
6
Implementation and Data Recommendations
This report contains two types of recommendation for improving productivity measurement: those that are conceptual and those that address issues related to implementation of new measures and data development. The model presented in Chapter 4 requires specific data inputs and, while considerable progress can be made using existing sources such as the Integrated Postsecondary Education Data System (IPEDS) of the National Center for Education Statistics (NCES), an ideal productivity measure will require new or improved capabilities as well.
In moving forward with plans to implement productivity measurement, program administrators will not be able to do everything suggested by this panel (and by others1) all at once. It is helpful, initially, to simply take stock of information that is available on input and output trends at various units of analysis, and then consider how far—with that data—one can get in constructing measures. This type of demonstration was a major motivation for working through the model presented in Chapter 4 using real data examples.
More generally, both with and beyond our model, we want to know how well—with current data and approaches—we can address questions of policy interest that arise:
- If measurable outputs have increased while resources have been stable or declining, has quality suffered?
________________
1See recommendations by the National Postsecondary Education Cooperative (2010).
- If outputs have declined while resources have increased or remained stable, has quality changed correspondingly?
- How do productivity trends in comparable states, institutions, or departments compare?
- Have changes in education delivery mode, student characteristics or important contextual variables (economic, demographic, political, institutional) had a measurable bearing on the trends?
- Are there clear indicators (spikes, dives, or other anomalies) that suggest data problems to be cleaned (as opposed to sudden changes in performance)?
- What evidence or further research could be brought to bear to answer these questions in the next step of the conversation?
The more accustomed administrators, researchers, and policy makers become to conversations that incorporate these kinds of questions, the better the selection of metrics and the potential to understand them are likely to become, and the more evident the need for high-quality data.
A general strategy of implementing improved metrics for monitoring higher education begins with the following assertions:
- Productivity should be a central concern of higher education.
- Policy discussions of higher education performance will lack coherence in the absence of a well-vetted and agreed upon set of metrics.
- Quality of inputs and outputs—and particularly changes in them—should always be a core part of productivity measurement discussions, even when it is not fully or explicitly captured by the metrics. Alternatively put, productivity measurement is not meaningful without at least a parallel assessment of quality trends and, at best, a quality dimension built directly into the metric.
- Some elements relevant to measuring productivity are difficult to quantify. This should not be used as an excuse to ignore these elements or to avoid discussions of productivity. In other words, current methodological defects and data shortcomings should not stunt the discussion.
Additionally, in devising measures to evaluate performance and guide resource allocation decisions, it is important to anticipate and limit opportunities to manipulate systems. The potential for gaming is one reason many common performance metrics should not be relied on, at least not exclusively, in funding and other decision-making processes. Simply rewarding throughput can create distortions and counterproductive strategies in admissions policies, grading policies, or standards of rigor. Clearly, a single high-stakes measure is a flawed approach; a range of measures will almost always be preferable for weighing overall performance. We note, however, that monitoring productivity trends would not be
introducing incentives to a world without them. Among the major incentives now in place are to enroll students, acquire research grants, improve standing in rankings, raise money, and win athletic competitions. The recommendations in this report are merely adding another incentive (and one more worthy than a number already in play) that will help round out the current set.
6.2. RECOMMENDATIONS FOR IMPROVING THE DATA INFRASTRUCTURE
A major element of the prescription for improving productivity measures for higher education involves developing more accurate and new kinds of information. Thus, identifying data needs is a key part of the panel’s charge. Much has been implied in this regard throughout the report and some specific data needs were highlighted in Chapter 4. Here, we reemphasize these in the form of additional recommendations. In thinking about new approaches, the panel had an advantage over practitioners and administrators in being able to think in terms of future goals by recommending changes to IPEDS, coordination of other existing data sources, or development of new data approaches altogether.
6.2.1. Data Demanded by the Conceptual Framework
The categories of data demanded by the modeling framework are, broadly:
- Output/Benefit information. Basic institutional data on credits and degrees can be enhanced through linkages to longitudinal student databases. In addition to their role in sharpening graduation rate statistics, longitudinal student surveys are needed to more accurately estimate degree costs, degree earnings value, and input/output quality.2
- Input/Cost information. Sources include institution and state-based expenditure accounting data; basic information about faculty time allocations3; and student unit records.
Ideally, for higher education, underlying data for productivity measurement would be as detailed and accurate as it is for the best-measured sectors of the economy. Information requirements—including the need for data at more granular levels,
________________
2Data Quality Campaign, 10 Essential Elements of a State Longitudinal Data System, see http://www.dataqualitycampaign.org/survey/elements [January 2012].
