
2
Some Basics of Computing and Communications Technology and Their Significance for Cybersecurity
The computers at the heart of information technology are generally stored-program computers. A program is the way an algorithm is represented in a form understandable by a computer. An algorithm is a particular method devised to solve a particular problem (or class of problems). Computers do what the program tells them to do given particular input data, and if a computer exhibits a particular capability, it is because someone figured out how to break the task into a sequence of basic steps, that is, how to program it.
A program is implemented as a sequence of instructions to the computer; each instruction directs the computer to take some action, such as adding two numbers or activating a device connected to it. Instructions are stored in the memory of the computer, as are the data on which these instructions operate.
A particularly important instruction is conditional. Let’s call X a statement about some particular data that is either true or false. Then if X is true, the computer does something (call it A); if X is not true, the computer does something else (call it B). In this way, the sequence of instructions carried out by the computer will differ depending on the exact values of the data provided to the computer. Furthermore, the number of possible sequences of instruction execution grows very rapidly with the number of decisions: a program with only 10 “yes” or “no” decisions can have more than 1000 possible paths, and one with 20 such decisions can have more than 1 million.
A second key point about computing is that information processed by computers and communication systems is represented as sequences of bits (i.e., binary digits). Such a representation is a uniform way for computers and communication systems to store and transmit all information; in principle, information can be synthesized without an original source per se simply by creating the bits and then can be used to produce everything from photo-realistic images to an animation to forged e-mail. Digital encoding can represent many kinds of information with which human beings interact, such as text, sound, images, and video/movies.
As bit sequences, information can be found in two forms—information at rest, that is, stored as a file on a device such as a hard disk or a memory card; and information in transit through a cable or over a wireless link from one location to another.
Why do these aspects of computing technology matter for security?
The fact that a program may execute different instructions in sequence depending on the data means that the programmer must anticipate what the program should do for all possible data inputs. This mental task is of course more difficult when the number of possible different data inputs is large, and many security flaws occur because a programmer has failed to properly anticipate some particular set of data (e.g., the program processes only numeric input, and fails to account for the possibility that a user might input a letter).
A further consequence is that for programs of any meaningful utility, testing for all possible outcomes is essentially impossible when treating the program as a black box and exercising the program by varying the inputs. This means that although it may be possible to show that the program does what it is supposed to do when presented with certain inputs, it is impossible to show that it will never do what it is not supposed to do with all possible inputs. For example, a program may always perform as it should except when one of the inputs is a particular sequence of digits; upon receiving that particular sequence, the program can (deliberately) perform some unexpected and hostile action.
The digital representation of information has a number of important security consequences as well. For example, representation of information as sequences of bits means that there is no inherent association between a given piece of information (whether text, data, or program) and its originator—that is, information is inherently anonymous. A programmer can explicitly record that association as additional encoded data, but that additional data can, in principle, be separated from the information of interest. This point matters in situations in which knowing the association between information and its originator is relevant to security, as might be the case if a law enforcement agency were trying to track down a cyber criminal.
The fact that a given sequence of bits could just as easily be a program as data means that a computer that receives information assuming it to be data could in fact be receiving a program, and that program could be hostile. Mechanisms in a computer are supposed to keep data and program separate, but these mechanisms are not foolproof and can sometimes be tricked into allowing the computer to interpret data as instructions. It is for this reason that downloading data files to a computer can sometimes be harmful to the computer’s operation—embedded in those data files can be programs that can penetrate the computer’s security, and opening the files may enable such programs to run.
Last, the representation of information as sequences of bits has facilitated the use of various mathematical techniques—cryptographic techniques—to protect such information. Cryptography has many purposes: to ensure the integrity of data (i.e., to ensure that data retrieved or received are identical to data originally stored or sent), to authenticate specific parties (i.e., to verify that the purported sender or author of a message is indeed its real sender or author), and to preserve the confidentiality of information that may have come improperly into the possession of unauthorized parties.
