
4
Overview of Data Science Methods
INTRODUCTION
Data applicable to personnel and readiness decisions are increasing rapidly as is the potential to make meaningful decisions enhanced by previously inaccessible information. Automation of tracking, the increase of new data types (e.g., social media, audio, video), enhanced storage of electronic records, repurposing of administrative records, and the explosion of modeling data have all increased the availability of data. However, making full use of these data requires not only proper storage and management (Dasu and Johnson, 2003; Wickham, 2014) but also advanced analytical capabilities.
This report considers data science in its broadest sense, as a multidisciplinary field that deals with technologies, processes, and systems to extract knowledge and insight from data and supports reasoning and decision making under various sources of uncertainty. Here, two aspects of data science are of interest: (1) the management and processing of data and (2) the analytical methods and theories for descriptive and predictive analysis and for prescriptive analysis and optimization. The first aspect involves data systems and their preparation, including databases and warehousing, data cleaning and engineering, and data monitoring, reporting, and visualization. The second aspect involves data analytics and includes data mining, text analytics, machine and statistical learning, probability theory, mathematical optimization, and visualization.
This chapter discusses some of the data science methods and practices being employed in various domains that pertain to the analysis capabilities relating to personnel and readiness missions in the Department of Defense
(DoD). Many of these methods are well known to the personnel and readiness community. Some of the important considerations discussed include how descriptive and predictive analytics methods can be used to better understand what the data indicate; how decision making under uncertainty can be enhanced through prescriptive analytics; and the usefulness and limitations of these approaches.
The proliferation of data and technical advances in data science methods have created tremendous opportunities for improving these analysis capabilities. This section focuses on data science methods, including those associated with data preparation and descriptive, predictive, and prescriptive analytics, thus providing some of the technical details and foundation for the data science methods that will be referenced in subsequent chapters. Figure 4.1 illustrates the typical evolution from data sources to analysis results. This chapter does not discuss considerations needed for all modeling (e.g., to avoid overfitting data and to evaluate stability in terms of cross-validation) but instead offers a nonexhaustive list of methods to introduce some key approaches relevant to the missions of the Office of the Under Secretary of Defense (Personnel & Readiness), referred to throughout the report as P&R. Many of these methods are well known to researchers in the personnel and readiness community and are only cursorily discussed, while others that the committee believes are not widely used have been explained in more detail. This chapter discusses just the methods, while Chapter 7 provides some examples of how the methods could be applied to P&R mission areas.
The increase in the volume of data does not in and of itself lead to better outcomes. There are challenges associated with storing, indexing, linking, and querying large databases, but perhaps the most significant challenge is drawing meaningful inferences and decisions from analysis of the data. As discussed in the 2013 National Research Council report Frontiers in Massive Data Analysis, “Inference is the problem of turning data into knowledge, where knowledge often is expressed in terms of entities that are not present in the data per se but are present in models that one uses to interpret the data” (NRC, 2013, p. 3). In drawing a meaningful inference, issues such as sampling bias (where a sample is collected in such a way that some members of the intended population are less likely to be included than others), provenance (where layers of inference are compounded, obscuring the original data), and compounding error rates (where several hypotheses are considered at the same time) all play a role in achieving quality results (NRC, 2013). This of course assumes that statistical and decision-making techniques are being applied properly and that the results are reproducible (NASEM, 2016).
The following section on data preparation discusses common data preparation tasks and methods, while the subsequent section on data analytics discusses descriptive and exploratory analysis, predictive analysis, and prescriptive analysis.
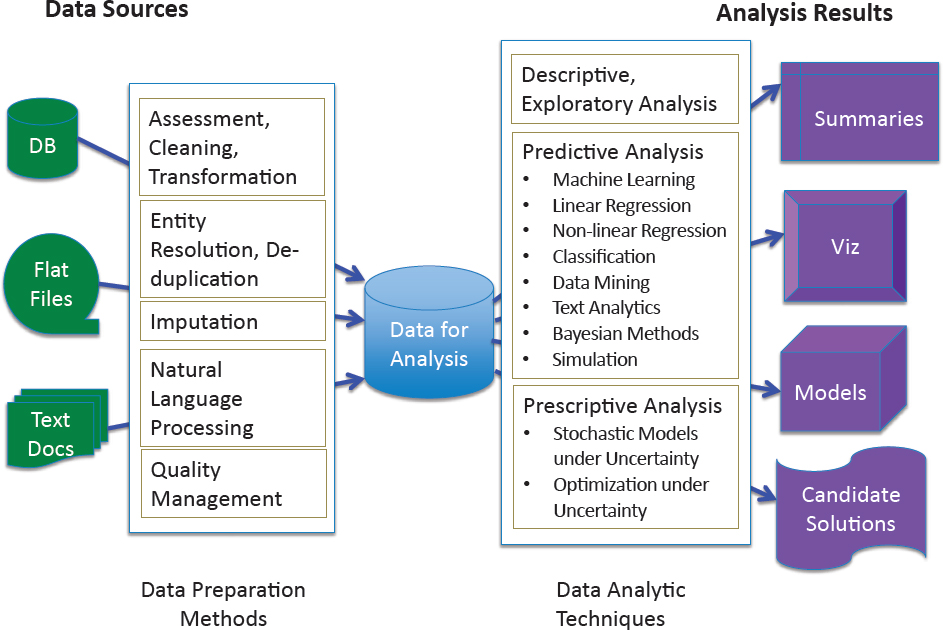
DATA PREPARATION
The foundation of data analytics is having appropriate data that are of sufficient quality, appropriately organized for the analysis task at hand. Unfortunately, data seldom arrive in a suitable state, and a necessary first step is getting them into a proper form to support analysis. This step, sometimes referred to as “data wrangling,” has been estimated to occupy up to 80 percent of the total analysis time according to a recent survey of data scientists by CrowdFlower (Biewald, 2015). This intensive overhead cuts down on the effective productivity of data analysts and may deter them from undertaking certain studies. The following sections discuss some of the tasks involved in preparing data for analysis and some techniques to assist analysts with those tasks.
Common Data Preparation Tasks
Data in their original form are not typically ready to be used without some initial work. This section discusses some steps commonly taken to prepare data for analysis, including locating, acquiring, and ingesting data; assessing and cleaning data; reconciling and making data uniform; extracting, restructuring, and linking data; coding and annotating data; and updating data as new information becomes available. These issues are discussed in this section, and ways to approach them will be discussed in the following section.
Data Location, Acquisition, and Ingestion
An analyst might need to first determine whether data suitable for a particular analysis exist in a particular organization and, if they do exist, how they can be accessed or how a copy can be obtained. Once the data are in hand, the analyst might need to load them onto a different system to work with them. If the data need to be loaded into a database management system (DBMS), then the analyst or database administrator will need to provide a database schema (definitions of the different tables and their formats) and possibly write scripts to ingest the data into the DBMS.
