
1
Introduction
Ensuring the delivery of high-quality, patient-centered care requires understanding the needs of the populations served. The nation’s health care data infrastructure does not provide the necessary level of detail to understand which groups are experiencing health care disparities or would benefit from targeted quality improvement efforts. Categories for collection and methods of aggregation for reporting race, ethnicity, and language data vary. Challenges to improving data quality include nonstandardized categories, a lack of understanding of why data are collected, health information technology (HIT) limitations, and a lack of sufficiently descriptive response categories, among others. Throughout the course of this report, the subcommittee addresses these challenges as it recommends a standardized approach to eliciting race, ethnicity, and language data and defines a standard set of categories for these data.
Hennepin County Medical Center in Minneapolis, Minnesota, may very well be one of the Midwest’s most diverse hospitals. Its patient population includes persons of Somali, Mexican, Ecuadorian, Russian, Vietnamese, and Bosnian heritage, born in this country or elsewhere, to name but a few of the populations in a state that has historically been populated by persons identifying themselves as White and of German and Scandinavian origin. As a March 2009 New York Times profile of the hospital emphasized, each of these ethnic groups brings “distinctive patterns” of illness, injury, language, and health beliefs (Grady, 2009), all of which affect how health professionals can best provide safe, timely, effective, patient-centered, efficient, and equitable care, as delineated in the Institute of Medicine’s 2001 report Crossing the Quality Chasm: A New Health System for the 21st Century (IOM, 2001).
Cultural lifestyle patterns (e.g., food choices and smoking habits) and beliefs about the use of health care influence the quality of care received regardless of the person’s country of origin, language, immigration status, or socioeconomic status (SES). The importance of knowing a patient’s race, ethnicity, and language need is not limited to understanding the issues facing recent immigrants’ health access or outcomes; race, ethnicity, and language data can reveal risks for health care disparities in native-born as well as foreign-born populations. Such data ideally allow:
-
Targeted interventions by health plans and health system providers when certain populations have higher than average or potentially avoidable hospitalizations;
-
Identification of differentials in health status, quality of care, and outcomes among populations (even when insurance status is the same) by agencies such as the Centers for Medicare and Medicaid Services (CMS);
-
Planning of language assistance services to support physicians and other staff that interact directly with diverse patient populations; and
-
Development of health promotion outreach strategies to specific groups (e.g., outreach efforts to Somali women who are susceptible to vitamin D deficiency to prevent later, more costly emergency department visits for diagnosis and pain treatment) by public health departments and health care providers working in collaboration.
One of the biggest barriers most health systems face in improving quality and reducing disparities within their own walls is systematically identifying the populations they serve, addressing the needs of these populations, and monitoring improvements over time. This systematic analysis may reveal no disparities in the delivery of health care, but that different groups may have different health care needs (e.g., educating Somali women on the need for vitamin D, earlier cancer screening for racial and ethnic groups at increased risk, addressing ethnocultural beliefs regarding temperature and onset of childhood asthma among Puerto Ricans, therapeutic strategies to reduce risk of diabetic kidney disease among Pima Indians) (American Cancer Society, 2009; Grady, 2009; Pachter et al., 2002; Pavkov et al., 2008). Identification of differences has the ultimate goal of being able to improve the quality of care for each person to enhance his or her health.
Strong evidence exists that there are disparities in health and the quality of health care received by different populations (AHRQ, 2008; IOM, 2003; Kaiser Family Foundation, 2009). In conceptualizing an approach to addressing disparities in health care systems, Kilbourne and colleagues describe three critical phases: detection of disparities, understanding of factors, and development and implementation of interventions (Figure 1-1) (Kilbourne et al., 2006). The detection phase includes three key components: defining health care disparities, identifying vulnerable populations, and developing valid measures. The detection phase requires organizations to systematically collect relevant demographic data and to link these data to measures of quality. This phase brings health systems one step closer to understanding where the disparities (or differential health care needs) exist, which can lead to understanding why they exist and identifying some of the causal factors. Once systems have detected and understood disparities, they are better positioned to develop and implement targeted interventions to reduce those disparities (Kilbourne et al., 2006). The fundamental step is collecting data that adequately describe populations, allowing for the stratification of quality measures at a level of detail that can identify variation in health and health care among at-risk groups (Hasnain-Wynia and Rittner, 2008).
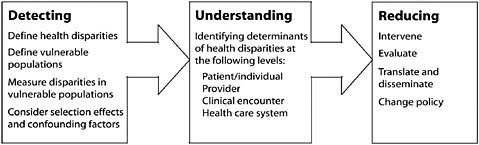
FIGURE 1-1 A framework for reducing disparities in health care systems.
SOURCE: Kilbourne et al., 2006.
The subcommittee’s task is to develop recommendations on standardized categories of race, ethnicity, and language data to support the processes of recognizing differential needs in health care, and identifying and reducing or eliminating disparities. Race, ethnicity, and language information can inform point of care needs, application of resources, and decisions in patient–provider interactions in ways that improve absolute levels of health care quality for all. At the microsystem level, physician practices and individual hospitals can use data to understand the population being served, address disparities in care that exist, and monitor improvements over time. At an intermediate level, data can be used—for example by health plans or states—to make cross-institutional comparisons to detect variations in quality of care between entities serving similar populations. And at the macro level, through national reporting and aggregation, population data can indicate where consistent disparities in care exist nationally (Thomas, 2001).
This chapter provides background on key issues and challenges surrounding the categorization and collection of race, ethnicity, and language data for health care quality improvement. First, the complexity of defining the concepts of race and ethnicity is explored. Next, the chapter examines challenges to the collection of these demographic data, the impetus for standardization, the utility of the current Office of Management and Budget (OMB) race and Hispanic ethnicity categories, and the need for more detailed data on race, ethnicity, and language need. The chapter concludes by reviewing the subcommittee’s study charge and providing an overview of the remainder of this report.
DEFINING RACE AND ETHNICITY
The concepts of race and ethnicity are defined socially and culturally and, in the case of federal data collection, by legislative and political necessity (Hayes-Bautista and Chapa, 1987). OMB, for example, states that race and ethnicity categories “are social-political constructs and should not be interpreted as being scientific or anthropological in nature” (OMB, 1997a). Scientific findings provide empirical evidence that there is more genetic variation within than among racial groups; thus, racial categories do not represent major biological distinctions (Cooper and David, 1986; Williams, 1994; Williams et al., 1994) and instead capture socially constructed intersections of political, historical, legal, and cultural factors.
