
4
Healthcare Data: Public Good or Private Property?
INTRODUCTION
By virtue of the origins of clinical data with individual patients, and because these data are often compiled with public funds, they have many characteristics of a public good or public utility. This situation suggests implicitly that these data should be shared widely and used for the common good of improving the nation’s health and healthcare system. However, private entities also collect and analyze clinical data, often at great expense; place a proprietary value on clinical data; and protect these data as their own intellectual property. One of the goals of Clinical Data as the Basic Staple of Health Learning: Creating and Protecting a Public Good was to evaluate the nature of goods, both public and private, in the healthcare data marketplace and to propose concepts, opportunities, and guidance for improving access to and sharing of medical data. This chapter reviews perspectives on clinical data; effects of the medical care data marketplace on research priorities, gaps, and possibilities; characteristics of a public good or utility—and on which dimensions healthcare data compare; distinctions that can be made within data types or sources; barriers to broader sharing of and access to medical data; and the conceptual advances, guidance, or policy needed.
David Blumenthal, director of the Institute for Health Policy at Massachusetts General Hospital and Partners Health System, and now the U.S. national coordinator for Health Information Technology, describes the theoretical concept of a public good as a way to guide practical policy development around clinical data. Using biomedical research as an example,
Blumenthal explores how research data can have characteristics of a public good while simultaneously holding significant value and inherent costs as a private database asset. In addition, he discussed how taxpayer-funded data, collected and stored in a variety of public and private institutions, provide another opportunity to consider such data a public good. With taxpayer-funded data there is an obligation to evaluate the incentives of data aggregation along with the benefits of making such data more available. Ultimately this may lead to opportunities to have the public, legal, and legislative arenas address the future utility of clinical data.
The potential to support evidence-based medicine through the wide variety of prescription drug and medical databases continues to grow because these data can offer greater insight into the practices of care delivery and safety surveillance. Current data sources have been constructed to serve as potential resources for research and commercial endeavors. William Crown, president of i3 Innovus, offers ideas on the elements to consider in building large, multifaceted data assets. From a private-sector perspective, Crown outlines some of the potential standardization, privacy, and statistical challenges associated with data aggregation and provides insight into the variety of sources of clinical data. As guidance for future database developments, he characterizes the increasing demand for a data resource that draws information from multiple, diverse sources of medical data and, in turn, synthesizes those data into a tool available for a wide range of healthcare activities, including research and evidence generation.
Given the growing complexity of data gathering, access, and pooling, many legal issues must be considered. Nicolas Terry, Chester A. Myers Professor of Law and codirector of the Center for Health Law Studies at Saint Louis University School of Law, provides an overview of legal rules and regulations that preclude effective data sharing and aggregation. Terry elaborates on concepts of property and inalienability rules, the disconnect between federal and state regulations, and the continued development of legal models protecting privacy of health data. One area discussed is the notion of a combined National Committee on Vital and Health Statistics (NCVHS) secondary stewardship model with that of the European data directives, which might guard against data misuse while addressing the growing need for access to patient clinical information by supporting strong obligations for data stewards.
CHARACTERISTICS OF A PUBLIC GOOD AND HOW THEY ARE APPLIED TO HEALTHCARE DATA
David Blumenthal, M.D., M.P.P.
Director, Institute for Health Policy at Massachusetts General Hospital/Partners Health System Physician, Massachusetts General Hospital
This paper will review the classic definition of a public good and discuss how that definition applies to healthcare information under varying circumstances. The paper will also examine rationales for making data publicly available even when they do not meet the classic definition of a public good. These rationales apply to situations in which government has supported—through financial or other means—the development of the data in question or in which making the data publicly available has major benefits (i.e., positive externalities) that are not captured in normal market transactions. The purpose is to provide a framework for evaluating the case for public release of varying types of data; one Roundtable theme is to ensure that publicly funded data are used for the public benefit.
Some say that in theory, there is no difference between theory and practice, but in practice there is. The observations that follow are made on the assumption that theory still matters. I will start with rather esoteric, highly abstract observations, then make the argument that theory actually provides practical guidance in the development of policy and action.
Theory is of practical importance because it strongly affects the political thinking of key actors, whether they are aware of this effect or not. Ideology is a powerful force in our highly partisan political environment. This ideology concerns first and foremost the role of markets in our polity, and assumptions about what markets do well and do not do well. Decisions about the management of health information will involve politics at many levels and they will, consequently, involve ideology. If information is to be treated in any respect as a public good, it will be necessary to keep in mind that nonmarket mechanisms have a role in its management and distribution.
What is a public good? Many of us think we know what a public good is, and the term is often used, but it is a term in which intuition is not a good guide. There is a common supposition that a public good is something that is so good that somebody—usually the government—should make sure that anyone who wants and needs it can get it. This intuitive definition of a public good, however, is a reflection of moral, not economic, reasoning.
The Economics 101 definition of a good is that it is a product or service. It has no intrinsic merit; its goodness is determined by its value in the marketplace. Diamonds and gold have goodness in that they have market value. Straw is not so good unless you believe, as in the fairy tale, that straw can be turned into gold; alchemists broke many wands over that effort.
But markets don’t always work. When markets fail it means they have ceased to be efficient at determining or recognizing the value of a good or service. When that happens, socially optimal rates of production or patterns of distribution are not achieved.
Where and when do markets fail? One time where they fail is when there is a moral revolt against the operation of markets. Markets can also fail in the cases of pure public goods and quasi-public goods. An example of a market that has failed because of public abhorrence is the slave market. This market was common at one time, but of course it is no longer permitted in the United States. Many other markets are banned in the United States on moral grounds: contract killing, sale of human organs, selling votes, illicit substances such as heroin, and sale of cigarettes to minors. The fact that restrictions on gambling and alcohol have declined shows that moral restrictions can change over time. Another example is prostitution, which is not only allowed, but flourishes in a few parts of this country.
Another type of market failure is more relevant to the discussion at hand and defines the pure public good in economic terms. Pure public goods cannot be efficiently traded for two reasons: they are nonrival and they are nonexcludable. Defining a good as nonrival means that using the good does not preclude others’ use of the good. In effect, the marginal cost of nonrival goods use is zero, and therefore an efficient market should price the marginal use of that good at zero. No money should be made in an efficient market from the sale of that product. In accordance with a Roundtable theme, we must correct the market failure for expanding electronic health records.
A good is nonexcludable if, even if wholly owned and paid for, its use and benefit by others cannot be prevented. Both Einstein’s theory of mass-energy equivalence and the double-helix nature and structure of the DNA molecule are examples of public goods. Both are the products of fundamental research. The theory of special and general relativity and the structure of molecules of DNA are nonrival because, no matter how often the research results are used, their value remains and they are available for general use. Furthermore, it would have been virtually impossible for these findings to have had any value if they were not widely shared. Einstein did not just dream up his theory in isolation—he validated it by sharing it broadly within the community of physics to allow it to be critiqued. Similarly, Watson and Crick broadly shared their findings. In fact, replication of this kind of research result is critical to establishing its value. The scientific method in itself requires broad dissemination of results to confirm their validity, and once disseminated, their use can’t be restricted. That is, they are fundamentally nonexcludable.
The public-good nature of basic research is something that people of every political persuasion in this country accept. Across the spectrum of
ideological opinions about markets, from those who cherish them to those who revile them, there is no question that basic research is nonrival and nonexcludable, and that its support is an appropriate and necessary role of government. That is why the National Institutes of Health (NIH) and the National Science Foundation (NSF) are not controversial public programs. Differences on degrees of support may vary in terms of the inherent value of their basic research, but few argue that markets could achieve what these agencies do. In fact, the government produces many examples of classic public goods without controversy. One is national defense. For example, an individual’s use of an aircraft carrier for protection does not exclude general use of it, nor does it diminish the value to others.
There are also quasi-public goods. These are a little more relevant to our discussion of healthcare data. A quasi-public good is one whose production or consumption generates or might generate effects on third parties. It might be a case in which my contract with you has an effect on somebody else in this room who is not a party to that contract. It could be a positive or a negative effect. The consequences of the effect on the third party are not captured in the market transactions between the individuals who participate in the private purchase and sale.
There are also cases where goods may be nonrival, but not nonexcludable, or perhaps nonexcludable, but not nonrival. These are things that don’t exactly fit the definition of a public good, but there is a public feel to them. There are also many examples of goods that are quasi-public because of their externalities—their effects on third parties not directly involved in the market transactions involving the goods. Energy production and, to an even greater extent, energy consumption are cases in point. Another is chemical production with the pollution of air and water. Clearly this has externalities.
Applied biomedical research has aspects of a public good as well as aspects of a quasi-public good. Knowledge concerning research related to a particular drug or device can be appropriated up to a point. It is excludable within limits and it is rival within limits. Clearly one can keep this kind of information secret and benefit from it in a marketplace, and many medical device companies make their living without patenting by keeping secret how their devices are produced. In some such cases making the information available would broadly benefit society, leading to the advancement of other knowledge. Keeping knowledge private causes a loss of efficiency, but we tolerate this loss for the gain that is created by the incentives for innovation resulting from the opportunity for economic gain.
