
Computational Cognitive Neuroscience and Its Applications
LAURENT ITTI
University of Southern California
Los Angeles, California
A number of tasks that can be effortlessly achieved by humans and other animals have until recently remained seemingly intractable for computers. Striking examples of such tasks exist in the visual and auditory domains. These include recognizing the face of a friend in a photograph; understanding whether a new, never-seen object is a car or an airplane; quickly finding objects or persons of interest like one’s child in a crowd; understanding fluent speech while also deciphering the emotional state of the speaker; or reading cursive handwriting. In fact, several of these tasks have become the hallmark of human intelligence, while other, seemingly more complex and more cognitively involved tasks, such as playing checkers or chess, solving differential equations, or proving theorems, have been mastered by machines to a reasonable degree (Samuel, 1959; Newell and Simon, 1972). An everyday demonstration of this state of affairs is the use of simple image, character, or sound recognition in CAPTCHA tests (completely automated public Turing tests to tell computers and humans apart; see von Ahn et al., 2004) used by many websites to ensure that a human, rather than a software robot, is accessing the site. (CAPTCHA tests, for example, are used by websites that provide free e-mail accounts to registered users, and are a simple yet imperfect way to prevent spammers from opening thousands of e-mail accounts using an automated script.)
To some extent these machine-intractable tasks are the cause for our falling short on the early promises made in the 1950s by the founders of artificial intel-
ligence, computer vision, and robotics (Minsky, 1961). Although tremendous progress has been made in just a half century, and one is beginning to see cars that can drive on their own or robots that vacuum the floor without human supervision, such machines have not yet reached mainstream adoption and remain highly limited in their ability to interact with the real world. Although in the early years one could blame the poor performance of machines on limitations in computing resources, rapid advances in microelectronics have now rendered such excuses less credible. The core of the problem is not only how many computing cycles one may have to perform a task but also how those cycles are used and in what kind of algorithm and computing paradigm.
For biological systems, interacting with the visual world (in particular through vision, audition, and other senses) is key to survival. Essential tasks like locating and identifying potential prey, predators, or mates must be performed quickly and reliably if an animal is to stay alive. Thus, biological visual systems may have evolved to become particularly attuned to some visual features or events that may indicate possible dangers or rewards. Taking inspiration from nature, recent work in computational neuroscience has hence started to devise a new breed of algorithms, which can be more flexible, robust, and adaptive when confronted with the complexities of the real world. I focus here on describing recent progress with a few simple examples of such algorithms, concerned with directing attention toward interesting locations in a visual scene, so as to concentrate the deployment of computing resources primarily onto these locations.
MODELING VISUAL ATTENTION
Positively identifying any and all interesting targets in one’s visual field has prohibitive computational complexity, making it a daunting task even for the most sophisticated biological brains (Tsotsos, 1991). One solution, adopted by primates and many other animals, is to break down the visual analysis of the entire field of view into smaller regions, each of which is easier to analyze and can be processed in turn. This serialization of visual scene analysis is operationalized through mechanisms of visual attention. A common (although somewhat inaccurate) metaphor for visual attention is that of a virtual “spotlight,” shifting toward and highlighting different subregions of the visual world, so that one region at a time can be subjected to more detailed visual analysis (Treisman and Gelade, 1980; Crick, 1984; Weichselgartner and Sperling, 1987). The central problem in attention research then becomes how best to direct this spotlight toward the most interesting and behaviorally relevant visual locations. Simple strategies, like constantly scanning the visual field from left to right and from top to bottom, like many computer algorithms do, may be too slow for situations where survival depends on reacting quickly. Recent progress in computational neuroscience has proposed a number of new, biologically inspired algorithms that implement more efficient strategies. These algorithms usually distinguish between a bottom-up
drive of attention toward conspicuous, or salient, locations in the visual field, and a volitional and task-dependent top-down drive of attention toward behaviorally relevant scene elements (Desimone and Duncan, 1995; Itti and Koch, 2001). It is important to note here how we separate the notion of salience from that of relevance, although both have often been colloquially associated. Simple examples of bottom-up salient and top-down relevant items are shown in Figure 1.
Koch and Ullman (1985) introduced the idea of a saliency map to accomplish attentive selection in the primate brain. This is an explicit two-dimensional map that encodes the saliency of objects in the visual environment. Competition among neurons in this map gives rise to a single winning location that corresponds to the most salient object, which constitutes the next target. If this location is subsequently inhibited, the system automatically shifts to the next most salient location, endowing the search process with internal dynamics.
