
5
Overview of Technologies for Protecting and for Misappropriating Digital Intellectual Property Rights: The Current Situation and Future Prospects
Mark Stefik and Teresa Lunt
The subject that I will address today is technological capabilities and possibilities relative to database protection. I must say that my own background on technological protection hasn't had as much to do with databases as with other forms of electronic publication and digital publication. In many ways, extending ideas about protection to databases is something new, which is what I hope to explore with you a bit today. I expect to talk to you about both the current situation and future prospects. Teresa Lunt, recently of the Defense Advanced Projects Research Agency and now working at Xerox, will say some things in a video presentation about extending those ideas about database protection. Her work, in the past, has included a number of things on intrusion detection and security models for databases.
I must say at the outset, I am not here as an advocate for using necessarily the kinds of technological measures that I will be talking to you about today. I want to show you what is possible, what the inhibitions are for it today, and to just raise the awareness about the kinds of technology that may be coming down the path. In particular, one of the things that I want to emphasize in most of the examples will be a kind of protection that is outside the regimes that Richard Gilbert was just talking to us about. He talked about copyright; he talked about trade secret; he talked about patent. In fact, in terms of the legal basis, I am going to discuss measures that are more like contract law. They are not exactly the same as contract law, and the differences are interesting, but let me show you what is coming.
I will start with an example of buying digital work online and some of the notions that underlie the technological protection. In this example, we have someone buying a digital work online from a publisher. In some sense, money is flowing between the buyer and the publisher, and the digital work of some kind is flowing back. We will presume that along with the digital work are conveyed digital rights.
When the buyer is in the process of negotiating for this digital work, we also can presume that the possible rights and costs for those rights come back first and show up as a number of terms and conditions. I will call this a digital contract, because we can think of the notion that the buyer is going to pay for the rights to use the work in various ways.
In this case the digital contract says the rights are browsing, loading, and printing, although one can add more detail as to the meanings of those terms and conditions. If the buyer okays the rights and he is convinced that he is going to get what he wants and is not going to get other surprises, having bought the work, we can presume the transaction is agreed to; and now he can use the work on the computer. The computer is going to enforce the contract, in a way.
There is a sense in this example that exercising the right is like exercising a transaction. For example, with the use of ATM cards, you think of a transaction as walking up to an ATM machine, popping in your card, typing a password, and transferring some money, let 's say, from your savings account to your checking account. That is a transaction. There are various things
about that transaction that make it nonintermptible. So, for example, let's say you are transferring $100. You can't interrupt it halfway through and end up with $100 in both places, and you can't lose $100 in the transaction. The transaction either happens all the way or it doesn't happen at all. That is part of what is meant by a transaction in database terminology.
In our case, if the buyer decides he wants to read something, then that reading is like engaging in a transaction. If he wants to lend it to a friend, we will have to go through a process of what it means to lend out a database. Typically, if you lend out a book, while your friend has the book, you can't use it, and then when he returns it to you, you can use it again. There is a period of time during which only one copy is in use. That is different from making a copy, in which case both people can use it at the same time. And, if he wants to reuse some portion of the database—digitally extract some portion of the work—that comes under the category of derivative works.

FIGURE 5.1 What's in a right?
One of the inventive aspects of creating this kind of technology was to invent a rights language and to understand the different kinds of rights that matter. Depicted in Figure 5.1 are the elements of a typical right whereby, if you bought a digital work, there would be a collection of rights and each right would have the following kinds of elements to it. The first would be a permission category that identifies a right. There are three kinds of so-called transporting rights: copy, transfer, and loan, which should be clear from the previous example. Then, there are rendering rights. These include things like playing—if it is music, you could play it on a loudspeaker or a video; you could play it on a speaker. If it is a computer game, you could play it. Printing is rendering to a medium outside the zone of trust. If you think of the computer as being a trusted system, then printing the work on a piece of paper means that it is no longer being controlled digitally in any way. Exporting means to move a file copy of the work in some form
outside the regime of trust. Each of those things is a separable kind of right.
Derivative work rights include the right to edit or make changes to the work, but with limits on the kinds of changes that can be made. In other words, you might be able to extract portions of it, but if you extract a certain section, maybe you have got to extract a certain amount or longer. This would be an attempt electronically to control quoting things out of context. Extracting is embedding the right to include the work in some larger work and also have rights travel with it to the larger work. Another permission category includes various kinds of file management rights. I will skip over those in the interest of time.