People have been racially categorized by the federal government since the first U.S. Census was conducted in 1790 (Bennett, 2000). Since then, the national statistical system has employed a variety of racial categories, most of which stem from racial classifications that originated in the mid-eighteenth century (Witzig, 1996). Commentators have noted that it is remarkable how little the categories have changed, despite what is now known about the lack of correlation between racial phenotypes and genetic differences (Cavalli-Sforza et al., 1994; Diamond, 1994; Witzig, 1996).
The complex history of racial identification in the United States (Byrd and Clayton, 2000; Smedley, 1999) results in concepts of race and ethnicity that not only have changed over time,1 but also are subject to self-perceptions, which may also change (Ford and Kelly, 2005; Hahn, 1992); technical decisions defining who belongs in which category; and the perceptions of a person recording another individual’s race. In the latter instance, for example, individuals who self-identify as American Indians are frequently classified as White by health care workers when a determination is made by observation alone, without self-report (Izquierdo and Schoenbach, 2000).
Imprecision in defining and using the terms race and ethnicity is apparent in the conflicting and overlapping terminologies used even by the government bodies responsible for statistical data collection and classification. In some instruments, the federal government considers race and ethnicity to be distinct concepts (Grieco and Cassidy, 2001); in other instruments, questions on race include racial, national origin, and ethnicity response options. The term race is often used synonymously with ethnicity, ancestry, nationality, and culture (Williams, 1994; Yankauer, 1987). For example, Census 2000 and 2010 forms ask, “What is this person’s race?” (U.S. Census Bureau, 2009) and provide response categories that blur definitions of race, national origin, and ethnicity. Such practices
|
1 |
The 2000 Census: Counting Under Adversity provides an extensive review of the historical development of the racial and ethnic classifications used by the Bureau of the Census. Chapter 3 in Multiple Origins, Uncertain Destinies: Hispanics and the American Future reviews the origins of Hispanic ethnicity and its relationship to race. |
both reflect and reinforce the lack of uniformity in how the term ethnicity is perceived (Macdonald et al., 2005; Thernstrom et al., 1980). The term Hispanic is often listed alongside terms that define racial groups (e.g., Asian and White), resulting in many Hispanics beginning to view themselves as a separate race. Thus, when Hispanics are required to choose a race in addition to their Hispanic ethnicity, many self-identify as “Some other race” (NRC, 2006). The Census Bureau’s definition of “Some other race” is included in Table 1-1.
Race and ethnicity can be important statistical predictors of an individual’s risk for good or poor health outcomes and access to care (NRC, 2004b; Wallman et al., 2000; Williams, 1994). However, a multitude of factors that are both correlated with and independent of race and ethnicity may affect group differences in health and health care. The model presented in Figure 1-2 indicates the complex relationships between environmental conditions, socioeconomic status, discrimination, racism, and health care. In this model, health care (called medical care in the figure), or lack thereof, is viewed as both a risk factor and resource that impacts an individual’s health status. Because of the complex relationships depicted in this model, the concepts of race and ethnicity should be dealt with deliberatively, purposefully, and thoughtfully (Williams et al., 1994).
A 2004 National Research Council committee charged with defining the measurement of racial discrimination concluded that “race is a salient aspect of social, political, and economic life” and that collecting data on race and ethnicity is therefore necessary to “monitor and understand differences in opportunities and outcomes for population groups” (NRC, 2004c, p. 33). Thus, while there have been flaws in applying the terms race and ethnicity, the terms remain important to use in distinguishing the diversity of the U.S. population.
While recognizing a certain lack of precision and consistency in the terms race and ethnicity for defining population groups that would be unacceptable with any other variable used in scientific inquiry (Kagawa-Singer, 2009), the subcommittee chose to adopt the definitions put forth in the 2003 IOM report Unequal Treatment: Confronting Racial and Ethnic Disparities in Healthcare. Race is considered a “socioeconomic concept wherein groups of people sharing certain physical characteristics are treated differently based on stereotypical thinking, discriminatory institutions and social structures, a shared worldview, and social myths” (IOM, 2003, p. 525).2 For the purposes of this report, the subcommittee considers ethnicity to be a concept referring to a shared culture and way of life, especially reflected in language, religion, and material culture products (IOM, 2003). The subcommittee makes a distinction between the limited OMB and Census Bureau use of the term ethnicity to connote solely Hispanic ethnicity and the concept of granular ethnicity advanced in this report and further defined in Chapters 2 and 3. Additionally, the subcommittee recognizes that linguistic barriers can present significant challenges to both patients and providers and thus has adopted a definition of language that is inclusive of communication needs. This report develops an approach to the collection of data on these key variables and offers a framework of race, ethnicity, and language categories and questions for the collection and use of these data in health care quality improvement efforts.
CHALLENGES TO COLLECTING RACE, ETHNICITY, AND LANGUAGE DATA
A variety of entities, such as states, health plans, health professionals, hospitals, community health centers, nursing homes, and public health departments—as well as the public—play roles in obtaining, sharing, and using race, ethnicity, and language data. All of these entities, though, have different reasons for and ways of categorizing, collecting, and aggregating these data. In interviews and testimony before the subcommittee, representatives of hospitals, health plans, physicians, and custodians of federal health care databases consistently identified several challenges to improving the quality and availability of race, ethnicity, and language data in patient–provider encounters and at various levels of the health care system (Box 1-1). The principal challenges in obtaining these data for use in quality improvement assessments include a lack of standardization of categories to foster data sharing and aggregation (Lurie et al., 2005; Siegel et al., 2007), a lack of understanding of why the data are being collected
TABLE 1-1 Categories and Definitions Promulgated by the OMB and the U.S. Bureau of the Census
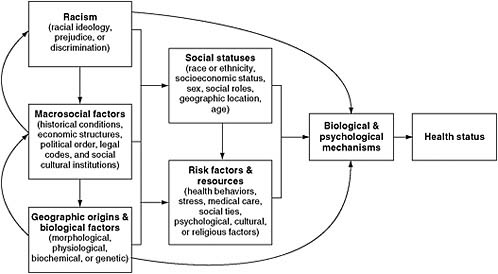
FIGURE 1-2 Williams, Lavizzo-Mourey, and Warren’s framework for understanding the relationships between race, medical/health care, and health.
