
3
Building Blocks of Intraseasonal to Interannual Forecasting
An ISI forecast is made utilizing observations of the climate system, statistical and/or dynamical models, data assimilation schemes, and in some cases the subjective intervention of the forecaster (see Box 3.1). Improvements in each of these components, or in how one component relates to another (e.g., data assimilation schemes expanded to include new sets of observations; observations made as part of a process study to validate or improve parameters in a dynamical model), can lead to increases in forecast quality. This portion of the report discusses these components of ISI forecasting systems, with an emphasis on assessing quality among forecast systems following a change in forecast inputs. Past advances that have contributed to improvements in forecast quality are noted, and the section ends by presenting areas in which further improvement could be realized.
HISTORICAL PERSPECTIVE FOR INTRASEASONAL TO INTERANNUAL FORECASTING
Scientific weather prediction originated in the 1930s, with the objective of extending forecasts as far into the future as possible. Studies at MIT under Carl Gustaf Rossby consequently included longer time scales than just the daily prediction issue. Jerome Namias became a protégé of Rossby, and took on the task of extending to longer scales as director of the “Extended Forecast Section” of the Weather Bureau/National Weather Service. The approaches developed emphasized upper level pressure patterns that could persist or move according to the Rossby barotropic model, and could provide “teleconnections” from one region to another. These patterns were then used to infer surface temperature and precipitation patterns. The latter were initially done by subjective methods, but soon statistical approaches were adopted through the work of Klein. For more than a few days in advance, prediction of daily weather would necessarily have low skill and so monthly or longer forecasts were obtained as averages. Work by Lorenz in the 1960s explained the lack of atmospheric predictability after more than about 10 days in terms of the chaotic nature of the underlying dynamics (see Chapter 2). At about the same time, Namias was emphasizing the need to consider underlying anomalous boundary conditions as provided by SSTs, soil moisture, and snow cover. The importance of changing tropical SSTs through ENSO was first identified by Bjerknes in the late 1960s. A first 90-day seasonal outlook was released by NOAA in 1974.
|
BOX 3.1 TERMINOLOGY FOR FORECAST SYSTEMS Observation—measurement of a climate variable (e.g., temperature, wind speed). Observations are made in situ or remotely. Many remote observations are made from satellite-based instruments. Statistical model—a model that has been mathematically fitted to observations of the climate system using random variables and their probability density functions. Dynamical or Numerical model—a model that is based, primarily, on physical equations of motion, energy conservation, and equation(s) of state. Such models start from some initial state and evolve in time by updating the system according to physical equations. Data assimilation—the process of combining predictions of the system with observations to obtain a best estimate of the state of the system. This state, known as an “analysis”, is used as initial conditions in the next numerical prediction of the system. Operational forecasting—the process of issuing forecasts in real time, prior to the target period, on a fixed, regular schedule by a national meteorological and/or hydrological service. Initial conditions/Initialization—Initial conditions are estimations of the state (usually based on observational estimates and/or data assimilation systems) that are used to start or initialize a forecast system. Initialization can include additional modification of the initial conditions to best suit the particular forecast system. |
Progress since the 1960s can be discussed in terms of advances in forecasting approaches (including their evaluation) and improved understanding and treatment of underlying mechanisms. One major direction of advancement in forecasting has been that of dynamical modeling (see “Dynamical Models”section in this chapter). Generally the dynamical models continued to improve according to advancements in computational resources and a growing knowledge of the key processes to be modeled. However, official forecasts in the United States depended on subjective interpretation of these objective products. In addition, various statistical (empirical) modeling approaches were developed and improved to remain as capable as the dynamical approaches in their validation. Other countries have been developing similar capabilities for seasonal prediction since the 1980s, largely depending on numerical modeling.
Recognition of the role of tropical SST anomalies, especially those associated with ENSO, in driving remote climate anomalies has led to much work in predicting tropical SST. Some of the key advancements in estimating these SSTs developed during the TOGA international study in conjunction with the deployment of the Tropical Atmosphere Ocean (TAO) array in the 1980s and 1990s (NRC, 1996; see “Ocean Observations” section in this chapter and “ENSO” section in Chapter 4).
Further expansion of the efforts in ISI forecasting have been undertaken by CLIVAR (Climate Variability and Predictability), a research program administered by the World Climate
Research Programme (WCRP). CLIVAR supports a variety of research programs9 around the world focused on cross-cutting technical and scientific challenges related to climate variability and prediction on a wide range of time scales. CLIVAR also helps to coordinate regional, process-oriented studies (WCRP, 2010).
What follows is a description of the “building blocks” of an ISI forecasting system: observations, statistical and numerical models, data assimilation schemes. The quality and use of forecasts are also discussed. It is a broad overview, offering some historical context, an evaluation of strengths and weaknesses, and potential avenues for improvement. At the conclusion of Chapter 3, the key potential improvements are summarized; the Recommendations (Chapter 6) have been made with these improvements in mind.
OBSERVATIONS
Observations are an essential starting point for climate prediction. In contrast to weather prediction, which focuses primarily on atmospheric observations, ISI prediction requires information about the atmosphere, ocean, land surface, and cryosphere. Also in contrast to weather prediction, the observational basis for ISI prediction is both less mature and less certain to persist. Indeed, both continuing evolution and the need to sustain observations for ISI prediction are seen as issues at present and into the future. International cooperation and the governance of the World Meteorological Organization do much to ensure continuity of weather observations. Similar international cooperation is being developed for climate observations, but formal international commitments to these observations are not the general case. The following sections describe some of the platforms available for making these observations, and the increase in the number of observations over time.
Observations of quantities that end-users track, such as sea surface temperature and precipitation, and of quantities that record the coupling between elements of the climate system, such as soil moisture and air-sea fluxes, are particularly useful to assess both the realism of models and identify longer-term variability and trends that provide the context for ISI variability. However, current observational systems do not meet all ISI prediction needs, or are not always used to maximum benefit by ISI prediction systems. Some observations for the Earth system needed for initialization are not being taken, or are not available at a spatial or temporal resolution to make them useful. Some observations have not been available for a sufficiently long period of time to permit experimentation, validation, verification, and inclusion within statistical or dynamical models. In yet other cases, the observations are available, but they are not being included in data assimilation schemes. Additionally, regionally enhanced observations or studies that target learning more about the processes that govern ISI dynamics, including developing improved parameterizations of processes that are sub-grid scale in dynamical models, are needed.
New observations, both in situ and remotely sensed, may be available through research programs. Part of the challenge is to integrate these new observations, assess their utility and impact, and then, if the observations contribute to ISI prediction, develop the advocacy required to sustain them. Integration of observational efforts, as in CLIVAR climate process teams or by
bringing together observationalists with operational centers to engage in observing system simulation studies and assessments of the improvement stemming from observations have merit. Heterogeneous networks of observations, at times obtained by different organizations, may need better integration into accessible data bases and particular attention from partnered observationalists and modelers. For all observations, appropriate attention to metadata and data quality, including realistic estimates of uncertainty, are essential to ensuring their use and utility.
Atmosphere
Over the years the conventional meteorological observing system evolved from about 1,000 daily surface pressure observations in 1900 to about 100,000 at the present. Likewise, upper air observations (rawinsondes, pilot balloons, etc.) grew from less than 50 soundings in the 1920s to about 1,000 in the 1950s (of which most were pilot balloons). Today, there are about 1,000 rawinsondes used regularly (Dick Dee, personal communication). Satellite observations, introduced into operations in 1979, ushered in a totally new era of numerical weather prediction, although it was only in the 1990’s that the science of data assimilation (see “Data Assimilation” section in this chapter) progressed enough to demonstrate that there was a clear positive impact from satellite data when added to rawinsondes in the Northern Hemisphere. Figure 3.1 illustrates the huge increase of different types of available satellite observations in the last two decades assimilated for ECMWF operational forecasts. These satellite products have not only grown in number, but also in diversity. They can provide information about atmospheric composition and hydrometeors, as well as vertical profiles of thermodynamic properties.
The assimilation of each of these observing systems poses a new challenge, and the full impact of each may not become clear for years because of the partial duplication of information among the different systems. It is often difficult to attribute an increase in prediction quality to the incorporation of a new set of observations in an ISI forecasting system. Some examples of improvements arising from the assimilation of specific observations, such as AMSU radiances, are discussed in the “Data Assimilation” section of this chapter.
The incorporation of targeted observations that focus on atmospheric processes that are sources of ISI predictability could also contribute to ISI forecast quality. In some cases, these observations exist for research purposes but are not being exploited by ISI forecast systems. In other cases, these observations do not exist. For example, high resolution observations of the vertical structure of the tropical atmosphere could improve the understanding of the MJO, the ability to validate current dynamical models, and perhaps the parameterization of these models. This is part of the mission of the Dynamics of the MJO experiment (DYNAMO; http://www.eol.ucar.edu/projects/dynamo/documents/WP_latest.pdf).
Oceans
As mentioned in Chapter 2, the oceans are a major source of predictability at intraseasonal to interannual timescales. The ocean provides a boundary for the atmosphere where heat, freshwater, momentum, and chemical constituents are exchanged. Large heat losses and evaporation at the sea surface cause convection and make surface water sink into the interior,
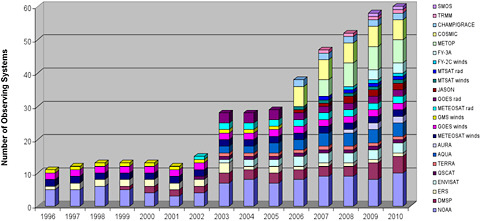
FIGURE 3.1: Number of satellite observing systems available since 1989 and assimilated into the ECMWF system. Each color represents a different source/platform. SOURCE: Courtesy of Jean-Noel Thepaut, ECMWF.
while surface heating and the addition of freshwater make surface water buoyant and resistant to mixing with deeper water.
Variability in the air-sea fluxes, in oceanic currents and their transports, and in large-scale propagating oceanic Rossby or Kelvin waves all contribute to the dynamics of the upper ocean and the sea surface temperature. In turn, the states of the ocean surface and sub-surface can force the atmosphere on intraseasonal to interannual timescales, as is clearly evident in the ENSO and MJO phenomena. Therefore, the initialization of sea surface and sub-surface ocean state is required for near-term climate prediction. Unfortunately, the comprehensive observation of the global oceans started much later than in the atmosphere and even today there are challenges that prevent collection of routine observations over large parts of the ocean.
The significant climatic impacts of ENSO, especially after the 1982–1983 event, demonstrated that a sustained, systematic, and comprehensive set of observations over the equatorial Pacific basin was needed. The TAO/Triangle Trans-Ocean Buoy Network (TRITON) array was developed during the 1985–1994 Tropical Ocean Global Atmosphere (TOGA) program (Hayes et al., 1991, McPhaden et al., 1998). The array spans one-third of the circumference of the globe at the equator and consists of 67 surface moorings plus five subsurface moorings. It was fully in place to capture the evolution of the 1997–1998 El Niño. In 2000, the original set called TAO was renamed TAO/TRITON with the introduction of the TRITON moorings at 12 locations in the western Pacific (McPhaden et al., 2001). TAO/TRITON has been the dominant source of upper ocean temperature and in situ surface wind data near the equator in the Pacific over the past 25 years and has provided the observational underpinning for theoretical explanations of ENSO such as the recharged oscillator
(e.g. Jin, 1997). It provides a key constraint on initial conditions for seasonal forecasting at many centers around the world.
After the success of the TAO/TRITON array, further moored buoy observing systems have been developed over the Atlantic (PIRATA) and Indian (RAMA) oceans under the Global Tropical Moored Buoy Array (GTMBA) program. The moorings allow simultaneous observations of surface meteorology, the air-sea exchanges of heat, freshwater, and momentum, and the vertical structure of temperature, salinity, horizontal velocity, and other variables in the water column. Thus, they provide the means to monitor both the air-sea exchanges and the storage capacity of the upper ocean. The PIRATA array was designed for the purpose of improving the understanding of ocean-atmosphere interactions that affect the regional patterns of climate variability in the tropical Atlantic basin (Servain et al., 1998). The array, launched in 1997 and still being extended, currently has 17 permanent sites. The RAMA array was initiated in 2004 with the aim of improving our understanding of the east Africa, Asian, and Australian monsoon systems (McPhaden et al., 2009). It currently consists of 46 moorings spanning the width of the Indian Ocean between 15ºN and 26ºS. It is expected to be fully completed in 2012.
The maintenance of the GTMBA is absolutely essential for supporting climate forecasting. However, there are many difficulties in maintaining these arrays, not the least of which is identifying institutional arrangements that can sustain the cost of these observing systems (McPhaden et al., 2010). Away from the equator, the permanent in situ moored arrays are sparser and address sample the characteristic extra-tropical regions of the ocean-atmosphere system under the international OceanSITES program. Few such sites exist in high latitude locations, but efforts are underway in the United States (under the National Science Foundation Ocean Observatories Initiative) and in other countries to add sustained high latitude ocean observing capability.
