
7
Internet Navigation: Current State
At this point in the development of Internet navigation, there are at least seven basic ways for a user to navigate to a desired Web resource, which is generally located on a page within a Web site. Five of them are direct—users’ actions take them immediately to the desired resource. Two are indirect—users must first employ a navigation service, either a directory or a search engine, to find the address of a desired resource and then, using that information, go to the desired resource. These basic ways can be and often are used in combination with one another. Table 7.1 summarizes and characterizes the various Internet navigation aids and services.
This discussion is concerned with navigation across the Internet and not specifically with navigation within sites, although the tools deployed in both cases are usually similar. Most Web sites—except those with only a few pages—now incorporate one or more means of navigation within the site itself. These include hyperlinks, directories (menus), site maps, and search engines. Because they are usually limited to the contents of the site, the problems of general-purpose Web navigation aids are diminished. For example, the context is delimited, the users are relatively homogeneous, the scale is relatively small, and material that is difficult to automatically index (such as multimedia and images) can usually be manually indexed.
TABLE 7.1 Principal Internet Navigation Aids and Services
|
Method |
Steps |
Indexing Process |
File Structure |
Match |
|
|
1. |
Domain Name—known or guessed |
1 or 2 |
Human |
Hierarchical |
Exact |
|
2. |
Hyperlink |
1 |
Human |
Network |
Exact |
|
3. |
Bookmark |
1 |
Human |
Flat or hierarchical |
Exact |
|
4. |
KEYWORDa |
1 |
Human |
Flat or hierarchical |
Exact |
|
5. |
Metadata |
1 |
Human |
Flat or hierarchical |
Exact |
|
6. |
Directory |
2 |
Human/computer |
Hierarchical or multi-hierarchical |
Fuzzy |
|
7. |
Search engine |
2 |
Computer |
Inverted |
Ranked |
|
a“KEYWORD” is capitalized to distinguish it from the use of keywords in traditional information retrieval or in Internet search engines (see Sections 7.1.4 and 7.1.7). In this use, each KEYWORD is part of a controlled vocabulary for which the match to a specific Internet resource is one to one. |
|||||
7.1 NAVIGATION AIDS AND SERVICES
7.1.1 Direct Access via a Uniform Resource Locator or Domain Name
One of the major factors in the success of the Web was the development of Uniform Resource Locators (URLs) for Web sites. Because those identifiers offered a standardized way to identify resources on the Web, resource providers and resource seekers had a common way to refer to their locations. But the URLs were intended as codes hidden behind meaningful objects—the anchor text—in a document, not directly typed by the user. The designers of the Web may have been surprised when URLs began appearing on the sides of buses and on billboards.
URLs are typically not managed to be permanent and can be difficult to remember, especially when they require many elements to describe a resource deep within a Web site. (Examples of such URLs abound in the footnoted references throughout this report.) Despite their flaws, however, they have thrived as a robust means of navigation.
In some browsers, users can also navigate through the Web by typing only a domain name because the browsers will automatically expand it into a URL that may identify a Web site. This use of domain names for navigation is effective to the degree that the searcher knows or is able to guess the domain name exactly and is satisfied with being taken to the home page of a Web site. If the name entered is incorrect, then the browser, e-mail server, or other Internet service consumes resources (in the local computer and in the Internet) trying to find a DNS match. Mistaken
guesses can create extra traffic and burden the DNS, as discussed in Chapter 3. However, most browsers now treat invalid domain names as search terms and return a list of possible matches.1
Furthermore, as Web sites have grown more complex, discovering the site has often had to be followed by a second navigation process to find relevant information or pages within the site. But some users would prefer to go directly to the page that contains the specific information being sought. Remembering or guessing does not suffice for such navigation because the URLs of inner pages comprise more than the domain name.
In addition, as network services proliferate and as additional top-level domains are added, users will have many more sites of interest to which to navigate, but at the probable cost of domain names that are more difficult to remember or guess. Furthermore, not only information, entertainment, and service resources, but also many personal electronic devices and home appliances may well be connected to the Internet. For convenience, users will probably want to assign easy-to-remember domain names to such devices. But because of competition for the easiest and shortest names, they may have to settle for less-readily remembered ones. In either event, they can use bookmarks (see Section 7.1.3) to simplify access.
For these reasons, remembering or guessing correct domain names is likely to become less dependable and, therefore, a less important aid to navigation as the number of locations on the Internet continues to expand.
7.1.2 Direct Access via Hyperlinks
Because the Web is a network of sites through which users can navigate by following links between documents on the sites, once the first site has been found, one can move across sub-networks of related and relevant information and services. The address of the linked-to information may be visible or, more typically, hidden behind anchor text. A human being defines the linkages within and from a site during site design.
There is no publicly available Internet-wide file of links; they are maintained locally. However, linkage information is collected and used by all major search engines as an important part of the ranking of responses. For example, Google maintains an extensive file of linkages, and it is possible to use Google to find all the pages that link to a given page (within the scope of what is indexed by Google; see “The Deep, Dark, or Invisible Web” in Section 7.1.7).
|
1 |
As discussed in Chapter 4, VeriSign tried to offer a service to users who enter an incorrect .com or .net domain name that directed them to possible matches, raising technical and policy issues. |
Navigation by following hyperlinks is an effective tool for moving between related sites once the first relevant site has been found. However, since Web site operators establish the linkages, they may or may not lead to the specific sites of interest to the user. Thus, navigation by hyperlinks is both a valuable and a limited aid. It generally must be supplemented by other means of finding starting sites and of identifying sites of interest that may not be on the radiating set of paths from the initial point.
7.1.3 Direct Access via Bookmarks
The URLs for sites of continuing interest that have been found after a search and those of frequently accessed sites can be stored locally—“bookmarked” or placed on a “favorites” list—and managed in most browsers. By doing so, the user can return directly to a location, perhaps deep within a site, with a single click. However, these local files can become difficult to manage over time, due both to scaling problems (as the list of bookmarks grows, it may require its own database) and to the likelihood of broken links or changed content as URLs age. For these reasons, bookmarks may become less useful with the scaling and maturing of the Internet, leading users to rely on search engines to find even familiar sites and Web pages.
The bookmark/favorite mechanism as implemented in current browsers and described above is fairly weak, providing a simple association between a name (provided by either the user or the Web page) and a URL. Richer methods are possible. For example, prior experience in both information retrieval and software engineering suggests that it would be useful to store, in some form, both the query that produced the reference and information about how long the reference was likely to remain current. With this information available, it would become easier to repeat the discovery process when a link went bad, perhaps even automatically. Some work is now underway to recast bookmarks as a type of local cache with this information included and some reference updating and recovery capabilities. That work also expects to unify the results of multiple types of navigation, from search engine output, to Uniform Resource Identifiers (URIs) obtained from colleagues, to links obtained from pages being traversed, into a single framework. (In information retrieval and library practice since the early 1960s, queries have been stored and then periodically executed to support Current Awareness or Selective Dissemination of Information services.2 However, unlike the bookmark case, the queries are run by a service on a regular schedule and not by users only when they need to update their bookmarks.)
7.1.4 Direct Access via KEYWORDS
The term “keyword” is used in several contexts, with slightly different meanings, in Internet navigation.
Its most common current use is to denote the terms entered into the search window of a search engine for matching against the search engine’s index of words appearing on Web pages.3 In this meaning, a “keyword” can be any phrase and can be treated in a variety of ways by individual search mechanisms. It is also used in this sense in search engine marketing to refer to the search terms for which a particular marketer is willing to pay.4
However, “keyword” has also been used to denote terms in a controlled vocabulary linked to specific Internet locations by a specific Internet (generally, Web) service. To distinguish this meaning, it is written here in capitals. Typically, KEYWORDS are associated with a particular organization or service and that organization or service has paid to have them linked uniquely to its location. Usually, just a single KEYWORD (or phrase) is entered and only one site appears in the response. They apply, however, only within a specific Web service and are not generally interpretable in the same way by others. One of the best-known uses of KEYWORDS is that of America Online (AOL) in which KEYWORDS can be typed into the AOL address bar.5 AOL KEYWORDS link uniquely to a network resource—“NYTIMES” links to www.nytimes.com, or to an AOL feature or service—“STOCK MARKET” links to the AOL Market News Center. (The latest versions of AOL now offer a choice between: “Go to AOL keyword: ‘NY Times’” or “Search the Web for ‘NY Times’”.) Typing the AOL KEYWORDS into MSN or into Internet Explorer will not necessarily lead to the same location. Indeed, both “NYTIMES” and “STOCK MARKET” when typed into Internet Explorer and Netscape Navigator6 are treated as search terms (keywords in the more general sense), and the response is a ranked list of possibly matching sites.
|
3 |
This is similar to the sense in which “keyword” has conventionally been used in information retrieval, where a “keyword” is “one of a set of individual words chosen to represent the content of a document.” See Korfhage, Information Storage and Retrieval, 1997, p. 325. |
|
4 |
The marketer’s site or advertisement will appear as one of the responses to any query that includes those keywords. In this context, there generally are several keywords entered in the query and many responses in the list produced by the search engine. This use of “keyword” is treated in detail in Section 7.2.2. |
|
5 |
See Danny Sullivan, “AOL Search Big Improvement for Members,” SearchEngineWatch.com, 1999, available at <http://searchenginewatch.com/sereport/article.php/2167581>. See also Dominic Gates, “Web Navigation for Sale,” The Industry Standard, May 15, 2000, available at <http://www.thestandard.com/article/0,1902,14735,00.html?body_page=1>. |
|
6 |
Test carried out in March 2005. |
Several years ago, there were a number of attempts to offer more widely applicable KEYWORDS on the public Internet. A service offered by RealNames, Inc. was available for several years. It was adopted, for example, by MSN, which, however, terminated its use in June 2002.7 RealNames closed shortly thereafter. KEYWORDS have been replaced in most cases—except for services catering to non-English language users8 and AOL—by search engines, which provide a wider-ranging response to keyword terms, and by the sale of search engine keywords to multiple bidders.
