
INTRODUCTION AND GENERAL DISCUSSION OF METRICS
In this chapter, the committee begins by discussing metrics in general, including terminology and a kind of taxonomy of metrics, what metrics cannot do, and some thoughts on measuring trust and confidence. In the recommendations section, the committee offers recommendations about objectives and partnership, working with and learning from other agencies, and prioritization. Following the first set of recommendations, the committee gives specific advice concerning border security (the Weapons of Mass Destruction Proliferation Prevention Program (WMD-PPP), and the Cooperative Biological Engagement Program (CBEP) program because the programs illustrate the points well.23 Those sections are followed by recommendations on independent evaluation and factoring time and change into metrics. Chapter 3 closes with a set of important issues for Cooperative Threat Reduction (CTR) that are sometimes seen as metrics issues, but in fact are not.
On Metrics
Metrics are used in many private and public domains: strategic planning and assessment; business planning and assessment; manufacturing and service planning and assessment; policy analysis; campaign planning and assessment; product/service design and assessment; systems analysis; systems engineering, and engineering management. The term “metrics” is very broad and additional terms are useful to differentiate the full range of metrics that are needed for a large, important program like the CTR Program. A list of the most common terms used for metrics can be found in Box 3-1.
The terms in Box 3-1 provide a much richer understanding of the purposes and the types of metrics. Unfortunately, there is significant overlap in the terminology. Systems thinking can help to organize similar terms into categories that provide a reduced set of terms and allowed the committee to perform its assessment of the current CTR metrics and identify opportunities for improvement. Figure 3-1 shows six categories of metrics: input, process, environmental, output, value, and benefit cost metrics. The term on the top of each category is the term the committee uses in the report to assess the CTR metrics. The terms in parentheses are similar terms binned in the categories. Leading and lagging indicators are shown because they are an alternative way of grouping the six metric categories based on the timeliness of the metric for determining corrective action.
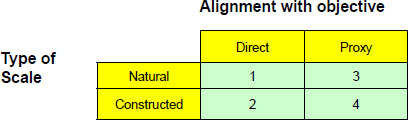
In addition to the purpose of the metric and the category of metrics, another important distinction is what the committee will call the “type” of metric or measure. The type of measure has two dimensions: the linkage to the objective, and the type of the scale. A “direct metric” is a measure directly linked to the objective, such as the number of nuclear missiles dismantled. Analysts and managers prefer to use a direct metric because it directly reflects progress toward the objective
![]()
23 The committee offers general advice for all of the CTR programs, but CBEP and WMD-PPP are open-ended, expanding capacity-building programs and the committee has additional specific advice for them.
that a program is trying to achieve. “Proxy measures” are indirect measures used when direct metrics are not possible (cannot be measured) or are unavailable, such as when the direct metric is not timely. For example, cholesterol level is a proxy measure for the risk of heart disease. A proxy measure typically does not encompass all of the important aspects of status or performance, so managers sometimes use multiple proxy measures. Multiple proxies can increase the data collection requirements and only provide marginal capability to assess the achievement of the objective, but they may be all that are available.
The type of measure can be natural or constructed. A natural measure is a metric that has a commonly accepted definition arising from an objective measurement. Temperature and weight are examples of natural scales, as are silos destroyed and chemical destruction facility availability. Natural scales are preferred because people understand them intuitively and are easier to measure. Constructed scales are designed to measure the achievement of an objective. The five star scale used to assess the quality of a product, security classification levels (unclassified, confidential, secret), heat index, and body mass index are all constructed scales. Constructed scales require clear definitions to be operational to assessors and managers.
BOX 3-1 Common Terms Used for Metrics
• Cost effectiveness: Assesses attainment of an objective or task relative to the costs.
• Benefit cost measure: A metric reflecting benefits attained relative to the costs, which may be monetary or other costs.
• Value versus costs – Compares the value aligned with our objectives to the costs.
• Value measure – Align with our objectives, which we value.
• Measure of effectiveness – Assesses achievement of an assigned objective or task.
• Measure of merit – Another term that tells us how we achieve something we care about.
• Outcome measure – Focuses on the ultimate intended or unintended results.
• Performance measure: Describes how well a subsystem, system, or process meets its required performance.
• Output measure – Outputs usually refer to direct results of a process.
• Efficiency measure: A measure of how resources used in a project or program.
• Process measure – Captures some attribute of a process.
• Input measure – Identifies the resources or activities provided prior to a process.
• Resource measure: Identifies the resources (e.g., dollars, people’s time, or materials) used by system or process.
• Leading indicators: Measures that provide early indicators of impact and effectiveness and allow managers to take corrective action on the process if required.
• Lagging indicator: A measure that is available after the current activity allowing corrective action only for future processes and operations.
• Environmental measure: A factor that could have a direct or indirect impact on the system or process but is not under the control of the program or project managers.
• Adversary measures: Assesses the potential or actual actions of adversaries that can have a direct impact on the process or system.
• Threat measures: Assess capabilities and intent of a potential opponent
• Criteria – Factors that differentiate alternatives.
• Attribute – Characteristic of a system or process.
• Metric – A standard of measurement.
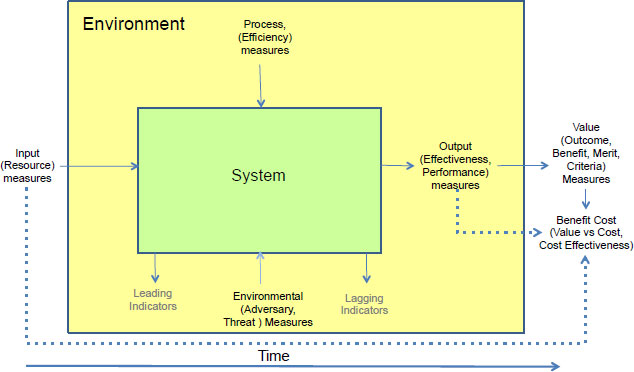
FIGURE 3-1 Metrics organized into six categories using systems thinking. The term on the top of each category is the term the committee uses in the report to assess the CTR metrics. Depending on the metrics’ timeliness it could also be assessed as a leading or lagging metric.
For each objective, the Department of Defense’s (DoD) best option is to identify a natural, direct metric. If that is not possible, the objective may be decomposed into tasks that are more measureable. If DoD cannot identify a natural, direct metric then DoD should develop a constructed scale metric. Because proxy measures only capture part of the objective, proxy measures should only be used if decomposition and constructed scales are not practical (see Table 3-1). There are other important qualities that make a metric more or less attractive: validity, reliability, sensitivity to change from interventions, cost of collection, and overlap with other measures of objectives.
TABLE 3-1 Classification of metrics by alignment with objective and type of scale ranked according to preference (1 to 4). The first preference is a direct, natural measure because it focuses directly on the objective and is well understood. The second preference is a direct, constructed measure. It is more important to be directly focused on the objective even if managers have to design a constructed scale. The third preference is a natural proxy measure, and the last preference is a constructed, proxy measure.
What Metrics Cannot Do
The committee already described the important role of metrics in strategic (program) planning and tactical (project) implementation. However, it is also important to emphasize that metrics are a management tool and are not an end in themselves. There is some information that metrics cannot tell us, and there are several metrics implementation challenges.
First, metrics are only as good as the strategic thinking devoted to their development. For complex problems there is always the potential that an important objective was omitted when metrics were developed. Because metrics should follow from and be aligned with objectives, weaknesses or oversights in strategic thinking may lead to deficiencies in metrics. Stated another way, no set of metrics, no matter how elaborate or sophisticated, can compensate for a flawed strategy; hence the necessity of a sound strategic underpinning and well-formulated objectives. The best guarantee that one has a full set of metrics is meaningful discussion with all key stakeholders including the strategic and tactical leaders in the host country.
One aspect of strategy development that often requires special attention or emphasis is the identification of alternatives. There are usually multiple options for pursuing a given set of objectives, each with its own advantages and disadvantages. Arguments about metrics sometimes reflect more fundamental disagreements about how best to solve a problem, not how to measure it. Although a set of metrics can measure the impact and effectiveness of a project or program against objectives, and can even be used to compare competing options in some cases, metrics alone cannot ensure that the best option or options have been identified and are being implemented.
Second, metrics do not necessarily or automatically identify the cause of an adverse trend on a metric. This is especially true for output metrics. Managers and overseers may need a separate investigation, perhaps using specialized measures of the contributing causes to events or outputs to identify and understand the root cause of a metric trend. Following these trends can also lead to the observation of “unintended consequences,” which may be positive or negative but worthy of note.
