
KEY SPEAKER THEMES
Schneeweiss
• Accounting for bias is a major challenge confronting the use of observational data to gain important insights into real-world treatment effects.
• No single study design will satisfy all information needs of decision makers. A mix of studies could address the same question and complement each other in terms of internal and external validity, precision, timeliness, and cost in light of logistical constraints and ethics guidelines.
Small
• Instrumental variables can help correct for the effects of unmeasured confounders.
• Weak instrumental variables are useful for reliably detecting only large effects because of their sensitivity to even small biases.
Ryan
• Databases with health care data from observational studies contain valuable information, but the manner in which study results are generated and interpreted needs to be rethought to capitalize on the value of the databases.
• Study designs, including cohort, case-control, and self-controlled case series (SCCS), have varying performance characteristics when they are applied to different data sources or health outcomes of interest.
One of the major limits on the utility of observational studies is bias in various forms. Selection bias, for example, arises when a study population is not randomly selected from the target population, and measurement or information-related bias can result when data are missing from or misclassified in an electronic health record. To start the discussion on how to manage and control for bias in observational studies, Sebastian Schneeweiss, professor of medicine and epidemiology at Brigham and Women’s Hospital and Harvard Medical School, provided an introduction to the issue of bias, laying the groundwork for presentations by Dylan Small, associate professor of statistics at the University of Pennsylvania, on instrumental variables, and Patrick Ryan, head of epidemiology analytics at Janssen Research and Development and participant in the Observational Medical Outcomes Partnership, on an empirical attempt to measure and calibrate for error in observational analyses. After comments by John B. Wong, professor of medicine at the Tufts University Sackler School of Graduate Biomedical Sciences, and Joel B. Greenhouse, professor of statistics at Carnegie Mellon University, an open discussion among the panelists and workshop attendees ensued.
AN INTRODUCTION TO THE ISSUE OF BIAS
In his short introduction to the subject of bias, Sebastian Schneeweiss described “effectiveness” to be a combination of the efficacy measured in randomized controlled trials and the suboptimal adherence and potential subgroup effects that reflect the reality of routine care. The appeal of observational studies lies in the potential to measure this reality through the linkage and analysis of electronic data that were generated in the process of providing care. The challenge with the use of such health care data, he explained, lies in accounting for the various forms of bias inherent in such data. These biases arise in large part because the investigator analyzing the data had no control over how and when the data were collected.
Surveillance-related biases occur when data collection is not uniform according to both how it was collected and the actual information collected. Missing information and misclassified information that are directly or indirectly related to the health outcomes of interest may cause bias. As an example of this type of bias, Schneeweiss described a study of new users and nonusers of statins that aimed to identify unintended clinical effects. At the baseline, the results of liver function tests were recorded for some 60 percent of new users, but those data were recorded for only 9 percent of nonusers.
Selection-related biases include confounding, in which patients with worse prognoses tend to be treated differently. Failure to fully adjust for those factors or proxies thereof leads to bias. Selection-related biases also arise when treatments change between the baseline and the time when the outcome is measured. The most common time-related bias, said Schneeweiss, is known as immortal time bias,1 which occurs when the follow-up period is incorrectly attributed to groups exposed to a treatment or intervention, particularly in studies with nonuser groups.
Schneeweiss also discussed opportunities for managing some of these biases. Confounding, for example, can be managed by use of the naturally occurring variation in the nation’s health care system. It should be possible, he said, to screen for naturally occurring variation through the use of propensity score analyses and apply instrumental variable analyses to use this variation for unbiased estimation, when appropriate (see the description of the presentation of Dylan Small on p. 20). Negative controls are useful as a diagnostic tool for residual confounding, if such controls can be established. As-treated versus intention-to-treat analyses can help describe a plausible range of bias by informative censoring, and inverse probability of discontinuous weighting can account for such bias, as can other methods that rely on characterizing the factors leading to a change in treatment.
Researchers have a growing appreciation, Schneeweiss said, for the idea of creating study portfolios that include multiple studies with different data sources, both primary and secondary, and different experimental designs. The issue here is to determine the optimal way to arrange multiple studies so that they complement each other according to their speed, validity, and generalizability and so that together they provide the most valid and comprehensive information for decision makers.
