
THE SCIENCE AND APPLICATIONS OF SYNTHETIC AND SYSTEMS BIOLOGY
Introduction
Humans have been modifying the genetic characteristics of plants and animals for millennia by controlling the breeding of species in order to select for certain traits or characteristics and to reduce or eliminate others. The discovery of the structure of DNA in 1953, the recognition of its importance as the carrier of heritable genetic information, followed by the development of recombinant DNA technology two decades later, paved the way for powerful technologies to manipulate genes directly and in such a way that the genotype and phenotype of an organism can be altered with utmost precision in a single generation.
The realization of viral and microbial genomics, in the last few decades of the 20th century, coupled with the completion of the initial draft of the human genome sequence in 2001, reflect a fundamental shift in the way biology is studied, and has opened a portal to vast postgenomic possibilities. Because of the Human Genome Project, scientists have already identified more than 1,800 genes associated with particular diseases. More recently, scientists have developed techniques to more efficiently synthesize or modify larger segments of DNA, marking a significant change in the way people study biological systems and a growing capacity for both experts and amateurs to manipulate such systems.
Until the past decade, the work was often painstakingly slow, and able to address only relatively straightforward challenges such as the manipulation of one gene at a time. More novel or complex genetic modifications would be difficult
to construct using the more conventional recombinant DNA1 (rDNA) techniques of the 1970s and 1980s. In the past decade or two newer approaches—combining engineering and biological techniques—have enhanced researchers’ abilities to manipulate DNA. These new synthetic techniques allow for genes and long chains of DNA to be designed and constructed from scratch using a computer and relevant chemical compounds, rather than by employing a “trial-and-error” approach to the identification and insertion of pieces of existing genes from living cells into a novel host environment.
In May 2010, researchers at the J. Craig Venter Institute announced that they had produced the first functional, self-replicating, bacterium whose entire nuclear genome had been synthesized artificially in the laboratory, albeit using a naturally occurring genome sequence as a template (Gibson et al., 2010). While the achievement did not, as some media reports at the time suggested, represent the “creation of life,” it did propel the nascent field of synthetic biology into the mainstream, and generated a number of questions and much speculation about the potential power, utility and risks associated with work in this field.
Although biologists may have a long way to go before they have enough knowledge and the tools necessary to design and build life, the emerging field of synthetic biology has already reduced several novel products and lead compounds for drugs and vaccines, fuel, biofabrication of materials, and other industrial applications. Most, if not all, of these products and compounds are being generated via the type of top-down approach, with scientists reengineering existing cells to do things that they do not normally do. By inserting the genetic machinery for metabolic pathways into Escherichia coli and other host organisms, scientists are attempting to create microbial bio-factories for the production of pharmaceutical ingredients, flavors, fragrants, and other chemical products (Ro et al., 2006). The goals also include compounds and cells with new phenotypes and functionalities, such as cells that can produce carbon-neutral biological fuels with properties that are similar to those of petroleum-based fuels (Fortman et al., 2008; Keasling, 2010) and novel drugs (Li and Vederas, 2009).
The United Kingdom’s Royal Academy of Engineering observed that “[s]ystems biology aims to study natural biological systems as a whole, often with a biomedical focus, and uses simulation and modeling tools in comparisons with experimental information. Synthetic biology aims to build novel and artificial biological parts, devices and systems. Many of the same methods are used and as such there is a close relationship between synthetic biology and systems biology. But in synthetic biology, the methods are used as the basis for engineering applications” (Royal Academy of Engineering, 2009, emphasis added). While both disciplines use similar approaches, systems biology uses these approaches to better understand the inner-workings of life, whereas synthetic biology emphasizes
_______________
1 Recombinant DNA: DNA that is created in the laboratory by splicing together DNA molecules from different sources, usually for replication in a host organism.
the application of the lessons learned from systems biology for the purpose of engineering (or reengineering) living systems to behave in specified ways.
Many potential applications of synthetic and systems biology are relevant to the challenges associated with the detection, surveillance, and responses to emerging and re-emerging infectious diseases. On March 14 and 15, 2011, the Institute of Medicine’s (IOM’s) Forum on Microbial Threats convened a public workshop in Washington, DC, to explore the current state of the science of synthetic biology, including its dependency on systems biology; discussed the different approaches that scientists are taking to engineer, or reengineer, biological systems; and discussed how the tools and approaches of synthetic and systems biology were being applied to mitigate the risks associated with emerging infectious diseases. Through invited presentations and discussion, participants explored the ways in which synthetic and systems biology are contributing to drug discovery, development, and production; vaccine design and development; and infectious disease detection and diagnostics. In addition, workshop participants considered how synthetic biology could be used to engineer, or reengineer, microbial host cells to detect environmental toxins, produce carbon-neutral fuels, and produce novel raw materials.
Organization of the Workshop Summary
This workshop summary was prepared by the rapporteurs for the Forum’s members and includes a collection of individually authored papers and commentary. Sections of the workshop summary not specifically attributed to an individual reflect the views of the rapporteurs and not those of the members of the Forum on Microbial Threats, its sponsors, or the IOM. The contents of the unattributed sections are based on presentations and discussions at the workshop.
The summary is organized into sections as a topic-by-topic distillation of the presentations and discussions that took place at the workshop. Its purpose is to present information from relevant experience, to delineate a range of pivotal issues and their respective challenges, and to offer differing perspectives on the topic as discussed and described by the workshop participants. Manuscripts and reprinted articles submitted by some but not all of the workshop’s participants may be found, in alphabetical order, in Appendix A.
Although this workshop summary provides a description of the individual presentations, it also reflects an important aspect of the Forum’s philosophy. The workshop functions as a dialogue among representatives from different sectors and allows them to present their views about which areas, in their opinion, merit further study. This report only summarizes the statements of participants at the workshop over the course of two consecutive days. This workshop summary report is not intended to be an exhaustive exploration of the subject matter nor does it represent the findings, conclusions, or recommendations of a consensus committee process.
What Is Synthetic Biology?
The idea of managing or manipulating biology to identify or develop specific characteristics is not new. Scientists have used DNA to create genetically engineered cells and organisms for many years; the entire biotechnology industry has grown around our expanding abilities in this area.
—Presidential Commission for the Study of Bioethical Issues (2010)
Synthetic biology is not an entirely new science. Rather, aspects of it are an outgrowth of what plant and animal breeders have been doing for thousands of years and genetic engineers have been doing for decades—mixing and matching genetic material with the goal of “creating” novel plants and animals with desirable traits. What differentiates synthetic biology from genetic engineering is its goal of designing new genetic systems and organisms using standardized parts from the “ground up.”
Although the term “synthetic biology” has been used in various ways, it is generally understood to describe research that combines biology with the principles of engineering to design, construct, or adapt existing DNA, or other biological structures into standardized, interchangeable, building blocks for use in creating genetic systems that carry out desired functions. The vision behind this science is that these biological “parts” can be joined to create engineered cells, organisms, or biological systems that reliably behave in predictable ways to perform specific tasks (Khalil and Collins, 2010; NSABB, 2010; Presidential Commission for the Study of Bioethical Issues, 2010; Royal Academy of Engineering, 2009). Synthetic biologists eventually hope to be able to program cells, cell systems, or organisms to perform specific tasks and functions (see Figure WO-1).
Synthetic biology may also involve modifying naturally occurring genomes2 to allow these modified genomes to function in new contexts or to create entirely novel organisms. In 2010, when scientists at the J. Craig Venter Institute, Rockville, Maryland, reported having designed, synthesized, and assembled a complete Mycoplasma mycoides genome which they then transplanted into an M. capricolum recipient cell, creating a continuously self-replicating cell controlled by an artificial genome, much of the media proclaimed that the scientists had created “artificial” life (Gibson et al., 2010). Despite the “hype” surrounding this experiment the Venter Institute scientists did not create artificial, or even new, life.
In fact, Venter’s team did what breeders have been doing for millennia—they facilitated and helped to direct the transfer of genetic material from one organism into another. But they did it in a way that had never been done before. They developed new methods that allowed them to assemble an entire synthetic genome and fabricate its parts faster and with fewer errors than investigators have done in the past with other large pieces of DNA (Bedau et al., 2010). So while synthetic
_______________
2 An organism’s entire hereditary information usually encoded in DNA.
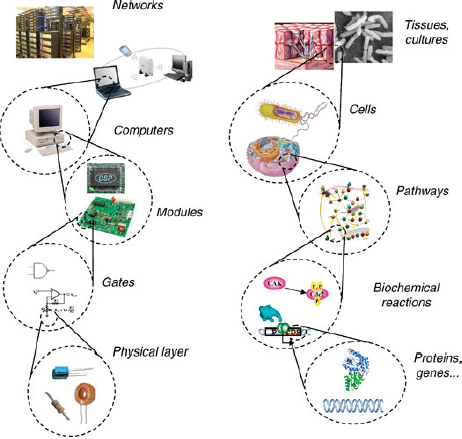
FIGURE WO-1 This figure illustrates the synthetic biology concept that complex biological systems can be broken down into their component parts in a similar way as more traditional engineering disciplines.
SOURCE: Andrianantoandro et al. (2006).
biology represents a revolutionary change in the way people interact with life, as James Collins of Boston University observed, “Synthetic biology is in its very early stages. Don’t believe the hype.” (Dr. Collins’ contribution to the workshop summary report can be found in Appendix A.)
Speaker Christopher Voigt of the University of California, San Francisco (UCSF)3 noted that one goal of synthetic biology was to be able to “mix and match” functions from the natural world in order to create organisms that carry out these functions in ways that a single, naturally occurring organism cannot. (Dr. Voigt’s contribution to the workshop summary report can be found in Appendix A.) Some researchers seek to exploit systems biology–derived
_______________
3 At the time of this workshop, Dr. Voigt was at the University of California, San Francisco. He is now at the Massachusetts Institute of Technology.
modeling tools to guide the design of synthetic gene networks. In fact, because of this element of design, some have compared synthetic biology to engineering (Khalil and Collins, 2010; NSABB, 2010; Presidential Commission for the Study of Bioethical Issues, 2010; Royal Academy of Engineering, 2009). Yet, naturally occurring living cells and organisms are complex adaptive systems, whose behavior lies far beyond our ability to re-create with currently available principles and components.
Biological Systems
One important driver of the rapid growth of synthetic biology has been a shift away from the traditional reductionist method for understanding biological processes to one that favors a more holistic “systems” approach. Historically, the typical way one examined biological systems had been to isolate a small subset of biological components, which could then be interrogated individually to better understand their structures and functions. This approach assumes that the interactions of biochemical components occur in isolation, resulting in discrete, cause-and-effect, relationships.
As our understanding of biology at the level of DNA, RNA, and proteins has increased, it has become clear that biological processes occur not in isolation but rather within the context of complex systems of components, regulated by intricate networks of feedback loops. These systems operate on a variety of levels: from that of RNA polymerase interacting with a DNA strand to start the process of DNA transcription, to a signal-transduction pathway within a cell, to complex interactions between systems of organisms. While our appreciation of the complexity of interactions within and between these systems has grown, there has been a corresponding recognition that the traditional, reductionistic, scientific approach severely limits our ability to understand complex biological phenomena and interactions within and between cells. Investigators have increasingly embraced systems approaches in their efforts to understand biological interactions, taking advantage of the power of mathematical and computer modeling to examine the complex interactions between components of a biological system (Royal Academy of Engineering, 2009).
What Is Systems Biology?4
The increased emphasis on understanding biological phenomena in the context of the system within which it occurs gave rise to systems or integrative biology—which is the “study of the behavior of complex biological organization and processes in terms of the molecular constituents” (Kirschner, 2005). It takes
_______________
4 This section was adapted from p. 173 of the 2006 Institute of Medicine report, Globalization, Biosecurity, and the Future of the Life Sciences. Washington, DC: The National Academies Press.
advantage of high-throughput, genome-wide tools—such as microarrays—for the simultaneous study of complex interactions involving molecular networks, including DNA, RNA, and proteins. It is, in a sense, classical physiology taken to a new level of complexity and detail.
The term “systems” comes from systems theory or dynamic systems theory: systems biology involves the application of systems- and signal-oriented approaches to the understanding of inter- and intracellular dynamic processes (Wolkenhauer et al., 2005). Systems-level problem solving in living systems is based on the observation that cellular behavior involves a complex coordination of dynamically interacting biomolecular entities. Systems biologists seek to quantify all of the molecular elements that make up a biological system and then integrate that information into network models that can serve to generate predictive hypotheses.
A growing number of investigators within the life sciences community are recognizing the utility of systems biology tools and approaches for studying complex regulatory networks—both inside the cell, as well as the regulatory networks that integrate and control function of distinctly different cell types in multi-cellular organisms like humans—and for making sense of the vast, and rapidly accumulating, genomic and proteomic data sets (Aloy and Russell, 2005; Goldbeter, 2004; Rousseau and Schymkowitz, 2005; Uetz et al., 2005). These efforts draw heavily on computational methods to model the biological systems.
Systems biology has become a valuable approach for drug discovery (Apic et al., 2005; Young and Winzeler, 2005). In medicine, disease is often viewed as an observable change of the normal network structure of a system resulting in damage to the system.5 A systems biology approach can provide insights into how disease-related processes interact and are controlled; guide new diagnostic and therapeutic approaches; and enable a more predictive, preventive, personalized medicine (Hood et al., 2004).
Relationship Between Synthetic and Systems Biology
Advances in synthetic biology are closely dependent on, and interactive with, advances in systems biology. When assembling new structures, whether single genes or more complex whole cells or organisms, the complexity imbued by interactions among components is vitally important to the proper functioning of the system-to-be. The key to successfully engineering, or reengineering, biological systems, is through understanding their complexity.
Synthetic biologists are making headway toward handling more complex structures in more efficient ways. Chris Voigt’s work with code refactoring is an example of how advances in synthetic biology are paving the way for more re-
_______________
5 Disease-perturbed proteins and gene regulatory networks differ from their healthy counterparts, because of genetic or environmental influences.
fined biological synthesis. Code refactoring is a reordering of the DNA sequence of a gene or gene cluster in order to eliminate inefficiencies—such as overlapping sequences—and otherwise alter the genetic code so that it can more readily be integrated into multiple genetic backgrounds.
Because synthetic and systems biology both employ similarly complex computational modeling and emphasize the role of the biological systems to contextualize and make sense of biological phenomena, the distinctions between these two disciplines sometimes seem blurred. Nevertheless, there is an important distinction between these two approaches. “While [s]ystems [b]iology attempts to obtain a quantitative understanding of existing biological systems, [s]ynthetic [b]iology is focused on the rational engineering of these systems” (Serrano, 2007).
Is Synthetic Biology a True Engineering Discipline?
DNA synthesis enables the de novo generation of genetic sequences that specifically program cells for any of a wide range of purposes, including the expression of a given protein. Technical developments continue to increase the speed, ease, and accuracy with which larger and larger sequences may be chemically generated. By the early 1970s, scientists had demonstrated that they could produce synthetic genes (Agarwal et al., 1974). Yet, it was the automation of de novo DNA synthesis and the development of the polymerase chain reaction (PCR) in the early 1980s that catalyzed the development of a series of cascading methodologies for the analysis of gene expression, structure, and function. Our ability to synthesize short oligonucleotides (typically 10 to 80 base pairs in length) rapidly and accurately has been an essential enabling technology for countless advances, not the least of which has been the sequencing of the human genome. The past few years have seen remarkable technological advances in this field, particularly with respect to the de novo synthesis of increasingly longer DNA constructs.
The field of synthetic biology is driven by this increasing capacity to make long, accurate, DNA molecules of pre-specified sequence. Indeed, DNA synthesis is arguably the most important tool in the synthetic biologist’s toolbox. Keynote speaker Andrew Ellington of the University of Texas emphasized that sequence information is the basic commodity of synthetic biology—it is fungible, digital, and portable. (Dr. Ellington’s contribution to the workshop summary report can be found in Appendix A.) Moreover, sequence information has the potential to be standardized, recoded, or programmed. Genome sequences, moreover, provide a huge amount of information about model organisms that synthetic biologists use as platforms for their gene circuit designs.
Ellington observed that this growing capacity for de novo synthesis is due, in large part, to the large number of participants in the commercial sector, as well as funding from the public sector. The chemical synthesis and ligation of large segments of a DNA template, followed by enzymatic transcription of RNA led to the de novo creation of the poliovirus genome in 2002 (about 7,500
nucleotides in length), from which the infectious, virulent virus was rescued following its transfection into permissive cells (Cello et al., 2002). The following year, scientists announced the successful assembly of a bacterial virus genome (Smith et al., 2003). Parallel efforts in industry and academia led to the synthesis and assembly of large segments of the hepatitis C virus genome, from which replication-competent RNA molecules were rescued. Ellington cautioned that even these systems would perform differently in different host “contexts” and in ways that are not entirely predictable.
Ellington went on to remark that, while scientists clearly are building synthetic biological systems that work, the “ability to model such systems—not make them work but model them in a true engineering way—is somewhat limited.” He pointed to the photographic bacteria built by Levskaya et al. (2005) and the “edge detector” E. coli built by Tabor et al. (2009)—illustrated in Figure WO-2—as examples of synthetic systems that clearly work.
Even those parts that are well characterized, quantitatively or otherwise, do not always behave as expected. As Ellington observed, “The construction of very large fragments of DNA is no longer a limitation in the engineering of biological systems. Predicting the behavior of complex genetic programs de novo is now the limiting step in the programming of cellular behavior” (Tabor et al. 2009). Ellington reported that the reengineered viruses that he and his team built did not function once they were actually inserted into host cells. Therefore, successfully building, or rebuilding, a virus or other biological system according to Ellington does not necessarily mean that the system is actually going to work.
Ellington and his team have applied a so-called “supercharging technology” to the anti-MS2 antibody (Lawrence et al., 2007). They synthesized a large number of genes that conferred either large negative or large positive charges on the antibodies, overexpressed them, and then tested them for functionality. In the end, only a few candidate antibodies were able to bind to MS2. Despite using the best predictive modeling available, the success rate was low enough that only by rapid prototyping of multiple, different antibody variants could they find ones that had both improved thermal resistance as well as improved affinity. Ellington concluded, “You can make a lot of DNA, but that doesn’t mean it is going to function the way you want it to.”
Added to this systems-level complexity is the challenge of evolution and the reality that genetically-based biological systems gain, and lose, functionality over time (Tabor et al, 2009). According to Ellington and others at this workshop, organisms are “evolutionary machines.” Not only does evolution happen, making it extraordinarily difficult to predict how an engineered biological system will behave over time but, as Ellington observed, a device that works in one host organism does not necessarily function the same way in another host organism.
Ellington commented that while the development of standardized parts was not impossible, our present capacity to accurately predict how these “parts” would function in a particular system is still “somewhat limited.” He referred to
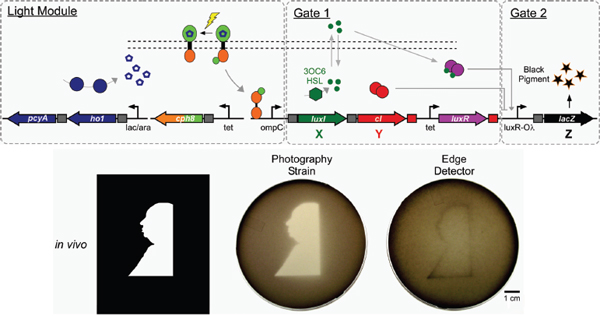
FIGURE WO-2 Construction of bacteria that are capable of light-dark edge detection.
SOURCE: Ellington (2011; adapted from Cell).
the “unrealized promise of BioBricks,”—“that we are going to be able to say that a given part works a given way in a system not yet determined.” He went on to observe that unfortunately, the complexity of organisms—and this is the systems biology part of things—dwarfs our ability to accurately model function.
The same technologies employed by synthetic biologists for “good” could also be exploited for malevolent purposes—a classical dual-use dilemma. Ellington pointed to DNA synthesis and the growing capacity to make larger pieces of DNA quickly and affordably as the greatest cause for concern. While the dual-use dilemma is real, Ellington observed that the threats posed by synthetic biology are dwarfed by the expansive realm of real microbial threats that already exist in nature.
Design and Complexity
Speaker Herbert Sauro, of the University of Washington, observed that the level of complexity in a synthetic biological system expands very quickly as the number of feedbacks in a system increases. (Dr. Sauro’s contribution to the workshop summary report can be found in Appendix A.) Simple linear pathways, whereby a perturbation of a single enzyme affects another enzyme in a predictable manner, according to Sauro, is largely understandable and engineerable; the greater the complexity, the less “engineerable” the system is. As depicted in Figure WO-3, if the pathway has any sort of feedback in it, understanding—and engineering—that pathway becomes slightly more complicated, requiring some simulation. Sauro observed that pathways with two or more feedbacks are virtually impossible to understand analytically and require a considerable amount of simulation.
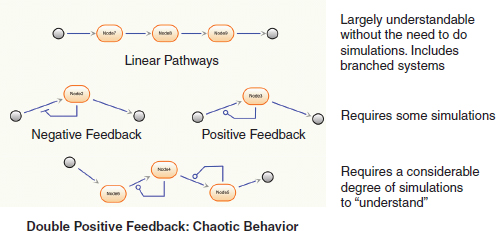
FIGURE WO-3 Biosynthetic pathways with increasing complexity.
SOURCE: Sauro (2011).
BOX WO-1
Early Synthetic Biology Designs: Switches and Oscillators
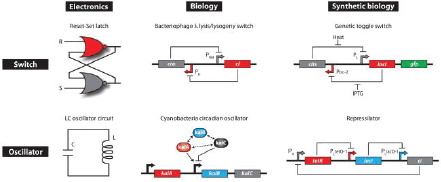
Switches and oscillators that occur in electronic systems are also seen in biology and have been engineered into synthetic biological systems.
Switches
In electronics, one of the most basic elements for storing memory is the reset–set (RS) latch based on logical NOR gates. This device is bistable in that it possesses two stable states that can be toggled with the delivery of specified inputs. Upon removal of the input, the circuit retains memory of its current state indefinitely. These forms of memory and state switching have important functions in biology, such as in the differentiation of cells from an initially undifferentiated state. One means by which cellular systems can achieve bistability is through genetic mutual repression. The natural PR–PRM genetic switch from bacteriophage λ, which uses this network architecture to govern the lysis–lysogeny decision, consists of two promoters that are each repressed by the gene product of the other (that is, by the Cro and CI repressor proteins). The genetic toggle switch constructed by Dr. Collins’ research group is a synthetically en-
James J. Collins, from Boston University, agreed with Sauro that it is very difficult to build biological systems that function in a predictable manner. Nonetheless, synthetic biology, according to Collins, is “taking inspiration” from engineering, electrical engineering in particular. As illustrated in Box WO-1, many of the earliest synthetic biology devices were the biological equivalents of electronic toggle switches, latches, oscillators, and other similar devices (Elowitz and Leibler, 2000; Gardner et al., 2001; Khalil and Collins, 2010).
Collins observed that many biologists have a misperception of engineering with respect to the importance of mathematical modeling. According to Collins, most practicing engineers use mathematical modeling as a guide only—in much the same way that synthetic biologists do. When actually assembling components, engineers rely on intuition and “tinkering,” often without even understanding how a system works.
gineered version of this co-repressed gene regulation scheme (Gardner et al., 2000). In one version of the genetic toggle, the PL promoter from λ phage was used to drive transcription of lacI, the product of which represses a second promoter, Ptrc2 (a lac promoter variant). Conversely, Ptrc2 drives expression of a gene (cI-ts) encoding the temperature-sensitive (ts) λ CI repressor protein, which inhibits the PL promoter. The activity of the circuit is monitored through the expression of a green fluorescent protein (GFP promoter). The system can be toggled in one direction with the exogenous addition of the chemical inducer isopropyl-β-d-thiogalactopyranoside (IPTG) or in the other direction with a transient increase in temperature. Importantly, upon removal of these exogenous signals, the system retains its current state, creating a cellular form of memory.
Oscillators
Timing mechanisms, much like memory, are fundamental to many electronic and biological systems. Electronic timekeeping can be achieved with basic oscillator circuits—such as the LC circuit (inductor L and capacitor C)—which act as resonators for producing periodic electronic signals. Biological timekeeping is achieved with circadian clocks and similar oscillator circuits, such as the one responsible for synchronizing the crucial processes of photosynthesis and nitrogen fixation in cyanobacteria. The circadian clock of cyanobacteria is based on, among other regulatory mechanisms, intertwined positive and negative feedback loops on the clock genes kaiA, kaiB, and kaiC. Elowitz and Leibler constructed a synthetic genetic oscillator based not on clock genes but on standard transcriptional repressors (the repressilator) (Elowitz and Leibler, 2000). Here, a cyclic negative feedback loop composed of three promoter–gene pairs, in which the “first” promoter in the cascade drives expression of the “second” promoter’s repressor, and so on, was used to drive oscillatory output in gene expression.
——————
SOURCE: Image and text: Khalil, A. S., and J. J. Collins. 2010. Synthetic biology: applications come of age. Nature Reviews Genetics 11:367-379. Reprinted with permission from Nature Publishing Group.
As discussed by Ellington and Sauro, evolution can, for example, change the dynamics of a synthetic biological system. As Sauro explained, the unpredictable nature of, and responses to, selection makes it very difficult for synthetic biologists to control the behavior of their engineered systems. In 2008, a group of investigators built a genetic circuit containing a luminescence gene luxR. As illustrated in Figure WO-4, the Lux-R protein was activated when the bacterial signaling molecule acyl homoserine lactone (AHL) was present in the environment, triggering production of green fluorescent protein; GFP production was observed to degrade and terminate after 30-40 generations (Canton et al., 2008).
Sauro and colleagues subsequently constructed a variety of circuits derived from the Canton et al. (2008) circuit and demonstrated that the system loses functionality over time due to the evolution of nonluminescent mutant cells with smaller metabolic loads that grow faster than the bioluminescent cell lines
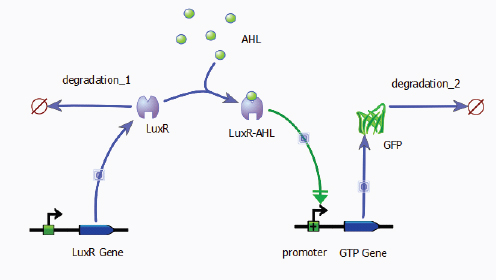
FIGURE WO-4 Improving mutational robustness in a genetic circuit.
SOURCE: Sauro (2011; adapted from Canton et al. [2008]).
(Sleight et al., 2010). Sauro went on to explain that, “every time you put a circuit into a cell, you are overloading it. The minute you overload it, the growth rate goes down a little bit.” If any mutants emerge that can grow faster than the synthetic cell type, they will eventually become the predominant cell type in the population.
Sauro and his team have demonstrated how reengineering components of genetic circuits, by using different transcriptor terminators, can prolong the evolutionary time over which a device is effective (Sleight et al., 2010). Sauro is also exploring the possibility of actually using directed evolution, instead of engineering, to build more robust and stable circuits. On a more practical level, Jay Keasling of the University of California, Berkeley, and his team of investigators engineered a Saccharomyces cerevisiae yeast to produce artemisinic acid by modifying an existing metabolic pathway in the yeast and adding in a gene from Artemisa annua to convert the product into the drug precursor (Ro et al., 2006). (Dr. Keasling’s contribution to the workshop summary report can be found in Appendix A.)
Synthetic Biology: Top-Down Versus Bottom-Up Approaches
Over the past 10 years, two different experimental approaches have emerged in synthetic biology. Both seek novel biological structures or systems with predictable properties and functions. The first, known as the “top-down” approach, involves modifying or reengineering an existing, functioning organism, biologi-
cal system, or genome to perform new tasks. Top-down synthetic biology experiments have predominated in the first decade of the field, allowing researchers to test designed biological circuits in a “chassis”6—such as E. coli—that is already functioning and self-replicating. The “bottom-up” approach, involves synthesizing functioning circuits and systems entirely from “scratch” using nonliving materials such as DNA nucleotides and lipid monomers. Bottom-up synthetic biology is still in its infancy—the assembly of standardized components into a functioning system is significantly more challenging than modifying an existing system to perform a new task (Bedau et al., 2010; Benner and Sismour, 2005; Fritz et al., 2010; Purnick and Weiss, 2009; Royal Academy of Engineering, 2009). Figure WO-5 provides a simplified conceptual framework for top-down versus bottom-up perspectives in the synthetic biology design process.
Most top-down systems biology experiments fall into one of two categories:
- attempts to combine useful elements from several different living systems to create a modified organism that can perform a desired task, and
- attempts to simplify existing organisms down to only those parts that are essential for life.
Examples of experiments in the first category include the engineering of a Saccharomyces cerevisiae yeast, allowing it to synthesize a precursor of the antimalarial drug artemisinin (Ro et al., 2006), and the modification of Salmonella spp. to produce spider silk (Widmaier et al., 2009). An example of the second category of top-down experiments is the attempt to create a minimal genome (Glass et al., 2006). The goal behind this effort is to develop a simplified “chassis organism” into which synthesized parts could be added with fewer complications than investigators currently confront when working with wild-type organisms (Glass et al., 2006; NSABB, 2010; Presidential Commission for the Study of Bioethical Issues, 2010).
The practitioners of bottom-up synthetic biology believe that it represents the future of the field, potentially allowing researchers to design entirely new forms of life. One of the key milestones for bottom-up synthetic biologists is the development of libraries of diverse, well-characterized biological components that can be assembled to form new systems—analogous to how one assembles component parts on a computer motherboard. The aspirational goal of this effort is to one day be able to select these “parts” from a catalogue and use them to create completely synthetic “novel” self-replicating life forms that are purpose-built rather than derived from a preexisting organism.
_______________
6 In the context of synthetic biology, chassis refers to the cell or organism in which the engineered DNA or biopart is embedded in order to produce the desired device or system (Royal Academy of Engineering, 2009).
