
Appendix B
Computation
EVOLUTION OF COMPUTING
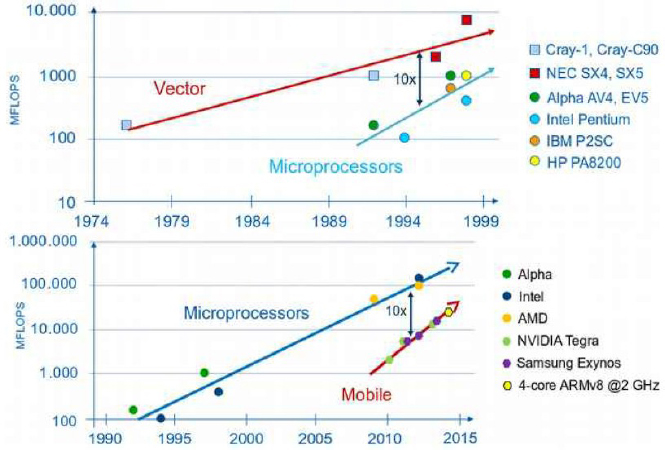
In 1946, John von Neumann created the first direct ancestor of modern digital computing (Dahan-Dalmedico, 2001). In early computers, instructions and data were sent to a central processing unit, where single operations on every clock cycle acted on their operands held in registers, and the results were sent back to memory. As processors got faster reliably, computing power grew following a power-law relationship. A major technological upheaval occurred with the advent of vector processing in the 1970s. Vector processors allowed a steady data stream to flow through a pipeline of operations in sequence so that many operations could be performed concurrently. This approach led to specialized machines that were dramatically faster and opened up revolutionary new computational capabilities. Owing to specialized hardware, such as memory technologies capable of continuously feeding the vector registers, these machines were expensive, and so computations per dollar remained on the same power-law curve.
This power-law behavior is often referred to as Moore’s law, based on Gordon Moore’s observation that transistor density on a chip doubled roughly every 18 months (Chien and Karamcheti, 2013; Kogge et al., 2008). Another feature of microprocessor design, known as Dennard scaling, enabled the power density on a chip to remain constant as transistors became smaller. The results of Moore’s law and Dennard scaling allowed the explosive growth in computational capacity to continue for several decades and made possible the personal computing revolution of the 1980s. Computing became inexpensive and ubiquitous, and a mass market for commodity parts developed. As a result, systems for parallel computation could be built using commodity parts, rather than the specialized hardware of vector supercomputers. Today, nearly all supercomputers are built from parts destined for the mass market.
Current computing technologies are reaching some physical limits (see Kogge et al., 2008, for an indispensable guide to hardware trends of the next decade). In particular, Dennard scaling no longer holds for conventional silicon technologies today. This is causing the electrical power needs of faster chips to grow faster than the mass-market applications can support. Thus, raw processing speed of a single arithmetic operation has stalled at about 1 GHz now for a decade. All advances in computational volume are delivered by packing ever more concurrency onto a chip. As outlined by Kogge et al. (2008), this yields systems with millions of commodity parts, and so high rates of hardware failure must be taken into account in system design.
Simultaneously, the mass market for computing itself is now driven by the mobile market, rather than desktops and servers. This has even more stringent power requirements than the first generation of commodity computing,
and it is likely that this market is already economically dominant. Figure B.1 shows how the difference in power-law slopes drove vectors out of the market, and why this is likely to be repeated as mobile chips replace today’s high-performance computing processors.
MODERN HIGH-PERFORMANCE COMPUTING
Below is a survey of hardware and software for the current generation of high-performance computing technologies for computation- and data-intensive applications.
Computation
The basic conceptual model of a processor consists of (a) arithmetic-logic units; (b) registers, which contain data to which arithmetic-logic units have read and write access; and (c) memory, where results are written. The finite representation of real numbers uses floating-point arithmetic. Floating-point arithmetic is nonassociative (i.e., a+[b+c] may not be equal to [a+b]+c), and so the results are dependent on the order of operations. The memory location of a particular word is its address. At the end of a program, results held temporarily in memory are written to storage.
