
2
Functional Information and the Emergence of Biocomplexity
ROBERT M. HAZEN,* PATRICK L. GRIFFIN,* JAMES M. CAROTHERS,† and JACK W. SZOSTAK‡
Complex emergent systems of many interacting components, including complex biological systems, have the potential to perform quantifiable functions. Accordingly, we define “functional information,” I(Ex), as a measure of system complexity. For a given system and function, x (e.g., a folded RNA sequence that binds to GTP), and degree of function, Ex (e.g., the RNA–GTP binding energy), I(Ex) = −log2[F(Ex)], where F(Ex) is the fraction of all possible configurations of the system that possess a degree of function > Ex. Functional information, which we illustrate with letter sequences, artificial life, and biopolymers, thus represents the probability that an arbitrary configuration of a system will achieve a specific function to a specified degree. In each case we observe evidence for several distinct solutions with different maximum degrees of function, features that lead to steps in plots of information versus degree of function.
Complex emergent systems, in which interactions among numerous components or “agents” produce patterns or behaviors not obtainable by individual components, are ubiquitous at every scale of the physical universe, for example in neural networks (Deamer and Evans, 2006), turbulent fluids (Frisch, 1995), insect colonies (Camazine et al., 2001), and spiral galaxies (Carlberg, 1992). Complex systems also appear in a range of artificial symbolic contexts, including genetic algorithms (Mitchell, 1996), cellular automata (Wolfram, 2002), artificial life (Adami, 1995), and models of market economies (Holland, 1995).
Life, with its novel collective behaviors at the scale of molecules, genes, cells, and organisms, is the quintessential emergent complex system. Furthermore, the ancient transition from a geochemical world to a living planet may be modeled as a sequence of emergent events, each of which increased the chemical complexity of the prebiotic world (De Duve, 1995; Morowitz, 2002; Hazen, 2005).
Given this ubiquity and diversity, it is desirable to understand the characteristics of emergent complex systems, as well as the factors that might promote complexity in evolving systems. However, complexity has proven difficult to define or measure with precision (Gell-Mann, 1995; Adami, 2003; Shalizi, 2006). A central objective of this study, therefore, is to examine “functional information” (Szostak, 2003) as a quantitative measure of complexity that may be applicable to the analysis and prediction of attributes of a wide range of phenomena in physical and symbolic systems, including evolving biological systems.
An extensive literature explores historical developments and recent advances in the study of complexity and information (Kåhre, 2002; Gell-Mann and Lloyd, 2003; Von Baeyer, 2003; Shalizi, 2006) as well as their application to understanding biological systems (Morowitz, 1978; Bell, 1997; Allen et al., 1998; Solé and Goodwin, 2000; Camazine et al., 2001; Adami, 2003; Avery, 2003; Ricard, 2003). Despite this rich literature, previous discussions of complexity have not generally focused on the relationship between information content and function (Lehman et al., 2000). We propose to measure the complexity of a system in terms of functional information, the information required to encode a specific function.
SYSTEMS AND THEIR FUNCTIONS
In this chapter we consider the functional information of both symbolic systems (letter sequences and Avida artificial life genomes) and biopolymers (RNA aptamers). These systems share several characteristics: first, they consist of numerous individual components or “agents”; second, the agents can combine in a combinatorially large number of different configurations; and third, some configurations display functions that
are not characteristic of the individual agents. Analyses of these systems address fundamental questions about the relationship between information content and function. For example, How much information does it take to encode a function? Are there multiple distinct solutions? How are solutions distributed in configuration space? How much more information does it take to encode a given improvement in function? What environmental factors might influence these relationships?
The function of some emergent systems is obvious: a sequence of letters communicates a specific idea, a computer algorithm performs a specific computation, and an enzyme catalyzes at least one specific reaction. Less obvious are the functions of systems of many interacting inanimate particles, such as molecules, sand grains, or stars, but these systems may also be described quantitatively in terms of function, for example, in terms of their ability to dissipate energy or to maximize entropy production through patterning (e.g., Bertalanffy, 1968; Nicolis and Prigogine, 1977; Swensen and Turvey, 1991; Emanuel, 2006). Living systems, by contrast, typically display multiple essential functions (Allen et al., 1998; Ayala, 1999; McShea, 2000). This consideration of complexity in terms of the function of a system, as opposed to some intrinsic measure of its patterning or structural intricacy, distinguishes our treatment from many previous efforts.
QUANTIFYING COMPLEXITY
Development of a quantitative measure of complexity has proven difficult for at least three reasons, each of which relates to the diversity of systems that may be labeled “complex.”