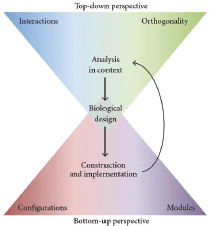
FIGURE WO-5 General conceptual framework for incorporating top-down and bottom-up perspectives in the synthetic biology design process. Due to our incomplete knowledge of biology, the design of biological systems through synthetic biology is currently an iterative process that incorporates both top-down and bottom-up design considerations. First, a design objective is identified. Next, a suitable synthetic biological system is designed given the known properties of well-characterized components (bottom-up). The synthetic system is then constructed and inserted into a larger biological context with which the synthetic system may interact (top-down), and performance of the combined system is assessed. If the system fails to meet performance requirements, this new information can be used to refine the design and repeat the cycle. Our ever-improving understanding of biology should reduce the number of iterations necessary to achieve a specific design objective.
SOURCE: Fritz et al. (2010).
Applications of Systems Biology
Mathematical methods that enable quantitative descriptions of the dynamic interplay between the molecules in living cells are being developed and, for the first time, it is possible to envisage a comprehensive molecular description of the functional circuitry of cellular systems.
—Bakker et al. (2010)
The grand challenge for biology and medicine at the beginning of the 21st century is to understand the biological complexity that emerges from interactions between our genomes and the environment. As speaker Bali Pulendran of Emory University observed, we are uniquely poised to tackle this challenge of biological complexity by the convergence of a new intellectual framework (a systems rather than a reductionistic view) and new technologies (for measuring and visualizing the behavior of genes, molecules, cells, organs, and organisms), coupled with the
innovation of computational and mathematical tools for dealing with complex data sets. (Dr. Pulendran’s contribution to the workshop summary report can be found in Appendix A.) The convergence of these disparate threads offers us an unprecedented opportunity to understand the fundamental features of life—from a holistic rather than solely reductionistic viewpoint; from a predictive rather than descriptive viewpoint; and, in short, from a systems biological viewpoint (Pulendran et al., 2010).
Systems biologists seek to quantify all of the molecular elements that make up a biological system and then integrate that information into network models that can serve to generate predictive hypotheses (Herrgård et al., 2008). A growing number of investigators are appreciating the utility of a “systems” approach for studying complex regulatory networks—both inside the cell, as well as among distinct cell types in multi-cellular organisms—and for making sense of the rapidly accumulating genomic and proteomic data sets (Aloy and Russell, 2005; Goldbeter, 2004; Rousseau and Schymkowitz, 2005; Uetz and Finley, 2005).
Despite the fact that this is still a young science—arguably in need of a “clear methodology”—scientists are relying on the tools and approaches of systems biology to make tremendous leaps in their understanding of various physiological phenomena, such as the mammalian immune response, and creating the potential for synthetic biologists to translate that knowledge into practice (Westerhoff et al., 2009). Speaker Bernhard Palsson, of the University of California, San Diego, observed that systems biology is being applied “more and more” to the study of infectious diseases. (Dr. Palsson’s contribution to the workshop summary report can be found in Appendix A.) Speakers Stephen Johnston of Arizona State University and Bali Pulendran remarked that the field of vaccinology may have reached a point where, with the appropriate support, it could become a more predictive science, guided by rational design rather than by Pasteurian trial and error.
Synthetic Biology Tools, Technologies, and Approaches
The rapid growth of bio- and other relevant technologies over the past 30 years has been driven by two processes working together: a quantitative increase in performance and decrease in cost of existing technologies and instruments, and qualitative changes resulting from unplanned new inventions, unexpected discoveries, and unexpected historical events. Synthetic biology would not be possible without a series of key technologies that have enabled investigators to design, fabricate, and manipulate DNA.
The following section briefly discusses five key sets of tools and technologies that drive synthetic biology: DNA sequencing, which has led to over 100 million gene sequences from approximately 260,000 different species being stored in public databases; DNA synthesis, which enables researchers to “reprint” whichever sequences they choose; directed evolution, which enables the rapid modifi-
cation of preexisting proteins and chemical pathways so that they perform new functions; high throughput screening (HTS), which provides scientists with the means to perform and measure large numbers of biochemical reactions rapidly; and computational modeling, which allows researchers to make qualitative or quantitative predictions about how their engineered systems are likely to function.
DNA Sequencing
DNA sequencing allows one to map an organism’s genetic composition. Sequencing advances were instrumental to the success of the Human Genome Project and have allowed complete and large-scale DNA sequencing of many bacterial, and several plant and animal genomes. These genome sequences have provided a huge amount of information about many of the model organisms, such as E. coli, into which synthetic biologists often place their design circuits. Sequencing also allows synthetic biologists to verify whether their designed DNA circuits and parts have been correctly fabricated (Royal Academy of Engineering, 2009).
Significant reductions in the cost of DNA sequencing have also allowed the technology to proliferate (see illustration of this point in Figure WO-6). While it took years and cost approximately US$300 million to sequence the first human genome a decade ago, second-generation sequencers now accomplish the same feat in a matter of days for approximately US$20,000. It is anticipated that with the next generation of DNA sequencers the cost to sequence an entire human genome will drop to several hundred dollars (Metzker, 2010). Similarly, sequencers that once cost millions of dollars can now be purchased on eBay® for less than one thousand dollars.
DNA Synthesis
DNA synthesis is a technology that enables the de novo generation of genetic sequences that specifically program cells for the expression of a given protein. It is not new, but technical enhancements continue to increase the speed, ease, and accuracy with which larger and larger sequences may be chemically generated. DNA synthesis is arguably the most important tool in the synthetic biologist’s toolbox.
By the early 1970s, scientists had demonstrated that they could produce synthetic genes (Agarwal et al., 1974). However, it was the automation of de novo DNA synthesis and the development of the polymerase chain reaction PCR in the early 1980s that catalyzed the development of a series of cascading methodologies for the analysis of gene expression, structure, and function. Our ability to synthesize short oligonucleotides (typically 10 to 80 base pairs in length) rapidly and accurately has been an essential enabling technology for countless advances, not the least of which has been the sequencing of the human genome.
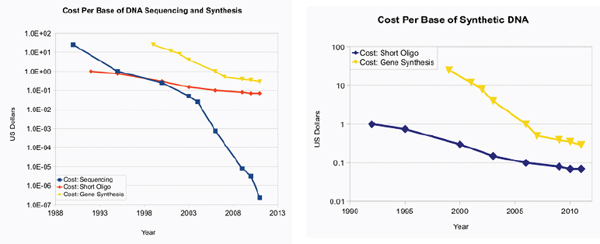
DNA synthesis technology is currently limited by its high error rate coupled with the cost and time involved to create long DNA constructs of high fidelity; yet, even this constraint is rapidly changing. As discussed earlier in this chapter, the J. Craig Venter Institute announced last year that they had synthesized a modified version of the entire 1 million base pair genome of Mycoplasma mycoides. This technological feat marked a new milestone in the length of a DNA molecule that could be accurately synthesized and assembled (Gibson et al., 2010). Current estimates for generating simple oligonucleotides on chips are approximately $0.50 per base pair—including synthesis of the oligonucleotides plus error correction (Carlson, 2010; Figure WO-6). While chip technology reduces the cost of DNA synthesis, scale-up has been limited by high error rates and other technical challenges. A novel method for highly parallel gene synthesis was used to assemble a DNA construct 50 times larger than previously published attempts (Kosuri et al., 2010).
Speaker George Church of Harvard University remarked that the current standard for producing DNA constructs is to sequence multiple configurations and then discard those that are incorrect as the sequencing error rate is significantly lower—around 10–5-10–7—than the synthesis error rate of 1 in 500. In his prepared remarks, Church discussed four commercially available, homology-directed technologies for synthesizing DNA on chips. One of the most commonly used methods for large-scale genome engineering is doubled-strand break repair, which Church and colleagues have optimized to a point where large amounts of DNA, including multiple oligonucleotides, can be integrated into a host genome with nearly 100 percent efficiency (Mosberg et al., 2010). An entirely automated method called Multiplex Automated Genome Engineering has now been developed that inserts thousands of unique constructs into E. coli host cells in a combinatorial fashion and then uses accelerated directed evolution to select for cells with the desired properties (Mosberg et al., 2010).
The greater challenge, according to Church, is integrating a synthesized piece of DNA into a host genome so that the DNA functions efficiently. Several protein- or RNA-directed recombination strategies have been developed for inserting DNA into defined places, rather than randomly, all of which have been tested in mammalian genomes (Muñoz et al., 2011; Urnov et al., 2005). Biologists have also developed several DNA homology-directed strategies that have been tested in bacterial genomes and are beginning to show promise in mammalian genomes (e.g., Costantino and Court, 2003; Link et al., 1997; Wang et al., 2009; Yu et al., 2000; Zhang et al., 1998).
Directed Evolution
First described in the literature almost 20 years ago, directed evolution is an accelerated mutagenesis technology that allows biologists to generate novel proteins and chemical pathways, as well as whole organisms, with desired properties
in a more cost-effective manner than conventional breeding and in a fraction of the time (Chen and Arnold, 1993). Synthetic biologists use directed evolution to rapidly modify preexisting proteins and chemical pathways so that they perform new functions, and to develop new parts without needing to understand the mechanistic properties of a pathway or system at the level that would be necessary to design the parts from scratch (Dougherty and Arnold, 2009; Forster and Church, 2010).
Classical genetic breeding starts with a parental pool of related sequences (e.g., genes, proteins), sometimes created by random mutagenesis, that then gives rise, through a single round of replication, to an offspring pool of molecules. The “best” offspring—as determined by the investigators under selective conditions—are identified and used as the parental pool for the next generation. This iterative selection process is repeated for several generations. Directed evolution is used to improve and optimize biological molecules, pathways, networks, and even whole organisms by mimicking Darwinian evolutionary adaptation in the laboratory. Conceptually, directed evolution is closely related to artificial selection, performed previously on microorganisms by selecting for new traits during growth under specific conditions that favor these traits. The “novel” aspect of directed evolution is that instead of relying on natural or random mutations induced in a whole genome by mutational events, the rate, general location and nature of the mutations are specified and controlled, usually by performing the mutagenesis in vitro. One introduces mutations into the DNA segment of interest, and expresses the DNA either in a whole microorganism, or in vitro. The next step is “selection,” the goal of which is to identify improved sequences. This may be carried out by either screening the resulting clones for the desired properties or by artificial selection. Important for an evolutionary process, the improved sequence(s) are fed back into the process, which is iterative. Mutations are accumulated in an evolutionary fashion, until the desired phenotype is reached (or not).
With directed evolution, sequence diversity is generated by mutating or fragmenting and recombining (“shuffling”) the DNA sequence or gene of interest and creating a library of genetic variants. A schematic of the steps used in directed evolution studies is presented in Figure WO-7. The reassortment that occurs in DNA shuffling yields a higher diversity of functional progeny sequences than can be generated by a sequential single-gene approach.
One of the earliest demonstrations of DNA shuffling involved four separately evolved members of a single gene family from four different microbial species. Some of the selected, shuffled “hybrids,” illustrated in Figure WO-8, encoded proteins with 270 to 540 times greater enzymatic activity than the most active parental sequence (Crameri et al., 1998). Even if that same recombined enzyme could have been evolved through single-gene mutagenesis (and this is unlikely), the process would have been dramatically slower. Evidence from at least one study demonstrates that the best parent is not necessarily the one most similar in sequence to the best chimeric offspring and therefore might not represent the optimal starting point for single-gene evolution (Ness, 1999).
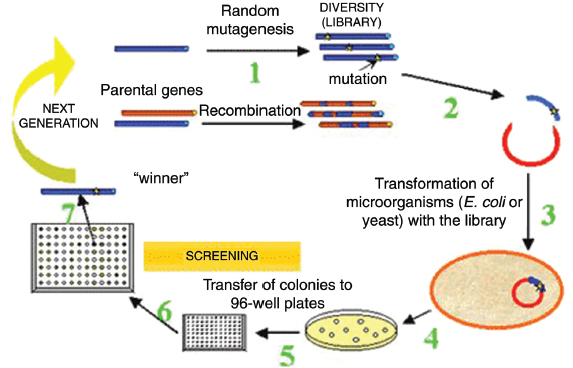
FIGURE WO-7 Schematic presentation of directed evolution studies. In place of screening, one can exploit selection using conditions that favor the growth of mutants with desired properties.
SOURCE: Institute of Molecular Biology and Biotechnology (www.imbb.forth.gr).
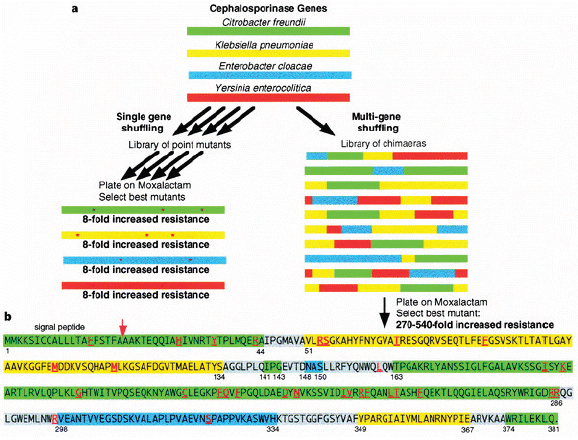
FIGURE WO-8 Breeding by DNA shuffling. (a), Comparison of single sequence shuffling versus sequence family shuffling. (b), Sequence of a chimeric mutant obtained by family shuffling. The segments derived from Enterobacter are shown in blue, those from Klebsiella are shown in yellow, and those from Citrobacter are shown in green. The grey segments are where the crossovers have taken place. Because of DNA homology in the grey segments, the exact location of the crossover cannot be determined more exactly. The amino-acid point mutations are shown with underlined red letters. The numbers at the beginning and end of each segment are the numbers from the GenBank protein files of the wild-type enzymes and differ from those used for the Enterobacter cloacae enzyme.
SOURCE: Reprinted by permission from Macmillan Publishers Ltd: Nature. Crameri, A., S-A. Raillard, E. Bermudez, and W. P. C. Stemmer. 1998. DNA shuffling of a family of genes from diverse species accelerates directed evolution. Nature 391:288-291, copyright 1998.
Directed evolution has advanced to the point where scientists are not just evolving single genes—they are evolving entire genomes. In 2002, biologists used whole-genome DNA shuffling to improve the production of tylosin (an antibiotic) in the bacterium Streptomyces fradiae. After only two rounds of shuffling, a bacterial strain was generated that produced tylosin at a rate comparable to strains that had gone through 20 generations of sequential selection (Zhang et al., 2002). That same year (2002), a report was published describing the shuffling of a portion of the HIV genome to create a new strain of HIV that was able to replicate in a monkey cell line that had previously been resistant to viral infection (Pekrun et al., 2002). By 2003, reports described the shuffling of many mammalian DNA sequences together into a single bacterial cell line. In one study, scientists shuffled the gene of a cytokine from seven genetically similar mammalian species (including human) to generate an “evolved” cytokine that demonstrated a 10-fold increase in activity compared to the human cytokine alone (Leong et al., 2003). The DNA shuffling approach allows researchers to rapidly modify preexisting proteins and chemical pathways to perform new functions. This enables investigators to develop new circuitry components without the need to understand the underlying mechanistic properties of a pathway or system at the level that would be required to design the part from scratch (Dougherty and Arnold, 2009).
Directed evolution allows investigators to identify a suboptimal or even nonfunctional design and improve it in a fairly reliable fashion. This is critical for synthetic biology. With this technique, investigators can now take suboptimal human designs and fine-tune them. There’s no counterpart in any other engineering/design field—it is a great advantage of biological engineering.
Using Directed Evolution to Create Life from Scratch: Is It Possible? Speaker Gerald Joyce, of The Scripps Research Institute, focused his remarks on whether one could create artificial “life” from scratch using the tools and approaches of bottom-up synthetic biology. (Dr. Joyce’s contribution to the workshop summary report can be found in Appendix A.) A relevant question, then, is “what is life” and what are the essential characteristics of life? A working definition of life, according to Joyce, is “a self-sustained chemical system that is capable of undergoing Darwinian evolution” (Joyce, 1994). The key principles of Darwinian evolution are, first, heritable variation of form and function among a population of individuals; second, competition for finite resources by those individuals; and third, preferential reproduction of variants that operate most effectively in the competitive environment (Joyce, 2011).
In considering synthetic biology from scratch, the focus is on the evolution of functional molecules rather than organisms (Joyce, 2011). Joyce further observed that the principles of directed molecular evolution are the same as the principles of Darwinian evolution, namely inherited profitable variation. In chemical terms, Darwinian evolution involves three processes: (1) reproduction of information-carrying molecules (inherit); (2) selection of molecules that meet some fitness cri-
teria (profitable); and (3) maintenance of chemical diversity among the population of molecules (variation) (Joyce, 2011). As highlighted in Figure WO-9, Darwin observed, in The Origin of Species (1859), that “any variation if it be profitable…to an individual of any species…will generally be inherited by its offspring.”
Over the past 20 years the tools and approaches of directed molecular evolution have become very powerful but also routine. In Joyce’s view, investigators are no longer discussing this approach as a technology but are, instead, using it as a technique. There are many methods available for introducing molecular variation, both for generating initial combinatorial libraries and for maintaining variation in a population (Joyce, 2011). Additional approaches have been developed to select molecules on the basis of their inherent physical properties, capacity for binding to a target, ability to serve as a substrate for a reaction, ability to form a chemical bond, or ability to cleave a chemical bond. Joyce further observed that there are various methods for reproducing the profitable molecules in order to bring about the inheritance of selectively advantageous traits. If the selected molecules are DNA or RNA, then it is relatively straightforward to achieve their amplification by using the appropriate polymerase enzyme(s), resulting in large numbers of progeny. If the molecules selected are proteins, which cannot be amplified directly, then one must amplify nucleic acid molecules that encode, and are physically linked to, the corresponding proteins (Joyce, 2011).
Arguably, the ultimate bottom-up synthetic biology achievement would be to build life from scratch. Joyce explained that none of the technologies available

FIGURE WO-9 Principles of evolution.
SOURCE: Darwin (1859).
for amplifying molecules are self-sustaining. The informational molecules that keep systems running, such as T7 RNA polymerase, reverse transcriptase, etc., are evolved outside the systems. None of the known directed evolution technologies, at the moment, meet generally agreed-upon criteria for a working definition of life: “a self-sustained chemical system capable of undergoing Darwinian evolution.”
As Joyce observed, the pioneering Miller-Urey experiments of the 1950s did not meet the criteria of “life” either (Miller, 1953). Although Miller and Urey created the necessary preconditions for the spontaneous formation of amino acids from scratch, their synthesized “prebiotic soup”—or “prebiotic consommé” as Joyce described it—contained no informational components and therefore had no self-sustaining capacity, let alone a capacity for Darwinian evolution. Joyce stated that, in the 60 years since the famous Miller and Urey experiment, the field has advanced to a point where scientists are “getting close” to creating life, with a great deal of focus on RNA molecules and their likely critical role in the early history of life on Earth (Cheng and Unrau, 2010; Joyce, 2002; Lincoln and Joyce, 2009; Ricardo and Szostak, 2009). Some RNA molecules have the capacity to catalyze their own replication and, therefore, the potential to evolve—with replication copying errors giving rise to the genetic variation upon which natural selection acts. In fact, as Joyce remarked, many scientists suspect that DNA and protein-based life evolved from an “RNA world” when genetic information was encoded in RNA, approximately 4.2 to 3.6 billion years ago (Atkins et al., 2011; Joyce, 2002).
Self-Sustained Darwinian Evolution7 An explicit goal of Joyce’s research is to construct a system of RNA molecules that undergo self-sustained Darwinian evolution (Joyce, 2011). According to Joyce, this goal was recently achieved, although the system still lacks the complexity and inventiveness of what one might regard as life. The self-sustained evolving system employs populations of RNA enzymes that catalyze the RNA-template joining of RNA substrates. The enzymes contain about 55 essential nucleotides and can be made to join pairs of RNA substrates of almost any sequence (Rogers and Joyce, 2001). If the substrates, once joined, form additional copies of the enzymes, then self-replication can be achieved. The newly formed enzymes behave similarly, resulting in exponential growth (Paul and Joyce, 2002). Initially the process could not be sustained indefinitely and was informationally restricted by the requirement that the original and newly formed enzymes must have the same sequence.
Joyce and his team then developed an improved version of the replication system that employs two different RNA enzymes that catalyze each other’s synthesis, enabling their cross-replication and sustained exponential growth (Kim and Joyce, 2004; Lincoln and Joyce, 2009). Each enzyme of the cross-replicating
_______________
7 The following section is adapted from the contributed manuscript by Joyce in Appendix A, pages 236-243.
pair contains two substrate-binding domains that recognize corresponding oligonucleotide substrates through Watson-Crick pairing.8 During cross-replication, the “Watson” enzyme joins two pieces of RNA to form the “Crick” enzyme, while the “Crick” enzyme joins two pieces of RNA to form the “Watson” enzyme. Information is passed back and forth between these two enzymes in the form of particular sequences within the two substrate-binding domains.
Joyce observed that it was now possible, following optimization of the cross-replication system, to achieve a 100-fold amplification in the absence of any biological materials in just a few hours at a constant temperature (Lincoln and Joyce, 2009). The only informational macromolecules in the system are the enzymes and their components, which themselves are subject to Darwinian evolution within the system. The only other components are MgCl2, a buffer to maintain pH, and H2O. Evolution can occur because there are many potential variants of the cross-replicating enzymes that must compete for a finite supply of substrates and can undergo mutation through recombination of the two substrate-binding domains.
Beginning with a small seed of the cross-replicating enzymes, Joyce explained that amplification occurred with exponential growth and was only limited by the amount of substrate available. The amplification profile follows the logistic growth equation:
[enzyme]t = a / (1 + be–ct),
where a is the maximum extent of amplification, b is the degree of sigmoidicity, and c is the exponential growth rate. This equation also describes population growth for biological organisms constrained by the carrying capacity of their local environment.
Joyce remarked that cross-replication of the RNA enzymes could be sustained indefinitely by continuing to supply the necessary substrates to the culture. This is most conveniently achieved through a serial transfer procedure, whereby a small aliquot of material is taken from a spent reaction mixture and transferred to a new reaction vessel that contains a fresh supply of substrates. The new reaction mixture contained only those enzymes that were carried over in the aliquot, and these enzymes immediately resume exponential amplification in the new mixture. Within a period of 24 hours, according to Joyce, an overall amplification factor of >109 can be achieved (Lincoln and Joyce, 2009).
As illustrated in Figure WO-10 and discussed by Joyce, over a period of 100 hours, the two starter cultures effectively disappeared as new variants emerged and were selected for through recombination. More recently, Joyce and colleagues started a culture with 64 variants of each ribozyme (M. Robertson and G. F. Joyce, unpublished data).
_______________
8 In the canonical Watson-Crick DNA base pairing, adenine (A) forms a base pair with thymine (T) and guanine (G) forms a base pair with cytosine (C).
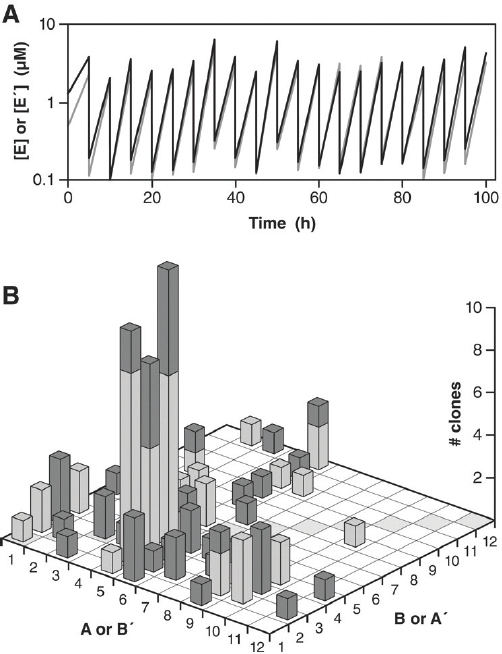
FIGURE WO-10 Self-sustained amplification of a population of cross-replicating RNA enzymes, resulting in selection of the fittest replicators. (A) Beginning with 12 pairs of cross-replicating RNA enzymes, amplification was sustained for 20 successive rounds of ~20-fold amplification and 20-fold dilution. The concentrations of all E (black) and E′ (gray) molecules were measured after each incubation. (B) Graphical representation of 50 E and 50 E′ clones (dark and light columns, respectively) that were sequenced after the last incubation. The A and B (or B′ and A′) components of the various enzymes are shown on the horizontal axes, with nonrecombinant enzymes indicated by shaded boxes
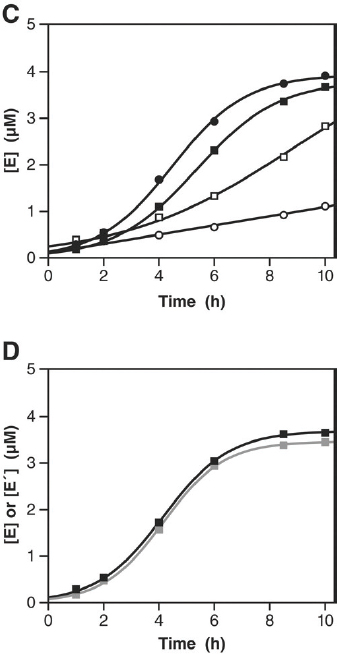
along the diagonal. The number of clones containing each combination of components is shown on the vertical axis. (C) Comparative growth of E1 (circles) and A5B3 (squares) in the presence of either their cognate substrates alone (solid symbols) or all substrates that were present during serial transfer (open symbols). (D) Growth of A5B3 (black curve) and B5′A3′ (gray curve) in the presence of the eight substrates (A5, B2, B3, B4, B5′, A2′, A3′, and A4′) that make up the three most abundant cross-replicating enzymes.
SOURCE: Adapted from Lincoln and Joyce (2009).
The next step beyond self-replication with Darwinian evolution, Joyce remarked, is to build a system whose replication is contingent on other functions by, for example, installing an aptamer9 on the ribozyme that recognizes a particular substance. When the aptamer recognizes the substance, it changes structure and allows the replicator to replicate (Lam and Joyce, 2009, 2011). There is a wide range of potential diagnostic and environmental sensor applications for such a system.
Joyce emphasized that even though the replicator that he and his colleagues built can do something that no other system outside of biology can do—sustain replication with exponential growth—it is not “alive” in the classic Darwinian definition of “life.” This point is illustrated in Figure WO-11.
Mutation occurs through recombination, and the investigators are exploring increasing the genetic variation available for selection. In an effort to create that system, Joyce and his team are working with starter cultures containing 256 variants of each ribozyme, resulting in the production of 65,536 recombinants. Joyce does not, however, consider the replicator a living system because thus far it lacks the capacity for inventing novel function.
The ultimate application, Joyce said, would be a replicator that invents its own function by evolving over time in response to the constraints of its environment—a feat that would require a significant level of genetic complexity. As Joyce observed, life on Earth, although vulnerable to extreme changes of environmental conditions, has demonstrated extraordinary resiliency and inventiveness in adapting to highly disparate niches.10 Perhaps the most significant invention of life is a genetic system that has an extensible capacity for inventiveness, something that likely will not be achieved soon for synthetic biological systems (Joyce, 2011).
High-Throughput Screening
High-throughput screening (HTS) is the process of sorting through large numbers of diverse biomolecular or chemical compounds in an efficient manner in order to rapidly identify molecules with properties of interest. Such technologies are essential to achieving any benefit from the construction of large and diverse libraries of compounds, as they are used to select a particular compound having the desired properties. These properties might include desirable biochemical or enzymatic activities for a potential therapeutic agent. Advances in miniaturized screening technologies—bioinformatics, robotics, and a variety of other technologies—have all contributed to the improved biological assay efficiency that characterizes HTS (Gulati et al., 2009). DNA or oligonucleotide microarrays—“DNA chips”—are routinely employed in both basic and applied
_______________
9 An aptamer is an oligonucleotide or peptide molecule that binds to a specific target molecule.
10 For a more in-depth discussion see contributed manuscript by Joyce in Appendix A, pages 236-243.
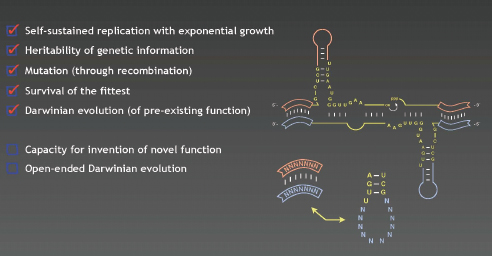
FIGURE WO-11 Is it alive? (no).
SOURCE: Joyce (2011).
research to facilitate the large-scale screening and monitoring of gene expression levels, gene function, and genetic variation in biological samples, and to identify novel drug targets.
The process of screening large numbers of compounds against potential disease targets is characterized by a collection of technologies that strive to increase biological assay efficiency through the application of miniaturized screening formats, and advanced liquid handling, signal detection, robotics, informatics, and a variety of other technologies. Over the past several years, the industry has witnessed a revolution in screening capabilities resulting in the ability of a user to screen more than 100,000 compounds per day for potential biological activity. Evaluating upwards of 1,000,000 compounds for biological (or other) properties in a screening campaign is now commonplace in the pharmaceutical industry.
Metagenomic Mining In addition to screening DNA databases, scientists are screening the natural world for potentially useful DNA sequences. Metagenomic mining involves the extraction of microbial genes from environmental samples without having cultivated the organisms (Rondon et al., 2000). It has been estimated that more than 99 percent of microorganisms in most environments have not been cultured in the laboratory. Because of this, very little is known about their genomes, genes, and encoded enzymatic activities. The isolation, archiving, and analysis of environmental DNA—the so-called metagenomes—have enabled scientists to mine microbial diversity, and has allowed investigators to access the metagenomes of environmental microbial communities, identify protein coding sequences, and even reconstruct biochemical pathways, providing insights into the properties and functions of these organisms. The generation and analysis of
(meta)genomic libraries is thus a powerful approach to harvest and archive environmental genetic resources, leading to the identification of the organisms that are present, what they do, and how their genetic information may have applications to the human condition (Ferrer-Costa et al., 2005). The evaluation of background genetic diversity will enable projections of mutation rates and emergence of new species that could be important for public health applications.
