
Page 311
Speech Processing for Physical and Sensory Disabilities
SUMMARY
Assistive technology involving voice communication is used primarily by people who are deaf, hard of hearing, or who have speech and/or language disabilities. It is also used to a lesser extent by people with visual or motor disabilities.
A very wide range of devices has been developed for people with hearing loss. These devices can be categorized not only by the modality of stimulation [i.e., auditory, visual, tactile, or direct electrical stimulation of the auditory nerve (auditory-neural)] but also in terms of the degree of speech processing that is used. At least four such categories can be distinguished: assistive devices (a) that are not designed specifically for speech, (b) that take the average characteristics of speech into account, (c) that process articulatory or phonetic characteristics of speech, and (d) that embody some degree of automatic speech recognition.
Assistive devices for people with speech and/or language disabilities typically involve some form of speech synthesis or symbol generation for severe forms of language disability. Speech synthesis is also used in text-to-speech systems for sightless persons. Other applications of assistive technology involving voice communication include voice control of wheelchairs and other devices for people with mobility disabilities.
Page 312
INTRODUCTION
Assistive technology is concerned with "devices or other solutions that assist people with deficits in physical, mental or emotional function" (LaPlante et al., 1992). This technology can be as simple as a walking stick or as sophisticated as a cochlear implant with advanced microelectronics embedded surgically in the ear. Recent advances in computers and biomedical engineering have greatly increased the capabilities of assistive technology for a wide range of disabilities. This paper is concerned with those forms of assistive technology that involve voice communication.
It is important in any discussion of assistive technology to distinguish between impairment, disability, and handicap. According to the International Classification of Impairments, Disabilities, and Handicaps (World Health Organization, 1980), an impairment is "any loss or abnormality of psychological, physiological or anatomical structure or function"; a disability is "a restriction in the ability to perform essential components of everyday living"; and a handicap is a "limitation on the fulfillment of a role that is normal for that individual." Whereas handicap may be the result of a disability that, in turn, may be the result of an impairment, these consequences are not necessarily contingent on each other. The fundamental aim of assistive technology is to eliminate or minimize any disability that may result from an impairment and, concomitantly, to eliminate or minimize any handicap resulting from a disability.
Figure 1 shows the extent to which different forms of assistive technology are being used in the United States, as measured by the 1990 Health Interview Survey on Assistive Devices (LaPlante et al., 1992). Of particular interest are those forms of assistive technology that involve voice communication. Assistive devices for hearing loss are the second most widely used form of assistive technology (4.0 million Americans as compared to the 6.4 million Americans using assistive mobility technology). It is interesting to note that in each of these two widely used forms of assistive technology one specific device dominates in terms of its relative use—the cane or walking stick in the case of assistive mobility technology (4.4 million users) and the hearing aid in the case of assistive hearing technology (3.8 million users). It should also be noted that only a small number of people with hearing loss who could benefit from acoustic amplification actually use hearing aids. Estimates of the number of people in the United States who should wear hearing aids range from 12 million to 20 million, or three to five times the number who actually do (Schein and Delk, 1974). A less widely used form of assistive technology
Page 313
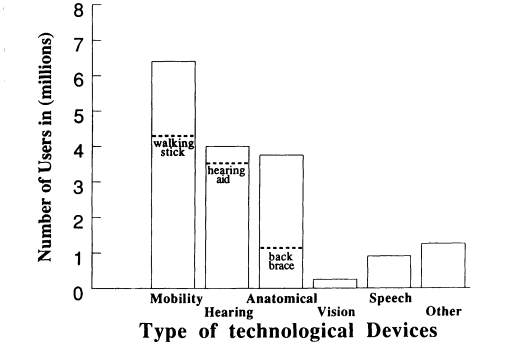
FIGURE 1 Users of assistive technology. The numbers of users (in millions)
of various types of assistive technology are shown. The three most widely
used types of assistive technology (mobility, hearing, and anatomical) all
include a specific device that is used substantially more than any other (walking
stick, hearing aid, and backbrace, respectively). The labeled dashed lines
within the bars show the numbers of users for each of these specific devices.
Note that eyeglasses were not considered in this survey. The diagram is
based on data reported in LaPlante et al. (1992).
involving both speech and language processing is that of assistive devices for people with speech and/or language disabilities. Devices of this type typically involve some form of speech synthesis or symbol generation for severe forms of language disability. Speech synthesis is also used in text-to-speech systems for sightless persons. A relatively new form of assistive technology is that of voice control of wheelchairs, hospital beds, home appliances, and other such devices by people with mobility disabilities. This form of assistive technology is not widely used at present, but it is likely to grow rapidly once its advantages are realized.
The demand for a given form of assistive technology has a significant effect on the research and development effort in advancing
Page 314
that technology. Hearing aids and related devices represent the most widely used form of assistive technology involving voice communication. Not surprisingly, the body of research on assistive hearing technology and on hearing aids, in particular, is large, and much of the present chapter is concerned with this branch of assistive technology.
ASSISTIVE HEARING TECHNOLOGY
Background
Assistive technology for hearing loss includes, in addition to the hearing aid, assistive listening devices (e.g., infrared sound transmission systems for theaters), visual and tactile sensory aids, special alarms and text telephones (also known as TTYs, as in TeleTYpewriters, or TDDs, as in Telecommunication Devices for the Deaf). The use of this technology increases substantially with age, as shown in Table 1. Whereas only 3.9 percent of hearing-aid users are 24 years of age or younger, over 40 percent are 75 or older. The use of TDDs/TTYs also increases with age, but the growth pattern is not as systematic (the highest percentage of users, 32.1, being in the 45- to 64-year age group). Note that this table does not specifically identify tactile sensory aids, visual displays of various kinds (e.g., captioning of television programs), or cochlear implants. Whereas the number of users of tactile aids or cochlear implants is measured in the thousands (as compared to the millions and hundreds of thousands of hearing-aid and TTY/ TDD users, respectively), the use of these two less well-known forms of assistive hearing technology is growing steadily. Visual displays
TABLE 1 Use of Hearing Technology Age by Group
| Percentage of Users as a Function of Age | ||||||
| Device | Total No. of Users (millions) | 24 years and under | 25-44 years | 45-64 years | 65-74 years | 75 years and over |
| Hearing Aid | 3.78 | 3.9 | 6.0 | 19.7 | 29.1 | 41.3 |
| TTY/TDD | 0.17 | 12.7 | 13.3 | 32.1 | 13.8 | 27.5 |
| Special | ||||||
| Alarms | 0.08 | 9.2 | 22.3 | 31.5 | 6.6 | 30.2 |
| Other | 0.56 | 4.3 | 10.0 | 24.2 | 25.2 | 36.4 |
NOTE: Percentages (summed across columns) may not total 100 because of rounding.
SOURCE: LaPlante et al. (1992).
Page 315
for deaf people, on the other hand, are very widely used in the form of captioned television.
An important statistic to note is the high proportion of older people who use hearing aids (about two in five). There is, in addition, a large proportion of older people who have a hearing loss and who should but do not use a hearing aid. Not only is this combined proportion very high (over three in five), but the total number of older people with significant hearing loss is growing rapidly as the proportion of older people in the population increases.
A related factor to bear in mind is that people with visual disabilities rely heavily on their hearing. Older people with visual disabilities will have special needs if hearing loss becomes a factor in their later years. This is an important concern given the prevalence of hearing loss in the older population. Similarly, people with hearing loss whose vision is beginning to deteriorate with age have special needs. The development of assistive technology for people with more than one impairment presents a compelling challenge that is beginning to receive greater attention.
Assistive devices for hearing loss have traditionally been categorized by the modality of stimulation—that is, auditory, visual, tactile, or direct electrical stimulation of the auditory nerve (auditory-neural). Another more subtle form of categorization is in terms of the degree of speech processing that is used. At least four such categories can be distinguished: assistive devices (a) that are not designed specifically for speech; (b) that take the average characteristics of speech into account, such as the long-term speech spectrum; (c) that process articulatory or phonetic characteristics of speech; and (d) that embody some degree of automatic speech recognition.
The two methods of categorization, by modality and by degree of speech processing, are independent of each other. The many different assistive devices that have been developed over the years can thus be specified in terms of a two-way matrix, as shown in Table 2. This matrix provides some revealing insights with respect to the development of and the potential for future advances in assistive hearing technology.
