
5
Improving Data Collection Across the Health Care System
While a range of health and health care entities collect data, the data do not flow among these entities in a cohesive or standardized way. Entities within the health care system face challenges when collecting race, ethnicity, and language data from patients, enrollees, members, and respondents. Explicitly expressing the rationale for the data collection and training staff, organizational leadership, and the public to appreciate the need to use valid collection mechanisms may improve the situation. Nevertheless, some entities face health information technology (HIT) constraints and internal resistance. Indirect estimation techniques, when used with an understanding of the probabilistic nature of the data, can supplement direct data collection efforts.
Addressing health and health care disparities requires the full involvement of organizations that have an existing infrastructure for quality measurement and improvement. Although hospitals, community health centers (CHCs), physician practices, health plans, and local, state, and federal agencies can all play key roles by incorporating race, ethnicity, and language data into existing data collection and quality reporting efforts, each faces opportunities and challenges in attempting to achieve this objective.
To identify the next steps toward improving data collection, it is helpful to understand these opportunities and challenges in the context of current practices. In some instances, the opportunities and challenges are unique to each type of organization; in others, they are common to all organizations and include:
-
How to ask patients and enrollees questions about race, ethnicity, and language and communication needs;
-
How to train staff to elicit this information in a respectful and efficient manner;
-
How to address the discomfort of registration/admission staff (hospitals and clinics) or call center staff (health plans) about requesting this information;
-
How to address potential patient or enrollee pushback respectfully; and
-
How to address system-level issues, such as changes in patient registration screens and data flow.
Previous chapters have provided a framework for eliciting, categorizing, and coding data on race, ethnicity, and language need. This chapter considers strategies that can be applied by various entities to improve the collection of these data and facilitate subsequent reporting of stratified quality measures. It begins by examining current
practices and issues related to collecting and sharing data across the health care system. Next is a discussion of steps that can be taken to address these issues and improve data collection processes. This is followed by a review of methods that can be used to derive race and ethnicity data through indirect estimation when obtaining data directly from many patients or enrollees is not possible.
COLLECTING AND SHARING DATA ACROSS THE HEALTH CARE SYSTEM
Health care involves a diverse set of public and private data collection systems, including health surveys, administrative enrollment and billing records, and medical records, used by various entities, including hospitals, CHCs, physicians, and health plans. Data on race, ethnicity, and language are collected, to some extent, by all these entities, suggesting the potential of each to contribute information on patients or enrollees. The flow of data illustrated in Figure 5-1 does not even fully reflect the complexity of the relationships involved or the disparate data requests within the health care system. Currently, fragmentation of data flow occurs because of silos of data collection (NRC, 2009).
No one of the entities in Figure 5-1 has the capability by itself to gather data on race, ethnicity, and language for the entire population of patients, nor does any single entity currently collect all health data on individual patients. One way to increase the usefulness of data is to integrate them with data from other sources (NRC, 2009). Thus there is a need for better integration and sharing of race, ethnicity, and language data within and across health care entities and even (in the absence of suitable information technology [IT] processes) within a single entity.
It should be noted that a substantial fraction of the U.S. population does not have a regular relationship with a provider who integrates their care (i.e., a medical home) (Beal et al., 2007). For some, a usual source of care is the emergency department (ED), a situation that complicates the capture and use of race, ethnicity, and language data and their integration with quality measurement. While health plans insure a large portion of the U.S. population, their direct contact tends to be minimal, even during enrollment. Hospitals, which tend to have more developed data collection systems, serve only a small fraction of the country’s population. As a result, no one setting within the health care system can capture data on race, ethnicity, and language for every individual.
Health information technology (HIT) may have the potential to improve the collection and exchange of self-reported race, ethnicity, and language data, as these data could be included, for example, in an individual’s personal health record (PHR) and then utilized in electronic health record (EHR) and other data systems.1 There is little reliable evidence, though, on the adoption rates of EHRs (Jha et al., 2009). While substantial resources were devoted to this technology in the American Recovery and Reinvestment Act of 2009,2 it will take time to develop the infrastructure necessary to fully implement and support HIT (Blumenthal, 2009). Thus, the consideration of other avenues of data collection and exchange is essential to the subcommittee’s task.
Until data are better integrated across entities, some redundancy will remain in the collection of race, ethnicity, and language data from patients and enrollees, and equivalently stratified data will remain unavailable for comparison purposes unless entities adopt a nationally standardized approach. Methods should be considered for incorporating these data into currently operational data flows, with careful attention to concerns regarding efficiency and patient privacy.
Hospitals
Because hospitals tend to have information systems for data collection and reporting, staff who are used to collecting registration and admissions data, and an organizational culture that is familiar with the tools of quality improvement, they are relatively well positioned to collect patients’ demographic data. In addition, hospitals have a history of collecting race data. With the passage of the Civil Rights Act of 19643 and Medicare legislation in 1965,4
|
1 |
A PHR is a medical or health record owned and maintained by a patient him- or herself. EHRs are further defined in Chapter 6. |
|
2 |
American Recovery and Reinvestment Act of 2009, Public Law 111-5 § 3002(b)(2)(B)(vii), 111th Cong., 1st sess. (February 17, 2009). |
|
3 |
The Civil Rights Act of 1964, Public Law 88-352, 78 Stat. 241, 88th Cong., 2d sess. (July 2, 1964). |
|
4 |
The Social Security Act of 1965, 89th Cong., 42 U.S.C. § 7, 1st sess. (July 30, 1965). |
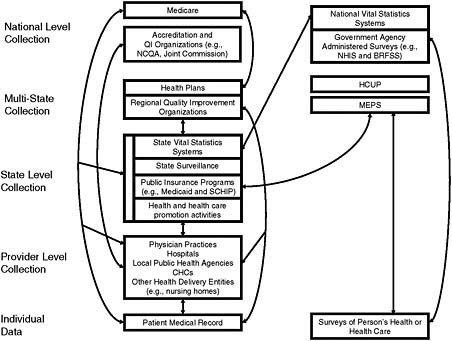
FIGURE 5-1 A snapshot of data flow in a complex health care system.
there was a legislative mandate for equal access to and desegregation of hospitals (Reynolds, 1997). Therefore it is not surprising that more than 89 percent of hospitals report collecting race and ethnicity data, and 79 percent report collecting data on primary language (AHA, 2008).
This culture of data collection has limitations, however. Historically, the data were never intended for quality improvement purposes, but to allow analysis to ensure compliance with civil rights provisions. Additionally, hospital data collection practices are less than systematic as the categories collected vary by hospital, and hospitals obtain the information in various ways (e.g., self-report and observer report) (Regenstein and Sickler, 2006; Romano et al., 2003; Siegel et al., 2007). Furthermore, compared with the number of people who are insured or visit an ambulatory care provider, a relatively small number of people are hospitalized in any one year (see Figure 5-2). Thus, while hospitals are an important component of the health care system and represent a major percentage of health care expenditures, they are only one element of the system for collecting and reporting race, ethnicity, and language data.
Hospitals also face challenges associated with collecting accurate data and using these data for quality improvement and reduction of disparities. A 2006 National Public Health and Hospitals Institute (NPHHI) survey asked hospitals that collected race and ethnicity data whether they used the data to assess and compare quality of care, utilization of health services, health outcomes, or patient satisfaction across their different patient populations. Fewer than one in five hospitals that collected these data used them for any of these purposes (Regenstein and Sickler, 2006). Additionally, only half of hospitals that collected data on primary language maintained a database of patients’ primary languages that they could track over time (Hasnain-Wynia et al., 2006).
Many of the above challenges can be attributed largely to the many staff and departments or units that need to be engaged in the process to ensure systematic data collection and use. Hospitals have multiple pathways (inpatient, outpatient, ED, urgent care) through which patients enter the system. For example, the ED is the source of 45 percent of all hospital admissions (Healthcare Financial Management Association, 2007).