3IPEDS provides some data on teaching loads; the Delta Cost Project (2009) includes some data on staffing. One could push for time use surveys of faculty time allocations, including hourly accounts of research activity, instruction, and service. This would be difficult though as faculty do not bill by the minute or hour, and much research is done off-campus; furthermore, how would conceptual breakthroughs or mental crafting of language be accounted for when they occur during the course of another activity, such as teaching or hiking?
and input and output quality indicators—extend beyond what is currently available in IPEDS and other sources, though these provide an excellent start.
Another logical source of information to support productivity measurement is the quinquennial economic census surveys, a reliable source of expenditure and other data—including total labor costs and total hours—for most sectors of the economy, including many nonprofits. Statistics for other service industries have improved a great deal in recent years, in part as a result of periodic enhancements to the economic census. However, Bosworth (2005:69) notes that “the higher education community successfully lobbied to be exempted from these reporting requirements; thus the Census Bureau is blocked from gathering data and we lack even the most basic information about the education industry. For example, we do not know with any degree of detail who is employed in higher education, how much capital is being spent, or how many computers are being used.”
The higher education sector has not been covered in the economic census since 1977, when it was introduced there (it only appeared once). This decision to omit this sector should be revisited, specifically to evaluate the costs of reintroducing it to the census and the benefits in terms of value added to existing data sources.
Recommendation (12): Every effort should be made to include colleges and universities in the economic census, with due regard for the adequacy of alternative data sources and for the overall value and costs added, as well as difficulties in implementation.
The Department of Education could require that institutions file the census forms in order to maintain eligibility to participate in Title IV programs.
For purposes of constructing the National Income and Product Accounts (NIPAs) and productivity measures, BEA and BLS may also benefit from such a reversal of policy. Census data would provide details on employment by broad categories (it is now difficult to find statistics on employment in higher education industry), along with a range of other operational and performance information. It would facilitate construction of value-added statistics for most of the inputs (including capital goods) that are useful for broad measures of productivity. Additionally, participation in the economic census would harmonize data reporting formats used in other industries. An alternative to this recommendation would be to take advantage of the established IPEDS framework, which includes institution identifiers, and then import economic census style questions into it.
6.2.2. Envisioning the Next Generation IPEDS
IPEDS provides valuable information annually (or biannually) on institutional characteristics, degree completions, 12-month enrollment, human resources (employees by assigned position, fall semester staff, salaries), fall semester
enrollment, finance, financial aid, and graduation rates for all private and public, nonprofit and for-profit postsecondary institutions that are open to the general public and that provide academic, vocational, or continuing education for credit.4 Even so, fully specified productivity measurement of the type envisioned by the panel requires more complete and different kinds of information than what is currently available in IPEDS. For some purposes, greater data disaggregation, such as at departmental levels, and quality dimensions are needed. More comprehensive longitudinal student databases are essential for calculating better tailored and more clearly defined graduation rates and for estimating full degree costs and values.
Box 6.1 summarizes IPEDS data that may be useful in the measurement of higher education productivity, enumerating its significant advantages and remaining challenges for its improvement.
For the model proposed in Chapter 4, institutional data submission requirements are not exceedingly onerous. As noted above, many of the needed variables—credit hours, enrollments, degrees—are already reported to IPEDS. The most significant change required to fully implement output differentiation is to link credit hours to degree or field.
Recommendation (13): Institutions should collect credit-hour data that track both individual students and the departments of record. The necessary information exists in most institutions’ student registration files. IPEDS should report these data along with the numbers of degrees awarded.
Chapter 4 provides details about how exactly the credit-hour data should be structured and the statistics extracted.5
A side benefit of following students is that it creates new opportunities for calculating more sophisticated graduation rates as well. Cohort-based statistics such as those produced through IPEDS Graduation Rate Survey typically restrict the denominator to first-time, full-time students. For institutions that enroll large numbers of part-time students and beginning transfers, this will not yield a meaningful number.6 Including these students in the cohort allows for more
________________
4See http://nces.ed.gov/ipeds/ [July 2012].
5In applying this approach to, among other things, discover the course components that go into producing a certain kind of degree, credit hours could be calculated by degree program and institution one time and the results applied in subsequent cohorts for that institution. The calculation may not have to be done every year, though that might not be such an onerous task once systematized. “One-time” benchmarks that are refreshed periodically may be adequate.