Hearing Aids and Assistive Listening Devices
Column 1 of Table 2 identifies assistive devices using the auditory channel. Hearing aids of various kinds are covered here as well as assistive listening devices (ALDs). These include high-gain telephones and listening systems for rooms and auditoria in which the signal is transmitted by electromagnetic means to a body-worn re-
Page 316
TABLE 2 Categories of Sensory Aids
| Modality | |||||
| 1 | 2 | 3 | 4 | ||
| Type of Processing | Auditory | Visual | Tactile | Direct Electrical | |
| 1 | Nonspeech specific | Early hearing aids | Envelope displays | Single-channel vibrator | Single-channel implant |
| 2 | Spectrum analysis | Modern hearing aids | Spectrographic displays | Tactile vocoder | Spectrum-based multi-channel implants |
| 3 | Feature extraction | Speech-feature hearing aids | Speech-feature displays | Speech-feature displays | Speech-feature implants |
| 4 | Speech recognition | Speech recognition-synthesis | Automated relay service and captioning | Speech-to-Braille conversion | — |
ceiver. Low-power FM radio or infrared transmissions are typically used for this purpose. The primary function of most assistive listening devices is to avoid the environmental noise and reverberation that are typically picked up and amplified by a conventional hearing aid. FM transmission is typically used in classrooms and infrared transmission in theaters, auditoria, houses of worship, and other public places. Another application of this technology is to allow a hard-of-hearing person to listen to the radio or television at a relatively high level without disturbing others.
Most conventional hearing aids and assistive listening devices do not make use of advanced signal-processing technology, and thus a detailed discussion of such devices is beyond the scope of this chapter. There is a substantial body of research literature in this area, and the reader is referred to Braida et al. (1979), Levitt et al. (1980), Skinner (1988), Studebaker et al. (1991), and Studebaker and Hochberg (1993).
It should be noted, however, that major changes are currently taking place in the hearing-aid industry and that these changes are
Page 317
likely to result in greater use of advanced speech-processing technology in future hearing instruments. Until now the major thrust in hearing-aid development has been toward instruments of smaller and smaller size because most hearing-aid users do not wish to be seen wearing these devices. Miniature hearing aids that fit entirely in the ear canal and are barely visible are extremely popular. Even smaller hearing aids have recently been developed that occupy only the innermost section of the ear canal and are not visible unless one peers directly into the ear canal.
The development of miniature hearing aids that are virtually invisible represents an important turning point in that there is little to be gained cosmetically from further reductions in size. The process of miniaturizing hearing-aid circuits will undoubtedly continue, but future emphasis is likely to be on increasing signal-processing capability within the space available. There is evidence that this change in emphasis has already begun to take place in that several major manufacturers have recently introduced programmable hearing aids— that is, hearing aids that are controlled by a digital controller that, in turn, can be programmed by a computer.
The level of speech processing in modern hearing aids is still fairly elementary in comparison with that used in other forms of human-machine communication, but the initial steps have already been taken toward computerization of hearing aids. The potential for incorporating advanced speech-processing techniques into the coming generation of hearing instruments (digital hearing aids, new types of assistive listening devices) opens up new possibilities for the application of technologies developed for human-machine communication.
Hearing instruments that process specific speech features (row 3, column 1 of Table 2) are primarily experimental at this stage. The most successful instruments, as determined in laboratory investigations, involve either extraction of the voice fundamental frequency (FO) and/or frequency lowering of the fricative components of speech. It has been shown by Breeuwer and Plomp (1986) that the aural presentation of FO cues as a supplement to lipreading produces a significant improvement in speech intelligibility. It has also been shown by Rosen et al. (1987) that severely hearing-impaired individuals who receive no benefit from conventional hearing aids can improve their lipreading capabilities by using a special-purpose hearing aid (the SiVo) that presents FO cues in a form that is perceptible to the user by means of frequency translation and expansion of variations in FO.
A common characteristic of sensorineural hearing impairment is that the degree of impairment increases with increasing frequency. It has been suggested that speech intelligibility could be improved for
Page 318
this form of hearing loss by transposing the high-frequency components of speech to the low-frequency region, where the hearing impairment is not as severe (see Levitt et al., 1980). Whereas small improvements in intelligibility (5 to 10 percent) have been obtained for moderate amounts of frequency lowering (10 to 20 percent) for moderate hearing losses (Mazor et al., 1977), the application of greatest interest is that of substantial amounts of frequency lowering for severely hearing-impaired individuals with little or no hearing above about 1000 Hz. A series of investigations on frequency-lowering schemes for hearing impairments of this type showed no significant improvements in speech intelligibility (Ling, 1969). These studies, however, did not take into account the phonetic structure of the speech signal. When frequency lowering is limited to only those speech sounds with substantially more high-frequency energy than low-frequency energy (as is the case with voiceless fricative consonants), significant improvements in speech intelligibility can be obtained (Johansson, 1966; Posen et al., 1993). Frequency lowering of fricative sounds has also proven to be useful in speech training (Guttman et al., 1970). A hearing aid with feature-dependent frequency lowering has recently been introduced for clinical use.
Hearing aids that involve speech recognition processing (row 4, column 1, Table 2) are still highly experimental. In one such application of speech recognition technology, the output of a speech recognizer was used to drive a special-purpose speech synthesizer in which important phonetic cues in the speech signal are exaggerated (Levitt et al., 1993). It has been shown that the perception of certain speech sounds can be improved significantly for people with severe hearing impairments by exaggerating relevant acoustic phonetic cues. For example, perception of voicing in consonantal sounds can be improved by increasing the duration of the preceding vowel (Revoile et al., 1986). This type of processing is extremely difficult to implement automatically using traditional methods of signal processing. In contrast, automatic implementation of vowel lengthening is a relatively simple matter for a speech recognition/synthesis system.
The major limitations of the experimental speech recognition/ synthesis hearing aid evaluated by Levitt et al. (1993) were the accuracy of the speech recognition unit, the machine-like quality of the synthetic speech, the time the system took to recognize the speech, and the physical size of the system. The last-mentioned limitation does not apply if the system is to be used as a desk-mounted assistive listening device.
Page 319
Visual Sensory Aids
The development of visual sensory aids for hearing impairment follows much the same sequence as that for auditory aids. The earliest visual sensory aids were concerned primarily with making sounds visible to a deaf person (Bell, 1876). The limitations of these devices for representing speech were soon recognized, and attention then focused on more advanced methods of signal processing that took the average spectral characteristics of speech into account. The sound spectrograph, for example, is designed to make the spectral components of speech visible. (A high-frequency emphasis tailored to the shape of the average speech spectrum is needed because of the limited dynamic range of the visual display.) This device also takes into account the spectral and temporal structure of speech in the choice of bandwidths for the analyzing filters.
The visible speech translator (VST), which, in essence, is a real-time-version sound spectrograph, belongs in the category of sensory aids that take the average characteristics of the speech signal into account (Table 2, row 2). The VST was introduced in the belief that it would provide a means of communication for deaf people as well as being a useful research tool (Potter et al., 1947). Early experimental evaluations of the device supported this view. Figure 2 shows data on the number of words that two groups of hearing subjects (B and C) and one deaf subject (A) learned to recognize using the VST. The deaf subject reached a vocabulary of 800 words after 220 hours of training. The curve for this subject also shows no evidence of flattening out; that is, extrapolation of the curve suggests that this subject
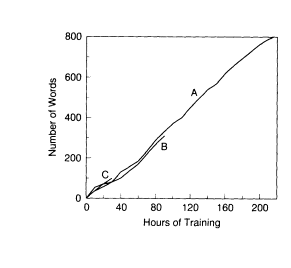
FIGURE 2 Early results obtained with the visible
speech translator. The diagram shows the number
of words learned by each of five subjects as
a function of the amount of training (in hours). Curve
A relates to a deaf engineer; curves B and C are related
to two groups of two young adults each with no
engineering background. Adapted from Potter et al. (1947).
Page 320
would have continued to increase his vocabulary at the rate of about 3.6 words for each hour of training.
Subsequent evaluations of the VST have not been as impressive. These studies showed that the device was of limited value as an aid to speech recognition (House et al., 1968), although several subsequent studies have shown that speech spectrum displays can be of value in speech training (Stark, 1972). In the speech-training application the user need only focus on one feature of the display at a time, whereas in the case of a visual display for speech recognition several features must be processed rapidly.
Liberman et al. (1968) have argued that speech is a complex code; that the ear is uniquely suited to interpret this code; and that, as a consequence, perception of speech by modalities other than hearing will be extremely difficult. It has since been demonstrated that it is possible for a human being to read a spectrogram without any additional information (Cole et al., 1980). The process, however, is both difficult and time consuming, and it has yet to be demonstrated that spectrogram reading is a practical means of speech communication.
A much easier task than spectrogram reading is that of interpreting visual displays in which articulatory or phonetic cues are presented in a simplified form. Visual aids of this type are categorized by row 3, column 2 of Table 2. Evidence of the importance of visual articulatory cues is provided by experiments in speechreading (lipreading). Normal-hearing listeners with no previous training in speechreading have been shown to make substantial use of visual cues in face-to-face communication when the acoustic signal is masked by noise (Sumby and Pollack, 1954). Speechreading cues, unfortunately, are ambiguous, and even the most skilled speechreaders require some additional information to disambiguate these cues. A good speechreader is able to combine the limited information received auditorially with the cues obtained visually in order to understand what was said. Many of the auditory cues that are lost as a result of hearing loss are available from speechreading. The two sets of cues are complimentary to a large extent, thereby making speechreading with acoustic amplification a viable means of communication for many hearing-impaired individuals. A technique designed to eliminate the ambiguities in speechreading is that of ''cued speech" (Cornett, 1967). In this technique, hand symbols are used to disambiguate the speech cues in speechreading. Nearly perfect reception of conversational speech is possible with highly trained receivers of cued speech (Nicholls and Ling, 1982; Uchanski et al., 1994).
