
6
Supercomputing Infrastructures and Institutions
Supercomputing is not only about technologies, metrics, and economics; it is also about the people, organizations, and institutions that are key to the further progress of these technologies and about the complex web that connects people, organizations, products, and technologies. To understand supercomputing, one needs to understand the structure of the supercomputing community and the structure of the supercomputing landscape of concepts and technologies. Such a structuralist approach to supercomputing is necessarily less quantitative, more subjective, and more speculative than approaches that are more congenial to economists or engineers. However, it provides a necessary corrective for a study that might otherwise measure the trees but might not view the forest. The committee presents such an approach to supercomputing in this chapter.
It is useful to think of supercomputing infrastructure as an ecosystem. The Encarta dictionary defines an ecosystem as “a localized group of interdependent organisms together with the environment that they inhabit and depend on.” A supercomputer ecosystem is a continuum of computing platforms, system software, and the people who know how to exploit them to solve supercomputing applications such as those discussed in Chapter 4.
In supercomputing ecosystems, the “organisms” are the technologies that mutually reinforce one another and are mutually interdependent. Examples include the following:
-
Vector architectures, vectorizing compilers, and applications tuned for the use of vector hardware;
-
Shared memory architectures, scalable operating systems, OpenMP-compliant compilers and run-time systems, and applications that can take advantage of shared memory; and
-
Message passing architectures, parallel software tools and libraries, and applications that are designed to use this programming model.
The organism space tends to group according to the architecture class, the programming language and models used on the system, the algorithms, the set of applications and how the code is being tuned (e.g., vector version versus cache version), what application program packages are available, and so on. The success of supercomputer architectures is highly dependent on the organisms that form around them.
The architecture and the balance among its key configuration parameters (such as number of processors or memory size) are the dominant factors in determining the nature of the technologies in the ecosystem. For example, early supercomputers such as the CDC 7600 had rather small memories compared with their computing speed and the requirements of the applications that users wanted to run. That characteristic led to the development of system tools to reuse memory during execution (overlay management software) and to the use of different algorithms in certain cases, and it excluded certain classes of applications, together with a part of the user community. A second example is the speed of I/O to local disk, which can have a major impact on the design of application programs. For example, in a number of chemistry applications, if the ratio of I/O speed to computation performance is below a certain (well-understood) level, the application will run faster by recomputing certain quantities instead of computing them once, writing them to disk, and then reading them in subsequent phases of the job. Some widely used chemistry programs use this recompute strategy. Another common example of the impact of system performance characteristics on programming is that a message passing programming style is most often used when shared memory performance is below some threshold, even if shared memory programming tools are provided.
Because all current supercomputers have highly parallel architectures, the system software and the algorithms used have to be designed or adapted to function on such machines. As discussed in Chapter 5, the characteristics of the processors and the interconnection network (latency and bandwidth of access to memories, local and remote) are key features and determine to a large extent the algorithms and classes of applications that will execute efficiently on a given machine. Low latency and high-bandwidth access to memory not only yield higher performance—much
higher on some applications—but enable the use of less complex algorithms and ease the programming task. However, these features also lead to higher hardware costs and are typically available on systems that use less advanced device technology and run at a slower clock rate. Even for machines with such hardware features, software tools or compiler directives are often needed to achieve high fractions of peak speed. In short, the micro- and macro-architecture of a supercomputer determine to a large extent the complexities of the other technologies in its ecosystem. Grid computing environments may provide a way to integrate many components of the supercomputing ecosystem. But they will also create even more complex ecosystems.
Without software, the hardware is useless; hence, another important part of the ecosystem is the system software. By system software is meant the operating system components as well as tools such as compilers, schedulers, run-time libraries, monitoring software, debuggers, file systems, and visualization tools. But in supercomputing ecosystems, the existence of software with certain functionality is not sufficient. Unlike the situation with PCs, almost all of which use the same type of processor, in supercomputing environments the mere existence of system software is not enough to create an effective supercomputing ecosystem. For example, if the supercomputer configuration has thousands of processors but the operating system is designed for systems with only a few processors, many operating system tasks will run unacceptably slowly or even fail to execute. This inadequacy was observed for computers from several different vendors, and until those gross inefficiencies were removed, the systems saw little use. Additional examples of software technology that may be required for a supercomputing ecosystem to be effective are global parallel file systems and fault tolerance.
Libraries are also part of the ecosystem. Examples include message passing libraries (e.g., MPI) and numerical libraries that embody algorithms that are efficient on the supercomputer’s architecture and that are implemented appropriately (e.g., PETSc and ScaLAPACK).
To enable effective use of a supercomputer, the system software and libraries must be tailored to the particular supercomputer that is the focus of the ecosystem. As pointed out above, some of this software, such as compilers and run-time libraries, may require extensive customization, while others, such as networking software, might require relatively little. The nature of the user’s interface to the system—for example, the programming languages or the job scheduler—is also part of the ecosystem.
