
Page 217
The Roles of Language Processing in a Spoken Language Interface
SUMMARY
This paper provides an overview of the colloquium's discussion session on natural language understanding, which followed presentations by Bates and Moore. The paper reviews the dual role of language processing in providing understanding of the spoken input and an additional source of constraint in the recognition process. To date, language processing has successfully provided understanding but has provided only limited (and computationally expensive) constraint. As a result, most current systems use a loosely coupled, unidirectional interface, such as N-best or a word network, with natural language constraints as a postprocess, to filter or resort the recognizer output. However, the level of discourse context provides significant constraint on what people can talk about and how things can be referred to; when the system becomes an active participant, it can influence this order. But sources of discourse constraint have not been extensively explored, in part because these effects can only be seen by studying systems in the context of their use in interactive problem solving. This paper argues that we need to study interactive systems to understand what kinds of applications are appropriate for the current state of technology and how the technology can move from the laboratory toward real applications.
Page 218
INTRODUCTION
This paper provides an overview of the natural language understanding session at the Colloquium on Human-Machine Communication by Voice held by the National Academy of Sciences (NAS). The aim of the paper is to review the role that language understanding plays in spoken language systems and to summarize the discussion that followed the two presentations by Bates and Moore. A number of questions were raised during the discussion, including whether a single system could provide both understanding and constraint, what the future role of discourse should be, how to evaluate performance on interactive systems, and whether we are moving in the right direction toward realizing the goal of interactive human-machine communication.1
Background: The ARPA Spoken Language Program
Much of the research discussed at the natural language understanding session was done in connection with the Advanced Research Projects Agency's (ARPA) Spoken Language Systems program. This program, which started in 1989, brought together speech and language technologies to provide speech interfaces for interactive problem solving. The goal was to permit the user to speak to the system, which would respond appropriately, providing (intelligent) assistance. This kind of interaction requires the system to have both input and output capabilities, that is, for speech, both recognition and synthesis, and for language, both understanding and generation. In addition, the system must be able to understand user input in context and carry on a coherent conversation. We still know relatively little about this complex process of interaction, although we have made significant progress in one aspect, namely spoken language understanding.2
In the ARPA Spoken Language Systems program, multiple contractors are encouraged to develop independent approaches to the core problem of spoken language interaction. To focus the research,
1 I am indebted to the many contributors during the colloquium's discussion who raised interesting questions or provided important material. For the sake of the flow of this paper, I have folded these questions or comments into appropriate sections, rather than summarizing the discussion separately.
2Spoken language understanding focuses on understanding user input, as opposed to communicating with the user, which is a bidirectional process that requires synthesis and generation technologies.
Page 219
common evaluation is used to compare alternate technical approaches within a common task domain. To ensure that test results are comparable across sites, the sites choose a task domain, collect a common corpus of training material, and agree on a set of evaluation metrics. The systems are then evaluated periodically on a set of (previously unseen) test data, using the agreed upon evaluation metrics. The evaluation makes it possible not only to compare the effectiveness of various technical approaches but also to track overall progress in the field.
For the Spoken Language Systems program, the Air Travel Information System (ATIS) (Price, 1990) was chosen as the application domain for the common evaluation. This is a database interface application, where the data were drawn from a nine-city subset of the Official Airline Guide, containing airline, schedule, and ground transportation information.3 To support this effort, sites cooperated to collect a training corpus of 14,000 spontaneous utterances (Hirschman et al., 1992), and, to date, there have been four formal evaluations in this domain (Hirschman et al., 1993; Pallett, 1990, 1991; Pallett et al., 1992, 1993). At the start of the Spoken Language Systems program in 1989, an accepted metric had evolved for speech recognition, namely word accuracy (Pallett, 1989); however, no comparable metric was available for measuring understanding. Over the past 4 years, the research community has developed an understanding metric for database interface tasks, using either speech or typed input (Bates et al., 1990; Hirschman et al., 1992). To date, there is still no agreed upon metric for the rich multidimensional space of interactive systems, which includes the system's ability to communicate effectively with the user, as well as an ability to understand what the user is trying to accomplish.
The remainder of this paper is divided into four sections: "The Dual Role of Language Processing" discusses the role of language processing in providing both understanding and constraint; "The Role of Discourse" outlines several sources of discourse and conversational constraints that are available at the inter-sentential level; "Evaluation'' returns to the issue of evaluation and how it has affected research; and the final section, "Conclusions," summarizes these issues in terms of how they affect the development of deployable spoken language systems.
3There is now an enlarged 46-city version of the ATIS database; it will be the focus of the next round of evaluation.
Page 220
THE DUAL ROLE OF LANGUAGE PROCESSING
At the outset of the ARPA Spoken Language Systems program, two roles were envisioned for natural language processing:
• Natural language processing would interpret the strings of words produced by the speech recognition system, to provide understanding, not just transcription.
• Natural language would provide an additional knowledge source to be combined with information from the recognizer, to improve understanding and recognition by rejecting nonsense word strings and by preferring candidate word strings that "made sense."
Approaches to Spoken Language Understanding
To achieve reasonable coverage, a spoken language system must understand what the user says, even in the face of hesitations, verbal repairs, metonymy, and novel vocabulary, as illustrated by Moore by in this volume.4 And the system must do this despite the noise introduced by using speech (as opposed to text) as the input medium. This means that it is not possible to use strict rules of grammar to rule out nongrammatical utterances. Doing so results in a significant degradation in coverage.