There have been several attempts to develop sensory aids that provide visual supplements to speechreading. These include eye-
Page 321
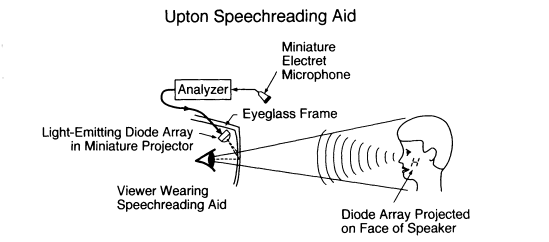
FIGURE 3 Eyeglasses conveying supplementary speech-feature cues. The
speech signal is picked up by a microphone mounted on the frame of a pair
of eyeglasses. The signal is analyzed, and coded bars of light indicating the
occurrence of certain speech features, such as frication or the noise burst in a
stop consonant, are projected onto one of the eyeglass lenses. The light beam
is reflected into the eye so as to create a virtual image that is superimposed
on the face of the speaker. This device, known as the eyeglass speech reader,
is a more advanced version of the eyeglass speechreading aid developed by
Upton (1968). (Reproduced from Pickett et al. (1974).
glasses with tiny lights that are illuminated when specific speech features are produced (Upton, 1968). A more advanced form of these eyeglasses is shown in Figure 3. A mirror image is used to place these visual cues at the location of the speaker, so that the wearer of the sensory aid does not have to change his/her focal length while looking at the speaker and simultaneously attempting to read the supplementary visual cues (Gengel, 1976).
Experimental evaluations of visual supplements to speechreading have shown significant improvements in speech recognition provided the supplemental cues are extracted from the speech signal without error (Goldberg, 1972). In practice, the supplemental cues need to be extracted automatically from the speech signal, usually in real time and often in the presence of background noise and reverberation. Practical systems of this type have yet to show the improvements demonstrated by the error-free systems that have been evaluated in the laboratory. Erroneous information under difficult listening conditions can be particularly damaging to speech understanding. Un-
Page 322
der these conditions, missing cues may be preferable to misleading cues.
In contrast to the limited improvement obtained with visual-feature displays for speech recognition, displays of this type have been found to be of great value in speech training. Visual displays of the voice fundamental frequency are widely used for teaching speech to children with hearing impairments (McGarr et al., 1992; Risberg, 1968). Further, computer-based speech-training systems have been developed that, in addition to providing a range of visual displays of articulatory features, allow for the student to work interactively with the computer, including the use of video games to maintain the student's motivation (Kewley-Port et al., 1987; Ryalls et al., 1991; Watson et al., 1989; Yamada et al., 1988).
Another very useful application of speech-processing technology in this context is that of synthesizing the speech of deaf students in order to develop a model of the underlying speech problem and investigate possible methods of intervention. In one such study, timing errors in the speech of deaf children were simulated and then removed systematically in order to determine the effect of different training schemes on speech intelligibility. It was found that prolongation of speech sounds, a common problem in the speech of deaf individuals, was not a major factor in reducing intelligibility but that distortion of the duration ratio between stressed and unstressed syllables reduced intelligibility significantly (Osberger and Levitt, 1979).
Visual displays that present speech information in the form of text are increasingly being used by deaf and severely hearing-impaired individuals. Displays of this type, as categorized by row 4 of Table 2, depend on the use of speech recognition, either by machine or other human beings. In the case of a telephone relay service, the speech produced by the hearing party in a telephone conversation is recognized by a typist at a central location who types out the message, which is then transmitted to the deaf party by means of a text telephone (or TTY/TDD). The deaf party then responds, either by voice or by typing a message on his/her text telephone, which is converted to speech by either a speech synthesizer or the participating typist. Many users of the relay service do not like the participation of a third party (the typist) in their telephone conversations.
In the case of real-time captioning, a stenographer transcribes what is said on a shorthand typewriter (e.g., a Stenograph), the output of which is transmitted to a computer that translates the symbols into standard text. Displays of this type are increasingly being used at lectures and meetings involving deaf participants. These systems have also proved useful to both deaf and hearing students in the
Page 323
classroom (Stuckless, 1989). A related application of real-time captioning, which is also growing rapidly, is that of captioning movies and television programs for deaf viewers.
Telephone relay services, real-time captioning, and traditional methods of captioning are expensive enterprises, and methods for automating these techniques are currently being investigated. Automatic machine recognition of speech is a possible solution to this problem provided the error rate for unconstrained continuous speech is not too high (Kanevsky et al., 1990; Karis and Dobroth, 1991). Another issue that needs to be considered is that the rate of information transmission for speech can be high and captions often need to be shortened in order to be comprehended by the audience in real time. Synchronization of the caption to the sound track also needs to be considered as well as issues of lighting and legibility. The preparation of captions is thus not as simple a task as might first appear.
A communication aid that is rapidly growing in importance is the text telephone. Telephone communication by means of teletypewriters (TTYs) has been available to deaf people for many years, but the high cost of TTYs severely limited their use as personal communication aids. The invention of the acoustic coupler and the mass production of keyboards and other basic components of a TTY for the computer market made the text telephone (an offshoot of the TTY) both affordable and practical for deaf consumers. Modern text telephones also make use of computer techniques in storing and retrieving messages in order to facilitate the communication process.
A major limitation of text telephones is the time and effort required to generate messages in comparison with speech. A second limitation is that both parties in a telephone conversation need to have text telephones. The recently introduced telephone relay service eliminates the need for a text telephone by the hearing party, but the rate of communication is slow and there is a loss of privacy when using this service.
Most of the earlier text telephones use the Baudot code for signal transmission, which is a robust but relatively slow code in comparison with ASCII, which is used almost universally for computer communications. The use of the Baudot code makes it difficult for users of these text telephones to access electronic mail, computer notice boards, and computer information services. Methods for improving the interface between text telephones using the Baudot code and modern computer networks using the ASCII code are currently being developed (Harkins et al., 1992). Most modern text telephones are capable of communicating in either Baudot or ASCII.
The ways in which text telephones are used by the deaf commu-
Page 324
nity need to be studied in order to obtain a better understanding of how modern speech recognition and speech synthesis systems could be used for communicating by telephone with deaf individuals. A possible communication link between a deaf person and a hearing person involves the use of a speech recognizer to convert the speech of the hearing person to text for transmission to a text telephone and a speech synthesizer to convert the output of the deaf person's text telephone to speech. The problem of converting speech to text is well documented elsewhere in this volume (see Makhoul and Schwartz). The problem of converting the output of a text telephone to speech in real time is not quite as great, but there are difficulties beyond those considered in modern text-to-speech systems. For state-of-the-art reviews of text-to-speech conversion see the chapters by Allen and Carlson in this volume. Most deaf users of text telephones, for example, have developed a telegraphic style of communication using nonstandard syntax. In many cases these syntactic forms are carried over from American Sign Language. The use of text generated in this way as input to a speech synthesizer may require fairly sophisticated preprocessing in order to produce synthetic speech that is intelligible to a hearing person.
Issues that need to be considered in converting the output of a text telephone to speech in real time include:
• whether synthesis should proceed as typed, on a word-byword basis, or whether to introduce a delay and synthesize on a phrase or sentence basis, so as to control intonation appropriately and reduce pronunciation errors due to incorrect parsing resulting from incomplete information;
• rules for preprocessing that take into account the abbreviations, nonstandard syntactic forms, and sparse punctuation typically used with text telephones; and
• methods for handling typing errors or ambiguous outputs.
For example, omission of a space between words is usually easy to recognize in a visual display, but without appropriate preprocessing an automatic speech recognizer will attempt, based on the combination of letters, to produce a single word that is likely to sound quite different from the two intended words.
The above issues present an immediate and interesting challenge to researchers concerned with assistive voice technology.
Tactile Sensory Aids
The possibility of using vibration as a means of communication was explored by Gault (1926) and Knudsen (1928). This early re-
Page 325
search focused on the use of single-channel devices without any preprocessing to take the characteristics of speech into account. The results showed that only a limited amount of speech information, such as the temporal envelope, could be transmitted in this way. This limited information was nevertheless found to be useful as a supplement to speechreading and for purposes of speech training. Single-channel tactile aids have since found a very useful practical application as alerting systems for deaf people. These devices fall under the category of nonspeech-specific tactile aids (column 3, row 1 of Table 2).
