
2
Behavioral Tools and Techniques
In what ways might particular tools and techniques from the behavioral sciences assist the intelligence and counterintelligence community? A variety of devices and approaches derived from the behavioral sciences have been suggested for use or have already been used by the intelligence community. In the workshop’s first session, speakers described several of these, with a particular emphasis on how the techniques have been evaluated in the field. As Robert Fein put it, “Our spirit here is to move forward, to figure out what kinds of new ideas, approaches, old ideas might be useful to defense and intelligence communities as they seek to fulfill what are often very difficult and sometimes awesome responsibilities.”
To that end the speakers provided case studies of various technologies with potential application to the intelligence field. One common thread among all of these disparate techniques, a point made throughout the workshop, is that none of them has been subjected to a careful field evaluation.
DECEPTION DETECTION
People in the military, in law enforcement, and in the intelligence community regularly deal with people who deceive them. These people may be working for or sympathize with an adversary, they may have done something they are trying to hide, or they may simply have their own personal reasons for not telling the truth. But no matter the reasons,
an important task for anyone gathering information in these arenas is to be able to detect deception. In Iraq or Afghanistan, for example, soldiers on the front line often must decide whether a particular local person is telling the truth about a cache of explosives or an impending attack. And since research has shown that most individuals detect deception at a rate that is little better than random chance, it would be useful to have a way to improve the odds. Because of this need, a number of devices and methods have been developed that purport to detect deception. Two in particular were described at the workshop: voice stress technologies and the Preliminary Credibility Assessment Screening System.
Voice Stress Technologies
Of the various devices that have been developed to help detect lies and deception, a great many fall in the category of voice stress technologies. Philip Rubin, chief executive officer of Haskins Laboratories and chair of the Board on Behavioral, Cognitive, and Sensory Sciences at the National Research Council, offered a brief overview of these technologies and of how well they have performed on objective tests.
The basic idea behind all of these technologies, he explained, is that a person who answers a question deceptively will feel a heightened degree of stress, and that stress will cause a change in voice characteristics that can be detected by a careful analysis of the voice. The change in the voice may not be audible to the human ear, but the claim is that it can be ascertained accurately and reliably by using signal-processing techniques.
More specifically, many of the voice stress technologies are based on the assumption that microtremors—vibrations of such a low frequency that they cannot be detected by the human ear—are normally present in human speech but that when a person is stressed, the microtremors are suppressed. Thus by monitoring the microtremors and noting when they disappear, it should be possible to determine when a person is speaking under stress—and presumably lying or otherwise trying to deceive.
A number of different voice stress technologies have been manufactured and marketed, most of them to law enforcement agencies, but some also to insurance fraud investigators and to various intelligence organizations, including a number in the U.S. Department of Defense. One of the earliest products was the Psychological Stress Evaluator from Dektor Corporation. Originally developed in 1971, it has gone through numerous modifications, and a version is still being sold today. Other voice stress technologies include the Digital Voice Stress Analyzer from the Baker Group, the Computer Voice Stress Analyzer from the National Institute for Truth Verification, the Lantern Pro from Diogenes, and the Vericator from Nemesysco.
Over the years, these technologies have been tested by various researchers in various ways, and Rubin described a 2009 review of these studies that was carried out by Sujeeta Bhatt and Susan Brandon of the Defense Intelligence Agency (Bhatt and Brandon, 2009). After examining two dozen studies conducted over 30 years, the researchers concluded that the various voice stress technologies were performing, in general, at a level no better than chance—a person flipping a coin would be equally good at detecting deception. In short, there was no evidence for the validity or the reliability of voice stress analysis for the detection of deception in individuals.
Furthermore, Rubin said, not only is there no evidence that voice stress technologies are effective in detecting stress, but also the hypothesis underlying their use has been shown to be false. If indeed there are microtremors in the voice, then they must result from tremors in some part of the vocal tract—the larynx, perhaps, or the supralaryngeal vocal tract, which is everything above the larynx, including the oral and nasal cavities. Using a technique called electromyography to measure the electrical signals of muscle activities, physiologists have found that there are indeed microtremors of the correct frequency—about 8 to 12 hertz—in some muscles, including those of the arm. So it would seem reasonable to think that there might also be such microtremors in the vocal tract, which would produce microtremors in the voice. However, research has found no such microtremors, either in the muscles of the vocal tract or in the voice itself. So the basic idea underlying voice stress technologies—that stress causes the normal microtremors in the voice to be suppressed—is not supported by the evidence.
