
1
Clinical Data as the Basic Staple of the Learning Health System
INTRODUCTION
A modern evidence and value-driven healthcare system must have the capacity to learn and adapt—to track performance in real-time and generate and apply information for future improvements in safety, quality, and value of care received. As information technologies supporting clinical documentation continue to advance, the volume of clinical data generated in the natural course of care rapidly grows. Understanding, accessing, managing, and interpreting the widening variety of healthcare data available requires coordination of resources, efforts, and incentives to ensure that researchers, clinicians, and patients have access to the right data, in the right context, at the right time (Detmer, 2003; Kawamoto and Ginsburg, 2009; NRC, 2009). Integrated datasets and other approaches to link data and broaden or share findings only extend the potential to use these data to learn what works in health care. Fostering broader access to and appropriate use of these data will be key to progress—and will require both cross-sector discussions to better characterize the technical, organizational, and legal barriers that currently limit the use of existing and emerging data resources and cooperative action to address these challenges (Arrow et al., 2009; Piwowar et al., 2008). These and other issues were the focus of discussion at the Institute of Medicine (IOM) Roundtable on Value & Science-Driven Health Care’s February 2008 workshop, Clinical Data as the Basic Staple of Health Learning: Creating and Protecting a Public Good (Box 1-1).
|
BOX 1-1 Issues Motivating Discussion
|
The Roundtable and Clinical Data
The IOM’s Roundtable on Value & Science-Driven Health Care provides a trusted venue for key stakeholders—patients, health providers, payers, employers, manufacturers, health information technology, researchers, and policy makers—to work cooperatively on innovative approaches to generating and applying evidence to drive improvements in the effectiveness and efficiency of medical care in the United States. Participants seek the development of a learning health system that is designed to generate and apply the best evidence for the collaborative healthcare choices of each patient and provider; to drive the process of discovery as a natural outgrowth of patient care; and to ensure innovation, quality, safety, and value in health care. They have set a goal that, by the year 2020, 90 percent of clinical decisions will be supported by accurate, timely, and up-to-date clinical information, and will reflect the best available evidence.
Central to fulfilling the Roundtable’s goal is a change in how the healthcare system is structured to capture and apply the results of clinical experience. This publication, Clinical Data as the Basic Staple of Health Learning, summarizes the workshop’s examination of the current national profile of healthcare data sources; the tools and datasets employed to transform data linkage and application; the notion of clinical data as a public good; and the legal and social elements of data privacy and security. Through invited presentations, workshop participants explored these issues and discussed possible next steps in the creation and maintenance of the next generation of data utility.
Overview and State of Play
Composed of information ranging from determinants of health (e.g., biomedical, demographic, and genetic factors; health behaviors; socioeconomic factors and environmental factors) and measures of health and health status (e.g., laboratory data, physical exam findings, imaging studies, diagnoses, treatments prescribed, responses to interventions applied) to documentation of care delivery, healthcare data in the United States are distributed widely across the healthcare system. These data are captured as part of the delivery of clinical care, administration and claims processes, and research. Stored across the country—in personal and electronic health records, paper charts, claims receipts, and research registries in office practices, hospitals, academic medical facilities, insurance companies, and research labs—these data may represent discrete test results or information from handwritten notes about the interaction between a healthcare provider and a patient. They are collected and maintained by organizations supporting these activities in numerous databases (NRC, 2009).
Healthcare data and databases are used for many purposes. Patients, providers, payers, researchers, and government registries collect health information with the goal to assess and improve care provision and treatment, advance discovery and research, direct reimbursement, develop the evidence base for medical practice, and inform public health and health reform policy development. Progress in health information technology and analytic tools have dramatically expanded our capacity to capture and use these data. However, few sources, taken individually, provide comprehensive, longitudinal views about individual patients or have data in sufficient numbers to adequately power studies of safety and effectiveness. Instead, data that collectively could provide a picture of individual and population health, advance our understanding of what works in practice, and improve health outcomes are fragmented across a complex system of collection and storage. Potential exists for these data to be used to fill substantial knowledge gaps in health care, including research on best practices, reducing costs,
increasing quality, and on effectiveness of medical interventions in clinical practice (Hrynaszkiewicz and Altman, 2009; IOM, 2009; Kawamoto and Ginsburg, 2009; Safran, 2007).
As detailed in the chapters that follow and briefly summarized here, complicating the use of these data are technical, cultural, and legal barriers. Terminology used for data collection in different organizations and sectors are not standardized and numerous systems of electronic data collection lack interoperability, making synthesis and comprehensive analysis of pooled data a tremendous challenge (NRC, 2009). While such technical barriers will require collaboration by the stakeholders involved in issues relating to clinical data, issues around data ownership (including societal concerns about privacy or the treatment of data as a proprietary commodity) pose significant challenges to realizing the full potential of clinical data as the basic staple of a learning health system (Piwowar et al., 2008).
The advent of electronic health information technology as a means for collecting, housing, and analyzing clinical data has prompted concern about who has access to what data and for what purpose. With the goal of ensuring the protection of an individual’s privacy while still permitting information exchange necessary for providing appropriate clinical care and research, the Department of Health and Human Services (HHS) developed a set of federal standards for protecting the privacy of personal health information under the 1996 Health Insurance Portability and Accountability Act (HIPAA) (IOM, 2009). Certain provisions raised concerns among healthcare institutions, research entities, and providers about compliance and among patients about privacy and security of these data. The HIPAA Privacy Rule in particular has been the focus of much discussion about data sharing for both clinical and research endeavors, and some have suggested variable interpretations of this rule have hampered important health research (IOM, 2009; Ness, 2007).
In February 2009, the IOM released a report, Beyond the HIPAA Privacy Rule: Enhancing Privacy, Improving Health Through Research, authored by an IOM consensus committee charged in part with proposing “recommendations to facilitate the efficient and effective conduct of important health research while maintaining or strengthening the privacy protection of personally identifiable health information” (IOM, 2009). The report characterizes the tension between individual privacy concerns and potential societal benefits reaped from sharing of clinical data as follows: “The primary justification for protecting personal privacy is to protect the interests of individuals. In contrast, the primary justification for collecting personally identifiable health information for health research is to benefit society. But it is important to stress that privacy also has value at the societal level because it permits complex activities, including research and public health activities, to be carried out in ways that protect individuals’
dignity” (Ness, 2009). The report notes several examples of important findings derived from medical research databases (Box 1-2), and suggests that the opportunities will only expand with health information technology advancement. The committee’s recommendations aimed at promoting both enhanced privacy and research are presented in Appendix D.
