
18- How to Cite an Earth Science Dataset?
Mark Parsons1
University of Colorado
I represent the Federation of Earth Science Information Partners (ESIP). It is a federation of more than a hundred data centers and related organizations, predominantly in the United States. The primary sponsors of ESIP are federal science agencies NASA, NOAA, EPA, and there are several other sponsors such as NSF and USGS that are getting increasingly more involved in our work. I am going to focus my talk on best practices and guidelines of how to cite science data. I also want to mention that some of my presentation will be related to the International Polar Year (IPY), a very large international and interdisciplinary project that started to work on these issues.
There is a lot of input going into the process of creating data citation and attribution guidelines at ESIP. We hope that these guidelines will be adopted by the general assembly in January of 20122. The main purposes of data citation as we see them are:
• Credit for data authors and stewards.
• Accountability for creators and stewards.
• Track impacts of the dataset.
• Assist data authors in verifying how their data are being used.
• Aid reproducibility of research results through a direct, unambiguous connection to the precise data used.
The last purpose is the primary, most important purpose and the most difficult to achieve. I also want to note that we see citation as a reference and a location mechanism, but not as a discovery mechanism, per se.
Data citation in the earth sciences is currently done using one of these approaches or styles:
• Citation of traditional publication that actually contains the data, e.g., a parameterization value.
• Not mentioned, just used, e.g., in tables or figures.
• Reference to name or source of data in text.
• URL in text (with variable degrees of specificity).
• Citation of related paper (e.g., the UK Climate Research Unit recommends citing their well-known surface temperature records using two old journal articles which do not contain the actual data or full description of methods)
• Citation of actual data set typically using recommended citation given by data center.
• Citation of data set including a persistent identifier or locator, typically a DOI.
______________________
1 Presentation slides are available at http://sites.nationalacademies.org/PGA/brdi/PGA_064019.
2 The Guidelines were adopted in January.
The National Snow and Ice Data Center (NSIDC) distributes a variety of different snow cover products derived from the Moderate Resolution Imaging Spectrometer (MODIS). The results of a quick analysis of how many scientific papers mention use of “MODIS Snow Cover Data” (according to Google Scholar) and how often the data sets themselves are formally cited shows a huge disparity, illustrating the infrequency of proper data citation in practice. Moreover, the lack of data citation standards introduces the possibility that informal references to data do not point to the exact data set actually used.
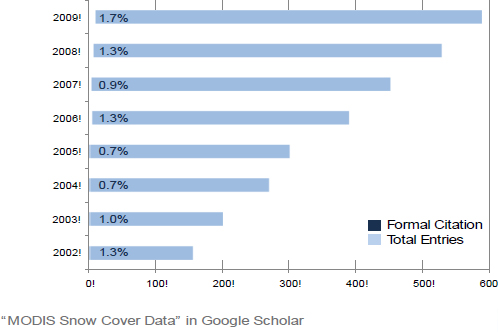
FIGURE 18-1 MODIS snow cover data in Google Scholar.
There are a number of data citation guidelines available to scientists. These include the ones from the International Polar Year and DataCite project. Also, institutions such as NASA and NOAA request acknowledgments. Overall, approaches range from specific data citation, to general acknowledgment, to recommending citing a journal article or even a presentation. This is reflected also in the results of this study titled “Data Citation in the Wild” by Enriquez et al. (2010):
We found that few policies recommend robust data citation practices: in our preliminary evaluation, only one-third of repositories (n=26), 6% of journals (n=307), and 1 of 53 funders suggested a best practice for data citation. We manually reviewed 500 papers published between 2000 and 2010 across six journals; of the 198 papers that reused datasets, only 14% reported a unique dataset identifier in their dataset attribution, and a partially-overlapping 12% mentioned the author name and repository name. Few citations to datasets themselves were made in the article references section.3
This shows clearly that the data author is not being fairly credited.
