
7
Intuitive Theories of Behavior
Hal R. Arkes and James Kajdasz
In 1972, the U.S. Supreme Court ruled in Neil v. Biggers (409 U.S. 188 1972) that jurors may use a witness’s confidence in assessing the witness’s accuracy. The justices’ entirely reasonable assumption was that more confident witnesses are necessarily more accurate. However, substantial research over the past 40 years suggests that this intuitive theory is incorrect: Confidence is not closely related to accuracy.
For many years the Wall Street Journal ran contests to determine the accuracy of stock movement when predicted by dartboards versus expert stockbrokers. A panel of stockbrokers picked stocks they thought would appreciate in value. Competing against them were Wall Street Journal staff members who threw darts at a listing of stocks. The stocks on the list that were punctured by the darts were the stocks “chosen” by the staffers. After several months, the stock prices of the two sets of stocks were compared. The intuitive theory was that the expertise of the stockbrokers would easily swamp the darts’ total ignorance. The contest was eventually stopped, probably because the superiority of the stockbrokers was so embarrassingly minimal.
We all have intuitive theories regarding appropriate reasons for high confidence, the benefits of expertise, and other judgment and decision-making topics. However, many of these theories have required substantial alteration due to research findings over the past 40 years. The goal of this chapter is to present these intuitive theories and outline their shortcomings. Because research suggests that mere awareness of these shortcomings is not sufficient for the avoidance of their negative influence, some education or
training may be required to prevent these intuitive theories from interfering with sound intelligence tradecraft.
INTUITIVE THEORY #1:
WHY PEOPLE BEHAVE IN PREDICTABLE WAYS
Richard Nixon was known as a fierce anticommunist. His congressional and national campaigns were characterized by severe condemnations of those whom he accused of being “soft.” Yet President Nixon visited China in 1972, a trip that began to thaw the long-frozen relations between the two countries.
Anwar Sadat authorized the Yom Kippur War against Israel in 1973. This was another in a series of hostile events between Egypt and Israel that had begun with the founding of Israel 25 years earlier. Yet in 1977 Sadat visited Israel, a trip that led to a comprehensive peace agreement 2 years later between the formerly bitter enemies.
These two examples plus many others illustrate that predicting the behavior of individuals who have previously exhibited consistent behavior is not an easy task. The mistaken belief that people have a stable personality that manifests itself in consistent behavior was criticized many years ago by David Fischer (1970) in his classic book, Historians’ Fallacies. He termed the error in question “the fallacy of essences,” which is predicated on the belief that every person, nation, or culture has an essence that governs much of the behavior of that entity. Fischer was particularly blunt in his derogation of the fallacy of essences: “This most durable of secular superstitions is not susceptible to reasoned refutation. The existence of essences, like the existence of ghosts, cannot be disproved by any rational method” (p. 68). Referring to those people who endorse this fallacy as “essentialists,” Fischer continues, “The essentialist’s significant facts are not windows through which an observer may peek at the inner reality of things, but mirrors in which he sees his own a priori assumptions reflected” (p. 68). Of course, analysts must be on guard not to let their conclusions be nothing more than mere depictions of a priori assumptions.
Contemporaneous with Fischer’s book were a pair of psychological research programs. One of the most famous controversies in the history of psychology was largely engendered by the research of Walter Mischel (1973), who pointed out convincingly that the cross-situational consistency of any person’s behavior was surprisingly low. For example, extroverts did not seem to behave in a gregarious manner in all situations, and introverts did not seem to behave in a reserved manner in all situations. Mischel emphasized that the situation exerted far more influence on a person’s behavior than personality theorists had previously thought. Aggressive
children may be obedient at school, but defiant at home. Conscientious people may work hard on the job, but be sloths at home. Factors such as rewards, punishments, and other contingencies must be taken into account in predicting behavior, and when they are considered, predictability of behavior is markedly enhanced. For example, Vertzberger (1990) attributed some of Israel’s failure to anticipate the Yom Kippur War as due to the Israeli military’s underestimation of the domestic and external pressures on Sadat to initiate military operations. Instead, Vertzberger concluded that the Israeli military relied on negative stereotypes about the Arab armies. This is the crux of the fallacy of essentialism: attributing cause to stable internal factors and disregarding the powerful influence of situational external factors.
The second highly relevant psychological research program contemporaneous with Fischer’s book pertains to “the fundamental attribution error” (Ross, 1977, p. 183), which is defined as the tendency “… to underestimate the impact of situational factors and to overestimate the role of dispositional factors in controlling behavior.” A dispositional factor would be one’s personality, for example. In a famous study, undergraduates concocted and then asked esoteric questions to other undergraduates in a mock quiz game. The questioners knew the answers to these questions because they created them. The questions were in areas of interest or expertise of the questioner, which meant that the respondents performed poorly in answering them. Observers who witnessed this mock quiz show and were aware of the drastically different roles of the questioners and responders nevertheless rated the former as far more knowledgeable than the latter. This result seems grossly unfair. The superior “knowledge” of the questioners was because their role gave them a tremendous advantage. The poor performance of the respondents was because their role put them at a tremendous disadvantage. Yet observers did not take this external factor of assigned role into account, instead attributing differing impressions of the two members of the pair to an internal factor—knowledge. Observers’ overattribution of cause to internal factors is the fundamental attribution error (Ross et al., 1977). Ross and others do not deny the existence of personality factors. Their point is simply that observers overemphasize such internal factors, which results in less accurate predictions and judgments.
Why does the fundamental attribution error occur? Observers are simply not aware of many (or sometimes any) of the situational factors that might influence an actor’s behavior. As a result the observer is left with an internal attribution by default: “It’s his personality.” “He’s an anticommunist.” “He’s militarily incompetent.” The actor, on the other hand, is more aware of the external factors influencing his or her behavior,
so external attributions are more likely, and the fundamental attribution error is therefore less prevalent among actors than among observers (Storms, 1973).
As another example, Robert F. Kennedy and A. Schlesinger’s recollection (1969), Thirteen Days: A Memoir of the Cuban Missile Crisis, led to a much different view of that time period than the prevailing view when the crisis occurred 7 years earlier. Immediately following the confrontation with the Soviets, the general view of the American public was that the Kennedy brothers had behaved with bravery and intelligence. These were very positive internal attributions by the public, who were in the position of observers. However, Robert Kennedy’s rendition of the events seemed to imply that the President and his advisers were responding with what they perceived as an extremely constrained set of options available to them. In other words, Robert Kennedy asserted that external factors were largely responsible for the actions they took. Again, although observers make internal attributions (“He’s brave”), actors are more likely to make external ones (“Krushchev said he’d do this, so we just had to respond accordingly.”). Of course, intelligence analysts are in the role of observers who may or may not be aware of the external factors that may be influencing an actor’s behavior, so it is understandable why the fundamental attribution error might be a temptation.
