
What Do Test Scores Really Mean?
Test scores weigh heavily in many admissions decisions. While published college rankings provide average freshman class scores for individual schools, schools use the scores they receive in a wide variety of ways. As we have noted, arguments about many of these uses have landed in courtrooms across the nation and will likely soon be heard by the Supreme Court. The tests that provide these scores, however, are complicated instruments with specific purposes, and their technical characteristics are not as well understood as they should be, given their important role.
Perhaps the most pervasive misconception about both the SAT and the ACT is that they are precisely calibrated scientific measures (akin to scales or thermometers) of something immutable: ability. A score on either test is, in the eyes of many people, a statement of the individual's intellectual capacity as pitiless and mutely accurate as the numbers denoting his or her height or weight. Although most students who take an admissions test more than once know that scores fluctuate, even very small score differences will seem significant if the measure is regarded as very precise. One consequence of the misconception is that it contributes to misunderstandings in volatile discussions of fairness. Test scores are often used as key evidence in support of claims that an admissions decision was unfair: that is, if student X's score was higher than that of student Y, admitting student Y but not student X was unfair. This argument rests on two important assumptions that deserve examination: that the test measures the criterion that should bear the greatest weight in an admissions decision and that the score is a precise measure of this criterion. To evaluate these assumptions, it is necessary to begin with a closer look at the content of the tests and at the available evidence regarding their statistical properties. The first step is to recognize the important differences between the tests—although many of the individual items on the two tests may look quite similar, the scores represent different approaches to the task of predicting academic success.
The SAT
The SAT I was conceived as a means of identifying the likelihood that students with a wide range of academic preparation could success-
fully do college-level work.1 It was designed to measure verbal and mathematical reasoning by means of multiple-choice questions. (The mathematics section also includes some machine-scorable items in which the students generate answers and record them on a grid.) In its current form, the test devotes 75-minutes to the verbal section and 60-minutes to the mathematics section.2 The verbal questions are of three kinds (descriptions from College Board materials quoted in Jaeger and Wightman, 1998:32):
- analogy questions, which assess ''knowledge of the meaning of words, ability to see a relationship in a pair of words, and ability to recognize a similar or parallel relationship;
- sentence completion questions, which assess "knowledge of the meaning of words" and "ability to understand how the different parts of a sentence fit logically together;" and
- critical reading questions, which assess "ability to read and think carefully about several different reading passages."
The mathematics section also has several question or item types, all of which contribute to the goal of assessing "how well students understand mathematics, how well they can apply what is known to new situations, and how well they can use what they know to solve nonroutine problems" (Wightman and Jaeger, 1998:34). Each of the sections generates a score on a scale of 200 to 800; thus, the combined scores range from 400 to 1600. No subscores are calculated. Because of the procedures used to ensure that scores from different administrations3 of the test can be com-
pared, it is actually possible to score 800 without answering all of the questions correctly.
The fact that neither section is intended to draw on specific knowledge of course content is the foundation for the claim that the test provides an equal opportunity for students from any school to demonstrate their abilities. Reading passages, for example, include contextual information about the material, and all questions are meant to be answerable without "outside knowledge" of the content. Supporters argue that the test thus ameliorates disparities in school quality. Others have criticized it for precisely this reason, arguing that a test that is independent of curriculum sends the message to students that effort and achievement are less significant than "innate" ability.
The Act
The ACT, first administered in 1959, has a different design. First, there are more parts to it. In addition to multiple-choice tests of "educational development," which are the basis for the score, students also complete two questionnaires that cover the courses they have taken; their grades, activities, and the like; and a standardized interest inventory.
The test battery has four parts:
- a 45-minute, 75-item English test that yields subscores (that is, scores on a portion of the domain covered by a subset of the test questions) in usage/mechanics and rhetorical skills, as well as an overall score;
- a 60-minute, 60-item mathematics test that yields an overall score and three subscores, in pre-algebra and elementary algebra, intermediate algebra and coordinate geometry, and plane geometry and trigonometry;
- a 35-minute, 40-item reading test that yields an overall score and two subscores, for arts and literature and social sciences and science; and
- a 35-minute, 40-item science reasoning test that yields only a total score. It addresses content "likely to be found in a high school general science course" drawn from biology, chemistry, physics, geology, astronomy, and meteorology.
Each of the four tests is scored on a scale from 1 to 36 (subscores within the tests are on a 1 to 18 scale); the four scores are combined into a composite score on the 1 to 36 scale.