-
Systems may be complex in terms of information content, physical structure, and/or behavior. Consider three stages in the life cycle of a multicellular organism: a fertilized egg, a live adult, and a postmortem adult. All three states are complex, but they are complex in different respects. All three states possess the sequence information (a genome) necessary to grow a living organism. Living and dead adult organisms also display complex anatomical structures, but only living organisms possess behavioral complexity. Any universal definition of complexity must thus have the potential to quantify complexity independently in terms of information, structure, or behavior.
-
It has been difficult to define complexity in terms of a metric that applies to all complex systems. No obvious common thread exists in comparing the complexity of symbolic systems, such as language, with those of physical agents, such as cells. Parameters useful in characterizing symbolic systems (e.g., algorithm- or information-based complexity metrics)
-
generally differ from those used to analyze systems of interacting particles (e.g., Newtonian dynamics or maximum entropy models). Gell-Mann (1995) concludes, “A variety of different measures would be required to capture all our intuitive ideas about what is meant by complexity.”
-
Complex emergent systems are diverse in terms of their dimensionality. Sequences of letters, computer code, or bipolymers can be treated as one-dimensional strings of symbolic information (or as points in a high-dimensional sequence space). On the other hand, many physical emergent systems, including those composed of many interacting sand grains, cells, organisms, or stars, exhibit time-dependent behaviors in two or three spatial dimensions. It is desirable for a complexity formalism to apply to this range of dimensionalities.
Despite this diversity, a common thread is present: All complex systems alter their environments in one or more ways, which we refer to as functions (Bigelow and Pargetter, 1998). In the words of von Baeyer (2003), “Information gathering by itself, without observable effects on the gatherer’s behavior, is a pointless pursuit.” Function is thus the essence of complex systems. Accordingly, we focus on function in our operational definition of complexity. Therefore, although many previous investigators have explored aspects of biological systems in terms of information (e.g., Schneider et al., 1986), we adopt a different approach and explore information in terms of the function of a system (including biological systems).
Szostak and coworkers (Szostak, 2003; Carothers et al., 2004) introduced “functional information” as a measure of complexity. They proposed that the complexity of an information-rich system, such as RNA aptamers (RNA structures that bind a target molecule), can be quantified in the context of specific functions of the system, in contrast to prior formalisms based on genomic, sequence, or algorithmic information (e.g., Lenski et al., 1999; Adami, 2003). Here we examine applications of this formalism to letter sequences, the artificial life platform Avida (Adami, 1998), and RNA aptamers.
FUNCTIONAL INFORMATION AS A MEASURE OF SYSTEM COMPLEXITY
Many emergent systems of interacting agents can be described in terms of their potential to accomplish one or more quantifiable tasks. Consider a system that can exist in a combinatorially large number of different configurations (i.e., a 100-nt RNA strand comprised of four different nucleotides, A, U, G, and C, with 4100 different possible sequences). Assume that a small fraction of these configurations accomplishes a specified function x to a high degree (corresponding to a high information
content). Typically, a significantly greater number of configurations will prove somewhat less efficient in accomplishing function x (corresponding to lower information content), whereas the majority of configurations will display little or no function (Lenski et al., 2003; Carothers et al., 2004).
Accordingly, “degree of function x” (Ex) is a measure of a configuration’s ability to perform the function x. For example, in an enzymatic system Ex might be defined as the increase in a specific reaction rate that is achieved by the enzyme. In the case of a sequence of letters, Ex might represent the probability that the sequence conveys a desired message to a particular recipient. And in a system with water flowing over sand ripples, Ex might be defined as the rate of energy dissipation by turbulence, compared with flow over a smooth, unpatterned surface. The units or scale of Ex may be somewhat arbitrary and will depend on the nature of function x. Thus, for example, catalytic efficiency might be recorded in terms of rate enhancement or in terms of decreased activation energy (proportional to the log of the rate enhancement).
In the formalism of Szostak (2003; see also Morowitz, 1978, p. 252), functional information [I(Ex)] is calculated with reference to a specific degree of function x, designated Ex. Typically, a small fraction, F(Ex), of all possible configurations of a system achieves at least the specified degree of function, ≥Ex. Accordingly, we define functional information in terms of F(Ex):
Thus, in a system with N possible configurations (e.g., a sequence of n RNA nucleotides, which has N = 4n discrete possible sequences):
where M(Ex) is the number of different configurations that achieves or exceeds the specified degree of function x, ≥Ex
In every system, the fraction of configurations, F(Ex), capable of achieving a specified degree of function will generally decrease with increasing Ex (Szostak, 2003). The largest possible functional information of a system is exhibited in the case of a single configuration that displays the highest possible degree of function, Emax:
where I is measured in bits. This maximum functional information is thus equivalent to the maximum number of bits necessary and sufficient to specify any particular configuration of the system.
