
1
Discussion Framework
Paul Uhlir1
Factual data are fundamental to the progress of science and to our preeminent system of innovation. Freedom of inquiry, the open availability of scientific data, and full disclosure of results through publication are the cornerstones of public research long upheld by U.S. law and the norms of science. The rapid advances in digital technologies and networks over the past two decades have radically altered and improved the ways that data can be produced, disseminated, managed, and used, both in science and in all other spheres of human endeavor. New sensors and experimental instruments produce exponentially increasing amounts and types of raw data. This has created unprecedented opportunities for accelerating research and creating wealth based on the exploitation of data as such. Every aspect of the natural world, from the subatomic to the cosmic, all human activities, and indeed every life form can now be observed and stored in electronic databases. There are whole areas of science, such as bioinformatics in molecular biology and the observational environmental sciences, that are now primarily data driven. New software tools help to interpret and transform the raw data into unlimited configurations of information and knowledge. And the most important and pervasive research tool of all, the Internet, has collapsed the space and time in which data and information can be shared and made available, leading to entirely new and promising modes of research collaboration and production.
Much of the success of this revolution in scientific data activities, apart from the obvious technological advances that have made them possible, has been the U.S. legal and policy regime supporting the open availability and unfettered use of data. This regime, which has been among the most open in the world, has placed a premium on the broadest possible dissemination and use of scientific data and information produced by government or government-funded sources. This has been implemented in several complementary ways: by expressly prohibiting intellectual property protection of all information produced by the federal government and in many state governments; by contractually reinforcing the traditional sharing norms of science through open data terms and conditions in federal research grants; and by carving out a very large and robust public domain for noncopyrightable data, as well as other immunities and exceptions favoring science and education, from proprietary information otherwise subject to intellectual property protection.
PUBLIC-DOMAIN INFORMATION DEFINED
It is worthwhile at the outset to clearly define what we mean by “public-domain information.” Jerome Reichman and I characterize it as “sources and types of data and information whose uses are not restricted by intellectual property or other statutory regimes and that are accordingly available to the public for use without authorization or restriction.” For analytical purposes, data and information in the public domain can be divided into two major categories:
-
information that is not subject to protection under exclusive intellectual property rights or other statutory restriction; and
-
information that qualifies as protectible subject matter under some intellectual property regime, but that is contractually designated as unprotected.
The first major category of public-domain information can be further divided into three subcategories: (i) information that intellectual property rights cannot protect because of the nature of the source that produced it; (ii) otherwise protectible information that has lapsed into the public domain because its statutory term of protection has expired; and (iii) ineligible or unprotectible components of otherwise protectible subject matter.
This presentation focuses primarily on categories 1(i) and 2, so I will just say a few words about categories 1(ii) and (iii) here. Information that has lapsed into the public domain because it has exceeded the statutory term of protection under copyright is currently the life of the author plus 70 years in the United States. This category constitutes an enormous body of creative works with great cultural and historical significance. Because of the long lag time in entering the public domain, however, it is not of great importance to most types of research.
The other subcategory of information that is not subject to protection under exclusive intellectual property rights consists of ineligible or unprotectible components of otherwise protectible subject matter, such as an idea, fact, procedure, system, method of operation, concept, principle, or discovery, all of which are expressly excluded from statutory copyright protection. Thus, all ideas or facts contained in an otherwise copyrighted work have been—at least in the past—unprotected and could be used freely. Although this public-domain material is highly distributed among all types of works, it is of particular concern to research and education and will be discussed in some detail later in the symposium.
Finally, a third, related category is information that becomes available under statutorily created immunities and exceptions from proprietary rights in otherwise protected material. Instead of being in the public domain because it is unprotectible subject matter, it is otherwise protected content that is allowed to be subject to certain unprotected uses under limited circumstances, subject to case-by-case interpretation. Such immunities and exceptions allow for the use of proprietary information for purposes such as scholarship, research, critical works, commentaries, and news reporting, but their specific nature and extent varies greatly among different jurisdictions. Known as “fair uses” in the United States, they also tend to be quite controversial and are frequently in dispute by rights holders. Although copyright law has not formally treated these immunities and exceptions as public domain per se, a number of them may be construed as functional equivalents of “public-domain uses.” Because many immunities and exceptions are allowed only in the context of not-for-profit research or education, this category of public-domain uses, although relatively small, is especially important.
The main goal in this opening presentation is to coarsely map out the scope and nature of the public domain that has served the American scientific enterprise so well for many years. We divide the producers of scientific data into three sectors, namely, government agencies (primarily but not exclusively federal), academic and other nonprofit research institutions, and private-sector commercial enterprises. Figure 1-1 presents a conceptual framework for analysis of this information regime, as well as a useful summary of the relative rights across the spectrum of information producers in all three sectors. Because of time constraints, I will focus only on the scope of the public domain in government and academia.
