
Session 1:
Introduction to Big Data
Session 1 of the workshop focused on introducing the concepts of big data and their application to several different disciplines. Presentations were made by Dan Crichton, Jet Propulsion Laboratory (JPL), Jed Pitera, IBM Research-Almaden, and Dave Shepherd, Department of Homeland Security (DHS).
FRONTIERS IN MASSIVE DATA ANALYSIS AND THEIR IMPLEMENTATION
Daniel Crichton, Director, Center for Data Science and Technology, Jet Propulsion Laboratory
Mr. Crichton explained that he manages multiple projects and programs in scientific data systems for planetary, Earth, and other disciplines. JPL has a data science and technology center that supplies the infrastructure needs and end-to-end systems for scientific data systems across multiple disciplines. Mr. Crichton said that he was also a member of the committee that wrote the NRC report Frontiers in Massive Data Analysis (2013) and would describe some of the findings and recommendations of that study.
Mr. Crichton stated at the outset that all observational science platforms, whether from a Mars rover, an Earth observing system, or a neonatal sensor system for an infant, have certain elements in common: All simultaneously provide numerous forms of measurement and observation. He noted that there are several challenges in space systems, and probably in other domains as well:
- Space systems are developed and deployed worldwide, and data are generated across complex, interconnected systems. Mr. Crichton said that there are many producers of the data; as a result, the data are highly distributed, with limited data sharing.
- Systems are heterogeneous and located in different physical systems. As a result, the data are stored in a variety of formats, and access to data can be difficult.
- The data sets are so massive that they stress traditional analysis approaches.
Mr. Crichton explained that the elements to collect data are traditionally built independently, with each element supporting a single type of data and data collection. The concept of big data is the opposite: Big data seek to look at the end-to-end architecture needed to support an entire system. The big data approach considers ways to scale and systematize analyses. He showed that the amount of data produced at JPL has been increasing at a significant and highly nonlinear rate.
Mr. Crichton explained the importance of an architectural approach to big data. He said that the National Aeronautics and Space Administration (NASA), for instance, had captured its data in high-quality archives, but NASA did not originally consider the full data life cycle; instead, it pushed the burden of data analysis to the individual researchers. In contrast, the big data approach supplies a technical infrastructure with an overall architecture. In addition, Mr. Crichton stressed that the technical infrastructure should be built independently of the data and their structure. In general, technology changes rapidly, and data should not become obsolete on the same rapid time scale as the technology. Once the infrastructure is in place to support data capture, it is also important to be able to analyze the data. Mr. Crichton suggested the adoption of more advanced techniques for data analysis to increase the efficiency of data analysis in a distributed environment. He gave the example of a space mission with an interferometer. In the past, such a mission would provide a few hundred terabytes of data; now that same mission format will provide tens to hundreds of petabytes of data. This data explosion requires changes to data storage, processing, and management.
Mr. Crichton briefly described the big data life cycle, from data generation to archiving and analysis. In between, data triage is conducted; if the data are too massive, data reduction steps may be necessary to reduce their overall size. However, any data reduction requires inferences to be developed about the data, adding uncertainty to the data.
Mr. Crichton pointed out that NASA has specific challenges to the standard data collection paradigm. He defined three challenges that are encountered in space data systems in particular:
- How do we store, capture, and transmit data from extreme environments?
- How do we triage massive data for archiving?
- How can we use advanced data science methods to systematically derive scientific inferences from massive, distributed science measurements and models?
Mr. Crichton said that NASA’s data are collected by onboard instruments, and NASA is limited as to how much data can be returned to the ground. It is therefore interested in onboard computing to perform data reduction. However, the science community is not always in favor of data reduction. In any case, onboard data collection systems are likely to reach a capacity constraint in the near future, which will force a change in system implementation.
Mr. Crichton then listed a set of technology trends identified by the NRC report on massive data (NRC, 2013):
- Distributed systems. This trend includes different access mechanisms and ownership rules, data federation, linking, etc.
- Scalable infrastructures and technologies to optimize computing and data-intensive applications. Mr. Crichton noted that the trend is moving toward data-intensive computing rather than high-performance computing.
- Service-oriented architectures.
- Ontologies, models and information representation. Mr. Crichton stated a need to agree on how to represent data; this can be very difficult, as different scientists will have different emphases within the same data set.
- Scalable database systems with different underlying models.
- Federated data security mechanisms. Different access permission rules will create both authentication and authorization issues.
- Technologies for the movement of large data sets. Mr. Crichton pointed out that this is a big challenge in the high-energy physics community in particular.
