
1
The Accelerated Strategic Computing Initiative
Paul Messina
California Institute of Technology and Department of Energy
While the increase in computing power over the past 50 years has been staggering, the scientific community will require unprecedented computer speeds as well as massive memory and disk storage to address the pressing problems that the nation will face in the 21st century. One such problem is ensuring the safety and reliability of the nation's nuclear arsenal while fully adhering to the Comprehensive Test Ban Treaty. To address this problem, the U.S. Department of Energy (DOE) established the Accelerated Strategic Computing Initiative (ASCI) in 1996.1 The goal of ASCI is to simulate the results of new weapons designs as well as the effects of aging on existing and new designs, all in the absence of additional data from underground nuclear tests. This is a daunting challenge and requires simulation capabilities that far surpass those available today.
The goal of ASCI, however, is not a pipe dream. With funding from ASCI, the computer industry has already installed three computer systems, one at Sandia National Laboratories (built by Intel), one at Los Alamos National Laboratory (LANL) (an SGI-Cray computer), and another at Lawrence Livermore National Laboratory (LLNL) (an IBM computer), that can sustain more than 1 teraflops on real applications. At the time they were installed, each of these computers was as much as 20 times more powerful than those at the National Science Foundation (NSF) Supercomputer Centers (the Partnerships for Advanced Computational Infrastructure), the National Energy Research Supercomputing Center, and other laboratories. And this is only the beginning. By 2002, the computer industry will deliver a system 10 times more powerful than these two systems and, in between, another computer will be delivered that has three times the power of the LANL/LLNL computers. By the year 2004—only 5 years from now—computers capable of 100 trillion operations per second will be available.
Who needs this much computing power? ASCI clearly does, but the other presentations at this workshop indicate that many chemical applications could also make use of this capability. Similar
computational needs can be put forward by climate and weather modelers, computational materials scientists, and biologists, for example. In the summer of 1998, NSF and DOE sponsored the "National Workshop on Advanced Scientific Computing," which described the opportunities that this level of computing power would create for the research programs funded by NSF and DOE.2 The good news is that, as a result of the enormous investment that ASCI is making in these machines, it is likely that computers of this power will become available to the general scientific community, and at substantially reduced cost.
Asci's Need for Advanced Simulation Capability
The ASCI program is a direct result of President Clinton's vision, a vision shared by Congress as well, that the United States can ensure the safety and reliability of its nuclear stockpile without additional nuclear testing. DOE's ASCI program has been designed to create the leading-edge computational modeling and simulation capabilities that are needed to shift from a nuclear test-based approach to a computational simulation-based approach. There is some urgency to putting this simulation capability in place as the nuclear arsenal is getting older day by day—the last nuclear test was carried out in 1992, so by the year 2004, 12 years will have passed since the last test. In addition, nuclear weapons are designed for a given lifetime. Over 50 percent of the weapons in the U.S. arsenal will be beyond their design lifetime by the year 2004, and there is very little experience in aging beyond the expected design life of nuclear weapons. Finally, the individuals who have expertise in nuclear testing are getting older, and, by the year 2004, about 50 percent of the personnel with first-hand test experience will have left the laboratories. The year 2004 is a watershed year for DOE's defense programs.
The Challenges
The Accelerated Strategic Computing Initiative is an applications-driven effort with a goal to develop reliable computational models of the physical and chemical processes involved in the design, manufacture, and degradation of nuclear weapons. Based on detailed discussions with scientists and engineers with expertise in weapons design, manufacturing, and aging and in computational physics and chemistry, a goal of simulating full-system, three-dimensional nuclear burn and safety simulation processes by the year 2004 was established. A number of intermediate, applications-based milestones were identified to mark the progress from our current simulation capabilities to full-system simulation capabilities. Before developing the three-dimensional burn code, codes must be developed to simulate casting, microstructures, aging of materials, crash fire safety, forging, welding of microstructures, and so on.