Speaker George Church of Harvard University and his research team used metagenomic mining to identify hundreds of soil bacteria able to subsist on antibiotics as their sole carbon source (Dantas et al., 2008). That such a phylogenetically diverse group of soil bacteria subsists on antibiotics points to a vast unrecognized and unappreciated environmental reservoir of microorganisms that are naturally resistant to antibiotics. Many of the bacteria sampled are closely related to human pathogens (Dantas et al., 2008).
Church discussed how he and others have been using metagenomic mining as a tool for tapping into novel microbial capabilities. Metagenomic mining has been used to extract and express a novel alkane biosynthesis pathway from cyanobacteria in E. coli (Schirmer et al., 2010). Synthetic biologists now can use the genetic and enzymatic machinery of this newly discovered pathway to engineer cells to convert renewable raw materials into biofuels (Sommer et al., 2010).
Recycling the “Trash” from HTS: Implications for Emerging Infectious Disease Management Speaker Stephen Johnston of Arizona State University explored how synthesized sequences, genes, and proteins are creating genomic and proteomic resources for a range of HTS-based applications, such as proteomic screening for vaccines. With the capacity to clone or chemically synthesize entire pathogen genomes, scientists are now able to produce on a single array, or chip, the proteins for all of those genes and screen those proteins for immunoreactivity—such as antibody reactivity and T-cell reactivity. Investigators are also able to probe immunoreactive proteins for their potential to serve as vaccine targets (Borovkov et al., 2009; Stemke-Hale et al., 2005). Johnston observed that some pathogen proteomes are very reactive, whereas others have only a small proportion of immunoreactive proteins. In an HTS technique known as expression library immunization, all of a pathogen’s genes are synthesized and arrayed in groups and used to vaccinate mice that are then challenged with the pathogen of interest. Groups that confer protection are interrogated further in order to identify which gene product(s) are actually protective (Barry et al., 1995; Borovkov et al., 2009; Talaat and Stemke-Hale, 2005).
Expression library immunization is also being used to screen for other types of compounds. Johnston and colleagues have used the technique to identify the gene B2L which is believed to be associated with the hyperaccumulation of dendritic cells that occurs following parapox infection. Infected individuals are protected only by a transient period of innate immunity. But that transient protection afforded is so strong that animals vaccinated with Baypamun®, a parapox
vaccine developed by Bayer Pharma of Leverkusen, Germany, are protected from virtually all pathogens for four to five days. (The vaccine is usually administered to animals being transported under conditions of close confinement.)
In a further application of HTS, Johnston and colleagues are making antibodies much more quickly and less expensively, by using the protein “leftovers” of synthetic biology. Conventional production of antibodies for the entire human genome has been estimated to cost $750 million and take 10 years. Instead of using proteins as the starting material, Johnston’s group decided to start with synthetic antibodies known as synbodies—random peptide pairs linked together by scaffolds. The technique involves “throwing” the synbodies onto an array containing thousands of human proteins and identifying ligands by observing where on the array the peptides bind (Diehnelt et al., 2010; Greving et al., 2010; Williams et al., 2009).
Compared to conventional antibody production, which takes about three months and involves extracting the antibody from an animal model at a cost of approximately $3,000 per antibody, generating a high-affinity synbody using this novel synthetic approach takes about five days at one-third of the cost of conventional methods. According to Johnston, the ability to synthesize genes and other molecules, like synbodies, and then screen those compounds for their bioactivity holds great promise for vaccine discovery, antibody production, drug discovery, diagnostics, and other tools for managing emerging infectious diseases.
Rebuilding Complex Functions Encoded by Multiple Genes Speaker Christopher Voigt’s group, at the University of California, San Francisco, has been working with several of these gene clusters as part of an effort to develop a methodology for reengineering entire gene clusters. Several gene clusters have been found to have useful functions with potentially very valuable industrial applications (Fischbach and Voigt, 2010). The challenge, according to Voigt, is that the underlying regulation of many of these gene clusters is very complicated, poorly understood, and highly embedded in the natural regulation of the host organism.
Voigt’s research team is interested in a cluster of genes that Salmonella typhimurium uses to build a hypodermic-like needle for the secretion of virulent proteins (Marlovits et al., 2004). The type III secretion system is a common virulence mechanism in Gram-negative bacteria. As illustrated in the cryo-electron microscopy image of Figure WO-12, they form large needle-like appendages that go through both the inner and the outer bacterial membranes and then extend out from the surface. They are normally used to deliver proteins to host cells to do things like rearrange the actin networks to promote invasion or control the trafficking of the bacteriosome inside the cell (Kubori et al., 2000; Marlovits et al., 2004; Sukhan et al., 2003).
In order to harness that needle for other purposes, Voigt and his team are attempting to reengineer the gene cluster in a host organism. S. typhimurium,
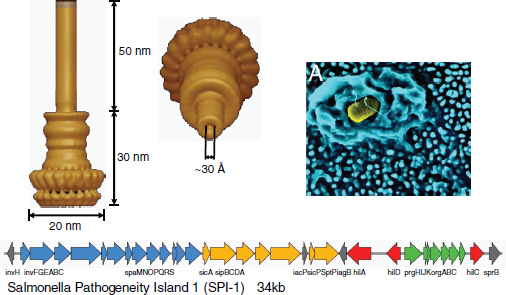
FIGURE WO-12 Type III secretion system.
SOURCE: Adapted from Kubori et al. (2000), Marlovits et al. (2004), and Sukhan et al. (2003).
Voigt said, maintains very tight control over when the needle is produced. The conditions must be exactly right for that particular stage of virulence.11 Hijacking the system for another purpose requires breaking through the tight regulation, which Voigt described as a “very nontrivial task.”
Voigt’s group has developed a technology for completely erasing all of the native regulation underlying a single gene cluster in order to have, as Voigt described it, complete control over all of the functions encoded by that gene cluster—when to turn the function on and off—and optimizing the function(s), through a process known as refactoring. “Refactoring” is a term derived by analogy from the software industry. It refers to a modification in the software code without a loss of the basic functionality of that software. When software manufacturers experience a problem with their software, they may fix that problem by rewriting the code in such a way that the underlying software continues to function unchanged. In synthetic biology, refactoring involves rewriting the DNA sequence so that it is easier to engineer but in such a way that the fundamental functionality of that sequence remains the same. A schematic of this approach is illustrated in Figure WO-13.
_______________
11 The needle will only be produced (the genes only turned on) for the time required for that stage of virulence to be completed.
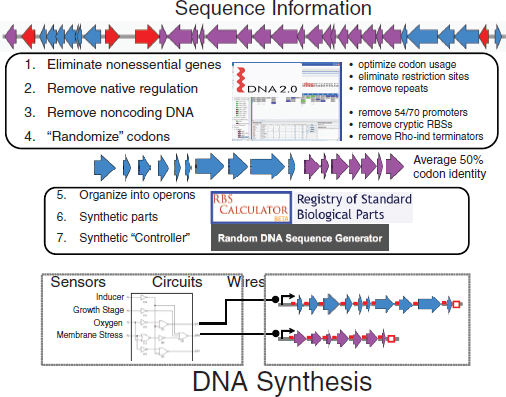
FIGURE WO-13 “Refactoring” gene clusters.
SOURCE: Voigt (2011), DNA2.0 logo kindly provided by DNA2.0 Inc.
As Voigt explained, refactoring gene clusters involves at least six elements:
- eliminating all nonessential genes—everything in the cluster that is not critical to the desired function;
- removing all native regulation within the gene cluster, as well as all noncoding DNA;
- eliminating all of the unknown regulation that might be occurring within each gene (i.e., by removing internal promoters), so that the gene encodes only the amino acid sequence that is being produced;
- organizing the genes into operons that do not necessarily follow the order of genes in the natural system;
- filling in all of the necessary regulation with synthetic parts; and
- building a synthetic controller for the system. The controller contains all of the sensors that feed information into the system (e.g., light, growth stage, oxygen, and membrane stress).
The first refactored system built by Voigt and his team was a nitrogen fixation system in Klebsiella oxytoca. The scientists refactored the 20-gene cluster, 25,000 base-pair section of DNA, responsible for reducing atmospheric nitrogen into ammonia (Rubio and Ludden, 2008). The researchers synthesized DNA sequences to build 3,000 to 8,000 base pair units, optimized each unit so that it functioned as close to wild-type levels as possible, and then assembled the refactored cluster in much the same way that Hutchison and his team put together their genomic-size pieces of DNA. Voigt said that the final refactored cluster had only about 0.3 percent of the activity of its wild-type counterpart.
Voigt’s research team is also applying the same refactoring process to the previously mentioned gene cluster responsible for type III secretion in S. typhimurium—the mechanism that S. typhimurium uses to inject virulent proteins into mammalian cells. The cluster is a 34,000 base–pair region of the genome. The encoded “needle” is an 80-nanometer structure that passes through both the inner and outer membranes of the bacterial cell and provides a means of transport for proteins inside the cell to exit. Voigt and his team chose to work with this system because they wanted to harness it to export other, nonvirulent recombinant proteins. Voigt remarked that, while there are a number of scenarios where having such a system in place would be desirable, there are few mechanisms for transporting proteins through the double membranes of Gram-negative bacteria.
Spider silk has a similar tensile strength yet is much lighter than steel. Until recently there has been no way to produce spider silk in sufficient quantities to explore its use in new materials. A significant finding that could have widescale application is the synthetic engineering of Salmonella species that can secrete spider silk. Large-scale production of spider silk by engineered Salmonella could lead to new, superstrong and light weavable materials, that could have major applications in the aeronautic, automotive, and transportation industries (Royal Academy of Engineering, 2009).
Voigt’s team demonstrated that they could modify the type III secretion system of Salmonella using synthetically designed genes to, in effect, turn the Salmonella into small spider silk factories (Widmaier and Voigt, 2010; Widmaier et al., 2009). Refactoring was exploited by Voigt’s team as a means to overcome two key challenges: first, the difficulty in turning the natural gene cluster “on” under conditions that are relevant for the production of proteins, or creating the pathogenic conditions needed for turning it on; and second, the short length of time that the natural system remains turned on, which makes it difficult to exploit for production.
Computational Modeling
It is impossible to discuss the rapid progress in biology and genetics without also acknowledging the concurrent rise in computational ability made possible by the growth in the processing power and storage capacity of computers over
the past 30 years. These technologies have led to an explosion in data accessibility and have matured computing to a point at which computational modeling is being used to analyze systems-level biological complexity. Synthetic biologists routinely use computational models,12 or computer replicas of living systems (“silicon cells”), to make qualitative or quantitative predictions about how their engineered systems are likely to function, based not just on molecular properties of the components but also on dynamics of the system as a whole (Westerhoff and van Dam, 1987). Computational models provide researchers with a tool for mining the vast and growing wealth of biological data and predicting how their engineered network(s) might function in the context of a larger system. They serve as the basis for the forward-engineering approach that many synthetic biologists aspire to achieve.
As a way to interpret computational modeling results and to guide construction of their engineered systems, many investigators employ computer-aided design (CAD) systems (Goler et al., 2008; MacDonald et al., 2011). According to speaker Paul Freemont of the Imperial College London, CAD-based modeling and biological design are a major focus of activity at the newly formed Centre for Synthetic Biology and Innovation (CSynBI), the United Kingdom’s first national synthetic biology center. (Dr. Freemont’s contribution to the workshop summary report can be found in Appendix A.)
CAD-built models typically show up on a computer screen as three-dimensional models of the system; the DNA sequences represented in the models can be synthesized and then tested in living systems. Sauro described a CAD software application called TinkerCell (www.tinkercell.com) that allows users to diagram and analyze biological systems using a combination of modeling and experimental results (Chandran et al., 2009). The application’s flexible framework enables the addition of new functions via a flexible plug-in framework; the functions can be written in any of several programming languages (e.g., C, C++, MATLAB). The driving force behind the TinkerCell initiative, Sauro said, was the desire to connect the different types of information emerging from computational modeling results, experimental results, and biological parts data.
Microbial Systems Biology: Building Genome-Scale Metabolic Networks
The field of microbial systems biology is being driven by a growing number of well-curated computational reconstructions of biochemical reactions that underlie cellular processes (Feist et al., 2009). Speaker Bernhard Palsson, of the University of California, San Diego, observed that, over the past decade, microbial systems biologists have reconstructed several organism-specific, genome-scale metabolic networks and have used the networks for a variety of basic and
_______________
12 There are numerous software tools available for computational modeling, many of which are listed on the Systems Biology Markup Language website (www.sbml.org).
applied research activities, including metabolic engineering and the study of bacterial evolution. Palsson explained that the networks differ from biochemical networks diagrammed in textbooks; every reaction has a known genetic basis and is directly linked to a genetic element in the target organism. Moreover, according to Palsson, microbial metabolic systems biology is being applied more and more to infectious disease and speaks to the interesting coupling that takes place between the host and the pathogen, and the many different microenvironmental niches that pathogens find in the human body.
A microbial cell is a very crowded and interconnected space, placing severe constraints on biological functioning. Metabolic network data provide scientists with a tool for understanding pathways in the context of the cell or organism as a whole and for predicting the systems-level flow of metabolites (Orth et al., 2010). One of the greatest attributes of these curated databases that effectively become knowledge bases, Palsson said, is that they can be accessed mathematically in a way that allows investigators to examine the underlying biochemical basis of genotype-phenotype relationships and to make quantitative predictions.
According to Palsson, everyone working with a particular target organism would like a community consensus reconstruction of that target organism (Herrgård et al., 2008). Given the importance of genome-scale reconstruction in microbial systems biology, the technique has rapidly matured to a point at which there are standard operating procedures for genome-scale network reconstructions (Thiele and Palsson, 2010). In fact, some of the procedures have been partially automated (Henry et al., 2010). Still, network reconstruction is a difficult endeavor, as computing phenotypes from genome information requires going through a multistep process of testing many possible functions; the process also requires characterizing the genome metastructure (Cho et al., 2009).13
Palsson added that most genome annotations, which serve as the starting point for reconstructions, are incomplete and often have numerous errors, with as much as 25 percent of some genomes needing to be corrected, for poorly characterized organisms, before the reconstruction process can even begin. H. influenzae was the first microbial organism to have its reconstructed metabolic network published with over 70 curated networks published, and now a much greater number will become available (Edwards and Palsson, 1999; Singh et al., 2002). Organisms with published metastructures that enable genome-wide metabolic network reconstruction include Mycoplasma genitalium (Gibson et al., 2008), Helicobacter pylori (Palsson and Zengler, 2010), and Geobacter sulfurreducens (Qui et al., 2010). The phases and data requirements needed to generate a metabolic reconstruction are illustrated in Figure WO-14.
More recently, the application of network reconstruction was expanded beyond metabolism by building a genome-wide network representing the complete
_______________
13 Organization of the genome with respect to where the various structural and functional components are located.
FIGURE WO-14 Phases and data used to generate a metabolic reconstruction. Genome-scale metabolic reconstruction can be divided into four major phases, each of which builds from the previous one. An additional characteristic of the reconstruction process is the iterative refinement of reconstruction content that is driven by experimental data from the three later phases. For each phase, specific data types are necessary that range from high-throughput data types (for example, phenomics and metabolomics) to detailed studies that characterize individual components (for example, biochemical data for a particular reaction). For example, the genome annotation can provide a parts list of a cell, whereas genetic data can provide information about the contribution of each gene product toward a phenotype (for example, when removed or mutated). The product generated from each reconstruction phase can be used and applied to examine a growing number of questions, with the final product having the broadest applications.
SOURCE: Reprinted by permission from Macmillan Publishers Ltd: Nature Reviews Microbiology, copyright 2009.
cellular biochemical machinery for protein and RNA synthesis in E. coli (Thiele et al., 2009). Palsson remarked that the RNA modification information contained in the expanded network is especially noteworthy because of the constraints that RNA modifications place on the functioning of metabolic activities. When combined with metabolic networks, Palsson observed, genome-scale reconstructions of transcriptional and translational machinery provide maps of every known antibiotic target with the exception of DNA gyrase. Investigators can use these networks to predict not only how a small molecule will likely impact a particular protein in a network but what type of metabolic response that small molecule will likely induce; one can even examine the likely phenotypic results of off-target binding. Currently, Palsson and his team are reconstructing the E. coli operon network, with the goal of integrating all three genome-scale networks—metabolic, transcription/translation, and operon/regulatory. As Palsson and colleagues concluded, this work represents a crucial step toward the important and ambitious goal of whole-cell modeling (Thiele et al., 2009).
While genome-scale reconstructions are driving the rapid growth of microbial systems biology, Palsson emphasized that the curation and integration of high-throughput data remains a significant challenge (Palsson and Zengler, 2010). Palsson and his team are using transcription and translation network reconstructions to better understand how pathogenicity islands in various species are regulated at a genome-scale level, and how pathogenic microbes differ from nonpathogenic organisms. Palsson and his team are doing this by first mapping all of the genes in the reconstructed networks of well-known non-pathogenic organisms—such as E. coli—onto the genomes of related pathogenic organisms (uropathogenic E. coli) and then conducting what is known as gap-filling analysis to generate hypotheses about pathogenicity (Cho et al., 2009; Orth and Palsson, 2010).
A Systems-Level Approach to Understanding and Developing More Effective Vaccines
Most vaccines have been designed and developed through trial and error, with scientists having no idea how they confer protective immunity. Systems biology has enormous potential to radically transform the field of vaccinology by providing biologists with the means to understand how vaccines “work” when they stimulate the immune response (Pulendran et al., 2010). The major objectives of speaker Bali Pulendran’s research program at Emory University are to take a systems-level approach toward understanding how some of the many existing successful vaccines mediate immune responses. The ultimate goal of his research is to use this knowledge to rationally design new vaccines (Pulendran and Ahmed, 2006) and apply the same systems-level approach to identify biological signatures that predict immunogenicity, adverse vaccine reactions, and vaccine ineffectiveness in certain populations (Nakaya et al., 2011; Pulendran et al., 2010; Querec et al., 2009; Thomas and Doherty, 2009).
The live attenuated yellow fever vaccine 17D (YF-17D) developed over 65 years ago is one of the most effective vaccines ever made, Pulendran remarked. Over 600 million people worldwide have been protected against this vector-borne disease through the administration of this vaccine. Yet, despite the vaccine’s “success” scientists know very little about how the vaccine actually works. The first clues to how the vaccine “works” were reported in 2006, and suggest that the vaccine activates multiple Toll-like receptors (TLRs) via multiple subsets of dendritic cells,14 eliciting a broad spectrum of immune responses (Querec et al., 2006).
More recently, this same team of investigators used a systems biology approach to identify early genetic signatures that predict immunogenicity—either T-cell or antibody responses—in humans so that individuals can be classified as low versus high responders (Querec et al., 2009). Pulendran remarked that he and his colleagues were excited by the feasibility of the systems-level approach, which had not previously been applied to vaccinology, despite its widespread use in predicting cancer therapy response(s). One of the genes expressed early on in the infection process, and that was well correlated with a subsequent CD8+ T-cell response, was EIF2AK4, or GCN2, a key gene in the integrated stress response. When cells are stressed in response to amino acid starvation, the protein encoded by EIF2AK4/GCN2 is phosphorylated and the translation of mRNA is shut down. Other genes involved in integrated stress response, all of which have the ultimate effect of shutting down mRNA translation, include
- PKR (which senses viral infections),
- HRI (senses oxygenative stress), and
- PEK (senses endoplasmic reticulum stress).
Pulendran and his colleagues were curious about the link between expression of these various integrated stress-response genes and YF-17D vaccination. For example, does YF-17D vaccination stimulate the stress response? More specifically, does EIF2AK4/GCN2 “sense” the yellow fever vaccine, and if so, how? They discovered that vaccination leads to the rapid phosphorylation of the EIF2AK4/ GCN2 protein and the robust formation of stress granules. Using EIF2AK4/GCN2 knockout mice, the investigators demonstrated that immunization with YF-17D leads to a remarkably impaired T-cell response, suggesting that the EIF2AK4/ GCN2 gene plays a critical role in the induction of adaptive immune responses to this virus. Pulendran observed that these results, while confirming the link between the stress response gene(s) and immunogenicity of YF-17D, were also puzzling. Preliminary data suggest that activation of the gene EIF2AK4/GCN2, a gene involved in amino acid sensing, triggers a process known as autophagy, whereby dendritic cells—the cells of the immune system activated by the yellow
_______________
14 Dendritic cells present antigen to T-cells. TLRs are innate receptors expressed by dendritic and other cells of the immune system. TLRs have evolved to sense highly conserved molecular patterns within microbes and viruses.
fever vaccine—start consuming their own cytosols. This process, in turn, makes the dendritic cells very efficient at processing viral antigens and communicating that information to T-cells (Nimmerjahn et al., 2003).
Pulendran’s research team has been conducting clinical trials with both the trivalent inactivated influenza vaccine (TIV) and the live attenuated influenza vaccine (LAIV; or FluMist®) to determine whether a genetic signature approach can be used to predict immunogenicity (Nakaya et al., 2011). Generally, FluMist® was observed to induce a much weaker response (as measured by hemagglutination inhibition [HAI] titers15) than the inactivated influenza vaccine does, suggesting that the trivalent inactivated influenza vaccine induces a stronger immune response than the live, attenuated, vaccine (Nakaya et al., 2011). Pulendran noted that this finding contradicts the epidemiological data that have demonstrated that LAIV is, in fact, an effective vaccine in some subjects and that the HAI titer is only one of numerous metrics that can be used to measure the immune response.
In addition, individuals immunized with TIV were found to express several B-cell genes that were correlated to the maximum HAI response and that a cluster of about 150 genes appeared to segregate among “low” versus “high” responders (Nakaya et al., 2011). These genes include TNFRSF17, which is also one of the best predictors of neutralizing antibody response to the yellow fever vaccine. This conserved expression of immune responsiveness to an antigen suggests that there may be common predictors of immunogenicity among different vaccines with many genes targeted by the transcription factor XPB-1. Taken together, a handful of genes have been correlated with predicting the maximum HAI response with a greater than 90 percent degree of accuracy. This observation is illustrated in Figure WO-15.
Pulendran expressed the hope that the growing effort to identify gene profiles that correlate with different types of immune system responses—both the innate and adaptive immune responses—may eventually lead to development of a generic vaccine chip containing 50 to 100 genes that can be used to predict the immune responsiveness to a broad range of vaccines. Figure WO-16 illustrates a schematic of such a chip.
Currently, Pulendran and his team are exploring the biology of various genetic signatures in order to determine which ones are predictive signatures of immunogenicity. From an immunological perspective, some of the predictive genes, such as TNFRSF17, make sense, Pulendran observed. The potential roles of other genes in protective immune responses to vaccines are not as obvious. For example, CaMKIV knockout mice have a defect in short-term memory and are unable to find their way around mazes (Kang et al., 2001). At the same time, CaMKIV (calcium-calmodulin dependent kinase 4) has been found to play a critical role in calcium sensing and signaling. As illustrated in Figure WO-17,
_______________
15 HAI tests measure the amount of serum antibodies directed against a hemagglutinating virus, with higher levels, or titers, being associated with greater protection.
FIGURE WO-15 XBP-1 target genes correlated to the maximum HAI response.
SOURCE: Image by Nakaya, provided by Pulendran (2011).
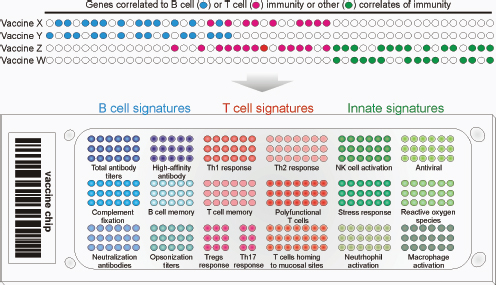
FIGURE WO-16 Schematic for theoretical construction of a generic vaccine chip. (Top) Systems biology approaches allow the identification of predictive gene signatures of immunogenicity for many vaccines. Vaccines with similar correlates of protection may or may not share the same gene markers. The identification of predictive signatures of many vaccines would enable the development of a vaccine chip. (Bottom) This chip would consist of perhaps a few hundred genes, subsets of which would predict a particular type of innate or adaptive immune response (e.g., magnitude of effector CD8+ T-cell response, frequency of polyfunctional T-cells, balance of T helper 1 [Th1], Th2, and Th17 cells, high-affinity antibody titers, and so on). This would allow the rapid evaluation of vaccinees for the strength, type, duration, and quality of protective immune responses stimulated by the vaccine. Thus, the vaccine chip is a device that could be used to predict immunogenicity and protective capacity of virtually any vaccine in the future.
SOURCE: This figure was published in Immunity, 33, Pulendran, B., Li, S., Nakaya, H. I., Systems Vaccinology, 516-529, Copyright Elsevier (2010).
CAMK4 expression on postvaccination day 3 is negatively correlated to serum antibody HAI response on day 28 postvaccination, leading to the conclusion that CAMK4 plays a role in the regulation of antibody response, with CAMK4 knockout mice showing a greater flu-specific antibody response (Nakaya et al., 2011).
Knowledge of how the yellow fever vaccine induces an immune response could have applications in the development of novel vaccines for use in protection against other pathogens. Pulendran observed that the yellow fever vaccine’s activation of four different TLRs, for example, seemed to be associated with the longevity of the effectiveness of the vaccine. If a synthetic system could be engineered with the same TLR ligands, it may be possible to invoke a similar long-lasting immune response in other vaccines. Pulendran observed that this is an
FIGURE WO-17 CAMK4 expression on post-vaccination day 3.
SOURCE: Pulendran (2011; adapted from Nakaya et al. [2011]).
example of where you can mimic a live virus by using some version of synthetic biology. A hypothetical schematic of this “ideal” is illustrated in Figure WO-18.
Systems biology promises to offer a new paradigm in vaccinology. Systems approaches applied to clinical trials may lead to the generation of new hypotheses about the biological mechanisms underlying vaccine-induced immunity. Such hypotheses can then be tested with animal models or in in vitro human systems. The insights gained from experimentation can then guide the design and development of new vaccines.
A Systems-Level Approach to Understanding the Immune Response and Managing Immunotherapy
A systems approach to disease is predicated on the idea that the analysis of dynamic, disease perturbed, networks and the detailed mechanistic understanding of disease that it provides can transform every aspect of how we practice medicine—better diagnostics, effective new approaches to therapy and even prevention.
—Heath et al. (2009)
Cells of the immune system are almost always characterized by their functional potential rather than their functional performance. Such a phenotypic classification implies a cellular functional capacity, but it does not describe the actual functions. Because of this naming convention, results from assays that measure immune cell phenotype can be, and often are, misleading. Speaker Jim Heath of the California Institute of Technology explained how a functional analysis, spe-
FIGURE WO-18 A framework for systems vaccinology. Systems biology approaches applied to clinical trials can lead to the generation of new hypotheses that can be tested and ultimately lead to developing better vaccines. For example, immune responses to vaccination in clinical trials can be profiled in exquisite depth with technologies such as microarrays, deep sequencing, and proteomics. The high-throughput data generated can be mined using bioinformatics tools and can be used to create hypotheses about the biological mechanisms underlying vaccine-induced immunity. Such hypotheses can then be tested with animal models or in vitro human systems. The insights gained from experimentation can then guide the design and development of new vaccines. Such a framework seeks to bridge the so-called gaps between clinical trials and discovery-based science, between human immunology and mouse immunology, and between translational and basic science and offers a seamless continuum of scientific discovery and vaccine invention.
SOURCE: This figure was published in Immunity, 33, Pulendran, B., Li, S., Nakaya, H. I., Systems Vaccinology, 516-529, Copyright Elsevier (2010).
cifically a systems-level functional analysis of a network of signaling proteins, might yield more accurate and helpful information about whether and how the immune system is responding to any given therapy. Although he used the example of cancer immunotherapy, and specifically adoptive T-cell immunotherapy for the treatment of melanoma, Heath said that the technologies were general enough that they could also be useful for monitoring T-cell responses to vaccination.
Adoptive T-cell immunotherapy, a technique pioneered by Steven Rosenberg at the National Institutes of Health, involves extracting T-cells from the patient’s body, genetically modifying them so that they recognize antigens expressed on the surfaces of the specific cancer cells to be targeted, and then expanding and re-infusing these modified T-cells back into the patient’s body (Rosenberg et al., 1988). A timeline for this type of immunotherapy is presented in Figure WO-19. When adoptive T-cell immunotherapy works, Heath said, it is a valuable treatment for advanced cancers; the patients are effectively immunized against their own cancers. But getting immunotherapy to work is a nontrivial exercise, made all the more challenging by the fact that it is difficult to even know if the targeted therapy is working until about 1 to 2 months into the treatment, when a positron emission tomography (PET) or computed tomography (CT) scan, or other diagnostic imaging, reveals whether the cancer is shrinking or not.
Within the first few days of the therapy, Heath said, early inflammatory responses on the skin can indicate whether the therapy is working. Following that initial inflammatory skin response, according to Heath, you are “flying blind” until images can be gathered later in the treatment process. In the interim, flow cytometry can be used, but again, the results can be misleading. Flow cytometry can be used to measure the populations of the engineered tumor-antigen-specific T-cells that were infused into the patient. The general idea is that a persistent population of those cell phenotypes is a necessary (but not sufficient) condition for successful therapy. Heath mentioned one patient—Patient 5—whose flow cytometry results suggested that the patient was responding well to therapy when in fact the cancer was returning; the patient ultimately died. Heath and his colleagues hypothesized that “a comprehensive functional analysis of defined T-cell populations, assayed over time, can reveal not just when and how the therapy is working but when and how it fails.” Figure WO-20 summarizes the clinical trial timeline and results for “Patient 5.”