SOURCE: Adapted, with permission, from Public Health Reports 2009. Copyright 1994 Public Health Reports.
(Hasnain-Wynia et al., 2007; Regenstein and Sickler, 2006), a lack of space on collection forms and in collection systems (Coltin, 2009; Hasnain-Wynia et al., 2007; Ting, 2009), health information technology (HIT) limitations (e.g., field capacity and linkages among systems) (Coltin, 2009), and the fact that the current OMB categories are not sufficiently descriptive of locally relevant population groups (Friedman et al., 2000; NRC, 2004b). These issues, though challenging, are not insurmountable; thus, the subcommittee seeks to identify options for moving forward and improving the categorization, collection, and aggregation of race, ethnicity, and language data so
they can be used to stratify quality performance metrics, organize quality improvement and disparity reduction initiatives, and report on progress.
Standardizing Categories
The reasons for standardizing race, ethnicity, and language categories for data collection for health care quality improvement are four-fold: (1) ensuring that equivalent categories are being collected and compared across settings; (2) minimizing the reporting burden that arises when multiple entities require different sets of incompatible categories; (3) optimizing the ability to share data across systems of payers, health care settings, government agencies, and political jurisdictions; and (4) going beyond the OMB categories to develop response options that are more relevant for the identification of needs for quality improvement. Sharing and comparing data across systems calls for a common vocabulary to avoid omission of categories that might be critical to monitoring disparities and to allow mapping of categories from one system to another.
The expansion of electronic health records (EHRs)3 and integration of data systems creates an opportunity to establish uniform categories and coding practices. Developing linkages among health data systems would provide a more comprehensive picture of health care quality. Doing so would be greatly facilitated by having the ability to “read” comparable data from disparate sources, a proposition that requires standardized categories, coding, and procedures for aggregating granular data to broader categories whenever necessary.
Current Status of National Standards for Categorizing and Collecting Race, Ethnicity, and Language Data
In specifying a system that can provide uniformity and comparability in the collection and use of data by federal agencies, OMB provides a minimum standard for collecting and presenting data on Hispanic ethnicity and race (see Box 1-2) (OMB, 1997b). The driving force for the development of this standard in the 1970s was the need for comparable data for civil rights monitoring; thus the categories reflect legislatively based priorities for data on particular population groups, including congressionally mandated separate counts of the Hispanic population (Wallman et al., 2000). Because the standard was not designed with regard to health or health care specifically, the groups identified by the OMB categories may not be the only analytic groups useful for advancing health care quality improvement.
The OMB standard was envisioned as a minimum reporting requirement, and more discrete categorization is encouraged as long as these categories can be rolled up to the six OMB race and Hispanic ethnicity categories (OMB, 1997a). For example, the Census Bureau and some Department of Health and Human Services (HHS)–sponsored national surveys use the OMB minimum categories plus other categories that can be aggregated into the minimum categories for analysis and reporting.
No nationally standardized minimum set of languages comparable to the OMB race and Hispanic ethnicity categories exists. HHS, in conformance with Department of Justice principles to prevent discrimination and to ensure access to federally funded programs, has provided guidance on the importance of collecting language data (HHS, 2003) in its Culturally and Linguistically Appropriate Services (CLAS) standards. Four of the 14 standards are federally mandated for all health care organizations that receive federal funds. These organizations must offer and provide competent language assistance services and must make documents available in “the languages of the commonly encountered groups and/or groups represented in the service area.” The CLAS standards do not list language categories to be used for data collection and analysis but seek to ensure the provision of language assistance services and culturally competent care in all health care settings (Office of Minority Health, 2001).
In agencies that are not federal or organizations that do not receive federal funds or federal contracts, race, ethnicity, and language data may not be collected because state, local, and private sector data collection is not universally mandated. Furthermore, those data that are collected do not necessarily adhere to a uniform set of categories; hospitals, health plans, community health centers, employers, and providers collect data in disparate ways.
|
3 |
EHRs are further defined in Chapter 6 of this report. |
|
BOX 1-2 The 1997 OMB Revisions to the Standards for the Classification of Federal Data on Race and Hispanic Ethnicity Hispanic Ethnicity
Race
Features
Use of the Standards
|
An Approach to Improving the Categorization and Aggregation of Data
The OMB categories are not sufficiently descriptive to distinguish among locally relevant ethnic populations that face unique health problems and may have dissimilar patterns of care and outcomes (Hasnain-Wynia and Baker, 2006). When more detailed data are collected and used locally, aggregation to the OMB categories loses detailed quality-related information for specific populations. As linkages among quality reporting systems become more common and allow aggregation of data from multiple sources, consistent methods of identifying subgroups will facilitate more robust analyses of detailed population data at the local, regional, state, and national levels. Any national standard list of categories for those subgroups must capture the full diversity of the U.S. population. The keys to the usefulness of such a list across the country are balancing that comprehensiveness with the desired level of granularity to describe locally pertinent groups, and resolving any administrative and logistical barriers to collecting a sufficient number of informative categories to help guide quality improvement.
The three principal means of obtaining race, ethnicity, and language data are self-report, observation, and indirect estimation. Self-report, which reflects how individuals view themselves, is the widely preferred approach as it has been adopted by OMB (OMB, 1997b) and is considered by researchers to be the “gold standard” (Higgins and Taylor, 2009; Wei et al., 2006). The Interagency Committee for the Review of the Racial and Ethnic Standards reviewed the OMB standards prior to the 1997 revisions and determined that self-report respects “individual dignity” by allowing an individual to determine how he or she classifies himself or herself as opposed to classification being assigned by another person (OMB, 1997a).
The Health Research and Educational Trust (HRET) Toolkit and the National Health Plan Collaborative
(NHPC) have provided guidance on collecting data on race, Hispanic ethnicity, more detailed ethnicity, and language need (Hasnain-Wynia et al., 2007; NHPC, 2008). The HRET Toolkit was recently endorsed by the National Quality Forum (NQF, 2008); however, the languages are limited to those most common at the national level, it includes a single “multiracial” category instead of an instruction to allow persons to “Select one or more,” and there is no “Other, please specify:__” option to capture additional categories with which individuals identify. Therefore, the framework for categorization and collection spelled out by this report provides a national standard for more thorough categorization and collection than has previously been put forth.
