
6
Generalizability of Benefit-Cost Analyses
Although methods for estimating costs and valuing outcomes raise many important conceptual issues, they are of less interest to policy makers than accurate general conclusions that can be drawn from a body of research. As the methodological discussions suggest, generalizing from studies of the benefits and costs of early childhood interventions poses its own complexities. Mark Lipsey discussed the potential value of meta-analysis for this purpose, and Howard Bloom examined some broad design and analysis considerations.
META-ANALYSIS
Lipsey began by suggesting that, when research findings can be generalized, it means that the same intervention will produce the same or nearly the same effect despite variation on some dimensions, such as the characteristics of the providers or recipients of the intervention, the setting, and perhaps certain nonessential features of the intervention itself. Ideally, a generalization is based on a relatively large sample of research studies of effectiveness; the studies will have used representative probability samples of the population of interest and random assignment in order to provide both internal and external validity in the same study. That ideal is hard to attain, Lipsey noted. Studies that have evidence of internal but not external validity and that use samples that are “not-too-unrepresentative” are more common.
Meta-analysis across such studies provides a next-best approach to
drawing as much information as possible from multiple studies, particularly when the interventions are similar and the samples represented are diverse across the studies. The most important feature of a meta-analysis is representation of the effects on a certain outcome in terms of a standardized effect size that can be compared across studies. Analysis then focuses on the distribution of effect sizes—the central tendency of that distribution and also the variation around that mean. The key question is the extent to which that variation is associated with or can be explained by moderator variables, such as differences in setting, subject characteristics, and so on. So, in essence, meta-analysis is the empirical study of the generalizability of intervention effects.
A few issues make this analysis challenging. First, the question of what constitutes the “same” intervention is complicated. Few interventions are crisply and unambiguously defined, and the developers of an intervention may modify it as they learn from experience. At what point are the modifications sufficient to produce a different intervention? In general, meta-analyses are designed to focus on a type of intervention defined generically, rather than in terms of a specific intervention protocol. However, there are no formal typologies to which researchers could turn for grouping similar interventions in areas like early childhood programs. Because there is no “periodic table of the elements for social interventions,” Lipsey pointed out, classification is a judgment call, and not all analysts will make it in the same way.
A related problem is that, even with any reasonably concise definition of a particular intervention, variability abounds. A statistical test used in meta-analysis, the Q test, is a tool for answering the question of whether or not the between-study variation on the effect sizes for a given outcome is greater than one would expect from the within-study sampling error. Lipsey explained that “it’s not unusual to find three, four, five, six, eight, even ten times as much variability across studies [of social interventions] as one would expect just from the sampling error within.” This degree of variability—far greater than what is typical in medical studies, for example—is inconsistent with a conclusion that the effects can be generalized. Figure 6-1 illustrates the major sources of variance in studies of social interventions, using the results of an analysis of meta-analyses of psychological, education, and behavioral interventions (Wilson and Lipsey, 2001). The numbers reflect the rough proportions of different sources of variation. Lipsey highlighted how much of the variability is associated with aspects of the methodology—almost as much as is associated with the characteristics of the interventions themselves.
In other words, he noted, “effect size distributions are being driven almost as much by the input of the researchers as they are by the phenomenon that researchers are studying.” And this variability may obscure
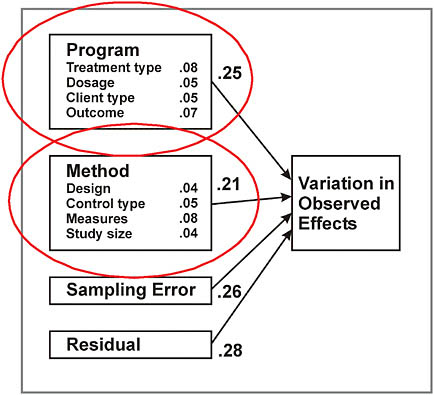
FIGURE 6-1 Many sources of variance in observed effects of social interventions.
NOTE: Estimates based on 300 meta-analyses of intervention studies.
SOURCE: Lipsey (2009).
any real effects. The fact that there is so much variability across studies also highlights important questions about interpreting a single study. The results of single studies are partly a function of the design, procedures, measurement, timing, and so forth; but without the context of other studies, that variability is not evident. Lipsey explained that the methodological variability not only results from differences in design associated with randomization, but also stems from variation in the way outcomes are operationalized. Because there is no settled way of measuring, for example, the noncognitive outcomes of pre-K programs, researchers have been creative, using parent reports, teacher reports, observations, or various standardized scales. They presume that these measures are all targeting the same underlying construct, but there is little evidence to support that presumption.
The biggest problem, however, may be that methodological variation tends to be confounded with substantive variables. Suppose two stud-
ies with different outcomes and samples also show different results that suggest the intervention may work better for African American children than for white children. In fact, those different results may be the result of different measurement procedures or other methodological differences between the two studies and not differential effectiveness of the intervention at all. Since there is significant variation even among studies of a very specific intervention, it is important to consider other factors that may be just as influential on the results.
Still another complication arises because so many studies are small-scale research and development projects, in which the researcher has designed a program and then evaluates it. In practice, there are very few studies in which an independent evaluator studies a real-world program implemented in routine practice. Lipsey reported that his meta-analytical work indicates that research and development studies showed approximately twice the effect size as studies of routine practice. This suggests that one cannot necessarily expect the effects from research and development studies to carry forward when the program is scaled up in a real-world setting.