Third, metrics do not identify the best corrective action when a metric trend is not according to plan. Focusing on the root cause of an adverse trend on a metric may require a new objective and one or more new metrics. Unfortunately, if the metric is a lagging metric it may be too late for effective corrective action. It may, however, still be useful in future planning.
Fourth, it is important to remember that metrics are dynamic. The initial metrics may be well suited to the formulation and initiation stages of a program but may not adequately account for issues and concerns that arise later during program implementation. Therefore, it is important that the objectives and the metrics be dynamically updated throughout the project lifecycle, while avoiding the problem of “moving the goalpost.”
Fifth, metrics cannot measure something that does not happen. Deterrence and some kinds of prevention are in some sense unknowable and unmeasureable. Proxy measures may be possible in these cases. The U.S. Government has a model of what leads to or exhibits risk. That model may be explicit (a stated set of risk factors that can lead to national security risks for the United States) or implicit (unstated assumptions about risk factors), but same model forms the basis for program strategy and planning. Proxy measures can be derived from the model, but the most desired outcomes (no WMD attacks) cannot be shown to follow directly from any particular actions.
This is why in assessing the overall effectiveness of the metrics for a program like CBEP, DoD has to step back from the numbers and ask itself whether the metrics reveal if the program is succeeding in establishing the human and institutional relationships, the interactions, and the transparency that result in trust and confidence between and among the partners.
Measuring Trust, Confidence, and Goodwill
How does one measure intangible impacts such as goodwill, mutual respect, collegiality, partnership, trust, and confidence? These are some of the objectives of scientist engagement programs, and they seem to be goals for which anecdotal rather than hard quantitative measures might be appropriate.
In some fields of endeavor, surveys are crafted to learn respondents’ opinions, and conclusions are drawn from sufficiently large samples. For example, an extensive study of Russian WMD scientists was conducted to determine if respondents would be tempted by offers of WMD employment in rogue states (Ball et al., 2004). In the absence of International Science and Technology Center assistance, the risk of scientists “going rogue” was assessed as being significantly greater than with the assistance firmly in place. In the words of the study’s authors:
Our data from an unprecedented survey of 602 Russian physicists, biologists, and chemists suggest that the threat of WMD brain drain from Russia should still be at the forefront of our attention. Roughly 20 percent of Russian physicists, biologists, and chemists say they would consider working in rogue nations such as North Korea, Iran, Syria, or Iraq (still considered a rogue state at the time of the survey). At the same time, the data reveal that U.S. and Western nonproliferation assistance programs work. They significantly reduce the likelihood that Russian scientists would consider working in these countries. (Ball et al., 2004)
Surveys may be helpful in CTR programs. At the same time, DoD should be careful in relying on surveys, as there can be volunteer or self-selection bias (who participates) and response bias (deliberate or inadvertent skewing of responses to conform to an expectation rather than reflecting true beliefs), and a variety of other potential problems.
Another study (Revill, 2009) used surveys and other non-traditional measures to assess the effectiveness of dual-use educational efforts. In that study, concepts from the social sciences are proposed to augment the toolkit of traditional metrics. The author concludes that a multi-pronged approach to assessment seems the most likely to yield useful actionable results, at least in their field of endeavor. They note:
With these points in mind, it is possible to identify a number of traditional and less orthodox methods of evaluation. However, as standalone measures none is likely to be successful in generating a holistic evaluation of any programme or process. Rather it is likely that a mixed method will be required to evaluate dual-use education that blends a number of different methods including inter alia, Questionnaire/Surveys; Likert model questionnaires; Social Network Analysis Content Analysis and Impact Evaluations. Using these combinations of measures it is argued that there is great scope for assessing dual-use educational objectives during and after a project and thus providing a much clearer understanding of what the process has achieved and how it could be improved in the future.
Ultimately, one might simply take responsible, reliable, and collegial behavior to be an indicator of outcomes (i.e., did the scientist contact international colleagues when
dangerous infections or anomalies arose? Are the laboratory operations transparent and comfortable with international collaboration?).
RECOMMENDATIONS TO IMPROVE METRICS
The committee has several recommendations for how DoD can improve its metrics for the CTR programs.
Objectives and Partnership
For each program in the DoD Metrics Report, DoD should include a concise statement of its objectives and of how the program is intended to reduce threat or risk.
Objectives for projects and the overall CTR Program in a partner country are developed jointly between the United States and the partner country. An agreed set of metrics should also be built into projects from the outset. They may change, but the parties responsible for the projects should know at any given time the metrics that will be used to measure impact and effectiveness.
The CTR Program was established by Congress with clear authorities and each activity must begin with a clear statement of the United States’ authorized overall objectives. DoD then needs to work with partner countries to define mutual, high-level objectives for their joint efforts. To measure impacts and effectiveness, metrics must include output metrics (e.g., changes in interdiction rates at borders) not just input metrics (e.g., training materials provided). DoD should identify the capabilities it needs to achieve its high-level objectives, the objectives for each capability, and where possible develop its metrics from outputs linked to the capacities that the programs are trying to build. DoD should also build the program and capability objectives into the DoD-partner agreement, and include provisions for metrics and the means to carry out those measurements.
As DoD takes CTR to new countries, it has opportunities to utilize lessons from 20 years of experience with cooperative threat reduction. The committee summarizes a logical order to developing metrics as follows.
1. State clearly the high-level objectives of the overall U.S. CTR Program, including linkage to threat or risk.
2. Work with the partner country to define high-level objectives for joint activities in their country. U.S. goals and partner-country goals need not match exactly, but they must be compatible.
3. Identify the capabilities needed to achieve the high-level objectives.
4. Define objectives for each capability being developed.
5. Define metrics with the partner country at the outset based on capability objectives. Agree on baseline, milestones, and measures of success. Different metrics may be appropriate for different stages of the program.
6. Build metrics—including exercises, if appropriate—into the implementation of the program.
7. Evaluate results independently (U.S. only) and together with partner country.
8. Feed evaluation back into decision-making process. If circumstances or other factors lead to a change in objectives, the metrics may need to be revised.
Working with and Learning from Other Agencies
DoD plans to leverage other U.S. Government agencies’ experience, capabilities, and assets as CTR expands to new countries and as it continues existing programs. DoD also needs to communicate, coordinate, and cooperate with relevant agencies.
As noted in Chapter 2, DoD plans to leverage other U.S. Government agencies’ experience, capabilities, and assets as CTR expands to new countries and as it continues existing programs. DoD also needs to communicate, coordinate, and cooperate with relevant agencies.
One might argue that cooperation should be measured implicitly by looking at outcomes. Unlike safety and security (discussed in regard to the Chemical Weapons Elimination Program in Chapter 2), cooperation itself is an input and an outcome. So, why create metrics for cooperation if cooperation is an input measure (means) rather than an outcome (an end in itself)? It can be difficult to link interagency cooperation to a particular outcome in CTR, but there is experience indicating that problems arise from lack of coordination and lack of cooperation. It stands to reason that an agency newly entering a partner country will be more effective in that country if it learns from agencies that already work there. Furthermore, cooperation can serve as a leading indicator (as long as it is not simply a checkbox metric)—by the time an outcome measure indicates a problem, it may be too late to correct the lack of cooperation. The committee has struggled with this problem: A whole-of-government approach is critical to the success of some programs, and especially some planned programs, so a metric for interagency consultation, coordination, and cooperation would be a useful indicator for the implementation of a program. But the committee has not identified or developed a metric that is more than a checklist. Therefore, the committee encourages DoD, CTR experts outside of DoD, and experts in program assessment and evaluation to consider this challenge, but the committee makes no recommendation on a metric for taking a whole-of-government approach, important as it may be.
DoD is not the only agency engaged in capacity-building programs. U.S. Customs and Border Protection conducts a mission similar to the PPP along many thousands of kilometers of border and has developed metrics for its mission and operations. The United States Department of Agriculture’s Animal and Plant Health Inspection Service is a leader in an international surveillance network that has many parallels to the global network DoD leadership envisions for biothreats. United States Agency for International Development operates programs with partners across the world to foster democratic institutions, compared to which DoD’s capacity-building programs seem relatively tangible. The DoD Defense Security Cooperation program also shares important similarities with the DoD CTR Program and may in some cases serve as a model. Not only can DoD learn from other agencies, but DoD will be working with other agencies in a “whole of government” effort, and they might already have mechanisms in place for measuring impact and effectiveness that would be useful to DoD CTR.