Later research has further elucidated the basic principles behind computing salience (Figure 2). One important principle is the detection of locations whose local visual statistics significantly differ from the surrounding image statistics, along some dimension or combination of dimensions that are currently relevant to the subjective observer (Itti et al., 1998; Itti and Koch, 2001). This significant difference could be in a number of simple visual feature dimensions that are believed to be represented in the early stages of cortical visual processing: color, edge orientation, luminance, or motion direction (Treisman and Gelade, 1980; Itti and Koch, 2001). Wolfe and Horowitz (2004) provide a very nice review of which elementary visual features may strongly contribute to visual salience and guide visual search.
Two mathematical constructs can be derived from electrophysiological recordings in living brains, which shed light onto how this detection of statistical odd man out may be carried out. First, early visual neurons often have center-surround receptive field structures, by which the neuron’s view of the world consists of two antagonistic subregions of the visual field, a small central region that drives the neuron in one direction (e.g., excites the neuron when a bright pattern is presented) and a larger, concentric surround region that drives the neuron in the opposite direction (e.g., inhibits the neuron when a bright pattern is presented) (Kuffler, 1953). In later processing stages this simple concentric center-surround receptive field structure is replaced by more complex types of differential operators, such as Gabor receptive fields sensitive to the presence of oriented line segments (Hubel and Wiesel, 1962). In addition, more recent research has unraveled how neurons may react with similar stimulus preferences but be sensitive to different locations in the visual field. In particular, neurons with sensitivities to similar patterns tend to inhibit each other, a phenomenon known as nonclassical surround inhibition (Allman et al., 1985; Cannon and Fullenkamp, 1991; Sillito et al., 1995). Taken together these basic principles suggest ways by which detecting an odd man out, or a significantly different item in a display, can be achieved in a very economical (in terms of neural hardware) yet robust manner.

FIGURE 1 (Top) Example where one item (a dark-red and roughly horizontal bar1) in an array of items (bright-green bars) is highly salient and immediately and effortlessly grabs visual attention in a bottom-up, image-driven manner. (Bottom) Example where a similar item (a dark-red and roughly vertical bar) is not salient but may be behaviorally relevant if your task is to find it as quickly as possible; top-down, volition-driven mechanisms must be deployed to initiate a search for the item. (Also see Treisman and Gelade, 1980.) Source: Itti and Koch, 2000. Reprinted with permission from Elsevier.
|
1 |
To see figures in color, go to the 2007 U.S. FOE Presentations page at <http://www.nae.edu/frontiers>. |
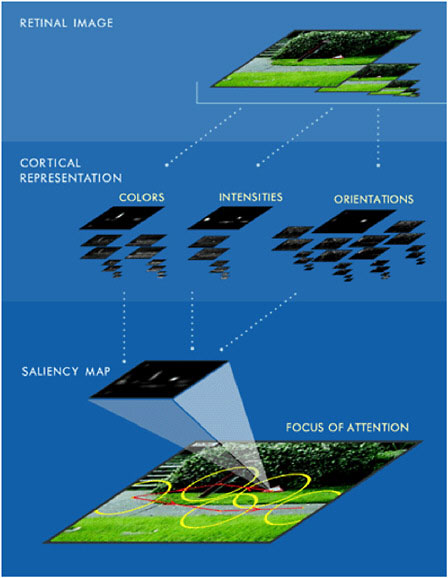
FIGURE 2 Architecture for computing saliency and directing attention toward conspicuous locations in a scene. Incoming visual input (top) is processed at several spatial scales along a number of basic feature dimensions, including color, luminance intensity, and local edge orientation. Center-surround operations as well as nonclassical surround inhibition within each resulting feature map enhance the neural representation of locations that significantly stand out from their neighbors. All feature maps feed into a single saliency map that topographically represents salience irrespectively of features. Attention is first directed to the most salient location in the image, and subsequently to less salient locations. Source: <http://iLab.usc.edu>.