Mr. Crichton then described the framework for data-intensive systems built at NASA’s JPL. The framework is open source, and it has been applied in various settings by the broader community. He said that there is no single big data solution; instead, one must bring the different building blocks together for each problem in such a way that they can be scaled and optimized. The framework is known as Object Oriented Data Technology (OODT).1 OODT was originally developed to support NASA’s Planetary Data System (PDS), a system recommended by an earlier NRC study. The data were stored on tapes, and the quality was beginning to erode; an NRC study recommended the development of the PDS (NRC, 1995).
_________________
1 OODT can be explored online at http://oodt.apache.org/. Accessed February 20, 2014.
The purpose of the system is to collect, archive, and make accessible digital data and documentation produced from NASA’s exploration of the solar system. Mr. Crichton explained that the data have international operability and have been validated against a common set of structures and data standards.
Mr. Crichton then described the earth science data pipeline: Systems are built to capture data. Those data are sent to the ground station; higher-order data products are developed; the results are archived; and the results are provided to the community at large. This system has worked well; currently, it consists of a well-curated repository of about 7 PB, though that number will increase rapidly. Mr. Crichton said that JPL is also supporting the Earth System Grid Federation, which informs the entire earth science modeling community and also supports the Intergovernmental Panel on Climate Change (IPCC) assessments.
Mr. Crichton then said it is important to evolve from data archiving to scalable data analytics. Data analytics requires automated methods to identify and detect data patterns across a variety of disciplines and under many different operational paradigms. He pointed out that a system could be used to study Twitter patterns for security purposes, for example. Mr. Crichton said that JPL is focusing on the transition from the data computation to the source of the data. This paradigm is likely to become increasingly important in the next 5 years, as data sets become more and more massive. More analysis tools and capabilities will be needed at the site of the data repositories. Mr. Crichton predicted that merely distributing data would soon become an obsolete approach. Instead, research services and analytics will be a more advantageous approach, as users will need services rather than just the data.
Mr. Crichton explained the elements to enable big data analytics for NASA. A schematic of these elements is shown in Figure 1. Currently, there are a variety of data sources, including satellite archives, airborne instruments, in situ data, and ground sources. These constitute a massive data set that has been brought together but that was not originally designed to be integrated. The data science infrastructure, such as the data, algorithms, and machines, informs data analytics. Big data triage includes the following elements:
- Detection. Identify elements of interest.
- Classification. Organize data automatically and in real time.
- Prioritization. Use the information to inform adaptive data compression.
- Understanding. Explain events for humans to understand and interpret the results.
Mr. Crichton pointed out that the same challenges exist in other fields, not just planetary science or earth science. For example, cancer research databases will probably require similar automatic processing of data, and astronomy and planetary science will also likely need automatic processing and feature detection.
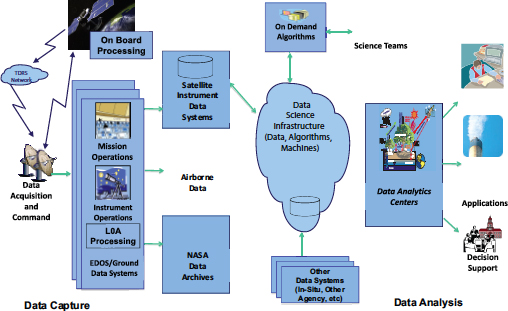
FIGURE 1 The elements of systematic analysis of massive data for NASA. SOURCE: Dan Crichton, Jet Propulsion Laboratory, presentation to the committee on February 5, 2014, Slide 17.
Mr. Crichton then explained that the 2013 NRC Frontiers report emphasized how to systematize and automatically analyze data. The report also stressed the need to bring together experts in multiple disciplines to solve these big data problems.
Mr. Crichton concluded with several of his own recommendations:
- Invest in capturing and maintaining data in well-annotated, accessible, structured data repositories.
- Bring together cross-disciplinary groups to understand how to systematize massive data analysis and increase efficiencies.
- Develop computing architectures for sharing and analyzing highly distributed, heterogeneous data, aided by international cooperation and coordination.
- Enhance sustainability in both the data and the technology infrastructures while keeping the two on separate paths to maintain the long-term health of the system.
In the discussion period, several participants suggested mapping these ideas onto advanced materials and manufacturing. Some other participants noted that the materials and manufacturing communities may not even have the models to analyze the data; in this case, care has to be taken not to “throw the baby out with the bath water” during the data triage process. In the materials community, it is currently very important to capture the raw data. A few participants discussed the need to (1) understand the best way to downselect the data rather than to capture all of it and (2) focus on models to best understand the salient features of the data that are necessary to retain.