We cannot meet the above simulation needs unless computing capability progresses along with the simulation capability. To this end, the first ASCI computing system, an Intel system ("Option Red"), was installed at Sandia National Laboratories in Albuquerque in 1997. Sandia and the University of New Mexico wrote the operating system for this machine and, by 1996, it had achieved more than 1 trillion arithmetic operations per second (teraflops) while still at the factory. It also had over one-half terabyte of memory, the largest of any computing system to date. Next, "Option Blue" resulted in the acquisition of two machines: an IBM system at LLNL ("Blue Pacific") and an SGI/Cray system at LANL ("Blue Mountain"). The IBM system achieved its milestone of over 1 teraflops on an application
on September 22, 1998, an event that was announced by Vice President Gore just one week before this workshop. The “Blue Mountain” machine was delivered in October 1998 and became operational in mid-November.
This is the current status of the ASCI computing systems, but the story does not stop here. As follow-on to the Livermore acquisition, the same IBM contract that led to the 3-teraflops system will be used to procure a 10-teraflops/5-terabyte (memory) system in mid-2000. A 30+ teraflops machine is scheduled for delivery in June of the year 2001, and a 100-teraflops machine is to be delivered in 2004. The above computer schedule is tied directly to the scientific and engineering application needs through detailed estimates of the computing power, memory, and disk storage that the applications will need at any given time.
To follow the pace outlined above, it is necessary to substantially accelerate what the U.S. computer industry would otherwise do. This requires a partnership between ASCI, the applications scientists and engineers, and the U.S. computer industry. In order to produce a computer capable of 100 teraflops by the year 2004, ASCI settled on the strategy of using the products that industry was already concentrating on—relatively small, commodity-priced building blocks—and assembling those components into big systems with the needed computing power. This process seems more efficient because smaller building blocks present fewer problems from an innovation standpoint, there is a much larger commercial market for them (which results in cheaper unit costs), and other applications would be able to benefit from the knowledge created in combining smaller elements. Designing and building a single computer from the ground up might benefit the ASCI applications, but would not serve the rest of the scientific community except by replication of the entire system.
The disadvantage of building a computer system from many smaller units is that the interconnections between these units can become overwhelmingly complicated. Scientists nowadays use 32 or 64 processors, but a different method is needed to connect 6,400 processors. Not only does the network have to have different characteristics, but the software does also. The software must have fast (low-latency) access to memory, even on systems such as these, which have a very complicated memory structure. This is necessary not only for large-scale simulations, but also for the transfer of data and the visualization of results. There is another problem associated with the use of computer systems of this power and complexity: the burden on the user. It will be a challenge to keep the overhead on the user at a reasonable level, especially if the user is at a remote site.
Where Are We Now?
There has been an Intel-designed and Intel-built ASCI computer at Sandia National Laboratories in Albuquerque for 2 years. It has 4,500 nodes, 9,000 processors (two per node), and a peak performance of 1.8 teraflops. During that 2-year period, it was the fastest computer on the planet for scientific simulation. It has a fair amount of memory—half a terabyte—and a very high speed network interconnecting the 4,500 nodes. It is physically a very big system, built from the highest-volume manufactured building blocks available—the Intel Pentium Pro microprocessor. This machine has been used for a number of breakthrough simulations and has been invaluable for the scientific and engineering application teams in their efforts to develop simulation software that scales to large numbers of processors.
The nodes on the two so-called Blue systems, Blue Mountain at Los Alamos (SGI/Cray) and Blue Pacific at Livermore (IBM), are symmetric multi-processors (SMPs), which are interconnected by a scalable, high-speed communications network. The IBM terascale computer system, which was delivered to LLNL in January 1999, is a three-machine aggregate system where each machine comprises 512 four-processor nodes, 488 of which are used for computing. The remaining nodes connect to a router
TABLE 1.1 Characteristics of ASCI Computer Systems
|
|
Machine |
|
|
|
|
|
Characteristics |
Intel (Sandia) |
Blue Pacific (Livermore) |
Blue Mountain (Los Alamos) |
Projected 10 Teraflops |
Projected 30 Teraflops |
|
Performance (peak teraflops) |
1.8 |
3.9 |
3 |
10 |
30 |
|
Dates operational |
May 1997 |
September 1998 |
November 1998 |
June 2000 |
June 2001 |
|
Processor |
Pentium Pro |
Power PC |
MIPS R10000 |
Power PC |
? |
|
Number of nodes |
4,568 |
1,464 |
48 |
512 |
? |
|
Processors per node |
2 |
4 |
128 |
16 |
? |
|
Number of processors |
9,000 |
5,856 |
6,144 |
8,192 |
>8,000 (?) |
that links the three separate machines. All together, the Blue Pacific system contains 5,856 processors and has a theoretical peak performance of 3.9 teraflops. The SGI/Cray computer at Los Alamos has only 48 nodes, but each node has 128 processors (SGI Origin 2000s). The peak performance of the SGI/Cray Blue Mountain system is around 3.1 teraflops. These two computer systems, although they use the same fundamental architecture, clearly represent two extremes of that architecture. There is n trade-off between a more complex interconnection of fairly simple nodes in the one case and a simpler connection of more complex building blocks, SMPs with 128 processors sharing memory and providing cache coherence, in the other case. Although the two architectures are the same, tuning a scientific application to be equally efficient on both computers is difficult because the interconnect network is different, as is the amount of shared memory for each processor.