KEYWORDS have many of the same strengths and weaknesses as domain names for navigation. If known, they lead exactly to the location to which the purchaser of the KEYWORD wishes to lead the searcher (which may not be the same as the searcher’s intent). If guessed, they either succeed, lead to the wrong site, or fail. However, since many browsers and services now treat non-URL entries in their address lines as search terms, “failure” now generally produces a ranked list of possible matches. Thus, KEYWORD systems—including AOL’s—now default to search systems, just as domain name guesses generally do.9
Unlike the DNS, a variety of KEYWORD systems applicable to specific topic areas and with or without hierarchical structure are conceptually possible. Implementation of a KEYWORD system on the Web requires an application or a service, such as a browser or Netpia, that recognizes the KEYWORD terms when entered into its address line or when they reach the service’s name server. And, whereas in the early days of the Web such an innovation might have been relatively easy, the general implementation of standardized browser software in various versions makes the widespread introduction of a new feature much more difficult
|
7 |
See Danny Sullivan, “RealNames to Close After Losing Microsoft,” SearchEngineWatch.com, June 3, 2002, available at <http://www.searchenginewatch.com/sereport/article.php/2164841>. The committee heard testimony from Keith Teare, then chief executive officer of RealNames, at its July 2001 meeting. |
|
8 |
Two prominent native language KEYWORD systems are the following: (1) Netpia, a Korean Internet service, offers Native Language Internet Address (NLIA) for 95 countries (as of May 2, 2005). NLIA enables substitution of a native language word or phrase (a KEYWORD) for a unique URL. See <http://e.netpia.com>. (2) Beijing 3721 Technology Co., Ltd., has offered Chinese language keywords since 1999. See <http://www.3721.com/english/about.htm>. |
|
9 |
In July 2004, Google added a “Browse by Name” feature to its search, enabling a user to enter a single name in the tool bar and returning a single site if the term is specific or well known; if not, it defaults to a traditional search. It is not clear how the single response names are selected and whether or not they are paid for. See Scarlett Pruitt, “Google Goes Browsing by Name,” PC World, July 15, 2004, available at <http://www.pcworld.com/news/article/0,aid,116910,00.asp>. |
(although specific services, such as AOL or Netpia, can still implement them for their users).
Moreover, within any specific database, digital library, or community repository (such as the large databases of primary scientific data being assembled around the world), terms can take on local meanings. Generally speaking, meanings are constrained by the use of a controlled vocabulary, which defines each term as applied in this system. Well-known examples of controlled vocabularies include the Library of Congress Subject Headings, the Medical Subject Headings (MeSH), Subject Headings for Engineering (SHE), and the Association for Computing Machinery (ACM) Classification System.
KEYWORD systems also face the problems that arise from scale. The larger the number of locations to which they seek to assign simple and unique names, the greater the pressure to become complex and structured. The system must either remain manageably small or develop an institutional framework that allows decentralization, while centrally determining who can use which names to designate which locations. AOL and Netpia both centrally determine the assignment of names. However, Netpia implements KEYWORDS through decentralized name servers located at collaborating ISPs, while AOL implements its smaller list of KEYWORDS through its own service system.
7.1.5 Direct Access via Metadata
Since the early days of the Web, there has been a desire—especially, but not only, by those in the library and information science community—to establish a more consistent and more controlled way to categorize and describe Web resources based on the use of “data about data,” or metadata.10
However, differences between the Web11 and conventional libraries and data collections complicate fulfillment of that desire. First, the number, scope of content, and diversity of form of resources on the public Web exceed that in any library. Second, the quality of the, often self-provided, metadata is highly variable. And third, there is no organization or group of organizations that is able and willing to assume responsibility
|
10 |
For an overview, see Tony Gill, Introduction to Metadata: Metadata and the World Wide Web, Getty Research Institute, July 2000, available at <http://www.getty.edu/research/conducting_research/standards/intrometadata/2_articles/gill/index.html>. |
|
11 |
Hypertext Markup Language (HTML)—the programming language of Web site construction—specifies the expression of metadata in the form of “metatags” that are visible to search engines (as they collect data from the Web—see Box 7.2) but are not typically displayed to humans by browsers. To see metatags, if they are present on a Web page, go to View/Source in Internet Explorer or View/Page Source in Netscape Navigator. |
for assigning metadata tags to a significant portion of the resources accessible on the Web, as the Library of Congress does for books.
Efforts to adapt metadata for the description and categorization of sufficiently valuable Web resources began in the mid-1990s, when standard ways to express metadata—metadata schemes—were proposed as the answer to interoperability and scaling of the expanding Web.12 But a reexamination in 2002 of the mid-1990s’ recommendations forced their proponents to consider why metadata had not been successfully used.13 The error was in their assumptions: They had expected to find high-quality—clean and honest—information, not the large amount of misrepresented and deliberately incorrect metadata that was provided for resources on the Web.
It seems that any feasible attempt to develop metadata schemes and apply them broadly to the Web would have to be decentralized and based on the efforts of a large number of autonomous organizations with specific knowledge of the content and quality of the resources they describe. Yet decentralization raises the question of coordination among the many potentially inconsistent and non-interoperable metadata schemes that the autonomous organizations might otherwise develop. Through coordination, their separate efforts could cover a significant portion of the Web and open access to their resources to a wider audience beyond the organizations themselves. Two approaches have been taken to the coordination of metadata schemes produced by autonomous organizations.
The first approach to coordination is for organizations to collaborate in defining common metadata elements that will be used by all of them as a core for their metadata schemes. The best known and best developed of these is the Dublin Metadata Core Element Set, known as the Dublin Core,14 so named because it originated at a meeting in Dublin, Ohio, that was sponsored by the Online Computer Library Center (OCLC). It comprises fifteen metadata elements, which were thought to be the minimum number required to enable discovery of document-like resources on the Internet. Thus, Dublin Core can be used to discover an item, to determine
|
12 |
See Clifford A. Lynch and Hector Garcia-Molina, Interoperability, Scaling, and the Digital Libraries Research Agenda, 1995, available at <http://www-diglib.stanford.edu/diglib/pub/reports/iita-dlw/main.html>, accessed July 9, 2004. |
|
13 |
Christine L. Borgman, “Challenges in Building Digital Libraries for the 21st Century,” Proceedings of the 5th International Conference on Asian Digital Libraries (ICADL 2002), Ee-Peng Lim, Schubert Foo, Christopher S.G. Khoo, H. Chen, E. Fox, U. Shalini, and C. Thanos, editors (Lecture Notes in Computer Science, Vol. 2555), Springer-Verlag, 2002, available at <http://www.springer.de/comp/lncs/index.html>. |
|
14 |
The Dublin Core Web site is at <http://www.purl.org/dc/>. Official reference definitions of the metadata elements can be found there. |
where fuller descriptions can be found, and to identify its detailed format (e.g., MARC for books or the Environmental Markup Language for biocomplexity data). Dublin Core works best when a professional cataloger creates descriptions. To achieve wide adoption, some believe that it needs to be made more suitable to machine-generated descriptions.15
The second approach to coordination is to provide a higher-level structure that can incorporate multiple metadata schemes, enabling them to be deployed in combination to describe a resource with the assurance that the resultant description will be correctly interpreted by any computer program that is compatible with the higher-level structure. The best known and best developed of these higher-level structures is the Resource Description Framework (RDF) developed by the World Wide Web Consortium (W3C).16 It extends another W3C standard, Extensible Markup Language (XML),17 which is used to describe data where interchange and interoperability are important, to describe resources. Any Web resource—that is, any object with a URI—can be described in a machine-understandable way in the RDF, although for some objects the description might contain little information. The resource—Web object—is described by a collection of properties—its RDF description. These properties can come from any metadata scheme since the RDF description incorporates reference information about the metadata scheme and the definition for each property. The advantage of the RDF is that it provides a widely applicable framework within which specialized metadata sets can be combined. For example, to describe geographic resources on the Web, an RDF description might incorporate the Dublin Core to describe the bibliographic provenance and a geographic metadata scheme to describe the geographic coverage of each resource. The developers of the RDF believe that its existence will encourage the development of a large number of metadata schemes for different resource domains and that where there is overlap in their coverage, they will, in effect, compete for adoption by those who describe resources. See Box 7.1.