If the technologies that make up a supercomputing ecosystem constitute the “organism,” the environment that they inhabit and depend on includes people with the relevant skills (such as expertise in parallel algorithms) and projects with certain requirements (for instance, research
whose conduct requires supercomputers). The people with the expertise to produce the software, design the algorithms, and/or use the supercomputer are determinants of the scope (or sphere of influence) of the ecosystem associated with that supercomputer.1
Many industrial users depend on commercial software packages such as MSC NASTRAN or Gaussian. If those packages run poorly or not at all on a given supercomputer, the industrial users will be missing from the ecosystem, reducing the financial viability of that supercomputer. On the other hand, at national laboratories and research universities, almost all application programs are developed by individual research teams that do not depend on the availability of commercial software packages. As a result, a given installation may become favored by users of one or a few application classes, creating an ecosystem that is essentially a “topical center” because of the expertise, libraries, configuration details (such as storage and I/O), and visualization capabilities that are suitable for that class of applications. Expertise and sharing of methodologies might be as big a factor in creating the topical ecosystem as the use of the same software package by many projects.
Ecosystems are stable over several generations of a computer family, sometimes for one or two decades. As supercomputing hardware has become more complex, the barriers to creating a new ecosystem have risen, mostly due to the large effort required to develop a robust and full-featured software environment for complex architectures. Hence, creating a new ecosystem requires a significant, protracted effort and often also research and development of new software technologies. Vectorizing compilers took decades to mature and relied on the results of many academic research projects. Parallelizing compilers are still in their infancy more than 20 years after parallel computers came into use. The cost and time—and research and development in many different areas (compiler technology, operating system scalability, hardware, etc.)—make it very difficult to mount projects to introduce supercomputers with novel architectural features, especially if they require new programming paradigms for their efficient use.
Among the challenges in introducing new architectural features is finding ways to make them usable through languages and concepts that users can easily relate to familiar tools. If the learning curve for using a new system is too steep, there will be little development of system software and especially of applications, and users will simply not attempt to modify their applications to run on it. This is why programming languages persist for decades. For instance, Fortran 77 (a modest evolution of Fortran 66) is still heavily used 27 years after it first became a standard.
The large cost in human effort and time to adopt new programming languages and programming paradigms raises barriers that further stabilize the ecosystem. Many supercomputer applications are very complex, entail hundreds of thousands of lines of code, and require multidisciplinary teams with tens of people. Like supertankers, they cannot change direction quickly.
Another factor that contributes to the stability of ecosystems is that different technologies have different lifetimes and different starting points. It is almost never the case that one is afforded a clean-sheet starting point, where hardware, software, applications, and interfaces can all be designed from scratch. This reality calls for long-term ecosystem planning: Application packages have to be ported and maintained, new systems have to interoperate with old ones, the same people have to operate the new and the old systems, and so on. A lack of continuity in platforms and a lack of platform independence in software raise the costs of hiring and retaining appropriate personnel. Long-term planning is also needed because buildings cost money and can often account for a substantial portion of the total costs of procurement. To amortize that investment, it is desirable that a given facility be designed to serve for several ecosystem generations.
SUPERCOMPUTING ECOSYSTEM CREATION AND MAINTENANCE
Supercomputing system evolution is not all that different from generic computing system evolution, with the same patterns of horizontally integrated ecosystems (for example, the Wintel ecosystem) and vertically integrated ecosystems (such as the ecosystem created by IBM mainframes) and with the same high cost of change. From this process point of view, there is very little difference between supercomputing systems and generic computing systems except that, since the architectural platform differences are so radical, it can be much more expensive to port applications in the supercomputing ecosystem than in the generic ecosystem. That expense, coupled with the very small number of supercomputers sold, greatly inhibits the development and porting of commercial software packages to supercomputer platforms.
Designing, developing, and deploying a truly radical new computing platform is a very difficult and expensive project. An example of the height of the barriers is illustrated by the IBM Blue Gene (BG) project.2 The BG/
|
2 |
See <http://www.research.ibm.com/bluegene/index.html>. The 8,192-processor BG/L prototype at IBM Rochester was 4th on the June 2004 TOP500 list, while the 4,096 prototype at IBM Watson was 8th. |
L system that is currently being developed and built is substantially less innovative than the initial BG concept. The instruction set architecture is a known one, so that compilers, many parts of the operating system, and many software tools do not have to be written ab initio and so that users will find a somewhat familiar environment. Even so, for BG/L a large consortium is being formed of academic groups and research laboratories that are users and developers of very high end applications to build a community around this class of HPC architectures, which, in its largest configurations, will have an order-of-magnitude more nodes than previous multiple instruction, multiple data (MIMD) systems. The consortium is being formed to provide additional human capital to study the new architecture in the context of many applications, to develop some of the software tools or to migrate existing open source tools, and to provide input on hardware and software improvements that should be made for future generations of the Blue Gene family. The forming of a consortium reflects the fact that even a very large and profitable company like IBM does not have enough in-house expertise in all the necessary areas and cannot justify the investments needed to hire such experts. It is further evidence of the complexity of current supercomputer environments compared with those of only 20 years ago. Formation of the consortium is also an explicit attempt to quickly create an ecosystem around the Blue Gene platforms.
How Ecosystems Get Established
Traditionally, supercomputing ecosystems have grown up around a particular computer vendor’s family of products, e.g., the Cray Research family of vector computers, starting with the Cray-1 and culminating in the T-90, and the IBM SP family of parallel computers. While a given model’s lifetime is but a few years, the similarity of the architecture of various generations of hardware provides an opportunity for systems and application software to be developed and to mature. Cray-1 serial number one was delivered in 1976 with no compiler and an extremely primitive operating system. Twenty years later, there were good vectorizing compilers, reliable and efficient operating systems, and thick books that catalogued the hundreds of commercial application software packages available on the Cray vector machines.
