
2
The Data Access, Confidentiality Tradeoff
This chapter presents participants' views on the workshop's overarching theme—the balancing of data protection needs and requirements against the benefit of access to linked longitudinal data. Academic researchers were understandably more vocal about improving data detail and access, while data stewards were more concerned about security and protection of confidentiality. The lines between the two communities are not always clearly drawn, however. For instance, most federal agencies are accountable for both functions, protecting the interests of data subjects through procedures that ensure appropriate standards of privacy and confidentiality, and facilitating responsible dissemination to users (National Research Council and Social Science Research Council, 1993).
It is impossible to specify a universally applicable optimal tradeoff between data access and data protection. The value of data-intensive research is highly variable, as are mission, operation, and data production across agencies. The panel that produced the report Private Lives and Public Policies recognized this variability and did not advocate trying to identify such a tradeoff (National Research Council and Social Science Research Council, 1993). However, workshop participants expressed general optimism about the possibilities for developing tools that would enhance, on a case-by-case basis, the ability to increase data access without compromising data protection or, conversely, to increase confidentiality without compromising data access.
ROLE OF LINKED LONGITUDINAL MICRODATA IN RESEARCH AND POLICY
The nation faces a range of increasingly complex policy issues in such areas as social security, health care, population aging, changing savings patterns, advancing medical technology, and changing family structure. Addressing these issues will require increasingly sophisticated data and behavioral modeling. Microdata sets, such as those from the Health and Retirement Study (HRS), offer the most promising means of answering specific questions such as how social security interacts with pensions and savings in household efforts to finance retirement, how social security age eligibility requirements affect retirement rates and timing, and how changes in out-of-pocket medical expenses affect utilization of federal programs.
Survey data sets, particularly those linked to administrative records, facilitate a broad spectrum of research that can shed light on such questions, and that could not otherwise be reliably conducted. Additionally, linking to existing information can streamline the data production process by reducing the need to duplicate survey activities. Linking of survey and administrative data has the potential to both improve data quality and reduce data production costs.
Research Benefits of Linking Survey and Administrative Data
Researchers attending the workshop expressed the view that data linking opens up a wide range of research and modeling options. Richard Burkhauser of Cornell University presented his paper (coauthored by Robert Weathers, also of Cornell), “How Policy Variables Influence the Timing of Social Security Disability Applications,” to lead off the opening session. His presentation focused on how the HRS made his study possible. Burkhauser and other participants praised the HRS, calling it a clear “case study” of the potential of linked longitudinal data to advance policy-oriented social science research.
For his application, Burkhauser was able to model the effects of social security on economic behavior, including retirement decisions. This type of analysis follows in the tradition of economic research conducted during the 1970s that used the Retirement History Survey and the Exact Match File, which actually linked Current Population Survey data to Internal Revenue Service (IRS) and social security records.1 In the opinion of several partici-
|
1 |
These data stimulated significant research in the 1970s and set the agenda for the 1980s. However, during the 1980s, budget cutbacks, combined with the emerging emphasis on confidentiality, affected the ability of the Social Security Administration and other agencies to produce and disseminate new data. |
pants, the HRS files, along with new data sets from other sources, such as the Disability Evaluation Study, will be the key inputs for models that will allow researchers to address policy questions about household savings patterns, social security solvency, worker retirement patterns, and other issues that require accurate and detailed financial information.
The HRS longitudinal data set follows about 22,000 persons aged 50 and above and their spouses; data are collected every other year. With the consent of participating individuals, survey data are linked to social security earnings histories and also to some employer pension plan data. Linked records that allow identification at as low as the state level are maintained internally. The HRS is available in a public use-form, and with linkages to social security and pension information under restricted conditions. Access to geocoding is also restricted; to gain such access, a researcher must go through an institutional review board with a research plan and data protection provisions. Firm-level data have been linked as well, and while access to Medicare data has not yet been authorized, work on associated data collection processes and restricted access protocols is in progress. Multiple linkages are also permitted, typically under even more restricted conditions.
