
12
Chemical Data in the "Internet Age"
W. Gary Mallard
National Institute of Standards and Technology
Introduction
It is difficult to determine whether discussion of the Internet as a force shaping the way we work is growing faster than the growth of the Internet itself. However, within chemistry and chemical engineering the use of the Internet as a resource for communication is exploding. Scientific publication on the Internet is just beginning. The use of the Internet as an information source in science is also still in its infancy. This paper discusses the changes that are driving the growing use of the Internet and what needs to be done to ensure that the new resources emerging fulfill the needs of the chemical community. Three factors can be identified as the primary drivers:
|
1. |
Reduction in traditional data resources. The loss of funding for a number of activities that provided information to chemists—cuts in library budgets, reductions in central research laboratories by industries, changing funding priorities at federal agencies—have all led to a reduction in the methods for finding needed data. Many libraries have had to cut out information specialists just when the increasing costs of journals have forced users to spend more time finding data. It is no longer possible in a number of large chemical companies to call on a department that specializes in physical property measurement and estimation. It is difficult to find funding for detailed critical evaluation projects, especially in the area of thermodynamics, thermophysical properties, or kinetics. |
|
2. |
Demand for faster access to data. The need to obtain more information faster is not new, but the ability of computer databases to supply that information in new ways has driven a desire for ever more information. There is a growing sense that information should be available instantly, even if the real need for it is far more long term. In addition, the use of new drag discovery techniques and the development of substructure searching have also fueled demands for more information about a larger set of compounds. |
|
3. |
Increase in need for data for modeling and simulation. The use of modeling has dramatically increased the need for data and, as is discussed below, has changed the nature of the data needed. Simulation of combustion, the atmosphere, urban air-sheds, and chemical reactors has required extensive data on kinetics, transport properties, and photophysics. |
Data Needs
The type of data needed in chemistry is changing. The traditional data requirements were for limited sets of data that were used to create correlations, to provide estimates, to test theories. This was a “retail” version of data usage. In industry, government, and academia, this work was typically done by individuals who had a strong background in the underlying physical principles embodied in the data. Errors in transcription were clear, and bad data usually stood out because data were used typically in sets and plotted against other related data. The data correlations were often extended to domains where measurement was either difficult or expensive. Predictions were made from the correlations but again, the background of the practitioners was such that the fundamental physical principles and "reasonableness" of the data were uppermost in their minds. The errors were mostly well appreciated, because the underlying science was closely coupled to the data analysis. The use of the resulting data was related to the confidence that the data were correct or at least that a firm understanding of the bounds of the uncertainty existed.
The use of modeling and simulation has placed new demands on data resources. These result in part from the different and often more complex systems that are being modeled, but also in part from the new requirements for complete data sets. The need for completeness comes about from the very nature of modern modeling programs, which take all aspects of the physics and chemistry into account—at least in principle. Since all physical and chemical processes are included, it is necessary to have data for the parameters that are used in describing the individual subprocesses of the model: diffusion coefficients, heat capacities, heats of formation, rates of reaction, and so on. Because it is essential that some value be placed in the model, there is a need to supply values for parameters for which there are little or no experimental data. This has given rise to a host of estimations and a greater need to determine the role of uncertainty in the modeling process.
For many of the unknown parameters, it is possible to show that any physically reasonable value will be acceptable since the underlying process is not a determinative of the outcome of the model. Thus, if one is in need of a diffusion coefficient for a radical, one can take the limits of the H atom (for which there are experimental data) and some molecule with a molecular weight twice that of the radical. Barring very unusual effects of polarity, the actual value of the diffusion constant will be in that range. By looking at the effect of the high and low values, it becomes possible to set limits on how much of an effect the high level of uncertainty will have on the final result. However, if the same calculation is to be applied to an ion, a completely different set of approximations must be used. The number and scope of the processes modeled in a modern simulation are so large that it is unlikely that anyone has the scientific background to ensure that all of the estimates are "reasonable." This is especially true since the definition of reasonable is a strong function of the problem: what is a small effect in one system may be large in another because of the difference in the process controlling the outcome of the model. For the most part we do not have modeling code that determines the "reasonableness" of the values used as input, nor do we have data resources that can provide physical limits for otherwise unknown data.
