
3
Technical Issues in Test Development
The year 1 evaluation encompassed an expansive review of pilot test and field test design features, including plans for numbers of items developed, numbers of examinees responding to each item, student sampling procedures, equating the various forms, and analyzing the resulting data. This year 2 evaluation focuses on the following:
-
the extent to which the design for pilot testing will result in items that represent the content and achievement-level specifications, are free of bias, and support test form assembly;
-
plans for the implementation of VNT pilot testing;
-
plans for assembling field test forms likely to yield valid achievement-level results; and
-
technical adequacy of revised designs for field testing, equating, and linking.
For this interim report, we focus primarily on the first three issues related to the pilot test, but not on forms equating or linkage in the field test. The committee believes that review of the pilot test plans at this time is important so that NAGB and its contractor can consider our findings and recommendations before it is too late to make changes. Field test plans will be addressed in the committee 's final report, along with further review of issues related to the pilot test.
The committee reviewed the following documents:
-
Linking the Voluntary National Tests with NAEP and TIMSS: Design and Analysis Plans (American Institutes for Research, 1998g)
-
Designs and Item Calibration Plan for the 1999 Pilot Test (American Institutes for Research, 1998f)
-
Designs and Item Calibration Plans for Including NAEP Item Blocks in the 1999 Pilot Test of the VNT (American Institutes for Research, 1998e)
-
Proposed Plan for Calculator Use (American Institutes for Research, 1998j)
-
Field Test Plans for the VNT: Design and Equating Issues (American Institutes for Research, 1999c)
-
Score Reporting, Draft (American Institutes for Research, 1998l)
-
Test Utilization, Draft (American Institutes for Research, 1998n)
-
Score Reporting, Scoring Examinees, and Technical Specifications: How Should These be Influenced by the Purposes and Intended Uses of the VNT? (American Institutes for Research, 1999g)
-
Selected Item Response Theory Scoring Options for Estimating Trait Values (American Institutes for Research, 1999h)
Many of these documents describe design options on which the Governing Board has not yet taken a definitive position. It is hoped that our review of these documents in this interim report will be useful to NAGB in deciding about such options.
SCORE REPORTING
One of the primary recommendations of the NRC's Phase I report was that decisions about how scores will be computed and reported should be made before the design of the VNT test forms can be fully evaluated (National Research Council, 1999a:51). NAGB and AIR are developing and evaluating options for test use and have conducted focus groups that include consideration of reporting options, but no further decisions about score computation and reporting have been made. We believe that decisions are needed soon. We have chosen to take up this topic in our interim report to provide advice for those decisions.
Three options for computing student scores were identified in a paper prepared for the VNT developer's technical advisory committee (American Institutes for Research, 1999h). One option is pattern scoring, which assigns an overall score to each possible pattern of item scores, based on a model that relates examinee ability to the probability of achieving each observed item score. With pattern scoring, a student 's score depends on the particular pattern of right and wrong answers. As a result, individuals with the same number of correct responses may get different scores, depending on which items were answered correctly. Conversion of response strings to reported scores is complicated, and it is not likely to be well understood nor accepted by parents, teachers, and others who will have access to both item and total scores.
Another scoring approach is to use nonoptimal weights, with the weights determined according to either judgmental or statistical criteria. For example, easy items can be given less weight than more difficult items; multiple-choice items can be given less weight than open-ended items, or all items can be weighted in proportion to the item's correlation with a total score. Use of such a scoring procedure would make conversion from the number correct to the reported score less complex than with pattern scoring, but it is not as straightforward as a raw score approach.
The raw score approach is the most straightforward method: a total score is determined directly by summing the scores for all the individual items. Multiple-choice items are scored one for a correct answer and zero for an incorrect answer or for no answer. Open-ended response items are scored on a 2-, 3-, or 5-point scale according to a predefined scoring rubric. The particular subset of items that are responded to correctly—whether easier or harder, multiple-choice, or open-ended —is not relevant. We agree with Yen's conclusion (American Institutes for Research, 1999h) that for tests with adequate numbers of items, different item weighting schemes have little impact on the reliability or validity of
the total score. Given that test items and answer sheets will be available to students, parents, and teachers, we believe that this straightforward approach makes the most sense.