To understand how cryptographic methods span a range of communication and storage needs, consider the general problem of securing a private message sent from Alice to Bob. Years ago, such a process was accomplished by Alice writing a letter containing her signature (authentication). The letter was sealed inside a container to prevent accidental disclosure (confidential transmission). If Bob received the container with an unbroken seal, it meant that the letter had not been disclosed or altered (data integrity), and Bob would verify Alice’s signature and read the message. If he received the container with a broken seal, Bob would then take appropriate actions.
With modern cryptographic techniques, each of the steps remains essentially the same, except that automated tools perform most of the work. Mathematical operations can scramble (encrypt) the bit sequences that represent information so that an unauthorized party in possession of them cannot interpret their meaning. Other mathematical operations descramble (decrypt) the scrambled bits so that they can be interpreted properly and the information they represent can be recovered. Still other operations can be used to “sign” a piece of information in a way that associates a particular party with that information. (Note, however, that signed information can always be separated from its signature, and a different signature (and party) can then be associated with that information.)
2.2 COMMUNICATIONS TECHNOLOGY AND THE INTERNET
Computers are frequently connected through networks to communicate with each other, thus magnifying their usefulness. Furthermore, since computers can be embedded in almost any device, arrays of devices can be created that work together for coherent and common purposes.
The most widely known example of a network today is the Internet, which is a diverse set of independent networks, interlinked to provide its users with the appearance of a single, uniform network. That is, the Internet is a network of networks. The networks that compose the Internet share a common architecture (how the components of the networks interrelate) and protocols (standards governing the interchange of data) that enable communication within and among the constituent networks. These networks themselves range in scale from point-to-point links between individual devices (such as Bluetooth) to the relatively small networks operated by individual organizations, to regional Internet service providers, to much larger “backbone” networks that aggregate traffic from many small networks, carry such traffic over long distances, and exchange traffic with other backbone networks.
Internally, the Internet has two types of elements: communication links, channels over which data travel from point to point; and routers, computers at the network’s nodes that direct data arriving along incoming links to outgoing links that will take the data toward their destinations.
Data travel along the Internet’s communication links in packets adhering to the standard Internet Protocol (IP) that defines the packets’ format and header information. Header information includes information such as the origin and destination IP addresses of a packet, which routers use to determine which link to direct the packet along. A message from a sender to a receiver might be broken into multiple packets, each of which might follow a different path through the Internet. Information in the packets’ headers enables the message to be restored to its proper order at its destination. However, as a general rule, it is not possible to specify in advance the particular sequence of routers that will handle a given packet—the routers themselves make decisions about where to send a packet in real time, based on a variety of information available to those routers about the cost of transmission to different routers, outages in adjacent routers, and so on.
The origins and destinations of data transiting the Internet are computers (or other digital devices), which are typically connected to the Internet through an Internet service provider (ISP) that handles the necessary technical and administrative arrangements. The links and routers of the Internet provide the critical connectivity among source and
BOX 2.1 A More Refined View of Internet Architecture
The separation of the Internet into nodes for transmitting and receiving data and links and routers for moving data through the Internet captures the essence of its original architectural design, but in truth it presents a somewhat oversimplified picture. Some of the more important adjustments to this picture include the following:
• Content delivery networks. Certain popular sites on the Web serve a large number of end users. To increase the speed of delivering content from these sites to end users, these Web sites replicate the most popular content on content delivery networks located across the Internet. When a user requests content from these popular sites, the content is in fact delivered to the user by one of these content delivery networks.
• Other networks. As noted in the main text, the Internet is a network of networks. Each network within the Internet is controlled by some entity, such as an Internet service provider, a business enterprise, a government agency, and so on. The controlling entity has relationships with the users to whom it provides service and with the entity controlling the larger network within which this network is embedded. Each relationship is governed by negotiated terms of service. These entities do have capabilities for monitoring traffic and modulating connectivity on their networks, so that, for example, they can cut off certain nodes that are pumping hostile or adverse traffic onto the larger Internet.
• Cloud computing and storage. Cloud computing and storage, as well as services such as Internet search, are Internet applications. Various vendors also sell to end users cloud-based services that provide software and even infrastructure on demand. However, from the standpoint of individual users, cloud computing may appear to be located among the links and routers, because the information technology on which such applications run is not co-located with end users.
