
7- Data Citation in the Earth and Physical Sciences
Sarah Callaghan 1
Rutherford Appleton Laboratory, United Kingdom
When I was asked to speak about the physical and earth sciences, I thought this was a very broad area to cover! So I decided that the best approach was to focus in on a number of issues and examples.
I am a member of the British Atmospheric Data Center (BADC) and we are one of the United Kingdom’s National Environmental Research Centre’s (NERC’s) data centers. NERC funds the majority of the earth sciences and ecological research work in the United Kingdom. I am part of a federation of data centers, which covers the environmental sciences broadly, including hydrology, atmosphere, ecology, ocean and marine, and so on. We deal with a lot of data from many different fields.
It is important in our work to define what a dataset is for ourselves because otherwise, datasets can get very fuzzy. We define a dataset as a collection of files that share some administrative and/or project heritage. In the BADC we have about 150 real datasets and thousands of virtual datasets. We have also 200 million files containing thousands of measured or simulated parameters. The BADC tries to deploy information systems that describe those data, parameters, projects and files, along with services that allow one to manipulate them. Also, in 2010 we had 2800 active users (of 12000 registered), who downloaded 64 TB of data in 16 million files from 165 datasets. To put that into context, less than half of the BADC data users or consumers are atmospheric science users. We have people coming to us to download data for all sorts of reasons, even including school children.
So, what are data for us? Data can be anything from:
• A measurement taken at a single place and time (e.g., water sample, crystal structure, particle collision)
• Measurements taken at a point over a period of time (e.g., rain gauge measurements, temperature)
• Measurements taken across an area at multiple times by a static instrument (e.g., meteorological radar, satellite radiometer measurements)
• Measurements taken over and area and a time by a moving instrument (e.g., ocean traces, air quality measurements taken during an airplane flight, biodiversity measurements)
• Results from computer models (e.g., climate models, ocean circulation models)
• Video and images (e.g., cloud camera images, photos and video from flood events, wildlife camera traps)
• Physical samples (e.g., rock cores, tree ring samples, ice cores)
______________________
1 Presentation slides are available at http://www.sites.nationalacademies.org/PGA/brdi/PGA_064019.
Historically speaking, even though it was very labor-intensive to create new datasets, it was often (relatively) easy to publish the data in a visual form, like an image, graph or table. This picture is an example of one of the earliest published datasets. It was created by Robert Hooke and dates back to 1665.
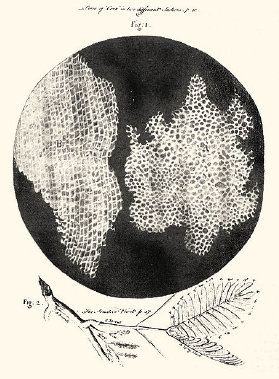
FIGURE 7-1 Suber cells and mimosa leaves.
SOURCE: Robert Hooke, Micrographia, 1665.
One of the big drivers for data citations in the earth and physical sciences is to make it easier to identify products and projects when one is comparing them.
A major example of this is a set of experiments being done by climate modelers all over the world under the auspices of the World Meteorological Organization (WMO) via the World Climate Research Program (WCRP). It is called CMIP5: Fifth Coupled Model Intercomparison Project. These climate model experimental runs will produce the climate model data that will form the basis of the fifth assessment report for the Intergovernmental Panel on Climate Change (IPCC). In particular, CMIP5 aims to:
• Address outstanding scientific questions that arose as part of the AR4 (the most recent IPCC assessment report) process,
• Improve understanding of climate, and
• Provide estimates of future climate change that will be useful to those considering its possible consequences.
The method used in CMIP5 is based on a standard set of model simulations which will:
• Evaluate how realistic the models are in simulating the recent past,
• Provide projections of future climate change on two time scales, near term (out to about 2035) and long term (out to 2100 and beyond), and
• Understand some of the factors responsible for differences in model projections, including quantifying some key feedbacks such as those involving clouds and the carbon cycle.