One participant asked about data repositories and how to ensure that data remain accessible in the future. Mr. Crichton responded that it is important to separate the data from the technology. Data need to be captured in formats that are stable, even if that means that the format is not contemporary. The data need to be software independent and to rely upon conceptual models that are static. Mr. Crichton said that archives typically require at least a 50-year expected time window.
Mr. Crichton was also asked about how to address differing data quality. He responded that peer review of data is necessary to assess usability, and that the international community needs to agree to standard models and to a consistent peer review process. He said that federal research should make its data available and citable: Citations allow the reader to have confidence that the data set is publication-quality.
Jed Pitera, Manager, Computational Chemistry and Materials Science, IBM Research-Almaden
Dr. Pitera explained that he manages IBM’s research team in computational chemistry and materials science at IBM Research-Almaden. He said that this group generates large volumes of structured data and that it focuses on computation more than on data. His research group examines computational problems in soft condensed matter (i.e., polymeric materials), which includes the computational screening of chemical reactions, the development of multiresolution algorithms, models for future technologies for lithography and nanopatterning, and models of fundamental interactions in chemistry and physics. In addition to his group’s data needs, Dr. Pitera pointed out that IBM also must analyze large amounts of unstructured data to support its business applications.
To add nuance to the word “big” in big data, Dr. Pitera described some of its specific challenges. He stated that big data are often described in terms of the four V’s:
- Volume. Volume refers to the physical amount of data. Dr. Pitera stated that problems related to volume in big data are scaling and the cost of dealing with that much information as much as structural problems.
- Velocity. Velocity is both the rate at which data are collected and the time between receiving input and requiring an output. Dr. Pitera gave several examples of different time frames: In some instances, the maximum duration is several minutes (such as the time scale of a “coffee break,” the time it takes for a researcher to get a coffee and return to work); in other instances, the maximum duration is a few seconds (such as the time a call center operator might need to return an answer to a client).
- Variety. Data come in a wide variety of formats.
- Veracity. There are many sources of uncertainty associated with data quality. Data can be limited by instrument quality, as well as interpretation quality, and data can be influenced by various data artifacts.
Dr. Pitera stated that managing the four V’s requires expertise in data (acquisition, integration, cleansing, storage, protection, and management), domain (models and hypotheses), informatics (algorithms, simulations, and rules), mathematics (analysis), systems (scale and velocity), and visualizations (sharing results). He said that his group’s efforts focus primarily on the first two areas of expertise (data and domain): How do we get data, ingest them, and structure the domain of interest to capture the needed information? He posited that there are opportunities for big data in all types of study. The discovery phase focuses on conducting computational experiments, mining the literature (the published literature, as well as unpublished laboratory documentation), and finding new materials or repurposing existing ones. Dr. Pitera postulated that people tend to focus on the discovery phase. However, the material must be made usable, and integration remains a challenge. Life-cycle issues, including continuous reengineering and monitoring, are all topics to be explored.
Dr. Pitera described three representative projects in materials and big data:
- Harvard’s Clean Energy Project. This is a distributed computing project that focuses on using big data for materials discovery. It seeks to identify new photovoltaic materials with higher efficiency rates. This involves large-scale calculations, along with data mining and analytics.2
- Pharmaceuticals. Pharmaceutical companies wish to mine patent data and medical literature to identify new relationships between drugs and disease.
- Mining equipment. The goal of this project is to understand predictive equipment maintenance for heavy mining machinery.
_________________
2 See http://cleanenergy.molecularspace.org/about-cep/. Accessed June 2, 2014.
Dr. Pitera noted that the latter two projects are being developed in IBM’s Accelerated Discovery Laboratory, an exploratory collaboration space for experimental big data projects that include government and academic and other private partners.
In closing, Dr. Pitera reminded participants that materials are complex, more than just a set of chemical reactions. Understanding a material requires knowledge about its statistical composition, processing history, and other metadata. He said that systems to manage data improve daily and asked if an IBM Watson3 for materials would be useful. He pointed out that if the same questions are asked repeatedly, then a Watson would be useful and the development costs could be justified. If not, what other type of infrastructure could be used? Finally, Dr. Pitera suggested that big data should perhaps be thought of as useful data that just happen to be big. He said that it may make sense to implement data reduction or extraction to leave the big data regime—in other words, it may be better to make the haystack smaller.