The excellent access to memory of such high-bandwidth systems and the availability of good optimizing compilers and reliable libraries tuned to the system’s architecture can yield much higher performance (by a factor of as much as 30) on some applications—and with less programming effort—than can commodity clusters. Even though less programming effort may be required, expertise is still quite important. People who were
proficient in the efficient use of Cray vector computers became valued members of projects that used those systems, and small consulting firms were established to sell such expertise to groups that did not have it. The existence of a cadre of people with the expertise to use a particular supercomputer family further strengthens the corresponding ecosystem and adds to its longevity.
One can see the benefits of these two ecosystems in the more recent Earth Simulator. As the committee observed in Chapter 5, the Earth Simulator has three kinds of parallelism, requiring multiple programming models to be used in an application. However, once the applications developer does multilevel problem decomposition, there is an HPF compiler that performs vectorization, shared-memory parallelization, and distributed-memory communication, thus partially shielding the application programmer from those issues.
More recently, commodity cluster systems that use open, de facto software standards have become a significant component of the high-end computing scene, and modest ecosystems are forming around them. In many cases, cluster hardware is based on microprocessors that use the Intel x86 instruction set, providing some stability for the hardware and node architecture. Open source software suited to large clusters and high-end computing is becoming available, such as versions of the Linux operating system, parallel file systems such as PVFS, message-passing libraries such as MPICH, and visualization toolkits such as VTK. Reinforcing the trend toward clusters are factors such as these:
-
The low entry cost, which enables even small university groups to acquire them;
-
Their proliferation, which provides a training ground for many people, some of whom will use them as a development platform for software tools, libraries, and application programs, thus adding technologies to the ecosystem;
-
The local control that a group has over its cluster, which simplifies management and accounting;
-
The relative ease of upgrades to new processor and interconnection technologies; and
-
Their cost effectiveness for many classes of applications.
Software challenges remain for the nascent cluster ecosystem. Since communication is more expensive on clusters, minimizing communication plays a big role in achieving good performance. The distribution of data and computation across nodes has to be planned carefully, as part of algorithm design, particularly because there is no hardware support for remote data access and because load balancing is more expensive. Tasks
that are done by hardware in a high-bandwidth system have to be done in software in a cluster. Current vector systems further reduce programming effort because they have high-quality compilers available, facilitating the immediate use of legacy codes. Compilers for clusters have a much shorter history of development and are much less mature, even when they use vectorization technology.
The computer industry has shifted over the last decades from a model of vertically integrated systems to one of horizontally integrated systems. In a vertically integrated model, vendors develop the technology required across most of the layers of the system. Thus, IBM designed and manufactured almost everything associated with a mainframe: It designed and manufactured the chips and their package, the disks, the operating system, the compilers and tools, the databases, and many other specialized applications. The same was largely true of supercomputing manufacturers such as Cray. Today the dominant model is that of horizontal integration. Thus, Intel designs and manufactures chips, Microsoft develops operating systems and applications running on those and other chips, and Dell integrates both into one system. The same evolution has happened with high-end systems. Cray is still responsible for the design of most hardware and software components of the Cray X1; most of the value of such a product is produced by Cray. On the other hand, cluster systems are based on integration of technologies provided by many vendors, and the cluster integrators contribute only a small fraction of the product value.
A vertically integrated, vendor-driven ecosystem has the advantages that there are fewer variables to contend with and that there is centralized control of the hardware architecture and most of the software architecture. If the supercomputer vendor is successful financially, then commercial applications software is likely to emerge, lowering the barriers for use. On the other hand, a vertically integrated ecosystem might become fragile if the vendor encounters financial difficulties, switches to a new hardware architecture, or abandons its own proprietary operating system as a result of increasingly high costs. The tight integration that (1) ensured smooth functioning of the software on the hardware and (2) enabled the development of proprietary features that application developers and users came to rely on will now make it much more expensive to transition to another system, either from the same vendor or a different one.
Horizontal integration can provide a less arduous migration path from one supercomputer platform to another and thus a longer-lived, though less tightly coupled, ecosystem. Those advantages are gained through the use of portable software environments and less reliance on the highly specific characteristics of the hardware or proprietary vendor software. Such portability has its cost—a smaller fraction of the potential
performance will be achieved, perhaps much smaller. A second disadvantage of the horizontal integration approach is that the various software components will not have been designed to be used in concert with one another; independently designed and implemented components will be less compatible and the integration less cohesive and more fragile. The fragility results from the independence of the efforts that produce each component; changes may be made to one component without considering whether the new version will still interface with other software in the ecosystem.
In a horizontal market, the role of integrators that assemble the various technologies into a coherent product becomes more important. Such integrators (for example, Linux Netwox3) have appeared in the cluster market, but their small size relative to that of the makers of the components they assemble implies that they have little clout in ensuring that these components fit well together. Furthermore, an integrator may not have the scope to provide the kind of ongoing customer support that was available from vertically integrated companies.
