
4- Data Citation —Technical Issues— Identification
Herbert Van de Sompel1
Los Alamos National Laboratory
I am going to speak today about a slightly narrow topic, which is about the identification of data as part of the citation process. I will also talk about different use cases, such as assigning credit, accessing and reusing the data, and involving both humans and machines. To make clear what I am talking about, I will give some alternate examples of a citation:
• Bollen, J., Van de Sompel, H., Hagberg, A., Chute, R. A Principal Component Analysis of 39 Scientific Impact Measures. PLoS ONE, 4 (6), pp. e6022, 2009. doi:10.1371/journal.pone/0006022
• Bollen, J., Van de Sompel, H., Hagberg, A., Chute, R. A Principal Component Analysis of 39 Scientific Impact Measures. PLoS ONE, 4 (6), pp. e6022, 2009. doi:10.1371/journal.pone/0006022 http://www.dx.doi.org/10.1371/journal.pone/0006022
• Bollen, J., Van de Sompel, H., Hagberg, A., Chute, R. A Principal Component Analysis of 39 Scientific Impact Measures. PLoS ONE, 4 (6), pp. e6022, 2009. http://www.dx.doi.org/10.1371/journal.pone/0006022
These are the three considerations that merit more attention:
• The nature of identifiers for citation, access, and re-use.
• Catering to human and machine agents.
• Granularity, both spatial and temporal.
First, let us examine the nature of identifiers for these different use cases:

FIGURE 4-1 Data publication—data citation
______________________
1 Presentation slides are available at http://www.sites.nationalacademies.org/PGA/brdi/PGA_064019.
At the left-hand side, we have someone who is sharing data (e.g., data generation, data use, and data publication) and, at the right-hand side, there is someone who wants to do something with the data (e.g., access the data, reuse the data, and cite the data). The first consideration is about the nature of the identifier. We have these two parties and in order for the consumer to access, use and cite the data, some information needs to be made available by provider. I am going to distinguish between identifiers that enable citation and identifiers that enable access and reuse.
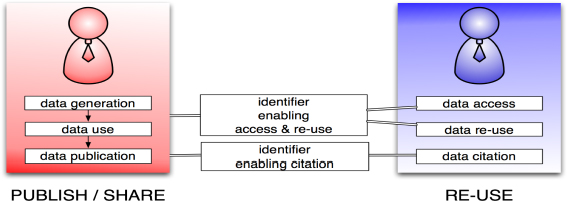
FIGURE 4-2 Identifiers that enable citation, access, and reuse.
If you look at the identifiers that enable citation, we can think of two choices. We have identifiers like the DOIs that are used extensively, but we also have the choice for a HTTP URI. Moreover, an HTTP URI could be based on a DOI (i.e., the HTTP version of a DOI) or it could be any other stable, cool HTTP URI.
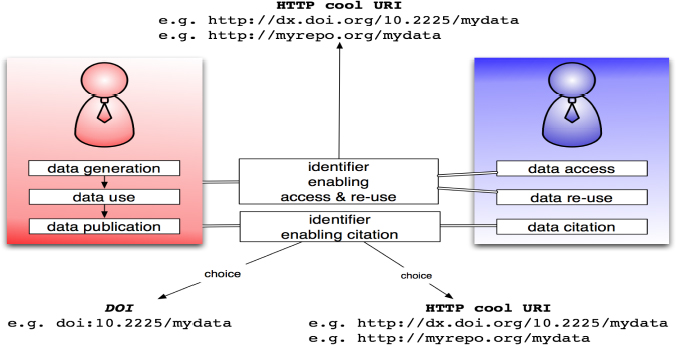
FIGURE 4-3 Actionable and non-actionable identifiers for citation, access, reuse.
When thinking about identifiers for enabling accessing and reuse, there is only one choice because the focus with this regard is on access. Access means an identifier that is actionable using widely deployed technologies such as web browsers, web crawlers, etc. This yields the use of HTTP URIs for access. So, DOIs as such can be used for citation, whereas cool HTTP URIs (including the HTTP version of a DOI) can be used for citation, access, and reuse. This was the first consideration.