Rubin did not claim that voice stress technologies do not work, only that there has been extensive testing with very little evidence that such technologies do work. It is possible that some of the technologies do work under certain conditions and in certain circumstances, but if that is so, more careful testing will be needed to determine what those conditions and circumstances are. And only when such testing has been carried out and the appropriate conditions and circumstances identified will it make sense to carry out field evaluations of such technologies. At this point, voice stress technologies are not ready for field evaluation.
For the most part, Rubin said, the intelligence community has now stayed away from voice stress technologies mainly because of the absence of any evidence supporting their accuracy. But the law enforcement community has taken a difference approach. Despite the lack of evidence that the various voice stress technologies work, and despite the absence of any field evaluations of them, the technologies have been put to work by a number of law enforcement agencies around the country and around the world. It is not difficult to understand the reasons, Rubin said. The
devices are inexpensive. They are small and do not require that sensors be attached to the person being questioned; indeed, they can even be used in recorded sessions. And they require much less training to operate than a polygraph.
Many people in law enforcement believe that the voice stress technologies do work; even among those who are convinced that the results of the technologies are unreliable, many still believe that the devices can be useful in interrogations. They contend that simply questioning a person with such a device present can, if the person believes that it can tell the difference between the truth and a lie, induce that person to tell the truth.
Preliminary Credibility Assessment Screening System
With the reliability of voice stress technologies called into question, the intelligence community needed another way to screen for deception. Donald Krapohl, special assistant to the director of the Defense Academy for Credibility Assessment (DACA), described to the workshop audience how, several years ago, the Pentagon asked DACA for a summary of the research on voice stress technologies. DACA, which is part of the Defense Intelligence Agency in the Department of Defense, provided a review of what was known about voice stress analysis, and, as Krapohl put it, “it was rather scary to them, and they decided to pull those technologies back.”
The need for deception detection remained, however, and DACA’s headquarters organization, the Counterintelligence Field Activity (CIFA),1 was given the job of finding a new technology that would do the same job that voice stress technologies were supposed to perform but with significantly more accuracy. There were a number of requirements in order for a device to be effective in the field: it had to have low training requirements, as it would be used by soldiers on the front line rather than interrogation specialists; ideally it would require no more than a week of training. It needed to be highly portable and easy to use for the average soldier. It needed to be rugged, as inevitably it would be dropped, get wet, and get dirty.
And it had to be a deception test, not a recognition test. That is, instead of recognizing when someone knows something that they are trying to hide—the so-called guilty knowledge test—it should be able to detect when someone was giving a deceptive answer to a direct question. There is a great deal of research concerning the guilty knowledge
test, Krapohl explained, but the test is not particularly useful in the field because the interviewers must know something about the “ground truth.” Deception tests, by contrast, are not as well understood by the scientific community, but they are far more useful in the field, where interviewers may not know the ground truth.
The final requirement for the device was that it needed to be relatively accurate as an initial screening tool. It was never intended to provide a final answer of whether someone was telling the truth. Its purpose instead was to provide a sort of triage: when soldiers in the field question someone who claims to have some information, they need to weed out those who are lying. The ones who are not weeded out at this initial stage would be questioned further and in more detail. There are polygraph examiners who can perform extensive examinations, Krapohl explained, but their numbers are limited. “So if you could use a screening tool up front to decide who gets the interview, who gets the interrogation, who gets the polygraph examination, the commanders thought that would be very useful,” he said. “It was not designed to be a standalone tool. It was designed only as an initial assessment.”
The contract to develop such a device was given to the Applied Physics Laboratory at Johns Hopkins University along with Lafayette Instruments. The first prototype of the instrument, called the Preliminary Credibility Assessment Screening System, or PCASS, was finished in January 2006, and it was delivered to DACA for validation.
The PCASS consists of three sensors connected to a personal digital assistant. Two of the sensors are electrodermal sensors, which measure the electrical conductivity of the skin, and one is a photoplethysmograph, which is attached to a finger and used to measure changes in blood flow. The signals from the sensors are fed through an analog-to-digital converter and sent to the personal digital assistant for analysis.