An example of a vertically integrated ecosystem that did not survive for very long is the Thinking Machines CM-5, a product of Thinking Machines Corporation (TMC). The CM-5 had a unique proprietary architecture and a software environment with highly regarded components: languages, compilers, mathematical software libraries, debuggers, and so forth. The largest CM-5 configuration was world-leading for a while. When TMC went out of business, users had to migrate to different systems that had less sophisticated software as well as different hardware architecture. One component of the ecosystem that adapted quickly to different systems was the group of highly skilled TMC employees. Many of the people who produced the CM-5 software environment were hired en masse by other computer companies because of their expertise, although their new employers have not attempted to produce as sophisticated an environment for their own systems.
Message passing libraries are an example of software technology that can stimulate the evolution of an ecosystem around an architecture family, in this case, processor-memory nodes connected by a network of some sort. Message passing has been the dominant programming model for parallel computers with distributed memory since the mid-1980s. Clusters fall into this class of computers. While the functionality provided in different systems was similar, the syntax and semantics were not. As early as the mid-1980s there were attempts to develop de facto standards for
message passing libraries, but it was not until the MPI effort in 1993-1994 that a standard was developed and was widely adopted. It is worth noting that Argonne National Laboratory’s MPICH was the first available implementation of the MPI standard and served as the basis for almost all MPI libraries produced by computer manufacturers. The wide availability of robust, open source MPI implementations was an important factor in the rapid and widespread proliferation of the commodity cluster supercomputer.
Potential Barriers for New Ecosystems
Each ecosystem has a critical mass below which it cannot survive; if it is too close to the critical mass, there is a high risk that a catastrophic event may wipe it out. A supercomputing ecosystem that is too small is not economically viable and cannot evolve fast enough to compete. Even if it is viable, but barely so, a few wrong decisions by company managers or national policy makers may destroy it. The demise of companies such as TMC or Kendall Square Research and the near demise of Cray clearly illustrate these points.
There are good reasons to believe that the critical mass needed to sustain a computer ecosystem has increased over the last decades. Computer systems have become more complex, so they are more expensive to develop. This complexity arises at all levels of current systems. It has been asserted that the development cost of Intel microprocessors has increased by a factor of 200 from the Intel 8080 to the Intel P6. Operating systems, compilers, and libraries are larger and more complex—the code size of operating systems has grown by two orders of magnitude in two decades. Application codes are larger and more complex, in part because of the complexity of the platforms on which they sit, but mostly because of the increased sophistication of the applications themselves. The increases can be explained, in large part, by the growth of the computer industry, which can support and justify larger investments in computer technologies. A small supercomputing niche will not be able to support the development of complex hardware and software and will be handicapped by a lack of performance or function relative to commodity computer products. As a result the critical mass of a viable supercomputing ecosystem is greater than it once was. This is an obstacle to the establishment of new supercomputing ecosystems.
Horizontal integration is another obstacle to the establishment of new ecosystems. It is not only that small agile vessels have been replaced by large supertankers that are hard to steer; they have been replaced by flotillas of supertankers that sail in tight formation and that all need to be steered in a new direction in order to achieve change.
Horizontal integration admits more specialization and provides a larger market for each component maker, thus allowing more R&D investments and faster technology evolution. This has clearly benefited the mainstream computer industry, in which vertically integrated servers, such as IBM mainframes, have become an anomaly. On the other hand, horizontal integration solidifies the boundaries across components and technologies provided by different vendors. System-level changes that require coordinated changes of multiple components provided by multiple vendors are less likely to occur. In other words, one trades off faster progress within a paradigm (the paradigm defined by agreed-upon interfaces at the various layers) against more frequent changes of the paradigm.
There are many examples of the difficulty of effecting such coordinated changes. For example, software-controlled cache prefetching is a well-known, useful mechanism for hiding memory latency. The instruction sets of several modern microprocessors have been modified to support a prefetch instruction. However, to take advantage of software controlled prefetching, one needs significant changes in compilers and libraries, and perhaps also application codes. As long as prefetch instructions are unavailable on the large majority of microprocessors, compiler writers and, a fortiori, application writers have limited incentives to change their code so as to take advantage of prefetching. As long as software and applications do not take advantage of prefetch instructions, such instructions add to hardware complexity but bring no benefit. Therefore, these instructions have been allowed, in one or more cases, to wither into a no-op implementation (i.e., the instructions have no effect), since that simplifies the microprocessor design and does not affect perceived performance. Software controlled prefetching did not catch on, because one could not coordinate multiple microprocessor designers and multiple compiler providers.
There are clear historical precedents for vertically integrated firms successfully introducing a new design (for instance, the introduction of the Cray), as well as many examples of such ambitions failing (which are amply documented in this report). In the present horizontal environment it is difficult for entrepreneurs with the ambition to effect radical changes to coordinate the changes across many areas of computing. Instead, today’s supercomputing entrepreneurs tend to accept many component designs as given and try to improve in their own niche. Thus, a particular type of innovative design that might benefit supercomputing users does not get done. It is conceivable that the benefit of faster progress on each component technology (e.g., faster progress on commodity microprocessors) more than compensates for the lack of coordinated changes across a spectrum of technologies. However, it is also conceivable that supercom-
puting is stuck in a local optimum and is unable to move out of it because of the high costs and high risks and the small size of the market (and hence the small size of the reward even if a better global design point can be reached).
