
2
Building Infrastructure to Enable Data
Sharing and Management
Highlights
- Many types of data are captured in digital form and are stored in diverse databases; this variability presents challenges in terms of accessing and using the digital health record (DHR) data (Lovestone).
- Fifty years of data collected by the Rochester Epidemiology Project (REP) have enabled the study of the prevalence and incidence of Alzheimer’s disease (AD) and mild cognitive impairment, and the identification of subjects for clinical and biomarker studies (Rocca).
- The European Medical Information Framework (EMIF) project aims to integrate data from multiple existing cohorts in Europe, including 500,000 participants in the U.K. Biobank (Lovestone).
- The European Prevention of Alzheimer’s Disease (EPAD) study will build on EMIF to establish a patient registry, identify a cohort of trial-ready individuals, and draw from that cohort for a standing proof-of-concept trial of AD therapies (Lovestone).
- Medicare claims data offer another rich source of research data on more than 50 million Americans. Linkage of Medicare claims data to other data sources provides added value and may be used for “reverse translational research” to generate hypotheses on treatment efficacy and side effects (Bynum).
NOTE: These points were made by the individual speakers identified above; they are not intended to reflect a consensus among session participants.
Medical records have long been used for epidemiological research around the world. In the early 1960s, physicians at Oxford University began organizing and linking medical records collected by Britain’s National Health Service with administrative records related to birth, death, hospitalization, etc. (Acheson, 1964). Similar efforts to link and store medical and administrative data have been implemented in Australia (Holman et al., 1999) and Canada (Doiron et al., 2013). In the United States, the use of DHRs for research has lagged, in part because of privacy concerns, including those explored in Chapter 3 (Herrick et al., 2010).
Digital health data exist in varied formats (including coded and uncoded or narrative or contextual data) and may be sourced from multiple databases, including those established for epidemiological and other research studies, Medicare administrative data, social networks, and market data. A few participants noted that integrating these data to maximize learning presents many challenges given the heterogeneity in data types, the lack of common nomenclature and ontology, the widespread distribution of data warehouses, and the enormous amount of data collected. One challenge of accessing data from preexisting datasets is that the data are housed in multiple research environments that are private and remote and cannot be moved. Several different systems have emerged to enable access and analyses of these data through trusted third parties, which enable users to query the data and receive analyses without actually having access to the raw data. A challenge not exclusive to DHRs, a recommendation in the IOM’s 2015 report Sharing Clinical Trial Data: Maximizing Benefits, Minimizing Risk was that “special attention is needed to the development and adoption of common protocol data models and common data elements to ensure meaningful computation across disparate trials and databases. A federated query system of ‘bringing the data to the question’ may offer effective ways of achieving the benefits of sharing clinical trial data while mitigating its risks” (IOM, 2015, p. 15).
Several initiatives are under way to explore the use of DHRs on AD research. For example, OptumLabs1 has a database of de-identified data from the American Medical Group Association, the Mayo Clinic, United-Health Group, among others, for 150 million patients. OptumLabs is working with several partners, including the Global CEO Initiative on AD,2 to accelerate AD research specifically focusing on disease predic-
______________
1See https://www.optum.com/optumlabs.html (accessed November 12, 2015).
2See http://www.ceoalzheimersinitiative.org (accessed November 12, 2015).
tion, progression, and care delivery.3 In addition, PCORnet,4 the National Patient-Centered Clinical Research Network, which “integrates health data for studies and catalyzes research partnerships” from data based in health systems (clinical data research networks) and data from groups of patients (patient-powered research networks), created a network for Alzheimer’s and dementia patients and caregivers. While not an exhaustive list, several additional examples of projects currently under way internationally are discussed in this chapter.
ROCHESTER EPIDEMIOLOGY PROJECT
A number of ongoing epidemiological and natural history studies have revealed interesting correlations between a variety of exposures and the aging process. Walter A. Rocca, professor of epidemiology and neurology at the College of Medicine, Mayo Clinic, described one study that he directs—the Rochester Epidemiology Project (REP).5 The REP now contains nearly a half century of medical records from a single county (Olmsted) in Minnesota. The data culled from these records include demographics, medical diagnoses, surgical procedures, other medical services and procedures, drug prescriptions, laboratory tests, immunizations, and lifestyle factors. The records were collected initially on paper and have been used primarily for research purposes. Between 2000 and 2006, the paper records were progressively replaced with DHRs, a portal was created to enable searching of the records, and the catchment area was expanded beyond Olmsted County to include seven more counties in southeastern Minnesota (Rocca et al., 2012). To date, the data collected have yielded more than 2,400 publications.