Heath described the engineered T-cells that are used in adoptive T-cell immunotherapy as “tremendously complicated drugs”—that need continuous monitoring. Engineered T-cells are “asked” to carry out more than 20 distinct functions, from finding, targeting, and killing the tumor to replicating and recruiting other cells of the immune system to the tumor to induce phagocytosis of the dead tumor cells. In addition, these cells are being asked to play roles in controlling, mediating, and promoting the inflammatory response in a directed fashion. As Heath observed, if you want to understand the nature of these engineered T-cells, you
FIGURE WO-19 Adoptive T-cell immunotherapy. Cells are extracted from a cancer patient, and then genetically engineered to express a specific T-cell receptor (TCR) against a specific peptide/major histocompatibility complex (p/MHC) antigen, called the MART-1 antigen, that is on the surface of melanoma tumors. The engineered cells are expanded to ~109 cells and then reintroduced back into the patient. The data shown are flow cytometry data of CD3+ T-cells, from patient F5-1, before and after the genetic engineering process that makes them MART-1 antigen–specific.The MART-1 antigen is associated with the heavy pigmentation of melanoma tumors. At right are presented PET scans from a melanoma cancer patient participating in the immunotherapy trial. The patient exhibits a significant positive response by day 30. For the PET scan corresponding to 30 days after infusion of the engineered T-cells, most of the metabolic activity in the metastatic tumors has decreased. The brain, the bladder, and the kidneys continue to appear dark due to the clearance of fluorodeoxyglucose (FDG) through those organs.
SOURCE: Heath (2011).
cannot just look at the T-cell population. One must also look at these functions at the single-cell level, which is where the technology challenge comes.
Monitoring the function of engineered T-cells requires gathering data on individual cell activity via the measurement of the secreted (functional) proteins that describe that activity. Flow cytometry, the established single-cell proteomic technique, is used to measure the membrane proteins that are used to phenotype the cells. For example, a MART-1 antigen-specific CD3+/CD8+ T-cell is identified, using multiplexed flow cytometry, by the MART-1 T-cell receptor, and the CD3 and CD8 membrane proteins. This classification, however, does not characterize the functional performance of those cells.
One way to characterize T-cell functional performance is to measure the secreted proteins that are associated with the specific functions. An overall assessment of T-cell performance can then be estimated by the numbers of functions that each T-cell is performing. An analogy is to consider a highly functioning T-cell as a “Superman®” drug. As functional performance decreases, the T-cells can be considered, successively, as Batman®, Robin®, and finally Homer Simpson® T-cells. This is illustrated in the following cartoon (Figure WO-21).
A simple picture of the effectiveness of a T-cell therapy is to quantitate the numbers of Superman®, Batman®, etc., T-cells. The technical challenge is to measure large numbers of secreted proteins from individual, phenotypically defined T-cells, and to perform that measurement on a statistically representative number of T-cells.
In order to meet this technological challenge, Heath and his colleagues developed two technologies: (1) a nucleic acid cell sorting (NACS) technology for epitope spreading analysis for capturing a large library of tumor antigen-specific T-cells (T-cells associated with the melanoma) (Kwong et al., 2009) and (2) a single-cell barcode chip (SCBC) technology for the T-cell functional analysis (Ma et al., 2011; Shin et al., 2010). Heath remarked that, at its present stage, the SCBC allows for 1,500 individual single-cell experiments to be conducted simul-
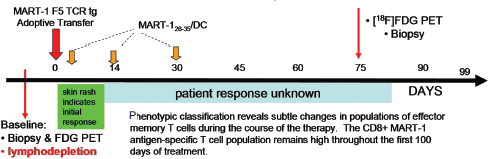
FIGURE WO-20 Clinical trial timeline on patient 5.
SOURCE: Heath (2011).

FIGURE WO-21 The effectiveness of T-cells based upon their functionality is reflected in this analogy. T-cells can do at least 20 to 30 separate key functions, such as replicating and tumor killing. The most effective T-cells have many functions, while the least effective T-cells may not have any. From a perspective of fighting a disease, highly functional (Superman® or Batman®) T-cells are desired.
taneously in a miniaturized array format, with up to 20 proteins quantitatively assayed per single cell. Within the SCBC, individual cells are isolated within ~2 nanoliter volume chambers, and each of these chambers is equipped with a full barcode structured antibody array.
As an initial demonstration of the potential effectiveness and value of this approach, Heath reported that he and his team initially conducted this functional analysis on a single melanoma cancer patient, at a single time point. Heath’s team looked at a set of MART-1 antigen-specific CD8+ T-cells. The MART-1 antigen specificity of these T-cells was genetically engineered for the melanoma immunotherapy. By phenotypic analysis, these T-cells were 90 percent homogeneous and could be classified as effective memory T-cells (Ma et al., 2011). By functional analysis, however, they were all over the map. In the top 63 percent of the population, there were approximately 50 different functional phenotypes represented; there were populations of highly functional “Supermans®” at one extreme to populations of “Homer Simpsons®” on the other. These cells were compared against peripheral blood monocytes (PBMCs) collected from healthy individuals. The cells from the healthy donors were, by and large, low-functioning “Homer Simpsons®,” exhibiting about one function per cell. The average functional capacity of the MART-1 CD8+ T cells from the melanoma cancer patient was significantly higher—about 5.3 functions per cell.
Heath and his team next conducted a longitudinal study in a single patient (unpublished). They quantitatively measured more than 1 million protein functions over the course of therapy. They conducted what is known as principal
component analysis. In such an analysis, the single-cell data are mathematically condensed into vectors, or “functional directions.” If, for example, 20 variables (proteins) are measured for each single cell, then 20 principle components can be extracted. Those principle components can, in certain ways, recapitulate the original data. The top principal component may recapitulate a large percentage (say, 20 percent) of the data, whereas the bottom principle components will only capture a fraction of a percent of the data. Thus, the top couple of principle components can be used to describe the dominant functional directions of the immune cells. By recording how those functional directions changed over time, Heath was able to describe a “movie of how the therapy proceeded.” The researchers separately investigated two phenotypes of engineered cells: MART-1 antigen-specific CD4+ T-cells, and MART-1 antigen-specific CD8+ T-cells. The MART-1 CD4+ exhibited highly coordinated functions, including a small number of anti-tumor functions, but persisted for only a short period of time. By post-infusion day 30, those cells had almost completely disappeared from circulation. By contrast, the engineered MART-1–specific CD8+ cells were observed to persist for the duration of the study but were only effective cancer killers for the first couple of weeks, after which their anti-tumor functions were replaced by other functions. As illustrated in Figure WO-22, the disappearance and loss of function of the MART-1-specific CD4+ and MART-1–specific CD8+ cells, respectively, suggests that this engineered immunity is a short-lived and perhaps ineffective therapy. However, additional measurements indicate that this engineered therapy triggers the development of an acquired immune response. Heath’s group was able to capture that acquired response by measuring the populations of CD8+ T-cells that were not MART-1 antigen–specific, but instead were specific for a spectrum of other tumor antigens associated with melanoma. Those cells begin to appear at significant levels around days 20-30 following the start of therapy, and persist with tumor-killing functions for about 2 months. It is possible that this acquired immune response constitutes the majority of tumor killing that occurs during the 90-day period over which the therapy was monitored.
Not only did Heath and his team devise a way to monitor the therapy over time, they found that although the engineered cells kick-started the killing, they were not the dominant killing cells over time. Heath suggested (and has subsequently confirmed) that a similar analysis performed on different melanoma cancer patients participating in the immunotherapy trial would reveal different results that reflect the individual patient’s response to therapy. These types of analyses can provide input for designing improved immunotherapy trials, and perhaps contribute to customizing that therapy in order to optimize individual-patient therapeutic responses.
The technologies that Heath’s research team developed while building a chip for use in immunotherapy monitoring can also be used to examine and describe immune cell function in terms of functional protein signaling networks. Heath emphasized an important distinction between functional protein signaling
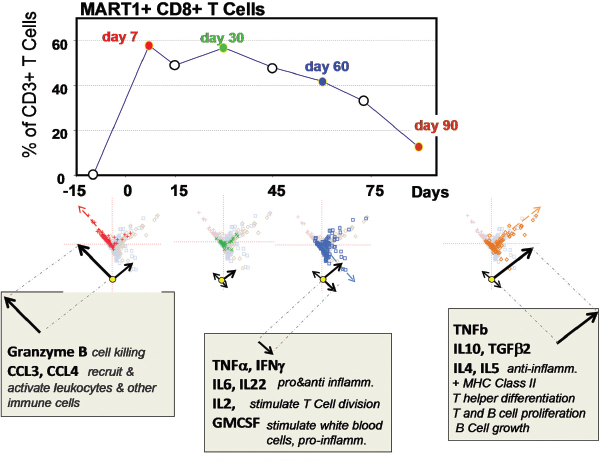
FIGURE WO-22 Data showing the persistence of the population of engineered MART-1 antigen–specific CD8+ T-cells and the evolving functional performance of those cells. The graph at top illustrates the population of the engineered cells, as a function of time, over a 90-day period following infusion of the engineered cells into the melanoma cancer patient. Below the graph are plotted the three dominant principal components that describe the functional directions of those T-cells. The data are color encoded to match the day of sampling. A description of the dominant components is provided in the boxes, given as the names of the dominant proteins associated with the component and at least a few of the biological functions that those proteins represent. Note that the strong tumor-killing functions seen on day 7 are reduced by day 30, and then replaced by non-anti-tumor functions at later dates.
SOURCE: Heath (2011).
networks and transcriptome networks. As Heath discussed, in a transcriptome network one observes a lot of positive and negative interactions, but it is unclear whether these interactions translate into actual, functional proteins. Functional protein signaling networks, on the other hand, are organized around both positive and inhibitory reactions among proteins and include directional interactions of varying strengths. In a study of macrophages, Heath and colleagues demonstrated the value of functional protein signaling networks. Specifically, Heath’s team demonstrated that these networks could be used to predict how perturbations, such as the introduction of antibodies into the system, would likely impact the system (Shin et al., 2011).
In summary, Heath’s systems-level approach has led to development of a single-cell proteomic chip (SCPC) platform that allows for hundreds of reactions, or experiments, to be conducted simultaneously. Initial studies have demonstrated that the platform can be used as a way to monitor at least one type of tumor immunotherapy. The technology is general enough that it should be applicable to monitoring vaccination responses as well. Heath’s initial results revealed that the actual (functional) immune response was different from what was expected—the dominant tumor-killing cells were not the engineered T-cells but arose from acquired immunity that was triggered by the engineered immunity. This same platform technology might also be used to evaluate how targeted therapies could influence normal cellular programming.
A Systems-Level Approach to Drug Discovery
Systems biology may become a valuable approach for drug discovery (Apic et al., 2005; di Bernardo et al., 2005; Young and Winzeler, 2005). In medicine, disease is often viewed as an observable change of the normal network structure of a system resulting in damage to the system; disease-perturbed proteins and gene regulatory networks differ from their healthy counterparts, due to genetic or environmental influences. A systems biology approach may provide insights into how disease-related processes interact and are controlled, guide new diagnostic and therapeutic approaches, and enable a more predictive, preventive, personalized medicine (Hood et al., 2004).
Speaker Hans Westerhoff, of the University of Manchester and the VU University Amsterdam, discussed how his research team has been using a systems biology approach to develop better drug targets. (Dr. Westerhoff’s contribution to the workshop summary report can be found in Appendix A.) According to Westerhoff, before the utilization of a systems approach to drug discovery, much of the focus of parasitic disease research and drug targeting was through research on the molecular basis of infection. Yet this approach is not quite accurate since, as Westerhoff explained, function depends on network function, on biological function. The viability of a parasite or the effectiveness of a parasite depends not on a molecule but on a network that produces the infection.
Westerhoff described how in silico network modeling may be used to identify better drug targets for the treatment of African trypanosomiasis,16 a vector-borne disease caused by the parasitic Trypanosoma brucei, which is transmitted to humans through the bite of a tsetse fly (Glossina genus) (IOM, 2011). Westerfhoff and his colleagues are using in silico modeling to conduct a biochemical network analysis of trypanosome glycolysis and identify novel drug targets (Bakker et al., 2010). Westerhoff remarked that the drug targets identified using a systems-level, network approach are very different than targets identified using a conventional single-molecule approach.
The conventional single-molecule approach pointed to phosphofructoskinase (PFK) and other enzymes that control glycolysis in mammals as potential drug targets, while the network approach suggested that, in fact, these enzymes exert very limited control in trypanosomes. Rather, the uptake of glucose across the plasma membrane is a much more important pathway-controlling step and a more promising potential drug target (Bakker et al., 2010). Knock-out experiments confirmed these predictions. Westerhoff went on to state that the “viability of a parasite or effectiveness of a parasite depends not on a molecule but on a network that produces this infection. So one should really look at the network effect.…If you look at the network way of doing it, then you see that it is an entirely different target.”
Using Systems Biology to Make Better Antibiotics
Antibiotic resistance in bacteria is neither surprising nor new. However, antibiotic resistance is accumulating and accelerating over time and space, contributing to an ever-increasing global public health crisis. Some strains of bacteria are resistant to all but a single drug, and some may soon have no effective treatments left in the “medicine chest.” The crisis is compounded by the dearth of novel antibiotic compounds in the drug development pipeline (IOM, 2010).
In his prepared remarks, speaker James J. Collins, of Boston University, discussed how he and his research team are using systems biology to study how one particular class of antibiotics, the quinolones, work and how the antimicrobial action of not just quinolones but other existing antibiotic classes could be enhanced by small-molecule inhibitors (Dwyer et al., 2007; Kohanski et al., 2007, 2010a,b). In the past, quinolones were generally thought to kill bacterial cells by inhibiting bacterial DNA gyrase (topoisomerase II or topoisomerase IV), interfering with replication and causing extensive DNA damage (Hancock, 2007). Dwyer et al. (2007) conducted a systems-level analysis of gene expression data to demonstrate that the anticipated DNA-damage response signature, in response to the DNA gyrase inhibitor norfloxacin, represented only a small fraction of the 800 genes with altered expression (see Figure WO-23). Norfloxacin also triggered
_______________
16 Sleeping sickness.
significant up-regulation of additional genes involved in the oxidative damage response, iron uptake and utilization, and iron sulfur cluster synthesis pathways. Through subsequent genetic knockout and phenotype experiments, the scientists discovered that the antibiotic triggers a novel oxidative damage cellular death pathway and that induction of this additional pathway appears to contribute significantly to how quinolones kill.
This systems-level analysis was repeated with eight other antibiotics; norfloxacin, ampicillin, and kanamycin were found to induce similar responses, including lethal hydroxy radical formation (Kohanski et al., 2007) (see Figure WO-24). “These studies…show that there is a lot more to understand about antibiotics, a frightening observation when one considers that research on antibiotics has malingered for decades, especially given the enormous importance of these medicines and the growing difficulties with multidrug-resistant ‘Super-bugs’” (Hancock, 2007).
On a more practical level these and subsequent studies led Collins and colleagues to wonder if it was possible to enhance the potency of certain antibiotics by blocking the pathways that bacterial cells use to protect themselves against antibiotic-induced oxidative damage (Kohanski et al., 2008, 2010a). By knocking out RecA, a protein that senses DNA damage and activates the bacterial SOS response (a DNA repair pathway), the investigators were able to potentiate
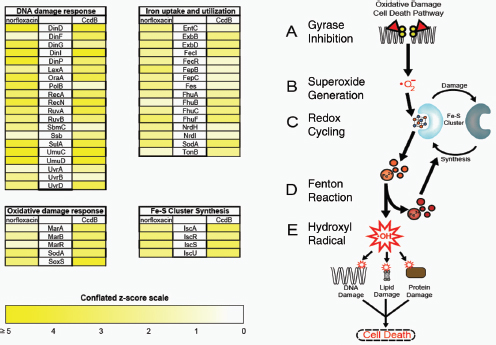
FIGURE WO-23 Gyrase inhibitors induce an oxidative damage cellular death pathway.
SOURCE: Dwyer et al. (2007).
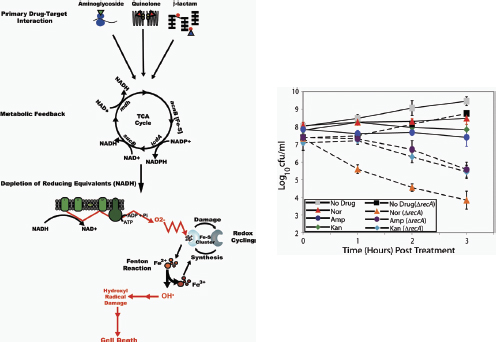
FIGURE WO-24 A common mechanism induced by bactericidal antibiotics.
SOURCE: Reprinted from Cell, 130/5, Michael A. Kohanski, Daniel J. Dwyer, Boris Hayete, Carolyn A. Lawrence, James J. Collins, A Common Mechanism of Cellular Death Induced by Bactericidal Antibiotics, 797-810, Copyright (2007), with permission from Elsevier.
several different antibiotics. Using a RecA inhibition assay, the scientists were able to screen over 50,000 bioactive compounds. They were also able to identify a number of small molecules with drug-like properties. Collins noted that their lead candidate compound increased the potency of an aminoglycoside antibiotic, gentamicin, by 1,000-fold.
Currently, these investigators are expanding the search for other small molecules that can be coupled with drugs in other classes of antibiotic. Collins’ team is also exploring how silver salts can be used to enhance the killing power of certain antibiotics. According to Collins, they have identified three modes of action for silver salts:
- increase in membrane permeability;
- misregulation of the TCA cycle and electron transport chain, thereby increasing the production of free radicals; and
- breaking down iron-sulphur clusters, further feeding the production of free radicals.
Vancomycin, a glycopeptide antibiotic typically prescribed for Gram-positive bacterial infections, when used in combination with silver salts, can also kill Gram-negative bacteria. Preliminary data demonstrate that 90 percent of infected animals survive when administered silver salts together with vancomycin. When vancomycin is administered alone, only 10 percent of the experimentally-infected animals survive—a nine-fold increase in antibiotic effectiveness.
Collins and his team are also using a systems-wide approach to study the evolution of drug resistance when bacteria are challenged with sublethal levels of antibiotics. Kohanski et al. (2010b) delivered sublethal levels of various antibiotics, selected for drug-resistant bacteria, and screened the genomes of those bacteria. They observed not only an increased mutation rate associated with sublethal antibiotic exposure but also a correlation between the change in mutation rate and the formation of reactive oxygen species (i.e., the same reactive oxygen species identified as the product of a common antibiotic killing pathway by Dwyer et al. [2007] and Kohanski et al. [2007]).
Collins observed that antibiotics are serving as active mutagens—the antibiotics themselves are leading to increased levels of resistance. This observation was supported by a recently published study in the Proceedings of the National Academy of Sciences (Read et al., 2011). The investigators reported that while the current practice of aggressive pharmacologic treatment of infections is intended to suppress the appearance of resistant strains, this approach, in fact, promotes the evolution of resistance. The authors suggested that current practices should be reevaluated using evidence-based methods (Read et al., 2011).
PROGRESS IN SYNTHETIC BIOLOGY: FROM THE TOGGLE SWITCH TO THE SYNTHETIC CELL
Unlike systems biologists, who adopt a big-picture approach to biology by analyzing troves of data on the simultaneous activity of thousands of genes and proteins, synthetic biologists reduce the very same systems to their simplest unique component parts. They create models of genetic circuits, build the circuits, see if they work, and adjust them if they do not, learning underlying principles of biology in the process.
Because the molecular nature of many cellular reactions is only partially understood, most synthetic genetic circuits require considerable further empirical refinement after the initial computational work. Some scientists use directed evolution to streamline the empirical process. After inserting mutated DNA circuits into cells and selecting for those cells (and the circuits therein) that performed the best, researchers can evolve an effective product in just a couple of generations (Yokobayashi et al., 2002).
One of the goals of the field is to transform bacteria into tiny programmable computers. Just like electronic computers, the living bacterial circuits would use both analog and digital logic circuits to perform simple computations. For
example, researchers are working to develop modular units, such as sensors and actuators, input and output devices, genetic circuits to control cells, and a microbial model organism into which to assemble these pieces. If they are successful, a “registry of biological parts” may enable researchers to go to the freezer, get a part, and hook it up (Registry of Standard Biological Parts). The computing power of programmable cells will likely never rival that of their electronic counterparts. But, the beauty of synthetic biology lies in what living cells can do.
The earliest recognition of a biological “on-off switch” was the discovery of the lac operon by Jacob and Monod (Monod and Jacob, 1961). Monod and Jacob observed that the living cell controls its manufacture of proteins through a feedback mechanism analogous to a toggle switch in the presence or absence of a substrate. The discovery that enzyme synthesis was under tight regulatory control earned Jacob, Lwoff, and Monod the Nobel Prize in Physiology or Medicine in 1965.
The earliest synthetic biology devices were the biological equivalents of electrical devices. In 2000, two research teams developed the first synthetic genetic “circuits”—a toggle switch that controls gene expression (Gardner et al., 2000), and an oscillator (“the repressilator”) that periodically induces production of green fluorescent protein (GFP) in E. coli (Elowitz and Leibler, 2000). A toggle switch exists in one of two states, alternating between the states in response to a specific stimulus. The Gardner et al. (2000) system was engineered using two promoters, each repressed by the gene product of the other; one of the repressors was temperature sensitive (cITS), and the other was sensitive to isopropyl β-d-1-thiogalactopyranoside (IPTG). The state of the system (i.e., position of the switch) was monitored through the expression of a GFP promoter. These investigators demonstrated that the system toggled in one direction when the temperature was raised and toggled in the other direction when exposed to IPTG.
An oscillator is a timing mechanism and oscillator circuits play important roles in many biological systems (e.g., circadian rhythm). The Elowitz and Leibler (2000) system, dubbed “the repressilator,” was engineered with three promoter-gene pairs, with the first promoter driving expression of the second promoter’s repressor, and so on. As with the toggle switch, the state of the system was monitored via expression of a GFP promoter.
Reliance on an engineering-based methodology does not necessarily mean that the prototype is a perfect rendition of its model. As Collins observed, most engineers use modeling as a guide to the design and construction of their systems, relying a great deal on intuition and “tinkering” during the actual assembly of parts. As alluded to earlier, because the molecular nature of many cellular reactions is only partially understood, most synthetic genetic circuits require considerable empirical refinement following the initial computational work. This process has been referred to as the “iterative process of modeling and experiment” that is required to build synthetic genetic systems with desired characteristics (Atkinson et al., 2003).
After inserting mutated DNA circuits into cells and selecting for those cells and circuits that perform the “best,” researchers can evolve an effective product in just a couple of generations (Yokobayashi et al., 2002). Neither approach to modeling biological behaviors is a perfect approximation of what happens in the real world. Systems biologists have a long way to go with respect to developing a comprehensive understanding of how biomolecules interact to yield a healthy, functioning cell and how perturbations interfere with that functioning (Atkinson et al., 2003). Just as advances in systems biology have helped to drive the recent rapid growth of synthetic biology, further advances in systems biology will continue to move the field of synthetic biology forward. It is hoped that better models will lend greater predictability to synthetic biology. In the meantime, synthetic biologists have been using the same basic methodologies to engineer a variety of additional synthetic devices (Atkinson et al., 2003; Elowitz and Leibler, 2000; Gardner et al., 2000).
Synthetic Biology: Building a Better Biosensor
Constructing bioreporter bacteria that detect toxic chemicals can be seen as one of the early accomplishments in the field of synthetic biology. In such bacteria, a rational design for a genetic circuit is produced from cellular sensory and regulatory components that can translate chemical detection by the cell into a quantifiable reporter protein signal. Experience over the past 15 years has yielded a wide range of genetic components for use as sensor elements, DNA switches and reporter proteins, and generated an array of genetic tools for configuring these components into suitable bacterial host cells.
—van der Meer and Belkin (2010)
The early discovery and creation of toggle switches and oscillators led to the development of the first synthetic biosensors—modified bacteria that can detect and “report” the presence of a particular substance or environmental condition. Speaker Christopher French of the University of Edinburgh observed that synthetic biology is especially amenable to novel biosensor development since molecular recognition is a core function of biology, allowing for the creation of biosensors with high sensitivity and specificity. (Dr. French’s contribution to the workshop summary report can be found in Appendix A.) Unlike the many synthetic biology devices that “count” or turn things on and off—such as counters, oscillators, and switches—that essentially duplicate what computers do, French stated that a practical argument could be made that synthetic biologists “should concentrate on letting the biology do what biology is good at, which is biocatalysis and molecular recognition, and develop good interfaces that allow cells and machines to talk to each other.”
Biosensors have been developed that function at a variety of levels within cells, allowing researchers to alter the transcription of particular genes (transcriptional biosensors), change how expressed genes are translated into proteins

FIGURE WO-25 “Hello World” was the first image taken by the team at the University of Texas at Austin/UCSF with their photosensitive bacterial photographic “film” (this is a later, more polished version).
SOURCE: http://openwetware.org/wiki/LightCannon.
(translational biosensors), and trigger signal-transduction pathways in response to a compound (posttranslational biosensors) (Khalil and Collins, 2010). In one of the first synthesized biosensors, researchers modified E. coli to detect the presence of the explosive trinitrotoluene (TNT) by designing a protein that binds to TNT molecules (DeGrado, 2003; Looger et al., 2003). Biosensors have also been developed that induce E. coli to form biofilms in response to DNA damage and that detect the presence of red light, effectively turning a layer of E. coli into a sheet of photographic film (see Figure WO-25) (Kobayashi et al., 2004; Levskaya et al., 2005). These early biosensors have served primarily as “proofs-of-concept” demonstrating their potential for widespread applications in medicine, environmental protection, and environmental remediation (van der Meer and Belkin, 2010).
Christopher French’s work with bioreporters, which are whole-cell biosensors17 designed to detect arsenic in drinking water, illustrates this potential (Joshi et al., 2009). French explained that whole-cell biosensors are particularly “ideal” for environmental applications because they are self-manufacturing and therefore can be produced at a very low cost. Moreover, at least in principle, they
_______________
17 Whole-cell biosensors are sensors that utilize a component of a living cell as the biological recognition component.
can be very easy to use, with the analyte simply binding to some type of recognition molecule in the device and the device processing an output signal in response to the analyte binding to the recognition molecule—any of a large number of signal-transduction pathways can be hijacked. Despite these advantages, French said, whole-cell environmental biosensors have not made much of an impact on the market. He asked, why not? And what can synthetic biology do to improve the situation?
French explained that arsenic is a popular target for environmental biosensors because there is an enormous need for an inexpensive and simple way to detect arsenic in groundwater. In addition, arsenic biosensors are easy to make. Most bacteria have an arsenic detoxification operon which consists of a single promoter (ars). In nature, the operon is expressed in the presence of soluble forms of arsenic. In the laboratory, it is relatively simple, French said, to generate an arsenic biosensor by linking the ars operon to a reporter gene. A variety of different reporter systems have been exploited for this purpose, including the use of luminescence, fluorescence, and chromogenic processing (Stocker et al., 2003). Arsenic biosensors are not only relatively simple to make, but are also commercially available. The company Aboatox Oy (Turku, Finland) sells luminescence-based arsenic (and mercury) biosensors based on the work of Marko Virta from the University of Finland (Tauriainen et al., 1999; Turpeinen et al., 2003).
Despite the popularity of arsenic as a target for environmental biosensors and the commercial availability of such devices, arsenic biosensors have not yet made a significant impact on the arsenic screening market. French reviewed how the students in the International Genetically Engineered Machine (iGEM) competition wanted to develop a device that would be less expensive to produce than currently available biosensors and that would be easy for people to use for monitoring their local water supplies. They decided to use pH as the output, rather than luminescence or any of the other output signals devised in the past (Joshi et al., 2009). The use of pH is advantageous because it can be easily visualized using a pH indicator and readily quantified using an inexpensive pH electrode or some other electrical detection device. Basically, the biosensor works via the arsenic promoter’s control of β-galactosidase, which catalyzes the first step of lactose fermentation; when arsenic is present the cells ferment lactose and produce large amounts of acid. It has subsequently been improved in numerous ways—from adding bicarbonate to increase the device’s sensitivity—to developing a simple webcam-based system that can read and report results in real time (de Mora et al., 2011).
Testing of this device has demonstrated that it works well under real-world environmental conditions, yielding clear results at arsenic concentrations as low as 0.5 ppb (de Mora et al., 2011). French identified several ways that synthetic biology approaches can be used to improve whole-cell environmental biosensors. First, there may be advantages to using an alternative chassis—in addition to or instead of E. coli—such as Bacillus subtilis. B. subtilis is a spore-forming bac-
terium. At a certain stage of its lifecycle, it undergoes a transformation and produces extremely resilient, dormant spores that can be stored at room temperature for decades, even centuries. B. subtilis spores can go from dormancy to a vegetative state within 50 minutes after being provided the appropriate growth medium.
French’s research team has built a B. subtilis–based demonstration biosensor, called the Bacillosensor. The Bacillosensor is a chromogenic system based on the xylE reporter gene.18 French remarked that although the Bacillosensor is not as sensitive as the E. coli arsenic biosensor, it has the potential to yield fewer false positives since the dormant spores can be boiled without injury and the samples sterilized before analysis. In addition, while most whole-cell biosensors developed to date require that the analyte enter the cell before it can be detected, it is possible to construct a device that detects an extracellular analyte by building a two-component sensor system with both an extracellular and a transmembrane domain (e.g., Dwyer et al., 2003). French also discussed whether it was possible to build, either by rational design or through random mutagenesis and screening, a universal biosensor platform capable of detecting a wide range of analytes that do not normally enter cells.