From the variety of the national security programs that have comparable metrics challenges to the CTR Program, the committee selected three of these programs for comparison to gain insights into the CTR metrics approach. The Defense Security Cooperation Program, Capacity Building in Iraq and Afghanistan, and the DoD Capabilities Based Planning Program each illustrate important aspects of CTR. Table 3-2 displays several features of the four programs: the program purpose, scope, number of programs, objectives, metrics, and use of metrics.
The Defense Security Cooperation Program uses metrics to assess security cooperation gaps and the contributions of projects in each of the geographic regions assigned to each Combatant Command (COCOM) under the Unified Command Plan. In addition, many of the supporting commands and services (e.g., U. S. Army Pacific Command and Marines) use metrics to assess the contributions of their security cooperation programs to command missions and security objectives.
The Defense Security Cooperation Agency serves as the DoD focal point … for the development and implementation of security assistance plans and programs, monitoring major weapon sales and technology transfer issues, budgetary and financial arrangements, legislative initiatives and activities, and policy and other security assistance matters. (DoD Directive, 5105.65)
Capacity Building in Iraq and Afghanistan is a complex process that uses metrics to assess the progress of the approved Campaign Plan and to assess the progress of individual projects that build specific infrastructure capabilities in specific locations. The typical approach
TABLE 3-2 Comparison of the CTR Program with other DoD programs that face challenges developing metrics
| Program Feature | Cooperative Threat Reduction | Defense Security Cooperation | Capacity Building in Iraq and Afghanistan | DoD Capabilities Based Planning |
| Purpose | Reduce nuclear, biological, and chemical WMD risk to U.S. national interests | Increase security cooperation to support U.S. national interests | Build the infrastructure to provide for security and economic development | Develop future U.S. military capabilities |
| Scope | CTR Program objectives | Defense and COCOMs regional objectives | Mission assigned by President and Commander’s Campaign plan | Capability gaps are identified in defense mission areas |
| Sub-Programs | Several projects for each major program | Many projects in each COCOM | Many projects to develop country capacity | Capability gaps determine need for weapons systems |
| Objectives | CTR and project objectives | COCOM regional security objectives | Commander’s objectives | Acquisition program objectives |
| Metrics | Project only | Metrics for each region and country | Metrics for each objective | Key Performance Parameters and Key System Attributes |
| Use of Metrics | Evaluate progress of the 4 annual projects | Identify gaps and assess annual projects | Assess campaign progress and project progress | Assess program progress |
to metrics is to develop a hierarchy of missions, objectives, tasks, and metrics. While quantitative data are obtained on each of the metrics, typical reporting to senior leaders may use red, yellow, and green colors to simplify the quick identification of gaps and problem areas (where red means the objectives have not been met, yellow means they have partially been met, and green means they have been or will soon be fully met). Due to the long time horizons to build national capacity, the operational analysts that perform and present the data to senior leaders report a tension between the focus of the project leaders who are interested in reporting on the successful completion of their short-term projects and the campaign planners who must assess the long-term impact and effectiveness against campaign objectives.
The DoD capabilities based planning process replaced the threat based planning process used in the Cold War. Paul Davis defined capabilities based planning as “planning under uncertainty to provide capabilities suitable for a wide range of modern-day challenges and circumstances while working within an economic framework that necessitates choice (Davis, 2002). The process has grown in complexity but the basic ideas are straightforward. The process begins by assessing each mission area to define the joint capabilities that will be needed in the future. This typically is done using a hierarchy of capabilities, objectives, tasks, and metrics. The next step is a capability gap analysis to identify the capability gaps for each mission. After the capability gaps are identified, a functional solution analysis identifies and evaluates joint concepts to provide the needed capability. Finally, where necessary, acquisition programs are initiated to obtain the capability to fill the gap. A capability development document defines the program success metrics which are called Key Performance Parameters with minimum performance (threshold) and aspirational goals (objective levels) and Key System Attributes.
Comparing the CTR Program with similar programs provides insights into the different uses of metrics. One of the major differences between the CTR Program and the other three programs is that the CTR metrics do not address the full scope of the threat in each of the WMD areas. Instead, the metrics address only the scope of the funded projects. While the project metrics are useful in assessing the annual project status, they do not help Congress and senior leaders in DoD and other parts of the government to understand the full scope of the potential for cooperative threat reduction which could help identify the need for and scope of future projects.
Observations from Non-Security Programs
Across areas as diverse as public health, poverty reduction, democracy promotion, public education and others, experts have been attempting for years to employ systematic efforts to understand the effectiveness of their programs. Cultural sensitivities associated with many of these initiatives, constraints of limited resources as well as a sincere interest in positive change have motivated multiple and sustained efforts to develop effective metrics for these programs. Their task is made more complicated by the fact that their objectives – improving public health, reducing poverty, developing democracy, and increasing educational achievement – are at least as difficult to measure as those of capacity building and improving cooperation through CTR projects. Despite the challenge of trying to measure objectives difficult to quantify, much progress has been made in developing methodologies and metrics to do just that. A few examples may provide useful lessons for the DoD CTR programs.
The field of global public health assistance (see e.g., Unite for Sight, 2010) has spent considerable resources on healthcare efforts—as much as $14 billion in 2004 (Kates et al., 2004)—and therefore donors as well as communities affected have increasingly demanded better
understanding of results of those investments. This has led to the explicit differentiation between outputs (goods or services generated by the programs) and outcomes (impacts of programs). For management and contracting purposes, it is important to track outputs, but far more important is measuring outcomes, which in the public health area as well as other areas, include “changes in behavior, attitude, skills, knowledge or condition” (Unite for Sight, 2010; see McAllister, 1999).
How does one measure attitudinal and behavioral change that would ensure that the desired outcomes are achieved? Stating the objectives as part of the initial program design by focusing on outcomes over outputs allows for the development of metrics that, while perhaps more difficult to measure, gets closer to understanding the extent to which the program actually reaches the stated goals.24 The global health assistance community has been working to further develop these methodologies and metrics. Specific efforts include those of the Health Metrics Network and the Institute for Health Metrics and Evaluation. The World Health Organization and International Monetary Fund also continue to work on the challenge of metrics development necessary for understanding outcomes/impact.
Another equally challenging area to measure is that of democracy assistance, beginning with the definition of “democracy” itself. Attempts to better understand the considerable challenge of measuring such a difficult object as “improving democracy” led the U.S. Agency for International Development to ask National Academy of Sciences to bring social science methodologies to bear on the challenge. The report resulting from this request concluded that due to the difficulty of the overall challenge, a host of methodologies is needed to more effectively conduct impact evaluations, defined as evaluations that assess whether and how the specific program made an impact in the expected (or even unexpected) ways. In other words, the methodologies for evaluating the impact of projects are designed to understand what would have happened if the USAID programs did not occur. The methodologies proposed in the 2008 report include case studies, systematic interviews, and randomized studies (NRC, 2008).
Perhaps more important than the adoption of a particular methodology is the selection of a rigorous methodology designed from the outset to measure progress toward the objectives of the program along with its impacts and effectiveness.25 In the USAID context, there are three types of objectives: project monitoring (routine oversight or project management), project evaluation (is the project having its intended affect), and country assessment (is the country as a whole improving). Each of these objectives requires different metrics that specifically and systematically match these tasks with corresponding measures.
Equally important is the collection of appropriate data for each of these measures both before the project begins (baseline data) and after the project is completed (outcome data). The same data should be collected wherever possible for comparable individuals, groups, or communities that, whether by assignment or for other reasons, did not participate in the program. (NRC, 2008). The 2008 report concludes that determining effective metrics for each of the
![]()
24 Moreover, public health programs require a considerable degree of cooperation and integration with local government and community leaders to establish joint goals, methods of implementation, and measurement of outcomes/impact. Learning more about these interactions may provide helpful insights for DoD since there is important overlap between the ability of a public health system to benefit the public overall as well as to accomplish security objectives.
25 What is the difference between progress and impacts? Consider the Chemical Weapons Elimination program. Years were spent planning and constructing the chemical weapons destruction facility. Although the program may be making good progress, that part of the program has little impact until it begins operations actually destroying chemical agent.
objectives and the collection of baseline and outcome data will lay the groundwork for appropriate impact evaluations of USAID’s programs.
Finally, however, they found that “even if USAID were to complete a series of rigorous evaluations with ideal data and obtained valuable conclusions regarding the effectiveness of its projects, these results would be of negligible value if they were not disseminated throughout the organization in a way that led to substantial learning and were not used as inputs to planning and implementation of future [democracy and governance] projects” (NRC, 2008). This same learning process would be useful to DoD as it evaluates the impact of its CTR programs.