Alternatively, the minimum functional information of a system is zero for configurations with the lowest degree of function, Emin, because all possible states have Ex ≥ Emin:
In this formulation, functional information increases with degree of function, from zero for no function (or minimum function) to a maximum value corresponding to the number of bits necessary and sufficient to specify completely any configuration of that system.
Functional information is defined only in the context of a specific function x. For example, the functional information of a ribozyme may be greater than zero with respect to its ability to catalyze one specific reaction but will be zero with respect to many other reactions. Functional information therefore depends on both the system and on the specific function under consideration. Furthermore, if no configuration of a system is able to accomplish a specific function x [i.e., M(Ex) = 0], then the functional information corresponding to that function is undefined, no matter how structurally intricate or information-rich the arrangement of its agents.
It is important to emphasize that functional information, unlike previous complexity measures, is based on a statistical property of an entire system of numerous agent configurations (e.g., sequences of letters, RNA oligonucleotides, or a collection of sand grains) with respect to a specific function. To quantify the functional information of any given configuration, we need to know both the degree of function of that specific configuration and the distribution of function for all possible configurations in the system. This distribution must be derived from the statistical properties of the system as a whole [as opposed, for example, to the statistical properties of populations evolving in a fitness landscape (Wright, 1942)]. Any analysis of the functional information of a specific functional sequence or object, therefore, requires a deep understanding of the system’s agents and their various interactions.
Three examples (letter sequences, the artificial life platform Avida, and RNA aptamers) serve to illustrate the concept of functional information.
THE FUNCTIONAL INFORMATION OF LETTER SEQUENCES
Systems of many interacting components can occur in a combinatorially large number of different configurations. Functional information depends on the fraction of all possible configurations that achieve at least a specified degree of function. Sequences of letters provide a conceptually familiar example. Consider various sequences of n letters that convey the message: “A fire has just started in a house at the corner of Main Street
and Maple Street.” Many different sequences of letters are capable of conveying that information. To determine the functional information of any particular sequence we must specify three parameters:
-
n, the number of letters in the sequence.
-
Ex, the degree of function x of that sequence. In the case of the fire example cited above, Ex might represent the probability that a local fire department will understand and respond to the message (a value that might, in principle, be measured through statistical studies of the responses of many fire departments). Therefore, Ex is a measure (in this case from 0 to 1) of the effectiveness of the message in invoking a response.
-
M(Ex), the total number of different letter sequences that will achieve the desired function, in this case, the threshold degree of response, ≥Ex.
The functional information, I(Ex), for a system that achieves a degree of function, ≥Ex, for sequences of exactly n letters is therefore
Note that 26n is the total number of possible arrangements of a 26-letter alphabet in a sequence of n letters, and in this treatment we assign equal probability to all possible sequences. The important more general case of configurations of unequal probabilities is a straightforward extension of the treatment of Shannon (Shannon, 1948; Klir, 2006), as discussed by Carothers et al. (2004). Greater clarity of expression can be added through additional characters such as “space,” “capital,” and “period”; however, in this example we use only 26 letters. As in all combinatorially large emergent systems, most sequences convey no information (i.e., have no discernable function). Functional information is determined by identifying the fraction of all sequences that achieve a specified outcome.
Consider, for example, sequences of 10 letters that have a high probability (![]() ) of evoking a positive response from the fire department. Such sequences might include “FIREONMAIN,” “MAINSTFIRE,” or “MAPLENMAIN.” Additionally, some messages containing phonetic misspellings (FYRE or MANE), mistakes in grammar or usage (FIREOFMAIN), or typing errors (MAZLE or NAPLE) may also yield a significant but lower probability of response (0 << Ex < 1). Given these variants, on the order of 1,000 combinations of 10 letters might initiate a rapid response to the approximate location of the fire. Thus,
) of evoking a positive response from the fire department. Such sequences might include “FIREONMAIN,” “MAINSTFIRE,” or “MAPLENMAIN.” Additionally, some messages containing phonetic misspellings (FYRE or MANE), mistakes in grammar or usage (FIREOFMAIN), or typing errors (MAZLE or NAPLE) may also yield a significant but lower probability of response (0 << Ex < 1). Given these variants, on the order of 1,000 combinations of 10 letters might initiate a rapid response to the approximate location of the fire. Thus,
Numerous additional 10-letter sequences convey some relevant information but would result in a lower probability of response (0 < Ex < 1): “FIREHELPME,” “DANGERFIRE,” or “BURNINGNOW.” A lower degree of function, Ex, will generally correspond to a larger number of effective letter sequences, M(Ex).