6NPEC (2010) offers recommendations for (1) counting and defining the composition of an initial cohort of students; (2) counting and defining who is a completer; (3) understanding the length or time of completion; and (4) incorporating students who transfer out of an institution. Available: http://nces.ed.gov/pubs2010/2010832.pdf [July 2012]. The panel agrees with most of these recommendations.
BOX 6.1
Integrated Postsecondary Education Data System (IPEDS)
IPEDS describes itself as “the primary source for data on colleges, universities, and technical and vocational postsecondary institutions in the United States.” Elements of IPEDS will be essential to most attempts to measure productivity in a consistent manner across state lines, within states that do not have their own consistent statewide reporting processes for all public institutions, and across both public and private institutions. IPEDS collects detailed descriptive data from all public and private institutions in the United States that wish to be eligible for federal student financial aid, which almost all do.
Productivity-Related Content
Completions
Degrees and certificates awarded are the only elements of the IPEDS system that are broken down by discipline. They are reported for every institution, with field of study and degree level (e.g., associate, bachelor, > one-year certificate, etc.), first/second major, and student demographic characteristics.
Finances
Expenditures are reported by the purpose of the expense (e.g., instruction, research, public service, student services, academic support, etc.) and by the type of expense (i.e., salaries, benefits, plant operations, depreciation, and other). For measurement of instructional productivity using IPEDS data, the direct instructional and student services expenses, plus a prorated share of academic support, institutional support, and plant operations constitute the relevant portion of the total expenditure.
Enrollment
Student credit hours are a core measure for productivity analysis. IPEDS collects only aggregate data on undergraduate and graduate enrollments for each institution. Definitions provided to reporting institutions allow for translation among different calendar systems and for calculation of full-time equivalent enrollments based on numbers of semester/quarter/clock or other units.
Institutional Characteristics
This file contains elements that could be used to group like institutions for productivity analysis. Relevant groups include Carnegie classification, public or private control, Historically Black College and Universities, geographical details, etc.
Human Resources
For degree-granting institutions, the number of employees and their compensation are reported by faculty and tenure status, and equal employment opportunity (EEO) category:
Staff whose primary responsibility is instruction, research, and/or public service:
- Executive/administrative/managerial
- Other professionals (support/service)
- Technical and paraprofessionals
- Clerical and secretarial
- Skilled crafts
- Service/maintenance
Advantages
- IPEDS is the primary national data source for cross-sector and cross-state comparisons.
- Terms are defined independently of state or system-level categories.
- Completions data are reported at a high level of detail.
- IPEDS does not change quickly. Most data fields have been consistently defined over many years, allowing for reliable analysis of trends.
Challenges
- Credit-hour enrollments, staffing patterns, and finance data are available as aggregate numbers only, with no discipline-level detail.
- Incoming student data are limited. Other than a few average data points in the Institutional Characteristics file, IPEDS does not have information about students’ level of academic preparation (including remediation or advanced placement), credits transferred in, socioeconomic background, or academic objectives at time of entry.
- IPEDS does not change quickly. Changes typically require strong consensus among institutions, Congressional action, or both, and take many years to implement fully.
- Institutional interpretations of human resources categories, and to a lesser extent finance and degree discipline classifications, vary widely in practice. Required human resources files are designed primarily for equal opportunity reporting and auditing, rather than productivity analysis.
- For cross-institution comparisons of costs and outcomes, researchers need data on discipline mix. Many state systems already identify enrollment by major in their data sources. Classification structures in IPEDS are complicated by varying levels of interdisciplinarity among institutions, different types of academic organization, evolution of categories over time, and external factors such as financial incentives to encourage students to major in STEM fields or to award more degrees in those areas. Weights assigned to disciplines for the purpose of assessing productivity would also risk creating external pressure to adjust discipline classification. Data on distribution of degrees granted across majors has been shown to be an important predictor of six-year graduation rates in many educational production function studies. Given this coverage, it is not clear that collecting data on departmental level progression of students makes sense, especially since there is so much movement of students across fields of study during their period of college enrollment.
completeness; however it can also create new problems because part-time students have differing credit loads and transfer students bring in varying numbers of previously earned credits. This renders fair comparisons difficult because, unlike the first-time full-time population, not all subpopulations are starting from the same baseline.