A factor that tends to foster reliance on internal, stereotypic explanations is cognitive load. Researchers found that people who were trying to remember a difficult 8-digit number while viewing a conversation tended to rely more on the stereotype they had of the conversation’s participants than people who had to remember an easy 2-digit number. For example, cognitively busy people who watched a conversation between a doctor and a hairdresser tended to remember the former as more intelligent, stable, and cultured, whereas the latter was remembered as more extroverted, talkative, and attractive, even if the stereotype-congruent traits were not actually present in the appropriate conversation participant (Macrae et al., 1993). Relying on a stereotype is an internal attribution: “She is a doctor, so that’s why she is likely to be intelligent.” Of course, being a physician and being intelligent are indeed highly related. However, relying on such associations will serve as a “… mirror in which … one sees … [one’s] own a priori assumptions reflected,” as Fischer warned (1970, p. 68). In other words, contrary evidence is likely to be disregarded when cognitive load is high and stereotypic explanations are available.
Essentialism or the fundamental attribution error comprises an intuitive theory that is eminently sensible. If an observer cannot perceive the external causes, it is reasonable to default to an internal attribution that would have cross-situational consistency. After all, essential personality factors or other stable causes persist from one situation to another. However, the evidence
is that external causal factors account for far more causal influence than we generally appreciate (Ross, 1977).
INTUITIVE THEORY #2:
HIGH-CONFIDENCE PREDICTIONS ARE LIKELY TO BE CORRECT
An intuitive theory probably endorsed by most people and officially endorsed by the Supreme Court is that predictions or judgments made with high confidence are more likely to be correct than predictions or judgments made with low confidence. However, research suggests that even expert decision makers such as physicians can lack a strong relation between confidence and accuracy. Before inserting a right-heart catheter, physicians were asked to estimate three separate indexes of heart functioning. The 198 physicians who participated in this research were also asked to state their confidence in each estimate. After each catheter was inserted and “read,” the researchers could assess the relation between the accuracy of each physician’s estimate and his or her confidence in that estimate. The relation was essentially zero! Like intelligence analysts, these physicians were bright, dedicated, and conscientious. They were confronted with a relatively high-stakes situation in which getting the right answer was exceedingly important. Yet the estimates in which they expressed high confidence were no more likely to be correct than those in which they expressed low confidence (Dawson et al., 1993).
Research highly relevant to the everyday tasks confronting the intelligence analyst is that of Philip Tetlock (2005), who posed forecasting problems to 284 professionals over the course of several years. These professionals were highly educated persons who had advanced training or graduate degrees in their field of expertise. They were employed in government service, by think tanks, in academia, or in international institutions. They were asked questions concerning issues such as the longevity of apartheid, the secession of Quebec, and the demise of the Soviet Union. Two indexes were used primarily to assess the accuracy of their forecasts. “Discrimination” refers to the ability to assign different probability to events that eventually do occur from events that do not occur. Figure 7-1a contains the data for a forecaster with perfect discrimination and one with poor discrimination. Forecasters’ discrimination accounted for only 16 percent of the variance, leaving 84 percent of the variance unexplained.
The second index relating accuracy and confidence is “calibration,” which pertains to the tendency to assign higher probabilities to higher objective frequencies of occurrence. For example, if I assign an estimated probability of occurrence of 90 percent to 10 separate events, I am well calibrated if 9 of those 10 events do actually occur. Similarly, if I assign an estimated probability of occurrence of 60 percent to 10 separate events, I
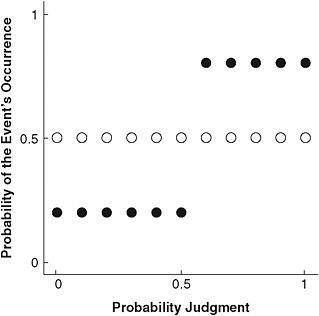
FIGURE 7-1a Low- and high-discrimination forecasters.
NOTE: The forecaster depicted by the open circles has very poor discrimination. The forecaster depicted by the filled circles has excellent discrimination.
am well calibrated if 6 of those 10 events do actually occur. Good calibration denotes a good match between confidence and proportion correct. Figure 7-1b contains the data for a forecaster with perfect calibration and one with poor calibration. In general, Tetlock’s forecasters expressed levels of confidence that were approximately 15 percent removed from reality. Forecasters did give lower confidence ratings to those events that did not occur, but their confidence was not sufficiently low. They did give higher confidence ratings to events that did occur, but their confidence was not sufficiently high. In other words, confidence and accuracy were related, but the magnitude of the relation was small. As a comparison, weather forecasters have near-perfect calibration (Murphy and Winkler, 1984), despite public perception to the contrary.
Mandel (2009) reported a research study done with Canadian intelligence analysts making predictions about upcoming political events. Their discrimination and calibration were far superior to those of Tetlock’s participants. Here the application of the intuitive theory relating confidence and accuracy would be much more justified. What might account for the relatively better performance among the Canadian sample? Two factors are most likely. First, the Canadian participants were asked questions about
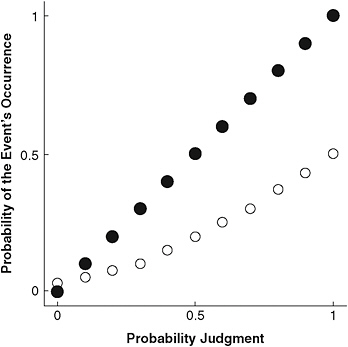
FIGURE 7-1b Low- and high-calibrated forecasters.
NOTE: The forecaster depicted by the open circles has poor calibration. The forecaster depicted by the filled circles has excellent calibration.
specific events in the Middle East or Africa that would or would not occur within the subsequent year. In general, these were specific strategic intelligence issues that the analysts had been thinking about for an extended period of time rather than questions posed “on the spot.” Second, the judgments made by the Canadian participants were subject to scrutiny by their peers and superiors before the judgment was finalized. The judgments made by Tetlock’s participants would not be evaluated by persons other than the researchers. The accountability such as that imposed on the Canadians has been shown to improve calibration and discrimination, as well as the complexity of the ensuing description of the raw data (Tetlock and Kim, 1987).
Other factors are also important in improving the accuracy–confidence relation from that manifested by Dawson and colleagues’ (1993) physicians to that manifested by Mandel’s Canadian analysts. One is the role of feedback. Physicians normally insert the catheter, obtain the results, and then apparently conclude that the results are pretty much what they would have anticipated. This “confirmation” of their nonexistent prediction is simply
a manifestation of hindsight bias, which is defined as the tendency after an event has occurred to exaggerate the extent to which we think we could have predicted it beforehand (Fischhoff, 1975). With no actual prediction with which to compare the outcome data, we are free to assume that we would have made a high-quality forecast. To maximize one’s learning, one needs to make a prediction and then obtain feedback. The physicians in the Dawson et al. (1993) study had never been forced previously to make an a priori prediction to which they could have compared the catheter data. Mandel’s participants, on the other hand, were asked to make a binary prediction about the occurrence or nonoccurrence of an event during a specified time period. At the end of the period, the event either had or had not taken place. This was perfect feedback that could then be compared to the forecast. The bases for the matches and mismatches could then be discussed with the analyst—an ideal learning opportunity likely to improve the confidence–accuracy relation.