A tactile aid that takes the spectrum of speech into account is the tactile vocoder. An early vocoder of this type was developed by Gault and Crane (1928), in which each of the fingers was stimulated tactually by a separate vibrator that, in turn, was driven by the speech power in a different region of the frequency spectrum. The tactile vocoder provided significantly more information than a single-channel vibrator, but the amount of information was still insufficient to replace the impaired auditory system, although the device could be used as a supplement to speechreading and for speech training.
The tactile vocoder has been studied intermittently over the years (Pickett and Pickett, 1963; Sherrick, 1984). As transducer technology has improved, coupled with improved signal-processing capabilities, corresponding improvements in speech recognition using tactile aids have been obtained. In a recent study by Brooks et al. (1986), for example, a highly motivated individual with sufficient training acquired a vocabulary of about 1000 words using taction only. This result is remarkably similar to the best results obtained thus far for a visual spectrum display (see Figure 2). As noted earlier, spectrograms are hard to read for the reasons cited by Liberman et al. (1968), and the ultimate limitation on the human perception of speech spectrum displays may be independent of whether the information is presented tactually or visually.
An important advantage of tactile sensory aids is that these devices can be worn conveniently without interfering with other important sensory inputs. In addition, a wearable sensory aid allows for long-term exposure to the sensory stimuli, thereby facilitating learning and acclimatization to the sensory aid. There are examples of deaf individuals who have worn spectrum-based tactile aids for many years and who are able to communicate effectively in face-to-face situations using their tactile aid (Cholewiak and Sherrick, 1986). Wearable multichannel tactile aids (two to seven channels) have been available commercially for several years, and several thousand of these devices are already in use, mostly with deaf children (D. Franklin, Audiological Engineering, personal communication, 1993). Experimen-
Page 326
tal evaluations currently in progress indicate that these wearable tactile aids have been significantly more effective in improving speech production than speech recognition skills (Robbins et al., 1992).
Relatively good results have been obtained with speech-feature tactile aids (row 3, column 3 of Table 2) for both speech production and speech reception. These devices, however, are not as widely used as spectrum-based tactile aids, possibly because they are not yet ready for commercialization.
Figure 4 shows a schematic diagram of a tactile aid worn on the lower forearm that provides information on voice fundamental frequency, FO. The locus of tactile stimulation is proportional to the value of FO. When FO is low, the region near the wrist is stimulated; as FO is increased, the locus of stimulation moves away from the wrist. The use of supplemental FO cues presented tactually has been shown to produce significant improvements in lipreading ability (Boothroyd et al., 1988), although this improvement is less than that
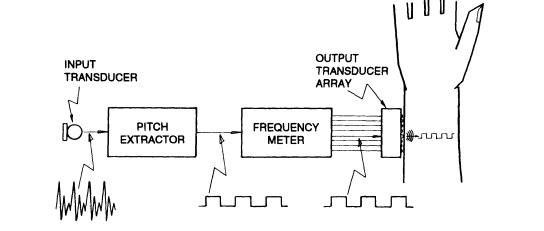
FIGURE 4 Wearable tactile display for voice fundamental frequency. Speech
signals from the input transducer (an acoustic microphone or a surface-mounted
accelerometer) are delivered to a pitch extractor that generates a square wave
whose frequency equals one-half that of the fundamental voice frequency. A
pitch period meter times the "off" period of each cycle and thereby determines
which of eight output channels will be activated during the "on" period.
Frequency scaling is such that the channel number is proportional to the
logarithm of voice fundamental frequency. The electronic components are
housed in a body-worn unit, the output of which is connected by wire to a
transducer array worn on the wrist. Reproduced from Boothroyd and Hnath (1986).
Page 327
obtained when the supplemental FO cues are presented auditorially (Breeuwer and Plomp, 1986). The tactile FO display has also been found to be of value as a speech-training aid (McGarr et al., 1992). A very useful feature of this aid is that it can be worn outside the classroom, thereby providing students with continuous feedback of their speech production in everyday communication.
It is important for any speech-feature sensory aid (tactile, visual, or auditory) that the speech features be extracted reliably. An experiment demonstrating the value of a tactile aid providing reliable speech-feature information has been reported by Miller et al. (1974). The key elements of the experiment are illustrated in Figure 5. Several sensors are mounted on the speaker. One picks up nasal vibrations; the second picks up vocal cord vibrations; and the third, a microphone, picks up the acoustic speech signal. These signals are delivered to the subject by means of vibrators used to stimulate the subject's fingers. The subject can see the speaker's face but cannot hear what is said since the speech signal is masked by noise delivered by headphones.
The vibrators provide reliable information on three important aspects of speech production: nasalization, voicing, and whether or not speech is present. The first two of these cues are not visible in speechreading, and the third cue is sometimes visually ambiguous. Use of the tactual cues resulted in significant improvements in speechreading ability with relatively little training (Miller et al., 1974). An important implication of this experiment is that speech-feature tactile aids are of great potential value for improving articulatory cues provided by speech recognition. Cues designed to supplement those used in speechreading are delivered reliably to the user.
The central problem facing the development of practical speech-feature tactile aids is that of extracting the articulatory cues reliably. This problem is particularly difficult for wearable sensory aids because the signal picked up by the microphone on the wearable aid is contaminated by environmental noise and reverberation.
Tactile sensory aids involving speech recognition processing (row 4, column 3 of Table 2) are at the threshold of development. These devices have the potential for improving communication with deaf-blind individuals. In one such system, a discrete word recognizer is used to recognize speech produced by a hearing person. The speech is then recognized and converted to Braille (or a simpler form of raised text) for use by the deaf-blind participant in the conversation. A system of this type has already been developed for Japanese symbols by Shimizu (1989).
Page 328
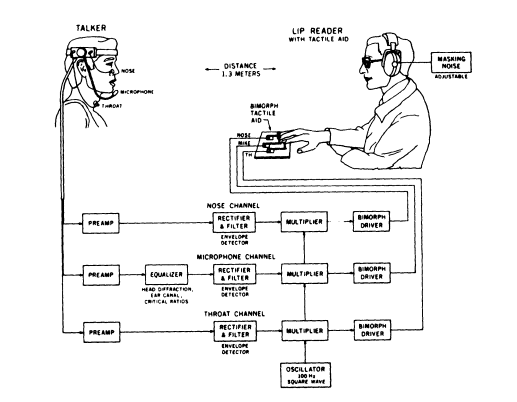
FIGURE 5 Three-channel speech-feature tactile aid. Three sensors are used
to pick up nasal vibration, throat vibration, and the acoustic speech signal,
respectively. The envelope of each signal is amplified and delivered to three
vibrators for stimulating the subject's fingers. The vibrotactile stimuli served
as supplementary speechreading cues. Masking noise is used to eliminate
acoustic cues during testing. Reproduced from Miller et al. (1974).
Direct Electrical Stimulation of the Auditory System
It has been demonstrated that a deaf person can hear sound when the cochlea is stimulated electrically (Simmons, 1966). One possible explanation for this is that the deafness may be due to damage to the hair cells in the cochlea which convert mechanical vibration to neural firings, but that the neurons connected to these hair cells may still be functional and can be triggered by the electromagnetic field generated by a cochlear implant.
Most of the early cochlear implants consisted of a single wire electrode inserted in the cochlea (House and Urban, 1973). These implants were not designed specifically for speech signals but were
Page 329
very helpful in providing users with the sensation of sound and the ability to recognize common environmental sounds.
More advanced cochlear implants have been designed specifically for speech. In one such prosthesis, the Ineraid, the speech signal is filtered into four frequency bands. The signal in each band is then transmitted through the skin (using a percutaneous plug) to a set of electrodes inserted in the cochlea (Eddington, 1983). The geometry of the electrode array is such that the four frequency bands stimulate different regions of the cochlea in a manner consistent with the frequency-analyzing properties of the cochlea. This cochlear implant is categorized by row 2, column 4 of Table 2.
A cochlear implant that uses speech-feature processing (the Nucleus 22-channel cochlear implant system) is shown in Figure 6. This prosthesis, categorized by row 3, column 4 of Table 2, was developed by Clark et al. (1983, 1990). A body-worn signal processor, shown on the left in the figure, is used to analyze the incoming acoustic signal picked up by an ear-mounted microphone. The FO and the two lowest-formant frequencies (F1 and F2) are extracted from the acoustic signal, modulated on a carrier, and then transmitted electromagnetically across the skin to a decoding unit mounted in the mastoid (a bony section of the skull behind the ear). The decoded signals take the form of pulses that are transmitted to an array of electrodes inserted in the cochlea, as shown by the dotted line in the photograph. The electrode array consists of a flexible cable-like structure ringed with 32 bands of platinum of which 10 serve as mechanical support and the remaining 22 bands serve as electrodes. Each electrode is connected to the decoder in the mastoid by means of an extremely fine flexible wire contained within the cable.
The pulses from the decoder are delivered to the electrodes so as to stimulate those regions of the cochlea that in normal speech perception would correspond roughly to the frequency regions that would be stimulated by formants 1 and 2. The rate of pulsatile stimulation is proportional to FO for voiced sounds, random stimulation being used for voiceless sounds. The pulses used to stimulate different frequency regions of the cochlea are interleaved in time so as to reduce interference between adjacent channels of stimulation. The method of stimulation thus provides important speech-feature information (FO, formant frequencies Fl and F2, and whether the speech is voiced or voiceless).