The purpose of patent law is to mitigate the efficiency loss. The critical feature of patent law is that in order to get a patent, one must reveal the science and practice that led to the patent. To obtain exclusivity, the monopoly that is granted by the government requires making public the
information underlying the patent. That makes scientific progress based on protected information possible, while individuals enjoy economic fruits of innovation.
In the course of this workshop’s discussions of large private clinical databases, some of the examples used are of groups that have made public the data they collect available to third parties essentially free of charge, usually out of altruism. That is wonderful, of course, but as a society we have not organized ourselves around altruism as a guarantee of any particular outcome. The real-world, large clinical databases have an aspect of a quasi-public good because they are not pure public goods in any sense. They are definitely excludable. Kaiser could exclude others from the use of their database, as could my own institution, the Partners Health System. These data create opportunities for private gain. The data create competitive advantage by enabling organizations to learn from their experience, perhaps to achieve better outcomes than their rivals; for example, they may learn how to treat a certain disease better. Organizations might be willing to sell clinical information, but are probably not sharing information for free. This is the equivalent of using trade secrecy for medical practice, and it is possible today.
As with applied research, there is a nonrival aspect to such information. In a local market, it is true that people compete with others on a new treatment for diabetes or coronary artery disease; however, someone in Singapore probably could not compete with me, and there might be enormous gains to sharing the knowledge with people in Singapore. When discussing large clinical databases, the fact is that the marginal cost of using the database is virtually nothing. The data runs and bytes of information are there whether used or not. They are not used up.
The principal questions for this discussion concern what to do with privately maintained databases that have private costs and value: databases, in other words, that given parties will neither construct nor share out of altruism, but for which large externalities exist. Therefore, in effect, a way must be found to realize these benefits without losing the incentive to put the database together.
Also relevant to this discussion is the existence of another type of less controversial informational public good. Data found at the NIH, for example, or developed through the National Health Interview Survey or National Census represent situations where the taxpayer has paid for the information to be collected. The data may not be very useful by the time they actually move into the public domain, but eventually they become available. Restrictions are placed on such data—for example, for national security purposes, not all defense-related data are public. Additionally, at certain times, making data available to the public is inefficient. The Bayh-Dole Act of 1980 was meant to remedy underuse of results of publicly funded research when there was no way to privatize the resulting intel-
lectual property. The legislation sought to encourage, by creating private incentives, the use of publicly developed information.
In general, there are two solutions to determine whether information is a quasi-public good or a public good. The first solution is to increase the appropriateness or excludability of information. We have used patents and copyrights to do that. The second is to have the government produce the good in question. NIH and NSF are examples of those. In closing, we need to acknowledge that this is not going to be simple. Joseph Stiglitz, who won the Nobel Prize in economics, recently wrote this about public goods: “The concept of intellectual property … is not just a technical matter. There are judgment calls and trade-offs, with different people … affected differently by alternative decisions…. In practice, decisions are made on a case-by-case basis.”
CHARACTERISTICS OF THE MARKETPLACE FOR MEDICAL CARE DATA
William Crown, Ph.D.
President, i3 Innovus
This paper will consider the various sources of medical and prescription drug data that are available to support real-world safety surveillance and other types of evidence-based medicine. It will consider why these databases are initially constructed, the implications this has for their use as research tools, and their commercial applications. The paper will conclude with some thoughts about how it might be possible to construct a data asset that would represent the broad experience of patients from several national databases.
Although we often lament the inadequacies of research databases in the United States, we are data rich compared with most other nations. We have national probabilistic surveys (e.g., National Medical Expenditure Survey [NMES]/Medical Expenditure Panel Survey [MEPS]; Medicare Current Beneficiary Survey [MCBS]; Surveillance, Epidemiology, and End Results [SEER]; National Long Term Care Survey [NLTCS]; and National Health and Nutrition Examination Survey [NHANES]); hospital discharge data from payers (e.g., Healthcare Cost and Utilization Project [HCUP]/National Immunization Survey [NIS]); pharmaceutical claims (e.g., drug-switch data from IMS and Wolters-Kluwer); linked enrollment; medical and drug claims databases from commercial health plans and large self-insured employers; and combinations of such databases assembled and made available in the form of commercial databases by data aggregators such as Ingenix, Medstat, and Pharmetrics. In addition, there are a variety of government databases, including state Medicaid files (Medicaid Statistical Information System [MSIS] and State Medical Research Files [SMRF]) and the Medicare
5 percent sample available from the Centers for Medicare & Medicaid Services (CMS). Integrated medical claims, prescription drug data, and enrollment information are also assembled by the Department of Defense. Although not necessarily available to outside researchers, electronic medical record (EMR) databases exist for several health plans. Large physician practices also frequently have such data and, as a by-product of providing EMR software, several vendor organizations have built aggregated EMR databases. Finally, numerous patient registries follow patients longitudinally if they have a given condition or have been treated with a particular therapy. This is not an exhaustive list, of course, but it provides a sense of the breadth of data available in the United States (Box 4-1).
|
BOX 4-1 Sources of U.S. Medical Care Data
|
The national probabilistic surveys and, to a lesser extent, the disease registries are probably the only types of data in our list that are collected specifically for research purposes. We end up using the other types of data for research, but that was not their original purpose. Although voluminous for their service types, the large inpatient databases such as HCUP and the NIS, as well as the prescription drug databases from organizations such as IMS and Wolters-Kluwer, typically are not linked to other data types such as outpatient medical claims. As a result, they are not as useful for most questions regarding safety surveillance, comparative effectiveness, or evidence-based medicine.
My focus here is on the linkage of drug data with medical claims because those sources provide the most comprehensive view of drug treatment or treatment of a patient, whether it is with a procedure or with a pharmaceutical, and then capture all the other healthcare uses of those patients. This is also true with respect to medical records in certain settings (staff model health maintenance organizations), and not necessarily true in other settings (e.g., specialized oncology or cardiovascular clinics).
A variety of sources of linked medical and drug claims data are available. Large commercial health plans and employers often have such data, but for their own systems. There are companies that provide data aggregation services, pooling data from multiple sources, such as health plans and employers. These organizations reformat and standardize the data and feed back to the contributing sources information on healthcare use and benchmarking. Sometimes they also measure correspondence with practice guidelines. Data aggregators also provide similar services to government agencies. For example, for many years CMS has funded the development of state Medicaid databases (tape-to-tape, MSIS, and SMRF) that combine longitudinal deidentified data on beneficiary enrollment, medical claims, and drug claims. Similarly, CMS has historically built linked inpatient and outpatient claims datasets for the entire Medicare population and made a 5 percent sample of these files available to researchers.
With a few notable exceptions, the kinds of rich, longitudinal data that we have in the United States either do not exist or are not accessible to researchers in other parts of the world. Examples of what is available include the Nordic registries in Norway, Sweden, and Finland. Probably the best known research database outside of the United States is the United Kingdom’s General Practitioner Research Database, an outpatient encounter database. In addition, the Saskatchewan data in Canada are similar to U.S. claims data.
The federal government, actuarial consulting firms, academic researchers, and pharma are among those who license commercial U.S. research databases. Claims aggregators spend literally hundreds of millions of dollars entering these data, pooling them, standardizing them, and trying to turn
them into something useful. It is easy to underestimate what a big job that is. Consider, for example, that there is no such thing as a hospitalization in a claims database—all you have is many events happening in the hospital. Every encounter generates a claim. You have to figure out what constitutes a hospital stay, when the person was admitted, and when he or she was discharged, then roll up all the events that take place between the dates of admission and discharge and, in essence, create a hospital stay. Researchers have to cull bad information (e.g., men who show up as having had hysterectomies). It takes a lot just to process the volume of claims information in such databases even when the format is similar. One might think that data from commercial health plans would be formatted in similar ways, but they actually have different formats and different record layouts. Data aggregation is further complicated when you start thinking about pooling across different data sources. For example, how do you effectively combine information from different health plans, where one plan has fee-for-service dollar amounts attached to each service provided and another plan is fully capitated and only the service encounters are recorded? Similar issues arise in the pooling of medical records data across multiple sources when these sources use different medical record systems. The complexity of pooling claims data with medical records data is even more complicated. In short, an enormous amount of effort and considerable financial investment are required to develop large databases that pool information across multiple sources.
After putting all this effort into creating these databases, it is not surprising that claims aggregators commonly create deidentified research databases that they then license to third parties. They license the data to the federal government and to actuarial consulting firms that use the data to develop benefit designs. They also license the data to academic researchers, generally at reduced rates. The largest market for these commercially licensed databases undoubtedly is pharma, which uses the data for a variety of purposes, including outcomes research, safety monitoring, tracking market trends, and many others.
In terms of content, the standard medical claims database includes enrollment information and pharmacy, physician, and facility claims (Figure 4-1).
