model and then make ad hoc adjustments only as necessary. The adjustments may be likened to the manner in which early regression procedures were informally modified to deal with outliers and collinearity,
20.4.1 Crucial Likelihood Ratio
The record linkage process attempts to classify pairs in a product space A × B from two files A and B into M, the set of true matches, and U, the set of true nonmatches. Fellegi and Sunter (1969) considered ratios of probabilities of the form
(20.1)
where γ is an arbitrary agreement pattern in a comparison space Γ. For instance, Γ might consist of eight patterns representing simple agreement on the largest name component, street name, and street number. Alternatively, each γ ∈ Γ might additionally account for the relative frequency with which specific values of name components such as “Smith,” “Zabrinsky,” “AAA,” and “Capitol” occur.
20.4.2 Theoretical Decision Rule
The decision rule is equivalent to the one originally given by Fellegi and Sunter [1969, equation (19)]. In the following, r represents an arbitrary pair, γ ε Γ is the agreement pattern associated with r, and R is the ratio corresponding to r that is given by equation (20.1). The decision rule d provides three designated statuses for pairs and is given by:
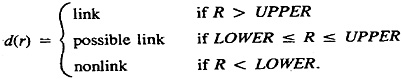
(20.2)
The cutoff thresholds UPPER and LOWER are determined by a priori error bounds on false matches and false nonmatches. Rule 20.2 agrees with intuition. If γ ∈ Γ consists primarily of agreements, then it is intuitive that γ ∈ Γ would be more likely to occur among matches than nonmatches and ratio (20.1)
would be large. On the other hand, if γ ∈ Γ consists primarily of disagreements, then ratio (20.1) would be small.
Fellegi and Sunter (1969) showed that rule (20.2) is optimal in that for any pair of fixed upper bounds on the rates of false matches and false nonmatches, the clerical review region is minimized over all decision rules on the same comparison space Γ. The theory holds on any subset such as pairs agreeing on a postal code, street name, or part of a name field. The ratio R or any monotonically increasing transformation of it (such as given by a logarithm) is referred to as a matching weight or total agreement weight. In actual applications, the optimally of rule (20.2) is heavily dependent on the accuracy of the estimated probabilities in equation (20.1). The probabilities in equation (20.1) are called matching parameters.
20.4.3 Basic Parameter Estimation Under the Independence Assumption
Fellegi and Sunter (1969) were the first to observe that certain parameters needed for rule (20.2) could be obtained directly from observed data if certain simplifying assumptions were made. For each γ ∈ Γ, they considered
P(γ) = P(γ|M)P(M) + P(γ|U)P(U) (20.3)
and noted that the proportion of pairs with γ ∈ Γ could be computed directly from available data. If γ ∈ Γ consists of a simple agree/disagree pattern associated with three variables satisfying the conditional independence assumption that there exist vector constants (marginal probabilities) m ≡ (m1, m2, . . . , mK) and u ≡ (u1, u2,. . . , uK) such that, for all γ ∈ Γ,
(20.4)
then Fellegi and Sunter provide the seven solutions for the seven distinct equations associated with equation (20.3).
If γ ∈ Γ represents more than three variables, then it is possible to apply general equation-solving techniques such as the method of moments (e.g., Hogg and Craig 1978, pp. 205–206). Because the method of moments has shown numerical instability in some record linkage applications (Jaro 1989) and with general mixture distributions (Titterington et al. 1988, p. 71), maximum-likelihood-based methods such as the Expectation-Maximization (EM) algorithm (Dempster et al. 1977, Wu 1983, Meng and Rubin 1993) may be preferred.
The EM algorithm has been used in a variety of record linkage situations. In each, it converged rapidly to unique limiting solutions over different starting
points (Thibaudeau 1989; Winkler 1989a, 1992). The major difficulty with the parameter-estimation techniques (EM or an alternative such as method of moments) is that they may yield solutions that partition the set of pairs into two sets that differ substantially from the desired sets of true matches and true nonmatches. In contrast to other methods, the EM algorithm converges slowly and is stable numerically (Meng and Rubin 1993).
20.4.4 Adjustment for Relative Frequency
Newcombe et al. (1959) introduced methods for using the specific values or relative frequencies of occurrence of fields such as surname. The intuitive idea is that if surnames such as “Vijayan” occur less often than surnames such as “Smith,” then “Vijayan” has more distinguishing power. A variant of Newcombe's ideas was later mathematically formalized by Fellegi and Sunter (1969; see also Winkler 1988, 1989c for extensions). Copas and Hilton (1990) introduced a new theoretical approach that, in special cases, has aspects of the Newcombe's approach; it has not yet applied in a record linkage system. While the value-specific approach can be used for any matching field, strong assumptions must be made about independence between agreement on specific value states of one field versus agreement on other fields.
The concepts of Fellegi and Sunter (1969, pp. 1192–1194) describe the problem well. To simplify the ideas, files A and B are assumed to contain no duplicates. The true frequencies of specific values of a string such as first name in files A and B, respectively, are given by
and
If the mth string, say “Smith,” occurs fm times in File A and gm times in File B, then pairs agree on “Smith” fmgm times in A × B. The corresponding true frequencies in M are given by
Note that hj = min (fj, gj), where j = 1, 2, · · · m. For some implementations, hj is assumed to equal the minimum, and P(agree jth value of string | M) = hj|NM and P (agree jth value of string | U) = (fjgj- hj)/(NA · NB- NM). In practice, observed values rather than true values must be used. The variants of how the hj frequencies are computed involve differences in how typographical errors are modeled, what simplifying assumptions are made, and how fre-
quency weights are scaled to simple agree/disagree probabilities (Newcombe 1988; Fellegi and Sunter 1969; Winkler 1988, 1989c). As originally shown by Fellegi and Sunter (1969), the scaling can be thought of as a means of adjusting for typographical error. The scaling is
P (agree on string ![]() (agree on jth value of string | M),
(agree on jth value of string | M),
where the probability on the left is estimated via the EM algorithm or another method. With minor restrictions, the ideas of Winkler (1989c) include those of Fellegi and Sunter (1969), Newcombe (1988, pp. 88–89), and Rogot et al. (1986) as special cases.
In some situations, the frequency tables are created “on-the-fly” using the files actually being matched (Winkler 1989c); in others, the frequency tables are created a priori using large reference files. The advantage of on-the-fly tables is that they can use different relative frequencies in different geographic regions; for instance, Hispanic surnames in Los Angeles, Houston, or Miami and French surnames in Montreal. The disadvantage of on-the-fly tables is that they must be based on files that cover a large percentage of the target population. If the data files contain samples from a population, then the frequency weights should reflect the appropriate population frequencies. For instance, if two small lists of companies in a city are used and “George Jones, Inc” occurs once on each list, then a pair should not be designated as a link using name information only. Corroborating information such as address should also be used because the name “George Jones, Inc” may not uniquely identify the establishment.
20.4.5 Jaro String Comparator Metrics for Typographical Error
Jaro (1989) introduced methods for dealing with typographical error such as “Smith” versus ”Smoth.” Jaro's procedure consists of two steps. First, a string comparator returns a value based on counting insertions, deletions, transpositions, and string length. Second, the value is used to adjust a total agreement weight downward toward the total disagreement weight. Jaro's string comparator was extended by making agreement in the first few characters of the string more important than agreement on the last few (Winkler 1990b). As Table 20.5 illustrates, the original Jaro comparator and the Winkler-enhanced comparator yield a more refined scale for describing the effects of typographical error than do standard computer science methods such as the Damerau-Levenstein metric (Winkler 1985a, 1990b).
Jaro's original weight-adjustment strategy was based on a single adjustment function developed via ad hoc methods. Using calibration files having true matching status, Jaro's strategy has been extended by applying crude statistical curve fitting techniques to define several adjustment functions. Different curves were developed for first names, last names, street names, and house numbers.
Table 20.5 Comparison of String Comparators Rescaled Between 0 and 1
|
Strings |
Winkler |
Jaro |
Damerau-Levenstein |
|
|
billy |
billy |
1.000 |
1.000 |
1.000 |
|
billy |
bill |
0.967 |
0.933 |
0.800 |
|
billy |
blily |
0.947 |
0.933 |
0.600 |
|
massie |
massey |
0.944 |
0.889 |
0.600 |
|
yvette |
yevett |
0.911 |
0.889 |
0.600 |
|
billy |
bolly |
0.893 |
0.867 |
0.600 |
|
dwayne |
duane |
0.858 |
0.822 |
0.400 |
|
dixon |
dickson |
0.853 |
0.791 |
0.200 |
|
billy |
susan |
0.000 |
0.000 |
0.000 |
When used in actual matching contexts, the new set of curves and enhanced string comparator improve matching efficacy when compared to the original Jaro methods (Winkler 1990b), With general business lists, the same set of curves could be used or new curves could be developed. In a large experiment using files for which true matching status was known, Belin (1993) examined effects of different parameter-estimation methods, uses of value-specific weights, applications of different blocking criteria, and adjustments using different string comparators. Belin demonstrated that the original Jaro string comparator and the Winkler extensions were the two best ways of improving matching efficacy in files for which identifying fields had significant percentages of minor typographical errors.
20.4.6 General Parameter Estimation
Two difficulties arise in applying the EM procedures of Section 20.4.3. The first is that the independence assumption is often false (Smith and Newcombe 1975, Winkler 1989b). The second is that, due to model misspecification, EM or other fitting procedures may not naturally partition the set of pairs into the desired sets of matches M and nonmatches U.
To account for dependencies between the agreements of different matching fields, an extension of an EM-type algorithm due to Haberman (1975, see also Winkler 1989a) can be applied. Because many more parameters are associated with general interaction models than with independence models, only a fraction of all interactions may be fit. For instance, if there are 10 matching variables, the degrees of freedom are only sufficient to fit all three-way interactions (e.g., Bishop et al. 1975, Haberman 1979); with fewer matching variables, it may be necessary to fit various subsets of the three-way interactions.
To address the natural partitioning problem, A × B is partitioned into three sets of pairs C1, C2, and C3 using an equation analogous to (20.3). The EM procedures are then divided into three-class or two-class procedures. When appropriate, two of the three classes are combined into a set that represents
either M or U. The remaining class represents the complement. When both name and address information is used for matching, the two-class EM tends to divide a set of pairs into those agreeing on address information and those disagreeing. If address information associated with many pairs is indeterminate (e.g., Rural Route 1 or Highway 65 West), the three-class EM can yield a proper partition because it tends to divide the set of pairs into (1) matches at the same address, (2) nonmatches at the same address, and (3) nonmatches at different addresses.
The general EM algorithm is far slower than the independent EM algorithm because the M step is no longer in closed form. Convergence is speeded up by using variants of the Expectation-Conditional Maximization (ECM) and Multicycle ECM (MCECM) Algorithm (Meng and Rubin 1993, Winkler 1989a). The difficulty with general EM procedures is that different starting points often yield different limiting solutions. However, if the starting point is relatively close to the solution given by the independent EM algorithm, then the limiting solution is generally unique (Winkler 1992). The independent EM algorithm often provides starting points that are suitable for the general EM algorithm.
Figures 20.1–20.8 illustrate that the automatic EM-based parameter-estimation procedures can yield dramatic improvements. Because there were no available business files for which true matching status was known, files of individuals having name, address, and demographic characteristics such as age, race, and sex were used. Each figure contains a plot of the estimated cumulative distribution curve via equation (20.2) versus the truth that is given by the 45-degree line. Figures 20.1–20.4 for matches and Figures 20.5–20.8 for nonmatches successively display fits according to (1) iterative refinement (e.g., Newcombe 1988, pp. 65–66), (2) three-class, independent EM, (3) three-class, selected interaction EM, and (4) three-class, three-way interaction EM with
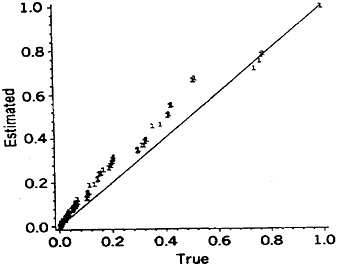
Figure 20.1 Estimates vs. truth, cumulative distribution of matches—two-class, iterative.
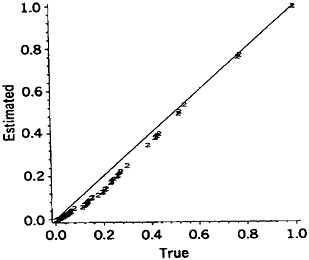
Figure 20.2 Estimates vs. truth, cumulative distribution of matches—three-class, independent EM.
convex constraints. Iterative refinement involves the successive manual review of sets of pairs and the reestimation of probabilities given a match under the independence assumption. Iterative refinement is chosen as a reference point (Figures 20.1 and 20.4) because it yields reasonably good matching decision rules (e.g., Newcombe 1988; Winkler 1990b). The algorithm for fitting selected interactions is due to Armstrong (1992). The EM algorithm with convex constraints that predispose a solution to the proper region of the parameter
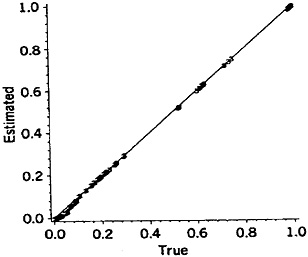
Figure 20.3 Estimates vs. truth, cumulative distribution of matches—three-class, selected interaction EM.
space is due to Winkler (1989a; also 1992, 1993b). All three-way interactions are used in the last model.
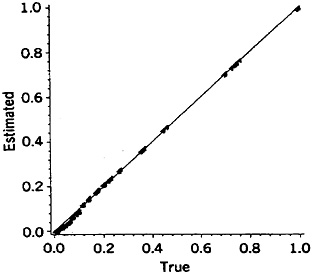
Figure 20.4 Estimates vs. truth, cumulative distribution of matches—three-class, three-way interaction EM, convex.
The basic reason that iterative refinement and three-class independent EM perform poorly is that independence does not hold. Three-class independent EM yields results that are closer to the truth because it divides the set of pairs that agree on address into those agreeing on name and demographic information and those that disagree. Thus, nonmatches such as husband-wife and
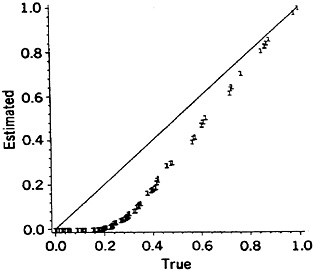
Figure 20.5 Estimates vs. truth, cumulative distribution of nonmatches—two-class, iterative.
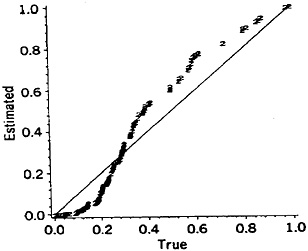
Figure 20.6 Estimates vs. truth, cumulative distribution of nonmatches—three-class, independent EM.
brother-sister pairs are separated from matches such as husband-husband and wife-wife. As shown by Thibaudeau (1993) with these data, departures from independence are moderate among matches whereas departures from independence among nonmatches (such as the husband-wife and brother-sister pairs at the same address) are quite dramatic.
The selected interaction EM does well (Figures 20.3 and 20.7) because true
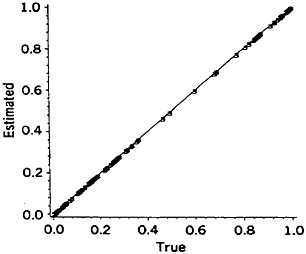
Figure 20.7 Estimates vs. truth, cumulative distribution of nonmatches—three-class, selected interaction EM.
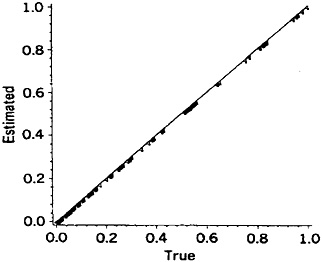
Figure 20.8 Estimates vs. truth, cumulative distribution of nonmatches—three-class, three-way interaction EM, convex.
matching status is used to determine the interactions that must be included. It is unreasonable to expect that true matching status will be available for many matching situations or that the exact set of interactions that were developed for one application will be suitable for use in another. Furthermore, loglinear modeling in latent-class situations is more difficult than for basic loglinear situations where such modeling is known to be difficult (e.g., Bishop et al. 1975). To alleviate the situation, it may be suitable to take a model having all three-way interactions and use convex constraints that bound some probabilities. The bounds would be based on similar matching situations. The all three-way interaction model without convex constraints does not provide accurate fits (Winkler 1992), If the convex constraints are chosen properly, then the three-way interaction EM with convex constraints provides fits (Figures 20.4 and 20.8) that are nearly as good as those obtained with the selected interaction EM (Winkler 1993b).
20.5 EVALUATING THE QUALITY OF LISTS
The quality of lists is primarily determined by how useful the available variables are for matching. For large files, the first concern is how effective common identifiers (blocking criteria) are at reducing the set of pairs to a manageable size. The effectiveness of blocking criteria is also determined by the estimated number of missed matches. Applying a greater number of matching variables generally improves matching efficacy. Name information generally provides more distinguishing power than receipts, sales, or address informa-
tion. Parameter estimates must be as good as possible. Improving parameter estimates can reduce clerical review regions by as much as 90 percent.
20.5.1 Quality of Blocking Criteria
While use of blocking criteria facilitates the matching process by reducing the number of pairs to be considered, it can increase the number of false non-matches because some pairs disagree on the blocking criteria. The following describes an investigation of how well different sets of blocking criteria yield sets of pairs containing all matches (Winkler 1984, 1985b). The sets of pairs were constructed from 11 U.S. Energy Information Administration (EIA) lists and 47 state and industry lists containing 176,000 records. Within the set of pairs from the original set of files, name and address information allowed 110,000 matches to be identified. From the remaining 66,000 records, there were 3050 matches having similar names and addresses and 8510 matches having either a different name or a different address. The remaining 11,560 matches (18 percent of the 66,000 records) were identified via intensive manual review and were used in analyzing various blocking criteria.
In the subsequent analysis, only the 3050 matches having similar names and addresses were considered. In the blocking criteria displayed in Table 20.6, NAME represents an unparsed name field. Only the first few characters from different fields were used. These criteria were the best subset of several hundred criteria that were considered for blocking a list of sellers of petroleum products (Winkler 1984). Table 20.7 illustrates that for certain sets of lists it is quite
Table 20.6 Blocking Criteria
|
1. 3 digits ZIP code, 4 characters NAME 2. 5 digits ZIP code, 6 characters STREET 3. 10 digits TELEPHONE 4. 3 digits ZIP code, 4 characters of largest substring in NAME 5. 10 characters NAME |
Table 20.7 Incremental Decrease in False Nonmatches—Each Set Consists of Pairs in the Union of Sets Agreeing on Blocking Criteria
|
Group of Criteria |
Rate of False Nonmatches |
Matches/ Incremental Increase |
Nonmatches/ Incremental Increase |
|
1 |
45.5 |
1460/NA |
727/NA |
|
1–2 |
15.1 |
2495/1035 |
1109/289 |
|
1–3 |
3.7 |
2908/413 |
1233/124 |
|
1–4 |
1.3 |
2991/83 |
1494/261 |
|
1–5 |
0.7 |
3007/16 |
5857/4363 |
difficult to produce groups of blocking criteria that give a set of pairs that include all matches. With the union of pairs based on the best two sets of criteria, 15.1 percent of the matches were dropped from further consideration; with three, 3.7 percent. The last (fifth) criterion was not useful because it enlarged the set of pairs with only 16 additional matches while adding 4363 nonmatches.
20.5.2 Estimation of False Nonmatches Not Agreeing on Multiple Blocking Criteria
If estimates of the numbers of missed matches are needed, then lists can be sampled directly. Even with very large sample sizes, the estimated standard deviation of the error rate estimate often exceeds the estimate (Deming and Gleser 1959). If samples are not used, then following the suggestion of Scheuren (1983), capture-recapture techniques as in Sekar and Deming (1949; see also Bishop et al. 1975, Chapter 6) can be applied to the set of pairs captured by the first four sets of blocking criteria of Section 20.5.1 (Winkler 1987). The best-fitting loglinear model yields the 95 percent confidence interval (27, 160). The interval, which represents between 1 and 5 percent of true matches, contains the 50 matches that were known to be missed by the blocking criteria and found via intense clerical review.