Data Assessment and Cleaning
Data from transactional (administrative) systems are often repurposed for analysis projects. Data that might be sufficient for operational use might nevertheless present problems for analysis. For example, if a “language skills” field in a personnel record is examined only by humans, then variation in values such as “Chinese (Cantonese),” “Cantonese,” or “Chinese
(Yue dialect)” might present few analytical challenges to a human with some knowledge of linguistics. However, if examined by a computer algorithm, it might have to be regularized before use with data analysis routines. Administrative data can also have spurious and missing values, differences in data representations (such as different formats for dates and times), compound values (e.g., a list of languages instead of a single language), and various kinds of noise (such as those that arise from data-entry errors). An analyst wanting to repurpose a data source will need to spend time assessing what kinds of quality problems might exist in the data and whether the data can be adapted for the current study. Once quality is assessed, there will likely be a data-cleaning phase, in which errors, inconsistencies, and duplicates are detected and either corrected or excluded. Even when data have been specifically collected for a study—rather than being repurposed from another use—there can be quality problems. For example, surveys can have a missing or inappropriate response or have entire sections that were not completed or failed to cover certain segments of the target population.
Data Uniformity and Reconciliation
If an analysis is to use multiple data sources, how a particular data item is interpreted or collected across sources can vary. For example, one source might break down spoken versus written language skills, while another lists only the language. Or, one source might refer to explicit instruction or testing in a language, while another relies on self-reported capabilities. Reconciling such variation will ultimately require the analyst to decide what is appropriate for a given study. However, there is sometimes little or no clear documentation on the precise meaning of different fields, complicating the job of the analyst.
Data Extraction, Restructuring, and Linking
Data often arrive in a form that does not directly match the input requirements of the analysis tools, especially if they are being repurposed from another use. Some data values might be captured in free-text fields, a data set as a whole might have the wrong organization, or the values for analysis could be split up across several files. As an example of wrong organization, the analyst might have a collection of records, each with a date of enlistment and current pay rate. A statistical package that would correlate the two might want two parallel lists, one with enlistment dates and the other with pay rates. Overcoming such problems can necessitate a significant effort by the analyst to pull appropriate values from text fields (or write a script that will do this), to restructure the data, or to link corresponding records across two or more files.
Data Coding and Annotation
Sometimes in preparation for analysis, data values need to be mapped to a fixed set of categories, particularly for survey responses. For example, a field listing a job title might need to be first classified as to “Service,” “manufacturing,” “construction,” and so forth. Data might need to be further “adorned” with additional information before analysis. For example, a geographic analysis might require addresses in the data to be “geocoded”: translated in latitude–longitude pairs.
Data Currency and Refresh
Most administrative data sources are not static. It may take considerable time to acquire a data set, ingest it, clean it, and otherwise prepare it for analysis, by which time the data may be out-of-date. Even if existing records do not change (e.g., history of past pay slips), a data source may be augmented periodically (i.e., new pay slip records added every 2 weeks), meaning a copy of that source will need to be refreshed if it is to remain current. It might seem that using a data source in situ at its original location would avoid problems with stale or incomplete data. However, such use is often not feasible because the data source cannot be accessed remotely, the host system does not want to allow the additional processing load of analytic queries, or the data cannot be cleaned in place.
Data Preparation Methods
With such large amounts of a data analyst’s time being spent on data preparation, techniques that reduce such overhead have high value. This section describes some of the main data preparation methods.
Reusing Attention
Avoiding data preparation tasks by capturing results of previous work is the first step in reducing an analyst’s load. The bounding constraint in data analysis is often human attention, so reusing that attention where possible helps conserve that resource. Too often, data preparation work results in a spreadsheet or data set that resides on a personal workstation and is not even visible to others who might benefit from its use. Having shared repositories of data with various degrees of preparation can at least spread the investment of human attention. In commercial practice, such repositories span the range from “data lakes” (Stein and Morrison, 2014)
that merely collect raw data in one place to full-fledged data warehouses1 that regularize, clean, and integrate data according to a common schema.
Some authors have suggested a virtual warehouse approach that leaves data in their source system and provides a federated search or query capability over the collection of sources. This approach does not seem good for P&R analyses for several reasons:
- The original data often reside in production systems that would not necessarily tolerate the additional load of analytic queries.
- Federated approaches are predicated on using a common query language, such as SQL, across sources that share a data model, such as relational databases, a requirement that is not met by many of the potential data sources the committee considered.
- The federated approach generally does not accommodate transformed or restructured versions of the data, as it is usually not possible to create arbitrary new data sets at the sources.
- Federation entails repeated transfer of information to answer various requests, with each transfer increasing the risk of data interception, either in transit or at the originating or receiving system. This risk may not be tolerable for many of the sensitive and confidential sources in this domain.
Data Assessment, Cleaning, and Transformation
For structured data, such as relational databases,2 there is a wide range of mature commercial tools for data preparation, especially in connection with data warehousing and data integration activities (Rahm and Do, 2000). Data profiling tools have been available for decades but are still the subject of active research (Naumann, 2013). Data profiling collects statistics and other information about a data set, such as min and max values, frequent values, and outliers, in order to understand the nature and quality of the data before further processing. Extract-transform-load (ETL) tools have been around since the advent of data warehousing (Kimball and Caserta, 2004). Such tools help extract data from source systems, transform it appropriately, and then load it into a target system, often a data warehouse. The transform stage is generally the richest, having a rule-driven framework encompassing both data manipulation and data validation.
___________________
1 A data warehouse can be viewed as a kind of database, organized to facilitate reporting and analysis. Hence it often combines data from multiple sources across an enterprise and is generally updated periodically in a batch fashion, in contrast to online transaction processing (OLTP) databases, organized to support small, frequent updates.
2 Relational databases are databases structured to recognize relations among stored items of information—for example, by storing data in tables with rows and columns.
Data manipulation includes dropping columns, recoding values, calculating new columns, splitting or combining values, joining tables, and aggregating or reordering data. Data validation can include checking format, testing values ranges, and look-up in tables of legal values.
More recently, tools have appeared to work with broader classes of data. One example is OpenRefine (formerly Google Refine), an open-source tool for data cleaning and transformation that can work with CSV files, XML data, RDF triples, JSON structures, and other formats (Verborgh and De Wilde, 2013). The PADS project (Fisher and Walker, 2011) works with an even broader class of inputs, so-called ad hoc data formats. Ad hoc data formats are those arising from particular applications where there is no existing base of tools for manipulating the data and can arise in areas such as telecommunications, health care, sensing, and transportation. PADS uses a data description of a given source to generate a range of tools, such as parsers, validators, statistical analyzers, and format converters. Furthermore, PADS facilitates learning the data description given a set of examples from a source.
Entity Resolution and De-Duplication
A common task in data preparation is identifying multiple records that refer to the same thing. This task can arise for many reasons, such as the lack of a clean database (e.g., an address list that has repeated information) or combining two data sources about the same subject (even if the individual sources are duplicate-free). There is a large body of tools to handle this problem, known variously as entity resolution, object identification, reference reconciliation, and several others (Getoor and Machanavajjhala, 2012). These tools use a variety of approaches, such as approximate match, clustering, normalization, probabilistic methods, and even crowdsourcing.