These data elements are linked together via a unique member ID. This is extraordinarily rich information in one sense; in a health plan context, it captures every interaction with the healthcare sector reimbursed by the patient’s insurance—every procedure and date of service, diagnosis, prescription drug filled, use of the emergency room or hospital, and so forth. By rolling all of this information together for each plan member, one can create episodes of care and can follow patients longitudinally in the data, collecting all the information about adverse events, total healthcare use, and more. Of course, all of this is subject to drawbacks given that these data
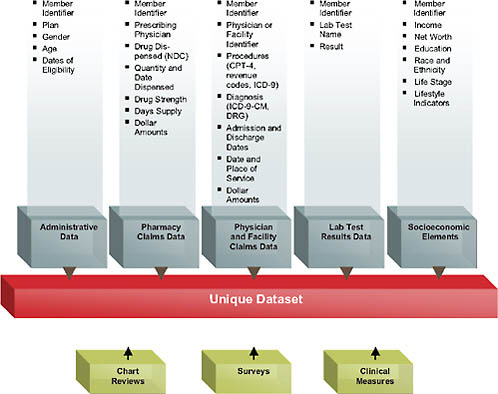
FIGURE 4-1 Data availability in a large health plan.
were never intended for research purposes, so there are inherent pitfalls, such as falsely inferring causality or erroneous coding. Depending on the database, there may also be information on laboratory test results or the social demographics of patients. The addition of sociodemographics such as income, net worth, education, self-reported race/ethnicity, and so forth represents an attempt to further enhance the data that are typically available just from the administrative claims and to try to find additional sources of variation and healthcare use that one wouldn’t be able to observe from the health claims themselves.
The discussion thus far has focused on deidentified databases. However, in certain situations, such as in large health plans or physician practices, there is also the possibility to access protected health information (PHI), under Institutional Review Board (IRB) approval, to abstract medical charts and conduct surveys of the patients related to reasons for medication behaviors and health-related quality of life. Those data can then be combined with the administrative data already captured for these patients in the system. For example, when patients are found to be switching medications, it
is always possible to try to analyze this move with deidentified data, looking at factors such as changes in benefit design on subsequent drug switches. However, the real reasons for the switching behavior may not be observable in the claims data. A patient may discontinue an antihypertensive drug because he or she feels no direct physical evidence showing the drug is effective in lowering blood pressure. Alternatively, the patient may not like the idea of being dependent on a drug, may be concerned about side effects, or may they think the drug is not really working. In short, a variety of reasons for behaviors cannot be observed in the claims data and can only be gathered from the patient. Similarly, to fully understand behaviors of physicians, it is necessary to interview them.
Large retrospective claims databases can be particularly useful for safety signal detection. However, because of a variety of issues about the reliability of diagnostic coding in such databases, it is desirable to have access to medical records for the patients represented in the data. Again, this requires access to the PHI.
Aside from data quality issues themselves, there are challenges in drawing reliable inferences about cause and effect from observational data of any sort. Nonetheless, with current statistical methods, we can do a lot with observational data to control for confounders. Moreover, these data represent the real world, as opposed to the carefully controlled settings of clinical trials, which typically cover only small, carefully selected patient populations and therefore do not necessarily represent the patient populations that ultimately are going to use the drug. Also, follow-up periods are often short.
From the standpoint of forecasting what is going to happen in the real world, there are at least as many dangers in the use of clinical trials data to predict real-world outcomes as there is danger in inferring cause and effect from observational data. At least in the latter case, we observe real-world outcomes in actual patient populations using the drug. Both types of information have a role. Randomization enables reliable statistical inferences about cause and effect to be drawn for the patient population in the trial. Real-world observational studies allow us to see what transpires in actual clinical practice.
From the standpoint of payers, one issue from a health economics standpoint is establishing the value of pharmaceutical treatments and other interventions. This is particularly the case given that so many of the new products emerging from clinical development programs now are biologics, with very high price points, 10, 20, 30, or even 100 times the price of existing conventional pharmaceuticals. In many countries (especially northern Europe, Canada, and Australia), coverage and reimbursement of new therapies has been predicated on the demonstration of relative cost effectiveness. However, estimates of comparative cost-effectiveness have generally combined efficacy and safety data from clinical trials with real-
world cost data from other sources. The reality is that historically we have not had good data from clinical trials regarding effectiveness in real-world patient populations in order to figure out relative cost-effectiveness. This is going to drive a need for real-world data collection—going beyond retrospective data to collect clinical data that we typically do not have in these administrative databases to get the clinical endpoints about effectiveness. It is a significant challenge to collect information about patient-reported outcomes—in particular, health-related quality of life.
Where are we headed? In terms of the trade-offs between a pooled mega-database and pulling data from different data aggregators, the need is growing for a mega-database that would pull data from different health plans, the Department of Veterans Affairs, Medicare, and so forth. Then we would need to standardize the data, and create a public good that will be available for research, for cost-effectiveness studies, and for real-world drug safety to be able to understand guideline compliance of physician practices and other issues. There are some real challenges (Box 4-2).
|
BOX 4-2 Mega-Database or Distributed Network?
|
One of the biggest challenges is the need to deduplicate the data. For example, in order for the database to be valuable, it is necessary to recognize that person A—who originally starts out as an enrollee with United HealthCare and then 6 months later switches to Aetna—is the same person. That is a big challenge. Conceptually, the simplest way to accomplish deduplication is to pool the data. In terms of statistical analysis of rare outcomes, this would result in huge sample sizes. As a consequence, the ability to follow large cohorts of people longitudinally would provide researchers with the statistical power to detect extremely rare events that could not be detected, or certainly not in a statistically significant way, within smaller subsets of the data. There are some real advantages to that.
As discussed earlier, however, a significant challenge to constructing a pooled mega-database for the purposes of evidence-based medicine is the cost of building and maintaining such a database. Even the construction of a pooled database built from similar data streams (e.g., commercial health plans) is a huge task. Pooling data from sources with very different data structures (e.g., medical claims and EMRs) would be a monumental effort.
Institutions contributing information to a pooled database generally have a variety of concerns. For example, although health plans generally have an interest from a public health standpoint in contributing their data to a pooled database, they may have concerns about the potential to inadvertently provide their competitors with information on charges and payments for different types of services, benefit design, and more. Health plans are also very concerned about protecting patient confidentiality. Any time patient-level data (even though they are deidentified) are made available to third parties, the potential exists for reidentification of a patient either intentionally or by accident.
Finally, data aggregators who have invested tremendous amounts of money in creating their databases will be hesitant to turn them over to a pooled database unless they have a commercial incentive that enables them to recoup the value of the investments they have made in constructing these databases.
For all of these reasons, we need an alternative to the pooled mega-database model. One alternative is a distributive research network. Databases already exist in different health plans that use a common EMR provider. As a result, the data are fairly similar and could be combined. Similarly, large commercial health insurance databases already exist that link patient enrollment, medical claims, and drug claims. Rather than trying to pool everything in one massive file, these large subsets of data could be kept as separate nodes in a distributed network. It would be possible to conduct research within the databases represented by each of the nodes through a standard research protocol, and then to pool the results
afterward. Such an approach is potentially a way to address the possible concerns of data contributors. The chief disadvantage of this approach is the patient deduplication issue, which, of course, is a major strength of the pooled mega-database model.
One issue currently being considered by the Food and Drug Administration (FDA) Sentinel Network is exactly this issue—how to develop methods either with restricted databases or with IRB approval for the deduplication function to pool data across multiple sources. Although the FDA is interested primarily in drug safety, it seems clear that the Sentinel Network might also meet the objectives of a public good database for the purposes of evidence-based medicine and comparative effectiveness research. It is fair to say that broad interest is coalescing around the virtues of creating a public database to support evidence-based medicine and safety research. We will get there a lot faster if we recognize the practical challenges raised by alternative data models, as well as the issues and concerns of all the stakeholders.
LEGAL ISSUES RELATED TO DATA ACCESS, POOLING, AND USE
Nicolas P. Terry, LL.M.
Chester A. Myers Professor of Law, Codirector, Center for Health Law Studies
Saint Louis University Law School
Introduction
The legal system enters the “public good” debate because it reflects and thus perpetuates the current “excludability” state of clinical data with property and intellectual property models. Furthermore, market exchanges or shifts to public good “nonexcludability” face legal barriers (e.g., privacy, confidentiality, and security) that are designed to reduce or eliminate negative externalities suffered by data subjects. This paper identifies the major clusters of legal rules that create barriers to clinical data morphing into a public good: property or inalienability rules, federal–state disconnects, and evolving data protection models. The paper concludes with some observations on approaches to resolving the current excludability rules and, somewhat counterintuitively, argues that a more rigorous data protection model will be required as a prerequisite for greater access to patient data.
Three clusters of legal issues potentially create barriers to the adoption of a public good model for clinical data. They are described herein as property rules, federal–state vectors, and data protection. However, to understand them requires some initial observations regarding the legal sys-
tem and its historically unsatisfactory interaction with health information technologies (HITs).
First, in this debate the legal system is neither a spectator nor an independent actor. Legal models enter the equation because they reflect and so perpetuate the intended or perceived current state of public policy. The frame for “public goods” analysis begins with the recognition that they exhibit the characteristics of “nonexcludability” and “nonrivalrous” consumption (Cowen, 2002). These characteristics may cause market failures in information properties because they encourage free riders and can create positive externalities (Cowen, 2002). As Yochai Benkler explains, we apply legal protection to information properties because of our willingness “to have some inefficient lack of access to information every day, in exchange for getting more people involved in information production over time” (Benkler, 2006). That is, we “trade off some static inefficiency to achieve dynamic efficiency” (Benkler, 2006). By enabling excludability regimes (via property or, more typically, intellectual property laws), we seek to promote a dynamic efficiency model. Today, the legal system considers itself as being under a mandate to create or support structures that treat clinical data as a private good (NRC, 2003c). It follows that any move away from clinical data excludability to public good status must deal not only with the technical legal barriers also with their economic underpinnings.