The PCASS is used very much like a polygraph, with an interview phase in which the person being tested is asked a series of questions about such things as personal health, followed by a review of the test questions, then the asking of the test questions, which are designed to be answered with a yes or a no. Where PCASS differs from a polygraph is in how the test results are presented. Unlike a polygraph, which delivers a collection of data records that must be interpreted by someone trained in polygraphy, the PCASS device flashes the words “red,” “yellow,” or “green” on a screen. “Red” indicates that the person had significant physiological reactions when asked significant questions, indicating that the person may have provided deceptive answers. “Green” indicates no significant physiological responses to the relevant questions, and “yellow” appears when the test was inconclusive.
One of the key facts about PCASS is that it was designed specifically
to detect deception, which made it possible, Krapohl said, to create an algorithm that considers all of the response data and provides a straightforward answer to the question of whether a person is being deceptive: yes, no, or maybe. It does not provide nearly as much information as a polygraph can, but that is not its purpose.
Krapohl described three tests that have been done to assess the accuracy of PCASS, two of them carried out by DACA and one by Battelle. The DACA tests were simulated bombing scenarios in which U.S. Army trainees at Ft. Jackson in South Carolina were randomly assigned to two groups, bombers and innocents. The bombers were instructed to take a simulated bomb and place it near a vehicle in a simulated village called Dragon City on the Ft. Jackson grounds; the innocents were told to walk to a particular area and stay there for 15 minutes. Afterward both innocents and bombers were given a PCASS examination by mid-level enlisted soldiers who had been recently trained by DACA on using PCASS.
The Battelle test was quite different. It was carried out in Columbus, Ohio, by people recruited from the community. The scenario involved the theft of a diamond ring from an office, and the PCASS examinations were carried out by retired law enforcement officers who had been recently trained in the use of PCASS.
The results of the three tests were significantly better than chance. Of the 109 guilty people in the three studies, the PCASS operators identified 75 of them as guilty, 11 of them as innocent, and the results for 23 were inconclusive. Of the 117 innocent people, the operators identified 78 of them as innocent, 19 as guilty, and the results for 20 were inconclusive.
If the inconclusives are considered to be errors, the operators were correct about 68 percent of the time. However, Krapohl noted, in practice the inconclusive results are not exactly errors because in the field a person who scores inconclusive will be given the test again in a day or two. If the inconclusive scores are not included in the results, the operators scored nearly 84 percent correct. The accuracy rates were highest in the Battelle test, whose operators got nearly 92 percent of the identifications right when the inconclusive scores are not considered.
It is not clear why the Battelle group scored higher, Krapohl said. The two scenarios were quite different, with one involving the planting of a bomb and the other the theft of a ring, and that may be part of the explanation. Perhaps the retired law enforcement officers who performed the tests had interrogation experience that allowed them to perform better even with a device they had just learned to use, or perhaps the civilians did not do as good a job as the Army soldiers in fooling the test. Whatever the reason for the difference, Krapohl said, the three tests indicate that PCASS does a good job of detecting deception in these created sce-
narios even when operated by people with relatively little experience in its use.
The technique is now being used by U.S. forces in a number of arenas, said Anthony Veney. Those arenas include Iraq and Afghanistan as well as Colombia, where PCASS is being used in counter-drug operations, he said.
As designed, the main function of the device has been as an initial assessment of whether someone is being deceptive, Veney said. “We use this as a triage tool. We needed to be able to quickly tell if an individual on the battlefield was telling us the truth. Once the person is back in an interrogation center, we have a very expert corps of interrogators that will have at him. We can use other tools like polygraphs to determine credibility.”2
PCASS allows soldiers who have been trained quickly in the technique to determine whether a person needs to be questioned further or to decide whether a person should be allowed to work on a U.S. forward operating base or in a U.S. installation in a battle zone, Veney explained. For example, for a source reporting information that he says he has collected, if he comes back red on a PCASS test, it is reasonable to assume that the source is not being honest and is not providing reliable information, so no further attention is paid to what he has to say. Similarly, if someone is requesting employment on or access to a base but comes up red on the test, he is sent away. However, Veney said, coming up green is not considered proof of trustworthiness. A person who comes up green on one test will continue to be tested over time.
