
Chapter 4
Assessments of Student Performance
Standards-Based Assessment
Assessments have long held a strong influence on educational practice, particularly in Title I. From its inception, Title I required the use of “appropriate objective measures of educational achievement” in order to ensure that the program was achieving its goal of reducing the achievement gap between low-income and higher-income students. In carrying out this requirement, states and school districts, for the most part, used standardized norm-referenced tests to measure the achievement of eligible students—both to determine eligibility and to measure gains. As a result, Title I increased dramatically the number of tests states and districts administered; one district administrator estimated that the Title I requirements doubled the amount of testing in the district (Office of Technology Assessment, 1992).
The influence of the federal program on schools was not always healthy, and many critics argued that the tests actually contributed to the limited improvement in student performance the program demonstrated (Advisory Committee on Testing in Chapter 1, 1993). In particular, some critics charged that the tests contributed to undesirable instructional practices. Because of the great weight attached to test scores, the critics contended, teachers tended to overemphasize test-taking strategies or the relatively low-level skills the tests measured, rather than focus on more challenging abilities or demanding content. At the same time, critics pointed out, many schools placed less emphasis than they might have placed on topics or subjects not tested, such as science and social studies.
In addition, critics noted that the tests failed to provide timely or useful information for teachers; that states and districts inappropriately used the tests as exclusive instruments to determine educational need; and that the aggregate data accumulated from the various districts and states were incomplete and of mixed quality.
The 1994 reauthorization of Title I was intended to change all that. The goal of the law was to harness the power of assessment to positive ends, using assessments to drive challenging instruction for all students. The mechanism for doing so was the requirement that assessments be “aligned” to the challenging standards for student performance. Teaching students to do well on the tests would mean that students would be learning what they needed to achieve the standards. Moreover, the assessment data would inform students, parents, teachers, and members of the public how well students were performing against the standards, rather than in comparison to other students.
In its effort to use assessment to promote instructional change, the Title I law was also tapping in to a reform movement in assessment. Like the critics of Title I testing, assessment critics contended that the traditional tests used in most schools and school districts—typically, norm-referenced, multiple-choice tests—narrowed the curriculum to the low-level knowledge and skills tested and provided inadequate and sometimes misleading information about student performance. In part, these critics drew on data showing the effects of the tests on instruction. But they also drew on a strain of research on student learning that emphasized the importance of students' abilities to use their knowledge to solve problems that reflect the world they encounter outside the classroom. To assess such abilities—and to promote instruction that fosters the development of such abilities in children—reformers called for new assessments that would measure student abilities to understand, analyze, and organize knowledge to solve complex problems.
These assessments, for example, might ask students to gather data and determine the mathematical procedures necessary to design a solution involving architecture or flying. Or they might ask students to read historical documents and analyze what they've read, together with what they know from other sources, to interpret a key event in history. Or they might ask students to conduct a science experiment in order to come up with a reasoned argument on an environmental issue.
In addition to tapping student knowledge in new ways, these types of assessments are also aimed at reporting results differently from traditional tests. Most significantly, the results would indicate whether students had attained challenging standards that demanded that they demonstrate such abilities.
Findings
Alignment. The ability of tests to reach all the ambitious goals set out by reformers depends, first of all, on the alignment between tests and standards. Alignment is a necessary condition of the theory of action of standards-based reform; indeed, the Title I statute requires state assessments to “be aligned with the State's challenging content and performance standards.” Alignment ensures that the tests match the learning goals embodied in the standards. At the same
time, aligned assessments enable the public to determine student progress toward the standards.
A study conducted for the committee found that alignment may be difficult to achieve (Wixson et al., 1999). The study examined assessments and standards in elementary reading in four states. Using a method developed by Webb (1997), the researchers analyzed the cognitive complexity of both the standards and the assessment items, and estimated the extent to which the assessment actually measured the standards.
The study found that, of the four states, two had a high degree of alignment, one was poorly aligned, and one was moderately aligned. Of the two highly aligned states, one, State A, achieved its alignment, at least in part, because it relied on the commercial norm-referenced test it used to develop its standards, and the standards were the least cognitively complex of any of the states analyzed. State B, whose standards were at the highest level of cognitive complexity, meanwhile, had the lowest degree of alignment; only 30 percent of its objectives were measured by the state-developed test.
The other two states administered two tests to measure reading. In State C, which had a high degree of alignment, the state-developed comprehension test measured essentially the same content and cognitive levels as the norm-referenced test. In State D, however, a second test—an oral-reading test—did make a difference in alignment. But overall, that state's assessments and standards were moderately aligned.
The Wixson study suggests a number of possible reasons why attaining alignment is difficult. One has to do with the way states went about building their assessments. Unless a state deliberately designed a test to measure its standards—or developed standards to match the test, as State A did in the study—it is unlikely that the test and the standards will be aligned, particularly if a state uses an off-the-shelf test. Commercial tests designed for off-the-shelf use are deliberately designed to sell in many states; since standards vary widely from state to state, such tests are unlikely to line up with any single state's standards. Thus states using commercial tests are likely to find gaps between the tests and their standards.
But even when states set out to develop a test to measure their standards, they are likely to find gaps as well. In large part, this is because a single test is unlikely to tap all of a state's standards, particularly the extensive lists of standards some states have adopted. In addition, the ability of tests to tap standards may be limited by the constraints imposed on tests, such as testing time and cost. Time constraints have forced some states to limit tests to a few hours in length, and as a result, they can seldom include enough items to measure every standard sufficiently. Financial constraints, meanwhile, have led states to rely more heavily on machine-scored items, rather than items that are scored by hand. And at this point, many performance-based tasks—which measure
standards such as writing skill and the ability to communicate mathematically—require more costly hand scoring.
Similarly, the technical requirements for tests—particularly when consequences are attached to the results—have led some states to limit the use of performance items. Researchers have found that the technical quality of some performance items may have been insufficiently strong for use in high-stakes situations (Western Michigan University Evaluation Center, 1995; Koretz et al., 1993; Cronbach et al., 1994).
Researchers at the National Center for Research on Evaluation, Standards, and Student Testing (CRESST) have developed an approach to building performance assessment that is designed to link directly the expectations for learning embedded in content standards to the tasks on the assessment. Known as model-based performance assessment, the approach combines a means of enabling states and districts to assess student learning against standards with a way, through clear specifications, of providing instructional guidance to classroom teachers (Baker et al., 1991, 1999; Baker, 1997; Glaser, 1991; Mislevy, 1993; Niemi, 1997; Webb and Romberg, 1992).
Validity of Inferences. The ability of tests to accomplish the reformers' aims of reporting student progress on standards and informing instruction depends on the validity of the inferences one can draw from the assessment information. For individual students, a one-or two-hour test can provide only a small amount of information about knowledge and skill in a domain; a test composed of performance items can provide even less information (although the quality of the information is quite different). For classrooms, schools, and school districts, the amount of information such tests can provide is greater, since the limited information from individual students can be aggregated and random errors of measurement will cancel each other out.