The architecture of the ASCI Blue Pacific and Blue Mountain computers—interconnected SMPs—will be the dominant architecture over the next few years. Moore's law will lead to faster processors,3 of course, and there will be different sizes of shared memory processor building blocks and different flavors of the interconnect, but this will be the fundamental architecture by which we will attain the 30-and 100-teraflops performance levels. It is just not feasible to create a super-fast processor in the next 5 years that could attain such performance levels with only 100 or so processors. So, we have to deal with the level of complexity that SMP-based architectures imply. The specifications for these computer systems are summarized in Table 1.1. Figure 1.1 shows the ASCI platforms road map.
It is worth noting, however, that these levels of complexity are not overly different from what we have been dealing with in some laboratories and universities for over 15 years. In 1986 there were systems containing 512 processors (as separate nodes) that presented many of the challenges that ASCI is facing. Soon after those efforts, a few thousand processors were successfully connected. However, this does not diminish the challenge that ASCI is undertaking. It is one thing to get a few computational kernels running on a parallel computer and another thing to get the massive codes used to simulate physical and chemical systems running efficiently on the complex ASCI machines.
As an example of the applications now possible on the ASCI machines, a three-dimensional calculation used the ARES code to simulate Rayleigh-Taylor turbulent mixing and hydrodynamic instabilities found in supernovae and contained over 35 million zones and used 1,920 processors on the
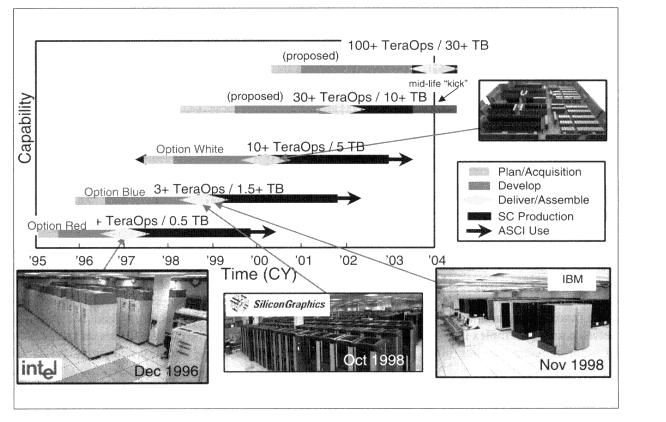
Figure 1.1
ASCI computing systems.
Blue Pacific (Figure 1.2). The ARDRA code was used to simulate the neutron flux emitted by a Nova laser experiment in a calculation using 160 million zones in 33 hours using 3,840 processors. Efficient and accurate neutron and photon transport calculations have been conducted on the Blue Mountain machine, demonstrating a l-ram grid resolution using 100 million particles. On a single-processor machine like those typical of most research environments, these calculations would take 10 to 100 years to run. Perhaps more important, some ASCI simulations have already led to insights about what caused some previously not-understood historical nuclear test results.