In short, the main use for PCASS is on the front lines where soldiers need help in determining who seems trustworthy and who seems to have something to hide. But the technique is not assumed to give a definite answer, only a conditional one.
Because PCASS is used on the front lines, it has never been field tested, Veney explained. “This is way too dangerous on the battlefield, to have scientists roaming around doing additional research.” Still, it has proved its value in various ways, he said. In a recent operation in Iraq, for example, it allowed U.S. forces to identify a number of individuals who were working for foreign intelligence services and others who were working for violent extremist organizations. “It has been a godsend on the battlefield,” Veney said. In Colombia, PCASS made it possible to determine that several people who had claimed to the Colombian government
that they belonged to FARC, the Revolutionary Armed Forces of Colombia, actually did not belong to it.
Still, Krapohl said, there is more work to be done. The group at DACA thinks, for example, that by taking advantage of some of the state-of-the-art technologies for deception detection, it should be possible to develop more accurate versions of PCASS. In particular, by using the so-called directed lie approach—in which those being questioned are instructed to provide false answers to certain comparison questions—it should be possible to get greater standardization and less intrusiveness, he said.
Still, the issue of field evaluation remains, Krapohl said. Although the technique has been tested in the laboratory, there are no data on its performance in the field. “Doing validation studies of the credibility assessment technology in a war zone has a number of problems that we have not been able to figure out,” he said. Nonetheless, DACA researchers would like to come up with ideas for how PCASS and other credibility assessment technologies might be evaluated in the field.
In later discussions at the workshop, it became clear that a number of participants had serious doubts about the effectiveness of PCASS in the field, despite the fact that it is in widespread use and, as Veney noted, popular among at least some of the troops in the field. “Everybody in this room knows that there are real limitations to it,” Fein said. “I think we can do better than put something out there that has such limitations.” And Brandon commented that “if we were doing really good field validation with the PCASS” then it might well become obvious that other, less expensive methods could do at least as good a job as PCASS at detecting deception. There are a number of important questions concerning the validity and reliability of PCASS that can be addressed only by field evaluation, and until such validation is done, the troops in the field are relying on what is essentially an unproved technology.3
PREDICTION METHODS
One of the most common tasks given to intelligence analysts is to predict the future. They may be asked, for example, to forecast the chances
that one country will invade another or to predict whether a dictator will be overthrown. Peering into the future in this way demands a great deal of information about the present—much of which may be uncertain or simply not available—along with an understanding of the psychology of individuals, the dynamics of groups, and the inner workings of government bodies.
As Neil Thomason of the University of Melbourne noted in his workshop presentation, the standard technique in the intelligence community for making such predictions has been what might be called the expert judgment model: “You know the material, you talk with your colleagues, you think it over a lot, and you write up your final thoughts.” It is an approach that depends on individual analysts applying their knowledge, experience, and judgment to come up with the best predictions they can.
But how good are the predictions made by this expert judgment approach? As a partial answer, Thomason offered some data concerning the difficulties experts have in accurately predicting U.S. Supreme Court decisions.
Such predictions are extremely difficult to get right, he noted. There are nine Supreme Court justices, each with his or her idiosyncrasies, and the cases are heard against a huge background of legal precedent and, often, conflicting political agendas. Ruger and colleagues (2004) compared the predictions of 2002 Supreme Court decisions made by legal experts with those made by a crude flow chart, generated more or less mechanically and without any understanding of the legal issues involved. The issue for each case was a simple yes-or-no question: Will the Supreme Court reverse the ruling of the lower court?
The experts were from major law schools or appellate attorneys, and they made predictions only on cases in their areas of expertise. The study found that they were right about 59 percent of the time—better than flipping a coin, but not by much. The crude flow chart did much better, getting the right answer 75 percent of the time.
Similarly, Thomason said, a meta-analysis by Grove and colleagues (2000) examined about 140 studies pitting expert judgment against actuarial models, some of them very crude. Of these studies, the experts outperformed the actuarial models in only 8, the models outperformed the experts in 65, and the performance of the experts and the models was about the same in the remaining 63.
None of this shows that analysts in the intelligence community could be outperformed by predictive models, Thomason said, but it does suggest the possibility that such models can be used to improve expert judgments. And, indeed, over the past several decades, the intelligence community occasionally has used various models and approaches to help improve
predictions. The speakers at the workshop discussed two approaches in particular: structured-thinking techniques, also known as structured analytic techniques, and Bayesian analysis.