Types of Data Resources
To satisfy the needs discussed above will require changes in the way that data resources are managed. Three broad categories of data resources are discussed to illustrate the problems in meeting these needs.
1. Archive. The archive is a set of numeric data of specific properties for specific chemical compounds with full literature references. The data should be clearly identified as to property (heat of
combustion per mole or per gram), including phase (liquid, solid, gas, amorphous), conditions (pressure, temperature, etc.), experimental technique, and ancillary data used to derive the property. Chemical compounds should be identified by structures, Chemical Abstracts Service registry numbers or Beilstein numbers, formulas, and names—including synonyms, common names, and trade names.
In addition, the archive should have removed any obvious errors in data transcription in the original text and adjusted the data for changes in ancillary information (for example, the definition of the calorie, or changes in the heat of formation of a by-product in the reaction).
Wherever possible, automatic comparisons should be made to further detect errors. This may even extend to automatic comparison of the data with estimation programs. The obvious errors revealed by automatic checking should be corrected. However, archive data are not presumed to have been examined in detail as to their accuracy. The uncertainty assigned to each data element in the archive is presumed to be the value assigned by the original author. The archive is not presumed to have extended this definition.
While this represents an ideal minimum, it is never realized fully.
2. Review. The review is expected to meet all of the requirements of the archive, but also to have been examined by a qualified scientist. Where appropriate, an attempt must have been made to reconcile data from different experimental methods, as well as from estimations and from high-quality calculations if they exist. Specific experimental and computational results should have been merged to provide an uncertainty assignment that reflects the range of values in which consensus scientific judgment expects the value to fall. For the common case where only a single experimental determination is available, it may be necessary to examine that datum in light of other related compounds. In many cases the experimental data can only be compared to estimated values.
3. Critical evaluation. Critically evaluated data should meet all of the criteria set for the review and archive data elements, but the evaluation should also place the data in the context of other related data. Thus, to evaluate the data for reaction of the OH radical with butane critically, it is essential to examine the data not only for the reaction of OH + butane, but also for OH + propane, OH + pentane, and more broadly OH + hydrocarbons. To do such a critical evaluation clearly requires a thorough review to have been made of each of the components. For some experimental data it is possible to use thermodynamic arguments to ensure the overall consistency of the data. Using the kinetics example above, if an independent measure of the free energy of reaction and the reverse rate constant are available, then there is a constraint on the forward rate. The evaluation must then examine the quality of these additional components also. As might be expected, the number of data sets that can be regarded as critically reviewed is very small. There will always be significant fractions of the data that cannot be critically reviewed owing to lack of experiments.
In the "retail" model of data usage, the difference between these types of data resources is not as important as it is when the "user" of the data is a modeling program. Even when there is direct personal use by a scientist, a lack of specific technical background to which the data relate may cause many of the same problems as would occur with direct computer usage. In both of these cases, the absence of an informed user can cause serious problems.
Only when there has been a critical evaluation with a clear indication of the uncertainty of the values reported can data be used in a fully automated fashion. Even in this case there is an obligation by the user to respect the uncertainty values and to assess how they affect the final output of the model. For complex models with high levels of uncertainty in a number of critical parameters, the computational cost of such an assessment can be high, but the data resource has provided the information needed to solve the problem.
Given the limits on critical evaluation, it is fortunate that for many problems a set of values that are of only "review" quality will suffice. In this case there is a single value for the parameter and a single uncertainty. The overall quality cannot be assumed to be as high, but in many cases it is sufficient. Again, the model must make use of the uncertainty.
The use of archive data in automatic systems is problematic. Often there are multiple values for a single parameter, and the reported uncertainties do not encompass all the data. In other cases the archive will contain data that upon examination will be viewed as inaccurate. There is no simple automatic mode to deal with the range of problems that will be encountered here, although it can be sufficient to take data with multiple values and use the average with an appropriately large uncertainty. The success of such an approach will depend on the problem.