20.5.3 Number of Matching Variables
As the number of matching variables increases, the ability to distinguish matches usually increases. For instance, with name information alone, it may only be feasible to create subsets of pairs that are held for clerical review. With name and address information, a substantial number of the matches can be correctly distinguished. With name, address, and financial information (such as receipts or income), it may be possible to distinguish most matches automatically.
Exceptions occur if some matching variables have extreme typographical variations and/or are correlated with other matching variables. For instance, consider the following. Two name fields are available for each record of the pairs. The first is a general business name that typically agrees among matches. The second name field in one record corresponds to the owner of a particular business license (e.g., in some states, all fuel storage facilities must be licensed) and in the other record the name field corresponds to the accounting entity that keeps financial records. While the owner of a particular business license will sometimes correspond to the financial person (owner of a gasoline service station), the two names will often disagree among true matches. When both name fields are used in software that assumes that agreements are uncorrelated, contradictory information can cause loss of distinguishing power. Expedient solutions are to drop the contradictory information in the second name field or to alleviate the problem via custom software modifications.
Table 20.8 Examples of Agricultural Names
|
John A Smith John A and Mary B Smith John A Smith and Robert Jones Smith Dairy Farm |
20.5.4 Relative Distinguishing Power of Matching Variables
Without a unique identifier such as a verified employer identification number (EIN), the name field typically has more distinguishing power than other fields such as address. The ability of name information to distinguish pairs can vary dramatically from one set of pairs to another. For instance, in one situation properly parsed name information, when combined with other information, may produce good automatic decision rules; in other situations it may not.
As an example of the first situation, consider the 1992 U.S. Census of Agriculture in which name parsing software was optimized to try to find surnames (or suitable surrogates) and first names. Because the overwhelming majority of farming operations have names of the form given in Table 20.8, the resultant parsed names will likely all have “Smith” as a surname that will yield good distinguishing power when combined with address information. The exception can occur when two names containing “Smith” have the same address. A similar situation occurs with the 1992 match of the Standard Statistical Establishment List (SSEL) of U.S. businesses with a list of small nonemployers from an Internal Revenue Service (IRS) 1040C file of records for which EIN was unavailable.
General business lists can signify the second situation of the poor decision rule because of the ways in which the name field can be represented. For instance, the same business entity may appear in the following forms given in Table 20.9. Even if name parsing software can properly represent name components, it may be difficult to use the components to distinguish matches. If the name information and clerical-review status were retained, then clerical review could be reduced during future updates. Each business could be represented by a unique record that has pointers to significant name variations of matches and nonmatches along with match status. If a potential update record
Table 20.9 Examples of Business Names That Are Difficult to Compare
|
John A Smith and Son Manufacturing Company, Incorporated John Smith Co John Smith Manufacturing J A S Inc. John Smith and Son |
is initially designated as a possible link because of a name variation, then the associated name variations could be searched to decide whether a record with a name similar to the potential update record had previously been clerically reviewed. If it had, then the prior follow-up results could be used to determine whether the new record is a match.
20.5.5 Good Matching Variables But Unsuitable Parameter Estimates
Even when name and other matching variables can be properly parsed and have agreeing components, automatic parameter estimation software may not yield good parameter estimates because the lists have little overlap or because model assumptions in the parameter-estimation software are incorrect. In either situation, matching parameters are usually estimated via an iterative procedure involving manual review. Generally, matching personnel start with an initial set of parameters. The personnel review a moderately large sample of matching results and estimate new parameters via ad hoc means. The review-reestimation process is repeated until matching personnel are satisfied that parameters and matching results will not improve much.
The most straightforward means of parameter reestimation is the iterative refinement procedure of Statistics Canada (e.g., Newcombe 1988, pp. 65–66; Statistics Canada 1983; Jaro 1992). After each review and clerical resolution of match results, marginal probabilities given a match are reestimated and matching (under the independence assumption) is repeated. Marginal probabilities given a nonmatch are held as constant because they are approximated by probabilities of random agreement over the entire set of pairs. If the proportion of nonmatches within the set of pairs is very high, then the random-agreement approximation is valid because decision rules using the random agreement probabilities are virtually the same as decision rules using true marginal probabilities given a nonmatch.
For the 1992 U.S. Census of Agriculture, initial estimates obtained via the independent EM algorithm were replaced by refined estimates that accounted for lack of independence. The refined estimates were determined by reviewing a large sample of pairs, creating adjusted probability estimates, and repeating the process. For instance, if two records simultaneously agreed on surname and first name, their matching weight was adjusted upward from the independent weight.
20.6 ESTIMATION OF ERROR RATES AND ADJUSTMENT FOR MATCHING ERROR
Fellegi and Sunter (1969) introduced methods for automatically estimating error rates when the conditional independence assumption (20.4) is valid. Their methods do not involve sampling and can be extended to more general situations. This section provides different methods for estimating error rates within
a set of pairs than those given in Section 20.4.6. Estimation of false non-matches due to pairs missed because of disagreement on blocking criteria is covered in Section 20.5. This section also describes new work that investigates how statistical analyses can be adjusted for matching error.
20.6.1 Sampling and Clerical Review
Estimates of the number of false matches and nonmatches can be obtained by reviewing a sample of pairs designated as links and nonlinks. Sample size can be minimized by concentrating the sample in weight ranges in which error is likely to take place. Using a weighting strategy that yields good distinguishing power with rule (20.2), most error among computer-designated links and non-links occurs among weights that are close to the thresholds UPPER and LOWER. Within the set of possible links that are clerically designated as links and nonlinks, simple random samples can be used. While the amount of manual review needed for confirming or correcting the link-nonlink designations can require substantial resources, reasonable estimates within the fixed set of pairs can be obtained. An alternative to sampling is to develop effective statistical models that allow automatic estimation of error rates. At present, such methods are the subject of much research and should show improvements in the future.
20.6.2 Rubin-Belin Estimation
Rubin and Belin (1991) developed a method of estimating matching error rates when the curves (ratio R versus frequency) for matches and nonmatches are somewhat separated and the failure of the independence assumption is not too severe. Their method is applicable to weighting curves R obtained via a one-to-one matching rule (Jaro 1989) and to which a number of ad hoc adjustments are made (Winkler 1990b). The one-to-one matching rule can dramatically improve matching performance because it can eliminate nonmatches such as husband-wife or brother-sister pairs that agree on address information. Without one-to-one matching, such pairs receive sufficiently high weights to be designated as possible links.
To model the shape of the curves of matches and nonmatches, Rubin and Belin require true matching status for a representative set of pairs. For a variety of basic settings, the procedure yields reasonably accurate estimates of error rates and is not highly dependent on a priori curve shape parameters (Rubin and Belin 1991; Scheuren and Winkler 1993; Winkler 1992). The SEM algorithm of Meng and Rubin (1991) is used to get 95 percent confidence intervals for the estimates.
While the Rubin-Belin procedures were developed using files of individuals (for which true match status was known), I expect that the procedures are also applicable for files of businesses. When one-to-one matching is used, the Rubin and Belin method can give better error rate estimates than a modified version
of the Winkler method given in Section 20.4.6 (e.g., Winkler 1992). If one-to-one matching is not used, then the Winkler method can yield accurate parameter estimates whereas the Rubin-Belin method cannot be applied because the curves associated with matches and nonmatches are not sufficiently separated.
20.6.3 Scheuren-Winkler Adjustment of Statistical Analyses
Linking information that resides in separate files can be useful for analysis and policy decisions. For instance, an economist might wish to evaluate energy policy by matching a file with fuel and commodity information for businesses against a file with the values and types of goods produced by the businesses. If the wrong businesses are matched, then analyses based on the linked files can yield erroneous conclusions. Scheuren and Winkler (1993) introduced a method of adjusting statistical analyses for matching error. If the probability distributions for matches and nonmatches are accurately estimated, then the adjustment method is valid in simple cases where one variable is taken from each file. Accurate estimates can sometimes be obtained via the method of Rubin and Belin (1991). Empirical applications have been performed for ordinary linear regression models (Winkler and Scheuren 1991) and for simple loglinear models (Winkler 1991). Extensions to situations of more than one variable from each file are under investigation.
20.7 COMPUTING RESOURCES AND AUTOMATION
Many large record linkage projects require new software or substantial modification of existing software. The chief difficulty with these projects is developing the highly skilled programmers required for the task. Few programmers have the aptitude or are allowed the years needed to acquire proficiency in advanced algorithm development and the multi-language, multi-machine approaches needed to modify and enhance existing software. For example, a government agency may use software that another agency spent several years developing in PL/I because PL/I is the only language their programmers know. Possibly more appropriate software written in C may not be used because the same programmers do not know how to compile and run C programs. The same PL/I programmers may not have the skills that allow them to make major modifications in PL/I software that they did not write or to port new algorithms in other languages to PL/I.
A secondary concern is lack of appropriate, general-purpose software. In many situations for which name, address, and other comparable information are available, existing matching software will work well if names and addresses can be parsed correctly. Directly comparable information might consist
of receipts for comparable time periods. Nondirectly comparable information might consist of receipts in one source and sales in another. To use such data, custom software modifications have to be added to software. The advantage of some existing software is that, without modification, they often parse a substantial percentage of the records in files.
20.7.1 Need for General Name-Parsing Software and What Is Available
At present, the only general-purpose business-name-parsing software that has been used by an assortment of agencies is the NSKGEN software from Statistics Canada. The software is written in a combination of PL/I and IBM Assembly language. NSKGEN software is primarily intended to create search keys that bring appropriate pairs of records together. Because it does a good job of parsing and standardizing names, it has been used for record linkage (Winkler 1986, 1987). I recently wrote general business-name-parsing software that was used in a match of the U.S. SSEL list of business establishments with the U.S. IRS 1040C list that contains many small establishments (Winkler 1993a). The software achieves better than a 99 percent parsing rate with an error rate of less than 0.2 percent with these lists. It has not yet been tested on a variety of general lists. The code is ANSI-standard C and, upon recompilation, runs on a number of computers. While name parsing software is written and used by commercial firms, the associated source code is generally considered proprietary.
20.7.2 Need for General Address-Parsing Software and What Is Available
Statistics Canada has the ASKGEN package (again written in PL/I and IBM Assembly language) which does a good job of parsing addresses (Winkler 1986, 1987). ASKGEN has recently been superseded by Postal Address Analysis System (PAAS) software. PAAS has not yet been used at a variety of agencies but, with limitations, has been used in creating an address register for the 1991 Canadian Census. The limitations were that most of the source address lists required special preprocessing to put individual addresses in a form more suitable for input to PAAS software (Swain et al. 1992). In addition to working on English-type addresses, the ASKGEN and PAAS software works on French-type addresses such as “16 Rue de la Place.”
At the U.S. Bureau of the Census, address-parsing software has been written in ANSI-standard C and, upon recompilation, currently runs on an assortment of computers. The software has been incorporated in all major Census Bureau geocoding systems, has been used for the 1992 U.S. Census of Agriculture, and was used in several projects involving the 1992 U.S. SSEL. As with name-parsing software, source code for commercial address-parsing software is generally considered proprietary.
20.7.3 Matching Software
At present, I am unaware of any general software packages that have been specifically developed for matching lists of businesses. While the ASKGEN and NSKGEN standardization packages were used with the Canadian Business Register in 1984, associated matching was based on search keys generated through compression and standardization of corporate names. One-to-many matches were reviewed by clerks who selected the best match with the help of interactive computer software. At the U.S. Bureau of the Census, I have been involved with the development of software for large projects in which the Fellegi-Sunter model was initially used and a number of ad hoc modifications were made to deal with name-parsing failure, address-parsing failure, sparse and missing data, and data situations unique to the files being matched. In every case, the ad hoc modifications improved matching performance substantially over performance that would have been available from the software alone. The recent projects were the 1992 U.S. Census of Agriculture, the 1993 match of the SSEL file of U.S. businesses with the IRS 1040C list of nonemployers, and the 1993 matching of successive years' SSEL files and the unduplication of individual years' files. The latter two projects used files from 1992. A set of software for agricultural lists and several packages for files of individuals are described below.
The U.S. Department of Agriculture (1980) has a system for matching lists of agricultural businesses, which was written in FORTRAN for IBM mainframes in 1979 and has never been updated. Name-parsing software is available as part of the system. The software applies Fellegi-Sunter matching to the subsets of pairs corresponding to individuals. The remaining records that are identified as corresponding to partnerships and corporations are matched clerically when an exact character-by-character match fails. If the pairs of businesses generally have names that allow them to be represented in forms similar to the ways that files of individuals have their names represented, then matching software (or modifications of it) designed for files of individuals can be used.
While the ASKGEN and NSKGEN packages from Statistics Canada have been given out to individuals for use on IBM mainframes, associated documentation does not cover installation or details of the algorithms. To a lesser extent, the lack of detailed documentation is also true for the USDA system. The software packages require systems analysts and matching experts for installation and use.
General matching software has only been used on files of individuals due to the difficulties of name and address standardization and consistency in business files. Available systems are Statistics Canada's GRLS system (Hill 1991, Nuyens 1993), the system for the U.S. Census (Winkler 1990a), Jaro's commercial system (Jaro 1992), and University of California 's CAMLIS system. None of the systems provides name- or address-parsing software. Only the Winkler system is free and, upon recompilation, runs on a large collection of
computers. Source code is available with the GRLS system and the Winkler system. The GRLS system has the best documentation.
20.8 CONCLUDING REMARKS
This chapter provides background on how the Fellegi-Sunter model of record linkage is used in developing automated matching software for business lists. The presentation shows how a variety of existing techniques have been created to alleviate specific problems due to name- and/or address-parsing failure or inappropriateness of assumptions used in simplifying computation associated with the Fellegi-Sunter model. Much research is needed to improve record linkage of business lists. The challenges facing agencies and individuals are great because substantial time and resources are needed for (1) creating and enhancing general name and address parsing/software; (2) performing, circulating, and publishing methodological studies; and (3) generalizing and adding features to existing matching software that improve its effectiveness when applied to business lists.
REFERENCES
Armstrong, J.A. ( 1992), “Error Rate Estimation for Record Linkage: Some Recent Developments, ” in Proceedings of the Workshop on Statistical Issues in Public Policy Analysis, Carleton University.
Belin, T.R. ( 1993), “Evaluation of Sources of Variation in Record Linkage Through a Factorial Experiment,” Survey Methodology, 19, pp. 13–29.
Bishop, Y.M.M., S.E.Fienberg, and P.W.Holland ( 1975), Discrete Multivariate Analysis, Cambridge, MA: MIT Press,
Brackstone, G.J. ( 1987), “Issues in the Use of Administrative Records for Administrative Purposes, ” Survey Methodology, 13, pp. 29–43.
Cooper, W.S., and M.E.Maron ( 1978), “Foundations of Probabilistic and Utility-Theoretic Indexing,” Journal of the Association for Computing Machinery, 25, pp. 67–80.
Copas, J.R., and F.J.Hilton ( 1990), “Record Linkage: Statistical Models for Matching Computer Records, ” Journal of the Royal Statistical Society, Series A, 153, pp. 287–320.
DeGuire, Y. ( 1988), “Postal Address Analysis,” Survey Methodology, 14, pp. 317– 325.
Deming, W.E., and G.J.Gleser ( 1959), “On the Problem of Matching Lists by Samples,” Journal of the American Statistical Association, 54, pp. 403–415.
Dempster, A.P., N.M.Laird, and D.B.Rubin ( 1977), “Maximum Likelihood from Incomplete Data via the EM Algorithm,” Journal of the Royal Statistical Society, Series B, 39, pp. 1–38.
Federal Committee on Statistical Methodology ( 1980), Report on Exact and Statistical
Matching Techniques, Statistical Policy Working Paper 5, Washington, DC: U.S. Office of Management and Budget.
Fellegi, I.P., and A.B. Sunter ( 1969), “A Theory for Record Linkage,” Journal of the American Statistical Association, 64, pp. 1183–1210.
Haberman, S, J. ( 1975), “Iterative Scaling for Log-Linear Model for Frequency Tables Derived by Indirect Observation,” Proceedings of the Statistical Computing Section, American Statistical Association, pp. 45–50.
Haberman, S. ( 1979), Analysis of Qualitative Data, New York: Academic Press.
Hill, T. ( 1991), “GRLS-V2, Release of 22 May 1991,” unpublished report, Ottawa: Statistics Canada.
Hogg, R.V., and A.T.Craig ( 1978), Introduction to Mathematical Statistics, 4th ed., New York: Wiley.
Jaro, M.A. ( 1989), “Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida,” Journal of the American Statistical Association, 89, pp, 414–420.
Jaro, M.A. ( 1992), “AUTOMATCH Record Linkage System,” unpublished, Silver Spring, MD
Meng, X., and D.B.Rubin ( 1991), “Using EM to Obtain Asymptotic Variance-Covariance Matrices: The SEM Algorithm,” Journal of the American Statistical Association, 86, pp. 899–909.
Meng, X., and D.B.Rubin ( 1993), “Maximum Likelihood via the ECM Algorithm: A General Framework,” Biometrika, 80, pp. 267–278.
Neter, J., E.S.Maynes, and R.Ramanathan ( 1965), “The Effect of Mismatching on the Measurement of Response Errors,” Journal of the American Statistical Association, 60, pp. 1005–1027.
Newcombe, H.B. ( 1988), Handbook of Record Linkage: Methods for Health and Statistical Studies, Administration, and Business, Oxford: Oxford University Press.
Newcombe, H.B., J.M.Kennedy, S.J.Axford, and A.P.James ( 1959), “Automatic Linkage of Vital Records,” Science, 130, pp. 954–959.
Nuyens, C. ( 1993), “Generalized Record Linkage at Statistics Canada,” Proceedings of the International Conference on Establishment Surveys, Alexandria, VA: American Statistical Association, pp. 926–930.
Rogot, E., P.Sorlie, and N.Johnson ( 1986), “Probabilistic Methods of Matching Census Samples to the National Death Index,” Journal of Chronic Disease, 39, pp. 719–734.
Rubin, D.B., and T.R.Belin ( 1991), “Recent Developments in Calibrating Error Rates for Computer Matching, ” Proceedings of the Annual Research Conference, Washington, DC: U.S. Bureau of the Census, pp. 657–668.
Scheuren, F. ( 1983), “Design and Estimation for Large Federal Surveys Using Administrative Records,” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 377–381.
Scheuren, F., and W.E.Winkler ( 1993), “Regression Analysis of Data Files That Are Computer Matched,” Survey Methodology, 19, pp. 39–58.
Sekar, C.C., and W.E.Deming ( 1949), “On a Method of Estimating Birth and Death
Rates and the Extent of Registration,” Journal of the American Statistical Association, 44, pp. 101–115.
Smith, M.E., and H.B.Newcombe ( 1975), “Methods of Computer Linkage of Hospital Admission-Separation Records into Cumulative Health Histories,” Methods of Information in Medicine, 14, pp. 118–125.
Statistics Canada ( 1983), “Generalized Iterative Record Linkage System,” unpublished report, Ottawa: Systems Development Division.
Swain, L., J.D.Drew, B.LaFrance, and K.Lance ( 1992), “The Creation of a Residential Address Register for Coverage Improvement in the 1991 Canadian Census,” Survey Methodology, 18, pp. 127–141.
Thibaudeau, Y. ( 1989), “Fitting Log-Linear Models When Some Dichotomous Variables Are Unobservable, ” Proceedings of the Section on Statistical Computing, American Statistical Association, pp. 283–288.
Thibaudeau, Y. ( 1993), “The Discrimination Power of Dependency Structures in Record Linkage, ” Survey Methodology, 19, pp. 31–38.
Titterington, D.M., A.F.M.Smith, and U.E.Makov ( 1988), Statistical Analysis of Finite Mixture Distributions, New York: Wiley.