Data Imputation
Missing values can cause problems for various kinds of analytic methods. In the face of such problems, one can seek alternative methods that tolerate missing data, or one can impute the missing value (fill it in with an estimate). Imputation methods can be as simple as inserting a default value or more complex, such as consulting a historical archive or using a statistical model. However, not all imputation methods are suitable for applying at the data preparation stage; rather, they are applied as part of analysis. For example, multiple imputation constructs several data sets from an initial data set with missing values, then runs the analysis on each and combines the results (Enders, 2010).
Natural Language Processing
Multiple individuals3 in both the government and commercial sectors told the committee that natural language processing (NLP) would soon “be ready for prime time,” for use in data preparation tasks. For example, the committee heard that the Defense Manpower Data Center’s (DMDC’s) Data Science Program is testing NLP methods against human coding of free-text data as part of a task to find predictors of outcomes for appeals of security clearance decisions. There are already some specialized tasks where NLP approaches have been very successful, such as named entity recognition (NER). NER is the process of extracting phrases from text that identify specific entities such as persons, places, and organizations. NER techniques are quite robust, and some work across multiple languages (Al-Rfou et al., 2015). Much current research focuses on broader NLP tasks, such as text analytics, which seeks to extract text features that can be used with structured analysis methods. Text analytics supports applications such as sentiment analysis, relationship extraction, and medical-record coding.
Automated Data-Quality Management
The advent of big data in many domains means that manual methods of data-quality assurance are no longer feasible. Thus, automated data-monitoring techniques are of increasing interest, with much of the initial work carried out in the context of data coming from sensors. Early efforts rely on human construction of rules that apply “sanity checks” to the data. For example, the National Oceanic and Atmospheric Administration’s guide for automated checking of buoy data has a rule that checks that near-shore instruments do not report significant swells originating from the direction of land (NDBC, 2009). However, there are machine-learning approaches that require less human intervention (Isaac and Lynes, 2003; Smith et al., 2012).
DATA ANALYTICS
Although some scientists and institutions have attempted to define the broad area of data analytics, it is difficult to do so. Davenport and Harris (2007) define data analytics to be the “extensive use of data, statistical and quantitative analysis, explanatory and predictive models, and fact-based management to drive decisions and actions.” Using the often-cited diagram in Figure 4.2, they go on to characterize analytics as starting with statisti-
___________________
3 These discussions occurred during the committee’s meetings, site visits, and follow-up discussions with relevant individuals. Please see Appendix C for a full list of public committee meetings and the Acknowledgments section of the front matter for a list of individuals who provided input to the study.
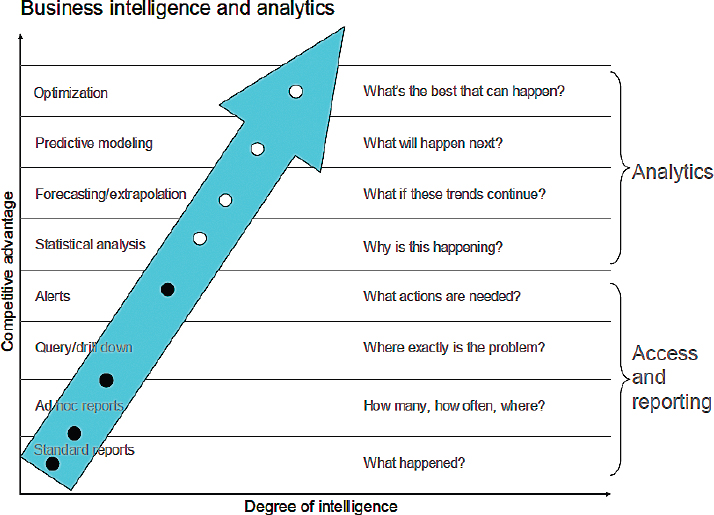
cal analysis (“Why is this happening?”), then moving on to forecasting/ extrapolation (“What if these trends continue?”), then moving to predictive modeling (“What will happen next”), and ending with optimization (“What is the best that can happen?”). Even before the book by Davenport and Harris, the term “predictive analytics” was used as early as 1999 (Brenda Dietrich, IBM, personal communication, September 23, 2015), and as early as 2005 IBM was using the term “prescriptive analytics” (Brenda Dietrich, IBM, personal communication, September 23, 2015), which corresponds to what Davenport and Harris called optimization.
Analytics is defined by Lustig et al. (2010) to comprise descriptive, predictive, and prescriptive analytics, where descriptive analytics is defined as a set of technologies and processes that use data to understand and analyze an organization’s performance; predictive analytics is defined as the extensive use of data and mathematical techniques to uncover explanatory and predictive models for an organization’s performance as represented by the inherent relationship between data inputs and outputs/outcomes; and prescriptive analytics is defined as a set of mathematical techniques that computationally determine a set of high-value alternative actions or decisions given a complex set of objectives, requirements, and constraints, with
the goal of improving organizational performance. In their recent book, Dietrich et al. (2014) characterize descriptive analytics as reporting what has happened, analyzing contributing data to determine why it happened, and monitoring new data to determine what is happening now; predictive analytics as using techniques such as statistics and data mining to analyze current and historical information to make predictions about what will happen in the future, typically producing both a statement of possible events that could occur and the associated probabilities of their occurring; and prescriptive analytics as covering analytics methods that recommend actions with the goal of finding an action (or set of actions) that will maximize the expected value (e.g., utility) associated with the outcome.
Models are at the heart of many analytical approaches, from simple descriptive summaries to detailed theoretical representations grounded in physical laws. Statistical models are a central component of all analytics. Data (observations) are integrated through statistical representations to create empirical understandings of reality. Descriptive analytics can characterize the underlying population represented by the data, and the processes that generated the data, in order to make predictive inferences about the population. Probability models are at the foundation of statistical models that enable the descriptions of the observed data to formulate inferences about the population from which these data were observed.
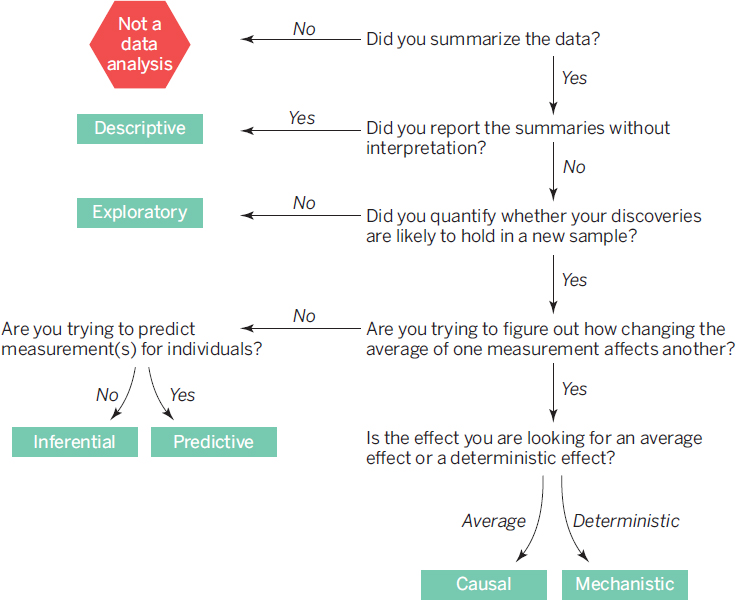
Leek and Peng (2015) provide a helpful overview of models and the types of questions they can address. They present six types of models from descriptive to causal (see Figure 4.3). This overview is a helpful characterization of moving from raw data to predictive analytics. They also highlight the common mistakes in the use of models such as using correlation to imply causation or using exploratory analyses to imply a predictive model structure.