The formulation of functional information also applies to systems in which sequences of varied lengths are combined. For letter sequences of any length from 1 to n letters,
Varying the maximum length, n, of the letter sequence has a significant effect on the maximum possible degree of function, Ex, as well as the number of states, M(Ex), that achieve that degree of function. Sequences of 1, 2, or 3 letters are unlikely to convey sufficient information to achieve any response. With 4 letters, however, a few suggestive configurations exist (FIRE, MAIN, or MAPL), although all such sequences possess a high degree of ambiguity (i.e., Ex << 1).
On the other hand, with longer letter sequences (n >> 10), the number of messages of a given degree of function increases dramatically, with new opportunities for explicit instructions (and hence maximum degree of function, Ex = 1). With a sufficient number of letters, any arbitrary degree of accuracy and precision in a message can be communicated. Note, however, that arbitrarily long sequences are not necessarily more effective at conveying information and thus may not increase the functional information of a system. For example, consider sequences of letters that begin with the following 22 letters:
FIREATMAINSTANDMAPLEST …
Such a sequence should invariably summon the fire department, no matter what or how many additional letters are placed at the end of the sequence. Thus, for this admittedly contrived fire department scenario, the fraction of sequences that achieve the desired outcome attains a maximum value at ≈20 letters. In competitive systems, notably genetic information constrained by length-selective pressure in living systems (e.g., Mills et al., 1967; Andersson and Andersson, 1999; Shigenobu et al., 2000; Nakabuchi et al., 2006), longer sequences may prove inefficient and do not necessarily confer an advantage. (Indeed, in the case of reporting a fire, an overly long and detailed message might delay response time.)
Note that in this formulation of functional information the maximum possible value, I(Emax), arises when a message is so specific that only a single letter sequence out of all possible letter sequences achieves a desired
outcome. In the case of a sequence of n letters, that maximum functional information occurs when M(Ex) = 1:
Although this conceptual example is qualitative, it introduces key concepts that are required to quantify functional information in any emergent system with numerous configurations. Of special interest is the relationship between information and degree of function. Letter sequences point to the existence of discrete “classes” of functional configurations, based in this case on the appearance of familiar words (“FIRE” and “MAIN”) as well as their mutations (“FYRE” and “MANE”). We explore the role of such multiple classes of solutions in the subsequent sections on Avida and RNA aptamers.
We conclude that rigorous analysis of the functional information of a finite system with respect to a specified function x requires knowledge of two attributes: (i) all possible configurations of the system (e.g., all possible sequences of a given length in the case of letters or RNA nucleotides) and (ii) the degree of function x for every configuration.
These two requirements are difficult to meet in many systems. In the case of letter sequences, for example, the sequence is obvious, but it is difficult to determine quantitatively the degree of function of many sequences. By contrast, it is relatively straightforward to determine the degree of function (for example, the ligand affinity) of any given RNA sequence, but impossible with present technology to measure all sequences in a large population, e.g., ≈1014 randomly generated 100-mers as used in some aptamer evolution studies (although single-molecule methods may ultimately provide a technical solution to this challenge). However, these concepts may be placed on a firmer footing in the case of computational systems, such as the artificial life platform Avida.
THE FUNCTIONAL INFORMATION OF AVIDA POPULATIONS
We have adapted the artificial life platform Avida (Adami, 1998; Lenski et al., 2003) to explore the distribution of function in an emergent system. The digital organisms that populate the virtual world of Avida are “computer programs that self-replicate, mutate, and adapt by natural selection” (Lenski et al., 1999) and as such share many (although not all) of the attributes ascribed to biological life. Accordingly, artificial life models have been used as a means of exploring ideas about organic biology that are not readily amenable to experimentation. Here we explore the functional information of randomly generated populations of Avida organisms. Understanding the origin and evolution of complex biologi-
cal systems motivates this work; however, the first task is to demonstrate an approach for quantifying the relationship between information and functional behavior in a well characterized emergent system, whether or not unambiguous biological insight is immediately revealed.
Avida organisms consist of multiple lines of machine instructions, termed its “genome.” Each organism operates as a formal computer similar to that outlined by Turing (1936), and the computational properties of each organism are determined by the sequence of machine instructions stored in its memory. A population of Avida organisms can be thought of as a multitude of identical computers running many different simple programs, where differences between any two members of the population arise solely from the differences in the programs being run.