Current practice for NAEP is to summarize performance in terms of achievement levels (basic, proficient, and advanced) by reporting the percentages of students scoring at each achievement level. To remain consistent with NAEP, the VNT will also report scores using these achievement-level categories. One shortcoming of this type of reporting is that it does not show where the student placed within the category. For instance, was the student close to the upper boundary of basic and nearly in the proficient category? Or, did he or she only just make it over the lower boundary into the basic category? This shortcoming can be overcome if achievement-level reporting is supplemented with reporting using a standardized numeric scale, such as a scale score. This manner of reporting will show how close a student is to the next higher or next lower achievement-level boundary. To ensure clear understanding by students, parents, and teachers, the released materials could include a table that allows mapping of the number right score to the scale score for each VNT form, and the cutpoints for each achievement level could be fixed and prominently displayed on the standardized numeric scale.
Tests that report performance according to achievement-level categories might include a series of probabilistic statements regarding achievement-level classification errors. For example, a score report might say that of the students who performed similarly, 68 percent would actually be at the basic level of achievement, 23 percent at the proficient level, and 5 percent at the advanced level. Although provision of information regarding the precision with which performance is measured is essential, we do not believe these sorts of probabilistic statements are particularly helpful for parents and do not recommend their use for the VNT. In conducting focus groups on reporting issues with parents and teachers, NAGB and its contractor, AIR, have developed a potential reporting format that combines NAEP achievement levels with a continuous score scale. In this format, error is communicated by a band around a point estimate on the underlying continuous scale. Reporting of confidence band information will allow parents to see the precision with which their children are placed into the various achievement levels without having to grapple with classification error probabilities. We believe that parents will find information about measurement uncertainty more useful and understandable if it is reported by means of confidence bands rather than as probabilistic statements about the achievement levels.
Two aspects of the approach used in the reporting issues focus groups deserve further consideration. First, in an effort to communicate normative information, the distance between the lower and upper boundaries for each NAEP achievement level was made proportional to the percentage of students scoring at the level. The underlying scale thus resembles a percentile scale. The midpoint of this scale tends to be in the basic range. We are concerned that this format may emphasize the status quo, what students can do now, rather than the rigorous standards behind the achievement levels.
A second concern with the current NAGB/AIR scheme is the continued use of the NAEP score scale for labeling both the individual point estimates and the boundaries between achievement levels. The committee is concerned that the three-digit numbers used with the NAEP scale convey a level of accuracy, although quite appropriate for estimates of average scores for large groups, that is inappropriate for communicating results for individual students.
Figure 3-1 shows an example of how measurement error and resulting score uncertainty might be reported using confidence bands. In this example, we created a 41-point standard score scale with 10, 20, and 30 defining the lower boundary of the basic, proficient, and advanced levels. While 41 points may be a reasonable number of score levels, the issue of an optimal score scale cannot be decided independent of decisions about the difficulty of each test form and the accuracy of scores at different levels of achievement. It is likely, for example, that the final VNT accuracy targets will not yield the same amount of information at each achievement level.
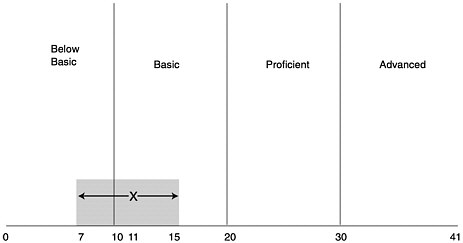
FIGURE 3-1 Sampling report format combining achievement-level reporting with a standardized numeric scale. The score of 11 on this test is in the basic range. The shaded area shows the range of probable scores if the test were taken again. Statistically, scores would be expected to fall within the shaded range (between 7 and 15) 95 percent of the time.