In 2010 the Institute for Operations Research and the Management Sciences (INFORMS) defined analytics as comprising descriptive, predictive, and prescriptive analytics, focusing on predictive analytics based on methods from data mining, machine learning, and statistics, and on prescriptive analytics based on methods from stochastic modeling and mathematical optimization.4 Following in kind, this section presents data analytics methods in those same terms.
As described in detail above, data cleaning and linking challenges need to be overcome before any analysis can occur. In most cases, study resources are largely utilized during these stages. Predictive and prescriptive models require follow-on efforts to calibrate, correct, and reanalyze results, which makes them difficult to undertake in a resource-constrained environment
___________________
4 The website for the Analytics Society of INFORMS is https://www.informs.org/Community/Analytics, accessed October 7, 2016.
where urgent decisions for resolving pressing problems are needed. Lastly, the confidence and significance of results need to be assessed for all data analyses. It is important to validate all results to see if they make sense and represent effects as expected.
The following sections describe some approaches toward descriptive and exploratory analysis (using data to summarize and visualize the current state), predictive analysis (using data to determine patterns and predict future outcomes and trends with methods such as linear and nonlinear regression, classification, data mining, machine learning, text analysis, Bayesian methods, and simulation), and prescriptive analysis (using data to determine a set of decisions and/or actions that gives rise to the best possible results based on various predicted outcomes from predictive analytics and subject to various constraints using stochastic models of uncertainty, mathematical optimization under uncertainty, and optimal solutions).
Descriptive and Exploratory Analysis
Descriptive analytics are the most common form of data analytics because their primary purpose is to summarize and understand existing data. They are typically the least challenging because they seek to summarize measurements in a data set without further interpretation. Exploratory data analysis goes a step further and builds on a descriptive analysis by searching for discoveries, trends, correlations, or relationships between the measurements to generate ideas or hypotheses (Leek and Peng, 2015).
The data used in descriptive and exploratory data analysis can be defined as categorical/discrete or continuous. Discrete data consist of particular finite or countably infinite values in a given discrete data set and can be numerical (e.g., the number of personnel deployed) or categorical (e.g., male or female). Continuous data, on the other hand, result when an observation can take on any value within a certain range or interval (e.g., temperature readings).
These data can be summarized in a number of ways. Frequencies, distributions, and tabulations are used to examine the count of the occurrences of values within a particular group or interval. Calculating the central tendency—the mean, median, and mode of the data—summarizes the data into a single value that is typical or representative of all the values in the data set. Assessing the spread—the range, quartiles, variance, or standard deviation—shows how scattered the values are and how much they differ from the mean value.
The visualization or presentation of these data and analyses is an important means of conveying information. While there are a variety of ways to do this in a pictorial or graphic format, visualizations using bar charts, box plots, and scatter plots are common approaches.
Predictive Analysis
Predictive analysis goes a step beyond descriptive and exploratory analysis by extracting information from data sets to determine patterns and predict future outcomes and trends. Predictive analytics can be targeted to test a particular hypothesis or exploratory to formulate hypotheses (Hastie et al., 2008; NRC, 2013). There are a number of tools used for these analyses, some of the most common of which are briefly described in the following subsections.
Machine Learning
Machine learning methods were developed to deal with the need for out-of-sample prediction and address the problems of dealing with massive
data sets containing many predictors. Machine learning develops techniques for teaching computers to act without explicitly programming them. These techniques fall into three broad classes:
- Supervised. A teacher provides the computer with explicit examples (say, of a concept being learned) or feedback on the correctness of a particular decision.
- Unsupervised. The computer seeks to uncover hidden patterns without explicit labeling of examples or an error signal.
- Reinforcement. A software agent determines how to optimize its behavior from a local reward signal, but without explicit input–output pairs or feedback on suboptimal actions.
A wide range of such algorithms exist (over 50 different supervised learning algorithms now in the statistical computing software R5), and these different algorithms work well in different settings. Several “ensemble methods” have been developed to combine predictions across a range of learning algorithms to arrive at optimal predictions. All these methods are designed to maximize prediction at the expense of allowing the analysts to evaluate the effects of individual predictors. However, these predictors are often highly intercorrelated, and models with highly intercorrelated predictors usually have poor out-of-sample performance.
Machine learning tasks include learning a model that can predict discrete categories (classification, discussed below) or a continuous output (regression, discussed below); dimensionality reduction to simplify a multidimensional data set; clustering input data into cohesive groups; multivariate querying to find the objects most similar to each other or a particular candidate; and density estimation of an unobservable underlying density function.
Linear Regression
Linear regression is a widely used approach to modeling the relationship between a dependent variable and one or more explanatory variables using linear predictor functions, where unknown model parameters are estimated from the data. A common problem of dealing with large data sets is that it is difficult to develop models with thousands of predictors. Linear regression has many practical uses, particularly for predicting, forecasting, reducing errors, and quantifying the strength of the relationship between data. This type of analysis is often used because models that depend linearly on their unknown parameters are easier to fit than models that are non-
___________________
5 See the “R Project for Statistical Computing” website at https://www.r-project.org/.
linearly related to their parameters. Linear regression models are often fitted using the least squares approach, but they may also be fitted in other ways, such as by minimizing the “lack of fit” in some other mathematical norm (as with least absolute deviations regression), or by minimizing a penalized version of the least squares loss function as in ridge regression (L2-norm penalty) and lasso (L1-norm penalty) (Friedman et al., 2010).
Dimension reduction is often conducted to reduce the number of random variables under consideration. Two popular methods are the lasso and elastic nets. The lasso is a shrinkage and selection method for linear regression that minimizes the usual sum of squared errors, with a bound on the sum of the absolute values of the coefficients (Tibshirani, 1996). The lasso is a penalized least squares method imposing an L1-penalty on the regression coefficients and simultaneously provides both continuous shrinkage and automatic variable selection. However, the lasso is subject to limitations in some cases, including limited or unspecific variable selection and prediction performance dominated by the underlying ridge regression (Tibshirani, 1996).
The elastic net is a regularization and variable selection method that generalizes and outperforms lasso in some cases. Elastic net encourages a grouping effect, where strongly correlated predictors tend to be in or out of the model together, and is particularly useful when the number of predictors is much bigger than the number of observations (Zou and Hastie, 2005).
Nonlinear Regression
Nonlinear regression is a form of regression analysis in which observational data are modeled by a function that is a nonlinear combination of the model parameters and depends on one or more independent variables. The data are fitted by a method of successive approximations. In contrast to linear analysis, where the linear equation has one basic form, nonlinear equations can take many different forms. Nonlinear regression is typically computationally intensive and requires an iterative approach to solve, in contrast to linear regression, in which many solutions can be calculated without advanced computation.