Another aspect of specifying a particular right is the time period during which the right is good. For example, you could rent something to use once. You could have something that you could use for an hour, although you could use 15 minutes today, 15 minutes tomorrow, and 15 minutes the next day or that sort of thing. It could be something that runs for an hour, starting from the first moment you ask to start using it. Then there are differences between sliding intervals and fixed intervals.
In fact, there is a whole sublanguage within what is called the digital copyright language for expressing different sorts of things. For example, “Fee spec” has to do with how charging is monitored. Is it five minutes, is it five years, is it prepaid; do you write a ticket that you could use? In effect, the elements of the language that evolved for handling the fees evolved to handle a number of different commercial venues in which these might be exercised.
Finally, under the access specification, there are digital certificates, which is a way of characterizing either the identity or the nature of the organization that might be using it. For example, it might be registered to a given individual who carries a digital certificate attesting to who he is. In addition, there might be certificates that are different for commercial or not-for-profit or governmental organizations. Another example could be a poverty certificate that would attest the bearer gets special bargains because he afford the work otherwise. There is also the question of whether publishers of these works would be inclined to use those sorts of certificates and who would award those certificates and so on.
The rights language, then, is something that is interpreted the same way by all kinds of trusted systems. They would use the same terms to exercise the rights in the same way. All of the various rights described are potentially enforceable by a computer. There isn't an intent within the language to express the right to translate into German, since who would know, how would the computer decide if you had done a good job, and so on. So, things like that are basically not included in the rights language. The presumption is that to gain rights of that sort would require some mechanism outside the rights language. It is not a function of the trusted system.
An example of rights on a particular digital work is shown in Figure 5.2. At the top are things that apply to all the rights, such as where the charges go for exercising a certain right. As such, there is a copying right with a per-use fee of $5. Again, currencies and so on are also among the things that have to be accounted for in any such language as this. There is also a fee for playing the work. In this case, it is $0.10 per hour with a maximum of $0.50 per day. There is also a printing right with a per-use fee of $10 in this case. Then under the printing right, there are some other things, for example, requirements of the printer itself.
This is where protections like watermarks come in. Among the things that were discussed this morning was online access to works. We didn 't say anything about somebody who prints out a database. We won't have any kind of protection or control that extends in that regard. In this case, there is certain information that has to be encoded, and certain
characteristics the printer has to have. It has to be a certain kind of trusted printer.

FIGURE 5.2 Sample fees, terms, and conditions.
I am not going to cover the kinds of protection that can be associated with printers. However, there are protections like encrypted transmissions to printers, invisible inks, markings that show up in the paper, disappearing inks, and a zillion kinds of technologies that can be brought to bear here. I am just going to tell you that all of that is sort of future perfect, that Xerox knows how to do some of these things, and there are other companies working in this area, too.
The market is still quite nascent. For those of you who aren't already familiar with it, an example is a document that carries information about the document in the document's watermark. Where is the watermark? There are lots of ways to hide information on paper. You can do it in the gray scale of the color images of a picture. You can hide information in the spacing of the lines. You can carry things called glyphs or other one- or two-dimensional markings on the page which carry information. For example, an ordinary printer with 300 dots per inch can carry, I think, around 300 bytes of information in a square inch with quite ordinary technology. So, you can carry a fair amount of data with little glyph patches.
There are also things that you can do with paper, about threads of the paper and the like, bind the content to the actual page on which it is printed. The normal idea behind this business of watermarking, of course, is that it doesn't prevent copying necessarily. There are technologies for that, too. It is more that you can find out who printed it, so that in principle it is possible to leave an audit trail, to find out whether people paid for all the copies that seem to be in circulation, such that if someone pays to print one copy and walks over to a photocopier and makes 50 copies, it is possible to find out who printed it in the first place.
Some of the implementation and research issues involved in digital works are described
in Figure 5.3; one is competing systems. There are at least two, or possibly three, different rights languages that are used by different companies right now. So, there are no standards, just multiple offerings.

FIGURE 5.3 Research and implementation issues.