Accelerating Technology Developments
ASCI has an effort it calls "PathForward" whose goal is to enable U.S. companies to develop technologies needed to produce the next-generation ultra-scale computing systems for ASCI. PathForward draws on the capabilities, availability, expertise, and products currently being produced by leading computer companies, focusing on interconnect technologies, data storage technologies, systems software, and tools for large-scale computing systems. These technologies, while critical to ASCI's platform needs, are areas in which private sector development would not otherwise take place, at least not in the time frame required by the stockpile stewardship program. At the same time, they are

- Turbulent mixing, as it occurs in supernovae, represents the combined effects of nuclear reactions and hydrodynamic mixing that are relevant to stockpile stewardship
- The combination of an efficient hydrodynamic algorithm and the performance capability of the Blue Pacific makes such a highly resolved three-dimensional simulation possible
Figure 1.2
AREAS supernova simulation. This calculation included a modest 1098 × 180 × 180 spatial mesh with more than 35 million zones. It was completed over a 72-hour period on 1,920 processors.
investments in which industry sees value for future products and markets: essential scaling and integrating technologies that enable ultra-scale computing systems to be engineered and developed out of commodity computing building blocks.
Simulation Development Environment
As we all know, software and algorithms are at least as important as hardware capabilities. Here we have some promising indicators. New methodologies for developing portable and modular application programs are starting to prove themselves. Some ASCI codes run on all three ASCI teraflops systems, and enhancements of those codes can be implemented in a fraction of the time that was required with traditional methods.
Algorithms that scale to 6,000 processors have been developed and implemented for a number of ASCI applications. Future ASCI machines are expected to have no more than 10,000 processors.
An objective is to provide a usable and scalable application-development environment for ASCI computing systems, enabling code developers to quickly meet the computational needs of scientists. The development staff works with code developers to identify user requirements and evaluate tool effectiveness, and it develops direct ties with platform partners and other software suppliers to ensure an effective development environment.
An essential part of the ASCI program is the challenge of solving three-dimensional computational problems that are far larger than we have ever solved before. This challenge translates to more data, more computational cycles, and a succession of more powerful computing platforms. From the compu-
tational viewpoint, the issue is not simply bigger and faster, but rather a fundamental shift in the way problems are solved. Codes, tools, algorithms, and systems that fail to scale properly as the data and hardware resources grow are useless to ASCI developers.
An evolving effort is a simulation development environment that promotes as much commonality across ASCI platforms as possible. Scalability of tool and library interfaces to address hundreds and thousands of central processing units is under investigation. Infrastructure frameworks and math software needed by the ASCI code teams are in progress, and tools to support code verification and validation are being evaluated. This includes current and emerging standards for languages and programming models, such as MPI and Open MP; common application programming interfaces for parallel input/output (I/O) and linear solvers; common parallel tools; and common ways of accessing documentation.
The Challenges Ahead
There are many challenges in addition to those associated with processing power and memory. A simplified way to look at the ASCI program is as a combination of large-scale computing resources, massive scientific databases, and tele-laboratories, all of which must be put into place to support scientific collaborations, perform large-scale simulations, explore complex data sets, and achieve scientific understanding. ASCI is attempting to build a simulation capability that provides a balanced system—one in which computing speed and memory, archival storage speed and capacity, and network speed and throughput are combined to provide a dramatic increase in the performance of scientific simulations. One really does not have a new simulation tool if all one does is collect a bunch of computers in a warehouse—it would be no more than the collections of PCs found in most universities or laboratories today. One must design and build a well-integrated computing system that eliminates the many possible bottlenecks to achieving the needed simulation performance levels (a concept very familiar to chemists).
Archival Storage Systems and Data Management
As computer systems such as those described in Table 1.1 become operational, they will produce a staggering amount of output data—hundreds of terabytes to tens of petabytes—per simulation run. We must be able to store that data and, later, recall it for analysis. This requires the development of efficient data-management techniques as well as fast input/output (I/O) mechanisms. Data management is becoming a very complex issue. There will be so much data that arbitrary file names will no longer be a reasonable format. Also, with a system consisting of thousands of processors and a complex of online disks and archival storage systems, these resources will have to be managed as a single system to provide a rational distributed computing environment.
Input/Output
Chemists are familiar with the importance of efficiently performing I/O—programs like GAUSSIAN do a tremendous amount of I/O. I/O is critical for many scientific simulations in addition to quantum chemistry applications. I/O has been a problem for massively parallel computers, for few systems in the past had truly scalable I/O subsystems. The new machines described in Table 1.1 provide much-enhanced I/O capabilities and, for the first time, we are beginning to find truly scalable I/O subsystems in massively parallel computer systems.