Addressing the Legality and Understanding the Purposes of Data Collection
The collection of data is impaired when its need is not well understood by health professionals and intake workers, and especially by patients themselves. Clinicians and administrators too often misperceive legal barriers and furthermore do not expect to see any disparities in their practice. Despite evidence of disparities at all levels of health and health care systems, hospital executives, physicians, and staff, for example, may believe that disparities are not a problem in their respective institutions (Weinick et al., 2008). Some worry that soliciting the information may put them at risk for offending patients, or if disparities are found, for accusations of discrimination (Hasnain-Wynia et al., 2004). Similarly, health plans have been concerned that they could be viewed as subjecting certain populations to discriminatory treatment by asking for such data in advance of enrollment. In fact, a few states prohibit the acquisition of race and ethnicity data at enrollment, but not thereafter.4 A 2009 analysis of federal and state laws found no federal laws or regulations prohibiting health plans from collecting race and ethnicity data (AHIP, 2009).
The HRET Toolkit, the National Health Law Program (NHeLP), and the HHS Office of Minority Health (OMH) all emphasize that the collection of race, ethnicity, and language data is permitted under Title VI of the Civil Rights Act of 1964 and is, in fact, necessary to ensure compliance with the statute (Berry et al., 2001; Hasnain-Wynia et al., 2007; Perot and Youdelman, 2001).5 The Civil Rights Act requires recipients of federal financial assistance to collect information that demonstrates compliance, including “racial and ethnic data showing the extent to which members of minority groups are beneficiaries of and participants in federally-assisted programs.”6 Furthermore, a July 2008 law7 mandated the Secretary of HHS to implement the collection of race, ethnicity, and gender data in the Medicare program in fee-for-service plans, Medicare Advantage private plans, and Part D prescription drug plans. The American Recovery and Reinvestment Act of 2009 (ARRA)8 also lays out expectations for the collection of race, ethnicity, and language data by specifying the inclusion of these variables in EHRs.
Although the legal basis for the collection of race and ethnicity data is well documented (AHIP, 2009; Perot and Youdelman, 2001; Rosenbaum et al., 2007; Youdelman and Hitov, 2001) and at least 80 program-specific statutes require the reporting and collection of race, ethnicity, and language data (Youdelman and Hitov, 2001), health care organizations may still perceive legal barriers, including concerns about the applicability of Health Insurance Portability and Accountability Act of 1996 (HIPAA)9 regulations, to collecting, sharing, and reporting these data. HIPAA restricts the use and disclosure of identifiable health information, but does not limit the collection of demographic data for quality improvement purposes (Kornblet et al., 2008).
A 2007 National Committee on Vital Health Statistics (NCVHS) report addresses the concern of the potential of harm arising from the use of data enabled by their collection and exchange through HIT. The report acknowledges the potential for “discrimination, personal embarrassment, and group-based harm” when the data are compiled and exchanged (NCVHS, 2007, p. 5). The report recommends the protection of all uses of health data by all users
|
4 |
California, Maryland, New Hampshire, New Jersey, New York, and Pennsylvania prohibit insurers from requesting an applicant’s race, ethnicity, religion, ancestry, or national origin in applications, but the states allow insurers to request such information from individuals after enrollment (AHIP, 2009). |
|
5 |
A list of legislation relevant to race, ethnicity, and language data is included in Appendix B. |
|
6 |
The Civil Rights Act of 1964, Public Law 88-352, 78 Stat. 241, 88th Cong., 2d sess. (July 2, 1964). |
|
7 |
Medicare Improvements for Patients and Providers Act of 2008, Public Law 110-275 § 118, 110th Cong., 2d sess. (July 15, 2008). |
|
8 |
American Recovery and Reinvestment Act of 2009, Public Law 111-5 § 3002(b)(2)(B)(vii), 111th Cong., 1st sess. (February 17, 2009). |
|
9 |
Health Insurance Portability and Accountability Act of 1996, Public Law 104-191, 104th Cong., 2d sess. (August 21, 1996). |
under a framework of data stewardship, a concept that encompasses “the responsibilities and accountabilities associated with managing, collecting, viewing, storing, sharing, disclosing, or otherwise making use of personal health information” (AMIA, 2007), and the subcommittee agrees.
Efforts to collect these data may also be hampered by intake workers and patient registration staff who feel uncomfortable soliciting them from patients, and who feel burdened by collecting data whose importance they do not understand and cannot adequately explain if patients challenge the need for these data. Patients, meanwhile, may be hesitant to provide race, ethnicity, and language data because of concerns about privacy and their own uncertainty as to why these data are needed. Perceived experiences of discrimination in medical care have been found to be associated with greater apprehension about providing race and ethnicity information among, for example, Blacks, Hispanics, and Mandarin/Cantonese-speaking Asians (Kandula et al., 2009). Potential health plan enrollees, for instance, may fear discriminatory access to coverage, while hospital patients may worry that language questions serve as a proxy for questions about immigration status.
Addressing Health Information Technology (HIT) Issues
Advances in HIT, including recent federal government financing and support, may open doors to advance data collection. Currently, however, collecting and utilizing race, ethnicity, and language data in health care settings may be complicated by challenges in capturing sufficient data and in linking available data from disparate sources (Schoenman et al., 2007). For example, many hospitals and physician offices that collect these data enter them with other demographic characteristics at intake. These demographic data, then, are typically included in practice management systems, which are separate from the HIT systems that capture clinical information used in quality measurement.
In many health care settings, space on data collection forms and space constraints in HIT systems can be barriers to including detailed demographic data (Hasnain-Wynia et al., 2007). For example, while OMB stipulates the separate collection of race and Hispanic ethnicity data, some legacy HIT systems allow only one field for capturing both elements. Similarly, some HIT systems are unable to collect the multiple responses that result from the “Select one or more” approach required by OMB (Coltin, 2009).
Some HIT collection systems utilize drop-down screens and keystroke pattern matching to increase the number of category choices they can offer. Other paper and electronic systems default to lengthy lists that are time-consuming for both staff and patients to comb through, or use shorter lists and classify many persons under an indiscriminant “other” category. Open-ended questions (e.g., “Other, please specify:__”), which allow write-in responses, may improve self-identification but can impose additional administrative burdens if labor-intensive manual coding must be undertaken in the absence of automated systems or optical scanning technology. However, the use of “Other, please specify:__” as an adjunct check-off box captures respondent answers and is thus useful to more accurately describing all members in a service population.