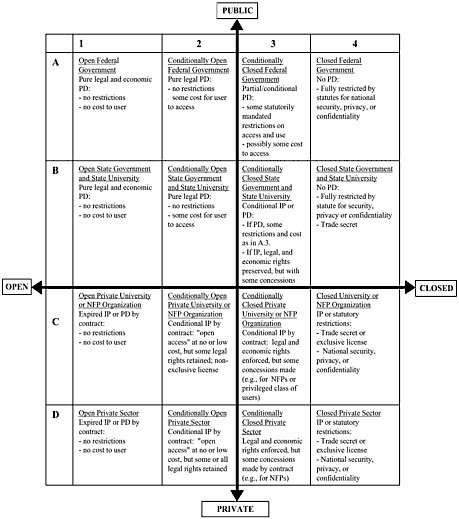
FIGURE 1-1 Conceptual framework for analysis of the S&T information regime. Copyright 2000 by Paul F. Uhlir. Notes: “PD”-public domain; “IP”-intellectual property; “NFP”-not-for-profit.
GOVERNMENT INFORMATION IN THE PUBLIC DOMAIN
The role of the government in supporting scientific progress in general, and in the creation and maintenance of the research commons in particular, cannot be overstated. The U.S. federal government produces the largest body of public-domain data and information used in scientific research and education. For example, the federal government alone now spends more than $45 billion per year on its research (as opposed to “development”) programs, both intramural and extramural, with a significant percentage of that invested in the production of primary data sources; in higher-level processed data products, statistics, and models; and in scientific and technical information, such as government reports, technical papers, research articles, memoranda, and other such analytical material.
At the same time, the United States—unlike most other countries—overrides the canons of intellectual property law that could otherwise endow it with exclusive rights in government-generated collections of data or other information. To this end, Section 105 of the 1976 Copyright Act prohibits the federal government from claiming protection in its publications. A large portion of the data and information thus produced in government programs automatically enters the public domain, year after year, with no proprietary restrictions, although the sources are not always easy to find. Much of the material that is not made available directly to the public can be obtained by citizens through requests under the Freedom of Information Act.
The federal government is also the largest funder of the production of scientific data by the nongovernmental research community, as a major part of that $45 billion investment in public research, and many of the government-funded data also become available to the scientific community in the research commons. However, government-funded data follow a different trajectory from that of data produced by the government itself, as I will discuss later on. The following are a number of well-established reasons for placing government-generated data and information in the public domain:
-
A government entity needs no legal incentives from exclusive property rights that are conferred by intellectual property laws to create information, unlike individual authors or private-sector investors and publishers. Both the activities that the government undertakes and the information produced by the government in the course of those activities are a public good.
-
The taxpayer has already paid for the production of the information. One can argue that the moral rights in that information reside with the citizens who paid for it, and not with the state entity that produced it on behalf of the citizens.
-
Transparency of governance and democratic values are undermined by restricting citizens from access to and use of public data and information. As a corollary, citizens’ First Amendment rights of freedom of expression are compromised by restrictions on redissemination of public information, and particularly of factual data. It is no coincidence that the most repressive political regimes have the lowest levels of available information and the greatest restrictions on expression.
-
Finally, there are numerous positive externalities—particularly through network effects—that can be realized on an exponential basis through the open dissemination of public-domain data and information on the Internet. Many such benefits are not quantifiable and extend well beyond the economic sphere to include social welfare, educational, cultural, and good governance values.
The federal government’s policies relating to scientific data activities date back to the advent of the era of “big science” following World War II, which established a framework for the planning and management of large-scale basic and applied research programs. The hallmark of big science, or “megascience,” has been the use of large research facilities or research centers and of experimental or observational “facility-class” instruments. The data from many of these government research projects, particularly in the past two decades, have been openly shared and archived in public repositories. Hundreds of specialized data centers have been established by the federal science agencies or at universities under government contract.
Scientific and technical articles, reports, and other information products generated by the federal government are also not copyrightable and are available in the public domain. Most research agencies have well-organized and extensive dissemination activities for such information, typically referred to as “scientific and technical information.”
Limitations on Government Information in the Public Domain
Without delving at this point into the growing pressures on the public domain, we need to outline a number of countervailing policies and practices that limit the free and unrestricted access to and use of government-generated data and information. First, there are important statutory exemptions to public-domain access based on national security concerns, the need to protect personal privacy of human subjects in research, and to respect confidential information. These limitations on the public-domain accessibility of federal government information, although often justified, must nonetheless be balanced against the rights and needs of citizens to access and use it.