The HRS also provides detailed survey information—some of it retrospective—about the health conditions and work patterns of respondents. However, it is the linkage to administrative records that is exceptionally valuable for policy research. Linking to social security data allows researchers to construct earnings histories and to determine each person's potential disability benefits. Past earnings are available to predict potential future earnings for cases in which individuals have not yet applied for benefits. Linking HRS data with administrative records and geographic information allowed Burkhauser and Weathers to answer questions that could not otherwise have been answered. For instance, the authors were able to estimate how disability allowance rates affected the timing and rate of application for benefits. Likewise, they were able to estimate the behavioral impact of expected benefit level, expected earnings, gender effects, and policy variables.
Linking to administrative records can improve data accuracy as well as data scope by giving researchers access to information that individuals may not be able to recall or estimate accurately in a survey context. Survey data can be biased as a result of flaws in respondent memory or understanding of measurement concepts. For instance, the HRS is linked to social security files containing lifetime earnings data that would be virtually impossible for respondents to recall or even find in records. Similar situations arise with regard to medical records. Also, survey data are devalued if they fail to capture variability of parameters accurately, since this variability is central to modeling efforts and, in turn, the ability to answer policy questions. HRS linkages introduce accuracy and detail to the data that are particularly constructive for modeling savings incentives, retirement decisions, and other dy-
namic economic behavior. The authors concluded that the HRS was a clear example in which the potential research benefits of linking were sufficiently large that the Social Security Administration could justify approving the linking proposal with minimal controversy.
Also in the first session, Rachel Gordon of the University of Illinois at Chicago presented a second example illustrating the benefits of data linking. Her research investigates the impact of community context on child development and socialization patterns, as well as the impact of the availability of child care on parents' work decisions. By having access to a National Longitudinal Survey of Youth (NLS-Y) file with detailed geographic codes for survey respondents, Gordon was able to add contextual data, such as the availability of child care, for the neighborhoods in which respondents lived. Gordon's application highlights the tradeoff between data precision and disclosure risks. Access to census tract-level geocoding permits more sensitive construction of community and child care variables central to the study but could, under certain conditions, greatly increase the indentifiability of individual NLS-Y records.
During the general discussion, participants cited other aspects of linking that increase data utility. Linking makes it possible to get more out of isolated data sets that would otherwise have limited application. The process can increase the value of data sets, reduce data collection redundancies, and improve data accuracy in a cost-effective manner, and provides added flexibility to meet unforeseen future research needs with existing data sets. For example, if the Census Bureau's Survey of Income and Program Participation could be linked to administrative tax return records, income data would likely be more accurate and the cost of the survey decreased. Robert Willis of the University of Michigan also made the point that this type of linking reduces response burden. If survey designers know that links can be made to administrative data, they can limit the length of questionnaires.
The benefits of linked data extend beyond social science research, which was the focus of this workshop. Robert Boruch from the University of Pennsylvania pointed out, for example, that linking records is essential for randomized field trials in the social sector (crime, welfare, education). J. Michael Dean from the University of Utah Medical Center reiterated these points for medical research, observing that there is no way to conduct high-quality clinical trials in many different areas without the capacity for linking; the same can be said of work in criminal justice.
Linking also facilitates research on infrequent events, such as rare diseases, that affect only a small percentage of the population. In such cases, working from general sample data does not provide adequate sample sizes for target groups. Population-based data, which are very expensive to collect, are often required. Linking can, in some instances, provide a much less costly substitute.
Assessing and Articulating the Social Value of Research
Robert Boruch noted in his presentation that 20 years ago, despite interagency agreements to link data sources at the IRS, the Census Bureau, and other agencies, examples of the benefits of linking were few and far between. In contrast, current research, as represented by workshop presentations in Session I, demonstrates the extent to which this landscape has changed. Yet several researchers expressed concern that it seems easier to discuss the risks associated with data provision than to communicate the benefits convincingly. They suggested that researchers have done a poor job of publicizing the value of their work. Boruch summarized the view, noting, “We do not sell social research well in this country, and that is part of the reason why at least a half dozen large private foundations are trying to understand how to do that job better.”
Of course, it can be difficult for agencies and organizations to assess the value of their data without carefully tracking the numbers and types of users, as well as information on those being denied access. The panel that produced Private Lives and Public Policies explicitly recommended establishing procedures for keeping records of data requests denied or partially fulfilled. This recommendation could be expanded to encourage full documentation of data usage. Developing archives and registries of data performance may serve as an effective first step toward fostering understanding by both the public and policy makers of the extent to which data-intensive research provides key information.