While technical issues such as interoperability and standards as well as privacy concerns have hampered efforts to share and utilize clinical data, many have observed that the needed shift to a data sharing culture—among scientists, clinical researchers, and health organizations—might pose a greater challenge (Altman, 2009; Blumenthal et al., 2006; Nature, 2005; Piwowar et al., 2008). Critical to promoting such a culture are clarification on roles and responsibilities with respect to clinical data; viewing the development of incentives, guidance, and appropriate requirements as critical to promote such a culture; and leadership from all sectors in health care.
The aims of the workshop and this publication are to provide an overview of these issues; to survey some of the current, potentially transformative research and clinical data initiatives under way; to discuss the notion of public and private goods; to consider implications of privacy, security, and proprietary concerns; and to suggest some possible opportunities to encourage a data sharing culture and the engagement of the public in advancing progress to the next generation of clinical data resources.
Perspectives on Clinical Data and Health Learning
To build a foundation for the presentations that would follow, each of the two days of the workshop began with a keynote address designed to take a broad look at relevant issues. The first day’s keynote speaker was David Brailer, chairman of Health Evolution Partners. As the nation’s first national coordinator for health information technology, Brailer led federal and private-sector efforts to improve healthcare quality, accountability, and efficiency through health information technology (HIT) and create a strong foundation for the adoption of digitalized medicine in the United States. His keynote presentation profiled current collection and use of clinical data and reflected on how these data might be used in the near future in terms of care delivery, research, and health outcomes. The second day’s keynote speaker, Carol Diamond, managing director of health programs from the Markle Foundation, presented a vision for future health care in which clinical data are treated as a public good as a way to illustrate current technical and policy challenges. Her remarks explored three key questions: What might be achieved if clinical data could be positioned as a public good? How would such a system work, and what are the technical and policy issues to engage in fostering its evolution? Do we want to define integrated data as a public good?
|
BOX 1-2 Examples of Important Findings from Medical Database Research (adapted from IOM, 2009) Herceptin and breast cancer: Data were collected from a cohort of more than 9,000 breast cancer patients whose tumor specimens were consecutively received at the University of San Antonio (1974–1992) from across the United States. Results showed that amplification of the HER-2 oncogene was a significant predictor of both overall survival and time to relapse in patients with breast cancer. This information subsequently led to the development of Herceptin (trastuzumab), a targeted therapy that is effective for many women with HER-2–positive breast cancer. Folic acid and birth defects: Medical records research led to the discovery that supplementing folic acid during pregnancy can prevent neural tube birth defects (NTDs). Studies in the 1970s found that vitamin (folate) deficiency and use of anticonvulsive drugs that deplete folate were associated with higher rates of NTDs, and studies in the 1980s found that use of folate supplements was associated with decreased rates. Population-based surveillance systems showed that the number of NTDs decreased 31 percent after mandatory fortification of cereal grain products. Effects of intrauterine DES exposure: Starting in the 1940s, diethylstilbestrol (DES) was used by millions of pregnant women to prevent miscarriages and other disorders in pregnancy. In the 1970s, retrospective studies of medical records began to show that infants exposed to DES during the first trimester of pregnancy had an increased risk as adults of breast, vaginal, and cervical cancer as well as reproductive anomalies. In November 1971, the Food and Drug Administration (FDA) sent a FDA Drug Bulletin to all U.S. physicians advising them to stop prescribing DES to pregnant women. Patient safety: Health services research estimated that tens of thousands of Americans die each year from medical errors in the hospital. A 1998 study led by David Bates (Brigham & Women’s Hospital) found that computerized order entry of prescriptions at Brigham & Women’s Hospital reduced medical error rates by 55 percent; rates of serious errors fell by 86 percent. In response to this groundbreaking work, hospitals around the country are installing their own computerized physician order entry systems. Mortality risks of antipsychotic drugs in the elderly: In 2005 the FDA issued a public health advisory stating that the atypical (second generation) antipsychotic medications increase mortality among elderly patients. This decision was based on the results of 17 placebo-controlled trials with such drugs that enrolled a total of 5,106 elderly patients with dementia who had behavioral disorders. Risk of death with older, conventional agents was not known. Results from two subsequent retrospective reviews of 27,000 and 37,000 medical records of elderly patients indicated that conventional antipsychotic medications are at least as likely as atypical agents to increase |
|
the risk of death among those patients. As a result, the FDA now requires that the prescribing information for all antipsychotic drugs contain the same information about risks found in the Warnings section. Child safety: Using the Partners for Child Passenger Safety (PCPS)—an ongoing child-focused, real-time, crash surveillance system established with the State Farm Insurance Companies in 1997—Flaura Winston (Children’s Hospital of Pennsylvania) found that only 25 percent of children between 3 and 7 years of age were appropriately restrained in crashes; children in seat belts alone were at a 3.5-fold increased risk of serious injury. Winston’s analysis of PCPS data led to the rapid adoption of belt-positioning boosters as the appropriate form of restraint for children once they have outgrown car seats. Appropriate restraint by children in this age group has doubled, and child fatality from crashes is at its lowest level ever. Obesity: Eric Finkelstein (RTI International) used data from the late 1990s to find that obesity is responsible for up to $92.6 billion in medical expenditures each year; approximately half of obesity-related healthcare costs are borne by Medicare and Medicaid. A 2002 study by Roland Sturm (RAND) found that the effects of obesity on a number of chronic conditions were larger than those of smoking or problem drinking. Since then, obesity has been escalated to the top of the list of health care priorities, and policy makers have appropriated funds for federal agencies to fund health services research that encourages people to understand the effects of diet and exercise on their health. Rural health: Stephen Mick (Virginia Commonwealth University) and colleagues examined rural hospital performance in the late 1980s and early 1990s. They found that activity typical of urban hospitals is beyond the capacity of most rural facilities and recommended that a new federal approach would be required to preserve rural acute-care services. This work helped form the intellectual basis for Medicare’s highly successful Critical Access Hospital program, which was designed to improve rural healthcare access and reduce closures of hospitals that provide essential community services. Workforce and health outcomes: In 1997, Jack Needleman (University of California–Los Angeles) and Peter Buerhaus (Vanderbilt University) analyzed more than 6 million patient discharge records from 799 hospitals in 11 states. They found that patients in hospitals with fewer registered nurses stay hospitalized longer and are more likely to suffer complications, such as urinary tract infections and upper gastrointestinal bleeding. This research established a causal link between the nursing shortage and outcomes, and helped move the nursing shortage into the public’s eye. SOURCES: Bates et al. (1998); FDA (1971, 2005, 2008); Finkelstein et al. (2003); Gill et al. (2007); Herbst et al. (1971); IOM (2000b); Mick et al. (1994); Needleman et al. (2002); Pitkin (2007); Schneeweiss et al. (2007); Slamon et al. (1987); Thorpe et al. (2004); Veurink et al. (2005); Winston et al. (2000). |
CLINICAL DATA AS THE BASIC STAPLE OF HEALTH LEARNING
David Brailer, M.D., Ph.D.