Problems in Providing Data
The problem of providing good data for modern computer models can be broken down into three broad classes:
1. Incomplete data sets. As noted above, a model must have data for each physical property, rate constant, and thermodynamic parameter within that model. There are broad classes of data for which there are simply no experimental data. For example, there are very few data for any radical diffusion constants, entropy, or heat capacity. Good estimates can be made, but experimental data are very scarce. In many cases the use of values essentially equal to zero will cause the model to fail, so some physically reasonable data must be included. For many properties this requirement is addressed by a combination of data for related properties plus models. This is the approach taken by the Design Institute for Physical Property Data (DIPPR) Committee of the American Institute of Chemical Engineers (AIChE), which has created an extensive set of data for use by the chemical process industry. A similar approach has been taken by NASA in stratospheric modeling. In general, this method has not been used outside very specialized areas.
2. Uncertain data. The reported uncertainty in most data is, at best, the experimental variation found. It is rare for any attempt to be made to assess systematic uncertainty in a measurement. Data in older literature can often be "rescued" by a better understanding of some systematic error that was not appreciated by the original investigator. While it is tempting to ignore data with identifiable errors, if the error is systematic and can be corrected for, the data may be useful. In many cases they are the only data available for the property of that compound. By eliminating the systematic error and at the same time recognizing that the correction probably carries its own uncertainty, it is possible to provide data that are useful. This is an important role for reviews of data.
One problem in some data sets is the uncertainty of the chemical identity. As noted above, there is a need for absolute chemical identity. This need is often not met in smaller data collections.
In addition, the failure to account for changes in auxiliary data can lead to serious errors in the reported data that are not present in the experiment. As an example, much of the data on fluorine-containing compounds in the literature before 1970 used an incorrect value for the enthalpy of formation of CF4 to derive the enthalpy of formation for other compounds. Simply providing the original enthalpy of formation from the literature will give a very incorrect sense of the state of the data. In this case providing the correct number from the original paper is not sufficient.
3. Errors in data compilation. Extracting the literature into electronic format is in itself an error-prone project: digits are inverted, signs are ignored, states are not defined. The goal of the compilation into electronic format is to add value to the data; these kinds of errors, for the most part, do the reverse.
Data Resources Currently Available
Three of the relatively few extensive electronic databases generally available today are discussed. Currently, there are no resources that will meet all the needs pointed out above. Examination of the resources that are available illustrates both the strengths of these resources and the unmet needs.
All resources are available via Internet connections, and one is free. The data sets are the Beilstein database, currently owned by Elsevier; the DIPPR 801 project of the AIChE, currently at Brigham Young University, but during most of its development at Pennsylvania State University; and the National Institute of Standards and Technology (NIST) Chemistry WebBook.1 These are very different efforts in size and history. Beilstein goes back into the 19th century and until recently was partially funded by the German government. The DIPPR project started in 1980 as a response to the need for high-quality data in the chemical process industry, and is funded by a consortium of members from industry and government. The NIST-funded Chemistry WebBook has been in existence for only 3 years and was developed specifically to deliver data over the Internet.
Beilstein Database
Beilstein is by far the largest of the three databases. Table 12.1 shows several of the types of queries to the Beilstein database and the number of molecules in the hit set. The list illustrates the origin of the Beilstein database as a database of organic chemistry. The properties useful in organic chemistry are well covered; for example, the fraction of molecules for which there are reaction data is quite high. Table 12.1 also gives some sense of the sheer scope of the database: there are more than 7 million distinct chemical species. Beilstein differentiates between optical isomers if there are data on the distinct isomers, so the number is higher than it would otherwise be. This again reflects the organic chemistry origins of the database. For physical property data—for example, the enthalpy of formation—the amount of data is not all that great. However, this may well represent all of the enthalpy of formation data for organic compounds.