One implication of this large degree of variation is that the average effect size is unrepresentative of the intervention effects when there is a broad distribution—so variability around the mean effect size is a more useful result to examine. For example, the average effect might be small, but the high end of the distribution could show quite large effect sizes while the low end showed a negative effect. Estimates of average effect sizes are typically used in benefit-cost analysis, so Lipsey urged that they be interpreted with caution.
What can be done about these difficulties? One approach is response surface or, more specifically, effect size surface modeling, an approach for statistically modeling the relationships between intervention effects and key explanatory variables.1 The response surface is defined by the multiple dimensions of interest along which effects—such as subject characteristics, intervention characteristics, settings, methodology, and the like—vary. Multivariate regression models are used to predict the expected outcomes for a range of scenarios, defined as particular relationships among these varying characteristics. With sufficient studies to map this surface, it is possible to make assumptions about various factors (such as methodology, clientele, setting, and so forth) and estimate the effect size that would be likely in a particular scenario—even if some combinations are not represented in any study.
The result of this sort of analysis is likely to provide a better characterization of intervention effects than a simple mean effect size across avail-
able studies, in Lipsey’s view. However, to conduct this analysis requires a relatively large number of diverse studies that provide detailed reporting on the dimensions of interest. Lipsey pointed out that many studies include pages of discussion of methodology, dependent variables, and so forth, with just a few sentences devoted to describing the intervention itself. Nevertheless, this multivariate modeling approach could make it possible to get more out of small, well-executed studies than from larger, more expensive studies that may represent less diversity on key dimensions and be somewhat underpowered, despite their size, for detecting moderator relationships on those dimensions.
DESIGN AND ANALYSIS CONSIDERATIONS
Building on Lipsey’s discussion, Howard Bloom addressed a few key issues that arise when researchers attempt to generalize from observed variation in intervention effects. He began with what he described as first principles:
-
The purpose of generalizing is to create knowledge by deepening understanding and to inform decisions by projecting findings beyond their immediate context.
-
Generalizations project findings to larger populations, sets of outcomes, types of interventions, or types of environments.
-
Generalization is done using both statistical sampling and through explanation.
He turned first to the question of how to plan for, analyze, and interpret subgroup findings. The dilemma, he explained, is reconciling different sorts of information into accurate findings that make sense to different audiences. Practitioners treat individuals, policy makers target defined groups, and researchers study averages and patterns of variation—yet all need to learn from the same sources of information. That dilemma translates into questions about how to test multiple hypotheses and identify statistically significant findings. Statistics, he noted, is very limited in its ability to deal with subgroup analysis without using extremely conservative adjustments in advance to avoid Type 1 errors, which tend to wipe out any hints of effects.
One participant noted that results may be very different, depending on whether the analysis uses an interaction model, in which there is a main effect and an interaction effect (as psychologists often prefer) or uses a split sample, and asked whether it would be best to report both. Bloom suggested that the difference is more than technical, that the two methods
actually answer different questions: “Is there a difference among the subgroups?” versus “Is there an interaction effect among several factors?”
Bloom suggested two points to guide effective generalizations. First is specifying subgroups of interest in advance, on the basis of theory, empirical evidence, and policy relevance. Findings that are relevant to subgroups that are defined after the study, based on the results, are exploratory, he suggested, and should be treated differently from findings that confirm (or disconfirm) a hypothesis that was tested. Second, it is important to consider both statistical and substantive significance. There are many ways to assess the statistical significance of findings, looking at the presence of an effect for different subgroups, the size of the effect, and so on. But translating complex findings into substantive messages for nonstatisticians is tricky. For example, small differences between results for subgroups could easily be misinterpreted as suggesting that an intervention was effective for one group and not for the other, when in fact the difference between the groups was not statistically significant.
As an example of a study that successfully modeled variation and effects across subgroups, sites, and studies, Bloom cited one conducted by MDRC of the effects of mandatory welfare-to-work programs for female single parents (Bloom, Hill, and Riccio, 2003). The researchers pulled together data from three MDRC studies to examine the effects of program implementation, the nature of the services offered, client characteristics, and economic conditions. They used a two-level hierarchical model of cross-site variation in experimental estimates of program effects; data covered 59 program offices in 8 states and more than 69,000 participants and included administrative records, participant surveys, and office staff surveys.
The programs studied provided basic education, assistance with job searches, and vocational training. The programs varied in the extent to which they emphasized personal attention to each client and the goal of helping clients secure employment quickly and in other aspects of implementation, and the studies used common measures of these sources of variation. The researchers wanted to find out which characteristics had the biggest impact on short-term outcomes—the outcome measure they used was client earnings during the first two years after they were randomly assigned to receive or not receive the intervention (they also had regional unemployment data for the period studied).
The study had a twofold purpose, however. It was designed not only to build understanding of the relationship between the ways the programs were implemented and their impact, but also to demonstrate a model for generalizing from a range of information. The key findings were the following:
-
A strong employment message markedly increased program effects (this was the strongest effect).
-
Emphasis on personal client attention increased program effects.
-
Large caseloads reduced program effects.
-
Reliance on basic education reduced program effects in the short run.
-
High unemployment reduced program effects.
-
Program effects did not vary consistently with client characteristics.
Perhaps more important, however, is success with a research model that makes use of preplanned subgroup analysis as well as common measures and protocols across studies. Others agreed, suggesting that if some modest core measures for critical outcomes and variables could be established for common use, it would greatly facilitate the work of meta-analysis.