Systems changes can involve training a large number (possibly hundreds) of hospital registration/admission staff (many of whom may be off site) and modifying practice management and EHR systems to ensure that proper
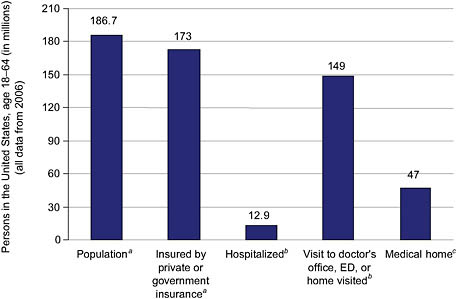
FIGURE 5-2 Opportunities to collect data within the health care system.
a U.S. Census Bureau, 2000.
b NCHS, 2009.
c Beal, 2004.
and consistent data fields are in place across multiple departments and units that serve as patient entry points. Ideally, these systems would be made interoperable through the development of interfaces that would make it possible to relay the data across different systems.
A Robert Wood Johnson Foundation initiative to reduce disparities in cardiac care required participating hospitals to systematically collect race, ethnicity, and language data and use the data to stratify quality measures. The ten hospitals in the collaborative initially cited the data collection requirement as one of the greatest challenges of the program, yet once they focused their efforts on these goals, they were able to bring together key stakeholders within each institution, implement needed IT changes, and train staff. As a result, they successfully began data collection within a relatively short time (Siegel et al., 2008). Other hospitals not part of this initiative are also successfully collecting race, ethnicity, and language data and linking them to quality measures (Weinick et al., 2008). Data collected at the hospital level are useful both for assessing the quality of hospital-provided services and, if shared with other entities, for facilitating analyses of quality across multiple settings. Box 5-1 provides an example of a statewide initiative to collect standardized race, ethnicity, and language data.
Community Health Centers
CHCs are front-line providers of care for underserved and disadvantaged groups (Taylor, 2004) and therefore are good settings for implementing quality improvement strategies aimed at reducing racial and ethnic disparities in care. Yet while CHCs serve diverse patient populations and, as organizations, understand the importance of demographic data for improving the quality of care, the accuracy of the race, ethnicity, and language data they collect may be limited (Maizlish and Herrera, 2006). More than 87 percent of surveyed CHCs reported inquiring about a patient’s need for language services, and 73 percent reported recording this information in the patient record (Gallegos et al., 2008); less is known, however, about the extent to which CHCs consistently collect patient
|
BOX 5-1 Statewide Race and Ethnicity Data Collection: Massachusetts In January 2007, all Massachusetts hospitals were required to begin collecting race and ethnicity data from every patient with an inpatient stay, an observation unit stay, or an emergency department visit. These data are included in the electronic discharge data each hospital submits to the state’s Division of Health Care Finance and Policy. As part of this effort, a standardized set of reporting categories was created and train-the-trainer sessions were held across the state. A report on this initiative notes: “The new efforts in Massachusetts are unique in the constellation of requirements and approaches being implemented in the state today. First, all acute care hospitals are required to collect these data, and a recommended data collection tool has been developed jointly by the city [Boston] and Commonwealth to standardize efforts across hospitals. Second, the tool and the required categories in which hospitals must provide patient-level discharge data to the [state] include an exceptionally detailed list of ethnicities, with 31 reporting categories that include 144 ethnicities or countries of origin. Third, the collaboration between the City of Boston, the Commonwealth of Massachusetts, and hospitals has been crucial to turning policy attention to reducing disparities in the quality of health care.” Acute care hospitals are required to report the basic OMB race categories along with 31 ethnicity categories: Asian Indian, Cambodian, Chinese, Filipino, Japanese, Korean, Laotian, Vietnamese, African American, African, Dominican, Haitian, European, Portuguese, Eastern European, Russian, Middle Eastern (or North African), Caribbean Island, American, Brazilian, Cape Verdean, Central American (not otherwise specified), Colombian, Cuban, Guatemalan, Honduran, Mexican (Mexican, Mexican American, Chicano), Puerto Rican, Salvadoran, South American (not otherwise specified), and Other Ethnicity. SOURCES: Massachusetts Executive Office of Health and Human Services, 2009; Weinick et al., 2007, 2008. |
race and ethnicity data beyond the basic OMB categories included in their national Uniform Data System (HRSA, 2009).5
Like hospitals, CHCs face challenges to collecting data, such as the need to train staff, the need to modify existing HIT systems, and the need to ensure interoperability between the practice management systems where demographic data are collected and recorded and the EHR systems where the demographic data can be linked to clinical data for quality improvement purposes. In 2006, only 26 percent of surveyed CHCs reported some EHR functionality, yet 60 percent reported plans for installing a new EHR system or replacing the current system (Shields et al., 2007). Collection of demographic data can also increase the burden of data entry for staff, particularly for those CHCs that still use paper forms to collect these data from patients (Chin et al., 2008).
Limited resources (both financial and human) and a high-need patient population present ongoing challenges to CHCs in their data collection and quality improvement efforts (see Box 5-2). Because 40 percent of CHCs’ patient populations are uninsured and because CHCs generally have a poor payer mix (Manatt Health Solutions and RSM McGladrey, 2007; National Association of Community Health Centers, 2006), they gain relatively less revenue than private physician practices from quality improvement interventions that lead to the delivery of more services (Chin et al., 2008). Even with increases in federal funding, CHCs struggle to meet the rising demand for care along with demands to increase quality reporting, reduce disparities, and develop EHR systems (Hurley et al., 2007).
|
BOX 5-2 Collecting and Using Data: The Alliance of Chicago Community Health Services The Alliance of Chicago Community Health Services developed a customized EHR system to provide decision support for clinicians and link clinical performance measures with key patient characteristics to identify disparities in performance and inform quality improvement efforts. The alliance of four CHCs across 32 clinical sites implemented the centralized EHR system in 2005–2006. The system is hosted in a secure facility, allowing its data to be accessed by providers via the Internet. The aggregate data means CHCs can look at trends across populations and compare outcomes by different communities, different CHCs, or different demographic groups. The system integrates patient race and ethnicity data, which is collected and stored in the practice management system, with clinical data stored in the EHR system. The processes of development and implementation required reconsiderations of workflow design, customization, and decision support. For example, implementation required analyzing and redesigning hundreds of clinical workflow patterns in busy CHCs and developing the right strategies for training staff. Additionally, some CHCs were collecting race and ethnicity data using paper forms and then transferring the data first into practice management systems and then into EHR systems for linkage with quality data. Lack of standardization for quality measures and data specifications made some of the tasks even more difficult. The standard ultimately decided upon for collection was the OMB standard categories. Now that the systems are in place, it is possible for clinics to move forward with collecting more granular data. The Alliance is now serving as a model for CHC systems in New York, California, and Detroit. SOURCES: De Milto, 2009; Kmetik, 2009; Rachman, 2007. |
Physician and Group Practices
The structure and capabilities of primary and specialty care entities vary tremendously, ranging from large groups or health centers with highly structured staff and advanced information systems to solo physician practices with correspondingly small staff. The ability and motivation of these entities to collect and effectively use race, ethnicity, and language data consequently also vary given the investments in HIT systems and staff training required for these functions. At the same time, these settings have direct contact with patients, ideally as part of an ongoing caregiving relationship. Thus, they are well suited to explaining the reasons for collecting these data, as well as using the data to assess health care needs and patterns of disparities. Physician practices, however, are less likely than hospitals or CHCs to collect race, ethnicity, and language data from patients (Nerenz et al., 2004).
Medical groups may believe either that it is unnecessary to collect these data or that collecting them would offend patients (Nerenz and Darling, 2004). Physician practices may not see the utility of the data and may believe that they should not bear the burden of collecting the data and linking them to quality measures (Mutha et al., 2008). A number of physicians and practice managers interviewed in 2007 thought it was illegal to collect these data, and many did not understand how the data would be used (Hasnain-Wynia, 2007). However, most of the interviewees (physicians, nurse managers, and practice managers) indicated that they thought it would not be problematic to collect these data from their patients if they could explain why the data were being collected and how they would be used (see Box 5-3). Indeed, Henry Ford Medical Group has collected race and ethnicity data for more than twenty years, and the Palo Alto Medical Foundation, a multispecialty provider group with several clinics, has recently begun to collect race and ethnicity data for use in analyses of disparities (Palaniappan et al., 2009).