PILOT TEST PLANS
Forms Design
Key features of the pilot test forms design are the use of school clusters, the use of hybrid forms, NAEP anchor forms, and item calibration procedures. Each of the first three features affects the item calibration plan.
Use of School Clusters
Current plans for pilot testing call for each participating school to be assigned to one of four school clusters. School clusters are used in the data collection design to minimize item exposure and to improve item security. Schools are assigned to clusters using a combination of random and systematic stratified sampling to maximize the equivalence of examinees across clusters. Forms are assigned to schools within each school cluster so that all schools in a given cluster are administered the same set of pilot forms. The forms are then distributed within each classroom in a given school in a systematic manner so that the examinees completing the different forms within each school cluster will be randomly equivalent. The introduction of school clusters increases the complexity of the data collection design—from a random-groups design to a common-item nonequivalent-groups design. The larger
the number of school clusters used, the fewer the number of items that will be threatened by a security breach. However, as the number of school clusters increases, creating equivalent school clusters becomes more difficult, and the analyses become more complex. We believe that the choice of four school clusters is a good compromise between the need to minimize item exposure and the need to produce accurate item parameters. It is probably the smallest number needed to significantly increase security while also minimizing the complexity for administration and analysis.
Use of Hybrid Forms
The pilot test design calls for the creation of a number of “hybrid forms” that are comprised of the first half (45-minute session) of one form (e.g., 1a) paired with the second half of another form (e.g., 2b). Each pilot test form will resemble an operational “final” form insofar as possible with respect to length and administration time, distribution of items by content and format, and distribution of items with respect to other factors (such as calculator use). The use of hybrid or overlapping forms in the data collection design has merit because it permits accurate estimation of item parameters even if the groups within school clusters turn out to not be equivalent. Another advantage of the hybrid design is that it will allow intact NAEP blocks to be combined with VNT half-test blocks, which will provide a basis for comparing VNT and NAEP item difficulties and putting the VNT item parameters on the NAEP scale. To the extent that the NAEP blocks cover the content domain, it also will allow an assessment of the extent to which the VNT and NAEP measure the same areas of knowledge. Thus, we agree with the plan that a hybrid or other overlapping forms design be used in the pilot test.
Generally, data for item calibration must be collected either by administering different collections of items to equivalent samples of students or by administering overlapping collections of items to different samples of students. In the proposed pilot test design, parameters for items appearing in different forms must be placed on the same scale. Without the hybrid forms, the only way to do this is to assume that the random assignment of forms to students within school clusters has worked and has created equivalent groups of students taking each form. This assumption is somewhat risky because logistical problems commonly arise during test administration, leading to unintended deviations from the forms distribution plan. Such deviations affect the equivalence of the groups receiving each form. Thus, a more conservative procedure is to use an overlapping forms design, such as the one proposed by AIR, that provides for different groups of individuals within each school cluster to take overlapping forms.
The rationale for the use of the overlapping forms design is not clearly described in the materials we reviewed. The contractor needs to provide a better explanation for incorporating the hybrid form design into the pilot study data collection design. The contractor suggests that two advantages of the hybrid forms design are that it provides some protection against violations of the assumption of local independence and that it permits investigation of item context effects. However, violations of local independence are most likely to occur within item sets, and item context effects are most likely to occur because of changes in item order within a test section. Thus, both of these effects are more likely to occur among items within a session than across sessions. It is therefore unclear to us how the proposed design will provide protection against these particular effects, although we endorse the use of hybrid forms, as noted above, for other reasons.
NAEP Anchor Forms
A major feature of the proposed VNT is that student performance will be reported in terms of
NAEP achievement levels. To facilitate linking of the two assessments, the most recent version of the pilot test design calls for the inclusion of NAEP item blocks in two of the four school clusters. The proposed item calibration plan calls for the estimation of NAEP item parameters along with VNT item parameters and, thus, implicitly assumes that NAEP and VNT measure the same content constructs. This assumption can be questioned since the distribution of item formats differs for the two assessments (e.g., differing numbers of constructed-response and multiple-choice items). Data for the groups of examinees in the proposed design who take VNT items in one session and NAEP items in the other session (e.g., 1a:Nb) can be used to assess the extent to which VNT and NAEP measure the same skills. For example, correlations between scores from two VNT sessions, between two NAEP sessions, and between a VNT session and a NAEP session can be computed and compared. We strongly support the inclusion of NAEP blocks in the pilot test design to provide data on the feasibility of a common calibration of VNT and NAEP items as a means of linking the two scales.