Networks
There will be a need for high-speed networks to connect users to the archival storage systems so that they can access and analyze the results of past simulations. Much of the analysis of the output of the simulations will be done using visualization techniques, but these will not be the simple visualization techniques of today. Because of the tremendous amount of data that will be produced, the user must be able to switch easily from coarse resolution, providing a broad overview of the results, to fine resolution, providing a detailed view of a small region of the data very efficiently. Otherwise even the highest-speed networks available will be overwhelmed.
Data Analysis and Visualization
We will have to develop new techniques to allow users to analyze the data. If the needs of the applications are to be met on schedule, we must develop a Comparable schedule for the development of the infrastructure for "seeing and understanding" the results. To do this will require not just developing bigger display screens, but also innovation in how we display and interact with graphical data. To develop plans to address this problem, ASCI has collaborated with the National Science Foundation on a series of workshops. A report describing the output of these workshops was recently published that lays out a 10-year research and development agenda for visualization and data manipulation.4 ASCI will be tackling this problem collaboratively with the academic community as well as other scientific communities.
The scientists and engineers involved in ASCI will be linked together by "data and visualization" corridors, so that users can access and interact with the needed resources. The capabilities provided by the "data and visualization corridors" are crucial for impedance matching between the computing systems, the large-scale simulations, and the users because the associated time scales are very different. People work in minutes and hours, and computer results in some cases can take days, and in some cases milliseconds, for generation. In the end, the system must operate at human time scales, for it is humans who are seeking knowledge. The development of the "data and visualization” corridors is also an effort that will be performed in collaboration with the research community in general.
Other challenges abound. For example, how do you represent the data? Isosurfaces and streamlines are possible methods; movies or images can be used to analyze many billions of numbers. The data sources may be real-time or the results of simulation, while other sources may be historical. The scientists and engineers involved in these activities are separated geographically, and there is often temporal separation because they need to refer to previous results. To guide this effort, a road map has been developed for the data-visualization efforts in the ASCI program. The road map links applications, computers, data management, and visualization corridors to ensure that all of the needed capabilities are developed in a timely fashion.
I/O is also important in analyzing the results of the simulations, to "see and understand" the information buried in the data. We estimate that scientists and engineers will need to be able to interact in real time with about 75 billion bytes of data by early 2000. Along with this is a requirement to be able to perform queries on a data archive containing roughly 30 terabytes with transfer rates of perhaps 6 gigabytes a second. This is much faster than anyone can do right now, and yet it is critical to achieving the goals of ASCI. By the time we reach the end of the year 2000, we estimate that ASCI's scientists and
engineers will need to interact with a quarter of a terabyte extracted from an archive of at least 100 terabytes with a 20-gigabytes-per second transfer rate. And, the growth will not stop there; the root cause of these high requirements is the detail with which ASCI must be able to simulate weapons systems.
Scientific Simulation Software
Developing scientific simulation software for SMP-based parallel computer systems presents a number of challenges because it entails use of a "hybrid programming model." The hybrid-programming model incorporates both of the standard programming models for parallel computers: the shared-memory and message-passing programming models. The shared-memory programming model relies on the ability of the programmer to access memory by its location or name. This approach provides reasonable performance with as many as 128 nodes, all sharing memory. However, although the memory within an SMP is shared, to attain reasonable performance the user must explicitly make the program parallel. Current compiler technology is not yet at the point that it can be relied on to produce efficient parallel code on more than 8 to 16 processors. To pass data between the SMP nodes, the programmer must send an explicit message that communicates the need for a piece of data. This message is passed to the node on which the data resides, which then transmits the requested data to the original node. This is the message-passing programming model. Both the shared-memory and the message-passing models have been in use for some years but with very, very few exceptions, not together. Although it is possible to use the message-passing model within the SMP node as well as between the SMP nodes, the hybrid programming model will provide the best performance for the overall system since it can take full advantage of the fast shared-memory access possible within a node. So, we have some new things to learn!