Prioritization
The committee judges that using a consistent framework to prioritize and refine metrics within a program would help DoD and other CTR decision makers. Using such a framework, DoD can identify the highest priority metrics, ensuring that the metrics are useable and useful, and allow decision makers to feed results back into the overall CTR objectives and budgetary process. Any of several decision-making or prioritizing frameworks would work, including the decision analysis technique of swing-weight analysis and the DoD capabilities based planning process.
As noted in Chapter 2, DoD developed each set of metrics ab initio, using a different approach for each program, i.e. chemical, biological, borders, and nuclear. The committee found it difficult to identify what were the most important metrics and what might be missing from DoD’s metrics because DoD used a different approach for each program. Although each CTR program is distinct and possibly unique, the committee’s suggestion that DoD consider using a consistent framework is based on best practices, the fact that using a consistent framework is easier, and the committee’s hopes that DoD will maximize what it can accomplish with metrics. Using a well-developed framework helps ensure completeness (Did we include everything that matters?), internal consistency (Did we double count? Do these pieces fit together logically?), and focus (Did we remove what doesn’t matter?). It also helps with management and oversight because it offers the possibility that managers might be able to compare across programs, and does not require the managers and overseers to learn a new framework for each program. The burden then is on those who prefer using different frameworks to argue why they should be different.
An important component of measuring what matters is prioritizing among capabilities and within sets of metrics. Not all goals are equally important and the act of prioritization will help focus limited resources. DoD should use a consistent framework to prioritize and refine metrics within program, for both the decision and the prioritization frameworks. In this report, the committee highlights the decision analysis technique called swing-weight analysis (described below) and the framework used widely in DoD called capabilities based planning.
Using a consistent framework does not mean that the metrics for each CTR program or program activity should be the same, but that a common framework should be used for defining objectives and metrics should flow from those objectives. This will make the metrics useable and useful, and allow decision makers to feed results back into the objectives and budgetary process. Prioritization is a critical component of the effective and efficient use of metrics in program
assessment and management.26 Prioritization is also an essential part of the capabilities based planning process. The objectives and the capabilities needed to meet those objectives are prioritized.
A key technique for prioritizing metrics is the swing weight matrix (Parnell et al., 2011), which can and has been used as the prioritization tool in a capabilities based planning exercise. A swing weight matrix defines the importance and range of variation for a set of metrics. The idea of the swing weight matrix is straightforward: a metric that is very important to the decision should be weighted higher than a metric that is less important. A metric that differentiates between alternative outcomes is weighted more than a metric that does not differentiate between alternative outcomes (see Box 3-2).
BOX 3-2 Swing Weights, A Simple Example
Decision makers use swing weights to identify the most important metrics for a decision (Keeney and Raiffa, 1976). Swing weights depend on importance and range of variation for the metric. The importance is a subjective judgment and the variation in the metric is a factual assessment. For example, consider a car buyer who plans to select the car based on n factors or car metrics. Many people would subjectively judge that car safety is an important metric in the decision to purchase a car because they value the safety of the passengers (themselves, their family, and their friends). Using a website that summarizes car features, the buyer finds that each car receives a rating on a 5 star safety scale, where a one-star car is in the bottom category, meeting only minimal safety requirements for crashes and rollover events, and each additional star represents better safety. A five-star car performs well on all of the crash and rollover tests. Consider the following sequence of judgments and the resulting impact on the swing weights.
1. Suppose that the buyer is willing to consider any car that has a safety rating of 1 to 5 stars. Safety is very important and the metric variation is large. Therefore, the metric might be assigned a high weight, say 20%. The other n -1 metrics would have a total weight of the remaining 80%.
2. After some thought, suppose the buyer decides to consider only cars with a safety rating of 3 to 5 stars. Safety is still very important but the metric variation has been significantly reduced. Therefore, one might assign a lower weight, say 10%. The other n-1 metrics would have a total weight of 90%. The extra 10% would be spread by the same relative proportions of the weights of the n-1 metrics.
3. After rethinking again, suppose the buyer decides to consider only cars with a safety rating of 4 to 5 stars. Safety is still very important but the metric variation has been reduced. Therefore, the buyer might assign a lower weight, say 5%. The other n-1 metrics would have a total weight of 95%. The extra 5% would be spread by the same relative proportions of the weights of the n-1 metrics.
4. Finally, suppose the buyer decides to consider only cars with a safety rating of 5 stars. Because all cars under consideration have the same safety rating, safety is no longer a metric that distinguishes among the alternatives. Therefore, the buyer would assign a weight of zero. The other n -1 metrics will have a total weight of 100%.
![]()
26 Large programs typically have many metrics. The Pareto Principle or the 80/20 Rule applies to metrics. The 80/20 rule was initially developed by economist Pareto in 1906 when he noted that about 20 percent of the people owned 80 percent of the wealth in Italy. Juran, a U.S. quality expert, extended the Pareto rule to management in the 1930s. For example, many project managers have observed that about 20 percent of the tasks on a project require about 80 percent of the time and resources. Likewise, not all metrics are equally important and some metrics may not be significant enough to spend the time and effort to collect and analyze data and report results. Applying the 80/20 rule to metrics, we would expect that about 80 percent of the importance is in about 20 percent of the metrics.
The first step is to create a matrix (for example, Table 3-3) in which the top row defines the metric importance and the left side represents the range of variation. The levels of importance and variation can be thought of as constructed scales that have sufficient clarity to allow program managers to uniquely place every metric in one of the cells. Continuing from the discussion of priorities in Chapter 2, an illustrative swing weight matrix for the CBEP program is displayed in Table 3-3. Using the swing weight matrix to prioritize the metrics, the importance is defined in three levels, with direct reduction in threat being the most important. The vertical scale defines four levels of the gap between the desired capability and the current capability.
TABLE 3-3 An illustrative swing weight matrix for the CBEP program.
| Importance, fi, of the metric i (on a scale from low = 1 to a high = 100)a | ||||
| Direct reduction in the biological threat | Demonstrated use of biosafety and biosecurity procedures | Development of biosafety and biosecurity plans and procedures | ||
| Variation in the capability due to the range of the metric | Large capability gap | Consolidate EDPb - 100 Secure EDP- 100 | Copies of EDP strains sent to United States - 50 | Major biosafety and biosecurity plans - 10 |
| Medium capability gap | Budget sustainment resources - 50 | Demonstrated EDP detection and timely reporting - 25 | Other important plans - 5 | |
| Small capability | Research programs aligned with national & international EDP priorities - 10 | Other detection and timely reporting - 5 | All other plans and procedures - 1 | |
| None | Eliminate known biological weapons (assume none in the 6 partner countries) | |||
a EDP = especially dangerous pathogen
b There may be more than one metric with a weight of 100.
The swing weights are assessed by assigning the most important metric an arbitrary value, e.g., 100. The rest of the weights are then assessed relative to the most important metric or any assessed metric. Table 3-3 provides an illustrative example of a possible swing weight assessment. The metric weights can easily be normalized to sum to 100 using the following equation.
![]()
In this illustrative case there are n = 10 metrics, and each metric i would have a normalized weight wi.27 Additional details on the mathematical constraints on the swing weights (decrease as
![]()
27 As it is described here, swing weight can help to prioritize and assign importance weights to individual metrics. If the metrics are both quantitative and intercomparable on the same scale using a performance function, then once those weights are established, a summary score can be calculated by multiplying the graded performance score on each metric with the metric’s importance weight, then summing up all the weighted scores to get an overall measure of aggregate performance. However, even if the metrics are quantitative, mixing them together might be invalid or just misleading (for example, the metrics might be nonlinear or interdependent). The mathematical assumption is that the measures are mutually preference independent (Kirkwood, 1997).
you go down and to the right) and techniques for assessing the weights and performing sensitivity analysis can be found in Parnell et al. (20ll).28
Border Security Metrics
Law enforcement agencies, whether the U.S. Border Patrol or local police, have a long tradition of collecting and using statistics to measure various aspects of their operations and performance. When combined with the judgment and experience of trained professionals, such data can be and have been used effectively to focus resources, communicate priorities, and identify and adjust to changing conditions, such as changes in the patterns of illegal activity or evolution in the capabilities or behavior of criminals or illegal border crossers.
For example, for border security, a classic metric is the number of illegal alien apprehensions per year (or month or quarter).29 Although data supporting this metric are routinely collected and easily compiled, it is widely understood that interpreting the metric is not simple because it reflects not only effectiveness of detection and interdiction (the rate of apprehensions, given the flow of illegal crossings), but also the highly dynamic nature of cross- border traffic, which depends on many factors such as relative economic conditions on both sides of the border, seasonal patterns, tactics of the illegal crossers and their facilitators, and the perceived risks of apprehension (including both the chance of being caught and the consequences if it happens—ranging from “catch and release,” to temporary detention, longer-term imprisonment, deportation to various points in the country of origin, and so forth).
