
14- Data Citation in the Dataverse Network®
Micah Altman1
Director of Research, MIT Libraries
Head/Scientist, Program for Information Sciences
Non-Resident Senior Fellow, The Brookings Institution
Overview of the Dataverse Network
The Dataverse Network ® (DVN) project is an open source application for discovering, publishing, citing, and preserving research data. (See Crosas 2011 for a detailed description) Created by Gary King (2007), and based on over a decade of digital library research (Altman, et al. 2001), the DVN has been described as the “state of the practice” in open source data sharing infrastructure (Novak, et al. 2011).
The DVN functions as an institutional repository system designed specializing in quantitative data, a federated library and catalog system, and as virtual archiving system. There are multiple installations of the DVN software. Each “Dataverse Network” is hosted on its own host server, and hosts numerous virtual archives, each known as a “dataverse.” A Dataverse can act as a virtual archive for a journal, a department, a research group, an individual, or a library. The DVN server allows an institution to provide unified backup services, citation generation, discovery, preservation and other sorts of core services while enabling the owners of the virtual archives to manage content deposit, dissemination, terms of use, and branding.
Dataverse Networks can be used to host metadata, text, images, and data from many different disciplines. The first version of the DVN allowed deposit of any format, and provided enhanced services for individual microdata tables. Support for other data structures, such as social network data and time-series, have been added as the software evolved and as the evidence base of social science research has shifted (see Altman & Klass 2005; Altman & Rogerson 2008).
The first installation of the DVN was at the Harvard Institute for Quantitative Social Sciences (IQSS). That installation has been officially incorporated into the Harvard Library system, but remains open to researchers world-wide. It provides search, data access, and data hosting, at no charge. The Harvard DVN functions also as a federated catalog of over 50,000 social science data data sets, including the holdings of the Data Preservation Alliance for the Social Sciences [Altman, et al. 2009] and the Council of European Social Science Data Archives. The current holdings of the Harvard DVN are predominantly used for social science research.
Additional Dataverse Networks are hosted at the University of North Carolina, in Thailand, and elsewhere around the world. Most DVN’s are federated using the open-archives metadata protocol, and so almost five hundred virtual archives may be searched and browsed from a single location.
______________________
1 This is an updated, corrected, and expanded version of the original presentation, which is available at http://sites.nationalacademies.org/PGA/brdi/PGA_064019.
A data citation in depth
We will start with a brief example. Figure 14-1 below shows the home page from my own scholarly virtual archive (or “dataverse”). This is virtual archive contains all of the data that I have disseminated as part of my own research. Note that although this virtual archive is organized as a single collection, many of the datasets listed actually are distributed by different archives, and may be stored in different locations.
FIGURE 14-1 Micah Altman’s Dataverse.
Shown below is the catalog page for a particular dataset in this collection. The catalog page for this dataset shows descriptive information about it. The “data and analysis” tab (not shown), allows users to download the data itself, and to perform on-line analyses.
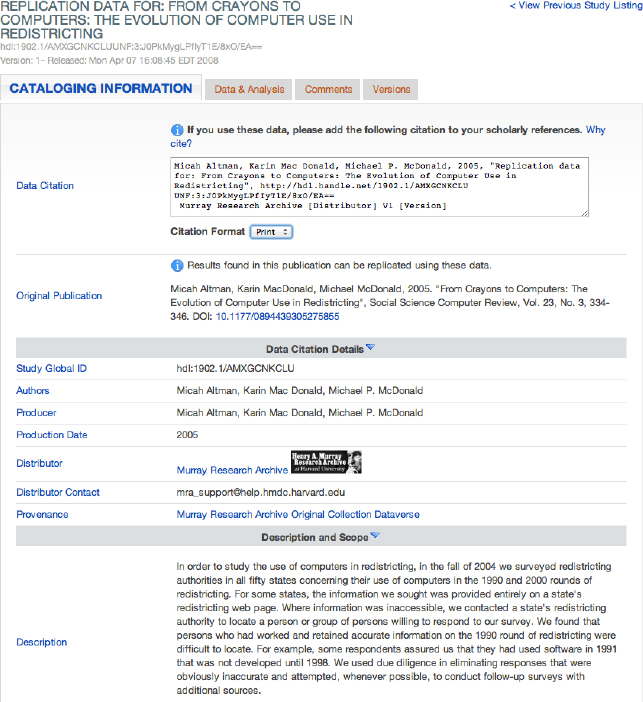
FIGURE 14-2 Catalog page for data to replicate “From Crayons to Computers: The Evolution of Computer Use in Redistricting.”