Yet the information available from large-scale tests about the performance of schools and school districts is still limited. One reason for this is because overall averages mask the performance of groups within the total, and the averages may be misleading. This is particularly problematic because variations within schools tend to be greater than variations among schools (Willms, 1998). For example, consider two schools. School A has a high proportion of high-achieving students, yet its low-achieving students perform very poorly. School B has fewer high performers than School A, yet its lower-achieving students perform considerably better than those at School A do. Using only average scores, a district policy maker might conclude that School A is more effective than School B, even though a number of students in School A perform at low levels. School B's success in raising the performance of its lower-achieving students, meanwhile, would get lost.
Determining whether a school's superior performance is the result of superior instructional practices is difficult in any case, because academic perfor-
mance depends on many factors, only some of which the school can control (Raudenbush and Willms, 1995). Because of differences in student composition, test scores by themselves say little about “school effects,” or the influence of attending a particular school on student performance. However, using statistical techniques to control for student background factors, Raudenbush and Willms (1995) have shown that it is possible to compute at least the upper and lower bounds of school effects. Separately, Sanders (Sanders and Horn, 1995) has developed a statistical method to calculate the effect on student performance of individual teachers within a school. Sanders's method has been used in several districts to determine the “value added” that teachers provide.
Instructional Sensitivity. Tests vary in the extent to which they respond to and inform instructional practice. Many tests, particularly those designed to test a range of standards, are relatively insensitive to instruction; changing teaching practices to reflect standards may not result in higher test scores on such assessments. But even tests that do capture the results of instructional improvement may not be as informative as they might; the ways the tests are scaled and results are reported tell little about what caused students to succeed or not succeed.
Determining the instructional sensitivity of assessments requires careful study of classroom practices and their relations to student performance. To carry out such studies, researchers need data on the type of instruction students receive. By showing whether instructional practices related to the standards produce gains in assessment performance while other practices do not, researchers can demonstrate whether an assessment is instructionally sensitive (Cohen and Hill, 1998; Yoon and Resnick, 1998).
Multiple Purposes. Tests should be constructed in different ways, depending on the purpose for which they are used. A test intended to inform the public and policy makers about the condition of education is more likely than other types of tests to include a broad range of items designed to provide information about students' mastery of, say, 8th grade mathematics. These tests are typically administered at most once a year, and often the results come back too late for teachers to use them to make adjustments in their instructional programs.
A test intended for instructional guidance, in contrast, is more likely than others to include items that tap a particular topic—say, algebra—in greater depth, so that teachers have an idea of students' specific knowledge and skills, and possible misconceptions. These tests, usually administered by classroom teachers, are given relatively frequently.
The technical quality of a test should be appropriate for its intended use. For measures used for accountability, system monitoring, and program evaluation, the Standards for Educational and Psychological Testing (American Educa-
tional Research Association, American Psychological Association, National Council on Measurement in Education, 1985; in press) should be followed. These standards include guidelines for validity, reliability, fairness, test development, and protection of test takers' rights.
Using the same test for multiple purposes poses problems. The broad, public-information-type of test will provide too little information too infrequently to help teachers redesign their instructional practices to address the particular needs of their students. The instructional-guidance test will provide too little information about the range of student knowledge and skills in a subject area—or may be misinterpreted to suggest more than it actually offers. At the same time, instructional guidance tests are often scored by teachers; using such tests for accountability purposes may provide an incentive for teachers to report the best possible results, throwing into question the accuracy and value of the information they provide.
Yet undue attention on the accountability measure encourages schools to focus all their efforts on raising the performance on that measure, which may not be equivalent to improving performance generally. In some cases, schools resort to inappropriate practices, such as teaching specific test items, or items like test items, in order to raise scores. These practices do little to improve student learning (Shepard, 1989; Koretz et al., 1991).
However, preliminary evidence suggests that careful attention to instructional guidance assessments appears to contribute to higher performance. Principals who testified before the committee described the way their schools used regular and frequent teacher-made assessments to monitor the progress of every student and to gauge the effectiveness of the instructional program. And a study of successful high-poverty schools in Texas found that such schools administered frequent assessments and used the data in their instructional planning (Ragland et al., 1999). These schools used assessment data from classroom assessments, district tests, and state tests to develop a well-rounded picture of student performance in order to make decisions about instructional strategies.
Recommendations
- Teachers should administer assessments frequently and regularly in classrooms for the purpose of monitoring individual students' performance and adapting instruction to improve their performance.
- Assessment should involve a range of strategies appropriate for inferences relevant to individual students, classrooms, schools, districts, and states.
- The overwhelming majority of standards-based assessments should be sensitive to effective instruction—that is, they should
-
detect the effects of high-quality teaching. Districts, schools, and teachers should use the results of these assessments to revise their practices to help students improve performance.
- Standardized, norm-referenced tests of content knowledge should be used as indicators of performance and should not be the focus of instruction.
- Multiple measures should be combined in such a way that enables individuals and schools to demonstrate competency in a variety of ways. Such measures should work together to support the coherence of instruction.
Questions to Ask
|
❑ |
Do schools conduct regular assessments of individual students' performance and use the data to adjust their instructional programs? |
|
❑ |
Do assessments include a range of strategies appropriate for their purposes? |
|
❑ |
Do the state, district, and schools collect information to determine the instructional sensitivity of their assessments? |
|
❑ |
Do multiple measures, including district and state tests, complement one another and enable schools to develop a coherent instructional program? |
Criteria
As states and districts develop assessments, the committee recommends using the following criteria:
Coherence. Assessments are most efficient and effective when various measures complement each other. Assessments should be designed to measure different standards, or to provide different types of information to different constituents. In designing assessments, states or districts should examine the assessments already in place at various levels and determine the needs to be filled.
Transparency. Results from the array of assessments should be reported so that students, teachers, parents, and the general public understand how they were derived and what they mean.
Validity. The inferences from tests are valid when the information from the test can support them. Validity depends on the way a test is used. Inferences that may be valid for one purpose—for example, determining eligibility for a particular program—may not be supportable for another—such as program evaluation. Validity of inferences depends on technical quality; the stability and
consistency of the measurement help determine whether the inferences drawn from it can be supported.
Fairness. A test must produce appropriate inferences for all students; results should not be systematically inaccurate for any identifiable subgroup. In addition, results should not be reported in ways that are unfair to any group of students.
Credibility. Tests and test results must be believable to the constituents of test information. A test that supports valid inferences, that is fair, and that is instructionally sensitive may not provide meaningful information or foster changes in practice if teachers or policy makers do not trust the information they receive from the test.
Utility. Tests will serve their purpose only if users understand the results and can act on them. To this end, tests must be clear in describing student achievement, in suggesting areas for improvement of practice, in determining the progress of schools and school districts, and in informing parents and policy makers about the state of student and school performance.
Practicality. Faced with constraints on time and cost, states and districts should focus their assessment on the highest-priority standards. They should examine existing measures at the state and district levels and implement assessments that complement measures already in place.
Examples
The following two examples of assessments come from districts pursuing standards-based reform. Each district has created a mosaic of assessment information that includes frequent assessments of individual student progress at the classroom level; portfolios and grade conferences on student work at the school level; performance assessments at the district level; and standards-referenced tests at the state level. All of these are compiled into reports that show important constituencies what they need to know about student performance.