To achieve reasonable coverage, the language-processing components have developed techniques based on partial analysis—the ability to find the meaning-bearing phrases in the input and construct a meaning representation out of them, without requiring a complete analysis of the entire string.5 The current approaches to language understanding in the ARPA community can be divided into two general types:
• A semantics-driven approach identifies semantic constructs on the basis of words or word sequences. Syntax plays a secondary role—to identify modifying phrases or special constructions such as dates.
4During the discussion, R. Schwartz (Bolt, Beranek, and Newman) made an interesting observation. He reported that, given recognizer output from people reading the Wall Street Journal, human observers could reliably distinguish correctly transcribed sentences from incorrectly transcribed ones. Given recognizer output from the ATIS task, the observers could not reliably distinguish correctly transcribed output from incorrectly transcribed output, due to the irregularities that characterize spontaneous speech.
5Actually, partial analysis is equally critical for large-scale text-understanding applications, as documented in the Proceedings of the Fourth Message Understanding Conference (1992) and the Proceedings of the Fifth Message Understanding Conference (1993).
Page 221
These systems differ in their approach to building the semantic constructs and include recursive transition networks to model the semantic phrases (Ward, 1991; Ward et al., 1992), template-matching (Jackson et al., 1991), hidden Markov models (HMMs) to segment the input into semantic "chunks" (Pieraccini et al., 1992), and neural networks or decision trees (Cardin et al., 1993).
• A syntax-driven approach first identifies syntactic constituents, and semantic processing provides an interpretation based on the syntactic relations. Recent syntax-driven systems are coupled with a backup mechanism to make use of partial information (Dowding et al., 1993; Linebarger et al., 1993; Seneff, 1992a; Stallard and Bobrow, 1993). In this approach the syntactic component first tries to obtain a full parse; failing that, partial syntactic analyses are integrated into a meaning representation of the entire string.
Both styles of system have shown increasing coverage and robustness for the understanding task. The next section discusses how successful these systems have been in providing constraint for understanding or recognition.
Interfacing Speech and Language
The architecture of a spoken language system, in particular the interface between the recognition and language components, is closely related to the role of the language-processing component. For understanding, the minimal interface requirement is a word string passed from the recognizer to the language-understanding component for interpretation. However, if the language-understanding component is to provide an additional knowledge source to help in choosing the "right answer," it must have access to multiple hypotheses from the recognizer. The N-best interface (Chow and Schwartz, 1990; Schwartz et al., 1992)6 has proved to be a convenient vehicle for such experimentation: it makes it easy to interface the recognition and understanding components, it requires no change to either component, and it permits off-line exploration of a large search space. Also, there has recently been renewed interest in word networks as a compact representation of a large set of recognition hypotheses (Baggia et al., 1991; Glass et al., 1993).
The language-processing component can provide help either to
6The N-best interface produces the top N recognizer hypotheses, in order of recognizer score.
Page 222
recognition (choosing the right words) or to understanding (given multiple inputs from the recognizer). For recognition there are several ways the language-processing component can distinguish good word string candidates from less good ones. First, it is possible that a linguistically based model could provide lower perplexity than simple n-gram models. For example, the layered bigram approach (Seneff et al., 1992) combines a linguistically based grammar with sibling-sibling transition probabilities within the parse tree, to produce a grammar with lower perplexity than a conventional trigram model.7
Another approach is to use the language-understanding component for filtering or, more accurately, for preference based on parsability: the system prefers a hypothesis that gets a full parse to one that does not. At Carnegie-Mellon University (CMU), Ward and Young recently reported interesting results based on the tight coupling of a set of recursive transition networks (RTNs) into the recognizer, in conjunction with a bigram language model (Ward and Young, 1993); use of the RTN provided a 20 percent reduction in both word error and understanding error, compared to the recognizer using the word-class bigram, followed by the RTN for understanding.8
In experiments at the Massachusetts Institute of Technology (MIT) the TINA language-understanding system was used in a loosely coupled mode to filter N-best output. This produced a very small decrease in word error (0.2 percent, from 12.7 percent for N = 1 to 12.5 percent for N = 5) but a somewhat larger decrease in sentence recognition error (1.7 percent, from 48.9 percent for N = 1, to 47.2 percent for N = 5).9
Alternatively, if the language-processing system can provide scores for alternate hypotheses, the hypotheses could be (re)ranked by a weighted combination of recognition and language-understanding score. Use of an LR parser produced over 10 percent reduction in error rate for both sentence error and word error when used in this way (Goddeau, 1992).10 In summary, there have been some preliminary successes
7This model has not yet been coupled to the recognizer, to determine its effectiveness in the context of a complete spoken language system.
8These results were obtained using an older version of the recognizer and a somewhat higher-perplexity language model. Future experiments will determine whether this improvement carries over to the newer, higher-accuracy recognizer.
9These experiments were run on the February 1992 test set using TINA to prefer to the first parsable sentence; the best results were achieved for N in the range of 5 to 10; as N grew larger, both word and sentence error began to increase again.
10This system was not used for understanding in these runs but only for improving the recognition accuracy.