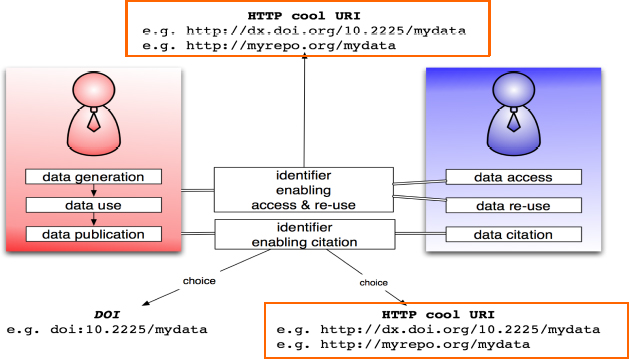
FIGURE 4-4 Cool HTTP URIs can be used for citation, access, and reuse.
The second consideration is about catering to human and machine agents when talking about accessing and reusing data. When it comes to papers, the typical end-user is a person. However, when it comes to data, the most important consumer most likely is going to be a machine. It is not clear at this point how machine agents will be enabled to access and reuse the data. This means that we need to think carefully about aspects such as links, metadata, and discovery measures to cater to machines.
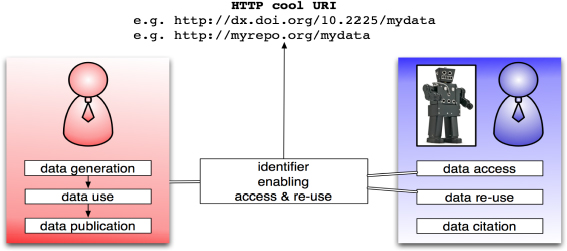
FIGURE 4-5 Data access and reuse by both human and machine agents.
As you know it today, we have a URI that sits somewhere in a citation and these are the reference data sheets for humans and machines.
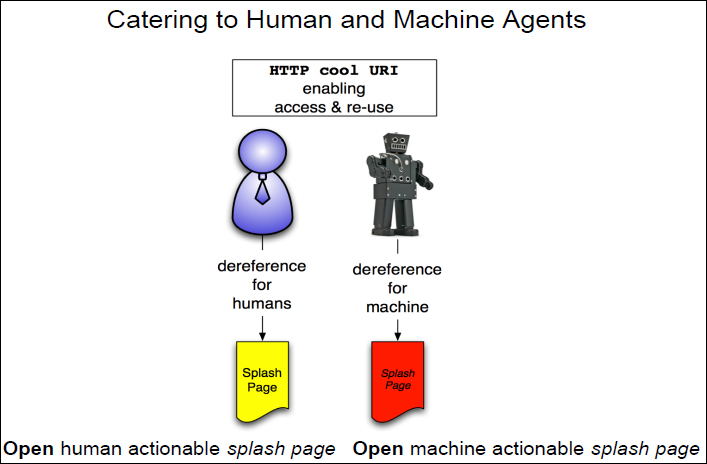
FIGURE 4-6 Splash pages for humans and machines.
When it comes to machine processing, there is some critical thinking that needs to be done about what has to be involved there. This is not only about discovery of the data or metadata that supports discovery of the data. This is about metadata that supports understanding of the data and interacting with the data in automated ways.
For example, for any dataset, there can be several URIs involved, including URIs for the splash pages (one for human and one for machine agents) and URIs for multiple components of the dataset. Maybe there are different formats of the same data available, in which case there are even more URIs and the need to express a format relationship. We have to distinguish between all those URIs and make sure that it is clear to the machine what each URI stands for. We need technical metadata about the data so that the machine can automatically interact with the data, process it. Also, not all data is necessarily being downloaded; some is accessed via APIs. In this case, a description of those APIs is required. Overall, a rich description of the data that is able to be processed by machines is required.
The third consideration is granularity and I am going to distinguish between two types. One is spatial and by spatial I mean dimensions in the dataset, and the other is temporal.
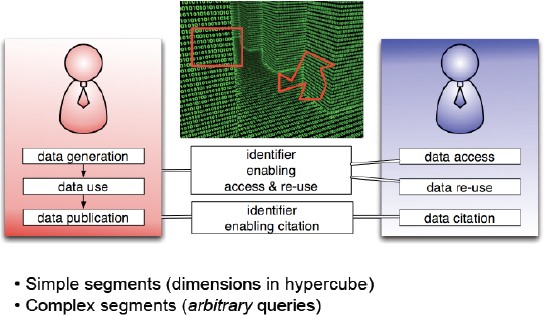
FIGURE 4-7 Identifying, accessing, and reusing parts of a dataset.
Regarding spatial granularity: There is a need to say I have used this entire data set, but I actually only worked with the parts of it. It is important to be able to describe that slice or segment of the dataset.