Alternative Competing Hypotheses
The basic idea behind structured-thinking techniques, Thomason explained, is to help experts structure their thinking so that various biases are alleviated or even avoided altogether. There is a well-known, well-established psychological literature on such biases that informs the techniques.
In intelligence circles, the best known and most commonly used structured-thinking technique is called Analysis of Competing Hypotheses, or ACH. It was developed in the 1970s by Richards J. Heuer, Jr., the same veteran intelligence officer at the Central Intelligence Agency (CIA) who wrote Psychology of Intelligence Analysis (Heuer, 1999). ACH is now used reasonably widely, not only in the intelligence community, but also in other fields in which one must make the best judgment on the basis of uncertain data.
The basic idea behind ACH, Thomason explained, is that there is a tendency among experts—as, more generally, among all of us—to ignore certain hypotheses and certain data when trying to make sense of a situation. The natural approach is to choose a hypothesis that seems most likely to be true and to see if the data support it. If supported, then the hypothesis is assumed to be correct; if not, the next most likely hypothesis is examined.
In contrast, the first step in ACH is to list at the outset all possible hypotheses, preferably by working with a number of people with different perspectives. Then one lists all the arguments and data that support or rebut each of the hypotheses. This process forces analysts to consider all of the hypotheses and all of the evidence. A series of steps follows: deciding how useful the various arguments and bits of evidence are in deciding among the hypotheses, using the evidence and arguments to attempt to disprove the various hypotheses, forming a tentative conclusion, analyzing the sensitivity of the conclusion to various key bits of evidence, and considering the consequences if particular pieces of evidence are wrong. After that, there follows a discussion of various hypotheses, not just one, and how likely each is to be correct.
Heuer’s belief, Thomason said, was that this approach would force analysts to pay attention to various alternatives, including hypotheses that they might otherwise ignore or play down and data that did not fit with their preferred theories. And many intelligence analysts do indeed believe that their predictions are much better because of ACH. But there
are very few studies to back this up. “Having looked at the literature, it just is not a proven process,” Thomason said. “As far as I can tell, the evidence is scant. There haven’t been many tests of it.”
To begin with, Thomason said, there is not a single ACH approach. Over time a number of variants on Heuer’s original approach have appeared, and Heuer himself has continued to modify the approach. For example, he initially called for a group of analysts to cooperate in generating a list of hypotheses, at which point a single analyst could take over. Others have since modified ACH to have such cooperation throughout the entire process. This might work better than the original method, or it might not—the issue is an empirical one that needs to be tested. More generally, Thomason commented, since there are a large number of different ACH approaches, evaluation requires a large number of tests.
A second question is, which sorts of people will find ACH most useful? Is it good for all analysts? Under all conditions? It might be, for instance, that ACH works best for experts because they are most likely to be dogmatic and in love with their own favorite hypotheses, even though they know many alternatives. Or it could be that it works best for novices, because it pushes them to think of more alternatives than they would otherwise imagine. Or maybe it is counterproductive for novices, since they don’t know enough to eliminate certain hypotheses and so their final products would be almost contentless. It is unclear.
In short, Thomason said, the question that needs to be asked is not, Does ACH work? but rather “For what situations (if any) and what types of people (if any) and under which conditions (if any) does a particular approach to ACH improve analysts’ expert judgments?”
Thomason said that the bottom line of the few studies that have been carried out apparently is that the approach has some promise and some problems. “It certainly isn’t obvious to me that it works. It certainly isn’t obvious to me that under certain circumstances it might not be counterproductive. I don’t know.”
It is frustrating, he said, that although ACH was originally proposed a third of a century ago and although it has achieved “a cult-like status” in the intelligence community, there have been so few studies that have tested whether and under what circumstances it actually works to improve the predictions of analysts. In part because of the intellectual isolation of the intelligence community, Thomason added, few researchers in informal logic or other areas pay attention to ACH, and so the normal scientific process that takes place in academia when a new theory or approach is suggested has not happened with ACH. The few experiments that were performed on ACH were not followed up, and the interesting results that come out of those experiments have not been developed. To fully understand the strengths and weaknesses of the various forms of
ACH, Thomason said, research conducted by the intelligence community must be supplemented by outside academic research. “It seems to me,” he said, “that limiting research on ACH and other structured techniques to the intelligence community probably means this [lack of serious science] will just go on indefinitely.”
