
8
Operational Test and Evaluation
Following our discussion of the role of developmental testing in assessing system reliability in Chapter 7, this chapter covers the role of operational testing in assessing system reliability. After a defense system has been developed, it is promoted to full-rate production and the field if it demonstrates in an operational test that it has met the requirements for its key performance parameters. The environment of operational testing is as close to field deployment as can be achieved, although the functioning of offensive weapons is simulated, and there are additional constraints related to safety, environmental, and related concerns.
In this chapter we first consider the timing and role of operational testing and then discuss test design and test data analysis. The final section considers the developmental test/operational test (DT/OT) gap.
TIMING AND ROLE OF OPERATIONAL TESTING
The assessment of the performance of defense systems, as noted in Chapter 1, is separated into two categories, effectiveness and suitability, a major component of the latter being system reliability. Operational testing is mainly focused on assessing system effectiveness, but it is also used to assess the reliability of the system as it is initially manufactured. Even though reliability (suitability) assessment is a somewhat lower priority than effectiveness, there is strong evidence (see below) that operational testing remains important for discovering reliability problems. In particular, the reliability estimates from operational testing tend to be considerably lower than reliability estimates from late-stage developmental testing. Although
the benefit of operational testing is therefore clear for discovering unexpected reliability problems, because operational testing is of short duration it is not well-suited for identifying reliability problems that relate to longer use, such as material fatigue, environmental effects, and aging.
Moreover, although operational testing may identify many initial reliability problems, there is a significant cost for defense systems that begin operational testing before the great majority of reliability problems have been discovered and corrected. Design changes made during operational testing are very expensive and may introduce additional problems due to interface and interoperability issues. Given that many reliability problems will not surface unless a system is operated under the stresses associated with operational use, and given that operational testing should not be relied on to find design problems for the reasons given above, the clearly cost-efficient strategy would be to require that defense systems are not considered ready for entry into operational testing until the program manager for the U.S. Department of Defense (DoD), the contractor, and associated operational test agency staff are convinced that the great majority of reliability problems have been discovered and corrected. One way to operationalize this strategy is to require that defense systems not be promoted to operational testing until the estimated reliability of the system equals its reliability requirement under operationally relevant conditions. An important additional benefit of this strategy would be that it would eliminate, or greatly reduce, the DT/OT reliability gap (discussed below), which currently complicates the judgment as to whether a system’s reliability as assessed in developmental testing is likely to be found acceptable in operational testing.
In addition to using developmental tests that include stresses more typical of real use (see Chapter 7), there are three additional steps that the DoD could adopt to reduce the frequency of reliability problems that first appear in operational testing.
First, DoD could require that contractor and developmental test interim requirements for reliability growth, as specified in the approved test and evaluation master plan, have been satisfied. Failure to satisfy this requirement, especially when substantial shortcomings are evident late in the developmental test program, is a strong indicator that the system is critically deficient.
Second, DoD could specify that reports (i.e., paper studies) of planned design improvements are, by themselves, inadequate to justify promotion to operational testing. Instead, DoD could require that system-level tests be done to assess the impact of the design improvements.
Third, DoD could require that reliability performance from contractor and developmental tests are addressed and documented for the complete spectrum of potential system operating conditions given in the operational
mode summary/mission profile,1 including both hardware and software performance. Doing so might help indicate areas that have not been fully tested under operationally relevant conditions. Separate software testing, possibly disconnected from hardware presence, also may be needed to fully explore a system’s performance profile.
There are some other respects in which operational testing is limited, which places yet additional weight on developmental testing as the primary opportunity for discovery of design problems. Operational testing presents, at best, a snapshot of system reliability for new systems for two major reasons. First, the results are somewhat particular to the individual test articles. Second, the prototypes used in operational testing will be used only for short durations, not even close to the intended lifetimes of service or availability expected of the system. Thus, until developmental testing makes greater use of accelerated life testing in various respects (see Chapter 6), along with more operational realism in non-accelerated tests, there remains a good chance that some reliability problems will not appear until after a system is deployed. To address this problem, we recommend that DoD institute a procedure that requires that the field performance of post-operational test configurations (i.e., new designs, new manufacturing methods, new materials, or new suppliers) are tracked and the data used to inform additional acquisitions of the same system, and for planning and conducting future acquisition programs of related systems (see Recommendation 22 in Chapter 10).