Similarly, exchanges between data stewards that facilitate nonrival consumption of information properties (including interinstitution sharing of records data for outcomes research and the sale of clinical data for marketing purposes) or novel public goods exceptions to nonexcludability regimes may impose negative externalities on the data subjects. Data protection laws are designed to eliminate or reduce these externalities.
Second, the legal system is rife with uncertainties. To the befuddlement of “real” scientists, lawyers seems to spend less time providing efficient “yes/no” answers, and far more billable time delivering annoyingly inefficient “maybe” responses (Solum, 1987).1 Consider some of the real or perceived barriers to HIT and how many physicians have been discouraged from improving access to care by using telemedicine because of uncertainties about the impact of state licensure laws, the standard of care, or the application of malpractice insurance (Terry, 2004). This sense of uncertainty or indeterminacy is increased by the legion of “legacy laws,” such as records laws predating electronic clinical data collection and the potential for data mining of records to improve outcomes and effectiveness.
Overall, it is tempting to recall a well-known phrase coined by an Australian judge discussing the interaction of law and medicine: “Law,
marching with medicine but in the rear and limping a little” (Windeyer, 1970). As discussed below, these tendencies toward indeterminacy are exacerbated by the relationship between federal and state regulatory and statutory models. Furthermore, interlocking problems of indeterminacy, outdatedness, and overlapping or contradictory legal regimes applied to HIT and health information exchange (HIE) reinforce the sense of unintended consequences. Such consequences range from the technical (e.g., regulatory safe harbors notwithstanding, stark and antikickback barriers to market transactions between providers to accelerate the adoption of e-prescribing and electronic health records, or EHRs2) to the conceptual (e.g., the Health Insurance Portability and Accountability Act’s, or HIPAA’s, compliance-based, provider-centric data protection model that tends to confirm the proprietary, or private goods, nature of clinical data by encouraging providers to wall off the data as “theirs” rather than treat it as held in trust for their patients or the public).
Property/Inalienability Rules
Ownership of Medical Records
State law continues to dominate the records space. Licensure laws create duties of accuracy, completeness, legibility, and timeliness (Nev. Rev. Stat., 2008; N.M. Stat., 1978; Wyo. Stat. Ann., 2005), while other state laws regulate the alteration of records (Nev. Rev. Stat., 2008) or their retention (La. Rev. Stat. Ann., 2001; N.M. Stat. Ann., 2008). Providers who breach these standards may face disciplinary sanctions (Nieves vs. Chassin, 1995; Schwarz vs. Bd. of Regents, 1982). State malpractice principles weigh in on some questions about the sufficiency of records (Thomas vs. United States, 1987), while the emerging tort of spoliation of evidence increasingly deters alteration or destruction of records (Pikey vs. Bryant, 2006; Rosenblit vs. Zimmerman, 2001). Increasingly, national accreditation standards such as the Joint Commission on Accreditation of Healthcare Organizations (JCAHO) rules3 and federal Medicare standards (CMS, 2005) are entering the records space by mandating record retention rules.
This mixed legal basis carries over to the question of property rights in clinical data. It is generally accepted that doctors own the medical records they keep about patients (Regensdorfer vs. Orange Regional Medi-
cal Center, 2005; Waldron vs. Ball Corp., 1994). Statutes in some states (Fla. Stat., 2009) and practices endorsed by the American Medical Association (AMA, 1983) confirm this position. State statutes have extended this model to hospitals and their ownership of records (Fla. Stat., 2009; Tenn. Code Ann., 2004).
Arguably, the position on ownership of records is slightly more complicated. Although patients may not own the actual paper records, they may have some ownership rights in the information contained in the records (although this position has been rejected by the High Court of Australia [Breen vs. Williams, 1996]). The federal HIPAA confidentiality rule sought to be agnostic on the issue, purporting to govern only use and disclosure of certain records. However, HIPAA grants quasi-property interests to patients in their records by recognizing rights of access (CMS, 2003a) and modification (CMS, 2003b).
Although it did not address the issue of property rights in records or other clinical data, the well-known case of Moore vs. Regents, University of California,4 is a useful starting position from which to predict the likely judicial attitude to property-based arguments by patients (Moore vs. Regents, University of California, 1990). In Moore, the Supreme Court of California held that a leukemia patient did not have a property-based interest in his removed tissue from which the defendant established a potentially profitable cell line. The court reasoned that the extension of the conversion tort, by which such interests may be protected, would potentially “punish innocent parties” (downstream researchers) or “create disincentives to the conduct of socially beneficial research.”5 However, another reason for the conclusion flowed from the same court’s recognition of causes of action for breach of fiduciary duty or lack of informed consent that could provide remedies against the physician. Moore, therefore, begs the question of whether a physician or hospital should obtain consent from a patient regarding the use of the patient’s data beyond the point of care. Similarly, would a fiduciary duty be breached if a provider sought to monetize data extracted from a record?
One final property-related complication regarding EMR may require attention. Some EMR technology providers (the owners of the enabling software platform) may retain proprietary rights in that technology and so to an extent the records built on that platform (Harty-Golder, 2007). In most cases this issue should be resolved in advance by licensing agreements between the healthcare provider and the software vendor. However, as
interoperability (e.g., a standardized export format) increases, the importance of this issue should diminish.
IP and Trade Secret Protections
In most situations, and as is generally the case with information properties, the legal system will treat the content of records and derived clinical data as more abstract properties that potentially are protected by the law of intellectual property (IP). Clinical data claims for IP protection could arise under patent or copyright laws. In practice, however, related protections under the law of trade secrets may be more important.
In 2007 the Supreme Court took some initial steps away from limitless patentability by tightening the requirement of “obviousness” as applied to patent claims (KSR vs. Teleflex, 2007). Notwithstanding, there is authority that medical records software is patentable (Micro Chem., Inc. vs. Lextron, Inc., 2003), although it is doubtful whether that status extends to the actual record created using the software.
The law of copyright protects most written works. However, records data or derived clinical data may be viewed as merely factual, and copyright law does not protect facts, including medical and biographical facts (N.Y. Mercantile Exch., Inc. vs. Intercontinental Exchange, Inc., 2007). In limited situations, the question of copyright protection might be satisfied by the way the facts are arranged (Inc. vs. Chinatown Today Pub. Enterprises, Inc., 1991; Matthew Bender & Co. vs. West Publ. Co., 1998) or by their supplementation with creative work (CCC Information Servs. vs. MacLean Hunter Mkt. Reports, 1994; Harper & Row, Publishers, Inc. vs. Nation Enterprises, 1985). Furthermore, although facts themselves can never be the subject of copyright, their organization may be protected as a “compilation” (United States Code, 1992). In Feist Publications, Inc., v. Rural Telephone Service Co., a case dealing with lists of subscribers in a telephone directory, the Supreme Court limited copyright protection for nonoriginal, noncreative works (Feist Publications, Inc. vs. Rural Telephone Service Co., Inc., 1991). Notwithstanding, the creativity threshold is quite low. The Feist court famously held that “‘Original,’ as the term is used in copyright, means only that the work was independently created by the author (as opposed to copied from other works), and that it possesses at least some minimal degree of creativity” (Feist Publications, Inc. vs. Rural Telephone Service Co., Inc., 1991). Thus, it has been stated, “a compilation of preexisting facts … can still meet the constitutional minimum for copyright protection if it features original selection, coordination or arrangement of those facts” (Victor Lalli Enterprises, Inc. vs. Big Red Apple, Inc., 1991).6
Traditional intellectual property systems protect inventors or authors with a term-limited monopoly when they market their expressions or inventions. It is as likely, however, that most “owners” of records or derived clinical data will seek to protect them by keeping them private or “secret.” Indeed, the application of data protection rules, discussed below, essentially mandates “secrecy.” Looked at this way, patient records and derived clinical data are more analogous to customer lists and other business records (Unistar Corp. vs. Child, 1982). Therefore, data with economic value that are kept secret and reasonably secure may be treated as trade secrets under state law.7
As in the case of customer lists, patient records are often tangentially protected through contract. Thus, when doctors become employees, shareholders, or members of a medical practice, they often enter a contractual agreement stating that records are owned by the practice and containing a restrictive covenant not to compete if they leave the practice. The terms of these contracts (particularly the covenant not to compete) are often not enforced by the courts when to do so would adversely affect the public interest in patient choice and physician mobility (Ohio Urology, Inc. vs. Poll, 1991; Valley Med. Specialists vs. Farber, 1999).
The stewards of clinical data (again, in part motivated by data protection laws) likely will protect their data with security and related rights management systems. Those who circumvent these protections may face actions brought under the Computer Fraud and Abuse Act (United States Code, 2009) or the Digital Millennium Copyright Act (United States Code, 1998).
