
11
The Wired Laboratory
David R. McLaughlin
Eastman Kodak Company
This presentation describes how Kodak has used computers and information technology to enhance operations in its research laboratories. This has been an effort to create an electronic or computerized laboratory, and to deliver information at the scientist's fingertips. Some perspective is given on what is meant by the "wired laboratory" and why a commercial enterprise would be interested in having one. It includes areas of impact, examples from our operations, and some speculation about the future.
This discussion is presented from the perspective of an analytical division, within a materials research organization, supporting a commercial business. The business environment requires that a profit be made. This is done by selling more products, by making them at decreasing cost, and by generating new products that sell—more efficiently than the competition. The materials research organization supports the business by developing new materials that can be used to produce new or better products more efficiently. The analytical division contributes to this efficiency by providing measurements and information that are key to understanding and controlling material properties and manufacturing processes. The examples used in this discussion originate from a spectroscopic chemical structure characterization laboratory. The concepts, however, apply equally well for other analytical and chemical information.
The drive to be efficient in all aspects of business is intense. The wired laboratory allows research to be more efficient in the generation and use of information and knowledge. It is these gains in efficiency that have made this work worthwhile in a business producing high-technology chemical-based products.
How Have Advances in Computing Technology Helped with Efficiency in the Analytical Chemistry Laboratory?
Advances in computing technology have helped with efficiency in the analytical chemistry laboratory in four main ways. The first is through automation and simplification of analytical and synthetic tasks. This area includes the use of computer-controlled robots and measurement systems and can
improve repeatability and increased utilization of equipment. There are numerous examples of applications and vendors of combinatorial testing and synthesis; these are not reviewed here.
The second area is in information and knowledge management. Combinatorial methods produce large amounts of data. Managing the data and extracting useful information and knowledge from it has been made feasible through advances in computing technology. Even without the use of combinatorial methods, good information and knowledge management is valuable. Information provides value over time. Previous analyses can help with current problems, and historical information can help with the design of new materials and products. Making this information available in a usable and timely manner is an important benefit of a wired laboratory.
The third area is that of generating and maintaining data in electronic (digital) form. While this may seem like an obvious requirement for modern information management, it is a valuable first step on its own. Having data in electronic form greatly reduces the barriers to its use. Much of the time involved in applying modeling and chemometrics—the analysis of analytical data to extract more information—is consumed in collating and formatting data. Simply collecting and saving the data in electronic form allows more time to be devoted to developing more sophisticated calculations.
The fourth area is data analysis and chemometrics. One of the general efficiency trade-offs in routine analytical measurements is between sample preparation and data analysis and interpretation. Analytical techniques requiring less sample preparation often produce larger, more complicated data sets that increase interpretation time. The phenomenal increases in computing power and capacity have helped to reduce that time. In addition, the chemometrics techniques available today yield information not otherwise obtainable. The direct exponential curve resolution algorithm (DECRA) for separating mixture spectra is an example.1
Examples From a Wired Laboratory
Quantum—Model of an Integrated Spectroscopy Information System
In the late 1970s, the molecular spectroscopy laboratory at Kodak began to utilize computing technology to improve the efficiency and quality of structure elucidation using nuclear magnetic resonance (NMR) and infrared (IR), mass (MS), and ultraviolet and visible (UV/Vis) spectroscopy data. The ultimate aim was to automate the analysis of routine samples completely. At that time, our expert spectroscopists would receive a number of difficult analysis problems, but would also receive many samples that were routine characterization problems. For example, did the chemist successfully synthesize the material he wanted? We recognized that we could use computers and information systems to make our operation more efficient by automating routine analyses and by providing tools to aid with difficult analyses.
The components of the system that resulted from this project are illustrated in Figure 11.1. The complete system, called QUANTUM, combines spectral and structural analysis software with a sample management system (SoftLog) and a spectral database (SDM).