In parallel to the development of the moored buoy arrays, the observation of SST has improved markedly over the last 20 years. SST is a fundamental variable for understanding the complex interactions between atmosphere and ocean. Since 1981, operational streams of satellite SST measurements have been put together with in situ measurements to form the modern SST observing systems (Donlon et al., 2009). Since 1999 more than 30 satellite missions capable of measuring SST in a variety of orbits (polar, low inclination, and geostationary) have been launched with infrared or passive microwave retrieval capabilities. New approaches to integrate remote sensing observations with in situ SST observations that help reduce bias errors are being taken (Zhang et al., 2009).
Despite the evident progress, an important issue remains: satellite observations of SST only started in the 1980s and satellites have a relatively short life span. Therefore, further work is necessary to ensure the “climate quality” of the data over long periods. This would facilitate the generation of SST re-analysis products for operational seasonal forecasting (Donlon et al., 2009).
Even with the evident progress made with the tropical moored buoy arrays and the improvement of the satellite measurements of SST, as recently as the late 1990s there were still vast gaps in observations of the subsurface ocean. Such observations are needed for seasonal to interannual prediction. The ability of the ocean to provide heat to the atmosphere, the extent to which the upper ocean can be perturbed by the surface forcing, and the dynamics of the ocean that lead to changes in the distribution of heat and freshwater all depend on the vertical and horizontal structure of the ocean and its currents.
Surface height observations by satellite altimeters have added information about the density field in the ocean and thus, for example, the redistribution of water properties and mass
along the equator associated with ENSO. Efforts to quantify the state of the ocean were further improved by the international implementation of the Argo profiling float program (http://www.argo.ucsd.edu/). Until then, most sub-surface ocean measurements were taken by expendable bathythermograph (XBT) probes measuring temperature versus depth and by shipboard profiling of salinity and temperature versus depth from research vessels, which are both limited in their global spatial coverage and depth. The Argo program was initiated in 1999 with the aim of deploying a large array of profiling floats measuring temperature and salinity to 1,500 to 2,000 meters deep and reporting in real time every 10 days. To achieve a 3º x 3º global spacing, 3,300 floats were required between 60ºS and 60ºN. As of February 2009, there are 3,325 active floats in the Argo array. After excluding floats from which data was not passing the quality control and those in high latitudes (beyond 60º latitude) or in heavily sampled marginal seas, the number of floats is only 2,600. Argo data is distributed via the internet without restriction and about 90% of the profiles are available within 24 hours of acquisition. Quality control continues after receipt of the data, particularly for the salinity observations. To improve the quality of data from Argo floats, ship-based hydrographic surveys obtaining salinity and temperature profiles are needed, and the process may require several years before the Argo data experts are confident that the best data quality has been achieved (Freeland et al., 2009). However, the real time Argo data is a critical contribution. With it, the depth of the surface mixed layer can be mapped globally, thus determining the magnitude (depth and temperature) of the oceanic thermal reservoir in immediate contact with the atmosphere.
Internationally, there is a coordinated effort under the Joint Commission on Oceanography and Marine Meteorology (JCOMM) of the World Meteorological Organization (WMO) and the International Oceanographic Commission (IOC) to coordinate sustained global ocean in situ observations, including Argo floats, surface SST drifters, Volunteer Observing Ship-based measurements, tropical moored arrays, and the extra-tropical moored buoys. Remote observations of surface vector winds combined with drifting buoy data can be used to identify the wind-driven flow of the upper ocean, thus complementing the ability of Argo floats and altimetry to observe the density-driven flow. Future satellite observations of interest include those of surface salinity.
The in situ ocean observing community will benefit from an ongoing dialog with those interested in improving prediction on intraseasonal and interannual timescales. Programs such as the World Climate Research Programme’s (WCRP) CLIVAR work to coordinate sustained observations in the ocean with focused process studies that improve understanding of climate phenomena and processes. Distributed and sustained ocean and air-sea heat flux observations with global and full depth coverage are being used to identify biases and errors in coupled and ocean models. These include the surface buoys and associated moorings of OceanSITES and the repeat hydrographic survey lines done in each basin every 5–10 years. The moorings provide high temporal resolution sampling from the air-sea interface to the seafloor, while the surveys map ocean properties along basin-wide sections. Both programs provide data sets that quantify the structure and variability of the ocean that are often found in model fields. In contrast, denser sampling arrays are deployed for a limited duration as part of process studies. These studies are
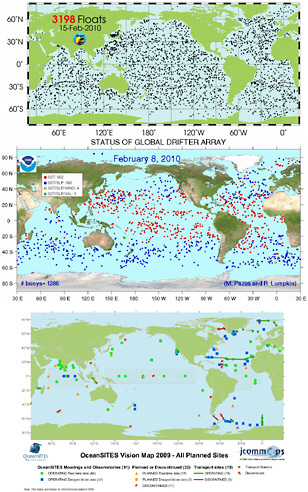
FIGURE 3.2 Examples of the spatial distribution of various ocean observations mentioned in the text. Top panel: Argo floats, which can provide surface and sub-surface information. SOURCE: Argo website (http://www.argo.ucsd.edu/) Middle panel: Drifters, which can provide SST, SLP, wind, and salinity information (see colors in legend). SOURCE: NOAA (http://www.aoml.noaa.gov/phod/dac/gdp.html). Bottom panel: OceanSITES, intended for long-term observations for depths up to 5000m in a stationary location. SOURCE: (OceanSITES http://www.jcommops.org/FTPRoot/OceanSITES/maps/200908_VISION.pdf)
designed to improve our understanding of physical processes and to aid in the parameterization of the processes not fully resolved by models. CLIVAR also works to build connectivity among the observing community, researchers investigating ocean processes and dynamics, and climate modelers. Process studies by CLIVAR and others add to understanding of ocean dynamics, develop improved parameterizations of processes not resolved in ocean models, and guide longer term investments in ocean observing.
Land
The land variables of potential relevance for seasonal prediction—the variables for which accurate initialization may prove fruitful—are soil moisture, snow, vegetation structure, water table depth, and land heat content. These variables help determine fluxes of heat and moisture between the land and the atmosphere on large scales and thus may contribute to ISI forecasts. In addition, some of these variables are associated with local hydrology and hydrological prediction (e.g., observations of snow in a mountain watershed in the winter can provide information on spring water supply). This evolution in the use of land and hydrological observations mirrors the emerging interest in new types of ocean observations, noted in the previous section.
Despite their importance to the surface energy and moisture balances and fluxes, our ability to measure such land variables on a global scale is extremely limited. Thus, alternative approaches for their global estimation have been, or still have to be, developed.
Soil Moisture
Of the listed land variables, soil moisture (perhaps along with snow) is probably the most important for subseasonal to seasonal prediction. For the prediction problem, however, direct measurements of soil moisture are limited in three important ways. First, each in situ soil moisture measurement is a highly localized measurement and is not representative of the mean soil moisture across the spatial scale considered by a model used for seasonal forecasting. Second, even if a local measurement was representative of a model’s spatial grid scale, the global coverage of existing measurement sites would constitute only a small fraction of the Earth’s land area, with most sites limited to parts of Asia and small regions in North America. Finally, even if the spatial coverage were suddenly made complete, the temporal coverage would still be lacking; long historical time series (decadal or longer) may be needed to interpret a measurement properly before using it in a model.
Satellite retrievals offer the promise of global soil moisture data at non-local scales. Data from the Scanning Multichannel Microwave Radiometer (SMMR) and Advanced Microwave Scanning Radiometer—Earth Observing System (AMSR-E) instruments, for example, have been processed into global soil moisture fields (Owe et al., 2001; Njoku et al., 2003). Figure 3.3 shows an example of the mean soil moisture as observed by the SMMR instrument. Such instruments, however, can only capture soil moisture information in the top few millimeters of soil, whereas the soil moisture of relevance for seasonal prediction extends much deeper, through the root zone (perhaps a meter). The usefulness of satellite soil moisture retrievals or their associated raw radiances will likely increase in the future as L-Band measurements come online
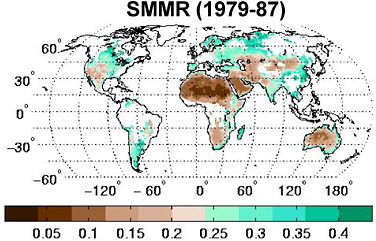
FIGURE 3.3 Mean soil moisture (m3/m3) in upper several millimeters of soil, as estimated via satellite with the SMMR instrument using the Owe et al. (2001) algorithm. SOURCE: Adapted from Reichle et al. (2007).
and data assimilation methods are further developed (see section on “Data Assimilation” in this chapter and the soil moisture case study in Chapter 4).
Currently, global soil moisture information for model initialization has to be derived indirectly from other sources. A common approach is to utilize the soil moisture produced by the atmospheric analysis already being used to generate the atmospheric initial conditions. This approach has the advantage of convenience, and the soil moisture conditions that are produced reflect reasonable histories of atmospheric forcing, as generated during the analysis integrations—if the analysis says that May is a relatively rainy month, then the June 1 soil moisture conditions produced will be correspondingly wet.
The main meteorological driver of soil moisture, however, is precipitation, and analysis-based precipitation estimates are far from perfect. Thus, a more careful approach to using model integrations to generate soil moisture initial conditions has been developed in recent years. This approach is commonly referred to as LDAS, for “Land Data Assimilation System”, although the term is something of a misnomer; true land data assimilation in the context of the land initialization problem is discussed further in the “Data Assimilation” section below. LDAS systems are currently in use for some experimental real-time seasonal forecasts and are planned for imminent use in some official, operational seasonal forecasts.
An operational LDAS system produces real-time estimates of soil moisture by forcing a global array of land model elements offline (i.e., disconnected from the host atmospheric model) with real-time observations of meteorological forcing. (Here, real-time may mean several days to a week prior to the start of the forecast, to allow time for processing.) Real-time atmospheric data assimilation systems are the only reasonable global-scale sources for such forcings as wind speed, air temperature, and humidity. However, the evolution of the soil moisture state depends even more on precipitation and net radiation, whose reanalysis estimates are not reliable.
Consequently, LDAS systems use alternative sources such as merged satellite-gauge precipitation products (e.g., CMAP, or the Climate Prediction Center Merged Analysis of Precipitation) and satellite-based radiation products (e.g., AFWA AGRMET, or Air Force Weather Agency Agricultural Meteorology Modeling System). The LDAS system may still need atmospheric analysis data for the sub-diurnal time sequencing of the forcing, but the alternative data sources prove invaluable for “correcting” these precipitation and radiation time series so that their temporal-averages are realistic.
Such LDAS systems also require global distributions of surface parameters (vegetation type, soil type, etc.), currently available in various forms (e.g., Rodell et al., 2004). Consistency between the parameter set used for the LDAS system and that used for the full forecast system is an important consideration.
Snow
Real-time direct measurements of snow on the global scale do not exist, though some measurements are available at specific sites, for example, in the western United States (Snowpack Telemetry, SNOTEL) and through coded synoptic measurements made at weather stations (SYNOP). For global data coverage, satellite measurements are promising—certain instruments (e.g., MODIS) can estimate snow cover accurately at high resolution on a global scale. Satellite snow retrievals, however, also show significant limitations. For the seasonal forecasting problem, snow cover is not as important as snow water equivalent (SWE), which is the amount of water that would be produced if the snowpack were completely melted. Satellite estimates of SWE are made difficult by the sensitivity of the retrieved radiances to the morphology (crystalline structure) of the snow, which is almost impossible to estimate a priori—a given snowpack may have numerous vertical layers with different crystalline structures, reflecting the evolution of the snowpack with time through compaction and melt/refreeze processes. Compounding the difficulty of estimating SWE from space are spatial heterogeneities in snowpack associated with topography and vegetation.
The LDAS approach described above can provide SWE in addition to soil moisture states, assuming the land model used employs an adequate treatment of snow physics. In the future, the merging of LDAS products with the available in situ snow depth information and satellite-based snow data in the context of true data assimilation (see “Data Assimilation” section) will likely provide the best global snow initialization for operational forecasts.
Vegetation Structure
Current operational seasonal forecast models treat vegetation as a boundary condition, with prescribed time-invariant vegetation distributions and (often) prescribed seasonal cycles of vegetation phenology, e.g., leaf area index (LAI), greenness fraction, and root distributions. Early forecast systems relied on surface surveys of these quantities, and modern ones generally rely on satellite-based estimates.
Reliable dynamic vegetation modules would, for the seasonal prediction problem, allow the initialization and subsequent evolution of phenological prognostic variables such as LAI and rooting structure. A drought stressed region, for example, might be initialized with less leafy
trees, with subsequent impacts on surface evapotranspiration, and the leaf deficit would only recover if the forecast brought the climate into a wetter regime. However, the use of dynamic vegetation models in seasonal forecasts is not on the immediate horizon for forecast centers, in light of other priorities and the need to develop these models further.
Water Table Depth
The use of water table depth information in historical and current operational systems is prevented by two things. First, outside of a handful of well-instrumented sites, such information does not exist (though GRACE satellite measurements of gravity anomalies can provide useful information at large scales); the global initialization of water table depth given current measurement programs is currently untenable. Second, even if such observations were available, land surface models used in current seasonal forecasting systems do not model variations in moisture deeper than a few meters below the surface, so that the observations, if they did exist, could not be used. The lack of deep water table variables in the models also prevents the estimation of water table depth through the LDAS approach. Given the long time scales associated with the water table, improvements in its measurement and modeling do have the potential to contribute to ISI prediction.