On the labor input side of the production function, it would be helpful to have data that clarifies more detailed categories for employees. IPEDS does not distribute labor hours into all categories; it does include the proportion of FTE allocated to instructional time. A complete dataset underlying productivity measurement would identify major job categories and how time is allocated on average at a given level of aggregation. In Chapter 5, we recommended that institutions be charged with collecting data on employees by personnel category, making time allocation approximations—focusing on instruction, research, and service—and reporting the results in a revised IPEDS submission that would be subject to the same kind of audit used by other agencies in data collection.
A number of international data efforts are already heading in these new directions, developing microdata and quantitative indicators for higher education institutions, including time in research and other activities. The European Commission, for example, appointed the EUMIDA Consortium to “explore the feasibility of building a consistent and transparent European statistical infrastructure at the level of individual higher education institutions” (Bonaccorsi, Daraio, and Simar, 2006). The goal of the project is to “provide institutions and policy makers with relevant information for the benchmarking and monitoring of trends for modernisation in higher education institutions…. [M]ost European countries collect data on their universities, either as part of R&D and higher education statistics or as part of budgeting/auditing systems.”7 U.S. educational institutions and the Department of Education may benefit from assessing these efforts.
6.2.3. Administrative Data Sources
Beyond IPEDS, a number of existing administrative databases can be tapped in constructing useful performance measures. The potential of the kinds of administrative data sources described below depends heavily on the ability of researchers and policy analysts to link records across state boundaries and across elementary, secondary, postsecondary, and workforce boundaries (Prescott and Ewell, 2009). This, in turn, depends upon the presence of secure unique identifiers, such as social security numbers, in all the databases of interest. At present, use of such identifiers is limited (or, more importantly, is perceived to be limited) by the provisions of Family Educational Rights and Privacy Act (FERPA) regulations. Clarification or re-regulation of FERPA might considerably enhance the usefulness of these administrative databases.
________________
7See http://isi.fraunhofer.de/isi-de/p/projekte/us_eumida.php [July 2012].
Much of the potential of source linking involves data collected and maintained at various levels, ranging from local to federal. For example, administrative data such as that maintained by the IRS’s Statistics of Income program and by the Social Security Administration (SSA) can enhance the robustness of studies of the economic benefits associated with postsecondary education (Dale and Krueger, 2002). In principle (and with due attention to legal confidentiality), longitudinal files linking individuals’ earning and their educational attainment can be created. BLS data and states’ Unemployment Insurance Wage Recordscould be substitutes for this as well; typically, this kind of research must take place in census data centers.
Institutional and System-Level Data
In many instances, information on higher education inputs and outputs can be obtained inexpensively from institutions’ accounting and management systems. In fact, much of the detailed data on human resources and finances needed for ideal analysis of productivity is maintained only by institutions. Many systems and institutions have studies that distinguish expenditures and staffing by discipline and course level in ways that are well suited to the type of analyses recommended in this report.
Micro-level data related to learning outcomes and program quality—for example, exam results and assignments, course evaluations, student surveys, and faculty and staff credentials—are also available in some cases. As has been noted throughout this report, longitudinal student data is especially valuable for tracking the quality of incoming students and the value of higher education attainment. An example of this kind of resource is the longitudinal study recently developed for the University of Virginia that collects data on students following them from kindergarten through college, and then adds the capacity to link to unemployment insurance job records thereafter.8
Among the advantages of institution and state-level data are their high levels of detail and accuracy, which are necessary to support evaluation of quality within programs, departments, institutions, and systems. Among the challenges found in institution and state-level data are that methods developed to support day-today business operations are often not well configured for research and analysis. Further, data are often not comparable across institutions or across time since they have been built up historically using different practices, and tend to focus more on financial information than on the physical data needed for productivity measurement (see Figure 6.1).
________________
8The project is being developed by the State Council of Higher Education for Virginia, which makes higher education public policy recommendations, and it will be available to researchers with appropriate safeguards to ensure confidentiality of records.
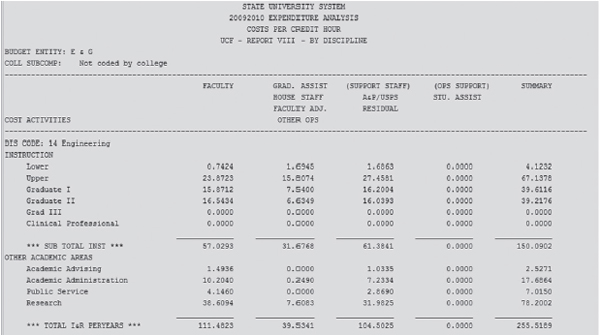
FIGURE 6.1 “Person-years” reported for Engineering at one university, by activity type, 2009-2010.