Page 223
TABLE 1 Language Understanding Scores for N = 1 vs. N = 10
| Category | N= 1 | N = 10 |
| T | 498 (72%) | 528 (77%) |
| F | 80 (12%) | 81 (12%) |
| N.A. | 109 (16%) | 78 (11%) |
| Weighted error | 39 | 35 |
using linguistic processing as an additional knowledge source for recognition. However, more experiments need to be done to demonstrate that it is possible to use the same language-processing system in both recognition and language understanding to produce word error rates that are better than those of the best current systems.
It is clearer that language processing can be used to improve understanding scores, given alternatives from the recognizer. Early results at MIT showed a significant improvement using the language component as a filter and an additional but smaller improvement by reordering hypotheses using a weighted combination of recognizer and parse score (Goodine et al., 1991; Hirschman et al., 1991). An additional improvement in the number of sentences correctly understood was obtained by tightly coupling the language processing into the recognizer. l In recent MIT results using the N-best interface and the TINA language-understanding system (Seneff, 1992a) as a filter, TINA produced a significant improvement in understanding results. Table 1 shows the results for a test set of 687 evaluable utterances (the February 1992 test set): the error rate (1 - % Correct) dropped from 28 percent for N = 1 to 23 percent for N = 10. Similarly, the
11These results were obtained in VOYAGER domain, using a word-pair grammar and a language-understanding system trained with probabilities that required a full parse. It is not clear that the improvement would have been as dramatic with a lower-perplexity language model (e.g., bigram) or with a robust parsing system.
12 The weighted error is calculated in terms of obtaining a correct answer from the database; an incorrect answer is penalized more heavily than no answer: Weighted Error = #(No_Answer) + 2*#(Wrong_Answer).
13Overall, using the top N hypotheses affected 41 of the 687 sentences; the system answered an additional 31 queries (26 correctly, 5 incorrectly); 7 queries went from "incorrect" to "correct" and 3 from "correct'' to "incorrect."
Page 224
weighted error rate12 dropped from 39 percent for N = 1 to 35 percent for N = 10.13
At other sites, BBN also reported success in using the language-understanding system to filter the N-best list (Stallard and Bobrow, 1993).
In summary, it is clear that natural language understanding has contributed significantly to choosing the best hypothesis for understanding. There are some promising approaches to using linguistically based processing to help recognition also, but in this area it is hard to compete with simple statistical n-gram language models. These models have low perplexity, are easily trained, and are highly robust. For these reasons it still seems quite reasonable to keep the loosely coupled approach that uses different techniques and knowledge sources for recognition and understanding. The n-gram models are highly effective and computationally efficient for recognition, followed by some more elaborate language-understanding "filtering" to achieve improved hypothesis selection. I return to the issue of how language processing systems can provide constraint in the section "The Role of Discourse" in moving beyond the sentence to the discourse and conversational levels.
Progress in Spoken Language Understanding
One of the benefits of common evaluation is that it is possible to track the progress of the field over time. Figure 1 shows the decline of error rates for spoken language understanding since the first benchmark in June 1990. The figure plots error metrics for the best-scoring system at each evaluation, as scored on context-independent utterance—sutterances that can be interpreted without dialogue context.14 The data are taken from the Defense Advanced Research Project Agency (DARPA) Benchmark Evaluation summaries (Pallett, 1990, 1991; Pallett et al., 1992, 1993). The figure shows four distinct error metrics:
1. sentence error, which is a recognition measure requiring that all the words in a sentence be correctly transcribed;
2. natural language understanding, which uses the transcribed input to compute the understanding error rate (100 - % Correct);
3. spoken language understanding, which uses speech as input and the same understanding error metric; and
14This set was chosen because it is the set for which the most data points exist. During the most recent evaluation, the best results for all evaluable queries did not differ significantly from the results for the context-independent queries alone.
Page 225
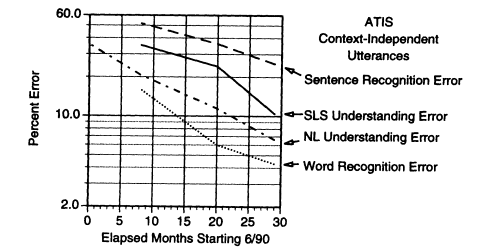
FIGURE 1 Error rate decrease over time for spoken language systems. (SLS, Spoken language system; NL, natural language.)
4. word error, which remains the basic speech recognition metric.
In Figure 1 we observe several interesting points. First, it is easier to understand sentences than to recognize them—that is, the sentence-understanding error is much lower than the sentence recognition error (10.4 percent compared to 25.2 percent). This is a significant difference and is due to the fact that many recognition errors do not significantly affect understanding for this task (e.g., confusing "a" and "the"). This means that the best current spoken language ATIS system understands almost 90 percent of its (evaluable) input.15Second, we can see how much of the error is due to understanding the perfectly transcribed input and how much is due to recognition errors. For the 1993 evaluation, the natural language error was at 6.6 percent, while the spoken language weighted error was at 10.4 percent. We can conclude that the natural language component was responsible for about 60 percent of the error and recognition for about 40 percent. This was borne out by a detailed error analysis furnished
150nly answers that have a database response can be evaluated using current evaluation technology. Therefore, the understanding figures all refer to evaluable utterances, which constitute approximately two-thirds of the corpus; the remainder of the utterances include system-initiated queries, polite forms that have no answer ("Thank you"), and other utterances that have no obvious database answer.