Another, perhaps more fundamental, issue is that there are really different communities here. We talked a little bit today about the specialness of the scientific community. I told a joke the other night about how special we are. What other community in the world pays to publish its work? Normally you get paid to publish. No, we pay to publish. A friend of mine characterized scientific publication as right only. This is based on the measurement that approximately 0.75 people read the average scientific article, including the reviewer. But we really are special in a lot of ways and have different values and notions about that.
In this case, I want to compare scientific publication with not only the great variety of different communities for what you may think of as being text- or paper-based works, but also music and movies, which are, in fact, very different. For example, the movie industry has only a limited interest in making it easy to extract or use portions of movies. I had a conversation with people when the DVD standards were being promoted, wondering why they were so limited in terms of the kinds of things they could express. All they really wanted to express at that point were things that would prevent copying. I said, “Well, what if I want to reuse 15 seconds of this movie for something, even for film school?” They said, “Well, sure, we can talk about that. That will be $10,000; shall I put it on your card?” There was a real sense that they weren't interested in the smaller sorts of transactions, although multimedia systems are beginning to push the envelope in that a little bit.
Another whole region of issues is how we want to handle fair use. In the digital arena, fair use has lots of open questions. One of the possibilities is to allow people to have a fair-use
license, which means that they could use words without paying for them in ways that other people might not. This is a very different concept of fair use. Those of you who have a legal background recognize that fair use is actually a legal defense; it is not exactly a right. It has nothing to do with licensing. So, in a way, I am relabeling different concepts here with the name “fair use,” to give you a sense of what it might be for.
Let's suppose you have to go to school for a little bit to take a class and pass some test to understand fair use. So, now you have some kind of digital work under the guise of fair use, then turn around and turn it loose on the Internet, causing economic harm to the original publisher. The question is, Who is going to pay for that extra risk? Will there be an insurance regime for that? I see issues such as how we handle security issues or vulnerability as being quite open.
The other comment is that the sort of personal computers we are using right now have very little security. The biggest risk is viruses. If a security-disabling computer virus turns things loose or disables property protection regimes, it is not you who are liable. You didn 't do it on purpose. You don't have the usual liability standards.
Finally, the notion of digital certificates requires a public key infrastructure system that isn't available yet. A lot of this technology is coming, but it is not developing very quickly.
Now that I have provided an overview of the state of technology relative to documents and other kinds of digital works, I would like to consider the question, What does it mean to translate security technology into databases? I will summarize Teresa Lunt's videotaped presentation on databases. Teresa first discussed the label-based controls that are used in so-called trusted database system products. Since a database is a finite size, you can protect certain portions of the database or certain classes of information defining levels of protection to parts of the database. Labels are used to identify classes of information. Some examples might be proprietary, customer-sensitive, personnel, and so on.
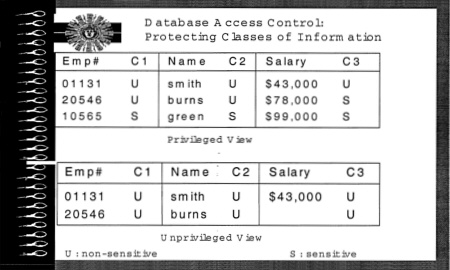
FIGURE 5.4 Database access controls: Protecting classes of information.
The example in Figure 5.4 shows two classes of information, sensitive and nonsensitive. Queries that return information label each item returned with its sensitivity label (most commercial systems label only rows and not individual data items, as in this example). The query result at the top of the figure, labeled Privileged View, can be returned to a user who is permitted to see both sensitive and nonsensitive information. The query result at the bottom of the figure, labeled Unprivileged View, can be returned to a user who is permitted only nonsensitive information. Generally these labels are ordered, so that users who are permitted sensitive information are also automatically permitted nonsensitive information. In preference to, or in addition to, labels, most database systems use access control lists to control access to data. If a username is on the access control list (ACL) for a table or a column in a table, that user can access the data. The ACL further specifies what the user is allowed to do with those data, whether read or read/write. It is conceivable that database access controls could be augmented for other types of rights (e.g., copy, loan, print, derivative work, transfer) that would be useful for digital libraries of documents, videos, music files, and images. Database access controls could also be augmented to provide validity periods for rights. Access control lists or label names could be extended or replaced with lists of certificates, which could indicate identity or category of person or organization (e.g., academic, nonprofit, commercial, government, country). Database views or composite objects could be associated with fees and fee certificates for different kinds of uses.