U.S. Department of Agriculture ( 1980), “Record Linkage System Documentation,” unpublished report, Washington, DC: National Agricultural Statistics Service.
Van Rijsbergen, C.J., D.J.Harper, and M.F.Porter ( 1981), “The Selection of Good Search Terms,” Information Processing and Management, 17, pp. 77–91.
Winkler, W.E. ( 1984), “Exact Matching Using Elementary Techniques,” technical report, Washington DC: U.S. Energy Information Administration.
Winkler, W.E. ( 1985a), “Preprocessing of Lists and String Comparison,” in W. Alvey and B.Kilss (eds.), Record Linkage Techniques—1985, U.S. Internal Revenue Service, Publication 1299 (2–86), pp. 181–187.
Winkler, W.E. ( 1985b), “Exact Matching Lists of Businesses: Blocking, Subfield Identification, Information Theory,” in W.Alvey and B.Kilss (eds.), Record Linkage Techniques—1985, U.S. Internal Revenue Service, Publication 1299 (2– 86), pp. 227–241.
Winkler, W.E. ( 1986), “Record Linkage of Business Lists,” technical report, Washington, DC: U.S. Energy Information Administration.
Winkler, W.E. ( 1987), “An Application of the Fellegi-Sunter Model of Record Linkage to Business Lists,” technical report, Washington, DC: U.S. Energy Information Administration.
Winkler, W.E. ( 1988), “Using the EM Algorithm for Weight Computation in the Fellegi-Sunter Model of Record Linkage,” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 667–671.
Winkler, W.E. ( 1989a), “Near Automatic Weight Computation in the Fellegi-Sunter Model of Record Linkage,” Proceedings of the Annual Research Conference, Washington, DC: U.S. Bureau of the Census, pp. 145–155.
Winkler, W.E. ( 1989b), “Methods for Adjusting for Lack of Independence in an Application of the Fellegi-Sunter Model of Record Linkage,” Survey Methodology, 15, pp. 101–117.
Winkler, W.E. ( 1989c), “Frequency-Based Matching in the Fellegi-Sunter Model of
Record Linkage,” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 778–783.
Winkler, W.E. ( 1990a), “Documentation of Record-Linkage Software,” unpublished report, Washington, DC: U.S. Bureau of the Census.
Winkler, W.E. ( 1990b), “String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage,” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 354–359.
Winkler, W.E. ( 1991), “Error Model for Analysis of Computer Linked Files,” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 472–477.
Winkler, W.E. ( 1992), “Comparative Analysis of Record Linkage Decision Rules,” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 829–834.
Winkler, W.E. ( 1993a), “Business Name Parsing and Standardization Software,” unpublished report, Washington, DC: U.S. Bureau of the Census.
Winkler, W.E. ( 1993b), “Improved Decision Rules in the Fellegi-Sunter Model of Record Linkage, ” Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 274–279.
Winkler, W.E., and F.Scheuren ( 1991), “How Matching Error Affects Regression Analysis: Exploratory and Confirmatory Results,” technical report, Washington. DC: U.S. Bureau of the Census.
Wu, C.F.J. ( 1983), “On the Convergence Properties of the EM Algorithm,” Annals of Statistics, 11, pp. 95–103.
Yu, C.T., K.Lam, and G.Salton ( 1982), “Term Weighting in Information Retrieval Using the Term Precision Model,” Journal of the Association for Computing Machinery, 29, pp. 152–170.
Linking Health Records: Human Rights Concerns*
Fritz Scheuren, Ernst and Young, LLP
1. Purpose
The purpose of this paper is to provide an introduction or “starter set” for reflecting on human rights issues that arise when bringing together or linking the health records of individuals. In particular, the paper will discuss the potential role of record linkages in the proposed new United States health information system; specifically, how linkage applications may affect both the rights of individuals to privacy and their rights of access to health care services.
Four potential types of record linkages will be covered (see Figure 1 below). The primary concern will be with linkages of health records, such as the computerized enrollment and encounter records proposed to be created under the Health Security Act or other health care reform legislation[1]. As the columns of Figure 1 indicate, linkages for both statistical and administrative purposes will be considered. As the rows of Figure 1 imply, there will be a discussion of record linkage within the health system, e.g., records of individuals may be linked to records of providers or insurers. The paper will also consider linkages of health care records with records from other systems, such as vital records or social security, income tax, and welfare program records.
In all, the paper is organized into eight sections: the present introduction and statement of purpose (Section 1); a background section on what is meant by record linkage—both in general and with respect to health record systems (Section 2); then there are four short sections, each devoted to a cell in Figure 1 (Sections 3 to 6); and, finally, a brief overall summary with recommendations (Section 7). The main questions to be addressed throughout are the extent to which linkages should be permitted, for what purposes, and under what conditions. An Afterword has been included (as Section 8) to afford room for a more personal comment.
Figure 1. —Potential Types of Health Record Linkages
(Cell entries reference paper section where topic covered)
|
Linkages |
Purposes |
|
|
Administrative |
Statistical |
|
|
Within health record system |
Section 3 |
Section 4 |
|
With other Record systems |
Section 6 |
Section 5 |
|
* |
Reprinted with permission. See Note at end of paper. |
2. Background
This section is a review of automated record linkage techniques, the nature of record linkage errors, and some overall system concerns in a world where multiple opportunities exist to carry out record linkages.
2.1 Types of Record Linkages
It seems fairly safe to speculate that once human beings began to keep records there were efforts to link them together. Until well into this century, though, such work was done manually and often only with great difficulty and expense; however, there now exist four broad types of automated record linkage (see Figure 2) — each of which will be described below by means of an example.
Figure 2. —Examples of Linkage Types and System Structures
|
Type of Record Linkage |
Record System Structure |
|
|
Intended for Linkage |
Incidental to Linkage |
|
|
Deterministic |
Social Security and Medicare systems |
National Death Index (NDI) |
|
Probabilistic |
1990 Census Post Enumeration Survey |
NDI Links to the Current Population Survey |
In the United States, the first National experience with automated record linkage systems was the assignment, beginning in 1935, of social security numbers (SSN's) to most wage workers. Initially this system was based on a single punch card for each worker; these cards were updated using the SSN as an account identifier and a cumulative total kept of taxable wages received under covered employment. Record linkages at the Social Security Administration were computerized in the 1950's and SSN's are issued now to virtually all Americans.
From its inception, the intended use of the social security number was to carry out record linkage. Efforts, not always successful, were made so that SSN's, when assigned, would be unique and each person would have just one[2]. Further, the wage reporting system was designed so that updates by SSN would be conducted in a manner relatively free of error. Put another way, the social security system was designed or intended all along for automated record linkage and a straightforward, so-called deterministic linkage rule of exact matching on SSN's was to be the basic approach.
Birth and death registration in the U.S. offers a useful contrast to social security. These vital registers, which became complete only in the 1930's, were not intended for automated linkage operations [3]. Identifying items, like names, are on these records, of course, and could be used as matching keys but would not always be unique alone—common surnames like Smith or Johnson or Williams being notable cases where linkage problems might be particularly severe. Automated linkages to U.S. death records did not begin nationally until the inception in the 1970's of the National Death Index or NDI. The NDI in its original operations relied
on multiple exact matches as a way to locate potential linkages;[4] hence, as shown in Figure 2, the NDI may serve as an example of a deterministic automated linkage approach that was added on to a system not initially designed for such a use.
Deterministic match rules are easy to automate but do not adequately reflect the uncertainty that may exist for some potential links. They can also require costly manual intervention when errors occur in the matching keys. More complicated methods were needed that weighed the linkage information, allowing for errors and incompleteness, and minimizing the clerical intervention required to select the best link from all those possible. Such techniques are called probabilistic. The main theoretical underpinnings for probabilistic matching methods were firmly established by the late nineteen sixties with the papers of Tepping[5] and, especially, Fellegi and Sunter[6]. Sound practice dates back even earlier, at least to the nineteen fifties and the work of Newcombe and his collaborators[7].
The Fellegi-Sunter approach is basically a direct extension of the classical theory of hypothesis testing to the problem of record linkage. A mathematical model is developed for recognizing records in two files which represent identical units (said to be matched). As part of the process there is a comparison between all possible pairs of records (one from each file) and a decision made as to whether or not the members of the comparison-pair represent the same units, or whether there is insufficient evidence to justify either of these decisions. The three outcomes from this process can be referred to as a “link,” “nonlink,” or “potential link.”
In point of fact, Fellegi and Sunter contributed the underlying theory to the methods already being used by Newcombe and showed how to develop and optimally employ probability weights to the results of the comparisons made. They also dealt with the implications of restricting the comparison pairs to be looked at, that is of “blocking” the files, something that generally has had to be done when linking files that are at all large.
Many of the major public health research advances made in recent decades have benefitted at least in part from probabilistic linkage techniques. Included are such well known epidemiological findings as the effects of smoking, risks from radiation exposure, asbestos and many other carcinogens arising in the workplace, through diet or other exposures—increasingly in populations with genetic predispositions [8]. These benefits have to be considered when exploring record linkage impacts on privacy and other rights. We will return to this point at the end of this paper where trade-offs are explicitly considered.
Most of these automated linkages, like Newcombe's studies of radiation exposure at Chalk River (and elsewhere), were not envisioned when the records were originally created. Some probabilistic linkage systems were intended, however—notably for “post enumeration” surveys (PES's), carried out to evaluate U.S. decennial census coverage. For example, the PES for 1990 was particularly well designed for carrying out probabilistic linkages [9]. Another good example of a continuing probabilistic linkage that has been a real success for statistical purposes is the bringing together of the NDI and Current Population Survey[10]. This linkage, though, was not planned into the design of either of the data sets being employed.
2.2 Nature of Linkage Errors and Identifying Information
All linkage operations are subject to two main types of errors: matching records together that belong to different entities (false matches) and failing to put records together that belong to the same entity (false non-matches). These errors can have different human rights implications, depending on what the linkages are used for (see Figure 3).
Figure 3. —Linkage Error Implications on Human Rights
|
Types of Linkage Error |
Linkages Used for— |
|
|
False Matches |
Data about that individual |
Information about a class of individuals |
|
False Nonmatches |
Potentially very serious |
May be less serious |
If the linkage is to assemble data about an individual so an administrative or diagnostic determination can be made about that individual, then the consequences of any error could be grave indeed. Potentially, a different (lower) standard of accuracy could be tolerated, provided a suitable adjustment is made when analyzing the results of linkage operations whose purpose is to obtain information about a group[11]. More will be said about these issues in later sections, particularly how this distinction affords an opportunity to both preserve individual privacy rights—through group matches, say—but still attain societal information needs.
If an efficient (low cost, essentially error free) health care linkage system is a goal, then consideration needs to be given to the establishment of a health identification “number.” In ideal circumstances, personal identifying information on a medical record should satisfy the following requirements [12].
-
The identifying information should be permanent; that is, it should exist at the birth of a person to whom it relates or be allocated to him/her at birth, and it should remain unchanged throughout life.
-
The identifying information should be universal; that is, similar information should exist for every member of the population.
-
The identifying information should be reasonable; that is, the person to whom it relates and others, should have no objection to its disclosure for medical purposes.
-
The identifying information should be economical; that is, it should not consist of more alphabetic, digits and other characters than necessary.
-
The identifying information should be simple; that is, it should be capable of being handled easily by a clerk and computers.
-
The identifying information should be available.
-
The identifying information should be known; that is, either the person to whom it relates or an informant acting on his/her behalf should be able to provide it on demand.
-
The identifying information should be accurate; that is, it should not contain errors that could result in its discrepancy on two records relating to the same person.
-
The identifying information should be unique; that is, each member of the population should be identified differently.
The social security number, incidentally, fails several of these tests. Only now is it beginning to be issued at birth; also it is far from being accurately reported. In practice, too, because of incentives created by the SSN's use in the tax system, the number is not always unique. Some people use more than one SSN, even in the same year, and more often over longer periods of time. Multiple uses of the same SSN by different people have been common, as well.
Concerns about the risks to health records from unauthorized disclosures are greater with an identifier like the SSN which is widely available on many large private data bases, like credit files, and of course many nonhealth related Federal, state and other government files [13]. In the Office of Technology Assessment's 1993 report[14] on privacy the following recommendation is made with regard to the SSN.
The use of the social security number as a unique patient identifier has far-reaching ramifications for individual health care information privacy that should be carefully considered before it is used for that purpose.
Elsewhere[15] the stronger recommendation has been made not to use the SSN as a health identifier. Its use could lead to matching errors and might greatly increase the potential for unregulated linkages between health and nonhealth data sets.
2.3 Some Proposed Health Record Linkage Systems
The proposed Health Security Act[16] calls for the establishment of a National Health Board to oversee the creation of an electronic data network. The types of information collected would include: enrollment and disenrollment in health plans; clinical encounters and other items and services from health care providers; administrative and financial transactions and activities of participating states, regional alliances, corporate alliances, health plans, health care providers, employers, and individuals; number and demographic characteristics of eligible individuals residing in each alliance area; payment of benefits; utilization management; quality management; grievances, and fraud or misrepresentation in claims or benefits[17].
The Health Security Act specifies, among other things, the use of uniform paper forms containing standard data elements, definitions, and instructions for completion; requirements for use of uniform health data sets with common definitions to standardize the collection and transmission of data in electronic form; uniform presentation requirements for data in electronic form; and electronic data interchange requirements for the exchange of data among automated health information systems.
A prototype health care record linkage system may be worth considering as well since it spells out an initial schematic of a person-level health or patient record. Data could come from an array of health care settings, linked together using a “linkage processor.” This processor would determine the linkage and also assign the unique patient identifier in the actual patient record. Record types would differ by the type of provider from which they are derived. The functions of the record linkage software program are outlined in Figure 4. It is anticipated that the patient identifying information would be housed in a person's primary care unit. The linkage processor stores the patient identifying data and generates the unique identifier. It processes records from other providers and links the record as shown. Some initial data categories and identifying information are outlined in Figure 5[18].
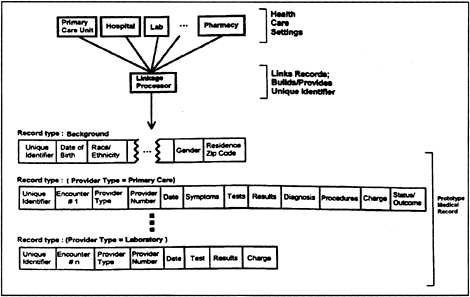
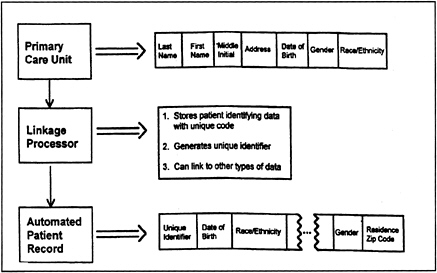
2.4 Additional System Concern
In all data capture systems, of course, it is important to explicitly build-in the means to address privacy rights, the degree to which confidentiality promises are required (and kept), and the means used to make individual data physically secure. While such concerns are general, record linkage systems have some unique aspects that may bear discussion—particularly the systems described in Section 2.3 above. Figure 6 summarizes these, emphasizing the additional complexity introduced by the linkage environment and the degree to which linkage systems are or should be “auditable.” By “auditable” is meant that, at a minimum, each access to identifiable data is controlled and a log kept of the individuals who obtained the data and of all transactions that occurred (in other words, an audit trail is kept so that outside monitoring is possible).
Figure 6. —Some Overall Record Linkage System Concerns
|
Linkage Issues |
Complexity |
Auditability |
|
Privacy |
Extremely high, may be beyond our current understanding, without training and experience |
May be very difficult to establish, maintain, or use in monitoring access |
|
Confidentiality |
||
|
Security |
||
Tore Dalenius has provided a good review of privacy, confidentiality, and security goals in statistical settings[19]. His work may afford a point of departure for the discussion here. In common speech, the words: privacy, confidentiality and security partially overlap in usage and often have meanings that depend greatly on context. Each can also have an emotional content which makes precise definitions difficult, even contentious. For example, Dalenius quotes Westin (1967) as saying about privacy:
Few values so fundamental to society as privacy have been left so undefined in social theory or have been the subject of such vague and confused writing by social scientists.
A good start on giving meaning to the word “privacy,” or “information privacy” (our context here), might be the definition first articulated by Justice Brandeis as the “right to be let alone…the most comprehensive of rights and the right most valued by civilized man”[20]. Attempts to update this definition have been many and will undoubtedly continue. All afford the individual or data subject some, sometimes sole, rights over what matters they want to keep private and what matters they are willing—or want—to reveal.
Record linkage settings pose a particular challenge to an individual 's ability to exercise his or her privacy rights. The sheer complexity of the setting makes it hard to clarify for the subject what the potential benefit or harm may be to permitting access. Consider the linkage of just two files, say, of “n” and “m” variables respectively. Cognitively for the individual involved the linkage decision may seem like one of no particular moment. The combined file will consist of data already given out earlier—a single file of “n + m” —rather than two separate files. But a deeper look —at relationships, for example, between variables—shows that a combinatorial explosion of facts about an individual has taken place—from, say, 2n + 2m to 2n+m. (Incidentally, to illustrate what this means, assume just that n=m=11; then the combined file has over 1000 times more information about the relationships between variables than the two files separately.)
Ready examples come to mind where individuals present themselves in one way (to get Medicaid or Medicare, say) but in another setting (perhaps a job interview) give a different, even a contradictory set of “facts.” When records from these two encounters are linked, obviously the implications may be many, since these differences would be revealed [21].
Obtaining data at different points in time and for different primary purposes is a difficulty that is peculiar to linkage settings. The privacy decision an individual may wish to make could, therefore, change over time and might depend on the particular data items as well as the purposes for which a release from their privacy rights is being sought. Singer et al.,[22] for example, advocate that—
Patients sign an informed consent or a notification statement at regular intervals, not simply the first time a patient visits the provider's office,
They then go on to recommend that the consent or notification statement spell out to whom the information about the patient may be disseminated, for what purposes, and what the patient's rights are with respect to this information. Such an approach, especially as it relates to secondary uses of data and the time period for which the informed consent is valid seems clearly required in a linkage setting where patient specific information may accumulate over time and from many sources (not just one provider). It may be necessary for a regulatory body to develop regulations standardizing the contents of informed consent and disclosure policies. These regulations could definitely state what constitutes an “informed consent” and legitimate non-consented disclosure. Even then, only experience will tell whether true informed consent will be possible for most individuals.
Indeed, without wishing to jump to conclusions, it may be reasonable to conjecture that, for some kinds of data linkage at least and certain individuals, our technological abilities to electronically merge data sets may have outstripped our sense of what a data subject would have to “consent to in an informed way” for the systems to be built on an entirely voluntary basis. If this is so, then simply creating the health linkage system envisioned might in and of itself take away the privacy rights of some people.
The problem of complexity in record linkage systems may warrant the attention being given to complexity in general systems[23]. Linear thinking alone may, in any case, be insufficient to address what will happen not only to the individual's ability to manage his or her own data but to the system's integrity overall. What confidentiality promises can be made and kept in such a world? How can one even speculate realistically about the risks to data corruption or unauthorized disclosure? Recent experiences elsewhere[24] do not encourage belief that reasonable ways exist of being clear about even what the threats are.
Among the crucial “fail safes” is to provide an audit trail for every query against a record and any retention of a data subset. Such systems already exist for some real time settings, although not necessarily in a way that would allow a simple scale-up. A crucial step is the maintenance of these systems so they operate properly[25]. While beyond the scope of this paper, it might be noted that the expense of this maintenance step and a mechanism to “monitor the monitoring” needs a lot of attention, too. Arguments in favor of doing record linkages for efficiency reasons have not fully weighed these costs. In Brannigan and Beier[26] still other sound system architecture issues and recommendations are made that would be needed to implement essential confidentiality and security procedures, especially if large scale record linkages are to be employed.