A third type of cochlear prosthesis uses an external electrode mounted on the round window of the cochlea. An advantage of this type of prosthesis, known as an extracochlear implant, is that electrodes are not inserted into the cochlea with the attendant danger of
Page 330

FIGURE 6 Multichannel speech-feature cochlear prosthesis (Nucleus 22-channel
cochlear implant system). Speech is picked up by a microphone and delivered
to a body-worn processor (shown on the left) that extracts and encodes
the speech features of interest (voice fundamental frequency, formant frequencies).
The encoded signals are transmitted electromagnetically across
the skin. The decoding unit is mounted in the mastoid (a bony section of the
skull behind the ear). The decoded signals take the form of pulses that are
transmitted to an array of electrodes inserted in the cochlea, as shown by the
dotted line in the photograph. Diagram reprinted courtesy of the Cochlear Corporation.
damaging whatever residual hearing may be left. A disadvantage of this approach is that relatively high-current densities are needed, which can cause nonauditory side effects, such as facial nerve stimulation. The use of a single electrode also limits the amount of speech information that can be delivered. In the prosthesis developed by Douek et al. (1977), FO was delivered to the electrode. Significant improvements in speechreading ability were obtained using this technique.
Much controversy exists regarding the relative efficacy of the various cochlear implants that have been developed. Dramatic improvements in speech understanding have been demonstrated for each of the major types of cochlear implants. For the more advanced implants, a high proportion of implantees have even demonstrated the ability to converse without the use of speechreading, as in a telephone conver-
Page 331
sation. These success stories have been widely publicized; in the majority of cases, however, improvements in communication ability have been significant but much less dramatic.
A major clinical trial was recently undertaken in an attempt to resolve the controversy regarding relative efficacy (Cohen et al., 1993). Three types of cochlear implants were compared: a single-channel implant, a multichannel spectrum-based implant, and a multichannel speech-feature implant. The results showed that both multichannel implants produced significantly greater improvements in communication ability than the single-channel implant. Differences between the two multichannel implants were either small or not statistically significant. Toward the end of the clinical trial, a new form of stimulus coding was introduced for the multichannel speech-feature cochlear implant. The improved processor encoded additional spectral information in three high-frequency bands by stimulating electrodes close to the high-frequency end of the cochlea. This new method of coding was found to provide a small but significant improvement in communication ability. New methods of coding using interleaved pulsatile stimuli for spectrum-based cochlear implants are currently being investigated (Wilson et al., 1993).
The one entry in Table 2 that, at present, remains unfilled is that of a cochlear prosthesis using speech recognition technology (row 4, column 4). A possible future application of this technology would be a system analogous to the speech recognition/speech synthesis hearing aid in which speech is first recognized and then regenerated so as to enhance those speech features that cochlear implant users have difficulty understanding.
Noise Reduction
A common problem with all sensory aids is the damaging effects of background noise and reverberation on speech understanding. These distortions also reduce overall sound quality for hearing aids and cochlear implants. Signal processing for noise reduction is an important but large topic, the details of which are beyond the scope of this chapter. There are, however, several aspects of the noise reduction problem that are unique to sensory aids and that need to be mentioned.
The most common method of combating noise and reverberation in practice is to place a microphone close to the speaker and transmit the resulting signal, which is relatively free of noise and reverberation, directly to the input of the sensory aid. FM radio or infrared transmission systems are commonly used for this purpose. It is not
Page 332
always feasible to use a remote microphone in this way, and various alternative solutions to the problem are currently being investigated.
A method for reducing the effects of noise that is currently used in many modern hearing aids is to filter out high-level frequency components that are believed to be the result of amplifying environmental noise. It has been argued that the intense components of the amplified sound, which may include noise, will mask the less intense components of the amplified sound and that these less intense components are likely to include important components of the speech signal.
Many common environmental noises have relatively powerful low-frequency components that, if amplified, would interfere with the weaker high-frequency components of speech. High-pass filters are typically used to reduce this type of environmental noise, but these filters also eliminate the speech signal in those frequency bands, thereby reducing intelligibility when only speech is present. To address this problem, adaptive filtering is used in which the cutoff frequency of the filter is adjusted automatically depending on the level of the signals to be amplified. If the low-frequency power is relatively high (e.g., the ratio of low- to high-frequency power is larger than that typical of speech), it is assumed that most of the low-frequency power is due to environmental noise, and the filter cutoff frequency is adjusted so as to attenuate the low frequencies. In this way the filter eliminates mostly noise, although some components of the speech signal will still be lost. An alternative approach to this problem is to use two-channel compression amplification and to reduce the gain in the low-frequency channel when there is excessive low-frequency power.
Experimental evaluations of the above forms of noise reduction have yielded mixed results. Some studies have reported significant gains in speech intelligibility, whereas other studies have shown decrements (Fabry, 1991; Fabry et al., 1993; Graupe et al., 1987; Van Tasell et al., 1988). Most of these studies, unfortunately, did not use appropriate control conditions and, as a consequence, these studies cannot be treated as conclusive (Dillon and Lovegrove, 1993). Substantial individual differences have also been observed in most of these studies, indicating that, depending on the nature of the hearing impairment and the circumstances under which the sensory aid is used, different forms of signal processing may be required for different people and conditions of use (Levitt, 1993).
A form of noise reduction that has yielded good results as a front end to a speech-feature cochlear implant is that of spectrum subtraction (Hochberg et al., 1992). This form of noise reduction is relatively effective in extracting the strongly voiced components of the speech
Page 333
signal from a random noise background. Since the Nucleus speech-feature cochlear implant depends heavily on reliable estimation of the first two formant frequencies during voiced sounds, it is not surprising that a variation of the spectrum-subtraction method of noise reduction (the INTEL technique developed by Weiss and Aschkenasy, 1981) showed a significant improvement in speech understanding when used as a front end to this cochlear implant. The improvements obtained were equivalent, on average, to an increase in the speech-to-noise ratio of 5 dB.
Perhaps the most promising form of noise reduction for wearable sensory aids at the present time is that of a microphone array for automatically focusing in on the speech source. A directional array of this type using microphones mounted on the frame of a pair of eyeglasses can produce improvements in speech-to-noise ratio of 7 to 11 dB under conditions typical of everyday use (Bilsen et al., 1993; Soede, 1990). A relatively simple nonadaptive method of signal processing was used in the above study. Adaptive methods of noise cancellation using two or more microphones appear to be even more promising (Chabries et al., 1987; Peterson et al., 1987; Schwander and Levitt, 1987). An important practical limitation of these techniques, however, is that they will not provide any benefit in a highly reverberant acoustic environment or if both speech and noise come from the same direction.
OTHER FORMS OF ASSISTIVE TECHNOLOGY INVOLVING VOICE COMMUNICATION
Speech Processing for Sightless People
People with severe visual impairments are heavily dependent on the spoken word in communicating with others and in acquiring information. To address their needs, talking books have been developed. High-speed playback is a very useful tool for scanning an audio text, provided the speech is intelligible. Methods of processing speeded speech to improve intelligibility have been developed using proportional frequency lowering. When an audio recording is played back at k times its normal speed, all frequencies in that recording are increased proportionally by the ratio k. The effect of this distortion on intelligibility is reduced considerably if the playback signal is transposed downward by the same frequency ratio. Methods of proportional frequency transposition were developed some time ago (Levitt et al., 1980). These techniques work well for steady-state sounds but are subject to distortion for transient sounds. Re-
Page 334
cent advances in compact disc technology and computer-interactive media have eliminated much of the inconvenience in scanning recorded texts.
A second application of assistive speech technology is the use of machine-generated speech for voice output devices. These applications include reading machines for the blind (Cooper et al., 1984; Kurzweil, 1981); talking clocks and other devices with voice output; and, in particular, voice output systems for computers. The use of this technology is growing rapidly, and, with this growth, new problems are emerging.
One such problem is linked to the growing complexity of computer displays. Pictorial symbols and graphical displays are being used increasingly in modern computers. Whereas computer voice output systems are very effective in conveying alphanumeric information to sightless computer users, conveying graphical information is a far more difficult problem. Innovative methods of representing graphical information using machine-generated audio signals combined with tactile displays are being experimented with and may provide a practical solution to this problem (Fels et al., 1992).
A second emerging problem is that many sightless people who are heavily dependent on the use of machine-generated speech for both employment and leisure are gradually losing their hearing as they grow older. This is a common occurrence in the general population, as indicated by the large proportion of people who need to wear hearing aids in their later years (see Table 1). Machine-generated speech is usually more difficult to understand than natural speech. For older people with some hearing loss the difficulty in understanding machine-generated speech can be significant. For the sightless computer user whose hearing is deteriorating with age, the increased difficulty experienced in understanding machine-generated speech is a particularly troublesome problem.