SOURCE: State University System of Florida Expenditure Reports. Available: http://www.flbog.org/about/budget/expendanalysis.php [October 2012].
State Student Unit-Record Databases
All but five states have constructed databases that cover enrollments and degrees granted in higher education (Garcia and L’Orange, 2010). At minimum, student-level databases contain one record for every student enrolled in a given term or year in all of the state’s public institutions. Many have expanded data content that includes detailed academic activities such as specific course enrollments, placement test scores and remedial work, and financial aid sources. Many of these state sources have also begun including data from nonpublic institutions (both proprietary and not-for-profit). Records can, in principle, be linked together to create the kinds of longitudinal databases required to analyze retention, degree completion, and patterns of student flow among institutions within a state. Increasingly, they are being linked with similar databases addressing elementary and secondary schooling and entry into the workforce to enable large-scale human capital studies.
The primary challenges to effective use of these databases are (a) the lack of standardized definitions across them, (b) incomplete institutional and content coverage, and (c) relative inexperience in linking methodologies to create comprehensive longitudinal databases. Federal action to standardize data definitions and to mandate institutional participation in such databases as a condition of receiving Title IV funding would help stimulate productive use.
Recommendation (14): Standardization and coordination of states’ student record databases should be a priority. Ideally, NCES should revive its proposal to organize a national unit record database.
Such a data system would be extremely valuable for both policy and research purposes. This is a politically difficult recommendation that may take years to realize. In the meantime, progress can be made through the adoption of standard definitions, based on IPEDS and the Common Data Set, for all data elements in state longitudinal databases, plus linkages among them.9
Valuable administrative data are also collected and maintained by state and federal agencies. Wage record and employment data are among the most relevant for estimating productivity and efficiency measures.
Unemployment Insurance Wage Record Data
Under federal guidance, all states maintain databases of employed personnel and wages paid for the purpose of administering unemployment compensation programs. These employment and earnings data can be linked via Social Security Numbers (SSNs) to educational data by researchers interested in estimating such things as return on investment for various kinds of postsecondary training programs and placement rates in related occupations.
The comparative advantage of Unemployment Insurance (UI) data is in its capacity to provide aggregate estimates of outcomes—earnings by industry—for graduates and nongraduates. Additionally, such data are not easily subject to manipulation. The value of UI data for productivity measurement is most obvious for comparatively sophisticated models wherein outputs (i.e., degrees) are weighted in proportion to their contribution to students’ short-term or lifetime earnings potential or other career-related outcomes; or studies that make use of employment records to track and compare the earnings of graduates in different disciplines to establish weights. There may also be uses for these data in assessing compensation of higher education personnel and in establishing the quantities or weights of inputs in calculations of productivity.
Though a powerful national resource, the potential of UI data is limited by several factors. First, most UI systems contain data only at the industry level for the reported employee, and not the actual occupation held within that industry. Industry is not always a good proxy for occupation. Universities, for example, employ police officers, landscapers, and social workers. Some employees may thus be misclassified when conducting placement studies—for example, a nurse working in a lumber camp being classified as a forest products worker. A simple
________________
9This kind of work is being piloted by the Western Interstate Commission for Higher Education, Gates Foundation data sharing project. The panel also applauds work ongoing by the Common Data Standards Project, currently under way at the State Higher Education Executive Officers association.
fix that federal authorities could make would be to mandate inclusion of the Standard Occupational Classification (SOC) code in all state UI wage records. Second, each state maintains its own UI wage record file independently under the auspices of its labor department or workforce agency. And, whether for postsecondary education or employment, it is difficult to coordinate multi-state or national-level individual unit record databases. For this reason, state databases cannot track cohorts of graduates or nongraduates across state lines without some agreement to do so.
Recommendation (15): The Bureau of Labor Statistics should continue its efforts to establish a national entity such as a clearinghouse to facilitate multi-state links of UI wage records and education data. This would allow for research on issues such as return on investment from postsecondary training or placement rates in various occupations.
Such an entity could also begin to address a third major limitation of UI wage records—the fact that they do not contain data on individuals who are self-employed or employed in the public sector. Linkages to public employee and military personnel databases could be established on a national basis and self-employment earnings and occupation data, with the appropriate privacy safeguards, might be obtained from the IRS. Additionally, economic analyses of earnings often require looking many years after graduation to see the economic value of some degrees (some biology majors, for example, may have low reported earnings during medical school and residency programs, but very high wages afterward).