An Escalating Federal-State Legal Vector
Traditionally the regulation of medical records has been a creature of state law. Given the national initiatives for HIPAA transactions, privacy and security, and HIE, it should follow that the legal environment would be a cohesive federal one. That model seems increasingly unlikely. To take just the issue of privacy, the federal HIPAA code is less than comprehensive, leaving unprotected large swathes of patient data. Yet, unlike its security code, HIPAA’s Privacy Rule does not preempt more stringent state protections (a phenomenon leading to what is known as the HIPAA floor). Therefore, if anything, the post-HIPAA years have seen an increase in state legislation impacting HIT. Even in the case of HIE, an area once considered purely national policy, states have started to address incentives and disincentives as federal legislative activity and funding have slowed.
State Restrictions on Data Collection, Processing, or Security
Several states have clinical data protection legislation that is more protective of patient data than is HIPAA. The most likely area for additional protection is to apply data protection to a more expansive list of custodians than HIPAA’s narrow “current entities” model. A few seek to go considerably further. For example, a recently defeated New Hampshire bill (House kills medical privacy bill, 2008) would have increased data protection considerably beyond HIPAA protection standards by restricting data use to the point of care, thereby potentially outlawing many marketing and research uses (Guay, 2008; U.S. House of Representatives, 2008).
Other state legislation operates on the periphery of HIPAA. For example, an Arizona bill would prohibit non-U.S. outsourcing of medical data processing absent patient consent,8 while several states (Georgia, 2008; South Dakota, 2008) are set to join the ranks of those controlling data acquisition through subcutaneous Radio Frequency Identification (RFID) tags.9
Increasingly, states regulate the use of either individual or aggregated (even de-identified) clinical data. Thus, a majority of states have legislation prohibiting employment discrimination based on genetic information.10 A minority of states go farther and prohibit the genetic testing of employees (NCSL, 2008c). Most states apply a similar model to applications for health insurance (NCSL, 2008a), and some states have extended that to disability and life insurance (NCSL, 2008b). As is the case with health privacy, much of this activity in the states is a function of Congress’s apparent inability to pass comprehensive legislation dealing with the issues.11
Recent legislation in New Hampshire (N.H. Rev. Stat. Ann., 2007), Maine (Maine State Legislature, 2005), and Vermont (Vermont, 2007) has placed varying levels of restrictions on the secondary uses of pharmacy information (New Hampshire, YEAR; MRSA, 2007). In the aftermath, pharmacy data aggregators have successfully challenged such legislation in the federal courts for violation of protected commercial speech principles (IMS Health vs. Sorrell, 2007; IMS Health, Inc. vs. Ayotte, 2007; IMS
|
8 |
See generally Nicolas P. Terry, Under-Regulated Healthcare Phenomena in a Flat World: Medical Tourism and Outsourcing, 29 W. N. Eng. L. Rev. 421-72 (2007) and H.B. 2401. |
|
9 |
See, e.g., Cal. Civ. Code § 52.7. |
|
10 |
For example, New Jersey law requires: “No person shall obtain genetic information from an individual, or from an individual’s DNA sample, without first obtaining informed consent from the individual…. ” N.J. Stat. § 10:5-45. However, the statute does not apply to “anonymous research where the identity of the subject will not be released” N.J. Stat. § 10:5-45 (a)(5). |
|
11 |
The Genetic Information Nondiscrimination Act has twice been approved by the House (in 2007 and 2008). See generally National Human Genome Research Institute, Legislation on Genetic Discrimination, http://www.genome.gov/10002077#2. |
Health Corp. vs. Rowe, 2007). Notwithstanding this unfriendly reception, Maryland introduced H.B. 50 and Washington is considering similar legislation. An Arizona bill may go even farther in that it extends the prohibition to commercial uses of “records relating to prescription information that contain patient-identifiable and prescriber-identifiable data.”12
Finally, breach notification statutes demonstrate one of the most rapid explosions of regulation in the privacy-confidentiality-security constellation. California passed the first such statute in 2003. By 2008, with 9 often-conflicting bills languishing in various congressional committees, 39 additional states had passed similar legislation requiring a data steward to inform data subjects when their data have been compromised. Most of these statutes apply only to financial identity theft. However, a growing number also seem to apply to cases of medical identity theft, only granting providers a safe harbor when they are subject to and in compliance with HIPAA.13
State Initiatives in HIT and HIE Policy
In February 2008 the Government Accountability Office (GAO) reported that there is still no national strategy for HIT (GAO, 2008). This echoed the previous month’s conclusion by the California Healthcare Foundation that “The President’s HIT adoption agenda has raised consciousness about HIT and EHRs. Beyond the laying of a conceptual foundation, however, there is as yet no measurable increase in HIT or EHR adoption.” Dealing with the specifics of the Administration’s proposed National Health Information Network (NHIN), the Foundation concluded, “[t]hough it represents a worthy goal, the NHIN is impractical and cannot be implemented” (Fried, 2008).
As they observe the failure of high-profile regional health information organization (RHIO) projects (Miller and Miller, 2007), state actors may now perceive that the Office of the National Coordinator for Health Information Technology (ONCHIT) lacks a coherent, sustainable strategy or, at least, that its flat budgets confirm there will be no centralized funding that goes beyond demonstration projects. Into this real or perceived vacuum, some states are floating their own “carrots” and “sticks” designed to provide new impetus toward HIE projects. Recent state initiatives (few of which have met with legislative approval) have included the funding of a pilot program for clinical data sharing (West Virginia, 2008a), mandating the use of EMRs (Indiana, 2008), prohibiting providers from buying EMRs
that lack interoperability (New Jersey, 2006), and granting providers a state tax credit to offset investments in EMRs (West Virginia, 2008b).
Overall, the Agency for Healthcare Research and Quality’s (AHRQ’s) 2007 Health Information Security and Privacy Collaboration Privacy and Security Project report (AHRQ, 2007) noted more than 300 current state initiatives relating to HIT and HIE. As these initiatives continue and state data-related laws run faster and deeper than federal protections do, unraveling them and finding agreement on a federal model for data protection and sharing will become immeasurably more difficult. At the same time, such local activity steadily increases legal indeterminacies and risks for interstate data stewards and processors.
Data Protection
The need to protect the privacy of health information is broadly accepted, yet the mechanisms for its assurance continue to be controversial. Pre-HIT protection for medical records was formally achieved with a patchwork of state statutory and common-law rules. In practice, however, the fragmentation of paper records across innumerable data silos provided the greatest protection. Electronic aggregation of records, powerful data-mining technologies, and a growing market for secondary uses have exponentially increased the negative externalities faced by data subjects (Terry, 2008). As is well known, in 2000 the federal government sought to address the costs to data subjects imposed by the HIPAA transactional standards with apparently comprehensive privacy and security regulations (HHS, 2000). In the years that followed, innumerable critical questions have been raised about the HIPAA codes, primarily regarding the costs (to data custodians), reach, and enforcement of the privacy regulations. These questions have multiplied14 since President George W. Bush announced the federal EHR initiative (House, 2004).
With regard to data protection, the clinical data as a public good question requires a threshold issue to be addressed. HIPAA only applies to identified clinical data (HHS, 2002a). If a public good use of clinical data to improve outcomes and effectiveness research only contemplates the use of deidentified data, is there any substantial implication of data protection?
The short answer is that legal indeterminacies surrounding deidentification, variations in institutional data policies and practices, and uncertainties about the contemplated “public” secondary uses place data protection front and center as a potential barrier to outcomes research. The NCVHS has noted that some data custodians erroneously believe they have satisfied the
deidentification safe harbor with anonymity or pseudoanonymity. Equally, some highly ethical (or risk-averse) providers use anonymity or pseudoanonymity when they could legally use identified data.15 Furthermore, business associate agreements frequently lack clarity on the requirements for adequate deidentification, while complications arise from HIPAA’s “Limited Dataset” Safe Harbor for research, public health, or healthcare operations and its required data use agreement (NCVHS, 2007). However, perhaps the most difficult challenge regarding reliance on deidentification is the increased use of data in records (e.g., genetic information and geocoding data) that exposes apparently deidentified datasets to reidentification.
The HIPAA Privacy Model
HIPAA’s data protection regulation is technically complex and obstinately opaque. Its basic concept, however, is quite simple—arguably too simple. The model imagines a provider-controlled zone where individually identifiable patient data can flow quite freely (referred to as the “green” zone). In HIPAA-speak this green zone is referred to as “treatment, payment, or health care operations” (HHS, 2002a). There are two regulatory “walls” between the green zone and the “red” zone in which patient data generally should not circulate. First, the HIPAA Privacy Rule includes a general rule that green zone data custodians may not disclose data into the red zone. This is a confidentiality rule, albeit one that HIPAA mislabels as one of privacy (Terry and Francis, 2007). Second, the HIPAA Security Rule imposes technical and process obligations on data stewards to build a security wall that impedes those in the red zone (e.g., hackers) from accessing data stored in the green zone. Using regulated contracts, health insurers and providers may extend the green zone to include their “business associates” (e.g., law firms) (HHS, 2002b).