It would be straightforward to have ACH and other structured-thinking techniques tested by the general scientific community of psychologists, Thomason suggested. It is simply a matter of providing the funding. And since the basic psychology of ACH should work equally well on problems outside the intelligence community, it should be possible to perform the tests in various settings with various types of participants. This should offer insight into which settings and for which types of users ACH is most effective in improving expert judgment.
Once these tests have been done, researchers can move on to field evaluation in the intelligence community. This should be relatively straightforward, Thomason said, and could be carried out in a variety of arenas that would not necessarily need to fall inside the intelligence community. One could, for instance, repeat the study on predicting Supreme Court decisions but do it with two groups: one group of legal specialists trained in ACH and a second group without ACH training. The results would be easy to interpret: if ACH works, the group using it should make more accurate predictions.
During the discussion session, Frank Stech from the MITRE Corporation agreed with Thomason that validation is important but suggested that it is understandable that ACH has not yet been validated despite having been developed more than 30 years ago. “Validation has been difficult in a number of fields,” he said, mentioning medicine as another area in which field studies are difficult to design. “We don’t need to just pick on the intelligence analysts.” Thomason responded that specialists in these other fields generally make a concerted effort to evaluate techniques even if the studies are difficult to design and perform. It is the lack of effort that has set the intelligence community apart, he said. Even when a study has produced interesting results, people have failed to pay attention or to follow up on it. “That is just way below scientific standards in academia.”
Randolph Pherson of Pherson Associates, stating that he is publishing a book with Heuer on instructional analytic techniques, noted that the largest chapter in the book is a detailed discussion of the importance of field validation. Indeed, Pherson said that he and Heuer are preparing some proposals and recommendations for strategies for performing validations of ACH and other techniques. Heuer himself recognizes that the techniques are ultimately of little use if there is no proof that they actually work, Pherson said, and so Heuer has pushed for field evaluation of those techniques.
In response, Thomason commented on the fact that, even with Heuer’s urging, the various versions of ACH have never been seriously evaluated. It is testimony to just how difficult it has been to have methods used by the intelligence community assessed in the field.
Applied Bayesian Analysis
A second approach to improving prediction applies Bayesian analysis, a statistical approach that uses observations and other evidence to regularly revise and update a hypothesis. Charles Twardy of George Mason University described APOLLO, a software application that uses an advanced form of Bayesian analysis called Bayesian network modeling to help analysts predict the likely behavior of a country’s leader or other persons of interest.
There is nothing new about using Bayesian analysis to improve prediction, Twardy said. From 1967 to 1979 the CIA had at least one active research group applying basic Bayesian analysis to making predictions. The analysts used their own intuition to assign an initial probability to an event and then modified that probability, either intuitively or mathematically, as certain events happened or failed to happen. The main difference between the Bayesian approach and the intuitive approach is that, for the Bayesian approach, the analysts had answered a series of what-if questions ahead of time about the probabilities of something being true if something else happened. Then, as events unfolded, the Bayesian method modified the initial estimated probability according to a mathematical formula that depended on the answers to the series of questions. Thus, although the Bayesian analysis did depend on input from the analysts, the analysts were not directly involved in modifying the probability over time.
One of the initial tests of Bayesian methods in intelligence analysis was a retrospective one. Some years after the end of the Korean War, the CIA research group examined the events leading up to the massive Chinese invasion of North Korea on November 25, 1950. At the time, the invasion by the Chinese caught the United Nations and U.S. forces completely off guard. However, Twardy said, a retrospective analysis using the Bayesian method applied to evidence available in mid-November estimated that the odds were three to one that the Chinese were about to intervene in the war on a large scale. If such an analysis had been performed at the time, the United States would not have been surprised by the invasion.
The retrospective analysis was more suggestive than convincing, Twardy noted, since things always seem clearer in hindsight. What was needed was evidence that it is possible to come to the right conclusion ahead of time.