Misbehavior in any of these components reroutes, delays, or drops traffic inappropriately, or otherwise provides unreliable information, thus posing security risks.
destination computers, but nothing else. (Distinguishing between source/destination computers transmitting and receiving data and links and routers moving data through the Internet captures the essence of its original architectural design, but in truth it presents a somewhat oversimplified picture. Some of the more important adjustments to this picture are described in Box 2.1.)
Figure 2.1 provides a schematic that illustrates the architecture of the Internet. Applications that are directly useful to users are provided by the source and destination computers. Applications are connected to each other using packet-switching technology, which runs on the physical infrastructure of the Internet (e.g., fiber-optic cable, wireless data
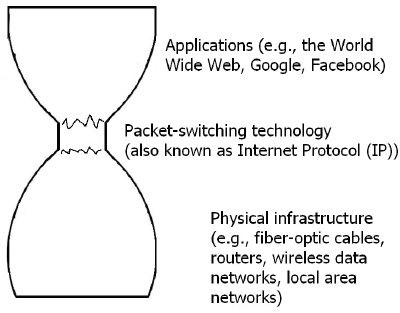
FIGURE 2.1 A schematic of the Internet. Three “layers” of the Internet are depicted. The top and bottom layers (the applications layer and the physical infrastructure layer) are shown as much wider than the middle layer (the packet-switching layer), because within each of the wide layers is found a large number of largely independent actors. But within the packet-switching layer, the number of relevant actors is much smaller, and those that do have some control over the packet-switching layer act in tight coordination.
networks, local area networks). Users navigate the Internet using the arrangements described in Box 2.2.
The various applications, the packet-switching technology, and the physical infrastructure are often called layers of the Internet’s architecture, and one of the most significant features of this architecture is that different parties control different layers. Applications (and the infrastructure on which they run) are developed, deployed, and controlled by millions of different entities—companies, individuals, government agencies, and so on. Each of these entities decides what it wants to do, and “puts it on the Internet.” The physical infrastructure responsible for carrying packets is also controlled by a diverse group of telecommunications and Internet service providers that are a mix of public and private parties with interests—monetary or otherwise—in being able to carry data packets. (In the United States, these service providers are mostly entities in the private sector.)
The middle layer—the packet technology (in this context essentially
BOX 2.2 Internet Navigation
How can a user navigate from one computer to another on the Internet? To navigate—to follow a course to a goal—across any space requires a method for designating locations in that space. On a topographic map, each location is designated by a combination of a latitude and a longitude. In the telephone system, a telephone number corresponding to a landline designates each location. On a street map, locations are designated by street addresses. Just like a physical neighborhood, the Internet has addresses—32- or 128-bit numbers, called IP addresses (IP for Internet Protocol)—that define the specific location of every device on the Internet.
Also like the physical world, the Internet has names—called domain names, which are generally more easily remembered and informative than the addresses that are attached to most devices—that serve as unchanging identifiers of those devices even when their specific addresses are changed. The use of domain names on the Internet relies on a system of servers—called name servers—that translate the user-friendly domain names into the corresponding IP addresses. This system of addresses and names linked by name servers is called the Domain Name System (DNS) and is the basic infrastructure supporting navigation across the Internet.
Conceptually, the DNS is in essence a directory assistance service. George uses directory assistance to look up Sam’s number, so that George can call Sam. Similarly, a user who wants to visit the home page of the National Academy of Sciences must either know that the IP address for this page is 144.171.1.30, or use the DNS to perform the lookup for www.nas.edu. The user gives the name www.nas.edu to a DNS name server and receives in return the IP address 144.171.1.30. However, in practice, the user almost never calls on the DNS explicitly—rather, the entire process of DNS lookup is hidden from the user in the process of viewing a Web page, sending e-mail, and so on.