Soil Heat Content
Real-time in situ measurements of subsurface heat content are spotty at best and far from adequate for the initialization of a global-scale forecast system. Satellite data have limited penetration depth; they can only provide estimates of surface skin temperature. Global initialization of subsurface heat content can thus be accomplished in only two ways: (1) through an LDAS system, as described above, and (2) through a land data assimilation approach that combines the LDAS system information with observations of variables such as soil moisture, snow, and skin temperature. For maximum effectiveness, the land models utilized in these systems need to include temperature state variables representing at least the depth of the annual temperature cycle (i.e., a few meters).
Polar Ice
Polar regions are important components of the climate system. The most important parameters are those that influence the exchange of heat, mass, and momentum with the atmosphere and global oceans. NASA, NOAA, and DOE have polar-orbiting satellites that are collecting relevant data in the Arctic region. The National Snow and Ice Data Center (http://nsidc.org/) is supported by NOAA, NSF, and NASA to manage and distribute cryosphere data. The National Ice Center (http://www.natice.noaa.gov/) is funded by the Navy, NOAA, and the Coast Guard to provide snow, ice (ice extent, ice edge location), and iceberg products in the Arctic and in the Antarctic.
The NRC Report Towards an Integrated Arctic Observing System (NRC, 2006) advocated observation of “Key Variables” using in situ and remote sensing methods. These
include albedo; elevation/bathymetry; ice thickness, extent, and concentration; precipitation; radiation; salinity; snow depth/water equivalent; soil moisture; temperature; velocity; humidity; freshwater flux; lake level; sea level; aerosol concentration; and land cover. Observing methods and recommendations are reviewed and presented in the Cryosphere Theme Report of the Integrated Global Observing System (IGOS 2007). Their cryospheric plan includes satellite-based, ground-based, and aircraft-based observations together with data management and modeling, assimilation, and reanalysis systems.
In terms of monitoring climate variability and change and weather and climate prediction, these reports identify the priority cryosphere observations as: long-term consistent records of cryosphere variables, high spatial and temporal resolution fields of snowfall, snow water equivalent, snow depth, albedo and temperature, and mapping of permafrost and frozen soil, lake and sea ice characteristics. Remote sensing methods can be used to address sea ice extent (recorded since the late 1970s) and ice thickness (recorded more recently, with IceSat) in order to investigate ice mass balance and the movement. Aerial sea ice reconnaissance needs to continue. Relevant in situ methods include the use of autonomous underwater vehicles (AUVs), moorings, and automated weather stations.
More specific recommendations are provided by Dickson et al. (2009), who assert that climate models do not represent Arctic processes well, limiting our ability to understand change in the Arctic seas and the impact of that change on climate. They also advocate that observations are needed for the Norwegian Atlantic current transport of heat, salt, and mass into the Arctic Ocean and of the amounts that enter by the Fram Strait and the Barents Sea; the change in sea ice in response to inflows into the Arctic of warmer water; the change and variability in temperature and salinity profiles beneath the ice, as by Ice-Tethered Profilers (ITPs); and, in general, all quantities relevant to the estimation of ocean-atmosphere heat exchange in the Arctic. For improving sea ice prediction, Dickson et al. (2009) recommends improved sea ice thickness measurements, especially in the spring. Such improved measurements could be obtained from below and above the ice as well as on the ice, using (for example) laser and radar altimetry, tiltmeter buoys on the ice surface, and floats or moorings below the ice with upward looking sonars.
STATISTICAL MODELS
Statistical and dynamical predictions are complementary. Advances in statistical prediction are often associated with enhanced understanding, which may lead to improved dynamic prediction, and vice versa. In addition, both techniques can ultimately be combined to provide better guidance for decision support.
Linear Models
What follows is a description of techniques used in statistical prediction models. Many of these techniques are similar to validation schemes for numerical models, for which the strengths and weaknesses are shown in Table 2.1. Also, a more in-depth description is provided in Appendix A.
Correlation and Regression
There is a long history of using correlation patterns to identify teleconnections, beginning with the landmark Southern Oscillation studies of Walker in the early 20th century (Katz, 2002) and increasing exponentially since (e.g., Blackmon et al., 1984; Wallace and Gutzler, 1981). The idea of teleconnections in meteorology is tied closely to that of correlations. Base points in locations, such as the center of the Nino3.4 box (Hanley et al., 2003), have served as the origin for teleconnection analysis throughout the globe (Ding and Wang, 2005) and have formed the basis for forecast quality (Johansson et al., 1998). The relationships between two locations can be calculated by measuring the mean squared error between the base point and the remote location. Large correlations correspond to a large degree of covariability and a correspondingly small mean squared error. Linear regression is an extension of correlation where directionality is assumed in diagnosing relationships between a predictor variable and a response variable or predictand.
Most often, the variance of the response variable is partitioned into components that are explained or unexplained by the predictor. The coefficient of determination (known as R2) gives the amount of variance explained by the predictor and is often used to assess the goodness of fit for a given model, though it has been criticized as a forecast performance index for verification as it ignores bias (Murphy, 1995). If the assumptions regarding the distribution of the data are met, significance of the model parameters can be assessed through t-tests. In cases when the assumptions are not met, bootstrapping of the (x,y) pairs or the model residuals has been shown to be effective (Efron and Tibshirani, 1993).
Often the problems addressed by regression require multiple predictors to give meaningful answers. The statistical model, multiple regression, is a generalization of simple regression. Rather than pairs of data measured simultaneously, n-tuples of data are used where all of the predictors, x1, x2, … ,xm and the predictand, y, form the training data that are observed over n cases.
Historically, the most common application of regression methodology has been for relating numerical model output to some predictand at a future time using linear regression. The method is called “model output statistics” (MOS) by Glahn and Lowry (1972). This is related to another regression technique, known as the perfect prog (PP) method (Klein et al., 1959) where both predictors and response variables are observed quantities in the training dataset. These methods are popular, as they utilize information at relatively larger scales to represent sub grid scale processes. MOS has the advantage over PP of correcting for forecast model biases in the mean and variance. The disadvantages of MOS include rebuilding the equations with changes in models and assimilation systems. Brunet et al. (1988) offer detailed comments on the relative advantages of each method, claiming PP was superior for shorter-range forecasts and MOS for longer time leads.
When cross-correlations are used to establish relationships between two non-adjacent locations, the maps of correlations are termed teleconnections. The earliest instance of using such a methodology was to establish the correlation structure of the Southern Oscillation (Walker, 1923). Maps of teleconnectivity at widely separated locations at a given geopotential height have been constructed to establish the centers of action of various modes in the mid-troposphere (Wallace and Gutzler, 1981). A catalogue of such teleconnections, based on
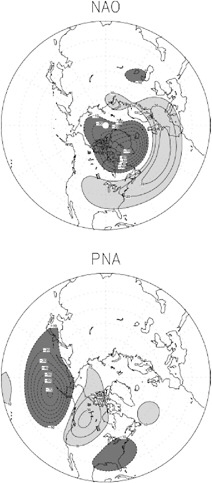
FIGURE 3.4 Example of two teleconnection patterns (North Atlantic Oscillation (NAO); Pacifc-North American pattern (PNA)), shown as anomalies in the 500-hPa geopotential height field. Dark shading indicates negative anomalies, and light shading indicates positive anomalies.The patterns emerge from a rotated Empirical Orthogonal Function analysis of monthly mean 500-hPa geopotential heights. Contour interval is 10 m. SOURCE: Johansson (2007).
principal component loadings (used to summarize the linked regions) was created by Barnston and Livezey (1987).
Empirical Orthogonal Functions (EOF)/Principal Component Analysis (PCA)
The use of eigentechniques was pioneered by Pearson (1902) and formalized by Hotelling (1933). The key ideas behind eigentechniques are to take a high dimensional problem that has structure (often defined as a high degree of correlation) and establish a lower dimensional problem where a new set of variables (e.g., eigenvectors) can form a basis set to reconstruct a large amount of the variation in the original data set. In terms of information theory, the goal is to capture as much signal as possible and omit as much noise as possible. While that is not always realized, the low dimensional representation of a problem often leads to useful results. Assuming that the correlation or covariance matrix is positive semidefinite in the real domain, the eigenvalues of that matrix can be ordered in descending value to establish the relative importance of the associated eigenvectors. Sometimes the leading eigenvector is related to some important aspect of the system. However, modes beyond the first are rarely related to specific physical phenomena owing to the orthogonality imposed on the EOFs/PCs. One possibility is to transform the leading PCs to an alternate basis set. This process is known as PC rotation (Horel, 1981; Richman, 1986; Barnston and Livezey, 1987) and has been shown to offer increased stability and isolation of patterns that match more closely to their parent correlation (or covariance) matrix. For example, in Figure 3.4, the rotated EOFs that are derived from monthly 500-hPa geopotential height data define two teleconnection patterns, the North Atlantic Oscillation (NAO) and the Pacific North American (PNA) pattern. These patterns explain a relatively large portion of the variance in the 500-hPa geopotential height data and can be related to the large-scale dynamics of the atmosphere as well as incidences of extreme weather in certain locations. In cases where the data lie in a complex domain, eigenvectors can be extracted in “complex EOFs.” Such EOFs can give information on travelling waves, under certain circumstances, as can alternative EOF techniques that incorporate times lags to calculate the correlation matrix (Branstator, 1987). As was the situation for correlation analysis, EOF/PCA are data compression methods. They do not relate predictors to response variables.
Canonical Correlation Analysis(CCA)/Singular Value Decomposition (SVD)/Redundancy Analysis (RA)
A multivariate extension of linear regression is canonical correlation analysis (CCA). It can be thought of as multiple regression where there is more than one predictor (x1, x2,…, xm) and multiple response variables (y1, y2,…,yp). Consequently, CCA is useful for prediction of multiple modes of variability associated with climate forcing (Barnston and Ropelewski, 1992). The goal of CCA is to isolate important coupled modes between two geophysical fields. Singular value decomposition (SVD) is analogous to CCA when applied to an augmented covariance matrix. Despite the similarity, Cherry (1996) argues that the techniques have different goals. Both techniques can lead to spurious patterns (Newman and Sardeshmukh, 1995), particularly when the observations are not independent and the cross-correlations/cross-covariances are weak relative to the correlations within the x’s and y’s. In such cases, pre-
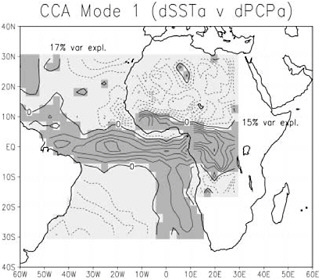
FIGURE 3.5: Patterns relating errors in SST to errors in precipitation. Dark gray areas in the ocean indicate areas of “warm” errors; lighter shading indicates “cold” errors. Over land, dark gray indicates “wet” errors; lighter shading indicates “dry” errors that accompany the pattern of errors in SST. Contours are in normalized units, with a 0.1 contour interval. SOURCE: Goddard and Mason (2002).
filtering the predictors and response variables with EOF or PCA may have benefits (Livezey and Smith, 1999). Given the oversampling in time and space of most climate applications, PCA is often used as the initial step to establish a low dimensional set of uncorrelated basis vectors subject to CCA (Barnett and Preisendorfer, 1987). Despite the potential pitfalls, CCA has been shown to exhibit considerable skill for long-range climate forecasting (Barnston and He, 1996) and is one of the favored techniques for relating teleconnections to climate anomalies. Figure 3.5 shows an example of how CCA has been used to relate errors in SST in the tropical Atlantic Ocean to errors in model-produced estimates of precipitation in parts of Africa. Recently, redundancy analysis (RA), a more formal modeling approach based on regression and CCA, has been applied successfully to find coupled climate patterns useful in statistical downscaling (Tippett et al., 2008).
Constructed Analogues
Natural analogues are unlikely to occur in high degree-of-freedom processes (see Table 2.1 regarding historical use of analogues in prediction). In reaction to this, van den Dool (1994) created the idea of constructing an analogue having greater similarity than the best natural analogue. The construction is a linear combination of past observed anomaly patterns in the
predictor fields such that the combination is as close as desired to the initial state. Often, the predictor (the analogue selection criterion) is based on a reconstruction from the leading eigenmodes of the data field at a number of periods prior to forecast time. The constructed analogue approach has been used successfully to forecast at lead times of up to a year (van den Dool et al., 2003) and usually outperforms natural analogues forecasting one meteorological variable from another contemporaneously. A constructed analogue yields a single linear operator derived from data by which the system can be propagated forward in time.
Nonlinear Models
Most of the linear tools have nonlinear counterparts. Careful analysis of the data will reveal the degree of linearity. Additionally, comparison of the skill for linear versus nonlinear counterparts will reveal the degree of additional information to be gained by nonlinear methods. Specific recommendations on techniques to apply are given in Haupt et al. (2009).
Logistic Regression
Logistic regression is a nonlinear extension of linear regression for predicting dichotomous events as the response variable. The function that maps the predictor to the response variable is called the logistic response function, which is a monotonic function ranging from zero to one10. This involves minimizing the loss function using a nonlinear procedure. Logistic regression has been applied successfully to problems such as precipitation forecasting (Applequist et al., 2002), medium range ensemble forecasts (Hamill et al., 2004), and blocking beyond two weeks (Watson and Colucci, 2002).