This HIPAA data protection model has several important (and unsatisfactory) properties. First, as follows from the description above, the protective model is almost exclusively disclosure-centric. That is, HIPAA does not limit or regulate collection of data. Thus, there are no controls over what or how much data can be collected, for example, by reference to a proportionality rule. Similarly, there is no requirement that patients must opt in or may opt out regarding the collection of certain types of data (e.g., psychiatric or gynecological records). Furthermore, HIPAA does not place any restrictions on secondary uses of data, other than simple patient consent that is mainly oblivious to the informational and bargaining asymmetries between the parties (HHS, 2002c). Additionally, for example, there is no prohibition
(consent notwithstanding) on the sale of clinical data for commercial purposes (that would be described as an inalienability rule). Finally, the HIPAA model shows little respect for its own red–green zone boundaries because it features broad exceptions (e.g., public health, judicial, and regulatory) to its protective model that do not require patient consent to data processing and that are susceptible to “function creep” (HHS, 2002e).
Personal Health Records and Consumer-Directed Health Care
Perhaps the greatest flaw of the HIPAA data protection model is how quickly it has been rendered wanting by new technologies. Designed to reduce the negative externalities imposed on data subjects in HIPAA transactions, it became obvious that the model was flawed in its applicability to emerging interoperable health record systems (Terry and Francis, 2007). Now, the emergence of personal health record (PHR) models raise far more serious issues. In contrast to the more familiar charts, paper records, and electronic medical records maintained by healthcare providers, PHRs are medical records created and maintained by patients. PHRs are provided by the patient’s health insurer, healthcare provider, or employer, or even on an independent, commercial site potentially supported by advertising (collectively, PHR providers). However, HIPAA only applies to a relatively narrow range of healthcare entities (HHS, 2002d) that engage in certain types of transactions (HHS, 2002f). It is highly unlikely that most PHR providers will be directly subject to HIPAA data protection rules, although some state privacy statutes may apply and the Federal Trade Commission could exert some general control over PHR providers that promulgate their own privacy policies.
Currently, only 2 percent of the population uses PHRs (California HealthCare Foundation, 2008). However, robust growth is likely if the national EHR initiative slows and as major technology companies such as Microsoft, Google, and Inuit enter the PHR space (Lohr, 2007).
Working Toward Solutions
Information Property
Arrayed against the IOM public goods goal, the current aggregation of IP and related laws and technologies maintains excludability and so denies public use; what, in a broader context, James Boyle has referred to as “the second enclosure movement” (Boyle, 2003). There are certainly signs that the clinical data enclosure movement already has momentum. Many forthcoming health-quality initiatives, such as pay-for-performance (P4P) or consumer-directed health care (Jost, 2007), that seek to resolve
outstanding market failures in health care are heavily data driven; those who control the data are likely to have disproportionate control over the metrics. The AMA seems to have taken the position that their members should seek to monetize records data (O’Reilly, 2005). Indeed, a member of the AMA Board of Trustees noted, “there is tremendous economic value to the cumulative data in terms of analyzing patterns,” and suggested that control of such data is central to doctors having influence on emerging P4P programs (NRC, 2003b).
Of course, property and IP debates are not new to the scientific community, as evidenced by the worldwide literature on gene patenting and attempts to balance research incentives and public goods arguments (Caulfield et al., 2006; ORNL, 2008). One theme that has emerged in the legal literature is to inquire whether IP rights holders should owe concomitant “public” duties. For example, Patricia Roche and George Annas have called for a comprehensive genetic privacy law that goes beyond the current model seen in state antidiscrimination laws (Roche and Annas, 2001, 2006). Jacqueline Lipton has argued more broadly that proprietary rights in “information property,” while necessary to provide incentives and protect private property, must be balanced by broad new duties placed on rights holders, such as obligations of accuracy, confidentiality, and “an obligation to facilitate scientific, technical, and educational uses of information.”16 Agreement on how to operationalize such an approach has been elusive. Presumably, the IOM or NIH could explore with data rights holders the possibility of publishing clinical data under a creative commons license that permits noncommercial research (NRC, 2003a). Similarly, some form of compulsory licensing model may be possible (NRC, 2003a), although this approach has gained no traction in the gene-patenting arena and policy makers have tended to take the opposite approach in related areas, such as stimulating public benefits by increasing proprietary rights under the Orphan Drug Act.17
As actors seek to find a place for “public goods” considerations at the clinical data table, they must learn from broader (and not wholly successful) experiences recalibrating private and public interests in intellectual property. Of course “[c]opyright protection … is not available for any work of the United States Government,”18 but that does not apply to most federally funded research. Furthermore, the Bayh-Dole Act changed the rules of the game for patent rights flowing from government-funded research.19 More recently, the GAO, in examining contracting issues with
funded researchers, has discussed the tensions inherent in the monetizing of publicly funded research (GAO, 2008). Perhaps predictive of a future public goods regime for clinical data, the NIH has addressed the nature of the results of funded research with a policy addressing data sharing (NIH, 2003) and has required the public availability of manuscripts prepared by funded investigators (NIH, 2008).
Data Protection Models
The HIPAA privacy and health records debates have been marked by a serious disconnect between data custodians and government policy makers on one side and privacy advocates on the other. In the context of the federal NHIN project, the Bush Administration has narrowly framed the privacy–confidentiality issue, merely identifying divergent state laws as impeding implementation. This has been translated into a mandate to replace the HIPAA “floor,” whereby more stringent state privacy protections are not preempted, with existing or reduced HIPAA protections as the new “ceiling” (Terry and Francis, 2007). The issue has even been raised in some tense exchanges between the GAO and ONCHIT. In its June 2007 report on HIT and privacy, the GAO recommended that “The Secretary … define and implement an overall approach for protecting health information” (GAO, 2007). The Department of Health and Human Services (HHS) responded that it already had a “comprehensive and integrated approach for ensuring the privacy and security of health information…” (GAO, 2007). When the GAO pushed back, ONCHIT agreed that an “overall approach” was required and instituted further study.20 Yet, in its February 2008 report on nationwide HIT implementation by the HHS, the GAO noted, “Our recommendation for protecting health information has not yet been implemented” (GAO, 2008).
It may be seen as counterintuitive and as propagating still more legal barriers to public goods access to clinical data, but a stronger data protection model for medical privacy is a necessary predicate for greater sharing of patient data. Patients who lack trust in how data stewards or researchers treat their records will hide information from their doctors. Many of those doctors will perceive HIE as inconsistent with their professional standards of confidentiality or as creating liability “traps,” and either refuse to participate or, if given no choice, reduce or distort their charting (Terry and Francis, 2007). In the words of the NCVHS, “Erosion of trust in the healthcare system may occur when there is divergence between what individuals reasonably expect health data to be used for and when uses are made for other purposes without their knowledge and permission” (NCVHS, 2007).
A system that tolerates a lack of trust and the exposure of patients to discrimination, embarrassment, or stigma (NCVHS, 2007) will face reactions that compromise individual care and distort the data required for outcomes research.
The United States is not alone in confronting this tension between data protection and public utility. For example, a recent report by the New Zealand Law Commission noted, “there remains an outstanding issue as to whether there is a strong enough public mandate for the use of personal health information without consent for research in the public good.” Similarly, a 2007 Canadian study noted very high (89 percent) public support for health quality research, yet only 11 percent of respondents felt no need for notification or consent regarding such research. Only 4 percent of respondents would deny all use, 32 percent would require consent for each use, 29 percent would be satisfied with a broad notification model, and 24 percent wanted notification and opt-out processes (Willison et al., 2007; Woolley and Propst, 2005).
If trust and transparency are the ideals in structuring a data protection model for medical data, what should follow? These ideals reflect patient expectations on how their data are processed and information they require before permitting unexpected uses. Current patient expectations likely are limited to point-of-care and continuum-of-care uses. There is probably also an increasing expectation of data access and use for personal health management (e.g., interoperability of EMR and PHR systems and any necessary processing).
Patients’ expectations are unlikely to include the array of possible secondary uses for their clinical data, including the generation of outcomes and effectiveness research. As the NCVHS has suggested, “secondary use” is “an ill-defined term” that should be abandoned “in favor of precise description for each use of health data” (NCVHS, 2007). Indeed, the Stewardship Framework report identified a variety of such health-related (in contrast to law enforcement or regulatory) uses, including (1) payment; (2) healthcare operations (including internal quality assessment); (3) quality measurement, reporting, and improvement; (4) clinical research; (5) public health research; and (6) sale or barter of the data for commercial uses, including marketing (NCVHS, 2007).
A simplistic data protection model would simply outlaw some or all of these uses, but thereby deny patients the benefits of appropriate uses and resulting research. A more robust yet sophisticated protective model must be able to distinguish between these uses and adjust the responsibilities of data stewards and processors accordingly.
Although not sufficiently granular for our current purposes, the European Union data directive suggests a data protection model that imposes far more powerful obligations on data stewards and “chain of trust” data
processors (e.g., HIPAA’s business associates). It is a model that rotates around a proportionality rule (“adequate, relevant and not excessive”), that applies to both collection and disclosure of data, and that limits the reprocessing of data for purposes incompatible with the original purpose of collection.
Applying a focused version of this model to clinical data, patient expectations would be met by relatively unimpeded use of data for point-of-care and continuum-of-care purposes (a far more restricted green zone). Trust will be further earned by permitting patient opt-out or data sequestering. Patient acceptance of some secondary uses will be more likely secured with strict limitations on commercial uses (a larger red zone). Between these extreme groupings, patient trust about research must be earned through transparency. The more patients learn about the uses projected for their data, are informed of its level of deidentification, and understand the feedback loop whereby outcomes research will improve their own care, the more likely they are to support a broader public agenda. The guarantee of transparency to the patient when data are applied for research is another theme of the Roundtable.