Chairman, Health Evolution Partners
The idea that clinical data are a basic staple of the learning system is perhaps one of the least appreciated and most important aspects of American health care. It is about more than clinical data per se because the need for data is obvious. At its core, it is about whether clinical data are a public or private good. A significant gap exists between our desire to use clinical information to improve health care and the reality that we see in today’s healthcare market, where clinical information is proprietary and used for strategic benefit.
To view this challenge in its broader context, one must take a step back. The United States is well into the big step of health information technology adoption. In 2004, President Bush declared the goal that most Americans would have access to electronic health records (EHRs) in 10 years, and to achieve this goal, he created the Office of the National Coordinator for Health Information Technology. This step struck a chord of resonance with Americans who view change in the healthcare industry as necessary, if not inevitable. The concept of health information technology is not new. It follows at least 30 years of work that preceded our progress today. The work followed the publishing of the seminal papers on how information given to a clinician at the right time and at that teachable moment can have a profound effect on care.
This goal is a significant challenge to the status quo of health care, and we have made some good progress toward meeting it. Our nation is far along in efforts to develop standards for interoperable HIT and to certify HIT products that meet minimum standards. In health care, standards development and certification are the equivalents of cellular handsets and wireless connectivity for telecommunications. They are the basic building blocks for producing portable health information. Many hospitals are far along with putting electronic records in place. Many physicians are still struggling, but we are still seeing signs of incremental progress in adoption among physician groups, particularly large ones. Most importantly, the public has become aware of health information as an asset or a good. Consumer awareness is a critical foundation that is necessary for ensuring that HIT serves as an enabler for portable clinical information. Today, several insurers are differentiating their services in national markets based on their solutions for health information access. Companies such as Microsoft, Google, and others are beginning to offer health information access as part of their industry’s vertical solutions. The United States has made enormous progress because the public has begun to appreciate how important infor-
mation is in their care experience. As the American public begins to want and demand more, the direction of change will sharpen and accelerate.
Yet numerous open issues remain. We are still facing enormous difficult incentives. Misaligned incentives have evolved from our perilously obsolete reimbursement system. We still have a privacy paradigm from a paper age. We do not have a framework for privacy that recognizes that health information is no longer a static good, but instead is a portable, moving, compounding, and growing asset. We do not have even the consciousness to understand what we do about this privacy challenge because most are still focused on what did and did not work under the old paper-based privacy statutes.
In spite of these obstacles, person-based portability of health information that truly moves along with the patient across healthcare settings is closer than it was. We have seen some great examples at the national level through the American Health Information Community, the advisory council of former Department of Health and Human Services Secretary Michael Leavitt, and at the state level with Regional Health Information Organizations. However, interoperable health information is still a novelty and the exception rather than the rule. New information-sharing efforts have encountered challenges in taking the health information assets that we have produced, whether they are at a regional level or in a big healthcare system, and truly used them as a health improvement asset. The true test of health information interoperability is whether the information is truly useful to clinical care.
Using the prescription process as an example, there are two large needs for improving prescription use, which include (1) the indication of why a patient is taking that drug, and (2) a termination order recognizing that the drug was stopped or another drug was substituted. Just those two simple examples of why the drug was given and when and why it was stopped have impaired most analyses of prescribing patterns, and we cannot think of how to put this information into the workflow of a doctor in a way that does not cause disruption and backlash. We can tell that story again with respect to laboratory information, and referrals to specialists, or within genomics.
Although we face numerous challenges, the fundamental tension that must be navigated is between adoption and interoperability. Interoperability—the capacity to share, integrate, and apply health information from disparate sources—was the principal priority of the nation’s health information agenda from 2004 forward, but the adoption agenda to push health information tools into point-of-service use is now beginning to overtake the interoperability agenda. Those two goals are in conflict because we lack all of the components necessary for EHRs and other information tools to be able to share information in a way that achieves our goals for the learning health system. The Office of the National Coordinator chose to put interoperability first to
take advantage of that lack of a legacy. This has been viewed as a one-time opportunity that required purposeful restraint that would push adoption, but not make it a relentless drive during the early part of the President’s 10-year agenda.
Health information is a key vehicle for changing the healthcare system, but how do we create the data or evidence? How do we actually get assembled, coherent, representative, timely, and valid health information that can inform decisions at a patient level or at a broad population level or even at a very large population level?
The data and evidence are coming together. We know how to make this work. We do not lack knowledge in how to create a compiled, intelligent, useful, analytically sound, and interpretable set of clinical information. Today, we mostly know how to do this in laboratory experiments in very controlled circumstances, but many industries outside of health care have demonstrated the ability to take the artifacts of production—such as the information spun off from cars being made or financial services being offered, or some combination of those—and turn that information into data that can help manage workflow, manage processes, and identify opportunities for improvement or opportunities for failure. Establishing this “intelligence” does not happen as a single event because it is a generational shift, and this current generation of basic point-of-service transactions will probably be inadequate as infrastructure to take us far in health care.