Page 226
by Wayne Ward (CMU, personal communication, 1993) for these results. These figures lead to several conclusions:
• Both speech recognition and language understanding have made impressive progress since the first benchmarks were run in 1990; the understanding error rate has been reduced by a factor of 3 for both spoken language and natural language in less than 2 years. In speech recognition the word error rate has been reduced by a factor of 4 and the sentence recognition error by a factor of 2.
• Language-understanding technology has been able to accommodate to spoken language input by using robust processing techniques; these techniques have included heavy use of application-specific semantic information and relaxation of requirements to find a complete syntactic analysis of an entire utterance.
• To date, the loosely coupled N-best interface has proved adequate to provide multiple hypotheses to the language-understanding component; this allows statistical n-grams to provide constraint during recognition, followed by use of the language-understanding component to filter out N-best candidates. To make tighter coupling worthwhile, language-understanding systems will have to provide additional constraint without duplicating the "cheap" knowledge available from the statistical n-gram models and without losing robustness and coverage.
These figures paint a very optimistic picture of progress in spoken language understanding. However, we need to ask whether we have just gotten better at doing a very limited task (the ATIS task) or whether the field as a whole has made progress that will carry over in reasonable ways to new application domains. Because, to date, the research community has not developed any metrics in the area of portability, it is impossible to make any quantitative statements. However, there is evidence from the related field of natural language message understanding that systems are getting better, that they can be ported to new domains and even to new languages, and that the time to port is being reduced from person years to person months.16 Because the natural language systems use similar techniques of partial or robust parsing and application-specific semantic rules, it seems reasonable to conclude that spoken language systems are not just getting better at doing the ATIS task but that these results will carry over to new
16This information comes from the recent Proceedings of the Fifth Message Understanding Conference (1993), in which a number of sites reported on systems that were built in one domain and then ported to both a new domain and to a new language, often by a single person working on it for a few months.
Page 227
domains. However, there is a critical need to develop realistic measures of portability and to assess the degree to which current systems are now portable.
THE ROLE OF DISCOURSE
The preceding section discussed the state of language understanding and the limited constraint it provided. The systems discussed above focused mainly on within-sentence constraint. It is clear that there is significant constraint between sentences which results from constraints and coherence and conversational conventions. This section outlines ways in which these higher levels provide constraint, based on recent work in the context of MIT's ATIS system (Seneff et al., 1991; Zue et al., 1992).
Constraints on Reference
When the system is in an information-providing role, as in the ATIS application, it introduces new objects into the discourse in the course of answering user queries. Thus, if the user says, "Do you have any flights from Pittsburgh to Boston next Wednesday in the morning?," the system will respond with a set of flights, including airline code plus flight number, departure, and arrival time, etc., as shown in Figure 2.
This display introduces new entities—"US674," "US732," and "US736"—into the conversation. Prior to this display, it would be relatively unlikely that a user would talk about one of these flights by flight number (unless he or she is a frequent flyer). However, after this display, it is quite likely that, if a flight number is mentioned, it will correspond to one of the displayed flights. The MIT system currently uses the list of previously displayed flight numbers to filter the N-best output. This is helpful since otherwise there is no way to choose among word string hypotheses that differ only in numbers (e.g., ''U S six seventy" vs. "U S six seventy-four").
The same observation holds true for other displays—for example,
| AIRL# | FROM | TO | LEAVE | ARRIVE | DURA | STOPS |
| US674 | PIT | BOS | 1200 | 1328 | 88 | 0 |
| US732 | PIT | BOS | 710 | 839 | 89 | 0 |
| US736 | PIT | BOS | 840 | 1006 | 86 | 0 |
FIGURE 2 System display introducing new referents.
Page 228
fare restrictions: "What is AP slash fifty-seven?" is a common response to displaying the fare code restriction table. From these examples, it is clear that:
• certain classes of objects only become available for reference once the system has introduced them in the course of providing information to the user and
• certain kinds of abbreviations may elicit follow-on questions requesting clarification.
Both phenomena provide constraints on what the user is likely to say next. This kind of constraint is particularly useful since it allows the system to choose among syntactically equivalent strings (e.g., several numbers or several strings of letters), which is information not readily available from other knowledge sources.
Constraints from Mixed Initiative
The previous discussion points to the system's role in contributing to the discourse. But the system can do far more than passively provide information to the user—it can take the lead in eliciting additional information to narrow the scope of the query or to converge more quickly on a solution. For example, to book a flight, the user must provide certain kinds of information: departure city, destination city, travel date, class of flight, etc. The system can take the initiative in requesting this information, asking for information on the date of travel, class of service, and so forth. The MIT system takes this kind of initiative in "booking mode" (Seneff et al., 1991). In a recent investigation I looked at the responses to five different system queries (request for place of departure, for destination, for one-way vs. roundtrip flight, for travel date, and for fare class). These responses to system-initiated queries occur at a rate of 6.4 percent in a training corpus of 4500 utterances. By knowing that a user is responding to a system query, we get both syntactic constraint and strong semantic constraint on the content of these responses: at the syntactic level, over 70 percent of the responses are response fragments, not full sentences. At the semantic level, the user provides the requested (and therefore predictable) semantic information in over 90 percent of the cases. This mode of interaction clearly imposes very strong constraints for recognition and understanding, but these constraints have not yet been incorporated into running systems in the ARPA community, in part because the evaluation metrics have discouraged use of interactive dialogue (see discussion in the section "Evaluation" below).