Historically, the system began with the research and development of analysis tools. As John Pople mentioned earlier, in Order to test our success, we needed to have data. Reference spectra associated with chemical structures were needed to develop and test analysis software for predicting spectra, given the structure, or the structure, given a spectrum. Databases of literature spectra were purchased and put into the system, but they were not adequate. The majority of compounds made at Kodak have never
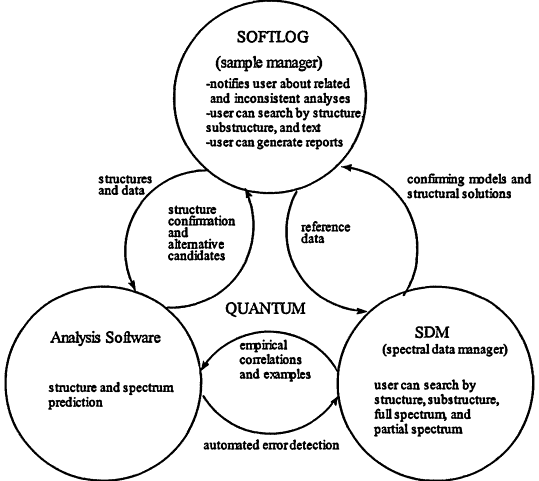
Figure 11.1
Components of an integrated spectroscopy information management environment.
appeared in the public literature. To test the analysis routines, it was necessary to gather information on Kodak-specific compounds. To gather that knowledge efficiently, the structure and associated spectra need to be readily accessible to the computer. This information was also needed for the analysis software to successfully eliminate routine work. It is not practical to enter that information into the computer just to get a routine analysis answer. It needs to be there for some other reason.
Integrated sample management software (SoftLog) that incorporated chemical structures and spectral data was developed to meet this need. These systems are now commonly known as LIMS (laboratory information management systems).2 SoftLog incorporated several important features not typically available in LIMS. These include full and substructure searches, spectral display and search, easy
|
2 |
LIMSource, LIMSource: the best site for LIMS and lab data management system info, <http://www.limsource.com/> (1998). |
incorporation of results into the reference database, and a logical interface to fully automated analysis software. In addition, the user is automatically informed of previous sample or material analyses, inconsistent results, reference data, and related compounds such as impurities, models, by-products, or precursors. The notification of other analyses of the same material included data from spectroscopy laboratories dispersed across the entire corporation. This was particularly useful, because it made analysis information initially obtained in a research environment available to analytical laboratories supporting development.
There is a lot of interaction between the components of QUANTUM. The analysis software is used to check the quality of data going into the reference database and provide predictions for current analyses. The reference database provides models for current analyses and the data necessary to develop the analysis software. SoftLog provided the primary daily interface for users and means for gathering information in electronic form. This is also the part of the system that has changed the most with changes in user interface and desktop technology.
This integrated model of a spectroscopy information system is useful. Even though QUANTUM is 15 years old, the underlying systems are still in use. The greatest use is now through a Netscape browser using the corporate intranet.
Walk-up Spectroscopy Laboratory—Instruments Online
As mentioned above, the initial goal was to make the work of spectroscopists more efficient. Part of that goal was to free them from spending time analyzing simple or routine samples. From the company's perspective of efficiency, the real goal was to reduce the amount of time between the chemist's initial awareness that he needed an analysis and when he got the data or analytical result. The pursuit of this goal has led us to develop walk-up laboratories where the chemists interact directly with automated analytical instruments.
The walk-up laboratories provide rapid access to high-quality, state-of-the-art analytical instrumentation via a one-stop structure characterization area staffed by experts. The laboratory staff maintains the quality of the instrumentation and the integrity of both the methodology and the data. They also work to develop new analytical techniques and methods to the point where they are robust, rapid, and automated enough to function in a walk-up environment.
One last goal of the walk-up laboratory is to provide access to the analytical data and information through a simple, user-friendly, at-your-desk interface. This interface should allow all scientists involved in the chemical commercialization process access to all analytical data generated throughout the company.
The first technique we provided in walk-up mode was NMR. To use the system, chemists enter the laboratory, place their NMR tube in an empty slot for the sample-loading robot, enter some information identifying themselves and their sample on a computer, and select their choice of experiments. A label is then printed, which is placed on a board next to the slot containing their sample. This label is used to identify the samples after the experiments are completed. The NMR spectra are usually available over the network, automatically phased and transformed, by the time the chemists walk back to their office. If needed, the raw data is available for reprocessing.
The NMR facility offers a 300-MHz Varian spectrometer with a 4-nucleus probe and experiments including 1H,13C,19F,31P, DEPT, COSY, and HETCOR. The autosampler will hold 50 samples that are processed in a prioritized order to minimize the turnaround time for most users. The facility is available 24 hour/day, 7 days/week, with an average analysis time of 10 minutes. All of the data are saved on
servers and are available remotely. Spectral predictions are available using both Kodak and Advanced Chemistry Development software.