Artificial Neural Networks (ANN)
Artificial Neural networks (ANNs) have been applied successfully to numerous prediction problems, including ENSO (Tangang et al., 1998) and precipitation forecasts from teleconnection patterns (Silverman and Dracup, 2000). An ANN is composed of an input layer of neurons, one or more hidden layers, and an output layer. Each layer comprises multiple units connected completely with the next layer, with an independent weight attached to each connection. The number of nodes in the hidden layer(s) is dependent on the process being modeled and is determined by trial and error. Such models require considerable investigator supervision to train as nonlinear techniques are prone to overfitting noise (finding solutions at local minima). During the training process the error between the desired output and the calculated output is propagated back through the network. The goal is to find the network architecture that generalizes best.
Support Vector Machines (SVM)
Support vector machines (SVM) are a form of supervised learning techniques that use kernels to arrive at solutions at the global minimum or generalization error. For data existing in high dimensional space, SVM will separate the data into several subsets, attempting to achieve an optimal linear separation. This can be useful for noisy data sets.
SVM have been applied to cloud classification problems (Lee et al, 2004), wind prediction (Mercer at al., 2008) and severe weather outbreaks (Mercer et al., 2009). Comparison of SVM to standard logistic regression in Mercer et al. (2009) suggests that SVM is equal or superior to the more traditional techniques in minimizing misclassification of forecasts. On the ISI time scale, Lima et al. (2009) have shown that kernelized methods lead to additional skill in ENSO forecasts over traditional PCA techniques
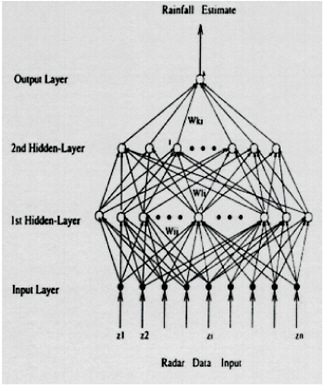
FIGURE 3.6 Schematic of an Artificial Neural Network (ANN) for forecasting rainfall from radar data. The network is composed of “nodes” (circles) that are linked by “weights” (arrows). The number of hidden layers and number of nodes in each layer can be specified by the user, or determined through experimentation. Weights are determined by training the network on a subset of the data. SOURCE: Figure 2 from Trafalis et al. (2005).
Composites
Determination of climate system processes often involves univariate or bivariate displays of the slowly varying forcing (e.g., ENSO, MJO). Investigating how such signal propagates through the climate system can be accomplished through correlation or regression. These approaches are unconditional as all the data are used to establish the pertinent relationships. Another possibility is to condition the relationships on subsets of time when the climate system is in a given state. Such states are termed composites. A key aspect of creating these states is to measure the intra-state variability to ensure that all cases assigned to a given state have commonality. The quality of a composite is often tested by calculating the means of each group to insure adequate separation. Relating climate linkages to such composites is commonly performed to relate forcing to effects in climate studies (e.g., Ferranti et al. 1990; Hendon and Salby 1994; Myers and Waliser, 2003; Tian et al. 2007 for the MJO). Most often, correlations are used to establish the linkages, although comparisons can be based on linear or nonlinear statistics.
Figure 3.7 provides an example of how composites can distinguish, better than linear methods, anomalous precipitation patterns in the continental United States associated with the SST anomalies in the tropical Pacific Ocean. The figure shows that the patterns of precipitation associated with warmer-than-average SST are not necessarily “mirror images” of the patterns of precipitation associated with colder-than-average SST. For example, for the warmer-than-average SST composite, areas of the Midwest exhibit significantly drier-than-average conditions during March, while the Great Plains experience wetter-than-average conditions (third row, left column). By comparison, the composite representing precipitation associated with colder-than-average SST shows near-average conditions for much of the Midwest, with significantly drier-than-average conditions across the Great Plains (third row, right column).
DYNAMICAL MODELS
With the advent of computers, it became feasible to solve the fluid dynamical equations representing the atmosphere and the ocean using a three-dimensional gridded representation. Physical processes that could not be resolved by this representation, such as turbulence, were parameterized using additional equations. The computer software that solves this set of equations is referred to as a dynamical or numerical model. The earliest dynamical models were developed for the atmosphere for the purposes of weather forecasting, and dynamical (or physical) models for other components of the climate system (land, ocean, etc.) followed thereafter.
Evolution of Dynamical ISI Prediction
Some of the earliest attempts at making ISI predictions with dynamical models were performed to essentially extend the range of weather forecasts. Miyakoda et al. (1969) described two-week predictions made with a hemispheric general circulation model (GCM). Miyakoda et al. (1983) used an atmospheric general circulation model (AGCM) with a horizontal resolution of 3–4 degrees and 9 levels in the vertical, which was the state of the art for weather forecasting at the time. Their study used a 30-day prediction to forecast a blocking event that occurred
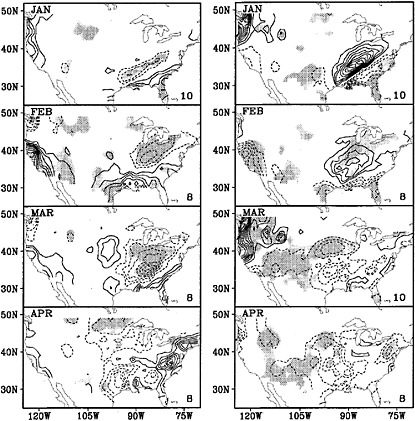
FIGURE 3.7. Composites of monthly-mean precipitation anomalies associated with months experiencing warm SST (left column) or cold SST (right column) in the tropical Pacific for January through April. These maps illustrate that opposite signed SST anomalies do not necessarily produce opposite signed precipitation anomalies (e.g., the areas experiencing wetter-than-average conditions when SST is warm are not necessarily drier-than-average when SST is cold, and vice versa). Contour interval is 10 mm of precipitation; solid contours are for wet anomalies; dashed contours are for dry anomalies. Shading indicates areas of statistical significance. SOURCE: Adapted from Livezey et al. (1997).
during January 1977. The success of the prediction was attributed to improved spatial resolution and better representation of subgrid-scale processes.
Extended range numerical predictions of this sort were referred to as dynamical extended range forecasting (DERF) to distinguish them from short and medium range weather forecasts. The numerical models used for extended range forecasts were the same AGCMs that were then being used for weather forecasting. These AGCMs solved the basic three-dimensional fluid
dynamical equations numerically, using either finite-differencing or spectral decomposition. The AGCMs also incorporated physical parameterizations of shortwave and longwave radiation, moist convection, boundary layer processes, and subgrid-scale turbulent mixing. The complexity and resolution of these AGCMs increased throughout the 1990s in concert with computing power and understanding.
Although the DERF activities had some limited successes, they were barely scratching the surface of short-term climate prediction, in part because some processes were still poorly represented (e.g., MJO, see Chen and Alpert, 1990; Lau and Chang, 1992; Jones et al., 2000; Hendon et al., 2000) and there was no coupling to the ocean. One of the premises of the DERF approach was that there was enough information in the atmospheric initial conditions to make useful extended range predictions. In the terminology of Lorenz (1975), this would be predictability derived from knowledge of the initial condition. Because of the rapid decay of quality with lead time, one would not expect useful predictions on seasonal or longer time scales to arise solely from atmospheric initial conditions. To obtain forecast quality on longer timescales, one has to consider predictability arising from the knowledge of the evolution of boundary conditions or external forcing11 (Lorenz, 1975; Charney and Shukla, 1981).
One of the most important boundary conditions for an atmospheric model is sea surface temperature (SST). Variations in SST can heat or cool the atmosphere, influence the rainfall patterns, and thus change the atmospheric circulation. This is especially obvious in the tropical Pacific, where strong SST anomalies associated with the El Niño -Southern Oscillation (ENSO) phenomenon significantly alter atmospheric convection patterns. Although more subtle, and secondary to the initial conditions of the diabatic heating and circulation structure, SST as a boundary condition for properly initiating the MJO is also expected to be important (e.g., Krishnamurti et al., 1988; Zheng et al., 2004; Fu et al., 2006). The evolution in diabatic heating associated with ENSO and MJO events affects not only the local atmospheric circulation over the tropics, but also affects atmospheric circulation in extratropical regions such as North America through teleconnections (Wallace and Gutzler, 1981; Hoskins and Karoly, 1981; Weickmann et al., 1985; Ferranti et al. 1990).
The link between tropical Pacific SST and atmospheric anomalies elsewhere makes prediction of ENSO valuable for climate predictions in many remote regions. It is a continuing challenge to characterize this link (i.e., how a particular SST anomaly or evolution of anomalies may affect a given, remote location), especially given the complex interactions among local and remote processes that can contribute to predictability in a particular location. Better characterization of the link between ENSO (and other processes that affect boundary conditions for large-scale circulation) and the climate of remote locations is an important component for translating ISI forecasts into quantities useful for decision-makers (see “Use of Forecasts” section in this chapter).
In order to exploit atmospheric predictability associated with ENSO, one has to predict the SST in the tropical Pacific. The quasi-periodic nature of ENSO, with enhanced spectral power in the 4–7 year band, suggested that useful predictions might be possible months or seasons in advance. The next major step in short-term climate prediction came about when Cane et al. (1986) used a simple model of ENSO, a one-layer ocean representing the thermocline and a simple Gill-type model for the atmosphere, to make numerical predictions of ENSO events.
Successful predictions with the Cane-Zebiak model shifted the focus of short-term climate prediction to ENSO forecasting. ENSO is associated with much of the forecast quality at global scales in current forecast systems on seasonal to interannual timescales, although some other phenomena may dominate in specific regions. The type of model used by Cane and Zebiak is referred to as an Intermediate Coupled Model (ICM), because the atmospheric and the oceanic model are highly simplified. Following the success of the ICM approach, more sophisticated techniques were developed for ENSO prediction. One was the Hybrid Coupled Model (HCM) approach, where the atmospheric model remained simple but the one-layer ocean model was replaced by a comprehensive ocean general circulation model (OGCM). Neither the ICM nor the HCM approaches produced useful predictions of atmospheric quantities over continents. Therefore, a two-tier approach was used to produce climate forecasts over land. The SSTs predicted by the ICM/HCM (Tier 1) were used as the boundary condition for AGCM predictions (Tier 2).
Another approach to ENSO prediction was the use of a comprehensive coupled GCM (CGCM), where an AGCM is coupled to an ocean GCM, with the two models exchanging fluxes of momentum, heat, and freshwater. CGCMs were originally developed for studying long term (centennial) climate change associated with increasing greenhouse gas concentrations. CGCMs used for climate change used coarse spatial resolution to facilitate multi-century integrations. The shorter integrations required for ENSO prediction allowed finer spatial resolution, especially in the ocean, which could better resolve the processes important for ENSO. Finer resolution in the atmosphere improved forecast quality over the continents without requiring a two-tier approach. The quality of ENSO predictions in a CGCM arises almost exclusively from initial conditions in the upper ocean.
The major modeling/forecasting centers began to use CGCMs for ENSO prediction in the 1990s (Ji and Kousky, 1996; Rosati et al., 1997; Stockdale et al., 1998; Schneider et al., 1999) although the two-tier approach continued to be used operationally to predict the associated terrestrial climate. Atmospheric model resolution was initially about 2–4 degrees in the horizontal and the ocean model resolution was 1–2 degrees, often with substantially finer meridional resolution near the equator. Initial conditions were derived from an ocean data assimilation system.
Early attempts to use CGCMs for ENSO prediction fared poorly when compared to the ICM/HCM approaches or statistical techniques. CGCM predictions for ENSO suffered from “climate drift,” where the model prediction evolved from the “realistic” initial condition to its own equilibrium climate state. This led to a rapid loss in quality for ENSO predictions. Statistical corrections applied a posteriori (Model Output Statistics, see “Correlation and Regression” section in this chapter) had only limited efficacy in arresting this loss of quality. Anomaly coupling strategies, where the atmospheric and oceanic models exchange only anomalous fluxes, were also used (Kirtman et al., 1997), but did not address the underlying deficiencies of the component models.
Over the last decade, the ENSO forecast quality associated with CGCMs has improved significantly. Reductions in the model bias and improved ocean initial conditions have now enabled CGCMs to be competitive with statistical models. An important development has been the use of multi-model ensembles (MME), where predictions from a number of different CGCMs are combined to produce the final forecasts (Krishnamurti et al., 2000; Rajagopalan et al., 2002; Robertson et al., 2004; Hagedorn et al., 2005). The Development of a European Multi-model Ensemble System for Seasonal to Interannual Prediction (DEMETER) project included seasonal
predictions from seven different CGCMs, with atmospheric horizontal resolutions ranging from T42–T63 and oceanic horizontal resolution in the 1–2 degree range (Palmer et al., 2004). The MME forecast quality of the DEMETER ensemble (and other ensembles) beats the quality of any single CGCM that is part of the ensemble (Palmer et al., 2004; Jin et al., 2008). The MME anomaly correlation skill of Nino3.4 at 6 month lead time is 0.86 in the ensemble considered by Jin et al. (2008), with individual models showing lower correlations (some as low as 0.6).
