
Appendix C
Elicitation of Expert Opinion
Expert judgment about the value of a model parameter or other quantity can be obtained using many methods (Morgan and Henrion, 1990; O’Hagan et al., 2006; U.S. Environmental Protection Agency, 2009). The terms “expert elicitation” and “structured expert elicitation” (or “structured expert judgment”) are typically used to describe a formal process in which multiple experts report their individual subjective probability distributions for the quantity. This usage is distinct from less formal methods in which someone provides a best guess or other estimate of the quantity. In practice, experts may provide a full probability distribution or a few fractiles of a distribution (often, three or five).
Expert elicitation can be distinguished from other formal methods of collecting experts’ judgments, such as group processes. These processes include expert committees (like those of the National Academies of Sciences, Engineering, and Medicine or the Intergovernmental Panel on Climate Change), in which experts reach a consensus through loosely structured or unstructured interaction, and more structured group processes such as the Delphi method (Dalkey, 1970; Linstone and Turoff, 1975), in which experts provide a probability distribution or other response, receive information on other experts’ responses (without associating individuals with responses), provide a revised response, and iterate until the process converges.
An important concern with expert elicitation is that subject-matter experts (like most other people) have little experience or skill in reporting their beliefs in the form of a subjective probability distribution. Their
judgments about probabilities and other quantities are often consistent with the hypothesis that they are influenced by cognitive heuristics that lead to systematic biases (as elucidated by Tversky and Kahneman, 1974). Also, to be most useful, subjective probability distributions must be well calibrated. Unfortunately, many experts (and others) prove to be overconfident in that they provide probability distributions that are too narrow, that is, the true or realized values are too frequently in the tails of their estimated distributions.
The hypothesis that an expert is well calibrated can be tested if the expert provides distributions for multiple quantities for which the values can be known, so one can determine the fractile of the corresponding subjective distribution at which each true or realized value falls. Calibration means that the realizations are consistent with the hypothesis that they are random draws from the experts’ corresponding distributions. For example, the expected fraction of realizations that fall outside the ranges defined by the expert’s 10th and 90th percentiles for the corresponding quantities is 20 percent; the probability that the actual number of realizations outside these intervals could have arisen by chance if the expert were well calibrated can be calculated using conventional statistical methods.
Expect elicitation can be conducted using more or less elaborate methods. Many practitioners use an elaborate approach (Morgan and Henrion, 1990; Evans et al., 1994; Budnitz et al., 1997; O’Hagan et al., 2006; Goossens et al., 2008; U.S. Environmental Protection Agency, 2009; Morgan, 2014). Knol et al. (2010) outline a seven step procedure for organizing an expert elicitation, illustrated in Figure C-1.
Expert elicitation is often conducted by a study team consisting of an interviewer and a subject-matter expert (who may be assisted by other personnel). The study team meets with and interviews each expert individually. The interviewer is familiar with issues of subjective probability and appropriate methods for eliciting judgments but may have little familiarity with the subject about which judgments are elicited, while the subject-matter expert is familiar with the topics about which judgments are elicited and the available theory, measurements, and other evidence from which the experts may form their judgments.
An expert-elicitation study often includes three distinct steps. First, the study team collects a set of relevant background studies that are provided to each expert, to make sure each is familiar with and can easily consult the relevant literature.
Second, there is an in-person meeting of the study team and all the selected experts, at which the experts discuss and if necessary clarify the definition of the quantities about which their judgments will be elicited; discuss the strengths and weaknesses of available empirical studies and
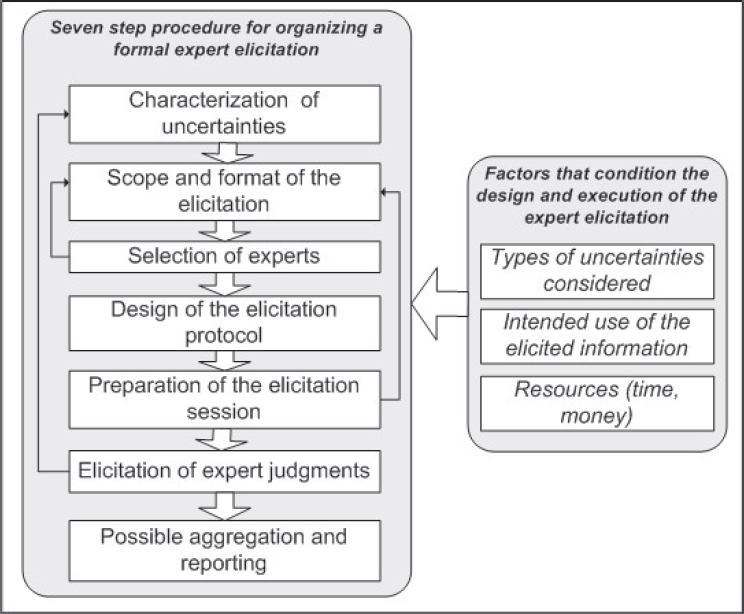
SOURCE: Knol et al. (2010, Figure 1).