Primary care sites typically do not have structured information available about care provided at other locations, so their ability to analyze data on quality of care by race, ethnicity, and language is generally limited to measures involving routine prevention and primary care. Physician practices with EHR systems tend to use the system for administrative rather than quality improvement purposes (Shields et al., 2007), but EHR systems can
|
BOX 5-3 Collecting Data in Small Physician Practices The National Committee for Quality Assurance (NCQA) launched a quality improvement demonstration program for small physician practices serving minority populations. With funding from The California Endowment, NCQA provided grants and technical assistance to small practices (five physicians or fewer). The goal of the project was to learn what types of resources and tools these practices need in order to conduct and sustain quality improvement activities, especially in serving disadvantaged populations. After the project, participants reported a greater appreciation for the importance of collecting race and ethnicity data, although few practices began to do so systematically. Before the project, needs assessment surveys showed that only 15 percent of physicians had a “written standard identifying and prominently displaying in the medical record the language preferred by the patient.” While few of the practices began formal data collection, staff at most practices expressed an understanding of the value of this information. The project also improved the participants’ understanding of the legal issues related to collecting data from patients on race, ethnicity, and language need. For example, one physician reported, “You guys have taught me that it is not illegal to identify race. That’s such a batted about issue, but it is not against HIPAA regulations to identify race and culture and language in the medical chart.” However, practical barriers to data collection remained. One challenge faced by practices was the lack of standardized fields in EHR systems. Practices that sought to collect data usually created their own method for documenting race and ethnicity. SOURCE: NCQA, 2009. |
be tailored to link quality measures and demographic data (Kmetik, 2009). Data on race, ethnicity, and language need collected in these settings could be useful throughout the health care system if mechanisms were in place for sharing the data with other entities (e.g., health plans) that have an ongoing obligation and infrastructure for analysis of data on quality of care which can be stratified by race, ethnicity, and language need and can look at episodes of care and care coordination.
Multispecialty group practices, which provide a range of primary care, specialty care, inpatient care, and other services, may be in a strong position to collect race, ethnicity, and language data because they have regular contact with large numbers of patients over long periods of time, can place the data collection in the context of improvement of care rather than administration of health insurance benefits, and typically have the necessary staff and other forms of infrastructure (e.g., a shared EHR system at all care sites). A single EHR system may facilitate the sharing of race, ethnicity, and language data across sites and levels of care, assuming that the data are present and available in the system.
Health Plans
Health plans, including Medicaid managed care and Medicare Advantage plans, have the capabilities necessary to systematically compile and manage race, ethnicity, and language data, and thus have roles to play in quality improvement (Rosenthal et al., 2009). Plans, though, may have limited opportunities for direct contact during which the data can be collected and the need for the data explained. While there are multiple points at which the data can be collected (e.g., disease management programs, member surveys, enrollment), a principal occasion for contact is during enrollment, when fears about discriminatory use of the data may be greatest. California, Maryland, New Hampshire, New Jersey, New York, and Pennsylvania prohibit insurers from requesting an applicant’s race, ethnicity, religion, ancestry, or national origin in applications, but the states do allow insurers to request such
|
BOX 5-4 Successful Collection of Data by a Health Plan: Aetna Aetna was the first national, commercial plan to start collecting race and ethnicity data for all of its members. In 2002, Aetna began directly collecting these data using electronic and paper enrollment forms. Multiple mechanisms are now used to capture race, ethnicity, and language data. The data may be updated at any point of contact, including at enrollment, when members speak to customer service or patient management representatives, and when members access an online member portal. Since 2002, more than 60 million Aetna members have provided race, ethnicity, and/or primary language information. As of 2009, Aetna had collected this information from more than 6 million members, representing approximately 30–35 percent cumulative coverage of race, ethnicity, and language data for its currently enrolled population. Aetna’s success with direct collection has shown that no negative public reaction occurs when plans collect this information. SOURCES: NCQA, 2006; Personal communication, W. Rawlins, Aetna, May 3, 2009. |
information from individuals once enrolled (AHIP, 2009). There are no legal impediments to collecting these data after enrollment.
As many individuals enroll in plans through their place of employment, employers provide one avenue for the collection of race, ethnicity, and language need data. It is possible in principle for individuals to self-identify during open enrollment in a health plan, with the individual’s employer conveying the enrollee’s race and ethnicity data to the plan through an electronic enrollment transaction. The plan could then use these data for quality improvement interventions and measurement. In fact, the Health Insurance Portability and Accountability Act of 1996 (HIPAA) 834 enrollment standard6,7 provides for the transmittal of race and ethnicity data. However, the HIPAA Transactions Rule applies only to health plans, health care clearinghouses, and certain health care providers. Thus, while race and Hispanic ethnicity may be captured in the enrollment transaction and plans are required to accept the standard transaction if it is sent to them, employers rarely use the standard and are not required to do so. As a result, this avenue of data collection is not currently operational, although pending legislation encouraging the use of electronic enrollment transaction standards may make it more common in the future.8
A study conducted by America’s Health Insurance Plans (AHIP) found that 54 percent of plans collected race and ethnicity data, and 56 percent collected primary language data. The National Health Plan Collaborative (NHPC), a public–private partnership to improve quality of care and reduce disparities,9 focused on collecting demographic data on enrollees. NPHC viewed direct data collection as the gold standard since this method supports interventions and direct outreach to individuals, but NHPC members realized that obtaining data through direct methods can take years to achieve in a health plan setting (Lurie, 2009). Likewise, the limited success of Aetna with data collection (see Box 5-4) after several years of concerted effort suggests that the upper limit of data collection by health plans with presently known direct methods may be far below the level necessary for
identifying disparities in quality of care through stratified analysis, for example, of Healthcare Effectiveness Data and Information Set (HEDIS) data.
While the use of racial, ethnic, and language identifiers for coverage, benefit determination, and underwriting is prohibited, the collection of these data for improving quality and reducing health care disparities is both permitted and encouraged. Low participation by plan members in reporting race, ethnicity, and language data may be indicative of low trust of the industry (Coltin, 2009). Despite informing members of how data will be used, plans may also face internal legal concerns about taking on unnecessary liability through threats of legal action due to misperceptions regarding the purposes of collection.
Surveys
Federal and state health agencies administer surveys that are primary sources for estimating the health of a population and current and future needs for health care services (Ezzati-Rice and Curtin, 2001; Mays et al., 2004). For example, a number of studies reviewed in Chapter 2 employed surveys such as the National Health Interview Survey (NHIS), the National Latino and Asian American Survey (NLAAS), and the California Health Interview Survey (CHIS). Surveys can capture data not included in administrative and utilization data—notably data on the uninsured and reports on financial and nonfinancial barriers to seeking care. Other surveys, such as the Consumer Assessment of Healthcare Providers and Systems (CAHPS), are designed to assess plans, hospitals, and medical groups and capture respondents’ self-reported race and ethnicity. These surveys are resources for quality measurement and improvement. While some can be linked to specific health care delivery sites, most are not, so they tend to be a data collection system that is parallel to, rather than integrated with, care delivery.
A fundamental feature of surveys, whether self-administered by mail or interviewer-administered in person or by phone, is that a respondent’s race, ethnicity, and language need are self-identified and not ascribed by the interviewer. However, cues from the interviewer, a respondent’s suspicion of lack of confidentiality, or the social and political context can influence a respondent’s answer (Craemer, 2009; Foley et al., 2005). Moreover, conducting surveys of representative population-based samples in diverse settings requires an assessment of the need for in-language interviews (Ponce et al., 2006), balanced by the costs associated with high-quality translations and trained bilingual interviewers. For surveys conducted in multiple languages (e.g., the CHIS is conducted in English, Spanish, Cantonese, Mandarin, Vietnamese, and Korean), the language of the interview conveys, to some extent, the respondent’s language preference in communicating health information.
Surveys are charged with obtaining stable estimates for population groups defined not only by race, ethnicity, and language, but also by geography and other demographic characteristics. Cost, logistical issues, and protection of respondents’ confidentiality constrain the granularity of reportable race and ethnicity estimates (Madans, 2009). To ensure usable data on population groups, the NHIS oversamples Blacks, Asians, and Hispanics (Madans, 2009), but lower coverage is provided for smaller groups, such as Native Hawaiian or Other Pacific Islanders (NHOPI), in the NHIS (e.g., there were fewer than 10 Samoan respondents in NHIS 2007).