The learning system is where actions are accompanied by feedback that is linked to accountabilities, whether they are incentives or changes in action. This occurs through an integrated process. Information drawn from actual experience in care delivery must be able to shape the care delivery process. Specifically, the data that inform our policy or inform population care should not be separate from what is really going on in care.
The learning system requires data that are structured, meaningful, representative, and duplicable in a way that supports consistent interpretations and conclusions across many different episodes. Today, even diagnosis codes do not always mean the same thing because they are used differently for the billing process in different kinds of organizations, and yet we want to be able to have those data artifacts compiled and used comparatively.
Finally, we want to have the means of evaluating the system so that we can translate findings into accountabilities and responses. That simple ability to drive information through a process is clearly what is required for clinical information to be used effectively in a learning system.
Many healthcare organizations of varying sizes are looking at this agenda and seeking leadership. They are looking for clarity on how they should go about compiling, analyzing, structuring, and creating accountability, but this effort cannot be teased out from the broader issues that are shaping health care. Thinking about ways of making health care smarter is
increasingly difficult when there are fundamental problems that providers, payers, and consumers are facing in terms of access and cost. To evolve a learning system in the midst of these competing near-term problems, we must relentlessly continue to pursue things that make clinical data structured, intelligent, useful, assembled, and applied in a way that makes care better. When we as actors begin to address this today, we go back to the foundational question: Who is going to do that? Who will control it and to what end?
This is not an easy question and the outcome is unknown. Under one scenario, health information could become a true public good as something that is truly nonproprietary. Under another scenario, clinical information could become a private good as something that is used differentially, for comparative advantage that benefits some, but not all. The reality today is that clinical information is largely a private good. Whether it helps or harms health care is an unanswered question.
The old English common-law adage that possession is nine-tenths of the law was originally applied to real property, largely to land. It was a rule of logic, as most old English common-law was, that applied to disputes about ownership. Figuratively speaking, the rule of nine-tenths applies to health information. Nothing in federal or state statutes, regulation, or other guidance says to providers or to any other data originator—a lab, hospital, physician, or device manufacturer—that they control the health information they produce. Yet in aggregate, the confluence of rules and business practices largely give nine-tenths of the benefit to data producers to control health information.
For example, HIPAA creates de facto control over health information by providers. First, patients cannot direct that their information be sent to a third party. Although some providers do this as a courtesy to patients, others still do not. The law is very clear that no provider is required to send a patient’s health information to anyone other than the patient. This results in a barrier to true portability where agents acting on behalf of people to compile and move their information are at a disadvantage compared to the data originator.
Second, providers are not obliged to make data available in formats or through modalities that are not convenient to the data producer. There is a very good, paper-era reason for this rule. Such a requirement might have imposed a tremendous cost of infrastructure conversion or information technology on providers during the paper paradigm when HIPAA was established. We are in a different world today, although we do not have the ability to actually get information in a raw, useful, assembled analyzable format.
Third, providers have a long period of time to comply with the data request—as long as 120 days in most states—which makes shared information useless to most patient care.
Because of these limitations imposed by law regarding time, format, and distribution, we live in a world today where providers clearly own and control health information. This adversely affects its portability and it makes it hard to address the kinds of goals we have for it as a public good or as a staple of a learning system. These are only three limitations that have been identified. There are other regulatory barriers to portable, available, and acceptable health information.
Why does this matter? In our healthcare delivery system today, strategic use of health information is anchoring quasi-geographic cartels. So, much of healthcare delivery is controlled by a single physician group, hospital or integrated system, lab, specialty group or alliance, specific imaging center, etc. This is not apparent if one looks at a Herfindahl index—a metric of market concentration. However, the Herfindahl index and other market concentration tools are limited to understanding the micromarkets that occur in neighborhoods of health care.
The American public is clear that the primary attribute they want with health care is geographic access. Many factors affect access and choice of providers, and health information is one of them. In many instances, consumers stay with their existing providers because they are concerned that their health information could be lost if they move around, thereby reducing their ability to shop, which is an ability to exercise the kind of choice that should exist. This lack of choice hinders this emerging consumer force that has shaped other industries, but has been slow to assemble in health care. Whether in retail or technology, only a small share of consumers seeking transparency and value has driven the characteristics of products that the majority of other consumers use. Health care will eventually be the same, but in the near term, that small share of consumers is unable to exercise meaningful choice because their health information is difficult for them to get or to use.
The antithesis of transparency is proprietary health information. As consumers seek health care that is transparent and accountable, they are striking at the heart of health information as a source of competitive advantage in the marketplace. Many health systems, whether for profit or nonprofit, are seeking ways to use health data to maintain high price points and to differentiate their products and services. Proprietary use of health information will necessarily become a key component of their success.
As an example, one for-profit healthcare company stated the following in its S-1 (Initial Public Offering) filing with the Securities and Exchange Commission: “We have developed proprietary methods of care that are protected by patent and that cannot be easily replicated because of our unique information technology capabilities and use of health information.” This is one of many healthcare companies that is making substantial investments in health information technology to drive long-term profitability. This raises
the important question of how we ensure that health information is not used in a way that creates a quality gap where some have access to it and others do not.
Another example may find more resonance. If pay for performance becomes a key means for producing revenue for our healthcare system, the system will be required by bond underwriters and others to secure the means of the revenue production. A whole subindustry has evolved around this, which includes two of the higher profile healthcare initial public offerings of 2007. Both of these companies are focused on revenue maximization or, as they call it, revenue cycle management. One focuses on physicians and the other focuses on hospitals. If revenue production is shifted away from volume and toward performance, these organizations will be obliged to create means by which they secure their performance-based revenue. This places enormous pressure on healthcare systems to protect their intellectual property and trade secrets on how they deliver care and the ability to understand which approaches to treatment work and which do not.
The future of an industry in which health information is proprietary does not need to happen. Providers should be able to gain advantage from being performance driven, yet they should not gain advantage from health information that is exclusive to them as a private good. Health information as a public good can enable competitive differentiation while supporting the evolution of the learning system as well as true consumer choice, which happens only when information follows the consumer.
There is a limited window to achieve these interoperability goals that underlie the learning health system. This brief period can allow us to ensure that the unintended consequences of policies that result in the nine-tenths possession rules are not allowed to continue. This opportunity is not only for the development of information standards, but also for their requirement as a part of our health policy that the American public understands and demands for portable health information.