Linkage of medical and administrative data allowed REP to structure the data according to time, place, and person (see Figure 2-1), providing meaningful data that enabled the study of prevalence and incidence as
______________
3See https://www.optum.com/news-events/news/global-ceo-initiative-on-alzheimersdiseaselaunches-program-harness-power-of-big-data-accelerating-pace-alzheimersresearch.html (accessed November 12, 2015).
4See http://www.pcornet.org (accessed November 12, 2015).
5See http://rochesterproject.org (accessed September 10, 2015).
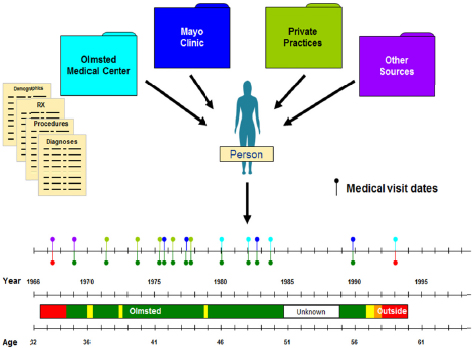
FIGURE 2-1 Linkage of records from multiple sources enables extraction of meaningful data structured into time, place, and person.
SOURCE: Presented by Walter Rocca at the Workshop on Assessing the Impact of Applications of Digital Health Records on Alzheimer’s Disease Research on July 20, 2015. Modified from St. Sauver et al., 2011.
well as the identification of subjects for cohort and case-controlled studies, clinical trials, and biomarker studies. For example, this database was used to identify individuals between the ages of 70 and 89 who were invited to participate in the Mayo Clinic Study of Aging (MCSA) (Roberts et al., 2008). From this cohort, cognitively normal subjects who had undergone neuroimaging tests were selected to track the temporal progression of imaging biomarkers in the preclinical stage of AD. These data were used to support an assessment of the research criteria for preclinical AD published by a workgroup commissioned by the Alzheimer’s Association and the National Institute on Aging in 2011 (Jack et al., 2012). The assessment showed that cognitively normal individuals could be classified according to their biomarker profiles into one of five groups: normal (Stage 0), one of three preclinical stages of AD (stages I–III), or a fifth group with “suspected non-AD pathophysiology” (Jack et al., 2012, p. 765).
MCSA data have also been used to study age-specific population frequencies of amyloidosis and neurodegeneration (Jack et al., 2014) as well as the effects of age, sex, and ApoE-ε4—a marker known to increase the risk of AD—on memory, brain structure, and amyloid deposition in the brain (Jack et al., 2015). These data may also be used in upcoming clinical trials to identify potential trial subjects, obtain baseline and/or run-in data, study long-term outcomes and side effects after the trial phase is complete, and make comparisons to control subjects.
EUROPEAN PREVENTION OF ALZHEIMER’S DISEASE
Simon Lovestone described a multinational AD prevention program in Europe launched recently by the Innovative Medicines Initiative (IMI). Established in 2008 by the European Union and the European pharmaceutical industry, IMI is the world’s largest public–private partnership, with the aim of accelerating drug development for a variety of conditions, including AD. One IMI project is the European Medical Information Framework (EMIF), which initially plans to focus on AD and obesity. In 2015, IMI launched the European Prevention of Alzheimer’s Disease Consortium with nearly €26 million (more than $28 million) from the European Commission, an additional €30 million (about $32.5 million) from the European Federation of Pharmaceutical Industries and Associations, as well as another €8 million ($8.7 million) from other sources. EPAD brings together partners from academia and industry in the precompetitive space to advance the development of AD therapies. To ensure a global reach for these efforts, IMI is also collaborating with the Global Alzheimer’s Platform,6 which was established in 2014 by the Global CEO Initiative on Alzheimer’s Disease and the New York Academy of Sciences.
The overall structure of EPAD is illustrated in Figure 2-2, beginning with the integration of datasets from several existing cohorts in Europe, brought together by EMIF, and ending with an innovative, self-sustaining, adaptive clinical trial. The data sources include 500,000 participants in the U.K. Biobank for Dementia Research, which was established in 2005 as a volunteer research cohort of randomly chosen
______________
6See http://www.usagainstalzheimers.org/gap (accessed September 25, 2015).