Benefits
We turn now to the assumption that the score on an admissions test should be given the greatest weight in the selection process. Performance on both the SAT and ACT is used as an indicator of how well students are likely to do in college. This outcome is most frequently measured by freshman-year grade point average, and numerous studies have been conducted with data from both tests to determine how well their scores do predict freshman grades—that is, their predictive validity. Warren Willingham provided an overview of current understandings of predictive validity for the workshop. In practice, both tests have an average correlation with first-year college grades that ranges from .45 to .55 (a perfect correlation would be 1.0).4 The correlations vary for a number of reasons, and research suggests that several factors work to make them seem lower than they actually are. Most important of these is selection bias. Student self-selection restricts the pool of applicants to any given institution, and it is only the scores and grades of the students who were selected from that pool that are used to calculate predictive validity. Since those students are very likely to be academically stronger than those not selected, the capacity of tests and scores to have predicted the rejected students' likely lower performance does not enter into the equation. In addition, freshman grades are not based on uniform standards, but on often subjective judgments that vary across disciplines and institutions; this factor also tends to depress the tests' predictive validity (Willingham, 1998:3, 6–8). This point also underscores the problems with using freshman-year grades as the criterion variable; like the test scores themselves, GPAs that are calculated to two decimal points lend this measure a deceptively precise air. They are used as the criteria for prediction because there is no superior alternative.
Most colleges rely in admissions as much (or more) on high school GPAs or class rank as they do on test scores, and the predictive validity of both numbers together is higher than that of either one alone (Willingham, 1998:8). It is important to note that the high school GPAs are also a "soft" measure—grading standards range as widely at that level as they do in college. However, GPAs reflect several years of performance, not just several hours of testing time. Using high school grades and test
scores together is very useful specifically because they are the sources of different kinds of information about students, and "two measures are better than one" (Willingham, 1998:16). Moreover, because both SAT and ACT scores generally predict slightly higher college grades for minority students than they actually receive, "it is not dear that the answer to minority group representation in higher education lies in improved prediction.... The challenge is not conventional academic prediction but rather to find valid, socially useful, and workable bases for admitting a broader range of talent" (Willingham, 1998:19–20).
Few colleges would define successful students only by the criterion of their freshman-year GPA. One study has shown that other, qualitative measures—specifically high school honors, school reference, applicant's essay, and evidence of persistence—have been used to identify students likely to be successful in broader ways more explicitly related to institutional goals (see Willingham, 1998:14). Although institutions may have success with such efforts, it is clear that test scores and GPAs provide reliable and efficient information that many admissions officers could not easily do without. But test scores were not designed to provide information about all of the factors that influence success in college, which is why test developers specifically recommend that a student's score be used as only one among many criteria considered in the admission process.
It is well known that conflicting impulses motivated the pioneers of college admissions tests—some hoped to open the nation's ivory towers to able students from diverse backgrounds while others sought "scientific" means of excluding particular groups (see Lemann [1995a, 1995b], for a detailed account of the thinking of some of the pioneers). The legacy of association with now-discredited theories about racial differences, and with xenophobic and racist policies of the early twentieth century, lends impact to still-common charges that standardized tests are biased against minority groups and women (National Research Council, 1982:87–93). However, whatever the problems in the construction of earlier instruments, a considerable body of research has explored the possibility of bias in the current admissions tests, and it has not substantiated the claim that test bias accounts for score disparities among groups (see Jencks, 1998).
The steering committee concludes that the standardized tests available today offer important benefits that should not be overlooked in any discussion about changing the system:
- The U.S. educational system is characterized by variety. Public, private, and parochial schools each apply their own standards, and public schools are controlled locally, not nationally. Curricula, grading standards, and course content vary enormously. In such a system, standardized tests are an efficient source of comparative information for which there is currently no substitute.
- Standardized tests can be provided at a relatively low cost to students and offer valuable efficiencies to institutions that must review thousands of applications.
- Standardized tests provide students with an opportunity to demonstrate talent. For students whose academic records are not particularly strong, a high score can lead admissions officers to consider acceptance for a student who would otherwise be rejected.
Limitations
Both the SAT and ACT cover relatively broad domains that most observers would likely agree are relevant to the ability to do college work. Neither, however, measures the full range of abilities that are needed to succeed in college; important attributes not measured include, for example, persistence, intellectual curiosity, and writing ability. Moreover, these tests are neither complete nor precise measures of "merit"—even academic merit. Consequently, the assumption that either test measures the criterion that should bear the greatest weight in admissions is flawed. Both tests provide information that can help admissions officers to make sense of other information in a student's record and to make general predictions about that student's prospects for academic success. The task of constructing a freshman class, however, requires additional information.