These NMR experiments provide information on the chemical environments surrounding individual atoms in a molecule. They can also provide connectivity information such as the number of attached protons or, from the two-dimensional experiments, what protons and carbons are next to each other. This information allows a chemist to confirm the structure of most molecules. Chemists recently hired by Kodak have all used this kind of information themselves in graduate school and are very comfortable with it. They have also remarked, “If only I had had something like this when I was in graduate school, it would have saved me so much time.” That, of course, was our objective.
In addition to NMR, the walk-up laboratory provides access to advanced MS, chromatography, and IR techniques. The MS system provides a 3,000-atomic-mass-unit range, atmospheric pressure chemical ionization (APcI) and electrospray ionization techniques, and loop injection, or short column, separation. Data output includes averaged, background-subtracted spectra for both positive and negative ions and a theoretical isotope pattern display based on the chemist's proposed formula. This provides a molecular weight and formula confirmation in an average of 3 minutes.
The chromatography system produces integrated chromatograms at five wavelengths with area percentages and a diode-array spectrum (160 to 600 nm) for each peak. The average analysis time for this technique is down to 15 minutes. One of these instruments will soon be linked to a mass spectrometer system. When this is complete, a single 10to 15-minute experiment will provide concentration, spectral, and molecular-weight information on mixtures.
The walk-up facility in place at Kodak is a nice example of how efficiency can be improved. Turnaround time for sample analysis has improved by 7 to 10 times, or probably more from the chemist's perspective. This kind of routine analytical analysis is no longer a bottleneck. In fact, chemists often use this facility rather than running thin-layer chromatography plates because it is just as fast and produces more useful information presented in a readily interpretable form. These efficiency gains have been accomplished by using automation to reduce analysis times and by placing the analysis in the hands of the people who need the results. It is successful because it is managed by analytical personnel who maintain quality, provide training and consultation for the users, and are rewarded for improving the efficiency of others. It provides additional value because the information is saved electronically and made available to all who need it.
Improvements in both analytical and computer technology have been critical factors in making the walk-up laboratory possible. The computer and networking technologies provide a robust interface between the users and expensive analytical equipment. They are used for data acquisition, processing, storage, retrieval, and presentation. Analytical and computing technologies have combined to make a system that is robust and automated enough for routine use and that has significant business value.
Electronic Information and Knowledge Management
Information is data in context. Information has value, but only if it can be readily combined with other information. Many science-based companies have been generating information in compartmentalized laboratories in ways that make it difficult to access. Paper- and people-based methods of information management delay a scientist's ability to use this knowledge at a pace consistent with the business need for cycle time improvement and increased efficiency. This is why electronic access to research information and analytical data is necessary.
One area where this efficiency is important is in the movement of new chemicals from research through scale-up to manufacturing. As a chemical moves from inception to final product, fitness-for-
use specifications need to be established, and regulatory information must be filed with governments. Government filings require gathering all the compositional and safety information we know about a material. Knowledge of this information for related materials at the time of new research can be used in designing safer materials initially, rather than disqualifying them late in the commercialization process. When fitness-for-use specifications are established, all of the by-products that may be produced are considered. The spectra of many of these are identified initially in research samples. When manufacturing problems occur, quite often the problem is related to a minor component that has been identified somewhere earlier in the commercialization process. Having available a trail of information on that material saves a tremendous amount of time in an environment where time has a significant financial impact.
Information and knowledge management helps scientists learn from the previous experiences of others across the corporation. This becomes increasingly difficult as organizations and their collections of proprietary knowledge grow large and research occurs at worldwide locations. Without electronic access to it, efforts to use information would be very inefficient. An important area where the need is to access the data, rather than the final reports and conclusions, is modeling. Modeling to develop new and better materials is an important part of increasing research efficiency, but it requires electronic access to structures and property data.
Electronic access to analytical data also helps us to perform analyses the least number of times, maximizing the effects of previous results. Multiple scientists working on the same, or different, projects can make use of the results of the same tests. Data collected for one project may be of use years later on a new project. Compounds that were not suitable for one application may be good on another or may be good data points for modeling on other projects.