STUDY CHARGE AND APPROACH
The IOM, under a contract with the Agency for Healthcare Research and Quality (AHRQ), formed the Subcommittee on Standardized Collection of Race/Ethnicity Data for Healthcare Quality Improvement to report on the issue of standardization of race, ethnicity, and language variables; define a standard set of race, ethnicity, and language categories; and define methods of obtaining race, ethnicity, and language data (Box 1-3). To address this charge, the subcommittee identifies categories and types of questions that allow for the development of uniform standards for the collection, aggregation, and reporting of race, ethnicity, and language data for quality improvement in health care settings.
The subcommittee’s title and its charge refer specifically to health care but not health in general. The subcommittee recognizes that health care is one element that contributes to people’s health, and that the effects of race, ethnicity, and language on health in general are important. However, the language in the statement of task, specifically “in healthcare quality improvement” and “report on quality of care,” led the subcommittee to focus its discussion and recommendations on the health care domain. In its recommendations regarding the collection of
|
BOX 1-3 Statement of Task: Subcommittee on Standardized Collection of Race/Ethnicity Data for Healthcare Quality Improvement A subcommittee of experts will report to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports regarding the lack of standardization of collection of race and ethnicity data at the federal, state, local, and private sector levels due to the fact that the federal government has yet to issue comprehensive, definitive guidelines for the collection and disclosure of race and ethnicity data in healthcare quality improvement. The subcommittee will focus on defining a standard set of race/ethnicity and language categories and methods for obtaining this information to serve as a standard for those entities wishing to assess and report on quality of care across these categories. The subcommittee will carry out an appropriate level of detailed, in-depth analysis and description which can be included in the overall report by the committee and as a separate stand alone report. |
race, ethnicity, and language data, the subcommittee emphasizes areas such as care delivery sites (e.g., hospitals, physician practices) and public and private insurers involved in measuring and improving the quality of health care. Nonetheless, recommendations can apply to data collection activities in public health (e.g., state-sponsored immunization registries) when those data can be used to target interventions and resources to ensure equity in care and health outcomes. The subcommittee’s recommendations include surveys addressing the quality of care or the utilization of care.
Vital statistics data sets present a special case, since data from birth or death certificates may be linked to data from health care settings to identify disparities in health care and health outcomes. Knowledge about differentials in mortality along race and ethnicity lines can help care providers focus inquiries about specific populations to determine the quality of their care. However, these data collection activities are organized and supported for purposes beyond health care and health care quality improvement, and recommendations set in the narrower context of health care quality improvement may conflict with other important considerations. The subcommittee did not focus its discussions on vital statistics data collection processes, nor do its recommendations specifically include those processes. New national standards have been set for birth and death records, incorporating categories beyond those set by OMB; states and localities are free to use additional categories and are encouraged to do so along the lines of the subcommittee’s recommendations.
The subcommittee was formed in conjunction with the Committee on Future Directions for the National Healthcare Quality and Disparities Reports. The subcommittee met in person four times during the course of the four-month study and conducted additional deliberations through telephone conferences. It heard public testimony from a wide range of experts during two public workshops and additional interviews. Staff and committee members met with and received information from a variety of stakeholders and interested organizations, including health plans, advocacy groups, health services researchers, and HIT implementation experts.
The subcommittee has approached its task by evaluating the two interrelated purposes and uses of data collection (Figure 1-3): improvements in individual patient–provider care interactions, and system-level improvement. In patient–provider interactions, effective two-directional communication is essential to the provision of high-quality, patient-centered care. Quality care can depend on a provider’s identification and understanding of the cultural beliefs and experiences of his or her patients, and on the expression and understanding of health care needs communicated by patients. Health services researchers have adopted the term cultural competence to describe the goal of creating a health care system and workforce that are capable of delivering high-quality care to all patients through an array of efforts, including training of physicians and availability of health care interpreters (Betancourt et al., 2005). Knowledge of a patient’s race, ethnicity, and language and communication needs can assist in the
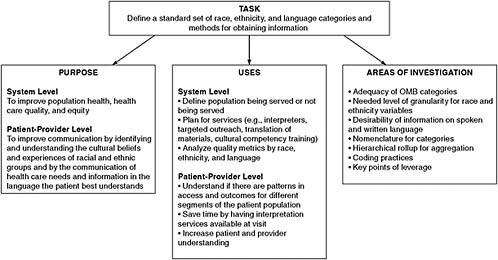
FIGURE 1-3 Overview of purposes and uses of race, ethnicity, and language data to guide subcommittee’s investigation of issues of categorization and collection.
provision of patient-centered care by accounting for the “impact of emotional, cultural, social, and psychological issues on the main biomedical ailment” (Hedrick, 1999, p. 154). At the system level, race, ethnicity, and language data serve an evidentiary purpose for improving population health, health care quality, and equity by identifying variations related to these characteristics. System-level analyses include variations across a broad range of health care entities, including physician practices, community health centers, hospitals, health plans, state government bodies, and federal agencies.
The subcommittee approached its task by defining two terms in its framework for recommendations; the term variable refers to the dimensions of race, ethnicity, and language on which is it important to have data; the term categories refers to the possible discrete groupings of individuals that can occur in any variable. The subcommittee developed principles to guide its deliberations, including the need for:
-
Nomenclature for each variable and its categories that would maximize individuals’ ease and consistency of identification with those categories;
-
Local decision making about categories that would be useful given the size and diversity of the population served or surveyed, as well as the consideration that quality improvement activities tend to be locally based;
-
A framework that would allow some flexibility in approaches to collection but retain uniform categories, in recognition of the different capacities of information systems; and
-
Fostering comparability across the variety of actors that collect and use these data.
Building on Previous Studies
In developing its rationale and framework for standardization, the subcommittee considers previous research on the categorization, collection, and use of race, ethnicity, and language data in health care settings. In 2000,
Congress asked the National Academies to assess the ability of HHS data collection systems to measure racial, ethnic, and socioeconomic disparities. The request resulted in the 2004 National Research Council report Eliminating Health Disparities: Measurement and Data Needs, which recommends actions for HHS to take to ensure the routine collection and reporting of race and ethnicity data. The report acknowledges the importance of collecting data on race, ethnicity, socioeconomic status, and language and acculturation for use in making statistical inferences about disparities, but notes the lack of standardized collection and reporting of these data across all entities (NRC, 2004b).