The second factor important in tightening the confidence–accuracy relation is to consider contrary evidence. In one exemplary study control group, participants were asked to answer two-option multiple-choice questions and indicate their confidence in their chosen answer. As usual, the confidence–accuracy relation was similar to that found by Tetlock: confidence exceeded accuracy. A second group was asked to provide a reason supporting the alternative it selected as the correct one, and another group was asked to generate a reason that supported the alternative choice—the option not selected. This study by Koriat and colleagues (1980) had two interesting findings. First, the group providing the supporting reason had the same elevated confidence as the control group, suggesting that people left to their own devices generate reasons supporting their choice. Second, being forced to generate a contrary reason markedly improved the confidence–judgment relation. The structured analytic technique known as “analysis of competing hypotheses” (ACH) fosters consideration of evidence contrary to the hypothesis tentatively being favored. This technique exploits the motivation behind the Koriat et al. study, although the efficacy of ACH in intelligence tradecraft has not been extensively tested. (However, see Folker, 2000, and Lehner et al., 2008.)
Another technique designed to prevent one’s concentration largely on supporting evidence has been advocated by Neustadt and May (1986), who taught a course at Harvard entitled “The Uses of History.” Neustadt and May recommended that decision makers who confront an uncertain situation list those factors that are known, those that are presumed, and those that are unclear. The list of factors in that third column might help keep overconfidence under control and improve the confidence–judgment relation. Without the entries in that column, people would generate primarily supporting reasons, which would in turn inflate confidence, which would
then cause an unwarranted belief that their prediction would be highly accurate.
INTUITIVE THEORY #3:
EXPERTISE HAS ONLY BENEFITS, NOT COSTS
We’ll use a definition of “experts” proposed by Shanteau (1992, p. 255): “… those who have been recognized within their profession as having the necessary skills and abilities to perform at the highest level.” Expertise obviously has enormous advantages over naïveté. However, expertise has some surprising pitfalls that need to be recognized and avoided. The problem is that experts may know many facts within a particular domain, but may not necessarily make good decisions within that domain.
Consider again the study in which physicians were asked to estimate three measures of cardiac functioning before they inserted a right-heart catheter into a patient (Dawson et al., 1993). Although more experienced physicians’ estimates were no more accurate than those of their less experienced colleagues, the veteran physicians were significantly more confident. In one sense these results should not have been surprising, because Einhorn and Hogarth (1978) showed more than 30 years ago that merely rendering more decisions within a domain ineluctably leads to more confidence in those decisions. Of course, experts do have more experience than rookies.
Experts Versus Algorithms
A second possible comparison is not between experts and nonexperts, but between experts and simple algorithms. An example of a simple algorithm is to predict the probability of an event in the next 5 years to be equal to the relative frequency of that event in the past 5 years. What is the probability that Quebec will vote to secede from Canada? The answer is simply to report the consistent results of the last such referendums. Tetlock’s 284 professionals who participated in his research exhibited substantially inferior calibration and discrimination compared to the algorithms (Tetlock, 2005). This is an extremely common finding (Grove et al., 2000), which is troubling. Experts are indisputably much more knowledgeable than novices and cognitively vacuous algorithms. What factors are impeding the experts’ performance?
The first factor is that in a rich data source, an expert can find some evidence to support nearly any prediction or conclusion. In this sense experts are too adroit. In one research study undergraduates and graduate students in finance were asked to make predictions about the fate of various companies’ stocks. Both groups of participants were given background
and financial information for each company. Despite their vastly superior knowledge, the finance graduate students actually performed worse. A major problem in their predictions is captured by the statistical index known as “scatter,” which is an amalgamation of multiple standard deviations. The finance students were aware of far more potential predictors than were the novices, so their predictions flitted from reliance on one cue to another as each company’s complex financial information was presented for evaluation. This inconsistency led to high scatter, which led to poor prediction performance. The undergraduates who knew much less than the experts based their predictions on the few cues they were able to apprehend. Their scatter was lower, which improved their prediction performance (Yates et al., 1991).
The greater consistency of algorithms is also what gives them an advantage over experts. Simple algorithms are boringly consistent. Plug some predictors into a simple algorithm that forecasts political instability, and you will get an answer. Plug it in again, and you will get the same answer. This is not so with humans, who can be inconsistent, overworked, and otherwise distracted. Humans are needed to create the algorithms, and only humans can perform the absolutely essential task of identifying the potentially relevant cues. However, Tetlock (2005) showed that in making the actual predictions, the algorithms bested their creators.
The cognitive adroitness with which experts are blessed can pose an additional problem. Given a rich data source such as those commonly found in the intelligence community, an expert can generally find a “broken leg cue” that can be used to override an algorithm or any other prediction. To use an example based on Meehl (1954), consider the task of predicting whether a professor will see a movie today. Our algorithm employs factors such as the day of the week and the type of movie available to make its prediction. However, the prediction fails because the algorithm cannot consider the fact that the professor cannot leave the house because he has a broken leg, a condition that negates the normally accurate forecast made by the algorithm.
Experts are able to find broken leg cues in a rich data source. Whether such a cue truly should override a prediction is highly problematic. In general, allowing people to override a prediction based on what they think is a genuine broken leg cue causes a decrease in the accuracy of the prediction (Lawrence et al., 2002) because people are prone to attribute more diagnosticity to such cues than they actually deserve. Note the irony of this situation. Novices are less likely to presume that they know enough to override the prediction (Arkes et al., 1986), and they perceive fewer candidate cues that could signify a broken leg. Thus they do not override the prediction, and therefore can perform better. Due to their understandably higher level
of confidence, experts are more likely to presume that they do know enough to override, and they thus can perform worse.
Schema-Based Reasoning
A second important cost of expertise is that experts have the background knowledge with which they can fill in knowledge gaps with concocted data. Students in a hearing and speech science class were shown four symptoms of Down’s syndrome. Approximately half the students were able to make the diagnosis. Half were not. Twelve days later these same students were shown 12 symptoms, 4 of which were the ones shown previously, 4 of which were symptoms of Down’s syndrome that had not been shown before, and 4 of which were unrelated to Down’s syndrome. All subjects indicated whether they had seen each symptom 12 days earlier. Those students who had not been able to make a diagnosis during the first presentation relatively confidently (and correctly) deemed all eight of the new symptoms as not having been shown earlier. However, those students who had been expert enough to make the diagnosis of Down’s syndrome were uncertain whether the “new” symptoms related to Down’s syndrome had been shown 12 days before. They were quite certain that the symptoms unrelated to the syndrome were new, but those new related ones were problematic. “I know that a fissured tongue is characteristic of a child with Down’s syndrome, and I know that this child has Down’s syndrome. So I wonder if I may have seen it 12 days ago when the child’s symptoms were presented.” This indecision is caused by the fact that the knowledge base of the better students led them to suspect that data consistent with their diagnosis might have been seen. The less knowledgeable students had a more impoverished database—they could not make a diagnosis—so this identification problem was not present for them. The benefit of expertise was manifested in the finding that the students who could make the correct diagnosis were highly confident that the old symptoms consistent with Down’s syndrome actually had been shown the week before, and they were also highly confident that the new symptoms inconsistent with Down’s syndrome had not (Arkes and Harkness, 1980).
A related study was done by Arkes and Freedman (1984). Baseball experts know that if (1) there is one out and men on first and third, (2) the team in the field attempts a double play, and (3) a run is scored, then it may be inferred that the batter was safe at first. Baseball experts and nonexperts read exactly this scenario and were later asked to state whether various sentences had appeared in the story. One such sentence was “The batter was safe at first,” a sentence that never appeared. Experts mistakenly thought that it had. Nonexperts correctly deemed it “new.”