WIMS—Web-based Information Management System
The types of analytical information needed in an analytical information management system include project and sample information, chemical structures and reactions, reports and conclusions, and spectral and image data. The ideal system would provide an intuitive, easy-to-use graphical user interface that is platform independent (PC, Mac, or UNIX). It would be capable of easily displaying and manipulating images (spectra, structures, and figures) along with all other analytical information, would allow easy downloading of data for local reprocessing, and would easily link or cross-link to existing proprietary and legacy databases. In addition, it should be based on technology that is widely accepted and not unique to our own environment, is dynamic and continually developed for improved capability by many other people, is low in cost for software development and maintenance, and provides worldwide access. About 4 years ago, we realized that "the Web is the way" to meet these needs.
Based on the knowledge gained from the SoftLog sample management system, the new Web-based Information Management System, WIMS, was developed for spectroscopy.3 WIMS has since been expanded to provide extensive sample tracking and data management across the analytical community. Significant advantages have been gained through data searching and allowing our clients to examine spectral information, reports (as text, Word, Excel, or HTML documents), and other analytical data directly. As a sample manager, WIMS is used to log samples in and out with descriptive fields customized by technologies, to attach structures, reports, and spectra directly to a sample or group of

Figure 11.2
Typical WIMS sample view page for NMR.
samples, and to calculate throughput statistics. The database can be searched by any combination of sample fields, technologies, and reports. It also allows automated reports to be generated and e-mailed to clients. The commercial Web-based S3LIMS product from Advanced Chemistry Development was inspired by these original concepts.4
Figures 11.2, 11.3, and 11.4 provide some examples of WIMS displays. A typical display for a sample in the NMR technology area is shown in Figure 11.2. In this view, the descriptive sample fields for this technology are displayed along with most of the important functional links, like uploading and viewing reports. An important feature of this view worth highlighting is the lack of clutter. An attempt has been made to fill the screen with as much information as is useful without wasting space that causes users to scroll in their browsers. Interesting graphics that do not add utility may be neat initially, but quickly become annoying to users.
Other links on the sample view page include links to display associated spectra (Figure 11.3) and associated structures (Figure 11.4). Following the associated spectral link retrieves the NMR spectrum from an NMR data server and displays it along with the acquisition parameters. The display can be zoomed and printed. The data are also available for local reprocessing if needed.
|
4 |
Advanced Chemistry Development, S3LIMS: spectral laboratory information management system, <http://www.acdlabs.com/ slims/> (1998). |
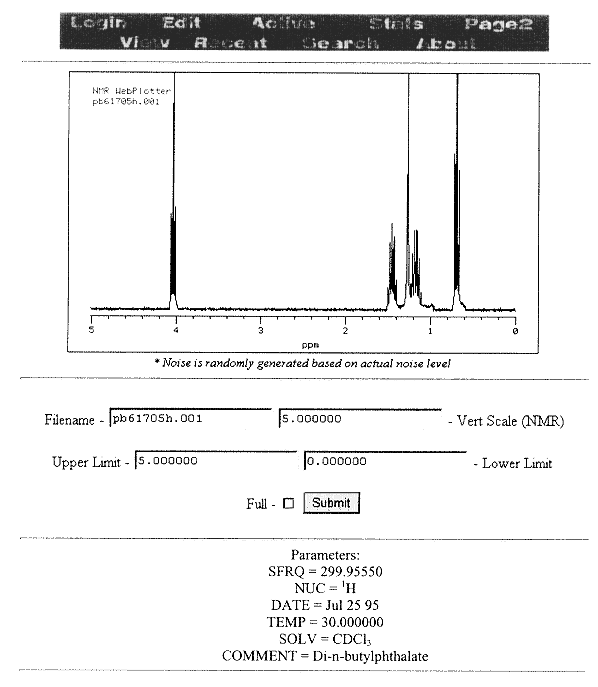
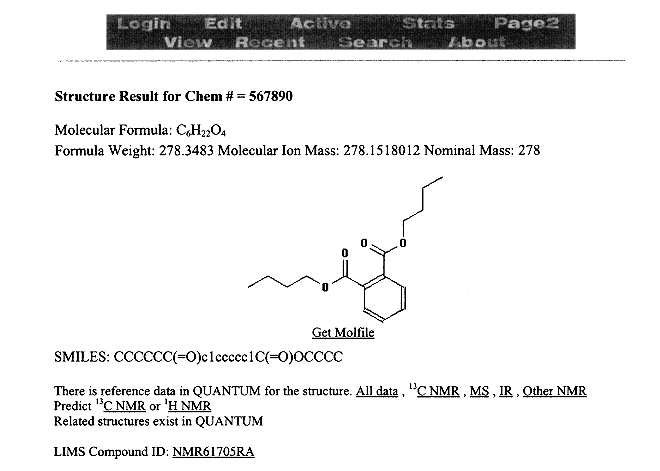
Figure 11.4
Typical WIMS display of a chemical structure associated with a WIMS sample, showing links to additional information.