The Beilstein database is strictly archival; no attempt is made to do any evaluation and the review literature is not covered. The database is excellent in terms of its chemical identity. In fact, of the three databases discussed here, it is by far the best. Because of its size it will have the most errors—no matter how carefully a database is created, as it becomes larger the number of errors grows.
There are some problems in Beilstein that are unique. As an example, two enthalpy-of-formation values from the same reference are given for 3-oxa-tricyclo[3.2.1.02.4]octane (Figure 12.1) as 53,900 J/mol and 98,000 J/mol. There is no indication that the first value is the enthalpy of formation for the gas phase and the second the value for the liquid phase. In order to determine what the values refer to, it is necessary either to observe that the enthalpy of vaporization is the difference between these values, or to go to the original paper. Given completely electronic access to the data, the information about the enthalpy of vaporization may not have been accessed. In addition, both values are sign reversed. The problem of sign reversal is fairly common in the Beilstein electronic database and probably arises from the convention in much of the thermochemical data literature of giving a table of values as -ΔHfor rather than showing the sign in the table.
|
1 |
For more information on the Beilstein database, see <http://www.beilstein.com/products/xfire/>. A subset of the DIPPR database can be accessed at <http://dippr.byu.edu/>. The NIST WebBook can be found at <http://webbook.nist.gov>. |
TABLE 12.1 Molecules in the Beilstein Database, by Query Type
|
Type of Data As Defined by Beilstein Query |
Number of Molecules |
|
Enthalpy of formation (Hfor) |
7300 |
|
Entropy data (all) |
3655 |
|
Heat capacity (cp) |
1946 |
|
Boiling point at pressure (bp.p) |
642000 |
|
Viscosity (bulk, kinematic, dynamic) |
5000 |
|
NMR spectra for1H |
32000 |
|
Reaction (all) |
4,600,000 |
|
Total number of chemical species |
7,300,000 |
Another example, which in many respects represents a more serious problem, is the entry for hexamethyldisiloxane. This gives two values for its enthalpy of formation, -815,800 and 815,400 J/mol, which are reported to be measured at 25 and 298.2 °C, respectively. These data are referenced to the same authors within a 3-year period. Again, there are a number of mistakes obvious to the expert, and in this case even to the non-expert, but the information is not usable in a system seeking to obtain high-quality information automatically.
The final example of problems in Beilstein is one that is inherent in the way that data are taken for the database. In this case the literature is cited correctly: there are two experimental determinations of the enthalpy of formation of 1,2-difluoro-1,1,2,2-tetrachloroethane: -891.788 kJ/mol and -928 kJ/mol from 1954 and 1982, respectively. However, both determinations are based on different enthalpy of formation data for CF4. When the experimental values are corrected for the currently accepted CODATA value for the enthalpy of formation data for CF4, the results are -925.5 kJ/mol and -937 kJ/mol. The agreement between the two experiments is quite good, but without the adjustment this would not be seen.
The first two examples are criticisms of the data quality in Beilstein. The last is not, but it is a warning to anyone who uses the data to proceed cautiously. It is not clear to what extent the problems illustrated above are general in the database. Used as a resource to find available literature data it is invaluable, but it cannot be used uncritically as a direct resource for numerical values.
Figure 12.1
3-oxa-tricyclooctane.
DIPPR Project
The DIPPR Project 801 of the AIChE was designed from the start to provide complete physical property data for the molecules in the database. For each of the more than 1,700 molecules, the available experimental data listed in Box 12.1 are collected and evaluated. For properties for which experimental data do not exist, the DIPPR project estimates the data and, if necessary, their temperature dependence.
The data in the DIPPR database is ideal for use in modeling. It is reviewed, and a recommended value or equation as a function of temperature is given for each property for each molecule. There are some problems in that the estimations are not as clearly indicated as might be desired, but this is being corrected. The uncertainty values are all expressed in terms of ranges and not as absolute values. For some properties this is reasonable, but for thermochemical data, it is essential to know the uncertainty directly.