Oversampling is a viable strategy to increase coverage of smaller populations. Yet oversampling incurs costs associated with the rarity of the population and the expense of the survey modality (e.g., the marginal cost of adding one more Samoan respondent would be greater for in-person household interviews than for telephone interviews). Other issues relate to the clustering of a population in a designated area (if area-based oversampling is used) and the specificity and sensitivity of surname lists (if list-assisted oversampling is used). Information on granular ethnicities may also be gleaned from surveys with an explicit focus on specific ethnic groups (e.g., NLAAS) and on subregions (e.g., CHIS).
Another strategy for estimating the health and health care needs of ethnic groups is to combine years of survey data (Barnes et al., 2008; Freeman and Lethbridge-Cejku, 2006; Kagawa-Singer and Pourat, 2000). Some of the findings on variations within and among population groups reported in Chapter 2 were generated from pooled analyses of the NHIS sample to increase the size of the samples. Pooling, however, may not work for the smallest population groups; for example, it would take at least 8 years of NHIS data to obtain the sample size needed for reportable estimates on the NHOPI population. Over such a long time span, significant changes can compromise the validity and relevance of such estimates for health care policy and planning purposes. Where pooling is useful,
standardized measures of demographic variables would improve the quality of the pooled data. Given the limitations of survey sampling, administrative databases offer the potential to collect data on higher numbers of smaller ethnic groups and make statistically reliable analytic comparisons across groups (e.g., a hospital administrative database versus a sample of hospital patients).
IMPROVING DATA COLLECTION PROCESSES
The above discussion of challenges faced by various health and health care entities highlights how important it is for data capture and quality to overcome HIT constraints and minimize respondent and organizational resistance. Integration of data systems has the potential to streamline collection processes so that data can be reported easily, and an individual will not need to self-identify race, ethnicity, and language need during every health encounter. Until such integration is achieved, enhancing legacy HIT systems, implementing staff training, and educating patients and communities about the reasons for and importance of collecting these data can help improve data collection processes.
The collection of race, ethnicity, and language need data by various entities within the health care system raises the possibility that conflicting data may, in some instances, be assigned to a single individual. An individual may self-identify in one clinical setting according to a limited set of choices, whereas another setting may offer more detailed, specific response options, or the individual’s race may have been observed rather than requested and then recorded by an intake worker. There is value in developing a hierarchy of accuracy by which conflicting data can be adjudicated. As previously discussed in this report, OMB prefers self-reported data, and researchers view self-report as the “gold standard” (Higgins and Taylor, 2009; OMB, 1997; Wei et al., 2006). Other methods of collecting these data (e.g., observer report) have been found to be inaccurate compared with self-reported data, resulting in undercounts of certain population groups (Buescher et al., 2005; Hahn et al., 1996; West et al., 2005; Williams, 1998). Thus, in this hierarchy of accuracy, self-report can be understood as being of superior validity. The subcommittee is aware of few systems in which race and ethnicity data are collected in more than one way and compared against self-report for validation. Therefore, the subcommittee cannot make generalizations about which sources or systems are likely to be of superior validity, other than commenting that self-report is preferred over observer-report.
The Health Level 7 (HL7) standards allow for data to be attributed as observer report or self-report, which may facilitate the resolution of conflicting data. There is no solid evidence in favor of the quality of data from any one locus of data collection (e.g., a health plan or hospital), except to the extent that location is correlated with data collection methods. If a provider, for example, collects these data through self-report and hospital records involve observer assignment, then favoring the self-reported data from the provider setting would make sense if the data were linked and conflicting data were found.
Not all data systems capture the method through which the data were collected, and some systems do not allow for data overrides. The interoperability of data systems may, for example, prohibit a provider from updating data on a patient that were provided by the patient’s health plan. Thus, while self-reported data should trump indirectly estimated data or data from an unknown source, ways of facilitating this process logistically warrant further investigation. Data overriding should be used with caution, as overriding high-quality data with poor-quality data reduce the value for analytic processes.
Enhancing Legacy HIT Systems
The varied and limited capacities of legacy HIT systems challenge the collection, storage, and sharing of race, ethnicity, and language data. A single hospital, for example, may use different patient registration systems, which may not have the capacity to communicate with one another. Often, these systems operate unidirectionally, meaning that a system may be able to send or receive information but be unable to do both. Thus, a central system may be able to send data on a patient’s race, ethnicity, and language to affiliated outpatient settings, but data collected in outpatient settings may not flow back to the central system (Hasnain-Wynia et al., 2004). Additionally, some quality data are derived from billing or other sources, requiring further linkages.
In ambulatory care settings (both CHCs and physician practices), race, ethnicity, and language need data are usually collected during the patient registration process and stored in practice management systems. However, clinical performance data may be captured in an another system, meaning that race, ethnicity, and language data in the practice management system need to be imported into the EHR system to produce quality measures stratified by these variables. Practice management systems and EHR systems therefore need to be interoperable.
As technology vendors have adopted standardized communication protocols such as HL7, interoperability has improved for exchange of data such as race and ethnicity (HL7, 2009). Such standards are not universally accepted, however, so some HIT components can communicate without modification, while others require upgrading to ensure that race, ethnicity, and language data can be collected, stored, and shared. While transitioning from legacy HIT systems to newer systems is challenging, especially in physician practices (Zandieh et al., 2008), the American Recovery and Reinvestment Act of 200910 provides stimuli for moving forward with national standard HIT systems.
Most hospitals have the capacity to make changes in their HIT systems, patient registration screens, and fields in house, but some hospitals must go through a corporate office to make these changes. The engagement and support of a hospital’s IT department are important to the success of such efforts.
Implementing Staff Training
Staff of hospitals, physician practices, and health plans have expressed concern about asking patients, enrollees, or members to provide information about their race, ethnicity, and language need (Hasnain-Wynia, 2007). Staff may believe, for example, that patients might be confused or offended by such a request. Furthermore, staff may be concerned about the time-sensitive nature of modern clinical practice and want to ensure that these questions can be asked efficiently.
To ensure that these data are collected accurately and consistently, health care organizations need to invest in training all levels of staff. This may include incorporating the usefulness of these data for detecting and addressing health care needs into the training of health professionals, administrative staff, and hospital and health plan leadership. For example, those responsible for directly asking patients or enrollees for this information can receive front-line training to learn about the importance of collecting these data; how they will be used; how they should be collected; and how concerns of patients, enrollees, and members can be addressed (Hasnain-Wynia et al., 2004, 2006, 2007; Regenstein and Sickler, 2006). When there is direct contact between staff and patients, for instance, if staff do not understand the greater accuracy of directly reported data, they may make their own observations of an individual’s race and/or ethnicity.
Specific training points to be emphasized will depend on the context and on how the data are being collected and utilized. For example, because health plan staff do not have face-to-face contact with enrollees, demographic information is often gathered through telephone encounters. Telephone training may also be needed for staff of hospitals, CHCs, and physician practices because preregistration by telephone may occur before hospital admission or ambulatory care appointments. Contra Costa Health Plan monitored the frequency with which staff were asking for these data and implemented performance metrics to ensure staff compliance. Generally, providers have face-to-face contact with patients and may find response rates are better during that time. Therefore, staff training at clinical sites may need to emphasize elements of face-to-face communication. The Health Research & Educational Trust (HRET) Disparities Toolkit, which has been endorsed by the National Quality Forum (NQF), offers a matrix for addressing patient reluctance under different scenarios (Hasnain-Wynia et al., 2007; NQF, 2008). Questions for requesting these data may introduce response bias, in the absence of adequate staff training.11
Before embarking on formally training staff to collect data, each entity needs to assess its data collection practices and delineate what is being done currently and what will change. The changes need to be clearly communicated during staff training sessions. Despite differences among health care settings, standardizing specific
|
BOX 5-5 Standardizing Direct Data Collection
|
components of data collection within each organization will facilitate staff training processes. Suggestions to this end are presented in Box 5-5.
Educating Patients and Communities
Baker and colleagues (2005, 2007) found that while most patients believe health care providers should collect data on race and ethnicity, minority patients may feel uncomfortable with providing this information. Informing patients that the data are being collected to monitor and improve the quality of care for everyone helps improve patients’ comfort level. Thus, in health and health care settings, providing a rationale for asking the questions may make patients and enrollees feel better about responding. The HRET Toolkit provides suggested wording for this purpose: “We want to make sure that all our patients get the best care possible. We would like you to tell us your racial/ethnic background so that we can review the treatment that all patients receive and make sure that everyone gets the highest quality of care.”