The difficult question, however, is how to implement this more robust data protection model. In its Stewardship Framework report (NCVHS, 2007), the NCVHS did an admirable job in suggesting tweaks to the HIPAA model by calling for stronger guidance, strengthening of business agreements and their parties’ expectations, and calling on the Federal Trade Commission to increase its footprint in areas not regulated by HIPAA (such as PHRs). It is an approach that is perhaps attuned to the current political and legislative realities that apply to the data protection debate. However, it is hard to see how a patchwork of additional protections, particularly when based on a model as flawed as HIPAA, can deliver the robust model that is a predicate to patient-supported outcomes research. The NCVHS also recommended that “HHS should work with other federal agencies and the Congress … for more inclusive, federal privacy legislation so that all individuals and organizations that use and disclose individually identifiable health information are covered by the data stewardship principles inherent in such legislation, including a range of organizations not currently covered by HIPAA” (NCVHS, 2007). This is a difficult and likely unpopular agenda. However, it is difficult to see any alternative if there is to be a long-term accommodation of patient and researcher interests.
In conclusion, in the context of data protection and ownership, and patient expectations, it follows that there are two broad sets of legal barriers to a public goods future for clinical data. The first set of issues is somewhat process oriented. Thus, policy makers and legislators dealing with HIT and HIE issues must be better informed of the technologies and future technologies they seek to regulate to better reduce indeterminacies
and unintended consequences. Equally, few HIT or HIE issues are particularly local or are amenable to local or state legislative solutions. The federal legislative logjam on matters such as genetic discrimination, HIT funding, and effective data protection must be cleared to reduce the barriers posed by an escalating number of state “solutions.”
However, the larger and more substantive barriers are as much a function of underlying policies as their legal transcription. Information properties in data and an inability to agree on an effective data protection model create immensely difficult barriers. These barriers will not be reduced with better legislative or regulatory drafting. Instead, they require a sober appreciation by all stakeholders in the clinical data space that they must support fundamental reforms.
REFERENCES
AHRQ (Agency for Healthcare Research and Quality). 2007. Privacy and security solutions for interoperable health information exchange: Impact analysis. http://healthit.ahrq.gov/portal/server.pt?open=514&objID=5554&mode=2&holderDisplayURL=http://prodportallb.ahrq.gov:7087/publishedcontent/publish/communities/k_o/knowledge_library/features_archive/features/impact_analysis_of_the_privacy_and_security_solutions_for_interoperable_health_information_exchange_project.html (accessed August 20, 2008).
AMA (American Medical Association). 1983. Sale of a Medical Practice. Medical Code of Ethics, E-704. http://www.ama-assn.org/ama/pub/physician-resources/medical-ethics/code-medical-ethics/opinion704.shtml (accessed February 3, 2010).
Benkler, Y. 2006. The wealth of networks: How social production transforms markets and freedom. New Haven, CT, and London, UK: Yale University Press.
Boyle, J. 2003. The second enclosure movement and the construction of the public domain. Law & Contemporary Problems 33.
Breen vs. Williams. 1996. 186 CLR 71.
California HealthCare Foundation. 2008. The state of health information technology in California: Consumer perspective. http://www.chcf.org/documents/chronicdisease/HITConsumerSnapshot08.pdf (accessed August 20, 2008).
Caulfield, T., R. M. Cook-Deegan, F. S. Kieff, and J. P. Walsh. 2006. Evidence and anecdotes: An analysis of human gene patenting controversies. Nature Biotechnology 24(9):1091–1094.
CCC Info. Servs. vs. MacLean Hunter Mkt. Reports. 1994. 44 F.3d 61 (2nd Cir. Conn.).
CMS. 2003a. Access of individuals to protected health information. 45 C.F.R. § 164.524. http://edocket.access.gpo.gov/cfr_2003/octqtr/pdf/45cfr164.524.pdf (accessed February 4, 2010).
———. 2003b. Amendment of protected health information. 45 C.F.R. § 164.526. http://edocket.access.gpo.gov/cfr_2003/octqtr/pdf/45cfr164.526.pdf (accessed February 4, 2010).
———. 2005. 42 C.F.R. § 482.24(b)(1). http://edocket.access.gpo.gov/cfr_2007/octqtr/pdf/pdf/42cfr482.24.pdf (accessed February 3, 2010).
Cowen, T. 2002. The concise encyclopedia of economics: Public goods and externalities. http://www.econlib.org/library/Enc/PublicGoodsandExternalities.html (accessed August 21, 2008).
Desktop Marketing Systems Pty Ltd vs. Telstra Corporation Limited. 2002. FCAFC 112.
Directive 95/46/EC of the European Parliament and of the Council of 24 October 1995 on the protection of individuals with regard to the processing of personal data and on the free movement of such data. 1995. Official Journal L 281:31–50.
Feist Publications, Inc. vs. Rural Telephone Service Co., Inc. 1991. 499 U.S. 340, 111 S.Ct. 1282.
Fla. Stat. 2009. Ownership and control of patient records; report or copies of records to be furnished. § 456.057. http://www.leg.state.fl.us/Statutes/index.cfm?App_mode=Display_Statute&Search_String=&URL=Ch0456/Sec057.HTM (accessed February 3, 2010).
Fried, B. M. 2008. Gauging the progress of the National Health Information Technology Initiative: Perspectives from the field. http://www.chcf.org/documents/chronicdisease/GaugingTheProgressOfTheNationalHITInitiative.pdf (accessed August 20, 2008).
GAO (Government Accountability Office). 2007. Testimony before the Subcommittee on Information Policy, Census, and National Archives Committee on Oversight and Government Reform, U.S. House of Representatives. Health information technology: Efforts continue but comprehensive privacy approach needed for national strategy, GAO-07-988t. http://www.gao.gov/new.items/d07988t.pdf (accessed August 20, 2008).
———. 2008. Testimony before the Senate Committee on the Budget: Health information technology—HHS is pursuing efforts to advance nationwide implementation, but has not yet completed a national strategy. GAO-08-499t.
Georgia. 2008. The Microchip Consent Act of 2008. H.B. 940. http://www.legis.state.ga.us/legis/2007_08/pdf/hb940.pdf (accessed February 24, 2010).
Guay, V. 2008. Health record privacy rules may get tighter, Foster’s Daily Democrat. http://fosters.com/apps/pbcs.dll/article?AID=/20080210/GJNEWS01/67136800 (accessed February 23, 2010).
Harper & Row, Publishers, Inc. vs. Nation Enterprises. 1985. 471 U.S. 539.
Harty-Golder, B. 2007. EMR Ownership Questions. Medical Laboratory Observer. July 2007: 54. http://www.mlo-online.com/articles/0707/0707liab&lab.pdf (accessed February 23, 2010).
HHS (Department of Health and Human Services). 2000. Security & Privacy. 45 C.F.R. Part 164. http://ecfr.gpoaccess.gov/cgi/t/text/text-idx?c=ecfr&sid=d63854405945c9ab56b93612fcc5e089&rgn=div5&view=text&node=45:1.0.1.3.71&idno=45 (accessed February 24, 2010).
———. 2002a. Other requirements related to uses and disclosures of protected health information. 45 C.F.R. § 164.514. http://edocket.access.gpo.gov/cfr_2002/octqtr/pdf/45cfr164.514.pdf (accessed February 24, 2010).
———. 2002b. Uses and Disclosures: Organizational Requirements.45 C.F.R. § 164.504. http://edocket.access.gpo.gov/cfr_2002/octqtr/pdf/45cfr164.504.pdf (accessed February 24, 2010).
———. 2002c. Uses and Disclosures for which an authorization is required. 45 C.F.R. § 164.508. http://edocket.access.gpo.gov/cfr_2002/octqtr/pdf/45cfr164.508.pdf (accessed February 24, 2010).
———. 2002d. Definitions. 45 C.F.R. § 160.103. http://edocket.access.gpo.gov/cfr_2002/octqtr/pdf/45cfr160.103.pdf (accessed February 24, 2010).
———. 2002e. Uses and disclosures for which consent, or authorization, or opportunity to agree or object is not required. 45 C.F.R. § 164.512. http://edocket.access.gpo.gov/cfr_2002/octqtr/pdf/45cfr164.512.pdf (accessed February 24, 2010).
———. 2002f. Applicability. 45 C.F.R. § 164.104(a). http://edocket.access.gpo.gov/cfr_2002/octqtr/pdf/45cfr164.104.pdf (accessed February 24, 2010).
House, T. W. 2004. Transforming health care: The President’s health information technology plan. http://www.whitehouse.gov/infocus/technology/economic_policy200404/chap3.html (accessed August 20, 2004).
House kills medical privacy bill. 2008. New Hampshire Business Review.
IMS Health Corp. vs. Rowe. 2007. 532 F.Supp.2d 153 (D. Me.). Suit has also been filed regarding the Vermont legislation.
IMS Health, Inc. vs. Ayotte. 2007. 490 F.Supp.2d 163 (D. N.H. 2007).
IMS Health, Inc. v. Sorrell, No. 1:07-CV-188 (D. Vt. Apr. 23, 2009).