other evidence; are familiarized with the elicitation procedures; and are introduced to concepts of subjective probability and common cognitive heuristics and biases (such as overconfidence). Such preparation may also include practice judgments about quantities whose values are subsequently revealed.
The third step is in-person interviews with each expert, during which the expert provides subjective probability distributions for the relevant quantities. These interviews often take several hours. The interviewer is primarily concerned with the procedure, framing questions to elicit the expert’s best judgment, minimizing effects of cognitive heuristics, question order, and other factors. The subject-matter expert is more concerned with the expert’s responses and rationales and can query the expert about the basis for the stated distributions, pursue the lines of evidence she or he finds more and less persuasive, and explore the extent to which the
expert has incorporated evidence that seems to conflict with the stated distribution. In some cases, either the expert or the study team may draft an explanation of the expert’s rationale, which the expert is expected to endorse (after revision, as appropriate). The expert may be invited to revise her or his responses after the interview, if desired.
During the elicitation process, it is common to help the expert address the quantity from multiple perspectives, to help in reporting her or his best judgment. For example, the same concept could be framed alternatively as a growth rate or a growth factor (or a future level conditional on a specified current level). If the expert provides a distribution about the growth rate, the study team could convert this to a distribution for the growth factor and allow the expert to contemplate whether this distribution is compatible with her or his beliefs or if the distribution for the growth rate needs to be adjusted. (Alternatively, the distribution for the growth factor could be elicited and the implied distribution of the growth rate derived from it.)
Similarly, the study team can help the expert view the estimated distribution from multiple perspectives, allowing adjustment until comfortable with the result. For example, the procedure could first ask for the median, described as the value such that the true quantity is equally likely to be larger or smaller. Then the expert could be asked, “If you learned the true value was larger than the median, what value do you judge it equally likely that the true value is above or below (i.e., what is the upper quartile of the distribution)?” The lower quartile can be elicited by an analogous question, after which the team can ask whether the expert believes it equally likely the true value is inside or outside the interquartile range.
An alternative to this series of questions is to begin by asking the expert for some extreme fractiles (e.g., the 10th and 90th percentiles) and then the more central fractiles such as the median. An advantage of eliciting fractiles in the tails (before the center) is to help protect against the problem of overconfidence that can arise from beginning with a central value and then adjusting away from it, but not sufficiently far, consistent with the “anchoring and adjustment” heuristic of Tversky and Kahneman (1974). To help the expert report extreme fractiles, the team might ask the expert to describe conditions under which the quantity would be larger than the expert’s largest (or smaller than the expert’s smallest) fractile; thinking about these conditions may induce the expert to revise these fractiles.
As an alternative to this elaborate, in-person interview process, elicitations can be conducted through telephone, email, or survey methods. A disadvantage of these less intensive methods is that the study team has less ability to help the expert think carefully about multiple lines of evidence and to view the issue from multiple perspectives. There seems
to be little evidence from which one can judge the effects of alternative elicitation procedures on the quality of the resulting distributions, because investigators have not often elicited distributions for the same or similar quantities using alternative procedures.
As alluded to in the above example of growth rate or growth factor, it is not always clear what quantity is best to elicit. When several quantities are logically related, it is probably best to encourage the expert to think carefully about all of them: at a minimum, it may be helpful for the expert to evaluate the implications of the offered distribution for one quantity on the implied distribution for the others. A related question is the degree of disaggregation: the process could elicit an aggregate quantity, the components from which it can be calculated, or both. The best approach may be the one with which each expert is most comfortable. If distributions for components are elicited, constructing the implied distribution for the aggregate requires information on the conditionality between the components, that is, the distribution for one component conditional on (in principle) all possible realizations of the other components. If the expert provides a distribution for only the aggregate, in principle she or he must take account of this conditionality implicitly.