NCVHS has historically emphasized to its HHS counterparts the necessity and benefits of collecting race, ethnicity, and language data, among other variables, under the premise that these data are essential to monitoring the health of the nation (NCVHS, 2001, 2004, 2005). In several reports over the past decade, the NCVHS Subcommittee on Populations has discussed challenges to collecting and using these data. The present report addresses these data collection challenges and proposes a framework for moving forward with standardized data collection across all health and health care entities, not just within HHS agencies or by recipients of federal funds. Previous reports have reiterated the importance of collecting more detailed ethnicity data than are captured by the OMB standard categories; this report proposes a template of categories so that entities wishing to collect detailed data can do so in systematic, uniform ways.
Limitations of the Study
Like previous IOM committees, the subcommittee recognizes the linkages among socioeconomic status, health literacy, and immigration with race, ethnicity, and language; however, these dimensions were beyond the scope of its charge. Lower socioeconomic status has been associated in the literature with poor health outcomes and high mortality rates since at least the early twentieth century (Isaacs and Schroeder, 2004; Link and Phelan, 1996; Lutfey and Freese, 2005). Time in the United States and immigration status also have implications for one’s health and access to health care (Kagawa-Singer, 2006, 2009; Oh et al., 2002; Portes and Hao, 2002; Wadsworth and Kubrin, 2007).
While the subcommittee focuses exclusively on the categorization of race, ethnicity, and language—as it was charged to do—it recognizes that some differences in health care among racial, ethnic, and language groups reflect differences in socioeconomic status, immigration, and health literacy. Studying the roles of these constructs nevertheless presumes categorizations of race, ethnicity, and language of reasonable credibility and consistency for patients from whom the data are collected, providers who collect the data, and those analyzing the data for quality improvement purposes.
While the subcommittee concludes that a full consideration of HIT technicalities is beyond the scope of its charge, its members are mindful of HIT considerations in its recommendations. The subcommittee also notes the timeliness and relevance of its work to Section 13001 of ARRA.10 The intersection between the subcommittee’s work and emerging HIT standards will be further discussed in Chapter 6 of this report.
OVERVIEW OF THE REPORT
The subcommittee is charged with recommending standards for the categorization and collection of race, ethnicity, and language data. Collection of data at various levels of the health care system implies that the data must be amenable to reporting and aggregation in consistent ways. To frame how the purposes and uses outlined in Figure 1-3 could best be met, the subcommittee addresses the following areas:
-
Defining the specific variables to be collected: race (including the applicability of the OMB categories), ethnicity (whether limited to Hispanic ethnicity or expanded to other groupings), language (whether encompassing English language proficiency and spoken and/or written language needed for effective communication);
-
Describing the nomenclature for each variable to ensure that the categories for each contain as valid and reliable data as possible;
-
Defining a classification system for race and ethnicity that allows a hierarchical rollup so categorical data can be combined;
-
Suggesting standardized approaches to coding race, ethnicity, and language categories to foster data linkages; and
-
Addressing key points of leverage to ensure both patient–provider and system-level improvement.
Chapter 2 reviews the available research on how more discrete categorization of ethnicity can reveal disparities and allow more precise targeting of initiatives for health care quality improvement. Chapter 3 addresses the utility of the OMB categories in capturing important cultural and social groups for statistical reporting before considering the collection of more granular ethnicity data and how standard coding of categories can allow for the sharing of data beyond a single service site. The chapter examines the geographic distribution of racial and ethnic groups across the United States and the need for balance between nationally uniform categories for data collection and flexibility in how different subsets of categories are used for local quality improvement. Chapter 4 reviews different approaches germane to the collection of language data, explores the need for data on spoken and written language, and examines language coding practices. Chapter 5 covers the challenges and barriers faced by health care organizations and providers of care in collecting these variables. The chapter explores how these challenges can be addressed through direct collection methods and use of indirect estimation techniques. Chapter 6 examines the role of various entities in informing and shaping the uptake of standardized categories of race, ethnicity, and language data. The chapter describes the opportunities afforded through the adoption of EHRs and more integrated HIT systems that are likely to extend the capabilities of health care providers at all levels to collect and use these data systematically.
Race, ethnicity, and language data are tools for fighting discrimination, understanding disparities, and providing culturally and linguistically relevant services (Burdman, 2003). Thus, these data are useful and important for identifying and, ultimately, acting to reduce and eliminate disparities in health status and health care. These data alone, however, cannot address how to fix the issues brought to light in Chapter 2. Measurement cannot ensure the provision of culturally and linguistically appropriate care that incorporates racial and ethnic sensitivities, accommodates diverse views and approaches, and reduces disparities by improving access and quality.
REFERENCES
AHIP (America’s Health Insurance Plans). 2009. A legal perspective for health insurance plans: Data collection on race, ethnicity, and primary language. Washington, DC: America’s Health Insurance Plans.
AHRQ (Agency for Healthcare Research and Quality). 2008. National Healthcare Disparities Report. Rockville, MD: AHRQ.
American Cancer Society. 2009. Can breast cancer be found early? http://www.cancer.org/docroot/CRI/content/CRI_2_4_3X_Can_breast_cancer_be_found_early_5.asp (accessed June 13, 2009).
AMIA (American Medical Informatics Association). 2007. Data stewardship definition. http://www.amia.org/files/definition_of_data_stewardship.pdf (accessed July 7, 2009).
Bennett, C. 2000. Racial categories used in the decennial censuses, 1790 to the present. Government Information Quarterly 17(2):161-180.
Berry, E. R., S. Hitov, J. Perkins, D. Wong, and V. Woo. 2001. Assessment of state laws, regulations and practices affecting the collection and reporting of racial and ethnic data by health insurers and managed care plans. Washington, DC: National Health Law Program (NHeLP).
Betancourt, J. R., A. R. Green, J. Emilio Carrillo, and E. R. Park. 2005. Cultural competence and health care disparities: Key perspectives and trends. Health Affairs 24(2):499-505.
Burdman, P. 2003. Exposing the truth and fiction of racial data. California Journal 11:40-46.