When Contra Costa Health Plan began requesting these data from its members, call center staff read a script developed from the HRET Toolkit before asking about race and ethnicity. Employees found the script time-consuming to read in the call center environment, resulting in a reevaluation of its collection methods. The rationale for the data collection is no longer automatically provided in advance; instead, the data are requested when other information, such as the member’s address and phone number, are being verified.12 Contra Costa’s experience highlights the need for adapting best practices to what will be most successful in specific circumstances.
Informing and engaging communities may facilitate data collection efforts. For example, community-based organizations can be informed of the purposes of the data collection and be used as avenues for passing this information on to constituencies. Within health care settings, information pamphlets, cafeteria table tent cards, and posters in languages other than English (Hasnain-Wynia et al., 2007) may help patients and their families understand what is being asked and why.
USING PROBABILISTIC INDIRECT ESTIMATION OF RACE AND ETHNICITY DATA
When direct collection of race and ethnicity data is incomplete or impossible, it may be useful to infer some information about a person’s race or ethnicity from other information that is already available or can readily be obtained for use in analyses of associations between race and ethnicity and outcomes of interest. Such inferences can be useful when the limits of direct collection of racial and ethnic data have been reached for a given data system or as an interim measure while data are being collected from individuals. This use of predictive variables rather than direct collection of information from patients is termed “indirect estimation.” A number of indirect estimation approaches can be applied to race and ethnicity data, including linking area-level population data from the Census Bureau to quality data, using names for indirect estimation, and attributing Bayesian probabilities to indirectly estimated data.
Linking Area-Level Data to Quality Data
One of the simplest indirect approaches is to use area-level population data derived from the Census. Such data include the racial and ethnic composition of an area (percent in each race and ethnicity category), as well as socioeconomic measures such as median income, percent in poverty, distribution by years of educational attainment, percent reporting limited English proficiency, or an overall indicator of socioeconomic status combining several such measures. Until 2000, these measures were collected from the long-form sample of the decennial Census and released in tabulations by a range of Census geographical units from the state to the block group. More recently, collection of these data has shifted to the American Community Survey, a continuous data collection process from which tabulations are released for 1-, 3-, or 5-year accumulations depending on the level and population of the geographic unit. The numerous applications of the methodology reflect the ease with which addresses can be linked to area data, either by “geocoding” addresses to small areas or by using tabulations for zip code tabulation areas, which approximate postal zip codes.
Analyses with area variables may proceed either by categorizing variables into ranges or by regressing on the numerical value of the variable. For example, researchers might block groups into categories with zero to 10 percent, 10 to 20 percent, and 20 to 30 percent Hispanic residents. If the researchers then found that the block groups with higher concentrations of Hispanic residents also had higher rates of diabetes, a higher rate of diabetes among Hispanics than non-Hispanics might be inferred. Additionally, it is possible to regress the diabetes rate on the percent Hispanic, finding that the diabetes rate increases (along the fitted regression line) by a certain amount (e.g., 0.15 percentage points) for each 1 percentage point increase in the percent Hispanic. Thus, it might be possible to conclude that 0.15 or 15 percentage points is the difference in rates for Hispanics and non-Hispanics. There is a substantial literature on the use of area measures in health research (Krieger et al., 2003a, 2003b, 2003c, 2005), comparing the effects of using data aggregated to various geographic levels; generally, the conclusion has been that effects are detected more sensitively when data are linked to smaller (more detailed) geographic units.
When an outcome is regressed on an area variable defined as the percentage in a particular group (such as the percentage African American or the percentage in poverty), the regression coefficient can be interpreted as the effect of being a member of that group. This analysis, sometimes known as “ecological inference,” is technically correct only under the assumption that the outcome is related to individual effects (membership in the group), but not to the degree of concentration of the group in the area. For example, diabetes rates are higher for African Americans than for Whites; if rates for each group were uniform across the country (and assuming for presentation that there are only these two groups), the average rate in each area would be directly related to the percent African American. In fact, the rate would be a weighted average of the rates for the two groups, where the weights are the percentages of each group in the area; in other words, the effects would be purely compositional. The assumption of uniformity could be violated, however, if African Americans in highly segregated areas have different socioeconomic and health characteristics (e.g., probability of having diabetes) than their counterparts living in integrated areas.
Because of concerns about such possible “noncompositional” effects, the literature on the use of area effects often regards effects of area-level race and ethnicity measures as representing a combination of compositional
effects (the average of effects of individual-level characteristics across the population of the area) and contextual effects (the effects of being in an area of a certain kind). By this logic, the area-level variables might be relevant to include in models even when individual-level measures are available and included. When individual-level variables are not available, the area composition variables can allow only approximate estimation of disparities at the individual level. However, results from area-level analyses can still be very useful in revealing disparities. For example, if residents of areas with high proportions of African American residents are shown to have higher rates of a health or health care problem than those in areas with few African American residents, this is good evidence for disparities even if a precise estimate of average African American–White differences cannot be obtained.
The accuracy of this method is directly dependent on the proportion of the targeted group in the particular area. Community rates of racial and ethnic segregation will affect the method’s accuracy in catchment areas. This method also generally works better for African Americans than for other racial and ethnic groups because their rates of segregation, particularly in Eastern cities, are much higher than those of other groups. Also, rates may differ considerably depending on the unit of analysis (e.g., zip code, Census tract, Census block). Smaller units may be more useful, particularly for groups with lower numbers in the community. Zip code data are readily available, while analysis using Census blocks or block groups requires the additional step of geocoding addresses to the relevant unit of analysis.
Data collection efforts that include an individual’s address can be useful for indirectly estimating race and ethnicity. EHR standards and other administrative databases (e.g., registration and billing) include demographic data elements such as address and date of birth (Certification Commission for Healthcare Information Technology, 2007). Appropriate handling of these data is important because addresses are highly identifiable. HIPAA Privacy Rule requirements for deidentifying data protect individuals but may, in some cases, raise barriers to exchanging address data, as is sometimes necessary for indirect estimation processes.
Using Names for Indirect Estimation
Names have been used as indicators of racial and ethnic identity. For each name there is a corresponding racial and ethnic composition based on self-identification of people with that name in Census data. These data have been summarized in lists of common Spanish and Asian surnames and more specific lists of surnames associated with different Asian-origin ethnicities (Elliott et al., 2008; Fiscella and Fremont, 2006; Sweeney et al., 2007; Wei et al., 2006), but the exact race and ethnicity of those with each name are more informative. For example, a large proportion of those with the surname “Rodriguez” are Hispanic, while those with the surname “Lee” might include substantial proportions of Asian Americans, African Americans, and Whites. While surnames are not useful for identifying groups without distinctive ethnicity-related surnames, identification of African Americans through distinct given names has shown some success (Ting, 2009).
Attributing Bayesian Probabilities to Indirectly Estimated Data
The distributions of race and ethnicity in an area or for a particular name can be interpreted as probabilities that a randomly chosen person from the class (of residents of the area or persons with that name) is a member of each race or ethnicity. For example, if all one knows about an individual is that he lives in a block group in which 37 percent of the residents are African American, one might say there is a 37 percent probability that he is African American. Similar statements can be made using names. Note that the information about race and ethnicity obtained in this way is probabilistic rather than deterministic: even if someone’s block group is 90 percent Hispanic, one can say only that there is a 90 percent chance he is Hispanic, not that he is definitely Hispanic.
An important benefit of this formulation is that probabilities from different pieces of information can be combined formally to generate a summary combined probability. Technically, under the assumption that the two pieces of information—block group composition and name—are independent given the person’s race, they can be combined using Bayes’s theorem to produce a posterior probability for each race and ethnicity that summarizes the two pieces of information (Elliott et al., 2008; Fiscella and Fremont, 2006; Fremont et al., 2005). In particular, the racial and ethnic proportions in a small area can be regarded as prior probabilities that an individual from
that area would be from each race and ethnicity group, while the probabilities that a person from each race and ethnicity would have the individual’s name (e.g., the probability that a Hispanic would have the name “Gomez,” the probability that a non-Hispanic White would have the name “Gomez”) constitute the likelihood for each race and ethnicity. For example, a person named “Gomez” in a block group that is 50 percent Hispanic is more likely to be Hispanic than either a person named “Smith” in a block group that is 50 percent Hispanic or a person named “Gomez” in a block group that is 20 percent Hispanic.