Operational testing is limited to the exercising of the system in specific scenarios and circumstances (based, to a great extent, on the operational mode summary/mission profile). Given the limited testing undertaken in operational testing and the resulting limited knowledge about how the system will perform under other circumstances of operational use, due consideration should be taken when developing system utilization plans, maintenance, and logistics supportability concepts, and when prescribing operational reliability and broader operational suitability requirements.
Although this discussion has stressed the differences between developmental and operational testing, there are also strong similarities. Therefore, much of the discussion in Chapter 7 (and other chapters) about the importance of experimental design and data analysis for developmental testing also apply to operational testing. In the next two sections on design and data analysis we concentrate on issues that are particularly relevant to operational testing.
_______________
1 This profile “defines the environment and stress levels the system is expected to encounter in the field. They include the overall length of the scenarios of use, the sequence of missions, and the maintenance opportunities” (National Research Council, 1998, p. 212).
The primary government operational test event is the initial operational test and evaluation. It is an operationally realistic test for projected threat and usage scenarios, and it includes production-representative hardware and software system articles, certified trained operators and users, and logistics and maintenance support compatible with projected initial fielding.
Ideally the extent of the initial operational test and evaluation event would be of sufficient duration to provide a reasonable stand-alone assessment of initial operational reliability, that is, it should be of sufficient length to provide an acceptable level of consumer risk regarding the reliability of the system on delivery. This requirement would entail an extensive testing period, use of multiple test articles, and a likely focus on a single or small set of testing circumstances. To keep consumer risks low, the system might have been designed to have a greater reliability than required to reduce the chances of failing operational testing (although the procedure described in Chapter 7 on identifying a minimally acceptable level could reduce the need for this approach).
Unfortunately, in many cases, often because of fiscal constraints, producing an estimate of system reliability that has narrow confidence intervals may not be feasible, and thus it may be advisable to pursue additional opportunities for assessing operational reliability. Such an assessment could best be accomplished by having the last developmental test be operationally flavored to enhance prospects for combining information from operational and developmental tests. (This approach could also aid in the detailed planning for initial operational testing and evaluation.)
One way to determine in what way full-system developmental testing could be more operationally realistic relative to a reliability assessment would be to allow for early and persistent opportunities for users and operators to interact with the system. This approach would also support feedback to system improvement processes—which should be encouraged—whether within dedicated test events or undertaken more informally. Also, one or more focused follow-on tests could be conducted after the initial operational testing, allowing previously observed deficiencies and newly implemented redesigns or fixes to be examined. However, achieving a test of suitable length for reliability remains a challenge; thus, it is far better for the emphasis to be on developmental testing to produce a system whose reliability is already at the required level.2
_______________
2 Some appeals to use sequential methods have been made to make testing more efficient. However, even though learning could be accommodated during operational testing as part of a sequential design, practical constraints (e.g., delaying scoring conferences until failure causes are fully understood) limit its use.
We argue above about the importance of modifying developmental test design to explore potentially problematic components or subsystems that have been found in contractor testing. The same argument applies to the relationship between developmental and operational testing. If a reliability deficiency is discovered in developmental testing and a system modification is made in response, then it may be useful to add some replications in operational testing to make sure that the modification was successful. We understand that operational test designs often attempt to mimic the profile of intended use represented in the operational mode summary/mission profile. However, such designs could often be usefully modified to provide information on problems raised in developmental testing, especially when such problems either have not been addressed by design modifications, or when such design modifications were implemented late in the process and so have not been comprehensively tested.
To greatly enhance the information available from the analysis of operational testing, it is important to collect and store reliability data on a per test article basis to enable the construction of complete histories (on operating times, operational mode summary/mission profile phase or event, failure times, etc.) for all individual articles being tested. If operational testing is done in distinct test events, then this ability to recreate histories should remain true across tests. Also, it would be valuable for data to be collected and stored to support analyses for distinct types of failure or failure modes, as mentioned in Chapter 7.