Byrd, W., and L. Clayton. 2000. A medical history of African Americans and the problem of race: Beginnings to 1900,An American health dilemma, Volume 1. New York: Routledge.
Cavalli-Sforza, L. L., P. Menozzi, and A. Piazza. 1994. The history and geography of human genes. Princeton, NJ: Princeton University Press.
Coltin, K. 2009. Implementation challenges for health plan collection of race, ethnicity & language data. Harvard Pilgrim Health Care. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, February 9, 2009. Washington DC. PowerPoint Presentation.
Cooper, R., and R. David. 1986. The biological concept of race and its application to public health and epidemiology. Journal of Health Politics, Policy and Law 11(1):97-116.
Diamond, J. 1994. Race without color. Discover 15:82-89.
Ford, M. E., and P. A. Kelly. 2005. Conceptualizing and categorizing race and ethnicity in health services research. Health Services Research 40(5):1658-1675.
Friedman, D. J., B. B. Cohen, A. R. Averbach, and J. M. Norton. 2000. Race/ethnicity and OMB Directive 15: Implications for state public health practice. American Journal of Public Health 90:1714-1719.
Grady, D. 2009. Foreign ways and war scars test hospital. New York Times, March 28, A1.
Grieco, E. M., and R. C. Cassidy. 2001. Overview of race and Hispanic origin. Washington, DC: U.S. Census Bureau.
Hahn, R. A. 1992. The state of federal health statistics on racial and ethnic groups. JAMA 267(2):268-271.
Hasnain-Wynia, R., and D. W. Baker. 2006. Obtaining data on patient race, ethnicity, and primary language in health care organizations: Current challenges and proposed solutions. Health Services Research 41(4):1501-1518.
Hasnain-Wynia, R., and S. S. Rittner. 2008. Improving quality and equity in health care by reducing disparities. Chicago, IL: Northwestern University.
Hasnain-Wynia, R., D. Pierce, and M. A. Pittman. 2004. Who, when, and how: The current state of race, ethnicity, and primary language data collection in hospitals. New York: The Commonwealth Fund.
Hasnain-Wynia, R., D. Pierce, A. Haque, C. H. Greising, V. Prince, and J. Reiter. 2007. Health Research and Educational Trust Disparities Toolkit. www.hretdisparities.org (accessed December 18, 2008).
Hayes-Bautista, D. E., and J. Chapa. 1987. Latino terminology: Conceptual bases for standardized terminology. American Journal of Public Health 77:61-68.
Hedrick, H. L. 1999. Cultural competence compendium. Chicago, IL: American Medical Association.
HHS (U.S. Department of Health and Human Services). 2003. Guidance to federal financial assistance recipients regarding Title VI prohibition against national origin discrimination affecting limited English proficient persons. Washington, DC: U.S. Department of Health & Human Services.
Higgins, P. C., and E. F. Taylor. 2009. Measuring racial and ethnic disparities in health care: Efforts to improve data collection. Princeton, NJ: Mathematica Policy Research.
IOM (Institute of Medicine). 2001. Crossing the quality chasm: A new health system for the 21st Century. Washington, DC: National Academy Press.
———. 2003. Unequal treatment: Confronting racial and ethnic disparities in healthcare. Edited by B. D. Smedley, A. Y. Stith and A. R. Nelson. Washington, DC: The National Academies Press.
Isaacs, S. L., and S. A. Schroeder. 2004. Class: The ignored determinant of the nation’s health. New England Journal of Medicine 351(11):1137-1142.
Izquierdo, J. N., and V. J. Schoenbach. 2000. The potential and limitations of data from population-based state cancer registries. American Journal of Public Health 90(5):695-698.
Kagawa-Singer, M. 2006. Population science is science only if you know the population. Journal of Cancer Education 21:S22-S31.
———. 2009. Measure of race, ethnicity and culture: Population science isn’t science unless you know the population. UCLA School of Public Health. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, March 12, 2009. Newport Beach, CA. PowerPoint Presentation.
Kaiser Family Foundation. 2009. Putting women’s health care disparities on the map: Examining racial and ethnic disparities at the state level. Menlo Park, CA: The Henry J. Kaiser Family Foundation.
Kandula, N., R. Hasnain-Wynia, J. Thompson, E. Brown, and D. Baker. 2009. Association between prior experiences of discrimination and patients’ attitudes towards health care providers collecting information about race and ethnicity. Journal of General Internal Medicine 24(7):789-794.
Kilbourne, A. M., G. Switzer, K. Hyman, M. Crowley-Matoka, and M. J. Fine. 2006. Advancing health disparities research within the health care system: A conceptual framework. American Journal of Public Health 96(12):2113-2121.
Kornblet, S., J. Prittsa, M. Goldstein, T. Perez, and S. Rosenbaum. 2008. Policy brief 4: Patient race and ethnicity data and quality reporting: A legal “roadmap” to transparency. Washington, DC: The George Washington University School of Public Health and Health Services.
Link, B. G., and J. C. Phelan. 1996. Understanding sociodemographic differences in health: The role of fundamental social causes. American Journal of Public Health 86:471-473.
Lurie, N., M. Jung, and R. Lavizzo-Mourey. 2005. Disparities and quality improvement: Federal policy levers. Health Affairs 24(2):354-364.
Lutfey, K., and J. Freese. 2005. Toward some fundamentals of fundamental causality: Socioeconomic status and health in the routine clinic visit for diabetes. The American Journal of Sociology 110(5):1326-1372.
Macdonald, S., V. Stone, R. Arshad, and P. de Lima. 2005. Ethnic identity and the Census. http://www.scotland.gov.uk/Resource/Doc/54357/0013571.pdf (accessed September 2, 2009).
NCVHS (National Committee on Vital and Health Statistics). 2001. Medicaid managed care data collection and reporting. Hyattsville, MD: U.S. Department of Health and Human Services.
———. 2004. Recommendations on the nation’s data for measuring and eliminating health disparities associated with race, ethnicity, and socioeconomic position. Hyattsville, MD: U.S. Department of Health and Human Services.
———. 2005. Eliminating health disparities: Strengthening data on race, ethnicity, and primary language in the United States. Hyattsville, MD: U.S. Department of Health and Human Services.
———. 2007. Enhanced protections for uses of health data: A stewardship framework for ‘secondary uses’ of electronically collected and transmitted health data. Hyattsville, MD: U.S. Department of Health and Human Services.