The assumptions for this application of Bayes’s theorem are not likely to hold exactly; for example, a Hispanic in an area of Hispanic concentration (perhaps with many recent immigrants) might be more likely to have the name “Gomez” and less likely to have the name “Smith” than a Hispanic in an integrated area. Nonetheless, this probability calculation provides a principled way of combining multiple indicators of race and ethnicity. This procedure has been implemented with health plan datasets (Elliott et al., 2008). A similar procedure, but using ad hoc rules based on lists and cutoffs rather than formal probability calculations, was used to create a file of imputed racial and ethnic identifications for Medicare beneficiaries (Bonito et al., 2008).
Combining evidence about individuals in this way will tend to improve the accuracy of predictions in the sense that individuals’ probabilities of belonging to each race and ethnicity will become more differentiated and therefore more informative. For this reason, a combined approach is preferable when possible. However, the fact that these are still only probabilities and not certainties has several implications for the use of indirectly estimated race and ethnicity. First, collapsing probabilities to a single imputed racial and ethnic classification for each individual loses useful information and can be misleading. For example, suppose each person is assigned the race and ethnicity classification with the highest probability. Then in a population of individuals for whom the probability of being non-Hispanic White is 60 percent and the probability of being African American is 40 percent, all of those individuals would be classified as non-Hispanic White, although the proper inference would be that the split is 60/40 percent. Another classification approach would be to impute randomly from the given probabilities (in the previous example to divide the population randomly in a 60/40 ratio). While this approach would yield a more realistic distribution of race and ethnicity for the group, the random imputations would have no relationship to any actual differences between Whites and African Americans, and therefore an analysis using this approach would, perhaps falsely, lead to the conclusion that there are no health differences between the two groups. For these reasons, it is essential to record probabilities from indirect estimation rather than a single assignment.
On the other hand, probabilities can be used analytically to draw useful conclusions about disparities. As described above, regressing on probabilities can generate estimates of racial and ethnic differences, although these estimates are valid only under the assumption that variations in outcomes of interest within each racial and ethnic group are uncorrelated with the calculated probabilities. In several illustrative analyses, disparities identified with this methodology closely matched those identified using individual race and ethnicity variables (Elliott, 2009). For example, for estimates of disparities for Black versus White, Hispanic versus White, and Asian versus White, the sign of the coefficient based on indirectly estimated data matched that based on self-reported data 38 out of 39 times, with a significance level of 0.05 (Elliott, 2009).
Using Indirectly Collected Data
Indirect race and ethnicity identifications can be used in quality improvement efforts when direct identifications are unavailable (see Box 5-6). In addition to aggregate analyses such as those described above, they can be used in examining characteristics of patients who suffered specific health problems or health care deficits. For example, mapping of the residences of such patients together with indirectly derived race and ethnicity could illuminate patterns of problems that could be addressed through targeted interventions. To plan services and conduct community-based targeted interventions, NQF recommends using proxy data from geocoding, surname analysis, and Bayesian estimation. NQF’s recommendation also states that indirectly estimated data should not be used to target interventions for individual patients (NQF, 2008).
Indirect methods are best applied to population-based assessments of quality of care and can be used to identify “hotspots” where individuals who are at risk of or are receiving poor care are clustered. Knowing that a provider group’s service area overlaps with a hotspot can be instructive, allowing the group to improve service delivery to
|
BOX 5-6 The Use of Indirectly Collected Data by a Health Plan: Wellpoint, Inc. Wellpoint, the largest member of the BlueCross BlueShield Association, recognizes that while it is preferable to collect race, ethnicity, and language data via self-report, plans often encounter data collection plateaus due to the costs of adding data collection and storage fields to HIT systems, the costs of multiple attempts at collection, inaccurate data from external entities, and internal legality concerns. Wellpoint partnered with the RAND Corporation to develop a low-cost, easy-to-implement alternative to collecting primary source data. The initiative resulted in an analytic model for indirectly estimating race and ethnicity using a combination of geocoding, surname analysis, a proprietary African American first-name list, and logistic regression. The indirectly estimated data can be used to examine differences among groups in various health indicators by linking proxy race and ethnicity data with member claims data and quality process measures. The data are also used to develop maps used for business decisions regarding the design of quality improvement programs and community collaboration projects. In 2008, Wellpoint began using the proxy data to channel culturally and linguistically appropriate screening reminder messages to members. The indirect methodology allows analysis of members who do not respond to requests for self-reported data, decreases the selection bias among self-reported respondents, and makes plan, regional, and practice-level analysis more accurate. SOURCES: NCQA, 2008; Ting, 2009. |
specific communities. While targeting entire hotspots may be relatively ineffective for plans that do not dominate the market, community interventions in which plans pool efforts may be cost-effective (Fremont, 2009).
The use of indirectly estimated data at the individual level is limited by the probabilistic nature of the data and the consequent possibility of error. The subcommittee has considered a number of potential uses of indirect estimates, ranging from those that posed very little risk of harm to the patient to those that posed unacceptable risk. At one end of this spectrum, using indirect estimation to target mail distribution of health information tailored to the needs, language, or cultural style of a particular group would at worst lead to some misdirected and wasted mailing. At the other end, erroneous assumptions about race and ethnicity in personal contacts with patients could lead to offense and mistrust. In particular, the subcommittee finds that the clinical and interpersonal risks of including indirectly estimated identifications in individuals’ medical records far outweigh any potential benefits given the danger of misreading the identification as certain, the likely interpersonal costs of such misreading, and the possibility of clinical consequences from relying on erroneous identification. Instead, if indirect estimation of race and ethnicity is to be used, the estimated probabilities should be stored in a system that is distinct from medical records but can be merged with medical record data to create analytic files for identification of disparities.
Recommendation 5-1: Where directly collected race and ethnicity data are not available, entities should use indirect estimation to aid in the analysis of racial and ethnic disparities and in the de-
velopment of targeted quality improvement strategies, recognizing the probabilistic and fallible nature of such indirectly estimated identifications.
-
Race and ethnicity identifications based on indirect estimation should be distinguished from self-reports in data systems, and if feasible, should be accompanied by probabilities.
-
Interventions and communications in which race and ethnicity identifications are based on indirect estimation may be better suited to population-level interventions and communications and less well suited to use in individual-level interactions.
-
An indirectly estimated probability of an individual’s race and ethnicity should never be placed in a medical record or used in clinical decision making.
-
Analyses using indirectly estimated race and ethnicity should employ statistically valid methods that deal with probabilistic identifications.
SUMMARY
There are both opportunities for and challenges to the collection of data on race, ethnicity, and language need at all organizational levels in the U.S. health care system. The infrastructure of the current health care system does not facilitate the data exchanges necessary to capture race, ethnicity, and language data for all populations. No one locus of data collection has a clearly superior balance of opportunities and challenges and the ability to serve as the primary data collection point for a large fraction of the U.S. population. Until such a clearly preferred locus of data collection emerges, it will be necessary for existing entities to collect these data using standardized categories and work to develop methods and policies for sharing the data so as to reduce the duplication of effort that occurs when all entities attempt to collect the data at most or all encounters.
All entities should collect these data, knowing their limitations and constraints, and implement steps to address these limitations and constraints. These steps can improve data collection processes by addressing HIT constraints and minimizing respondent and organizational resistance. To enhance legacy HIT systems, standardized communication protocols are needed to permit interoperability, and some systems will require upgrading. Training staff and educating communities about the importance of collecting race, ethnicity, and language data for improving health and the quality of health care are also necessary.
Direct collection of race and ethnicity data is preferable to observation and to indirect methods. When direct collection is impossible or has not been completed, however, indirect approaches can be employed. These approaches include linking area-level population data from the Census to quality data, using data like names to infer race and ethnicity, and attributing Bayesian probabilities to indirectly estimated data. At the same time, indirect estimates are always inferior to data obtained directly from individuals, and data based on indirect estimation should never be included in an individual’s medical record.