Another limitation derives from the fact that government-generated data are not necessarily provided cost free. The federal policy on information dissemination, the Office of Management and Budget’s (OMB) Circular A-130, stipulates that such data should be made available at the marginal cost of dissemination (i.e., the cost of fulfilling a user request). In practice, the prices actually charged vary between marginal and incremental cost pricing, and these fees can create substantial barriers to access, particularly for academic research.
Another major barrier to accessing government-generated data and information in practice, which I have already alluded to, arises from the failure of agencies to disseminate them or to preserve them for long-term
availability. As a result, large amounts of public-domain information are either hidden from public view or have been irretrievably lost.
Yet another limitation derives from OMB Circular A-76, which bars the government from directly competing with the private sector in providing information products and services. This policy substantially narrows the amount and types of information that the government can undertake to produce and disseminate. As regards science, the traditional view has been that basic research, together with its supporting data, are a public good that properly fall in the domain of government activity, although the boundary between what is considered an appropriate public and private function continues to shift in this and other respects.
Finally, the government is required to respect the proprietary rights in data and information originating from the private sector that are made available for government use or, more generally, for regulatory and other purposes, unless expressly exempted. To the extent that more of the production and dissemination functions of research data are shifted from the public to the private sector, this limitation becomes more potent.
ACADEMIC INFORMATION IN THE PUBLIC DOMAIN
The second major source of public-domain data and information for scientific research is that which is produced in academic or other not-for-profit institutions with government and philanthropic funding. Databases and other information goods produced in these settings become presumptively protectible under any relevant intellectual property laws unless affirmative steps are taken to place such material in the public domain. In this case, the public domain must be actively created, rather than passively conferred. This component of the public domain results from the contractual requirements of the granting agencies in combination with longstanding norms of science that aspire to implement “full and open access” to scientific data and the sharing of research results to promote new endeavors.
The policy of full and open access or exchange has been defined in various U.S. government policy documents and in National Research Council reports as “data and information derived from publicly funded research are [to be] made available with as few restrictions as possible, on a nondiscriminatory basis, for no more than the cost of reproduction and distribution” (that is, the marginal cost, which on the Internet is zero).2 This policy is promoted by the U.S. government (with varying degrees of success) and for most government-funded or cooperative research, particularly in large, institutionalized research programs (such as “global change” studies or the Human Genome Project) and even in smaller-scale collaborations involving individual investigators who are not otherwise affiliated with private-sector partners. It is necessary, however, to look beyond the stated policies and rules built around government-funded data to gain some deeper insights into how they are actually implemented in academic science. In this regard, it is useful to further subdivide the producers of government-funded data into two distinct, but partially overlapping, categories.
The Zone of Formal Data Exchanges
In the first category, the research takes place in a highly structured framework, with relatively clear rules set by government funding agencies on the rights of researchers in their production, dissemination, and use of data. Publication of the research results constitutes the primary organizing principle. Traditionally, the rules and norms that apply in this sphere—which we call “the zone of formal data exchanges”—aim to achieve a bright line of demarcation between public and private rights to the data being generated, with varying degrees of success.
For example, government research contracts and grants with universities and academic researchers seek to ensure that the data collected or generated by the beneficiaries will be openly shared with other researchers, at least following some specified period of exclusive use—typically limited to 6 or 12 months—or until the time of publication of the research results based on those data. This relatively brief period is intended to give the researcher sufficient time to produce, organize, document, verify, and analyze the data being used in preparation of a research article or report for scholarly publication. Upon publication, or at the expiration of the specified period
of exclusive use, the data in many cases (particularly from large research facilities) are placed in a public archive where they are expressly designated as free from legal protection, or they are expected to be made available directly by the researcher to anyone who requests access.
In most cases, publication of the research results marks the point at which data produced by government-funded investigators should become generally available. The standard research grant requirement or norm has been that, once publication occurs, it will trigger public disclosure of the supporting data. To the extent that this requirement is implemented in practice, it represents the culmination of the scientific norms of sharing. From here on, access to the investigator’s results will depend on the method chosen to make the underlying data publicly available and on the traditional legal norms—especially those of copyright law—that govern publications.
These organizing principles derive historically from the premise that academic researchers typically are not driven by the same motivations as their counterparts in industry and publishing. Public-interest research is not dependent on the maximization of profits and value to shareholders through the protection of proprietary rights in information; rather, the motivations of academic and not-for-profit scientists are predominantly rooted in intellectual curiosity, the desire to create new knowledge and to influence the thinking of others, peer recognition and career advancement, and the promotion of the public interest.