This research focuses on the ability of a small fraction of all randomly generated Avida organisms to perform computational tasks that arise through the coordinated execution of multiple machine instructions (Lenski et al., 2003). None of these computational tasks can be performed by the execution of a single instruction; indeed, the shortest functional program requires five instructions. The computational ability (function) of Avida organisms thus emerges from the interaction of instructions (the agents), making Avida an ideal model for characterizing complex emergent systems.
In a typical Avida experiment, we generate 107 random instruction sequences (i.e., 107 different individual genomes), each sequence 100–500 instructions in length, from the default set of 26 different machine instructions. Although most sequences display no function, a small subset of sequences code for the ability to compute logic operations (such as “not” or “and”) or arithmetic functions (addition and subtraction).
The set of computational tasks Avida organisms can perform allows for varied solutions, analogous to variations seen in nature. This characteristic is underscored by the fact that in its evolution apparatus Avida does not consider how a task is accomplished but only the resulting function, i.e., whether or not it is executed. The Avida platform does not specify preferred approaches to problem solving, which allows novel solutions to appear through evolution. There may be great variety among these solutions, and they may be very different from those that might have been arrived at by design (Lenski et al., 1999).
MEASURES OF AVIDA FUNCTION
Just as there is no unique measure of function in natural systems, there is no unique measure of the degree of function in an Avida sequence population. We chose to consider three distinct measures of function: (i) the number of times a sequence is able to compute a specific task, for example,
addition or not/and; (ii) the total number of all tasks the sequence is able to compute, because many sequences can perform multiple distinct operations; and (iii) the total number of different tasks the sequence is capable of computing.
Each of these measures of function correlates to strategies that biological organisms employ to increase their fitness. Some organisms rely on the ability to perform one action very well, others rely on the ability to perform multiple actions moderately well, and still others take advantage of flexibility, the ability to do many different tasks (Wilson, 1992). However, unlike with living organisms, quantifying the extent of these traits in Avida is straightforward and unambiguous. Most of the discussion that follows, however, focuses on execution of a single task.
Functional sequences constitute a tiny minority of the Avida genome space. Therefore, to explore fully the distribution of function within a sequence space, a large number of randomly generated sequences (i.e., equal probability) must be surveyed (see Methods). Such random explorations of genome space are similar to the strategies used in the directed evolution of RNA structures (e.g., Ellington and Szostak, 1990; Wilson and Szostak, 1999). Note, however, that this type of random sampling is not possible with living organisms because the portion of genome space explored in an evolution experiment will be constrained by the topology of the underlying fitness landscape and the particular configuration of the environment maxima (van Nimwegen et al., 1999; Lehman et al., 2000; Taverna and Goldstein, 2000; Sasaki and Nowak, 2003).
AVIDA RESULTS
Random sampling of genome space has yielded several interesting results related to the frequency and distribution of functional configurations. By using Avida’s default set of 26 machine instructions, a randomly generated sequence with length of a magnitude of ≈102 lines was found to be functional (i.e., was able to perform at least one logic or arithmetic operation at least once) with probability P ≈ 10−3. The functional fraction of a population decreases with decreasing sequence length until it reaches zero for populations with sequences of a length of four machine instructions or less.
We observe regular, reproducible structure in the distribution of task execution frequency, for example, in the number of not/and or addition operations executed (Ex) versus functional information (Fig. 2.1). This plot, which illustrates the distribution of function for 107 randomly generated 300-instruction genomes, is continuous over most values of Ex, for example, between 2 and 48. However, at several values of Ex, discontinuities appear. At Ex > 73 these discontinuities point to isolated individual
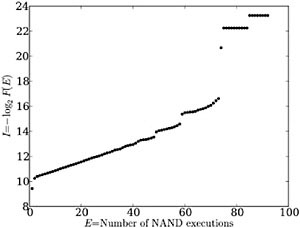
FIGURE 2.1 Distribution of the not/and (NAND) function in 300-line Avida genomes in a randomly generated sample of 107 genomes. The degree of function, E, is the number of times NAND is executed by the genome, whereas functional information, I (in bits), is −log2 of the fraction of all sequences that achieves at least that degree of function, F(E). Note the discontinuities, which are a recurrent feature in these experiments.
genomes of high functionality; such outliers always appear, but they may occur at different values of Ex for repetitions of this experiment. However, other discontinuities (notably those between 48/49 and 58/59) are robust, always appearing in experiments on 300-instruction genomes. Thus these gap-like features reflect an intrinsic behavior of Avida genomes.