REFERENCES
AHA (American Hospital Association). 2008. Annual survey of hospitals and health systems. Chicago, IL: American Hospital Association.
AHIP (America’s Health Insurance Plans). 2009. A legal perspective for health insurance plans: Data collection on race, ethnicity, and primary language. Washington, DC: America’s Health Insurance Plans.
Baker, D. W., K. A. Cameron, J. Feinglass, P. Georgas, S. Foster, D. Pierce, J. A. Thompson, and R. Hasnain-Wynia. 2005. Patients’ attitudes toward health care providers collecting information about their race and ethnicity. Journal of General Internal Medicine 20(10):895-900.
Baker, D. W., R. Hasnain-Wynia, N. R. Kandula, J. A. Thompson, and E. R. Brown. 2007. Attitudes toward health care providers, collecting information about patients’ race, ethnicity, and language. Medical Care 45(11):1034-1042.
Barnes, P. M., P. F. Adams, and E. Powell-Griner. 2008. Health characteristics of the Asian adult population: United States, 2004-2006. Hyattsville, MD: National Center for Health Statistics.
Beal, A. C. 2004. Policies to reduce racial and ethnic disparities in child health and health care. Health Affairs 23(5):171-179.
Beal, A. C., M. M. Doty, S. E. Hernandez, K. K. Shea, and K. Davis. 2007. Closing the divide: How medical homes promote equity in health care: Results from The Commonwealth Fund 2006 Health Quality Survey. New York: The Commonwealth Fund.
Blumenthal, D. 2009. Stimulating the adoption of health information technology. New England Journal of Medicine 360(15):1477-1479.
Bonito, A. J., C. Bann, C. Eicheldinger, and L. Carpenter. 2008. Creation of new race-ethnicity codes and socioeconomic status (SES) indicators for Medicare beneficiaries. Final report, sub-task 2. Rockville, MD: RTI International.
Buescher, P. A., Z. Gizlice, and K. A. Jones-Vessey. 2005. Discrepancies between published data on racial classification and self-reported race: Evidence from the 2002 North Carolina live birth records. Public Health Reports 120(4):393-398.
Certification Commission for Healthcare Information Technology. 2007. Certification of ambulatory EHRs. Chicago, IL: Certification Commission for Healthcare Information Technology.
Chin, M. H., A. C. Kirchhoff, A. E. Schlotthauer, J. E. Graber, S. E. Brown, A. Rimington, M. L. Drum, C. T. Schaefer, L. J. Heuer, E. S. Huang, M. E. Shook, H. Tang, and L. P. Casalino. 2008. Sustaining quality improvement in community health centers: Perceptions of leaders and staff. Journal of Ambulatory Care Management 31(4):319-329.
Coltin, K. 2009. Implementation challenges for health plan collection of race, ethnicity & language data. Harvard Pilgrim Health Care. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, February 9, 2009. Washington, DC. PowerPoint presentation.
Craemer, T. 2009 May 25. Can a survey change one’s race? An experiment on context effects and racial self-classification. Paper presented at the Annual Meeting of the American Association for Public Opinion Association, Fontainebleau Resort, Miami Beach, FL.
De Milto, L. 2009. Bolstering electronic health records at four community health centers in Chicago with race, ethnicity and language data. Princeton, NJ: Robert Wood Johnson Foundation.
Elliott, M. 2009. Use of indirect measures of race/ethnicity to target disparities. RAND Corporation. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, March 12, 2009. Newport Beach, CA. PowerPoint presentation.
Elliott, M. N., A. Fremont, P. A. Morrison, P. Pantoja, and N. Lurie. 2008. A new method for estimating race/ethnicity and associated disparities where administrative records lack self-reported race/ethnicity. Health Services Research 43(5):1722-1736.
Ezzati-Rice, T. M., and L. R. Curtin. 2001. Population-based surveys and their role in public health. American Journal of Preventive Medicine 20(4):15-16.
Fiscella, K., and A. M. Fremont. 2006. Use of geocoding and surname analysis to estimate race and ethnicity. Health Services Research 41(4p1):1482-1500.
Foley, K. L., J. Manuel, and M. Vitolins. 2005. The utility of self-report in medical outcomes research. Evidence-Based Healthcare and Public Health 9(3):263-264.
Freeman, G., and M. Lethbridge-Cejku. 2006. Access to health care among Hispanic or Latino women: United States, 2000-2002. Advance Data (368):1-25.
Fremont, A. 2009. Practical applications of indirect estimates of race/ethnicity & lessons learned. RAND Corporation. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, March 12, 2009. Newport Beach, CA. PowerPoint presentation.
Fremont, A. M., A. Bierman, S. L. Wickstrom, C. E. Bird, M. Shah, J. J. Escarce, T. Horstman, and T. Rector. 2005. Use of geocoding in managed care settings to identify quality disparities. Health Affairs 24(2):516-526.
Gallegos, J., E. Mulamula, J. Patnosh, and C. Ulmer. 2008. Serving patients with limited English proficiency: Results of a community health center survey. Bethesda, MD: National Association of Community Health Centers.
Hahn, R. A., B. I. Truman, and N. D. Barker. 1996. Identifying ancestry: The reliability of ancestral identification in the United States by self, proxy, interviewer, and funeral director. Epidemiology 7(1):75-80.
Hasnain-Wynia, R. 2007. Collecting race, ethnicity, and primary language data in small physician practices. Chicago, IL: Health Research and Educational Trust/AHA. PowerPoint presentation.
Hasnain-Wynia, R., D. Pierce, and M. A. Pittman. 2004. Who, when, and how: The current state of race, ethnicity, and primary language data collection in hospitals. New York: The Commonwealth Fund.
Hasnain-Wynia, R., D. Pierce, A. Haque, C. H. Greising, V. Prince, and J. Reiter. 2007. Health Research and Educational Trust Disparities Toolkit. www.hretdisparities.org (accessed December 18, 2008).
Hasnain-Wynia, R., J. Yonek, D. Pierce, R. Kang, and C. H. Greising. 2006. Hospital language services for patients with limited English proficiency: Results from a national survey. Chicago, IL: Health Research and Educational Trust/AHA.
Healthcare Financial Management Association. 2007. The emergency department as admission source. Westchester, IL: Healthcare Financial Management Association.
Higgins, P. C., and E. F. Taylor. 2009. Measuring racial and ethnic disparities in health care: Efforts to improve data collection. Princeton, NJ: Mathematica Policy Research.
HL7 (Health Level 7). 2009. What is HL7? http://www.hl7.org/about/hl7about.htm (accessed May 22, 2009).
HRSA (Health Resources and Services Administration). 2009. The Health Center Program: Program assistance letter 2009-02, Uniform Data System changes for calendar year 2009. Rockville, MD: U.S. Department of Health and Human Services.
Hurley, R., L. Felland, and J. Lauer. 2007. Issue Brief No. 116: Community health centers tackle rising demands and expectations. Washington, DC: Center for Studying Health System Change.
Jha, A. K., C. M. DesRoches, E. G. Campbell, K. Donelan, S. R. Rao, T. G. Ferris, A. Shields, S. Rosenbaum, and D. Blumenthal. 2009. Use of electronic health records in U.S. hospitals. New England Journal of Medicine 360(16):1628-1638.
Kagawa-Singer, M., and N. Pourat. 2000. Asian American and Pacific Islander breast and cervical carcinoma screening rates and Healthy People 2000 objectives. Cancer 89(3):696-705.
Kmetik, K. 2009. American Medical Association. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, February 10, 2009. Washington, DC. PowerPoint Presentation.
Krieger, N., J. T. Chen, P. D. Waterman, D. H. Rehkopf, and S. V. Subramanian. 2003a. Race/ethnicity, gender, and monitoring socioeconomic gradients in health: A comparison of area-based socioeconomic measures—the Public Health Disparities Geocoding Project. American Journal of Public Health 93(10):1655-1671.
———. 2005. Painting a truer picture of US socioeconomic and racial/ethnic health inequalities: The Public Health Disparities Geocoding Project. American Journal of Public Health 95(2):312-323.