While this dataset is in my own scholarly dataverse, it is formally “distributed” by the Murray Research Archive, as indicated through the distributor information in the citation above. This indicates that the dataset was reviewed by the Murray Archive and complied with its selection policies. This also indicates that the Archive takes “archival” responsibility for it, and will continue to ensure its long-term availability. Other datasets in my collection are distributed by ICPSR, and by the IQSS Dataverse Network.
The DVN system provides several varieties of citation related to the dataset. One citation, shown below, is used for articles related to the dataset. In this case, the dataset is explicitly identified as a “replication dataset”, containing all of the information necessary to replicate a published article.

FIGURE 14-3 Citation for original publication with which data are associated.
The printed citation for the dataset is shown below. Note that it shows a separate persistent identifier and separate publication information, because, in this case, data and publication are distributed separately.

FIGURE 14-4 Printed data citation example.
The Dataverse Network software produces citations that are based on a community standard first proposed by Altman and King (2007). The hundreds of virtual archives (“dataverses”) using the system automatically produce these citations for all of their datasets. This standard is also in use by the member archives of the Data Preservation Alliance for Social Sciences (Data-PASS 2012).
The Altman-King standard is light-weight, as it requires a minimal number of elements, and does not impose a specific presentation on these. Data citations that follow this standard will, at a minimum, include the following information: author(s), date, title, and a persistent identifier that is drawn from any standardized and web-resolvable identifier scheme (e.g., DOI, handle, PURL, LSID). 2
This minimal citation standard has a number of extensions:
1. First, where feasible, the standard recommends the inclusion of a URI corresponding to the persistent identifier; a Universal Numeric Fingerprint, which provides fixity information; and explicit versioning information.
2. Second, a default ordering of the elements is suggested for presentation and parsing—but elements may be reordered if explicitly labeled.
3. Third, the standard is extensible, and citations can include elements from any other XML-ized citation schema, simply by using XPath syntax and labeling conventions. The Dataverse Network System currently uses these extensions to indicate the producer and distributor for the dataset.
______________________
2 In addition, Data-PASS recommends that (a) cited data be deposited in a archive, and (b) data citations be included in along with other publications in journal articles and indices—generally data citations should not be presented only in an ad-hoc location, such as the publication text, acknowledgement, figure labels or substantive footnotes.
4. Fourth, the standard provides an extension for citing subsets (portions) of the dataset. The Dataverse Network System uses this to create citations for each of the data extracts it produces.
These points are illustrated in the citation below, which is associated and drawn from a separate study in the independent Odum Dataverse Network. This citation includes optional extension fields imported from the Data Documentation Initiative (DDI) metadata standard, which are used to indicate the data distributor, version, and the attributes of the data subset extracted. Note that separate UNF’s are calculated for both the subset extracted and the dataset in its entirety.

FIGURE 14-5 Data subset citation example.
The Universal Numeric Fingerprint (UNF) is a novel part of the Altman-King citation standard. (The first version of the UNF algorithm was developed in Altman, et al 2003, and it has been extended in Altman-King 2007, and Altman 2008.) A UNF is a short, fixed-length string that summarizes the entire dataset. Thus it provides “fixity,” enabling a future user of the dataset to verify that the dataset they possess is semantically identical to the one originally cited in a publication. Similar to a cryptographic hash function, the UNF is tamper-proof, and will change if the values represented by the dataset change. Unlike a cryptographic hash, the UNF is invariant to the specific file format used to store/serialize the dataset. A UNF works by first translating the data into a canonical form; computing an approximation of that canonical form using a specified precision; and applying a cryptographic hash function to the approximation of the canonical object. The advantage of canonicalization is that it renders UNFs format- independent: if the data values stay the same, the UNF stays the same—even when the data set is moved between software programs, file storage systems, compression schemes, operating systems, or hardware platforms. Extensions to the UNF algorithm (Altman 2008), describe methods for computing UNFs over more complex objects, using recursion.
Data citation use cases and principles
Altman and King (2007) motivate their data citation standard on the basis of provenance, replicability, and attribution. Data citations should contain information that is sufficient to: locate the dataset that is referred to as evidence for the claims made in the citing publication; verify that the dataset one has located is the semantically identical to the dataset used by the original authors of the citing publication; and correctly attribute the dataset.
In the last five years, citation practices have evolved. To explore this issue, the Institute for Quantitative Social Science convened a workshop for leaders in publishing, data archiving, and data citation research, with the aims of identifying use cases and principles for data citation. The discussions facilitated through this workshop lead to a consensus on a number of additional core use cases, operational requirements, and principles.
Time prohibits describing these use cases and operational requirements in detail. To summarize they were grouped into five categories:
• Attribution. Data citations are used for enabling appropriate legal and scholarly attribution for the cited work.3
• Persistence. Citations are used to refer to, and to manage, objects that are persistent.
• Access. Citations are used to facilitate short and long term access to the object, by humans and by machine clients.