Many computational models of human visual search have embraced the idea of a saliency map under different guises (Treisman, 1988; Wolfe, 1994; Niebur and Koch, 1996; Itti and Koch, 2000). The appeal of an explicit saliency map is the relatively straightforward manner it allows the input from multiple, quasi-independent feature maps to be combined and to give rise to a single output: the next location to be attended. Related formulations of this basic principle have been expressed in slightly different terms, including defining salient locations as those that contain spatial outliers (Rosenholtz, 1999), which may be more informative in Shannon’s sense (Bruce and Tsotsos, 2006). Similarly, a more general formulation has been proposed by which salient locations may be more surprising in a Bayesian sense (Itti and Baldi, 2006). Electrophysiological evidence points to the existence of several neuronal maps, in the pulvinar, the superior colliculus, and the intraparietal sulcus, which appear to encode specifically for the saliency of a visual stimulus (Robinson and Petersen, 1992; Gottlieb et al., 1998; Colby and Goldberg, 1999). Presumably, these different brain areas encode for different aspects of salience, from purely bottom-up representations to more elaborated representations that may incorporate top-down influences and behavioral goals.
Fully implemented computational models of attention, although relatively recent, have spawned a number of exciting new technological applications, including
-
automatic target detection (e.g., finding traffic signs along the road or military vehicles in a savanna) (Itti and Koch, 2000);
-
robotics (using salient objects in the environment as navigation landmarks) (Frintrop et al., 2006; Siagian and Itti, 2007);
-
image and video compression (e.g., giving higher quality to salient objects at the expense of degrading background clutter) (Osberger and Maeder, 1998; Itti, 2004);
-
automatic cropping or centering of images for display on small portable screens (Le Meur et al., 2006); and
-
medical image processing (e.g., finding tumors in mammograms) (Hong and Brady, 2003).
FROM ATTENTION TO VISUAL SCENE UNDERSTANDING
How can cognitive control of attention be integrated with the simple framework described so far? One hypothesis is that another map exists in the brain that encodes for top-down relevance of scene locations (a task relevance map, or TRM) (Navalpakkam and Itti, 2005). In the TRM a highlighted location might have a particular relevance because, for example, it is the estimated target of a flying object; it is the next logical place to look at given a sequence of action, recognition, and reasoning steps, like in a puzzle video game; or one just guesses there might be something worth looking at there. Clearly, building computational
models in which a TRM is populated with sensible information is a very difficult problem, tantamount to solving most of the problems in vision and visual scene understanding.
Recent work has demonstrated how one can implement quite simple algorithms that deliver highly simplified but useful task relevance maps. In particular, Peters and Itti (2007) (Figure 3) recently proposed a model of spatial attention that (1) can be applied to arbitrary static and dynamic image sequences with interactive tasks and (2) combines a general computational implementation of both bottom-up (BU) saliency and dynamic top-down (TD) task relevance (Figure 4). The novelty lies in the combination of these elements and in the fully automated nature of the model. The BU component computes a saliency map from 12 low-level, multiscale visual features, similar to the process described in the previous section. The TD component computes a low-level signature of the entire image (the “gist” of the scene) (Torralba, 2003; Peters and Itti, 2007) and learns to associate different classes of signatures with the different gaze patterns recorded from human subjects performing a task of interest. It is important to note that while we call this component top-down, it does not necessarily imply that it is high level—in fact, while the learning phase certainly uses high-level information about the scenes, that becomes summarized into the learned associations between scene signatures and expected behavior in the form of TD gaze position maps. It is also important to realize how, while the computation of image signatures relies on a visual processing algorithm, the association between signatures and predicted gaze positions is learned and thus forms a descriptive behavioral model.
We measured (Peters and Itti, 2007) the ability of this model to predict the eye movements of people playing contemporary video games. We found that the TD model alone predicts where humans look about twice as well as does the BU model alone; in addition, a combined BU×TD model performs significantly better than either individual component. Qualitatively the combined model predicts some easy-to-describe but hard-to-compute aspects of attentional selection, such as shifting attention leftward when approaching a left turn along a racing track. Thus, our study demonstrates the advantages of integrating bottom-up factors derived from a saliency map and top-down factors learned from image and task contexts in predicting where humans look while performing complex visually guided behavior. In continuing work we are exploring ways of introducing additional domain knowledge into the top-down component of our attentional system.