3. Administrative Data Linkages Within the Health System
By an administrative data linkage we mean a linkage of data about an entity done with the intention of taking some direct action regarding that entity. In a health setting the most obvious example would be to assemble (link) data about a patient from multiple sources in order to improve the diagnosis or treatment of that individual. We will start with this case (subsection 3.1) and then go on to discuss administrative health linkages more generally (subsection 3.2).
3.1 Linkages for Direct Patient Care
Figure 7 lays out some of the dimensions in administrative record linkages aimed at improving the health of a patient. The Figure has five rows and two columns. Each row covers a broad area dealing with, respectively, overall issues, technical (and administrative) aspects, legal matters, the perception of the public and of experts. The primary focus of the Figure is to directly address under what conditions linkages should be permitted (Column 1) and areas for future study (Column 2). Since the goal of this paper is to just be a “starter set,” only illustrative suggestions have been made in the cells, both here and elsewhere.
Among the general conditions for linkage a signed notification statement seems needed[27]. In this context, a “notification statement” might tell the patient who will have access, for what purposes and with what oversight. Hoffman in a recent paper makes the observation that “too many people may already have insufficiently monitored access to hospital patient records. He seconds Mark Siegler's thesis that “medical confidentiality, as it has been traditionally understood by patients and doctors, no longer exists.” Siegler, after a patient
Figure 7. —Administrative Data Linkages Conducted for the Health of Patients
|
Broad Areas |
Possible Response |
|
|
Under what conditions (Column 1) |
For future study (Column 2) |
|
|
Overall Recommendations |
Just notification needed; if for use of patient and patient caregivers only |
Concerns about coercive aspects of government “monopoly” in health care |
|
Technical Aspects |
Encryption to prevent unauthorized access and reduce risks of reidentification |
Concerns about how to monitor operation |
|
Legal Questions |
For federal records, subject to the Privacy Act; use seemingly fully permitted now. |
Electronic data linkages across governmental jurisdictions deserve more study, also roles of intermediaries (e.g., Health Information Trustee—HR 4077) |
|
Public Views |
Direct evidence lacking but indirect evidence suggests that health uses to aid patients would be seen very positively. |
Concerns about public view of risks associated with system need to be better understood. |
|
Expert Opinion |
An obvious use, seemingly favored by all. |
Need to continue research on uniform reporting issues so as to obtain promised benefits of electronic linkages without an undue burden. |
expressed concern about the confidentiality of his hospital record, scanned his medical chart and enumerated “at least 25 and possibly as many as 100 health professionals and administrative personnel …[who] had access to the patient's record,” all with legitimate reasons to examine the chart [28].
Secure physical access is essential and any linkage stipulated as done for diagnosis and treatment of a patient should be available only for the use of the patient and his or her caregivers. Concerns exist about the patient data requested for such encounters and whether the demands and burdens on the patient are reasonable. The collection of uniform patient data has clear advantages; the specific data required, though, will need external review, possibly by a regulatory body —similar to that discussed earlier on consent standards. After all there are privacy rights given up by patients to their caregivers and these should be limited to an essential minimum.
Patient and primary caregiver controlled access might involve encryption techniques or other measures designed to prevent or at least reduce the risks of unauthorized (unmonitored) use. Linkages might be time limited to reduce exposure further. As noted, Brannigen and Beier [29] have made numerous other important suggestions. System administrative issues are extensive and concerns about monitoring operations deserve continued study.
Fair information practices must be adhered to—as required, say, in the Privacy Act and reinforced by pending legislation [30]. Continuing study of state and local restrictions[31] should be pursued to find good working models and to anticipate areas where weaknesses may arise in the National System, if litigation occurs. The Privacy Journal has regularly compiled state and Federal privacy laws and is a useful resource here[32].
Direct evidence of public reaction is lacking on linkages used solely to aid the patient. Such use is presumed to be very positively received. There is a large segment, though, of the public[33] that are concerned about any electronic record linkage system of the scope envisioned, mainly because of their general mistrust of government and other large institutions. These individuals or some of them, at least, might not think the benefits to be derived warrant the risks they perceive for abuse inherent in such a large-scale record linkage effort.
Virtually all “experts” take the position that notification of the use envisioned here is enough. One exception is Goldman[34] which states:
Personally-identifiable health records must be in the control of the individual. Personal information should only be disclosed with the knowing, meaningful consent of the individual
The distinction between consent and notification may not be as important here as elsewhere. With notification there is always a “quid pro quo”—give this data about yourself if you want to participate. In this setting patients are often asked to give what amounts to “coerced ” consent; therefore, the distinction may be in name only. Logically, however, it seems inconsistent to withhold information about yourself that could be used to aid you. Unquestionably, though, a refusal to comply could mean denial of access to health care services.
3.2 Other Health Administrative Linkages
Many other health linkages are possible besides those directly involved with patient care. These could range—
-
From linking treatments received by a patient to the costs of those treatments;
-
To associating outcome measures (death or survival, say) to the types of medical procedures employed; and
-
Even to linkages whose intent was to detect fraud or malpractice.
Data about a hospital or other health facility might be sought by looking at all the records of the patients that can be linked to that hospital. The number of possibilities, in fact, is very large —too large to cover in any depth here. Some observations may be helpful, nonetheless, to fix a few of the ideas about what the privacy rights dimensions are:
-
First, in administrative linkages such as these, the patient may become just a data point in an endeavor focussed elsewhere[35]. The dehumanizing aspect of this change of focus is inherently unsettling. Provisions like those in Figure 7 seem insufficient when the person looking at the data is not the primary caregiver but an administrator concerned about financial results, the efficiency of a medical technique, etc. —i.e., someone without any personal relationship to the patient.
-
Second, to handle the changed circumstances, among other things a “need to know” principle[36] might be applied to limit the routine availability of detailed health and demographic data. To illustrate: If data about, say, a hospital 's performance is needed only hospital-level patient aggregates might be provided, rather than complete individually identifiable patient detail.
Clearly much greater safeguards seem needed once there is no longer a personal bond between the patient and the individual using the data about that patient. Arguably, establishing a convincing system that would warrant the patient and public trust required here may be exceedingly difficult.
An important issue that may deserve comment is the “final” disposition of a patient's health (and related financial) records when the patient dies. Even for federal record systems, the Privacy Act no longer offers any protection, for example. We are learning more and more about the genetic causes of some illnesses. Matching records from deceased patients could put their descendants (or other relatives) at risk for possible differential treatment. If the view is taken, as quoted above in Goldman that the patient “owns” his or her records then, by inference, upon death the estate of the patient owns that patient 's records and their disposition is a matter to be settled by the heirs. In any event, inter or intra-generational record linkage needs careful consideration and might be done, as a rule, only with the consent of all individuals so linked.
4. Research Data Linkages Within the Health System
It can be argued that some research uses of data linkages within the Health System are administrative and so are already covered by the discussion in Section 3, especially subsection 3.2. There can be a fine line between applied research (intending to serve a permissible administrative purpose) and basic research (involving possibly an unanticipated analysis of variables originally obtained for another purpose).
Rather than try to draw the line, however, we will confine our attention to “basic research” since this involves some potentially new issues. In particular, our discussion will focus on researchers who are in some sense outside the Health Care System—i.e., individuals that do not already have access to the patient data. Such a decision has consequences, of course. For example, important issues, like what research doctors do when using data about their own patients, go undiscussed. On the other hand, there is already an extensive body of practice on this topic and record linkage issues do not seem primary.
In any event, for the basic research setting we have confined attention too, figure 8 attempts to set out a summary of the main issues. As in Figure 7 earlier, included are some overall recommendations, legal and procedural questions are addressed, as well as perceptions concerns (both by the public and among the experts). These are further elaborated below.
Notification of patients about basic research uses may be sufficient in some settings while a specific consent may be needed in others. All basic research should be authorized by a review board mechanism of some sort with an annual public report, perhaps, to an outside citizens body. Requirements for securing consent pose difficult logistical and statistical problems that need extensive study. Anonymous group matching offers a potentially promising middle ground that could allow individual consent decisions to be honored, yet may not greatly sacrifice approved scientific ends[37]. However, as Figure 8 states, an extensive development and evaluation period is needed before this approach will prove its value.
Figure 8. —Basic Research Data Linkages within the Health System
|
Broad Areas |
Possible Response |
|
|
Under what conditions (Column 1) |
For future study (Column 2) |
|
|
Overall Recommend-ations |
Notification and even maybe consent required for individual linkages, plus research review board authorization |
Statistical properties of group linkages and their use need extensive study when consent not given. |
|
Technical Aspects |
Elimination of all obvious (and not so obvious) identifiers. Access to data also limited by reidentification risks and “need to know” |
Research on use of synthetic data. Continuous study of (ever) changing reidentification risks. |
|
Legal Questions |
Laws often unreasonably require no risk of redisclosure. |
Research on “proof of harm” issue. Legislative and litigation research on contract based research access. |
|
Public Views |
Significant negative sentiment tied to distrust of government and lack of a specific clear purpose. |
Study reactions to longterm (lifelong) record linkage |
|
Expert Opinion |
For the most part strongly favor broad basic research uses requiring only notification. |
Nonmedical uses of health system records need more study. |
The elimination of all identifying items about a patient would seem to be a necessary prerequisite for broad access to the health system data base by outside researchers. The risks of potential reidentification [38] are an ongoing concern, especially as nonhealth electronic systems grow in size and potentially have common variables which overlap those in health data bases. Research access through contractual arrangements as proposed by Herriot[39] has already begun in some settings (where it might be evaluated) and deserves study in others (where is has yet to be applied). The development of wholly synthetic data sets[40] also warrants work
and may be potentially promising because of the public assurances that can be given which might satisfy even those who greatly distrust government.
As noted earlier, there are a significant minority of individuals who oppose linkages and this group grows larger when there is no clear and compelling purpose for such linkage, except an ill-defined one—like “basic research.”[41] Lifelong patient linkage projects which are particularly attractive basic research tools may be subject to potentially severe public reaction if done without continuing consent (as occurred in Sweden [42]).
In general, even the strongest human rights advocates make an exception for research uses of individual data, stating[43] that “Information that is not personally-identifiable may be provided for research and statistical purposes.” Given the growing power of probabilistic matching, though, we may not be far from the day when the only way to remove personally-identifiable information about some individuals is to remove all direct data concerning such individuals from a research file. Additionally, there may be some concerns about the appropriateness of nonmedical uses of health care records as, say, for the decennial census,[44] a point more appropriately covered in the next section.
5. Research Linkages between Health and Other Record Systems
Our discussion of basic research issues within the health system (Section 4) forms a bridge to a discussion of research data linkages between health and other record systems. Many parallels exist, as may be seen by comparing Figure 8 with Figure 9 below. There are, however, some new elements too:
-
First, deterministic matching algorithms should be possible within the health system, assuming some form of health identifier is settled on. Generally, though, unless the SSN is used as the health identifier, only probabilistic matching methods will be available between health and nonhealth record systems; hence greater uncertainty about linkage quality will exist.
-
Second, these nonhealth systems were clearly intended for nonhealth purposes; thus, their use in health record linkage research, through the simple expedient of health legislation, say, seems problematic. In fact, a strong case might be made for “consent only access” to at least some of them. Also any retroactivity in this expanded use should not be taken lightly either.
-
Third, there seems to be a wide range of record linkage options, spanning matches to vital records at one end of the spectrum[45] (a traditional epidemiological tool) with tax records at the other [46] (something seldom done). The views of experts and the public appear to move predictably along this continuum from some acceptance to almost none[47].
-
Fourth, even anonymous group matching methods need more study in this setting and not just their statistical efficiency as noted in Figure 8 but their public acceptability. Black males seem particularly opposed to, at least, some linkages. Concerns like those in Fisher et al. [48] merit examination here too.
As already noted, at least some experts are concerned about proposals using health records to improve the accuracy of the decennial census population count[49]. In fact, except in cases where explicit consent is obtained, it may make sense to confine all matches of health records to nonhealth records solely to those research purposes related to health. The control of any linkages between health and nonhealth records, say with Census Bureau data, needs careful study too[50]. Most Federal statistical agencies, for example, currently lack
auditable record linkage systems[51]. and would have to greatly increase internal controls to meet what should be stringent electronic access (and audit) standards[52].
Figure 9. —Research Data Linkages between Health and Other Record Systems
|
Broad Areas |
Possible Response |
|
|
Under what conditions (Column 1) |
For future study (Column 2) |
|
|
Overall |
Generally consent should be required plus research review board authorization |
Same as Figure 8. |
|
Technical Aspects |
Same as Figure 8. |
Same as Figure 8. |
|
Legal Questions |
Conforming legislation needed to Tax Code, Social Security Act, etc. |
Research on “proof of harm” issue. Legislative and litigation research on contract-based research access. |
|
Public Views |
Significant minority would not consent to individual linkages |
Research on reactions to group linkages for statistical purposes. Study parallel to HIV testing. |
|
Expert Opinion |
For the most part strongly favor health research uses only requiring notification. |
Nonmedical uses of any linkages need more study. |
6. Nonresearch Linkages between Health and Other Record Systems
As may be apparent by now, in this paper there has been a progression from linkage opportunities that might be viewed by most individuals as beneficial, even to be encouraged, to linkages that are more problematic. This section discusses linkages that, in the view of many, may be dangerous and should generally be discouraged.
Figure 10 sets out a summary of possible issues in nonresearch linkages between health and nonhealth systems. Some overall observations on this figure might be worth making too—highlighting what is new or controversial.
With the exception of a court order in a criminal case, all nonresearch linkages for nonhealth reasons should be prohibited. Even health administrative linkages (say, to use IRS address information to locate a person for health reasons) should be carefully limited (as is the case now). Areas for future study might include research on notification issues and consent-based exceptions. After all, new health needs keyed to helping individuals may arise over time and hence notification statements might need to be changed or at least their understanding reviewed periodically.
Figure 10. —Nonresearch Administrative Data Linkages between Health and Nonhealth Record Systems
|
Broad Areas |
Possible Response |
|
|
Under what conditions (Column 1) |
For future study (Column 2) |
|
|
Overall Recommendations |
For nonhealth reasons only with a court order. For health reasons only to directly aid patients. |
Continuing research on (changing?) understanding of all consent or notification statements. |
|
Technical Aspects |
Minimizing redisclosure risks, especially to open or decentralized systems like vital records. |
Continuing research on record keeping practices in nonhealth record systems, government and private. |
|
Legal Questions |
Ban any use of a new health identifier in nonhealth record systems. |
Study conforming legislative needs. |
|
Public and Expert Opinion |
In generally close agreement, with a majority favoring restrictions on nonhealth uses. |
Continuous routine monitoring. |
Existing systems, especially vital records, have many variables in common with health care record systems. Vital records are also quite open and hence they pose a significant risk of redisclosure, especially in public use (or other widely available) research files. If an independent health identifier is not used, then perhaps the SSN, for example, should be removed, or access to it restricted on birth and death records.
A legal ban, of course as generally advocated, should be imposed on the use of any new health identifier created, except in health systems. Research on other obvious and not so obvious identifiers, e. g., geographic details, should be ongoing to be sure that (legislated?) health record practices keep up with technology and the changing nature of unauthorized disclosure risks.
Public and expert opinion appear to both strongly oppose nonhealth administrative use of health record systems[53]. Additional public opinion research, though, seems needed on this point and others. For example, what are the public's views on the risks to any new health system from the existing centralized federal record systems (at IRS and SSA, for instance)? What about their views on the real danger of probabilistic matches to private data bases or to open or decentralized government systems, like vital records?
7. Summary Recommendations
Throughout this paper recommendations have been made that address aspects of privacy concerns in any large scale record linkage activity involving the proposed new health system or between that system and others. Figure 11 below provides a brief summary of these.
Figure 11. —Selected Permissible Record Data Linkages by Purpose and Under What Conditions
|
Type of Data Linkage |
Permissible and Under What Conditions |
|
Administrative Data Linkages for the health of the patient |
Just notification needed; if for use of patient and patient caregivers only |
|
Other Administrative Data Linkages of Patient Records within the health system. |
Greater safeguards seem needed once there is no longer a personal bond between patient and service provider (caregiver) |
|
Basic Research Data Linkages within the Health System |
Notification and even maybe consent required for individual linkages; research review board authorization. |
|
Research Data Linkages between Health and Other Record systems |
Generally consent should be required plus research review board authorization. |
|
Nonresearch Administrative Data Linkages between Health and Nonhealth Record Systems |
For nonhealth reasons, only with a court order. For health reasons, only to directly aid patients. |
The overall treatment of linkage opportunities in this paper has gone from situations that simply called for a signed notification statement, preferably at regular intervals (Section 3), to suggested (Section 4) or required (Section 5) informed consent—for linkage research in the health system or linked record research more generally Finally (in Section 6), there was a brief discussion of how to prevent matching for nonhealth administrative purposes, except in rare instances. In all of these discussions, recommendations have been given along with the views of others; also areas for future study have been highlighted.
Frankly, this paper advocates a “go slow,” careful approach to any attempt at data linkages undertaken as part of health care reform. It is unlikely that all the potential vulnerabilities of the new linkage system will be learned by anything other than experience—hopefully not too hard won. Prototyping linkage experiments [54] are key. Patient consent and notification experiments will also be needed, as well as continuous study of public and patient opinion. An evolutionary rather than revolutionary strategy seems to represent the kind of humility and listening needed to avoid major blunders, especially in any advertent or inadvertent “takings” of privacy rights.
Much of the motivation around health reform speaks to efficiencies that can be gained with standardization of reporting and electronic data networking. These arguments seem to have merit; however, even if true, such changes will require a great many people to learn to do things in new ways and potentially paper records may need to continue to be employed for a long time (even if all new encounters are captured electronically).
Because the job is so big, it is important to begin now but incrementally. If structured properly, an orderly transition could be conducted, leaving ample time for human rights impacts to be respected.
8. An Afterword
An afterword may be worth making concerning the recommendations about “rights” in this paper; in particular, the rights to privacy and consent need to be set alongside the rights to universality and nondiscriminatory treatment[55].
Record linkage can aid a society in achieving advances in the well being its citizens. This point may have been lost in the detailed discussion of privacy and consent concerns. For example, the epidemiological literature is full of health studies that use record linkage techniques to advance knowledge[56].
The benefit side of record linkage can be oversold, however. A recent Science article may be worth quoting in this regard[57].
Over the past 50 years, epidemiologists have succeeded in identifying the more conspicuous determinants of noninfectious diseases—smoking, for instance, which can increase the risk of developing lung cancer by as much as 3000%. Now they are left to search for subtler links between diseases and environment causes or lifestyles. And that leads to the Catch-22 of modern epidemiology. On the one hand, these subtle risks—say, the 30% increase in the risk of breast cancer from alcohol consumption that some studies suggest — may affect such a large segment of the population that they have potentially huge impacts on public health. On the other, many epidemiologists concede that their studies are so plagued with biases, uncertainties, and methodological weaknesses that they may be inherently incapable of accurately discerning such weak associations. As Michael Thun, the director of analytic epidemiology for the American Cancer Society, puts it, “With epidemiology you can tell a little thing from a big thing. What's very hard to do is to tell a little thing from nothing at all.” Agrees Ken Rothman, editor of the journal Epidemiology: “We're pushing the edge of what can be done with epidemiology.” With epidemiology stretched to its limits or beyond, says Dimitios Trichopoulos, head of the epidemiology department at the Harvard School of Public Health, studies will inevitably generate false positive and false negative results “with disturbing frequency.”
Where does all of this leave things? The claim that the present paper is just a “starter set” is believed mainly to be true; but, in some places, even that may exceed current knowledge. What, in fact, many of the recommendations call for is simply more empirical work and hard thinking. Particularly crucial are two of these:
-
Establishing ongoing programs of experimentation (e.g., on consent and notification statements), plus public opinion research on privacy issues, both in general and with a particular focus on record linkage [58].
-
Instituting statistical work on group matching or other techniques that would lessen the tradeoff between the competing values of furthering scientific research and safeguarding personal privacy[59].
In the end, of course, the recommendations made here are simply the author's weighing of the evidence from the perspective of nearly 25 years of experience working on record linkage.