Page 229
Several of the European SUNDIAL spoken language systems use system initiative and have achieved improved recognition accuracy by developing specialized language models for the set of system states corresponding to the different system queries. For example, in the SUNGerm train reservation system (Niedermair, 1992), 14 such dialogue-dependent states were distinguished, which provided perplexity reduction ranging from 16 to 60 percent, depending on the state. This also resulted in improved recognition accuracy (ranging from 0 to 16 percent, again depending on the state). A similar approach was used in the French SUNDIAL system (Andry, 1992), which distinguished 16 dialogue states and used distinct word-pair grammars, resulting in significant improvement in word recognition and word accuracy.
Order in Problem Solving and Dialogue
There is also constraint-derived implicitly from the task orientation of the application. People tend to perform tasks in a systematic way, which provides ordering to their exploration of the search space. For example, in looking at opening sentences for tasks in the ATIS domain, we find that 94 percent of the initial sentences contain information about departure city and destination city, as in "What is the cheapest one-way fare from Boston to Denver?" Information such as date and departure time is typically added before "fine tuning" the choice by looking at things like fare restrictions or ground transportation. It is clear that the structure of the problem and the way that information is stored in the database constrain the way in which the user will explore this space. There have been ongoing experiments at CMU (Young and Matessa, 1991) in this area, using hand-crafted knowledge bases to incorporate dialogue state information. There have also been some stochastic models of dialogue—for example, that of Nagata (1992), in which illocutionary-force trigrams (e.g., transitions from question to response) were computed from training data, resulting in significant reduction in "perplexity'' for assignment of illocutionary force.
Discourse Constraints in a Spoken Language System
The discourse-level sources of constraint described above appear promising. There is one potential drawback: current systems are not very portable to new domains. Presently, it requires a good system developer to create a new lexicon, a new set of semantic and syntactic rules, and a new interface to whatever application is chosen. If we
Page 230
add to this another set of rules that must be handcrafted, namely discourse rules, portability is even more difficult. For this reason, approaches that can be automatically trained or ones that are truly domain and application independent should provide greater portability than approaches that require extensive knowledge engineering.
Even though these types of constraint look promising, it is always hard to predict which knowledge sources will complement existing knowledge sources and which will overlap, producing little improvement. Building spoken language systems is very much an iterative trial-and-error process, where different knowledge sources are exploited to see what effect they have on overall system performance. This leads into the next section, which raises the issue of evaluating system performance.
EVALUATION
Evaluation has played a central role in the ARPA Spoken Language System program. The current evaluation method (Hirschman et al., 1992, 1993) provides an automated evaluation of the correctness of database query responses, presented as prerecorded (speech or transcribed) data in units of "scenarios."17 The data are annotated for their correct reference answers, expressed as a set of minimal and maximal database tuples. The correct answer must include at least the information in the minimal answer and no more information than what is in the maximal answer. Annotation is done manually by a trained group of annotators. Once annotated, the data can be run repeatedly and answers can be scored automatically using the comparator program (Bates et al., 1990).
This methodology has evolved over four evaluations. In its current form, both context-independent utterances and context-dependent utterances are evaluated. The remaining utterances (about 25 to 35 percent of the data) are classified as unevaluable because no well-defined database answer exists. For evaluation the data are presented one scenario at a time, with no side information about what utterances are context independent, context dependent, or unevaluable. The availability of a significant corpus of transcribed and annotated training data (14,000 utterances of speech data, with 7500 utterances
17A scenario is the data from a single user solving a particular problem during one sitting.
Page 231
annotated) has provided an infrastructure leading to very rapid progress in spoken language understanding—at least for this specific domain.
It is clear that this infrastructure has served the research community well. Figure 1 showed a dramatic and steady decrease in error rate in spoken language understanding over time. However, it is now time to look again to extending our suite of evaluation methods to focus research on new directions. The preceding section argued that natural language understanding could contribute more constraint if we go beyond individual sentences to look at discourse. Unfortunately, the present evaluation methods discourage such experimentation on several grounds. First, mixed initiative dialogue is explicitly disallowed in the evaluation because it may require an understanding of the system's side of the conversation. Because the current evaluation makes use of prerecorded data and assumes that the system will never intervene in a way to change the flow of the conversation, mixed initiative may disrupt the predictable flow of the conversation. If developers were allowed to experiment with alternative system response strategies, there would be no obvious way to use complete prerecorded sessions for evaluation. This is a serious problem—it is clearly desirable and useful to have a static set of data, with answers, so that experiments can be run repeatedly, either for optimization purposes or simply to experiment with different approaches. This kind of iterative training approach has proved highly successful in many areas. Nonetheless, we are at a crossroads with respect to system development. If we wish to exploit promising methods that use system-initiated queries and methods to model the flow of queries to solve a problem, we must be able to evaluate the system with the human in the loop, rather than relying solely on off-line recorded data.
Second, there is a potential mismatch between the notion of a canonically correct answer and a useful answer. There are useful answers that are not correct and, conversely, correct answers that are not useful. For example, suppose a user asks, "Show Delta flights from Boston to Dallas leaving after 6 p.m."; furthermore, suppose the system does not understand p.m. and misinterprets the query to refer to flights leaving after 6 a.m. This happens to include those after 6 p.m., as is clear from the answer, shown in Figure 3.