While the RDF may provide a useful framework within which various metadata schemes may be developed and combined, it does not resolve the more difficult problem of actually using these metadata schemes to describe resources on the Web. That problem has three components: determining
|
15 |
See Carl Lagoze, “Keeping Dublin Core Simple: Cross-Domain Discovery or Resource Description,” D-Lib Magazine 7(1), 2001, available at <http://www.dlib.org/dlib/january01/lagoze/01lagoze.html>.Lagoze provides a useful discussion of the tradeoffs in simple and complex metadata descriptions and the relationship between Dublin Core, RDF, and other schema. |
|
16 |
See Resource Description Framework (RDF)/W3C Semantic Web Activity, available at <http://www.w3c.org/rdf>,and RDF Primer Primer [correct as written], available at <http://notabug.com/2002/rdfprimer/>. |
|
17 |
See Extensible Markup Language (XML), available at <http://www.w3c.org/xml>. |
|
BOX 7.1 Despite the problems of characterizing most resources on the public Web with RDF metadata, there are islands of application and, over the long term, they may extend to cover ever more terrain. With that prospect in mind, Tim Berners-Lee and his colleagues at the W3C have proposed a way of linking these islands into a formalized network of knowledge that they call the “Semantic Web.”1 They do so by introducing “ontologies” that consist of relational statements (propositions) and inference rules for specific domains of knowledge and are used to define terms used on the Web. In their vision, the Semantic Web would enable Web agents to draw upon that network of machine-accessible knowledge to carry out complex functions with less explicit direction than is currently required. While its area of application is far broader than navigation, its developers foresee, for example, that software agents will “use this information to search, filter, and prepare information in new and exciting ways to assist the Web user.”2 Like metadata and RDF, the applicability and feasibility of the Semantic Web remains the subject of dispute between its advocates and the skeptics.3 The practical implementation and use of the Semantic Web is highly dependent on the broad adoption of RDF and the ontologies it requires. That work has proceeded slowly thus far.
|
who will assign the metadata to each resource; finding incentives for metadata use; and determining how the metadata will be used.
The resolution of that three-component problem is easiest within communities, whether organized by topic, geographic region, or some other shared subject area.18 Individual communities in several academic disciplines are creating their own repositories with their own metadata frameworks. Among the repositories that have been established are IRIS for
|
18 |
See Chris Sherman, “Search Day—Metadata or Metagarbage,” SearchEngineWatch.com, March 4, 2002, available at <http://www.searchenginewatch.com/searchday/article.php/2159381>. |
seismology, KNB for biocomplexity, and NCAR—among others—for environmental data.19 Other communities have established portals to gather resources and links to other resources on their topic of interest. Communities build these metadata-based repositories and portals out of self-interest—with accurate metadata they can provide better access to community resources. As both the creators and the users of the metadata, the self-interest of cohesive communities leads them to want trustworthy metadata and to provide the resources needed to create and keep them current and accurate.20
Solving that three-component problem is more difficult for the general Web user “community.” Metadata would either have to be supplied by independent editors (as it is now for use in directory services) or applied by the resource providers and collected automatically by search engines. Although search engines look at the metatags—a type of information about a Web page that can be placed in the code describing the page but not made visible to users—on Web sites, it is not always clear whether and how they make use of the metadata they find there. And the fundamental difficulty of unreliable self-assigned metadata is difficult to overcome through automatic means.
However, one important current use of metadata is to characterize images and audio and video files on the general Web so that they can be indexed and found by search engines. The metadata tags are generally either extracted from text accompanying the images or supplied manually by editors or the resource provider and appear, generally, to be reliable. (See Section 8.1.3.)
Thus, it is highly unlikely that general metadata schemes, even if they were designed, could be reasonably implemented for the Web generally. However, metadata schemes may be practical and useful for specific sets of resources with interested user communities, such as professional organizations, museums, archives, libraries, businesses, and government agencies and for non-textual resources, such as images, audio, and video files. Moreover, even in specialized resources, establishing the framework and assigning the metadata terms to a large number of items are very different matters, since the latter is far more labor intensive. Thus, the widespread use of metadata would become easier with the improvement of automatic
|
19 |
IRIS (Incorporated Research Institutions for Seismology) is at <http://www.iris.edu/>; KNB (The Knowledge Network for Biocomplexity) is at <http://knb.ecoinformatics.org/home.html>; and NCAR (National Center for Atmospheric Research) is at <http://www.ncar.ucar.edu/ncar/>. |
|
20 |
See, for example, work done by the Education Network Australia, including EdNA Online, The EdNA Metadata Standard, 2003, available at <http://www.edna.edu.au/edna/go/pid/385>, and the listing of activities at <http://www.ukoln.ac.uk/metadata>. |
indexing (automatic metadata tagging), a topic that has long been pursued in information retrieval.21
7.1.6 Navigation via Directory Systems
In general, the term “directory” refers to a structured collection of objects organized by subject, much like a library card catalog or yellow pages telephone listing. Structuring a directory—usually using a taxonomy of some form—and placing objects under specific subject headings are done by humans. They may assign the same subject heading to more than one object and the same object may be assigned to more than one subject—that is, it may appear under more than one heading. In the case of Internet directories, the objects are Internet locations—Web sites or Web pages, typically.
Only the Web sites that have been submitted to or found by an Internet directory service and whose content has been classified and described, either by the editors of the directory or by the creators of the Web site, will be available in the directory. As a result of the heavy requirements for skilled labor, Internet directories can include only a small selection of all the sites connected by the Web. However, in contrast to search engines, they have the advantage of being able to incorporate listings of many Web sites in the “dark” Web (see “The Deep, Dark, or Invisible Web” in Section 7.1.7) because the sites themselves solicit a listing or because they become known to the directory editors through other means.
The listings, categorized under subject hierarchies, can be browsed by narrowing down subject categories or can be searched by matching search terms against summary descriptions of the Web site content.22 For example, the Yahoo! directory of the Internet classifies Web sites by 14 topics. Under the “computers and Internet” topic, there are two commercial (sponsored) categories and 48 additional categories. The latter grouping includes topics such as “communications and networking” with 1108 entries grouped into 40 subtopics; “supercomputing and parallel computing” with 9 subtopics and 11 sites; and “software” with 50 subtopics.23
Users search a typical, hierarchically organized directory by starting at the top of the tree and moving deeper along branches labeled (by the directory editors) with terms that seem to match their interests.24 Thus, a
user interested in administration tools for the DNS could trace the following path in Yahoo!:
Directory→Computers and Internet→Communications and Networking→Protocols→DNS→Administration Tools25
The success of the user’s navigation depends on the user’s skill in identifying appropriate paths (but backing up and trying another path is relatively easy), on the editors’ skill in describing and placing the site in the directory, and on the site’s accuracy in describing itself to the editors (unless they visit and characterize each site themselves).
Directories present the user with a taxonomic view of some of the Web sites on the Internet, which can enable users to reach their goals through successive refinement. However, if the taxonomy is poorly implemented or does not roughly match the view of the user, it can be very difficult to use. There are hundreds of directories, general and specific, available on the Web and listed in various directories of directories.26
Work is now underway by several groups (a majority with at least loose links to each other)27 to reexamine analogies to the time-tested “yellow pages” model for the Internet. Whereas search engines are modeled on a “search through the visible Web and see where appropriate material can be found” model (augmented, as discussed below, by paid placements), a yellow pages system is one in which all of the entries are there because their owners want them there, there is considerable content-owner control over presentation, and although a classification system is used to organize the information, the categories in which a listing is placed are generally chosen by the listing (content) owner, not the site operator or an automated process. In its paper form, that type of system has been thoroughly demonstrated over the years and is useful precisely because the information content is high and the amount of extraneous material low. Since the combination of several of the factors discussed in this section has resulted in most searches for products leading to merchants that sell those products, and to a good deal of extraneous information as well, a directory that is organized the way the merchants want (and pay for) may be more efficient technically and economically. Of course, these models can apply to many types of listings, goals, and content other than commercial ones.
|
25 |
Directory accessed on March 5, 2005. |
|
26 |
See, for example, the directory of directories at Galileo (Georgia’s Virtual Library) <http://www.usg.edu/galileo/internet/netinfo/director.html>. |
|
27 |
For example, the work by Beijing 3721 Technology Co., Ltd. (also known as “3721”), which was recently acquired by Yahoo! |
One of the major differences between a traditional yellow pages and some of these systems is that the yellow pages (and even their online versions that support broader geographical scope28) are organized around a single hierarchical category system. That is necessitated by the organization of the material for publication on paper. But a computer-based system can take advantage of a multi-hierarchical environment in which, for example, the location of an entity (at various degrees of precision) is specified in a hierarchy different from that for content descriptors (such as category of store), rather than having to be a superior category in the hierarchy.
Because directories are typically built and maintained by humans, they can cover only a small portion of the Web, have difficulty keeping up with changes in locations, and are labor intensive. (However, as noted above, specialized directories that are supported by those who want to be found, such as commercial yellow pages listings, can overcome the latter two problems.) One way to address all of these problems is to decentralize responsibility for maintaining the directory, just as the DNS name files are decentralized. For example, 475 “guides” who are selected and trained to cover a specific subject area maintain the About.com directory.29 Its 475 “guides” are responsible for “more than 50,000 topics with over 1 million pieces of original content, which are grouped into 23 channels.”30 Another way, which is becoming common, is to combine directories with search engines, which index a much larger portion of the Web using automated processes. Netscape began an ambitious directory project using volunteers and called Open Directory, which continues to this day and is incorporated into Google.