Nevertheless, the metric can be informative if carefully interpreted. The number of apprehensions by the U.S. Border Patrol has declined significantly over the past decade, from a high of 1.7 million in fiscal year 2000, to 463,362 in 2010, a remarkable decline that may reflect a significant improvement, if one can determine that a greater decline was not possible. In other words, it is reasonable to judge this decline to represent an improvement, but this cannot be known for certain, nor can the exact reasons for the decline (economic recession in the United States versus increased risks of failure versus changed tactics, for example) be known with any precision. More importantly, while the number (or rate) of illegal crossers who are not apprehended, which is of key concern to many stakeholders, cannot be measured precisely, it can in fact be estimated through analysis of know evasions, investigative intelligence, interior enforcement actions, and other poll data regarding the number of illegal aliens present in the United States. Making that estimate is important to understand whether a decline in apprehensions is actually indicative of successful tactics. Further, while this estimation is difficult in the United States, it may be even more difficult elsewhere.
Other easily collected and compiled border security metrics include:
• miles of pedestrian and vehicle fencing
• number of border patrol agents
• numbers of various classes of equipment deployed such as unmanned aircraft systems, remote video surveillance systems, mobile surveillance systems, unattended ground sensors
![]()
28 See Parnell et al. (2011).
29 See www.cbp.gov/linkhandler/cgov/border_security/border_patrol/uslop_statistics/total_apps_25_10.ctt/total_apps_25_10.pdf; accessed November 11, 2011.
• quantities of contraband seized (pounds of marijuana, cocaine, heroin, methamphetamine, numbers of weapons, amounts of currency, etc.)
• incidents of violence against border patrol agents
• percentage of time detection machines are operational
Similar kinds of data are collected by CTR partner agencies in the WMD-PPP. Again, while useful and informative, such statistics measure activities and to some extent outputs, but not overall effectiveness or results. Recognizing the limitations of these kinds of traditional statistics, beginning in 2004, the U.S. Border Patrol formulated an alternative metric to supplement the traditional ones: “miles of border under operational control” (see GAO, 2011). This was a constructed metric that relied on integral judgments by local border patrol officials about the level of security in their area, using a five-level scale. The five levels were:
1. controlled: continuous detection and interdiction resources at the immediate border with high probability of apprehension upon entry
2. managed: multi-tiered detection and interdiction resources in place to fully implement the border control strategy with high probability of apprehension after entry
3. monitored: substantial detection resources in place, but accessibility and resources continue to affect ability to respond
4. low-level monitored: some knowledge is available to develop a rudimentary border control strategy, but the area remains vulnerable because of inaccessibility or limited resource availability
5. remote/low activity: information is lacking to develop a meaningful border control strategy because of inaccessibility or lack of resources (see GAO, 2011)
A recent assessment based on these definitions and on information supplied by the border patrol found 873 miles of the southwestern U.S. border were under “operational control,” defined as either “controlled” or “managed.” Of these 873 miles, 129 were “controlled” and 744 were “managed,” and these figures showed significant improvement over past years. The remaining 1,120 miles of southwestern U.S. border were found to be not under operational control (GAO, 2011).
Although the operational-control metric comes closer to measuring results or effectiveness than the more traditional measures, it still has shortcomings. As the definitions indicate, it is somewhat subjective and combines aspects of “resources in place,” which is an input, and probability of apprehension, which is an output. The probability of apprehension cannot be measured directly, although it might be inferred with some uncertainty from other data and exercises.
In addition, questions have been raised about whether the “operational control” measure properly reflects the overall objectives of border security. In Congressional testimony, Border Patrol Chief Michael J. Fisher explained: “Operational control is the ability to detect, identify, classify and then respond to and resolve illegal entries along our U.S. Borders.” He further cautioned: “The term is tactical in nature and by current use can only be achieved by incrementally applying resources to a point where field commanders can consistently respond to and resolve illegal entries. Operational as a measure does not accurately incorporate the efforts of [Customs and Border Protection] partners and the significance of information and intelligence in an increasingly joint and integrated operating environment. The Border Patrol is currently taking steps to replace this outdated measure with performance metrics that more accurately
depict the state of border security” (Fisher, 2011). This approach is built on a perception that as resources increase, the cost of getting caught also increases, therefore, the illegal entries decrease.
U.S. Customs and Board Protection Commissioner Alan Bersin in a different hearing said: “The success of our efforts … must be measured in terms of the overall security and quality of life of the border region; the promotion and facilitation of trade and travel; and the success of our partnerships in enhancing security and efficiency” (Bersin, 2011).
This debate, which will undoubtedly continue in Congress and elsewhere in the years to come, is a reminder of the fundamental point the committee emphasizes elsewhere in this report. The debate is a reflection of the operational reality that an effective boarder security system cannot rely upon a single actor or point of failure. Specifically, to be useful, metrics must be linked to, and ideally derived from, a clearly defined and agreed set of fundamental goals and objectives. Where fundamental differences exist about objectives, metrics can reveal or illustrate those differences, but cannot not resolve them. However, through an iterative process focused both on objectives and metrics, clarity about metrics can potentially inform and shed light on debates about goals and objectives.
The DoD Metrics Report mentions that “one way to measure the effectiveness of enhancements objectively is through testing; that is, standardized exercises that can be conducted before and after enhancements are made to measure the impact of those enhancements.” In addition, the Report presents a set of more detailed project-level metrics that are intended to capture a wide range of specific impacts or effects in relation to a detailed hierarchy of goals and objectives.
The committee recognizes the difficulty of establishing a compelling overall effectiveness metric. As the section on border security metrics suggests, the question remains difficult and controversial even for the U.S. Border Patrol. In the absence of an overall effectiveness metric, it may be necessary to settle for a set of activity-based and output-based metrics. However, the committee has several recommendations for improvement.
As discussed elsewhere in the report, the committee believes that tests and exercises, including the use of red teams if and where appropriate, have an essential role in measuring effectiveness of CTR programs. The committee agrees with the potential value of exercises for measuring the impact of border security cooperation and is aware that such exercises have been conducted (e.g., the annual Operation Sea Breeze joint training exercise on the Black Sea). Although care should be taken in interpreting the results of exercises, to guard against overly optimistic appraisals and the tendency to perform better during an exercise than during unplanned events, the committee recommends that the WMD-PPP add exercise-based metrics explicitly to its collection of metrics.
The metrics defined in terms of “miles of border enhanced” and “number of ports of entry enhanced” are reasonable input metrics that measure the delivery of tools to accomplish border security goals. There is also precedent for them in other CTR programs implemented by other U.S. agencies such as the Department of Energy Materials Protection, Control and Accounting Program (numbers of facilities/buildings/sites with rapid/comprehensive security upgrades) and the Second Line of Defense Program (number of border crossings equipped with radiation detection capabilities). However, these are numerator statistics. To put them in perspective, denominators should also be provided. For example, comparing these numbers to the total number of miles of border and the total number of ports of entry that were determined to be within the scope of the program. The committee recognizes that selecting the denominators
raises additional questions, such as “how was the scope of the program determined?” For example, most programs will not seek to upgrade 100% of all the possible borders or ports of entry, but will instead focus on providing a “model” for some subset identified through a prioritization or a risk assessment process, leaving the partner country with the task of extending the model as appropriate to the remainder of the border. The committee recommends that this step be made explicit and visible in the metrics because it ties closely to the question of overall goals and objectives of the program. Although disagreements and controversies may arise, evaluation is best served by making those explicit and explaining the planning assumptions on which the program is founded, even though full consensus may be lacking.