Footnotes
[1] Health Security Act (1993). Washington, DC: U.S. Government Printing Office. See also, for example, Donaldson, M.S. and Lohr, K.N., (eds.) (1994). Health Data in the Information Age: Use Disclosure and Privacy, Committee on Regional Health Data Networks, Institute of Medicine: National Academy Press.
[2] Herriot, R. and Scheuren, F. (1975). The Role of the Social Security Number in Matching Administrative and Survey Records, Studies from Interagency Linkages; U.S. Social Security Administration.
[3] Despite early advocates, like Dunn, H.L. (1946). Record Linkage, American Journal of Public Health, 36, 1412–1416.
[4] Patterson, J.E. and Bilgrad, R. (1985). The National Death Index Experience: 1981–1985, Record Linkage Techniques—1985, Proceedings of the Workshop on Exact Matching Methodologies, Arlington Va.; Washington, DC: U.S. Department of Treasury.
[5] Tepping, B. (1968). A Model for Optimum Linkage of Records, Journal of the American Statistical Association, 63, 1321–1332.
[6] Fellegi, I.P. and Sunter, A. (1969). A Theory of Record Linkage, Journal of the American Statistical Association, 64, 1183–210.
[7] Newcombe, H.B. (1967). Record Linking: The Design of Efficient Systems for Linking Records into Individual and Family Histories, American Journal of Human Genetics, 19, 335–359. Newcombe, H. B.; Kennedy, J.M.; Axford, S.J.; and James, A.P. (1959), Automatic Linkage of Vital Records, Science, 130, 3381, 954–959. Newcombe, H.B. and Kennedy, J.M. (1962), Record Linking: Making Maximum Use of the Discrminating Power of Identifying Information, Communications of the Association for Computing Machinery, 5, 563–566.
[8] See, for example, Beebe, G.W. (1985). Why are Epidemiologists Interested in Matching Algorithms? Record Linkage Techniques, Proceedings of the Workshop on Exact Matching Methodologies, Arlington, Va.; Washington, DC: U.S. Department of Treasury. See also,[56] and[57].
[9] See, for example, Winkler, W. and Thibaudeau, Y. (1991). An Application of the Fellegi-Sunter Model of Record Linkage to the 1990 U.S. Census, Statistical Division Report Series, CENSUS/SRD/RR— 91/09. See also, Belin, T. and Rubin, D. (1995). A Method of Calibrating False-Match Rates in Record Linkages, Journal of the American Statistical Association, 90, 694–707.
[10] Rogot, E.; Sorlie, P.D.; Johnson, N.J.; Glover, C.S.; and Treasure, D.W. (1988). A Mortality Study of One Million Persons: First Data Book, NIH Publication No. 88–2896, Bethesda, MD: Public Health Service, National Institute of Health.
[11] Oh, H.L. and Scheuren, F. (1975). Fiddling Around with Matches and Nonmatches, Proceedings of Social Statistics Section, American Statistics Association. Also, Scheuren, F. and Winkler, W.E. (1997), Regression Analysis of Data Files that Are Computer Matched—Parts I and II, in this volume: Record Linkage Techniques—1997, Washington, DC: National Academy Press. (Part I appeared previously in Survey Methodology, (1993), 19 (1) 39–58, Statistics Canada; Part II was delivered at the XII Methodology Symposium, Ottawa Canada, November 1, 1995, under the title Linking Data to Create Information and will be included in a forthcoming issue of Survey Methodology.)
[12] Fair, M. (1995). An Overview of Record Linkage in Canada, presented at the American Statistical Association Annual Meetings in Orlando, FL, August 1995.
[13] Davis, K. (1995). Guarding Your Financial Privacy, Kiplinger's Personal Finance Magazine, 49.
[14] Office of Technology Assessment (1993). Protecting Privacy in Computerized Medical Information, Washington, DC: U.S. Government Printing Office.
[15] Scheuren, F. (1993). Correspondence with Dr. Elmer Gabrieli on a health identifcation number, in Guide for Unique Healthcare Identifier Model, ASTM, Philadelphia, May, 1993 draft. Ironically, public opinion poll data suggest that the American people favor the adaptation of the SSN, rather than the introduction of a new health identifier. See[33] for details.
[16] Health Security Act (1993). Washington, DC: U.S. Government Printing Office.
[17] Donaldson, M.S. and Lohr, K.N., (eds.) (1994). Health Data in the Information Age, Use, Disclosure, and Privacy, Committee on Regional Health Data Networks, Institute of Medicine: National Academy Press.
[18] Schwartz, H.; Kunitz, S.; and Kozloff, R. (1995). Building Data Research Resources From Existing Data Sets: A Model for Integrating Patient Data to Form a Core Data Set, presented at the American Statistical Association Annual Meetings in Orlando, FL, August 1995.
[19] Dalenius, T. (1988). Controlling Invasion of Privacy in Surveys, Continuing Education Series, Statistics Sweden.
[20] Olmstead v. United States. 277 U.S. 438. 478 (1928) (Justice Brandeis dissenting).
[21] Some implications are obvious. For example, “information in medical records can conceivably affect you for the rest of your life if revealed to an employer or insurance company, ” (The Washington Post Health Section, February 8, 1994). The obvious cases are not the only ones to be worried about, though. The combinatorial possibilities are so great that they may not only impair full consent to linkage by patients but also access decisions by data stewards.
[22] Singer, E.; Shapiro, R.; and Jacobs, L (1995). Privacy of Health Care Data: What Does the Public Know? How Much Do They Care? Paper submitted with support from the American Association for the Advancement of Science, Science and Human Rights Program.
[23] Horgan, J. (1995). From Complexity to Perplexity, Scientific American, June 1995, 104–109. See also, Waldrop, M.M. (1992), Complexity. New York: Simon and Schuster.
[24] Superhack, Scientific American, July Issue, 1994, 17. This is a story of a group of about 600 computer “hacks,”' collaborating over the internet, who broke a computer security encryption algorithm. About 17 years earlier, it was predicted that this feat would take 40 quardrillion years. Once the effort started, it took 8 months! For more on this, see also, Science, May, 1994, 776–777.
[25] In contrast, consider The Washington Post, July 18, 1994, where there is a story about how, despite an existing monitoring system, inadequate controls were used for access to sensitive information.
[26] Brannigan and Beier (1995), Medical Data Protection and Privacy in the United States: Theory and Reality, paper submitted with support from American Association of the Advancement of Science, Science and Human Rights Program.
[27] Singer, E., Shapiro, R., and Jacobs, L (1995), op. Cit.
[28] Hoffman, B. (1990). Patient Confidentiality and Access to Medical Records: A Physician's Perspective, Health Law in Canada, 10:210–12. Siegler, M. (1982), Confidentiality in Medicine—A Decrepit Concept, New England Journal of Medicine, 307:1518–21, as summarized by Cummings, N. (1993), Patient Confidentiality, Second Opinion, 112–116.
[29] Brannigan and Beier (1995), op. cit.
[30] Introduced by Condit as HR 4077 in the 103rd Congress; also reintroduced (again by Condit) in the 104th Congress as HR 435.
[31] As recommended by OTA (1993), op. cit.
[32] For example, Smith, R.E. (1992). Compilation of State and Federal Privacy Laws, Privacy Journal.
[33] Inferred from Harris-Equifax (1993), Health Care Information Privacy: A Survey of the Public and Leaders, New York: Louis Harris and Associates. See also, Blair, J. (1995), Ancillary Uses of Government Administrative Data on Individuals: Public Perceptions and Attitudes, Unpublished Working Paper, Committee on National Statistics, National Academy of Sciences. As Blair points out (and this author confirmed by calling Harris and Associates), the Harris-Equifax survey has important limitations on its interpretability; nonetheless, its main conclusions are in essential agreement with other research on privacy concerns. Blair summarizes these as well. Roughly, almost no matter how you ask the question, there are always about one sixth to one fifth of the population who oppose electronic record linkages on privacy grounds. Conversely, again almost no matter how you ask the question, about the same fraction will favor beneficial sounding linkages on efficiency grounds. The two thirds or so in the middle will differ in their opinions depending on the specifics. See also,[55].
[34] Goldman, J. (1994). Regarding H.R. 3137: Data needs and related issues for implementing health care reform, Statement before the House Post Office and Civil Service Subcommittee on Census, Statistics and Postal Personnel, Washington, DC. For an excellent expression of an alternative view, see Newcombe (1995), When Privacy Threatens Public Health, Canadian Journal of Public Health, 86, 188–192.
[35] Kluge, E.H. (1993). Advanced Patient Records: Some Ethical and Legal Considerations Touching Medical Information Space, Methods of Information in Medicine, 95–103.
[36] Brannigan and Beier (1995), op. cit.
[37] Spruill, N. and Gastwirth, J. (1982). On the Estimation of the Correlation Coefficient from Grouped Data, Journal of the American Statistical Association, 77, 614–620. Gastwirth, J., and Johnson, W.O. (1994), Screening With Cost-Effective Quality Control: Potential applications to HIV and Drug Testing, Journal of the American Statistical Association, 89, 972–981. Contrast Gastwirth, J. (1986), Ethical Issues in Access to and Linkage of Data Collected by Government Agencies, Proceedings of the American Statistical Association, Social Statistics Section, 6–13.
[38] See, for example, Jabine, T.B. and Scheuren, F. (1985). Goals for Statistical Uses of Administrative Records: The Next Ten Years, Journal of Business and Economic Statistics.
[39] Wright, D. and Ahmed, S. (1990). Implementing NCES's New Confidentiality Protections, American Statistical Association, 1990 Proceedings on the Section on Survey Research Methods, Alexandria, Va.: American Statistical Association.
[40] Rubin, D.B. (1993). Comments on Confidentiality, A Proposal for Satisfying all Confidentiality Constraints through the Use of Multiple-Imputed Synthetic Microdata, Journal of Official Staistics.
[41] Harris-Equifax (1993) and Blair (1995), op. cit., See also,[33]. Clearly, though, we do not know enough to be sure.
[42] Dalenius, T. (1988). op. cit.
[43] Goldman, J. (1994). op. cit.
[44] Singer, E.; Shapiro, R.; and Jacobs, L (1995). op. cit.
[45] Fair, M. (1995). op. cit.
[46] But see, for example, Scheuren, F. (1994). Historical Perspectives on the Estate Multiplier Technique, Statistics of Income, Estate Tax Wealth Compendiun, U.S. Internal Revenue Service.
[47] Scheuren, F. (1985). Methodological Issues in Linkage of Multiple Data Bases, Record Linkage Techniques—1985, Washington, DC: Department of the Treasury, Internal Revenue Service,155–178. Scheuren, F. (1995), Review of Private Lives and Public Policy, Journal of the American Statistical Association, March 1995 Issue.
[48] Fisher, J. et al. (1995). Gaining Respondent Participation: Issues of Trust, Honesty and Reliability, Paper submitted with support from American Association of the Advancement of Science, Science and Human Rights Program.
[49] Singer, E.; Shapiro, R.; and Jacobs, L (1995). op. cit.
[50] One joint control option that may be of interest arose in the project described in Rogot, E. et al. (1988). op. cit.
[51] Scheuren, F. (1995). op. cit.
[52] Brannigan and Beier (1995). op cit.
[53] This might be inferred from the 1993 Harris-Equifax Questions on access to patient health data by insurance companies and employers. Harris-Equifax, op. cit. Also, from Blair (1995) and the other research started by Scheuren (1985). See[33] and[47].
[54] Schwartz, H. et al. (1995). op. cit.
[55] As elaborated in Chapman, Audrey R. (1997). Introduction: Developing Health Information Systems Consistent with Human Rights Criteria, Health Care and Information Ethics: Protecting Fundamental Human Rights, Kansas City, MO: Sheed and Ward, 3–30.
[56] Cited earlier were Beebe[8] and Fair[12], among others. See also, endnotes[7],[10], and[34]. Also of note in this context is the paper by Sugarman, Jonathan, et al. (1997). Improving Health Data among American Indians and Alaska Natives: An Approach from the Pacific Northwest, Health Care and Information Ethics: Protecting Fundamental Human Rights, Kansas City, MO: Sheed and Ward, 88–113.
[57] Taubes, G. (1995). Epidemiology Faces its Limits, Science, July 14, 1995, 164–169.
[58] As advocated in Scheuren, F. (1985). Methodological Issues in Linkage of Multiple Data Bases, Record Linkage Techniques—1985, Internal Revenue Service and as pursued by him over the past 10 years through the sponsorship of numerous public opinion polls, asking various questions about linkage. Most of these are discussed in Blair, J. (1994). Ancillary Uses of Government Administrative Data, College Park, MD: University of Maryland Survey Research Center. Work at the Bureau of Labor Statistics,
with focus groups and other cognitive research techniques, has also been sponsored. At this point, the summary given already in endnote [33] represents the limited state of knowledge.
[59] Certainly, the seminal work of Spruill, Nancy and Gastwirth, Joseph (1982). On the Estimation of the Correlation Coefficient from Grouped Data, Journal of the American Statistical Association, 77, 614– 620.
Additional References
Acheson, E.D. ( 1967). Medical Record Linkage, Oxford, U.K.: Oxford University Press.
Copas, J.B. and Hilton, F.J. ( 1990). Record Linkage: Statistical Models for Matching Computer Records, Journal of the Royal Statistical Society, Ser. A, 153 (Part 3), 287–320.
Dunn, H.L. ( 1946). Record Linkage, American Journal of Public Health, 36, 1412–1416.
Jaro, M.A. ( 1989). Advances in Record-Linking Methodology as Applied to Matching the 1985 Census of Tampa, Florida, Journal of the American Statistical Association, 84, 414–420.
Kilss, B. and Alvey, W. (eds.) ( 1985). Record Linkage Techniques—1985, Proceedings of the Workshop on Exact Matching Methodologies, Arlington, Virginia, May 9–10, 1985), Washington, DC: Department of the Treasury, Internal Revenue Service.
Newcombe, H.B. ( 1967). Record Linking: The Design of Efficient Systems for Linking Records into Individual and Family Histories, American Journal of Human Genetics, 19. 335–359.
Newcombe, H.B., and Kennedy, J.M. ( 1962). Record Linking: Making Maximum Use of the DiscriminatingPower of Identifying Information, Communications of the Association for Computing Machinery, 5, 563–566.
Rogot, E.; Sorlie, P.D.; Johnson, N.J.; Glover, C.S.; and Treasure, D.W. ( 1988). A Mortality Study of One Million Persons: First Data Book, NIH Publication No. 88–2896, Bethesda, MD: Public Health Service, National Institute of Health.
Roos, L.L.; Wajda, A.; and Nicol, J.P. ( 1986). The Art and Science of Record Linkage: Methods that Work with Few Identifiers, Computers in Biology and Medicine, 16, 45–57.
Scheuren, F. ( 1985). Methodological Issues in Linkage of Multiple Data Bases, Record Linkage Techniques— 1985, Washington, DC: Department of the Tresury, Internal Revenue Service, pp. 155–178.
Scheuren, F.; Alvey, W.; and Kilss, B. ( 1986). Record Linkage for Statistical Purposes in the United States, Proceedings of the Workshop in Computerized Record Linkage in Health Research, held in Ottawa, Ontario, May 21–23, 1986, G.R.Howe and R.A.Spasoff, (Eds.), Toronto: University of Toronto Press, pp. 198–210.
Donaldson, M.S. and Lohr, K.N., (Eds.) ( 1994). Health Data in the Information Age: Use, Disclosure and Privacy, Committee on Regional Health Data Networks, Institute of Medicine : National AcademyPress.
|
Note: This paper was commissioned for the Health Care and Information Ethics project, sponsored by the American Association for the Advancement of Science (AAAS) when Fritz Scheuren was working for George Washington University. It appeared as a chapter in Audrey R.Chapman (Ed.), (1997). Health Care and Information Ethics: Protecting Fundamental Human Rights, Kansas City, MO: Sheed and Ward. The paper is reprinted here with permission, c 1997 by American Association for the Advancement of Science. All rights reserved. Except as permitted under the Copyright Act of 1976, no part of this paper may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by an information storage and retrieval system without permission in writing from the Publisher. Sheed & Ward is a service of The National Catholic Reporter Publishing Company. To order, write Sheed & Ward, 115 E.Armour Blvd., PO Box 419492, Kansas City, MO, 64141 –6492; or call (800) 333–7373. |
Record Linkage in an Information Age Society
Martha E.Fair, Statistics Canada
Abstract
As we move into the 21st century the acquisition, generation, distribution, and application of statistical knowledge in a timely fashion will become more important. Required are innovations in terms of the products, technologies, and the way in which we generate, disseminate, and use statistical data and information. It is anticipated that work units will shrink, funding will be limited, and there will be greater analytical uses of administrative, as well as survey and census data. There may need to be a fundamental rethinking and radical redesign of business processes and workplaces. Today's market, customer values and technologies are changing rapidly. Standards, cooperation and collaboration of various agencies, and software developments are very important. Access and control of sensitive information as well as the technical aspects of confidentiality are necessary. Data integration of a number of different sources, including census, survey, registry and administrative files in a variety of economic and social areas are sometimes required. The quality of the statistical information is also of concern.
One useful tool that has been developed for generating and using statistical data is computerized record linkage. Anticipated new developments and applications of this methodology for the 21st century are described. Emphasis is placed on the health area, particularly in these times of health reform.
Over the past 15 years, generalized systems have been developed at Statistics Canada. Briefly described is a new version of a generalized record linkage system (GRLS.V3) that is being put into place to carry out internal and two-file linkages. With an earlier mainframe system, large-scale death and cancer linkages for members of survey and other cohorts have been shown to be practicable using the Canadian Mortality Data Base, the Canadian Cancer Data Base and the Canadian Birth Data Base. This approach has greatly reduced respondent burden, lowered survey costs, and greatly refined the detection and measurements of differences in geographic, socioeconomic and occupational groups. Some of the past successes are described, particularly where longitudinal follow-up and creation of new sampling frames are required. For example, the Nutrition Canada Survey, the Canada Health Survey and Fitness Canada Surveys have been linked with mortality data. Some examples of the use of follow-up of census data are discussed (e.g., a study of farmers using 1971 Census of Agriculture and Census of Population).
Introduction—Statistical Data Needs for the 21st Century
Purpose
The purpose of this article is to discuss some of the issues surrounding statistical uses of record linkage, with a view to the expanded uses of probabilistic record linkage in the 21st century, particularly with respect to the generation and use of administrative and survey data. Record linkage is the bringing together of two or more pieces of information relating to the same entity (e.g., individual, family, business). In probabilistic record linkage, the comparison or matching algorithm yields for each record pair, a probability or “weight” which indicates the likelihood that record pairs relate to the same entity (Fair, 1995).
In the 21st century, it is anticipated that those carrying out and requiring record linkage of data should be prepared for change. Hardware and software needs for record linkage will range from global statistical systems for giant organizations on large super computers, to requests for linkages of small area data sets on small laptops. Integration of a variety of statistical survey and administrative data sources may be required. There is a move to reduce the complexity of data, to avoid unnecessarily duplicating data, and to have a single, unified view of an organization's information, with the data's physical location being almost transparent to the user. There is considerable re-engineering of data acquisition processes, including the editing, manipulating and grouping of files. This should improve the quality of the input files. Data models may be centered around the same individual, family or entity over time rather than a cross-sectional snapshot of an event. It is anticipated that databases will become more comprehensive and inclusive. There will be a need to develop and revise international data standards, such as for disease, geographic, industrial coding, and data exchange. Timeliness is important with many organizations moving to electronic data capture and optical imaging. Dissemination of products will be via a spectrum of medium, with emphasis on the usefulness to the customer. On-line access may be required for inquiry, downloading and reporting. New links between agencies and countries may be required, and hence confidentiality issues will be of prime importance. Here, it is useful that statistical and administrative record linkage applications be differentiated.
Today, we will examine some general topics first, namely:
-
evolving in response to customer needs in changing times;
-
some comments regarding the “information age;”
-
characteristics/indicators of success for an effective statistical system; and
-
moving from data to information.