During the discussion period, a participant brought up a challenge unique to materials science: A material is qualified based on its characteristics, not its composition. Two materials may qualify for the same application but have different compositions. Examples such as aluminum alloys and jet fuel were discussed. Participants also wondered what the community should do next to come together. Dr. Pitera suggested that effort should be put into the construction of appropriate data models. These models are likely to be domain-specific, as metallurgy differs from polymer chemistry, which in turn differs from inorganic glass. A uniform description for data models would need to involve many different communities.
Dave Shepherd, Program Manager, Homeland Security Advanced Research Projects Agency, Department of Homeland Security
Mr. Shepherd began by noting that he works in biology programs with homeland security applications and that his portfolio does not include materials or manufacturing. He explained that the goal of biosecurity is to alleviate any accidental or intentional release of pathogens or other causes of disease. He said that biosecurity is a predictive field, seeking to prevent disease exposure and spread by means of anticipation, and it requires a long-term perspective. He said that this predictive need was identified by an OSTP workshop in 2013.4 At the OSTP
_________________
3 Watson is an artificially intelligent computer system capable of answering questions posed in natural language. At one point Watson had access to 200 million pages of structured and unstructured content in a database consuming 4 TB of disk storage. See http://www.pcworld.com/article/219893/ibm_watson_vanquishes_human_jeopardy_foes.html. Accessed June 2, 2014.
4www.whitehouse.gov/sites/default/files/microsites/ostp/biosurveillance_roadmap_2013.pdf.
meeting, three of the five panel topics were related to big data (Big Data for Early Indications and Warnings, Big Data for Digital Surveillance/Digital Disease Detection, and Big Data Research and Analytics), and many of the problem sets discussed included the need for predictive tools.
Mr. Shepherd next explained that big data permit computer-assisted analytics, and algorithms and analytics can be used to classify and identify important information on a massive scale. Big data allow for correlations on a level that would not be possible with a smaller subset of information. One additional advantage for biosecurity is that surrogate data can be used. However, biosecurity big data sets tend not to be clean and do not contain consistent metadata. In addition, it can be difficult to find the right biosecurity data set for one’s needs.
Mr. Shepherd then went on to discuss three specific use cases for big data in biosecurity:
- Use Case 1: Algorithms for Analysis. This is an algorithm-oriented project to identify emerging technologies that can be used against the United States. It uses natural-language processing software to find descriptors in the scientific literature, patents, or other scientific documentation sources. The data must be up-to-date and continually harvested. Permissions are needed to access all the different possible data sources.
- Use Case 2: Size and Architecture. This project uses knowledge-based (KBase) data for modeling for predictive biology. KBase data combine data for microbes, microbial communities, and plants into a single integrated data model. These data are considered in a single, large-scale bio-informatics system. Users can upload their own data and build predictive models. This endeavor represents more of a community effort in big data. This project currently consists of 1 PB of stored data, and that amount is likely to increase significantly. Its plug-in architecture will allow other laboratories to use their own algorithms to analyze the data. This project mixes big data, high-performance computing, and cloud architecture.
- Use Case 3: Surrogate Data. Because the actual emergence of a novel biosecurity threat is rare, researchers seek to find surrogate data to help when new threats are encountered. Mr. Shepherd believed that the use of surrogate data is very helpful to this community, but that the idea of surrogate data may not be feasible in other communities. One example where excellent surrogate data for biosecurity exists, Mr. Shepherd noted, are data for the spread of antimicrobial resistance. Because outbreaks of antimicrobial resistance occur rather frequently, there are enough data to support predictive model development and verification. Like antimicrobial resistance, a novel biological threat can appear anywhere in the world, so
infrastructure to support the development of a geographic distribution map would be useful and would assist in analysis and prediction.
Mr. Shepherd pointed out that clinical data are not aggregated at a national level, and there is no infrastructure to support such data aggregation. He said that researchers are beginning to realize that a centralized database is unlikely to be viable. When human subjects and privacy are involved, data sharing becomes difficult. Instead, it may make the most sense to move the data processing to the individual holders of clinical data. Mr. Shepherd envisions a new model in which clinical data holders participate in a national, distributed, interconnected grid similar to the collaborative model that underlies Lawrence Livermore National Laboratory’s Earth Systems Grid Federation for the climate modeling community.
Mr. Shepherd then described some of the challenges associated with big data in biosecurity, noting that these probably apply to other fields as well:
- Data quality and access. There are many formats, resolutions, and source locations. The use of images increases the data storage and transmission needs.
- Personal data. There are ongoing concerns related to personal data, privacy, and civil liberties.