Kernel methods are a class of algorithms for pattern analysis of computational tools used for nonlinear regression analysis, including support vector machines (SVMs). SVMs are supervised machine learning models with associated learning algorithms that analyze data and recognize patterns. While SVM models are typically used for classification (Burges, 1998)—by representing example data as points in space, mapping example data into separate categories divided by a clear gap, mapping new data into that same space, and predicting which category data belong to based on which side of the gap they fall on—they can also be used for regres-
sion analysis (Vapnik, 1995). SVMs are largely characterized by the choice of their kernels, and SVMs thus link the problems they are designed for with a large body of existing work on kernel-based methods (Smola and Schölkoph, 1998).
Classification
Classification is the problem of identifying a set of categories to which a new observation belongs, on the basis of a training set of data containing observations whose category membership is known (e.g., differentiating e-mail messages to identify which should be filtered as spam). Classification is an instance of supervised machine learning where a training set of correctly identified observations is available. The corresponding unsupervised procedure is known as clustering and involves grouping data into categories based on some measure of inherent similarity or distance. Often, the individual observations are analyzed into a set of quantifiable properties, known variously as explanatory variables or features. These properties may variously be categorical (such as “A,” “B,” “AB,” or “O,” for blood type), ordinal (such as “large,” “medium,” or “small”), integer-valued (such as the number of occurrences of a particular word in an e-mail), or real-valued (such as a measurement of blood pressure). Other classifiers work by comparing observations to previous observations by means of a similarity or distance function. An algorithm that implements classification, especially in a concrete implementation, is known as a classifier. The term “classifier” sometimes also refers to the mathematical function, implemented by a classification algorithm, that maps input data to a category (Tang et al., 2014).
Classification uses categorical data and is often done with logistic regression or classification trees. Logistic regression measures the relationship between the categorical dependent variable and one or more independent variables by estimating probabilities using a logistic function, which is the cumulative logistic distribution (Cox, 1958). Classification trees are used to predict membership of cases or objects in the classes of a categorical dependent variable from their measurements on one or more predictor variables. The goal of classification trees is to predict or explain responses on a categorical dependent variable; as such, the available techniques have much in common with the techniques used in the more traditional methods of discriminant analysis, cluster analysis, nonparametric statistics, and nonlinear estimation. The flexibility of classification trees makes them a very attractive analysis option (Hill and Lewicki, 2006).
Regression tree analysis, in which a predicted outcome can be considered a real number, is also used in addition to classification tree analysis, in which the predicted outcome is the class to which the data belong. Clas-
sification and Regression Tree (CART) analysis is an umbrella term used to refer to both of the above procedures (Breiman et al., 1984).
Data Mining
Data mining (also called knowledge discovery) is the computational process of discerning a previously unknown pattern in a data set and transforming it into an understandable structure for further use. It lies at the intersection of statistics, machine learning (see below), and data management. While many data-mining techniques have been known for decades, the focus of late has been on methods that can work with large data sets (too large to fit in main memory). For example, while decision trees have been studied since the early 1980s, in the mid-1990s methods began to appear to build decision trees on disk-based data with limited passes over the data. Some of the main classes of data-mining algorithms are the following:
- Cluster detection. Trying to find natural groupings of data, for example, to help with summarization of a data set.
- Anomaly detection. Finding outliers in a data set, for example, to detect fraudulent banking transactions.
- Association rule learning. Discovering relationships between variables in data sets, for example, market-basket analysis, which tries to determine which items are commonly purchased together.
Sometimes the outputs of data-mining methods can be used directly to influence future action, or they might suggest hypotheses to test more rigorously with other methods (see Hastie et al., 2008).
Text Analytics
Text analytics (also called text data mining) seeks to extract useful, and generally machine-processable, information from unstructured or semistructured textual sources. It brings to bear techniques from a variety of areas, such as natural language processing (part-of-speech tagging, topic modeling, co-reference determination), information extraction (named-entity recognition, relationship extraction), information retrieval (novelty detection), and statistics (pattern learning). The great increase of textual sources—such as social media, online product and business reviews, and transcribed call records—have piqued interest in automated text analysis methods as data volumes have outstripped the capacity of human analysts. Application areas include sentiment analysis for brands, root cause deter-
mination in customer complaints, employee sentiment, and identification of insurance claims for subrogation.
NLP techniques are reaching a level of maturity such that they are suitable for preparation and analysis of unstructured text data. For example, Intel has begun using NLP techniques to help in analyzing the tens of thousands of responses to its annual organizational health survey. Companies are also turning more to external sources of data, such as demographic and labor data from both public and private sources. One study revealed that the true supply of candidates in underrepresented groups was much lower than publicly reported, leading to a shift in diversity efforts from recruitment to retention. In contrast, Intel noted that social media data were becoming less useful for studying current employees, as users are becoming savvier about their privacy settings. However, internal media, such as e-mail and discussion boards, can have value. For example, simply analyzing the promptness of replies to e-mail can reveal much about intra- and intergroup dynamics. Some companies have gone as far as instrumenting employees to track the scope and frequency of interpersonal communication. Olguín-Olguín and Pentland (2010) report on several studies where sensors were used to gather data on face-to-face interactions (sometimes together with electronic communications). Analysis of the resulting graph structures revealed a correlation between site productivity and difference in job attitude.
Bayesian Methods
Bayesian methods are powerful for integrating multiple types and sources of data; they cross into all areas of predictive analysis because they represent a state of knowledge or a state of belief via a probability distribution. The key ingredients for a Bayesian analysis are the likelihood function, which reflects information about the parameters contained in the data, and the prior distribution, which quantifies what is known about the parameters before observing data. The prior distribution and likelihood can be easily combined to form the posterior distribution, which represents total knowledge about the parameters after the data have been observed. Simple summaries of this distribution can be used to isolate quantities of interest and ultimately to draw substantive conclusions (Glickman and van Dyk, 2007).
Simulation
Simulation, sometimes referred to as modeling, simulation, and analysis (MS&A), is a form of predictive analytics useful for scenario development and analysis and what-if studies. As with all forms of predictive analytics, it relies heavily on a descriptive understanding of the underlying population
or phenomena of interest (reality being studied). DoD has a long history of using MS&A to study future scenarios, including force planning and war gaming. Defense Modeling, Simulation, and Analysis: Meeting the Challenge gives both a historical look back and a future outlook for MS&A in face of rapid changes within DoD that are affecting both composition of the force and future conflicts (NRC, 2006).
It is important to recognize that simulation answers the what-if question, not the what’s-best question, and aims to predict outcomes as opposed to determining best outcomes. Simulation by itself can never say anything about the quality of the solution—it can only provide statistical analyses of possible outcomes for a fixed set of prespecified decision parameters.