The DIPPR database illustrates the difficulty of providing high-quality complete data. The level and quality of the effort in the DIPPR project have been very high and the project has been going on for more than 17 years with fairly extensive resources, and yet only 1,700 compounds (all stable species) have been added to the database. For the molecules and properties in the database, DIPPR is usually a first choice.
|
Box 12.1 Data Evaluated in the DIPPR Project
|
||||||||||||||||||||||||||||||||||||||
The NIST Chemistry WebBook
The WebBook is a hybrid database. It is not complete (in the DIPPR sense of having all properties for all molecules in the database), yet is not just an archive (in the sense that reviews from the literature are included, as are reviews and evaluations done just for the WebBook). Table 12.2 gives some sense of the data in the three most recent releases of the WebBook.
Phase-change and thermochemical data have multiple data types. Data are both single points and temperature-dependent equations. As can be seen, the data for any given molecule are likely to be incomplete. The kinds of data are greater than in the case of the DIPPR database (not all data types are shown in Table 12.2) but are not currently as extensive as in the Beilstein database. DIPPR does have more extensive coverage of transport properties.
The WebBook makes use of the review literature in order to allow for later corrections arising from changes in auxiliary values—corrections from the authors and evaluations of the relative uncertainty of the various experimental methods to be incorporated. However, a large portion of the WebBook's data is archival, even if corrected for these changes.
The existence of a large set of data with extensive indexing has allowed the first steps toward evaluation to be made. A list of enthalpies of formation for carbonyl compounds from the WebBook (Figure 12.2) serves as an example of the kinds of problems that are revealed in the data.
In each of these cases, the data are as they appear in the literature and are fully corrected for auxiliary data. The first value for each molecule is from a single author, the remaining values from a number of authors. A pattern of higher stability appears to be measured by one author. How is this to be evaluated? The issue is that there is no simple way to evaluate this son of problem. The level of uncertainty here, which is on the border of what would be resolvable using the best of quantum calculations, may be significant in some applications. Moreover, there are other cases where this author has published values for which there are no other data. How is this to be evaluated as well? While these questions can be answered by expert evaluation of the experimental methods, the differences between experimental methods and high-level calculations, this level of evaluation cannot be done automatically,
TABLE 12.2. Attributes of the NIST Chemistry WebBook
|
|
Version |
||
|
Data Type |
3 |
4 |
5 |
|
Gas-Phase Ion-Energetics Data |
14,200 |
14,300 |
14,300 |
|
Gas-Phase Thermochemical Data |
2,800 |
5,800 |
6,100 |
|
Condensed-Phase Thermochemical Data |
4,600 |
5,300 |
5,500 |
|
Phase-Change Thermochemical Data |
8,800 |
9,400 |
9,500 |
|
Reaction Thermodynamic Data |
7,400 |
8,700 |
9,400 |
|
IR Spectra |
5,200 |
5,200 |
5,200 |
|
Mass Spectra |
8,300 |
10,600 |
10,600 |
|
Fluid Property Data Sets |
13 |
16 |
16 |
|
Vibrational/Electronic Spectra & Energy Levels |
— |
2,600 |
3,300 |
|
Spectroscopic Constants of Diatomic Molecules |
— |
600 |
600 |
|
Total Species with Data |
27,300 |
31,600 |
32,400 |
|
Release Date |
Aug-97 |
Mar-98 |
Nov-98 |
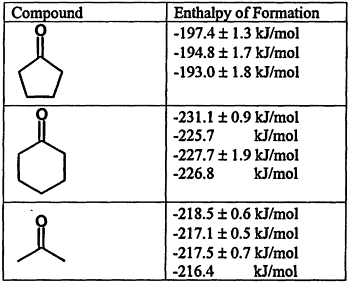
Figure 12.2.