Regardless of which methods are used, no single study design will
_______________
1 Immortal time refers to a span of time in the observation or follow-up period of a cohort during which the outcome under study could not have occurred. An incorrect consideration of this unexposed time period in the design or analysis will lead to immortal time bias. (S. Suissa. 2007. Immortal Time Bias in Pharmacoepidemiology. American Journal of Epidemiology 167(4):492–499.)
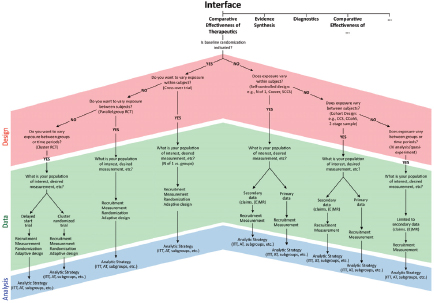
FIGURE 3-1 Study design decision tree for selecting design of studies of comparative effectiveness of therapeutics.
SOURCE: Reprinted with permission from PCORI.
satisfy the information needs of the decision maker. As a result, it is important to be transparent about the methods that are used to determine internal and external validity, precision, timeliness, and logistical constraints. Schneeweiss described the use of decision diagrams from the Patient-Centered Outcomes Research Institute (PCORI) Methodology Committee report (2012) (see Figure 3-1) that will encourage researchers to be more transparent about their implicit and explicit choices of study design, data, and analytical strategy, including their advantages and limitations. The use of flowcharts and decision diagrams might also help reduce the number of errors that result from investigators using data sources and methods incorrectly. Schneeweiss suggested that one opportunity for increasing transparency would be to develop an analytics infrastructure that allows other investigators to reanalyze data without having to move the data among investigators.
INSTRUMENTAL VARIABLES AND THEIR
SENSITIVITY TO UNOBSERVED BIASES
Dylan Small’s presentation focused on the use of the instrumental variable method as one approach to controlling for unmeasured confound-
ing. As an example, he discussed a 1994 study by Joshua Angrist and Alan Krueger of World War II veterans that examined the effect of military service on future earnings through the use of data measured in the 1980 census (Angrist and Krueger, 1994). At the time of that study, some studies suggested that military service would lower earnings because it interrupted an individual’s education or career, but other research suggested that military service would raise earnings because the labor market might have favored veterans after World War II and the GI Bill might have increased veterans’ education. The raw data on wages showed that World War II veterans earned about $4,500 more than nonveterans in 1980, suggesting that military service was associated with an increase in earnings. However, said Small, those data were not adjusted for any confounders. For example, someone who had been unhealthy or convicted of a crime would not have been eligible to serve in the military, and those factors, rather than military service per se, could account for lower later wages among nonveterans. “Health and criminal behavior are confounding variables, in that they are likely not comparable between the veterans and the nonveterans,” said Small.
If all the confounders can be measured, Small continued, they can be adjusted for by regression or propensity scores, but most observational studies have unmeasured confounders. In fact, in the study of Angrist and Krueger (1994), neither health nor criminal behavior was measured in the census, and as a result, a regression of earnings on the basis of veteran status would produce a biased estimate.
The instrumental variables strategy is one approach to addressing unmeasured confounders. Again using the study of World War II veterans for purposes of illustration (Angrist and Krueger, 1994), Small explained that the idea is to identify a variable that is independent of the unobserved variables and does not have a direct effect on the outcome yet that will affect the treatment, which in this case is veteran status. “If we can find such a variable, then the idea is that we can extract the variation in the treatment from the instrument that is independent of the unmeasured confounders,” said Small.
In a prototypical instrumental variable study, subjects are matched in pairs on the basis of whether or not the instrument encouraged an individual to get treatment. In this case, because birth is random, the matched pairs were individuals born in 1926 versus individuals born in 1928. Those born in 1926 were encouraged to become veterans by the year of their birth, while those born in 1928, who would have turned age 18 after the war had ended, were not encouraged to do so. Use of a two-stage squares method or permutation inference then produces the result that military service caused a substantial reduction of earnings of between $500 and $1,445 per year. As a check, this analysis was repeated with matched triples with men born
in 1924, 1926, and 1928. This analysis matched men on the basis of the quarter of their birth, race, age, education up to 8 years, and location of birth; it also showed that military service decreased earnings.