Community District 2 in New York City began its reform effort by changing the curriculum, rather than the assessments. The district administers a citywide mathematics and reading test, and a state test as well. Each year, the district reviews the results, school by school, with principals and the board, setting specific goals for raising performance, especially among the lowest-performing students. In addition, schools also administer additional assessments that they found are aligned with the curriculum. In that way, the intensive staff development around curriculum, which the district has made its hallmark, and the professional development the district provided on the assessment, produce the same result: teachers with significantly enhanced knowledge and skills about how to teach students toward challenging standards.
Schools in Boston also use a multifaceted approach to assessment. The state of Massachusetts has developed its own test, and the district uses a commercial test. In addition, schools have developed parallel assessments. One elementary school, for example, begins each September by assessing every student, from early childhood to grade 5, using a variety of methods: observation for young children (through grade 2), running records, writing samples. They repeat the running records and writing samples every four to six weeks. They examine the data in January and again in June to determine the children's progress. In that way, every teacher can tell you how her students are doing at any point. Teachers can adjust their instructional practices accordingly, and principals have a clear picture of how each classroom is performing. The district and state tests, meanwhile, provide an estimate of each school's performance for policy makers.
Assessing Young Children.
The 1994 Title I statute poses a problem for educators and policy makers interested in determining the progress of large numbers of disadvantaged students. Although 49 percent of children served by the program are in grades 3 and below, the law does not require states to establish assessments before grade 3. Without some form of assessment, schools and districts would have no way of determining the progress of this large group of students.
The law's emphasis on testing in grade 3 and above followed practice in the states, many of which have in recent years reduced their use of tests in the early grades. Only 5 states test students in grade 2; 3 test in grade 1; and 2 test in kindergarten (Council of Chief State School Officers, 1998).
The federal and state actions reflect their responses to the arguments of early childhood educators. These educators have long been committed to the ongoing assessment of young children for the purpose of instructional improvement. Indeed, ongoing assessment of children in their natural settings is part and parcel of high-quality early childhood educators' training. However, early childhood educators have raised serious questions about the use of tests for accountability purposes in the early grades, particularly tests used for making decisions about student tracking and promotion.
The press for accountability in education generally, along with the increasing emphasis on the early years, has brought the issue of early childhood assessment to the fore. Among state and district policy makers, the question of how best to assess and test young children, and how to do so in ways that are appropriate and productive, remains an issue of great concern and debate.
Findings
Assessing the knowledge and skills of children younger than age 8 poses many of the same problems as assessments of older children, as well as posing some unique problems. Like tests for older children, tests for young children should be appropriate to the purpose for which they are used, and they must support whatever inferences are drawn from the results.
The National Education Goals Panel's Goal 1 Early Childhood Assessment Resource Group (Shepard et al., 1998a) identified four purposes for assessment of children before age 8, each of which demands its own method and instrumentation. The four purposes are:
Instructional Improvement. Measures aimed at supporting teaching and learning are designed to inform students, parents, and teachers about student progress and development and to identify areas in which further instruction is needed. Such measures may include direct observations of children during classroom activities; evaluation of samples of work; asking questions orally; and asking informed adults about the child.
Identification for Special Needs. Measures aimed at identifying special problems inform parents, teachers, and specialists about the possible existence of physical or learning disabilities that may require services beyond those provided in a regular classroom.
Program Evaluation. Measures aimed at evaluating programs inform parents, policy makers, and the public about trends in student performance and the effectiveness of educational programs.
Accountability. Measures to hold individuals, teachers, or schools accountable for performance inform parents, policy makers, and the public about the extent to which students and schools are meeting external standards for performance.
In practice, however, tests for young children have been used for purposes for which they were not intended, and, as a result, inferences about children's abilities or the quality of early childhood education programs have been erroneous, sometimes with harmful effects (Shepard, 1994). For example, schools have used test results to retain children in grade, despite evidence that retention does not improve academic performance and could increase the likelihood that children will drop out of school. In addition, schools have also used tests to put students into academic tracks prematurely and inappropriately (National Research Council, 1999a).
These problems have been exacerbated by the type of assessments typically
used for accountability purposes—group-administered paper-and-pencil tests—which may be inappropriate for young children (Graue, 1999, Meisels, 1996). Such tests often fail to capture children's learning over time or predict their growth trajectory with accuracy, and they often reflect an outmoded view of learning. In contrast to older children, young children tend to learn in episodic and idiosyncratic ways; a task that frustrates a child on Tuesday may be easily accomplished a week later. In addition, children younger than 8 have little experience taking tests and may not be able to demonstrate their knowledge and skills well on such instruments. A paper-and-pencil test may not provide an accurate representation of what a young child knows and can do.
However, the types of assessments useful for instructional improvement, identification of special needs, and program evaluation may not be appropriate for use in providing accountability data. Instructional improvement and identification rely on measures such as direct observations of student activities or portfolios of student work, which raise issues of reliability and validity if used for accountability (Graue, 1999). Program evaluations include a wide range of measures—including measures of student physical well-being and motor skills, social development, and approaches to learning, as well as cognitive and language development—which may be prohibitively expensive to collect for all students.
However, it is possible to obtain large-scale information about what students have learned and what teachers have taught by using instructional assessments. By aggregating this information, district and state policy makers can use data on instructional assessment to chart the progress of children in the first years of schooling without encountering the problems associated with early childhood assessment noted above. To ensure accuracy, a state or district can “audit” the results of these assessments by having highly trained educators independently verify a representative sample of teacher-scored assessments. Researchers at the Educational Testing Service have found that such an approach can produce valid and reliable information about literacy performance (Bridgeman et al., 1995).
A second strategy might be to assess the full range of abilities that young children are expected to develop, and hold schools accountable for their progress in enabling children to develop such abilities, by assessing representative samples of young children. To ensure the validity of inferences from such assessments, the samples should represent all students in a school; sample sizes can be sufficiently large to indicate the performance of groups of children, particularly the disadvantaged students who are the intended beneficiaries of Title I. Individual scores would not be reported. Researchers are exploring methodologies to describe levels or patterns of growth, ability, or developmental levels.
Recommendations
- Teachers should monitor the progress of individual children in grades pre-K to 3 to improve the quality and appropriateness of instruction. Such assessments should be conducted at multiple points in time, in children's natural settings, and should use direct assessments, portfolios, checklists, and other work sampling devices. The assessments should measure all domains of children's development, particularly social development, reading, and mathematics.
- Schools should be accountable for promoting high levels of reading and mathematics performance for primary grade students. For school accountability in grades 1 and 2, states and districts should gauge school quality through the use of representative sampling, rather than the assessment of every pupil.
- Federal research units, foundations, and other funding agencies should promote research that advances knowledge of how to assess early reading and mathematics performance for both instructional and accountability purposes.
Questions to Ask
|
❑ |
Do teachers regularly assess the progress of students in early grades for the purpose of instructional improvement? |
|
❑ |
Is there in place a comprehensive assessment to hold schools accountable for the performance of children before grade 3? Does the assessment include measures of children's physical well-being and motor skills, approaches to learning, and language and cognitive development? |
|
❑ |
Does the assessment in the early grades measure performance of a representative sample of students? Or is an “audit” used to monitor a sample of teacher-administered and teacher-scored assessments? |
Criteria
Assessments for young children should follow the same criteria used for assessments generally, which were described above. In addition, such assessments should also meet additional criteria based on the unique problems associated with testing children from birth to age 8. The committee recommends that, in developing an assessment system for young children, states and districts should adhere to the following criteria:
Appropriateness. Assessments should reflect the unique developmental needs and characteristics of young children, and should be used only for the purposes for which they are intended. Information should be collected at multiple points in time in settings that are not threatening to young children.