Enthalpies of formation for selected carbonyl compounds from the NIST Chemistry WebBook.
so what data are to be used by a modeling code accessing this data? Averaged values may well be skewed because there is a systematic error in one of the measurements. The answer lies in part with the level of effort indicated by the DIPPR data project. If these data are important, then the effort needs to be made. In part the answer lies in some assessment of how accurate data need to be. The uncertainty given above is still small compared to that for many enthalpy-of-formation values. These may be "good enough," and an automatic average with high uncertainty will be all that is needed. However, the degree to which one can model, predict, and control a system sets many of the economic costs for a system. In general the cost of uncertainty in chemical operations is strongly nonlinear, and small improvements in the prediction and control can yield large improvements in costs.
User Demand for Data
One point needs to be made: the need for even less-than-perfect data is very large. The usage of the NIST WebBook in the third release is given in Figure 12.3. Access by a wide variety of users is running at over 5,000 hits per week, with between 40 and 50 percent of the users returning in any given week. In the 220 days that this edition was out, over 120,000 distinct Internet addresses (IP addresses) used the WebBook. Usage clearly tracks the academic calendar of the Northern Hemisphere. Usage over Christmas and the New Year is very low, but even so is more than 1,000 hits per week. Summer usage is lower than at other times, but still is more than 3,000 hits per week.
Comparable data were not available to the author for either the DIPPR or the Beilstein databases. Both have some charges associated with them, whereas the WebBook is currently free.
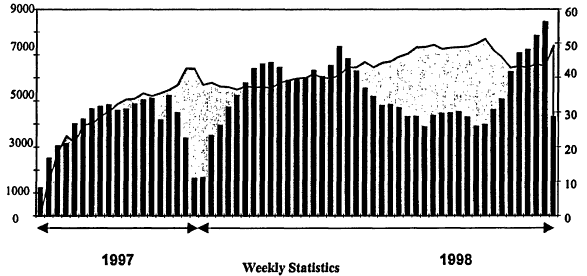
Figure 12.3
Usage of NIST WebBook in the third release. Number of users (left, bars) and percentage of returning users (right).
What Is Needed
The demand for data is clearly large, as can be seen by the usage for resources such as the WebBook. The WebBook, DIPPR, and Beilstein are currently not equipped to handle direct requests from modeling programs. The need for communication standards among modeling programs and the databases that they rely on has not been touched on here, but the absence of agreed-upon query structure that would make it reasonable for a database provider to support direct access by modeling programs is not the real limiting step for future use of the data. The limiting factor will be the lack of resources to produce high-quality evaluated data that can be used with confidence.
Building data collections, reviewing and evaluating the data, and distributing the resulting information are not free, but if done well, yield a very large return on investment. A high-quality data collection can save individual researchers thousands of hours collectively. In addition, the evaluation can reduce the uncertainty in data with the corresponding economic benefit of higher-quality modeling and prediction. It is essential that the data provided be subjected to high levels of quality control, that the uncertainty be evident, and that the modeling programs make use of the uncertainty.
Venues such as the WebBook can make some of these data more readily available. The WebBook has been actively seeking researchers who have developed extensive sets of data that they have at least reviewed, if not critically evaluated. These sets are being made available on the WebBook with full credit going to the reviewer. In many cases the archival journals are not interested in this work; often even if it is published, it is lost. Much of the older literature is also being actively evaluated; the authors and copyright holders are being sought for permission to add the data to the WebBook. At a minimum this kind of effort will bring more attention to data that are often valuable but difficult to find. It is hoped that bringing this kind of data to a wider audience will stimulate more such reviews and realization of the need to update some of the older reviews. The ultimate goal is to have electronically accessible all
numerical data for which there are good experimental data and to extend the data with high-quality predictions of known uncertainty where there are no experimental data.
Discussion
Allen Bard, University of Texas: Who pays for this now? The government is paying for this and will continue to do so?
Gary Mallard: At least for the foreseeable future the answer is yes. If you go to the WebBook you will find a little blurb there that says, "NIST reserves the right to charge for this in the future." We have tossed around the idea of having of a $50-a-year usage fee. I don't know whether we are ever going to do that. I think that the usage is general enough that we can justify it as a reasonable use of the taxpayers' money, but whether that continues in eras of tightening budgets is a question I cannot answer. But now we are doing it with internal funds.