The biggest barrier to the evolution of a supercomputing ecosystem around a new computing platform is the effort and time required to develop the necessary software (for performance especially, but also for functionality). New software does not get used until it is refined to the point of actual productivity. (Fortran 90, for example, may not yet have reached that point. Some widely used applications still use Fortran 77, even though F90 compilers are widely available, because there are still vendors with significant market share whose F90 compilers produce significantly slower executables than their F77 compilers.) The generated code must be efficient for supercomputing applications; achieving that efficiency requires large investments and years of evolution as experience is gained.
If a new language is involved, the barrier is even higher. Adoption will be slow not only until there are reliable compilers that produce efficient code but also until that language is available on systems from a number of vendors. Until the new language is widely adopted there is little incentive for vendors to support it, thus creating a chicken-and-egg problem. This is another instance of the barriers introduced by standardized interfaces, this time the interface between application designers and the system on which they run their application. For example, while the limitations of MPI as a programming model are widely acknowledged, the ASC program leadership has expressed little enthusiasm for architectural improvements that would require forfeiting the use of MPI, because of the large existing investment in MPI codes and the likelihood that MPI will continue to be needed on many of the ASC platforms.
The barriers to acceptance extend to algorithms as well. Users are often justifiably wary about replacing a known and trusted, if suboptimal, algorithm with a new one. There need to be better quality vetting and communication mechanisms for users to discover and evaluate new algorithms.
Users resist migrating to a new system, either hardware or software, that may survive only a few years; most supercomputing application programs evolve and are used over decades. In other words, another barrier to be surmounted is the need to guarantee longevity. Computers with different architectures from sources new to supercomputing may not be successful in the marketplace and thus will no longer be available. This can be true even for new models from established vendors. The effort required to adapt most supercomputer application programs to new environments is substantial. Therefore, code developers are reluctant to in-
vest the effort to migrate to different systems, even when they are likely to deliver a better than twofold increase in absolute performance or in cost/ performance. Codes will run for decades, so developers are risk averse.
The effort required to port applications to new systems is a major barrier as well. Few supercomputer users can afford to halt their primary activity for months in order to move their application software to a new environment. They need to finish their papers or their Ph.D. dissertations or to produce a result for their mission within a fixed time frame. The cost to the end user of introducing new systems must be reduced. That is quite difficult to accomplish while preserving high performance.
Wider use of technologies for more automated code generation and tuning will also facilitate migration between ecosystems. A vision of the future is to develop supercomputing ecosystems that are broader and more general, so that they can support a variety of supercomputers with different characteristics. This would have the advantages of economy of scale, more years for system software and tools to mature, and a larger base of installations to pay for the continued enhancement of the software. Users of new supercomputers that fit into one of those ecosystems would also benefit by not having to learn everything new (although new machines will always have differences from previous generations of machines that affect their use and performance). Open source software that can be ported to a variety of systems might be able to engender those more general supercomputing ecosystems. In this scenario, many aspects of the operating system and tools could be made to improve monotonically over time, and much of the software could be reused in new machines. Parallel file systems are a case in point. Projects to develop them require specialized expertise and take years to complete. Open source attempts such as PFVS4 and Lustre5 to develop an open, fairly portable parallel file system may eventually reduce the effort required to provide a parallel file system for new platforms.
Similarly, one can envision strategies for application programs that would lower the barriers for new supercomputing ecosystems to evolve. An example is the relatively new type of application programs known as community codes. These programs address a particular class of applications such as chemical reactions (NWChem)6 or climate modeling (CCSM).7 Because community codes are implemented by large teams, often at different institutions and having complementary expertise, they are
|
4 |
|
|
5 |
See <http://www.lustre.org/>. |
|
6 |
|
|
7 |
See <http://www.ccsm.ucar.edu/>. |
carefully designed for modularity (so that better models and algorithms can be inserted with moderate effort) and portability (so that porting them to new systems is not too onerous). Their modularity promises to reduce the effort to migrate the code to different platforms, since relatively few modules may need to be redesigned to use different algorithms or reimplemented to exploit new hardware features. Designing and developing such programs is still a challenging research topic, but there are success stories (NWChem, CCSM, SIERRA,8 PYRE,9 and others).
A related approach is to develop higher level codes or parameterized codes that can run well on a broader range of platforms, codes that are programmed for performance portability. Such codes would adapt to the changes in hardware parameters that result from different exponents in the rate of change of different technologies, such as the much faster increase in processor speeds than in memory speeds. The ratios of hardware component speeds determine to a large extent the performance that is achieved. Automated library tuning and domain-specific code generators are discussed in Chapter 5. Although this is a good research topic, it is hard (it has been around for some time). We do not yet do a good enough job mapping higher-level programming languages onto one single-target platform; it is even more difficult to map them well onto a broad range of platforms.