7.1.7 Navigation via Search Engines
Search engines rely on indices generated from Web pages collected by software robots, called crawlers or spiders.31 These programs traverse the Web in a systematic way, depositing all collected information in a central repository where it is automatically indexed.32 The selection and ranking of Web pages to include in the response to a query are done by programs that search through the indices, return results, and sort them according to a generally proprietary ranking algorithm. Consequently, basic search by search engines is often referred to as algorithmic search. (See Box 7.2 for an expanded description of how search engines work.)
|
28 |
See <http://www.superpages.com>. |
|
29 |
See <http://www.about.com>. |
|
30 |
About.com Web site, March 5, 2005. For more information see <http://ourstory.about.com/>. |
|
31 |
See <http://www.searchenginewatch.com> for a wealth of information about search engines and directories. |
|
32 |
Many search algorithms do not depend on the script or language used, so almost all the Internet’s visible Web pages can be included—regardless of their language. |
When Web site operators pay to have their sites listed in response to queries, the search is referred to as monetized search. The desire of Web sites to obtain advantageous positions in the listing of responses to queries relevant to their offerings has led to the development of specialized strategies and tactics that are called search engine marketing and optimization. Despite their best efforts, search engines cannot, for a variety of reasons, reach all sites on the World Wide Web. The untouched part of the Web is called, variously, the “deep,” the “dark,” or the “invisible” Web. Finally, the searcher can obtain more comprehensive results to a query by looking at the results of searches conducted by several search engines combined by a “metasearch” engine. The following sections examine these search engine topics in more detail.
Algorithmic Search
Because they are automated, search engines are the only currently available navigation aids capable of finding and identifying even a moderate fraction of the billions of Web pages on the public Internet. To index and retrieve that much information from the Web, search engine developers must overcome unique challenges in each of the three main parts that make up a search engine: the crawler, the indexer, and the query engine. (See Box 7.2.)
The principal challenges facing the crawler (robot or spider) are determining which Web sites to visit and how frequently to do so. Search engines vary substantially in the number of Web sites visited, the depth of their search, and the intervals at which they return. In general, increasing the size of the computing facility can increase the number, the depth, and the frequency of visits and, consequently, it is a business judgment by the search engine operators that determines these parameters.
The principal challenge facing the indexer is in determining when two terms are equivalent, bearing in mind singular versus plural versions, misspellings, differing translations or transliterations, synonyms, and so on. Moreover, these challenges are language-specific. These problems can be addressed to some extent during the creation of an index, but are often left to the search engine. A search engine typically allows for partial matching to the query and returns many results. Searching for “cook rutabaga” may return pointers to results with those words, but also to results containing “cooked rutabaga” or “cooking rutabaga.”
The major challenges facing the query engine are matching the query words appropriately and calculating the relevance33 of each response.
|
BOX 7.2 Search engines are technical systems comprising computer programs that perform three interrelated functions: searching the Web to collect Web pages, indexing the Web pages found, and using the index to respond to queries. The Web search programs, called crawlers or spiders, collect Web pages by traversing the Web, following links from site to site in a systematic way. By beginning with Web sites that are densely populated with links, a crawler is able to spread across the most frequently accessed parts of the Web, and then increase speed as it travels to other less frequently visited sites. Search engines use different algorithms to determine the coverage and depth of the pages that are visited. Some may focus more on breadth, covering only pages linked from the home page of a Web site, rather than depth, visiting pages deeper within the Web site’s hierarchical structure. Because of the constant changes of Web site content and the addition of new Web sites, Web crawling by search engines is never completed. The frequency with which Web pages are re-crawled directly affects the freshness of the results returned from a search engine query. Once the Web pages are retrieved, indexing programs create a word index of the Web by extracting the words encountered on each Web page and recording the Uniform Resource Locator (URL) and possibly additional information for each one. Indexes are then created that list the URLs of all pages on the Web for a given word. They may also record additional information about the word such as whether it appeared in a title, anchor text, heading, or plain text; the relative size of its type; and its distance from other words. In response to queries, query engines will search the index for the query words to find the pages where they appear. For example, if the query is for “CSTB committees,” the search engine will retrieve a list of all the pages on which both the strings “CSTB” and “committees” appear. A search may return tens or thousands or even millions of responses, which users will typically not examine in full. Therefore, the critical question is the order in which the retrieved list of pages is returned. The goal is to return the pages |
Determining the relevance of a response to a query is a complex problem, since relevance depends on the user’s specific needs, which may not be clear from the words chosen for the query. (See the example of a search for “Paris” in Section 6.1.6.) Different search engines use different criteria to calculate relevance, with examples being the location and frequency of words matching the query terms on a Web page and the patterns and quality of links among Web pages.
Relevant results, once retrieved, can be sequenced by other factors that the system or the user considers appropriate. Few people will view dozens, much less thousands, of matches to a query; typically, only the first one or a few pages of results are viewed. Among the 1400 or so re-
|
in decreasing order of relevance. The determination of relevance is both critical to the quality of response and very difficult to assess, because of the large number of indexed pages and the short queries that search engines typically receive. Each distinct search engine has developed its own proprietary algorithms for determining relevance. Google, currently the general-purpose search engine with the largest database, is noted for its algorithm, PageRank™, which uses the link structure of the Web as a key part of the relevance calculation. It assumes that a link from page A to page B is a vote by page A for the quality of content on page B. A’s vote is given higher weight if the Web site of page A is also highly linked. The relevance ranking assigned to a page by PageRank™ is based on the intrinsic value of the page plus the endorsements from the other pages linked to it. The qualitative performance of the PageRank™ algorithm is better than keyword algorithms alone, since it makes use of more information than just the content on the pages.1 The retrieved Web pages used to create the index may also be stored, or cached, beyond the time needed to create the index. Caching of results enables them to be returned more quickly in response to a request but also adds to the enormous storage capacity needed to create indexes required for large-scale search engines. Estimates of the computing resources used by one search engine to index the Web and handle 200 million queries per day—approximately one-third of the total daily Web searches—is 54,000 servers, over 100,000 processors, and 261,000 disks.2 Currently operating search engines include AlltheWeb, Alta Vista, Google, Inktomi, MSN Search, and Teoma. |
spondents to a survey of search engine users in the spring of 2002, only 23 percent went beyond the second page and only about 9 percent read more than three pages.34 Thus, the matching and ranking criteria of search engines strongly influence the material that people actually view and use.
No single set of matching and ranking criteria is likely to suit all users’ purposes. Consequently, it is in general users’ interest that multiple
|
34 |
See “iProspect Search Engine Branding Survey,” reported in “iProspect Survey Confirms Internet Users Ignore Web Sites Without Top Search Engine Rankings,” iProspect press release, November 14, 2002, available at <http://www.iprospect.com/media/press2002_11_14.htm>. |
search engines employing different relevance criteria be available. The more options, the more likely it is that users will find a search engine that consistently ranks highly the content or services they seek. Very skilled and experienced users might even want to know the criteria by which a search engine ranks its results, enabling them to choose the search engine whose criteria best meets their needs. However, commercial search services treat the details of their ranking algorithms as proprietary since they are a primary means of the services differentiating themselves from their competitors and of minimizing the capacity of Web site operators to “game” the system to achieve higher ranks.
Search engines are able to return a high proportion of all the relevant Web pages that are available for indexing—though often in such a large number that they exceed the searcher’s ability to review most of them—and to give a reasonable probability of retrieving less-well-known Web pages related to particular topics, though not necessarily in the first few pages of results. Furthermore, since information on the Web is dynamically changing, heterogeneous, and redundant, no manual system can list and remain current with more than a small fraction of all sites. Only search engines have the capacity to keep their indices relatively current by continually revisiting accessible sites, although (as noted above) the frequency with which sites are visited varies among search engines and, probably also, depends on specific site characteristics. As the Web expands, so may the number of responses that search engines return for a query, although the relationship is not generally proportional. Because it is likely that they will receive large numbers of responses to a query, searchers naturally favor search engines whose ranking of responses reliably provides close to the top of the listing the pages that best meet their needs.
Monetized Search
The growing use of search engines offers the opportunity for information and service providers to affect the presentation of search results to users through a variety of direct and indirect means. When viewed from the traditional information retrieval perspective, this appears to contradict a user’s “right” or expectation of neutrality in his or her information sources (except when seeking information from sources with an obvious viewpoint, such as political or commercial sources.) However, when seen from the marketing perspective, it is an especially efficient way for providers to reach prospective users just at the time when the users have expressed interest in what they have to offer.
The search engine companies have responded to the providers’ interest through a variety of advertising, “pay for placement” and “pay for inclusion” opportunities. These practices as a group are often called mon-
etized search. Payment can result in having an advertisement placed ahead or alongside of the search results for specified search terms, having a site visited more frequently or more deeply by the crawler, having a page assured a place in the results, or having a link placed at the top of the list of results. (However, concerns about the latter two practices—paid inclusion and paid ranking—have led some search engines that offer them either to phase them out or to consider doing so.35)
The consequence of these opportunities is that the first page of results of a search engine query for, say, “Florida holidays” generally now includes not only the neutral results ranked according to the relevance algorithm used by the engine, but also sponsored listings along the top or the sides from advertisers that paid to have their listings presented whenever the keywords “Florida” or “holiday” or “Florida holidays” appeared in the query.