We will then look at record linkage in more depth and examine:
-
today's situation;
-
examples of present uses of record linkage;
-
preparing for the future journey—the life cycle of events;
-
making the right connection; and
-
summary.
I will use examples of statistical applications of record linkage, with emphasis on those from Statistics Canada and the health research area in particular.
Evolving in Response to Customer Needs in Times of Change
Many of the common social, economic, occupational and environmental concerns of today are complex and multi-faceted. Change seems to have become the operative word. Policies, institutions, communities and businesses are changing at the global, national, provincial/state, regional and local levels. Institutions in North America and worldwide have undergone an unprecedented wave of consolidation. There is concern to identify and strive toward global statistical systems that can produce national statistical services that are comparable and readily accessible (Haberman, 1995). The capabilities of technology, especially communication and information technology are changing daily.
The tools and options for dissemination are expanding. There is a corresponding rising consumer expectation, particularly with respect to timeliness and quality of statistical data products. This has implications in terms of standard data concepts, definitions, coding, methodology used for record linkage, and development of national and provincial/state data bases. Communication and collaboration of various countries, particularly with respect to software and methodological developments, have benefited through a series of seven workshops regarding record linkage held in Canada (e.g., Carpenter and Fair, 1989) and others held in the United States (Kilss and Alvey, 1985).
Analysis of data sources from different countries is helpful and comparative international statistics are required. Joint analysis of data from different countries is common (e.g., a joint analysis of 11 underground miners studies to examine radon and lung cancer risks). There is a need for international collaborative works, such as the United Nations Scientific Committee on the Effects of Atomic Radiation, which aims to provide to the scientific and world community, its latest evaluations of the sources of ionizing radiation and the effects of exposures (United Nations, 1993). Here the major aim is to assess the consequences to human health of a wide range of doses of ionizing radiation and to estimate the dose of people all over the world from natural and man-made radiation sources. Linkage of a variety of data sources are required.
The social and economic structure is changing. There are new concepts of family, childhood and parenthood. This has important implications for the follow-up of households and individuals for longitudinal surveys and for administrative files. The Health of Canada's Children—A CICH Profile discusses some of the recent trends in Canada (Canadian Institute of Child Health, 1994). Some of the examples given are as follows. Families are changing—the structure of the families are different from what they used to be. In 1967, 65% of all Canadian families consisted of a male wage earner and a stay-at-home spouse. In 1990, this traditional family structure accounted for only 15% of families.
Our society is becoming more diverse. Families are rooted in more diverse cultural, religious, linguistic and ethnic backgrounds than in the past. In 1991, 13% of the Canadian population spoke a language other than French or English at home. Where surnames and forenames are used in probabilistic matching, we have found that special tables of weights have had to be developed by region, and sometimes over time. For example, there is quite a different distribution of name frequencies in Quebec, which is predominantly French, in British Columbia, where the number of Asian names have increased in recent years, and in Canada overall. Naming conventions are changing, with women often retaining their maiden name, as is particularly common in Quebec.
The role of women has changed. In the early 1960's less than a third of Canadian women worked outside the home. By 1996, about 80% of women are expected to be in the work force. Lifelong learning has become a necessity. Increasingly, the workplace requires a higher level of skills and a different set of skills than in the past. More and more jobs require people who can work in teams, who have high literacy, nu-
meracy and computing skills, who can then critically and creatively solve problems—and most of all, continue to learn new skills.
Figure 1. —Population by Age Group and Sex, Canada, 1993, 2016 and 2041
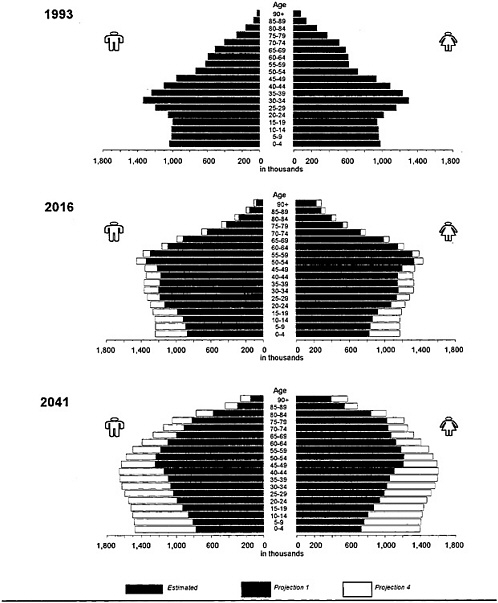
Source: George, M.V.; Norris, M.J.; Nault, F.; Loh, S.; and Dai, S.Y. (1994), Population Projections for Canada, Provinces and Territories 1993 –2016, Statistics Canada Catalogue No. 91–520, page 74.
Between 1971 and 1991, the age profile of the population changed from a traditional pyramid shape to a wide column, with fewer younger people and dramatically more older people. By 2041 the column will be top-heavy (see Figure 1—Source: George et al., 1994). Similarly in the United States, by 2025 more than 30% of the population will be over 55 year old. Persons aged 80 and over will outnumber any younger 5-year age group (UNDIESA, 1991).
The economy is restructuring. There is a heightened sense of economic anxiety. Driven by technological innovation, global competition and new trade arrangements, the economy is undergoing a fundamental restructuring. Governments are restructuring. At all levels, they are tightening up their spending to make programs more cost effective and more relevant to changing needs. This has been most apparent in the health sector in term of health reform. (Blomquist and Brown, 1994). At the same time, there are major reforms of social programs, not only to improve efficiency, but also to remake these programs.
The Information Age
The Tofflers have described our times as being that of the third wave (Toffler and Toffler, 1995). The First wave was agricultural and it lasted thousands of years until the 18th century. Then the Industrial Revolution created a novel concept of massification—mass production, mass markets, mass consumption, mass media, mass political parties, mass religion and weapons of mass destruction. This Second wave lasted about three hundred years. The Third wave is that of an information-age society. Because of the computer chip we are moving from an age in which we produce things to an age in which we produce information. But paradoxically, the more that national boundaries are usurped by our universal hook-up to the global computer network, the more we segment (Grant, 1996). With the complexities of the new system we require more and more information exchange among the various units of companies, government agencies, hospitals, associations, institutions and individuals. Factories, cities, even nations are receding and being replaced by smaller units of consumption and by minority political and religious interests. In the Tofflers' words, the world “de-massifies.”
We are in a time of redefining the workplace—and work itself. Work units are shrinking. The home may be the workplace of the future for many more people. Customized and semi-customized, highly diversified statistical products will be required—yet the cost of producing these diversified products must be minimal. There is a requirement of flexibility and choice by many clients.
There is a growing time crunch. Time itself is one of the most important economic resources. The ability to shorten time—by communicating swiftly or by bringing products in a timely fashion—may mean the difference between profit and loss (Toffler and Toffler, 1995). In the health area, there is a need for more flexible, fast-paced, information-rich systems which can act as surveillance systems and assist in identifying present and emerging health issues.
We may have to rethink and re-image our relationships. Amidst societal change, people more than ever need an anchor, a refuge, a place where they belong (Bank of Montreal, 1995). Traditionally, a sense of community has helped fill that need. This in the past, was often built around a common geographic location, a common workplace, a common history or tradition. Individuals now form commitments to a wide variety of communities based on shared experiences and values—family, profession, neighbourhood, age, ethnic background, talent, language. Barna (1990) notes that in the process of redefining what counts in life, many of us have decided that commitment is not in our best interest. Traditional concepts such as loyalty and the importance of memberships in various groups have been thrown out in favour of personal interest and self-preservation. This may have important implications for the workforce and for negotiations.
Characteristics and Indicators of an Effective Statistical System
Dr. Fellegi, the Chief Statistician at Statistics Canada, gave a 1995 Morris Hansen Lecture at the Washington Statistical Society. He described an effective statistical system as being characterized by its ability to:
-
illuminate issues, not just monitor them;
-
evolve in response to needs;
-
be aware of priority needs;
-
set priorities;
-
have a high level of public credibility, since few in society can verify national statistics; and
-
be free from undue political interference (Fellegi, 1995).
Three main indicators of success of statistical systems noted in this paper were:
-
How adaptable is the system in adjusting its product line to evolving needs?
-
How effective is the system in exploiting existing data to meet client needs?
-
How credible is the system in terms of the statistical quality of its outputs and its non-political objectivity? (Fellegi, 1995)
Moving from Data to Information
Two recent methodology symposium topics held at Statistics Canada are relevant. The XIIth International Symposium on Methodological Issues, held at Statistics Canada on November 1–3, 1995, was entitled “From Data to Information.” At this symposium topics included the role of statistics in making social policy, data integration, analytical methods, access and control of data, quality of statistical information, technical aspects of confidentiality, making data accessible to the general public, data warehousing, and electronic information dissemination. An earlier symposium dealt with re-engineering for statistical agencies (Statistics Canada, 1994). Re-engineering is a rethinking and radical redesign of the way business is carried out by an agency or corporation. The desired end results are lower production costs, quicker dissemination, and higher customer satisfaction.
There is a desire to understand and improve the performance of the health system. As noted in Health Data in the Information Age—Use, Disclosure and Privacy (Donaldson and Lohr, 1994) this in turn motivates proposals for the creation and maintenance of comprehensive, population-based health care data bases. Regional health care databases are being established around the United States and Canada. Guidelines are needed to realize the full potential of these files, as well as to reduce respondent burden.
Two critical dimensions of databases are their comprehensiveness and inclusiveness. Comprehensiveness describes the completeness of the records (i.e., the amount of information one has for each patient and for an individual over time). Inclusiveness refers to which populations in a geographic area are included in a database. The more inclusive a database, the more it approaches coverage of 100 percent of the population. The Census of Population, the vital statistics and morbidity files are important data sources for a variety of national health studies because of their comprehensiveness and inclusiveness.
Record Linkage
Today's Situation
Just as we have just looked into the future in a more general fashion, it is also good to reflect on some of the past development of record linkage methods. Some of today's data sources were created by individuals with a view to record linkage in the future (e.g., in Canada the vital statistics birth records were linked with Family Allowance files to determine the eligibility of applicants when this program was first implemented).
The initial definition of record linkage was in terms of the book of life (Dunn, 1946). The early development work had to do with investigating the feasibility of probabilistic linkage (Newcombe et al., 1959), the theory of record linkage (Fellegi and Sunter, 1969), the development of specific computer programs, followed by the development of generalized software (Hill, 1981) and national files, commercial software (Jaro, 1995) and other software (e.g., Chad, 1993). Communication and collaboration with agencies in various provinces in Canada, in the United States, the United Kingdom and Australia have aided record linkage developmental work (e.g., Kilss and Alvey, 1985; Gill et al., 1993; Jaro, 1995; Winkler and Scheuren, 1995).
One key technological development is the shift from a paper-based system of records to an electronic process for creating, transmitting and disseminating products. At Statistics Canada, the 1990s brought about a major revolution in advanced technology with the wide-scale introduction of Computer Assisted Interviewing (CAI) for household, agriculture and business surveys. Computer Assisted Personal Interviewing (CAPI) has been introduced with the Labour Force Survey supplements and longitudinal household surveys covering a wide range of topics including Survey of Income and Labour Dynamics, the National Population Health Survey and the National Longitudinal Survey of Children (Gosselin, 1995). Vital statistics (Starr and Starr, 1995), census and cancer registries are additional examples where re-engineering and change may be anticipated in the future. There has been a move from microfilming of source documents to optical imaging.
A generalized system initiative at Statistics Canada was started in response to the use of repetitive processes, particularly in survey taking. This includes sampling, data collection and capture, automated coding, edit and imputation, estimation, and record linkage (Doucet, 1995). This suite of software products has been developed with technologies that make them highly portable across major computing platforms.
The original version of generalized record linkage software (GRLS.V1) that was developed at Statistics Canada was for a mainframe environment. Currently under development is GRLS.V3 which runs in a client-server environment with ORACLE and a C compiler (Statistics Canada, 1996). GRLS will run on a PC or workstation which supports the UNIX operating system. This software allows for an internal linkage within a file (e.g., to create health histories in a cancer registry) or a two-file linkage (e.g., linkage of a survey file to mortality). This software is particularly useful where there is no unique, reliable, lifetime identifier on the files being linked.
GRLS has three important stages:
-
In the searching stage screens are used to specify the files, indicate the records to be compared (e.g., within pockets with similar phonetic code of the surname), specify the rules for comparison
-
(e.g., agree, disagree, partially agreement, or user-defined functions), and specify the weights to be assigned to the outcomes.
-
In the decision stage, the weights can be adjusted and threshold weights selected to define whether pairs are linked, possibly linked, or unlinked.
-
In the final grouping stage, the records are brought together appropriately. You can have conflicts resolved automatically (e.g., two records linking to one death record). This is called mapping, and one can select the appropriate type (e.g., 1–1, 1-many, many-1, many-many). You may also have the option to resolve conflicts manually via on-screen updates. The final output of GRLS is an ORACLE table containing the GROUP information.
It is very important to note that GRLS V3 does not modify the files it is linking. This means that the same file may participate concurrently in several two-file linkages. For example, one might want to link several (and unrelated) files against the same master file.
Record Linkage in the Toolbox of Software—Some Examples of its Use
Statistics Canada uses a common set of software products in re-engineering its administrative and statistical programs. This set of products is collectively referred to as the toolbox. Each toolbox product has a current release, an identified support level and a designated support centre. Currently the generalized record linkage software is part of this toolbox.
Record linkage is an important tool for the creation of statistical data, particularly in relation to census taking. Some of the important uses are as follows:
-
Data Quality. —Some European countries use population registers instead of a census (e.g., Denmark). It is also possible to use administrative data and record linkage to help impute missing or inconsistent data. Data sources can be examined to eliminate duplicate records for individuals and to identify missing records in databases (e.g., by the linkage of infant deaths and birth records or by the linkage of births and deaths with census records).
-
Bias. —The advantage of population-based record linkage includes the avoidance of selection bias, which can occur in cohort and case-control studies. Recall bias is usually avoided because the data are collected before the outcome or in ignorance of the outcome.
-
Coverage. —In Canada record linkage data is used to improve the census coverage (e.g., address register) as well as to estimate its coverage (e.g., reverse record check). With disease-specific registries, it is possible to use linkage to identify underreporting of cases (e.g., by linkage of cancer registries with death registrations, the linkage of hospital records with deaths for heart disease). This has important implications for diseases such as AIDS and cancer.
-
Tracing Tool. —Record linkage and administrative records are often used to follow-up cohorts to determine the individuals' vital status. Tracing is often needed for follow-up of industrial cohorts and for longitudinal surveys to obtain the cause of death and/or cancer. Mobility patterns of persons are important for the allocation of health resources.
-
Benchmarking/Calibration. —Combining results from several data collection sources may give improved estimates (e.g., use of income from tax, survey and census sources).
-
Sampling Frame. —Record linkage may be involved in setting up a sampling frame for surveys (e.g., census of agriculture farm register is used for the sampling of intercensal farm surveys).
-
Supplementary Surveys. —Several postcensal surveys have been carried out following the Canadian census. Examples include the aboriginal peoples, and the health and activity limitation surveys. Data from the survey can be linked with that available on the census.
-
Release of Public-Use Tapes. —Linkage can be used to examine public-use tapes for potential problems in their release (e.g., data crackers).
-
Building New Data Sources (e.g., Registries). —Some cancer registries combine a variety of data sources using record linkage to generate their registry. Some of the data sources include hospital admissions, pathology reports, records from clinics, and death registrations.
-
Creation of Patient-Oriented, Rather than Event-Oriented Statistics. — (e.g., for hospital admissions, for cancer registries, (Dale, 1989)).
The uses of linkage in analytical studies have often been varied, and are generally tied in with increased use of administrative records for statistical purposes and with the reduction of respondent burden. (A roundtable luncheon of the Social Statistics Section at the 1995 American Statistical Association, chaired by G.Hole, discussed some of the above and future uses of administrative records to complement/ supplement data from household surveys.)
A more complete list of some of the uses of record linkage have been described earlier (Fair, 1995; Newcombe, 1994). Some examples are as follow:
-
Mortality, cancer and/or birth follow-up of
-
cohorts (e.g., miners, asbestos workers)
-
case/control studies
-
clinical trials (e.g., Canadian Breast Screening study);
-
-
Building, maintaining and using registries (e.g., cancer and AIDS);
-
Creation of patient-oriented histories;
-
Follow-up of surveys (e.g., Nutrition Canada, Canada Health Survey, Fitness Canada);
-
Occupational and environmental health studies;
-
Examining factors which influence health care usage and costs; and
-
Regional variations in the incidence of disease.
A longitudinal National Population Health Survey is currently in progress in Canada. In the original survey approximately 95% of the respondents agreed to have their survey data linked to their provincial health records. This linkage will strongly enhance the data set' s potential usefulness because it will add respondents' interaction with the health care system.
Preparing for the Journey Ahead—The Life Cycle of Events
In the health area, this usually involves the linkage of various data sources over time. Figure 2 is an example of how we can view the life cycle of events from birth to death, health determinants, and outcomes in ranges of “illness” to “wellness.” Piecing together the various important components may involve gathering data from a number of different sources such as surveys to estimate the degree of “illness” or “wellness” of the population (e.g., Census, Health and Activity Limitation Survey (HALS), Aboriginal Peoples Survey (APS), National Population Health Survey (NPHS)), national databases of existing administrative records (e.g., Canadian Birth Data Base, the Canadian Cancer Data Base and the Canadian Mortality Data Base), and from a number of different perspectives. For example, within health determinants one may be interested in human biology, socio-economic status (e.g., income, education), employment and working conditions, personal health practices and coping skills, social support, social, economic and physical environment, health services, and public policy. As the population/individual progresses through the different stages of the life cycle, the degree of “wellness” can vary as indicated in the diagram. (See also Hertzman, Frank and Evans, 1994).
Figure 2. —The Life Cycle of Events
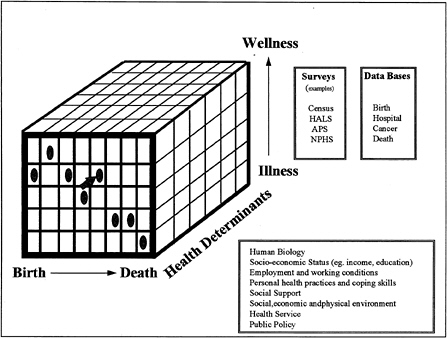
HALS—Health and Activity Limitation Survey
APS—Aboriginal Peoples Survey
NPHS—National Population Health Survey
Some examples, involving the use of census data, are as follows:
-
Maternal Health and Infant Birth—Death Linkages. —A study of regional differences in perinatal and infant mortality in the province of Ontario has been carried out. Infant and perinatal mortality in the 53 counties of Ontario were studied in two time periods—1970–72 and 1978–79. A considerable regional variation in the range of rates was found. Socio-economic factors were found to have an important influence on the maternal and infant determinants of mortality and in this way contributed to the variations in mortality over the province. Recently, there has been interest in establishing a Canadian Perinatal Health Surveillance system.
-
Occupational Studies. —There are strong pressures from society to determine and reveal the health risks to which it is exposed, especially where the harm is cumulative or latent for an extended period of time. These pressures come from three main sources. Organized labour has a special interest in conditions in the workplace which might lead to delayed effects, such as cancers among its members. Both the general public and environmental groups have frequently expressed concern over the possible consequences of exposure of the population at large to chemical and other agents. These agents are being produced in increasing numbers and quantities, and distributed both as commercial products and as contaminant wastes in ways that may result in ingestion or inhalation. The third source of pressure originates with professional groups whose work involves them in the detection and measurement of health risks and in setting safety regulations. Cancer incidence and mortality data are a main source of information to assist in the determination of health risks.
In light of urgent demands to protect workers' health, there is a need for a broad-based occupation-cancer database containing information on both cancer incidence and a wide range of occupations. A current feasibility study is examining the possibility of linking cancer, mortality and occupational, household and socio-economic data derived from the 1986 census data. The sample, consisting of seven geographic regions (4 urban and 3 rural), were selected based on census geography.