The answer is not correct—it includes flights that depart before 6 p.m., but it also includes the explicitly requested information. If the user is able to interpret the display, there will be no need to reask the query.
On the other hand, it is quite possible to get information that is canonically correct but not useful. Suppose the user asks, "What are
Page 232
User query:
Show Delta flights from Boston to Dallas leaving after six P M
System understands:
Show Delta flights from Boston to Dallas leaving after six
| AIRL | NUMBER | FROM | TO | LEAVE | ARRIVE | STOPS |
| DELTA | 1283 | BOS | DFW | 8:20 A.M. | 11:05 A.M. | 0 |
| DELTA | 169 | BOS | DFW | 11:20 A.M. | 2:07 P.M. | 0 |
| DELTA | 841 | BOS | DFW | 3:25 P.M. | 6:10 P.M. | 0 |
| DELTA | 487 | BOS | DFW | 6:45 P.M. | 9:29 P.M. | 0 |
FIGURE 3 Example of incorrectly understood but useful output.
the flights from San Francisco to Washington next Tuesday?" Furthermore, suppose the system misrecognizes "Tuesday" and hears "Thursday" instead. It then makes this explicit, using generation, so that the user knows what question the system is answering, and answers "Here are the San Francisco to Washington flights leaving Thursday" and shows a list of flights. If the set of Tuesday flights is identical to the set of Thursday flights, the answer is technically correct. However, the user should reject this answer and reask the question, since the system reported very explicitly that it was answering a different question. The user would have no reason to know that the Tuesday and Thursday flight schedules happened to be identical.
The current evaluation methods have evolved steadily over the past 4 years, and we now need to move toward metrics that capture some notion of utility to the user. The initial evaluation began with only context-independent utterances and evolved into the evaluation of entire scenarios, including context-dependent utterances."8 To push research toward making usable systems, we must take the next step and develop evaluation methods that encourage interactive dialogue and that reward systems for useful or helpful answers.
From mid-1992 to early 1993 there was an effort to investigate new evaluation methods that included interactivity and captured some notion of usability. During this period, four of the ARPA sites con-
18Unevaluable utterances are still not counted in the understanding scores, but they are included as part of the input data; system responses for unevaluable queries are currently just ignored. For recognition rates, however, all sentences are counted as included in the evaluation.
Page 233
ducted an experimental "end-to-end" evaluation (Hirschman et al., 1993) that introduced several new features:
• task completion metrics, where users were asked to solve travel planning tasks that had a well-defined answer set; this made it possible to judge the correctness of the user's solution and the time it took to obtain that solution;
• log-file evaluation by human judges, who reviewed the set of system-user interactions recorded on the session log file; the evaluators were asked to judge whether responses were correct or appropriate, thus making it possible to be more flexible in judging answer correctness and in evaluating interactive systems; and
• a user satisfaction questionnaire that asked the users to rate various aspects of the system.
This methodology still needs considerable work, particularly in factoring out variability due to different subjects using the different systems. However, this experiment was a first step toward a "whole-system" evaluation, away from evaluating only literal understanding.
CONCLUSIONS
We can draw several conclusions from the preceding discussion about the role of language understanding in current spoken language systems:
• Current systems can correctly answer correctly almost 90 percent of the spoken input in a limited domain such as air travel planning. This indicates that natural language processing has become robust enough to provide useful levels of understanding for spoken language systems in restricted domains. Given the variability of the input, spontaneous speech effects, effects of unknown words, and the casual style of spontaneous speech, this is an impressive achievement. Successful understanding strategies include both semantic-based processing and syntactic-based processing, which relies on partial understanding as a backup when complete analysis fails.
• The N-best interface has proved to be an adequate interface between the speech and language components; this allows the language-understanding component to apply some constraint by filtering or reordering hypotheses. But as language systems become better at providing constraint, a tighter interface may prove worthwhile.
• The discourse and conversational levels of processing would appear to provide significant constraint that is not being fully ex-
Page 234
ploited by the ATIS systems. Some of the constraint derives from use of user-system interaction, however, and the current data collection and evaluation paradigms discourage system developers from exploring these issues in the context of the common ARPA evaluation.
• We need new evaluation methods to explore how to make systems more usable from the user's point of view. This kind of evaluation differs from those used to date in the ARPA community in that it would require evaluating system plus user as a unit. When evaluating interactive systems, there seems to be no obvious way of factoring the user out of the experiment. Such experiments require careful controls for subject variability, but without such experiments we may gain little insight into what techniques help users accomplish tasks.
It is clear that spoken language technology has made dramatic progress; to determine how close it is to being usable, we need to understand the many complex design trade-offs involved in matching the technology with potential applications. For example, response speed is an important dimension, but it can be traded off for response accuracy and/or vocabulary size. It is important to look at applications in the context of the application needs—some applications may require high accuracy but only a small vocabulary, especially if the system can guide the user step by step through the interaction. Other applications may be more error tolerant but require greater flexibility to deal with unprompted user input.