Climate models are usually run on supercomputers, and produce a lot of data. For example, the numbers for CMIP5 are below:
Simulations:
~90,000 years
~60 experiments
~20 modeling centers (from around the world) using
~30 major model configurations
~2 million output “atomic” datasets
~10’s of petabytes of output
Of the replicants:
~ 220 TB decadal
~ 540 TB long term
~ 220 TB atmosphere-only
~80 TB of 3hourly data
~215 TB of ocean 3d monthly data
~250 TB for the cloud feedbacks
~10 TB of land-biochemistry (from the long term experiments alone)
These numbers are not particularly important from the point of view of data citation, but they do indicate the sheer volume of data that has to be dealt with. It is not only climate scientists who will have to work with these data, but members of the general public will also try and make sense of them. This is the sort of data that will impact how governments will plan for the next 10 to 50 years.
The researchers who are supporting the whole CMIP5 data management effort have spent a great deal of time and effort thinking about and preparing for how they can store and manage the data. Quality control of the data is also important, not only to ensure that valid cross-comparisons between model runs can be made, but also because this is important to the data provenance and it provides reassurance to the outside world that the data are not being deliberately hidden or obfuscated. CMIP5 (and the climate modelling groups involved in it) will continue to produce a lot of data! It is an international effort, with everyone involved wanting to ensure proper citation, attribution and location of the data produced. Citation will allow the researchers to have traceability and accountability for their datasets.
CMIP5 has issued the following guidelines for the citation of datasets (quote is from the CMIP5 website):
Digital Object Identifiers will be assigned to various subsets of the CMIP5 multi-model dataset and, when available and as appropriate, users should cite these references in their publications. These DOI’s will provide a traceable record of the analyzed model data, as tangible evidence of their scientific value. Instructions will be forthcoming on how to cite the data using DOI’s.
At the BADC, we have for many years now had a citation approach where in all our dataset catalogue pages you will find a little box which gives the proper way to cite that particular data set. We have attempted to produce some metrics on how many people actually used these citation instructions, unfortunately without great results. I think this is because users of our datasets do not have the culture of citing data in the first place.
That is something we need to change. We are currently working with all the other NERC data centers to assign DOIs to certain datasets that meet our technical criteria. We expect that this will make it more obvious to our users what the correct way to cite a dataset and use a DOI is, and will encourage more of our users to use the citations.
In terms of earth sciences, the Pangaea data center (http://www.pangaea.de) is further ahead than us when it comes to assigning DOIs to data sets. If you look at their repository catalogue pages they give the citation for the dataset with the DOI and then it says, “supplement to", which gives the citation for the paper of reference.
Finally, I work at the same site as ISIS, which is pulsed neutron and muon source produces beams of neutrons and muons that allow scientists to study materials at the atomic level using a suite of instruments, often described as ‘super-microscopes’. It supports a national and international community of more than 2000 scientists who use neutrons and muons for research in physics, chemistry, materials science, geology, engineering, and biology. ISIS is now issuing DOIs for experiment data to allow easy citation. Principal investigators will be sent DOIs shortly before their experiment is due to start. DOIs issued by ISIS are in the form of: 10.5286/ISIS.E.1234567. The recommended format for citation is: Author, A N. et al; (2010): RB123456, STFC ISIS Facility, doi:10.5286/ISIS.E.1234567
Let me conclude by saying that the flood of data is now so great that scientific journals cannot now communicate everything we need to know about a scientific event, whether that is an observation, simulation, development of a theory, or any combination of these. There is simply too much information, and it is too difficult to publish it in the standard journal paper format. Data always have been the foundation of scientific progress—without them, we cannot test any of our assertions. We need to provide a way of opening data up to scientific scrutiny, while at the same time providing researchers with full credit for their efforts in creating the data.
We need data citation not only to provide credit to the scientists who create data, but also for the general public to provide traceability and accountability and to show that as far as possible, we are doing our jobs the way we should. Also, there is serious pressure in the earth and climate
sciences to publish data, but there is also a need to ensure proper accreditation. Finally, how we communicate scientific findings is changing and data citation practices are a big part of that.
This page intentionally left blank.