In terms of intraseasonal and MJO prediction, evaluating and incorporating the role of ocean coupling has evolved somewhat independently. Given the shorter time scale relative to ENSO, the interaction with SST has been found to be mostly limited to the ocean mixed-layer (e.g, Lau and Sui, 1997; Zhang, 1996; Hendon and Glick, 1997). A number of model studies have indicated improvement in MJO simulation and prediction by incorporating SST coupling of various levels of sophistication (e.g., Waliser et al., 1999b; Fu et al., 2003; Zheng et al., 2004; Woolnough et al., 2007; Pegion and Kirtman, 2008).
Current Dynamical ISI Forecast Systems
Currently, CGCMs serve as the primary tool for dynamical ISI prediction. Improvements in atmospheric model resolution mean that it is no longer necessary to use a two-tiered approach for ISI prediction. In operational forecasting centers, CGCMs are used in conjunction with sophisticated data assimilation systems and statistical post-processing to produce the final forecasts. Typically, the atmospheric component of a CGCM is a coarse-resolution version of the AGCM used for short-term weather forecasts. A CGCM also includes a land component (as part of the AGCM), an ocean component, and optionally a sea ice component (Figure 3.8). CGCMs also include a comprehensive suite of physical parameterizations to represent processes such as convection, clouds, and turbulent mixing that are not resolved by the component models. In this section, we provide a brief overview of the state-of-the-art in model resolution for CGCMs used for ISI prediction at two of the major operational forecasting centers, NCEP and ECMWF.
The atmospheric component of the NCEP Climate Forecast System (CFS) (Saha et al., 2006), which became operational in August 2004, currently has a horizontal resolution of 200 km (T62) with 64 levels in the vertical. It is scheduled to have a six-fold increase in horizontal resolution in 2010. The oceanic component of the CFS is derived from the GFDL Modular Ocean Model version 3 (MOM3), which is a finite difference version of the ocean primitive equations with Boussinesq and hydrostatic approximations. The ocean domain is quasi-global extending from 74ºS to 64ºN, with a longitudinal resolution of 1º and a latitudinal resolution that varies smoothly from 1/3º near the equator to 1º poleward of 30º. The model has 50 vertical levels, with spacing between levels (resolution) ranging from 10 m near the surface to over 500 m in the bottom level. The atmospheric and oceanic components exchange fluxes of momentum, heat, and freshwater daily, with no flux correction. Soil hydrology is parameterized using a simple two-layer model. Sea ice extent is prescribed from observed climatology.
At ECMWF, the current generation of the Seasonal Forecasting System (v3) has an atmospheric model with a horizontal resolution of 120 km (T159), with 62 levels in the vertical (http://www.ecmwf.int/products/changes/system3/). In contrast, the current operational deterministic weather prediction AGCM used by ECMWF has a resolution of 16 km and 91 vertical levels. The ocean model has a longitudinal resolution of 1.4º and a latitudinal resolution that varies smoothly from 0.3º near the equator to 1.4º poleward of 30º. There are 29 levels in
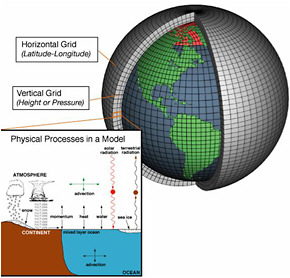
FIGURE 3.8 Schematic of a coupled general circulation model illustrating the horizontal/vertical grid, the different components (atmosphere, land, ocean), important physical processes, and air-sea flux exchange. SOURCE: NOAA.
the vertical. A tiled land surface scheme (HTESSEL) is used to parameterize surface fluxes over land. Sea ice is handled though a combination of persistence and relaxation to climatology.
Systematic errors are found in the mean state, the annual cycle, and ISI variance of climate simulations in the current generation of CGCMs (Gleckler et al., 2008). Model errors in the tropical Pacific, such as a cold SST bias or a ‘double’ Inter-tropical Convergence Zone, are particularly troublesome because they impact phenomena such as ENSO and the MJO that are important for ISI prediction. Indeed, the models often exhibit significant errors in the simulation of spatial structure, frequency, and amplitude of ENSO and the MJO. These errors lead to the degradation of ISI prediction quality in CGCMs. Although some of the systematic errors can be attributed to poor horizontal resolution of the CGCMs, other errors are attributable to deficiencies in the subgrid-scale parameterizations of unresolved atmospheric processes such as moist convection, boundary layers and clouds, as well as poorly resolved oceanic processes such as upwelling in the coastal regions. Improvements in both model resolution and subgrid-scale parameterizations are needed to address these problems.
Multi-Model Ensembles
As mentioned above, one source of error in dynamical seasonal prediction comes from the uncertainties arising from the physical parameterization schemes. Such uncertainties and
errors may be, to some extent, uncorrelated among models. A multi-model ensemble (MME) strategy may be the best current approach for adequately resolving this aspect of forecast uncertainty (Palmer et al., 2004; Hagedorn et al., 2005; Doblas-Reyes et al., 2005; Wang et al., 2008; Kirtman and Min, 2009; Jin et al., 2009)12. Figure 3.9 demonstrates how a multi-model ensemble can outperform the individual models that are used to form the ensemble. The MME strategy is a practical and relatively simple approach for quantifying forecast uncertainty. In fact, as argued in Palmer et al. (2004), Kirtman and Min (2009) and a number of studies using the DEMETER seasonal prediction archive and the APCC/CliPAS seasonal prediction archive, the multi-model approach appears to outperform any individual model using a standard single model approach (e.g., Jin et al., 2009; Wang et al., 2009). Although the “standard” MME approach applying equal weights to each model is relatively straightforward to implement, it has some shortcomings. For example, the choice of which models to include in the MME strategy is in practice ad-hoc and is limited by the “available” models. It is unknown whether the available models are in any sense optimal. Indeed, it is an open question as to whether more sophisticated single model methods such as perturbed parameters or stochastic physics will out perform MME strategies.
Developing alternative methodologies for combining the models can be challenging since the hindcast records for CGCMs used to assign weightings to the models are limited. Using predictions or simulations from AGCMs allows for longer records. One example is the super ensemble technique proposed by Krishnamurti et al. (1999), where the individual model weights depend upon the statistical fit between the model’s hindcasts with observations during a training period. If a model has consistently poor predictions for a variable at a specific location during the training period, the weight could be zero or negative. Another approach is the Bayesian combination approach developed by Rajagopalan et al. (2002) and refined by Robertson et al. (2004), in which the prior probabilities are equal to the climatological odds, and models are optimally weighted based on probabilistic likelihood based on past performance. An outstanding question for MME research involves explaining why some MME statistics, such as the ensemble mean, consistently outperform the individual models. Similarly, it would be valuable to improve our understanding of what the ensemble mean and ensemble spread represent and how differences among these statistics can be best evaluated following MME experiments.
DATA ASSIMILATION
For the purposes of climate system prediction, data assimilation (DA) is the process of creating initial conditions for dynamical models. Since ISI predictions are based on coupled ocean-land-atmosphere models, it seems apparent that data assimilation eventually needs to be carried out in a coupled mode. At the present, however, data assimilation is being done separately for different model components, with exceptions such as the partial coupling carried out in the recent NCEP reanalysis (Saha et al., 2010). In the following sections, the current approaches (non-coupled) for carrying out assimilation on atmospheric, ocean, and land observations are discussed.
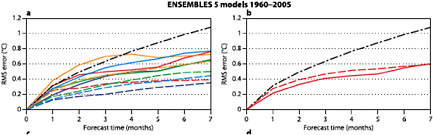
FIGURE 3.9 Comparison of RMSE of individual models to the multi-model mean for for Nino3 SST (solid) and ensemble standard deviation (spread) around the ensemble mean (dashed). The curves on the left represent individual models; the red curve on the right represents the multimodel mean The multi-model mean has a lower RMSE at nearly all forecast lead times, and a larger spread among its members, indicating that it outperforms any of the individual models. The black dash-dotted curve indicates the performance of a persistence forecast. SOURCE: Weisheimer et al. (2009).
Atmospheric Data Assimilation
Early efforts at data assimilation for short-term weather prediction used a priori assumptions about the statistical relationship between observed quantities and values at model gridpoints. The most sophisticated of these early methods was referred to as optimal interpolation (OI). Modern data assimilation for short-term numerical weather prediction objectively combines observations, model predictions started at earlier times, and a priori statistical information about the observations and the model to create initial conditions for updated model predictions.
The central theme of the evolution of atmospheric DA has been to use more information from the prediction model as both the models and the DA algorithms themselves have improved (Kalnay, 2003). In the earliest systems, the only information used from the model was the relative locations of model gridpoints (Daley, 1993). Later, short-term model predictions were used as a “first-guess” field that was then adjusted to be consistent with available observations (Lorenc, 1986).
A major advance was the development of variational data assimilation methods in which a cost function measuring the fidelity of the model’s estimation of the observed values is minimized using tools from variational calculus (LeDimet and Talagrand, 1986). Three-dimensional variational (3D-Var) techniques were implemented first (Parrish and Derber, 1992), with the most recent state from a model prediction being modified to better fit the observations. Variational techniques require a priori specification of a background error covariance, an estimate of the statistical relationship between different model state variables (Courtier et al., 1998). Although in principle OI and 3D-Var are nearly equivalent, (Lorenc, 1986), the ability of 3D-Var to find a global solution using all observations simultaneously resulted in less noisy and more balanced initial conditions for the predictions. More recently, four-dimensional variational (4D-Var) techniques have become the state of the art for operational numerical weather prediction. These techniques adjust the initial state of the model at an earlier time so that the
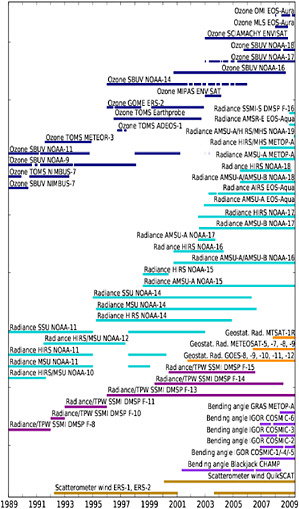
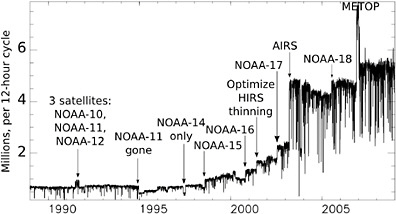
FIGURE 3.11 Number of satellite observations assimilated into the ECMWF ERA-Interim reanalysis (data assimilation system), with arrows indicating the introduction of new systems. SOURCE: ECMWF.
model evolves to fit a time sequence of available observations (Rabier et al., 1999). Predictions are then made by extending this model trajectory into the future.
Assimilation of remotely sensed atmospheric observations has played a large role in the increase in prediction quality over the last two decades (see “Atmospheric Observations” section, Figures 3.10, and 3.11). Figure 3.10 shows the types of remotely sensed satellite observations since 1989, and Figure 3.11 shows the number of satellite observations assimilated in the ECMWF Interim Reanalysis (ERA-Interim): about 1.5 million/day in 1989, jumping to 10 million/day in 2002 with the introduction of AIRS high resolution infrared sounder, and with another large increase from the high resolution infrared interferometer IASI (METOP). Figure 3.12 compares two recent reanalyses performed at ECMWF, the ERA 40, carried out with 3D-Var, and ERA-Interim, an experimental 4D-Var reanalysis. The obvious difference in performance between the two systems (which use the same observations but differ in their data assimilation systems) during the overlapping years quantifies the importance of the methods used for data assimilation, quality control, and advances in the model. It is remarkable that in the “reforecasts” from the ERA-Interim, it is possible to detect the improvement due to the introduction of AIRS in 2003, with a perceptible increase in anomaly correlation values in the five- and seven-day predictions.
The most recently developed methods for atmospheric data assimilation are ensemble Kalman filter (EnKF) techniques that use a set of short-term model predictions to sample the probability distribution of the atmospheric state. The ensemble provides information about both the mean state of the model and the covariance between different model variables. The ensemble members are adjusted using observations to produce initial conditions for a set of predictions. EnKF techniques are now in operational use for ensemble weather prediction (Houtekamer and Mitchell, 2005). Understanding the relative capabilities and advantages of 4D-Var and ensemble methods is an area of active research (e.g., Kalnay et al., 2007; Buehner et al., 2009a and b). There is a developing consensus that a “hybrid” approach combining a variational system (3D-Var or 4D-Var) with EnKF may be optimal.
In concert with using increasing amounts of information from the numerical model, increasingly sophisticated DA techniques facilitated the use of a more diverse set of observations. The earliest techniques were limited to assimilating observations of quantities that were one of the model state variables. Variational methods facilitated the assimilation of any observation that could be functionally related to the model state variables. However, a priori estimates of the relationship between errors in estimates of model state variables and the observed quantities were required. Ensemble methods automatically provide estimates of these relationships making it mechanistically trivial to assimilate arbitrary observation types. The types and numbers of observations assimilated for NWP has soared as DA techniques have improved in concert with the development of remote sensing systems that produce ever increasing numbers of observations.