Whole-cell biosensors are also “tunable.” According to French, by making very small changes in the configuration of the engineered components—by swapping the order of genes in the operon or placing the repressor gene under the control of another promoter—one can alter sensitivity or increase the range of detection of the biosensor (Stocker et al., 2003). French observed that while you can quite easily generate a wide number of different combinations of binding sites and promoters, putting the genes in different orders, and just screen them for the characteristics that you want. Alternatively, through rational design, it may be possible to develop a transcription amplifier of sorts that can be tuned to provide a desired dynamic range (iGEM, 2009). One can also engineer the system such that different analyte levels produce distinct signals, by incorporating multiple receptors with varying affinities for the analyte or by using multiple synthetic organisms (Wackwitz et al., 2008). One can also engineer novel outputs through using mutant luciferase enzymes or any of a variety of pigment genes. Whole-cell biosensors can also be engineered to produce electrical outputs as well as light signals (e.g., Nivens et al., 2004).
Building a Synthetic Genome from the Top Down—Reverse Engineering
Perhaps the most well-known synthetic biology proof-of-concept study is the J. Craig Venter Institute’s “synthetic cell.” In May 2010, the J. Craig Venter Institute (JCVI) announced that they had designed, synthesized, and assembled the complete genome of Mycoplasma mycoides and transplanted it into an M.
_______________
18 The xylE gene product converts a colorless catechol substrate into a yellow oxidation product (Zukowski et al., 1983).
capricolum recipient cell to create a continuously self-replicating M. capricolum cell controlled by the synthetic genome (Gibson et al., 2010). As Speaker Clyde Hutchison of the JCVI explained, the original intention of this work was to define the minimal set of genes required for cellular life. (Dr. Hutchison’s contribution to the workshop summary report can be found in Appendix A.) By leaving genes out during the assembly process, the scientists hoped to identify which genes were required to generate self-replicating cellular life. Over time, the scientists realized that the approach would have other value as well.
The synthetic genome installed was, for the most part, an artificially (re) constructed naturally occurring genome (Gibson et al., 2010). Starting with two digitized genomic sequences of Mycoplasma mycoides, researchers manipulated the genetic sequence on the computer, adding several new “watermark” sequences to further differentiate their new “synthetic” genome from the natural M. mycoides genome. The researchers then broke the genome up into smaller pieces, which they then synthesized and reassembled to form a complete 1 million basepair genome. Finally, the synthetically created genome was transplanted into a recipient M. capricolum cell, where it displaced the resident genome to form a new, self-replicating, bacterial cell (Gibson et al., 2010; Kwok, 2010). According to Hutchison, the scientists called the final product a “synthetic cell,” even though the only synthesized component was the nuclear genome. Although the cytoplasmic components of the recipient cell were not synthesized chemically (see Figure WO-26), they were replaced by molecules encoded by the synthetic genome as the new cells grew and divided.
While installing the complete genome into a recipient cell was certainly a technological challenge, Hutchison remarked that building the oligonucleotide starting material was equally challenging. At the time, the largest published DNA synthesis project was 32 kilobases (kb) (Kodumal et al., 2004). The investigators chose a bacterial species with the smallest known genome, Mycoplasma genitalium, as their starting point (Gibson et al., 2008). M. genitalium has 485 protein-coding genes, with about 100 non-essential proteins. The limitation in using M. genitalium, Hutchison said, is its very slow doubling time of 12 to 16 hours. When the project reached the transplantation stage—after the researchers had developed a methodology for designing and assembling the synthetic genome—they switched to a faster-growing Mycoplasma species, M. mycoides, with its larger genome (1.1 millibases [mb], compared to 583 kb) but with a doubling time of only 90 minutes.
The investigators began by designing the complete natural sequence (because they knew that it works), without leaving out any nonessential genes, and making sure that the sequence was correct, as a single base error19 could be lethal. The genome was then divided into 101 cassettes, each on the order of 5 to 6 kb in
_______________
19 Hutchison noted that many sequences in the databases are not exact—in fact, the researchers found about 30 significant base errors.
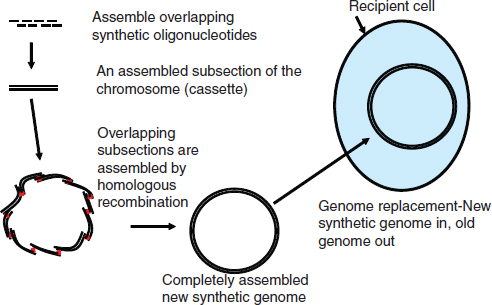
FIGURE WO-26 Overview of steps in making a cell controlled by a synthetic genome.
SOURCE: J. Craig Venter Institute (2011). Reproduced with permission.
length, and outsourced production of the cassettes. They assembled the overlapping cassettes in stages to make 144-kb quarter genomes (Gibson et al., 2009, 2010). Inasmuch as the quarter genomes were too large to clone in E. coli, the investigators developed a technique for cloning them in Saccharomyces cerevisiae (Benders et al., 2010). Finally, the scientists developed a transplantation procedure for replacing the complete genome of a recipient bacterial cell with the complete genome of the donor bacterial cell (Lartigue et al., 2007) and a technique for transplanting a bacterial genome that has been assembled in S. cerevisiae back into another bacterial cell (Lartigue et al., 2009).
Hutchison emphasized that the genome transplantation procedure they developed is distinctly different from natural transformation. Transplantation results in a clean replacement of the recipient genome by the donor genome, whereas transformation results in recombination between the donor and recipient genomes. Hutchison went on to state that the “synthetic cell” they produced grew at roughly the same rate as its wild-type counterpart, had the same appearance by electron microscopy, contained nearly identical proteins, and had the same donor cell genome with some minor differences (including two deletions of 4 and 6 kb and 14 missing genes). Currently, the Venter Institute scientists are generalizing the methods described here to other bacterial species, revisiting their original intention to define the minimal Mycoplasma genitalium genome, and experimenting with reorganizing the genome during the assembly process. In the future, syn-
thetic biologists may be able to transplant not just naturally occurring genomes but also novel genomes with useful properties that contain mixed-and-matched genes from a variety of sources.
HOW SYSTEMS AND SYNTHETIC BIOLOGY APPROACHES ARE BEING USED TO UNDERSTAND AND MANAGE BIOFILMS
Biofilms are a protective mode of growth that allows bacteria to survive in hostile environments. They are composed of populations or communities of microorganisms that adhere to biotic or abiotic surfaces. These microorganisms are usually encased in an extracellular polysaccharide matrix that they themselves synthesize and may be found on essentially any environmental surface in which sufficient moisture is present.
Biofilms may form:
- on solid substrates in contact with moisture,
- on soft tissue surfaces in living organisms, or
- at liquid–air interfaces.
Typical locations for biofilm production include rock and other substrate surfaces in marine or freshwater environments. Biofilm communities are also commonly associated with living organisms. Plant tissues are commonly associated with microbial populations on their external surfaces. Internal mammalian tissues such as teeth and intestinal mucosa, which are constantly bathed in a rich aqueous medium, rapidly develop complex aggregations of microorganisms enveloped in an extracellular polysaccharide envelope that they themselves produce.
Speaker Peter Greenberg of the University of Washington defined a biofilm as a “structured community of bacterial cells enclosed in a self-produced polymeric matrix.” (Dr. Greenberg’s contribution to the workshop summary report can be found in Appendix A.) Some experts qualify the definition further and consider only such structured communities that are attached to a surface to be true biofilms. Efforts to identify the composition of biofilms have led to the recognition of multiple polysaccharides, amyloid fibers which the bacterial cells use to adhere to surfaces and, in some cases, extracellular DNA (Whitchurch et al., 2002).
Biofilms are the cause of many persistent, chronic infections for which surgical removal—for example, in cystic fibrosis lung infections, bone infections, and heart valve infections—is a critical component of treatment (Costerton et al., 1999). Their protective nature makes biofilms inherently resistant to many antibiotic compounds regularly used to control non-encapsulated bacterial infections. According to speaker Paul Freemont of the Imperial College London, approximately 60 percent of all hospital-associated infections—more than one million
cases per year—are due to biofilms that have formed on indwelling catheters or implanted medical devices.
Biofilm communities are also ubiquitous in and on environmental surfaces. Biofilms are known to readily form in water pipes and in the ducts of heating, ventilation, and air conditioning (HVAC) systems, impeding heat transfer. Even a 100 micron-thick biofilm, according to speaker Timothy Lu of the Massachusetts Institute of Technology, can block energy transfer efficiency by up to 10 to 15 percent (Schnepf, 2010; Wanner, 2006). (Dr. Lu’s contribution to the workshop summary report can be found in Appendix A.) Biofilms also readily form on foods, serving as an important source of food contamination. Because of their threat to human and environmental health and their resistance to treatment, biofilm detection and dispersal has been the focus of a significant amount of systems and synthetic biology research. This section summarizes some of that work.
Systems Biologists Discover New Ways to Treat Biofilms
Speaker Peter Greenberg described how research on social activities of microbes has led to the development of novel ways to think about infection control. Quorum sensing is bacterial cell-to-cell signaling that allows for coordination of group activities (Parsek and Greenberg, 2005). The signals accumulate only in environments that support a sufficiently dense population (i.e., a quorum) of signal-generation bacteria (Fuqua and Greenberg, 2002; Fuqua et al., 1994). Quorum sensing controls virulence gene expression and has become a target for development of new therapies. Greenberg also discussed biofilms—organized groups of bacteria that can tolerate standard antibiotic treatment. Greenberg and colleagues discovered that iron (Fe) was an important signal for the development of mushroom-like structures that grow on the surface of Pseudomonas aeruginosa biofilms attached to glass and that a host iron chelator, lactoferrin, can block biofilm development (Banin et al., 2005; Singh et al., 2002). At low iron concentrations (i.e., sufficient for biofilm growth but still low), the biofilms that form are flat and thin. The researchers further discovered that even in high-iron environments, mutant P. aeruginosa cells that are unable to import iron form flat biofilms. They identified several iron receptors, including two receptors that identify iron chelated to ferrioxamine—the desferrioxamine, or DFO, receptors.
Recognizing the critically important role that iron plays in biofilm formation, Greenberg’s team collaborated with a research group that had figured out how to replace the iron attached to DFO with gallium (Ga), an inert metal with the same ionic radius as iron, to see if gallium would interfere with the cells’ DFO-Fe uptake systems and iron metabolism and thereby block biofilm development (Banin et al., 2008). The researchers demonstrated that, compared to traditional treatment with the antibiotic gentamicin, which kills some of the bacterial cells on the biofilm’s surface while leaving cells in the biofilm’s interior unscathed, or
Ga alone, treatment with a DFO-Ga complex effectively kills the entire biofilm population (Banin et al., 2008). DFO-Ga has been used in an animal model to potentiate the standard-of-care treatment for corneal infections.
This approach, according to Greenberg, represents a new way to treat bacterial biofilms. It is also testament to insights that are enabled by a systems-level approach to understanding biology. Greenberg went on to observe that, “I think this is a burgeoning field now, coming up with novel ways, based on the biology of the bacteria on biofilms, to attack them.”
How Systems Biology Is Leading to a Better Understanding of Antibiotic Resistance
Speaker Kim Lewis’ work at Northeastern University with persisters serves as another example of how a systems-level approach is leading to a better understanding of biofilm biology and potentially new approaches to managing biofilm aggregation and disaggregation. (Dr. Lewis’ contribution to the workshop summary report can be found in Appendix A.) Lewis referred to the limited efficacy of existing antibiotics against susceptible cells as “the paradox of chronic infections.” As Lewis explained, E. coli, in its free-living state, is antibiotic susceptible but, once it settles on a catheter or another biological implant and forms a biofilm, it becomes incredibly difficult to treat. E. coli is not the only microorganism to form these encapsulated communities. Biofilm diseases include pediatric infections of the middle ear by Haemophilus influenzae, dental diseases caused by Streptococcus and Actinomyces, infection of medical devices such as catheters and prosthetic hips and knees by Staphylococcus aureus and S. epidermidis, and, Pseudomonas aeruginosa–associated cystic fibrosis infections. An estimated 65 percent of all infections in developed countries are caused by biofilms (Lewis, 2007).
When a biofilm is treated with low concentrations of an appropriate antibiotic, the vast majority of cells die, but a small fraction persist and repopulate the biofilm, thereby sustaining infection, Lewis explained (Lewis, 2010). These “persister” cells are not mutants, but phenotypic variants that are dormant and, therefore, immune to antibiotic assault (Shah et al., 2006). Unlike resistant cells—which prevent bactericidal antibiotics from binding to their targets—persisters are tolerant of antibiotics because target molecules are inactive as a result of dormancy. “In order to understand tolerance, we need to appreciate that bactericidal antibiotics kill not by stopping functions, but by creating either corrupted products or toxic products that then kill the cell,” Lewis observed. “If the target is inactive, there will be no corrupted or toxic product and no death” (Kohanski et al. 2010a; Lewis, 2007). The small proportion of biofilm cells that are persisters, therefore, function as a pathogen refuge in the presence of antibiotic.
Lewis’ group examined intracellular toxins known to induce dormancy and found that these molecules also rendered cells highly tolerant to antibiotics
(Schumacher et al., 2009). One such toxin, called TisB, is activated by the bacterial SOS response, which also increases mutation rates and, thereby, opportunities for antibiotic resistance to emerge (Dorr et al., 2009, 2010). Lewis observed that when sublethal antibiotic exposures trigger the SOS response, it can lead to the creation of persisters that are multidrug tolerant.
He and coworkers then analyzed pathogen isolates from patients with chronic infections, whose exposure to periodic high doses of antibiotics would be expected to select for comparatively high levels of persistence (LaFleur et al., 2010; Lewis, 2007, 2010; Mulcahy et al., 2010). This is indeed what the researchers found, Lewis said, and these results clearly demonstrate that the ability to make persisters plays a key role in infection, and one distinct from resistance. “In acute infection, it is very important for the pathogen to be able to have resistance, both intrinsic and acquired,” Lewis explained. He went on to observe that chronic infections favor persister cells and tolerance, both of which are reinforced by selective pressure in the form of repeated high doses of antibiotic.
Lewis’ team is exploring the use of broad-spectrum prodrugs, such as metronidazole, a prodrug20 activated by nitrate reductase in bacteria (Lewis, 2007). Initial data have established proof-of-principle that the approach works. However, in terms of developing drugs to target persisters, there is no easy, or realistic, target, as persister formation involves multiple pathways. RelE, HipA, and TisB are just a few of many components. Lewis’ team has been using HTS in order to identify prodrug compounds that might show promise in targeting persister cells.
How a Systems-Level Understanding of Biofilms Is Influencing Antibiotic Drug Discovery
Part of why antbiotic discovery is still in a “Dark Age” is that most environmental microorganisms—more than 99 percent—are unculturable. Lewis and colleagues wanted to see if they could culture these microorganisms by growing them in their natural environment. In order to do this they built a diffusion chamber, embedded marine sediment inside the chamber, and then placed the chamber back in the marine sediment environment. In effect, the bacteria were “tricked” into perceiving the chamber as their natural environment. The recovery rate was about 40 percent, compared to <0.05 percent under standard culture conditions (Kaeberlein et al., 2002). The researchers have been using the same diffusion chamber technique and other similar in situ methods to recover a growing number of previously uncultivated microorganisms (Bollmann et al., 2007; Gavrish et al., 2008; Lewis et al., 2010).
Observing that some organisms in the diffusion chamber were able to grow only in the presence of other species from the same environment, the scientists
_______________
20 Prodrugs are benign until activated by a bacteria-specific enzyme, so they kill bacterial but not host cells.
hypothesized that cultivability requires the presence of some sort of environmental growth factor. Indeed, in a subsequent study, they found that siderophores21 from neighboring species induce growth of uncultured marine bacteria (D’Onofrio et al., 2010). Some bacteria lack the ability to produce their own sidephores and are chemically dependent on other species in their environment. Lewis said, “[unculturable bacteria] live in a precisely defined environment with a precise neighbor. That’s how they know where they are.”
Lewis and his team have found the same phenomenon in the human gut, where about half the bacteria are as yet uncultivated. Pairing different strains together, these investigators have identified “helper strains” that permit growth of previously uncultivated strains. They have also isolated a new class of growth factor—not a siderophore—that they believe may play a role in managing Crohn’s disease. The growth factor is produced by Faecalibacterium prausnitzii.
Synthetic Biology Approaches to Managing Biofilms
The easiest way to remove biofilms from surfaces is mechanically by, for example, brushing one’s teeth or surgically removing a biofilm infection. Unfortunately, mechanical removal of biofilms may not be practical in many situations, such as in industrial settings, where the current practice is to use biocides like chlorine bleach and quaternary ammonia. These compounds remove cells on the biofilm’s surface but do not remove cells living deep within the biofilm capsule—a situation similar to what happens when antibiotics, even antibiotics to which the bacterial infection has not evolved resistance, are used to treat biofilms in the human body.
Speaker Tim Lu and colleagues are exploring the potential to use engineered bacteriophages as a novel way to target and disaggregate biofilms once formed (Lu and Collins, 2007). A bacteriophage is any one of a number of viruses that infect bacteria. Bacteriophages are among the most common biological entities on Earth. Discovered as a therapeutic agent in the early 1900s, early efforts to commercialize bacteriophages were challenged by poorly controlled clinical trials. With the introduction of antibiotics over 70 years ago into clinical practice, very few investigators continued with their research in using phages as a therapeutic alternative to antibiotics. With antibiotic resistance having emerged as a major global health problem phage therapy is being seriously considered as a viable option in the treatment and control of antibiotic-resistant “superbugs.” Like antibiotics, phages do not readily penetrate biofilms. In order to get around this physiological barrier scientists are reengineering bacteriophages to express enzymes that digest the polysaccharide matrix capsule so that the phages can gain access to the interior cells of the biofilm. Investigators are also exploring
_______________
21 Siderophores are low-molecular-weight compounds with a high binding affinity for insoluble iron-III; microorganisms release siderophores to scavenge iron-III and then transport it back into the cell.
FIGURE WO-27 Two-pronged attack strategy for biofilm removal with enzymatically active DspB-expressing T7DspB phage. Initial infection of E. coli biofilm results in rapid multiplication of phage and expression of DspB. Both phage and DspB are released upon lysis, leading to subsequent infection as well as degradation of the crucial biofilm EPS component, β-1,6-N-acetyl-d-glucosamine.
SOURCE: Lu and Collins (2007).
the use of phages—in combination with co-administered antibiotics—as a way to prevent, or minimize, the evolution of resistance to antibiotics.
Lu discussed several efforts to develop enzymes that can break down the extracellular matrix of biofilms and reengineering phages to incorporate these enzymatic modules. Bacteriophages kill bacterial cells and are relatively easy to produce and deliver. By reengineering phages to express enzymatic modules, Lu and his colleagues hope to create a therapeutic product that is easy to produce and deliver and that is able to penetrate the biofilm’s interior through expression of the biofilm-degrading enzymatic modules (Lu and Collins, 2007).
As a proof-of-concept that phages can be used not just to kill but also to deliver biofilm matrix-removing enzymatic machinery into bacterial cells, much like a Trojan horse, the researchers re-engineered bacteriophage by incorporating the genetic circuitry for DspB.22 The goal was to create a phage that attacked not only the bacterial cells themselves but also the biofilm matrix. Figure WO-27 illustrates Lu’s experimental approach.
Lu and colleagues were able to demonstrate that, compared to non-enzymatic bacteriophages, biofilm removal was significantly enhanced when engineered enzymatic bacteriophages were used to attack and break down the biofilm’s protective matrix (Lu and Collins, 2007). After 48 hours, based on cell counts, the untreated biofilms were observed to have about 107 colony forming units (CFU)/ biofilm. Over the same time course, biofilms treated with natural phages had more than 104 CFU/biofilm, and biofilms treated with the engineered phages had less than about 103 CFU/biofilm (Lu and Collins, 2007).
_______________
22 DispersinB® (DspB) is an antibiofilm enzyme, which has been shown to inhibit and disperse biofilms.
Lu went on to discuss the possibility of engineering bacteriophages that could not only deliver biofilm matrix-degrading enzymes but also the genetic circuitry required to potentiate bactericidal antibiotic pathways that produce reactive oxygen leading to DNA damage. Both Lu and Collins discussed the possibility of shutting off the SOS repair pathway as a way to potentiate the effectiveness of bactericidal antibiotics. As illustrated in Figure WO-28, they found that engineering lysogenic phages to express the lexA3 repressor of the SOS pathway increased killing by quinolones by several orders of magnitude in vitro and increased survival of infected mice in vivo (Lu and Collins, 2009).
If left untreated, only 10 percent of mice infected with E. coli survived. When treated with antibiotic-potentiating phage, 80 percent of infected mice survived (Lu and Collins, 2009). These investigators also reported that the use of antibiotic-potentiating phage with antibiotics decreased the number of resistant bacterial cells that emerged later on (Lu and Collins, 2009). They tested a range of phage and antibiotic concentrations and, in almost all cases, the combination therapy enhanced bacterial killing. Lu remarked that engineering phage to target non-SOS genetic networks and/or overexpress multiple factors can produce effective antibiotic adjuvants (Lu and Collins, 2009).
FIGURE WO-28 Targeting bacterial defense networks. Schematic of combination therapy with engineered phage and antibiotics. Bactericidal antibiotics induce DNA damage via hydroxyl radicals, leading to induction of the SOS response. SOS induction results in DNA repair and can lead to survival.
SOURCE: Lu and Collins (2009).
Lu observed that the ability to engineer bacteriophages using synthetic biology methods is becoming easier and faster. The goal, Lu said, is to be able to use phages not just as a means of cell killing but also as a platform for delivering rationally designed antimicrobial agents into the biofilm matrix. After the genetic circuit controlling whatever it is that one wants to express has been identified, one can simply “pop” that circuitry into the bacteriophage and see if it works. Alternatively, one could take a nonrational approach and insert random modules into phages and select for those that work. It is not clear which approach is going to win out, Lu said.
THE PROMISE OF SYNTHETIC BIOLOGY
While there are only a handful of examples of synthetic biology research transitioning from basic to applied research, the growing number of proof-of-concept studies have reinforced both the value and the promise of the synthetic biology approach for product development. The few examples of discoveries that are being actively scaled up for widespread applications have the potential to revolutionize several industries—from drug discovery to materials manufacturing.
Speaker David Berry of Flagship Ventures observed that the biotechnology industry has evolved from a “deconstructive” approach—identifying single factors that make an impact—to a hybridized deconstructive-constructive approach—designing systems-level manufacturing platforms to efficiently produce those single factors. (Dr. Berry’s contribution to the workshop summary report can be found in Appendix A.) The power of synthetic biology, Berry remarked, is in its potential to streamline and simplify chemical processing and to facilitate faster and less expensive production. Synthetic biology tools and approaches are also being used to design and engineer novel single-factor products, such as protein therapeutics.
Metabolic Engineering as a Platform for the Production of Pharmaceuticals and Other Chemical Products
One can envision a future when a microorganism is tailor-made for production of a specific chemical from a specific starting material, much like chemical engineers build refineries and other chemical factories from unit operations.
—Keasling (2010)
That future may not be too far away. In many parts of the world, Anopheles mosquitoes have evolved resistance to quinine-based antimalarial drugs, such as chloroquine. As a result, the World Health Organization (WHO) in 2003 recommended the use of the non-quinine-based artemisinin as the drug of choice to treat malaria. Speaker Jay Keasling of the University of California, Berkeley, observed
that, due to an over delivery of the drug artemisinin following the 2003 WHO recommendation coupled with a subsequent price drop—to a point where it is now more profitable for farmers to grow food crops than Artemisia annua plants from which artemisinin is derived—the once plentiful artemisinin stockpile has been essentially depleted, creating what may soon become a huge unmet demand23 for an essential antimalarial treatment.
One often-cited example of a synthetic biology project that is working its way toward widescale industrial application is the creation of an engineered yeast that produces artemisinic acid, the immediate precursor to the antimalarial drug artemisinin. Artemisinin is highly effective against multidrug-resistant strains of malaria. But, because it is derived from the plant Artemisia annua (sweet wormwood), and not easily produced on an industrial scale, it is frequently and chronically in short supply (Specter, 2009). Jay Keasling and colleagues engineered a Saccharomyces cerevisiae yeast to produce artemisinic acid by modifying an existing metabolic pathway in the yeast and adding in a gene from A. annua to convert the product into the drug precursor (Ro et al., 2006).
Keasling’s work aims to engineer a microorganism to become a biofactory that produces artemisinic acid, the precursor to artemisinin. The ultimate goal of Keasling’s research is to reduce the cost of artemisinin-based antimalarial drugs by an order of magnitude by engineering a microbe that could produce artemisinin from an inexpensive, renewable resource. Stephanopoulos’s research group is also using metabolic engineering to explore and refine a novel microbial-based platform for the production of a range of pharmaceutical and chemical products, including a key intermediate molecule in the biosynthesis of the anticancer drug paclitaxel (Taxol®) (Ajikumar et al., 2010; Liu and Khosla, 2010).
Keasling’s work involved overcoming a multitude of significant technical and design challenges (Dietrich et al., 2010; Keasling, 2010). Keasling and his group used synthetic biology techniques to effectively substitute a microbe for the A. annua plant, whereby the reengineered microbe becomes a biofactory producing the same artemisinin chemical derived from the A. annua plant. They inserted into E. coli, a microbe that produces farnesyl pyrophosphate, all of the genes involved in converting farnesyl pyrophosphate into artemisinic acid. The first enzyme in the pathway is amorphadiene synthase, which converts farnesyl pyrophosphate into amorphadiene. Because they could not get access to the gene, Keasling’s team inserted a similar gene from tobacco that converts farnesyl pyrophosphate into 5-epi-artistolochene instead of amorphadiene. Although the substitution worked, the yield of artemisinic acid was very low—not nearly close enough to the estimated 1 gram per liter that the researchers needed to make it an economically viable option for commercial applications.
_______________
23 According to an artemisinin demand analysis conducted by the Boston Consulting Group, the predicted demand for the next several years is 250 to 300 million treatments annually.
They then synthesized the gene for amorphadiene synthase and optimized it for expression in E. coli by changing the codon usage, leading to a two-order-of-magnitude increase in production but still far below what was necessary before commercialization could be considered an option (Martin et al., 2003). Keasling’s team used directed evolution and other technologies to further optimize production and balance other parts of the multi-gene pathway (Anthony et al., 2009; Pfleger et al., 2006; Pitera et al., 2007). Although the final pathway, the conversion of amorphadiene into the desired end product, artemisinic acid, had been proposed in the literature, none of the genes had been identified.
In order to identify the genes involved in the final step in the pathway, Keasling and his team constructed a yeast—Saccharomyces cerevisiae—that produces amorphadiene with the goal of using the yeast system as a probe to screen a library of Artemisia annua genes and identify those involved in the hydroxylation of amorphadiene into artemisinic acid and then inserting these genes into E. coli (Paradise et al., 2008; Ro et al., 2006). Keasling’s research group developed a technique for isolating artemisinin-producing cells from the A. annua trichome oil sacs in order to develop a cDNA library from those cells’ genomes. Keasling’s team was able to identify an enzyme that was not only functional but also catalyzed the entire three-step oxidation reaction converting amorphodiene to artemisinic acid (Ro et al., 2006). Remarkably, Keasling explained, because of the toxicity of artemisinic acid, the engineered yeast cells maintained a series of pumps that excreted the toxic end product to the outside of the cell wall. Lowering the pH caused the product to fall off the cell wall. Keasling said, “This gave us the perfect purification process.” The same product can readily be transferred back into the E. coli chassis (Chang et al., 2007).
Keasling then found a way to link together all of the various reengineered pathways, or partial pathways, especially given that some of the metabolites produced by the reengineered pathways are toxic. Keasling said, “If you think about it, when we engineer metabolic pathways, we are basically expressing the genes that encode the enzymes in that pathway and flooding the cell with protein that catalyzes the transformations in that metabolic pathway. But we don’t connect those in any way, so the metabolites are able to drift around the cell.…It is as if the plumber threw the plumbing in your house and just expected the water to get from the street to your shower.” In order to build a system that would transport metabolites from one reaction to the next, Keasling’s team needed to either build what would be the equivalent of pipe threads to link the pathways together or at least find a way to hold the pathways close together in order to increase the chance that the metabolites would naturally diffuse from one reaction to the next. So they built a synthetic protein scaffold with binding domains that recruit the pathway enzymes and, in doing so, increase yield of the final end product even more—to about 500 mg per liter (Dueber et al., 2009).
The yeast developed by Keasling’s team has the potential to allow for production of artemisinin at a much larger scale and at a significantly lower cost than
conventionally manufactured artemisinin, which could help save millions of lives annually (Khalil and Collins, 2010; Ro et al., 2006; Royal Academy of Engineering, 2009; Specter, 2009). To accomplish this, Keasling helped start Amyris Biotechnologies, which has already increased the amount of artemisinic acid each cell can produce by a factor of more than one million and, through a partnership with Sanofi Aventis, is hoping to bring artimisinin derived from synthetically-produced artemisinic acid to the market soon. Sanofi Aventis has completed the scale-up process and, at the time of this workshop (March 2011), was outfitting a production facility in Eastern Europe. Keasling expected that the drug will be available by the end of 2011 or early 2012 and remarked that initially it will be available at cost with a long-term goal of reducing the price 10-fold. The cost of their synthetically-produced artimisinin is expected to be less than one dollar per treatment course, approximately one-tenth the current price of naturally produced artimisinin (Specter, 2009).