The results of both the Down’s syndrome and the baseball inference
studies can be explained by use of the concept of a schema (plural is “schemata”). Schemata are “… mental structures—units of organized knowledge that individuals have about their world” (Moates and Schumacher, 1980, p. 17). For example, I have a schema concerning the layout of a particular traffic intersection near my home. I have a schema concerning how to fix a flat tire. The hearing and speech science students who were able to make a diagnosis imposed their schema of Down’s syndrome onto the collection of symptoms they were shown. Two weeks later they could recall that schema, but they no longer had a crisp memory of the evidence that had instantiated the schema in the first place. As a result they were unable to determine whether “fissured tongue” was an old or new stimulus. It was consistent with the schema, which may have tempted the respondents into saying “old.” However, they had no actual memory of its presentation, which should have fostered the decision to call it “new.” Students who were not able to impose the schema of Down’s syndrome on the original set of symptoms had no such problem because there was no basis for incorrectly deeming it to be “old.” Thus they could confidently deem it “new.”
Similarly, the baseball experts could easily infer that the batter was safe at first because the attempt at the double play must have failed if the runner on third had scored. This inference composed the test sentence, so experts were prone to think this sentence had been presented. Their schematic knowledge concerning the rules of baseball usually confers a benefit. However, in this case it constituted a cost. Nonexperts could not make an inference about the fate of the batter, so there was no reason for them to think that the new sentence had been presented earlier.
Experts have highly structured schematic knowledge. Organizing knowledge into schemata is generally highly adaptive. When Jones is seen during a follow-up visit, the physician does not have to recall every symptom Jones had during the first visit. The doctor just needs to recall the diagnosis, which comprises a cognitively economical way of capturing all of the characteristics of the patient’s medical situation.
In their analysis of the failure of the Israeli Directorate of Military Intelligence (AMAN) to anticipate the Yom Kippur attack in 1973, Bar-Joseph and Kruglanski (2003) point out that the lack of information was not the cause of intelligence failures. It was the “… incorrect comprehension of the meaning of available information before the attack …” (p. 77) that caused the failure. Information consistent with the prevailing schema is accepted or inferred, but questionable data are mistakenly thought to be veridical, and inconsistent information is rejected. Kruglanski and Webster (1996) refer to this situation as “seizing and freezing.” An incorrect hypothesis—a schema of the situation—is seized. This schema freezes out contrary information. The incorrect schema persists. Those who do not share this overarching schema are less likely to freeze out the contrary
information, a point we will return to when we discuss the dangers of premature closure of hypothesis generation.
Cognitive Styles
Tetlock (2005) divided his experts into two gross categories—hedgehogs and foxes, based on the dichotomy invented by Isaiah Berlin. The hedgehogs have one large, overriding schema, such as “axis of evil,” with which they parsimoniously analyze world affairs. Foxes are less wedded to one overarching world view and instead “improvise ad hoc solutions” (p. 21) to explain and forecast individual events. We would say that hedgehogs are more schematic than foxes are, and Tetlock’s data illustrate the costs of such schemata. First, hedgehogs do not change their minds as much as foxes do when disconfirming data occur, the point made by Bar-Joseph and Kruglanski (2003). AMAN knew that the Egyptian military exercises seemed “unusually realistic” in the days preceding the Yom Kippur War, but that datum was interpreted to be consistent with the prevailing schema that this was the usual time for Egypt’s annual exercises. Hedgehogs more than foxes see the world in schematic terms, so hedgehogs are more likely to distort the data to fit the schema.
Second, their lower propensity to perform such data “management” may be the one reason why foxes have superior calibration and discrimination compared to hedgehogs. Because they can assume multiple perspectives rather than rely on one overarching perspective, foxes can more accurately distinguish what did and did not occur and can assign confidence levels more appropriately. These tasks are the essence of calibration and discrimination.
Third, hedgehogs are more likely than foxes to invoke “close-call counterfactuals” in explaining away their forecasting failures. “Sure, I predicted that Soviet hardliners would prevail, but if the conspirators had been just a little less inebriated, they would have succeeded in ousting Gorbachev.” To explain away a forecasting failure means to disregard important feedback, which might impair future judgments.
Related to this is a fourth point. Hedgehogs, more than foxes, are biased in their interpretation of evidence consistent and inconsistent with their opinion. Hedgehogs seem relatively unapologetic about denigrating contrary evidence and accepting consistent data, which is to be expected if their knowledge is more schematic than that of foxes. Table 7-1 summarizes some of the differences Tetlock hypothesizes between hedgehogs and foxes.
As a final example of the cost of expertise, consider some research that was motivated by the fact that delays in diagnosing celiac disease average an unbelievable 13 years! (Celiac disease is a digestive disorder resulting from intolerance to the protein gluten.) The researchers presented 84
TABLE 7-1 Hedgehogs Versus Foxes
|
Hedgehogs |
Foxes |
|
More schematic thinking |
Less schematic thinking |
|
Less responsive to disconfirming data |
More responsive to disconfirming data |
|
Inferior calibration |
Superior calibration |
|
Inferior discrimination |
Superior discrimination |
|
More likely to explain away disconfirmed forecasts |
Less likely to explain away disconfirmed forecasts |
|
SOURCE: Adapted from Tetlock (2005). |
|
physicians with a scenario consistent with celiac disease; 50 physicians misdiagnosed the condition! Thirty-eight of these 50 then underwent a “stimulated recall” in which they were asked to report their thoughts as the researchers and physicians jointly went back through the physicians’ information gathering that had occurred during the original diagnosis exercise. One conclusion was the following (Kostopoulou et al., 2009, p. 282): “Information inconsistent with the favorite irritable bowel syndrome diagnosis was overlooked.” Once an incorrect schema is substantiated, consistent evidence is noted, and inconsistent evidence is not. Physicians are exceptionally intelligent people who are trying their utmost to “get it right.” They are experts in their field. But experts are expected to impose a schema, which in the case of medicine is a diagnosis. Do we want our physicians to be capable of generating a diagnosis? Of course! But this expertise has a cognitive cost.
To counteract this cost, Vertzberger (1990, p. 355) suggested a “two-tiered system” of analysts, “… one tier to deal with current information on a daily basis, the other to deal with information patterns and processes that emerge over time…. A two-tiered system is also needed because of the effects of incrementalism and preconceptions that cause discrepant information to be assimilated into existing images…. To overcome the effects of both incrementalism and preconceptions, a new team of analysts (in addition to those permanently on the job) should be inexperienced in the specific issue area because experience can be counterproductive due to preconceptions.”
Vertzberger (1990) suggests the second tier of analysts should be inexperienced in the topic being analyzed! Because inexperienced analysts have no schema, they do not have the disadvantage of preconceptions, which can damage the unbiased consideration of incoming data. Of course, the experienced analysts have greater domain expertise, which is an essential benefit. But expertise has some costs, which the second tier of analysts might be able to minimize.