While it can be difficult to separate prediction and forecast improvements due to model enhancements, DA advances, and increased numbers of observations, there is no doubt that all three have played a major role in improvements in NWP during the last decade (Simmons and Hollingsworth, 2002). In the mid-1990s, operational NWP centers seemed to be faced with a saturation in prediction quality (see Figure 2.1 on ECMWF 500-hPa geopotential height anomaly correlation). Since then, however, the rate of quality improvement has accelerated again. This acceleration is generally attributed to the direct assimilation of globally distributed Advanced Microwave Sounding Unity (AMSU) radiances (English et al., 2000), but it is important to remember that these observations could only be used effectively with advanced DA techniques (e.g., 4D-Var) and improved models. Removing bias from the observations was also essential. Similar improvements in quality for intraseasonal to interannual prediction could be expected by implementing improved DA in ocean, land surface, and possibly cryosphere models.
Ocean Data Assimilation
As pointed out in Chapter 2, much of the information required for successful ISI predictions resides in the initial conditions for the ocean, land surface, and cryosphere components of the climate system. There is a much shorter history of prediction and data assimilation for these components. This is partially due to the difficulty of observing these systems. In situ observations of the ocean, especially in remote areas or the deep ocean, have been difficult and expensive to obtain. It is also difficult to take in situ observations of quantities like land surface temperature and moisture (Reichle et al., 2004), or snow and ice thickness and extent (Barry 1995). In the last two decades, the number of observations of the ocean has soared, as noted earlier in the Observations section. Moored buoy systems have been developed in all of the world’s tropical oceans and provide high frequency measurements of temperature, salinity, and currents. Global networks of autonomous drifting surface buoys and ocean sounders have been deployed, and remote sensing measurements of surface temperature, sea surface height, and ocean color are routinely available. Remote sensing observations of the land and cryosphere are also now available.
Since the ocean is considered to be the source of the majority of seasonal predictability, and the ocean is the best observed non-atmospheric climate system component, it has been natural to focus ISI DA efforts here. Sea surface temperature estimates, made using primitive assimilation techniques, have been available since the 1970s (Miyakoda et al., 1979) and
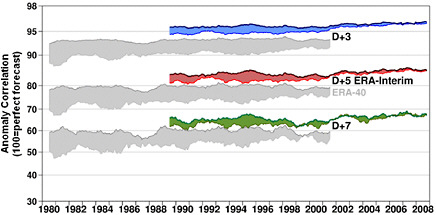
FIGURE 3.12 ECMWF 500-hPa geopotential height anomaly correlations from two different reanalysis systems. Gray: ERA-40 with 3D-Var (ca. 1998); Colors: ERA-Interim which uses 4D-Var (ca. 2005). “D+3” corresponds to the 3-day forecast; “D+5” the 5-day forecast; and, “D+7” the 7-day forecast. In each case the top line is the anomaly correlation of the forecasts started from the reanalysis for the Northern Hemisphere, and the bottom line is the corresponding forecast for the Southern Hemisphere. Note the improvement brought about by the improvement of the data assimilation system, which is especially important in the Southern Hemisphere. SOURCE: ECMWF.
continue to be produced (Reynolds et al., 2002). These methods are used routinely to produce products like analyses of the sea surface temperature. The first use of more modern data assimilation was a 3D-Var/OI system that used the Geophysical Fluid Dynamics Laboratory (GFDL) ocean forecast model and surface fluxes from the GFDL First GARP Global Experiment (FGGE) reanalysis to predict a “first-guess” for the assimilation (Derber and Rosati, 1989). While capable of assimilating observations of any model state variable, the system was primarily used with observations of temperature, and to a lesser extent salinity. Ocean DA systems based on this algorithm continue to be used at operational prediction centers like NCEP, ECMWF and UKMO. Many of them incorporate a number of heuristic enhancements, for instance the use of independently produced sea surface temperature analyses instead of observations of near-surface ocean temperature. Most current ocean DA efforts are using assimilation algorithms that would be regarded as outdated for atmospheric applications.
Ocean data assimilation has several major challenges compared to atmospheric data assimilation: (1) the observing system is sparser, and started later than the global atmospheric observing system, (2) the models are arguably worse in representing the real ocean, and (3) the time scales for forecasting are longer, so both the analyses and the forecasts (and the verifications) are less frequent. However, if advanced assimilation systems (4D-Var or EnKF) for the ocean are developed, tuned, and used operationally, similar improvements in the ocean analysis and predictions would be expected.
Here we briefly review two ocean DA systems that are currently in use: the NCEP Global Ocean Data Assimilation System (GODAS) and the ECMWF System 3 (S3), implemented in 200613.
NCEP GODAS
Coupled ocean-atmospheric forecasts and ocean data assimilation (ODAS) were pioneered at NCEP under the direction of Ants Leetmaa (Ji et al., 1998), who created a data assimilation system for the Pacific for the purpose of predicting ENSO. This was significantly improved, and the last version (RA6) of ODAS has been widely used (Behringer et al., 1998). RA6 was replaced by a Global Ocean Data Assimilation System (GODAS), which was coupled with the successful Climate Forecast System (Saha et al., 2006).
The numerical model in GODAS is the GFDL MOM-v3, with a horizontal resolution of 1º x 1º, enhanced to 1/3º in latitude within 10º of the equator. It has 40 levels with 10 m resolution in the upper 200 m, an explicit free surface, a Gent-McWilliams (Gent and McWilliams, 1990) mixing and a KPP (K-Profile Parameterization, Large et al, 1994) vertical mixing. The model is forced at the surface by analyzed momentum flux, heat flux, and fresh water flux produced by the NCEP atmospheric Reanalysis 2 (R2).
The GODAS data assimilation is based on the 3D-Var/OI of Derber and Rosati (1989). In addition the model top level is relaxed towards the Reynolds weekly SST analysis, and the surface salinity is relaxed towards the annual salinity climatology (from Levitus, 1982). GODAS assimilates temperature profiles from XBTs, moored buoys including TAO, TRITON and PIRATA, and from Argo profiling floats (see “Ocean Observations” section in this chapter). In addition, for each temperature profile, a synthetic salinity profile is created from a local climatology of the temperature-salinity relationship. These salinity profiles are also assimilated. Although observed salinity is not currently assimilated, experiments using Argo salinities (Huang et al, 2008) showed a clear improvement with a reduction of errors not only in salinity but also in currents.
One of the challenges for 3D-Var is defining appropriate multivariate background covariances that allow observations of one quantity to impact state variables of another type, for instance, having assimilation of salinity observations directly impact temperature state variables. The current GODAS is univariate in this sense. Multivariate GODAS was developed and tested but performs worse than univariate in assimilating salinity, possibly due to the use of synthetic salinity profiles.
Remote sensing measurements of sea surface height, which is a model state variable, from the TOPEX/Jason-1 altimetry have been available since 1992. Behringer (2007) indicates that assimilating surface heights (SSH) directly is not effective in this system, and instead it is used as a constraint on the baroclinic (temperature and salinity) analysis. When assimilated, it improves the anomalous SSH with respect to the observations but other aspects of resulting forecasts may be degraded.
ECMWF S3
The ECMWF S3 and NCEP GODAS systems are quite similar. The S3 (Balmaseda et al., 2008) is based on the HOPE-OI scheme. The ocean model (HOPE, Wolff et al., 1997) has the same resolution as MOM-v3 (1º x 1º horizontally) but only 29 vertical levels. It uses Optimal Interpolation (OI), which is nearly equivalent to the 3D-Var of GODAS. The operational system assimilates subsurface temperature and salinity, along with altimeter sea surface height anomalies. All observations in the upper 2000 m are assimilated. The sea surface temperatures are strongly relaxed to the Reynolds SST analysis. Surface forcing is similar to that in GODAS with fluxes from the ERA40 reanalysis (1959–June 2002) and the operational prediction system thereafter. Since the precipitation-evaporation flux is inaccurate in ERA40, a correction for precipitation (Troccoli and Kallberg, 2004) is used. An online additive bias correction has recently been added to the system (Balmaseda et al., 2008) that allows a reduction of the relative weight given to observations and reduces the strength of the relaxation to climatology. The main differences between the S3 and GODAS systems are that the S3 assimilates Argo salinities and altimeter data, and it includes a relatively sophisticated bias correction.
Improvements to Operational Ocean Data Assimilation Systems
There has been research with both 4D-Var (Weaver et al., 2003: Stammer et al., 2002) and EnKF (Keppenne and Rienecker, 2002) assimilation for the ocean. To date, the operational ISI community has been hesitant to adopt these more advanced assimilation methodologies because tests indicate that they may result in comparable and even worse forecasts, and in data sparse conditions they may not offer improvement. Since more advanced methods rely increasingly on the fidelity of the dynamical model, this may indicate that ocean models are not yet sufficiently accurate for these methods. Analogy to the atmosphere suggests that a program of model improvement combined with the incorporation of more sophisticated assimilation techniques that can make better use of all available observations is likely to lead to improvement for the ocean component of operational ISI predictions.
Land Data Assimilation
Land data assimilation systems (LDAS), as described in the “Land Observations” section, use surface meteorological forcing inputs that are based on observations as much as possible. Here we describe progress on another aspect of land assimilation, i.e., the merging of land surface state observations with estimates from the corresponding land model prognostic variables using mathematically optimal techniques.
A popular approach involves adjusting the land model’s soil moisture reservoirs in response to screen-level (2 m) observations of atmospheric temperature and humidity using Optimal Interpolation (OI). If simulated relative humidity is too low compared to observations, soil moisture is increased so that evaporation increases, thereby increasing the simulated humidity. While this approach for initialization has been used with success in many operational centers (with success measured as improved weather forecasts), errors in simulated relative humidity and temperature need not stem from errors in soil moisture; they could stem from
errors in parameterization, so that the modified soil moisture contents may not be more accurate than the original estimates. Drusch and Viterbo (2007) note that soil moisture profiles obtained through the OI approach are not necessarily sufficient for hydrological or agricultural applications; presumably, they may not be optimized for seasonal forecast initialization, either.
More recent land assimilation efforts have focused on the Kalman filter. ECMWF and Meteo-France, for example, are poised to implement in their operational NWP systems an extended Kalman filter (EKF) for assimilating soil moisture information derived from active and passive sensors (and potentially other variables as well). Currently, operational soil moisture retrievals are generated from Advanced Scatterometer (ASCAT) observations by the EUMETSAT satellite. The recently launched SMOS and the planned SMAP missions will provide L-band soil moisture information down to 5 cm in many areas. NASA/GSFC has pioneered the development of the ensemble Kalman filter (EnKF) for assimilating soil moisture retrievals or associated radiances into a land model; analyses with SMMR and AMSR-E soil moisture data show that EnKF assimilation produces soil moisture products with increased accuracy over model products or satellite retrievals alone (Reichle et al. 2007). Further plans for land data assimilation in various institutions include the use of a Kalman filter (EKF or EnKF) for snow data assimilation, the development of multivariate land data assimilation methods, and the assimilation of land variables as part of a coupled land data assimilation system.
USE OF FORECASTS
ISI forecasts can be valuable tools for decision makers. However, the use of a forecast is predicated on its quality. A forecast that is not sufficiently accurate or reliable is unlikely to be used to make decisions. The quality of a forecast can be determined through a variety of metrics (see “Forecast Verification” section in Chapter 2 for more details on forecast verification metrics). Typically, multiple metrics are used to provide an overall sense of forecast quality.
Understanding or improving forecast quality requires information about the predictions that go into a forecast. Increasingly, forecasts are generated from multiple prediction inputs, which can be objective (e.g., predictions from statistical or dynamical models) or subjective (e.g., expert opinion of forecasters). Detecting how these inputs or changes to these inputs affect forecasts is critical for improving forecast quality.
Finally, forecasts can be used by decision makers if they are provided in the appropriate format. A forecast regarding SST in the tropical Pacific may not be easily translatable to the local climate conditions of a particular user. In addition, different variables will have varying levels of value for different users. Some decision makers may require information about the seasonal mean values for particular meteorological variables, such as precipitation or temperature, while others may be more interested in certain extreme events, such as heat waves or incidents of heavy precipitation. Scale can also be important—some decision makers may require national or regional information, while others might be more focused on a city or even a piece of infrastructure. All of these factors can contribute to the utility of an ISI forecast with respect to societally-relevant decisions.
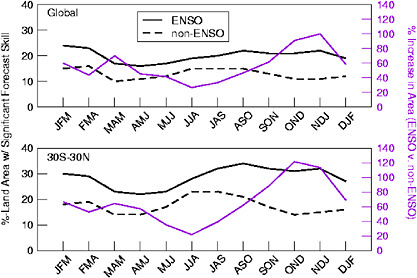
FIGURE 3.13 Seasonal precipitation forecasts are skillful over a larger portion of land during ENSO events (solid black line) than ENSO-neutral conditions (dashed black line). The purple line indicates the percentage increase in area between ENSO events and ENSO-neutral conditions. Top panel corresponds to the entire globe; bottom panel the area within 30º latitude of the equator. SOURCE: Goddard and Dilley (2005).