ECOSYSTEM WORKFORCE
As has already been stated, one of a supercomputing ecosystem’s most important investments is its investment in people. The technology is maintained, exploited, and enhanced by the collective know-how of a relatively small population of supercomputing professionals—from those who design and build the hardware and system software to those who develop the algorithms and write the applications programs. Their expertise is the product of years of experience. As supercomputing becomes a smaller fraction of research and development in information technology, there is a greater chance that those professionals will move out of supercomputing-related employment into more lucrative jobs. (For example, their systems skills could be reused at Google10 and their applications/algorithms skills would be useful on Wall Street.) In companies such
as IBM, Hewlett-Packard, and Sun, which design and build not only supercomputers but also other commercial systems, people with unique skills could migrate to those other parts of the company in response to changes in company priorities or in pursuit of personal opportunities. If the funding stream of an academic or national laboratory’s supercomputer center is unstable (e.g., NASA or NSF’s Partnerships for Advanced Computational Infrastructure (PACI)), their professionals will seek greener, more stable pastures elsewhere, often outside supercomputing. As senior professionals move out of supercomputing, it becomes harder to maintain the knowledge and skill levels that come from years of experience.
At the other end of the people pipeline are the graduate students who will eventually become the next generation of senior supercomputing researchers and practitioners. According to the 2001-2002 Taulbee Survey of the Computing Research Association (the most recent survey available), a total of 849 Ph.D. degrees were awarded in 2002 by the 182 responding computer science and computer engineering departments, the lowest number since 1989. Of the 678 reporting a specialty area, only 35 were in scientific computing, the smallest total for any specialty area. (The next smallest group was 46, in programming languages/compilers, while the largest was 147, in artificial intelligence/robotics.) A review of research grants and publications in computer architecture shows a steady decrease in the number of grants and publications related to parallel architectures, leading to a decrease in the number of Ph.D. dissertations in computer architecture research that is relevant to HPC. For example, while NSF CISE funded about 80 grants a year in areas related to parallel processing in the mid-1990s, that number had shrunk to about 20 a year at the beginning of the 2000s.11 During the same period, the number of papers containing terms such as “supercomputer,” “parallel computing,” “high-performance computing,” and “parallel architecture” shrank by a factor of 2 or more.12
Of course, many of the new Ph.D.’s entering the supercomputing employment market receive degrees from departments other than computer science and computer engineering departments (for example, aerospace engineering, mechanical engineering, chemistry, physics, molecular biology, and applied mathematics), so the true number of new people entering the field is difficult to know. There are a handful of interdisciplinary graduate or certificate programs targeted specifically at educating the next-generation supercomputing professional, for example Princeton’s
Program in Integrative Information, Computer and Application Sciences (PICASso) (http://www.cs.princeton.edu/picasso) and the Computational Science and Engineering Program at the University of California, Santa Barbara (http://www.cse.ucsb.edu/index.html), both of which are funded, in part, by NSF IGERT’s Computational Science and Engineering Graduate Option Program at the University of Illinois at Urbana-Champaign (http://www.cse.uiuc.edu/) and Pennsylvania State University’s graduate minor in computational science and engineering (http://www.psu.edu/dept/ihpca). Such programs are typically open to interested graduate students from a wide range of science and engineering majors.13 DOE’s Computational Science Graduate Fellowship and High Performance Computer Science Fellowship programs support approximately 80 graduate students a year (http://www.krellinst.org/work/workhome.html). These programs promise to help increase the supply of new supercomputing professionals, although the committee believes that some faculty members, like faculty in other interdisciplinary fields, may have concerns about their career paths. (The academic value system often fails to reward “mere” code developers with tenure even if they are critical to a project and have made important computational or computer science advances.) Even with these programs, the supply of new people well educated in computational science is rather small and may be below the replacement rate for the current population.
To maintain knowledge and skills at the senior level, it is important to make sure that incentives are provided to keep the senior professionals in the field. The first step is to determine the key institutions (from academia, industry, and the national laboratories) that are the repositories of this institutional memory. Often the software is built by a team of academic researchers, national laboratory employees, and government agency staff. Next, strategies must be developed that provide these institutions with the mission and the stability necessary to retain supercomputing professionals. Also important is enough flexibility in the supercomputing ecosystem so that people can move within it as the money moves.
The key institutions in academia have been the NSF centers and partnerships (currently with leading-edge sites at Illinois, San Diego, and Pittsburgh and with partners at many universities) that together provide a national, high-end computational infrastructure for academic super-
|
13 |
More information on computational science and engineering graduate programs can be found in SIAM’s Working Group on CSE Education, at <http://epubs.siam.org/sam-bin/dbq/article/37974>. Information on the elements that make up computational science and engineering education can be found at <http://epubs.siam.org/sam-bin/dbq/article/40807>. |
computing researchers and for advanced education in supercomputing. The PACI program evolved out of the NSF Supercomputing Program. Through these programs NSF has provided a reasonably stable funding base for academic supercomputing infrastructure (equipment and professionals) for over 15 years. The centers have brought together computer scientists, computational scientists, and scientists from a broad array of disciplines that use computer simulations, together with their research students, promoting fertile interdisciplinary interaction. However, NSF funding for the PACI program stayed flat despite major increases in NSF’s budget. The PACI program ended in September 2004, and the form and level of future support are uncertain. A recent report from the NSF Advisory Panel on Cyberinfrastructure14 makes numerous recommendations for ways to continue to provide supercomputing infrastructure for the academic community. For instance, the report says, “Subject to appropriate review, we anticipate that they [the PACIs] will play a continuing but evolving substantial role in the greatly enlarged activity we propose.” However, funding for NSF’s Cyberinfrastructure Program is pending. The leading-edge sites will receive some funding for the next 3 years, but no plans for technology refresh have been announced, and funding for the partners at other sites has been discontinued. Both the partnerships and the leading-edge sites are already in danger of losing key senior professionals.