Research Impact of Data Alteration Versus Access Restriction
Alternative methods for reducing statistical disclosure risks were discussed at length. At the most general level, the options fall into two categories—data alteration and access restriction. The discussion of these approaches is detailed in Chapter 4 and Chapter 5. On balance, researchers participating in the workshop expressed a preference for monitoring the behavior of scientists over altering the content of data sets to permit broader distribution. They favored licensing agreements, data enclaves, and the like over perturbation methods. They also advocated the use of legal remedies (discussed in Chapter 3 and Chapter 4) whenever possible as a nonintrusive (to rule-abiding researchers) alternative that rewards responsible data use.
Researchers expressed serious concern about the impact of statistical disclosure limitation techniques that distort variable relationships and that may have an unanticipated (or even anticipated) impact on modeling results. The perception among leading researchers appears to be that altered or, more specifically, synthetic data can solve some problems, but are inadequate for the majority of cutting-edge work. Regardless of its accuracy, this perception
implies that such data may be less likely to be used, which damages the research enterprise. Sophisticated data perturbation also increases the methodological knowledge researchers must have to understand data, utilize them legitimately, and produce interpretable results.
Several researchers cautioned that, although they would rather live with the burden of limited access than deal with synthetic data, data centers and other limited access arrangements do impose costs on research. To the extent that data centers favor large-budget research projects, less well-funded disciplines can be prevented from accessing important data resources. Also, an important reason for accessing a data set is to replicate findings of other researchers. Typically, programs used to create data files must be designed in such a way that they can be shared by others wishing to replicate work. When researchers must repeat the entire data acquisition process, documentation and replication become more cumbersome. Additionally, one participant noted that when projects must be approved by agencies that host data, the potential is created for censorship, as well as milder forms of restriction arising from a lack of familiarity with the scientific literature.
Participants also raised the issue of research timing as it relates to policy relevance. The benefits of research can be dampened when data acquisition is arduous and results are delayed. For instance, it took Burkhauser and Weathers 2 years to gain access to restricted data required for their analysis. Accessing previously linked data will become less time-consuming if data centers are able to streamline their procedures effectively.
At data enclaves, researchers must typically submit programs to center staff who then perform the necessary data processing steps. For Burkhauser and Weathers, this meant enlisting HRS staff to merge the data sets, run the programs, and produce output that could then be rechecked. The length of this iterative process depends on the turnaround time from the data center and the number of adjustments and resubmissions required by the researcher. This process can appear burdensome and inefficient to researchers accustomed to having access to detailed data, doing the coding, and creating extract files themselves. These researchers argue that one must understand the process of research to assess the effectiveness of a remote access program.
Another indirect consequence, noted by Rachel Gordon, of limiting access to small-area geographic codes for survey respondents is that doing so may conceal demand by researchers for better data of one type or another. If researchers know, for example, that they can link contextual information, this type of work will be done, and in the process, the type of information of interest to the research community will be revealed. This feedback can in turn be used by producing agencies and organizations to make funding and allocation decisions.
THE CONFIDENTIALITY PROTECTION CONSTRAINT: ASSESSING THE RISKS
In addition to estimating the value of data access, efficient and balanced policy requires accurately assessing the disclosure risks (and associated social cost) posed by microdata and linking.2 Risk of disclosure is affected by numerous data set characteristics. Level of geographic detail is often the factor cited first. Small-area geocodes can make reidentification possible using basic statistical techniques. More advanced computer science methods, outlined by Latanya Sweeney of Carnegie-Mellon University, can substantially increase the power of reidentification techniques. As the sample approaches its underlying population, the geographic unit must increase in size if a constant level of protection is to be maintained. Certain types of surveys, such as those for people with rare medical conditions, maintain high sample rates from the subpopulation from which they are drawn. Likewise, geographic units must increase in size with the number of variables that can be cross-referenced if disclosure risk is to be held constant.