Such evidence appeared with an experiment involving five analysts predicting the likelihood in mid-1969 that the Soviet Union would attempt to destroy China’s nascent nuclear capabilities. The five analysts used both conventional and Bayesian methods to estimate this likelihood over a period stretching from late August to late September 1969. In the conventional approach, the analysts assigned numerical probabilities based on their own judgment and intuition. The five analysts started out with varying estimates of the probability of a Soviet action—anywhere from 10 to 80 percent—and, as events unfolded throughout September 1969, all of them revised their estimates steadily downward until their estimated probabilities were close to zero.
For four of the five analysts, Twardy said, applying Bayesian statistics led them to the same conclusion—that the Soviets were not going to go to war with the Chinese—but it got them to that conclusion much more quickly. The results for two of the analysts are shown in Figure 2-1. “The Bayesian method generally made analysts revise their estimates faster than they would have intuitively done.”
Strangely, the Bayesian analysis performed by the fifth analyst (shown in Figure 2-2) had vastly different results from the analyses of the other four and by the end of September was still predicting a 75 percent chance
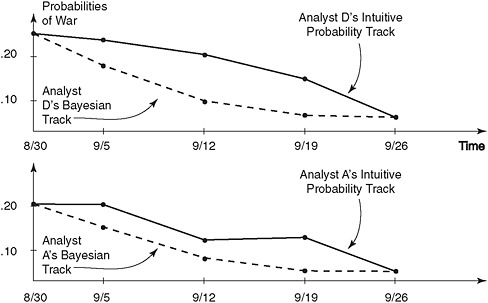
FIGURE 2-1 Probability tracks for Analysts A and D using both conventional and Bayesian methods.
SOURCE: Fisk (1972). Reprinted with permission.
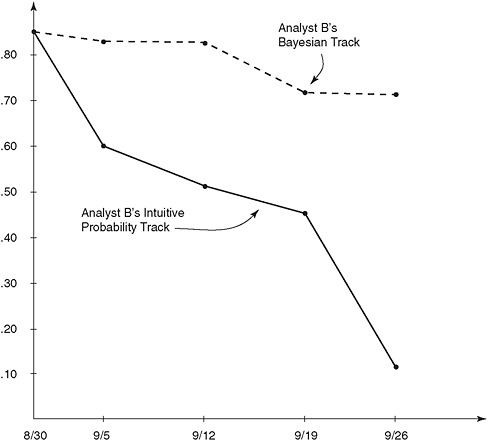
FIGURE 2-2 Probability tracks for Analyst B using both conventional and Bayesian methods.
SOURCE: Fisk (1972). Reprinted with permission.
that the Soviets would go to war, even as that analyst’s intuitive estimate had dropped almost to zero. “Here is why you need to do experiments,” Twardy commented. “Even though there are tremendous numbers of studies in the psychology literature that you are better off with Bayes, you never know what is going to happen when you give it to analysts.” It seems likely that the fifth analyst had somehow misunderstood how to apply the Bayesian analysis—and that is an important piece of information that only a field study could detect.
The research group’s work ended in 1979, and Twardy said he has seen no evidence that work with Bayesian methods continued beyond that. To all appearances, Bayesian analysis essentially vanished from intelligence analysis.
Recently, with the development of APOLLO, a descendant of those
original Bayesian analyses has appeared. APOLLO, created by Paul Sticha and Dennis Buede of HumRRO, and Richard Rees of the CIA relies on Bayesian networks instead of the much simpler Bayesian statistical calculations used by the CIA research group in the 1970s, but the goal is the same: to help analysts overcome their biases and improve the accuracy of their predictions by changing their probability estimates in response to things that happen or do not happen over time.
The standard example of how APOLLO can be put to use is in predicting what the leader of a foreign country is going to do in response to overwhelming labor strikes. Will he leave the country? Will he respond with violent repression of the strikes? To answer that question, a highly detailed “decision model” (see Figure 2-3) is created, ideally with the input of a number of analysts and experts assembled for a two-day meeting. The model traces how various eventualities affect one another, with probabilities assigned for each cause-and-effect relationship.
Once the model has been defined, all an analyst needs to do is to
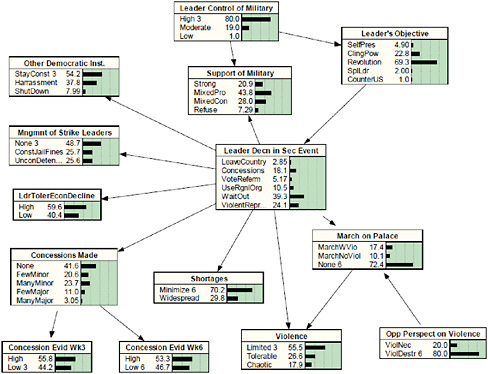
FIGURE 2-3 Example of a situation model. The hypothesis node is in the middle.