The Evolution of Resistance
Given that resistance to quinine-based antimalarial drugs is the main reason novel antimalarial compounds—and ways to produce those compounds—are needed, an obvious question is: what is the likelihood of resistance to artemisinin developing? Keasling explained that WHO has recommended that artemisinin be used only as a co-therapy, which is how he and his team are developing the drug and will be marketing it. His intention is to sell the microbially produced drug at a lower cost than conventional commercial drug production. Out-competing monotherapy production, he said, is one way to help with resistance. Developing derivatives of the drug is another. While he and his team have not considered the manufacture of derivatives of artemisinin, they can provide others with the artemisinic acid intermediate which others can chemically “decorate” in any way they choose. “No doubt people will be doing that,” he said.
A Metabolic Engineering Platform for the Discovery and Production of New Therapeutic Molecules
Speaker Greg Stephanopoulos’ work at the Massachusetts Institute of Technology exploits metabolic engineering as a platform for the discovery and production of new therapeutic molecules and revolves around the same isoprenoid pathway that Keasling uses in his research. (Dr. Stephanopoulos’ contribution to the workshop summary report can be found in Appendix A.) Isoprenoids are chemical precursors to many pharmaceuticals and other chemicals. Stephanopoulos noted that the isoprenoid pathway could be reengineered to generate upwards of 50,000 to 100,000 different compounds.
The isoprenoid pathway can be split into upstream and downstream pathways, both of which can be reengineered and opitimized in ways to maximize
production of the desired compound. The upstream pathway yields formation of a key intermediate molecule, isopentenyl pyrophosphate (IPP); the downstream pathway converts IPP into any of tens of thousands of different compounds. In addition to artemisinin and paclitaxel (Taxol®), some of the more commonly known compounds produced by the isoprenoid pathway are menthol, lycopene, and polyisoprene (rubber).
By engineering both the upstream pathway leading to IPP production and the downstream pathway leading to synthesis of taxidiene, a key intermediate in Taxol® production, as well as the biochemical step that immediately follows taxidiene synthesis, Stephanopoulos’s team has been able to dramatically increase microbial-based Taxol® production (Ajikumar et al., 2010). Instead of engineering the upstream mevalonate pathway, as Keasling and his team did, Stephanopoulos’s group focused on the 2-C-methyl-d-erythritol 4-phosphate (MEP) pathway. Stephanopoulos remarked that not only have Keasling’s group and others done a substantial amount of work with the mevalonate pathway, leaving less to learn, he wanted to challenge the conventional wisdom that the MEP pathway is not a good pathway for production of isoprenoids. As it turns out, the MEP pathway is about 25 percent more efficient in the synthesis of many downstream molecules.
Specifically, the scientists added extra copies of four genes known to be rate-limiting steps for IPP production to varying degrees (i.e., DXP, CDP-ME, ME-cPP, and DMAPP) and transferred two genes—the genes for geranylgeranyl diphosphate (GGPP) synthase and taxadiene synthase—that convert IPP into taxodiene—into E. coli. The researchers also reengineered an additional component of the downstream pathway that converts taxadiene into taxadien-5a-ol, improving taxadien-5a-ol production by 2,400-fold. By over-expressing the upstream and downstream pathways to varying degrees, Stephanopoulos’s team was able to create an optimized system that produces taxadiene on the order of 1-2 g/ liter, representing a 15,000-fold increase over the control (Ajikumar et al., 2010). During their experiments, the researchers discovered that production of taxadiene is inversely correlated with synthesis of another, unrelated metabolite, indole, and that balancing the pathways to optimize taxadiene production also modulates indole levels. To confirm that they had efficiently balanced the upstream and downstream pathways, the researchers used metabolic control analysis, a quantitative method for predicting how changes in various parameters such as enzyme concentration(s) will likely impact metabolite production (Quant, 1993).
Stephanapoulos observed that metabolic engineering can also be used for compound discovery by using metabolic pathway scaffolds to screen libraries of synthetic molecules and identify those compounds that yield the greatest amount of end product. The same metabolic engineering approach can also be used for biofuel production and discovery (Alper and Stephanopoulos, 2009).
Synthetic Biology Approaches to Developing Novel Protein Therapeutics
Speaker George Georgiou of the University of Texas at Austin identified two areas of protein therapeutic discovery and development where synthetic biology is having a significant impact: enzyme therapeutics and monoclonal antibody discovery. (Dr. Georgiou’s contribution to the workshop summary report can be found in Appendix A.) He observed that both areas are immediately relevant to emerging infectious disease management, as both enzymes and monoclonal antibodies have important antimicrobial properties.
Synthetic Biology and Enzyme Therapeutics
While the focus of Georgiou’s research is on the use of enzymes for the treatment of tumors, not for antimicrobial applications, he and his colleagues’ work nevertheless serves as a proof of principle that this approach may have a variety of applications beyond cancer therapy. Many tumors have metabolic defects that cause them to enter an apoptotic24 process and eventually die if deprived of a particular amino acid. Many central nervous system tumors, such as glioblastoma multiforme, for example, are highly sensitive to methionine depletion; if methionine is removed from their environment the tumor cells die within 3 days. In theory, methionine depletion is a potentially powerful therapeutic approach. Investigators have been attempting to develop a bacterial enzyme for depleting systemic methionine for the past several decades. The challenge, Georgiou said, is that bacterial enzymes are highly immunogenic, causing anaphylactic shock and death in preclinical trials using experimental animals.
Georgiou and his team set out to develop a human enzyme that would have the desired therapeutic effect without the immunogenicity of its heterologous bacterial counterpart. The methionine-degrading bacterial enzyme L-methionine-g-lyase (MGL) is structurally similar to the human enzyme cystathionine g-lyase (CGL). Using computational design and HTS, these investigators engineered a modified CGL with methionine-depleting capacity and reformulated the compound to have a circulation half-life25 of 35 hours. Georgiou’s team then developed a process for expressing the engineered enzyme in E. coli so that they could generate enough product to use in preclinical animal studies. Georgiou and his group are currently collaborating with an academic good manufacturing practice (GMP) facility in preparation for clinical research. In addition, Georgiou’s group has two other enzyme therapeutics in development, one for the systemic depletion of arginase and the other for the systemic depletion of asparagine.
_______________
24 Apoptosis is a process of programmed cell death by which cells undergo an ordered sequence of events that lead to death of the cell, as occurs during growth and development of the organism, as a part of normal cell aging, or as a response to cellular injury.
25 Half-life (biological) is the time it takes for a substance to lose half of its pharmacologic, physiologic, or radiologic activity.
Synthetic Biology and Antibody Discovery
Novel antibodies are typically discovered in one of two ways: the disease target molecule is purified and an antibody specific to that target is produced, or, antibodies are isolated from antigenically-responsive patients (see Figures WO-29A and B, respectively).
Georgiou remarked that the first method is not as easy as it sounds, especially with complex targets; investigators often need to make and sort through thousands of antibodies before finding one that is specific enough to have a therapeutic effect. The second method, in addiiton to being time-consuming, is also limited by the fact that “clonable” antibodies are not the same as antibodies that are actually eliciting the bulk of the immune response. The antibodies responsible for about 80 to 90 percent of humoral immunity, Georgiou said, are “hiding” in the bone marrow.
Georgiou and his team of investigators developed a set of “third wave” antibody discovery technologies for “mining” the hidden antibodies (see lower half of Figure WO-29B). The technologies involve isolating the desired bone marrow plasma cells and sequencing the entire genetic repertoire, mining the repertoire and identifying antigen-specific antibodies, synthesizing the antibody genes, and then expressing those genes in E. coli (Reddy et al., 2010). The researchers have applied the methodology to a variety of experimental animal species by immunizing animals with various protein antigens and then identifying antibodies with varying affinities to those proteins. Georgiou and colleagues have also developed a methodology to engineer aglycosylated monoclonal antibodies (Jung et al., 2010).
Georgiou offered his opinion that antibodies make for useful antimicrobials because of their specificity, predictability, and profitability for their commercial manufacturers. A number of antibodies are currently in late-stage development for the treatment of a variety of infectious diseases. In 2009, Merck & Co. signed a licensing agreement for a monoclonal antibody for use in the treatment of Clostridium difficile that was co-developed by Mederix Inc. and Massachusetts Biological Laboratories (News and Analysis, 2009). Elusys Therapeutics, Inc. (Pine Brook, New Jersey) is also developing an antibody engineered by Georgiou’s laboratory for use as a post-exposure prophylatic therapy for inhalational anthrax (see Leysath et al., 2009; Maynard et al., 2002; Mohamed et al., 2005). In addition to conventional antibodies, several investigators and commercial firms, such as Symphogen (Lyngby, Denmark), are developing polyclonal recombinant antibodies for use as broad-spectrum anti-infective therapeutics.
What Synthetic Ecosystems Are Teaching Biologists About Antibiotic Resistance and Antibiotic Drug Discovery
The study of how organisms interact with each other—and with their environment—falls under the purview of ecosystems analysis. Collins described two studies demonstrating the power of what he called “synthetic ecosystems”—
FIGURE WO-29A Antibody discovery strategies.
SOURCE: Georgiou (2011).
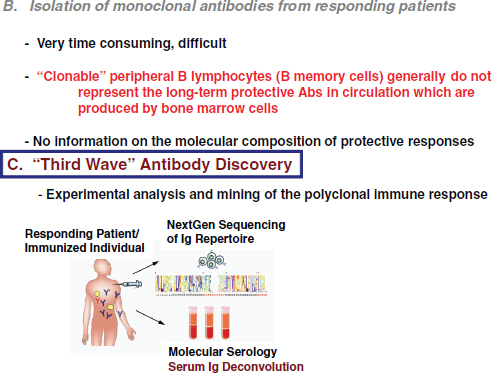
FIGURE WO-29B Isolation of monoclonal antibodies from responding patients.
SOURCE: Georgiou (2011).
engineered systems that provide for the coexistence of multiple microbes (Lee et al., 2010). Collins and his team engineered a bioreactor that allowed them to control, on a day-to-day basis, the level of antibiotic that the resident E. coli organisms were exposed to and track the evolution of resistance. They found that the large majority of bacterial cells evolve only very low-level antibiotic resistance and that the small minority of cells that do evolve high-level resistance protect their less-resistant neighbors by producing and secreting indole, a signaling molecule that turns on oxidative stress protective mechanisms. Collins referred to the highly resistant indole-producing cells as “bacterial charity workers.”
In the second synthetic ecosystem study, Collins and colleagues pitted E. coli against Candida albicans in what they viewed as a large-scale scheme of Andrew Fleming’s original “microbial wars” work. The scientists observed that E. coli always won. They investigated further and discovered that E. coli produces a small molecule that kills C. albicans. Currently, the researchers are trying to identify the molecule, with the ultimate goal of synthesizing it. Collins observed that the same synthetic ecosystem scheme could be used to pit any two microbes against each other and search for organisms that produce bactericidal molecules.
Building Synthetic Biological Diagnostic and Detection Devices
One of synthetic biology’s “early win” situations, in Paul Freemont’s opinion, was with the modification of biological systems to detect biological signals. While most classical biosensors, such as blood sugar level monitors, rely on electrochemistry—converting a concentration of a molecule into a digital display—synthetic biosensors are entirely genetically encoded. Genetically encoded biosensors are very simple devices. They typically use transcription regulators to bind to the analyte of interest, resulting in either the expression or repression of a reporter gene that codes for a particular output signal. Some biosensors utilize fluorescently-tagged proteins that respond directly to the analyte; others make use of aptamers.
Freemont and his research group have been working with genetically coded biosensors to see if they could design a biosensor capable of detecting the acyl-HSL quorum-sensing signals—discussed by Greenberg—that diffuse in and out of bacterial cells as biofilms develop. Freemont agreed with Greenberg that regulation of the gene circuit activated by acyl-HSL quorum sensing is complex, with other factors at play. Biofilm development is one of those factors and there is a clear relationship between quorum sensing and biofilm development (Kirisitis and Parsek, 2006).
Sixty percent of all hospital-associated infections are biofilms on indwelling medical devices. In fact, development of a urinary tract infection is widely considered almost inevitable for patients undergoing long-term indwelling catheterization. Freemont’s team wanted to develop a biosensor to detect P. aeruginosa biofilms on medical devices.
The synthetic biology approach taken to design the device included consideration of input (quorum sensing), sensing (what type of genetically encoded sensor would be used), output (fluorescent, luminescent, or enzymatic proteins), and the chassis (the host system). As proof-of-concept, the scientists’ initial goal was to engineer a three-stage cell-free amplification device that could detect nanomolar concentration levels of AHL and, within 3 to 6 hours, send a fluorescent signal indicating detection to an output device. The actual device would involve the LasR transcription factor binding to AHL and the LasR-AHL complex dimerizing and inducing transcription of AHL-responsive promoters. A schematic illustration of a simple biofilm biosensor is presented in Figure WO-30.
A cell-free design is essentially a biochemical mixture of the contents of the cell that has the ability to transcribe and translate a genetically encoded design into a device. Through modeling and in silico simulations, combined with in vivo testing of various parts—such as the various promoters controlled by LasR—Freemont’s team has developed two devices (“V” and “L”) for testing (MacDonald et al., 2011).
In one set of experiments, when the devices were tested on streaks of Pseudomonas aeruginosa, fluorescence production was readily observable at the tip of the devices. In another set of experiments that involved forming biofilms in 96-well plates, the devices responded differently to different strains of P. aeruginosa. These results are very exciting, Freemont remarked, because they represent the first time that an apparently effective biosensor device has progressed from the modeling stage all the way through in vivo testing. Freemont observed that, “This whole project has told us that if you get away from all the complexity and you look at the performance and the characteristics and the modeling, and you actually think of this as a device—and all you want is for it to work within certain parameters—then you can make quite a lot of progress without knowing absolutely everything about what’s going on.” The challenge now, he said, is to develop the
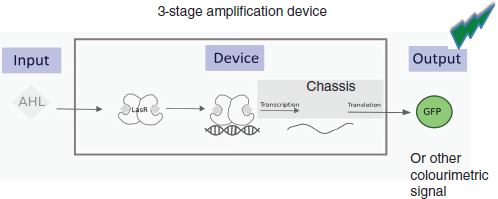
FIGURE WO-30 A simple biofilm biosensor.
SOURCE: Freemont (2011).
device into one that is cell-free and can actually detect biofilm development on catheters and other surfaces in real-world settings. That effort is ongoing.
Use of a Cell-Free Design Versus a Living Chassis
Freemont explained that the choice to use a cell-free system was based partly on a decision to stay away from the use of genetically modified organisms. Additionally, cell-free systems are simple to set up, as they have only three major components: the cell-free extract (the machinery required for transcription and translation), the premix (energy and resources required for the device to operate), and a DNA template. In terms of time, there is a lag as transcription begins, followed by a linear increase in production of the fluorescence, and ending with another lag as all of the components of the biochemical mixture are used up. Moreover, and arguably of greatest importance, cell-free systems can be very clearly defined.
Freemont remarked that “the great beauty of cell-free systems” is that they are easier to define than systems with a living organism’s entire genetic program operating in the background. Without the extra genetic coding of a host organism, cell-free systems can be built up from detailed modeling. Freemont and his research team are currently exploring the relationship between the properties of synthesized parts in cell-free systems and those same parts obtained in vivo. Freemont’s team has built a microfluidics platform for testing thousands of proteins and obtaining information on basic characteristics for each protein. It remains an open question whether this approach and the information gathered from it will be useful in the future design and construction of biological devices.
Implications of Synthetic Biology for Energy and the Environment
The potential applications for synthetic biology devices extend far beyond medicine. French’s work with whole-cell arsenic biosensors for drinking water, is just one example of the many ways that synthetic biology is being used in environmental applications (Joshi et al., 2009). Other investigators are developing similar systems for detecting other toxins (van der Meer and Belkin, 2010). In one of the earliest engineered environmental biosensors, Looger et al. (2003) designed a protein that can bind and detect TNT in soil. Future applications include engineering biosensors to detect heavy metals and other common persistent toxins in soil and water (Royal Academy of Engineering, 2009).
Scientists are also engineering microbes that can bioremediate oil spills, organic pollutants, and other environmental contaminants. For example, Hannink et al. (2001) added a modified nitroreductase (nfsI) gene from Enterobacter cloacae to tobacco plants, allowing the plant to tolerate, take up, and break down 2,4,6-trinitrotoluene (TNT). Bacterial enzymes inserted into tobacco plants demonstrated the ability of the engineered plants to remediate a range of halo-
genated organic pollutants (Mena-Benitez et al., 2008). One of the pollutants is 1,2-dichloroethane (1,2-DCA), which is used as an intermediate in the synthesis of vinyl chloride and other industrial chemicals and is listed by the U.S. Environmental Protection Agency as a priority pollutant and a probable human carcinogen. Researchers at the University of Cambridge added the gene for the enzyme pentaerythritol tetranitrate reductase (PETNR), normally found in Enterobacter cloacae, into tobacco plants, allowing the plant to break down TNT (French et al., 1999).
Building Microbial-Based Fuel Security
While there is a great deal of interesting work being done in the biotherapeutic market space, Berry suggested that the energy and fuel market, as well as other chemical product markets—including specialty chemicals, commodity chemicals, petrochemicals, agricultural chemicals, and other chemicals—completely dwarfs that sort of opportunity. Indeed, synthetic biology is providing a novel means to help address energy challenges through the design of organisms that can more efficiently manufacture biofuels and are less wasteful than the current processes used to make ethanol-based fuels (Fortman et al., 2008; French, 2009; Royal Academy of Engineering, 2009). Much of this research and development work is being sponsored and conducted by the U.S. Department of Energy and at private firms.
The market for synthesized microbial-based fuel production is driven not just by rising oil prices but also by increased consumer demand for environmentally friendly products and growing government regulations to curb greenhouse gas emissions. Berry estimated that 95 percent of the global market for petroleum and other products manufactured via chemical transformations have never been addressed biologically. He predicted a $3 trillion to $5 trillion-plus market for synthetic biology applications. Berry, a venture capitalist, estimated an additional $3 trillion-plus market for synthetic biology.
As three examples of how synthetic biology is being applied to the commercial development of nonpharmaceutical chemically-derived products, Berry mentioned Mascoma (Lebanon, New Hampshire), LS9, Inc. (south San Francisco, California), and Joule Unlimited, Inc. (Cambridge, Massachussetts). Mascoma is focused on the production of cellulosic ethanol fuels using engineered microbial organisms. Leveraging 20 years of effort to optimize a process first described in 1991, the company has used metabolic engineering techniques to develop a microbial-based system with near 90 percent efficiency (Lynd et al., 1991, 2005). According to Berry, the firm has ramped up to near-commercial scale at a demonstration plant in Rome, New York, and expects to break ground on a full commercial-scale refinery in Kinross, Michigan, soon.
While investigators have been studying the biofuel potential of ethanol since the 1970s, ethanol is not the only potential biofuel alternative. LS9 scientists have
harnessed the fatty acid biosynthesis pathway in E. coli to produce a fat molecule, with an efficiency of about 94 percent, which looks very much like diesel fuel. That molecule is then converted into diesel through subsequent processing. Additionally, LS9 is using the same system as a platform for producing other multibillion-dollar market chemicals. As Berry observed, this company has put itself in a position of basically being a biorefinery of sorts, where you can systematically make a single organism to go after different productions that leverage a common process. LS9 has ramped up production to demonstration scale at a facility in Okeechobee, Florida, and expects to break ground on a commercial plant in 2012.
A major challenge for all heterotrophic processes is the dependency of sugar as a core feedstock ingredient. The reality of this was made clear through the company’s development of LS9. LS9’s feedstock is any sugar source, which includes sugar cane, corn, cellulosics, and others. When the company was founded in 2005, the price of sugar was much lower than it is today. As a way to hedge against this sort of price fluctuation, Berry and colleagues began exploring the possibility of using CO2 as an input instead of sugar cane syrup, eliminating the need for dependency on not just a commodity but also arable land. Founded in 2007 by Flagship VentureLabs, Joule scientists have metabolically engineered a photosynthetic microbe to convert solar energy and waste CO2 into usable fuel (Robertson et al., 2011). The firm is also using the platform to produce other fuels and chemicals as well.
Joule opened a pilot plant in Leander, Texas, in 2010. According to Berry, the company expects to break ground on a commercial plant by the end of 2011. One advantage that Joule has over companies like Mascoma and LS9 is modularity26 and scalability—there is no risk involved with the scale-up of a solar panel, or reactor, as all solar panels function in the same way (as opposed to the scale-up of industrial fermenters, whose scale-up requires overcoming new chemical engineering challenges).
Synthetic Biology Meets Materials Engineering
As discussed earlier in this chapter, Chris Voigt’s work with spider silk protein-secreting Salmonella bacteria could have widescale material engineering applications. Spider silk has a similar tensile strength as steel, yet it is much lighter. By modifying the type III secretion system of Salmonella using synthetically designed genes, these investigators have essentially turned the bacterial cell into a small spider silk production factory (Widmaier et al., 2009). Large-scale production of spider silk by engineered Salmonella could lead to novel superstrong and lightweight weavable materials, which could have major implications
_______________
26 As Berry went on to state: “If you know one reactor works, you know two, or ten, or a hundred work because they are just repeats—much like the scaling of solar power. It’s not risk free, but very heavily risk mitigated. Fermenters scale in three dimensions, which do have the fundamental chemical engineering challenges.”
for the aeronautic, automotive, and other industries (Royal Academy of Engineering, 2009).
Synthetically engineered organisms could also one day produce the materials from which the next generation of aircraft, automobiles, and buildings are constructed. The 2010 iGEM team from Newcastle University developed a product called BacillaFilla (see Figure WO-31) in which an engineered B. subtilis uses quorum sensing to grow into and fill cracks in concrete and produce a mixture of calcium carbonate, levan glue, and filamentous cells that hardens and repairs the crack (Cathcart, 2011; Newcastle University 2010 iGEM Team, 2010). With further development, the product could help extend the life of concrete structures or even pave the way toward “self-healing” concrete.
While most systems and synthetic biologists who work with biofilms are seeking novel ways to treat biofilms, Lu noted that there are also some potential applications of biofilms. One of those applications is in materials engineering. Biofilm cells have evolved ways to produce very complex three-dimensional structures with unique properties (Epstein et al., 2011). Lu and his research team are exploring the possibility of capitalizing on the self-assembly mechanisms that enable biofilm cells to do what they do and leveraging the same mechanisms to produce new types of materials.
FIGURE WO-31 Cartoon describing Newcastle University 2010 iGEM team’s BacillaFilla.
SOURCE: http://2010.igem.org/Team:Newcastle.
Living Computers
Finally, the foundation is being laid for researchers to begin to develop computers made out of living cells (e.g., Baumgardner et al., 2009). While it is unlikely that biological computers would ever replace conventional computers in the near term they would certainly outperform conventional computers in certain situations, such as inside engineered cells. Cells that have been engineered to deliver a drug could be programmed to deliver doses directly to the target sites. The basic biological switches and oscillators developed over the past decade and previously discussed represent the first steps in this direction (Khalil and Collins, 2010; Royal Academy of Engineering, 2009).
CURRENT CHALLENGES IN SYNTHETIC BIOLOGY
Despite the field’s rapid development over the past decade, many of the speakers and the Forum’s members discussed what they perceived to be the many significant challenges that would need to be overcome for many of the promises of synthetic biology to become realities. Some speakers observed that significant technical hurdles such as the lack of standardization and incompatibility of bioparts must still be addressed before true “plug-and-play” engineering of biological systems can be achieved. It was also felt that a far better understanding of complex biological systems will be required before novel organisms could be designed from the bottom up. Coordination and ownership challenges might also need to be overcome in order to ensure that experiments are conducted safely and that discoveries can be built upon while still addressing intellectual property concerns. Finally, many participants discussed the legitimate ethical and regulatory concerns regarding the proprietary and potential safety issues of “designing life” that must continue to be transparently discussed and addressed by the scientific community as the field grows and evolves.
Technical and Scientific Challenges
We are still like the Wright brothers, putting pieces of wood and paper together.
—Luis Serrano (Kwok, 2010)
The field has had its hype phase. Now it needs to deliver.
—Martin Fussenegger (Kwok, 2010)
At its core, synthetic biology represents remarkable progress in the technical capacity to not just mix and match genetic material from different species but also to design and build genetic systems that do not exist in nature. Yet, arguably, it is the technical challenges more than anything else that are keeping synthetic biolo-
gists from achieving what some consider the ultimate prize: the ability to design an organism and effectively create new life. These technical challenges include:
- a lack of complete knowledge about how biological systems—from genetic circuits to whole cells to entire organisms—function,
- the inability to standardize parts and mix and match parts in different host organisms, and
- the problem of evolution (even synthetic biological systems change over time in unpredictable ways).
Bottom-up approaches in particular are far from reaching a point at which synthetic biologists will be able to build, from scratch, systems capable of doing novel things, let alone systems capable of self-replication and otherwise functioning as living organisms. Currently, the most interesting and potentially applicable synthetic biology approaches are all top down, reengineering existing organisms to perform functions that they normally would not do, such as produce a chemical precursor to an antimalarial drug, spider silk protein, or biofuels.
Does Systems Biology Trump Synthetic Biology?
Our understanding of physical laws and knowledge of material properties allow us to engineer bridges that do not collapse and car engines that convert energy into mechanical energy. Engineering biology, however, is different. Even the simplest bacterium comprises a system whose complexity is humbling.
—Fritz et al. (2010)
When asked whether systems biology trumps synthetic biology, many speakers said, “Yes.” Arguably the greatest challenge confronting the synthetic biologist is that scientists still do not understand many of the fundamental principles about how life “works.” Sauro remarked that there is a great deal of basic biological knowledge that needs to be generated before synthetic biology can create the “wow” results that are expected of it. The complexity of even basic cellular physiology is far beyond that of a circuit board or a transistor and there are few such physiological processes that biologists fully comprehend. It is not enough to understand the actual molecular parts that they are manipulating; synthetic biologists must also appreciate how those parts operate within the context of the host cell. In effect, synthetic biologists are trying to engineer life without knowing all the ground rules. As a result, despite efforts to develop the best possible predictive models, there is still a high degree of trial and error required to get synthesized biological parts to work together to form functioning circuits. As systems biology advances and scientists gain a better understanding of how the parts of a cell or other biological system interact, synthetic biology will become more predictive—and easier.
The Challenge of Standardization
“The beauty of synthetic biology,” Freemont observed, “is that it’s modular.” Others agreed. Voigt remarked that the vision for the future is to advance the design of large genetic systems to a point where it might be possible to simply “pop in” modules for various functions. Freemont discussed his research team’s ongoing efforts to construct a biosensor device that can detect the formation of Pseudomonas aeruginosa biofilms on indwelling catheters before the infections develop into full-blown urinary tract infections. The device that he and his colleagues have built—that his students refer to as the “infector detector”—can potentially be modularized with different inputs creating different outputs.
Another challenge facing synthetic biologists is that there is still a lack of standardized, well-characterized, and interoperable biological parts. The BioBricks® Foundation and the Registry of Standard Biological Parts are making progress in developing a common toolbox of biological components for synthetic biologists to use. Yet, the functions and properties of most parts remain poorly defined (Kelly et al., 2009). Sauro observed that biological parts in general (not necessarily BioBricks®) are poorly characterized, as the tradition of characterizing biological components has been losing ground to the use of high-throughput methods for collecting large quantities of data.
Part of the problem, Sauro observed, is that synthetic biologists rarely reported exactly what they did in their experiments, making the experimental results difficult for others to replicate. In particular, exact DNA sequences are often omitted from published papers (Peccoud et al., 2011). Moreover, synthetic biologists’ ability to make quantitative measurements is still relatively crude. This is especially true of high-resolution, system-wide, measurements.
Without a robust toolbox of standardized parts that function in a predictable and reliable manner, synthetic biologists are forced to design biological circuits ad hoc, limiting how complex their designed circuits and systems can be (Kwok, 2010). As Sauro observed, poor standardization also limits what can be done with new knowledge gained through synthetic biology experimentation. Improved standardization would allow researchers to electronically exchange designs and replicate experiments, send designs to “bio-fabrication centers” for assembly, and store designs in repositories and for publication purposes. Sauro pointed to the Synthetic Biology Open Language (www.sbolstandard.org), a platform for exchanging data among different software applications and connecting different types of synthetic biology information (e.g., modeling results, experimental results, biological parts data), as an example of an initiative aimed at providing standardization.
Despite the challenge of standardization, many researchers nonetheless are using BioBricks® in their research (Shetty et al., 2008). Acknowledging “serious quality control issues” with the Registry of Standard Biological Parts, French stated that he was a “fan” of BioBricks®. Without knowing how a biological
system works, one can use parallel combinatorial methods to assemble multiple combinations of parts and see which parts and combinations work(s), eliminating much of the unpredictability associated with the design process. BioBricks® also serve as the raw material for iGEM, an annual synthetic biology competition for students (see Box WO-2).
BOX WO-2
The International Genetically Engineered Machine Competition

The iGEM competition resembles a giant science fair for budding synthetic biologists. iGEM is a global synthetic biology competition involving mostly undergraduate students, although participants range from high school students to world experts in the field. At the heart of the competition is the BioBricks® standard, a format for interchangeable, composable DNA parts. Several months before the actual competition, competing teams receive a kit of DNA parts. Working at their own schools over a summer, teams design and build synthetic systems that operate in living cells. Examples of recent projects include an arsenic biosensor, wintergreen-scented bacteria, and color-coded microbes. Chris French remarked that, because students are unfettered by considerations of practicality or feasibility, they tend to come up with very interesting ideas. For example, in 2005, competitors developed a bacterial photography system (Levskaya et al., 2005); and in 2006, one group engineered a strain of E. coli that generated the aroma of bananas during the exponential growth phase and oil of wintergreen during the stationary phase. All of the parts used in the student projects are components that have been deposited in the Registry of Standard Biological Parts (http://partsregistry.org). The whole-cell biosensor for the detection of arsenic in groundwater that French described (see text) was a 2006 iGEM project. Beyond building biological systems, the broader goals of iGEM include growing and supporting a community of science guided by social norms.