In addition to detrimental effects on exposed citizens, disclosure events can negatively impact data-intensive research enterprises. Several workshop participants argued that more work is needed on assessing the impact of disclosure (or perceived high risk) on survey participation. If potential survey participants observe instances of disclosure, or even perceive that confidentiality is becoming less secure, it may become more difficult for data producing organizations and agencies to enlist their cooperation. Arthur Kennickell of the Federal Reserve Board suggested that disclosure of individuals in the Fed's Survey of Consumer Finances might endanger the whole study, even if it were just an annoyance for those involved. Similarly, if potential survey participants believe that linking increases risks, or that all data about them are available through linking, they may be less forthcoming with information and their time. A theme that emerged from the workshop was that advancing access and confidentiality objectives requires cognizance of the relationship between the perceptions of respondents and the ability to collect data.3 Developing better methods for eliciting consent and educating the public about
|
2 |
The risk-cost relationship question was raised but not answered at the workshop. Risk is a function of both the probability of and the potential damage from disclosure. Participants acknowledged the need to assess disclosure risks; they were less certain about how best to quantify harm—the true cost—that results from disclosure. This question requires additional attention. |
|
3 |
A report produced by the Panel on Privacy and Confidentiality as Factors in Survey Response (National Research Council, 1979) provides some evidence about respondent attitudes, indicating that promises about confidentiality and data security are often questioned by the public. |
the real risks associated with survey involvement maybe a cost-effective use of resources.
Absolute Versus Relative Risks Associated with Data Access and Linking
Discussions of disclosure risk often emphasize the isolated probability that identifiable information will be revealed about an individual from a survey or administrative data set. CNSTAT member Thomas Louis of the University of Minnesota suggested recasting the debate: instead of comparing risks with probability zero, one might consider how the probability of disclosure changes as a result of a specific data release or linkage, or from adding (or masking) fields in a data set. In this context, the question becomes what marginal risk is associated with an action.
For cases in which the same data are available elsewhere, even if not in the same form or variable combination, the added risk of releasing a research data file may be comparatively small. Given the current trend whereby more and more data are becoming available, it may be reasonable to assume that the marginal risk of releasing research data has actually diminished. The validity of this assumption is, at present, unknown since no one has estimated the risk of disclosure as a function of survey inclusion conditional on the existence of data available from other sources. If security risks are rising rapidly in general, the relative risk of scientific survey data may be decreasing.
Robert Gellman, consultant, described the sensitive data that are available from a wide range of sources. Records such as driver's licenses, voter registration information, vehicle licenses, property tax records, arrest records, and political contributions, to name a few, are readily available to the public in many jurisdictions. Additionally, marketers compile this information into lists that are also available, often at low cost. Companies have software designed to locate, retrieve, and cross-reference information to construct detailed consumer profiles and mailing lists. For a given individual, these lists may include name, address, age, date of birth, marital status, income, household size, number of credit cards, occupation, phone number, and even social security number. Much of this information is constructed from linkages across sources. However, these market-oriented data collectors are not typically building their products from longitudinal research data sources.
Some participants argued that policy makers need to consider how rules should differ and how each should apply to different types of data. There appear to be far more recorded instances of breached confidentiality with nonresearch data, or at least data used for nonresearch purposes.4 If this is
|
4 |
In fact, though there have been numerous cases reported anecdotally in which procedural rules governing data use were violated, there are no known cases in which a respondent was harmed as a result of disclosures from a research data set. |
true, legislation designed to protect against data misuse, if not carefully constructed, could extend unnecessarily to research data or, on the other hand, be too lax to safeguard the public from commercial data abuses.
Confusion over confidentiality risks associated with different types of data can inhibit the creation and productive exploitation of legitimate research data. The risks associated with participating in a well-designed and well-conducted scientific survey may be very different from those posed by marketing data; when these distinctions become blurred and all data production activities are viewed homogeneously, the public is more likely to believe that data endanger privacy. Although survey data may not add much to the danger, suspicions about data in general make collecting data more difficult, which in turn constrains data-intensive research.
J. Michael Dean pointed out the importance of comparing the risks posed by linked data against those posed by native data sets—that is, the original data from which the links were made. In many cases, he argued, the native databases are already sensitive and as such require adequate protection. The linking may create a combined data set that increases disclosure risks substantially, but this is not always the case. A disclosure incident occurring from a linked data source is not necessarily caused by the linking; it might have occurred from the stand-alone data as well. Again, the marginal risk associated with the link needs to be evaluated, preferably against the research benefit. This evaluation requires assessing the extent to which stewards and users of data sets are likely to be responsible for leaks. It is necessary to assess how likely people handling medical records or working at agencies are to be sources of leaks relative to users of linked data. Effort expended to protect the security of data at the source versus at the linking phase should be proportional to the relative disclosure risks posed at each point. Unfortunately, such assessments of relative risk have as yet typically not been made.