Prescriptive Analysis
The role of prescriptive analytics is to provide recommendations in support of decision-making processes, where the objective is to determine a set of decisions and/or actions that gives rise to the best possible results based on various outcomes predicted by predictive analytics and subject to various constraints. This activity is also called decision making under uncertainty or optimization under uncertainty and is often based on methods from stochastic modeling and mathematical optimization.
When solving an optimization problem, it may be possible to evaluate the solution quality of each option in the decision space and select a best option. For very small problem instances, this manual enumerative approach may work well. However, for the typical optimization problems encountered in the course of P&R missions, the enumerative approach is not feasible; simply evaluating a few options within a large decision space will almost surely not find a best option and would instead render solutions that differ significantly from a best option. The general class of optimization methods addresses these difficulties by efficiently searching through the decision space of possible options in a mathematically precise manner that does not look at the vast majority of options to identify a best set of decisions or actions with respect to the desired objective and subject to any given constraints.
In addition to providing optimal recommendations, prescriptive analytics can support an elevated form of what-if and scenario analysis that explores optimal solutions (as opposed to a particular option in the decision space) across a spectrum of objectives, conditions, and inputs. For example, optimization methods might be executed to solve an initial instance of the prescriptive analytics problem at hand; these optimization methods are then executed in an iterative manner under various changes of interest in the objective, constraints, assumptions, predictive models, model parameters, and so on to ultimately provide a recommendation.
This chapter discusses classes of prescriptive analytics from the perspective of two key areas that are intimately connected. The first concerns stochastic (or probabilistic) models of uncertainty, where the goal is to model different aspects of the decision-making problem and their various sources of uncertainty, often building on top of the results of predictive analytics. The second area concerns mathematical optimization of decisions within the context of stochastic models of uncertainty of different aspects of the problem, where the goal is to either (1) provide a set of decisions or actions at the start of the time horizon that gives rise to the best possible results over the horizon or (2) provide a set of adaptive decision-making policies for dynamic adjustments to decisions or actions throughout the time horizon as uncertainties are realized. These two key areas of prescriptive analytics are discussed in the following subsections.
It is important to note that this chapter focuses on classes of mathematical prescriptive analytics methods that have been developed and applied to address problems arising in the private sector with prescriptive decision-making problems related to P&R missions. As a brief illustrative example of the application of such prescriptive analytics methods, studies addressing the problem of retention typically start with a statistical analysis (predictive analytics) of the entire workforce, looking to identify characteristics of people most likely to leave. This analysis renders models that predict losses for the different groups of people and also produces models that predict the estimated change in losses for each group as a function of the amount of additional compensation provided to that group. Then mathematical optimization under uncertainty methods (prescriptive analytics) are developed, incorporating these predictive models to determine the best policy for the amount of compensation to be allocated to reduce losses (increase retention) for each group of people composing the workforce in order to best match demand. This decision-making optimization also takes into account the various trade-offs among other workforce policy levers such as hiring (recruiting) and reskilling (training) to best match demand. One such study for a business unit within IBM led to relative revenue-cost benefits over previous approaches commensurate with 2 to 4 percent of the total revenue targets for the business (refer to Cao et al. [2011], as well as some of the examples in Appendix D, for additional details.) The classes of prescriptive analytics methods described in this chapter create opportunities to evaluate, revisit, and improve some policy decisions related to P&R missions within DoD.
Stochastic Models of Uncertainty
A prerequisite for using optimization to determine a best set of decisions or actions is the development of stochastic models of the system
and the underlying processes associated with the decision-making problem. More specifically, stochastic models provide the main context for the formulation and solution of the optimization problem of a system of interest by capturing the relationships among actions and outcomes in the system, by characterizing the various sources of uncertainty in the system, and by capturing the dynamics of the system over time. In this regard, the stochastic models bring together a representation of different aspects of the decision-making problem that are sometimes taken directly from the output of predictive analytics, such as forecasts for future demand of DoD or Service personnel over time. These models are sometimes built on top of the output of predictive analytics for different aspects of the decision-making problem, such as predictions of attrition in certain personnel areas as part of a stochastic model of the availability of P&R personnel over time. These relationships, while critical, are often infused with subtleties and complex interactions.
Stochastic models characterize and predict how the system of interest and its underlying decision-making processes will behave over time under a specific set of decisions or actions. Various mathematical methods can be used to obtain such results for these stochastic models, ranging from analytical solutions to numerical computations or simulation. The most appropriate methods will often depend upon the complexity of the stochastic models and the formulation and solution of the optimization problem of interest within the context of the stochastic models. The domain knowledge needed for this area spans stochastic processes, probability theory, stochastic modeling, and simulation theory.
The interplay of stochastic models and data creates critical and complex dependencies. High-fidelity stochastic modeling of different aspects of the system of interest can be computationally intensive and require significant mathematical expertise, but it is a necessary component of the decision process. The outcome is high-quality and robust decisions that balance objectives, resource limitations, goals, processes, and organizational needs. Compromising on the quality of the underlying data, stochastic models, or use of optimization will likely lead to decisions that are less than the best—often much less.
To illustrate aspects of the points noted above, two examples of stochastic models of uncertainty involved in decision-making problems related to those of P&R are presented in Appendix D. The first example is based on the use of stochastic loss networks to model the probability of sufficient capacity or readiness of resources given uncertainty around the demand for such resources, as well as the interactions and dynamics of resources across different projects and tasks. The second example uses discrete-time stochastic processes to model the evolution of capabilities and readiness of personnel resources over time, given uncertainty around the
time-varying supply-side dynamics with personnel acquiring skills, gaining experience, changing roles, and so on, including some personnel leaving and other new personnel being introduced.
Mathematical Optimization Under Uncertainty
The role of mathematical optimization is to determine a set of decisions or actions that gives rise to the best possible results within the context of the stochastic models of the system of interest and subject to various constraints. More specifically, a general formulation of a single-period decision-making optimization problem can be expressed in terms of minimizing or maximizing an objective functional of interest subject to various constraint functionals. The objective functional and constraint functionals define the criteria for evaluating the best possible results with respect to the decision variables and other dependent variables, where these and related variables are based on the stochastic models of the system of interest. The relationships among these components of the optimization formulation are critically important and often infused with subtleties and complex interactions.
In addition to optimizing a set of one-time decisions, mathematical optimization also determines a set of adaptive decision-making policies for dynamic adjustments to decisions or actions throughout the time horizon as uncertainties are realized that give rise to the best possible results within the context of the stochastic models of the system of interest and subject to various constraints. More specifically, a general formulation of a multiperiod decision-making optimization problem can be expressed in terms of minimizing or maximizing over time an objective functional of interest subject to various constraint functionals. The time-dependent objective functionals and constraint functionals define the criteria for evaluating the best possible results over a given time horizon with respect to the time-dependent decision variables and other dependent variables, where these and related variables are based on the stochastic models of the system of interest. The relationships among these components of the optimization formulation are critically important and often infused with subtleties and complex interactions.