The ATIS domain focused on collecting spontaneous input from the user. This may not be the best way to build a real air travel information system, as Crystal (DARPA) pointed out during the discussion at the NAS colloquium. However, it has been an effective way of gathering data about what people might do if they could talk to a (passive) system. To drive the research forward, we may want to move on to larger vocabulary domains, or more conceptually complex applications, or real applications, rather than mock-ups, such as ATIS. However, even as we extend our abilities to recognize and understand more complex input, we must not lose sight of the "other side," which is the machine's communication with the user.
For the machine to be a usable conversational partner, it must help to keep the conversation "synchronized" with the user. This may mean providing paraphrases to let the user know what question it is answering—or it may involve giving only short answers to avoid unnecessary verbosity. To date, there has been very little work on appropriate response generation, how to use these responses to help the user detect system errors, or how the system's response may aid the user in assimilating the information presented.
Page 235
One of the major weaknesses of current systems, raised by Neuberg (Institute for Defense Analysis) during the NAS colloquium discussion, is that they do not know what they do not know—in terms of vocabulary and knowledge. For example, if you ask an ATIS system about whether you can pay with a credit card, you would like it to tell you that it does not know about credit cards, rather than just not understanding what was said or asking you to repeat your query; systems are just now beginning to incorporate such capabilities.19Keeping the user "in bounds" is an important aspect of overcoming fragility in the interface and may have a strong effect on user satisfaction in real systems.
Another major stumbling block to deployment of the technology is the high cost of porting to a new application. For language technology, this is still largely a manual procedure. Even for recognition that uses automated procedures for training, a significant amount of application-specific training data are required.20 To support widespread use of spoken language interfaces, it is crucial to provide low-cost porting tools; otherwise, applications will be limited to those few that have such a high payoff that it is profitable to spend significant resources building the specific application interface.
In conclusion, as the technology begins to move from the laboratory to real applications, it is critical that we address the system in its "ecological context," that is, the context of its eventual use. This means looking not only at the recognition and understanding technologies but at the interface and interactive dimensions as well. This can best be accomplished by bringing together technology deployers and technology developers, so that developers can study the tradeoffs among such dimensions as speed, accuracy, interactivity, and error rate, given well-defined criteria for success provided by the technology deployers. This should lead to a better understanding of spoken language system technology and should provide a range of systems appropriate to the specific needs of particular applications.
REFERENCES
Andry, F., "Static and Dynamic Predictions: A Method to Improve Speech Understanding in Cooperative Dialogues," ICSLP-92 Proceedings, pp. 639-642, Banff, October 1992.
19At the Spoken Language Technology Applications Day (April 13, 1993), the CMU ATIS system demonstrated its ability to handle a variety of "out-of-domain" questions about baggage, frequent flyer information, and cities not in the database.
20For example, for ATIS, over 14,000 utterances have been collected and transcribed.
Page 236
Baggia, P., E. Fissore, E. Gerbino, E. Giachin, and C. Rullent, "Improving Speech Understanding Performance Through Feedback Verification," Eurospeech-91, pp. 211214, Genoa, September 1991.
Bates, M., S. Boisen, and J. Makhoul, "Developing an Evaluation Methodology for Spoken Language Systems," Proceedings of the Third DARPA Speech and Language Workshop, R. Stern (ed.), Morgan Kaufmann, June 1990.
Cardin, R., Y. Cheng, R. De Mori, D. Goupil, R. Kuhn, R. Lacouture, E. Millien, Y. Normandin, and C. Snow, "CRIM's Speech Understanding System for the ATIS Task," presented at the Spoken Language Technology Workshop, Cambridge, Mass., January 1993.
Chow, Y.-L., and R. Schwartz, "The N-best Algorithm: An Efficient Procedure for Finding Top N Sentence Hypotheses," ICASSP-90, Toronto, Canada, pp. 697-700, 1990.
Dowding, J., J. Gawron, D. Appelt, J. Bear, L. Cherny, R. Moore, and D. Moran, "Gemini: A Natural Language System for Spoken Language Understanding," Proceedings of the Human Language Technology Workshop, M. Bates (ed.), Princeton, N.J., March 1993.
Glass, J., D. Goddeau, D. Goodine, L. Hetherington, L. Hirschman, M. Phillips, J. Polifroni, C. Pao, S. Seneff, and V. Zue, "The MIT ATIS System: January 1993 Progress Report," presented at the Spoken Language Technology Workshop, Cambridge, Mass., January 1993.
Goddeau, D., "Using Probabilistic Shift-Reduce Parsing in Speech Recognition Systems," ICSLP-92 pp. 321-324, October 1992.
Goodine, D., S. Seneff, L. Hirschman, and V. Zue, "Full Integration of Speech and Language Understanding," Eurospeech-91, pp. 845-848, Genoa, Italy, September 1991.
Hirschman, L., S. Seneff, D. Goodine, and M. Phillips, "Integrating Syntax and Semantics into Spoken Language Understanding," Proceedings of the DARPA Speech and Natural Language Workshop, P. Price (ed.), Morgan Kaufmann, pp. 366-371, Asilomar, February 1991.
Hirschman, L., et al., "Multi-Site Data Collection for a Spoken Language Corpus," ICSLP-92, Banff, Canada, October 1992.
Hirschman, L., M. Bates, D. Dahl, W. Fisher, J. Garofolo, D. Pallett, K. Hunicke-Smith, P. Price, A. Rudnicky, and E. Tzoukermann, "Multi-Site Data Collection and Evaluation in Spoken Language Understanding," Proceedings of the Human Language Technology Workshop, M. Bates (ed.), Princeton, N.J., March 1993.