It is also important to distinguish between organizationally linked data (such as the HRS) and individual user-linked data. The enormous growth of computing power and data availability is constantly changing the cost parameters of “snooping.” To begin with, the prospective linker must have software that can be expensive. Some probabilistic matching programs can cost thousands of dollars, while other types of data linking can be performed with tools as simple as Microsoft Access. The cost of linking is a deterrent, but this cost varies significantly with the type of linking performed. Latanya Sweeney reported that she is able to identify individuals from a range of publicly available data sources using simple software in combination with creative methods. However, her applications have thus far focused on localized geographic data sources, and it remains to be seen how far computer science-based methods can go toward identifying individuals from national longitudinal surveys linked to administrative records.
The probability of being able to identify a record within a longitudinal
research database also depends on the snooper's objective. Knowing whether an individual is in a sample makes an enormous difference in terms of identifiability (Juster, 1991). For instance, a snooper can guess with much greater certainty whether an individual is in a localized database of voter registration records than whether an individual is in the HRS. Of course, if the snooper is simply trying to identify a random record, that is another matter altogether.5 It is important to note that, for sample-based research data sets, a given level of confidentiality can generally be obtained with less protection than is required for population-based data sources, such as voter registration records, municipal registries, local censuses, and hospital administrative records.
A related issue is the need to distinguish among different kinds of data users. At one end of the spectrum are individuals whose data use is motivated by objectives other than disclosing identities intentionally; at the other end are those with vested interests in doing just that. The latter group may be involved in marketing, conflict resolution, law enforcement, or a range of other activities. It may be presumed that researchers typically fall at the “safe” end of the spectrum, and that those seeking information on specific individuals are less likely to rely on research data than on other sources. 6 However, the extent to which this generalization holds is not known.
Nonetheless, several participants expressed the view that access rules must be tailored to reflect risk levels posed by specific types of data users. When access rules are set universally, they typically tend to protect against the most dangerous users, limiting the ability to maximize the social return on data. It is highly unlikely that the same legal framework designed to protect individuals from marketers, employers, or the media is appropriate to apply to researchers and research data. The risks and benefits involved are not comparable.
On the other hand, several participants indicated that it is no simple task to regulate data access by class of user since traditional categories overlap, and data users may work in multiple areas. To establish clear rules and procedures for researchers, these participants suggested first gaining a clearer idea of who needs to be covered and in what way. No one has adequately sorted
|
5 |
This point also relates to the debate between Sweeney and Dean about the ease with which data sources can be linked. The distinction between Sweeney's position—that linking is inexpensive and requires only basic software —and Dean's—that linking is difficult and expensive—is at least partially tied to a snooper's objective. Sweeney's works suggests that it is technically possible to quickly link records of some individuals from two large files; at the same time, as Dean argued, building an accurate comprehensive linked data set from the two sources may require many identifiers and a high degree of sophistication. |
|
6 |
Similar arguments were advanced to support the view that regulating the behavior of data users is more efficient than altering the data to allow broader access. This discussion is reviewed in Chapter 4. |
out how identification of the various players, even those in the research community—e.g., top researchers, all researchers, graduate students—should work.
Quantifying Disclosure Risks and Costs, and Research and Policy Benefits
As suggested earlier, a fully informed data release policy requires quantitative estimates of the potential social costs and benefits associated with the release. Unfortunately, given case-by-case variability and uncertainty in the process of scientific discovery, there is no obvious mechanism available that can facilitate evaluation of the balance between disclosure risk and data utility. During Session III of the workshop, Sallie Keller-McNulty of Los Alamos National Laboratory and George Duncan of Carnegie-Mellon University presented a paper that begins to define such an operational construct.