The associated-structures link retrieves the structures from the QUANTUM structure database and displays them with links to other information resources. Typical links allow for display of spectra from our reference databases, predictions of chemical shifts, and links to other WIMS samples. In addition, the structure can be downloaded and used in a local drawing or modeling package. This capability was developed by building a Web wrapper around existing software. It makes this information available to a much larger collection of less frequent users.
Changes in computing technology have had a significant impact on sample management. The most notable one is the advent of Web technology and the realization that the Web is the way for user interfaces. The use of Web interfaces is cascading through all of the chemical property databases in the company. Modeling tools are also becoming available on the Web. Sets of compounds may be submitted to a calculation server to have parameters and estimated properties determined.
Simple interfaces achieve the greatest use. The QUANTUM system illustrated in Figure 11.1 was originally used primarily by experts. When a Web interface was added, usage increased by approxi-
mately 50 times. The Web interface has put valuable information within easy access of many more users. This provides real payback to the company.
Another point to learn from this experience is the value of information servers working as peers. The WIMS system involves several servers, each providing a service that is linked together via Web technology to provide the illusion of one system to users. A chemical structure server put up on the Web provides a simple mechanism for other developers to include structures on their Web pages. This is an important point, because it has been very difficult to acquire commercial software that will operate in this fashion. Most information system vendors develop software from the perspective that they are the center of the universe. All interactions happen initially from within their software, which is always in control. Their software will not operate as a peer.
The Electronic Laboratory Notebook
A model of the data-to-information pyramid is shown in Figure 11.5. A major research program may involve multiple projects, each with several experiments that may produce several samples requiring many tests that can produce lots of results. The amount of data present at a given level increases toward the bottom of the pyramid. Consequently, the bottom area has been first to make use of
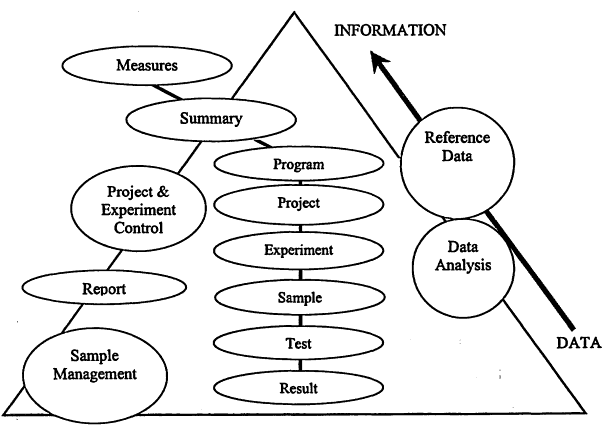
Figure 11.5
The data-to-information pyramid.
computing technology to help with its management. So far, the examples presented here have focused on results, tests, samples, and their associated information management and data analysis tools.
Over the past 2 years, work has progressed at the Kodak research facilities in England to apply computing technology to the next levels up in the diagram. Specifically, an electronic laboratory notebook has been developed to assist with the management of experiments, projects, and programs. Above this level are program measures and summaries useful for research management. These have not yet been addressed, as the traditional methods of providing summary reports and presentations will likely be adequate for several more years.
The electronic laboratory notebook (ELN) at Kodak is implemented as a collection of Lotus Notes databases and applications that enable the electronic storage and retrieval of experimental aims, methods, results, and conclusions. A few years ago, Kodak decided to switch to Lotus Notes for e-mail, making it a reasonable choice for this development. The ELN provides an environment that facilitates the sharing of information across research by means of controlled database access, searches, and hotlinks. It supports the principle of entering new data once and only once.