______________________
3 Available at: http://openwetware.org/wiki/DataONE:Notebook/Summer_2010.
In terms of measuring the impact of a data set, there are some measurement issues that make this process a bit challenging4. For example, data are not used in isolation. Often different data are combined or used with models and other analytic techniques. Also, impacts may be indirect (i.e., resulting from development of information, papers, tools, etc. that relied on derived data or products); they may be delayed (i.e., months or years for a peer-reviewed publication to be released, or a decision to be made and implemented); they may be unexpected (e.g., a new scientific discovery or a novel application of data collected for a different purpose); or they may be hard to compare (e.g., in scientific, economic, or ethical terms). Nevertheless, it is still important to try to track the use and impact of a data set because we need to justify investment in data acquisition, maintenance, distribution, and long-term stewardship. We also need to help the community become more effective and efficient in data management and use.
There are different possible citation metrics. These include:
Qualitative
- Examples of data use and impacts in key papers, discoveries, decisions.
- Assessment of broader impacts such as influence of data on attitudes and thinking (e.g., the Apollo 8 image of the Earth).
Quantitative
- Counts of papers that cite data in peer-reviewed journals.
- Weighted indicators of data citations (e.g., type and quality of citation, impact of journal).
Quantitative and Qualitative:
- Number of data citations in top peer-reviewed scientific journals and key reports by decision-makers.
- Data usage in other peer-reviewed journals, textbooks, reports, magazines, documentary films, online tools, maps, blogs, twitters, and the like.
However, as Heather Piwowar notes, tracking dataset citations using common citation tracking tools does not work. Traditional fields, such as author and date, are too imprecise and the Web of Science, Scopus, and other scientific publisher tools do not handle identifiers.5
I think that we need two basic strategies. One is that archives and data centers need to provide consistent and precise recommendations on how their data should be cited. The other strategy is more of the social strategy trying to get the publishers and the educators on board with the whole concept of data citation. I am going to focus on the first strategy in this presentation.
______________________
4See also Chen, R. S. and Downs, R. R. (2010). Evaluating the Use and Impacts of Scientific Data. National Federation of Advanced Information Services (NFAIS) Workshop, Assessing the Usage and Value of Scholarly and Scientific Output: An Overview of Traditional and Emerging Approaches. Philadelphia, PA, November 10, 2010. http://info.nfais.org/info/ChenDownsNov10.pdf.
5See Piwowar’s blog at http://researchremix.wordpress.com/2010/11/09/tracking-dataset-citations-using-common-citation-tracking-tools-doesnt-work/.
Below is the basic ESIP data citation model shown in contrast to the DataCite guidelines available at the time.
Per DataCite:
Creator. Publication Year. Title. [Version]. Publisher. [Resource Type]. Identifier.
Per ESIP:
Author(s). Release Date. Title [version]. [editor (s)]. Archive and/or Distributor. Locator. [date/time accessed]. [subset used].
I will use the rest of the talk to describe some of these differences and why we think they are important.
The first difference is that ESIP explicitly allows the recognition of roles other than the data creator or author. We call this “editor”, but there are multiple data management roles that might be captured. Whether or not they are appropriate can be open to question, but this approach gets a lot of traction with data stewards because particularly in earth sciences, data stewards frequently may have a significant role in developing and compiling the data sets and sometimes doing some quality control. They have similar levels of credit and accountability as the original authors do and I think that is important to recognize. For example, in the example below, the data authors were the designers of a large field experiment. The editors were responsible for managing the process of entering field data from notebooks, conducting manual and automated quality control, determining data formats, writing documentation, and so on.
Cline, D., R. Armstrong, R. Davis, K. Elder, and G. Liston. 2002, Updated 2003. CLPX-Ground: ISA snow depth transects and related measurements ver. 2.0. Edited by M. Parsons and M. J. Brodzik. Boulder, CO: National Snow and Ice Data Center. Data set accessed 2008-05-14 at http://nsidc.org/data/nsidc-0175.html.
Another concept I want to present is the notion of the identifier versus the locator. The easiest way for us to understand these concepts is probably to look at the human example.
Human ID: Mark Alan Parsons (son of Robert A. and Ann M., etc.).
• Every term defined independently (only unique in context/provenance).
• Alternative like a social security number requires a very well controlled central authority.
Human Locator: 1540 30th St., Room 201, Boulder CO 80303.
• Every term has a naming authority.
Data Set IDs: data set title, filename, database key, object id code (e.g., UUID), etc.
Data set Locators: URL, directory structure, catalogue number, registered locator (e.g. DOI), etc.