One concern with this analysis, said Small, is that gradual long-term trends might play a hidden role in influencing wages. In the study of World War II veterans, gradual long-term trends in apprenticeship, education, employment, and nutrition might bias comparisons of workers born 2 years apart. A sensitivity analysis would ask how departures from random assignment of the instrumental variable of various magnitudes might alter the study’s conclusions. In this case, sensitivity analysis showed that even a small amount of bias invalidates the inference that military service decreases earnings, but it does not invalidate the inference that military service raises earnings by $4,500 per year.
Small then discussed the strength of instrumental variables. A strong instrumental variable, he explained, has a strong effect on the treatment received. In the case of the earnings of World War II veterans, birth year is a strong variable if the years chosen are 1926 and 1928 because being born in 1926 substantially increases the chance that an individual would be a veteran compared with that for an individual born in 1928. Birth year is a weak variable if comparisons between 1924 and 1926 serve as the instrument because being born in 1924 raises only slightly the chance of being a veteran compared with that with being born in 1926. The effect obtained when a weak instrumental variable is chosen is increased variance. In this example, the 95 percent confidence interval for the effect of military service on income when a birth year of 1924 versus a birth year of 1926 is used as a comparator for 1928 was between a gain in income of $10,200 and a loss of income of $10,750, whereas the 95 percent confidence interval was an income between $500 and $1,445 lower for veterans.
Although it is possible to get a more precise inference with larger data sets, weaker instruments are still more sensitive to even small biases, Small explained. As a consequence, “weak instrumental variables can be dangerous to use and are probably only useful to detect enormous effects,” he said. “Conversely, strong instrumental variables that might be moderately biased can be useful, as long as we do a sensitivity analysis to see if we have inferences that are robust enough to allowing for a moderate amount of bias.” In closing, he listed some potential instrumental variables for health outcomes research (see Table 3-1), and he encouraged the community to work on creating useful instrumental variables.
TABLE 3-1 Strength of Potential Instrumental Variables in Health Outcomes Research
| Potential Instrumental Variable | Strength |
| Differential distance to nearest provider of Treatment A vs. Treatment B | Weak or strong |
| Geographic or hospital preference for Treatment A vs. Treatment B | Weak or strong |
| Physician preference for Treatment A vs. Treatment B | Weak or strong |
| Calendar time (one treatment may become more common over time | Weak or strong |
| Genetic variants | Usually weak |
| Timing of admission to hospital | Weak or strong |
| Insurance plan coverage for Treatment A vs. Treatment B | Weak or strong |
| Randomized encouragement at point of care for Treatment A vs. Treatment B when no clear-cut choice exists | Potentially strong |
SOURCE: Reprinted with permission from Dylan Small.
AN EMPIRICAL APPROACH TO MEASURING AND
CALIBRATING FOR ERROR IN OBSERVATIONAL ANALYSES
Before starting his formal presentation, Patrick Ryan noted that he was giving this talk on behalf of the Observational Medical Outcomes Partnership (OMOP) and that all of the data he would be discussing are available publicly at the Partnership’s website (http://omop.org). He then described what he called a framework for thinking about how to measure bias and how to quantify how well observational studies perform. The intent of this framework, he explained, is to use the information that it produces as the context for interpreting observational studies and to adjust and calibrate analytical estimates to be more in line with expectations.