Coherence. The assessment of young children should provide schools and districts with information about student performance that is related to the instructional goals for older students.
Examples
The following examples describe two approaches to measuring the performance of young children that provide information on the progress of students in early grades toward standards with methods that are appropriate and that yield valid and reliable information. The assessments also contribute to instructional improvement by providing teachers with information about their own students' performance. The South Brunswick assessment measures literacy skills; districts and states should supplement such an assessment with indicators of physical and motor development.
The South Brunswick, New Jersey Public Schools have developed and implemented an early literacy portfolio assessment for students in grades K-2. Under the system, students collect work in a portfolio that they carry with them all three years. Teachers rate the work on a 1-to-6 developmental scale; the ratings are moderated by ratings by another teacher. The ratings are aggregated by school and reported to the district. The district's goal is for all students to be at the 5.5–6 level by the end of 2nd grade.
The portfolio system was developed to follow two key principles. First, teachers believe that no high-stakes decision about a child or a teacher should be based on a single form of evidence. They therefore designed the system so that it includes various forms of assessment, such as observations of children's activities, work samples, and “test-like activities”—that is, on-demand responses to prompts. Second, they believe that the assessment should serve both a means of professional development and as an accountability measure. This system accomplishes this dual goal by allowing teachers to see information about student performance as work in a portfolio, not as points on a scale, and thus understand how to teach their own students, and by allowing the district to monitor school performance through the aggregated scores.
The Work Sampling System, which is in use in a number of districts, is an authentic, curriculum-embedded performance assessment. Developed at the University of Michigan, the assessment is based on teachers' observations of children at work in the class-
room—learning, solving problems, interacting with others, and creating products. Designed for students in preschool through grade 5, the Work Sampling System consists of three interrelated elements: developmental guidelines and checklists, portfolios, and summary reports. A brief observational assessment version of Work Sampling designed for Title I reporting is also available.
Studies of Work Sampling's effectiveness in urban communities, and particularly in Title I settings, demonstrate that the assessment is an accurate measure of children's progress and performance. It is a low-stakes, nonstigmatizing assessment that relies on extensive sampling of children's academic, personal, and social progress over the school year and provides a rich source of information about student strengths and weaknesses. In professional development associated with the system, teachers learn to observe, document, and evaluate student performance during actual classroom lessons. Through the checklists and other materials, teachers can translate their students' work into the data of assessment by systematically documenting and evaluating it, using specific criteria and well-defined procedures (Meisels, 1996).
Assessing Students With Disabilities
One of the most far-reaching features of the 1994 Title I statute was its requirement to include all students in assessment and accountability mechanisms, and in its definition of “all students,” the law refers specifically to students with disabilities. According to the law, states must “provide for the participation of all students in the grades being assessed.” To accomplish this, the law calls for “reasonable adaptations and accommodations” for students with diverse learning needs.
This requirement was reinforced and strengthened by the Individuals with Disabilities Education Act of 1997. That law requires states to demonstrate that children with disabilities are included in general state and district-wide assessment programs, with appropriate accommodations and modifications, if necessary. The law further states that the individualized education program (IEP), which is required to be developed for each student with a disability, must indicate the modifications required for the child to take part in the assessment; if the IEP process determines that a student is unable to participate in any part of an assessment program, the IEP must demonstrate why the student cannot participate and how the student will be assessed.
The law also requires states to develop alternate assessments for children who cannot participate in state and district-wide assessments, and to report to the public on the number of students with disabilities participating in regular and alternate assessment programs, and the performance of such students on the assessments.
These provisions break new ground. In the past, as many as half of all
students with disabilities have not taken part in state and district-wide assessments (National Research Council, 1999a). Although state policies vary widely, one survey found that 37 states in 1998 allowed exemptions from all assessments for students with disabilities, and another 10 allowed exemptions from some assessments for such students (Council of Chief State School Officers, 1998).
In addition, although many states have allowed students with disabilities to take the tests with accommodations and adaptations, the policies that determine which students qualify for accommodations have varied, and test results for students who are administered accommodated assessments have often been excluded from school reports.
Excluding such students from assessments and accountability is problematic. First, it sends a signal that such students do not matter, or that educators have low expectations for them, and that states and districts are not responsible for their academic progress. Second, exclusion throws into question the validity of school and district reports on performance; if such reports do not include the performance of a significant number of students, do they truly represent the level of student performance in a school or district? Third, leaving students with disabilities out of assessments deprives such students, their parents, and their teachers of the benefits of information on their progress toward standards.
Yet while including all students in assessments may be a worthwhile goal, doing so poses enormous problems. While for some students with disabilities, state and district tests yield valid and reliable information, for many others, the effects of accommodations on the meaning and validity of test results is unknown.
Findings
The population of students with disabilities is diverse. Altogether, about 10 percent of the school population is identified as having a disability. Such disabilities range from mild to severe, and include physical, sensory, behavioral, and cognitive impairments. Some 90 percent of the students who qualify for special services under the Individuals with Disabilities Education Act (IDEA) fall in the categories of either the speech or language impairment, serious emotional disturbance, mental retardation, or specific learning disability; of these, half have learning disabilities. However, the definitions of those categories vary from school district to school district and from state to state. Some have argued that the decision to classify students as having a disability may have more to do with educational policy and practices than with the students' physical or mental capabilities (National Research Council, 1997a).
Students who qualify for special education services under the IDEA are educated according to the terms of an individual education program (IEP), which is a program negotiated by the child's parents, the school, and service providers. Although evidence varies on the effectiveness of such plans, particu-
larly the degree to which they provide accountability, the IEP has become paramount in determining the services children with disabilities receive (Smith, 1990). Among other provisions, the IEP has generally determined whether or not a student will participate in testing programs, and if so, under what circumstances.
Participation in testing programs has varied. In addition to the number of students who have been excluded from tests, many others have taken tests that accommodate them in some way. States and districts generally employ four types of accommodations to tests (Thurlow et al., 1997):
- presentation format, or changes in ways tests were presented, such as Braille versions or oral reading;
- response format, or changes in the way students could give their responses, such as allowing them to point or use a computer;
- setting of the test, or changes in the place or situation in which a student takes a test, such as allowing students to take the test at home or in a small group; and
- timing, or changes in the length or structure of a test, such as allowing extended time or frequent breaks.
As the National Research Council's Committee on Goals 2000 and the Inclusion of Students With Disabilities found, the number of students who need such accommodations is unknown. Moreover, the extent to which states and districts employ any or all of these accommodations varies widely, depending on the population of the state, the state's standards and assessments, and other factors (National Research Council, 1997a).
However, because most students with disabilities have only mild impairments, the vast majority can participate in assessments with accommodations. Only a small number of the most cognitively disabled students, whose educational goals differ from the regular curriculum, will be required to take alternate assessments under the IDEA.