This second tier of analysis is similar to the technique of “Devil’s
Advocacy,” a popular technique used in organizations and a “Structured Analytic Technique” used in the intelligence community. This strategy involves assigning a group the task of criticizing a plan or suggestion in order to expose its weaknesses. The effectiveness of this strategy has been justifiably questioned, although research seems to indicate that if the devil’s advocate exhibits authentic disagreement with the plan rather than merely fulfilling a role of being a contrary individual, the technique is significantly more effective (Nemeth et al., 2001).
INTUITIVE THEORY #4:
MORE INFORMATION IS ALWAYS BETTER
This intuitive theory seems unassailable. However, we have already presented a hint suggesting that this theory might not be correct. The graduate students in finance in the Yates et al. (1991) study would have been able to discern and use much more of each company’s financial information than would the undergrads. Yet the finance graduate students predicted the future stock prices less accurately. As was pointed out earlier, the scatter of the finance students’ predictions was higher because they based their forecasts on varying amalgamations of the various available cues. Higher scatter means less consistent judgments.
A second reason why more information may be detrimental is that the extra information may be of low quality and may dilute the diagnosticity of the earlier information. Fifty-nine graduate students in social work were asked to read information about 12 clients and provide ratings indicating how likely it was that each client was a child abuser. In the personality profiles of most interest to this discussion, some clients’ descriptions had either one or two pieces of information that pretest subjects had indicated were highly diagnostic of being a child abuser, such as “He was sexually assaulted by his stepfather.” The researchers inserted into various profiles zero, two, four, or eight pieces of information that pretest subjects had indicated were nondiagnostic, such as “He was born in Muskegon.” The most important finding was that adding completely nondiagnostic information had a pronounced effect of diminishing the impact of the diagnostic information. “Dilution effect” is the apt name the researchers gave to this phenomenon (Nisbett et al., 1981). The additional information should have been disregarded. Instead it played a detrimental role with regard to the judge’s performance.
Graduate students in social work are not stupid or careless people. However, their predictions seemed to be based on a type of averaging rule or similarity judgment rather than on normative Bayesian reasoning. The more nondiagnostic information one has, the less the target person bears some similarity to the category into which he or she might be a candidate.
The average diagnosticity of the various pieces of information to the stereotype of a child abuser diminishes the more nondiagnostic information one has. Being born in Muskegon and working in a hardware store do not seem to be diagnostic of a child abuser, so when these two pieces of information are added to being sexually assaulted by one’s stepfather, the average diagnosticity is reduced compared to the scenario in which the diagnostic piece of information is not diluted. Of course, this averaging strategy is not normative. Here is a case in which more information, if not combined properly, will lead to worse judgments.
Perhaps the most prominent research program devoted to the use of a small number of predictors is that of Gerd Gigerenzer, who suggests that people use “fast and frugal” heuristics to make judgments. One such heuristic is called “Take the Best,” in which a judge “… tries cues in order, one at a time searching for a cue that discriminates between the two objects in question” (Gigerenzer et al., 1999, p. 98). For example, who is more likely to succeed Castro, person A or person B? A forecaster who uses the Take the Best (TTB) heuristic will first think of the best cue that would help answer this question, such as whether person A or person B is a blood relative of Castro. If one person is and the other is not, then the forecast is based on this single factor. If both persons are or are not blood relatives, then this cue cannot distinguish between the two candidates, and the next best cue is used, such as the number of years he or she has been prominent in the Cuban government. The judgment is made when the decision maker finds a cue that can discriminate between the two candidates. Note that this heuristic uses few cues, whereas a statistical technique such as multiple regression, for example, generally uses more cues. Gigerenzer and his colleagues have shown that TTB does approximately as well as, and sometimes better than, multiple regression in making accurate judgments on tasks such as predicting a high school’s drop-out rate or a professor’s salary. In other words, the extra information needed to feed a multiple regression equation is often not worth the effort. How can this be?
Because analysts do not think in a way that mimics a multiple-regression equation, and because most problems that confront analysts cannot be analyzed using such an equation, our consideration of this question should be directed at the high performance of TTB rather than its relative accuracy compared to that of multiple regression. One reason for its high performance is that TTB is not likely to succumb to the dilution effect. Few cues are scanned and only one is used, so there is less danger of dilution in TTB. Second, such problems are likely to have flat maxima; once the best cue or cues are considered, modest changes in the weights placed on those cues or the addition of cues with negligible validity will have only a small effect on accuracy. So TTB, which uses few cues and does not even address the issue of weights, is not going to suffer much of a diminution in its accuracy
by disregarding some potentially relevant cues. Third is the problem of “overfitting.” If I have developed a regression equation that predicts political instability in nations, I must have used some historical cases to develop that algorithm. My equation may fit the historical data quite well, but will it fit new cases, because they may differ in some important way from the countries I used to create the equation? In other words, the equation may fit the prior data that generated it better than the new data that it attempts to predict. Gigerenzer and colleagues (1999) provide examples that show that this shrinkage in fit may be smaller when going from an old to a new dataset when TTB is used than when multiple regression is used. The point is that once a decision maker appropriately employs a small number of diagnostic cues, the time, effort, and possibly the danger of obtaining the additional cues may not be worth the extra cost. More information is not necessarily better.
We will use a final study to drive home this point (Arkes et al., 1986). People who participated in this research were shown the grades that each of 40 University of Oregon undergraduates received in three courses taken during their senior year. The participants’ task was to decide on the basis of this evidence whether each of the 40 undergraduates had graduated with honors. Each participant was given a table accurately indicating that if the student in question received three grades of A, then the probability of graduating with honors was 79 percent; with two A’s it was 62 percent, with one A it was 39 percent, and with no A it was 19 percent. This experiment investigated two important factors. The first was incentive. Some participants were paid nothing; some were paid 10 cents per correct answer; some were told that the person who predicted correctly the highest number of times would get $5. The second factor was the type of instructions. Two groups of subjects—the control group and the “no-feedback” group—were both told that 70 percent correct was about as well as anyone could hope to do on this task. The former group, but not the latter, received feedback on every trial as to whether their prediction was correct. A third group—the “innovate” group—was told about this 70 percent expectation, but was also told “… we think that people who are extremely observant might be able to beat the 70 percent level. Give it a try.” The fourth and final group—the “debiasing” group—was told that people who try to beat the 70 percent expectation actually do worse. “So just follow an obvious strategy that will allow you to get most of the answers right” (Arkes et al., 1986, p. 97).
The results were highly instructive. First, both of the groups incentivized with money performed more poorly than did the group whose members received no money. Second, the control and “innovate” groups had nearly identical data. Third, the debiasing group did the best, with the no-
feedback group close behind. Both performed significantly better than did the control group subjects. These results teach us several lessons.
First, extra incentive can reduce performance! People who are highly motivated to “get it right” are not satisfied with using a rule that results in only a 70 percent accuracy level. Even though the task is probabilistic and not deterministic, that is, even though the correct answer cannot be known with certainty, decision makers who are highly motivated will want to squeeze out every iota of error variance. Who can blame them? If accuracy is very important, then this seems like a reasonable goal. However, if the task is probabilistic, then it is not possible to eliminate all error, and one must be satisfied with the best, albeit imperfect, prediction strategy. In this study those with high incentives were less likely to heed the obvious rule of “Choose ‘honors’ if the person had 2 or 3 A’s, choose ‘not honors’ otherwise.” They wanted to beat 70 percent, so they used highly creative, but invalid, strategies to try to maximize their performance.