As an example, Ryan discussed a study described in a paper published in the British Journal of Clinical Pharmacology that examined the risk of gastrointestinal bleeding in association with the drug clopidogrel (Opatrny et al., 2008). That paper described the results of a nested case-control observational study conducted using the United Kingdom’s General Practice Research Database. Ryan characterized the study as a typical observational study. In this particular case, the authors found that clopidogrel increased the risk of gastrointestinal bleeding with an adjusted rate ratio of 2.07 and a 95 percent confidence interval that spanned from 1.66 to 2.58. “How much can we believe that there is a doubling of risk?” asked Ryan. Framed another way, he wondered how far away the adjusted rate ratio of 2.07 is from the true value as a result of bias. For clarification, he defined the term
“coverage” to be the probability that the confidence interval contains the true effect, which, for 95 percent confidence intervals, would be the effect expected 95 percent of the time.
One way to qualitatively assess the performance of a method would be to use three to four negative controls pairs (drug and outcome pairs that have been shown not to have an association) in addition to the target outcome pair, as a means of assessing the plausibility of the result from an observational analysis. If the same outcome was not found for those negative controls, “maybe in some qualitative way, you would feel better about the plausibility of your effect,” said Ryan. What OMOP has been doing instead is use a large sample of negative and positive controls to empirically measure analysis operating characteristics and use those to calibrate study findings. For this example, OMOP implemented a nested case-control study with a standardized approach to matching cases and controls with a standard set of inclusion and exclusion criteria. As a data source, OMOP used a large U.S. administrative claims database, and the analysis estimated that clopidogrel increased the risk of gastrointestinal bleeding with an adjusted odds ratio of 1.86 and a 95 percent confidence interval of 1.79 to 1.93. Ryan said the tighter confidence interval was in large part a result of the larger data sample size that OMOP used in the analysis.
The OMOP team next took the same standardized implementation of that method and consistently applied it across a network of databases to a large sample of negative and positive controls. For gastrointestinal bleeding, the OMOP team specifically identified 24 drugs that it believed were associated with bleeding and 67 drugs for which they could find no evidence to suggest that the drug might be related to gastrointestinal bleeding, on the basis of product labeling and information in the literature. For these negative controls, if the 95 percent confidence interval was properly calibrated, then 95 percent, or 62 of 65, of the relative risk estimates would cover a relative risk of 1. In fact, the analysis found that only 29 of the 65 negative controls covered a relative risk of 1 and the error distribution demonstrated a positive bias and substantial variability for this case-control method, the same used in the clopidogrel study (see Figure 3-2).
A variety of measures can be used to measure the accuracy of a method, explained Ryan, but one of the challenges with the measurement of accuracy is that it is possible to make assumptions about benchmarking of an estimate only relative to the truth. For negative controls, the assumption is that they have a relative risk of 1, but it is not possible to assume the estimate of the effect for positive controls. Another approach is to measure discrimination, which is the probability that an estimate from an observational study can distinguish between no effect and a positive effect regardless of the size of the effect. Sensitivity and specificity are additional measures of accuracy, in which sensitivity is the percentage of positive controls that meet
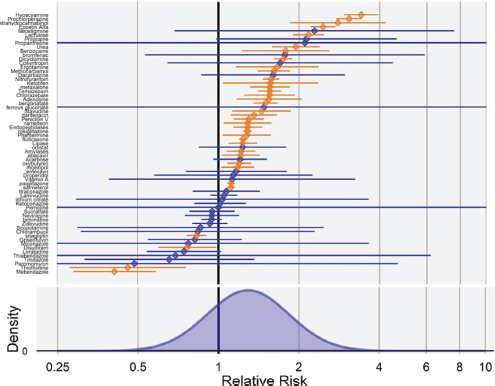
FIGURE 3-2 Case-control estimates for gastrointestinal bleeding negative controls. The y-axis lists the 65 negative controls, and the x-axis denotes relative risk. Values in orange are statistically significant; values in blue are not. The error distribution (bottom) demonstrates a positive bias of this method and substantial variability.
SOURCE: Reprinted with permission from Patrick Ryan.
a decision threshold of dichotomous criteria, and specificity is the percentage of negative controls that do not meet this same decision threshold.