Despite the common use of such accommodations, however, there is little research on their effects on the validity of test score information, and most of the research has examined college admission tests and other postsecondary measures, not achievement tests in elementary and secondary schools (National Research Council, 1997a).
Because of the paucity of research, questions remain about whether test results from assessments using accommodations represent valid and reliable indicators of what students with disabilities know and are able to do (Koretz, 1997). But a number of studies are under way to determine appropriate methods of including students with disabilities in assessments, including the National Assessment of Educational Progress (National Research Council, 1999a).
Recommendations
- Assessments should be administered regularly and frequently for the purpose of monitoring the progress of individual students with disabilities and for adapting instruction to improve performance.
- States and districts should develop clear guidelines for accommodations that permit students with disabilities to participate in assessments administered for accountability purposes.
- States and districts should collect evidence to demonstrate that the assessment, with accommodations, can measure the knowledge or skill of particular students or groups of students.
- States and districts should describe the methods they use to screen students for accommodations, and they should report the frequency of these practices.
- Federal research units, foundations, and other funding agencies should promote research that advances knowledge about the validity and reliability of different accommodations and alternate assessment practices.
Questions to Ask
|
❑ |
Are clear guidelines in place for accommodations that permit students with disabilities to participate in assessments administered for accountability purposes? |
|
❑ |
Is there evidence that the assessment, with accommodations, can measure the knowledge or skill of particular students or groups of students? |
|
❑ |
Are the methods used to screen students to determine whether they need accommodations for tests reported, including the frequency of such practices? |
Criteria.
Assessments for students with disabilities should follow the same criteria used for assessments generally, which were described above. In addition, such assessments should also meet additional criteria based on the unique problems associated with testing children with disabilities. The committee recommends that, in developing an assessment system for students with disabilities, states and districts adhere to the following criteria:
Inclusion. The assessments should provide a means of including all students; alternate assessments should be used only when students are so cognitively impaired that their curriculum is qualitatively different from that of students in the regular education program. The state or district should provide accommodations for those who can participate in the regular assessment.
Appropriateness. States and districts need to ensure that accommodations meet the needs of students, and that tests administered under different conditions represent accurate measures of students' knowledge and skills.
Documentation. States and districts should develop and document policies regarding the basis for assigning accommodations to students and for reporting the results of students who have taken tests with accommodations.
Examples
The following two examples describe state policies for assessing students with disabilities. Each sets as a goal including such students in the assessments, and each specifies the criteria for the use of accommodations. State policies should also call for documentation of the use of accommodations and for reporting results for students administered accommodated assessments.
According to Maryland state policy, “all students have a legal right to be included to the fullest extent possible in all statewide assessment programs and to have their assessment results be a part of Maryland's accountability system.” To accomplish this goal, the state department of education has developed guidelines for when students should receive accommodations, which accommodations are permissible for which tests, and when students may be excused or exempted from the tests.
Under the policy, accommodations:
- Enable students to participate more fully in assessments and to better demonstrate their knowledge and skills;
- Must be based on individual students' needs and not a category of disability, level of intensity, level of instruction, time spent in mainstream classroom, or program setting;
- Must be justified and documented in the individualized education program (IEP);
- Must not invalidate the assessment for which they are granted.
Students may be excused from assessments if they demonstrate “inordinate frustration, distress or disruption of others.” Decisions to exempt students must be made during an IEP committee meeting. Students who are not pursuing Maryland Learning Outcomes may be exempted.
Excused students are counted in the denominator for determining
the school's scores on the Maryland Student Performance Assessment Program.
Permitted accommodations include: scheduling accommodations, such as periodic breaks; setting accommodations, such as special seating or seating in small groups; equipment/technology accommodations, such as large print, Braille, or mechanical spellers or other electronic devices; presentation accommodations, such as repetition of directions, sign-language interpreters, or access to close-caption or video materials; and response accommodations, such as pointing, student tape responses, or dictation. If an accommodation alters the skill being tested—such as allowing a student to dictate answers on a writing test—the student will not receive a score on that portion of the test.
In Alabama, where the state requires students to pass an exit examination in order to earn a regular high school diploma, the state has developed guidelines to enable all students—including students with disabilities—to take the exam and earn the diploma. Under the guidelines, if an IEP team determines from test data, teacher evaluations, and other sources that the student will work toward the Alabama high school diploma, the student must receive instruction in the content on the exit examination. The IEP team also determines the accommodations the student will require in order to take the exam.
The state permits accommodations in scheduling, setting, format and equipment, and recording. The guidelines note that “an accommodation cannot be provided if it changes the nature, content, or integrity of the test. In addition, they state that students of special populations must be given practice in taking tests similar in content and format to those of the state test prior to participating in an assessment.
In all, more than 2,100 tenth graders in special education took the pregraduation examination in 1999, about 5 percent of the total who took the test that year.
Assessing English Language Learners
The requirement in the 1994 Title I statute to include “all students” in assessments and accountability provisions also refers to students for whom English is a second language. In order to “provide for the participation of all students in the grades being assessed,” the law called for states to assess English language learners “to the extent practicable, in the language and form most likely to yield accurate and reliable information on what these students know and can do to determine the students' mastery of skills in subjects other than English.”
As with students with disabilities, this provision represents a substantial departure from conventional practice for English-language learners. According
to the 1998 survey by the Council of Chief State School Officers, 29 states allow exemptions from all testing requirements for English-language learners, while another 11 states allow exemptions from some assessments for such students (Council of Chief State School Officers, 1998). In addition, all but 7 states allow some form of accommodation for English-language learners; however, students who are administered accommodated assessments are often excluded from school reports.
Excluding English-language learners from assessments raises the same issues that excluding students with disabilities brings to the fore: excluded students “do not count,” the exclusions throw into question the meaning and validity of test score reports, and students, parents, and teachers miss out on the information tests provide. Yet including such students also poses substantial challenges, and doing so inappropriately can produce misleading results. For example, an English-language mathematics test for students not proficient in the language will yield misleading inferences about such students' knowledge and skills in mathematics.
Findings
As with students with disabilities, the population of students for whom English is not the primary language is diverse. According to the U.S. Department of Education's Office of Bilingual Education and Language Minority Affairs, there are 3.2 million limited-English-proficient students nationwide in 1998, nearly twice as many as there were a decade before. Nearly three-fourths of the English-language learners speak Spanish, but the population includes students from many other language groups, including Vietnamese (3.9 percent), Hmong (1.8 percent), Cantonese (1.7 percent), and Cambodian (1.6 percent).
In addition to the diversity in native languages, English-language learners also vary in their academic skills. Some students may have come to the United States after years of extensive schooling in their native country, and they may be quite proficient in content areas. Others may have had only sketchy schooling before arriving in this country.
Moreover, those who are learning English do so at different rates, and they may be at different points in their proficiency in the language. For the most part, receptive language—reading and listening—develops before productive language—writing and speaking. As a result, a test given to students who have developed receptive language may underestimate these students' abilities, since they can understand more than they can express.