Item Calibration
Item calibration refers to the procedures used for estimating item parameters or characteristics of items such as difficulty level. For NAEP (and proposed for VNT), item calibration is accomplished using procedures based on item response theory, a statistical model that expresses the probability of getting an item correct as a function of the underlying ability being measured. Item characteristics are group dependent, that is, an item may appear easy or hard depending on the ability level of the group taking the item. Thus, to compare the difficulty parameter estimates of items that were administered to different sets of examinees, it is necessary to place (or link) the different sets of item parameter estimates on a common scale. For VNT items, the desire is to link the item parameters to the NAEP scale. The item calibration and linking process is technically complex, and the committee's findings and suggestions are described below in a technical manner in order to be of the most use to the test developers.
A variety of procedures can be used for obtaining item parameter estimates that are on the same scale using the common-item nonequivalent-groups design. The contractor (American Institutes for Research, 1998e) presents three options: (1) simultaneous (one-stage) calibration, (2) two-stage calibration and linking, and (3) the Stocking-Lord test characteristic curve (TCC) transformations. The contractor states that a disadvantage of the Stocking-Lord procedure is that “the procedure may result in the accumulation of relatively large amounts of equating error, given the large number of ‘links' in the chain of equatings required to adjust the test characteristic curves of some of the non-anchor forms. Also, it may be prohibitively time-consuming given the large number of computations required” (American Institutes for Research, 1998e:11). This rationale was presented as the primary reason for making the Stocking-Lord procedure the least preferred method for putting item parameters on a common scale.
There are several alternative ways in which the Stocking-Lord TCC procedure can be implemented for the VNT pilot test design. Two options that deserve more consideration are presented below. Both use a computer program developed by the Educational Testing Service (ETS) called PARSCALE, the program that is used to produce item parameter estimates for NAEP.
In option 1, for each school cluster, perform one PARSCALE run that simultaneously calibrates all items within that cluster. Select a school cluster to use as the base scale (say, cluster 1). Use the item parameters for the common items (i.e., form 1a, 1b, 2a, 2b) to compute a scale transformation from cluster 2 to cluster 1 and apply that transformation to the item parameter estimates for all items within cluster 2. Repeat this process for clusters 3 and 4. This option produces one set of item parameters for
all items in the non-anchor forms, but it results in four sets of item parameters for the items in the anchor forms.
In option 2, perform one PARSCALE run for the anchor forms, combining data across school clusters, and then perform the four within-cluster PARSCALE runs described in option 1. The base scale is defined using the item parameter estimates for the anchor items from the across-cluster run. In each cluster, a scale transformation is computed using the item parameter estimates from the within-cluster run and the item parameter estimates from the across-cluster run.
Option 1 for implementing the Stocking-Lord TCC method requires three scale transformations, and option 2 requires four scale transformations. Neither option requires a “large” number of transformations, and both are as easy to implement as the two-stage calibration and linking procedure.
The across-cluster PARSCALE run in option 2 is the same as the first stage of the two-stage calibration and linking procedure proposed by the contractor. The four within-cluster PARSCALE runs in options 1 and 2 are similar to stage two of the two-stage calibration and linking procedure, with the exception that the item parameters for the anchor items are estimated rather than fixed. An advantage of the Stocking-Lord TCC procedure over the two-stage calibration and linking procedure is that the multiple sets of parameter estimates for the anchor forms can be used to provide a check on model fit. Consequently, we suggest that the contractor select the calibration procedure that is best suited to the final data collection design, is compatible with software limitations, and permits item-fit analyses. To further assess the degree to which VNT and NAEP measure similar areas of knowledge, calibrations for VNT items could be performed and compared both with and without the NAEP items.