Before there was an electronic sample management system, chemists would submit analysis requests by completing paper forms. With the advent of an electronic system, some chemists would enter the information into the analytical data system and some would still submit paper requests that an analytical technician would enter. The paper request forms for spectroscopic analysis included space for a chemical reaction to be entered. This is useful for identifying impurities in structure characterization problems, but there was never enough added value to enter it into the analytical systems. Now the entire reaction and experimental conditions are maintained in the ELN and are available to the analyst through a hypertext link. The information is captured and maintained at its original source in a way that is useful to the originating scientists. Now that it is in electronic form, the information can be leveraged throughout the corporation.
There are four main Lotus Notes databases underlying the ELN. They are used to store experiments, projects and programs, reports, and summaries. Each database has templates for creating entries. Summaries can be generated automatically by tools in the ELN or entered by the scientists as part of their experiment. It is expected that this database of summaries will provide an important means for searching the ELAN.
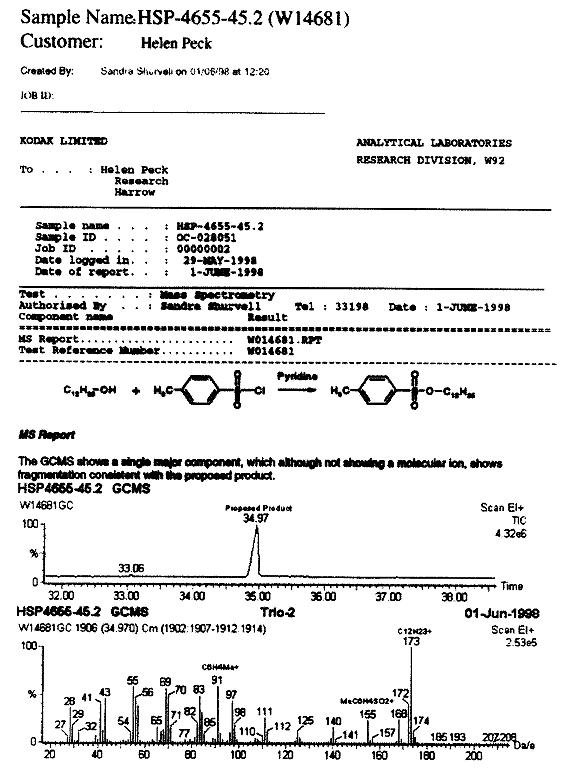
An example experiment from the Kodak ELN is shown in Figure 11.6. This is a page from a typical organic chemist's notebook. It shows the aim, chemical reaction, experimental details, results, summaries, and security. The security functions allow the author selective control over who can read and modify the document. There are also areas for entering or attaching any information or file the chemist wishes—in this case she added information about the starting materials. It is probably worth noting that this page closely resembles what the organic chemist would have entered into her hard-copy notebook.
Notice that the chemist performed a number of walk-up tests herself and included the results. There was some question about the mass spectroscopy results, and an expert analysis was requested. The result of that is entered in the ELN as "1 component with correct fragmentation for product" with a bookmark to the complete report, which is shown in Figure 11.7. The full report shows the reaction from the ELN, the spectra, and the comments from the expert analyst who adjusted the spectroscopic experimental conditions to obtain the result.
The electronic laboratory notebook is envisioned to be the tool of choice for scientists to log experimental aims, results, and conclusions. It is expected to enable knowledge sharing while maintaining security, allowing greater collaboration between researchers and increased productivity. There are good reasons to believe that it will be successful. First, computing and computing technology have progressed to a point where a successful ELN can finally be delivered. Second, and most important, the

ELN prototype was built at the request of chemists. Once the prototype was in place, 80 to 90 percent felt it was good enough to use and would recommend its use to their colleagues. This desire is widely shared among the research scientists. It is a reflection of the strong drive for continually improving research efficiency and the generation of more knowledge per unit time.
The Future
Information Management
In the wired laboratory of the future, all scientists will use an intelligent electronic laboratory notebook linked to all data-generating equipment. This will automatically provide all relevant information to the scientist and capture all of the knowledge that is generated. It will allow research to progress using sophisticated experimental design and modeling. Most materials will be modeled before they are made. In the intelligent electronic laboratory notebook, objects will be recognized as they are entered and linked to underlying databases automatically. The environment will be built with integrated links between systems communicating as peers. Much of this vision will be become reality over the next 5 to 10 years. Although electronic laboratory notebooks have been discussed and prototyped in the literature for some 10 years, there is now end-user pull for them, and computer hardware and software technology can now support them. They will drive much of the electronic laboratory of the future.