Providers’ payments have become the major source of revenue for most search engines, which searchers use for free. (See Section 7.2.2 for a further discussion of advertising and the search engine market.)
Search Engine Marketing and Optimization
The opportunity to pay for listings in response to certain key words on specified search engines has led to the development of search engine marketing. Its practitioners help operators of Web sites to decide which key words to pay for on which search engines to attract the greatest number of prospective customers to their sites. This is very similar to the role that advertising agencies play in helping advertisers to decide what ads to run in which media. However, advertising on search engines has the distinct advantage that the message is presented only to prospective customers who have expressed an interest in a topic that may be related to the advertisers’ wares at the time of their interest. In many cases, the advertiser pays only if prospective customers actually click on the link that takes them to the advertiser’s site.
Web site operators have also responded to their perceived business need to be ranked higher in the non-paid results of searches (e.g., florists in the search for “flowers”) by adopting means to improve their rankings.36 This has led to the development of search engine optimization in which the site design is optimized to include simple, common
|
35 |
See Stefanie Olsen, “Search Engines Rethink Paid Inclusion,” c/net news.com, June 23, 2004, available at <http://news.com.com/2100-1024-5245825.html>. |
|
36 |
See Mylene Mangalindan, “Playing the Search-Engine Game,” Wall Street Journal, June 16, 2003, p. R1. |
terms likely to turn up in searches and to include metatags (metadata) that are invisible to users but are picked up by some search engines. Specialized firms have grown up to help companies both in marketing and optimizing their Web sites.
Other approaches are less savory. For example, “pagejackers” falsify information in the meta tags on their site to emulate the appearance of another Web site that would rank higher; “spamdexers” seek placement under search terms that are unrelated to the content of their pages by placing many repetitions of the unrelated terms on their site in invisible form (e.g., white text on white background, which can nevertheless be read by the search engine). In response to providers’ tactics, search engines eliminate from their databases those companies that they believe are using unscrupulous methods to improve rankings.37 Not surprisingly, this has led to a continuing battle between Web site operators trying new ways to improve their ranking and search engines introducing countermeasures as each new tactic is discovered.
The Deep, Dark, or Invisible Web
Although they are far more comprehensive than directories, general search engines still index and retrieve only a portion of the content available on the Internet. First, they do not reach every page that is visible to them because of limits on how often they will crawl the Web, on the capabilities of their crawlers, and on how much of each visited site they will crawl. Second, a large majority of the information potentially reachable on the Web is not visible to them. The parts that they cannot see are called the “deep,” the “dark,” or the “invisible” Web.38 Various estimates place the size of the invisible Web at hundreds of times larger than the visible or public World Wide Web.39 Web pages can be invisible to search engines for a variety of reasons.40
A primary reason is the increasing use of databases to deliver content
|
37 |
See, for example, Google’s guidelines at <www.google.com/webmasters/guidelines.html>. |
|
38 |
See Chris Sherman and Gary Price, The Invisible Web, Information Today, Inc., Medford, N.J., 2001. |
|
39 |
See Michael K. Bergman, “The Deep Web: Surfacing Hidden Value,”August, Journal of Electronic Publishing 7(1, August), 2001, available at <http://www.press.umich.edu/jep/o7-01/bergman.html>. |
|
40 |
See Genie Tyburski and Gayle O’Connor, “The Invisible Web; Hidden Online Search Tool,” presentation to ABA Techshow, April 3, 2003, Chicago, available at <http://www.virtualchase.com/iweb>. |
dynamically. If material is available only in response to queries and actually does not exist until a question is asked, there is no practical way for a general search engine’s crawler to “see” it since those systems cannot synthesize the queries that will generate the relevant material. Thus, engines41 cannot crawl inside searchable databases such as library catalogs, the Thomas register of manufacturing information, or indexes of journal literature. A search engine query on “Shakespeare” may retrieve sites that specialize in Shakespearean memorabilia (as described in their Web pages), sites of theaters that are currently performing Shakespearean plays, and Shakespeare fan clubs, but usually will not retrieve catalog records for books in libraries or for records in archives. There are Web sites that serve as directories to many “invisible” resources, such as library catalogs and databases, on the Internet.42 Moreover, specialized search engines, such as those used by shopping comparison43 or travel reservation sites,44 are designed to synthesize the appropriate queries and submit them to multiple databases in order to obtain the comparison information requested by the user. Furthermore, as noted earlier, directories can be useful in this situation since they can manually identify or seek submission of database sites, enabling the searcher to find a relevant database and then submit a specific query to it.
Content virtualization45 produces a considerable amount of dynamic information that is unavailable to Web crawlers. Google has made an attempt to overcome some of the challenges of rapidly changing content and the increasing use of “virtual” content, particularly among large news Web sites, by creating special arrangements with news organizations to continually update, retrieve, and index content from a preselected list of news Web sites.46
|
41 |
See Clifford A. Lynch, “Metadata Harvesting and the Open Archives Initiative,” ARL Bimonthly Report 217:1-9, 2001. |
|
42 |
One such directory is “Those Dark Hiding Places: The Invisible Web Revealed,” which can be found at <http://library.rider.edu/scholarly/rlackie/Invisible/Inv_Web.html>. |
|
43 |
Such as, for example, epinions (www.epinions.com) and bizrate (www.bizrate.com). |
|
44 |
For example, Travelocity (www.travelocity.com) and Expedia (www.expedia.com), or metasites, such as SideStep (www.sidestep.com) and Mobissimo (www.mobissimo.com). |
|
45 |
“Content virtualization—or content integration as some know it—leaves data in its originating system and pulls it together in real time when requested by the user.” Quoted from Lowell Rapaport, “Manage Content Virtually,” Transform Magazine, April 2003, available at <http://transformmag.com/shared/cp/print_article_flat.jhtml?article=/db_area/archs/2003/04/tfm0304tp_1.shtml>. |
|
46 |
For more information about news aggregation services by Google, see <http://news.google.com/>. For other approaches to news aggregation services, see Blogdex at <http://blogdex.net/>. |
The dark Web also encompasses the vast intranets of many corporations, governments, and other organizations. Resources are not indexed if they are behind firewalls, require payment, or are otherwise coded “off limits” to search engines.
Progress on the dark Web problem is being made via efforts such as the Open Archives Initiative (OAI), which enables information providers to offer their metadata for harvesting.47 Additionally, new kinds of Web pages for which indexing is probably infeasible are emerging. Personalized content such as the “My Yahoo personal news page” is an example of this type of content, since it is created only when the user requests it and is not available to others on the Web. However, it comprises a selection of materials from public Web pages, so indexing it would add little other than information about an individual’s selections—and that would probably be constrained by considerations of privacy. Some ephemeral content, such as “instant messaging” and “chat,” is not indexed because it is dynamic and not readily accessible to search engines unless it is archived. Google indexes the complete Usenet archives and the archives of many important Internet mailing lists.
Another source of new and rapidly changing information on the Web is the profusion of journals in the form of Web logs, called blogs. Software that has made it very easy for individuals to construct and modify Web sites and the availability of services to house them have made Web publishing common. The ease of creating and changing blogs has lowered the barriers to entry for publishing to large audiences. This has led to their increasing number, types, and ranges of quality. They often incorporate a large number of links to other blogs and Web sites, making them a distinctive medium that contains not only the authors’ contributions, but also the authors’ identification of “communities of interest” whose ideas are germane to theirs.
These new forms of content pose further requirements for search engines to retrieve information more frequently and also to return the wide variety of information posted to Web logs in a useful way. Some of these challenges are being met by specialty search engines, which go beyond the features presented by Google. One of these is Daypop,48 which uses its own kind of link analysis to identify Web logs that are pointed to other Web log sites from their front pages, rather than from archived or back
|
47 |
Scholarly Publishing and Academic Resources Coalition, “The Case for Institutional Repositories: A SPARC Position Paper,” available at <http://www.arl.org/sparc/IR/ir.html>. |
|
48 |
See Greg Notess, “The Blog Realm: News Source, Searching with Daypop, and Content Management,” Online 26(5), 2002. For more information about Daypop, see <http://www.daypop.com/>; see also Technorati for another search engine approach to Weblogging, at <http://www.technorati.com/>. |
pages, and allows popular commentary, or responses to original posts on a Web log, to be comparatively searched across a number of Web logs.
Finally, multimedia materials are increasingly populating the Internet. They range from still photographs to full-length videos and films. These can readily be indexed by their descriptions, but unless a human indexer provides descriptive terms—metadata—a photo or song cannot yet be automatically searched and indexed by its content at a commercially viable scale.
The inability to search everything accessible via the Internet is not necessarily a problem, since much of it may not be useful and there is necessarily a cost associated with sorting through ever larger amounts of material. However, while some of the unsearchable material may be of little value, it is likely that some of it (say, major library catalogs or government databases) would be of great value, if it could be readily searched.
Metasearch Engines
“Metasearch” engines take the keywords entered by the user and submit them to a number of independent search engines. They present the combined results to the user. This would appear to offer the advantage of time saving and the possibility of getting the best results from the sum of the engines searched. However, whether those advantages are realized depends on how the metasearch engine combines and orders the results from several search engines, each using different relevance and ranking criteria. Among the metasearch engines available in 200449 were Dogpile, Vivisimo, Kartoo, and Mamma.