Teresa then discussed the structural inference problem that can be found in databases. She described an inference channel, which is a chain of relationships that allow high information to be inferred from low data. This inference channel is dependent on explicit data relationships rather than on data values and can result from incorrect or inconsistent labeling. A simple example of such an inference is shown in Figure 5.5.

FIGURE 5.5 Structural inference problem.
Teresa also discussed the statistical inference problem. That is, sensitive data such as
salaries can be inferred from statistical summaries, such as counts, averages, deviations, and so on. A statistic is sensitive if it reveals confidential information about an individual. The U.S. Census Bureau calls a statistic sensitive if n or fewer values contribute more than k% of the total. For example, in the query
select sum(earnings)
from census-data
where city = 'endicott',
the query result will be considered sensitive if there is one company in Endicott whose earnings are much greater than all the other businesses there combined. A sensitive statistic q is considered protected if and only if it is not possible to obtain an estimate that a < q < b with probability greater than p near 1, where b - a < k for small k. That is, it should not be possible to narrow down the possible range of values to a small range with high probability. The difficulty of compromise is the number of released statistics needed to perform such an estimation.

FIGURE 5.6 Countermeasures.
There are a number of countermeasures that can be taken, which are described in Figure 5.6. All of these countermeasures involve removing or altering information. For published statistics, such as databases given out on CD-ROM, more information must be removed or altered, because it is not possible to restrict in real time the kinds of queries that a user makes. For online databases, real-time controls can be used to prevent attacks involving the use of multiple overlapping queries to discover sensitive statistics. In using countermeasures thus there is a trade off between security and information loss. Some countermeasures involve less loss of information but also provide less security. It might be possible to define degrees of inference and to use these to define access rights, depending on the trust accorded to each user.
Let me summarize the challenges associated with security technology, whether it is applied to databases or whether it is applied to other forms of digital documents. The first thing is that the problems we are looking at here aren't really just technological. There is a combination of social, legal, and technological issues. Figure 5.7 summarizes some of the challenges in these three areas.

FIGURE 5.7 Summary: Social, legal, and technological challenges.
In the social area, there is really no established socially sanctioned approach to risk management relative to loss of income or loss of things on digital works. What is different here, for example, from digital works and, let's say, paper-based publishing is that the person receiving the digital work could—this, of course, depends on the market a little bit—in principle, distribute things as easily and as cheaply as the publisher. That is simply not true when we are talking about a paper-based publication or something like that. Of course, it is really not true for giant databases either. So, we have to examine the cases where that is true. The question that comes to mind is, Should we have the kind of digital property insurance to pay for the ones that get away?
From a legal perspective, we really don't have an established approach for digital fair use. At least, so say I, and I would be interested in hearing what the proposals actually are. There is no clear notion for legal trust boundaries, for example, if we wanted to have import/export restrictions on a particular database, which is not unusual in marketing a book, where one company might own the rights to distribute in Spain, and another might have the rights to distribute in France. How do you handle that for computers? If I am an American in France accessing the Internet on my laptop and downloading a file that is supposed to be used only in the United States, and then I carry my laptop back into the United States, have I exported it twice or not at all?
That is a conundrum that really is not addressed by current law. That is something that you could handle if it was declared that the laptop is actually an American computer and the trust boundaries have to do with loading things onto that computer. I am an American with various certificates attesting to my identity. The legal framework hasn't evolved to handle things that way yet.
Finally, on the technological side, the experimentation and the technology are more evolved for other works than for databases. It doesn't really handle the fine-grained protection or the kinds of uses that can be involved in this sort of combining or merging of databases, as we heard this morning. The rights for that could be extended to control access, inference, merging, and things like that, but they really haven't been yet. Current trusted systems are vulnerable to many things, the most serious of which I think is virus attack because it undermines the notion of liability. Finally, there is no widespread public key infrastructure.
GENERAL DISCUSSION
MR. BAND: I have two questions. First, my sense is that there are three main ways of distributing databases these days. One is print, one is on CD-ROM, and one is online databases. Could you quickly summarize the differences in the ability to protect, technologically, works and databases that are distributed in those three different ways, both now and, if possible, in five years?