NHPC (National Health Plan Collaborative). 2008. Toolkit to reduce racial & ethnic disparities in health care. Washington, DC: National Health Plan Collaborative.
NQF (National Quality Forum). 2008. National voluntary consensus standards for ambulatory care—measuring healthcare disparities. Washington, DC: National Quality Forum.
NRC (National Research Council). 2004a. The 2000 Census: Counting Under Adversity. Edited by C. F. Citro, D. L. Cork, and J. L. Norwood. Washington, DC: The National Academies Press.
———. 2004b. Eliminating health disparities: Measurement and data needs. Edited by M. V. Ploeg and E. Perrin. Washington, DC: The National Academies Press.
———. 2004c. Measuring racial discrimination. Edited by R. M. Blank, M. Dabady and C. F. Citro. Washington, DC: The National Academies Press.
———. 2006. Multiple origins, uncertain destinies: Hispanics and the American future. Edited by M. Tienda and F. Mitchell. Washington, DC: The National Academies Press.
Office of Minority Health. 2001. National standards for culturally and linguistically appropriate services in health care. Washington, DC: U.S. Department of Health and Human Services.
Oh, Y., G. F. Koeske, and E. Sales. 2002. Acculturation, stress and depressive symptoms among Korean immigrants in the United States. Journal of Social Psychology 142:511-526.
OMB (Office of Management and Budget). 1997a. Recommendations from the Interagency Committee for the Review of the Racial and Ethnic Standards to the Office of Management and Budget concerning changes to the standards for the classification of federal data on race and ethnicity. Federal Register (3110-01):36873-36946.
———. 1997b. Revisions to the standards for the classification of federal data on race and ethnicity. Federal Register 62:58781-58790.
Pachter, L. M., S. C. Weller, R. D. Baer, J. E. Garcia, A. Garcia, R. T. Trotter, M. Glazer, and R. Klein. 2002. Variation in asthma beliefs and practices among mainland Puerto Ricans, Mexican-Americans, Mexicans and Guatemalans. Journal of Asthma 39(2):119-134.
Pavkov, M. E., W. C. Knowler, R. L. Hanson, and R. G. Nelson. 2008. Diabetic nephropathy in American Indians, with a special emphasis on the Pima Indians. Current Diabetes Reports 8:486-493.
Perot, R. T., and M. Youdelman. 2001. Racial, ethnic, and primary language data collection in the health care system: An assessment of federal policies and practices. New York, NY: The Commonwealth Fund.
Portes, A., and L. Hao. 2002. The price of uniformity: Language, family, and personality adjustment in the immigrant second generation. Ethnic and Racial Studies 25:889-912.
Regenstein, M., and D. Sickler. 2006. Race, ethnicity, and language of patients: Hospital practices regarding collection of information to address disparities in health care. Princeton, NJ: Robert Wood Johnson Foundation.
Rosenbaum, S., S. Kornblet, and P. C. Borzi. 2007. An assessment of legal issues raised in “high performing” health plan quality and efficiency tiering arrangements: Can the patient be saved? Washington, DC: The George Washington University School of Public Health and Health Services.
Schoenman, J. A., J. P. Sutton, A. Elixhauser, and D. Love. 2007. Understanding and enhancing the value of hospital discharge data. Medical Care Research and Review 64(4):449-468.
Siegel, B., J. Bretsch, V. Sears, M. Regenstein, and M. Wilson. 2007. Assumed equity: Early observations from the first Hospital Disparities Collaborative. Journal for Healthcare Quality 29(5):11-15.
Smedley, A. 1999. Race in North America: Origin and evolution of a worldview, second edition. Boulder, Colorado: Westview Press.
Thernstrom, S., A. Orlov, and O. Handlin. 1980. Harvard encyclopedia of American ethnic groups, second edition. Boston, MA: Harvard University Press.
Thomas, S. B. 2001. The color line: Race matters in the elimination of health disparities. American Journal of Public Health 91(7):1046-1048.
Ting, G. 2009. Applications of indirect estimation of race/ethnicity data in health plan activities. Wellpoint. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, March 12, 2009. Newport Beach, CA. PowerPoint Presentation.
U.S. Census Bureau. 2000. State & County QuickFacts. http://quickfacts.census.gov/qfd/meta/long_68184.htm (accessed June 14, 2009).
———. 2001. Questions and answers for Census 2000 data on race. http://www.census.gov/Press-Release/www/2001/raceqandas.html (accessed April 17, 2009).
———. 2009. United States Census 2010 Form D-1(UL). Washington, DC: U.S. Census Bureau.
Wadsworth, T., and C. E. Kubrin. 2007. Hispanic suicide in U.S. metropolitan areas: Examining the effects of immigration, assimilation, affluence, and disadvantage. The American Journal of Sociology 112(6):1848-1885.
Wallman, K. K., S. Evinger, and S. Schechter. 2000. Measuring our nation’s diversity: Developing a common language for data on race/ethnicity. American Journal of Public Health 90(11):1704-1708.
Wei, I. I., B. A. Virnig, D. A. John, and R. O. Morgan. 2006. Using a Spanish surname match to improve identification of Hispanic women in Medicare administrative data. Health Services Research 41(4):1469-1481.
Weinick, R. M., K. Flaherty, and S. J. Bristol. 2008. Creating equity reports: A guide for hospitals. Boston, MA: The Disparities Solution Center at Massachusetts General Hospital.
Williams, D. R. 1994. The concept of race in health services research: 1966 to 1990. Health Services Research 29(3):261-274.
Williams, D. R., R. Lavizzo-Mourey, and R. C. Warren. 1994. The concept of race and health status in America. Public Health Reports 109(1):26-41.
Witzig, R. 1996. The medicalization of race: Scientific legitimization of a flawed social construct. Annals of Internal Medicine 125(8):675-679.
Yankauer, A. 1987. Hispanic/Latino: What’s in a name? American Journal of Public Health 77(1):15-17.
Youdelman, M., and S. Hitov. 2001. The current federal landscape in health care regarding the collection and reporting of data on race, ethnicity and primary language: A survey of the laws, regulations, policies, practices and data collection vehicles. In Racial, ethnic and primary language data collection: An assessment of federal policies, practices and perceptions, volume 2. Washington, DC: National Health Law Program (NHeLP).


