Therein lies the challenge for the use of clinical data as a staple of the learning health system. It must be more useful, specified, efficient, assembled, and valuable. It must be equitable and not something that can benefit just the well financed and the well organized. It must also continue to keep the healthcare marketplace competitive.
Ultimately, whether we have a learning health system depends on whether health information is a public good. The ultimate test of this will be if health information does in health care what the information revolution has done in every other industry, which is to push power away from the large institutional providers of services—financial service companies, airlines, the media, hospital, insurers, or labs—and out to consumers.
VISION FOR THE FUTURE: CREATING A PUBLIC GOOD FOR THE PUBLIC’S HEALTH
Carol C. Diamond, M.D., M.P.H.
Managing Director, Health Program, Markle Foundation
Introduction
What might be achieved if clinical data could be positioned as a public good? How would such a system work, and what are the technical and policy issues to engage in fostering its evolution? This paper examines key definitions, assumptions, and approaches currently driving health data and research approaches. It posits that we need a new 21st-century health information paradigm that serves the public good while creating and building trust. The paper hinges on several assumptions. First, we should be open to resetting some definitions and assumptions about research. Second, we should be ready to articulate new working principles based on new paradigms for how information is created, shared, and used. Third, we need an information policy framework that addresses public hopes and concerns.
Connecting for Health
Since 2002, the Markle Foundation has convened and operated Connecting for Health (CFH), a public–private collaborative that works to accelerate the development of a health information-sharing environment to improve the quality and cost effectiveness of health care. The initiative, supported and operated by Markle with additional support from The Robert Wood Johnson Foundation, brings together a diverse group of health, policy, and technology leaders, including consumer groups, clinicians, hospitals, government entities, privacy advocates, technologists, and businesses.
CFH works to create a networked environment where vital information is available when and where it is needed, in a private and secure manner, to improve healthcare quality and to reduce medical errors. CFH is founded on the principle that many participants in the healthcare system want and need access to information, including consumers, providers, and researchers who must help build the evidence base for the most effective high-quality approaches to health care.
Making critical data available to inform high-quality care depends on having a robust information policy framework in place that fosters public trust. An overarching framework for health information technology called the CFH Common Framework has guided this work (Figure 1-1).
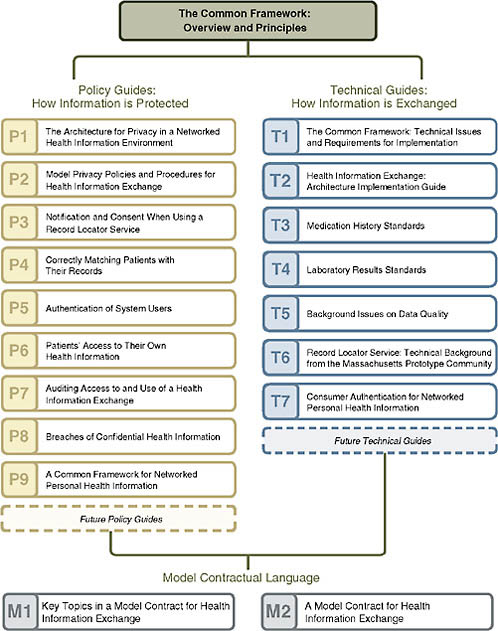
The CFH Common Framework outlines expectations for any health information technology effort in three areas:
-
Core privacy principles
-
Sound network design
-
Accountability and oversight mechanisms
These three key attributes of the framework are broadly applicable across HIT initiatives and business structures and can be used to help shape policies and technology choices for any HIT initiative, from regional health information exchange efforts to quality improvement. The framework is rooted in the assumption that key technical and policy decisions to create information sharing are inextricably linked, and must be jointly developed.
To apply and stress test the Common Framework, we worked with a diverse group of healthcare leaders and experts to develop detailed information policies and technical requirements that achieve the goals of the framework in three areas: (1) health information exchange (HIE) between individual healthcare providers or healthcare organizations (Markle Foundation, 2008a); (2) consumer access to their networked personal health information; and (3) public health and quality research using population-level information to support the nation’s goals of improving clinical research, quality research, and public health and safety. This paper will focus on the last area, population health.
Population Health
CFH has defined improving population health as meeting three critical goals:
-
Bolstering research capabilities and enabling clinical practice to fully participate in and use scientific evidence;
-
Increasing the effectiveness of our public health system; and
-
Empowering consumers and professionals with information about cost, quality, and outcomes.
The key objective is to improve how information is used to address research, public health, and quality measurement. Today, numerous and competing demands for data reporting are required of healthcare providers to satisfy the demands of researchers, those working for quality improvement efforts, and public health entities. However, the current healthcare environment is highly fragmented and poorly equipped to meet these often
redundant and idiosyncratic requests for data that occur daily. The result is that we often lack the robust information needed to measure and improve quality, conduct timely and effective research, and monitor threats to the public’s health.
Although the demand for data is increasingly distributed and diverse, this demand has not been met with a network-based response. The difficulties in collecting, cleaning, and analyzing data harvested from multiple systems have remained consistently challenging. The result is long lag times in using the data once collected, inability to consistently yield valuable information, significant gaps in knowledge, and a chasm between applying the knowledge gained and consistently achieving better care.
To better understand this gap, leaders of the Connecting for Health Steering Group were interviewed on the current state of data aggregation and analysis for clinical research, public health, and quality measurement. The results indicate there is significant frustration with the current paradigm on the part of providers, as well as others responsible for population health. Although tremendous efforts have been devoted to amassing data, these expensive data collection efforts have not produced the anticipated and hoped-for benefits in terms of quality improvement or cost reduction. There is disappointment that over time, decision makers are still struggling with poor data to inform critical decision making.
However, common expectations for information use emerged as well. Experts believe a better model would be one where research becomes a normative part of health care, in which every intervention with a patient is a chance to learn something. The data must be inextricably linked with decision support and remeasurement, not merely serve as an episodic hiccup of a data dump. Simply put, information has to be fed back to somebody who can make a better decision based on that data.
Three Core Attributes and Population Health
Our work in elaborating on the Common Framework more fully as a complete set of policy and technical approaches is just beginning. To provide a robust approach, each element of the Common Framework must be considered.