Forms Assembly and Item Survival Rates
The contractor has indicated that pilot test forms will be assembled to match the target form specifications to the extent possible. Although the idea of creating pilot test forms that resemble operational forms is reasonable, it implies an equal survival rate for various types of items. This is unlikely to be the case since constructed-response items tend to have lower survival rates than multiple-choice items. Constructed-response items may need to be piloted at a higher rate than multiple-choice items in order to produce sufficient items for the field test forms. The materials we reviewed did not specify the expected survival rates for the various item types nor did they discuss the rationale for determining item production or item survival rates. We could not tell on what basis production and survival rates are being estimated. We also could not tell how this information is being used to develop item writing orders or whether the cognitive labs are providing information that can be used to estimate item survival rates. This information needs to be explicitly stated and consideration should be given to inclusion of additional constructed-response items in expectation of lower survival rates for them than multiple-choice items.
PILOT TEST ANALYSES
The materials we reviewed included specifications for screening items according to item difficulty levels and item-total correlations based on the pilot test data. Plans should also be added for screening multiple-choice items for appropriate statistics on each incorrect (distractor) option, as well as for the correct option. In addition, plans should be added for screening items based on model fit for item response theory.
Differential Item Functioning
Additional specifications are needed for the ways in which items will be screened for differential item functioning (DIF) and the ways DIF results will be used in making decisions about the items. Differential item functioning refers to the situation that occurs when examinees from different groups have differing probabilities of getting an item correct, after being matched on ability level. For DIF analyses, examinees may be placed into groups according to a variety of characteristics, but often gender and ethnicity are the groupings of interest. Groupings are created so that one is the focal group (e.g., Hispanics) and the other is the referent group (e.g., whites). The total test score is generally used as the ability measure on which to match individuals across groups.
DIF analyses compare the probabilities of getting an item correct for individuals in the focal group with individuals in the referent group who have the same test score. Items for which the probabilities differ significantly (or for which the probabilities differ by a specified amount) are generally “flagged” and examined by judges to evaluate the nature of the differences. Good test development practice calls for symmetric treatment of DIF-flagged items. That is, items are flagged whenever the probability of correct response is significantly lower for one group than for the other after controlling for total test score, whether the lower probability is for the focal group or for the referent group.
A number of statistical procedures are available for use in screening items for DIF. The contractor has proposed to use the Mantel-Hanszel method for the pilot test data and methods based on item response theory for the field test data. The sampling plan will allow for comparisons based on race/ethnicity (African Americans and whites, Hispanics and whites) and gender (girls and boys). The sampling plan calls for oversampling during the pilot test in order to collect data for 200 African Americans, 168 Hispanics, and 400 girls on each item.
The proposed sample sizes and methods for DIF analyses are acceptable. However, little information is provided beyond that summarized in the above paragraph. The contractor needs to specify the ways in which DIF data will be analyzed and used. It is important to know what role DIF statistics will play in making judgments about the acceptability of items, whether strict cutoffs based on statistical indices be used, and whether human judgment will be part of decision making about items. It is also important to know whether expert judgmental reviews for sensitivity are being conducted prior to the pilot testing and whether the experts for such reviews will be consulted in evaluating items flagged for DIF. In addition, what will happen when DIF is evident for one focal group but not for others (e.g., for Hispanics but not for African Americans), and will treatment of flagged items be the same regardless of the direction of the DIF? For example, will items that exhibit extreme DIF in favor of the focal group be flagged (e.g., items that favor girls over boys) or only those that favor the reference group?
Computation of DIF statistics requires the formulation of a total score on which to match individuals. The pilot test form administration plan (which includes the hybrid forms) creates a series of half tests. Half tests are paired as described above, and items appear in only a single half test. Will the total score be formed using the half test in which the item appeared? In this case, the total score will be based on smaller numbers of items, which will affect the reliability of the ability estimate. Or will the total score be formed using the two paired half tests so that multiple estimates will exist for each item (e.g., 1a combined with 1b compared with 1a combined with 2b)? What are the plans for dealing with these issues?