7.1.8 Use of Navigation Aids
How much use is made of these aids to navigation? Complete data are unavailable, but use of search engines (and their associated directory services) is being measured. According to the Pew Internet & American Life Project:50
-
In total, Americans conducted 3.9 billion searches in June 2004.
-
The average search engine user conducted 33 searches in June 2004.
|
49 |
For a listing of metasearch engines, see Chris Sherman, “Metacrawlers and Metasearch Engines,” SearchEngineWatch.com, March 15, 2004, available at <http://searchenginewatch.com/links/article.php/2156241>. |
|
50 |
See Deborah Fallows, Lee Rainie, and Graham Mudd, “The Popularity and Importance of Search Engines,” data memo, Pew Internet & American Life Project, August 2004, available at <http://www.pewinternet.org/pdfs/PIP_Data_Memo_Searchengines.pdf>. The results came both from a telephone survey of 1399 Internet users and from tracking of Internet use by comScore Media Metrix. |
-
Eighty-four percent of Americans who use the Internet have used search engines—more than 107 million people.
-
On an average day, about 38 million of the 64 million Americans who are online use a search engine. Two-thirds of Americans who are online say they use search engines at least twice a week.
-
Using search engines is second only to using e-mail as the most popular Internet activity, except when major news stories are breaking, when getting the news online surpasses using search engines.
-
“There is a substantial payoff as search engines improve and people become more adept at using them. Some 87% of search engine users say they find the information they want most of the time when they use search engines.”
-
“More than two-thirds of search engine users say they consider search engines a fair and unbiased source of information.”
-
“… 92% of searchers express confidence in their skills as searchers—over half of them say they are ‘very confident’ they can accomplish what they want when they perform an online search.”
-
“… 44% of searchers say that all or most of the searches they conduct are for information they absolutely need to find.”
-
“A third of searchers say they couldn’t live without Internet search engines.” However, about a half say that, while they like using search engines, they could go back to other ways of finding information.
How do Internet users deploy the available aids to navigation? Do they generally go to the Web sites they seek by entry of a domain name or keyword or through bookmarks? Do they follow hyperlinks from Web page to Web page? Or do they commonly make use of search engines and directories? There is little publicly available research that addresses these specific questions. One analysis, based on survey data from March 2003 and 1 year earlier, provides some insights.51 According to that analysis, search engines produced 13.4 percent of site referrals on the day measured, which was an increase from 7.1 percent 1 year earlier. Navigation through entry of a known or guessed URL or use of a bookmark also increased from 50.1 percent to 65.5 percent over the year. The decline occurred in the flow along hyperlinks, which decreased from 42.6 percent to 21 percent. This survey indicates that Internet users tend to use certain sites and services consistently, visiting them repeatedly, using their book-
|
51 |
The data were collected on March 6, 2003, by WebSideStory’s StatMarket from about 12 million visitors to 125,000 sites using its proprietary analytical platform and were compared with figures from the previous year. Reported in Brian Morrissey, “Search Guiding More Web Activity,” CyberAtlas, March 13, 2003, available at <http://cyberatlas.internet.com/big_picture/traffic_patterns/article/0,1323,5931_2109221,00.html>. |
marks or remembered URLs. This suggests that much of their Web use is routine: checking e-mail, visiting a few standard sites, and exchanging instant messages with some Internet buddies. The need for search engines or directories arises primarily when a user needs a specific piece of information or wants a new or a replacement source of information, entertainment, or other material.
When a search is required, a survey of 1403 Internet users in spring 200252 showed a strong user allegiance to one or a small number of navigation services. More than half (52 percent) generally relied on the same search engine or directory and close to 35 percent used several interchangeably. Only 13 percent used different services for different kinds of searches. With respect to the usefulness of search engines, at that time almost half (45.9 percent) believed their searches were successful almost always. When they were not successful, 27 percent of the users switched to another search engine, rather than refining the search with more terms—only 7.5 percent did that. One third of the users felt that their searches were successful three-quarters of the time and 13 percent reported successful searches only half the time. (Though presented differently, these figures are not inconsistent with the results of the Pew study reported above.)
Users of diverse skills and interests, located across the world, have a range of information and services literally “at their fingertips,” whether at work, at home, or on the road, that far exceeds that available even to information specialists before 1993. This is true especially for those seeking commercial products and services. Comparable navigation tools for scholarly and public interest materials are generally less well developed.
Conclusion: The further development of Internet navigation services, such as subject-specific directories, that enable discovery of specialized databases and similar resources not readily indexed by search engines, is desirable. They can be of particular value to non-commercial groups, whose information resources may not be able to support active marketing.
Conclusion: As the material accessible through the Internet continues its rapid increase in volume and variety and as its societal importance grows, Internet navigation aids and services are likely to be challenged to deliver more precise responses, in more convenient forms, to more diverse questions, from more users with widely varying skills.
|
52 |
See “iProspect Search Engine Branding Survey,” reported in “iProspect Survey Confirms Internet Users Ignore Web Sites Without Top Search Engine Rankings,” iProspect press release, November 14 2002, available at <http://www.iprospect.com/media/press2002_11_14.htm>. |
Prospective improvements in Internet navigation technology and processes are discussed in Section 8.1.
7.2 INTERNET NAVIGATION—INSTITUTIONAL FRAMEWORK
In contrast to the provision of domain name services, Internet navigation is not the function of a single integrated technical system. While there is just one Domain Name System, there are many ways of navigating the Internet, only three of which currently involve distinct technical systems dedicated to navigation—KEYWORDS,53 search engines, and directories. Moreover, the institutional framework of the technical systems supporting Internet navigation is an open market, with many independent and competing providers offering their services. While some providers are non-profit or governmental institutions, such as national libraries or professional societies, the most frequently used navigation systems are provided by commercial organizations. This section concentrates on the commercial market for directory and search engine services.
7.2.1 The Commercial Providers of Navigation Services
As noted in Section 6.2.2, the early distinctions between providers of directories and providers of search engines—when each Web search site featured either algorithmic search engine results or human-powered directory listings54—have increasingly become blurred. Technology has helped to automate some of the classification processes for the Yahoo! directory,55 and most general-purpose Web search sites now feature search results from both human-based directories and crawler-based search engines, with one type providing the majority of search results. See Table 7.2 for a listing of navigation services and the sources of the results they provide.
The navigation services market is dynamic. The relationships shown in Table 7.2, which applied in July 2004, are continually changing. For
|
53 |
In June 2004, the commercial market for KEYWORDS comprised primarily AOL, Netpia, and Beijing 3721. Yahoo! purchased Beijing 3721 in 2004. |
|
54 |
See Danny Sullivan, How Search Engines Work, October 14, 2002, available at <http://searchenginewatch.com/webmasters/article.php/2168031>. |
|
55 |
In “A History of Search Engines,” Wes Sonnenreich explains that “as the number of links grew and their pages began to receive thousands of hits a day, the team created ways to better organize the data. In order to aid in data retrieval, Yahoo! became a searchable directory. The search feature was a simple database search engine. Because Yahoo! entries were entered and categorized manually, Yahoo! was not really classified as a search engine. Instead, it was generally considered to be a searchable directory. Yahoo! has since automated some aspects of the gathering and classification process, blurring the distinction between engine and directory.” See “A History of Search Engines,” available at <http://www.wiley.com/legacy/compbooks/sonnenreich/history.html>. |
TABLE 7.2 Navigation Services and the Providers of Their Results
|
Navigation Service |
Process Used to Obtain Main Results |
Provider of Main Results |
Provider of Paid Results |
Provider of Directory and/or Backup Results |
|
AllTheWeb (Overture-owned; Yahoo!-acquired) |
Search |
AllTheWeb |
Overture |
n/a |
|
Alta Vista (Overture-owned; Yahoo!-acquired) |
Search |
Alta Vista |
Overture |
LookSmart |
|
AOL Search |
Search |
|
|
Open Directory |
|
Ask Jeeves |
Search |
Teoma |
|
Open Directory |
|
|
Search |
|
|
Open Directory |
|
HotBot |
Search |
Choice of: Inktomi (Yahoo!-owned) Google, Ask Jeeves |
Overture |
n/a |
|
LookSmart |
Directory |
LookSmart |
LookSmart |
Zeal |
|
Lycos |
Search |
AllTheWeb |
Overture |
Open Directory |
|
MSN Search |
Search |
MSN/Search |
Overture |
n/a |
|
Netscape |
Search |
|
|
Open Directory |
|
Overture (Yahoo!-owned) |
Paid |
Overture |
Overture |
Backup from Inktomi |
|
Open Directory |
Directory |
Open Directory |
n/a |
n/a |
|
Teoma (Ask Jeeves-owned) |
Search |
Teoma |
|
n/a |
|
Yahoo! |
Search/Directory |
Inktomi (Yahoo!-owned) |
Overture |
Yahoo! |
|
SOURCE: Based on SearchEngineWatch.com, 2003, available at <http://www.searchenginewatch.com/webmasters/article.php/2167981#chart> and updated in March 2005. |
||||
instance, the early search engine Lycos, which began in 1994, ceased providing its own search listings in April 1999 and has since used AllTheWeb to power its Web search site. Google, which generates it own Web search results, also provides algorithmic search services to others such as AOL and, until March 2004, Yahoo!, which paid Google $7.2 million in 2002 for the search queries it handled.56
Over the past 4 years from 2000 to 2004 in the United States, Google rose from eleventh position among navigation sites with a 5.8 percent market share in December 2000, as measured by “audience reach,”57 to first position with an estimated share of 34.7 percent in February 2004, as measured by “share of search.”58 (See Figure 7.1.) The previous leading Web navigation site, Yahoo!, fell from a 48 percent share to second position with 30 percent during that time. Two of the other high-ranking Web navigation sites were MSN with 15.4 percent and AOL with 15 percent of searches in February 2004. However, note that during that period Inktomi provided search services for MSN, while Google provided search services for AOL. For international Internet users (English-language using populations), Google had an even larger lead in February 2004, capturing more than 43 percent of searches to Yahoo!’s 31 percent, MSN’s 14 percent, and AOL’s 7 pecent. (Since Google still provided search results to both Yahoo! and AOL in February 2004, its actual share of searches was closer to 80 percent, both internationally and in the United States After March 2004, without Yahoo!, its share dropped to 50 percent.)