• Discovery. Citations are used to locate instances of the dataset; and as part of the process of discovering derivative, parent, and related works
• Provenance. Citations are used to associate published claims with evidence supporting them, and to verify that the evidence has not been altered.
Moreover, the workshop identified a “first principle” for citing data:
data citations should be treated as first-class objects for publication.
This principle has a variety of implications that depend on the specific context of publication. Notwithstanding, workshop participants identified two broad corollaries: Citations to data should be presented along with citations to other works—typically in a “references” section; and data should be made as easy to cite as other works—publishers should not impose additional requirements for citing data, nor should they accept citations to data that do not meet the core requirements for citing other works.
The workshop articulated three additional principles, based on discussions of the core uses of data citation:
• At a minimum, all data necessary to understand assess extend conclusions in scholarly work should be cited.
• Citations should persist and enable access to fixed version of data at least as long as the citing work exists.
• Data citation should support unambiguous attribution of credit to all contributors, possibly through the citation ecosystem.
These principles have implications for the entire ecosystem of publication—there are implications for authors, editors, publishers, and software developers. Neither standards documents nor software can ensure that data is cited properly—but both can help. The Dataverse Network System, and the citations produced through it, appear consistent with these principles.
______________________
3 Note that these scholarly and legal attribution are conceptually separable: the first type of attribution is defined in terms intellectual property rights, whereas the second is defined in terms of scholarly norms.
References
Altman, M., Gill, J., & McDonald, M. (2003). Numerical issues in statistical computing for the social scientist. New York: John Wiley & Sons.
Altman, M. (2008). A Fingerprint Method for Scientific Data Verification. In T. Sobh (Ed.), Proceedings of the International Conference on Systems Computing Sciences and Software Engineering 2007 (311-316). New York: Springer Netherlands. Retrieved from http://www.box.net/shared/0x8ld06hceg0ltpjyfu4
Altman, M., & Crabtree, J. (2011). Using the SafeArchive System: TRAC-Based Auditing of LOCKSS. Archiving 2011 (165-170). Society for Imaging Science and Technology. Retrieved from http://www.imaging.org/IST/store/epub.cfm?abstrid=44591 http://www.box.net/shared/8py6vl9kxivo6u21rkn8
Altman, M., and King, G. (2007). A Proposed Standard for the Scholarly Citation of Quantitative Data. DLib Magazine, 13 (3/4), 1082-9873. SSRN. Retrieved from http://www.dlib.org/dlib/march07/altman/03altman.html.
Altman, M., and Klass, G. M. (2005). Current research in voting, elections, and technology. Social Science Computer Review, 23 (3), 269-273. Retrieved from http://ssc.sagepub.com/content/23/3/269.full.pdf. http://www.box.net/shared/1xlf6n7erk2bgu34z0nj.
Altman, M., Andreev, L., Diggory, M., King, G., Sone, A., Verba, S., Kiskis, D. L., et al. (2001). A digital library for the dissemination and replication of quantitative social science research: the Virtual Data Center. Social Science Computer Review, 19 (4), 458-470. Sage Publications. Retrieved from http://www.box.net/shared/d3cf8u0gtyml2nqq3u2f.
Altman, M., Crabtree, J., Donakowski, D., Maynard, M., Pienta, A., & Young, C. (2009). Digital Preservation Through Archival Collaboration: The Data Preservation Alliance for the Social Sciences. The American Archivist, 72 (1), 170-184. Retrieved from http://archivists.metapress.com/content/EU7252LHNRP7H188.
Altman, M. and Rogerson, K. (2008). Open Research Questions on Information and Technology in Global and Domestic Policis - Beyond “ E-. ” PS: Political Science and Politics XLI.4 (October, 2008): 835-837. Retrieved from: http://journals.cambridge.org/action/displayFulltext?type=1fid=2315612jid=PSCvolumeId=41issueId=04aid=2315604 http://www.box.net/shared/2tlvqxgnzu5p5sby2mzq.
Data Preservation Alliance for Social Sciences, “Data Citations”, 2012. Web page. Retrieved from: http://data-pass.org/citations.html.
Crosas, M. 2011. The Dataverse Network: An Open-source Application for Sharing, Discovering and Preserving Data. D-Lib Magazine. Volume 17.
King, G. 2007. An Introduction to the Dataverse Network as an Infrastructure for Data Sharing. Sociological Methods and Research. 36:173-199.
Novak, K., Altman, M., Broch, E., Carroll, J. M., Clemins, P. J., Fournier, D., Laevart, C., et al. (2011). Communicating Science and Engineering Data in the Information Age. Computer Science and Telecommunications. National Academies Press. Retrieved from: http://www.nap.edu/catalog.php?record_id=13282.