We also find that the number and specific location of these gaps, as well as the maximum values of I(Ex) and Ex, depend on the length of the sequences being studied (Fig. 2.2). For example, we examined the number of executions of the addition function for 106 randomly generated genomes of 100, 200, 300, and 500 instructions. We find that the maximum number of addition executions, Ex, increases with genome length. We often observe discrete highly functional genomes, representing outlier solutions, as well as reproducible gaps. For randomly generated genomes of 100, 200, 300, and 500 instructions, the first significant gap in addition execution frequency occurs at 19, 39, 59, and 69 executions, respectively.
ISLANDS OF FUNCTION
What is the source of the reproducible discontinuities in Figs. 2.1 and 2.2? We suggest that the population of random Avida sequences contains
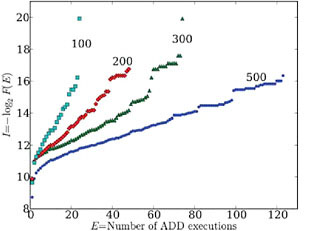
FIGURE 2.2 The frequency of the ADD function in 100-, 200-, 300-, and 500-line linear Avida genomes in randomly generated samples of 106 genomes. Degree of function, E, is the number of times the ADD function is executed by the genome, whereas functional information, I (in bits), is −log2 of the fraction of all sequences that achieves at least that degree of function, F(E). Note that maximum E increases with genome length.
multiple distinct classes of solutions, perhaps with conserved sequences of machine instructions similar to those of words in letter sequences or active RNA motifs (Knight and Yarus, 2003). Each class has a maximum possible degree of function; therefore, the discontinuities occur at degrees of function below which a major class of sequences is represented and above which it is not represented.
Fig. 2.3 demonstrates one possible model for this stepped behavior, based on discrete “islands” of solutions. In Fig. 2.3, the islands, each of which represents a specific distinct set of solutions to the function [i.e., fitness (z axis)], are conceptually represented as being close to each other in sequence space (projected on the x–y plane). Note, however, that these islands are a visual simplification. For example, in the case of RNA sequences, any given “island” of closely related functional solutions may be more realistically represented by a densely interconnected network that spans all of sequence space (Huynen et al., 1996; Lehman et al., 2000; Reidys et al., 2001). Similar consideration of function topologies has been applied to neural network connections (Ebner et al., 2002) and to viroid solutions infecting the same plant host (Codoñer et al., 2006). Avida may be similar, because the commands relevant to a given solution do not necessarily need to appear sequentially at a specific location
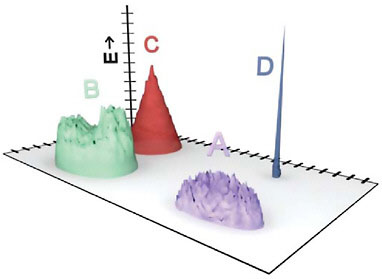
FIGURE 2.3 Schematic representation of four discrete functional classes, or “islands,” of solutions that display function. The vertical axis is degree of function, E, whereas the horizontal plane represents a two-dimensional projection in sequence space. The number of sequences with degree of function ≥E corresponds to the area intersected by the horizontal plane at that height along the E axis. Increasing E above the heights of the flat-topped islands A and B will result in discontinuities in the function E versus I, as illustrated in Figs. 2.1 and 2.2. Island C is a cone-shaped distribution, and island D represents a discrete solution of the type that might not be discovered in random sampling experiments.
in the string but can occur in different registers and can be spread apart by neutral commands.
Consider a case where four classes of solutions for the same function, labeled A–D, occur in the population (Fig. 2.3). Each class may contain a normal distribution of degrees of function, but each has a different topology in sequence space and a different maximum degree of function, Ex. For relatively low values of Ex, all four islands contribute functional sequences. As the value of Ex increases to just above the heights of flat-topped islands A and then B, discontinuities in the plot of Ex versus I(Ex) will occur (i.e., in Fig. 2.1 the height corresponding to island A would be Ex = 48 and the height of island B would be Ex = 58). This model also matches the observation that the continuous stretches of Ex versus I(Ex) are longest for populations of long sequences: Longer sequences allow for a greater number of distinct solutions whose superposition would serve to drown out individual discontinuities.
This model for generating discontinuities is plausible because multiple distinct solutions may exist in sequence space for a given task. For example, the shortest possible sequence (“gene”) for accomplishing subtraction is five lines long (Lenski et al., 2003). However, an alternative unrelated subtraction gene 10 lines long can be constructed within the Avida language using two’s-complement arithmetic (Zarowski, 2004). This second class of solutions reinforces the concept of “islands” of function in sequence space, where two or more types of solutions exist that achieve the same task but do so in an unrelated fashion.