Biological Engagement to Enhance Security
The CBEP metrics in the DoD Metrics Report represent many important aspects of the program and yet still have room for improvement. In meetings with the committee, DoD specifically asked the committee to provide advice on how to simplify the set of metrics for CBEP. Table 3-4 provides the committee’s tally of the CBEP metrics (the DoD Metrics Report
TABLE 3-4 Assessment of the Cooperative Biological Engagement Program Metrics
| Partner Domestic Stability (Environment) |
Partner Capability | Partner Outcome |
Total | |||
| Input | Process (Existence) | Output (Conditional)a | ||||
| 1. Secure & Consolidate | 1 | 1b(Consolidate EDP) | 2 | |||
| 2. Improve bio security & safety standards | 8 | 2 | 1b (Consolidate EDP) | 11c | ||
| 3. Detect, diagnose, & report | 8 | 17 | 25 | |||
| 4. Sustain capabilities | 2 (Budget) | 1 | 1 | 4 | ||
| 5. Engage scientific & technical people | 2 | 3 | 1 (Copies of EDP stains sent to U.S.) | 6 | ||
| 6. Eliminate BW technologies | 1 (Eliminate BW) | 1 | ||||
| Total | 0 | 2 | 20 | 23 | 4c | 49c |
a Output is conditional on the event occurring.
b Same measure.
c Includes one repeated metric. EDP = especially dangerous pathogens
calls the CBEP metrics indicators; see Appendix B) using the measurement concepts presented in this report. Three features should be noted. First, three important direct outcome metrics (one is duplicated) were identified. Second, one important input metric (the partner country budget for the program) was identified. These metrics are useful leading indicators of sustainability. Third, the specification of the minimum performance (threshold, in capabilities based planning parlance) and aspirational goal (objective) for each measure appear to match those used in the DoD acquisition process (see Box 3-3).
However, there are several areas for simplification and improvement in the development of the CBEP metrics.
• The presented structure in the DoD Metrics Report that suggests moving from program objective to capability is too cumbersome because the capabilities being developed through a CBEP program may support multiple objectives. This causes metrics to be
Box 3-3 Acquisition and Metrics
DoD has conducted the CTR Program as an acquisition program: DoD contracts with companies to implement CTR plans. Some of these plans are for elimination of nuclear warhead delivery vehicles; some are for acquiring capabilities (facilities, technology, and training). In some ways, this is not so different from other acquisition programs in DoD. For example, it is easy to see the parallel between DoD contracting with a company to tear down a building on a military base and DoD contracting with a company to destroy missiles or silos. But even the capacity building programs have parallels in other acquisitions. When DoD acquires a weapons system, the department is not just buying a weapon. A weapon on its own has little value. What DoD really acquires is a capability, comprising the equipment and the ability to operate and maintain the equipment.
DoD has a well developed process for acquisition, which includes evaluations of whether the department has not only taken possession of the equipment, but also acquired the capability to operate and maintain the equipment. In DoD acquisition parlance, there are two major milestones beyond the baseline for such an acquisition: initial operational capability (IOC) and full operational capability (FOC). The acquisition process is described in the Defense Acquisition Guidebook (DoD, 2011) and the following concise definitions of IOC and FOC can be found in the Glossary of Defense Acquisition Acronyms & Terms (DoD, 2005).
Initial Operational Capability (IOC)
In general, attained when some units and/or organizations in the force structure scheduled to receive a system 1) have received it, and 2) have the ability to employ and maintain it. The specifics for any particular system IOC are defined in that system’s Capability Development Document (CDD) and Capability Production Document (CPD).
Full Operational Capability (FOC)
In general, attained when all units and/or organizations in the force structure scheduled to receive a system 1) have received it, and 2) have the ability to employ and maintain it. The specifics for any particular system FOC are defined in that system’s Capability Development Document and Capability Production Document.
The IOC and FOC are different for each context and attaining the IOC and FOC for a complex acquisition typically requires that minimum performance be met on a variety of metrics. In some cases, that performance is established by exercises.
repeated.30 A better structure would be to use two steps. In the first step, DoD should identify the capabilities that are required to achieve the program objectives, i.e., what capabilities for capacity building. In the second step, goals are set for each capability and metrics toward achievement of the goals are identified.
• The CBEP has no benefit-cost metrics to assess the benefit or effectiveness the United States achieves for the resources invested in the program.
• There are no metrics of the environment. For example, perhaps it would be useful to assess the political, economic and social environments of a country in which CTR programs are being implemented. Such assessments may be beneficial in terms of understanding the potential for sustainability challenges. Another environmental metric could indicate how cooperative the partner country is.
• The metrics use 20 proxy metrics of the processes required for biological safety and security. This is a large number of proxy metrics compared to the three direct, outcome metrics. It would appear that two constructed, process metrics (safety and security) would be sufficient to encompass the information in the 20 proxy metrics.
• All of the 23 output metrics are conditional on the emergence of some disease outbreak, involving dangerous pathogens occurring and the partner country executing the correct procedure according to its plans. Again, these metrics provide the numerator but we do not know the denominator.
The committee’s overall assessment is that the CBEP metrics could be reasonably assessed with about 11 metrics instead of the 49 metrics listed in the DoD Metrics Report. The 11 metrics would be: 2 input (budgets), 3 process (safety, security, and technical engagement), and 2 output (safety and security), and the 4 outcome measures.
Why are these numbers of metrics important? The total number is important because if there are too many, it is difficult to understand the net result. Prioritization helps with this problem, making it possible to recognize the bottom line. Indeed, as noted above, DoD officials asked the committee to help managers identify the “bottom line.” The lower number after prioritization is manageable and better reflects what matters.
Independent Evaluation
Capacity building programs need independent evaluation of how the capabilities being built perform in action. This can be accomplished by several means, ranging from independent expert observations of routine operations to comprehensive exercises that test the full scope of capabilities. The level of effort can be tailored to the scope of the program, its resources, and its relative importance. DoD and its partners should build such independent evaluation into each project. The Defense Security Cooperation Program might be a good model for how to proceed.
Measuring progress in building capacity and effectiveness of programs to prevent low-frequency, high-consequence events is difficult. Assessment against standards and guidelines (e.g., is the partner’s action plan for interdicted nuclear material consistent with the International
![]()
30 See CBEP Objective 2: measures 1.1 and 2.1 are repeats of CBEP Objective 1: measures 1.1 and 2.1.
Atomic Energy Agency model action plan?) is one important component, but DoD and Congress care more about likely performance when the event occurs (i.e., how effectively can the partner implement the action plan?). Current thinking on evaluation suggests that the involvement of independent evaluations from the beginning and for all aspects of the evaluation, including data collection, is ideal. Independent evaluation establishes a degree of credibility that is hard to achieve by other means. Especially for capacity-building programs, some kind of independent evaluation is essential. Exercises are a good way to measure effectiveness and sustainment. Exercises can help measure both capability and performance in such programs. While exercises might be structured differently in different countries and for different projects, they should be built into the implementation and evaluation components of capacity-building projects and programs from the beginning, starting with a baseline evaluation and proceeding with midcourse and final or sustainment evaluations.
The kind of evaluation employed needs to be tailored to the scope of the program, its resources, and its relative importance. The evaluation might take the form of periodic expert observations of the project operations or the partner country’s capacities. It might be an impromptu test of a randomly selected part of the system (e.g., a border protection system), or it might be an exercise of the system, such as was performed for CBEP in Georgia. Ideally, the exercises would be designed by an entity independent from the groups being tested. Fully independent evaluation is not feasible for some of the programs, but recognition of why independent evaluation is desired (to avoid unintentional and intentional bias and to establish credibility) can help guide implementation of evaluations where truly independent evaluation is not done.
Care must be taken with any metrics, but especially exercise-based metrics, to avoid perverse incentives and gaming of the system. These programs are at least as much about human resources and relationships as about facilities and equipment. Because communication is a critical element of success, evaluation requires more than just the exercise or observation; it requires discussion afterward between credible parties (in expertise, authority, and attitude) on both sides.
Box 3-4 An Example of Exercises as Part of the Metrics for CTR
DoD used an exercise-based of means to test the capability of technologies, systems, and support procured by the DoD for the IOC assessment of the disease surveillance system in countries of the former Soviet Union (FSU), such as Georgia, Kazakhstan and Uzbekistan supported by what was then the Biological Threat Reduction Program under CTR. The IOC assessment included exercises in the recognition of clinical disease in humans and animals in the field, the collection of samples, the transport of samples to the appropriate laboratories, diagnosis the disease, reporting of results nationally and internationally as appropriate and destruction or storage of the agents in a secure repository. Prior to the IOC assessment, table top and field exercises were used as nongraded training exercises to focus on gap analysis for individuals and the overall system. Although the DoD acquisition process establishes many of the requirements for the implementation of CTR programs, the DoD Metrics Report does not make clear the relationship between the current metrics and the DoD acquisition process. For example, it is not clear whether DoD will use the IOC and the Full Operational Capability (FOC) as the sets of metrics to determine CBEP’s success. The DoD metrics used for the IOC assessments in the FSU countries appear to have been adopted for CBEP in the DoD Metrics Report. However, the initial application of the current metrics for CBEP yielded a different assessment from the IOC for one of the countries. If essentially the same metrics are used for the IOC and the evaluations based on the DoD Metrics Report, then one would expect that the results would be similar, absent any significant deviation in the performance of the host country.