- Analytics. Algorithms are not currently keeping pace with the enormous amount of data. More analytic processing capability is needed.
Mr. Shepherd concluded by saying that increased control over information has not led to increased biosecurity; instead, in the future, increased information sharing may be the way to increase biosecurity.
In the discussion, a participant suggested that it might be better to store the actual material instead of data describing the material. This brings up practical issues associated with how to store materials. This is true in biosecurity as well: Should you store the biological agent, data about the agent, or both?
A participant asked if the human immunodeficiency virus (HIV) and severe acute respiratory syndrome (SARS) would make good surrogates in biosecurity. Yes, said Mr. Shepherd, because emerging diseases, even ones that don’t represent a typical biosecurity scenario, can still provide modeling information.
Dr. McGrath pointed out that biosecurity is a large and difficult problem, larger in scope than what the materials community faces. He suggested interfacing with other communities that use predictive tools, such as the intelligence community. On the science side, he suggested working on sensor development and increasing basic knowledge and understanding.
A participant pointed out that cloud computing can be considered high-performance computing as well. Mr. Shepherd agreed and explained that he divided
them in his discussion so that high-performance computing referred to anything from chips to run times, and that cloud computing referred to how to work together.
Ms. Swink opened the discussion session with a summary of several statements she had found compelling. One was the importance of determining the necessary approach and the associated trade-offs: whether one needs to interface with a large mass of data, or whether one needs algorithms to select the salient features of the data one needs. She also brought up the concept of ontology and asked whether this is a driver in the materials research and development area. Finally, she asked if the idea of surrogate data had any analog in the materials and manufacturing community.
Dr. de la Garza pointed out the need for a holistic perspective on big data, because they involve not only data collection but also life-cycle information: data collection, procurement, analytics, and stable, archival-quality formats. He also noted that there are trade-offs between collecting all the data possible (even if we don’t know what to do with it) and collecting only the information we know we want. He observed, however, that most research decisions require an assessment of trade-offs, and this is no different. Dr. de la Garza also underlined the importance of prediction over reaction; big data analytics for prediction would be a powerful tool.
Some participants also discussed the idea of storing materials vs. storing data. Ms. Swink asked the group to consider the reestablishment of critical material repositories within DOD. She indicated that she is aware of a reluctance to do so. She also argued that there is a large financial difference between having stockpiles or archives: The workshop participants were more likely to be interested in the less-expensive archives. One participant mentioned the Air Force’s digital twin program, in which the digital representation of a material keeps information about the material properties; perhaps it would be valuable to include an actual sample to examine along with the digital twin. However, other workshop participants also pointed out that critical policy issues would need to be addressed, such as the amount of material to retain, access criteria, and other issues. Others argued that any sort of repository, even an archive, might be prohibitively expensive. It may be necessary to set priorities on which materials to retain.
Participants also discussed common elements across disciplines that rely on big data. Some of these common challenges are associated with moving data, connecting to different ontology models to describe the data, and tools to identify compounds. Another popular idea across disciplines was bringing the processing to the data source and other distributed data strategies. A participant noted that
a Hadoop5 might play a useful role in distributed data storage and processing as part of a larger solution.
A participant suggested that the materials science community look at examples in other disciplines to identify the costs associated with data storage. The participant suggested the fields of publishing, which is moving toward open access, and evolutionary biology, which has a significant amount of data but no repository structure. Another participant noted the utility of the open source model used by Dryad to provide access to data.6
Ms. Swink asked what steps the community should take now to move forward in data management. One participant suggested looking to the NSF program EarthCube as a model for how to work across different communities to develop ontologies and names.7 The materials community may suffer from the lack of conversation about ontologies.
Ms. Swink then asked if the materials science community has a “data” problem or a “big data” problem. She suggested that the problems are just data problems. She argued that important data issues in materials science, such as access to proprietary data and the lack of homogeneity, are not big data problems. She also pointed out that the long-time separation between materials development and product commercialization interferes with a company’s ability to understand the correlation and causality between product success and materials data.
_________________
5 Hadoop, developed by the Apache Software Foundation, is an open-source software framework for the storage and processing of large-scale data sets on clusters of distributed computers. See http://hadoop.apache.org/ for more information. Accessed February 20, 2014.
6 The Dryad Digital Repository is an open source to make available the data that underlie scientific publications. See http://datadryad.org for more information. Accessed February 24, 2014.
7 The NSF EarthCube program is an integrated data management program in the geosciences. See https://www.nsf.gov/geo/earthcube/ for more information. Accessed February 24, 2014.