As an occupational group, farmers have low overall mortality. However, a number of epidemiological studies suggest increased risk of certain cancers among farmers, including cancer of the stomach, lip, prostate, brain and skin, leukemia, Hodgkin's disease, multiple myeloma, and non-Hodgkin's disease.
A mortality and cancer cohort study of about 326,000 Canadian male farm operators enumerated in the 1971 Census of Agriculture has been carried out in collaboration with Health Canada (Fair, 1993). Seven major files were linked to create the data required for the analysis file in this study, namely:
-
the 1971 Census of Agriculture;
-
the 1971 Census of Population;
-
the 1971 Central Farm Register;
-
the 1981 Central form Register;
-
the Canadian Mortality Data Base;
-
the 1966–71–76–81–86 Census of Agriculture Longitudinal file; and
-
the Canadian Cancer Data Base.
Analyses of these data have examined prostate (Morrison et al., 1993) and brain cancer (Morrison et al., 1992) in particular.
-
Socio-Economic Gradients. —There has been an increasing awareness of the importance of supporting basic research designed to identify determinants of health in order to inform policy makers about how best to improve the population 's heath and how best to accomplish this goal efficiently and cost-effectively. As a result, the Manitoba Centre for Health Policy and Evaluation has collaborated with Statistics Canada to determine the feasibility of linking provincial administrative health care utilization with census data for a sample of Manitobans (Mustard et al., 1995).
Mortality and health services utilization have been described in relation to the socio-economic status measure, mortality and the use of health care services at seven different stages in the life course (ages 0–4, 5–14, 15–29, 30–49, 50–64, 65–74, 75+). The objective of the study was to identify those classes of morbidity which dominate utilization of health care services at each stage of life course and simultaneously, the classes of morbidity which show the greatest disparities in relation to socioeconomic status. The research resource of this project was created at a fraction of the cost of a population survey. Some of the public policy responses indicated by these data were:
-
to consider directing an even greater share of health care services to lower socio-economic groups;
-
to more aggressively target preventive medical and health services, especially in early adulthood; and
-
to formulate explicit public policies addressing health inequalities. (Mustard et al., 1995, p. 67).
Making the Right Connections and Summary
We are in a time of rapid changes in terms of markets, customer expectations and technologies for record linkage software development, hardware, and applications. There often needs to be an optimal balance between cost, quality and timeliness. Many of the existing data systems are on the threshold of change. There is a shift from single data base applications to electronic data transfer and warehousing, data sharing within broad subject matter areas, and to enterprise wide systems and data integration. There are various hardware and software environments being used. A variety of approaches can be used to assess user's needs. These include professional advisory committees, client-oriented program evaluations, interactions with professional and other associations, market feedback, and analytic programs.
One needs to have the capacity to acquire, generate, distribute and apply knowledge strategically and operationally (Toffler and Toffler, 1995). To a large extent the quality of record linkage in the future is dependent on the quality of the files being linked—quality in/quality out. There is a need to harmonize concepts and outputs. For example, it is anticipated that the Tenth International Revision of the Classification of Disease will be implemented. A restructured industry classification system known as the North American Industry Classification System is being developed. Uniform lifetime business and individual numbers are highly desirable for many of the new information systems. Further work is required in designing appropriate items for the data sets —for example, more detail may be available at the local level than on a national basis.
There is a need to integrate a number of different sources of data. As governments and agencies regionalize services, there are additional requests for small area data. It is important to have the capacity to use multiple definitions of geographic population areas of interest (e.g., enumeration area, postal code areas, school districts, health units) depending on the nature of the investigation.
There is a need to develop confidentiality procedures and screening rules for the generation and release of public use data files. All studies involving record linkage at Statistics Canada must satisfy a prescribed review and approval process. For example, the purpose of the record linkage activity must be statistical or research in nature and must be consistent with the mandate of Statistics Canada as described in the Statistics Act. The record linkage activity must have demonstrable cost or respondent burden savings over other alternatives, or be the only feasible option. It must also be shown to be in the public interest. A comprehensive list of recommendations for Federal statistics agencies in the United States is given in Duncan et al., 1993.
In conclusion, analysis of existing and future linked data sets is indispensable in illuminating the main social and economic issues we face not only today, but also into the future. We need to anticipate and look forward to issues of the 21st century where record linkage may serve as an important research tool.
References
Bank of Montreal ( 1995). Bank of Montreal 178th Annual Report 1995, Public Affairs Department of the Bank, Bank of Montreal Tower, 55 Bloor Street West, 4th Floor, Toronto, Ontario M4W 3N5.
Barna, G. ( 1990). The Frog in the Kettle: What Christians Need to Know About Life in the Year 2000, Regal Books, Ventura, California 93006.
Blomquist, A. and Brown D.M. (Eds.) ( 1994). Limits to Care: Reforming Canada's Health Care System in an Age of Restraint Available from: Renouf Publishing Company Limited, 1294 Algoma Road, Ottawa, Ontario K1B 3W8.
Canadian Institute of Child Health ( 1994). The Health of Canada's Children—A CICH Profile 2nd Profile. Available from: Canadian Institute of Child Health, 885 Meadowlands Drive, Suite 512 Ottawa, Ontario K2C 3N2.
Carpenter, M., and Fair, M.E. (Eds.) ( 1989). Canadian Epidemiology Research Conference—Proceedings of the Record Linkage Session and Workshop. Available from: Statistics Canada, Occupational and Environmental Health Research Section, R.H. Coats Building, Tunney's Pasture, Ottawa, Ontario K1A 0T6.
Chad, R. ( 1993). A Comparison of Three Different Computer Matches. Special Census/Administrative Record Match Working Group in Conjunction with the Year 2000 Researcher Development Staff, U.S. Bureau of the Census, Washington, DC, September 1993, (Matchers—Winkler, Slaven, Jaro).
Dale, D. ( 1989). Linkage As Part of a Production System. The Ontario Cancer Registry in Canadian Epidemiology Research Conference—Proceedings of the Record Linkage Sessions and Workshop, M.Carpenter and M.E.Fair, Eds. Available from: Statistics Canada, Occupational and Environmental Health Research Section, R.H. Coats Building, Tunney's Pasture, Ottawa, Ontario K1A 0T6.
Donaldson, M.S., and Lohr, K.N. (Eds.) ( 1994). Health Data in the Information Age—Use, Disclosure, and Privacy, Washington, D.C.: National Academy Press.
Doucet, E. ( 1995). Survey Re-Engineering: Is Our Information Technology Framework Up to It? Proceedings of Statistics Canada Symposium 94—Re-Engineering for Statistical Agencies, November
1994, Available from: Financial Operations Division, Statistics Canada, R.H. Coats Building, 6th Floor, Tunney's Pasture, Ottawa, Ontario K1A 0T6, P. 159–168.
Duncan, G.T.; Jabine, T.B.; and De Wolf, V.A. (Eds.) ( 1993). Private Lives and Public Policies—Confidentiality and Accessibility of Government Statistics, Washington, D.C.: National Academy Press.
Dunn, H.L. ( 1946). Record Linkage, American Journal of Public Health, 36, 1412–1416.
Fair, M.E. ( 1995). An Overview of Record Linkage in Canada, 1995 Proceedings of the Social Statistics Section of the American Statistical Association, American Statistical Association, 1429 Duke Street, Alexandria, Virginia 22314–3402, 25–33.
Fair, M.E. ( 1993). Recent Advances in Matching and Record Linkage from a Study of Canadian Farm Operators and Their Farming Practices, 1993 ICES Proceedings of the International Conference of Establishment Surveys, American Statistical Association, 1429 Duke Street, Alexandria, Virginia 22314– 3402, 600–605.
Fellegi, I.P. ( 1995). Characteristics of an Effective Statistical System, Morris Hansen Lecture, presented at the Washington Statistical Society, October 25, 1995
Fellegi, I.P. and Sunter, A.B. ( 1969). A Theory of Record Linkage, Journal of the American Statistical Association, 40, 1183–1210.
George, M.V.; Norris, M.J.; Nault, F.; Loh, S.; and Dai, S.Y. ( 1994). Population, Projections for Canada, Provinces and Territories 1993–2016, Statistics Canada, Demography Division, Catalogue No. 91–520. Available from: Marketing Division, Sales and Services, Statistics Canada, Ottawa, K1A 0T6.
Gill, L.; Goldacre, M.; Simmons, H.; Bettley, G.; and Griffith, M. ( 1993). Computerized Linking of Medical Records: Methodological Guidelines Journal of Epidemiology and Comm. Health, 47:4, 316– 319.
Gosselin, J.F. ( 1995). The Operational Framework at Statistics Canada, Proceedings of Statistics Canada Symposium ‘94—Re-Engineering for Statistical Agencies, November 1994. Available from: Financial Operations Division, R.H. Coats Building, 6th Floor, Tunney 's Pasture, Ottawa, Ontario K1A 0T6, 170–174.
Grant, Linda (of The Guardian) ( 1996). Riding the Wave, The Ottawa Citizen, January 20, 1996, B4.
Haberman, H. ( 1995). Towards a Global Statistical System, Proceedings of Statistics Canada Symposium 94—Re-Engineering for Statistical Agencies, November 1994. Available from: Financial Operations Division, R.H. Coats Building, 6th Floor, Tunney 's Pasture, Ottawa, Ontario K1A 0T6, 53– 60.
Hertzman, C.; Frank, J.; and Evans, R.G. ( 1994). Heterogeneitics in Health Status and the Determinants of Population Health, Why Are Some People Healthy and Others Not? The Determinants of Health of Populations, R.G. Evans; L.Barer; and T.M.Marmor, Eds. New York: Aldine De Gruyter, 74f.
Hill, T. ( 1981). Generalized Iterative Record Linkage System, Ottawa, Canada: Statistics Canada.
Jaro, M.A. ( 1995). Probabilistic Linkage of Large Public Health Data Files, Statistics in Medicine, 14, 491–498.
Kilss, B., and Alvey, W. (Eds.) ( 1985). Record Linkage Techniques—1985. Proceedings of the Workshop on Exact Matching Methodologies, Arlington, Virginia, May 9–10, 1985, Washington, DC: Department of Treasury, Internal Revenue Service.
Morrison, H.; Savitz, D.; Semenciw, R.; Hulka, B.; Mao, Y.; Morison, D.; and Wigle, D. ( 1993), Farmingand Prostate Cancer Mortality, American Journal of Epidemiology, 137, 270–280.
Morrison, H.I.; Semenciw, R.M.; Morison, D.; Magwood, S.; and Mao, Y. ( 1992). Brain Cancer and Farming in Western Canada, Neuroepidemiology, 11, 267–276.
Mustard, C.; Derksen, S.; Berthelot, J.M.; Wolfson, M.; Roos, L.L.; and Carriere, K.S. ( 1995). Socioeconomic Gradients in Mortality and the Use of Health Care Services at Different Stages in the Life Course, Manitoba Centre for Health Policy and Evaluation, Department of Community Health Sciences, Faculty of Medicine, University of Manitoba.
Newcombe, H.B. ( 1994). Cohorts and Privacy, Cancer Causes and Control, 5, 287–292.
Newcombe, H.B. ( 1988). Handbook of Record Linkage: Methods for Health and Social Studies, Administration and Business, Oxford, U.K.: Oxford University Press.
Newcombe, H.B.; Kennedy, J.M.; Axford, S.J.; and James, A.P. ( 1959). Automatic Linkage of Vital Records, Science, 130, 3381, 954–959.
Starr, P. and Starr, S. ( 1995). Reinventing Vital Statistics, The Impact of Changes in Information Technology, Welfare Policy and Health Care, Public Health Reports, 110, 535–544.
Statistics Canada ( 1996). Generalized Record Linkage System Concepts, Draft version dated 1996 February 14, Research and General Systems Development Division, Ottawa, K1A 0T6.
Statistics Canada ( 1994). Symposium ‘94 Re-engineering for Statistical Agencies, Catalogue No. 11– 522E, Occasional—November 1994. Available from: Marketing Division, Sales and Service, Statistics Canada, Ottawa, K1A 0T6.
Toffler A. and Toffler H. ( 1995). Creating A New Generation—The Politics of the Third Wave , Atlanta: Turner Publishing, Inc.
United Nations ( 1993). Sources and Effects of Ionizing Radiation—United Nations Scientific Committee on the Effects of Atomic Radiation, New York: United Nations Publication, United Nations.
United Nations Department of International Economic and Social Affairs (UNDIESA) ( 1991). The Sex and Age Distribution of Population, ST/ESA/ SER. A/122, New York.
Winkler, W. and Scheuren, F. ( 1995). Linking Data to Create Information, Proceedings of Statistics Canada Symposium ‘95—From Data to Information—Methods and Systems, November 1995, Statistics Canada, Ottawa K1A 0T6 (in press).
Computational Disclosure Control for Medical Microdata: The Datafly System
Latanya Sweeney, Massachusetts Institute of Technology
Abstract
We present a computer program named Datafly that uses computational disclosure techniques to maintain anonymity in medical data by automatically generalizing, substituting and removing information as appropriate without losing many of the details found within the data. Decisions are made at the field and record level at the time of database access, so the approach can be used on the fly in role-based security within an institution, and in batch mode for exporting data from an institution. Often organizations release and receive medical data with all explicit identifiers, such as name, address, phone number, and social security number, removed in the incorrect belief that patient confidentiality is maintained because the resulting data look anonymous; however, we show that in most of these cases, the remaining data can be used to re-identify individuals by linking or matching the data to other databases or by looking at unique characteristics found in the fields and records of the database itself. When these less apparent aspects are taken into account, each released record can be made to ambiguously map to many people, providing a level of anonymity which the user determines.
Introduction
Sharing and disseminating electronic medical records while maintaining a commitment to patient confidentiality is one of the biggest challenges facing medical informatics and society at large. To the public, patient confidentiality implies that only people directly involved in their care will have access to their medical records and that these people will be bound by strict ethical and legal standards that prohibit further disclosure (Woodward, 1996). The public is not likely to accept that their records are kept “confidential” if large numbers of people have access to their contents.
On the other hand, analysis of the detailed information contained within electronic medical records promises many advantages to society, including improvements in medical care, reduced institution costs, the development of predictive and diagnostic support systems, and the integration of applicable data from multiple sources into a unified display for clinicians; but these benefits require sharing the contents of medical records with secondary viewers, such as researchers, economists, statisticians, administrators, consultants, and computer scientists, to name a few. The public would probably agree these secondary parties should know some of the information buried in the record, but such disclosure should not risk identifying patients.
In 1996, the National Association of Health Data Organizations (NAHDO) reported that 37 states had legislative mandates to gather hospital-level data. Last year, 17 of these states reported they had started collecting ambulatory care (outpatient) data from hospitals, physician offices, clinics, and so on. Table 1 contains a list of the fields of information which NAHDO recommends these states accumulate. Many of these states have subsequently given copies of collected data to researchers and sold copies to industry. Since the information has no explicit identifiers, such as name, address, phone number or social security number, confidentiality is incorrectly believed to be maintained.
Table 1. —Data Fields Recommended by NAHDO for State Collection of Ambulatory Data
|
Patient Number Patient ZIP Code Patient Racial Background Patient Birth Date Patient Gender Visit Date Principal Diagnosis Code (ICD9) Procedure Codes (up to 14) Physician ID# Physician ZIP code Total Charges |
In fairness, there are many sources of administrative billing records with fields of information similar to those listed in Table 1. Hospital administrators often pass medical records along in part to independent consultants and outside agencies. There are the records maintained by the insurance companies. Pharmaceutical companies run longitudinal studies on identified patients and providers. Local drug stores maintain individualized prescription records. The list is quite extensive. Clearly, we see the possible benefits from sharing information found within the medical record and within records of secondary sources; but on the other hand, we appreciate the need for doctor-patient confidentiality. The goal of this work is to provide tools for extracting needed information from medical records while maintaining a commitment to patient confidentiality. These same techniques are equally applicable to financial, demographic and educational microdata releases, as well.
Background
We begin by first stating our definitions of de-identified and anonymous data. In de-identified data, all explicit identifiers, such as social security number, name, address and phone number, are removed, generalized or replaced with a made-up alternative. De-identifying data does not guarantee that the result is anonymous however. The term anonymous implies that the data cannot be manipulated or linked to identify any individual. Even when information shared with secondary parties is de-identified, we will show it is often far from anonymous.
There are three major difficulties in providing anonymous data. One of the problems is that anonymity is in the eye of the beholder. For example, consider Table 2. If the contents of this table are a subset of an extremely large and diverse database then the three records listed in Table 2 may appear anonymous. Suppose the ZIP code 33171 primarily consists of a retirement community; then there are very few people of such a young age living there. Likewise, 02657 is the ZIP code for Provincetown, Massachusetts, in which we found about 5 black women living there year-round. The ZIP code 20612 may have only one Asian family. In these cases, information outside the data identifies the individuals.
Table 2. —De-identified Data that Are not Anonymous
|
ZIP Code |
Birthdate |
Gender |
Ethnicity |
|
33171 |
7/15/71 |
m |
Caucasian |
|
02657 |
2/18/73 |
f |
Black |
|
20612 |
3/12/75 |
m |
Asian |
Most towns and cities sell locally collected census data or voter registration lists that include the date of birth, name and address of each resident. This information can be linked to medical microdata that include a date of birth and ZIP code, even if the names, social security numbers and addresses of the patients are not present. Of course, local census data are usually not very accurate in college towns and areas that have a large transient community, but for much of the adult population in the United States, local census information can be used to re-identify de-identified microdata since other personal characteristics, such as gender, date of birth, and ZIP code, often combine uniquely to identify individuals.
The 1997 voting list for Cambridge, Massachusetts contains demographics on 54,805 voters. Of these, birth date alone can uniquely identify the name and address of 12% of the voters. We can identify 29% by just birth date and gender, 69% with only a birth date and a 5-digit ZIP code, and 97% (53,033 voters) when the full postal code and birth date are used. These values are listed in Table 3. Clearly, the risks of re-identifying data depend both on the content of the released data and on related information available to the recipient.
Table 3. —Uniqueness of Demographic Fields in Cambridge Voter List
|
Birth date alone |
12% |
|
birth date and gender |
29% |
|
birth date and 5-digit ZIP |
69% |
|
birth date and full postal code |
97% |
A second problem with producing anonymous data concerns unique and unusual information appearing within the data themselves. Instances of uniquely occurring characteristics found within the original data can be used by reporters, private investigators and others to discredit the anonymity of the released data even when these instances are not unique in the general population. Also, unusual cases are often unusual in other sources of data as well making them easier to identify. Consider the database shown in Table 4. It is not surprising that the social security number is uniquely identifying, or given the size of the database, that the birth date is also unique. To a lesser degree the ZIP codes in Table 4 identify individuals since they are almost unique for each record. Importantly, what may not have been known without close examination of the particulars of this database is that the designation of Asian as a race is uniquely identifying. During an interview, we could imagine that the janitor, for example, might recall an Asian patient whose last name was Chan and who worked as a stockbroker for ABC Investment since the patient had given the janitor some good investing tips.
Table 4. —Sample Database in which Asian is A Uniquely Identifying Characteristic
|
SSN |
Ethnicity |
Birth |
Sex |
ZIP |
|
819491049 |
Caucasian |
10/23/64 |
m |
02138 |
|
749201844 |
Caucasian |
03/15/65 |
m |
02139 |
|
819181496 |
Black |
09/20/65 |
m |
02141 |
|
859205893 |
Asian |
10/23/65 |
m |
02157 |
|
985820581 |
Black |
08/24/64 |
m |
02138 |
Any single uniquely occurring value or group of values can be used to identify an individual. Consider the medical records of a pediatric hospital in which only one patient is older than 45 years of age. Or, suppose a hospital's maternity records contained only one patient who gave birth to triplets. Knowledge of the uniqueness of this patient 's record may appear in many places including insurance claims, personal financial records, local census information, and insurance enrollment forms. Remember that the unique characteristic may be based on diagnosis, treatment, birth year, visit date, or some other little detail or combination of details available to the memory of a patient or a doctor, or knowledge about the database from some other source.