When the objective and constraint variables are deterministic (e.g., a point forecast of expected future demand, possibly over time), then the solution of the optimization problem falls within the domains of mathematical programming and deterministic dynamic programming and optimal control methods, the details of which depend on the properties of the objective functional(s) and constraint functionals (e.g., linear, convex, or nonlinear objective and constraint functionals) and the properties of the decision variables (e.g., integer or continuous decision variables). On the other hand, when the objective and constraint variables are random
variables or stochastic processes (e.g., a distributional forecast of future demand or a stochastic process of system dynamics, possibly over time), then the solution of the optimization problem falls within the domains of mathematical optimization under uncertainty and stochastic dynamic programming and optimal control methods, the details of which again depend upon the properties of the objective functional(s) and constraint functionals and the properties of the decision variables. In addition, for the multiperiod case, a filtration is often included in the formulation to represent all historical information of a stochastic process up to a given time (but not future information), where both the decision variables and the system are adapted to this filtration.
Hence, mathematical optimization generally renders solutions that identify a set of decisions or actions at the start of the time horizon or identify a set of dynamic decision-making policies for dynamic adjustments to decisions or actions throughout the time horizon adapted to filtrations, in both cases having the goal of achieving the best possible results within the context of the stochastic models of the system of interest and subject to various constraints. Various mathematical methods can be used to obtain these solutions based in large part on the properties of the stochastic models of the system and its underlying decision processes. The most appropriate methods will often depend on the complexity of the underlying stochastic models of uncertainty and the details of the formulation of the optimization problem of interest within the context of the stochastic models. The domain knowledge needed for this area spans stochastic processes, probability theory, optimization theory, control theory, and simulation theory.
When point predictions are used exclusively, then mathematical programming is often most applicable, including linear programming (Vanderbei, 2013), convex optimization (Boyd and Vandenberghe, 2004), combinatorial optimization (Nemhauser and Wolsey, 1999; Schrijver, 2003; Lee, 2004), integer programming (Nemhauser and Wolsey, 1999; Conforti et al., 2014), nonlinear optimization (Ruszczynski, 2006), and deterministic dynamic programming and optimal control (Bertsekas, 2005). Otherwise, when richer probabilistic characterizations are available with analytical solutions of the stochastic models and processes, then mathematical programming, stochastic optimization (Chen and Yao, 2001; Yao et al., 2002), stochastic programming (King and Wallace, 2012), stochastic dynamic programming, and stochastic optimal control (Yong and Zhou, 1999; Bertsekas, 2012) are often applicable, with a best choice depending on the characteristics of the analytical solutions and the details of the formulation of the optimization problem. On the other hand, when simulation methods provide the only means of evaluating the stochastic models of the system and its underlying decision processes, then simulation optimization with stochastic approximation (Asmussen and Glynn, 2007; Nelson
and Henderson, 2007; Dieker et al., 2016) is often most applicable, where stochastic approximation algorithms consist of a combination of gradient methods for searching the feasible solution space and simulation methods for evaluating the system at any point in the feasible space; stochastic approximation can be similarly exploited when only numerical methods are available to evaluate the stochastic system models. Lastly, when a certain measure of robustness against uncertainty of the system and its underlying decision processes can be represented as deterministic variability in the value of the parameters of the decision-making problem itself or its solution, then robust optimization (Ben-Tal et al., 2009) is often most applicable.
Another form of mathematical optimization for prescriptive analytics concerns an elevated form of what-if and scenario analysis that explores optimal solutions across a spectrum of objectives, constraints, conditions, and other aspects of the problem formulation. As an illustrative example, a mathematical optimization under uncertainty method can be used to determine the solution of an instance of the single-period optimization problem above that maximizes the objective in expectation under a given set of standard deviations for the random variables involved, and then this step is repeated for different sets of standard deviations. Each such solution provides the decisions or actions that render the best possible result in expectation of a given level of variability. In the context of modern portfolio theory, this set of solutions can be used to define the efficient frontier where each portfolio solution has the feature that there exists no other portfolio with a higher expected return and the same standard deviation of return (level of risk). More generally, this approach supports investigation of the sensitivity of the optimal solution of a mathematical optimization under uncertainty problem with respect to aspects of the formulation together with associated trade-offs, thus aiding the decision-making process and enabling basic forms of risk hedging. Laferriere and Robinson (2000) consider a related approach that exploits ideas from stochastic programming in order to compute hedged decisions; the method was implemented by the U.S. Army TRADOC Analysis Center (White Sands Missile Range, New Mexico) in a decision-support system with extensive use in Army analysis.
A formal definition and discussion of both single-period and multiperiod forms of mathematical optimization under uncertainty is given in Appendix D. In addition, to illustrate aspects of the points noted above, Appendix D provides three detailed examples of mathematical optimization under uncertainty involved in decision-making problems related to those encountered by P&R. The first is based on optimization of stochastic loss networks to determine the best capacity and readiness of resources given uncertainty around the demand for such resources. The second is a stochastic dynamic program example based on optimization of discrete-
time stochastic decision processes of the evolution of capabilities and readiness of personnel resources over time given uncertainty around the time-varying supply-side dynamics. The third is an example of stochastic optimal control of the dynamic allocation of capacity for different types of resources in order to best serve uncertain demand so that expected net benefit is maximized over a given time horizon based on the rewards and costs associated with the different resource types.
Optimal Solutions
It is important that prescriptive analytics methods provide the user with some basis for understanding why the optimal set of decisions or actions provided will give rise to the best possible results subject to the specified constraints. A key element for doing so involves providing the user with the predicted outcomes from predictive analytics for the optimal set of decisions or actions, as well as the predicted outcomes for alternative sets of decisions or actions for comparison.
REFERENCES
Al-Rfou, R., V. Kulkarni, B. Perozzi, and S. Skiena. 2015. Polyglot-NER: Massive multilingual named entity recognition. Pp. 586-594 in Proceedings of the 2015 SIAM International Conference on Data Mining (S. Venkatasubramanian and J. Ye, eds.). Society for Industrial and Applied Mathematics, Vancouver, British Columbia, Canada.
Asmussen, S., and P.W. Glynn. 2007. Stochastic Simulation: Algorithms and Analysis. New York: Springer-Verlag.
Ben-Tal, A., L. El Ghaoui, and A. Nemirovski. 2009. Robust Optimization. Princeton, N.J.: Princeton University Press.
Bertsekas, D.P. 2005. Dynamic Programming and Optimal Control. Vol. I. 3rd ed. Nashua, N.H.: Athena Scientific.
Bertsekas, D.P. 2012. Dynamic Programming and Optimal Control. Vol. II. 4th ed. Nashua, N.H.: Athena Scientific.
Biewald, L. 2015. The data science ecosystem part II: Data wrangling. Computerworld. April 1. http://www.computerworld.com/article/2902920/the-data-science-ecosystem-part-2-data-wrangling.html.
Boyd, S., and L. Vandenberghe. 2004. Convex Optimization. New York: Cambridge University Press.
Breiman, L., J.H. Friedman, R.A. Olshen, and C.J. Stone. 1984. Classification and Regression Trees. Monterey, Calif.: Wadsworth & Brooks/Cole Advanced Books & Software.
Burges, C.J.C. 1998. “A Tutorial on Support Vector Machines for Pattern Recognition.” http://research.microsoft.com/pubs/67119/svmtutorial.pdf.