It is of critical importance that all failures are reported. If a failure is to be removed from the test data, then there needs to be an explanation that is fully documented and reviewable. It is also important that records are sufficiently detailed to support documented assessments of whether any observed failure should be discounted. Even if an event is scored as a “no test,” it is important that observed failures are scrutinized for their potential to inform assessments concerning reliability growth.
In order to determine what reliability model is most appropriate to fit to the data from an operational test, it is often extremely useful to graphically display the timeline of failures (possibly disaggregated by failure type or by subsystem) to check whether the assumption of a specific type of life distribution model is appropriate (especially the exponential assumption). In particular, time trends that suggest the beginning of problems due to wear-out or various forms of degradation are important to identify. Crowder et al. (1991) has many useful ideas for graphical displays of reliability data. Such graphical displays are also extremely important to use in assisting decision makers in understanding what the results from
developmental and operational testing indicate about the current level of performance. The U.S. Army Test Evaluation Command has some excellent graphical tools that are useful for this purpose (see, e.g., Cushing, 2012).
If the data have been collected and made accessible, then their comprehensive analysis can provide substantially more information to decision makers than a more cursory, aggregate analysis, so that decisions on promotion to full-rate production and other issues are made on the basis of a more complete understanding of the system’s capabilities. In other words, the analysis of an operational test should not be focused solely on the comparison of the estimated key performance parameters to the system’s requirements. Although such aggregate assessments are important because of their roles in decisions on whether the system has “passed” its operational test, there is other information that operational test data can provide that can be extremely important. For example, what if the new system was clearly superior to the current system in all but one of the proposed scenarios of use, but clearly inferior in that one? Such a determination could be important for deciding on tactics for the new system. Or what if the new system was superior to the existing system for all but one of the prototypes but distinctly inferior for that prototype? In this case, addressing manufacturing problems that occasionally resulted in poor quality items would be an important issue to explore. These are just two examples of a larger number of potential features of the performance of systems in such situations that can be discovered through detailed data analysis. In these two situations, there are statistical methods for quantifying heterogeneity across articles (e.g., random effects models) and describing performance across diverse conditions (e.g., regression models) that can be used to provide such assessments.
If there is a need to analytically combine developmental and operational test data to improve the precision of estimated reliability parameters, there are modeling challenges related to fundamental questions of comparable environmental conditions, operators and users, usage profiles, data collection and scoring rules, hardware/software configurations, interfaces, etc. (see discussion in Chapter 7). Such statistical challenges would confront any ex post facto attempts to formally combine operationally relevant results across these sorts of diverse testing events. (The specifics will vary across systems.) Although we strongly encourage attempts to address this challenge, such efforts should be considered difficult research problems for which only a few individual cases have been explored. Steffey et al. (2000) is one effort that we know of to address this problem, but their approach updates a single parameter, which we believe has limited applicability without proper extension. Also, again as mentioned above, the PREDICT technology can be considered an attempt to address this problem.
We also note that during an operational test event, a system’s aging,
fatigue, or degradation effects may be observable but may not have progressed to the point that an actual failure event is recorded. Examples include vehicle tread wear and machine gun barrel wear. Ignoring such information may prevent the diagnosis of the beginnings of wear-out or fatigue. When the effects are substantial, statistical modeling of degradation data can yield improved, operationally representative estimates of longer-term failure rates (see, e.g., Meeker and Escobar, 1998, Chs. 13 and 21; Escobar et al., 2003). The need for such analyses may be anticipated a priori or may arise from analysis of developmental test outcomes. Such analysis can be extremely important, because for some major performance-critical subsystems (e.g., aircraft engines) the development of empirical models for tracking reliability and projecting prudent replacement times can have profound cost and safety impacts. As results on operational reliability emerge from the initial operational test and evaluation (and possibly follow-on operational tests and evaluations), it is prudent to address these potential sources of information on lifetime ownership costs and factor these considerations into the planning for reliability growth opportunities. The flexible COHORT (COnsumption, HOlding, Repair, and Transportation) model of the Army Materiel Systems Analysis Agency (AMSAA) exemplifies this concept (see Dalton and Hall, 2010). Also, for repairable systems, displays of the failure distributions for new systems versus systems with varying numbers of repairs would be informative.