Measuring the degree of anonymity in released data poses a third problem when producing anonymous data for practical use. The Social Security Administration (SSA) releases public-use files based on national samples with small sampling fractions (usually less than 1 in 1,000); the files contain no geographic codes, or at most regional or size of place designators (Alexander et al., 1978). The SSA recognizes that data containing individuals with unique combinations of characteristics can be linked or matched with other data sources. So, the SSA's general rule is that any subset of the data that can be defined in terms of combinations of characteristics must contain at least 5 individuals. This notion of a minimal bin size, which reflects the smallest number of individuals matching the characteristics, is quite useful in providing a degree of anonymity within data. The larger the bin size, the more anonymous the data. As the bin size increases, the number of people to whom a record may refer also increases, thereby masking the identity of the actual person.
In medical databases, the minimum bin size should be much larger than the SSA guidelines suggest. Consider these three reasons: most medical databases are geographically located and so one can presume, for example, the ZIP codes of a hospital's patients; the fields in a medical database provide a tremendous amount of detail and any field can be a candidate for linking to other databases in an attempt to re-identify patients; and, most releases of medical data are not randomly sampled with small sampling fractions, but instead include most if not all of the database.
Determining the optimal bin size to ensure anonymity is tricky. It certainly depends on the frequencies of characteristics found within the data as well as within other sources for re-identification. In addition, the motivation and effort required to re-identify released data in cases where virtually all possible candidates can be identified must be considered. For example, if we release data that maps each record to 10 possible people and the 10 people can be identified, then all 10 candidates may even be contacted or visited in an effort to locate the actual person. Likewise, if the mapping is 1 in 100, all 100 could be phoned since visits may then be impractical, and in a mapping of 1 in 1000, a direct mail campaign could be employed. The amount of effort the recipient is willing to spend depends on their motivation. Some medical files are quite valuable, and valuable data will merit more effort. In these cases, the minimum bin size must be further increased or the sampling fraction reduced to render these efforts useless.
Of course, the expression of anonymity most semantically consistent with our intention is simply the probability of identifying a person given the released data and other possible sources. This conditional probability depends on frequencies of characteristics (bin sizes) found within the data and the outside world. Unfortunately, this probability is very difficult to compute without omniscience. In extremely large databases like that of SSA, the database itself can be used to compute frequencies of characteristics found in the general population since it contains almost all the general population; small, specialized databases, however, must estimate these values. In the next section, we will present a computer program that generalizes data based on bin sizes and estimates. Following that, we will report results using the program and discuss its limitations.
Methods
Earlier this year, Sweeney presented the Datafly System (1997) whose goal is to provide the most general information useful to the recipient. Datafly maintains anonymity in medical data by automatically aggregating, substituting and removing information as appropriate. Decisions are made at the field and record level at the time of database access, so the approach can be incorporated into role-based security within an institution as well as in exporting schemes for data leaving an institution. The end result is a subset of the original database that provides minimal linking and matching of data since each record matches as many people as the user had specified.
Diagram 1 provides a user-level overview of the Datafly System. The original database is shown on the left. A user requests specific fields and records, provides a profile of the person who is to receive the data, and requests a minimum level of anonymity. Datafly produces a resulting database whose information matches the anonymity level set by the user with respect to the recipient profile. Notice how the record containing the Asian entry was removed; social security numbers were automatically replaced with made-up alternatives; and birth dates were generalized to the year, and ZIP codes to the first three digits. In the next three paragraphs we examine the overall anonymity level and the profile of the recipient, both of which the user provides when requesting data.
Diagram 1. —The Input to the Datafly System is the Original Database and Some User Specifications, and the Output is a Database Whose Fields and Records Correspond to the Anonymity Level Specified by the User, in this Example, 0.7.
|
User |
-fields & records -recipient profile -anonymity 0.7 |
|||||||||
|
Original Medical Database |
Resulting Database, anonymity 0.7 |
|||||||||
|
SSN |
Race |
Birth |
Sex |
ZIP |
Datafly |
SSN |
Race |
Birth |
Sex |
ZIP |
|
819491049 |
Caucasian |
10/23/64 |
m |
02138 |
444444444 |
Caucasian |
1964 |
m |
02100 |
|
|
749201844 |
Caucasian |
03/15/65 |
m |
02139 |
555555555 |
Caucasian |
1965 |
m |
02100 |
|
|
819181496 |
Black |
09/20/65 |
m |
02141 |
333333333 |
Black |
1965 |
m |
02100 |
|
|
859205893 |
Asian |
10/23/65 |
m |
02157 |
222222222 |
Black |
1964 |
m |
02100 |
|
|
985820581 |
Black |
08/24/64 |
m |
02138 |
||||||
The overall anonymity level is a number between 0 and 1 that specifies the minimum bin size for every field. An anonymity level of 0 provides the original data, and a level of 1 forces Datafly to produce the most general data possible given the profile of the recipient. All other values of the overall anonymity level between 0 and 1 determine the minimum bin size b for each field. (The institution is responsible for mapping the anonymity level to actual bin sizes though Sweeney provides some guidelines.) Information within each field is generalized as needed to attain the minimum bin size; outliers, which are extreme values not typical of the rest of the data, may be removed. When we examine the resulting data, every value in each field will occur at least b times with the exception of one-to-one replacement values, as is the case with social security numbers.
Table 5 shows the relationship between bin sizes and selected anonymity levels using the Cambridge voters database. As A increased, the minimum bin size increased, and in order to achieve the minimal bin size requirement, values within the birth date field, for example, were re-coded as shown. Outliers were excluded from the released data and their corresponding percentages of N are noted. An anonymity level of 0.7, for example, required at least 383 occurrences of every value in each field. To accomplish this in the birth date field, dates were re-coded to reflect only the birth year. Even after generalizing over a 12 month window, the values of 8% of the voters still did not meet the requirement so these voters were dropped from the released data.
Table 5. —Anonymity Generalizations for Cambridge Voters Data with Corresponding Bin Sizes*
In addition to an overall anonymity level, the user also provides a profile of the person who receives the data by specifying for each field in the database whether the recipient could have or would use information external to the database that includes data within that field. That is, the user estimates on which fields the recipient might link outside knowledge. Thus each field has associated with it a profile value between 0 and 1, where 0 represents full trust of the recipient or no concern over the sensitivity of the information within the field, and 1 represents full distrust of the recipient or maximum concern over the sensitivity of the field's contents. The role of these profile values is to restore the effective bin size by forcing these fields to adhere to bin sizes larger than the overall anonymity level warranted. Semantically related sensitive fields, with the exception of one-to-one
replacement fields, are treated as a single concatenated field which must meet the minimum bin size, thereby thwarting linking attempts that use combinations of fields.
Consider the profiles of a doctor caring for a patient, a clinical researcher studying risk factors for heart disease and a health economist assessing the admitting patterns of physicians. Clearly, these profiles are all different. Their selection and specificity of fields are different; their sources of outside information on which they could link are different; and, their uses for the data are different. From publicly available birth certificate, driver license, and local census databases, the birth dates, ZIP codes and gender of individuals are commonly available along with their corresponding names and addresses; so these fields could easily be used for re-identification. Depending on the recipient, other fields may be even more useful, but we will limit our example to profiling these fields. If the recipient is the patient's caretaker within the institution, the patient has agreed to release this information to the care-taker, so the profile for these fields should be set to 0 to give the patient's caretaker full access to the original information. When researchers and administrators make requests that do not require the most specific form of the information as found originally within sensitive fields, the corresponding profile values for these fields should warrant a number as close to 1 as possible but not so much so that the resulting generalizations do not provide useful data to the recipient. But researchers or administrators bound by contractual and legal constraints that prohibit their linking of the data are trusted, so if they make a request that includes sensitive fields, the profile values would ensure that each sensitive field adheres only to the minimum bin size requirement. The goal is to provide the most general data that are acceptably specific to the recipient. Since the profile values are set independently for each field, particular fields that are important to the recipient can result in smaller bin sizes than other requested fields in an attempt to limit generalizing the data in those fields; a profile for data being released for public use, however, should be 1 for all sensitive fields to ensure maximum protection. The purpose of the profile is to quantify the specificity required in each field and to identify fields that are candidates for linking; and in so doing, the profile identifies the associated risk to patient confidentiality for each release of data.
Results
Numerous tests were conducted using the Datafly System to access a pediatric medical record system (Sweeney, 1997). Datafly processed all queries to the database over a spectrum of recipient profiles and anonymity levels to show that all fields in medical records can be meaningfully generalized as needed since any field can be a candidate for linking. Of course, which fields are most important to protect depends on the recipient. Diagnosis codes have generalizations using the International Classification of Disease (ICD-9) hierarchy. Geographic replacements for states or ZIP codes generalize to use regions and population size. Continuous variables, such as dollar amounts and clinical measurements, can be treated as categorical values; however, their replacements must be based on meaningful ranges in which to classify the values; of course this is only done in cases where generalizing these fields is necessary.
The Group Insurance Commission in Massachusetts (GIC) is responsible for purchasing insurance for state employees. They collected encounter-level de-identified data with more than 100 fields of information per encounter, including the fields in Table 1 for approximately 135,000 patients consisting of state employees and their families (Lasalandra, 1997). In a public hearing, GIC reported giving a copy of the data to a researcher, who in turn stated she did not need the full date of birth, just the birth year. The average bin size based only on birth date and gender for that population is 3, but had the researcher received only the year of birth in the birth date field, the average bin size based on birth year and gender would have increased to 1125 people. It is estimated that most of this data could be re-identified since collected fields also included residential ZIP codes and city, occupational department or agency, and provider information. Furnishing the most general information the recipient can use minimizes unnecessary risk to patient confidentiality.
Comparison to µ-ARGUS
In 1996, The European Union began funding an effort that involves statistical offices and universities from the Netherlands, Italy and the United Kingdom. The main objective of this project is to develop specialized software for disclosing public-use data such that the identity of any individual contained in the released data cannot be recognized. Statistics Netherlands has already produced, but has not yet released, a first version of a program named µ-Argus that seeks to accomplish this goal (Hundepool, et al., 1996). The µ-Argus program is considered by many as the official confidentiality software of the European community even though Statistics Netherlands admittedly considers this first version a rough draft. A presentation of the concepts on which µ-Argus is based can be found in Willenborg and De Waal (1996).
The program µ-Argus, like the Datafly System, makes decisions based on bin sizes, generalizes values within fields as needed, and removes extreme outlier information from the released data. The user provides an overall bin size and specifies which fields are sensitive by assigning a value between 0 and 3 to each field. The program then identifies rare and therefore unsafe combinations by testing 2- or 3-combinations across the fields noted by the user as being identifying. Unsafe combinations are eliminated by generalizing fields within the combination and by local cell suppression. Rather than removing entire records when one or more fields contain outlier information, as is done in the Datafly System, the µ-Argus System simply suppresses or blanks out the outlier values at the cell-level. The resulting data typically contain all the rows and columns of the original data though values may be missing in some cell locations.
In Table 6a there are many Caucasians and many females, but only one female Caucasian in the database. Tables 6b and 6c show the resulting databases when the Datafly System and the µ-Argus System were applied to this data. We will now step through how the µ-Argus program produced the results in Table 6c.
Table 6a. —There is Only One Caucasian Female, Even Though There are Many Females and Caucasians
|
SSN |
Ethnicity |
Birth |
Sex |
ZIP |
Problem |
|
819181496 |
Black |
09/20/65 |
m |
02141 |
shortness of breath |
|
195925972 |
Black |
02/14/65 |
m |
02141 |
chest pain |
|
902750852 |
Black |
10/23/65 |
f |
02138 |
hypertension |
|
985820581 |
Black |
08/24/65 |
f |
02138 |
hypertension |
|
209559459 |
Black |
11/07/64 |
f |
02138 |
obesity |
|
679392975 |
Black |
12/01/64 |
f |
02138 |
chest pain |
|
819491049 |
Caucasian |
10/23/64 |
m |
02138 |
chest pain |
|
749201844 |
Caucasian |
03/15/65 |
f |
02139 |
hypertension |
|
985302952 |
Caucasian |
08/13/64 |
m |
02139 |
obesity |
|
874593560 |
Caucasian |
05/05/64 |
m |
02139 |
shortness of breath |
|
703872052 |
Caucasian |
02/13/67 |
m |
02138 |
chest pain |
|
963963603 |
Caucasian |
03/21/67 |
m |
02138 |
chest pain |
Table 6b. —Results from Applying the Datafly System to the Data in Table 6a*
Table 6c. —Results from Applying the Approach of the µ-Argus System to the Data in Table 6a*
The first step is to check that each identifying field adheres to the minimum bin size. Then, pairwise combinations are examined for each pair that contains the “most identifying” field (in this case, SSN) and those that contain the “more identifying” fields (in this case, birth date, sex and ZIP). Finally, 3-combinations are examined that include the “most” and “more” identifying fields. Obviously, there are many possible ways to rate these identifying fields, and unfortunately different identification ratings yield different results. The ratings presented in this example produced the most secure result using the µ-Argus program though admittedly one may argue that too many specifics remain in the data for it to be released for public use.
The value of each combination is basically a bin, and the bins with occurrences less than the minimum required bin size are considered unique and termed outliers. Clearly for all combinations that include the SSN, all such combinations are unique. One value of each outlier combination must be suppressed. For optimal results, the µ-Argus program suppresses values which occur in multiple outliers where precedence is given to the value occurring most often. The final result is shown in Table 6c. The responsibility of when to generalize and when to suppress hes with the user. For this reason, the µ-Argus program operates in an interactive mode so the user can see the effect of generalizing and can then select to undo the step.
We will briefly compare the results of these two systems, but for a more in-depth discussion, see Sweeney (1997). The µ-Argus program checks at most 2- or 3-combinations of identifying fields, but not all 2- or 3-combinations are necessarily tested. Even if they were, there may exist unique combinations across 4 or more fields that would not be detected. For example, Table 6c still contains a unique record for a Caucasian male born in 1964 that lives in the 02138 ZIP code, since there are 4 characteristics that combine to make this record unique, not 2. Treating a subset of identifying fields as a single field that must adhere to the minimum bin size, as done in the Datafly System, appears to provide more secure releases ofnicrodata.
Discussion
The Datafly and µ-Argus systems illustrate that medical information can be generalized so that fields and combinations of fields adhere to a minimal bin size, and by so doing, confidentiality can be maintained. Using such schemes we can even provide anonymous data for public use. There are two drawbacks to these systems but these shortcomings may be counteracted by policy.
One concern with both µ-Argus and Datafly is the determination of the proper bin size and its corresponding measure of disclosure risk. There is no standard which can be applied to assure that the final results are adequate. What is customary is to measure risk against a specific compromising technique, such as linking to known databases, that we assume the recipient is using. Several researchers have proposed mathematical measures of the risk which compute the conditional probability of the linker's success (Duncan, et al., 1987).
A policy could be mandated that would require the producer of data released for public use to guarantee with a high degree of confidence that no individual within the data can be identified using demographic or semi-public information. Of course, guaranteeing anonymity in data requires a criterion against which to check resulting data and to locate sensitive values. If this is based only on the database itself, the minimum bin sizes and sampling fractions may be far from optimal and may not reflect the general population. Researchers have developed and tested several methods for estimating the percentage of unique values in the general population based on a smaller database (Skinner, et al., 1992). These methods are based on subsampling techniques and equivalence class structure. In the absence of these techniques, uniqueness in the population based on demographic fields can be determined using population registers that include patients from the database, such as local census data, voter registration lists, city directories, as well as information from motor vehicle agencies, tax as-
sessors and real estate agencies. To produce an anonymous database, a producer could use population registers to identify sensitive demographic values within a database, and thereby obtain a measure of risk for the release of the data.
The second drawback with the µ-Argus and Datafly systems concerns the dichotomy between researcher needs and disclosure risk. If data are explicitly identifiable, the public would expect patient consent to be required. If data are released for public use, then the producer should guarantee, with a high degree of confidence, that the identity of any individual cannot be determined using standard and predictable methods and reasonably available data. But when sensitive de-identified, but not necessarily anonymous, data are to be released, the likelihood that an effort will be made to re-identify an individual increases based on the needs of the recipient, so any such recipient has a trust relationship with society and the producer of the data. The recipient should therefore be held accountable.
The Datafly and µ-Argus systems quantify this trust by profiling the fields requested by the recipient. But recall that profiling requires guesswork in identifying fields on which the recipient could link. Suppose a profile is incorrect; that is, the producer misjudges which fields are sensitive for linking. In this case, these systems might release data that are less anonymous than what was required by the recipient, and as a result, individuals may be more easily identified. This risk cannot be perfectly resolved by the producer of the data since the producer cannot always know what resources the recipient holds. The obvious demographic fields, physician identifiers, and billing information fields can be consistently and reliably protected. However, there are too many sources of semi-public and private information such as pharmacy records, longitudinal studies, financial records, survey responses, occupational lists, and membership lists, to account a priori for all linking possibilities.
Table 7. —Contractual Requirements for Restricted-Use of Data Based on Federal Guidelines and the Datafly System
|
There must be a legitimate and important research or administrative purpose served by the release of the data. The recipient must identify and explain which fields in the database are needed for this purpose. |
|
What is needed is a contractual arrangement between the recipient and the producer to make the trust explicit and share the risk. Table 7 contains some guidelines that make it clear which fields need to be protected against linking since the recipient is required to provide such a list. Using this additional knowledge and the techniques presented in the Datafly System, the producer can best protect the anonymity of patients in data even when the data are more detailed than data for public-use. Since the harm to individuals can be extreme and irreparable and can occur without the individual's knowledge, the penalties for abuses must be stringent. Signifi-
cant sanctions or penalties for improper use or conduct should apply since remedy against abuse lies outside the Datafly System and resides in contracts, laws and policies.
Acknowledgments
The author acknowledges Beverly Woodward, Ph.D., for many discussions, and thanks Patrick Thompson, for editorial suggestions. The author also acknowledges the continued support of Henry Leitner and Harvard University DCE. This work has been supported by a Medical Informatics Training Grant (1 T15 LM07092) from the National Library of Medicine.
References
Alexander, L. and Jabine, T. ( 1978). Access to Social Security Microdata Files for Research and Statistical Purposes, Social Security Bulletin, (41), 8.
Duncan, G. and Lambert, D. ( 1987). The Risk of Disclosure for Microdata, Proceedings of the Bureau of the Census Third Annual Research Conference, Washington, D.C.: Bureau of the Census.
Hundepool, A. and Willenborg, L. ( 1996). µ- and t-ARGUS: Software for Statistical Disclosure Control, Third International Seminar on Statistical Confidentiality, Bled.
Lasalandra, M. ( 1997). Panel Told Releases of Medical Records Hurt Privacy, Boston Herald, Boston, (35).
National Association of Health Data Organizations. ( 1996). A Guide to State-Level Ambulatory Care Data Collection Activities, Falls Church, VA.
Skinner, C. and Holmes, D. ( 1992). Modeling Population Uniqueness, Proceedings of the International Seminar on Statistical Confidentiality, International Statistical Institute, 175–199.
Sweeney, L. ( 1997). Guaranteeing Anonymity When Sharing Medical Data, The Datafly System , MIT Artificial Intelligence Laboratory Working Paper, Cambridge, 344.
Willenborg, L. and De Waal, T. ( 1996). Statistical Disclosure Control in Practice, New York: Springer-Verlag.
Woodward, B. ( 1996). Patient Privacy in a Computerized World, 1997 Medical and Health Annual 1997, Chicago: Encyclopedia Britannica, Inc., 256–259.


























































































