——————
SOURCE: Image from The International Genetically Engineered Machine Competition (http://ung.igem.org/wiki/images/d/de/IGEM_basic_Logo_stylized.png); text from Presidential Commission for the Study of Bioethical Issues (2010).
The Challenge of the Robust Chassis
As with the parts, there is no standard chassis. In the context of synthetic biology, the chassis refers to the cell or organism onto which an engineered DNA construct or part is embedded in order to produce the desired device or system (Royal Academy of Engineering, 2009). Synthetic biologists typically insert their engineered circuits into Escherichia coli, but they also use Bacillus subtilis, Saccharomyces spp., and other microbial species. The lack of a standard chassis has presented a problem for those investigators seeking to develop a standardized set of biological parts since parts that work in one cellular environment may not work in another (Kwok, 2010).
The current effort among top-down synthetic biologists to create a minimal cell by stripping a simple bacterium down to only those parts required for basic survival represents an attempt to develop a standard model organism (Glass et al., 2006). It is critical that any engineered DNA or other component that is inserted into an organism not interfere with the normal metabolic processes of the organism (Royal Academy of Engineering, 2009). A major challenge with engineering a synthetic pathway inside a living cell is managing depletion of the metabolite serving as the source of the engineered reaction(s). Westerhoff explained that depletion of a metabolite jeopardizes cell function and, eventually, the cell will die. Another major challenge is the likelihood that a change in metabolite concentration will elicit a homeostatic response in the host cells that shuts down the engineered system. Building a robust chassis means building a chassis that is buffered against otherwise noticeable fluctuations in metabolite concentration.
When testing new parts in new chassis, Sauro emphasized the importance of allowing the engineered system enough time to reach a steady state. He described an experiment that he and his colleagues conducted with what he described as a “very, very simple experiment,” that is, a GFP attached to a lac-inducible promoter which will synthesize GFP when lactose is present and is being metabolized. When the rate of GFP synthesis was plotted over time, it demonstrated an exponential increase in production followed by a sharp plateau and then a downward plunge over the course of several hours. The investigators are still not sure why GFP synthesis collapsed so quickly. However, when they extended the experiment out to 16 hours, the system actually reached a steady state of production, remaining in the exponential phase. Sauro remarked that most synthetic biology experiments are conducted over a very short time period and emphasized the need to extend experiments over longer time periods. Sauro also emphasized the importance of considering the media in which host cells are grown. For example, the growth curve of E. coli is very different in different nutrient media. He surmised that cells undergo morphological changes in the presence of difference amino acids, which can affect the results of synthetic biology experiments.
What Does the Future Hold: Coordination, Growth, and Ownership Challenges
Given that an estimated $7 trillion is spent every year on biomedical research worldwide, Hans Westerhoff emphasized the urgency of developing worldwide platforms—and standards—for combining and coordinating efforts not just within synthetic and systems biology but across all areas of biomedical research. He described a European Union initiative to link all of the various and currently disjointed in silico human research programs, most of which currently are focused on single organ systems (e.g., Noble, 2008; Thomas, 2009), and construct an in silico human (the “virtual physiological human”; see www.vph-noe.ed) similar in concept to the in silico trypanosome that he and his colleagues are constructing (Bakker et al., 2010; Kohl and Noble, 2009). Both projects seek to create web-interfaced, experiment-based mathematical models of the physiologies of their respective organisms, providing a means for collaborative investigation and quantitative prediction. Bakker et al. (2010) predict that the modeling enabled by a “silicon trypanosome” will provide investigators with a way to identify the most suitable targets for developing novel antiparasitic drugs.
As a nascent and cutting-edge field, there is significant interest among both professional and amateur scientists alike in the developments of synthetic biology. As information about how to work with DNA has proliferated on the Internet and the cost of obtaining a basic DNA synthesis machine has dropped from hundreds of thousands of dollars to less than one thousand dollars on eBay®, a growing movement of “backyard,” amateur scientists has emerged who are conducting synthetic biology experiments. These so-called do-it-yourself (DIY) biologists operate outside of the infrastructure and constraints of traditional research institutions and without the support of large-scale grants. They are often compared to the early computer hackers who assembled the first home computers in their backyard garages.
However, because these “biohackers” are working with living organisms that could escape into the environment, there has been a significant debate within the traditional scientific community about whether to embrace or constrain the DIY biology movement. Some see it as a positive force that is helping to attract new scientists who could push the envelope of innovation. Others fear the risk of accidental release or the intentional creation of agents of bioterrorism should the DIY biology movement—practiced by individuals who lack formal scientific training and work in makeshift facilities—become further enabled to conduct synthetic biology experiments and more knowledgeable (Feuer, 2010). What is clear is that this movement, and others involving nontraditional life scientists, is not going away and the regulatory and organizational challenges they present must be addressed.
The iGEM competition, described earlier, is one way that the scientific community has responded to this challenge. By providing a curated community in which budding synthetic biologists from a variety of backgrounds can work to-
gether to develop innovative projects, iGEM encourages innovation and engagement while promoting laboratory standards and best practices. iGEM even helps link members up with online courses about synthetic biology to encourage ongoing study and learning (iGEM, 2011). Indeed, iGEM, the Registry of Standard Biological Parts and the BioBricks® Foundation are at the forefront of the kind of open-source science that many synthetic biologists argue is the best way to encourage innovation and progress in the field. The open source model of science promoted and embraced by many working in synthetic biology does, however, present some challenges, particularly in terms of intellectual property rights.
Given the wide array of sectors that synthetic biology could influence, and the potentially significant wealth that its research findings could generate, many of this workshop’s participants felt that it was important for the community to address the issue of intellectual property more rigorously. The challenge before the scientific and regulatory communities is to strike the appropriate balance between allowing researchers to benefit from their discoveries while simultaneously encouraging an environment of information sharing so that accomplishments can be built upon.
Regulatory Challenges
The novel technologies and innovative approaches being developed and used by synthetic biologists represent new ground for the regulatory agencies. The concern is exacerbated by the reality that the United States is entering a more austere budgetary climate, with doubts about whether expected increases in the Food and Drug Administration budget, including increased investments in regulatory science, will actually happen. The concern is especially great for large-scale multiplex profiling devices, or systems, given the difficulties regulators have had in the past with other (non-synthetic) multiplex assays (e.g., companion diagnostics to guide therapeutic decisions, and cancer diagnostics). Forum member George Poste observed that, “I have great concerns as to whether there is going to be both the resource availability as well as the intellectual agility needed to deal with some of these issues.”
From the beginning—just a mere decade ago—scientists have openly discussed how the synthetic biology community should regulate itself and whether there should be limits placed on the type of research conducted (Cho and Relman, 2010; Church, 2005). Some organizations have proposed recommendations for self-governance in an effort to proactively address the issues raised by these activities (Garfinkel et al., 2007). Indeed, the scientific literature, as well as the National Academies and other research institutions, has considered the potential risks of the “dark side” of synthetic biology and the technologies that it employs (Choffnes et al., 2006; Fraser and Dando, 2001; IOM/NRC, 2006; Parliamentary Office of Science and Technology, 2008; Relman et al., 2006; Royal Academy of Engineering, 2009). In order to improve the regulatory climate, Poste suggested
that the scientific community develop its own robust and rigorous standardization protocols. Others agreed and emphasized the need for early dialogue between scientists and regulatory authorities in order to get a better sense of what type of information regulators will need to interpret synthetic (and systems) biology data. The National Academy of Engineering hosted a workshop on how engineering ethics might contribute to the development of synthetic biology (Hollander, 2010).
The Presidential Commission for the Study of Bioethical Issues did not recommend that any immediate regulations or oversight be placed on synthetic biology research, noting that the field was still in its infancy and the potential benefits of the research outweighed the potential risks. Rather, it recommended that the government adopt a strategy of “prudent vigilance” by encouraging innovative research while proactively monitoring risks and updating regulations as necessary (Kaiser, 2010; Presidential Commission for the Study of Bioethical Issues, 2010).
Just as gene splicing sparked a global ethical and regulatory debate in the 1970s, the ability to manipulate living systems and the potential to create new life forms pose significant ethical and regulatory challenges as well. In the case of synthetic biology, the call for collaboration is not just a matter of combining and coordinating efforts among scientists in order to accelerate the generation of knowledge; it is also a matter of safety.
Agarwal, K. L., H. Büchi, M. H. Caruthers, N. Gupta, H. G. Khorana, K. Kleppe, A. Kumar, E. Ohtsuka, U. L. Rajbhandary, J. H. van de Sande, V. Sgaramella, H. Weber, and T. Yamada. 1974. Total synthesis of the gene for an alanine transfer ribonucleic acid from yeast. Nature 227:27-34.
Ajikumar, P. K., W. Xiao, K. E. J. Tyo, Y. Wang, F. Simeon, E. Leonard, O. Mucha, T. H. Phon, B. Pfeifer, and G. Stephanopoulos. 2010. Isoprenoid pathway optimization for Taxol precursor overproduction in Escherichia coli. Science 330:70-74.
Aloy, P., and R. B. Russell. 2005. Structure-based systems biology: A zoom lens for the cell. FEBS Letters 579(8):1854-1858.
Alper, H., and G. Stephanopoulos. 2009. Engineering for biofuels: Exploiting innate microbial capacity or importing biosynthetic potential? Nature Reviews Microbiology 7:715-723.
Andrianantoandro, E., S. Basu, D. K. Karig, and R. Weiss. 2006. Synthetic biology: New engineering rules for an emerging discipline. Molecular Systems Biology 2:2006.0028
Anthony, J. R., L. C. Anthony, F. Nowroozi, G. Kwon, J. D. Newman, and J. D. Keasling. 2009. Optimization of the mevalonate-based isoprenoid biosynthetic pathway in Escherichia coli for production of the anti-malarial drug precursor amorpha-4,11-diene. Metabolic Engineering 11:13-19.
Apic, G., T. Ignjatovic, S. Boyer, and R. B. Russell. 2005. Illuminating drug discovery with biological pathways. FEBS Letters 579(8):1872-1877.
Atkins, J. F., R. F. Gesteland, and T. R. Cech. 2011. RNA Worlds: From Life’s Origins to Diversity in Gene Regulation. Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press.
Atkinson, M. R., M. A. Savageau, J. T. Myers, and A. J. Ninfa. 2003. Development of genetic circuitry exhibiting toggle switch or oscillatory behavior in Escherichia coli. Cell 113(5):597-607.
Bakker, B. M., R. L. Krauth-Siegel, C. Clayton, K. Matthews, M. Girolami, H. V. Westerhoff, P. A. M. Michels, R. Breitling, and M. P. Barrett. 2010. The silicon trypanosome. Parasitology 137:1333-1341.
Banin, E., M. L. Vasil, and E. P. Greenberg. 2005. Iron and Pseudomonas aeruginosa biofilm formation. Proceedings of the National Academy of Sciences of the United States of America 102:11076-11081.
Banin, E., A. Lozinski, K. M. Brady, E. Berenshtein, P. W. Butterfield, M. Moshe, M. Chevion, E. P. Greenberg, and E. Banin. 2008. The potential of desferrioxamine-gallium as an anti-Pseudomonas therapeutic agent. Proceedings of the National Academy of Sciences of the United States of America 105(43):16761-16766.
Barry, M. A., W. C. Lai, and S. A. Johnston. 1995. Protection against mycoplasma infection using expression-library immunization. Nature 377:632-635.
Baumgardner, J., K. Acker, O. Adefuye, S. T. Crowley, W. DeLoache, J. O. Dickson, L. Heard, A. T. Martens, N. Morton, M. Ritter, A. Shoecraft, J. Treece, M. Unzicker, A. Valencia, M. Waters, A. M. Campbell, L. J. Heyer, J. L. Poet, and T. T. Eckdahl. 2009. Solving a Hamiltonian path problem with a bacterial computer. Journal of Biological Engineering 3:11.
Bedau, M., G. Church, S. Rasmussen, A. Caplan, S. Benner, M. Fussenegger, J. Collins, and D. Deamer. 2010. Life after the synthetic cell. Nature 465(7297):422-424.
Benders, G. A., V. N. Noskov, E. A. Denisova, C. Lartigue, D. G. Gibson, N. Assad-Garcia, R. Y. Chuang, W. Carrera, M. Moodie, M. A. Algire, Q. Phan, N. Alperovich, S. Vashee, C. Merryman, J. C. Venter, H. O. Smith, J. I. Glass, and C. A. Hutchison. 2010. Cloning whole bacterial genomes in yeast. Nucleic Acids Research 38(8):2558-2569.
Benner, S. A., and A. M. Sismour. 2005. Synthetic biology. Nature Reviews Genetics 6(7):533-543.
Bollmann, A., K. Lewis, and S. S. Epstein. 2007. Incubation of environmental samples in a diffusion chamber increases the diversity of recovered isolates. Applied and Environmental Microbiology 73(20):6386-6390.
Borovkov, A., D. M. Magee, A. Loskutov, J. A. Cano, C. Selinsky, J. Zsemlye, C. R. Lyons, and K. Sykes. 2009. New classes of orthopoxvirus vaccine candidates by functionally screening a synthetic library for protective antigens. Virology 395(1):97-113.
Canton, B., A. Labno, and D. Endy. 2008. Refinement and standarization of synthetic biological parts and devices. Nature Biotechnology 26(7):787-793.
Carlson, R. 2010. The context of current practices in synthetic biology. Paper read at Meeting of the Presidential Commission for the Study of Bioethical Issues, July 8-9, 2010, Washington, DC.
Cathcart, R. B. 2011. Anthropoic rock: A brief history. History of Geo- and Space Sciences 2:57-74. doi:10.5194/hgss-2-57-2011.
Cello, J., A. V. Paul, and E. Wimmer. 2002. Chemical synthesis of poliovirus cDNA: Generation of infectious virus in the absence of natural template. Science 297(5583):1016-1018.
Chandran, D., F. T. Bergmann, and H. M. Sauro. 2009. TinkerCell: Modular CAD tool for synthetic biology. Journal of Biological Engineering 3:19, doi:10.1186/1754-1611-3-19.
Chang, M. C. Y., R. A. Eachus, W. Trieu, D. Ro, and J. D. Keasling. 2007. Engineering Escherichia coli for production of functionalized terpenoids using plant P450s. Nature Chemical Biology 3:274-277.
Chen, K., and F. H. Arnold. 1993. Tuning the activity of an enzyme for unusual environments: Sequential random mutagenesis of subtilisin E for catalysis in dimethylformamide. Proceedings of the National Academy of Sciences 90(12): 5618-5622.
Cheng, L. K. L., and P. J. Unrau. 2010. Closing the circle: Replicating RNA with RNA. Cold Spring Harbor Perspectives in Biology 2:a002204.
Cho, B. K., K. Zengler, Y. Qiu, Y. S. Park, E. M. Knight, C. L. Barrett, Y. Gao, and B. Ø. Palsson. 2009. The transcription unit architecture of the Escherichia coli genome. Nature Biotechnology 27:1043-1049.
Cho, M. C., and D. A. Relman. 2010. Synthetic “life,” ethics, national security, and the nature of public discourse. Science 329:38-39.
Choffnes, E. R., S. M. Lemon, and D. A. Relman. 2006. A brave new world in the life sciences: The breadth of biological threats is much broader than commonly thought and will continue to expand. Bulletin of the Atomic Scientists September/October 2006:26-33.
Church, G. 2005. Let us go forth and safely multiply. Nature 438(24 November 2005):423.
Costantino, N., and D. L. Court. 2003. Enhanced levels of λ Red-mediated recombinants in mismatch repair mutants. Proceedings of the National Academy of Sciences of the United States of America 100(26):15748-15753.
Costerton, J. W., P. S. Stewart, and E. P. Greenberg. 1999. Bacterial biofilms: A common cause of persistent infections. Science 284:1318-1322.
Crameri, A., S. A. Raillard, E. Bermudez, and W. P. C. Stemmer. 1998. DNA shuffling of a family of genes from diverse species accelerates directed evolution. Nature 391:288-291.
Dantas, G., M. O. Sommer, R. D. Oluwasegun, and G. M. Church. 2008. Bacteria subsisting on antibiotics. Science 320(5872):100-103.
Darwin, C. 1859. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life. London, United Kingdom.
de Mora, K., N. Joshi, B. L. Balint, F. B. Ward, A. Elfick, and C. E. French. 2011. A pH-based biosensor for detection of arsenic in drinking water. Analytical and Bioanalytical Chemistry 400(4):1031-1039.
DeGrado, W. F. 2003. Computational biology: Biosensor design. Nature 423(6936):132-133.
di Bernardo, D., M. J. Thompson, T. S. Gardner, S. E. Chobot, E. L. Eastwook, A. P. Wojtovich, S. J. Elliott, S. E. Schaus, and J. J. Collins. 2005. Chemogenomic profiling on a genome-wide scale using reverse-engineered gene networks. Nature Biotechnology 23(3):377-383.
Diehnelt, C. S., M. Shah, N. Gupta, P. E. Belcher, M. P. Greving, P. Stafford, and S. A. Johnston. 2010. Discovery of high-affinity protein binding ligands—backwards. PLoS ONE 5(5):e10728. doi:10.1371/journal.pone.0010728.
Dietrich, J. A., A. E. McKee, and J. D. Keasling. 2010. High-throughput metabolic engineering: Advances in small-molecule screening and selection. Annual Review of Biochemistry 79:563-590.
D’Onofrio, A., J. M. Crawford, E. J. Stewart, K. Witt, E. Gavrish, S. Epstein, J. Clardy, and K. Lewis. 2010. Siderophores from neighboring organisms promote the growth of uncultured bacteria. Chemistry & Biology 17(3):254-264.
Dorr, T., K. Lewis, and M. Vulic. 2009. SOS response induces persistence to fluoroquinolones in Escherichia coli. PLoS Genet 5:e1000760.
Dorr, T., M. Vulić, and K. Lewis. 2010. Ciprofloxacin causes persister formation by inducing the TisB toxin in Escherichia coli. PLoS Biol 8(2): e1000317.
Dougherty, M. J., and F. H. Arnold. 2009. Directed evolution: New parts and optimized function. Current Opinion in Biotechnology 20(4):486-491.
Dueber, J. E., G. C. Wu, G. R. Malmirchegini, T. S. Moon, C. J. Petzold, A. V. Ullal, K. L. J. Prather, and J. D. Keasling. 2009. Synthetic protein scaffolds provide modular control over metabolic flux. Nature Biotechnology 27:753-759.
Dwyer, D. J., M. A. Kohanski, B. Hayete, and J. J. Collins. 2007. Gyrase inhibitors induce an oxidative damage cellular death pathway in Escherichia coli. Molecular Systems Biology 3:91. 10.1038/msb4100135.
Dwyer, M. A., L. L. Looger, and H. W. Hellinga. 2003. Computational design of a Zn2+ receptor that controls bacterial gene expression. Proceedings of the National Academy of Sciences of the United States of America 100(20):11255-11260.
Edwards, J. S., and B. Ø. Palsson. 1999. Systems properties of the Haemophilus influensae Rd metabolic genotype. Journal of Biological Chemistry 274:17410-17416.
Ellington, A. 2011. Synthetic Biology and Biodefense. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and systems biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Elowitz, M. B., and S. Leibler. 2000. A synthetic oscillatory network of transcriptional regulators. Nature 403(6767):335-338.
Epstein, A. K., B. Pokroy, A. Seminara, and J. Aizenberg. 2011. Bacterial biofilm shows persistent resistance to liquid wetting and gas penetration. Proceedings of the National Academy of Sciences of the United States of America 108(3):995-1000.
Feist, A. M., M. J. Herrgård, I. Thiele, J. L. Reed, and B. Ø. Palsson. 2009. Reconstruction of biochemical networks in microorganisms. Nature Reviews Microbiology 7:129-143.
Ferrer-Costa, C., M. Orozco, and X. de la Cruz. 2005. Use of bioinformatics tools for the annotation of disease-associated mutations in animal models. Protein Science 61(4):878-887.
Feuer, J. 2010. Outlaw biology. http://magazine.ucla.edu/features/outlaw_biology/ (accessed January 17, 2011).
Fischbach, M., and C. A. Voigt. 2010. Prokaryotic gene clusters: A rich toolbox for synthetic biology. Journal of Biotechnology 5:1277-1296.
Forster, A. C., and G. M. Church. 2010. Synthetic biology projects in vitro. Genome Res 17:1-6.
Fortman, J., S. Chhabra, A. Mukhopadhyay, H. Chou, T. Lee, E. Steen, and J. Keasling. 2008. Biofuel alternatives to ethanol: Pumping the microbial well. Trends in Biotechnology 26(7):375-381.
Fraser, C. M., and M. R. Dando. 2001. Genomics and the future biological weapons: The need for preventive action by the biomedical community. Nature Genetics 29:253-256.
Freemont, P. 2011. Developing a synthetic biology device that detects biofilm formation on indwelling catheters. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
French, C. E. 2009. Synthetic biology and biomass conversion: A match made in heaven? Journal of the Royal Society, Interface 6(Suppl. 4):S547-S558.
French, C. E., S. J. Rosser, G. J. Davies, S. Nicklin, and N. C. Bruce. 1999. Biodegradation of explosives by transgenic plants expressing pentaerythritol tetranitrate reductase. Nature Biotechnology 17(5):491-494.
Fritz, B. R., L. E. Timmerman, N. M. Daringer, J. N. Leonard, and M. C. Jewett. 2010. Biology by design: From top to bottom and back. Journal of Biomedicine and Biotechnology 2010:232016.
Fuqua, W. C., and E. P. Greenberg. 2002. Listening in on bacteria: Acyl-homoserine lactone signalling. Nature Reviews Molecular Cell Biology 3:685-695.
Fuqua, W. C., S. C. Winans, and E. P. Greenberg. 1994. Quorum sensing in bacteria: The LuxR-LuxI family of cell density-responsive transcriptional regulators. Journal of Bacteriology 176:269-275.
Gardner, T. S., C. R. Cantor, and J. J. Collins. 2000. Construction of a genetic toggle switch in Escherichia coli. Nature 403(6767):339-342.
Garfinkel, M. S., D. Endy, G. L. Epstein, and R. M. Friedman. 2007. Synthetic Genomics: Options for Governance. Rockville, MD: J. Craig Venter Institute.
Gavrish, E., A. Bollmann, S. Epstein, and K. Lewis. 2008. A trap for in situ cultivation of filamentous actinobacteria. Journal of Microbiological Methods 72:257-262.
Georgiou, G. 2011. Protein engineering and high throughput immune function analyses for the discovery of the next generation of protein therapeutics. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Gibson, D. G., G. A. Benders, C. Andrews-Pfannkoch, E. A. Denisova, H. Baden-Tillson, J. Zaverti, T. B. Stockwell, A. Brownley, D. W. Thomas, M. A. Algire, C. Merryman, L. Young, V. N. Noskov, J. I. Glass, J. C. Venter, C. A. Hutchison, and H. O. Smith. 2008. Complete chemical synthesis, assembly, and cloning of a Mycloplasma genitalium genome. Science 319:1215-1220.
Gibson, D. G., L. Young, R. Chuang, J. C. Venter, C. A. Hutchison, and H. O. Smith. 2009. Enzymatic assembly of DNA molecules up to several hundred kilobases. Nature Methods 6:343-345.
Gibson, D. G., J. I. Glass, C. Lartigue, V. N. Noskov, R. Chuang, M. A. Algire, G. A. Benders, M. G. Montague, L. Ma, M. M. Moodie, C. Merryman, S. Vashee, R. Krishnakumar, N. Assad-Garcia, C. Andrews-Pfannkoch, E. A. Denisova, L. Young, Z. Qi, T. H. Segall-Shapiro, C. H. Calvey, P. P. Parmar, C. A. Hutchison, H. O. Smith, and J. C. Venter. 2010. Creation of a bacterial cell controlled by a chemically synthesized genome. Science 329:52-56.
Glass, J. I., N. Assad-Garcia, N. Alperovich, S. Yooseph, M. R. Lewis, M. Maruf, C. A. Hutchison, H. O. Smith, and J. C. Venter. 2006. Essential genes of a minimal bacterium. Proceedings of the National Academy of Sciences of the United States of America 103(2):425-430.
Goldbeter, A. 2004. Computational biology: A propagating wave of interest. Current Biology 14: R601-R602.
Goler, J. A., B. W. Bramlett, and J. Peccoud. 2008. Genetic design: Rising above the sequence. Trends in Biotechnology 26:538-544.
Greving, M. P., P. E. Belcher, C. W. Diehnelt, M. J. Gonzalez-Moa, J. Emergy, J. Fu, S. A. Johnston, and N. W. Woodbury. 2010. Thermodynamic additivity of sequence variations: An algorithm for creating high affinity peptides without large libraries or structural information. PLoS ONE 5(11):e15432, doi:10.1371/journal.pone.0015432.
Gulati, S., V. Rouilly, X. Niu, J. Chappell, R. I. Kitney, J. B. Edel, P. S. Freemont, and A. J. deMello. 2009. Opportunities for microfluidic technologies in synthetic biology. Journal of the Royal Society Interface 6(Suppl 4):S493-S506.
Hancock, R. E. W. 2007. The complexities of antibiotic action. Molecular Systems Biology 3:142. doi:10.1038/msb4100184.
Hannink, N., S. J. Rosser, C. E. French, A. Basran, J. A. Murray, S. Nicklin, and N. C. Bruce. 2001. Phytodetoxification of TNT by transgenic plants expressing a bacterial nitroreductase. Nature Biotechnology 19(12):1168-1171.
Heath, J. 2011. Dynamics of clonal evolution: Immune system on a chip. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Heath, J. R., M. E. Davis, and L. Hood. 2009. Nanomedicine targets cancer. Scientific American February 2009:44-51.
Henry, C. S., M. DeJongh, A. A. Best, P. M. Frybarger, B. Lindsay, and R. L. Stevens. 2010. High-throughput generation, optimization and analysis of genome-scale metabolic models. Nature Biotechnology 28(9):977-982.
Herrgård, M. J., N. Swainston, P. Dobson, W. B. Dunn, K. Y. Arga, M. Arvas, N. Büthgen, S. Borger, R. Costenoble, M. Heinemann, M. Hucka, N. L. Novère, P. Li, W. Liebermeister, M. L. Mo, A. P. Oliveira, D. Petranovic, S. Pettifer, E. Simeonidis, K. Smallbone, I. Spasié, D. Weichart, R. Brent, D. S. Broomhead, H. V. Westerhoff, B. Kürdar, M. Penttilä, E. Klipp, B. Ø. Palsson, U. Sauer, S. G. Oliver, P. Mendes, J. Nielsen, and D. B. Kell. 2008. A consensus yeast metabolic network reconstruction obtained from a community approach to systems biology. Nature Biotechnology 26:1155-1160.
Hollander, R. D. 2010. Workshop notes on synthetic biology and engineering ethics. http://www.onlineethics.org/Topics/EmergingTech/TechEdu/SynBioWorkshop.aspx (accessed February 18, 2011).
Hood, L., J. R. Heath, M. E. Phelps, and B. Lin. 2004. Systems biology and new technologies enable predictive and preventative medicine. Science 306(5696):640-643.
Hutchison, C. 2011. Synthesis and installation of genomes. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
iGEM (International Genetically Engineered Machine competition). 2009. University of Cambridge. http://2009.igem.org/Team:Cambridge (accessed July 20, 2011).
——. 2011. Igem: Synthetic biology based on standard parts. http://ung.igem.org/Main_Page (accessed February 11, 2011.
IOM (Institute of Medicine). 2010. Antibiotic Resistance: Implications for Global Health and Novel Intervention Strategies. Washington, DC: The National Academies Press.
——. 2011. The Causes and Impacts of Neglected Tropical and Zoonotic Diseases: Opportunities for Integrated Intervention Strategies. Washington, DC: The National Academies Press.
IOM/NRC (Institute of Medicine and National Research Council). 2006. Globalization, Biosecurity, and Future of the Life Sciences. Washington, DC: The National Academies Press.
Joshi, N., X. Wang, L. Montgomery, A. Elfick, and C. E. French. 2009. Novel approaches to biosensors for detection of arsenic in drinking water. Desalination 248:517-523.
Joyce, G. F. 1994. Foreword. In Origins of Life: The Central Concepts, edited by D. W. Deamer and G. R. Fleischacker. Boston: Jones and Bartlett. Pp. xi–xii.
——. 2002. The antiquity of RNA-based evolution. Nature 418:214-221.
——. 2011. Synthetic biology “from scratch.” Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Jung, S. T., S. T. Reddy, T. H. Kang, M. J. Borrok, I. Sandlie, P. W. Tucker, and G. Georgiou. 2010. Aglycosylated IgG variants expressed in bacteria that selectively bind FcγRI potentiate tumor cell killing by monocyte-dendritic cells. Proceedings of the National Academy of Sciences of the United States of America 107(2):604-609.
Kaeberlein, T., K. Lewis, and S. S. Epstein. 2002. Isolating “uncultivable” microorganisms in pure culture in a simulated natural environment. Science 296:1127-1129.
Kaiser, J. 2010. Oversight but no strict rules for synthetic biology. Science 330:1166.
Kang, H., L. D. Sun, C. M. Atkins, T. R. Soderling, M. A. Wilson, and S. Tonegawa. 2001. An important role of neural activity-dependent CaMKIV signaling in the consolidation of long-term memory. Cell 106(6):771-783.
Keasling, J. D. 2010. Manufacturing molecules through metabolic engineering. Science 330: 1355-1358.
Kelly, J. R., A. J. Rubin, J. H. Davis, C. M. Ajo-Franklin, J. Cumbers, M. J. Czar, K. de Mora, A. L. Glieberman, D. D. Monie, and D. Endy. 2009. Measuring the activity of BioBrick promoters using an in vivo reference standard. Journal of Biological Engineering 3:4.
Khalil, A. S., and J. J. Collins. 2010. Synthetic biology: Applications come of age. Nature Reviews Genetics 11(5):367-379.