Finally, there are some estimates that are directly observed in operational testing, and there are some estimates that are model based and hence have a greater degree of uncertainty due to model misspecification. As the discussion above of life-cycle costs makes clear, whenever important inferences are clearly dependent on a model that is not fully validated, sensitivity analyses need to be carried out to provide some sense of the variability due to the assumed model form. Operational test estimates should either be presented to decision makers as being “demonstrated results” (i.e., directly observable in an operational test) or as “inferred estimates” for which the sensitivity to assumptions is assessed.
It is well known that reliability estimates using data from developmental testing are often optimistic estimates of reliability under operationally relevant conditions. Figure 8-1 shows the ratio of developmental test and operational test reliability for Army acquisition category I systems from 1995-2004. (The 44 systems depicted were chosen from a database of Army systems created by the Army Test and Evaluation Command to satisfy the following criteria: (1) systems with both DT and OT results, (2) reporting the same reliability metric—some version of mean time between
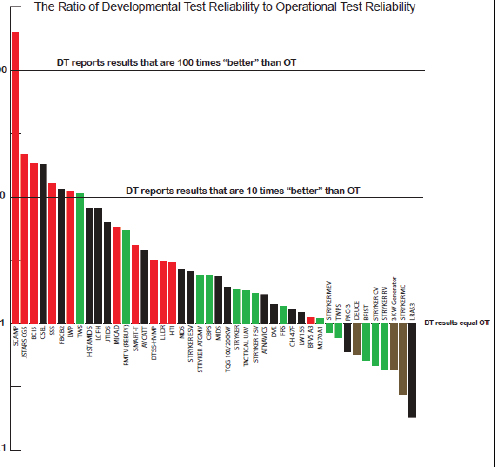
FIGURE 8-1 Comparison of developmental test and operational test reliability.
NOTES: DT = developmental testing, OT = operational testing. Red bars are systems where DT concluded reliability MET, but OT concluded NOT MET. Black bars are systems where DT and OT concluded NOT MET. Green bars are systems where DT and OT concluded MET. Brown bars are systems where DT concluded NOT MET, but OT concluded MET. The Y axis displays the log (reliability metric for DT/reliability metric for OT).
SOURCE: E. Seglie, Reliability in Developmental Test and Evaluation and Operational Test and Evaluation, p. 5). Unpublished.
failure, and (3) the DT and OT were relatively close in time.) This DT/OT gap is likely due to several aspects of developmental testing:
- the use of highly trained users rather than users typical of operational use,
- failure to include representation of enemy systems or countermeasures,
- the scripted nature of the application of the system in which the sequence of events is often known to the system operators, and
- representation of some system functions only through the use of modeling and simulation.
The last point above may be the reason that interface and interoperability issues often appear first in operational tests. Furthermore, as suggested by (3), the scenarios used in developmental testing often are unlike the scenarios used in operational testing, and it is therefore difficult to match the exercising of a system in developmental testing with the results of specific missions in operational testing (an issue we return to below).
The problem raised by the DT/OT gap is that systems that are viewed as having reliability close or equal to the required level are judged ready for operational testing when their operationally relevant reliability may be substantially smaller. As a result, either it will be necessary to find a large number of design defects during operational testing, a goal inconsistent with the structure of operational testing, or a system with deficient reliability will be promoted to full-rate production. (There is also, as stressed above, the inefficiency of making design changes so late in development.)
There are both design and analytic approaches to address the DT/OT gap. We start with design possibilities to address the four differences listed above (i.e., degree of training, representation of countermeasures and enemy forces, degree of scripting used, and representation of interfaces and interoperability). In terms of having users with typical training in tests, while we understand that it might be difficult to schedule such users for many developmental tests, we believe that systems, particularly software systems, can be beta-tested by asking units to try out systems and report back on reliability problems that are discovered. Second, for many types of enemy systems and countermeasures, various forms of modeling and simulation can provide some version of the stresses and strains that would result from taking evasive actions, etc. Third, relative to scripting, and closely related to the representation of enemy forces and countermeasures, there is often no reason why the system operator needs to know precisely the sequence of actions that will be needed. Finally, in terms of the representation of a system’s functions that have not been completed, this is one reason for having a full-system, operationally relevant test prior to delivery to DoD for developmental testing.