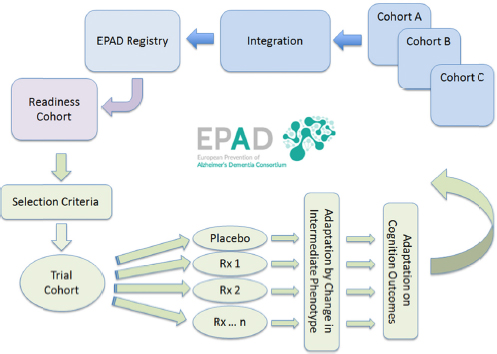
FIGURE 2-2 Overall structure of the European Prevention of Alzheimer’s Dementia (EPAD) Consortium. Following integration of data from multiple cohorts into a subject registry, a trial-ready cohort will be identified, from which subjects will be drawn for participation in a standing, multi-arm clinical trial of Alzheimer’s disease therapies.
SOURCE: Presented by Simon Lovestone at the Workshop on Assessing the Impact of Applications of Digital Health Records on Alzheimer’s Disease Research on July 20, 2015.
participants enrolled in the U.K. National Health Service (Sudlow et al., 2015). This cohort is expected to include approximately 30,000 incident cases of AD by 2027. Baseline data collected on all participants between 2005 and 2008 include Web-based questionnaires regarding cognitive and mental health, lifestyle factors such as occupation, and exposures. Everyone in the cohort contributes DNA for genotyping of 820,000 single-nucleotide polymorphisms. It is planned to have a subset, consisting of 100,000 subjects, has multimodal imaging, including brain, cardiac, and body fat magnetic resonance imaging (MRI); bone and joint dual-energy x-ray absorptiometry (DEXA) scans; and three-dimensional carotid artery ultrasound. In addition, DHR data from mental health providers are captured, including textual data from clinical encounters.
The EPAD Consortium plans to establish a registry of subjects from whom these data have been gathered; harness that registry to identify a cohort of 6,000 individuals ready to enroll in clinical trials; and draw from that cohort to initiate a standing, multi-arm, proof-of-concept clinical trial with an adaptive design that will enable the evaluation of multiple therapies, including combination therapies. The adaptive design enables arms to be advanced or dropped based on interim results as well as the incorporation of additional arms so that the trial will operate continuously.
Follow-up data from research cohorts are collected through connectivity to DHRs as part of EMIF. One example of this is the follow-up of U.K. BioBank participants using the Case Registry Interactive Search (CRIS) system (Stewart et al., 2009), which downloads, de-identifies, and enables use of both coded data (including diagnosis for example) and uncoded narrative textual data from health care providers with a 24-hour update. CRIS has used a natural language processing system called General Architecture for Text Engineering7 to parse textual data and extract meaning from a combination of free text and coded data. Most information relevant to the progression of cognitive impairment is collected in the uncoded textual data, said Lovestone. Moreover, these data represent real-world conditions, rather than the highly manipulated conditions inherent in a randomized clinical trial, where stringent inclusion and exclusion criteria limit the generalizability of results.
For example, in a post-marketing (phase IV) study of acetylcholinesterase inhibitors—the most widely used drugs prescribed for AD—keyword searching was used to identify cases (patients receiving these drugs) in the South London and Maudsley National Health Service Foundation Trust Biomedical Research Center Case Register (Perera et al., 2014). This approach enabled the analysis of Mini-Mental State Examination8 scores from more than 2,500 patient records collected in routine practice, a far larger number than would be practical to enroll in a randomized clinical trial. The rate of improvement among these real-world subjects mirrored that seen in clinical trials, supporting the validity of this approach (Perera et al., 2014). Importantly, the heterogeneity of subjects in the case register and the collection of extensive data on sociodemographic factors, comorbidities, and other variables provided a rich
______________
7See https://gate.ac.uk (accessed September 30, 2015).
8See http://www4.parinc.com/Products/Product.aspx?ProductID=MMSE-2 (accessed September 10, 2015).
source of data to study the effects of the drug in the presence of these covariates.
The EMIF catalogue contains data from multiple types of cohorts on AD or aging, including population-based and clinical cohorts, as well as European and national multicenter studies. Combined, these cohorts provide access to a total of more than 15,000 subjects with subjective or mild cognitive impairment as well as more than 30,000 controls. For example, cerebrospinal fluid–associated data are available from more than 5,000 subjects. The DHR data sources available through the EMIF platform are even larger, with a cumulative total of about 48 million subjects.