Science policy in the United States has long taken it for granted that these values and goals are best served by the maximum availability and distribution of the research results, at the lowest possible cost, with the fewest restrictions on use, and the promotion of the reuse and integration of the fruits of existing results in new research. The placement of scientific and technical data and databases in the public domain, and the long-established policy of full and open access to such resources in the government and academic sectors, reflects these values and serves these goals.
The Zone of Informal Data Exchanges
In the second category, individual scientists establish their own interpersonal relationships and networks with other colleagues, largely within their specialized research communities. In this category, which we call “the zone of informal data exchanges,” based on the work of Stephen Hilgartner and Sherry Brandt-Rauf, the scientists will more likely be working autonomously in what we refer to as “small science” research. They will generate and hold their data subject to their personal interests and competitive strategies that may deviate considerably from the practices established within the zone of formal exchanges and institutionalized by structured federal research programs. In this informal zone there will be other (nonfederal) sources of funding used, or the federal support that is available will be less prescriptive about open terms of data availability. Moreover, for research involving human subjects, strong regulations protecting personal privacy adds an additional cloak of secrecy.
The “small science,” independent investigator approach traditionally has characterized a large area of experimental laboratory sciences, such as chemistry or biomedical research, and field work and studies, such as biodiversity, ecology, microbiology, soil science, and anthropology. The data or samples are collected and analyzed independently, and the resulting data sets from such studies generally are heterogeneous and unstandardized, with few of the individual data holdings deposited in public data repositories or openly shared. The data exist in various twilight states of accessibility, depending on the extent to which they are published, discussed in papers but not revealed, or just known about because of reputation or ongoing work, but kept under absolute or relative secrecy. The data are thus disaggregated components of an incipient network that is only as effective as the individual transactions that put it together. Openness and sharing are not ignored, but they are not necessarily dominant either. These values must compete with strategic considerations of self-interest, secrecy, and the logic of mutually beneficial exchange, particularly in areas of research in which commercial applications are more readily identifiable.
What occurs is a delicate process of negotiation, in which data are traded as the result of informal compromises between private and public interests and that are worked out on an ad hoc and continued basis. Small science thus depends on the flow of disaggregated data through many different hands, all of whom collectively construct a fragile chain of semicontractual relations in which secrecy and disclosure are played out against a common need for access and use of these resources.
The picture that we paint of “big” and “small” science, and of the formal and informal zones of data exchange is, of course, overstated to clarify the basic concepts. The big science system is not free of individual strategic behavior that is typical of the small sciences, and the latter often benefit from access to public repositories where data are freely and openly available, rather than through the ad hoc transactional process. However, the “brokered networks” typical of small science are endemic to all sciences, and access to data is everywhere becoming more dependent on negotiated transacting between private stakeholders.
For the purposes of this symposium, we have chosen big science geophysical and environmental research that uses large observational facilities and small science biomedical experimental research that involves individual or small independent teams of investigators as emblematic of these two types of research and related cultures. We use them to provide real-world examples of the opportunities and challenges now inherent in the role of scientific and technical data and information in the public domain.
THE IMPETUS FOR THIS SYMPOSIUM
Although the scope and role of public-domain data and information are well established in our system of research and innovation, for reasons that subsequent speakers in this symposium will elaborate, there is another trend that is currently under way, which may be characterized as the progressive privatization and commercialization of scientific data and by the attendant pressures to hoard and trade them like other private commodities. This trend is being fueled by the creation of new legal rights and protectionist mechanisms largely from outside the scientific enterprise, but increasingly adopted by it. These new rights and mechanisms include greatly enhanced copyright protection in digital information, the ways in which access to and use of digital data are being contractually restricted and technologically enforced, and the adoption of unprecedented intellectual property rights in collections of data as such.
This countervailing trend is based on perceived economic opportunities for the private exploitation of new data resources and on a legal response to some loss of control over certain proprietary information products in the digital environment. At the same time, it is disrupting the normative customs and foundation of science, especially the traditional cooperative and sharing ethos, and producing both the pressures and the means to enclose the scientific commons and to greatly reduce the scope of data and information in the public domain.
Viewed dispassionately, the need to appropriately reconcile these two competing interests in a socially productive framework is imperative and the goal of such a reconciliation seems clear. A positive outcome would maximize the potential of private investment in data collection and in the creation of new information and knowledge, while preserving the needs of public research for continued access to and unfettered use of data and other public-domain inputs. These pressures, their potential impact on science, and the potential means for reconciling them in a win-win approach are the subjects of the next three sessions, respectively, of this symposium.