When Ryan and his colleagues compared the accuracy of cohort and self-controlled designs using different methods, databases, and outcomes, they found that each type of analysis has its own error distribution and all methods have low coverage probability. He said that from here one can take one of two directions: either improve the methods to reduce the magnitude of error or quantify the error and use it to adjust the estimates of the effect through empirical calibration. Instead of having a theoretical null distribution based only on sampling variability, it should be possible to use the empirical null distribution based on the uncertainty measured from negative controls when the method is applied to the data source. Application of this approach to the clopidogrel and gastrointestinal bleeding example produces a new range for the adjusted odds ratio of 0.79 to 4.57,
which Ryan explained means that the results are not statistically significant and that it is not possible to rule out the possibility that the effect is not larger than 4. Calibration, he said, does not influence discrimination, but it does tend to improve bias, mean squared error, and coverage.
Concluding his talk, Ryan said that observational studies contain valuable information but that there is a need to rethink how study results are interpreted to capitalize on the value of the databases. One approach, which OMOP is taking, is to conduct a systematic exploration of negative and positive controls, both to measure the operating characteristics of a given method and to use that measurement to revise initial estimates and consider the true uncertainty observed in those studies.
John B. Wong noted that the use of empirical adjustment in the methods that OMOP is developing has a real potential to reduce false-positive and false-negative results. He also remarked on the importance of Small’s work with instrumental variables and their use in quantifying the degree of bias associated with unmeasured confounding. He added that this work demonstrated that two-stage least-squares analysis should not be used with weak instrumental variables, that an increased sample size can produce useful results if the instrumental variable is valid, and that it is important to explicitly examine the sensitivity of a weak instrumental variable to biases.
Joel B. Greenhouse then reminded the workshop participants that this is not the first time that researchers have discussed how to best use observational studies. In particular, he mentioned the work of Jerome Cornfield, performed in the 1950s, that demonstrated a causal association between smoking and lung cancer (Cornfield, 2012). He recommended two papers originally published in 1959 and recently reprinted in Statistics in Medicine and the International Journal of Epidemiology (Cornfield, 2012; Cornfield et al., 2009). The first paper, said Greenhouse, outlined a defense of the evidence generated from observational studies and addressed every issue being discussed at the workshop (Cornfield, 2012). The second paper, which informed the Surgeon General’s report on smoking, looked at every alternative explanation for a link between smoking and lung cancer and found that none sufficed (Cornfield et al., 2009).
Greenhouse then noted the value of the methods that Ryan and his colleagues at OMOP are developing. Given Small’s presentation, he questioned the value of the instrumental variable approach for patient-centered outcomes research, particularly when a decision maker is trying to answer the question of what therapy is appropriate for a specific patient. He concluded his comments by noting that the strategy of conducting observational studies has not changed from Cornfield’s time. It is critical to start with
thoughtful objectives, including the identification of the target population of interest, and a well-designed study that uses appropriate measurements and information from multiple data sources to investigate and eliminate alternative hypotheses.
Session moderator, Michael S. Lauer, director of the Division of Prevention and Population Sciences at the National Heart, Lung, and Blood Institute, asked the panel if it was ever acceptable today to do a straightforward regression analysis of observational data. Schneeweiss answered that everyone attending the workshop should agree that one analysis of any kind by itself is no longer sufficient. He said that the biggest challenge today, which was highlighted by Small’s and Ryan’s presentations, is to ensure that investigators are properly using these new methods. Wong agreed with that assessment and noted that two papers on how to conduct and report on studies through the use of instrumental variables would be appearing in the May 2013 issue of the journal Epidemiology . Greenhouse added that, in addition to multiple methods, multiple studies conducted in different contexts and with different populations are needed. Small commented that he would like to see some thought put into how to report sensitivity analyses in a way that would be useful to clinicians and decision makers.
Nancy Santanello, vice president for epidemiology at Merck, asked the panel if any of the methods that they discussed or know about deals specifically with misclassification bias or provides a measure of the reliability of the data in large databases. Ryan said that the work that he discussed does not deal with misclassification separately but, rather, bundles all of the unmeasured confounders into one composite measure of error that is integrated into the subsequent analysis.