Kim, D. E., and G. F. Joyce. 2004. Cross-catalytic replication of an RNA ligase ribozyme. Chemistry & Biology 11(11):1505-1512.
Kirisitis, M. J., and M. R. Parsek. 2006. Does Pseudomonas aeruginosa use intercellular signalling to build biofilm communities? Cellular Microbiology 8(12):1841-1849.
Kirschner, M. W. 2005. The meaning of systems biology. Cell 121:503-504.
Kobayashi, H., M. Kærn, M. Araki, K. Chung, T. S. Gardner, C. R. Cantor, and J. J. Collins. 2004. Programmable cells: Interfacing natural and engineered gene networks. Proceedings of the National Academy of Sciences of the United States of America 101(22):8414-8419.
Kodumal, S. J., K. G. Patel, R. Reid, H. G. Menzella, M. Welch, and D. V. Santi. 2004. Total synthesis of long DNA sequences: Synthesis of a contiguous 32-kb polyketide synthase gene cluster. Proceedings of the National Academy of Sciences of the United States of America 101(44):15573-15578.
Kohanski, M. A., D. J. Dwyer, B. Hayete, C. A. Lawrence, and J. J. Collins. 2007. A common mechanism of cellular death induced by bactericidal antibiotics. Cell 130(5):797-810.
Kohanski, M., D. J. Dwyer, J. Wierzbowski, G. Cottarel, and J. J. Collins. 2008. Mistranslation of membrane proteins and two-component system activation trigger aminoglycoside-mediated oxidative stress and cell death. Cell 135(4):679-690.
Kohanski, M. A., D. J. Dwyer, and J. J. Collins. 2010a. How antibiotics kill bacteria: From targets to networks. Nature Reviews Microbiology 8(6):423-435.
Kohanski, M. A., M. A. DePristo, and J. J. Collins. 2010b. Sub-lethal antibiotic treatment leads to multidrug resistance via radical-induced mutagenesis. Molecular Cell 37(3):311-320.
Kohl, P., and D. Noble. 2009. Systems biology and the virtual physiological human. Molecular Systems Biology 5:292.
Kosuri, S., N. Eroshenko, E. M. Leproust, M. Super, J. Way, J. B. Li, and G. M. Church. 2010. Scalable gene synthesis by selective amplification of DNA pools from high-fidelity microchips. Nature Biotechnology 28(12):1295-1299.
Kubori, T., A. Sukhan, S. I. Aizawa, and J. E. Galán. 2000. Molecular characterization and assembly of the needle complex of the Salmonella typhimurium type III protein secretion system. Proceedings of the National Academy of Sciences of the United States of America 97(18):10225-10230.
Kwok, R. 2010. Five hard truths for syntheic biology. Nature 463:288-290.
Kwong, G. A., C. G. Radu, K. Hwang, C. J. Shu, C. Ma, R. C. Koya, B. Comin-Anduix, S. R. Hadrup, R. C. Bailey, O. N. Witte, T. N. Schumacher, A. Ribas, and J. R. Heath. 2009. Modular nucleic acid assembled p/MHC microarrays for multiplexed sorting of antigen-specific T cells. Journal of the American Chemical Society 131(28):9695-9703.
LaFleur, M. D., Q. Qi, and K. Lewis. 2010. Patients with long-term oral carriage harbor high-persister mutants of Candida albicans. Antimicrobial Agents and Chemotherapy 54:39-44.
Lam, B. J., and G. F. Joyce. 2009. Autocatalytic aptazymes enable ligand-dependent exponential amplification of RNA. Nature Biotechnology 27(3):288-292.
——. 2011. An isothermal system that couples ligand-dependent catalysis to ligand-independent exponential amplification. Journal of the American Chemical Society 133(9):3191-3197.
Lartigue, C., J. I. Glass, N. Alperovich, R. Pieper, P. P. Parmar, C. A. Hutchison, H. O. Smith, and J. C. Venter. 2007. Genome transplantation in bacteria: Changing one species to another. Science 317:632-638.
Lartigue, C., S. Vashee, M. A. Algire, R. Chuang, G. A. Benders, L. Ma, V. N. Noskov, E. A. Denisova, D. G. Gibson, N. Assad-Garcia, N. Alperovich, D. W. Thomas, C. Merryman, C. A. Hutchison, H. O. Smith, J. C. Venter, and J. I. Glass. 2009. Creating bacterial strains from genomes that have been cloned and engineered in yeast. Science 325:1693-1696.
Lawrence, M. S., K. J. Phillips, and D. R. Liu. 2007. Supercharging proteins can impart unusual resilience. Journal of the American Chemical Society 129(33):10110-10112.
Lee, H. H., M. N. Molla, C. R. Cantor, and J. J. Collins. 2010. Bacterial charity work leads to population-wide resistance. Nature 467(7311):82-85.
Leong, S. R., J. C. C. Chang, R. Ong, G. Dawes, W. P. C. Stemmer, and J. Punnonen. 2003. Optimized expression and specific activity of IL-12 by directed molecular evolution. Proceedings of the National Academy of Sciences of the United States of America 100:1163-1168.
Levskaya, A., A. A. Chevalier, J. J. Tabor, Z. B. Simpson, L. A. Lavery, M. Levy, E. A. Davidson, A. Scouras, A. D. Ellington, E. M. Marcotte, and C. A. Voigt. 2005. Synthetic biology: Engineering Escherichia coli to see light. Nature 438(7067):441-442.
Lewis, K. 2007. Persister cells, dormancy and infectious disease. Nature Reviews Microbiology 5:48-56.
——. 2010. Persister cells and the paradox of chronic infections. Microbe 5:429-437.
Lewis, K., S. Epstein, A. D’Onofrio, and L. L. Ling. 2010. Uncultured microorganisms as a source of secondary metabolites. The Journal of Antibiotics 2010:1-9.
Leysath, C. E., A. F. Monzingo, J. A. Maynard, J. Barnett, G. Georgiou, B. L. Iverson, and J. D. Robertus. 2009. Crystal structure of the engineered neutralizing antibody M18 complexed to domain 4 of the anthrax protective antigen. Journal of Molecular Biology 387:680-693.
Li, J. W. H., and J. C. Vederas. 2009. Drug discovery and natural products: End of an era or an endless frontier? Science 325:161-165.
Lincoln, T. A., and G. F. Joyce. 2009. Self-sustained replication of an RNA enzyme. Science 323: 1229-1232.
Link, A. J., D. Phillips, and G. M. Church. 1997. Methods for generating precise deletions and insertions in the genome of wild-type Escherichia coli: Application to open reading frame characterization. Journal of Bacteriology 179:6228-6237.
Liu, T., and C. Khosla. 2010. A balancing act for Taxol precursor pathways in E. coli. Science 330:44-45.
Looger, L. L., M. A. Dwyer, J. J. Smith, and H. W. Hellinga. 2003. Computational design of receptor and sensor proteins with novel functions. Nature 423(6936):185-190.
Lu, T. K., and J. J. Collins. 2007. Dispering biofilms with engineered enzymatic bacteriophage. Proceedings of the National Academy of Sciences of the United States of America 104(27): 11197-11202.
——. 2009. Engineered bacteriophage targeting gene networks as adjuvants for antibiotic therapy. Proceedings of the National Academy of Sciences of the United States of America 106(12):4629-4634.
Lynd, L. R., J. H. Cushman, R. J. Nichols, and C. E. Wyman. 1991. Fuel ethanol from cellulosic biomass. Science 251:1318-1323.
Lynd, L. R., W. H. van Zyl, J. E. McBride, and M. Laser. 2005. Consolidated bioprocessing of cellulosic biomass: An update. Current Opinion in Biotechnology 16:577-583.
Ma, C., R. Fan, H. Ahmad, Q. Shi, B. Comin-Anduix, T. Chodon, R. C. Koya, C-C. Liu, G. Kwong, C. G. Radu, A. Ribas, and J. R. Heath. 2011. A clinical microchip for evaluation of single immune cells reveals high functional heterogeneity in phenotypically similar T cells. Nature Medicine 17:738-743.
MacDonald, J. T., C. Barnes, R. I. Kitney, P. S. Freemont, and G. V. Stan. 2011. Computational design approaches and tools for synthetic biology. Integrative Biology 3:97-108.
Marlovits, T. C., T. Kubori, A. Sukahn, D. R. Thomas, J. E. Galan, and V. M. Unger. 2004. Structural insights into the assembly of the type III secretion needle complex. Science 306(5698):1040-1042.
Martin, V. J. J., D. J. Pitera, S. T. Withers, J. D. Newman, and J. D. Keasling. 2003. Engineering a mevalonate pathway in Escherichia coli for production of terpenoids. Nature Biotechnology 21:796-802.
Maynard, J. A., C. B. Maassen, S. H. Leppla, K. Brasky, J. L. Patterson, B. L. Iverson, and G. Georgiou. 2002. Protection against anthrax toxin by recombinant antibody fragments correlates with antigen affinity. Nature Biotechnology 20:597-601.
Mena-Benitez, G. L., F. Gandia-Herrero, S. Graham, T. R. Larson, S. J. McQueen-Mason, C. E. French, E. L. Rylott, and N. C. Bruce. 2008. Plant Physiology 147:1192-1198.
Metzker, M. L., 2010 Sequencing technologies—the next generation. Nature Reviews Genetics 11(1):31-46.
Miller, S. L. 1953. A production of amino acids under possible primitive Earth conditions. Science 117:528-529.
Mohamed, N., M. Clagett, J. Li, S. Jones, S. Pincus, G. D’Alia, L. Nardone, M. Babin, G. Spitalny, and L. Casey. 2005. A high-affinity monoclonal antibody to anthrax protective antigen passively protects rabbits before and after aerosolized Bacillus anthracis spore challenge. Infection and Immunity 73(2):795-802.
Monod, J., and F. Jacob. 1961. General conclusions: Telenomic mechanisms in cellular metabolism, growth, and differentiation. Cold Spring Harbor Symposium in Quantitative Biology 26:389-401.
Mosberg, J. A., M. J. Lajoie, and G. M. Church. 2010. Lambda Red recombineering in Escherichia coli occurs through a fully single-stranded intermediate. Genetics 186(3):791-799.
Mulcahy, L. R., J. L. Burns, L. Lory, and K. Lewis. 2010. Emergence of Pseudomonas aeruginosa strains producting high levels of persister cells in patients with cystic fibrosis. Journal of Bacteriology 192(23):6191-6199.
Muñoz, I. G., J. Prieto, S. Subramanian, J. Coloma, P. Redondo, M. Villate, N. Merino, M. Marenchino, M. D’Abramo, F. L. Gervasio, S. Grizot, F. Daboussi, J. Smith, I. Chion-Sotinel, F. Pâques, P. Duchateau, A. Alibés, F. Stricher, L. Serrano, F. J. Blanco, and G. Montoya. 2011. Molecular basis of engineered meganuclease targeting of the endogenous human RAG1 locus. Nucleic Acids Research 39(2):729-743.
Nakaya, H. I., J. Wrammert, E. K. Lee, L. Racioppi, S. Marie-Kunze, W. N. Haining, A. R. Means, S. P. Kasturi, N. Khan, G-M. Li, M. McCausland, V. Kanchan, K. E. Kokko, S. Li, R. Elbein, A. K. Mehta, A. Aderem, K. Subbarao, R. Ahmed, and B. Pulendran. 2011. Systems biology of vaccination for seasonal influenza in humans. Nature Immunology 12:786-795.
Ness, J. E. 1999. DNA shuffling of subgenomic sequences of subtilisin. Nature Biotechnology 17:893-896.
Newcastle University 2010 iGEM Team. 2010. Bacillafilla: Fixing cracks in concrete. http://2010.igem.org/Team:Newcastle (accessed 11 February 2011).
News and Analysis. 2009. Deal watch: Monoclonal antibodies targeting Clostridium difficile licensed to Merck. Nature Reviews Drug Discovery 8:442.
Nimmerjahn, F., S. Milosevic, U. Behrends, E. M. Jaffee, D. M. Pardoll, G. W. Bornkamm, and J. E. Mautner. 2003. Major histocompatibility complex class II-restricted presentation of a cytosolic antigen by autophagy. European Journal of Immunology 33(5):1250-1259.
Nivens, D. E., T. E. McKnight, S. A. Moser, S. J. Osbourn, M. L. Simpson, and G. S. Sayler. 2004. Bioluminescent bioreporter integrated circuits: Potentially small, rugged and inexpensive whole-cell biosensors for remote environmental sampling. Journal of Applied Microbiology 96(1):33-46.
Noble, D. 2008. Computational models of the heart and their use in assessing the actions of drugs. Journal of Pharmacological Sciences 107(2):107-117.
NSABB (National Science Advisory Board for Biosecurity). 2010. Addressing Biosecurity Concerns Related to Synthetic Biology. Bethesda, MD: NSABB.
Orth, J. D., and B. Ø. Palsson. 2010. Systematizing the generation of missing metabolic knowledge. Biotechnology and Bioengineering 107(3):403-412.
Orth, J. D., I. Thiele, and B. Ø. Palsson. 2010. What is flux balance analysis? Nature Biotechnology 28(3):245-248.
Palsson, B. Ø., and K. Zengler. 2010. The challenges of integrating multi-omic data sets. Nature Chemical Biology 6:787-789.
Paradise, E. M., J. Kirby, R. Chan, and J. D. Keasling. 2008. Redirection of flux through the FPP branch-point in Saccharomyces cerevisiae by down-regulating squalene synthase. Biotechnology and Bioengineering 100(2):371-378.
Parliamentary Office of Science and Technology. 2008. Synthetic biology. Postnote (298):1-4.
Parsek, M. R., and W. P. Greenberg. 2005. Sociomicrobiology: The connections between quorum sensing and biofilms. Trends in Microbiology 13:27-33.
Paul, N., and G. F. Joyce. 2002. A self-replicating ligase ribozyme. Proceedings of the National Academy of Sciences of the United States of America 99:12733-12740.
Peccoud, J., J. C. Anderson, D. Chandran, D. Densmore, M. Galdzicki, M. W. Lux, C. A. Rodriguez, G. Stan, and H. M. Sauro. 2011. Essential information for synthetic DNA sequences. Nature Biotechnology 29(1):22.
Pekrun, K., R. Shibata, T. Igarashi, M. Reed, L. Sheppard, P. A. Pattern, W. P. Stemmer, M. A. Martin, and N. W. Soong. 2002. Evolution of a human immunodeficiency virus type 1 variant with enhanced replication in pig-tailed macaque cells by DNA shuffling. Journal of Virology 76(6):2924-2935.
Pfleger, B. F., D. J. Pitera, C. D. Smolke, and J. D. Keasling. 2006. Combinatorial engineering of intergenic regions in operons tunes expression of multiple genes. Nature Biotechnology 24:1027-1032.
Pitera, D. J., C. J. Paddon, J. D. Newman, and J. D. Keasling. 2007. Balancing a heterologous mevalonate pathway for improved isoprenoid production in Escherichia coli. Metabolic Engineering 9(2):193-207.
Presidential Commission for the Study of Bioethical Issues. 2010. New Directions: The Ethics of Synthetic Biology and Emerging Technologies. Washington, DC: Presidential Commission for the Study of Bioethical Issues.
Pulendran, B. 2011. Using systems biology to understand and develop more effective vaccines. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Pulendran, B., and R. Ahmed. 2006. Translating innate immunity into immunological memory: Implications for vaccine development. Cell 124:849-863.
Pulendran, B., S. Li, and H. I. Nakaya. 2010. Systems vaccinology. Immunity 33(4):516-529.
Purnick, P. E. M., and R. Weiss. 2009. The second wave of synthetic biology: From modules to systems. Nature Reviews Molecular Cell Biology 10(6):410-422.
Quant, P. A. 1993. Experimental application of top-down control analysis to metabolic systems. Trends in Biochemical Sciences 18(1):26-30.
Querec, T., S. Bennouna, S. Alkan, Y. Laouar, K. Gorden, R. Flavell, S. Akira, R. Ahmed, and B. Pulendran. 2006. Yellow fever vaccine YF-17D activates multiple dendritic cells subsets via TLR2, 7, 8, and 9 to stimulate polyvalent immunity. Journal of Experimental Medicine 203(2):413-424.
Querec, T. D., R. S. Akondy, E. K. Lee, W. Cao, H. I. Nakaya, A. Pirani, K. Gernert, J. Deng, B. Marzolf, K. Kennedy, H. Wu, S. Bennouna, H. Oluoch, J. Miller, R. Z. Vencio, M. Mulligan, A. Aderem, R. Ahmed, and B. Pulendran. 2009. Systems biology approach predicts immunogenicity of the yellow fever vaccine in humans. Nature Immunology 10(1):116-125.
Qui, Y., B.-K. Cho, Y. S. Park, D. Lovley, B. Ø. Palsson, and K. Zengler. 2010. Structural and operational complexity of the Geobacter sulfurreducens genome. Genome Research 20:1304-1311.
Read, A. F., T. Day, and S. Huijben. 2011. Colloquium Paper: The evolution of drug resistance and the curious orthodoxy of aggressive chemotherapy. Proceedings of the National Academy of Sciences of the United States of America 108(Suppl. 2):10871-10877.
Reddy, S. T., X. Ge, A. E. Miklos, R. A. Hughes, S. H. Kang, K. H. Hoi, C. Chrysostomou, S. P. Hunicke-Smith, B. L. Iverson, P. W. Tucker, A. D. Ellington, and G. Georgiou. 2010. Monoclonal antibodies isolated without screening by analyzing the variable-gene repertoire of plasma cells. Nature Biotechnology 28(9):965-969.
Relman, D. A., E. Choffnes, and S. M. Lemon. 2006. In search of biosecurity. Science 311:1835.
Ricardo, A., and J. W. Szostak. 2009. Life on earth. Scientific American (September):54-61.
Ro, D., E. M. Paradise, M. Ouellet, K. J. Fisher, K. L. Newman, J. M. Ndungu, K. A. Ho, R. A. Eachus, T. S. Ham, J. Kirby, M. C. Y. Chang, S. T. Withers, Y. Shiba, R. Sarpong, and J. D. Keasling. 2006. Production of the antimalarial drug precursor artemisinic acid in engineered yeast. Nature 440:940-943.
Robertson, D. E., S. A. Jacobson, F. Morgan, D. Berry, G. M. Church, and N. B. Afeyan. 2011. A new dawn for industrial photosynthesis. Photosynthesis Research 107(3):269-277.
Rogers, J., and G. F. Joyce. 2001. The effect of cytidine on the structure and function of an RNA ligase ribozyme. RNA 7:395-404.
Rondon, M. R., P. R. August, A. D. Betterman, S. F. Brady, T. H. Grossman, M. R. Liles, K. A. Loiacono, B. A. Lynch, I. A. MacNeil, C. Minor, C. L. Tiong, M. Gilman, M. S. Osburne, J. Clardy, J. Handelsman, and R. M. Goodman. 2000. Cloning the soil metagenome: A strategy for accessing the genetic and functional diversity of uncultured microorganisms. Applied and Environmental Microbiology 66(6):2541-2547.
Rosenberg, S. A., B. S. Packard, P. M. Aebersold, D. Solomon, S. L. Topalian, S. T. Toy, P. Simon, M. T. Lotze, J. C. Yang, C. A. Seipp, et al. 1988. Use of tumor-infiltrating lymphocytes and interleukin-2 in the immunotherapy of patients with metastatic melanoma. A preliminary report. New England Journal of Medicine 319(25):1676-1680.
Rousseau, F., and J. Schymkowitz. 2005. A systems biology perspective on protein structural dynamics and signal transduction. Current Opinions Structural Biology 15(1):23-30.
Royal Academy of Engineering. 2009. Synthetic Biology: Scope, Applications, and Implications. London: Royal Academy of Engineering.
Rubio, L. M., and P. W. Ludden. 2008. Biosynthesis of the iron-molybdenum cofactor of nitrogenase. Annual Review of Microbiology 62:93-111.
Sauro, H. 2011. Design and complexity. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Schirmer, A., M. A. Rude, X. Li, E. Popova, and S. B. del Cardayre. 2010. Microbial biosynthesis of alkanes. Science 329(5991):559-562.
Schnepf, M. 2010. High cost of water treatment problems. The Network. http://www.chemaqua.com/downloads/cases/Network-High_Cost_of_WT.pdf (accessed July 19, 2011).
Schumacher, M. A., K. M. Piro, W. Xu, S. Hansen, K. Lewis, and R. G. Brennan. 2009. Molecular mechanisms of HipA-mediated multidrug tolerance and its neutralization by HipB. Science 323(5912):396-401.
Serrano, L. 2007. Synthetic biology: Promises and challenges. Molecular Systems Biology 3:158.
Shah, K., Z. Zhang, A. Khodursky, N. Kaldalu, K. Kurg, and K. Lewis. 2006. Persisters: A distinct physiological state of E. coli. BMC Microbiology 12(6):53.
Shetty, R. P., D. Endy, and T. F. Knight. 2008. Engineering BioBrick vectors from BioBrick parts. Journal of Biological Engineering 2:5, doi:10.1186/1754-1611-2-5.
Shin, Y. S., H. Ahmad, Q. Shi, H. Kim, T. A. Pascal, R. Fan, W. A. Goddard, and J. R. Heath. 2010. Chemistries for patterning robust DNA MicroBarcodes enable multiplex assays of cytoplasm proteins from single cancer cells. ChemPhysChem 11(14):3063-3069, doi: 10.1002/ cphc.201000528.
Shin, Y. S., F. Remacle, R. Fan, K. Huang, W. Wei, H. Ahmad, R. D. Levine, and J. R. Heath. 2011. Protein signaling networks from single cell fluctuations and information theory profiling. Biophysical. Journal 100:2378-2386.
Singh, P. K., M. R. Parsek, E. P. Greenberg, and M. J. Welsh. 2002. A component of innate immunity prevents bacterial biofilm development. Nature 417:552-555.
Sleight, S. C., B. A. Bartley, J. A. Lieviant, and H. M. Sauro. 2010. Designing and engineering evolutionary robust genetic circuits. Journal of Biological Engineering 4:12.
Smith, H. O., C. A. Hutchison, 3rd, C. Pfannkoch, and J. C. Venter. 2003. Generating a synthetic genome by whole genome assembly: phiX174 bacteriophage from synthetic oligonucleotides. Proceedings of the National Academy of Sciences of the United States of America 100:15440-15445.
Sommer, M. O. A., G. M. Church, and G. Dantas. 2010. A functional metagenomic approach for expanding the synthetic biology toolbox for biomass conversion. Molecular Systems Biology 6:360, doi:10.1038/msb.2010.16.
Specter, M. 2009. A life of its own: Where will synthetic biology lead us. The New Yorker (September 28): 1-8.
Stemke-Hale, K., B. Kaltenboeck, F. J. DeGraves, K. F. Sykes, C. H. Bu, and S. A. Johnston. 2005. Screening the whole genome of a pathogen in vivo for individual protective antigens. Vaccine 23(23):3010-3025.
Stocker, J., D. Balluch, M. Gsell, H. Harms, J. Feliciano, S. Daunert, K. A. Malik, and J. R. van der Meer. 2003. Development of a set of simple bacterial biosensors for quantitative and rapid measurements of arsenite and arsenate in potable water. Environmental Science and Technology 37(20):4743-4750.
Sukhan, A., T. Kubori, and J. E. Galán. 2003. Synthesis and localization of the Salmonella SPI-1 type III secretion needle complex proteins PrgI and PrgJ. Journal of Bacteriology 185(11):3480-3483.
Tabor, J. J., H. M. Salis, Z. B. Zimpson, A. A. Chevalier, A. Levskaya, E. M. Marcotte, C. A. Voigt, and A. D. Ellington. 2009. A synthetic genetic edge detection program. Cell 137(7):1272-1281.
Talaat, A. M., and K. Stemke-Hale. 2005. Expression library immunization: A road map for discovery of vaccines against infectious diseases. Infection and Immunity 73(1):7089-7098.
Tauriainen, S., M. Virta, W. Chang, and Karp. 1999. Measurement of firefly luciferase reporter gene activity from cells and lysates using Escherichia coli arsenite and mercury sensors. Analytical Biochemistry 272(2):191-198.
Thiele, I., and B. Ø. Palsson. 2010. A protocol for generating a high-quality genome-scale metabolic reconstruction. Nature Protocols 5:93-121.
Thiele, I., N. Jamshidi, R. M. T. Fleming, B. Ø. Palsson. 2009. Genome-scale reconstruction of Escherichia coli’s transcriptional and translational machinery: A knowledge base, its mathematical formulation, and its functional characterization. PLoS Computational Biology 5(3):e1000312. doi:10.1371/journal.pcbi.1000312.
Thomas, P. G., and P. C. Doherty. 2009. Rules to “prime” by. Nature Immunology 10(1):14-16.
Thomas, S. R. 2009. Kidney modeling and systems physiology. Wiley Interdisciplinary Reviews. Systems Biology and Medicine 1(2):172-190.
Turpeinen, R., M. Virta, and M. M. Häggblom. 2003. Analysis of arsenic bioavailability in contaminated soils. Environmental Toxicology and Chemistry 22(1):1-6.
Uetz, P., and R. L. Finley, Jr. 2005. From protein networks to biological systems. FEBS Letters 579(8):1821-1827.
Urnov, F. D., J. C. Miller, Y. L. Lee, C. M. Beausejour, J. M. Rock, S. Augustus, A. C. Jamieson, M. H. Porteus, P. D. Gregory, and M. C. Holmes. 2005. Highly efficient endogenous human gene correction using designed zinc-finger nucleases. Nature 435(7042):646-651.
van der Meer, J. R., and S. Belkin. 2010. Where microbiology meets microengineering: Design and applications of reporter bacteria. Nature Review Microbiology 8:511-522.
Voigt, C. 2011. Access through refactoring: Rebuilding complex functions from the ground up. Presentation given at the March 14-15, 2011, public workshop, “Synthetic and Systems Biology,” Forum on Microbial Threats, Institute of Medicine, Washington, DC.
Wackwitz, A., H. Harms, A. Chatzinotas, U. Breuer, C. Vogne, and J. R. van der Meer. 2008. Internal arsenite bioassay calibration using multiple bioreporter cell lines. Microbial Biotechnology 1(2):149-157.
Wang, H. H., F. J. Isaacs, P. A. Carr, Z. Z. Sun, G. Xu, C. R. Forest, and G. M. Church. 2009. Programming cells by multiplex genome engineering and accelerated evolution. Nature 460(7257): 894-898.
Wanner, O. 2006. Biofilms hamper heat recovery. Eaway News 60e:31-32. http://www.eawag.ch/medien/publ/eanews/archiv/news_60/en60e_wanner_hamper_heat.pdf (accessed July 19, 2011).
Westerhoff, H. V., and K. van Dam. 1987. Thermodynamics and Control of Biological Free-Energy Transduction. Amsterdam: Elsevier.
Westerhoff, H. V., C. Winder, H. Messiha, E. Simeonidis, M. Adamcyzk, M. Verma, F. J. Bruggeman, and W. Dunn. 2009. Systems biology: The elements and principles of life. FEBS Letters 583:3882-3890.
Whitchurch, C. B., T. Tolker-Nielsen, P. C. Ragas, and J. S. Mattick. 2002. Extracellular DNA required for bacterial biofilm formation. Science 295(5559):1487.
Widmaier, D. M., and C. A. Voigt. 2010. Quantification of the physiochemical constraints on the export of spider silk proteins by Salmonella type III secretion. Microbial Cell Factories 9:78.
Widmaier, D. M., D. Tullman-Ercek, E. A. Mirsky, R. Hill, S. Govindarajan, J. Minshull, and C. A. Voigt. 2009. Engineering the Salmonella type III secretion system to export spider silk monomers. Molecular Systems Biology 5:30-39.
Williams, B. A. R., C. W. Diehnelt, P. Belcher, M. Greving, N. W. Woodbury, S. A. Johnston, and J. C. Chaput. 2009. Creating protein affinity reagents by combining peptide ligands on synthetic DNA scaffolds. Journal of the American Chemical Society 131:17233-17241.
Wolkenhauer, O., M. Ullah, P. Wellstead, and K. H. Chang. 2005. The dynamic systems approach to control and regulation of intracellular networks. FEBS Letters 579(8):1846-1853.
Yokobayashi, Y., R. Weiss, and F. H. Arnold. 2002. Directed evolution of a genetic circuit. Proceedings of the National Academy of Sciences of the United States of America 24:16587-16591.
Young, J. A., and E. A. Winzeler. 2005. Using expression information to discover new drug and vaccine targets in the malaria parasite Plasmodium falciparum. Pharmacogenomics 6(1):17-26.
Yu, D., H. M. Ellis, E. Lee, N. A. Jenkins, N. G. Copeland, and D. L. Court. 2000. An efficient recombination system for chromosome engineering in Escherichia coli. Proceedings of the National Academy of Sciences 97(11):5978-5983.
Zhang, Y., F. Buchholz, J. P. Muyrers, and A. F. Stewart. 1998. A new logic for DNA engineering using recombination in Escherichia coli. Nature Genetics 20(2):123-128.
Zhang, Y. Z., K. Perry, V. A. Vinci, K. Powell, W. P. C. Stemmer, and S. B. del Cardayré. 2002. Genome shuffling leads to rapid phenotypic improvement in bacteria. Nature 415:644-646.
Zukowski, M. M., D. F. Gaffney, D. Speck, M. Kauffmann, A. Findell, A. Wisecup, and L. P. Lecocq. 1983. Chromogenic identification of genetic regulatory signals in Bacillus subtilis based on expression of a cloned Pseudomonas gene. Proceedings of the National Academy of Sciences 80(4):1101-1105.









































































































{kind=link}