Second, the fact that the control and “innovate” groups had nearly identical data suggests that people who are given no special instructions to “innovate” do so anyway. The strategies used by these participants were inventive, but invalid.
Third, debiasing worked in that people who were told to curb their attempts to beat the obvious strategy were able to restrain themselves and thus performed better than the two worst groups.
Fourth, being given no feedback about the correctness of their predictions resulted in relatively high performance. How can this be?! Consider what happens when a person uses the optimal strategy and is told that the prediction is incorrect. That person is tempted to abandon the current strategy and search for one that can squeeze out a higher proportion of correct answers. Because the strategy one would shift to in this situation must be inferior to the optimal strategy, performance would suffer. However, if one uses the best strategy and is not told that the prediction is incorrect, there is no temptation to abandon it.
This experiment plus the follow-up study, which showed that experts are most prone to abandon the best strategy, have some direct implications for persons in high-stakes situations. In most forecasting tasks performed by an intelligence analyst, eliminating all uncertainty would be impossible. Should a responsible analyst continue to search for more information? If the task truly is probabilistic, one cannot guarantee that the best option can ever be discerned or that the best option would accomplish the desired result. Hence further information gathering may be futile. Second, more cues might mean less valid cues, which may in turn inappropriately dilute the impact of the valid ones. Third, more cues may lead one to attend to bogus broken leg cues, which can tempt one to disregard the conclusions of a very good strategy. In a profound article, Einhorn (1986) pointed out
that one has to accept error to make less error. By this he meant that in a probabilistic task, one has to accept the fact that some error is inevitable. If one does not accept that and instead tries to convert the task to a deterministic task in which there is no error, then one will make more error by incorporating worthless cues and adopting suboptimal strategies. When the stakes are high, there is understandable reluctance to decide that all of the predictability has already been squeezed out of the situation. Indeed, accepting error is politically and pragmatically more difficult in some domains than in others. But consider the fact that even with X-rays, computed tomography (CT) scans, and an arsenal of lab tests, diagnosing a disease is not always possible. Is human behavior more predictable than a medical condition?
INTUITIVE THEORY #5:
ACCURATE, QUICKEST—AND DANGEROUS
Experts, one would hope, are able to quickly size up a situation, make superior assessments, and execute better quality decisions compared to novices who appear indecisive and seem to flail about as they attempt to comprehend the situation. Evidence for the quick and accurate expert can be found, for example, in the game of chess. Players rated as chess masters were compared to lower ranked class B players. The quality of the moves the players made during games was evaluated by a group of highly rated grand masters on a 5-point scale, where 5 = outstanding move and 1 = blunder. Regulation play is relatively slow paced, with approximately 2.25 minutes per move. In regulation play the average move quality of master players was nearly identical to the average move quality of class B players. The disparity between expert and novice became more apparent when speed of play was increased. In blitz play the time is highly restricted, giving players on average only 6 seconds per move. Under these conditions the novice B players made more blunder moves, increasing from 11 percent in regulation play to 25 percent blunders in blitz play, and their average move quality dropped to 2.68. The masters were able to maintain their average move quality at 3.02, with no increase in blunders observed. “[T]he move quality of master games was virtually unaffected by vastly increased time pressure” (Calderwood et al., 1988, p. 490). Klein (1998) observed similar quick and accurate decision-making performance in other experienced professionals. Fireground commanders were able to rapidly visualize how the fire was moving inside a building and choose an appropriate strategy. Nurses in the neonatal intensive care unit were able to look at a premature infant and know if the infant had become septic from infection, even though the less experienced could see no indication. The experts in these examples do not spend time comparing various alternatives, Klein argued.
Rather, based on their broad experience base, they simply know the correct, or at least reasonable, course of action to take. “Skilled decision makers make sense of the situation at hand by recognizing it as one of the prototypical situations they have experienced and stored in their long-term memory. This recognition match is usually done without deliberation” (Phillips et al., 2004, p. 305).
It’s not surprising, then, that rapid decisions are sometimes taken as a signal for expertise. However, to achieve high levels of accuracy, decision makers must know when to slow down the assessment and decision process. When a situation presents a novel scenario that does not map well onto past scenarios, the best decision makers recognize that quick and accurate assessment may not be possible. “Sometimes the decision maker runs up against a situation that is ambiguous or unfamiliar. The expert must then deliberate about the nature of the situation, often seeking additional information to round out the picture” (Phillips et al., 2004, p. 305).
Expertise is easier to acquire in some domains than others. According to Shanteau (1992), the characteristics of the domain dictate how easily expertise can be gained over time. He suggests that gaining expertise in a given domain is more difficult if (1) the domain is fluid and has changing conditions, (2) we have to predict human behavior as opposed to physical states, (3) we have less chance for feedback, (4) the task does not have enough repetition to build a sense of typicality, or (5) we confront a unique task. This is a discouraging list. The domain of intelligence analysis seems to contain many (if not all) of these limitations. Let’s consider each limitation in turn.
The firefighter, neonatal nurse, chess master, and intelligence analyst are all working in a domain that is, to some degree, fluid and changing. However, the infant’s body will not suddenly abandon one disease in favor of another. An intelligence target, on the other hand, can abandon one strategy in favor of another.
The firefighter and neonatal nurse are observing and predicting the physical state of a burning building or an infant’s biological system. Only the chess master and intelligence analyst are predominantly predicting human behavior. However, the behavior that can be exhibited on a chess board is highly restricted by a codified set of rules. This simplifies the task of the chess master by constricting the range of possible human behavior that must be considered. This restricted range makes it more likely that any given behavior has been observed before.
Repeated behavior allows the chess master to draw on feedback received during those past games. The firefighter also has encountered enough burning buildings to develop a sense of what is typical when a fire consumes a building. The neonatal nurse acquires a sense of how a typical infant should look and act. An intelligence analyst can develop a sense of what typical
message traffic is like. However, there is an important difference between the analyst and the other professionals when an atypical situation occurs. The experienced nurse or firefighter is likely to have encountered such a situation before, allowing them to draw on experience. The experienced intelligence analyst, some might argue, is more likely to deal with a turn of world events that has no precedent. Furthermore, the “real answer” to the analytic question may never be known, or may be debated by historians for decades. When taking an action to control a fire, the firefighter can see the fire’s response to that action. The neonatal nurse later learns the outcome of the patient. The chess master wins or loses the game. These professionals will benefit from feedback; the analyst often will not receive feedback.