Krieger, N., J. T. Chen, P. D. Waterman, M. J. Soobader, S. V. Subramanian, and R. Carson. 2003b. Choosing area based socioeconomic measures to monitor social inequalities in low birth weight and childhood lead poisoning: The Public Health Disparities Geocoding Project. Journal of Epidemiology and Community Health 57(3):186-199.
Krieger, N., P. D. Waterman, J. T. Chen, M. J. Soobader, and S. V. Subramanian. 2003c. Monitoring socioeconomic inequalities in sexually transmitted infections, tuberculosis, and violence: Geocoding and choice of area-based socioeconomic measures—The Public Health Disparities Geocoding Project (US). Public Health Reports 118(3):240-260.
Lurie, N. 2009. Needed: National standardization of race/ethnicity data to address health disparities. RAND Corporation. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, February 9, 2009. Washington, DC. PowerPoint presentation.
Madans, J. H. 2009. Race/ethnic data collection: Population surveys and administrative records. National Center for Health Statistics. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, February 9, 2009. Washington, DC. PowerPoint presentation.
Maizlish, N., and L. Herrera. 2006. Race/ethnicity in medical charts and administrative databases of patients served by community health centers. Ethnicity and Disease 16:483-487.
Manatt Health Solutions and RSM McGladrey. 2007. Improving commercial reimbursement for community health centers: Case studies and recommendations for New York. New York: RCHN Community Health Foundation.
Massachusetts Executive Office of Health and Human Services. 2009. FY2007 inpatient hospital discharge database documentation manual. Boston, MA: Division of Health Care Finance and Policy.
Mays, V. M., S. D. Cochran, and N. A. Ponce. 2004. Thinking about race and ethnicity in population-based studies of health. In Race & research, perspectives on minority participation in health studies. Washington, DC: American Public Health Association.
Mutha, S., R. Do, and N. Solomon. 2008. Incorporating cultural competence into pay-for-performance. Paper presented at Quality Health Care for Culturally Diverse Populations, September 22, 2008, Minneapolis, MN.
National Association of Community Health Centers. 2006. 2006 Data on Community Health Centers, summary of findings. Bethesda, MD: National Association of Community Health Centers.
NCHS (National Center for Health Statistics). 2009. Health, United States, 2008. Hyattsville, MD: Department of Health and Human Services.
NCQA (National Committee for Quality Assurance). 2006. Innovative practices in multicultural health care. Washington, DC: NCQA.
———. 2008. Innovative practices in multicultural health care. Washington, DC: NCQA.
———. 2009. Supporting small practices: Lessons for health reform. Washington, DC: NCQA.
Nerenz, D. R., and D. Darling. 2004. Addressing racial and ethnic disparities in the context of Medicaid managed care: A six-state demonstration project. Rockville, MD: HRSA.
Nerenz, D. R., C. Currier, and K. Paez, eds. 2004. Collection of data on race/ethnicity by private sector organizations, results of a medical group survey. In Eliminating disparities: Measurement and data needs, p.249-271. Washington, DC: The National Academies Press.
NQF (National Quality Forum). 2008. National voluntary consensus standards for ambulatory care—measuring healthcare disparities. Washington, DC: National Quality Forum.
NRC (National Research Council). 2009. Principles and practices for a federal statistical agency: Fourth edition. Edited by C. F. Citro, M. E. Martin and M. L. Straf. Washington, DC: The National Academies Press.
OMB (Office of Management and Budget). 1997. Recommendations from the Interagency Committee for the Review of the Racial and Ethnic Standards to the Office of Management and Budget concerning changes to the standards for the classification of federal data on race and ethnicity. Federal Register (3110-01):36873-36946.
Palaniappan, L. P., E. C. Wong, J. J. Shin, M. R. Moreno, and R. Otero-Sabogal. 2009. Collecting patient race/ethnicity and primary language data in ambulatory care settings: A case study in methodology. Health Services Research. http://www3.interscience.wiley.com/cgi-bin/fulltext/122465240/PDFSTART (accessed September 3, 2009).
Ponce, N. A., N. Chawla, S. H. Babey, M. S. Gatchell, D. A. Etzioni, B. A. Spencer, E. R. Brown, and N. Breen. 2006. Is there a language divide in Pap test use? Medical Care 44(11):998-1004.
Rachman, F. 2007. Chicago Alliance of Community Health Centers pioneers EHR implementation with AHRQ support Rockville, MD: AHRQ.
Regenstein, M., and D. Sickler. 2006. Race, ethnicity, and language of patients: Hospital practices regarding collection of information to address disparities in health care. Princeton, NJ: Robert Wood Johnson Foundation.
Reynolds, P. P. 1997. The federal government’s use of Title VI and Medicare to racially integrate hospitals in the United States, 1963 through 1967.American Journal of Public Health 87(11):1850-1858.
Romano, P. S., J. J. Geppert, S. Davies, M. R. Miller, A. Elixhauser, and K. M. McDonald. 2003. A national profile of patient safety in U.S. Hospitals. Health Affairs 22(2):154-166.
Rosenthal, M. B., B. E. Landon, S. L. Normand, T. S. Ahmad, and A. M. Epstein. 2009. Engagement of health plans and employers in addressing racial and ethnic disparities in health care. Medical Care Research and Review 66(2):219-231.
Shields, A. E., P. Shin, M. G. Leu, D. E. Levy, R. M. Betancourt, D. Hawkins, and M. Proser. 2007. Adoption of health information technology in community health centers: Results of a national survey. Health Affairs 26(5):1373-1383.
Siegel, B., J. Bretsch, K. Jones, V. Sears, L. Vaquerano, and M. J. Wilson. 2008. Expecting Success: Excellence in cardiac care. Results from Robert Wood Johnson Foundation Quality Improvement Collaborative. Princeton, NJ: Robert Wood Johnson Foundation.
Siegel, B., M. Regenstein, and K. Jones. 2007. Enhancing public hospitals’ reporting of data on racial and ethnic disparities in care. New York: The Commonwealth Fund.
Sweeney, C., S. L. Edwards, K. B. Baumgartner, J. S. Herrick, L. E. Palmer, M. A. Murtaugh, A. Stroup, and M. L. Slattery. 2007. Recruiting Hispanic women for a population-based study: Validity of surname search and characteristics of nonparticipants. American Journal of Epidemiology 166(10):1210-1219.
Taylor, J. 2004. The fundamentals of community health centers. Washington, DC: The George Washington University National Health Policy Forum.
Ting, G. 2009. Applications of indirect estimation of race/ethnicity data in health plan activities. Wellpoint. Presentation to the IOM Committee on Future Directions for the National Healthcare Quality and Disparities Reports, March 12, 2009. Newport Beach, CA. PowerPoint presentation.
U.S. Census Bureau. 2000. Census 2000 summary file 1: 100-percent data. Washington, DC: U.S. Census Bureau.
Wei, I. I., B. A. Virnig, D. A. John, and R. O. Morgan. 2006. Using a Spanish surname match to improve identification of Hispanic women in Medicare administrative data. Health Services Research 41(4):1469-1481.
Weinick, R. M., J. M. Caglia, E. Friedman, and K. Flaherty. 2007. Measuring racial and ethnic health care disparities in Massachusetts. Health Affairs 26(5):1293-1302.
Weinick, R. M., K. Flaherty, and S. J. Bristol. 2008. Creating equity reports: A guide for hospitals. Boston, MA: The Disparities Solution Center at Massachusetts General Hospital.
West, C. N., A. M. Geiger, S. M. Greene, E. L. Harris, I. L. Liu, M. B. Barton, J. G. Elmore, S. Rolnick, L. Nekhlyudov, A. Altschuler, L. J. Herrinton, S. W. Fletcher, and K. M. Emmons. 2005. Race and ethnicity: Comparing medical records to self-reports. Journal of the National Cancer Institute. Monographs. (35):72-74.
Williams, D. R. 1998. The quality of racial data. Washington, DC: U.S. Department of Health and Human Services.
Zandieh, S. O., K. Yoon-Flannery, G. J. Kuperman, D. J. Langsam, D. Hyman, and R. Kaushal. 2008. Challenges to EHR implementation in electronic- versus paper-based office practices. Journal of General Internal Medicine 23(6):755-761.




