Industrial institutions that have had the most success in keeping their professional employees are those that are specialized and physically located where there is little or no competition (for instance, Cray). Keeping their supercomputing professionals is easiest for those national laboratories and institutions (for instance, LANL or the Institute for Defense Analyses (IDA)) that have a long-term commitment to particular applications for which they have unique or near-unique responsibility—that is, those laboratories and institutions whose “mission” is protected. However, even in those organizations, uncertainties surrounding funding can cause professional employees to look elsewhere for perceived job security.
While it is important to keep senior professionals in the field, it is also important to continue to produce next-generation professionals. Funding models that encourage and support the education of the next generation, as well as those that provide the supercomputing infrastructure needed
for their education, are necessary. It is also important that students preparing for a career in high-performance computing have confidence that attractive employment opportunities will continue to exist.
CONSUMER INSTITUTIONS
Consumers of supercomputers can be roughly divided into national laboratory and academic researchers and commercial users. Supercomputing “centers” have evolved for the use of national lab and academic researchers. These centers provide access to supercomputers and support (so-called cycle shops), or they can offer a fuller complement of services, including advancing the state of the art in supercomputing software and workforce infrastructure. Some (e.g., NCAR or the DOE weapons laboratories) are targeted at a single application domain; others (e.g., NSF’s PACI and DOE’s NERSC) serve multiple domains. Supercomputing exists in for-profit companies when it can give them a competitive advantage.15
Supercomputing Centers
Supercomputing centers provide a community of users, sometimes from the same organization and sometimes not, with shared access to one or more supercomputers. A center normally employs professional staff to help run the installation as well as to help users run and improve their application codes to best effect. Supercomputing centers are typically housed in special-purpose facilities that provide the needed physical plant, notably floor space, structural support, cooling, and power. They also provide working space for the operational staff. Thanks to the Internet, users normally need not be physically present.
The computing infrastructure provided by a center includes more than computing hardware. Typically, the users also share access to licensed or purchased software and, increasingly, to very large quantities of archival data. Thus a supercomputing center leverages its investment by gaining enough users to keep the system in constant use, by using the system well, and by sharing essential software, data, and expertise that facilitate the applications. Most centers also provide expertise on effective use of the supercomputers and software packages they support, through consulting and training services and occasionally by loaning programmers with relevant expertise to the application projects.
The primary organizations that provide supercomputing centers are government mission agencies such as the Department of Energy and the
|
15 |
Cf. Chapter 4. |
Department of Defense, and the National Science Foundation. Some centers are sponsored directly by universities; some are managed by companies. The main purpose of a mission agency center is to support the computing related to its mission. The users that support that mission sometimes come from outside the agency—for example, from academia or from companies that contract with the agency.
In most instances, a supercomputing center is part of a larger organization that includes researchers who use the computational facilities, computational science software developers, and education and training groups. Having local users provides continuing dialogue for improving the center’s offerings and provides the justification for the host institution to house the facility. Having in-house software developers also facilitates better use of these systems.
The committee met with center directors from both NSF and DOE (see Appendix B). The center directors described a variety of difficulties they have had in planning supercomputing procurements, in ensuring that users can take full advantage of capability systems, and in balancing present-day needs against future demands.
-
Centers are often under pressure to raise funds to cover both operating costs and technology refresh. Center directors find it difficult to do long-range planning in light of the year-to-year uncertainties that surround both capital and operating budgets.
-
Centers are under pressure to use capability systems for capacity computing: (1) to respond to required measures of usage (such as having large numbers of jobs run and servicing large numbers of distinct users), (2) to satisfy influential users with noncapability needs, and (3) to make up for the lack of adequate capacity availability. Such use is increasingly hard to justify, in an era where capacity can be provisioned using cheap departmental clusters. Supercomputing centers have attempted to lessen the severity of this problem by developing software that facilitates the establishment and maintenance of departmental clusters. Suitably used grid computing infrastructure should further facilitate this shift.
-
NSF centers in particular have experienced mission creep—they are expected to move into new areas such as very high capacity networking, grid computing, and so on without adequate additional funding or adequate consideration of the effect on their capability computing responsibilities. The expectations come both from users and from external program reviewers.
-
Procurement is both very expensive and somewhat prolonged. Because of the time lags, it is speculative, in the sense that the delivered system may not meet expectations or requirements. (It is also expensive and difficult for the suppliers.) Procurement overheads cannot be amor-
-
tized over multiple platform acquisitions, and current processes do not facilitate the creation of long-term relationships with a vendor.
Industrial Supercomputing
In the context of this report, industrial supercomputing refers to the purchase and use of a supercomputer by a for-profit corporation. Supercomputers give commercial users capabilities similar to those that they give to defense and other government researchers. They enable scientists and engineers to study phenomena that are not readily observable such as the transient dynamics of semiconductor switching. Commercial supercomputers allow relatively inexpensive simulations to replace costly experiments, saving both time and money. An example is the crash testing of automobiles. Another driver for the commercial use of supercomputers is government regulations. Examples include the structural analysis of airplane frames, NOx/SOx analysis for combustion engines, and electromagnetic radiation for electronic devices.