SOURCE: Sticha, Buede, and Rees (2005). Reprinted with permission.
monitor the developing situation and input which events have happened. Perhaps six weeks after the strikes, the leader has responded with a few concessions, and there has been limited violence. The analyst checks off those possibilities in the model, does nothing with the possibilities that are still unknown, and the software automatically revises the probabilities of what the leader will do.
The model also offers other results of the analysis. It is possible, for example, to examine which events the predictions depend on most strongly and which events make little difference to the predictions. The model can also be used to work backward from observed actions to the motivations of the leader. For example, if a leader’s major goal is to stay in power, his responses to various events should be significantly different than if his goal is, say, to move his country toward democracy. The model helps untangle the various causes and effects and focus on what events imply about motivations.
More generally, APOLLO includes a psychology module that fits into the larger model and takes into consideration the self-image and other psychological characteristics of the leader. Psychologists can assess the various personality factors of a leader—by examining the content of speeches, for example—and then input these factors into the model to improve its predictive power.
APOLLO could be valuable to analysts in a number of ways, Twardy said. Its main goal is to improve predictive power, but it could be put to work in other ways as well. It could be used, for instance, to determine which pieces of information would be most useful in improving a prediction, so that intelligence collectors would know where to direct their efforts for the biggest payoff. Or, as noted above, it could help indicate what a leader’s motives are.
The group that developed APOLLO is now testing it, Twardy said. The original idea was to perform a randomized controlled trial, but they abandoned that plan for a couple of reasons. First, they did not think it would be possible to sign up as many analysts as they would need to get statistically significant results. Second, in a controlled trial, half of the analysts would not be assigned to use the method they had signed up for—APOLLO—so many of them would likely walk away before the end of the experiment, resulting in a bunch of annoyed analysts and statistically marginal results at best.
So the APOLLO group settled on a pre- and post-test design in which the probabilities are tested both before using the method and after, and one looks to see if using the method has improved the outcome. This is a workable approach, Twardy said, but it will take a long time to gather the data. Furthermore, the test would be most useful if the gain from the
APOLLO method was compared with gains from other methods, such as ACH, but that will require more work and more analysts.
One of the obstacles to evaluating analysts’ use of APOLLO—or even to convincing analysts to use a structured method like APOLLO in the first place—is how busy most of them are. Their days are filled by the responsibilities they already have, and unless something is done to give them more time or to restructure their incentives, Twardy said, they are unlikely to adopt something like APOLLO, much less participate in an evaluation of it. “So it might not even be feasible to do real field evaluations with analysts who are so pressed for time,” Twardy said.
As an alternative, he suggested, it might be possible to test APOLLO or similar techniques in the intelligence academies. The tests would not be as realistic as if they were carried out with working analysts, but at least the subjects would be analysts in training, and it would be much easier to get access to them. If that doesn’t work, tests could be carried out in professional schools, such as business schools, where they do forecasting. Or the tests could even be carried out with psychology undergraduates, the usual lab rat of psychology experiments. “You sacrifice more validity, but you get a lot more access.” And, he continued, there is no reason it wouldn’t be possible to do a tiered approach, in which much of the early work is done with psychology undergraduates, and then, after the bugs are fixed, further testing is done in the intelligence academies or with working analysts.
Finally, Twardy noted, one of the obstacles to incorporating APOLLO or something similar in the work of intelligence analysts—in addition to the extra time it demands from them—is the fact that it requires quantitative estimates of probabilities: there is a 20 percent chance that the striking workers will back down if the army is called in; there is a 40 percent chance that the army will take over the country if the leader flees; and so on. But although there has been some recent progress, Twardy said, it has traditionally been very difficult to get analysts to assign numerical probabilities to their estimates. They are more comfortable with words like probable, unlikely, or near certain. Unless they move from the qualitative to the quantitative in their predictions, APOLLO and similar techniques will be out of reach.

