The next question relates to a bill that passed last year. You are probably familiar with the Digital Millennium Copyright Act, which imposes all kinds of restrictions on the circumvention of copy controls and access controls. Looking ahead five years to the kinds of technology that you anticipate will be in existence, to what extent will a lot of problems that people have been talking about, the inability to protect databases, be taken care of by technology plus the Digital Millennium Copyright Act's prohibition of certain technology?
DR. STEFIK: The first question had to do with the different protection regimes for paper, CD-ROM, and the Internet. For works distributed on paper, I think things having to do with watermarks are the main kind of protection that I see, other than using copyright law itself. In principle, anything you can see with your eyes, you can take a picture of. In this case, all you can really do is have parts of the information embedded to make it possible to trace. There are different kinds of watermarks, using spread-spectrum technology and lots of other things that are vulnerable, to different degrees, to different kinds of attacks.
One aspect of security is the budget of the person who is releasing the information and publishing the information, and the budget of the attacker. Are we talking about the individual in the garage or are we talking about a well-funded threat? In a sense, it is sort of like an arms race. That is even true in the paperback media.
For CD-ROMs, many are keyed to the buyer's computer or have a code you have to type in, in some way, to protect it. Most of the CD-ROM-based things that are available right now really protect access. They don't have any controls once you have gained access, unless it is a software program that has to be used to interpret the CD-ROM and the systems were enabled in some way to prevent other programs from reading it. CD-ROM-based data as well as network-based data are always vulnerable to reverse engineering from a security point of view, accessible to anyone who can crack the system and get a copy in the clear or get a copy through the system that other way.
I think that the virus threat is just as serious for CD-ROM-based distribution as it is for Web-based distribution, in the sense that a virus could be something which undermines any protection regime that someone has put in place. To my mind, we probably won't address that seriously until we have computers that have a different approach to handling viruses. Instead of keeping a listing of all the bad genes, the viruses so to speak, it probably needs to have a way of certifying the so-called good genes—that is, knowing who you are—which is how the immune system actually works. In that case, you simply wouldn't be able to load a program that hasn't been certified as being “virus free” and doesn't disable things. That kind of a sweeping change in the way our personal computers work is going to take some cooperation between the major computer hardware and software manufacturers, and there hasn't been a big move in that direction yet.
You also asked about protection measures and the recent law about reverse engineering or breaking into systems, circumventing methods for preventing tampering. I would like to see how the law gets used as it moves forward. There have been a lot of questions about misuse of this kind of a law, if any kind of software has a legitimate use as well as use for breaking into things. I actually think that is going to end up being like an arms race. In the case of things like viruses, if someone turns loose a virus that, in fact, disables some protection regime, who is liable? How do you catch the person who turned it loose in the first place? I think that is an open question.
PARTICIPANT: I was wondering why you think that databases are less protected right now by the technology than other forms of material?
DR. STEFIK: One of the things that I might have meant is that the uses of a database, which of course is more fine grained, include things like inferential uses, and some people would like to protect those things. That is not worked out in the course of the document. You don't watch a movie and then try to tell people what to think. I mean, it is sort of analogous to using a database and merging data in a certain way. Even having ways of characterizing that thing and having intellectual controls on it is not really so well established.
The other thing about protecting some kinds of databases depends on what you are trying to protect. For example, if you had a database containing information that John Doe has AIDS and you are trying to protect that information from getting out, that is like one bit of data. There is essentially no way to keep someone from reading that off the screen and picking up the telephone and telling the wrong party that information. That is the kind of concern that comes up with databases that you wouldn't think of coming up in a copyright regime for something like a book. You can read a book and you can read anything in it and you can tell anybody anything you want. You are not as concerned about trying to protect individual facts or how individual elements of data may, in fact, be used.
Relative to the technology, there is a third possible meaning here. The kinds of technology using encryption and a variety of other kinds of technology that we are seeing in digital publishing simply haven 't been integrated in any way with database technology yet. I can't think of any reason why they couldn't be. It is just that either the research or the development hasn 't taken that path yet. So, that is all still in the future. There are some trusted systems, Oracle and a few like that, but they still tend to be pretty far behind the times relative to what they actually offer.