The CFH Common Framework provides three central requirements that can guide the development of responsible information policies. First, population health approaches should meet “Core Privacy Principles” that are the foundation for creating the necessary information policies for a trusted information-sharing environment for research and public health: openness and transparency, purpose specification, collection and use limitation, individual participation and control, data integrity and quality, and security safeguards and controls. These seven principles draw extensively
on Fair Information Practices and Organisation for Economic Co-operation and Development principles that have been in use within the United States and internationally for decades.
It is important to consider that policies should be implemented before and with technology development. Post hoc policies are typically difficult to implement and often result in piecemeal fixes to policy problems—such as responding to a data breach with a laptop encryption fix—rather than proactively addressing the issue.
The second requirement of the CFH Common Framework is sound network design. Population health efforts should encourage information sharing or “interoperability” among decision makers, allow for flexibility across information systems or applications, and protect information through technology choices. Rather than working toward large, centralized networks, these efforts should take advantage of opportunities to decentralize information and architecture as described above.
The third component of the framework is accountability and oversight. Like the network itself, the accountability mechanisms for achieving this new paradigm for research will be distributed and shared among many groups. As a major funder of research and knowledge creation, government will have a clear leadership and accountability role in establishing specific requirements that achieve this objective and can serve as a catalyst in implementing a 21st-century approach. Researchers and research entities must also challenge themselves to develop, support, and innovate around new models that support the use of their findings by the people who can most benefit from them.
The Connecting for Health First Principles for Population Health
To enable rapid progress in achieving population health goals, there is a need to embed analysis, decision support, and feedback loops throughout the system. We cannot predict exactly who future information users will be or what questions they will bring. Because their needs will change over time, we have to start thinking more flexibly about the information and how to produce and use it. This is not a matter of returning to our old habits of creating centralized analytic functions. The challenge is to create alternative models that use modern information technology and take into account a wide variety of users, many and growing data sources, and a new approach to research and evidence creation.
CFH has developed nine “First Principles for Population Health” based on the Common Framework attributes of privacy protections, sound network design, and appropriate oversight and accountability.
-
Designed for Decisions
A 21st-century health information environment will focus on improving the decision-making ability of the many actors in the health sector.
-
Designed for Many
The 21st-century health information environment should empower a rich variety of users.
-
Shaped by Public Policy Goals and Values
A 21st-century health information environment should achieve society’s goals and values; examples include improving health, safety, and efficiency and reducing threats to public health.
-
Boldly Led, Broadly Implemented
A 21st-century health information environment should be guided by bold leadership and strong user participation. The network’s value expands dramatically with the number of needs it can meet and the number of participants it can satisfy.
-
Possible, Responsive, and Effective
A 21st-century health information environment should grow through realistic steps.
-
Distributed But Queriable
A 21st-century health information environment should be composed of a large network of distributed data sources.
-
Trusted Through Safeguards and Transparency
A 21st-century health information environment should earn and keep the trust of the public through policies that provide safeguards and transparency.
-
Layers of Protection
A 21st-century health information environment should protect patient confidentiality by emphasizing the easy movement of queries and responses, rather than of raw data.
-
Accountability and Enforcement of Good Network Citizenship
A 21st-century health information environment should encourage and enforce good network citizenship by all participants.
As highlighted by these principles, a 21st-century approach needs to develop an information policy framework that broadly addresses public hopes and concerns. If we do not have an environment where people believe appropriate safeguards are in place to protect information, we will not realize our goals. Surveys indicate that consumers have serious concerns about the privacy of their health information (California HealthCare Foundation, 2005; FACCT Survey, 2003; Louis Harris & Associates, 1993). But we also know that if consumers believe safeguards are in place to protect their
information, they are willing to share personal information to help identify disease outbreaks or determine ways to improve the quality of health care (Markle Foundation, 2006).
A Vision for the 21st Century
A vision for 21st-century information sharing to improve population health will look at the problem from the perspective of the decision maker who needs to make better decisions. What would it look like if we achieved a future state where providers, consumers, payers, and policy makers all have access to information grounded in reliable evidence? In this regard, three CFH scenarios for the future were developed to illustrate the wide range of decisions that could be improved through better access to the right information at the right time (Markle Foundation, 2008b).
Scenario I:
A Physician Practicing in a 21st-Century Health Information Environment
A physician in a small, four-doctor internal medicine practice in the suburbs is about to meet with a patient. The physician is trying to decide whether to put the patient on a new oral hypoglycemic. She runs a standardized network query to get information about whether this might be the right treatment for the patient. Later, she will benchmark herself against other physicians who might be caring for similar patients. She is also able to determine the most appropriate treatment for the patient’s other presenting problem, a sputum infection. Although the literature indicates antibiotic A might be most appropriate, the latest information about a pneumonia outbreak in the local community suggests antibiotic B may lead to a better response. The scenario goes farther, imagining different financial models, new opportunities for collaboration, and a transformation of the basic care delivery model. This scenario is a way of imagining a future we want to achieve and is a starting place to outline the data “production function” that might get us there.
Scenario II:
The Consumer Seeking Health Information in a 21st-Century Health Information Environment
From the consumer perspective, this scenario depicts the case of a mother who has questions regarding the care of her young son, who is asthmatic. She is able to use a readily available information network to examine data about physician quality, and can identify and select a doctor skilled and experienced in treating children like her son.
Scenario III:
The Policy Maker Making Evidence-Based Decisions in a 21st-Century Health Information Environment
A third scenario is that of a policy maker who is faced with a decision about whether to reimburse a fictional new implantable renal device. This scenario addresses how a policy maker might approach such issues and how an information network could support decision making based on having access to evidence.
These scenarios provide an exciting glimpse of a future where evidence-based decision making is a matter of course. Yet the significant challenge that lies ahead is how to create the systems, analytic tools, and data sharing approaches that will support better decision making by consumers, providers, and policy makers. The IOM Roundtable on Value & Science-Driven Health Care has outlined a vision for a learning health system where clinical data are a staple resource. This is an important vision, but we may fail to achieve it if we are constrained by historical approaches for collecting and analyzing data.
It’s Time for a New Paradigm
Nearly a decade later, the IOM’s 2001 report Crossing the Quality Chasm: A New Health System for the 21st Century still provides an accurate description of the challenges at hand.