In addition to design changes, the DT/OT gap could be analytically accounted for by estimating the size of the gap and adjusting developmental testing estimates accordingly. Input into the development of such models could be greatly assisted by the creation of the database we recommend (see Recommendation 24, in Chapter 10) that would support comparison of reliability estimates from developmental and operational testing.
At the panel’s workshop, Paul Ellner of AMSAA commented on this challenge and what might be done to address it. He said that when the requirement is stated in terms of the mean time between failures, the developmental testing goal should be higher than the requirement because one needs to plan for a decrease in mean time between failures between developmental and operational tests because of both new failure modes surfaced by operational testing and higher failure rates for some failure modes that operational and developmental tests share.
Ellner said that a large DT/OT gap has three serious consequences:
- It places the system at substantial risk of not passing the operational test.
- It can lead to the fielding of systems that later require costly modifications to enhance mission reliability and reduce the logistics burden.
- It is not cost-effective, nor may it be feasible, to attain sufficiently high reliability with respect to the developmental test environment to compensate for poor or marginal reliability with respect to potential operational failure modes.
After all, he said, one cannot attain better than 100 percent reliability in developmental testing. Furthermore, that could be meaningless with respect to reliability under operationally relevant use if developmental testing cannot elicit the same failure modes as those that appear in operational use.
For a real example, Ellner mentioned a developmental test for a vehicle with a turret. During the developmental test, the vehicle was stationary, the system was powered by base power, and contractor technicians operated the system. In operational testing, the vehicles were driven around, the system was powered by vehicle power, and military personnel operated the system. In the developmental test, 8 percent of the failure rate was due to problems with the turret. However, when the user profile was weighted to reflect the operational mode summary/mission profile, 23.9 percent of the failure rate was due to problems with the turret. Even more striking, in operational testing, 60.4 percent of the failure rate was due to the turret.
To reduce the size of this DT/OT reliability gap, Ellner proposed ways of either modifying the design of developmental test events, or modifying the test analysis. For the design of developmental testing, it could be based more closely on the operational use profile through the use of what Ellner called ”balanced” testing, which is that the cumulative stress per time interval of test should closely match that of the operational mission profile.
In modifying the analysis, Ellner advocated a methodology that combines developmental and operational test data through use of Bayesian methods that leverage historical information for different types of systems
with respect to their previously observed DT/OT gaps (see, e.g., Steffey et al., 2000). One difficulty with this approach is that not only are the scenarios of use changing from developmental testing to operational testing to the field, but also the systems themselves are changing as the design is refined as a result of test results. The only way to know whether such dynamics can be successfully dealt with is to make use of case studies and see how estimates from such models compare with reliability estimates based on field performance.
Ellner distinguished between different phases of developmental testing, because some functionalities are often not exercised in early developmental tests, but only in later stages of developmental testing. Also, later developmental testing often involves full-system tests, while early developmental testing often involves component-level and subsystem tests. Restricting attention to the comparison of late-stage developmental to operational testing, Ellner pointed out that there may be “normalizations” that can be used to reweight scenarios of use in developmental tests to match the scenarios faced in operational tests (or field use). That is, when feasible, one could try to reweight the developmental test scenarios to reflect what would have been the stress rate used in operational testing. For example, if only 10 percent of the test excursions were on rough terrain, but 80 percent of anticipated operational missions are over rough terrain, then the estimated occurrence rate of terrain-induced failures could be suitably weighted so that in effect 80 percent of the developmental testing time was in rough terrain.
The panel is strongly supportive of the use of these mitigation procedures for reducing the magnitude of the DT/OT gap. Furthermore, the panel recommends investigating the development of statistical models of the gaps (see Recommendation 24, in Chapter 10).