Good progress is currently being made in improving both the quality and intelligibility of machine-generated speech (Bennett et al., 1993). For the special case of a sightless person with hearing loss, a possible approach for improving intelligibility is to enhance the acoustic characteristics of those information-bearing components of speech that are not easily perceived as a result of the hearing loss. The thrust of this research is similar to that underlying the development of the speech recognition/speech synthesis hearing aid (Levitt et al., 1993).
Page 335
Augmentative and Alternative Communication
People with a range of different disabilities depend on the use of augmentative and alternative methods of communication (AAC). Machine-generated speech is widely used in AAC, although the way in which this technology is employed depends on the nature of the disability. A nonvocal person with normal motor function may wish to use a speech synthesizer with a conventional keyboard, whereas a person with limited manual dexterity in addition to a severe speech impairment would probably use a keyboard with a limited set of keys or a non-keyboard device that can be controlled in various ways other than by manual keypressing. It is also possible for a person with virtually no motor function to use eye movements as a means of identifying letters or symbols to be used as input to the speech synthesizer.
A common problem with the use of synthetic speech in AAC is the time and effort required to provide the necessary input to the speech synthesizer. Few people can type at speeds corresponding to that of normal speech. It is possible for a motivated person with good motor function to learn how to use either a Stenograph or Palantype keyboard at speeds comparable to normal speech (Arnott, 1987). The output of either of these keyboards can be processed by computer so as to drive a speech synthesizer in real time. A high-speed keyboard, however, is not practical for a nonvocal person with poor motor function. It is also likely that for this application a keyboard with a limited number of keys would be used. In a keyboard of this type, more than one letter is assigned to each key, and computer techniques are needed to disambiguate the typed message. Methods of grouping letters efficiently for reduced set keyboards have been investigated so as to allow for effective disambiguation of the typed message (Levine et al., 1987). Techniques of this type have also been used with a Touch-Tone® keypad so that a hearing person using a Touch-Tone telephone can communicate with a deaf person using a text telephone (Harkins et al., 1992). Even with these innovations, this technique has not met with much success among people who are not obliged to use a reduced set keyboard.
Other methods of speeding up the communication process is to use the redundancy of language in order to predict which letter or word should come next in a typed message (Bentrup, 1987; Damper, 1986; Hunnicutt, 1986, 1993). A variation of this approach is to use a dictionary based on the user's own vocabulary in order to improve the efficiency of the prediction process (Swiffin et al., 1987). The
Page 336
dictionary adapts continuously to the user's vocabulary as the communication process proceeds.
For nonvocal people with limited language skills, methods of generating well-formed sentences from limited or ill-formed input are being investigated (McCoy et al., 1989). In some applications, symbols rather than words are used to generate messages that are then synthesized (Hunnicutt, 1993).
Computer-assisted instruction using voice communication can be particularly useful for people with disabilities. The use of computers for speech training has already been discussed briefly in the section on visual sensory aids. Similarly, computer techniques for improving human-machine communication can be of great value in developing instructional systems for people who depend on augmentative or alternative means of communication. A relatively new application of this technology is the use of computerized speech for remedial reading instruction (Wise and Olsen, 1993).
A common problem with text-to-speech systems is the quality of the synthetic voice output. Evaluations of modern speech synthesizers indicate that these systems are still far from perfect (Bennett et al., 1993). Much of the effort in the development of text-to-speech systems has been directed toward making the synthesized speech sound natural as well as being intelligible. In some applications, such as computer voice output for a hearing-impaired sightless person, naturalness of the synthesized speech may need to be sacrificed in order to improve intelligibility by exaggerating specific features of the speech signal.
The artificial larynx represents another area in which advances in speech technology have helped people with speech disabilities. The incidence of laryngeal cancer has grown over the years, resulting in a relatively large number of people who have had a laryngectomy. Many laryngectomies use an artificial larynx in order to produce intelligible speech. Recent advances in speech technology coupled with an increased understanding of the nature of speech production have resulted in significant improvements in the development of artificial larynxes (Barney et al., 1959; Sekey, 1982). Recent advances include improved control of speech prosody and the use of microprocessor-generated glottal waveforms based on recent theories of vocal cord vibration in order to produce more natural-sounding speech (Alzamora et al., 1993).
Unlike the applications of assistive technology discussed in the previous sections, the use of voice communication technology in AAC is highly individualized. Nevertheless, two general trends are apparent. The first is the limitation imposed by the relatively low speed
Page 337
at which control information can be entered to the speech synthesizer by the majority of candidates for this technology. The second is the high incidence of multiple disabling conditions and the importance of taking these factors into account in the initial design of assistive devices for this population. In view of the above, an important consideration for the further development of assistive technology for AAC is that of developing flexible generalized systems that can be used for a variety of applications involving different combinations of disabling conditions (Hunnicutt, 1993).
Assistive Voice Control: Miscellaneous Applications
Assistive voice control is a powerful enabling technology for people with mobility disabilities. Examples of this new technology include voice control of telephones, home appliances, powered hospital beds, motorized wheelchairs, and other such devices (Amori, 1992; Miller, 1992). In each case the set of commands to control the device is small, and reliable control using a standardized set of voice commands can be achieved using existing speech recognition technology. Several of these applications of voice control technology may also find a market among the general population (e.g., voice control of a cellular telephone while driving a car, remote control of a television set, or programming a VCR by voice). A large general market will result in mass production of the technology, thereby reducing cost for people who need this technology because of a mobility disability.
An additional consideration in developing assistive voice control technology is that a person with a neuromotor disability may also have dysarthria (i.e., unclear speech). For disabilities of this type, the speech recognition system must be capable of recognizing various forms of dysarthric speech (Goodenough-Trepagnier et al., 1992). This is not too difficult a problem for speaker-dependent automatic speech recognition for those dysarthrics whose speech production is consistent although not normal. Machine recognition of dysarthric speech can also be of value in assisting clinicians obtain an objective assessment of the speech impairment.
Voice control of a computer offers intriguing possibilities for people with motor disabilities. Relatively simple methods of voice control have already been implemented, such as remote control of a computer mouse (Miller, 1992), but a more exciting possibility that may have appeal to the general population of computer users (and, concomitantly, may reduce costs if widely used) is that of controlling or programming a computer by voice. The future in this area of assistive voice control technology appears most promising.
Page 338
ACKNOWLEDGMENT
Preparation of this paper was supported by Grant No. 5P50DC00178 from the National Institute on Deafness and Other Communication Disorders.
REFERENCES
Alzamora, D., D. Silage, and R. Yantorna (1993). Implementation of a software model of the human glottis on a TMS32010 DSP to drive an artificial larynx. Proceedings of the 19th Northeast Bioengineering Conference, pp. 212-214, New York: Institute of Electrical and Electronic Engineers.
Amori, R. D. (1992). Vocomotion: An intelligent voice-control system for powered wheelchairs. Proceedings of the RESNA International '92 Conference, pp. 421423. Washington, D.C.: RESNA Press.
Arnott, J. L. (1987). A comparison of Palantype and Stenograph keyboards in high-speed speech output systems. RESNA '87, Proceedings of the 10th Annual Conference on Rehabilitation Technology, pp. 106-108. Washington D.C.: RESNA Press.
Barney, H., F. Haworth, and H. Dunn (1959). Experimental transistorized artificial larynx. Bell Syst. Tech. J., 38:1337-1359.
Bell, A. G. (1876). Researches in telephony. Proceedings of the American Academy of Arts and Sciences, XII, pp. 1-10. Reprinted in Turning Points in American Electrical History, Britain, J.E., Ed., IEEE Press, New York, 1976.
Bennett, R. W., A. K. Syrdal, and S. L. Greenspan (Eds.) (1993). Behavioral Aspects of Speech Technology. Amsterdam: Elsevier Science Publishing Co.
Bentrup, J. A. (1987). Exploiting word frequencies and their sequential dependencies. RESNA '87, Proceedings of the 10th Annual Conference on Rehabilitation Technology, pp. 121-123. Washington, D.C.: RESNA Press.
Bilser, F. A., W. Soede, and J. Berkhout (1993). Development and assessment of two fixed-array microphones for use with hearing aids. J. Rehabil. Res. Dev., 30(1)7381.
Boothroyd, A., and T. Hnath (1986). Lipreading with tactile supplements. J. Rehabil. Res. Dev., 23(1):139-146.
Boothroyd, A., T. Hnath-Chisolm, L. Hanin, and L. Kishon-Rabin (1988). Voice fundamental frequency as an auditory supplement to the speechreading of sentences. Ear Hear., 9:306-312.
Braida, L. D., N. L. Durlach, R. P. Lippmann, B. L. Hicks, W. M. Rabinowitz, and C. M. Reed (1979). Hearing Aids-A Review of Past Research of Linear Amplification, Amplitude Compression and Frequency Lowering. ASHA Monograph No. 19. Rockville, Md.: American Speech-Language-Hearing Association.