Medicare billing data offer another rich source of data for research, according to Julie Bynum, associate director at the Center for Health Policy Research, Geisel School of Medicine at Dartmouth College. Medicare provides health insurance to Americans age 65 or older as well as younger people with disabilities or certain illnesses. Medicare claims data capture all services delivered (except for medications), with each service attached to a diagnosis, thus providing a central and uniformly collected source of data on more than 50 million people (CMS, 2015). As a health services research tool, these data provide long-term outcome information from a large, diverse population.
Bynum described a study she led in 2002 to examine the independent effect and association of dementia with the risk of hospitalization. At the time, there was a debate about whether patients with AD have more comorbid conditions than patients without dementia. Her team examined claims data from a 5 percent random sample of Medicare beneficiaries in 1999. Of the 1.2 million cases in this study, about 100,000 had a diagnosis of dementia. These data showed that the average number of chronic conditions among dementia patients was twice as high as in those with no dementia. Dementia patients were also older and had more than twice the mortality rate. Using regression techniques that adjusted for age, sex, race, and comorbidity, the team showed that dementia was associated with an average threefold increased risk of hospitalization at all levels of comorbidity (Bynum et al., 2004).
Although these data have been used by others to inform policy, Bynum highlighted an important caveat: a 20 percent mortality rate among dementia patients indicates that these were people in relatively
late stages of the disease, suggesting a failure to diagnose patients in early stages. The reasons are multifold, she said. First, an individual needs to seek care from a physician; then the clinician must accurately diagnose the condition and code it correctly on the claims form. At the time of this study, Bynum said there were financial disincentives to code patients with a diagnosis of AD. Since then, multiple studies have shown a decline in mortality among those with a dementia diagnosis, suggesting that people are being diagnosed at earlier stages of disease. Other weaknesses of using Medicare claims data, according to Bynum, include the cost of start-up and the fact that some populations are missing, for example, individuals with insurance plans that pay a fixed amount of money per patient, regardless of services used, such as Medicare Advantage.
One way to boost the value of these datasets, according to a few participants, is to link them to other data sources. Bynum described two studies where she linked data from relatively large cohort studies with outcomes measurable from billing data: The Health and Retirement Study (HRS) and the Nurses’ Health Study. HRS is a longitudinal study begun in 1992 with approximately 20,000 individuals over the age of 50, from whom data were captured every 2 years about their physical and mental health, financial status, employment, insurance coverage, and family support (NIA, 2015b). By linking survey data from HRS respondents who died between 1998 and 2007 with Medicare claims data at their last interview before dying, Bynum’s team, led by Lauren Hersch Nicholas, showed that approximately two-thirds had cognitive impairment prior to death (Nicholas et al., 2014). Participants in the Nurses’ Health Study have been followed for more than 30 years with serially collected cognitive measures in a subset of women over 70; this study is still under way but will investigate the role of early-stage cognitive impairment on risk of hospitalization.
Bynum is also using pharmaceutical billing data from Medicare (Part D) as a research tool to learn more about patients with a dementia diagnosis. Among more than 400,000 patients with more than 1 year of medication use in 2009, more than half had a low income, and more than 40 percent were newly diagnosed.
Beyond its use in health services research, Bynum suggested that Medicare claims data could provide population observations to inform clinical and basic science research, what she called “reverse translational research” (see Figure 2-3). For example, in research lead by Dr. Nancy Morden at Dartmouth, medication exposure information gleaned from pharmaceutical billing data, combined with clinical claims data, is being
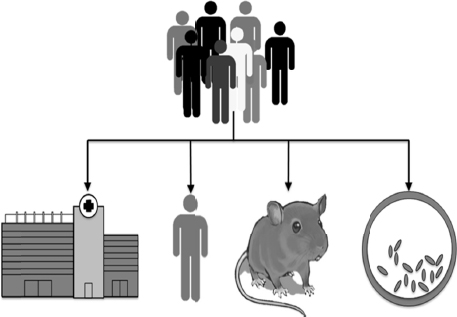
FIGURE 2-3 Reverse translational research: Using population observations from Medicare claims data to inform clinical and basic science research.
SOURCE: Presented by Julie Bynum at the Workshop on Assessing the Impact of Applications of Digital Health Records on Alzheimer’s Disease Research on July 20, 2015. Image courtesy of Nancy Morden, Geisel School of Medicine at Dartmouth College.
used to assess the influence of individual drugs or combinations of drugs on disease progression or incidence of adverse effects. The value of this approach is that clinical testing of exposure pairs is expensive and time intensive; thus, little is known about combined use.