Steven N. Goodman asked the panelists to discuss what they thought the most effective investments would be for further development of these methodologies. Ryan said that investment in methods development is needed and that PCORI should invest in new approaches to the use of instrumental variables and large-dimensional regressions, as well as in methods to evaluate the methods that are being developed. As an example, he said that he would like to see instrumental variable methods implemented, along with an assessment of how they work in practice. Schneeweiss agreed that the field is now at a place where it understands how these methods work and that their performance should be assessed; however, Schneeweiss thought that the bigger issue is that even the best methods used incorrectly will yield bad results. He suggested that it would be useful to simulate and insert into a data source a known association and to then try to identify that association as a “gold standard” for performance, an idea that Wong seconded.
Small said that he thought that it would be useful to validate performance in specific settings of some common types of instrumental variables, such as physician prescribing preferences or geographic variations. He thought that such studies could provide information on the types of data that need to be measured and collected to make these instruments valid in other settings. Dean Follmann, branch chief and associate director for biostatistics at the National Institutes of Health, thought that with many of the new databases being developed an opportunity exists to also consider new types of study designs that build context-specific instrumental variables into the studies. As an example, he proposed a hypothetical trial of a human immunodeficiency virus vaccine in Malawi in which the country’s 12 provinces would be randomized and then the vaccine would be administered to individuals in the randomized provinces at different times of the year. This would essentially create a trial with a built-in instrumental variable.
Changing the subject, Sheldon Greenfield, executive codirector of the Health Policy Research Institute at the University of California, Irvine, asked for workshop attendees to comment on the idea that observational studies should be held to some standard in terms of the variables included in those studies. In particular, when confounders are known but not available in a dataset, should investigators be required to find those variables or proxies for those variables in other data sets or even the original dataset? Greenhouse voiced the opinion that PCORI should invest in ensuring that databases with data from observational studies have the variables that are needed to do the types of investigations that will help clinicians and decision makers. Wong noted that the retrospective collection of data on unmeasured confounders is somewhat difficult and that doing so introduces new biases into any analysis.
A workshop participant from a remote site asked the panel to comment on the effect on bias of the requirement that PCORI must involve patients and other stakeholders in the design of research, given the lack of technical knowledge among patients. Lauer noted that innumeracy is a problem not just among patients but also among many clinicians. Wong said that he believes that patients can play an important role in deciding what outcomes are important so that investigators can then use the methods presented here, for example, to design their studies to address those outcomes.
Mark A. Hlatky, professor and Stanford Health Policy Fellow in the Department of Health Research and Policy at Stanford University, asked the panelists to provide some guidance on when to decide that a particular method is not yielding useful information. Ryan said that his approach is to use multiple methods to determine which method has the most desirable operating characteristics, discriminates best, has less bias, and has the best coverage. All things being equal, Ryan said that he would pick the analytical method that has the preferred operating characteristics. Small said that
for the instrumental variable method, it would be useful to do more power sensitivity analyses for observational studies that identify how much statistical power is needed to detect an effect yet still be insensitive to a bias of some plausible magnitude. If no power to detect an effect that allows even a small amount of bias exists, then it would useful to find some other study design or database for that study.
Santanello asked Ryan if the methods that OMOP developed to look at safety could be applied to look at comparative effectiveness. Ryan replied that the same data sources are used to examine safety and comparative effectiveness, so the same types of analytical strategies should work. The issue, he continued, is to decide how to create the reference set of positive and negative controls in the context of comparative effectiveness rather than safety.
Angrist, J., and A. B. Krueger. 1994. Why do World War II Veterans earn more than nonveterans? Journal of Labor Economics 85(5):1065–1087.
Cornfield, J. 2012. Principles of research: 1959. Statistics in Medicine 31(24):2760–2768.
Cornfield, J., W. Haenszel, E. C. Hammond, A. M. Lilienfeld, M. B. Shimkin, and E. L. Wynder. 2009. Smoking and lung cancer: Recent evidence and a discussion of some questions. International Journal of Epidemiology 38(5):1175–1191.
Opatrny, L., J. A. Delaney, and S. Suissa. 2008. Gastro-intestinal haemorrhage risks of selective serotonin receptor antagonist therapy: A new look. British Journal of Clinical Pharmacology 66(1):76–81.