If DoD continues to use the acquisition process for CTR programs, attainment of the IOC and FOC will serve as the main metrics of success or failure, so it would make sense to integrate the metrics used to evaluate attainment of the IOC and FOC with the formal metrics of the program. This would avoid competing assessments.
At the same time, there is some question whether acquisition is the right framework for some kinds of capacity building, such as bioengagement. Biological threat reduction began in the FSU where there had been an active biological weapons program, where the infrastructure, regulations, and training were similar, and the improvements by DoD in infrastructure and training were essentially the same. But the new mission and locations (Africa, Asia and South America) are different. While the overall objective may be the same, how DoD engages and how DoD supports these countries to meet the overall objective will likely be different. If relationships, trust, and a culture of responsibility are some of the outcomes CBEP seeks, is the acquisition model the best way to cultivate and measure those capacities? This question is worth DoD’s consideration as it implements the program and its metrics.
Building in Exercises From the Beginning
For exercises to be successful, DoD needs an agreement with the host country at the beginning of the program to determine how exercises will be used. Exercises can be used as a training tool or a formal measure of the success of a program. In most cases, exercises will probably be used for both training purposes as well as to measure the success of the program from both the host country and the U.S. funding perspective. It is important that the parties agree upon the informal and formal exercises, how and who will conduct the exercises, and how the outcomes will be used.
Exercises are about Learning
Informal exercises are most effective when they are used for training purposes without the stigma of a grade attached, and when they are about learning, gap recognition, and means of improving the system. Exercises provide an opportunity to discover performance gaps between individual components or elements of the system through system integration. These exercises offer a new means of determining gaps in individual or program capabilities for the host-country. When exercise observations are made by an outside party, even if it is the funding party, the exercise should be conducted with consideration for the local culture.
Formal exercises will likely be associated with milestones for programmatic funding and host country cooperation to meet the overall goals of the program. As the cooperative programs move toward meeting international regulations or guidelines, third party (i.e., independent) participation in the formal exercises becomes more important.
Preparation for Exercises
On the whole, the IOC assessment effort can be both costly and valuable. DoD implemented a formal plan to measure attainment of the IOC and the FOC within each country for the CBEP. While the overall requirements among the FSU countries were the same, the exact specifications and testing for each country differed based on the government-to-government agreements in the areas of disease surveillance, cooperative research, threat infrastructure elimination and engagement of selected host-country scientists. The FSU countries engaged are good examples of cooperation in meeting the overall goals of the biological CTR program, and they illustrate how each country poses unique challenges in meeting the formal metrics of the IOC.
As noted above, a number of informal table-top and field exercises were conducted in preparation for the formal IOC exercise. These table-top and field exercises were used as training events. The training exercises were conducted in a nonthreatening manner, so that the host country participants could gain experience and confidence in the use of the new infrastructure (e.g., biological safety level-2 laboratories and secure repositories for especially dangerous pathogens), equipment, diagnostic assays and standard operating procedures that were instituted through DTRA funding. The trainers consisted of DoD sponsored in-country prime contractor personnel and subject-matter experts from a number of government agencies that came to the FSU periodically. Preparation for the IOC took approximately one year, once the in-country disease surveillance system was sufficiently complete to be tested. Because DoD had funded all aspects of the infrastructure, equipment, diagnostic assays, and standard procedures, the IOC was truly a test of the complete disease surveillance system.a
Each organization that provided infrastructure, training, reagents, supplies, and procedures was involved in training of the local nationals so that they could meet the objectives of the IOC. Each organization was also involved in preparation of table-top exercises, and field exercises provided additional training after each event to rectify gaps. Metrics were determined for each portion of the disease surveillance program, based on standard operating procedures. The procedures were based on DTRA’s requirements for biosafety, security, disease recognition and diagnosis, and international and host government regulations, guidelines, and policies. To train and
conduct informal and formal exercises with U.S. personnel, all written materials related to biosafety, biosecurity, training materials, equipment manuals, and procedures of the disease surveillance system were translated into English and the host country’s language. Because DoD had a strong influence on the decisions regarding infrastructure, supplies, reagents, training, and procedures, it was easy to implement a systems approach for the disease surveillance program. DTRA’s approach was to work closely with FSU partners essentially to clone U.S. procedures (i.e., to attain IOC). Those procedures are, of course, most familiar to DoD and if a partner country asks to be trained on the U.S. procedures then using them makes sense; but other procedures might meet the disease identification and reporting goals. It seems that developing metrics that assess outcome and that do not specify a particular process (i.e., a more flexible approach) would work better in countries with different preexisting infrastructure and operations.
The resources required by DoD, the prime integrating contractor, and the supporting USG agencies were significant to meet the IOC. The IOC assessment was not only a test of the disease surveillance system but of DTRA, the prime integrating contractor and the U.S. government agencies involved in the training of local nationals. All groups worked to prepare the FSU countries to pass.
Exercises and Nunn-Lugar Global Cooperationb
The IOC and FOC represent major and critical tests of major procurements by DoD and may not be appropriate for countries with small engagement projects, but the concept of testing (exercises) should be similar, if the question is how well a country is safely and securely responding to especially dangerous pathogens.
Exercises under an expanded CTR Program could be similar in concept to what was previously tested in the FSU, but it is likely that DTRA will only be funding discrete parts of the disease surveillance system or supplementing existing programs. This will require harder to develop exercises because the procedures, diagnostic kits, safety and security infrastructure, and controls may be different than those funded by DoD. DoD’s approach has been to work closely with FSU partners essentially to clone U.S. procedures (i.e., to attain the IOC as noted above). If DoD is only supplementing the partner countries disease surveillance system, the exercises will need to be more flexible in training/testing general concepts and procedures, rather than prescribed diagnostic assay, procedures, and infrastructure.
DoD had significant influence in countries like Azerbaijan, Georgia, Kazakhstan, and Uzbekistan due to the funding supplied for the host country’s infrastructure and systems for acquiring, testing, securing, and reporting results of suspected especially dangerous microorganisms. As the economic situation has improved in some countries, DoD’s influence has decreased. Where the economic situation has improved, some countries have decided to move forward with their own initiatives without DoD’s funding, and replacing equipment that DoD was using to standardize diagnostic platform across countries. As a result, while the overall objectives of the CTR- implemented program disease surveillance system may remain the same, DoD will need to be more flexible in determining how to measure the outcomes. In other countries, the political situation is such that DoD may have less access or less timely access to facilities where DTRA has funded infrastructure, training, supplies, and procedures. Compare, for example, the free access that the U.S. government enjoyed when establishing the program in Georgia versus the efforts in Uzbekistan. Where it is more difficult to determine the overall success of the program due to a lack of access to facilities that DoD may have built, supplied, and trained, the international regulations or guidelines may still be achieved. DoD is also reexamining the infrastructure, equipment and supplies based on what can be sustained, but it is not clear how metrics will be applied to those countries for which that goal is not currently attainable as a result of economic unsustainability.
a Host country salaries were not paid by DTRA.
b The NRC Committee on Global Security Engagement has called this global cooperation CTR 2.0 (NRC, 2010).
Time and Change
DoD’s metrics and planning process should factor in more explicitly both planned and unplanned change over time. During the phases of active DoD involvement in a CTR project and afterward during sustainment, which is its own stage requiring resources (budgets, equipment, and trained people), clearer planning for how changes and metrics results will feed into decision making will make the metrics more credible and useful for both DoD and the partner country.
As mentioned in Chapter 2, the DoD Metrics Report deliberately does not consider future missions or changes in objectives,31 and although it notes that programs may change and expand to new geographic areas, some sections of the DoD Metrics Report make CTR appear to be a static program. Given that the circumstances in Africa, South East Asia, India, and elsewhere are very different from the contexts in which DoD has worked in the past, the metrics used will have to adjust accordingly, particularly those regarding capacity building and other more-difficult-to- measure objectives. Also, should the objectives (and therefore the metrics) remain unchanged if the budget available doubles? If it divides in half? If the goal is to modernize a country’s capabilities, how does DoD think about obsolescence of the equipment and techniques (the capability) it provides? DoD says that it will adjust and adapt its metrics by revising the Report annually, but without a vision for how change fits into the Program, it will be difficult for DoD to adapt well.
CTR projects change through planned evolution as they progress through different phases and timelines, scope, and even objectives change in unplanned ways as the environment and resources change. Indeed, changes will likely be made in response to results as reported through the metrics. Because of this iterative linkage, having more detail on the objectives development process and on how the metrics will be used in that process would be helpful in defining useful metrics going forward.