The second assumption on which many claims of unfairness rest—that the score is a precise measure—is also weak. A particular score summarizes a student's performance on a particular set of items on a particular day. If a student could take a test 50 or 100 times, his or her scores would vary (even if the student neither learned nor forgot anything between test administrations). Thus, assuming that the test is a valid measure of the targeted skills and knowledge, his or her performance (on those skills and that knowledge) could be described by this range. Ranges can overlap, as is illustrated in Figure 2, which shows the hypothetical performance of two students in multiple administrations of comparable forms
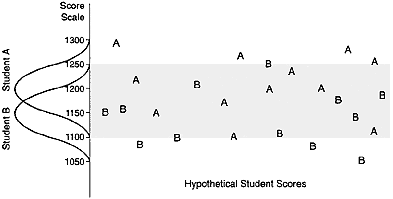
Figure 2
Hypothetical score ranges for students A and B. See text for discussion.
of the SAT. Student A, whose scores across many administrations would average 1200, would earn scores ranging between 1100 and 1300, and student B, who averaged 1150, would earn scores ranging between 1050 and 1250. Chance could dictate that any one of student A's many potential scores would be the one he or she actually received and submitted to colleges, as is true for student B (the shaded area indicates the potential overlap). Either student could seem to be the higher scorer.5 Thus, comparing any two students' scores can be misleading unless they are quite far apart.
Another way of looking at this point is to consider that only fairly large differences in scores could be of use in distinguishing among students who could and could not undertake the work at a particular institution. Using data collected from eleven very selective institutions, Vars and Bowen calculated that "the coefficient on the combined SAT score [verbal plus mathematics] implies that a 100-point increase in SAT score (for example, from 1100 to 1200) raises a student's predicted GPA by roughly 0.11 (from 3.0 to 3.11, for example)" (Vars and Bowen, 1998:463–464). In other words, even a school that has determined that the GPA predicted
by test scores is the criterion about which it cares the most would be on shaky ground in using a test score alone to discriminate among students whose scores are even relatively close together. A different sort of test—for example, a licensure exam designed to identify as potential air traffic controllers students who had mastered a specific minimum body of material—could be used to discriminate among students whose scores are quite close together. But such a test would have a cutoff score derived from a clear articulation of the knowledge necessary to perform the job safely and would likely contain many questions targeted toward refining the discrimination around the cutpoint. Such a test would be useful for identifying those who can and cannot perform particular tasks, but not for spreading all the test takers on a scale.6
Neither the SAT nor the ACT was designed to make fine distinctions at any point on their scales; rather, both were designed to spread students out across the scales, and both are constructed to provide a balance of questions at a wide range of difficulty levels. These tests are most useful, then, for sorting an applicant pool into broad categories: those who are quite likely to succeed academically at a particular institution, those who are quite unlikely to do so, and those in the middle. Such categories are likely to be defined differently by different institutions, depending on the rigor of their programs and their institutional goals. As Warren Willingham (1998:21) concluded about this point:
In the early stages of the admissions process, the [predictive] validity of school grades and test scores is put to work through college recruitment, school advising, self-selection, and college selection. In the process, applicants disperse to institutions that differ widely.... In later stages of the admissions process, colleges ... have already profited from the strong validity of these traditional academic predictors. At this point colleges face decisions among applicants in a grey area.... This is the time when decisions must ensure that multiple goals of a college receive adequate attention.
Given that a score is a point in a range on a measure of a limited domain, the claim that a higher score should guarantee one student preference over another is not justifiable. Thus, schools that rely too heavily on scores to distinguish among applicants are extremely vulnerable to the charge of unfairness. Any institution is justified in looking beyond scores
and GPAs in the interest of achieving educational goals—and this is as true for the rejection of a high-scoring applicant as for the acceptance of a low-scoring one—assuming it is equally willing to do so for every applicant.
As stated above, the steering committee has concluded that test scores have value in the admissions process. However, test scores are also sometimes used in ways that are not in line with their designs or stated purposes; beyond their technical capacities; or detrimental to important widely shared goals for the process, that is, that it be fair, open, and effective. More specifically, the steering committee has identified two persistent myths that have skewed the debate:
Myth: What admissions tests measure is a compelling distillation of academic merit that should have dominant influence on admissions decisions.
Reality: Admissions tests provide a convenient snapshot of student performance useful only in conjunction with other evidence.