The increase in computing speed made possible by the miniaturization of complementary metal oxide semiconductor technology is coming to an end, and speed increases now come from executing many instructions in parallel. When two concurrent computations use the same memory address, there is danger of a race condition, in which the results depend on the order of completion of operations. The central problem of parallel computing is running many operations in parallel, while avoiding race conditions and minimizing synchronization costs.
Parallel computing has two basic modes: single instruction, multiple data (SIMD) and multiple instruction, multiple data (MIMD). In SIMD parallelism, the same computation is performed on multiple data streams. SIMD architectures include the graphical processing unit, which was primarily designed for video but is now used for other applications, and pipelining, which includes vector processing. In pipelining, the data flow through a sequence
of instructions, and one result is delivered every clock cycle. Vector machines have specialized vector registers for this purpose. The Cray-1 had 64 vector registers (known as the vector length, measured in 64-bit words) and later generations of vector machines (e.g., NEC-SX 9) have vector lengths up to 256. Some modern conventional processors contain vector instructions, but with a much smaller vector length, usually 4 or 8.
In MIMD parallelism, completely different instructions are executed in parallel. This can take the form of task parallelism, in which the computation is composed into a task graph with dependencies, and independent tasks are scheduled in parallel.
Memory and Storage
In early parallel computing, different processors accessed the same memory banks. However, there are physical limits on the number of connections that can be made to a single memory bus, typically said to be about 16. For higher numbers, many shared-memory computers, each with its own memory, are networked into a cluster. This distributed memory computing architecture is often called symmetric multiprocessor or, more commonly, commodity clusters because the processors used are generally mass market and unspecialized. A recent processor architecture, called many-integrated core, puts an entire symmetric multiprocessor on a chip. Intel’s Xeon-Phi line (e.g., Knights Landing) is based on a many-integrated core architecture composed of individual Xeon (x86) cores.
Because memory access is slow compared to computation, there are layers of intermediate storage called caches. Current technologies often include many levels of cache (labeled L1, L2, etc., with L1 being closest to the registers). Each level of cache operates at a different speed and has a different size and a different unit (number of words simultaneously written) of access, called a cache line.
Storage is generally based on magnetic spinning disk technology. Parallelism in storage allows striping across multiple disks, which overcomes limits on the speed of writing to a single disk on a spindle. Parallel file systems (e.g., Lustre, GPFS, and Panasas) handle this task transparently. Tapes are often used for archival storage. Because tape is a linear medium (i.e., the tape needs to be spooled to a particular data location), it is not suitable for random access. Hierarchical storage management technology is used to handle many levels of storage: nearline, farline, and even offline.
New technologies are blurring the distinction between memory and storage. Nonvolatile random access memory and new hardware features, such as multichannel dynamic random access memory in Xeon-Phi (which can be configured either as a storage buffer or L4 cache), provide a continuous, many-level hierarchy spanning registers to tape. Programming such a hierarchy for computation- and data-intensive applications is one of the greatest high-performance computing challenges of our times.
Software
Concurrent streams of execution that access shared memory are called threads. A standard programming model for thread-based execution is OpenMP, which places directives or pragmas inside code indicating that a particular code section allows thread-safe parallel execution. Parallel execution streams in distributed memory are called processes, and the standard programming model is the message-passing interface (MPI), which allows communication and synchronization between processes. Hybrid MPI/OpenMP codes are currently common practice in compute-intensive applications. Partitioned global address space languages allow distributed memory to be programmed as though it were a unified global address space. Such languages include Co-Array Fortran, Unified Parallel C, Titanium (Java), and specialized languages not in wide use, such as Chapel and X10.
A similar approach is emerging for parallel data-intensive applications. MapReduce is a standard programming model for such applications. A computation, such as a search query, is dispatched to multiple data streams in parallel in the Map step, and the results are collated in the Reduce step. File systems designed specifically for
MapReduce, such as the Hadoop distributed file system, are an emerging alternative to the standard POSIX-based file systems of hierarchical directories and files common on commodity platforms.