To help educators determine the level of students' English-language proficiency, the Teachers of English to Students of Other Languages, the Center for Applied Linguistics, and the National Association for Bilingual Education have developed a set of standards (Teachers of English to Speakers of Other Languages, 1997). These standards complement the subject-area standards devel-
oped by other national organizations; they acknowledge the central role of language in the learning of content as well as the particular instructional needs of learners who are in the process of developing proficiency in English.
States have attempted to deal with the variability in students' English proficiency by developing policies to exempt students with limited English proficiency from statewide tests. But the criteria vary among the states. In most cases, the time the student has spent in the United States is the determining factor; in others, the time the student has spent in an English-as-a-second-language program has governed such decisions. However, some have argued that time is not the critical factor and instead have recommended that students demonstrate language proficiency before states and districts determine whether they will participate in assessments. A few states use such determinations, formally or informally (Council of Chief State School Officers, 1998).
In addition to exempting English-language learners from tests, most states permit some form of accommodations for such students. The most common accommodations are in presentation, such as repeating directions, having a familiar person administer the test, and reading directions orally; in timing, such as extending the length of the testing period and permitting breaks; and in setting, such as administering tests in small groups or in separate rooms. A few states also permit modifications in response format, such as permitting students to respond in their native language.
In addition to the modifications, 11 states also have in place alternate assessments for English-language learners. Most commonly these alternatives take the form of foreign-language versions of the test. In most cases, these versions are in Spanish; New York State provides tests in Russian, Chinese, Korean, and Haitian Creole as well. The second-language versions are not simple translations, however. Translations would not capture idioms or other features unique to a language or culture.
Second-language assessments are controversial. Since the purpose of the test is to measure students' knowledge and skills in content areas, many states have provided alternate assessments in subjects other than English; to test English ability, states have continued to rely on English-language assessments. The voluntary national test proposed by President Clinton would follow a similar policy; some districts that had agreed to participate pulled out after they realized that the fourth grade reading test would be administered only in English.
As with accommodations for students with disabilities, the research on the effects of test accommodations for English-language learners is inconclusive. It is not always clear, for example, that different versions of tests in different languages are in fact measuring the same things (National Research Council, 1997b). Moreover, attempts to modify the language of tests—for example, simplifying directions—have not always made English-language tests easier to understand (Abedi, 1995).
One recent study of the effects of accommodations in a large-scale testing program, the state assessment in Rhode Island, found that the state's efforts to
provide accommodations probably led to an increase in the number of English-language learners participating in the test and to gains in performance. However, the study concluded that the effects of the accommodations are uncertain, and that they may not work as intended (Shepard et al., 1998b).
Recommendations
- Teachers should regularly and frequently administer assessments, including assessments of English-language proficiency, for the purpose of monitoring the progress of English-language learners and for adapting instruction to improve performance.
- States and districts should develop clear guidelines for accommodations that permit English-language learners to participate in assessments administered for accountability purposes. Especially important are clear decision rules for determining the level of English-language proficiency at which English-language learners should be expected to participate exclusively in English-language assessments.
- Students should be assessed in the language that permits the most valid inferences about the quality of their academic performance. When numbers are sufficiently large, states and districts should develop subject-matter assessments in languages other than English.
- English-language learners should be exempted from assessments only when there is evidence that the assessment, even with accommodations, cannot measure the knowledge or skill of particular students or groups of students.
- States and districts should describe the methods they use to screen English-language learners for accommodations, exemptions, and alternate assessments, and they should report the frequency of these practices.
- Federal research units, foundations, and other funding agencies should promote research that advances knowledge about the validity and reliability of different accommodation, exemption, and alternate assessment practices for English-language learners.
Questions to Ask
|
❑ |
Are valid and reliable measures used to evaluate the level of students' proficiency in English? |
|
❑ |
Are clear guidelines in place for accommodations that permit English-language learners to participate in assessments administered for accountability |
-
purpose? Are decision rules in place that enable determination of the level of English-language proficiency at which English-language learners should be expected to participate exclusively in English-language assessments?
|
❑ |
Is there evidence that the assessment, even with accommodations, cannot measure the knowledge or skill of particular students or groups of students before alternate assessments are administered? |
|
❑ |
Are assessments provided in languages other than English when the numbers of students who can take such assessments is sufficiently large to warrant their use? |
|
❑ |
Are the methods used to screen students to determine whether they need accommodations for tests reported, including the frequency of such practices? |
Criteria
Assessments for English-language learners should follow the same criteria used for assessments generally, which were described above. In addition, such assessments should also meet additional criteria based on the unique problems associated with testing English-language learners. The committee recommends that, in developing an assessment system for English-language learners, states and districts adhere to the following criteria:
Inclusion. The assessments should provide a means of including all students; they should be exempt only when assessments, even with accommodations, do not yield valid and reliable information about students' knowledge and skills. The state or district should provide accommodations for those who can participate in the regular assessment.
Appropriateness. States and districts need to ensure that accommodations meet the needs of students, and that tests administered under different conditions represent accurate measures of students' knowledge and skills.
Documentation. States and districts should develop and document policies regarding the basis for assigning accommodations to students and for reporting the results of students who have taken tests with accommodations.
Examples
The following examples show the practices of a district and a state that have clear policies for including English-language learners in assessments. Both use measures of English-language proficiency to determine whether students can take part in the regular assessment or use a native-language test or an accommodation. Both disaggregate test results to show performance of English-
language learners who have taken native-language tests or tests with accommodations.
The Texas Assessment of Academic Skills (TAAS) is administered to every student in Texas in grades 3–8 and grade 10. The tests are used for both student and school accountability. For students, the 10th grade tests in reading, mathematics, and writing are designed as exit-level tests, which students must pass in order to graduate. For schools and districts, the tests are the centerpiece of a complex information and accountability system; schools are rated as “exemplary,” “recognized,” “acceptable,” or “low-performing” on the basis of scores on the TAAS, attendance rates, and dropout rates.
The state also administers a Spanish-language version of the TAAS in grades 3–6.
To determine which version of the test students take, language-proficiency assessment committees at each school, consisting of a site administrator, a bilingual educator, an English-as-a-second-language educator, and a parent of a child currently enrolled, make judgments according to six criteria. These are: literacy in English and/or Spanish; oral-language proficiency in English and/or Spanish; academic program participation, language of instruction, and planned language of assessments; number of years continuously enrolled in the school; previous testing history; and level of academic achievement. On the basis of these criteria, the committee determines whether a student is tested on the English-language TAAS, tested on the Spanish-language TAAS, or is exempted and provided an alternate assessment. Those entering U.S. schools in the 3rd grade or later are required to take the English TAAS after three years.
The results for students who take the Spanish TAAS or for those who are exempted are not included in the totals used for accountability purposes; however, the Spanish-language results are reported for each school. In 1997, 2.4 percent of the students in grades 3–8 were exempted because of limited English proficiency; another 1.48 percent of students took the Spanish TAAS.
In Philadelphia, the district administers the Stanford Achievement Test-9th Form (SAT-9) as part of an accountability system; the results are used, along with attendance rates, to determine whether schools are making adequate progress in bringing students toward district standards. The district also administers the Spanish-language version of the SAT-9, known as Aprenda, in reading and mathematics.