One criterion for choosing the quantity to be elicited is that it ought to be a quantity for which the true value can be, at least in principle, probably by some form of measurement. This criterion implies the quantity is sufficiently well defined to remove any ambiguity about what would be measured. It is sometimes described as a clairvoyance test, meaning that a clairvoyant would be able to report the true quantity (without requiring any clarification). In contrast, an abstract model parameter may not be suitable if the true value of that parameter depends on the assumption that the model is accurate, particularly if the expert rejects that assumption.
Another important question is how to select experts. Given the burden of elicitation, it may be too difficult to recruit a large number. Many studies use between 5 and 15; there is some evidence of sharply diminishing returns beyond about 10 (Hora, 2004). Typically, the experts who are sought span the range of defensible perspectives about a quantity, but it is not necessary or appropriate to have the distribution of experts match the population frequency of alternative views (within the expert community). Commonly advocated methods of expert selection include inviting people whose work is most often cited or asking such people whom they would nominate as well qualified. In general, the set of experts who provide judgments is made public, but the matching between individual experts and distributions is concealed. The rationale for this approach is that it allows experts freedom to provide their best judgments without concern for representing the position of an employer or other party.
After subjective probability distributions are elicited from multiple experts, the question remains how to use them (which is related to the question of which experts to select). At a minimum, it seems useful to report the distribution provided by each expert, so readers have some appreciation for the degree of homo- or heterogeneity among the responses. It may be useful to understand the reasons for large differences among experts’ distributions: for example, experts may differ significantly in their interpretation of the credibility or relevance of particular data or theories. Beyond this reporting, it seems useful to combine the distributions using either an algorithmic approach or (possibly) a social or judgmental approach. Some elicitation experts (Keith, 1996; Morgan, 2014) have argued not to combine the distributions of multiple experts, but rather that the overall analysis ought to be replicated using each expert’s judgments individually as input to the evaluation. To the extent the overall conclusion is insensitive to which expert’s distributions are used, this approach may be adequate; if the conclusions depend on the expert, one can either report the multiple conclusions that result from using each expert’s judgments individually or find some way to combine them. If the evaluation yields a probability distribution of some output (e.g., the SC-CO2), one could combine the multiple output distributions that result from using each expert’s distributions for the inputs using an algorithmic or other approach. It would be interesting to compare the properties of combining the experts’ distributions to use as input or conducting the analysis using each expert’s distributions alone then combining the output distributions.
A number of algorithmic methods for combining experts’ distributions have been studied. In principle, a Bayesian approach in which the experts’ distributions are interpreted as data and used to update some prior distribution seems logical, but it is problematic. Such an approach requires a joint likelihood function, that is, a joint conditional distribution that describes the probability that each expert will provide each possible subjective distribution, conditional on the true value of the quantity. This distribution encapsulates information about the relative quality of the experts and about their dependence, which may be difficult to obtain and to evaluate.
The most common approaches to combining experts’ distributions are a simple or weighted average. The simple average is often used because it seems fair and avoids treating experts differently. The notion of eliciting weights (from the experts about themselves or about the other experts) has been considered.
Cooke (1991) has developed a performance-weighted average, which has been applied in many contexts (Goossens et al., 2008). The weights depend on experts’ performance on “seed” quantities, which are quanti-
ties whose value becomes known after the experts’ provide distributions for them. Performance is defined as a combination of calibration and informativeness, where informativeness is a measure of how concentrated (narrow) the distribution is. Clearly the judgments of a well-calibrated expert who provides narrow distributions are more valuable than the judgments of an expert who provides poorly calibrated or uninformative distributions. A key question is whether one can identify seed quantities that have the property that one would put more weight on the judgment of an expert for the quantity of interest when that expert provides better calibrated and more informative distributions for the seed variables. Cooke and Goossens (2008) have shown that the performance-weighted average of distributions usually outperforms the simple average, where performance is again measured again by calibration and informativeness (and is often evaluated on seed variables not used to define the weights, because the value of the quantity of interest in many expert elicitation studies remains unknown). Some authors remain skeptical, however (e.g., Morgan, 2014). The simple average distribution may be reasonably well calibrated, but it tends to be much less informative than the performance-weighted combination.