For example, consider the Central Reference Laboratory (CRL) planned for Ukraine. DoD committed to paying for the design and construction of a new CRL facility for work on especially dangerous human pathogens. In the last few years, DoD became concerned that the facility would cost too much, both in capital costs and in maintenance and operation costs, which would undermine the independent sustainability of the project. To follow a more sustainable path, DoD proposed to the Ukrainian partners to use the interim CRL (an upgraded existing facility) rather than create a new green-field site. Ukraine reluctantly agreed. This adaptation reflected a better understanding of budget realities in both countries and experience building a new CRL elsewhere. This change is the kind of adaptation and course correction DoD wants to see in its programs. However, if DoD does not revise its metrics, the metrics will not reflect this positive outcome: A metric for progress on construction of the new CRL building would show no progress, but the capability might be in place more quickly and sustainably using the alternative approach.
![]()
31 ”The metrics described in this report are designed to measure appropriately the impact of each CTR program area, as the CTR program is currently constituted for Fiscal Year 2010, and does not attempt to speculate on what metrics might be appropriate for future areas of programmatic or geographic expansion. Neither do the metrics attempt to determine whether the activities of the CTR program are the “right” activities. The metrics described in this report are intended to best measure the effectiveness of the CTR Program in conducting these established programs. These metrics are not intended to revise the method for establishing these objectives.” (DoD 2010).
There is a school of thought that says that metrics should not change over the course of a project, even if other factors do. The committee notes that as social scientists have assisted the USAID in trying to develop rigorous metrics for its programs, an approach has been recommended that is, in essence, a set of experiments that attempt to establish causal links between aid and outcomes. Communities are identified either as recipients of a particular kind of aid project or as a control group. The projects must proceed with the same metrics and the same aid established at the outset to ensure the integrity of the experiment. However, controlled experiments are not the only way to measure outcomes and do not appear to be well suited to CTR programs. The needs and objectives of each project may be unique to the partner country and the environmental factors and objectives for the program change. It may be trivial to establish causal links to some desired outcomes and simply impossible for others.
If sustainability is an important objective for the CTR Program, change needs a more prominent role in DoD’s thinking, because it will be difficult to address sustainability without considering time and change explicitly. In the DoD Metrics Report, sustainability is mentioned as an objective for some programs, but the only factor considered in evaluating the sustainability of a project (the only metric) is cost (i.e., can the partner country pay for the program for the few years after the end of the CTR project). There is more to sustainability than cost and while measuring sustainability may be difficult, it is not impossible.
Evolution of Metrics Over Program Lifecycle
There is a natural evolution of cooperative threat reduction programs that should in principle be reflected in the metrics that measure impact and effectiveness. The metrics that are most useful and informative in the early stages of a program, where defining the ultimate program scope and priorities are a central focus, will generally differ from those that warrant closest attention toward the end of a program’s life cycle, where issues of sustainment and close-out come to the forefront. Some aspects of this evolution are already evident at least implicitly in the metrics described in the DoD Metrics Report, for example, the increased emphasis on sustainability and on partner country follow-through. The committee believes this concept of evolution of metrics should be more explicitly considered in future iterations of CTR metrics so that the progression of CTR activities through the successive phases would be more visible and prominent.
In many fields of application, such a progression is described in terms of “maturity models.” Examples include:
• Quality management. in his book Quality is Free, Crosby (1992), introduced a five-stage quality maturity model, which described the phases of a quality improvement program from inception to maturity, with the nature of the challenges evolving along the way. Although some metrics apply across all stages, e.g., measures of quality, others come and go as a program progresses through the five stages.
• Information technology, enterprise architecture, and software. Maturity models have been developed for many facets of information technology and a vast literature exists that could, with appropriate adaptations, be instructive for CTR programs. For example, for building enterprise architectures (EA, somewhat analogous to building threat reduction architectures) five stages have been defined: Stage 1: Creating EA Awareness; Stage 2: Building the EA Management Foundation; Stage 3: Developing the EA; Stage 4:
Completing the EA; Stage 5: Leveraging the EA to Manage Change. Clearly, some adaptation to the threat reduction context is necessary, but the basic stages—awareness, planning and design, building, and so forth, have parallels. For an entry point to the literature on enterprise architecture maturity models, see for example GAO (2003), and the references therein. DoD and other agencies have their own agency-specific products in this area as well, e.g., Department of Defense Architecture Framework.
Many maturity models have their roots, directly or indirectly, in concepts of process control or quality control pioneered by Shewhart, Deming, and others in the first half of the twentieth century which defined process and quality improvement in terms of an iterative improvement cycle, often described as plan, do, check, act, or PDCA. Depending on the field of application, the basic PDCA, stages may also be described as planning, implementation, evaluation, specification, production, inspection, always followed by iterative improvement cycles repeating the same basic steps.
The committee is not recommending a particular maturity model or vocabulary because the concepts are most useful if adapted to the problem at hand. The key point is that for CTR programs there is often a natural progression of stages from conception to completion, and natural metrics for each stage. Although details may differ from program to program, a series of questions often arise at each stage:
• What is the scope of the threat reduction challenge? Metrics can include the numbers and types of objects (sites, facilities, weapons, materials, infrastructure, people) that collectively make up the threat to be reduced.
• What tools are needed to manage or reduce the threat? Metrics include the delivery of specific tools (equipment, training, procedures, personnel, etc.).
• Are the tools being used, and used properly? Tests, exercises and routine evaluations can furnish metrics on the extent to which the tools are being used.
• Are the threat reduction capabilities, as implemented, effective? Having and using the tools is not by itself sufficient to ensure effectiveness. Metrics that measure results rather than merely outputs are needed at this stage.
• Is there a system in place to maintain and ensure effectiveness on an ongoing basis, and initiate corrective actions if necessary? Many of the sustainability metrics that are now being introduced are aimed at this stage.
At any given time, a program is likely to be focused mainly on one or two stages. Nevertheless, the committee believes it is helpful to consider and present the larger context as well. The overall scope of the threat reduction challenge and the portion that a given program is attempting to tackle is important contextual information that helps keep the overall objectives in focus over the overall program lifecycle even as more specific output- and activity-based metrics are the central focus during a given phase of a program. Even if different metrics are applied at various stages during the conduct of a project, it would be useful to have developed the various metrics from the start, recognizing that they might have to change.
OTHER MAJOR ISSUES FOR CTR IN THE FUTURE
Scope of the CTR Mission
It is beyond the scope of this study to say what is in or outside of the CTR mission. Some authorizers and appropriators questioned whether CBEP is in fact a defense mission. Fundamentally, whether DoD should be the agency to carry out the CBEP mission is only secondarily a metrics question. The primary question is whether the U.S. Government wishes to prioritize the work done under CBEP and what mix of government agencies is best equipped to carry it out. The increases in budget and scope to date, as well as the National Strategy for Countering Biological Threats, indicate that CBEP is a growing priority to the Administration, and DoD’s involvement reflects a conscious choice to use DoD because of its experience establishing on-going cooperative medical and bioresearch ventures (e.g., NAMRU-3 in Cairo and NAMRU-6 in Lima), conducting biodefense research, and working on threat reduction. Critics may dispute the decision to support the mission, to give DoD responsibility for the mission, or to give Defense Threat Reduction Agency responsibility for implementation, and they can legitimately point out that difficulties in developing reliable direct metrics, for the program’s impact and effectiveness raise the programmatic risks of the program, but mixing these issues with questions about the metrics themselves confuses matters and makes it more difficult to make progress in the program and in the debate about the program.
Recognizing Success/Completion
Finally, defining and measuring completion—how do we know when we are done?—and sustainability—will the changes take hold and will the partner nation support and sustain the programs when U.S. funding stops?—are critically important for the CTR programs, particularly the capacity building programs. What these mean and how they should be implemented and measured for a given program should be part of the formulation of objectives. There is a mismatch in the vision of sustainability and measuring completion of the program among different CTR decision makers in the Administration and on Capitol Hill. One vision might be called a project view, in which DoD partners with a nation, engages in a set of concrete activities with a well defined beginning and end, and then DoD exits and monitors sustainment after project completion. The other main vision might be called a relationship view, in which DoD partners with a nation, works with the partner to build a joint or multilateral network that is exercised regularly to maintain an on-going relationship with no defined end date. These visions appear mutually exclusive, but there are different phases to capacity building programs: the initial phase may involve intensive efforts and capital expenditures. There should be schedules and milestones for completion of this phase. The long-term relationship that follows may be open ended, but it also should require far less funding, which should allay concerns about programs with no exit strategy.


