Disruptions to the DNS affect the user experience. Disruptions may prevent users from accessing the Web sites of their choosing. A disruption can lead a user to a “look-alike” Web site pretending to be its legitimate counterpart. If the look-alike site is operated by a malevolent actors, the tricked user may lose control of vital information (such as login credentials).
a set of standards for the Internet Protocol discussed above)—is managed and specified by the Internet Engineering Task Force (IETF; Box 2.3). Notably, the IETF and thus the specifications of the Internet Protocol are not under the control of any government, although governments (and many others as well) have input into the processes that evolve the Internet Protocol.
It is the separation of the Internet into different layers that are managed separately that is responsible more than any other factor for the explosive growth of Internet applications and use. By minimizing what
BOX 2.3 The Internet Engineering Task Force
The Internet Engineering Task Force (IETF) is a large, open international community of network designers, operators, vendors, and researchers concerned with the evolution of the Internet architecture and the smooth operation of the Internet. It is open to any interested individual. The actual technical work of the IETF is done in its working groups, which are organized by topic into several areas (e.g., routing, transport, security, and so on). Much of the work is handled via mailing lists. The IETF holds meetings three times per year.
The IETF describes its mission as “mak[ing] the Internet work better by producing high quality, relevant technical documents that influence the way people design, use, and manage the Internet.” The IETF adheres to a number of principles:
• Open process. Any interested person can participate in the work, know what is being decided, and make his or her voice heard on an issue. All IETF documents, mailing lists, attendance lists, and meeting minutes are publicly available on the Internet.
• Technical competence. The issues addressed in IETF-produced documents are issues that the IETF has the competence to speak to, and the IETF is willing to listen to technically competent input from any source. The IETF’s technical competence also means that IETF output is designed to sound network engineering principles, an element often referred to as “engineering quality.”
• Volunteer core. IETF participants and leaders are people who come to the IETF because they want to do work that furthers IETF’s mission of “making the Internet work better.”
• Rough consensus and running code. The IETF makes standards based on the combined engineering judgment of its participants and their real-world experience in implementing and deploying its specifications.
• Protocol ownership. When the IETF takes ownership of a protocol or function, it accepts the responsibility for all aspects of the protocol, even though some aspects may rarely or never be seen on the Internet. Conversely, when the IETF is not responsible for a protocol or function, it does not attempt to exert control over it, even though such a protocol or function may at times touch or affect the Internet.
SOURCE: Adapted from material found at the IETF Web site at http://www.ietf.org.
the links and routers need to do (they only have to transport digitized data from A to B without regard for the content of that data), any given applications provider can architect a service without having to obtain agreement from any other party. As long as the data packets are properly formed and adhere to the standard Internet Protocol, the application provider can be assured that the transport mechanisms will accept the data for forwarding to users of the application. Interpretation of those packets is the responsibility of programs on the receiver’s end.
Put differently, most of the service innovation—that is, the applications directly useful to users—takes place at the source and destination computers, independently of the network itself, apart from the technical need for sending and receiving packets that conform to the Internet Protocol. The Internet’s architecture is an embodiment of the end-to-end argument in systems design that says that “the network should provide a very basic level of service—data transport—and that the intelligence—the information processing needed to provide applications—should be located in or close to the devices attached to … the network.”1 As a result, innovation requires no coordination with network architects or operators, as long as the basic protocols are adhered to. All of the services commonly available on the Internet today—e-mail, the World Wide Web, Facebook, Google search services, voice-over-IP communications services, and so on—have benefited from and been enabled by this architecture.
Why do these aspects of communications technology and the Internet matter for security?
The fundamental architecture of the Internet also has many implications for security. In particular, the end-to-end design philosophy of the Internet is that the Internet should only provide capability for transporting information from one point to another. As such, the Internet’s design philosophy makes no special provision for security services. Instead, the Internet operates under the assumption that any properly formed packet found on the network is legitimate; routers forward such packets to the appropriate address—and don’t do anything else.
Discussions of cybersecurity for “the Internet” often carry a built-in ambiguity. From the standpoint of most users, “the Internet” refers to all of the layers depicted in Figure 2.1—that is, users’ conception of “Internet security” includes the security of the source and destination computers connected to the Internet. From the standpoint of most technologists, however, “the Internet” refers only to the packet-switching technology. This distinction is important because the locus of many cybersecurity problems is found in the applications that use the Internet.