DISCUSSION AND CONCLUSIONS
Visual processing of complex natural environments requires animals to combine, in a highly dynamic and adaptive manner, sensory signals that originate from the environment (bottom-up) with behavioral goals and priorities dictated by the task at hand (top-down). In the visual domain, bottom-up and top-down guidance
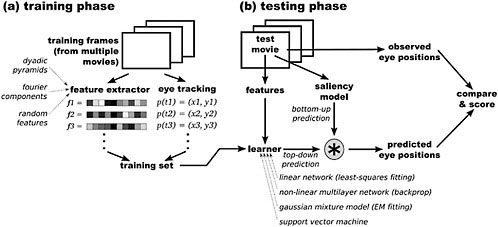
FIGURE 3 Schematic illustration of our model for learning task-dependent, top-down influences on eye position. First, in (a), the training phase, we compile a training set containing feature vectors and eye positions corresponding to individual frames from several video game clips that were recorded while observers interactively played the games. The feature vectors may be derived from either the Fourier transform of the image luminance; or dyadic pyramids for luminance, color, and orientation; or as a control condition, a random distribution. The training set is then passed to a machine-learning algorithm to learn a mapping between feature vectors and eye positions. Then, in (b), the testing phase, we use a different video game clip to test the model. Frames from the test clip are passed in parallel to a bottom-up saliency model, as well as to the top-down feature extractor, which generates a feature vector that is used to generate a top-down eye position prediction map. The bottom-up and top-down prediction maps can be combined with pointwise multiplication, and the individual and combined maps can be compared with the actual observed eye position. Source: Peters and Itti, 2007. Reprinted with permission. © IEEE.

FIGURE 4 Combined bottom-up plus top-down model and comparison with human eye movements. While a subject was playing this jet-ski racing game (upper left), his gaze was recorded (large orange circle in all four quadrants2). Simultaneously, the top-down map (upper right) was computed from previously learned associations between scene gist and human gaze (location of maximum top-down activity indicated by small red circle). The bottom-up saliency map was also computed from the video input (lower left, maximum at small blue circle). Both maps were combined, here by taking a pointwise product (lower right, maximum at small purple circle). This figure exemplifies a situation where top-down dominates gaze allocation (several objects in the scene are more bottom-up salient than the one being looked at). Source: Peters and Itti, 2007. Reprinted with permission. © IEEE.
of attention toward salient or behaviorally relevant targets have been studied and modeled extensively, as has more recently the interaction between bottom-up and top-down control of attention. Thus, in recent years a number of neurally inspired
|
2 |
To see figures in color, go to the 2007 U.S. FOE Presentations page at <http://www.nae.edu/frontiers>. |
computational models have emerged that demonstrate unparalleled performance, flexibility, and adaptability in coping with real-world inputs. In the visual domain, in particular, such models are achieving great strides in tasks, including focusing attention onto the most important locations in a scene, recognizing attended objects, computing contextual information in the form of the gist of the scene, and planning or executing visually guided motor actions.
Together these models present great promise for future integration with more conventional artificial intelligence techniques. Symbolic models from artificial intelligence have reached significant maturity in their cognitive reasoning and top-down abilities, but the worlds in which they can operate have been necessarily simplified (e.g., a chess board, a virtual maze). Very exciting opportunities exist to attempt to bridge the gap between the two disciplines of neural modeling and artificial intelligence.
ACKNOWLEDGMENTS
This work is supported by the Human Frontier Science Program, the National Science Foundation, the National Geospatial-Intelligence Agency, and the Defense Advanced Research Projects Agency. The author affirms that the views expressed herein are solely his own, and do not represent the views of the United States government or any agency thereof.
REFERENCES
Allman, J., F. Miezin, and E. McGuinness. 1985. Stimulus specific responses from beyond the classical receptive field: Neurophysiological mechanisms for local-global comparisons in visual neurons. Annual Review of Neuroscience 8:407-430.
Bruce, N., and J. K. Tsotsos. 2006. Saliency based on information maximization. Advances in Neural Information Processing Systems 18:155-162.
Cannon, M. W., and S. C. Fullenkamp. 1991. Spatial interactions in apparent contrast: Inhibitory effects among grating patterns of different spatial frequencies, spatial positions and orientations. Vision Research 31:1985-1998.
Colby, C. L., and M. E. Goldberg. 1999. Space and attention in parietal cortex. Annual Review of Neuroscience 22:319-349.
Crick, F. 1984. Function of the thalamic reticular complex: The searchlight hypothesis. Proceedings of the National Academy of Sciences 81(14):4586-4590.
Desimone, R., and J. Duncan. 1995. Neural mechanisms of selective visual attention. Annual Review of Neuroscience 18:193-222.
Frintrop, S., P. Jensfelt, and H. Christensen. 2006. Attentional landmark selection for visual SLAM. Pp. 2582-2587 in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’06). Piscataway, NJ: IEEE.
Gottlieb, J. P., M. Kusunoki, and M. E. Goldberg. 1998. The representation of visual salience in monkey parietal cortex. Nature 391:481-484.
Hong, B.-W., and M. Brady. 2003. A topographic representation for mammogram segmentation. Lecture Notes in Computer Science 2879:730-737.