Inc. vs. Chinatown Today Pub. Enterprises, Inc., 1991. 945 F.2d 509 (2nd Cir. N.Y.)
Indiana. 2008. H.B. 1342.
Jost, T. S. 2007. Health care at risk: A critique of the consumer-driven movement. Durham, NC: Duke University Press.
KSR vs. Teleflex, 2007. 127 S. Ct. 1727.
La. Rev. Stat. Ann. 2001. Legislation around retention of medical records. § 40:2144(F) (Supp. 2006).
Lohr, S. 2007. Google and Microsoft look to change health care. The New York Times.
Maine State Legislature. 2005. Confidentiality of prescription drug information. 22 M.R.S.A. § 1711-E. http://www.mainelegislature.org/legis/bills/bills_123rd/billpdfs/HP000502.pdf (accessed February 24, 2010).
Matthew Bender & Co. vs. West Publ. Co. 1998. 158 F.3d 693 (2nd Cir. N.Y.).
Micro Chem., Inc. vs. Lextron, Inc. 2003. 317 F.3d 1387 (Fed. Cir.).
Miller, R. H., and B. S. Miller. 2007. The Santa Barbara county care data exchange: What happened? Health Affairs (Millwood) 26(5):w568–w580.
Moore vs. Regents University of California. 1990. 51 Cal. 3d 120.
MRSA 1711. An act to amend the prescription privacy law. State of Maine Legislature. June 18, 2007. http://janus.state.me.us/legis/LawMakerWeb/summary.asp?ID=280022219. (accessed May 18, 2009).
NCSL (National Conference of State Legislatures). 2008a. Genetics and health insurance state anti-discrimination laws. http://www.ncsl.org/programs/health/genetics/ndishlth.htm (accessed August 20, 2008).
———. 2008b. Genetics and life, disability and long-term care insurance. http://www.ncsl.org/programs/health/genetics/ndislife.htm (accessed August 20, 2008).
———. 2008c. State genetics employment laws. http://www.ncsl.org/programs/health/genetics/ndiscrim.htm (accessed August 20, 2008).
NCVHS (National Committee on Vital and Health Statistics). 2007. Enhanced protections for uses of health data: A stewardship framework for “secondary uses” of electronically collected and transmitted health data. http://www.ncvhs.hhs.gov/071221lt.pdf (accessed August 20, 2008).
Nev. Rev. Stat. 2008. Failure to maintain proper medical records; altering medical records; making false report; failure to file or obstructing required report; failure to allow inspection and copying of medical records; failure to report other person in violation of chapter or regulations. §630.3062. http://leg.state.nv.us/NRS/NRS-630.html#NRS630Sec3062 (accessed February 3, 2010).
New Jersey. 2006. A.B. 1390.
New York Mercantile Exchange, Inc. v. IntercontinentalExchange, Inc. 05-5585-CV, 2007 WL 2189129, C.A.2 (N.Y.), 8/1/2007.
N.H. Rev. Stat. Ann. 2007. The Perscription Restraint Law. § 318:47-f.
Nieves vs. Chassin. 1995. 625 N.Y.S.2d 344 (N.Y. App. Div. 3d).
NIH (National Institutes of Health). 2003. Final NIH statement on sharing research data, NOT-OD-03-032. http://grants.nih.gov/grants/policy/data_sharing/ (accessed August 20, 2008).
———. 2008. Revised policy on enhancing public access to archived publications resulting from NIH-funded research, NOT-OD-08-033. http://grants.nih.gov/grants/guide/notice-files/NOT-OD-08-033.html (accessed August 20, 2008).
N.M. Stat. 1978. Medical Practice Act. § 61-6-15 D. http://www.nmmb.state.nm.us/pdffiles/MedicalPracticeAct.pdf (accessed February 3, 2010).
N.M. Stat. Ann. 2008. Legislation around retention of medical records. § 14-6-2.
NRC (National Research Council). 2003a. Responses by the research and education communities in preserving the public domain and promoting open access. In The role of scientific and technical data and information in the public domain: New legal approaches in the private sector. Washington, DC: The National Academies Press.
———. 2003b. The role of scientific and technical data and information in the public domain: New legal approaches in the private sector. Washington, DC: The National Academies Press.
———. 2003c. Scientific knowledge as a global public good: Contributions to innovation and the economy. In The role of scientific and technical data and information in the public domain: Proceedings of a symposium. Washington, DC: The National Academies Press.
Ohio Urology, Inc. vs. Poll. 1991. 72 Ohio App. 3d 446, 594 N.E.2d 1027 (Ohio Ct. App., Franklin County).
O’Reilly, K. B. 2005. AMA to set guidelines on control of record data. AMNews, American Medical Association.
ORNL (Oak Ridge National Laboratory). 2008. Human genome project information: Genetics and patenting. http://www.ornl.gov/sci/techresources/Human_Genome/elsi/patents.shtml (accessed August 20, 2008).
Pikey vs. Bryant. 2006. 203 S.W.3d 817 (Mo. Ct. App).
Regensdorfer vs. Orange Regional Medical Center. 2005. 799 NYS 2d 571.
Roche PA, Annas GJ. 2001. Protecting genetic privacy. National Review of Genetics 2:392–396.
Roche PA, Annas GJ. 2006. DNA Testing, Banking, and Genetic Privacy, 2:392-396; N Engl J Med 355; Aug. 10, 2006.
Rosenblit vs. Zimmerman. 2001. 766 A.2d 749 (N.J.).
Schwarz vs. Bd. of Regents. 1982. 453 N.Y.S.2d 836, 836–37 (N.Y. App. Div. 3d).
Solum, L. B. 1987. On the indeterminacy crisis: Critiquing critical dogma, U. Chi. L. Rev. 54: 462.
South Dakota. 2008. An Act to Prohibit the Implanting of a Microchip and Provide a Civil Recovery. H.B. 1141.
Tenn. Code Ann. 2004. Records property of hospitals—Access—Not Public—Funding for medical record requests. § 68-11-304(a)(1).
Terry, N. P. 2004. Prescriptions sans Frontières (or How I Stopped Worrying about Viagra on the Web but Grew Concerned about the Future of Healthcare Delivery), 4 Yale JHPLE 183.
Terry, N. P., and L. P. Francis. 2007. Ensuring the Privacy and Confidentiality of Electronic Health Records. University of Illinois Law Review 681:707–708.
Terry, Nicolas, 2008. What’s Wrong with Health Privacy? in Law and Bioethics, Eds. Sandra H. Johnson, Ana S. Iltis, and Barbara A. Hinze (NY: Routledge, 2008), 68-94.
Thomas vs. United States. 1987. 660 F. Supp. 216, 218. (D.D.C.)
Unistar Corp. vs. Child. 1982. 415 So. 2d 733 (Fla. Dist. Ct. App. 3d Dist.).
United States Code. 1992. Definitions. 17 U.S.C.S. § 101.
———. 1998. Digital Millennium Copyright Act. 17 U.S.C.S. § 1201 et seq.
———. 2009. Fraud and related activity in connection with computers. 18 U.S.C.S. § 1030 et seq. http://www.law.cornell.edu/uscode/18/1030.html (accessed February 4, 2010).
United States House of Representatives. 2008. An Act relative to patient health care information House Bill 1587. http://www.gencourt.state.nh.us/legislation/2008/HB1587.html (accessed August 31, 2010).
Valley Med. Specialists vs. Farber. 1999. 194 Ariz. 363, 982 P.2d 1277.
VICTOR LALLI ENTERPRISES, INC., vs. BIG RED APPLE, INC. No. 1577, Docket 91-7155. United States Court of Appeals, Second Circuit. Argued May 29, 1991. Decided June 13, 1991.
Vt. Stat. Ann. tit. 18, § 4631 (2007), Vermont Statute.
Waldron vs. Ball Corp. 1994. 619 N.Y.S. 2nd, 841, 210 A.D.2d 611 (A.D. 3rd. Dept.).Dept.).
Washington State Legislation. 2008. Prohibiting the sale or use of prescriber-identifiable prescription data for commercial or marketing purposes absent prescriber consent. S.B. 6241. http://apps.leg.wa.gov/billinfo/summary.aspx?year=2008&bill=6241 (accessed February 24, 2009).
West Virginia. 2008a. S.B. 544.
_____. 2008b. H.B. 2177.
Willison, D. J., L. Schwartz, J. Abelson, C. Charles, M. Swinton, D. Northrup, and L. Thabane. 2007. Alternatives to project-specific consent for access to personal information for health research: What is the opinion of the Canadian public? Journal of the American Medical Information Association 14(6):706–712.
Windeyer, J., Mount Isa Mines vs. Pusey, 1970. 125 CLR 383, 395 (Supreme Court of Queensland).
Woolley, M., and S. M. Propst. 2005. Public attitudes and perceptions about health-related research. Journal of the American Medical Association 294(11):1380–1384.
Wyo. Stat. Ann. 2005. Grounds for suspension; revocation; restriction; imposition of conditions; refusal to renew or other disciplinary action. § 33-26-402(a) (xxvii) (G). http://legisweb.state.wy.us/statutes/statutes.aspx?file=titles/Title33/T33CH26.htm (accessed February 3, 2010).


