I would like to draw some parallels here with ongoing work related to web-centric annotation of research materials as pursued by the Open Annotation and Annotation Ontology efforts. What you see in Figure 4-8 is an image that is being annotated. It is not the entire image that is annotated; it is just a segment thereof. And that segment is being described, in this case by means of an SVG document. A similar approach could be used when referring to parts of a dataset:
identify the dataset, and convey the part of the dataset that is of interest by means of an annotation to the dataset.
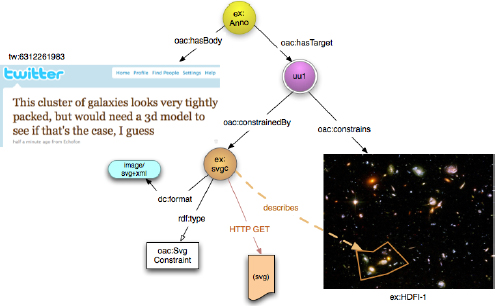
FIGURE 4-8 An annotation on a part of an image per the Open Annotation approach.
Regarding temporal granularity: We need to be able to refer to a certain version of a dataset as it changes over time, or a certain temporal state of the dataset when a dynamic dataset is concerned.
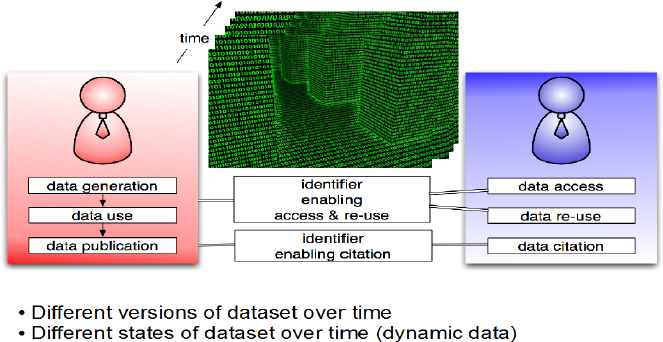
FIGURE 4-9 Dataset changes over time.
Here, again, I would like to draw a parallel with other work that I am doing. This is the Memento project, which is a simple extension of the HTTP protocol that allows accessing prior versions of resources. In order to do this, Memento uses the existing content negotiation capability of HTTP and extends it into the time dimension. So, what you have in Figure 4-10 a generic URI for a certain resource (URI-R). But the resource evolves over time and each version receives its own URI (URI-M1, URI-M2). Without Memento, you need to explicitly know URI-M1 and URI-M2 in order to access those respective versions. With Memento, you can access the old versions of the resource, only knowing the generic URI (URI-R) and a date-time. Memento can play a role in accessing prior versions of datasets.
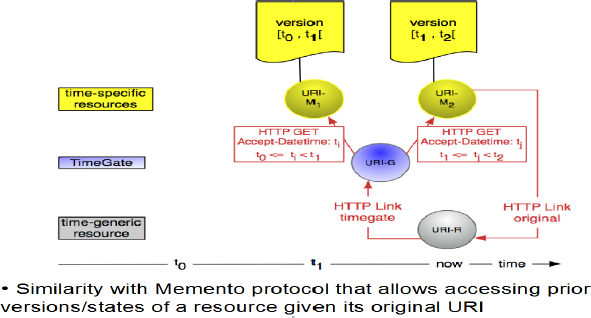
FIGURE 4-10 Memento allows to access old versions of resources using a generic URI and a date-time.
I would say that these granularity requirements are needed for both the data publisher and the data user. If we want to address those granularities, we need a solution that allows both the publisher and the user of the data to specify what that segment is going to be.
Finally, I see three options regarding identity in regarding the notion of granularity:
• Option 1. For citation, access and reuse: Mint a new identifier for each segment.
• Option 2. For citation, access and reuse: Use the entire dataset identifier with a query component.
• Option 3.
![]() For citation: Use the entire dataset identifier.
For citation: Use the entire dataset identifier.
![]() For access and reuse: Use an additional URI that refers to an annotation to the dataset that describes the segment (both spatial and temporal) of the dataset. The citation thus becomes a tuple [dataset URI; annotation URI].
For access and reuse: Use an additional URI that refers to an annotation to the dataset that describes the segment (both spatial and temporal) of the dataset. The citation thus becomes a tuple [dataset URI; annotation URI].
This page intentionally left blank.