Measuring Forecast Skill and Assessing Forecast Quality
Evolution over time in skill according to various metrics can occur for multiple reasons, the main two factors being changes in the sources of predictability within the climate system and changes in the forecast system. Given a constant forecast system, changes in, for example, correlation between the predictions and observations of the climate over time come primarily from changes in the sources of predictability. It is a matter of signal versus noise; the signal due to forcing from SSTs or soil moisture changes noticeably from year to year, whereas the noise due to the internal dynamics of the atmosphere remains largely constant (Kumar et al., 2000). Overall, the seasonal climate predictions are more confident, and many skill metrics are higher, during ENSO events (Figure 3.13: Goddard and Dilley, 2005), as demonstrated by comparing forecast verifications during El Niño and La Niña conditions against those during ENSO-neutral conditions. The influence of ENSO, and other drivers of teleconnection patterns, on predictability remains incompletely understood.
For the United States, as with many other regions, much of currently realized quality in official forecasts is due to ENSO (Livezey and Timofeyeva, 2008), and the rest is attributed to climate trends, at least for temperature. For the official precipitation forecasts most of the skill
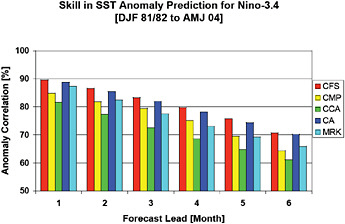
FIGURE 3.14 Nino3.4 correlation coefficient (predictions versus observations) for retrospective forecasts plotted as a function of lead time. The red and yellow bars correspond to dynamical models: the Climate Forecast System (CFS) is a state-of-the-art model developed in the mid-2000s (Saha et al., 2006), while the Coupled Model Project (CMP) prediction is older and was developed in the mid 1990s (Ji et al., 1995). CCA, CA, and MRK correspond to statistical models (Canonical Correlation Analysis, Constructed Analogues, Markov; several of these methods are discussed in “Statistical Models” section in this chapter and Appendix A). The figure highlights two points: (1) comparing the red and yellow bars indicates how coupled dynamical models have improved for this particular metric over the last two decades and (2) the statistical methods and the dynamical model methods are quite competitive with each other. SOURCE: Adapted from Saha et al. (2006)
assessed by the modified Heidke skill score derives from ENSO. Outside of ENSO, the skill assessment (Livezey and Timofeyeva, 2008) suggests that where trends are observed but skill is low, the information from trends has been underutilized by CPC. In the cases where skill is significant but the trends are negligible, it is suggested that the source of skill is the decadal scale variability captured through their statistical tool of Optimal Climate Normals. For temperature, the analysis does show that a few areas of positive Heidke skill in the official forecasts are found additionally during non-ENSO conditions in regions where temperature trends are weak (Livezey and Timofeyeva, 2008). Whether this indicates potential sources of predictability beyond ENSO and trend or is a lucky draw from a limited set of subjectively derived predictions is unclear.
In the case of a changing forecast system, one can demonstrate improvements in prediction quality by comparing the different forecast systems, such as the predictions of the newer system to those of older system over a common period. For example, when the correlation skill of Nino3.4 in the NCEP Climate Forecast System (CFS) dynamical model reached parity with that of statistical approaches (Figure 3.14), this was seen to be a significant
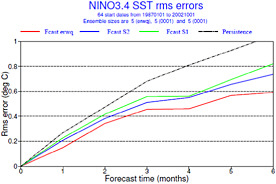
FIGURE 3.15 Improvement in forecasts from the latest ECMWF forecast system (red line) compared to earlier versions (blue and green lines). The black line corresponds to a Persistence forecast. Metric shown is RMS error for Nino 3.4 SST for 64 forecasts in the period 1987–2002. SOURCE: ECMWF, Anderson et al (2007).
accomplishment. Incremental improvements in the ECMWF dynamical model are illustrated through successive reduction in the RMSE of Nino3.4 predictions (Figure 3.15). Comparative assessments of new versus old forecast systems can really only be quantified for fully objective forecast systems, although one could demonstrate improvements of a newer objective system over a previous non-objective system (i.e., one involving subjective intervention). It should also be noted that these assessments of improvement potentially suffer from sampling issues, since there are typically not more than 20 years of retrospective forecasts for comparison. However, there are coordinated international efforts (e.g., the Climate Historical Forecast Project; CHFP) to extend the retrospective forecast period further back in time.
Currently, forecast quality is often difficult to compare across systems because of differences in forecast format, verification data, the choice of skill metrics, or even differences in graphical appearance. A mechanism to provide a consistent view of prediction quality across models was established in 2006 by the World Meteorological Organization. The charge was taken up by the lead center for the Standard Verification System of Long Range Forecasts (LC-LRFMME: http://www.bom.gov.au/wmo/lrfvs/) co-hosted by the National Meteorological Services of Australia and Canada. The LC-SVSLRF responsibilities include maintaining an associated website displaying verification information in a consistent and similar way. It allows forecasting centers to document prediction quality measured according to a common standard. The SVS is defined in Attachment II.8 (p. 122) of the WMO Manual on the Global Data-Processing and Forecasting System (WMO No. 485). Unfortunately, the goal of the comparative assessment envisioned by the WMO has not been achieved because it depends on the cooperation of the global producing centers (http://www.wmolc.org) to contribute consistent verification data, preferably in a common graphical format, which has not yet happened.
Comparative estimates of quality can be similarly difficult to quantify, even for the U.S. forecasts. One of the few studies to date compares the official subjective forecasts since 1995 with a newly implemented objective methodology that combines three statistical and one
dynamical tool (Figure 3.16; O’Lenic et al., 2008). As stated above, the objective combination outperforms the subjective forecasts. The skill metric used in that study is the Heidke score, which was discussed in the previous section; it is not advocated by the WMO-SVSLRF. Assessment of forecast quality from the NCEP CFS model does not use Heidke skill scores, but rather correlation, Brier skill scores (BSS), and reliability diagrams (Saha et al., 2006). In Saha et al. (2006), a widely used statistical tool is compared to the dynamical model, with the result that the two methods have comparable but complementary BSS; regions of highest skill rarely overlap. Their result strongly suggests that additional predictability that is seen by the statistical tool but not currently captured in the dynamical model could result from improvements to that model. It also suggests the benefit of using both statistical and dynamical modeling approaches for seasonal climate prediction.
Combined Forecast Systems
A growing body of literature touts the benefit of multiple prediction inputs in climate forecasts. Many national centers that produce real-time forecasts include one or more dynamical models, one or more statistical models, and perhaps also the subjective interpretation or experience of the forecasters involved. As this practice continues, and as more prediction inputs become openly available, it is possible to assess the relative benefits of each type of prediction input to the quality of the forecast. In addition, as more prediction data becomes openly available, new methods for making the best use of that information can be tested and documented.
Subjective Combination
Since the early 1970s, weather forecasts in the United States and elsewhere were subjectively derived using the objective input as guidance (Glahn, 1984). In the mid-1980s, comparison of the skill of these objective and subjective forecasts according to several metrics indicated that the subjective weather forecasts were generally more skillful than the objective ones for shorter lead times (e.g. 12–24 hours), whereas the two types of forecasts exhibited approximately equal quality for longer lead times (e.g. 36–48 hours; Murphy and Brown, 1984). The same study further showed that both types of forecasts had positive trends in correlation skill over the decade, with improvements in objective forecasts equaling or exceeding improvements in subjective forecasts.
The use of subjective guidance has continued to this day for weather and now climate forecasts. Many seasonal-to-interannual forecasting centers, particularly those that use multiple prediction inputs, maintain a subjective element in their forecasts. At CPC and UKMO, for example, inputs from both statistical and dynamical prediction tools are considered and discussed, prior to “creating” a forecast (Graham et al., 2006; O’Lenic et al., 2008). In some instances, a subset of the tools will be objectively combined prior to their consideration next to other tools. Starting around 2006, CPC began objectively combining its main prediction tools, which consist of the Climate Forecast System (CFS) dynamical model and three statistical prediction tools, using an adaptive regression technique. This consolidation serves as a “first guess” but then is discussed with a number of other inputs, which include other consolidations as
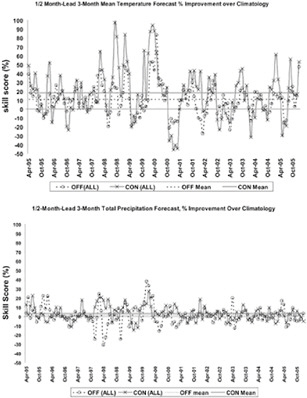
FIGURE 3.16 Objective forecasts tend to perform better than forecasts with a subjective element. Lines represent the percentage improvement of forecasts relative to climatology for a 3-month forecast issued with a 1/2 –month lead time. The mean skill of objective forecasts for the entire period (solid horizontal line, “CON” for “objective consolidation”) is above the mean skill of the forecasts with a subjective element for the entire period (dashed horizontal line, “OFF” for “official forecasts”). The individual forecasts (non-horizontal lines) throughout the period often indicate a similar relationship. Top panel: temperature; bottom panel: precipitation. SOURCE: Adapted from O’Lenic et al. (2008).
well as individual tools and may or may not incorporate historical forecast quality. Comparison of the official forecasts, which include the subjective intervention, against the purely objective consolidation indicates that the subjective element reduces forecast quality (O’Lenic et al., 2008), particularly during winter in the absence of a strong ENSO signal (Livezey and Timofeyeva, 2008).
A notable subjective element also exists in regional climate outlook forums (RCOFs14). These forums, initiated in the late 1990s by the WMO, National Meteorological and Hydrological Services (NMHSs) and other international organizations, bring together countries within a region, such as Southeastern South America or the Greater Horn of Africa, to develop a consensus outlook for the climate of the upcoming season. Seasonal climate predictions from the participating NMHSs are discussed in conjunction with those from international centers. The inputs are not combined objectively or systematically, although they do often consider past forecast quality in the discussions. Some analyses suggest that the subjective element of the process causes the forecasts to be quantitatively less skillful than if the input predictions were combined more objectively (Berri et al., 2005).
Efforts are underway to produce more consolidated inputs and other objective input tools that can be used in the RCOFs to encourage the reduction of the subjective element. One of these efforts includes the establishment of a Lead Centre of Long-Range Forecast Multi-Model Ensembles (LC-LRFMME15), which objectively combines the predictions contributed by the current nine Global Producing Centres (GPCs). However, associated skill information, which would presumably be provided by the WMO Lead Centre for the Long Range Forecast Verification System (LRFVS16), does not accompany these forecasts primarily because this model performance information is not provided by the GPCs. The GPCs also do not readily provide access to the historical model data that would allow users to evaluate the performance for themselves. In terms of other objective input tools, one that has been increasingly used in the RCOFs is the Climate Predictability Tool17, which allows forecasters to develop statistical predictions that use as input either observed precursors or dynamical model output.
Objective Combination of Predictions
As discussed in the previous sections, the few studies that have compared objective forecasts and the subjective forecasts to which they contribute indicate that the subjective element degrades the quality of the objective “first guess” (Berri et al., 2005; O’Lenic et al., 2008). But beyond that, objective methods allow a forecaster to demonstrate how the forecast would have performed in the past given new prediction inputs, which is not possible if the inputs are subjectively combined.
Statistical and dynamical predictions each have their own merits and should not necessarily be viewed as competitors. It is nonetheless desirable to compare the performance of statistical and dynamical tools when both exist for a given prediction target. This comparison can serve two purposes if there is a clear difference in performance: first, it may indicate that an important process is missing from one of the prediction approaches, and second, it may indicate that one of the predictions be given greater weight in the final forecast. Several studies have shown that statistical and dynamical methods have comparable quantitative skill for specific forecast targets such as ENSO (e.g. Saha et al., 2006) or precipitation in some parts of the world (e.g. Moura and Hastenrath, 2004). In other parts of the world, such as the United States, statistical and dynamical information bring complementary information (e.g. Saha et al., 2006).
The same can be said for different statistical predictions, such as those capturing ENSO teleconnections compared to those isolating recent trends (e.g. Livezey and Timofeyeva, 2008). In addition, considerable value can be gained by employing the two approaches together, such as model output statistics (MOS, see “Correlation and Regression” section in this chapter), which refers broadly to the statistical correction of dynamical models. MOS techniques can be used to correct systematic biases of dynamical models by translating the aspects of the observed variability that the model captures correctly into something that more closely resembles the observations (e.g. Feddersen et al., 1999; Landman and Goddard, 2002; Tippett et al., 2005).
By far, the greatest boost to objective combination of prediction inputs has come through advances in multi-model ensembles (MME). These advances within the climate community have been particularly rapid since the advent of publically available archives of model data, such as the DEMETER dataset for seasonal-to-interannual predictions (Palmer et al., 2004), with many decades of hindcasts, and the Coupled Model Intercomparison Project v3 (CMIP3) that provided the data of the climate change simulations of the 20th century and projections of the 21st century summarized in the 4th Assessment Report of the IPCC (IPCC, 2007). Although in each case the databases contain coupled ocean-atmosphere models with similar external forcing and/or initial conditions, the dynamical cores of the models and their physical parameterizations differ. The premise holds that although models have deficiencies, they do not all have the same deficiencies. Thus, combining models brings out the robust information they have in common and reduces the individual or random biases that they do not share, which can provide more reliable forecast information. By allowing scientists from all over the world to access a common set of models from different modeling centers, results are easier to compare and possible to replicate.