Supercomputers can offer companies a competitive advantage by, for instance, enabling the discovery of new drugs or other technologies, resulting in lucrative intellectual property rights. Accurately modeling the yield of an oil field can impact lease prices by hundreds of millions of dollars. Engineering analysis can also allow reducing the cost of prototyping new products and reducing the time to market.
Many of today’s commercial supercomputer applications were pioneered by scientists and engineers working on problems of great national importance. Over time, the technology they developed was transitioned to other uses (e.g., NASTRAN,16 KIVA17). As Moore’s law steadily reduced the cost and increased the performance of computers, a problem that was first only tractable as a critical national-scale problem then became approachable for a large corporation, then for an engineering department, and eventually for anyone with a desktop computer. This is not to suggest that industry no longer needs supercomputers. As pointed out in Chapter 4, industrial users not only are making more extensive use of high-performance computing than ever before, but they are also making more use of low-end supercomputers than ever before. Just as in defense and science, new problems arise that require increasingly higher fidelity and shorter turnaround times. John Hallquist, for one, contends that a 107 increase in
delivered computing power could be used for crash testing. However, it seems that the rate at which new codes are being developed or existing codes are being scaled up has slowed down. One way to help understand supercomputing use by the commercial sector is to partition it according to the application/industry sector. Another way is to partition it by market sector—consumer or capital equipment or government/defense industry. There are users in many fields who have applications that they would like to run on larger data sets, with less turnaround time. These users constitute the potential commercial market for supercomputers.
Figure 6.1 shows the relative share of the various sectors of the technical computing market in 1998-2003, the importance of the scientific research and classified defense sectors, the relative growth of new sectors such as biosciences, and the relative stability of sectors such as mechanical engineering. It also shows that no market is so large as to dominate all
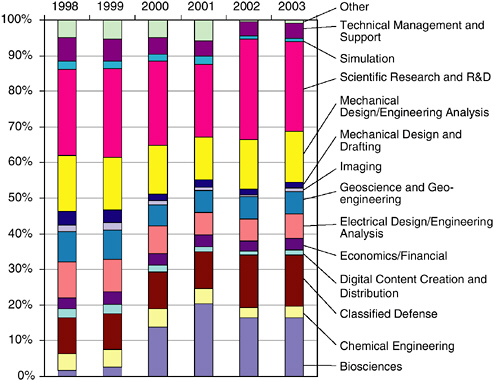
FIGURE 6.1 Revenue share of industry/applications segments, 1998-2003.
SOURCE: Earl Joseph, Program Vice President, High-Performance Systems, IDC; e-mail exchanges, phone conversations, and in-person briefings from December 2003 to October 2004.
others. As a result, large computer manufacturers have to develop systems that perform well on a very broad range of problems. This maximizes the potential return on investment when developing a product but has the unfortunate effect of delivering suboptimal performance to the different end users.
Figures 6.2 and 6.3 show the evolution of the worldwide technical computing market from 1998 to 2003. They indicate that the overall size of the market is about $5 billion, with less than $1 billion being spent on capability systems. The market exhibits significant fluctuations; the capability segment has been moving 10 or 20 percent up or down almost every year. Supercomputing vendors are hampered both by the small size of the high-end market and by the large year-to-year variations. The charts also indicate the significant impact of public acquisitions on this market—over 50 percent of the HPC market is in the public sector, as is over 80 percent of the capability market. Public sector purchases are very volatile, with large changes from year to year.
Industrial use is changing, and for reasons of competitive advantage, that industrial use is often not revealed. In fact, the ability of small groups
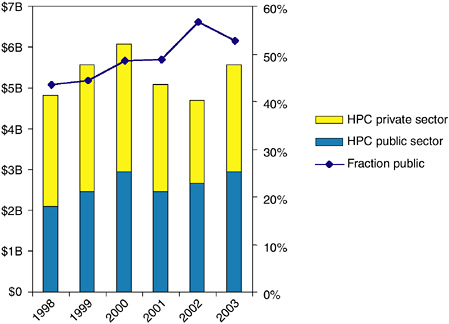
FIGURE 6.2 Worldwide HPC market. SOURCE: Earl Joseph, Program Vice President, High-Performance Systems, IDC; e-mail exchanges, phone conversations, and in-person briefings from December 2003 to October 2004.
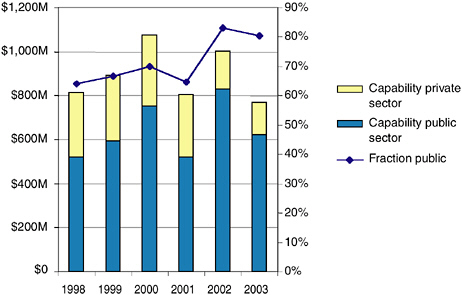
FIGURE 6.3 Worldwide capability markets. SOURCE: Earl Joseph, Program Vice President, High-Performance Systems, IDC; e-mail exchanges, phone conversations, and in-person briefings from December 2003 to October 2004.
to assemble PC clusters from existing office equipment means that today, managers of large commercial enterprises are often unaware of the supercomputers within their own companies. The overall decline in the technical computing market indicated by these charts may be due to this effect.