To determine how students should be tested, the district measures the students' English-language proficiency. The district has used the Language Assessment Scales (LAS), a standard measure that gauges proficiency on a four-point scale; more recently, district educators have developed their own descriptors of language proficiency. The district is currently conducting research to compare the locally developed descriptors with the LAS.
Students at the lowest level of proficiency—those who are not literate in their native language—are generally exempted from the
SAT-9, as are recently arrived immigrants who are level 2 (beginner). Those in the middle levels of proficiency, level 2 (beginner) and level 3 (intermediate), who are instructed in bilingual programs, are administered Aprenda in reading and mathematics, and a translated SAT-9 open-ended test in science. Those in levels 2 and 3 who are not in bilingual programs take the SAT-9 with accommodations. Those at level 4 (advanced) take the SAT-9 with appropriate accommodations.
Accommodations include extra time; multiple shortened test periods; simplification of directions; reading aloud of questions (for mathematics and science); translation of words and phrases on the spot (for mathematics and science); decoding of words upon request (not for reading); use of gestures and nonverbal expressions to clarify directions and prompts; student use of graphic organizers and artwork; testing in a separate room or small-group setting; use of a study carrel; and use of a word-match glossary.
All students who take part in the assessment are included in school accountability reports. Those who are not tested receive a score of zero.
For schools eligible for Title I schoolwide status (those with high proportions of low-income students), the district is pilot-testing a performance assessment in reading and mathematics. The performance assessment may become part of the district's accountability system. Students at all levels of English proficiency participate in the performance assessment, with accommodations (National Research Council, 1999a).
Reporting Assessment Results
In many ways, reporting the results of tests is one of the most significant aspects of testing and assessment. Test construction, item development, and scoring are means of gathering information. It is the information, and the inferences drawn from the information, that makes a difference in the lives of students, parents, teachers, and administrators.
The traditional method of reporting test results is in reference to norms; that is, by comparing student performance to the performance of a national sample of students, called a norm group, who took the same test. Norm-referenced test scores help provide a context for the results by showing parents, teachers, and the public whether student performance is better or worse than that of others. This type of reporting may be useful for making selection decisions.
Norm-referenced reporting is less useful for providing information about what students know or are able to do. To cite a commonly used analogy, norm-referenced scores tell you who is farther up the mountain; they do not tell you how far anyone has climbed. For that type of information, criterion-referenced, or standards-referenced, reports are needed. These types of reports compare
student performance to agreed-upon standards for what students should know and be able to do, irrespective of how other students performed.
It is important to note that the terms “norm-referenced” and “standards-referenced” are characteristics of reports, not tests. However, the type of report a test is intended to produce influences how it is designed. Tests designed to produce comparative scores generally omit items that nearly all students can answer or those that nearly all students cannot answer, since these items do not yield comparisons. Yet such items may be necessary for a standards-referenced report, if they measure student performance against standards.
Some of the ways test results are reported confound the distinction between norm-referenced and standards-referenced reporting. For example, many newspaper accounts and members of the public refer to “grade-level” or “grade-equivalent” scores as though these scores represent standards for students in a particular grade. That is, they refer to the scores as though they believe that, when 40 percent of students are reading “at grade-level,” two-fifths of students are able to read what students in their grade are expected to read, based on shared judgments about expectations for student performance. In fact, “grade level” is a statistical concept that is calculated by determining the mean performance of a norm group for a given grade. Half of the students in the norm group necessarily perform “below grade level,” if the test is properly normed.
Because of the interest among policy makers and the public for both types of information—information about comparative performance and performance against standards—several states combine standards-based reports with norm-referenced reports; similarly, states participate in the National Assessment of Educational Progress to provide comparative information as well.
By requiring states to “provide coherent information about student attainment of the state's content and student performance standards,” the Title I statute effectively mandates the use of standards-based reports. The law also requires states to set at least three levels of achievement: proficient, advanced, and partially proficient. However, the law leaves open the possibility that states can provide norm-referenced information as well.
Findings
Reporting results from tests according to standards depends first on decision rules about classifying students and schools. Creating those decision rules is a judgmental process, in which experts and lay people make decisions about what students at various levels of achievement ought to know and be able to do (Hambleton, 1998). One group's judgments may differ from another's. As a result, reports that indicate that a proportion of students are below the proficient level—not meeting standards—may not reflect the true state of student achievement. Another process may suggest that more students have in fact met standards (Mills and Jaeger, 1998).
The experience of the National Assessment Governing Board (NAGB) in setting achievement levels for the National Assessment of Educational Progress illustrates the challenges in making valid and reliable judgments about the levels of student performance. The NAGB achievement levels have received severe criticism over the years (National Research Council, 1998). Critics have found that the descriptions of performance NAGB uses to characterize “basic,” “proficient,” and “advanced” levels of achievement on NAEP do not correspond to student performance at each of the levels. Students who performed at the basic level could perform tasks intended to demonstrate proficient achievement, for example. Moreover, researchers have found that the overall levels appear to have been set too high, compared with student performance on other measures.
One issue surrounding the use of achievement levels relates to the precision of the estimates of the proportions of students performing at each level. Large margins of error could have important ramifications if the performance standards are used to reward or punish schools or school districts; a school with large numbers of students classified as “partially proficient” may in fact have a high proportion of students at the “proficient” level.
The risk of misclassification is particularly high when states and districts use more than one cutscore, or more than two levels of achievement, as NAEP does (Ragosa, 1994). However, other efforts have shown that it is possible to classify students' performance with a relatively high degree of accuracy and consistency (Young and Yoon, 1998). In any case, such classifications always contain some degree of statistical uncertainty; reports on performance should include data on the level of confidence with which the classification is made.
Another problem with standards-based reporting stems from the fact that tests generally contain relatively few items that measure performance against particular standards or groups of standards. While the test overall may be aligned with the standards, it may include only one or two items that measure performance on, say, the ability to identify the different types of triangles. Because student performance can vary widely from item to item, particularly with performance items, it would be inappropriate to report student results on each standard (Shavelson et al., 1993). As a result, reports that may be able to indicate whether students have attained standards can seldom indicate which standards students have attained. This limits their instructional utility, since the reports can seldom tell teachers which topic or skill a student needs to work on.
The challenges of reporting standards-based information are exacerbated with the use of multiple indicators. In some cases, the results for a student on two different measures could be quite different. For example, a student may perform well on a reading comprehension test but perform poorly on a writing assessment. This is understandable, since the two tests measure different skills; however, the apparent contradiction could appear confusing to the public (National Research Council, 1999b).
In an effort to help avoid such confusion and provide an overall measure of performance, many states have combined their multiple measures into a single
index. Such indices enable states and districts to serve one purpose of test reporting: to classify schools in order to make judgments about their overall performance. However, the complex formulas states and districts use to calculate such indices make it difficult to achieve a second important purpose of reporting: to send cues about instructional improvement. Teachers and principals may have difficulty using the index to relate scores to performance or to classroom practices.
Recommendations.
- Assessment results should be reported so that they indicate the status of student performance against standards.
- Performance levels of proficient or above should represent reasonable estimates of what students in a good instructional program can attain.
- Reports of student performance should include measures of statistical uncertainty, such as a confidence interval or the probability of misclassification.
- Reports of progress toward standards should include multiple indicators. When states and districts combine multiple indicators into a single index, they should report simultaneously the components of the index and the method used to compute it.