One result derived from these archives is that there is no single best model; one model may be best in some aspect, but turning to another aspect will highlight a different model (Gleckler et al., 2008; Reichler and Kim, 2008). Furthermore, it has been generally found that the multi-model mean outperforms the individual models (Hagedorn et al., 2005; Gleckler et al., 2008). Assigning weights to the individual models according to their historical performance (Rajagopalan et al,. 2002) can further improve upon the skill of MME relative to the simple model mean, provided that a sufficient number of hindcasts exist to distinguish the relative performance between models, i.e., about 40–50 years. Due to the need to fully cross-validate the weights assigned to models in the combination, it becomes difficult to improve upon the simple multi-model mean for MME with shorter hindcast histories (DelSole, 2007). The degree to which performance can be improved, both in terms of mean error reduction and probabilistic reliability, depends on the number of models involved, with more models yielding a higher quality MME (Robertson et al., 2004). However, it is not clear at what number the incremental benefit from adding more models begins to plateau. The magnitude of the benefit varies with the forecast target, including variable, region, and season, and with the quality of the individual models that contribute.
The wide community involvement in MME has shown that:
-
All models do have their deficiencies; the one weak point in the premise of MME is that models often do contain some common biases (Gleckler et al., 2008). It therefore makes good sense to calibrate models in terms of both their mean and variability to the greatest extent possible, prior to combination (e.g. Hagedorn et al., 2005).
-
Hindcast records are necessary to assess model performance prior to its inclusion in an MME. The hindcast may not be long enough for the purposes of weighting models, but it
-
needs to be long enough to vet the realism of the model’s mean state and variability relative to other models in the MME suite because poor models will degrade forecast quality.
-
Forecasts that objectively combine a number of prediction inputs allow information with different strengths and weakness to be distilled and yield more robust and reliable results. The prediction inputs can include statistical models, dynamical models, and the combination of the two. The main weakness of MME is a lack of design behind the specific models included; MME usually draws on whatever respectable models are available, and thus does not necessarily span all uncertainties in model physics.
Consideration of End User
Other approaches exist for going beyond the quality of a given forecast or model prediction to determine its value to a potential user. The provision of quantitative, probabilistic outlooks of societally-relevant variables can increase the use of climate forecasts even if the underlying quality were unchanged. Although seasonal climate forecasts are now commonly issued as probabilities for pre-defined categories (Barnston et al., 1999; Mason et al., 1999), those categories may not align with the risks and benefits of many decision makers. Additionally, users of the climate forecasts, from sectoral experts to the media, are often interested in relatively high resolution information that can be relevant to local concerns, even if it means reduced accuracy of the information. This information mismatch is one of the most commonly cited reasons for not using seasonal forecasts (e.g. CCSP, 2008). Good quality intraseasonal-to-interannual forecasts are only a starting point. In order for forecast information to be incorporated into climate risk management and decision making, it has to be in an appropriate format, at an appropriate space and time scale, and of the right variables to mesh with the decision models it is to inform.
One way to address the information mismatch between the coarse spatial resolution of global seasonal climate forecasts and the high-resolution needs of the end user is to use downscaling techniques. In statistical downscaling, the global climate forecast provides the input parameters for an empirical model with high spatial resolution. In dynamical downscaling, the global forecast is used to provide lateral boundary conditions to a high-resolution nested regional atmospheric model. Although downscaling has been used extensively in climate change research, its use on ISI timescales has been more on an exploratory basis. With increases in computing power, global climate models are starting to close the gap with the fine spatial resolution needs of the end user. However, there is still a window of a decade or so during which downscaling techniques will continue to add significant value to the dissemination of ISI forecasts.
Recent research has opened other possibilities of providing richer seasonal climate information. For example, the provision of the seasonal forecast as the full probability distribution as opposed to fixed, relative categories permits the determination of probabilistic risk of some decision-specific threshold (e.g. Barnston et al., 2000). Or, one may desire the characterization of the weather within the climate, such as the likely number of dry spells of a given duration. In some cases, certain weather characteristics of the seasonal climate may even be more predictable than the seasonal totals (e.g. Sun et al., 2005; Robertson et al., 2009). Similarly, Higgins et al. (2002, 2007) have documented how the character of daily weather changes over the United States during ENSO events. This information could complement
forecasts of the seasonal mean in ENSO years, particularly for the winter season, and provide true forecasts of opportunity (Livezey and Timofeyeva, 2008) if it were packaged and communicated in that manner.
Users can improve the application of forecast information if they are made aware of instances of conditional forecast skill (Frias et al., 2010) or forecasts with no skill. As shown in Figure 3.13, forecasts are often more skillful during ENSO events, which could guide decision makers to selectively use forecast information as part of their planning. Likewise, there may be certain regions or situations for which forecasts, or specific improvements to the building blocks of forecasts, offer little or no skill. For example, information on soil moisture can contribute to predictions of air temperature (see the soil moisture case study in Chapter 4; Figure 4.11), but the improvements are limited to certain key regions and seasons. In regions and seasons for which there is no forecast skill, or in situations where there is no forecast signal, operational centers can still provide a useful service through the issuance of information on the historical range of possible climate outcomes (i.e., climatology).
The difficulty for forecast centers in producing tailored forecasts is that what is needed is often specific to a particular problem, which in turn depends on the sector and location. This can be difficult for national or even regional forecast centers to provide on an operational basis. If the forecast data and the associated history are openly available, the tailoring of the information to the specific uses may be possible. The actual tailoring may be conducted by local forecast centers, intermediaries, or directly by the end-users. The national and international forecast centers could provide sufficient information through data archives, such that forecasts can be tailored to more specific decisions. This is not a trivial activity, however. Financial and computing resources would be required to maintain such a service.
Given the investments that have already contributed to the development of intraseasonal to interannual prediction information, such an infrastructure would be a very economical extension that could dramatically increase the use of climate forecasts. For example, users would be able to evaluate past performance in terms of their own relevant metrics, or even in terms of their own local or regional observational data. Forecast centers regularly assess the quality of their prediction models or forecast systems (O’Lenic et al., 2008; Barnston et al., 2009), which is necessary for their own feedback and interaction with the climate community. However, the value of access to data for verification, tailoring, or even just formatting should not be underestimated.
EXAMPLE OF AN ISI FORECAST SYSTEM
The building blocks of ISI forecasts systems have been described in detail above. Here we provide a specific example of how these basic building blocks ultimately culminate in an ISI prediction. This example is based on current operational forecasts at NCEP. The intent here is to highlight the complexity of the problem, the multitude of inputs to the process, and where and when subjective input is used. A flow chart for the forecast production procedure is given in Figure 3.17.
The forecast production process is described in detail in O’Lenic et al. (2008) and is summarized as follows. Climate Prediction Center operational seasonal forecasts are issued on the 3rd Thursday of each month at 8:30 AM, and a team of 7 forecasters at CPC rotates throughout the course of the year in preparing these forecasts. The process begins with a
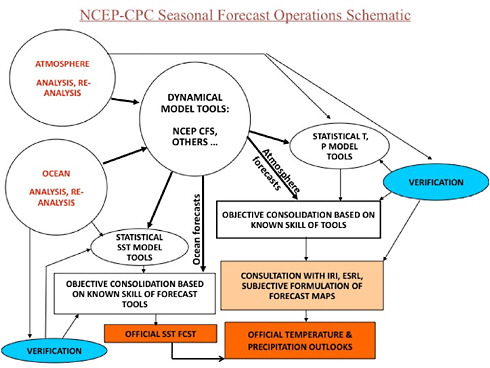
FIGURE 3.17 Graphical representation of the NCEP forecast system, showing the relationship among observations, climate system models, and data assimilation schemes as well as the steps where subjective judgment and verification are used. SOURCE: John Gottschalck, NCEP, personal communication.
comprehensive analysis of the state of the global oceans and atmosphere. This is largely based on best estimates of the current state of the climate system. Forecast tools, both CFS and statistical, are then consolidated into an objective first-guess forecast for U.S. temperature and precipitation. A telephone conference call is conducted the preceding Friday to discuss the current status of the climate system and the content of the available tools with partners in the broad climate community. Based on these discussions and the forecaster’s own interpretation of the forecast tools, the forecaster manually draws draft forecast maps for all thirteen forecast leads for both temperature and precipitation. A second conference call is then used to review the draft forecast maps with governmental climate partners only. Forecast maps are finalized and processed to produce images, raw data files, and files for the National Digital Forecast Database (NDFD) for a large range of users. Finally, the lead forecaster writes a “Prognostic Map Discussion” that includes a review of the climate system, rationale for the forecasts, and an overview of the forecast maps.
POTENTIAL IMPROVEMENTS TO ISI FORECAST SYSTEMS
In examining the components of existing ISI forecast systems and current practices, a number of opportunities for improvement have been identified. These opportunities are summarized here in a structure that parallels the previous discussion by component of the ISI forecast system. In Chapter 4, there is more detail about three specific ISI forecast topics: ENSO, MJO, and soil moisture. The illustrative nature of the three case studies, together with the opportunities identified here, provide the foundation for the recommendations presented in Chapter 6.
Observations
-
Many observations that could potentially contribute to ISI predictions are not being assimilated into ISI forecast systems (see DA bullet below).
-
The increase in the number of observations assimilated by ISI forecast systems has led to improvements in prediction. However, the attribution of these improvements to specific observations can be difficult to confirm. Also, study is required to determine the potential benefit for adopting new research observations as ongoing, operational climate observations to support ISI prediction.
-
Targeted observations for specific climate processes that are poorly understood could improve dynamical models by providing more realistic initial conditions, improved parameterizations of sub-grid scale processes, and/or data to be used in validation.
-
Sustained observations of the fluxes of heat and moisture between the atmosphere and ocean or between the land and atmosphere are useful for identifying biases and errors in dynamical models. Many processes that act to couple earth system components are poorly understood and undersampled, and observations of the coupling are needed.
Statistical and Numerical Models
-
Nonlinear statistical methods can augment linear statistics. While linear methods have been used in forecasting with moderate success in the past, positive skill is geographically dependent and primarily related to the presence of strong forcing, such as El Niño. Nonlinear techniques (e.g., nonlinear regression, neural networks, kernel methods) have been shown to be valuable in providing additional skill, especially at ISI timescales.
-
Present statistical models are not in competition with dynamical models and can be combined usefully with dynamical models. They offer quality in certain areas where dynamical models fail and may point to areas where dynamical models can be improved.
-
Proper cross-validation is an essential tool to estimate the true forecast skill. The use of repeated cross-validation on the same data, however, can inflate the estimated skill when models are tuned after each iteration. Such a process can result in overfitting. Data need to be divided into training and testing sets where the testing data are set aside for an unbiased estimation of true skill. It is acceptable to use subsets of the training data for model selection. However, the testing data have to be kept out of the tuning process and used for the final assessment of skill.
-
Most statistical tests assume stationarity, but the climate system is not stationary on ISI timescales. Statistical tests exist that can address such non-stationarity (e.g., variance stabilization techniques, Huang et al., 2004). Non-stationarity can also be exploited to improve predictions.
-
Dynamical models exhibit systematic errors in their representation of the mean climate, the annual cycle, and climate variability. While many of these shortcomings highlight opportunities for model improvement, they also contribute to forecast error. The physical processes associated with several sources of predictability (such as ENSO or the MJO) are not adequately simulated in numerical models.
-
Use of multi-model ensembles in an operational setting is still in its early stages. MMEs need to be developed further and research on proper methods of selection, bias correction, and weighting will likely help improve the forecasts.
Data Assimilation
-
The most advanced data assimilation algorithms are predominantly focused on atmospheric observations, while the DA schemes tend to be less advanced for the ocean than for the atmosphere. Ideally, data assimilation would be performed for the coupled Earth system. Specifically, more work is required to identify biases in the observational data and improve the ocean models so that advanced DA techniques can be applied to ocean observations.
-
Observations of many components of the Earth system are not part of DA algorithms. Estimates of prognostic states at the land surface (e.g. soil moisture) and cryosphere (e.g., snow, sea ice extent) are generally not assimilated with operational DA schemes. Some ocean observations are assimilated as part of operational forecasts but some are not (e.g., SSH).
Forecast Verification and Provision
-
Forecast quality assessment needs to be made and communicated through multiple metrics. Forecast quality has often been expressed through a single method (e.g., Heidke skill). Multiple metrics and graphical techniques, including ones that assess the quality of the probabilistic information, will provide a better assessment of the fidelity of the forecast system.
-
Access to archived hindcasts and real-time forecasts is required to tailor climate information to the needs of decision makers. Information regarding forecast quality and skill varies widely among forecast systems. Comparison among systems is critical for identifying opportunities for model improvement, as well as novel combinations of forecast models that may improve quality.
-
Subjective intervention into forecasts needs to be minimized and documented. The subjective component can limit reproducibility, restricting retrospective comparison of forecast systems. Although there are time constraints around issuing forecasts, it is helpful to have written documentation of the subjectivity of forecast preprocessing and post-processing to assess the relative performance of the inputs and outputs.















