Myth: Admissions tests are precise measures of understanding of the domains they cover.
Reality: Admissions tests are estimates of student performance with substantial margins of error.
In light of the limitations of the available standardized tests, the steering committee makes two recommendations:
- Colleges and universities should review their uses of test scores in the admissions process, and, if necessary, take steps to eliminate misuses of scores. Specifically, institutions should avoid treating scores as more precise and accurate measures than they are and should not rely on them for fine distinctions among applicants.
- Test producers should intensify their efforts to make clear—both in score reports and in documents intended for students, parents, counselors, admissions officers, and the public—the limits to the information that scores supply. This could be done by supplementing the interpretive material currently supplied with clear descriptions and representations—accessible to a lay audience—of such points as the significance of the standard error and the fact that the score is a point on a range of possible scores; the accuracy with which a score can predict future academic per-
- formance (in terms of the probability that a student will achieve a particular GPA, for example); and the significance of score differences.
Other Uses of Tests
Test scores have influenced the admissions system in the United States in some indirect but complex ways that also deserve examination. The selectivity of U.S. colleges is not a pure reflection of the respect accorded to their academic output. Rather, it is generally thought of in such terms as the ratio of students accepted to students who apply and of the average test scores of admitted classes. In recent years, rankings of U.S. colleges, particularly the one published by U.S. News and World Report, which assigns a relatively heavy weight to test scores, has fostered competition, especially among institutions in the top tier.7 This circumstance affects the system in several important ways.
For many colleges there are strong incentives to rank high and to maintain or increase the levels of competitiveness they have established—no one wants to seem to be declining in prestige—and public recognition of selectivity can also affect recruitment, alumni support, and other issues about which administrators are quite concerned. Unfortunately, the rankings also provide incentives for schools to encourage a large volume of applications, despite the fact that the large volume increases the difficulty of the selection process.
The strength of the competitive pressure, and how much it varies, can only be guessed at, but admissions officers and other administrators know that it would be possible to manipulate their policies in ways that would affect their rankings if they chose to do so. For example, Tom Parker, the director of admissions at Williams College, explained at the workshop that with the pool of applicants the school currently receives, it would be possible to admit a class that "has average SAT scores 100 points higher than Harvard." However, he noted, they could also alter their procedures in order to affect selectivity (by encouraging applicants who are very unlikely to be accepted) or yield (by discouraging those same applicants
|
7 |
A website devoted to the U.S. News and World Report rankings provides details about how they are calculated. Test scores are worth 40 percent of a ranking for "student selectivity," which is worth 15 percent of the overall ranking. "Acceptance rate," the ratio of students admitted to number of applicants, is worth an additional 15 percent of the "student selectivity" measure (see http://www.usnews.com/usnews/edu/college/rankings/weight.htm). |
and targeting others). Other admissions officers at the workshop concurred that these things are possible. None of those who spoke at the workshop advocated such actions, but virtually all acknowledged the pressures.
It is likely that test scores also play a significant role in the decisions students make about the schools to which they will apply, and it is worth noting that students' self-selection is a significant factor in their access to higher education. Most students see their first scores when they are in the 11th grade or earlier, and they have ample opportunity to compare them to the mean scores at various colleges. A decision not to apply to a particular school may make a great deal of sense if the criteria on which students are evaluated are extremely clear. For a nonselective public institution, the criteria are likely to be straightforward eligibility requirements, and the decision of whether to apply is likely to be straightforward as well. At a more selective institution, however, the criteria are likely to be far more complex and opaque to an aspiring student. The tendency for lower scoring students to opt out of competition at highly selective schools is likely to have a disparate effect on minorities since they have lower average test scores. This tendency is also likely to limit selective schools' opportunity to consider some of the very students they might want to recruit.
Uses of test scores outside of the selection process have effects as well. Scores have been used to identify talented middle-school students for academic enrichment programs and other similar purposes for which they were not intended. Scores calculated for neighborhoods, geographic regions, and the nation as a whole are cited as indicators of academic success and school quality and can even influence real estate values. Comparisons of the average SAT scores of black and white students are also cited as evidence of the advantage given to black applicants at particular institutions (Bowen and Bok, 1998:15–16). However, because black students are underrepresented among high scorers, their average scores would be lower if the selection process were completely race blind. Thus, the fact that black students are in fact underrepresented among high scorers at selective institutions is not evidence of anything in particular about selection at those institutions. Such uses of test scores only further dilute public understanding of standardized admissions tests, distorting the picture of both their benefits and their limitations.