In principle, security mechanisms can be situated at every layer. Depending on the layer, these mechanisms will have different properties and capabilities, and will be implemented by different parties.
Contrary to the Internet’s end-to-end design philosophy, some parties argue that the Internet needs security services that are more embedded into the Internet’s architecture and protocols and active in the packet-switching layer. These services would be able to monitor Internet traffic for a wide range of security threats, and perhaps take action to curb or
________________
1 See Jerome H. Saltzer, David P. Reed, and David D. Clark, “End-to-End Arguments in System Design,” ACM Transactions on Computer Systems 2(4):277-288, 1984.
reduce threat-containing traffic and thereby reduce the threat to application users. Further, this argument implies that the end-to-end design philosophy has impeded or even prevented the growth of such security services.
Those favoring the preservation of the end-to-end design philosophy argue that because of the higher potential for inadvertent disruption as a side effect of a change in architecture or protocols, every proposed change must be tested and validated. Because such changes potentially affect an enormous number of users, testing and validation can be difficult and time-consuming—and thus raise concerns about negative impacts on the pace of innovation in new Internet-based products and services. Moreover, actions driven by the requirements of protocols necessarily slow down the speed at which packets can be forwarded to their destinations. And any mechanisms to enforce security mechanisms embedded in Internet protocols may themselves be vulnerable to compromise that may have wide-ranging effects.
Others argue that security services should be the responsibility of the developers of individual applications. In this view, the security functionality provided can be tailored to the needs of the application, and providing security for the application in a decentralized manner does not affect the performance of the Internet as a whole. In addition, the scope and nature of security services provided need not be negotiated with stakeholders responsible for other applications. Countering this viewpoint is the perspective that applications-based security is a burden on end users.
Some security services can be provided at a distance from the applications. For example, some individual ISPs offer their customers (and only their customers) services that help to block hostile traffic or to inform them when they detect that a user’s security has been compromised. Such offerings are not uncommon, and they have a modest impact on users’ ability to innovate, but they are also generally insufficient to fully mitigate Internet-based threats to cybersecurity. In addition, individual organizations often connect to the Internet using gateways through which flows all the traffic to and from them, and the organizations place services for monitoring and filtering at those gateways.
Whether and how to violate the end-to-end principle in the name of security is an important policy issue today. How this issue is resolved will have profound implications for security.
2.3 INFORMATION TECHNOLOGY SYSTEMS
Information technology (IT) systems integrate computing technology, communication technology, people (such as developers, operators, and users), procedures, and more. Interfaces to other systems and control
algorithms are their defining elements; communication and interaction are the currency of their operation. Increasingly, the information exchanged among IT systems includes software (and, therefore, instructions to the systems themselves), often without users knowing what software has entered their systems, let alone what it can do or has done.
The Internet is an essential element of many IT systems—it is the connective tissue that turns a computer 1000 miles away into a component of the IT system with which you interact on your desk or in your hand. For example, Web pages today usually include a pictorial image, which is downloaded from a remote computer onto the displaying computer. But if the portion of the Web browser that displays the image is flawed, and an adversary constructs the image to have a hostile program embedded within it, displaying the image can run the program. Running a Web browser without such a flaw would result in a harmless display of the image.
The security implications of the systems nature of much of the information technology in our lives are addressed further in Chapter 3.
Why do these properties of IT systems matter for security?
Large IT systems—and most of the IT systems that underpin critical infrastructure and daily life alike are large systems—are not simply larger versions of small computer programs. With respect to their cybersecurity properties, they exhibit what might be called emergent behavior—behavior that is rooted in how and when such a system’s various components interact with each other.
That is, even an IT system constructed from components that are themselves entirely trustworthy is not necessarily secure. (And, as a general rule, the actual security properties of the components themselves also cannot be assured.) A secure component may be, for example, a program that has been formally proved to meet its specification. But this proof is valid only for the program as a whole. If another component can gain entry to this program in some unanticipated way (e.g., in the middle of the program), the proof may no longer apply.