Medical science and technology have advanced at an unprecedented rate during the past half-century. In tandem has come growing complexity of health care, which today is characterized by more to know, more to do, more to manage, more to watch, and more people involved than ever before. Faced with such rapid changes, the nation’s healthcare delivery system has fallen far short in its ability to translate knowledge into practice and to apply new technology safely and appropriately. (IOM, 2001)
Progress is dependent on a bold new action agenda that is open to resetting some of our definitions and assumptions of health information and research approaches. All too often a great deal of time, money, and effort are spent collecting, cleaning, and analyzing data, only for them to be held in separate siloed repositories. This approach cannot efficiently meet the current needs of the many information sources and users. It is also a brittle approach in the sense that each new question or problem often requires another time-consuming round of data collection, cleaning, and formatting. Attempts to collect data for each population health initiative place a huge burden on data providers, who must field many requests for their data and report them repeatedly in many ways to different repositories. There is also the issue of privacy and security. As multiple or redundant large datasets
are created, privacy vulnerabilities can increase. Furthermore, this approach often lacks timely feedback loops and fails to inform better decisions at the point of care, which is the ultimate objective. Without timely feedback loops, the motivation to report or send data is low and can result in poor participation or compliance rates. Finally, the current approach does not contemplate a role or access to information by the consumer.
The way forward must start with an accepted set of working principles that are rooted in 21st-century paradigms. Businesses of earlier centuries thrived on command and control paradigms, but today’s businesses depend on ideas and initiatives of the many. Other sectors such as banking or travel services or e-commerce are “networked.” By tapping into information networks, consumers can pay bills, book flights, or pay a stranger on eBay. In this environment, success relies on distributing decision-making authority, incentives, and the rapid innovation of tools that create value to the participants. The U.S. healthcare system needs to be transformed in similar ways.
Today’s environment is increasingly characterized by distributed needs for sharing and accessing actionable information for high-quality health care. The users and creators of clinical information—the “edges of the network”—are becoming increasingly sophisticated both in terms of having richer data and greater analytic capabilities. Because the information needed to conduct effective population health analyses is usually going to be distributed across many data sources in our highly fragmented healthcare system, leapfrogging the current paradigm will depend on finding ways to conduct these analyses effectively while allowing the data to remain distributed. In other words, rather than attempting to collect the data in centralized databases to address each research question, might it be more effective to push the question closer to the data, rather than always bringing the data to the question?
Several new models emerging within population health efforts take a distributed approach to how information is generated. One such example in public health that illustrates and provides important insights into the opportunities and challenges of this approach is the DiSTRIBuTE model developed and maintained by the International Society for Disease Surveillance (International Society for Disease Surveillance, 2008).
A longstanding goal of influenza surveillance has been to create a timely and accurate picture of flu-like illness trends regionally and nationally so that early detection and response to outbreaks can be managed. Traditionally, flu surveillance efforts have been based on a voluntary network of clinical providers who manually tally and report weekly counts of flu-like clinical visits during flu season. The considerable delay in reporting, high provider dropout, and lack of year-round data have been identified as major limitations with this system. More recently, national bioterrorism surveillance resources have been brought to bear on flu surveillance, and
have attempted to collect a broad range of raw patient data, from the clinical settings where data are generated, to derive whether or not somebody has the flu and thereby monitor flu trends. This recent approach, based on first collecting and then sending the required data fields to a centralized database, is cumbersome, and compliance with the reporting requirements on the part of clinical entities has been an ongoing challenge. In addition, the time for data collection, analysis, and communication is long making timely trend detection and response on the part of public health entities a difficult task.
Employing a different approach, the DiSTRIBuTE model considers those clinical delivery organizations that are already tracking flu-like rates by locally derived methods and asks whether meaningful information can be generated by electronically collecting only the summarized counts from each of these entities, regardless of how they were derived (Figure 1-2). This approach bypasses the need to collect full copies of detailed data fields at the individual patient level from each of these sources and limits the data request to the information that is truly the minimum required. The DiSTRIBuTE approach evaluates whether simply aggregating existing summary counts of locally determined flu cases can efficiently provide an accurate and timely trend analysis. Would it be possible to see and predict trends more quickly than manual reporting? More accurately? More comprehensively? So far the results are promising. Trend detection has been shown to be very effective as compared to other longstanding approaches, and timeliness of the information has improved. Also encouraging is that participation levels have increased over the life of the project. Within one year of its launch, the DiSTRIBuTE project has representative cities and states reporting from five of the nine national regions defined by the Centers for Disease Control and Prevention as well as Ontario, Canada. This provides data from more than 300,000 encounters per week—approximately equal to the entire national Sentinel Network output. Higher participation rates are likely due to two factors: the reduction of potential privacy or security concerns that local participants may have had about sharing individually identified data, and lowered barriers to entry for participation. The previously required effort to collect, assemble, and then report all the necessary data fields was replaced by simple requests of local participants to report weekly summary counts of flu cases they were already tracking.
Although this model is still being tested and requires further exploration regarding its potential applications to other research questions, it has demonstrated that a lot can be achieved quickly when new approaches are developed that focus on what information is really needed by a decision maker and how it will be used.
In a new paradigm, consumers should also be embraced as participants and producers of information. One example that demonstrates the chang-
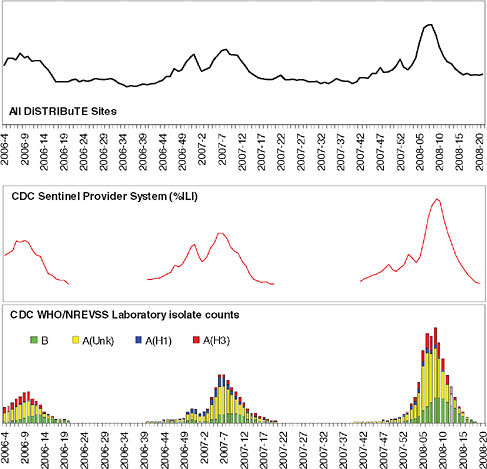
FIGURE 1-2 DiSTRIBuTE visualizations, week 2008–19 (ending Saturday, May 10, 2008). Time series depict respiratory, fever, and influenza-like syndrome emergency department visits by jurisdiction as percentage of total.