Success, however, will require the development of better search systems. Knowledge is information in context. Searches through large information resources must provide good contextual searching and answer set refinement. Without such tools, so many false positives or irrelevant answers are returned that the results are useless to the researcher. The summary database in the ELN may help with this problem. It is also an area of active research and development driven by the need for Web search engines.
Information systems will also benefit from better input devices. They will make it easier for scientists to interact with computer systems, particularly when generating information. These devices will be easily carded into the laboratory environment and written or drawn on, like pages in a paper notebook. Interfaces will allow chemists to draw their chemical structures on a sheet of paper and have them upload directly into the computer with a connection table that is searchable. There are already products on the market that are consistent with this direction. One example is the Cross notepad, 5 which allows information to be written on a portable tablet and uploaded as an image. It comes with software that can be trained to convert neatly written words and phrases to text.
The continued move to information systems will result in a nearly paperless laboratory. It will no longer be necessary to print reports so that they can be mailed or archived as they are today. This prediction applies to the laboratory and not to the office environment. People will still print information until another medium is found that is just as convenient and cost-effective. The need to archive information in printed form will be replaced by digital means.
Some obstacles exist for information management. One is the need for the current rate of increase in computer processing and storage capacity to continue or accelerate. The information systems will need to store staggering amounts of data. Perhaps a more limiting obstacle is the lack of good commercial software. Software must be available at reasonable cost and quality that is simple to support and maintain and is not wasteful of hardware resources. Software from multiple sources will need to
|
5 |
A.T. Cross Company, Cross Pen Computing Group: The Pad, <http://www.cross-pcg.com/crosspad/> (1998). |
cooperate in a peer-to-peer manner (standards may help with this). Better methods for dealing with software development are needed to improve quality and reliability and to deal with disruptive changes in technology. Unfortunately, the realities of the current software market do not appear to reward quality adequately. Differentiation and time to market seem to drive the greatest short-term profits.
Data Analysis and Instrumentation
Analytical technology in combination with data-analysis techniques will continue to advance, reducing the time required for sample preparation and data interpretation. In some cases, current analyses will be replaced by drastically different technologies that, perhaps after more calculation, yield the same or greater informational value. There will be a strong drive toward small-scale automated syntheses and testing. There will also be more applications of on-line and in-line sensing and control, with analytical instrumentation connected to networks and controlled remotely. These applications will extend the concepts of speed and robustness demonstrated in the walk-up analytical laboratory toward smaller size and price.
Success in these areas will likely involve greater use of embedded systems and plug-and-work components. Proposed extensions to JavaTM may prove useful in this arena.6 Increasingly, instrumentation will be controlled through Web interfaces. Several companies are beginning to produce low-cost boxes that can be used to connect almost any device to the Web. One example is advertised as the world's smallest Web server.7 The complete Web server is less than 4 inches square and is configured to provide real-time weather data from Cambridge, Massachusetts. It is designed to be simple and low cost. These devices may be excellent alternatives to PCs or UNIX boxes for connecting instruments to the network, particularly from a support perspective.
As more information becomes available only in electronic form and computerized processes become a critical part of business processes, dependence on the network increases. A robust, high-bandwidth network becomes a requirement. This may be more a cost issue than a technology issue.
Virtual reality techniques have been studied for decades. They provide excellent mechanisms for people to understand and interact with visual information. Particularly useful applications of virtual reality have occurred for fighter pilots and people with disabilities. Virtual reality is a tool that uses the senses to transmit a lot of information to the brain quickly in the form that it normally processes. It is meant to help unlock the power of the human mind. Interfaces common in the laboratory today are very poor by comparison. Widespread use of virtual reality is limited by our ability to collect appropriate information to display in this mode.
Tandem techniques that produce multidimensional data are now common in analytical chemistry laboratories. They are useful because they generally use a small amount of sample, require minimal sample preparation, and have relatively fast analysis times. At the same time, they generally produce large amounts of data that often require relatively long interpretation times. Techniques that produce information in three-dimensional space, such as 3D NMR, are easily understood when viewed through virtual reality techniques.