Breeuwer, M., and R. Plomp (1986). Speechreading supplemented with auditorily-presented speech parameters. J. Acoust. Soc. Am., 79:481-499.
Brooks, P. L., B. U. Frost, J. L. Mason, and D. M. Gibson (1986). Continuing evaluation of the Queens University Tactile Vocoder, Parts I and II. J. Rehabil. Res. Dev., 23(1):119-128, 129-138.
Chabries, D. M., R. W. Christiansen, R. H. Brey, M. S. Robinette, and R. W. Harris (1987). Application of adaptive digital signal processing to speech enhancement for the hearing impaired. J. Rehabil. Res. Dev., 24(4):65-74.
Cholewiak, R. W., and C. E. Sherrick (1986). Tracking skill of a deaf person with long-term tactile aid experience: A case study. J. Rehabil. Res. Dev., 23(2):20-26.
Page 339
Clark, G. M., R. K. Shepherd, J. F. Patrick, R. C. Black, and Y. C. Tong (1983). Design and fabrication of the banded electrode array. Ann. N.Y. Acad. Sci., 405:191-201.
Clark, G. M., Y. C. Tong and J. F. Patrick (1990). Cochlear Prostheses. Edinburgh, London, Melbourne and New York: Churchill Livingstone.
Cohen, N. L., S. B. Waltzman, and S. G. Fisher (1993). A prospective randomized cooperative study of advanced cochlear implants. N. Engl. J. Med., 43:328.
Cole, R. A., A. I. Rudnicky, V. W. Zue, and D. R. Reddy (1980). Speech as patterns on paper. In Perception and Production of Fluent Speech, R. A. Cole (Ed.). Hillsdale, N.J.: Lawrence Erlbaum Associates.
Cooper, F. S., J. H. Gaitenby, and P. W. Nye (1984). Evolution of reading machines for the blind: Haskins Laboratories' research as a case history. J. Rehabil. Res. Dev., 21:51-87.
Cornett, R. 0. (1967). Cued speech. Am. Ann. Deaf, 112:3-13.
Damper, R. I. (1986). Rapid message composition for large vocabulary speech output aids: a review of possibilities. J. Augment. Altern. Commun., 2:4.
Dillon, H., and R. Lovegrove (1993). Single-microphone noise reduction systems for hearing aids: A review and an evaluation. In Acoustical Factors Affecting Hearing Aid Performance, 2nd Ed., G. A. Studebaker and I. Hochberg (Eds.), pp. 353-370, Needham Heights, Mass.: Allyn and Bacon.
Douek, E., A. J. Fourcin, B. C. J. Moore, and G. P. Clarke (1977). A new approach to the cochlear implant. Proc. R. Soc. Med., 70:379-383.
Eddington, D. K. (1983). Speech recognition in deaf subjects with multichannel intracochlear electrodes. Ann. N.Y. Acad. Sci., 405:241-258.
Fabry, D. A. (1991). Programmable and automatic noise reduction in existing hearing aids. In The Vanderbilt Hearing Aid Report II, G. A. Studebaker, F. H. Bess, and L. B. Beck (Eds.), pp. 65-78. Parkton, Md.: York Press.
Fabry, D. A., M. R. Leek, B. E. Walden, and M. Cord (1993). Do adaptive frequency response (AFR) hearing aids reduce upward spread of masking? J. Rehabil. Res. Dev., 30(3):318-323.
Fels, D. I., G. F. Shein, M. H. Chignell, and M. Milner (1992). See, hear and touch the GUI: Computer feedback through multiple modalities. Proceedings of the RESNA International '92 Conference, pp. 55-57, Washington, D.C.: RESNA Press.
Gault, R. H. (1926). Touch as a substitute for hearing in the interpretation and control of speech. Arch. Otolaryngol, 3:121-135.
Gault, R. H., and G. W. Crane (1928). Tactual patterns from certain vowel qualities instrumentally communicated from a speaker to a subject's fingers. J. Gen. Psychol., 1:353-359.
Gengel, R. W. (1976). Upton's wearable eyeglass speechreading aid: History and current status. In Hearing and Davis: Essays Honoring Hallowell Davis, S. K. Hirsh, D. H. Eldredge, I. J. Hirsh, and R. S. Silverman (Eds.). St. Louis, Mo.: Washington University Press.
Goldberg, A. J. (1972). A visible feature indicator for the severely hard of hearing. IEEE Trans. Audio Electroacoust., AU-20:16-23.
Goodenough-Trepagnier, C., H. S. Hochheiser, M. J. Rosen, and H-P, Chang (1992). Assessment of dysarthric speech for computer control using speech recognition: Preliminary results. Proceedings of the RESNA International '92 Conference, pp. 159-161. Washington, D.C.: RESNA Press.
Graupe, D., J. K. Grosspietsch, and S. P. Basseas (1987). A single-microphone-based self-adaptive filter of noise from speech and its performance evaluation. J. Rehabil. Res. Dev., 24(4):119-126.
Page 340
Guttman, N., H. Levitt, and P. A. Bellefleur (1970). Articulation training of the deaf using low-frequency surrogate fricatives. J. Speech Hear. Res., 13:19-29.
Harkins, J. E., and B. M. Virvan (1989). Speech to Text: Today and Tomorrow. Proceedings of a Conference at Gallaudet University. GRI Monograph Series B, No. 2. Washington, D.C.: Gallaudet Research Institute, Gallaudet University.
Harkins, J. E., H. Levitt, and K. Peltz-Strauss (1992). Technology for Relay Service, A Report to the Iowa Utilities Board. Washington, D.C.: Technology Assessment Program, Gallaudet Research Institute, Gallaudet University.
Hochberg, I. H., A. S. Boothroyd, M. Weiss, and S. Hellman (1992). Effects of noise suppression on speech perception by cochlear implant users. Ear Hear., 13(4):263271.
House, W., and J. Urban (1973). Long-term results of electrical implantation and electronic stimulation of the cochlea in man. Ann. Otol. Rhinol., Laryngol., 82:504510.
House, A. S., D. P. Goldstein, and G. W. Hughes (1968). Perception of visual transforms of speech stimuli: Learning simple syllables. Am. Ann. Deaf, 113:215-221.
Hunnicutt, S. (1986). Lexical prediction for a text-to-speech system. In Communication and Handicap: Aspects of Psychological Compensation and Technical Aids, E. Hjelmquist & L-G. Nilsson, (Eds.). Amsterdam: Elsevier Science Publishing Co.
Hunnicutt, S. (1993). Development of synthetic speech technology for use in communication aids. In Behavioral Aspects of Speech Technology, R. W. Bennett, A. K. Syrdal, and S. L. Greenspan (Eds.). Amsterdam: Elsevier Science Publishing Co.
Johansson, B. (1966). The use of the transposer for the management of the deaf child. Int. Audiol., 5:362-373.
Kanevsky, D., C. M. Danis, P. S. Gopalakrishan, R. Hodgson, D. Jameson, and D. Nahamoo (1990). A communication aid for the hearing impaired based on an automatic speech recognizer. In Signal Processing V: Theories and Applications, L. Torres, E. Masgrau, and M. A. Lagunas (Eds.). Amsterdam: Elsevier Science Publishing Co.
Karis, D., and K. M. Dobroth (1991). Automating services with speech recognition over the public switched telephone network: Human factors considerations. IEEE J. Select. Areas Commun., 9(4).
Kewley-Port, D., C. S. Watson, D. Maki, and D. Reed (1987). Speaker-dependent speech recognition as the basis for a speech training aid. Proceedings of the 1987 IEEE Conference on Acoustics, Speech, and Signal Processing, pp. 372-375, Dallas, Tex.: Institute of Electrical and Electronic Engineering.
Knudsen, V. 0. (1928). Hearing with the sense of touch. J. Gen. Psychol., 1:320-352.
Kurzweil, R. C. (1981). Kurzweil reading machine for the blind. Proceedings of the Johns Hopkins First National Search for Applications of Personal Computing to Aid the Handicapped, pp. 236-241. New York: IEEE Computer Society Press.
LaPlante, M. P., G. E. Hendershot, and A. J. Moss (1992). Assistive technology devices and home accessibility features: Prevalence, payment, need, and trends. Advance Data, Number 127. Atlanta: Vital and Health Statistics of the Centers for Disease Control/National Center for Health Statistics.
Levine, S. H., C. Goodenough-Trepagnier, C. O. Getschow, and S. L. Minneman (1987). Multi-character key text entry using computer disambiguation. RESNA '87, Proceedings of the 10th Annual Conference on Rehabilitation Technology, pp. 177179. Washington, D.C.: RESNA.
Levitt, H. (1993). Future directions in hearing aid research. J. Speech-Lang.-Pathol. Audiol., Monograph Suppl. 1, pp. 107-124.
Page 341
Levitt, H., J. M. Pickett, and R. A. Houde (Eds.) (1980). Sensory Aids for the Hearing Impaired. New York: IEEE Press.