State Longitudinal Databases
Many states have databases that allow for longitudinal studies of students from K-12 education through postsecondary enrollment, degree completion, and beyond. The U.S. government has contributed significant resources in an effort to create or expand these databases over the last several years. For example, late in 2010, the U.S. Department of Labor, through its Workforce Data Quality Initiative, awarded more than $12 million to 13 states to build or expand longitudinal databases of workforce data that could also be linked to education data. As described in Chapter 2, these kinds of data are essential for research into and policy analysis of the link between employment and education, and the long-term success of individuals with varying levels and kinds of education.
Databases vary in age, depth, and breadth, all of which affect how they can be used for productivity measurement. The state-maintained databases all contain student-level enrollment and degree completion information, usually with aggregate numbers of credit hours—all useful for productivity measurement. They vary in the extent to which they include specific course-level detail. Many contain data about K-12 preparation, which affects productivity in higher education in the
sense that similar degrees represent different quantities of achievement (levels of preparedness) for different students. Many also include at least some data from private postsecondary institutions. Another asset of these kinds of databases is that they allow for analysis that crosses institutional boundaries. They also present many challenges: (1) the nature of the gaps in data vary by state; (2) access to records can be subject to state political considerations; (3) they are less useful in states with substantial mobility across state lines; and (4) they include no or only limited amounts of financial or human resources data.
National Student Clearinghouse
The National Student Clearinghouse (NSC) is a national postsecondary enrollment and degree warehouse that was established about fifteen years ago to house data on student loan recipients. It has since been expanded to include enrollment records for more than 94 percent of the nation’s postsecondary enrollments and almost 90 percent of postsecondary degrees, essentially rendering it a national database.10 Its primary function is administrative, verifying attendance and financial aid eligibility for the Department of Education, among other things. It also provides limited research services.
Proof of concept studies have demonstrated that the data contained in NSC records are capable of grounding accurate longitudinal tracking studies of college entrance and completion regardless of place of enrollment, thus overcoming one of the major limitations of state SUR databases (Ewell and L’Orange, 2009). Often when a student fails to re-enroll at an institution or within a state system of higher education, there is no record to indicate whether the student transferred or re-enrolled elsewhere, and therefore no way to know whether the credits earned prior to departure are part of an eventual credential. Similarly, when a degree is awarded, there is often imperfect information about the different institutions a student may have attended prior to the degree award from the graduating institution. NSC’s matching service can fill in some of these gaps for institutional or state-level cohorts of students. The major advantage is that it can provide information about cross-institution, cross-state, and cross-sector enrollments and degrees awarded that would not otherwise be available.
The major drawback of harnessing these data for such purposes, however, is the fact that reporting to the NSC is voluntary: institutions provide data because they get value in return in the form of the ability to track, and therefore account for, students who have left their institutions with no forwarding information. As a result, some safeguards on the use of NSC data for research purposes would need to be established and enforced. Additionally, only the enrollment and degree award events are recorded. Although 94 percent of college enrollments are represented, states and institutions with a disproportionate share of the nonparticipants
________________
10Available: http://www.studentclearinghouse.org/ [July 2012].
may not be able to benefit. Some researchers are also reporting problems with the matching algorithms that make the data difficult to use and interpret correctly.11
6.2.4. Survey-Based Data Sources
In this section, we describe several survey-based data sources that have value to developers of productivity and other performance metrics. A fuller accounting of data sources is provided in Appendix C.
NCES Postsecondary Sample Surveys
The National Center for Education Statistics conducts a number of relevant surveys: Baccalaureate and Beyond (B&B), Beginning Postsecondary Students (BPS), National Postsecondary Student Aid Survey (NPSAS), National Survey of Postsecondary Faculty (NSOPF), and the Postsecondary Education Transcript Study (PETS).12 These surveys use large national samples to provide research and policy answers to questions that cannot be addressed from IPEDS. They include information about students’ level of academic preparation, transfer patterns, socioeconomic status, financial resources, aid received, academic and nonacademic experiences during college, and persistence and degree attainment. NSOPF includes data about faculty activities, but have not been administered since 2003-2004. The samples are structured to provide reliable samples at the level of institutional sector (public four-year, two-year, private four-year, etc.) across the United States. Only limited additional disaggregation is possible without losing statistical significance.