If we look at the human ID, every term is defined independently and it is only unique in a certain context. We could use a title in combination with a location to find the relevant person, but it
would not necessarily be the right person. S/he might have retired. We could use his or her identifier but that may not describe her location or the person may have moved. This may be simplistic, but I see this same situation with data. There are data set IDs, some of them are informal, like dataset titles, and others are very formal, like a UUID. There are also data set locators like URLs or some registry based system like DOIs.
The point is that the locator and identifiers are different things, but sometimes locator can be used as an identifier (e.g., the person working in this position at this address). Hence the general use of the term “identifier” such as in DOI, is better described as a locator.
Indeed it is the registration of the location information in the DOI scheme that makes it attractive to groups like DataCite:
One of the main purposes of assigning DOI names (or any persistent identifier) is to separate the location information from any other metadata about a resource. Changeable location information is not considered part of the resource description. Once a resource has been registered with a persistent identifier, the only location information relevant for this resource from now on is that identifier, e.g., http://dx.doi.org/10.xx.6
Duerr et al (2011)7 conducted an assessment of identification schemes for digital earth science data as summarized in this diagram I adapted from their paper.
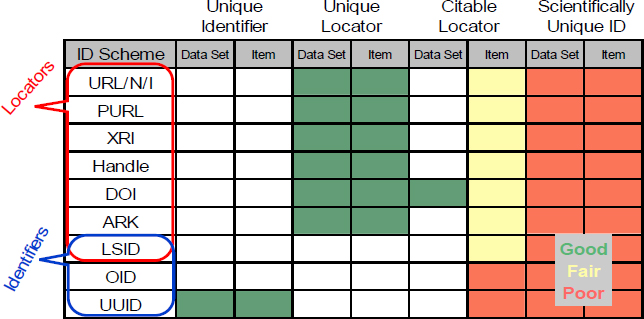
FIGURE 18-2 Assessment of identification schemes for digital earth science data.
SOURCE: Duerr et al (2011).
______________________
6 DataCite Metadata Scheme for the Publication and Citation of Research Data, Version 2.2, July 2011.
7 Duerr, R., R. Downs, C. Tilmes, B. Barkstrom, W. Lenhardt, J. Glassy, L. Bermudez, and P. Slaughter. 2011. On the utility of identification schemes for digital earth science data: an assessment and recommendations. Earth Science Informatics: 1-22. http://dx.doi.org/10.1007/s12145-011-0083-6.
The figure summarizes how different identifiers are more suitable for different purposes, and that often it depends on whether the scheme is actually a locator or an identifier. (Note that the LSID is a locator; but also the ObjectID part of it is an identifier and most people use a UUID for the ObjectID part of it.) Also the ARK could be considered a bit better than the rest of the locators because it has additional trust value, but the DOI stands out as the most appropriate locator for citation.
Why the DOI? Although the DOI is not perfect, it is well understood and accepted by publishers, and DataCite is working with Thomson Reuters to get data citations in their index. This broad acceptance gives DOIs a small edge, but, there are still some issues that need to be resolved. For example, what is the citable unit that should be assigned a DOI? Is it a file or a collection of files and, if so, how many? How do we handle different versions? When does a new version get a new DOI? How do we handle data that have been retired and deleted? Does their DOI persist? What does it point to?
Overall, we believe these issues can be largely resolved by, a well-defined versioning scheme, good tracking and documentation of the versions, and due diligence in archive and release practices. So, it is not a technical problem so much as a social problem demanding good professional practices.
Here are some initial suggestions on versioning and locators. At my data center, we did a study looking at different types of data, from satellite data, modeling output, historical photographs, to interviews and transcripts. We have the notion of a major version, a minor version, and an archive version. The archive version is not publicly available, it is just for us to track any changes in the archive. What constitutes a major or a minor version has to be done on a case-by- case basis. An individual steward has to work with their providers to figure it out, but in general, something that affects the entire dataset is going to be a major version. A small change such as changing a land mask might be a minor version.
DOIs should be assigned to major versions. Old DOIs for old versions should be maintained even if the data are no longer available. The old DOIs should point to some appropriate page that explains what happened to the old data if they were not archived. The older metadata record should remain with a pointer to the new version and with explanation of the status of the older version data. Major and minor versions (after the first version) should be exposed with the data set title and recommended citation. And while minor versions don’t get a new DOI, they should be explained in documentation, ideally in file-level metadata. Finally, applying UUIDs to individual files upon ingest aids in tracking minor versions and historical citations.