Levitt, H., M. Bakke, J. Kates, A. Neuman, and M. Weiss (1993). Advanced signal processing hearing aids. In Recent Developments in Hearing Instrument Technology, Proceedings of the 15th Danavox Symposium, J. Beilen and G. R. Jensen (Eds.), pp. 247-254. Copenhagen: Stougaard Jensen.
Liberman, A. M., F. S. Cooper, D. P. Shankweiler, and M. Studdert-Kennedy (1968). Why are spectrograms hard to read? Am. Ann. Deaf, 113:127-133.
Ling, D. (1969). Speech discrimination by profoundly deaf children using linear and coding amplifiers. IEEE Trans. Audio Electroacoust., AU-17:298-303.
Mazor, M., H. Simon, J. Scheinberg, and H. Levitt (1977). Moderate frequency compression for the moderately hearing impaired. J. Acoust. Soc. Am., 62:1273-1278.
McCoy, K., P. Demasco, Y. Gong, C. Pennington, and C. Rowe (1989). A semantic parser for understanding ill-formed input. RESNA '89, Proceedings of the 12th Annual Conference, pp. 145-146. Washington, D.C.: RESNA Press.
McGarr, N. S., K. Youdelman, and J. Head (1992). Guidebook for Voice Pitch Remediation in Hearing-Impaired Speakers. Englewood, Colo.: Resource Point.
Miller, G. (1992). Voice recognition as an alternative computer mouse for the disabled. Proceedings of the RESNA International '92 Conference, pp. 55-57, Washington D.C.: RESNA Press.
Miller, J. D., A. M. Engebretsen, and C. L. DeFilippo (1974). Preliminary research with a three-channel vibrotactile speech-reception aid for the deaf. In Speech Communication, Vol. 4, Proceedings of the Speech Communication Seminar, G. Fant (Ed.). Stockholm: Almqvst and Wiksell.
Nicholls, G., and D. Ling (1982). Cued speech and the reception of spoken language. J. Speech Hear. Res., 25:262-269.
Osberger, M. J., and H. Levitt (1979). The effect of timing errors on the intelligibility of deaf children's speech. J. Acoust. Soc. Am., 66:1316-1324.
Peterson, P. M., N. I. Durlach, W. M. Rabinowitz, and P. M. Zurek (1987). Multimicrophone adaptive beamforming for interference reduction in hearing aids. J. Rehabil. Res. Dev., 24(4):103-110.
Pickett, J. M., and B. M. Pickett (1963). Communication of speech sounds by a tactual vocoder. J. Speech Hear. Res., 6:207-222.
Pickett, J. M., R. W. Gengal, and R. Quinn (1974). Research with the Upton eyeglass speechreader. In Speech Communication, Vol. 4, Proceedings of the Speech Communication Seminar, G. Fant (Ed.). Stockholm: Almqvist and Wiksell.
Posen, M. P., C. M. Reed, and L. D. Braida (1993). The intelligibility of frequency-lowered speech produced by a channel vocoder. J. Rehabil. Res. Dev., 30(1):26-38.
Potter, R. K., A. G. Kopp, and H. C. Green (1947). Visible Speech. New York: van Nostrand Co.
Revoile, S. G., L. Holden-Pitt, J. Pickett, and F. Brandt (1986). Speech cue enhancement for the hearing impaired: I. Altered vowel durations for perception of final fricative voicing. J. Speech Hear. Res., 29:240-255.
Risberg, A. (1968). Visual aids for speech correction. Am. Ann. Deaf, 113:178-194.
Robbins, A. M., S. L. Todd, and M. J. Osberger (1992). Speech perception performance of pediatric multichannel tactile aid or cochlear implant users. In Proceedings of the Second International Conference on Tactile Aids, Hearing Aids, and Cochlear Implants, A. Risberg, S. Felicetti, G. Plant, and K. E. Spens (Eds.), pp. 247-254. Stockholm: Royal Institute of Technology (KTH).
Rosen, S., J. R. Walliker, A. Fourcin, and V. Ball (1987). A micro-processor-based acoustic
Page 342
hearing aid for the profoundly impaired listener. J. Rehabil. Res. Dev., 24(4):239260.
Ryalls, J., M. Cloutier, and D. Cloutier (1991). Two clinical applications of IBM's SpeechViewer: Therapy and its evaluation on the same machine. J. Comput. User's Speech Hear., 7(1):22-27.
Schein, J. D., and M. T. Delk (1974). The Deaf Population of the United States. Silver Spring, Md.: National Association of the Deaf.
Schwander, T. J., and H. Levitt (1987). Effect of two-microphone noise reduction on speech recognition by normal-hearing listeners. J. Rehabil. Res. Dev., 24(4):87-92.
Sekey, A. (1982). Electroacoustic Analysis and Enhancement of Alaryngeal Speech. Springfield, Ill.: Charles C. Thomas.
Sherrick, C. E. (1984). Basic and applied research on tactile aids for deaf people: Progress and prospects. J. Acoust. Soc. Am., 75:1325-1342.
Shimizu, Y. (1989). Microprocessor-based hearing aid for the deaf. J. Rehabil. Res. Dev., 26(2):25-36.
Simmons, R. B. (1966). Electrical stimulation of the auditory nerve in man. Arch. Otolaryngol., 84:2-54.
Skinner, M. W. (1988). Hearing Aid Evaluation. Englewood Cliffs, N.J.: Prentice-Hall.
Soede, W. (1990). Improvement of speech intelligibility in noise: Development and evaluation of a new directional hearing instrument based on array technology. Ph.D. thesis, Delft University of Technology, The Netherlands.
Stark, R. E. (1972). Teaching /ba/ and /pa/ to deaf children using real-time spectral displays. Lang. Speech, 15:14-29.
Stuckless, E. R. (1989). Real-time captioning in education. In Speech to Text: Today and Tomorrow. Proceedings of a Conference at Gallaudet University, J. E. Harkins and B. M. Virvan (Eds.). GRI Monograph Series B, No. 2. Washington D.C.: Gallaudet Research Institute, Gallaudet University.
Studebaker, G. A., and I. Hochberg, (Eds.) (1993). Acoustical Factors Affecting Hearing Aid Performance, Second Edition. Needham Heights, Mass.: Allyn and Bacon.
Studebaker, G. A., F. H. Bess, and L. B. Beck (Eds.) (1991). The Vanderbilt Hearing Aid Report II. Parkton, Md.: York Press.
Sumby, W. H., and I. Pollack (1954). Visual contribution to speech intelligibility in noise. J. Acoust. Soc. Am., 26:212-215.
Swiffin, A. L., J. Arnott, J. Pickering, and A. Newell (1987). Adaptive and predictive techniques in a communication prosthesis. Augment. Altern. Commun., 3:181191.
Uchanski, R. M., L. A. Delhorne, A. K. Dix, L. D. Braida, C. M. Reed, and N. I. Durlach (1994). Automatic speech recognition to aid the hearing impaired: Prospects for the automatic generation of cued speech. J. Rehabil. Res. Dev., 31(1):20-41.
Upton, H. (1968). Wearable eyeglass speech reading aid. Am. Ann. Deaf, 113:222-229.
Van Tasell, D. J., S. Y. Larsen, and D. A. Fabry (1988). Effects of an adaptive filter hearing aid on speech recognition in noise by hearing-impaired subjects. Ear Hear., 9:15-21.
Watson, C. S., D. Reed, D. Kewley-Port, and D. Maki (1989). The Indiana Speech Training Aid (ISTRA) I: Comparisons between human and computer-based evaluation of speech quality. J. Speech Hear. Res., 32:245-251.
Weiss, M. (1993). Effects of noise and noise reduction processing on the operation of the Nucleus-22 cochlear implant processor. J. Rehabil. Res. Dev., 30(1):117-128.
Weiss, M., and E. Aschkenasy (1981). Wideband Speech Enhancement, Final Technical Report. RADC-TR-81-53. Griffiss Air Force Base, N.Y.: Rome Air Development Center, Air Force Systems Command.
Page 343
Wilson, B. S., C. C. Finley, D. T. Lawson, R. D. Wolford, and M. Zerbi (1993). Design and evaluation of a continuous interleaved sampling (CIS) processing strategy for multichannel cochlear implants. J. Rehabil. Res. Dev., 30(1):110-116.
Wise, R., and R. Olson (1993). What computerized speech can add to remedial reading. In Behavioral Aspects of Speech Technology, R. W. Bennett, A. K. Syrdal, and S. L. Greenspan (Eds.). Amsterdam: Elsevier Science Publishing Co.
World Health Organization (1980). The International Classification of Impairments, Disabilities, and Handicaps. Geneva: World Health Organization.
Yamada, Y., N. Murata, and T. Oka (1988). A new speech training system for profoundly deaf children. J. Acoust. Soc. Am., 84(1):43.


