Note that when taking a linear combination of experts’ judgments, such as a simple or weighted average, it is desirable to average the probabilities, not the fractiles. Averaging the fractiles is equivalent to taking the harmonic mean of the probabilities, and hence it tends to yield very low probabilities on values for which any expert provided a small probability and to concentrate the distribution on values to which all experts assign relatively high probability (Bamber et al., 2016). Using the harmonic-mean probability is likely to accentuate the problem of overconfidence (distributions that are too narrow).
Expert elicitation is a method for characterizing what is known about a quantity; it does not add new information as an experiment or measurement would. Ideally, it captures the best judgments of the people who have the most information and deepest understanding of the quantity of interest. For some quantities, there may be so little understanding of the factors that affect its magnitude that informed judgment is impossible or can produce only uselessly wide bounds. For these quantities, neither expert elicitation nor any alternative can overcome the limits of current knowledge. Only additional research can push back those limits.
REFERENCES
Bamber, J.L., Aspinall, W.P., and Cooke, R.M. (2016). A commentary on “How to interpret expert judgment assessments of twenty-first century sea-level rise” by Hylke de Vries and Roderik SW van der Wal. Climatic Change, 137, 321.
Budnitz, R.J., Apostolakis, G., Boore, D.M., Cluff, L.S., Coppersmith, K.J., Cornell, C.A., and Morris, R.A. (1997). Recommendations for Probabilistic Seismic Hazard Analysis: Guidance on Uncertainty and Use of Experts. NUREG/CR-6372, Vol. 2. Washington, DC: U.S. Nuclear Regulatory Commission.
Cooke, R.M. (1991). Experts in Uncertainty: Opinion and Subjective Probability in Science. New York: Oxford University Press.
Cooke, R.M., and Goossens, L.H.J. (2008). TU Delft expert judgment data base. Reliability Engineering and System Safety, 93, 657-674.
Dalkey, N.C. (1970). The Delphi Method: An Experimental Study of Group Opinion. Technical report RM-5888-PR. Santa Monica, CA: RAND Corporation.
Evans, J.S., Gray, G.M., Sielken, R.L., A.E. Smith, A.E., Valdez-Flores, C., and Graham, J.D. (1994). Use of probabilistic expert judgment in uncertainty analysis of carcinogenic potency. Regulatory Toxicology and Pharmacology, 20, 15-36.
Goossens, L.H.J., Cooke, R.M., Hale, A.R., Rodic´-Wiersma, Lj. (2008). Fifteen years of expert judgement at TUDelft. Safety Science, 46, 234-244.
Hora, S.C. (2004). Probability judgments for continuous quantities: Linear combinations and calibration. Management Science, 50, 567-604.
Keith, D.W. (1996). When is it appropriate to combine expert judgments? Climatic Change, 33, 139-143.
Knol, A.B., Slottje, P., van der Sluijs, J.P., and Lebret, E. (2010). The use of expert elicitation in environmental health impact assessment: A seven step procedure. Environmental Health, 9, 19.
Linstone, H., and Turoff, M. (1975). The Delphi Method: Techniques and Applications, Reading, MA: Addison-Wesley.
Morgan, M.G. (2014). Use (and abuse) of expert elicitation in support of decision making for public policy. Proceedings of the National Academy of Sciences of the United States of America, 111, 7176-7184.
Morgan, M.G., and Henrion, M. (1990). Uncertainty: A Guide to Dealing with Uncertainty in Quantitative Risk and Policy Analysis. Cambridge, U.K.: Cambridge University Press.
O’Hagan, A., Buck, C.E., Daneshkhah, A., Eiser, J.R., Garthwaite, P.H., Jenkinson, D.J., Oakley, J.E., and Rakow, R. (2006). Uncertain Judgements: Eliciting Experts’ Probabilities. Hoboken, NJ: Wiley.
Tversky, A., and Kahneman, D. (1974). Judgment under uncertainty: Heuristics and biases, Science, 185, 1124-1131.
U.S. Environmental Protection Agency. (2009). Expert Elicitation Task Force White Paper: External Review Draft and Addendum: Selected Recent (2006-2008) Citations. Science Policy Council. Washington, DC: U.S. Environmental Protection Agency.