Cao, H., J. Hu, C. Jiang, T. Kumar, T.-H. Li, Y. Liu, Y. Lu, S. Mahatma, A. Mojsilovic, M. Sharma, M.S. Squillante, and Y. Yu. 2011. OnTheMark: Integrated stochastic resource planning of human capital supply chains. Interfaces 41(5):414-435.
Chen, H., and D.D. Yao. 2001. Fundamentals of Queueing Networks: Performance, Asymptotics and Optimization. New York: Springer-Verlag.
Conforti, M., G. Cornuejols, and G. Zambelli. 2014. Integer Programming. Switzerland: Springer International.
Cox, D.R. 1958. The regression analysis of binary sequences (with discussion). Journal of the Royal Statistical Society, Series B (Methodological) 20:215-242.
Dasu, T., and T. Johnson. 2003. Exploratory data mining and data cleaning. Wiley.
Davenport, T.H., and J.G. Harris. 2007. Competing on Analytics: The New Science of Winning. Boston: Harvard Business Review Press.
Dieker, A.B., S. Ghosh, and M.S. Squillante. 2016. Optimal resource capacity management for stochastic networks. Operations Research, submitted. http://www.columbia.edu/~ad3217/publications/capacitymanagement.pdf.
Dietrich, B.L., E.C. Plachy, and M.F. Norton. 2014. Analytics Across the Enterprise: How IBM Realizes Business Value from Big Data and Analytics. Indianapolis: IBM Press.
Enders, C.K. 2010. Applied Missing Data Analysis. New York: Guilford Press.
Fisher, K., and D. Walker. 2011. The PADS Project: An overview. In Database Theory-ICDT 2011. (T. Milo, ed.). Proceedings of the 14th International Conference on Database Theory, Uppsala, Sweden, March 21-23.
Friedman, J. , T. Hastie, and R. Tibshirani. 2010. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software 33(1):1-22.
Getoor, L., and A. Machanavajjhala. 2012. Entity resolution: Theory, practice and open challenges. Pp. 2018-2019 in Proceedings of the VLDB Endowment (Z.M. Ozsoyoglu, ed.). Vol. 5, Issue 12.
Glickman, M.E., and D.A. van Dyk. 2007. Basic Bayesian Methods. In Topics in Biostatistics (Methods in Molecular Biology) (W.T. Ambrosius, ed.). Totowa, N.J.: Humana Press Inc.
Hastie, T., R. Tibshirani, and J. Friedman. 2008. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer-Verlag.
Hill, T., and P. Lewicki. 2006. Statistics: Methods and Applications: A Comprehensive Reference for Science, Industry, and Data Mining. Tulsa, Okla.: StatSoft, Inc.
Isaac, D., and C. Lynes. 2003. Automated data quality assessment in the intelligent archive. Technical Report, Intelligent Data Understanding. NASA: Goddard Space Flight Center, Washington, D.C.
Kimball, R., and J. Caserta. 2004. The Data Warehouse ETL Toolkit. Indianapolis: Wiley.
King, A.J., and S.W. Wallace. 2012. Modeling with Stochastic Programming. New York: Springer-Verlag.
Laferriere, R.R., and S.M. Robinson. 2000. Scenario analysis in U.S. Army decision making. Phalanx 33(1):11-16.
Lee, J. 2004. A First Course in Combinatorial Optimization. New York: Cambridge University Press.
Leek, J., and R. Peng. 2015. What is the question? Science 347:1314-1315.
Lustig, I., B. Dietrich, C. Johnson, and C. Dziekan. 2010. The analytics journey. INFORMS Analytics Magazine, pp. 11-18.
NASEM (National Academies of Sciences, Engineering, and Medicine). 2016. Statistical Challenges in Assessing and Fostering the Reproducibility of Scientific Results: Summary of a Workshop. Washington, D.C.: The National Academies Press.
Naumann, F. 2013. Data profiling revisited. ACM SIGMOD Record 42(4): 40-49.
NDBC (National Data Buoy Center). 2009. Handbook of Automated Data Quality Control Checks and Procedures. Stennis Space Center, Mississippi.
Nelson, B.L., and S.G. Henderson, eds. 2007. Handbooks in Operations Research and Management Science, Chapter 19. Elsevier Science.
Nemhauser, G.L., and L.A. Wolsey. 1999. Integer and Combinatorial Optimization. Hoboken, N.J.: Wiley.
NRC (National Research Council). 2006. Defense Modeling, Simulation, and Analysis: Meeting the Challenge. Washington, D.C.: The National Academies Press.
NRC. 2013. Frontiers in Massive Data Analysis. Washington, D.C.: The National Academies Press.
Olguín-Olguín, D., and A. Pentland. 2010. Sensor-based organisational design and engineering. International Journal of Organisational Design and Engineering 1(1/2).
Rahm, E., and H.H. Do. 2000. Data cleaning: Problems and current approaches. IEEE Data Engineering Bulletin 23(4): 3-13.
Ruszczynski, A. 2006. Nonlinear Optimization. Princeton, N.J.: Princeton University Press.
Schrijver, A. 2003. Combinatorial Optimization: Polyhedra and Efficiency. Berlin Heidelberg: Springer-Verlag.
Smith, D., G. Timms, P. De Souza, and C. D’Este. 2012. A Bayesian framework for the automated online assessment of sensor data quality. Sensors 12(7):9476-9501.
Smola, A.J., and B. Schölkoph, 1998. “A Tutorial on Support Vector Regression.” http://www.svms.org/regression/SmSc98.pdf.
Stein, B., and A. Morrison. 2014. The enterprise data lake: Better integration and deeper analytics. PwC Technology Forecast: Rethinking Integration. www.pwc.com/us/en/technology-forecast/2014/cloud-computing/assets/pdf/pwc-technology-forecast-datalakes.pdf.
Tang, J., S. Alelyani, and H. Liu. 2014. Feature selection for classification: A review. In Data Classification: Algorithms and Applications (C.C. Aggarwal, ed.). Boca Raton, Fla.: CRC Press.
Tibshirani, R. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B (Methodological) 58(1):267-288.
Vanderbei, R.J. 2013. Linear Programming: Foundations and Extensions. 4th ed. New York: Springer-Verlag.
Vapnik, V. 1995. The Nature of Statistical Learning Theory. New York: Springer-Verlag.
Verborgh, R., and M. De Wilde. 2013. Using OpenRefine. Birmingham, UK: Packt Publishing.
Wickham, H. 2014. Tidy data. Journal of Statistical Software 59(10).
Yao, D.D., H. Zhang, and X.Y. Zhou, eds. 2002. Stochastic Modeling and Optimization, with Applications in Queues, Finance, and Supply Chains. New York: Springer-Verlag.
Yong, J., and X.Y. Zhou. 1999. Stochastic Controls: Hamiltonian Systems and HJB Equations. New York: Springer-Verlag.
Zou, H., and T. Hastie. 2005. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B 67(2):301-320.



