Because the nature of intelligence analysis often denies us the ability to make the quick, accurate assessments that experts in some other domains can make, a slower, more careful comparison of options is the only alternative. Herek et al. (1987) offer a picture of what careful analysis looks like and the better decisions it facilitates. The authors studied the policy decisions made by U.S. Presidents during 19 international crises. They suspected that the most effective policy makers were those who engaged in a careful search for relevant information, made a critical appraisal of viable alternatives, performed careful contingency planning, and exercised caution to avoid mistakes. They were interested in seeing whether such quality processes were observed to lead frequently to higher quality outcomes. They defined a poor-quality process as one exhibiting defective symptoms such as (1) gross omissions in surveying alternatives, (2) gross omissions in surveying objectives, (3) failure to examine major costs and risks of preferred choice, (4) poor information search, (5) selective bias in processing information at hand, (6) failure to reconsider originally rejected alternatives, and (7) failure to work out detailed implementation, monitoring, and contingency plans. A favorable outcome to the United States was one that did not increase international conflict or lead to military confrontation, escalation, or risk of nuclear war (rated separately by both conservative and liberal judges). In their study Herek et al. (1987) found that high-quality processes (e.g., careful survey of various alternatives, etc.) were much more likely to result in high-quality outcomes (r = 0.64). This is a very impressive statistic.
Ramifications of the Hasty Assessment
The consideration of various alternatives sometimes will involve a search for objective diagnostic indicators that favor one hypothesis over others. There may be pressure to make an assessment as quickly as possible. Thus there is the temptation to arrive at a conclusion after evaluating only a minimum of indicators. Accepting a hypothesis has unfortunate implications when it is done prematurely. For example, physicians may request no
more tests if they believe they have reached a diagnosis, when in fact that diagnosis is erroneous.
A possible strategy to counteract premature closure to a hypothesis might be to deem the current hypothesis as only tentative. Theoretically a tentative hypothesis can be revised as additional information is obtained. Unfortunately the very act of creating even a tentative or “working” hypothesis can have negative cognitive ramifications. The initial hypothesis, once formed, is resistant to change. Additional information is processed in a biased manner so that we are “apt to accept ‘confirming’ evidence at face value while subjecting ‘disconfirming’ evidence to critical evaluation, and as a result [we] draw undue support for [the] initial position from mixed or random empirical findings” (Lord et al., 1979, p. 2,098). This effect has been observed in a number of psychological studies.
In one experiment, a series of fictitious crime studies was created. The results showed mixed support for the effectiveness of capital punishment as a deterrent. People who had previously supported the death penalty interpreted the mixed results as supporting their view. Others who opposed the death penalty believed the same results supported their view (Lord et al., 1979)! In another study, supporters of nuclear deterrence believed the factual descriptions of near accidents showed that current safeguards were adequate. Supporters of nuclear disarmament believed the existence of such near accidents indicated just how possible a more serious accident was (Plous, 1991).
Why do we process this post-hypothesis information in a biased manner? Kruglanski and Webster (1996) argue that individuals exhibit a tendency toward cognitive permanence—a need to preserve past knowledge. Consolidating a hypothesis gives us understanding (or at least the illusion of understanding) of the world around us. This understanding allows a degree of predictability to guide us in our future actions. A lack of closure fosters an uncomfortable state; we are forced to revaluate previous knowledge we thought we could accept.
Bar-Joseph and Kruglanski (2003) offer an example of how the need for quick closure and the desire to make such closure permanent can hinder intelligence analysis. These authors believe that such factors contributed to the Israeli surprise during the 1973 Yom Kippur War. Two of the most influential intelligence analysts for Israel leading up to the war were Major General Eli Zeira (Director of Military Intelligence) and Lieutenant Colonel Yona Bandman (Israel’s lead analyst for Egyptian issues). Zeira and Bandman assessed the chance of an attack from Egypt across the Suez Canal as being “close to zero” as long as Egypt lacked a fighter force capable of challenging the Israeli Air Force and ballistic missiles with enough range to threaten greater Israel. Zeira and Bandman, according to Bar-Joseph and Kruglanski, exhibited behavior consistent with a high need
for cognitive closure. Such characteristics include a reluctance to interpret new information that might conflict with their views, discomfort with a plurality of opinions, and an authoritarian style of leadership (Bar-Joseph and Kruglanski, 2003, p. 84):
Both exhibited a highly authoritarian and decisive managerial style. Both lacked the patience for long and open discussions and regarded them as “bullshit.” Zeira used to humiliate officers who, in his opinion, came unprepared for meetings. At least once he was heard to say that those officers who estimated in spring 1973 that a war was likely should not expect a promotion. Bandman, although less influential … than Zeira, used to express either verbally or in body language his disrespect for the opinion of others. He was also known for his total rejection of any attempt to change a single word, even a comma, in a document he wrote.
It is not surprising, then, that Bandman and Zeira failed to revise their original estimate of the potential for an Egypt attack even though “In the days that preceded the Yom Kippur War, the Research Division of Military Intelligence had plenty of warning indicators which had been supplied (to them) by AMAN’s Collection Division and by the other Israeli collecting agencies” (Agranat, 1975, as cited in Bar-Joseph and Kruglanski, 2003, p. 76).
Earlier we mentioned the course taught by Neustadt and May that is the basis for their 1986 book, Thinking in Time. Their book advocates use of “Alexander’s Question,” which is named after Dr. Russell Alexander. This public health professor was a member of the advisory committee that met before the March 1976 decision to immunize the U.S. citizenry against the swine flu. He asked what new data might convince his colleagues that the nation should not be immunized against the flu. His query was not answered, according to Neustadt and May. What if Israeli intelligence officers Bandman and Zeira had been asked Alexander’s Question: “What information would make you revise your current view that the Egyptian army isn’t going to attack?” To answer that reasonable but pesky question, Bandman and Zeira would have had to state a priori what would constitute disconfirming evidence. If any such data subsequently occurred, then premature closure and distortion of new information would both be avoided because such data previously had been deemed to be highly informative.
Note that “Alexander’s Question” explicitly requests a decision maker to state what disconfirmatory evidence would be highly diagnostic. This request bears some similarity to structured analytic techniques currently advocated by some intelligence agencies. For example, ACH requires that analysts provide evidence supporting hypotheses contrary to the one currently being favored. Red Team Analysis requires that a subset of analysts take the role of an adversary in order to mimic what an actor within a different cultural and political environment would do. Team A/Team B is a
technique that pits two or more competing hypotheses against each other. All of these techniques are designed to give contrary views a fair hearing.
CONCLUDING COMMENTS
A problem with intuitive theories is that they remain unchallenged due to their apparent validity. The study of judgment and decision making is a relatively recent phenomenon, so it is understandable why intuitive theories have not been challenged much earlier. We are not under the illusion that mere awareness of the evidence we have presented will eliminate any detrimental influence of these theories on intelligence tradecraft. However, we have suggested some debiasing strategies that should make their negative sway less powerful. “Alexander’s Question,” Koriat and colleagues’ (1980) suggestion that reasons be provided for alternative courses of action, and the results from Tetlock and Kim (1987) and Mandel (2009) suggesting that instantiating accountability may improve judgment, are all potential affirmative steps one can take to introduce debiasing techniques into day-to-day intelligence tradecraft. Some research has already been performed to test the efficacy of structured analytic techniques (e.g., Folker, 2000; Lehner et al., 2008). The mixed results from these initial studies suggest that the techniques may be more effective with some tasks than others and with some participants than others. However, the results must be considered preliminary given the small number of tests with a limited number of participants. We suggest that further research be done in as realistic a manner as possible. This will allow testing of structured analytic techniques to determine if they do indeed improve intelligence performance and reduce reliance on tempting, but inaccurate, intuitive theories.