We note, by contrast, that purely random statistical functions do not display steps. For example, if the degree of function is defined as the frequency of the appearance of the number “1” in randomly generated sequences of 100 digits, then functional information follows a well behaved smooth curve (Fig. 2.4). Maximum functional information arises for the solitary state with 100 consecutive 1s, whereas an obvious uniform distribution follows for lesser degrees of function. This statistically random case is not stepped. By comparison, the structures depicted in Figs. 2.1 and 2.2 suggest that the tasks being considered as functions are neither trivial, nor are they achieved by essentially arbitrary or random, albeit rare, configurations of the system. The interactions in the Avida system, and perhaps many other complex systems, lead to distributions of function that prove far richer than in systems possessing statistically
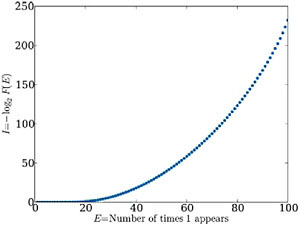
FIGURE 2.4 I(E) versus E for the statistically random system, where E is the number of times the digit 1 appears at least that many times in a sequence of 100 digits. This statistically random case is not stepped, in contrast to the topology of Avida genomes.
trivial function. It remains to be seen, however, whether the observed stepped relationship between I(Ex) and Ex is a general feature of functional information or an idiosyncratic characteristic of Avida genomes.
FUNCTIONAL INFORMATION AND RNA POLYMERS
The previous two examples, sequences of letters and Avida machine commands, illustrate the utility of the functional information formalism in characterizing the properties of symbolic systems that can occur in combinatorially large numbers of configurations. Functional information also has applicability to complex biological and biochemical systems; indeed, it was originally developed (Szostak, 2003; Carothers et al., 2004) to analyze aptamers (RNA structures that bind target ligands) and ribozymes (RNA structures that catalyze specific reactions). Thus, the degree of function, Ex, of these linear sequences of RNA letters (A, C, G, and U) can be defined quantitatively as the binding energy to a particular molecule or the catalytic increase in a specific reaction rate. We can easily specify every possible RNA sequence of length n, and we can (at least in principle) synthesize RNA strands and measure the degree of function of any given sequence. The behavior of aptamers and ribozymes thus lends itself to the type of quantitative analysis that we applied previously to letter sequences and Avida populations (Carothers et al., 2004).
In general, a single RNA nucleotide will display minimal catalytic or binding function, xmin. It follows that a minimum sequence length (nmin nucleotides) will be required to achieve any significant degree of ribozyme or aptamer function, Ex > Emin. Increasing the number of nucleotides (n > nmin) will generally lead to many more functional sequences, some of which will have a greater degree of function. Furthermore, for any given catalytic or binding function there exists an optimal RNA sequence of length nopt that attains the maximum possible degree of function, Emax. That sequence thus possesses the maximum possible functional information:
For degrees of function less than the maximum (Ex < Emax), an intermediate functional information obtains [I(Ex) < Imax (Emax)].
The in vitro evolution of RNA aptamers (e.g., Ellington and Szostak, 1990; Wilson and Szostak, 1999) provides a dramatic illustration of the evolution and selection of systems with high functional complexity. Aptamer evolution experiments begin with large populations (up to 1016 randomly generated RNA sequences), which are subjected to a selective environment, a test tube coated with a target molecule, for example. A small fraction of
the random RNA population will selectively bind to the target molecules. Those RNA strands are recovered, amplified with mutations (through reverse transcription, PCR, and transcription), and the process is repeated several times. Each cycle yields a more restricted RNA population with improved binding specificity (i.e., a higher degree of function, Ex).
Carothers et al. (2004), who analyzed the distribution of functional RNA aptamers in a random population, provide data on a specific example. They identify 11 distinct classes of GTP-binding RNAs, which are distinguished from each other both by nucleotide sequences (RNA motifs) (Knight and Yarus, 2003) and secondary stem–loop structures. The degree of function of these aptamers can be defined by a solution dissociation constant, a measure of the binding strength between GTP and the folded aptamer. Carothers and coworkers find that a 10-fold increase in GTP binding strength requires ≈10 additional bits of information (i.e., a 1,000-fold decrease in abundance in a population of random sequences). Such a finding is in accord with studies of biopolymers (Aronson et al., 1994; Wang and Unrau, 2005) that show functionally similar peptides with dissimilar primary structures, as well as reports of many distinct classes of protease enzymes (Rawlings and Barrett, 1993; Rawlings et al., 2006).