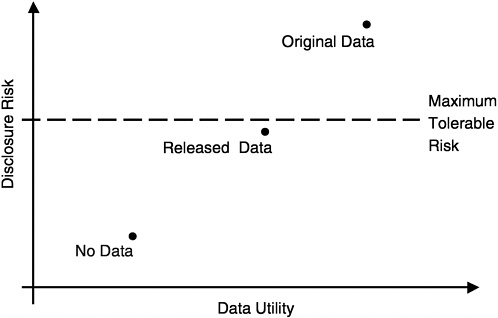
Statistical disclosure risks are defined by the ability of snoopers to draw inferences from de-identified data; linking is generally part of this process. The authors' framework, represented in the diagram below, essentially attempts to maximize data utility by minimizing necessary distortion, subject to a maximum tolerable risk constraint.
Data utility is a function of usefulness for statistical inference, and may be reflected in bias, variance, or mean square error characteristics inherent in the data. Options for maintaining tolerable risk include restricting data detail, restricting access to the data, or a combination of the two. Identifying an optimal data access strategy involves a difficult maximization problem since the parameters are not constant.
In their presentation, Duncan and Keller-McNulty emphasized restrictive
data release as opposed to restricted data access—specifically (1) data masking and (2) synthetic data. A goal of their work is to quantify disclosure risk and data utility, distinguishing between identity disclosure (e.g., associating the name of a respondent with a piece or pieces of released information) and attribute disclosure (e.g., estimating an attribute value associated with an individual). Keller-McNulty discussed how proponents of the framework might identify important parameters of the process intended to measure risk and data utility generically. Full utilization of their framework would entail comparison of statistical properties of raw versus perturbed data. The eventual goal would be to allow choices in setting parameters that would maximize the tradeoff between data utility and risk and thereby avoid distorting data more than is necessary.
The authors reviewed the algebra of some simple univariate examples that illustrate the framework for assessing risks associated with data dissemination strategies. Their conclusions pointed broadly to the need to (1) extend their univariate examples to more realistic settings, and (2) develop risk and utility measures that are a function of the masking parameters and other matrix factors used to create synthetic records. Finally, the authors noted that a multitude of possible dissemination strategies exist; level of masking and extent of synthetic iteration are specific to data set and application. In no case will the optimal tradeoff imply 100 percent disclosure prevention.
Latanya Sweeney was discussant for the Keller-McNulty and Duncan presentation. She has analyzed technical protections and risks from a computational science perspective, and is concerned with identifying optimal modes of releasing information so that inferences can be controlled—again in an environment where information about individuals is increasing at an exponential rate. It should be noted that Sweeney 's comments were directed toward a broad class of information and not specifically toward longitudinal research databases. This broadened focus provided essential context within which the relative risks of different types of data could be discussed.
Sweeney's computational approaches to assessing risk involve constructing functions that relate hierarchical data aggregation to data security. Working at the cell level, she has developed algorithms designed to balance the tension between the usefulness of data, as measured by the degree of aggregation (i.e., number of variables collapsed), and protection of anonymity. The matrix mask described by Keller-McNulty and Duncan could be used as a general representation for the hierarchical aggregation. Sweeney's method structures disclosure limitation into a generalized hierarchy in which variable suppression would typically be at the top. The algorithms compute how much a field is distorted as it is moved up the hierarchy toward suppression. Sweeney then computes a “precision metric” for a particular combination of data based on how far the variables must move up the table to obtain a given level of security.
In principle, one can obtain a given level of risk while minimizing required data distortion for each field and without resorting to uniform cell suppression. In computer programs such as DataFly, which generalizes values based on a profile of data recipients, and u-ARGUS, a similar program used by Statistics Netherlands, statistical disclosure limitation methods are used that do make data safer but less specific and the overall statistical relationships within the data set less accurate. The key is finding optimal levels of distortion across data set fields and exploiting tradeoffs between specificity and anonymity protection. Applying her techniques to u-ARGUS and DataFly, Sweeney concluded that the former tends to underprotect the data, while the latter tends to overdistort.
A central message of Sweeney's presentation was that an incredible range of resources can be directed toward cracking data security, yet technology can also offer solutions to those charged with producing and protecting data. In the future, sophisticated cryptographic techniques may be implemented. For example, researchers may be able to use cryptographic keys to access and link data. In this way, agencies could monitor access to the data and make the results of program runs anonymous. While such techniques are visions of the future, technological solutions, in Sweeney's view, already offer greater protection than legislative approaches, which tend to lag behind real-time needs and reflect outdated technological capabilities.