Sam Kounaves, Tufts University: Were these actual unique users, or return users, or just hits?
Gary Mallard: No, they are not hits. That is a very deceptive way of determining use. These are unique IP addresses, although we don't know the people behind them. In fact, we know there are more users than this because many commercial suppliers come through single addresses. The big companies all come through gateways. So, we don't know how many total users there are. We just know that there are 110,000 distinct IP addresses, and of those, on any given week about 45 to 50 percent of them have been there before.
Sam Kounaves: Have you ever considered advertising to have people come back on this Web like having an instrument company and some chemical company to support this sort of stuff?
Gary Mallard: It is a little tricky if you are the government. They think they pay taxes, and they do.
David Smith, DuPont: I have a suggestion for some of my friends in the audience. For those of you who are teaching thermodynamics, perhaps it would be a good exercise to have your students calculate the thermodynamic consistency of these articles for some of the compounds that you are interested in. A couple of hundred a year would probably be a worthwhile effort.
Gary Mallard: In the very early days when we had fewer users, there was a sudden spike. Whenever we see a sudden spike we wonder what is going on, and this spike was coming from someplace in Canada. It is pretty easy to trace these things back on the Web, and it turned out that in fact somebody had done just that—had told people to look up a certain number of compounds on the Web and get those data and put them into a report. I don't remember the details anymore. So for about 4 or 5 days, we had a lot of organic chemistry students at one university using this site, and at the time it made a spike. Today you wouldn't even see it.
David Dixon, Pacific Northwest National Laboratory: What is the structure of the database, and what were the manpower requirements to do the electronic version as compared to the manpower already working on the standard printed versions from which much of the electronic versions are derived?
Gary Mallard: The resources needed to do the data evaluation and collection do not really change, whether you are putting data out in an electronic format or in printed format, and so that number is constant and really represents whatever we can find at NIST. In a lot of cases, we have been taking data that we have had for a long time in printed format and just putting it in electronic format. So that is relatively inexpensive and fairly cost effective because it really just takes somebody with good data entry skills to put it in a spreadsheet, and we do a little processing on it.
One person works full time on the database itself. There is a Java applet that displays spectra that can be enlarged. The address is <webbook.nist.gov> and I would urge all of you to go there and try it. A lot of what that one person does is deal with issues on the Web, and we work very hard to make sure that if we display a Greek character it displays on a Sun system, on a Macintosh, and on Windows, and that is a non-trivial exercise. A lot of time is spent in making sure that this is a high-quality product that looks the same on everybody's browser, that the Java applet works the same on everybody's browser, and none of that is easy. So, in that sense there is one person devoted full time just to keeping this thing up on the Web.
The structure of the database is basically a file that is indexed under C-Tree, an available piece of software that is all C code and has been known to compile on more platforms than anything else known to man. We store everything as ASCII, because we feel that when you deal with things like the number of significant figures, you would like to capture that information and not lose it, and so we have some fairly sophisticated algorithms for looking at the number of significant figures. Also, when we convert from kilocalories, which is perhaps what the data was originally entered in, into kilojoules we try to retain all of that information and not have six significant figures of zeroes which aren't significant, but the structure of the database itself is basically just ASCII.
Jack Kay, Drexel University: Are the JANAF thermochemical tables included in this database?
Gary Mallard: Yes, not as tables but as equations in the new format, the Shomate coefficients where there is a 1/T term in the last term.
Robert Cordova, Elf Atochem: I was wondering about the relationship between this and database 19 for structures and properties.
Gary Mallard: What I didn't show you on that form was that in the very beginning we actually had some estimates in the database, and those estimates came out of some of the kind of code that was in the database for structures and properties. We removed all of the estimates. The WebBook really is a kind of evolutionary extension of the structures and properties database. There are a lot more thermochemical data in the WebBook, but the estimation tool that was a part of structures and properties is not there. I think eventually we will put it back, but we just haven't had the resources to do it yet.