Operational Form Difficulty and Information Targets
Targets for item difficulty or, more importantly, test information at different score levels need to be
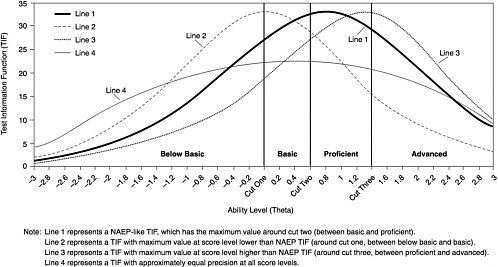
set before operational forms can be assembled. Item difficulty targets speak to the expected difficulty of the test forms. The test information function provides estimates of the expected accuracy of a test form at different score levels. Test difficulty and information functions are developed to be in accordance with the intended purposes and uses of a test, issues that have yet to be determined for the VNT. It is important that issues surrounding the purpose of the test be resolved soon. Without more information as to the purpose of the test and appropriate uses of the test scores, the contractor cannot formulate statistical test specifications, establish a score reporting scale, or finalize the field test data collection design.
Preliminary information is available from the contractor (American Institutes for Research, 1999g), which lays out the main issues, but more is needed. Figure 3-2, taken from the document, shows four potential test information functions for the VNT. As stated above, test information functions indicate the level of precision with which each ability level (or score) is estimated. Tests may be designed to maximize the amount of information provided at specific test scores, usually the test scores of most interest (e.g., where a cutpoint occurs or where most students perform). One of the test information functions (line 3) maximizes test information between the proficient and the advanced score levels. This function, in particular, will not be useful, since the majority of the examinees are likely to be at the basic score level. Another function (line 4) maximizes information across all score levels. If the VNT is being constructed from NAEP-like items, there may not be sufficient numbers of easy and hard items in the item pool to provide this level of measurement at the extremes. Use of target test information functions in test assembly will facilitate score comparability across forms and ensure that the measurement properties of the test support the intended score uses.
RECOMMENDATIONS
NAGB and its contractor have made progress in developing detailed plans for score reporting and for the design and analysis of pilot test data to screen items for inclusion in VNT forms. We have identified areas where additional detail is still needed, and we offer several recommendations for NAGB's consideration. We have reserved comment on difficult issues associated with the field test for our final report.
Recommendation 3.1 Given that test items and answer sheets will beprovided to students, parents, and teachers, test forms should bedesigned to support scoring using a straightforward, total correct-rawscore approach.
Recommendation 3.2 Achievement-level reporting should be supplementedwith reporting using a standardized numeric scale, and confidencebands on this scale, rather than probabilistic statements, shouldbe provided regarding the likelihood of classification errors.
Recommendation 3.3 Overlapping forms design (hybrid forms design)should be used for the pilot test, as planned. In addition, the contractorshould select the calibration procedure that is best suited to thefinal data collection design and in accord with software limitationsand should plan to conduct item-fit analyses.
Recommendation 3.4 Information regarding expected item survival ratesfrom pilot to field test should be stated explicitly, and NAGB shouldconsider pilot testing additional constructed-response items, giventhe likelihood of greater rates of problems with these types of itemsthan with multiple-choice items.
Recommendation 3.5 Detailed plans should be provided regarding itemanalyses of pilot test data. Specifically, methods for screeningmultiple-choice items for appropriate statistics on each distractorshould be used. Additional specifications should be provided forthe ways in which differential item functioning analyses will beconducted and their results used in making decisions about the items.
Recommendation 3.6 A target test information function should be decidedon and set. Although accuracy at all levels is important, accuracyat the lower boundaries of the basic and proficient levels appearsmost critical. Equivalent accuracy at the lower boundary of the advanced level may not be feasible with the current mix of items, and it maynot be desirable because the resulting test would be too difficultfor most students.