The last difference between ESIP and DataCite is the inclusion of “subset used” This is the concept of micro citation, which may be the most challenging aspect of data citation. In conventional literary citation this might take the form of citing a passage in a book and referencing a page number. We all know how to deal with page numbers in a book. But, how do we do it in a data set? Maybe we can put an identifier to it. If we have a particular query, we could capture the query and maintain sort of a query ID. Those kinds of technical approaches are probably the way forward but that is not the way the vast majority of group science data is managed today. So instead, we consider the concept of a structural index. This is similar to citing “chapter and verse” in a sacred text.
The key question then is what structure or structures can we use to organize data collections that might be common across earth sciences? The basic assumption of a “chapter-verse” style of reference is that there is a canonical version of data set. This is also assumed in the approach using the Unique Numerical Fingerprint. Unfortunately, most earth science data lack a canonical version. For example, data could be in different digital formats, where the contents are scientifically equivalent, but they are not identical because of the different formats. Therefore, we need to refer to “equivalence classes” not canonical versions, although we cannot deny the human readability of the chapter-verse style approach.
We probably need both approaches. We need the “chapter and verse” that makes sense to people and is easily conceived and communicated between people, but then we still need the precise location and identity of that rather mutable verse represented in a way that computers can readily understand and be precise about, i.e., the identifier. And then we cannot forget the fact that we have billions if not trillions of “verses” or “granules” that we are dealing with. Our human approach needs to make sense at a high level of aggregation, while the computer approach needs to handle the volumes and precision.
In earth science data, space and time can often serve as a structural index. We can simply refer to a spatial and temporal subset of the data. We might also consider what the Open Archives Information System Reference Model8 calls archive information units: An Archival Information Package whose Content Information is not further broken down into other Content Information components, each of which has its own complete Preservation Description Information.
Neither of these approaches is fully satisfactory, but following are some examples of doing it as best we can:
Hall, Dorothy K., George A. Riggs, and Vincent V. Salomonson. 2007, updated daily. MODIS/Aqua Snow Cover Daily L3 Global 500m Grid V005.3, Oct. 2007- Sep. 2008, 84°N, 75°W; 44°N, 10°W. Boulder, Colorado USA: National Snow and Ice Data Center. Data set accessed 2008-11-01 at doi:10.1234/xxx.
Hall, Dorothy K., George A. Riggs, and Vincent V. Salomonson. 2007, updated daily. MODIS/Aqua Snow Cover Daily L3 Global 500m Grid V005.3, Oct. 2007- Sep. 2008, Tiles (15,2;16,0;16,1;16,2;17,0;17,1). Boulder, Colorado USA: National Snow and Ice Data Center. Data set accessed 2008-11-01 at doi:10.1234/xxx.
Cline, D., R. Armstrong, R. Davis, K. Elder, and G. Liston. 2002, Updated 2003. CLPX-Ground: ISA snow depth transects and related measurements, Version 2.0, shapefiles. Edited by M. Parsons and M. J. Brodzik. Boulder, CO: National Snow and Ice Data Center. Data set accessed 2008-05-14 at doi:10.1234/xxx.
We have not solved all the issues related to data citation and attributions, but we believe that approximately 80 percent of citation scenarios for 80 percent of Earth system science data can be addressed with basic citations, i.e., [(Author(s). ReleaseYear. Title, Version. [editor (s)].
______________________
8 CCSDS (Consultative Committee for Space Data Systems). 2002. Reference Model for an Open Archival Information System (OAIS) CCSDS 650.0-B-1 Issue 1. Washington, DC: CCSDS Secretariat.
Archive. Locator. [date/time accessed]. [subset used]], and reasonable due diligence. We need to move forward with this now and not wait for the perfect solution.
Finally, as we go forward, I think that the concept of scientific equivalent is ripe for study and that we are beginning to look at the notion of how content equivalence and provenance equivalence can serve as a proxy for scientific equivalence. That is a big research question, but it should not stop us for moving forward on the citation issue in general. I want to emphasize that we can do something about data citation now and we should.