This set of surveys includes content in a number of areas that is relevant to productivity measurement. What an institution contributes to a student’s education should ideally be separated from what a student brought with him or her, in terms of credits earned elsewhere, level of preparation in earlier levels of education, and other experiences and aptitudes. NPSAS and its offshoots can help to assign the contribution share for degrees to multiple institutions or sectors when students transfer (as a significant percentage do), and to distinguish what institutions are contributing from what students bring with them at entry.
The BPS survey, conducted on a subset of NPSAS participants, is especially important for understanding sector-level productivity nationally, and has typically been started with a new cohort every eight years.
________________
11See http://www.spencer.org/resources/content/3/documents/NSC-Dear-colleagues-letter.pdf [July 2012].
12Baccalaureate and Beyond: http://nces.ed.gov/surveys/b%26b/; Beginning Postsecondary Students: http://nces.ed.gov/surveys/bps/; National Postsecondary Student Aid Survey: http://nces.ed.gov/surveys/npsas/; National Survey of Postsecondary Faculty: http://nces.ed.gov/surveys/nsopf/; and Postsecondary Education Transcript Study: https://surveys.nces.ed.gov/pets/ [July 2012].
These datasets have several positive attributes. Samples attempt to represent all students in U.S. higher education; longitudinal follow-ups track attainment across institutions, sectors, state lines; and students entering with different levels of preparation can be distinguished. They also present a number of challenges. National surveys are, by design, not useful as state- or institution-level resources; surveys are administered infrequently; and surveys are costly to implement and to scale up.
National Science Foundation
The National Science Foundation (NSF) conducts surveys on sciences and engineering graduate and postgraduate students.13 Information is collected on type of degree, degree field, and graduation date. Data items collected in NSF surveys are more attuned toward understanding the demographic characteristics, source of financial support and posteducation employment situation of graduates from particular fields of science, health, and engineering. These data are useful in understanding trends in salaries of science, technology, engineering, and mathematics (STEM) graduates.
NSF surveys concentrate on degree holders only. The sampling frame does not include individuals who have not graduated from a higher educational institution. There is no information on credits completed by degree and nondegree holders. Although the sampling frame is limited for purposes of calculating institutional productivity for undergraduate programs, it does collect information on post-bachelor degree holders, postdoctoral appointees, and doctorate-holding nonfaculty researchers. Sampling techniques and data items collected also make the NSF data useful for calculating department level (within STEM fields) output in terms of research and academic opportunities available to graduates.
The NSF survey of academic R&D expenditures is valuable to federal, state, and academic planners for assessing trends in and setting priorities for R&D expenditures across fields of science and engineering, though it is not directly related to instructional productivity.14 It has potential for indirect use in estimating the volume of research expenditure, by discipline, at different institutions in order to better untangle joint products. In contrast, IPEDS provides only aggregate research expenditure, with no disciplinary detail. This NSF survey may be the only national source for this limited purpose.
________________
13See http://nsf.gov/statistics/survey.cfm [July 2012].
14Survey description: http://www.nsf.gov/statistics/srvyrdexpenditures/ and WebCaspar data access: https://webcaspar.nsf.gov/ [July 2012].
Census and the American Community Survey
The American Community Survey (ACS), which replaced the Census long form, is a national sample survey of 2 million households that became fully implemented in 2005. ACS data are used to produce estimates for one-year, three-year, and five-year periods. Each month, the ACS questionnaire is mailed to 250,000 housing units across the nation that have been sampled from the Census Bureau’s Master Address File.15 As with the long-form of the Census, response to the ACS is currently required by law. The questionnaire has items on sex, age, race, ethnicity, and household relationship. Each observation is weighted to produce estimates. Weighting is done via a ratio estimation procedure that results in the assignment of two sets of weights: a weight to each sample person record, both household and group quarters persons, and a weight to each sample housing unit record. There are three education-related variables in the ACS: college or school enrollment in the three months preceding the survey date, current grade level, and educational attainment, including field of bachelor’s degree. ACS collects data from households and group quarters. Group quarters include institutions such as prisons and nursing homes but also college dormitories.
In terms of value for productivity measurement, no information is collected on credit hours and colleges or universities attended or completed by survey respondents enrolled in college. The questionnaire has items on various sources and amounts of income, and details on occupation and work in the year preceding date of survey. ACS data thus provides descriptive statistics of educational status of various population groups (even in small geographic areas like census tracts), but it lacks relevant information to calculate institutional productivity. In the ACS, survey respondents change from year to year. No household or person is followed over time. Therefore it is difficult to understand educational pathways which other education-related data sources address. At best, ACS provides a snapshot of educational status of the U.S. population based on a sample size larger than that of other data sources.