SOURCE: http://www.sydromic.org/projects/DiSTRIBuTE2008_02_09.doc (accessed August 31, 2010).
ing consumer role is a website called patientslikeme.com, an online community for patients with amyotrophic lateral sclerosis (ALS). On the site, patients share detailed information about themselves, their treatments, and their symptoms, building a warehouse of shared experiences and data. It is a highly sophisticated site built to accelerate the transfer of knowledge about what works and what does not from a patient perspective. It has been described as having information on the disease progression and history of more than 1,600 ALS patients—twice the number in the largest ALS trial in history. Remarkably, even before the trial results on lithium use for ALS were published, 50 patients worldwide had elected to start taking lithium
in collaboration with their doctors and were tracking their progression and blood levels on the site. This is more than twice the number of patients who were in the clinical trial itself. The site has data on historical forced vital capacity, the ALS Functional Rating Scale, and a standardized symptom battery. This example is compelling because it invites us to revisit our basic assumptions about the sources and uses of clinical data and about the nature and structure of the research process itself.
Conclusion
The future offers enormous possibilities. What if we create a climate of trust with a policy framework that truly enables information liquidity? What if we engage stakeholders in a constructive forward-looking process that prioritizes the creation of value for the participants? What if we embrace alternatives that involve and reward consumers for participating? What if we focus on the infrastructure requirements to push more questions to the data as opposed to trying to bring all the data to every question? What if we set our sights on a collective effort to address a small set of high-priority, public-good objectives using this new approach and enjoy some rapid learning?
Our “what if’s” present many challenges—but those challenges exist now with our traditional approaches and are unlikely to go away. The goal of getting actionable data as quickly as possible to the people who need to make decisions every single day should drive the solutions. Improving health and health care depends on it.
REFERENCES
Arrow, K., J. Bertko, S. Brownlee, L. P. Casalino, J. Cooper, F. J. Crosson, A. Enthoven, E. Falcone, R. C. Feldman, V. R. Fuchs, A. M. Garber, M. R. Gold, D. Goldman, G. K. Hadfield, M. A. Hall, R. I. Horwitz, M. Hooven, P. D. Jacobson, T. S. Jost, L. J. Kotlikoff, J. Levin, S. Levine, R. Levy, K. Linscott, H. S. Luft, R. Mashal, D. McFadden, D. Mechanic, D. Meltzer, J. P. Newhouse, R. G. Noll, J. B. Pietzsch, P. Pizzo, R. D. Reischauer, S. Rosenbaum, W. Sage, L. D. Schaeffer, E. Sheen, B. M. Silber, J. Skinner, St. M. Shortell, S. O. Thier, S. Tunis, L. Wulsin, Jr., P. Yock, G. Bin Nun, S. Bryan, O. Luxenburg, and W. P. M. M. van de Ven. 2009. Toward a 21st-century health care system: Recommendations for health care reform. Annals of Internal Medicine 150(7):493–495.
California HealthCare Foundation. 2005. National consumer health privacy survey. http://www.chcf.org/topics/view.cfm?itemID=115694 (accessed August 18, 2008).
Blumenthal, D., E. G. Campbell, M. Gokhale, P. R. Yucel, B. Clarridge, S. Hilgartner, and M. N. A. Holtzman. 2006. Data withholding in genetics and the other life sciences: Prevalences and predictors. Academic Medicine 81(2):137–145.
Detmer, D. E. 2003. Building the national health information infrastructure for personal health, health care services, public health, and research. BMC Medical Informatics and Decision Making 3(1). http://www.biomedcentral.com/1472-6947/3/1 (accessed August 31, 2010).
FACCT (Foundation for Accountability) Survey. 2003. Connecting for health: Consumer attitudes towards a personal health record. http://www.connectingforhealth.org/resources/phwg_survey_6.5.03.pdf (accessed August 18, 2008).
Hrynaszkiewicz, I., and D. Altman. 2009. Towards agreement on best practice for publishing raw clinical trial data. Trials 10(17).
International Society for Disease Surveillance. 2008. Home page. http://syndromic.org (accessed August 18, 2008).
IOM (Institute of Medicine). 2001. Crossing the quality chasm. Washington, DC: National Academy Press.
———. 2009. Beyond the HIPAA Privacy Rule: Enhancing Privacy, Improving Health Through Research. Washington, DC: The National Academies Press.
Kawamoto, K., H. F. Willard, and G. S. Ginsburg. 2009. A national clinical decision support infrastructure to enable the widespread and consistent practice of genomic and personalized medicine. BMC Medical Informatics and Decision Making 3(1).
Let data speak to data. 2005. Nature 438(7068).
Louis Harris & Associates. 1993. Health information privacy survey, 1993. New York: Louis Harris & Associates.
Markle Foundation. 2006. National survey on electronic personal health records. http://www.markle.org/downloadable_assets/research_doc_120706.pdf (accessed August 18, 2008).
———. 2008a. Connecting for health: The common framework. http://www.connecting-forhealth.org/commonframework/ (accessed August 19, 2008).
———. 2008b. Connectivity in the 21st century. http://www.connectingforhealth.com/connectivity/ (accessed August 18, 2008).
Ness, R. B. 2007. Influence of the hipaa privacy rule on health research. Journal of the American Medical Association 298(18):2164–2170.
NRC (National Research Council). 2009. Computational technology for effective health care: Immediate steps and strategic directions. Washington, DC: The National Academies Press.
Piwowar, H. A., M. J. Becich, H. Bilofsky, and R. S. Crowley. 2008. Towards a Data Sharing Culture: Recommendations for Leadership from Academic Health Centers. PLoS Medicine 5(9):e183.
Safran, C., M. Bloomrosen, W. E. Hammond, S. Labkoff, S. Markel-Fox, P. C. Tang, D. E. Detmer, with input from the expert panel. 2007. Toward a national framework for the secondary use of health data: An american medical informatics association white paper. Journal of the American Medical Informatics Association 14(1):1–9. http://www.healthlawyers.org/Members/PracticeGroups/HIT/Toolkits/Documents/5_Health_Data_AMIA_Summary.pdf (accessed August 18, 2008).


