7.2.2 The Business of Internet Navigation
The primary source of income for commercial Internet navigation services, which provide access to material on the public Internet, has become
|
56 |
See Yahoo proxy statement filed March 2002, p. 30, available at <http://www.sec.gov/Archives/edgar/data/1011006/000091205702010171/a2073396zdef14a.htm>. |
|
57 |
Nielsen NetRatings reported in Danny Sullivan, “Nielsen NetRatings Search Engine Ratings,” February 2003, available at <http://www.searchenginewatch.com/reports/print.php/34701_2156451>. “Audience reach” is the percentage of U.S. home and work Internet users estimated to have searched on each site at least once during the month through a Web browser or some other “online” means. |
|
58 |
The new metric generated monthly by comScore Media Metrix, beginning in January 2003, provides a better measure of market share by focusing on the number of searches that a search engine handles per month rather than the number of searchers that perform at least one query on the Web search site. The Web search site queries are based on a panel of 1.5 million Web users located within the United States and in non-U.S. locations. The February 2004 results are from a comScore Media Metrix press release on April 29, 2004, available at <http://www.comscore.com/press/default.asp>. |
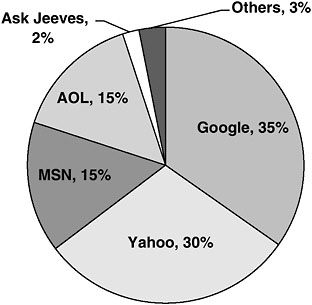
FIGURE 7.1 Company share of U.S. Web searches by home and work users, February 2004. SOURCE: comScore Media Metrix qSearch press release, April 28, 2004, available at <http://www.comscore.com/press/default.asp>.
selling advertising and placement on their sites.59 Consequently, as in many broadcast media, it is the content and service providers that are subsidizing users’ access to navigation services in order to present advertisements to them at the time of their expressed interest in a topic. This contrasts sharply with traditional commercial information search services, such as Lexis, Westlaw, and Dialog, which have obtained their income directly from their users, who pay to access the services’ proprietary (but free of marketing influence) information. Typically, those pay-for-access companies also provide other services, such as training, documentation, and extensive customer support, to their users.
|
59 |
Commercial search engine companies are exploring possibilities beyond their own search sites. For example, publishers such as the Washington Post have turned to Google or Overture to sell advertisements associated with the content that a visitor selects. See Bob Tedeschi, “If You Liked the Web Page, You’ll Love the Ad,” New York Times, August 4, 2003, available at <http://www.nytimes.com/2003/08/04/technology/04ECOM.html>. In addition, Google and others license their search engine technology for use by other Web sites and by corporate intranets. |
The advertising that supports search services can take several forms: banner advertisements, popup advertisements, or search-linked ads. Banners are typically displayed at the top or side of a Web page and are generally priced on a per-impression (view) basis, which means that the advertiser pays based on how many people see its advertisement, with prices quoted in CPMs (cost per thousand impressions), as is traditional in the advertising industry. A typical rate for a generic banner advertisement is 2 cents per impression, or $20 CPM. Banner sizes are standardized so that sellers and buyers of advertising space can find it easy to negotiate pricing and other contract terms.60 So-called “skyscrapers” are vertically oriented banner ads. Popup advertisements are similar to banners, except that they pop up as separate windows. Their shape is also standardized. (The intrusive nature of popup advertisements has led to a variety of software products—separate programs or browser features—that automatically prevent them from appearing.61)
Search-linked advertisements appear as the result of a search. For example, the searcher mentioned above who enters the keyword search term “Florida vacation” might see advertisements for Florida hotels, condo rentals, theme parks, towns and cities, and the like. These may be displayed as banners, popups, sidebars, or—as noted earlier—presented with the search results themselves. Sophisticated algorithms are used by the search services to select which advertisements will appear. These algorithms take into account, among other things, the amount the advertiser is willing to pay if the user clicks on the advertisement, the relevance of the advertisement, and the historic success of the advertisement in generating clicks. All services place limits on the number of advertisements they will display.
Not surprisingly, search-linked advertisements are much more valuable than generic banners. They are priced both by impression and by click-through. Practices differ among search services, but Google displays up to two advertisements at the top of the page (which it calls “Premium Sponsorships” and up to eight advertisements on the right side of the
|
60 |
Further information regarding these standards may be found at <http://www.iab.net/standards/guidelines.asp>. |
|
61 |
Additionally, software known as “adware” or “spyware” has been developed that is installed on a user’s computer and covertly gathers information about a user during navigation of the Internet and transmits such information to an individual or company. In turn, the individual or company transmits information back to the user’s computer to display specific banner advertisements based on the user’s navigation of the Internet. Such activity has resulted in state legislatures considering or enacting spyware regulation laws; see, for example, Utah Spyware Control Act (H.B. 323 2004), California law (A.B. 2787 April 13, 2004; S.B. 1436 March 23, 2004), and Iowa law (S.F. 2200 March 1, 2004), and litigation to undo such laws; see, for example, WhenU.com, Inc. v. Utah, No. 040907578 (Utah Dist. Ct. 3d Dist. April 23, 2004). |
page (which it calls “Adwords Select”). Typically, these ads can appear on every page of results.
At one time Google priced the top ads on a CPM basis and the side ads on a CPC (cost per click) basis. In the latter case, the advertiser pays only when the user actually clicks on an advertisement. However, Google has eliminated the CPM pricing, and now all its ads are priced on a CPC basis. The ads placed at the top of the page are chosen from the side ads on the basis of price and performance. Prices for a click-through are over 10 times as much as the price of a generic impression.62 However, some search engines will drop a click-through advertiser that does not produce a sufficient number of hits.
The two leading providers of search-linked advertisements (or monetized search) are Overture (now owned by Yahoo!) and Google, which also distribute search-linked advertisements to other search sites. The paid listings provided by Overture to its affiliated network of Web search sites, including Yahoo!, MSN, Infospace, and Alta Vista, have been estimated to have handled 46.8 percent of all U.S.-based paid searches; and the paid listings provided by Google, appearing on the search results pages of Google, AOL, Infospace and Ask Jeeves, accounted for 46.6 percent of all U.S. paid searches in January 2003.63 Google provides search services to several hundred other partners, in the United States and abroad, although AOL and Ask Jeeves are the biggest U.S. customers.
Search-linked advertisements have been very successful. According to its initial public offering (IPO) prospectus, Google had revenues of $961.9 million in 2003 and profits of $105.6 million, but without some unusual provisions, its operating profit margin is 62 percent. Before its acquisition by Yahoo!, Overture reported revenues of $103 million in 2000, $288 million in 2001, and $668 million in 2002. In 2003 it claimed over 95,000 advertisers, who received over 646 million clicks in the second quarter of 2003 for which they paid an average of 40 cents per click.64 These figures dramatically illustrate that Internet navigation services—unlike many other Internet services that were tested in the 1990s—have apparently found a financial model that is capable of supporting them and enabling their continued development. At the same time, the struggle to capture advertising dollars has been one of the forces driving the continuing consolidation of the industry, as some of the most successful search services have acquired their competitors in order to increase their share of the market.
|
62 |
From Overture, “Annual Report,” January 2003. |
|
63 |
See <http://www.imediaconnection.com/content/news/050503c.asp>. |
|
64 |
Data collected on August 16, 2002, and December 4, 2003, from <http://www.overture.com/d/USm/about/news/glance.jhtml>. |
Spending on paid listings (guaranteed separate listings on the search engine results pages) and paid inclusion (guaranteed inclusion in the regular search engine results, but ranking not assured)65—two of the three forms of search-related marketing—grew by 40 times in 4 years since 2000.66 Globally such spending is expected to grow 5-fold to $7 billion a year by 2007, from $1.4 billion in 2002. Outside the United States, 10-fold growth to $2 billion in 2007 from about $200 million in 2003 is expected. 67
The revenues from monetized search are often shared between the site and the search service that provides the advertisements. For example, Google currently provides algorithmic search and monetized search for AOL and they split the revenues from the monetization. Overture provided monetized search for Yahoo! on a shared-revenue basis until its acquisition, while Google provided algorithmic search service to Yahoo! until March 2004 for a flat fee. Google and Overture both use an auction model to price their search-linked advertisements: Users can specify a price that they are willing to pay for various positions, and the highest bidder gets the highest position in response to a specific query. For example, a rental car agency could bid to be listed first in any search for “rental cars.” Minimum bids vary, but generally the range of bidding starts at 5 cents a click and goes up to $100 for some mortgage-related items, although Google caps bids at $50. The model is sufficiently popular that, as noted earlier, a secondary market of search engine marketers/ optimizers has arisen to advise Web sites on how to optimize their bidding for queries.68 The details of the auction systems differ, but the advantage of auctions is that hundreds of thousands of prices can be set by actual demand rather than having to be preset and posted.