Hubel, D. H., and T. N. Wiesel. 1962. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. Journal of Physiology 160:106-154.
Itti, L. 2004. Automatic foveation for video compression using a neurobiological model of visual attention. IEEE Transactions on Image Processing 13:1304-1318.
Itti, L., and P. Baldi. 2006. Bayesian surprise attracts human attention. Pp. 1-8 in Advances in Neural Information Processing Systems, Vol. 19 (NIPS 2005). Cambridge, MA: MIT Press.
Itti, L., and C. Koch. 2000. A saliency-based search mechanism for overt and covert shifts of visual attention. Vision Research 40(10-12):1489-1506.
Itti, L., and C. Koch. 2001. Computational modeling of visual attention. Nature Reviews Neuroscience 2(3):194-203.
Itti, L., C. Koch, and E. Niebur. 1998. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 20:1254-1259.
Koch, C., and S. Ullman. 1985. Shifts in selective visual attention: Towards the underlying neural circuitry. Human Neurobiology 4:219-227.
Kuffler, S. W. 1953. Discharge patterns and functional organization of mammalian retina. Journal of Neurophysiology 16(1):37-68.
Le Meur, O., P. Le Callet, D. Barba, and D. Thoreau. 2006. A coherent computational approach to model bottom-up visual attention. IEEE Transactions on Pattern Analysis and Machine Intelligence 28(5):802-817.
Minsky, M. 1961. Steps toward artificial intelligence. Proceedings of the Institute of Radio Engineers 49:8-30.
Navalpakkam, V., and L. Itti. 2005. Modeling the influence of task on attention. Vision Research 45(2):205-231.
Newell, A., and H. Simon. 1972. Human Problem Solving. Englewood Cliffs, NJ: Prentice-Hall.
Niebur, E., and C. Koch. 1996. Control of selective visual attention: Modeling the “where” pathway. Neural Information Processing Systems 8:802-808.
Osberger, W., and A. J. Maeder. 1998. Automatic identification of perceptually important regions in an image using a model of the human visual system. Pp. 701-704 in Proceedings of the 14th International Conference on Pattern Recognition, Vol. 1. Piscataway, NJ: IEEE.
Peters, R. J., and L. Itti. 2007. Beyond bottom-up: Incorporating task-dependent influences into a computational model of spatial attention. Pp. 1-8 in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE.
Robinson, D. L., and S. E. Petersen. 1992. The pulvinar and visual salience. Trends in Neuroscience 15:127-132.
Rosenholtz, R. 1999. A simple saliency model predicts a number of motion popout phenomena. Vision Research 39:3157-3163.
Samuel, A. 1959. Some studies in machine learning using the game of checkers. IBM Journal 3(3):210-229.
Siagian, C., and L. Itti. 2007. Biologically-inspired robotics vision Monte-Carlo localization in the outdoor environment. Pp. 1723-1730 in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’07). Piscataway, NJ: IEEE.
Sillito, A. M., K. L. Grieve, H. E. Jones, J. Cudeiro, and J. Davis. 1995. Visual cortical mechanisms detecting focal orientation discontinuities. Nature 378:492-496.
Torralba, A. 2003. Modeling global scene factors in attention. Journal of the Optical Society of America A - Optics Image Science and Vision 20(7):1407-1418.
Treisman, A. 1988. Features and objects: The fourteenth Bartlett memorial lecture. Quarterly Journal of Experimental Psychology 40:201-237.
Treisman, A., and G. Gelade. 1980. A feature integration theory of attention. Cognitive Psychology 12:97-136.
Tsotsos, J. K. 1991. Is complexity theory appropriate for analyzing biological systems? Behavioral and Brain Sciences 14(4):770-773.
von Ahn, L., M. Blum, and E. Langford. 2004. How lazy cryptographers do AI. Communications of the ACM 47(2):57-60.
Weichselgartner, E., and G. Sperling. 1987. Dynamics of automatic and controlled visual attention. Science 238:778-780.
Wolfe, J. M. 1994. Guided search 2.0: A revised model of visual search. Psychonomic Bulletin and Review 1(2):202-238.
Wolfe, J. M., and T. S. Horowitz. 2004. What attributes guide the deployment of visual attention and how do they do it? Nature Reviews Neuroscience 5:1-7.
ADDITIONAL READING
Wolfe, J. M. 1998. Visual search. Pp. 13-74 in Attention, H. Pashler, ed. London: University College.