At present, it is not clear that virtual reality is necessarily the appropriate tool for understanding much of the multidimensional analytical data produced today. This is unfortunate, because computer
|
6 |
Sun Microsystems, Inc., JiniTM technology lets you network anything, anytime, anywhere, <http://java.sun.com/products/jini/> (1998). |
|
7 |
Phar Lap Software Inc., The World's Smallest Web Server, <http://smallest.pharlap.com/> (1998); Dr. Dobb's Journal, October, 40-46 (1998). |
monitors are also inadequate for displaying this data. Spectral interpretation often involves the fine detail spread across a wide, high-resolution x-axis. A computer monitor allows only a small portion of the detail to be viewed at one time.
There are some areas where scientists would like to “see” results to understand them. These include seeing how molecules are interacting with each other or flowing through processing equipment. The challenge to the analytical community is to devise real-time measurements that, when displayed with virtual reality, will enable this understanding.
Summary
There is a strong business need to generate new products with ever increasing efficiency. Automation of the data acquisition and information management functions of the laboratory can increase the efficiency with which the knowledge generated by research is applied to new products. This arises through increased ease of use, accuracy, and quality of information and knowledge made possible, in part, by the advancements in computers and computing technology.
As systems are developed, it is important to remember to keep them simple. They must be simple to build, simple to use, and simple to maintain. Software technology changes relatively rapidly. Keeping it simple helps incorporate new technology faster, deal with obsolescence, and deliver functionality to users faster. Rapid delivery of simple systems returns the greatest value.
The Web is the way for user interfaces, as long as the Web belongs to everybody. The peer-to-peer model of the Web is an excellent way to build sophisticated information systems from simple components.
Good-quality, reliable software available at reasonable cost is one of the most critical needs for the future.
Contributors
Many people have worked on the wired laboratory at Kodak, mostly part time. They have contributed to the development, philosophy, recognition, and acceptance of the value of working electronically. They are as follows: Brian Adams, Christine Alvarez, Brian Antalek, Gustav Apai, Todd Beverly, Derek Birch, Caroline D. Bradley, Doug Brown, Don Bushman, Juris L. Ekmanis, Nancy Ferris, Tammi Flannery, John Flynn, Susan M. Geer, Joan M. Hessenauer, J. Michael Hewitt, Peter Horne, Andrew J. Hoteling, Thomas C. Jackson, Emily Jones, Thomas F. Kaltenbach, Philip LaFleur, Mary Lee Lasota, William C. Lenhart, Ilia Levi, Thomas Marchincin, William McKenna, David McLaughlin, Frank M. Michaels, Stephen D. Miller, Wendy F. Miller, Peter Monacelli, Dominic J. Motyl, Vi Neri, Ian Newington, William F. Nichols, Ed Osborne, Alan Payne, Julia Pich, Bob Price, Ted Sears, Craig Shelley, John P. Spoonhower, John Trigg, John Paul Twist, Jon Waterhouse, Luann Weinstein, Antony Williams, Willem Windig, Barry Wythoff, and Agyare Yeboah.
Discussion
David Smith, DuPont: David, I am very interested in how this walk-up lab is located with respect to the community that it is trying to serve. I have worked at Kodak Park, so I have an idea of how large it is. It is as large as the Experimental Station, larger in fact, and frankly, I have a hard time imagining that a chemist is going to walk from one end of the Experimental Station to a walk-up laboratory to get a sample back in 10 minutes.
So, the question is, Do you have multiple instantiations of this laboratory in various parts of Kodak Park, or is it just located in one place with a high-density of chemists in the area?
David McLaughlin: The walk-up facilities are located in areas where there are high densities of people that need to use it. So, for example, in the main research complex where a lot of synthetic organic chemists are located, there is a concentration of analytical tools for structural characterization. In Kodak Park where the scale-up and delivery to manufacturing operation occur, there is, also, a lot of synthetic work that goes on. So, we have a very similar facility, but with techniques that are suited specifically to that environment. In yet another set of buildings there is testing of emulsions and photographic properties.
So, the walk-up facilities are distributed where the need is. When we first put up a walk-up facility there was only an NMR. We put it on the second floor. There was another NMR on the third floor. The chemists on the sixth floor would come and use the one in the walk-up facility on the second floor. The ones on the third floor would generally use the one on the third floor, even though it was an old instrument and gave poorer-quality results. They used it because it was convenient. Convenience is a big part of it. It is similar to the ease of use I described for the Web interface. If you create an easy, simple-to-use interface, then all of a sudden lots of chemists will begin using it. So, you do need to locate the walk-up facilities close to where they are needed.

