Questions to Ask
|
❑ |
Are assessment results reported according to standards? |
|
❑ |
Is there a way to determine whether the proficient level of achievement represents a reasonable estimate of what students in a good program can attain, over time, with effort? |
|
❑ |
Do reports indicate the confidence interval or probability of misclassification? |
|
❑ |
Are multiple indicators used for reporting progress toward standards? When these indicators are combined into a single index, are the components of the index and the method used to compute it simultaneously reported? |
Criteria
Relation to Standards. Assessment results provide the most useful information when they report student performance against standards. To the extent possible, reports indicating performance against particular standards or clusters of standards provide instructionally useful information.
Clarity. Reports that show in an understandable way how students performed in relation to standards are useful. Reports that combine information from various sources into a single index should include the more detailed information that makes up the index as well.
“Consumer Rights.” Assessment reports should provide as much information as possible to students, teachers, parents, and the public, and they should also help users avoid misinterpretations. The reports should state clearly the limits of the information available and indicate the inferences that are appropriate.
Examples
Figure 4-1 is an example of a school report that was developed by the National Center for Research on Evaluation, Standards, and Student Testing for the Los Angeles Unified School District. It shows a range of information on student performance—including test scores, course taking, and graduation rates—along with contextual information about the qualifications of teachers and the students' background. The test the district uses includes norm-referenced reports rather than standards-referenced reports. In addition, the report does not indicate the degree of statistical uncertainty of the test scores.
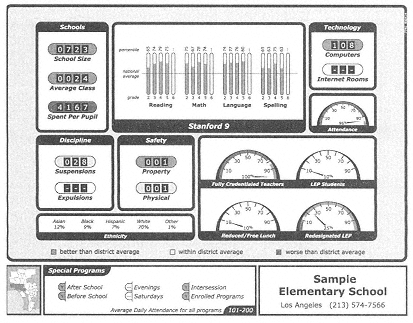
Figure 4-1
School report for the Los Angeles Unified School District.
Source: The National Center for Research on Evaluation, Standards and Student Testing (CRESST). Copyright 1999 by The Regents of the University of California and supported under the Office of Educational Research and Improvement (OERI), U.S. Department of Education. Used with permission.
Disaggregating Data
In addition to reporting overall data on student performance, states and districts also disaggregate the data to show the performance of particular groups of students. The Title I statute requires states and districts to report the performance of students by race, gender, economic status, and other factors. This requirement was intended to ensure that states and districts do not neglect disadvantaged students.
Disaggregating data helps provide a more accurate picture of performance and makes it possible to use assessment data to improve performance. For example, one state examined two districts that had vastly different overall rates of performance. But when state officials broke out the data by race and poverty, they found that poor black students performed roughly equally in both districts. This finding suggested that the higher-performing district's overall scores reflected its success with the majority of students, not all students.
This kind of information can be quite powerful. Rather than rest on their laurels, the high-performing district can look for ways to adjust its instructional program for poor black students. That suggests a strategy that might not be apparent if the district looked only at overall results.
In addition, states and districts can use disaggregated results to see the effects of their policies and practices on various groups. It may be, for example, that implementing a new form of assessment without changing the conditions of instruction in all schools could widen the gap in performance between white and black students. By looking at results for different groups of students, districts and states can monitor the unintended effects of their policies and make needed changes.
Findings
The idea of disaggregation stems in part from a substantial body of literature aimed at determining the effects of schooling on student performance (Raudenbush and Willms, 1995). These studies, which examined the variation in school performance after taking into account the background of the students in the schools, found that some schools do a better job than others in educating children, and the researchers have examined the characteristics of successful schools. However, as Willms (1998) points out, despite these findings, states and school districts continue to report misleading information about school performance by publishing overall average test scores, without taking into account the range of performance within a school.
Overall averages can be misleading because the variation in performance within schools is much greater than the variation among schools (Willms, 1998). That is, to take a hypothetical example, the difference between the performance of white students and black students in School A is much greater than the
difference between School A's performance and School B's performance. Simply reporting the schools' overall performance, without showing the differences within the schools, could lead to erroneous conclusions about the quality of instruction in each school. And if districts took action based on those conclusions, the remedies might be inappropriate and perhaps harmful.
Breaking down assessment results into results for smaller groups increases the statistical uncertainty associated with the results, and affects the inferences drawn from the results. This is particularly true with small groups of students. For example, consider a school of 700 students, of whom 30 are black. A report that disaggregates test scores by race would indicate the performance of the 30 black students. Although this result would accurately portray the performance of these particular students, it would be inappropriate to say the results show how well the school educates black students. Another group of black students could perform quite differently (Jaeger and Tucker, 1998).
In addition, states and districts need to be careful if groups are so small that individual students can be identified. A school with just two American Indian students in 4th grade risks violating the students' privacy if it reports an average test score for American Indian students.
Disaggregated results can also pose challenges if results are compared from year to year. If a state tests 4th grade students each year, its assessment reports will indicate the proportion of students in 4th grade in 1999 at the proficient level compared with the proportion of 4th graders in 1998 at that level. But the students are not the same each year, and breaking down results by race, gender, and other categories increases the sampling error. Reports that show performance declining from one year to the next may reflect differences in the student population more than differences in instructional practice.
Recommendations
- States, districts, and schools should disaggregate data to ensure that schools will be accountable for the progress of all children, especially those with the greatest educational needs.
- Schools should report data so that it is possible to determine the performance of economically disadvantaged students and English-language learners.
- In reporting disaggregated data, states and districts should report the associated confidence levels.
Questions to Ask
|
❑ |
Do schools collect and report data on performance of all groups within each school, particularly economically disadvantaged students and English-language learners? |
|
❑ |
Are there methods for determining the margin of error associated with disaggregated data? |
Criteria
Comprehensiveness. Breaking out test results by race, gender, income, and other categories enhances the quality of the data and provides a more complete picture of achievement in a school or district.
Accuracy. In order to enhance the quality of inferences about achievement drawn from the data, states and districts need to reveal the extent of error and demonstrate how that error affects the results.
Privacy. When groups of students are so small that there is a risk of violating their privacy, the results for these groups should not be reported.
Example
The following example describes the practice in a state that disaggregates test data for each school and uses the disaggregated data to hold schools accountable for performance.
Under the Texas accountability system, the state rates districts each year in four categories—exemplary, recognized, academically acceptable, and academically unacceptable—and rates schools as exemplary, recognized, acceptable, and low-performing. The ratings are based on student performance on the state test, the Texas Assessment of Academic Skills, the dropout rate, and the attendance rate. In order to earn a coveted “exemplary” or “recognized” rating, districts or schools must not only have a high overall passing rate on the TAAS, a low overall dropout rate, and a high overall attendance rate, but the rates for each group within a school or district—African Americans, Hispanics, whites, and economically disadvantaged students under the state's designations—must also exceed the standard for each category. Schools that might have met the requirements for a high rating because of high average performance but fell short because of relatively low performance by students from a particular group have focused their efforts on improving the lagging group's performance—a response that might not have taken place if they had not disaggregated the results.
