REFERENCES
Agranat (Investigation committee, Yom Kippur War). 1975. The report of the Agranat commission. Tel Aviv, Israel: Am Oved.
Arkes, H. R., and M. R. Freedman. 1984. A demonstration of the costs and benefits of expertise in recognition memory. Memory and Cognition 12:84–89.
Arkes, H. R., and A. Harkness. 1980. The effect of making a diagnosis on subsequent recognition of symptoms. Journal of Experimental Psychology: Human Learning and Memory 6:568–575.
Arkes, H. R., R. M. Dawes, and C. Christensen. 1986. Factors influencing the use of a decision rule in a probabilistic task. Organizational Behavior and Human Decision Processes 37:93–110.
Bar-Joseph, U., and A. W. Kruglanski. 2003. Intelligence failure and need for cognitive closure: On the psychology of the Yom Kippur surprise. Political Psychology 24:75–99.
Calderwood, R., G. A. Klein, and B. W. Crandall. 1988. Time pressure, skill, and move quality in chess. American Journal of Psychology 101:481–493.
Dawson, N. V., A. F. Connors, Jr., T. Speroff, A. Kemka, P. Shaw, and H. R. Arkes. 1993. Hemodynamic assessment in the critically ill: Is physician confidence warranted? Medical Decision Making 13:258–266.
Einhorn, H. 1986. Accepting error to make less error. Journal of Personality Assessment 50: 387–395.
Einhorn, H. J., and R. M. Hogarth. 1978. Confidence in judgment: Persistence in the illusion of validity. Psychological Review 85:395–416.
Fischer, D. H. 1970. Historians’ fallacies: Toward a logic of historical thought. New York: Harper.
Fischhoff, B. 1975. Hindsight is not equal to foresight: The effect of outcome knowledge on judgment under uncertainty. Journal of Experimental Psychology: Human Perception and Performance 1(3):288–299.
Folker, R. D., Jr. 2000. Intelligence analysis in theater joint intelligence centers: An experiment in applying structured methods. Occasional Paper No. 7. Washington, DC: Joint Military Intelligence College.
Gigerenzer, G., P. M. Todd, and the ABC Research Group. 1999. Simple heuristics that make us smart. Oxford, UK: Oxford University Press.
Grove, W. M., D. H. Zald, B. S. Lebow, B. E. Snitz, and C. Nelson. 2000. Clinical versus mechanical prediction: A meta-analysis. Psychological Assessment 12:19–30.
Herek, G. M., I. L. Janis, and P. Huth. 1987. Decision making during international crises: Is quality of process related to outcome? Journal of Conflict Resolution 31:203–226.
Kennedy, R. F., and A. Schlesinger, Jr. 1969. Thirteen days: A memoir of the Cuban missile crisis. New York: Norton.
Klein, G. A. 1998. Sources of power: How people make decisions. Cambridge, MA: The MIT Press.
Koriat, A., S. Lichtenstein, and B. Fischhoff. 1980. Reasons for confidence. Journal of Experimental Psychology: Human Learning and Memory 6:107–118.
Kostopoulou, O., C. Devereaux-Walsh, and B. C. Delaney. 2009. Missing celiac disease in family medicine: The importance of hypothesis generation. Medical Decision Making 29:282–290.
Kruglanski, A. W., and D. M. Webster. 1996. Motivated closing of the mind: “Seizing” and “freezing.” Psychological Review 103:263–283.
Lawrence, M., P. Goodwin, and R. Fildes. 2002. Influence of user participation on DSS and decision accuracy. Omega 30:381–392.
Lehner, P. E., L. Adelman, B. A. Cheikes, and M. J. Brown. 2008. Confirmation bias in complex analyses. IEEE Transactions on Systems, Man, and Cybernetics—Part A: Systems and Humans 38:584–592.
Lord, C. G., L. Ross, and M. R. Lepper. 1979. Biased assimilation and attitude polarization: The effects of prior theories on subsequently considered evidence. Journal of Personality and Social Psychology 37:2098–2109.
Macrae, C. N., M. Hewstone, and R. J. Griffiths. 1993. Processing load and memory for stereotype-based information. European Journal of Social Psychology 23:77–87.
Mandel, D. 2009. Applied behavioral sciences in support of intelligence analysis. Presentation at the public workshop of the National Research Council Committee on Behavioral and Social Science Research to Improve Intelligence Analysis for National Security, Washington, DC, May 15.
Meehl, P. E. 1954. Clinical versus statistical prediction: A theoretical analysis and a review of the evidence. Minneapolis: University of Minnesota Press.
Mischel, W. 1973. Toward a cognitive social learning reconceptualization of personality. Psychological Review 80:252–283.
Moates, D. R., and G. M. Schumacher. 1980. An introduction to cognitive psychology. Belmont, CA: Wadsworth.
Murphy, A. H., and R. L. Winkler. 1984. Probability forecasting in meteorology. Journal of the American Statistical Association 79:489–500.
Nemeth, C., K. Brown, and J. Rogers. 2001. Devil’s advocate versus authentic dissent: Stimulating quantity and quality. European Journal of Social Psychology 31:707–720.
Neustadt, R. E., and E. R. May. 1986. Thinking in time: Uses of history for decision makers. New York: Free Press.
Nisbett, R. E., H. Zukier, and R. E. Lemly. 1981. The dilution effect: Nondiagnostic information weakens the implications of diagnostic information. Cognitive Psychology 13:248–277.
Phillips, J. K., G. Klein, and W. R. Sieck. 2004. Expertise in judgment and decision making. In D. Koehler and N. Harvey, eds., Blackwell handbook of judgment and decision making (pp. 297–315). Malden, MA: Blackwell.
Plous, S. 1991. Biases in the assimilation of technological breakdowns: Do accidents make us safer? Journal of Applied Social Psychology 60:302–307.
Ross, L. 1977. The intuitive psychologist and his shortcomings. In L. Berkowitz, ed., Advances in experimental social psychology, vol. 10. (pp.173–220). New York: Academic Press.
Ross, L., T. M. Amabile, and J. L. Steinmetz. 1977. Social roles, social control, and biases in social-perception processes. Journal of Personality and Social Psychology 35:485–494.
Shanteau, J. 1992. Competence in experts: The role of task characteristics. Organizational Behavior and Human Decision Processes 53:252–266.
Storms, M. D. 1973. Videotape and the attribution process: Reversing actors’ and observers’ point of view. Journal of Personality and Social Psychology 27:165–175.
Tetlock, P. E. 2005. Expert political judgment: How good is it? How can we know? Princeton, NJ: Princeton University Press.
Tetlock, P. E., and J. I. Kim. 1987. Accountability and judgment processes in a personality prediction task. Journal of Personality and Social Psychology 32:700–709.
Vertzberger, Y. Y. I. 1990. The world in their minds: Information processing, cognition, and perception in foreign policy decisionmaking. Stanford, CA: Stanford University Press.
Yates, J. F., L. S. McDaniel, and E. S. Brown. 1991. Probabilistic forecasts of stock prices and earnings: The hazards of nascent experience. Organizational Behavior and Human Decision Processes 49:60–79.


