Jackson, E., D. Appelt, J. Bear, R. Moore, and A. Podlozny, "A Template Matcher for Robust NL Interpretation," Proceedings of the Fourth DARPA Speech and Natural Language Workshop, P. Price (ed.), Morgan Kaufmann, 1991.
Linebarger, M., L. Norton, and D. Dahl, "A Portable Approach to Last Resort Parsing and Interpretation," Proceedings of the ARPA Human Language Technology Workshop, M. Bates (ed.), Princeton, March 1993.
Nagata, M., "Using Pragmatics to Rule Out Recognition Errors in Cooperative Task-Oriented Dialogues," ICSLP-92, pp 647-650, Banff, October 1992.
Niedermair, G., "Linguistic Modeling in the Context of Oral Dialogue," ICSLP-92, pp. 635-638, Banff, 1992.
Pallett, D., "Benchmark Tests for DARPA Resource Management Database Performance Evaluations," ICASSP-89, pp. 536-539, IEEE, Glasgow, Scotland, 1989.
Pallett, D., "DARPA ATIS Test Results June 1990," Proceedings of the DARPA Speech and Natural Language Workshop Workshop, pp. 114-121, R. Stern (ed.), Morgan Kaufmann, 1990.
Pallett, D., "Session 2: DARPA Resource Management and ATIS Benchmark Test Poster
Page 237
Session", Proceedings of the Fourth DARPA Speech and Natural Language Workshop Workshop, P. Price (ed.), Morgan Kaufmann, 1991.
Pallett, D., et al. "February 1992 DARPA ATIS Benchmark Test Results Summary," Proceedings of the Fifth DARPA Speech and Natural Language Workshop, M. Marcus (ed.), Morgan Kaufmann, 1992.
Pallett, D., J. Fiscus, W. Fisher, and J. Garofolo, "Benchmark Tests for the DARPA Spoken Language Program," Proceedings of the Human Language Technology Workshop, M. Bates (ed.), Princeton, N.J., March 1993.
Pieraccini, R., E. Tzoukermann, Z. Gorelov, J.-L. Gauvain, E. Levin, C.-H. Lee, and J. Wilpon, "A Speech Understanding System Based on Statistical Representation of Semantics," ICASSP-92, IEEE, San Francisco, 1992.
Price, P., "Evaluation of Spoken Language Systems: The ATIS Domain," Proceedings of the Third DARPA Speech and Language Workshop, R. Stern (ed.), Morgan Kaufmann, June 1990.
Proceedings of the Fourth Message Understanding Conf., Morgan Kaufmann, McLean, June 1992.
Proceedings of the Fifth Message Understanding Conf., Baltimore, August 1993.
Schwartz, R., S. Austin, F. Kubala, J. Makhoul, L. Nguyen, P. Placeway, and G. Zavaliagkos, "New Uses for the N-Best Sentence Hypotheses Within the Byblos Speech Recognition System," ICASSP-92, Vol. I, pp. 5-8, San Francisco, March 1992.
Seneff, S., "Robust Parsing for Spoken Language Systems," ICASSP-92, pp. 189-192, San Francisco, Calif., March 1992a.
Seneff, S., "TINA: A Natural Language System for Spoken Language Applications," Computational Linguistics Vol. 18, No. 1, pp. 61-86, March 1992b.
Seneff, S., L. Hirschman, and V. Zue, "Interactive Problem Solving and Dialogue in the ATIS Domain," Proceedings of the Third DARPA Speech and Natural Language Workshop, P. Price (ed.), pp. 354-359, Asilomar, February 1991.
Seneff, S., H. Meng, and V. Zue, "Language Modelling for Recognition and Understanding Using Layered Bigrams," ICSLP-92, pp. 317-320, October 1992.
Stallard, D., and R. Bobrow, "The Semantic Linker—A New Fragment Combining Method," Proceedings of the ARPA Human Language Technology Workshop, M. Bates (ed.), Princeton, N.J., March 1993.
Ward, W., "Understanding Spontaneous Speech: The Phoenix System," ICASSP-91, pp. 365-367, May 1991.
Ward, W., and S. Young, "Flexible Use of Semantic Constraints in Speech Recognition," ICASSP-93, Minneapolis, April 1993.
Ward, W., S. Issar, X. Huang, H.-W. Hon, M.-Y. Hwang, S. Young, M. Matessa, F.-H Liu, and R. Stern, "Speech Understanding In Open Tasks," Proceedings of the Fifth DARPA Speech and Natural Language Workshop, M. Marcus (ed.), Morgan Kaufmann, 1992.
Young, S., and M. Matessa, "Using Pragmatic and Semantic Knowledge to Correct Parsing of Spoken Language Utterances," Eurospeech-91, pp. 223-227, Genoa, September 1991.
Zue, V., J. Glass, D. Goddeau, D. Goodine, L. Hirschman, M. Philips, J. Polifroni, and S. Seneff, "The MIT ATIS System: February 1992 Progress Report," Proceedings of the Fifth DARPA Speech and Natural Language Workshop, M. Marcus (ed.), February 1992.





