The major attraction of the ACS, for the purposes here, is its comprehensive population coverage. Its limitations are that it is a relatively new survey, with data available from 2006; only three education-related variables are present and the data are not longitudinal.
Bureau of Labor Statistics
The Bureau of Labor Statistics (BLS) conducts two longitudinal surveys, the National Longitudinal Survey of Youth 1979 (NLSY79) and National Longitudinal Survey of Youth 1997 (NLSY97). These gather information on education and employment history of young individuals. The survey begun in 1979 is still ac-
________________
15See http://www.census.gov/acs/www/ [June 2012].
tive, over three decades later.16 The schooling survey section collects information on the highest grade attended or completed, earning of GED/high school diploma, ACT and SAT scores, Advanced Placement (AP) test (grades, test taken date, subject of test, highest AP score received), range of colleges applied to, college enrollment status, field of major and type of college degree (bachelor or first professional), number and types (two-year or four-year) of colleges attended, credits received, major choice, college GPA, tuition and fees, sources and amounts of financial aid. Survey respondents were administered Armed Services Vocational Aptitude Battery test and Armed Forces Qualifications Test (only for NLSY79 respondents and Peabody Individual Achievement Test for NLSY97 respondents) and the respective scores are available in the dataset. The employment section has items on types of occupations, education requirements and income in different occupations and pension plans. Along with sections on employment and schooling, both the surveys cover areas such as health, family formation, relationships, crime and substance abuse, program participation, etc.
The National Longitudinal Surveys of Youth are important. They can track a survey respondent over time across more than one educational institution. For each institution attended by the respondent, information on credit hours, degree attained and other associated variables are collected. Information about each institution attended (IPEDS code) is available in restricted files. Using the IPEDS code a researcher can access the institutional information available in IPEDS survey files. The database is also helpful in looking at multiple enrollment patterns, kinds of jobs held, and information on graduates’ salaries. The National Longitudinal Surveys of Youth are among the longest-running longitudinal surveys in the country.
Even though the NLSY samples are representative of the U.S. youth population, one cannot calculate institutional productivity for single colleges or universities, unless a sufficient number of observations is available. The survey collects information on institutions attended by survey respondents. Therefore it is not comprehensive because data covering a reasonable period of time are not available for all institutions.
Student and Faculty Engagement Surveys
Student and Faculty Engagement surveys gather information on learning gains and are available in different formats for different types of institutions. For two-year and four-year undergraduate institutions, both students and faculty
________________
16See http://www.bls.gov/nls/ [June 2012].
are surveyed. For law schools, only students are surveyed. Participation in these surveys is optional.17
The National Survey of Student Engagement and the Law School Survey do not gather information on final output such as degrees and credit hours. Rather, their focus is on intermediate outputs, such as learning during enrollment. The community college engagement survey asks students to report the range of credit hours completed rather than the exact number of credit hours. The faculty surveys collect information on full-time/part-time status, number of credit hours taught and rank. There is no survey of nonfaculty staff. No information is collected on faculty or staff salaries. Information gathered in the surveys can be supplemented by individual institutions by linking student responses to other institutional data. Results from the survey can be used to estimate sheepskin effects. As students report a field of major, the results can be used to deduce learning gains in various fields.
The most useful attribute of student and faculty engagement surveys is that they collect data at the individual institution level and can be tailored to specific needs. Among their drawbacks is that participation at institutional, faculty, and student level is optional; and facility to convert survey results to productivity measures has not been developed.
________________
17Beginning College Survey of Student Engagement: http://bcsse.iub.edu/; Community College Faculty Survey of Student Engagement: http://www.ccsse.org/CCFSSE/CCFSSE.cfm/; Community College Survey of Student Engagement: http://www.ccsse.org/aboutsurvey/aboutsurvey.cfm/; Faculty Survey of Student Engagement: http://fsse.iub.edu/; Law School Survey of Student Engagement: http://lssse.iub.edu/about.cfm/; and National Survey of Student Engagement: http://nsse.iub.edu/html/about.cfm/ [July 2012]. The Community College Leadership Program at the University of Texas, Austin, conducts the community college survey. Other surveys are conducted by the Indiana University Center for Survey Research in cooperation with its Center for Survey Research.


