Furthermore, although the data of Carothers et al. (2004) are too few to draw definitive conclusions, there is a suggestion of a stepped relationship between binding strength (Ex) and functional information (I), a relationship analogous to that displayed by populations of Avida organisms (e.g., Fig. 2.1). These steps, if real, are likely caused by the existence of separate classes of GTP-binding solutions. Functional classes with greater numbers of stems represent a significantly smaller fraction of all RNA sequences, but they have the potential to display greater GTP-binding affinities.
FUNCTIONAL INFORMATION IN HIGHER-DIMENSIONAL SYSTEMS
Functional information provides a measure of complexity by quantifying the probability that an arbitrary configuration of a system of numerous interacting agents (and hence a combinatorially large number of different configurations) will achieve a specified degree of function. This concept was originally discussed in the context of biopolymer sequences that perform specific binding or catalytic functions (Szostak, 2003; Carothers et al., 2004). In the preceding sections we demonstrated that the extension of functional information analysis to one-dimensional systems of letters or Avida computer code is conceptually straightforward, requiring only specification of the degree of function of each possible sequence.
We suggest that the functional information formalism may also be applicable to complex physical structures in higher-dimensional systems.
Of special interest in this regard are biological systems that display complex emergent behavior, for example, through long-range chemical signaling among a collection of cells in social amoebas (Goldbeter, 1996; Brännström and Dieckmann, 2005; Schaap et al., 2006), cooperation among consortia of host organisms and symbionts (Moran, 2007, Chapter 9, this volume), or colonies of social insects (Solé and Goodwin, 2000; Camazine et al., 2001; Strassmann and Queller, 2007, Chapter 8, this volume). We propose that functional information can be applied, at least in principle, to any such emergent system that has the ability to perform a function.
Many emergent systems can be analyzed in terms of their ability to dissipate energy or maximize entropy production (Nicolis and Progogine, 1977; Lorenz, 2003; Whitfield, 2005; Emanuel, 2006). For example, consider the functional information of an assemblage of sand grains subjected to a steady flow of wind or water (e.g., Bagnold, 1988; Hansen et al., 2001). The formation of periodic sand dunes or ripples serves to initiate turbulent flow and thus increase energy dissipation. Functional information of the system can thus be measured as the fraction of all possible sand configurations, F(Ex), that achieve at least the corresponding energy dissipation, Ex. Such a problem might be analyzed with Monte Carlo simulations of numerous gravitationally stable sand configurations. The analytical challenge remains to determine the degree of function of a statistically significant random fraction of all possible configurations of the system so that the relationship between I(Ex) and Ex can be deduced.
CONCLUSIONS
A complexity metric is of little utility unless its conceptual framework and predictive power result in a deeper understanding of the behavior of complex systems. Analysis of complex systems in terms of functional information reveals several characteristics that are important in understanding the behavior of systems composed of many interacting agents. Letter sequences, Avida genomes and biopolymers all display degrees of functions that are not attainable with individual agents (a single letter, machine instruction, or RNA nucleotide, respectively). In all three cases, highly functional configurations comprise only a small fraction of all possible sequences. Furthermore, these three examples reveal that several discrete classes of functional configurations exist, a situation that can lead to distinctive step features in plots of information versus function.
The functional information formalism may also point to key factors in the origin and emergence of biocomplexity. In particular, functional information quantifies the probability that, for a particular system, a configuration with a specified degree of function will emerge. Furthermore, analysis of the relationship between information and function may reveal
how much more information is required to encode a given improvement in function. The formalism also points to strategies, such as increasing the concentration and/or diversity of molecular agents, that might maximize the effectiveness of chemical experiments that attempt to replicate steps in the origin of life.
METHODS
Determination of the computational properties of a randomly generated instruction sequence is accomplished within Avida’s analyze mode. The trace feature in analyze mode generates detailed information on the state of the virtual computer at each step in the processing of a genome, including a notation of when a recognized function has been executed. An automated script parsed these logs to collect all of the data necessary to determine the functional properties of each sequence and cataloged the genomes found to be functional to permit later study. Detailed documentation of the Avida software, including descriptions of the trace function and analyze mode, can be found online at the Digital Evolution Laboratory at Michigan State University web site (http://devolab.cse.msu.edu/software/avida/doc).
ACKNOWLEDGMENTS
We thank John Avise and Francisco Ayala for organizing this Sackler Colloquium; H. J. Cleaves, K. Esler, R. Lenski, H. Morowitz, C. Ofria, and D. Sverjensky for valuable comments and suggestions. This work was supported in part by the National Aeronautics and Space Administration Astrobiology Institute, the National Science Foundation, and the Carnegie Institution. J.W.S. is an Investigator of the Howard Hughes Medical Institute.




