Computer Systems Software
Because the systems being acquired by ASCI are all first-of-a-kind, perhaps even one-of-a-kind systems, the computer manufacturers typically cannot provide all the software and tools that are needed to efficiently operate and develop software for the computer. ASCI must provide the missing pieces. One task that ASCI has undertaken to accelerate the development of application software for these machines is the construction of a "problem-solving environment." The PSE provides an integrated set of tools, like compilers and debuggers, for producing code for these massively parallel computers. Problem generation and verification will need another set of such tools, as will high-speed storage and I/O. Finally, the distributed computing environment as well as the associated networks will have to be enhanced as well.
The Asci Alliances
Los Alamos, Livermore, and Sandia are not alone in this process. The academic community is contributing to understanding how to create the advanced simulations and how to run these simulations on terascale platforms. ASCI is funding five large university teams, each of which is attacking a very complex, multi-disciplinary simulation problem. These teams are in the first year of their initial 5-year funding and have already contributed a number of ideas both in computer science and in science and engineering. There are also a number of other university groups, about 30 in all, that are working on more focused aspects of the problem.
Caltech is one of the five university groups receiving ASCI funding. The Caltech team is tackling the reaction of various materials to shock waves. In the Caltech program a detonation is used to create a shock wave in a shock tube, which then impacts the test material. The goal is to develop techniques to simulate the effect of the shock wave on the test material and to understand how that effect is related to the composition of the test material. To simulate this very complex phenomenon, we must be able to simulate fluid flows, explosions, chemical reactions, shock waves, and materials properties. The effort requires simulations at the atomic level all of the way up to the macroscopic level. This type of academic research will contribute to a general understanding of how to perform complex, multi-disciplinary simulations and so will help general science as well as ASCI. There are a large number of scientific and engineering applications that need to be able to simulate such complex processes.
Asci's Contributions to the Greater Science Community
ASCI will contribute to science in several ways. It will provide the foundations for building a "science of simulation." Through ASCI we will gain a detailed understanding of all the topics and methods that are needed to create multi-physics simulation, multi-system engineering-design codes, and use them to carry out predictive simulations of complex phenomena. Science and industry alike will benefit from ASCI's development of vastly more powerful computational methods, algorithms, software tools, methodologies for program development, validation, and verification, code frameworks, and computing systems with ever greater computing power and massive memories.
ASCI projects are devoting considerable attention and resources to the development of physics models that are grounded on theory and experiment and lead to practical numerical computations. These models are then incorporated into the simulation programs and validated against experimental data and predictions based on accepted theory. While this approach is not unique, the difference here is the computational scale that is possible and use of multiple, intertwined physics models in a single simulation code.
ASCI is investing in better algorithms and computational methods. Even ASCI's extremely powerful platforms will not be able to tackle the weapons stockpile computations by applying brute-force algorithms.
Software design and development for such applications on such machines are particularly challenging and controversial aspects of multi-physics scientific simulations. The experience base is currently limited to a few isolated projects from which it is difficult to draw general conclusions. Instead, ASCI will carry out multiple substantial simulation projects that will provide proofs of principle, at scale, of software development methodologies and frameworks that provide portability, extensibility, modularity, and maintainability while delivering acceptable performance.
ASCI will have shown, through actual accomplishments, the potential of terascale simulations for a broad range of scientific and engineering applications. By doing so, and by demonstrating the feasibility of putting together and using computers of much greater scale than would otherwise be available, ASCI is also re-energizing both the scientific computing research community and the U.S. commercial computer industry. Several federal agencies are already planning to invest in very high-end computing, and others are sure to follow. Computer manufacturers are seeing renewed customer interest in much higher performance, and there is growing realization that there may be a financially viable approach to getting into the highest-end markets. The strategy consists of designing the standard mid-to-large-scale products that sell in large quantities so that they are also suited to serve as building blocks for truly large systems. In addition to stimulating the high-end computer industry, industry will inherit computational tools that will enable it to design better, more competitive products. Computer simulation is already
used extensively in product design and optimization. The much greater simulation capabilities developed by ASCI, hardware and software, will enable industries of all kinds to produce even better products.
Perhaps the most important product of ASCI will be a cadre of thousands of people with solid experience and expertise in predictive, multi-physics simulation. This alone will have a major impact on the future of scientific and engineering computing.