Since these auctions are subject to gaming, navigation services actively watch for potential fraud by advertisers and monitor the content of advertisers with editorial spot-checking. If they suspect cheating, the advertiser will be removed from bidding. To become qualified bidders, advertisers
|
65 |
Ask Jeeves announced in June 2004 that it was phasing out its paid inclusion program because its algorithmic search had become sophisticated enough to find all necessary Web sites and refresh them as required, making paying for inclusion unnecessary. See Stefanie Olsen “Search Engines Rethink Paid Inclusion,” c/net news.com, June 23, 2004, available at <http://news.com.com/2102-1024_3-5245825.html>. |
|
66 |
See Wall Street Journal On-line, accessed May 5, 2004. Data from InterActive Advertising Bureau, PriceWaterhouseCoopers LLP, eMarketer. |
|
67 |
According to U.S. Bancorp’s Piper Jaffray as reported by Mylene Mangalindan, “Playing the Search-Engine Game,” Wall Street Journal, June 16, 2003, available at <http://www.morevisibility.com/news/wsj-playing_the_searchengine_game.html>. |
|
68 |
See sites such as Wordtracker, at <http://www.wordtracker.com/>, and <http://www.paid-search-engine-tools.com/> for a description of their Keyword Bid Optimizer (KBO); and Traffick at <http://www.traffick.com/>. |
provide information about themselves, their business, their interests, the keywords on which they wish to bid, and how much they wish to bid.
These advertiser-driven business models for navigation services contrast with the non-commercial model of neutral information searching and navigation of public and academic libraries, although they more closely resemble the business models for newspapers and other media where advertising and editorial matter are expected to be rigorously separated. Nevertheless, users need to be cautious about how they treat the results of Internet searches, especially those about subjects with commercial significance. As noted above, the major search services currently identify the sponsored results (sponsored links or sponsored search listings) and set them off from the direct results of the algorithmic search, following the newspaper model. As long as the distinction is clear and users are aware of it, sponsored search should present few problems while providing the great benefit of “free” search services to the user. However, the potential for abuse exists. It would be possible, for example, for a search service to accept payment for assured placement in the “top 10” of what would appear to be a neutral listing. (None have been accused of doing so, but some will accept payment to ensure inclusion, but not ranking, in the otherwise neutral listing.) Or the distinct placement and typography of the sponsored listing could be weakened to the point that a casual user would not be aware of its difference from the algorithmic search results. Thus far, competition among sites and third-party evaluations have served as important countervailing forces. Should abuses grow, however, search services could find themselves under increased public pressure for government scrutiny or facing more disputes and criticism concerning such activities from other commercial entities. (See the discussion in Section 8.2.1.)
7.2.3 The Navigation Services Market
As seen above, a large number of navigation services have entered the market, attempting to achieve profitability by selling advertising. Although it can be very profitable, this has turned out to be a difficult and expensive venture. Furthermore, competition among search engines has forced them to invest in improved software and extensive computer and storage facilities with substantial communications capacity to increase the breadth, depth, and frequency of their coverage of the Web.
Consolidation
Over the past 4 years, there has been considerable consolidation in the search services market.69 Several large search engine service provid-
|
69 |
See, for example, <http://www.imediaconnection.com/content/news/050503c.asp>. |
ers have left the market, and others have been combined into a single firm. At the same time, there has been increased vertical integration as operators of Web sites have acquired operators of search engines. In 2003, Overture, with a primary focus on providing paid search listings, acquired Alta Vista for $140 million and AlltheWeb, the Fast Search and Transfer (FAST) Web search unit, for $70 million. Overture aimed to strengthen its core business of paid search listings by eventually integrating it with its algorithmic search and paid inclusion services.70 Also in 2003, however, the directory-based Yahoo! purchased the search engine Inktomi for $235 million, and then in July 2003, acquired Overture for $1.62 billion.71 Google, while not an aggressive acquirer, went public with an IPO in 2004 that raised $1.67 billion,72 which provided it with a war chest that can be used for acquisitions. The one new player that has entered the search services market is Microsoft, which built the staff and technology to launch its own search service, which it is very likely to integrate into its next-generation operating system. In February 2005, Microsoft unveiled a revised MSN search that bore strong visual similarities to Google’s search interface.73
Yahoo! has apparently decided to vertically integrate by buying both a paid-listing provider and a search engine. It is now able to produce by itself the paid listings previously supplied by an independent Overture and the algorithmic search services previously provided by Google. The net result of this latest phase of consolidation is that there are only a few major independent navigation services left—Google and Yahoo! are the largest.
In 2004, Google, which then provided search services to both Yahoo! and AOL, actually had 80 percent share of searches. This dropped when Yahoo! replaced Google with its own algorithmic search engine. However, whether the acquisitions result in sustained shifts in search shares will depend on whether, for example, users of the Yahoo! search site continue to search there or instead switch to another site that uses Google. These changes in the search services industry are likely to influence other
|
70 |
See Brian Morrissey, “Overture to Buy FAST,” Australia Internet.com, February 26, 2003, available at <http://www.breakfastforums.com.au/r/article/jsp/sid/12837>. |
|
71 |
See “Yahoo! to Acquire Overture,” press release, July 14, 2003, available at <http://www.corporate-ir.net/ireye/ir_site.zhtml?ticker=OVER&script=410&layout=0&item_id=430830>; and Mylene Mangalindan, Nick Wingfield, and Robert Guth, “Rising Clout of Google Prompts Rush by Internet Rivals to Adapt,” The Wall Street Journal, July 16, 2003. |
|
72 |
See Dawn Kawamoto and Stefanie Olsen, “Google Gets to Wall Street—and Lives,” c/net news.com, August 19, 2004, available at <http://news.com.com/Google+gets+to+Wall+Street—and+lives/2100-1038_3-5317091.html>. |
|
73 |
See Juan Carlos Perez, “Microsoft Turns Spotlight on Its Search Engine,” Computerworld, February 1, 2005, available at <http://www.computerworld.com/softwaretopics/software/story/0,10801,99416,00.html>. |
Web search sites, primarily AOL, which currently outsource both Web search results and paid listings, to consider creating or acquiring their own in-house services. Now that Microsoft has entered the search engine competition, it is possible that AOL will feel compelled to do the same.
Innovation
In the past, as described in Section 6.2, there has been a cycle of innovation, adoption, and displacement of navigation services. It began when some new search engine or directory emerged with new technology, or a better user interface, or both than the incumbent-favored service. The new service attracted attention and gained market share. Then as it and the Internet grew, its searches returned a larger number of irrelevant answers, even though its precision may not have changed. Then yet another new service with better technology or a better interface or both appeared. The market tipped to the new leader and the cycle repeated. If this innovative cycle were to continue into the future, or if more specialized navigation services were developed and succeeded, then the current consolidation might be only temporary, a pause until a significant new and better technology or services arose.
Rapid changing of the leader is unlikely to happen under current conditions in the navigation services industry (though the entry of Microsoft may represent an exception). The current consolidation reflects the increasing importance of economies of scale—the fact that the considerable hardware and software costs of developing and operating a search engine are independent of the number of users, whereas revenues from advertising are directly dependent on them. This makes it difficult for innovative services to start small and build volume over time unless they have a very large amount of patient investment capital. So in the future, competition among navigation services is more likely to take the form of rivalry among a small number of established large players rather than competition with a large number of small newcomers.
Conclusion: The Internet navigation services industry has successfully financed the development and evolution of services that meet many of the needs of a wide range of searchers at little or no cost to them, especially when they are seeking commercial material. At the same time, it has provided advertisers with an efficient, cost-effective means to gain access to potential customers at the time that they are most interested in the advertiser’s product or service.
Conclusion: The consolidation of the Internet navigation services industry could reduce the opportunity for innovative new services to enter
the market for general Internet-wide navigation in competition with existing services. However, the new services or their technology could alternatively be acquired by an incumbent, thus making it available to users, or could focus on a niche that is not well served by the more general services.
So long as no single service becomes dominant, each competitor will have continuing pressure to improve its offerings. The net effect of these factors on innovation cannot be predicted.
Conclusion: The importance of the Internet as the infrastructure linking a growing worldwide audience with an expanding array of resources means that improving Internet navigation will remain a profitable goal for commercial developers and a challenging and socially valuable objective for academic researchers.
Conclusion: Since competition in the market for Internet navigation services promotes innovation, supports consumer choice, and prevents undue control over the location of and access to the diverse resources available via the Internet, public policies should support the competitive marketplace that has emerged and avoid actions that damage it.




