Summary
Over the next few years, we will see remarkable increases in the power of high-end computing capabilities, from 1 teraflops today to 100 teraflops in 2004. DOE's Accelerated Strategic Computing Initiative is driving this increase and is using the resulting computer systems immediately—as soon as they are manufactured—to address a broad range of scientific and engineering simulations. These simulations are critical to ensuring the safety and reliability of the nation's nuclear arsenal. But because the approach is applications-driven, the computer systems being developed will lead to computers that are suitable for most, if not all, high-end technical computing applications.
To the extent possible, ASCI is using commercial building blocks to leverage the cost efficiency of the high-volume computing industry. This approach will make the resulting computer systems readily replicable for others—and, undoubtedly, at substantially reduced cost, because ASCI is funding much of the needed development efforts. The recent report from the NSF/DOE-sponsored "National Workshop on Advanced Scientific Computing" outlined a number of scientific and engineering areas that would be dramatically affected by access to this level of computing capability.5
Taking advantage of this new level of computing capability presents a large number of challenges. We have to consider the computing infrastructure as a whole—processing speeds and memory, data storage and management, data analysis and visualization, and networking speed and capacity—if we are to realize the promised dramatic increase in computing capability. We will also have to discover new computational algorithms, programming methods, and even problem formulations in some cases. Despite these challenges, the payoff will be substantial. The advances in computing power that will become available in the next 5 to 10 years will be so great that they will change the very manner in which we conduct the pursuit of science and technology.
Discussion
David Rothman, Dow Chemical Company: Let me say you have succeeded in convincing me how puny my computing project is right now. But one thing I think we have in common is that in any computing project you can identify a number of potential rate-limiting steps in getting to the goal, and you can generally identify one or two things that are very high risk items. Can you tell me what you see as the one or two of the highest-risk parts of this overall program you have to reach your goal?
Paul Messina: I would consider that the highest risk is the operating system and then, software, and tools. Also risky are general issues such as whether the compilers will reach the point of having a respectable fraction of the potential speed of the system. The next highest risk would be getting the algorithms in the time scales where they use fairly efficiently the thousands of processors.
I have no doubt whatsoever about the ability to do that for scientific algorithms given enough time, so it is the accelerated schedule that is a source of high risk; people are not used to having to program that way. So, it is a good combination of the system's software, which tends to lag pretty badly in terms of its ability to exploit these very complicated processors, and then the applications.
The one thing I did not emphasize at all is that the way we have obtained this wonderful Moore's curve for the processor increase in speed is not so much by having faster clocks on our cycle speeds, but by making the guts of the processor much more complicated. And so, theoretically, if everything works you get this wonderful speed. But it means keeping several arithmetic units busy, loading and storing data simultaneously, and that is a hard thing to do. So, to actually get the benefits of these faster processors, even one processor, is beyond what many compilers can do.
Andrew White, Los Alamos National Laboratory: Thom mentioned the Science Simulation Plan and the PITAC response as a new program for FY2000. How would this new initiative and ASCI/Stockpile Stewardship play together?
Paul Messina: One of the things that I hope to do in part during my 2 years in ASCI is to work out a way that the two efforts can get mutual benefit. So, specific things that I can imagine are that perhaps the SSX SSStar program will select machines that are similar to the ones that ASCI has selected. Then, these two things that I just identified as the highest-risk items, the system software and tools and the algorithms, could be developed jointly so that we would be able to actually use the machines. I would say that is a real target of opportunity, to have very similar machines instead of deciding to diverge here and therefore have to develop all new and different algorithms.
So, at the level of helping to mature the system, I would first think of software, tools, and the algorithms for the applications. One could imagine sharing facilities. That is practical, but often politically unpalatable, so I do not know that there is much hope of doing that. But I think that in figuring out how to use these new systems, making them robust earlier and sharing the results, and maybe even having joint teams doing applications, would help both tremendously.
Thom Dunning: I think one of the real benefits of ASCI is that it has made computational scientists start to ask such questions as, What would we do if we had 100 times more power on the desktop or 10,000 times more power on the very high-end systems? These are very good questions to be thinking about because that is the direction that the computer industry is taking us, whether it succeeds on the accelerated time scale as outlined with ASCI or whether it comes on a little more slowly.












